mirror of
https://github.com/NohamR/knowledge-kit.git
synced 2026-05-25 04:17:17 +00:00
docs: image url
This commit is contained in:
@@ -3,14 +3,14 @@
|
||||
|
||||
## 一、实时特征回流
|
||||
传统智能的问题、弊端是什么?
|
||||

|
||||
|
||||
|
||||
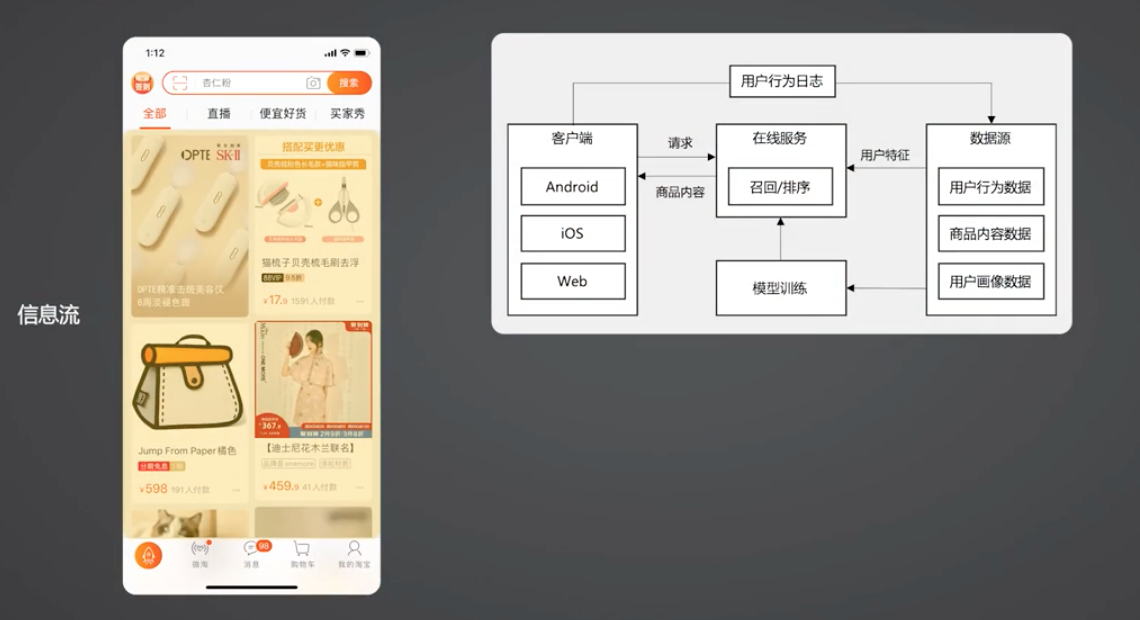
- 推荐系统需要收集用户的行为,将这些行为作为用户的意图表征,表征他的偏好,回流到服务端。
|
||||
- 服务端拿到这个数据,在发起一次实时请求的时候,会根据用户的行为特征,去商品池里面召回一批用户喜欢的商品,再返回给端上,给用户做展示
|
||||
- 同时,这个用户的行为数据,还会作为训练模型的一个样本
|
||||
|
||||
|
||||

|
||||
|
||||
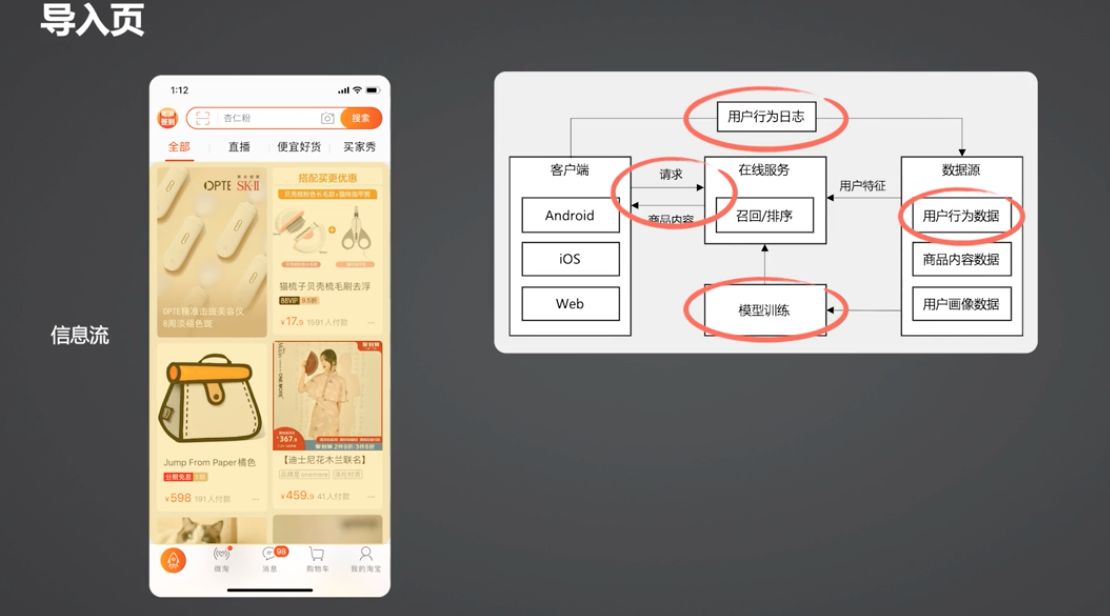
可以发现传统的推荐系统存在一些瓶颈:
|
||||
- 实时性不足
|
||||
行为数据回流的时效性,会影响算法对于用户意图变化的感知,会影响推荐的准确性。
|
||||
@@ -31,7 +31,7 @@
|
||||
|
||||
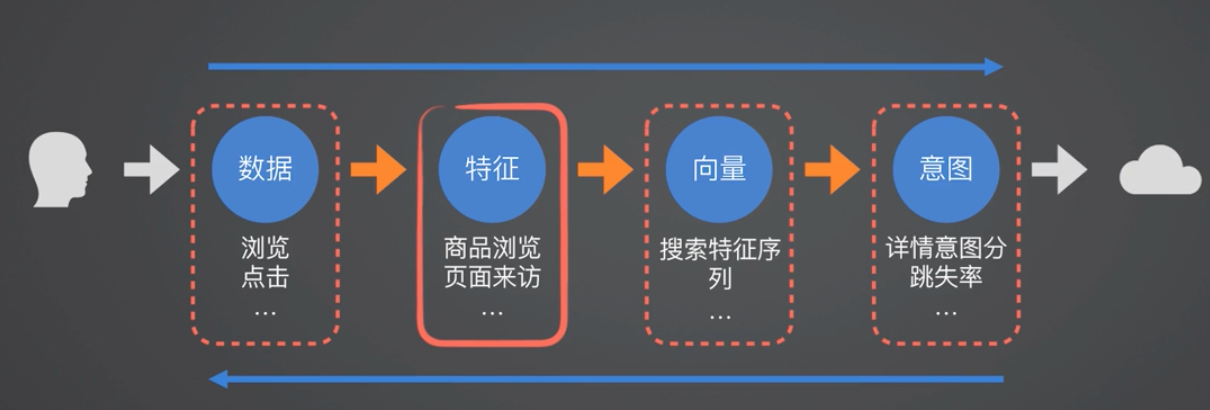
前面说过,用户的数据回流时效性会影响推荐的准确度。那么是不是可以把用户的特征、用户的数据,做到最实时的回流?
|
||||
这里,我们做了一些这样的尝试:
|
||||

|
||||
|
||||
|
||||
- 首先可以把用户的最原始的行为数据回流。比如用户在逛手淘的过程中产生的一些浏览、点击等行为回流到服务端
|
||||
- 同时,也可以把用户的这些原始行为数据做一定的聚合,生成一个信息量含量更高,但是数据量更小的用户特征数据(数据聚合)
|
||||
@@ -74,7 +74,7 @@
|
||||
|
||||
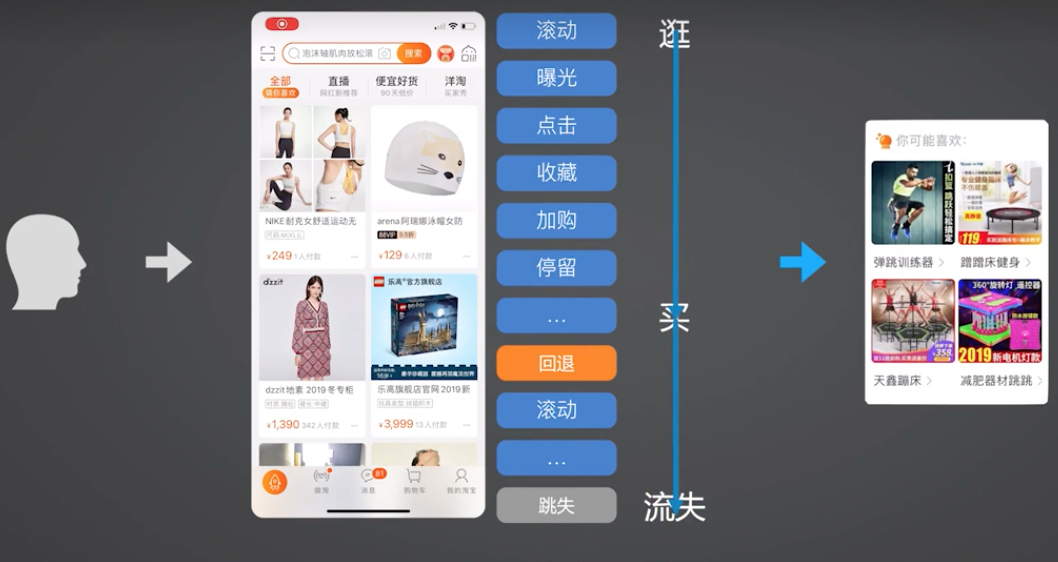
此时,从商品详情页到回退到外面这个商品列表页的时候,会根据用户刚刚的浏览、加购行为,推荐一个相似的商品。
|
||||
|
||||

|
||||
|
||||
|
||||
会根据用户刚刚浏览的这些行为,去给他推荐一个相似的商品。这个过程会发生很多行为,通过滚动、曝光等行为可以推测用户在信息流的浏览意图是逐渐从逛切换到了买。
|
||||
|
||||
@@ -87,7 +87,7 @@
|
||||
商品卡片的回退推荐策略落地上线后,效果是非常好的。比普通商品卡片的转换率高五六倍左右。
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
存在什么问题?
|
||||
类似程序员和产品设计沟通出的一种机制,可以理解为命令式编程,是人为先验地找到了一个能够代表用户意图的时机,也就是在回退时机。这种时机靠人去发现梳理,往往是很难覆盖全面的。依赖于对于用户强意图的梳理、选择。那么有没有一种方式可以自动的去预测用户意图的变化?
|
||||
@@ -100,7 +100,7 @@
|
||||
|
||||
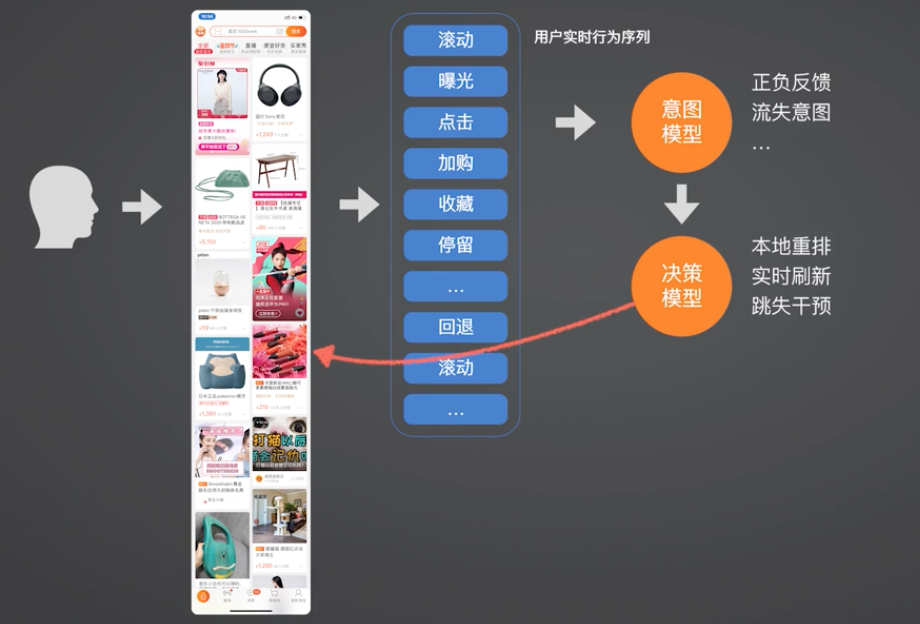
在信息流上面做了另外一个尝试:在本地进行了一次端上的重排。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
一个用户在逛信息流的过程中,会产生滚动、曝光、点击、加购、收藏、停留、回退、滚动这些行为。从用户的实时的行为序列中,其实是表征了用户背后的一个隐式的意图表达。
|
||||
@@ -114,7 +114,7 @@
|
||||
做完决策后,就可以将这个决策结果通知到前台,去做相应的响应。
|
||||
|
||||
还存在一些问题:
|
||||

|
||||

|
||||
|
||||
决策选择还是受限于产品策略。程序员还需要和产品去约定设计产品策略。开发和产品共同约定,在用户的某一时机之下,接下来对应的一个处理是什么。它的整个呈现形式和所处业务域还是存在紧密关系的。
|
||||
|
||||
@@ -134,7 +134,7 @@
|
||||
|
||||
|
||||
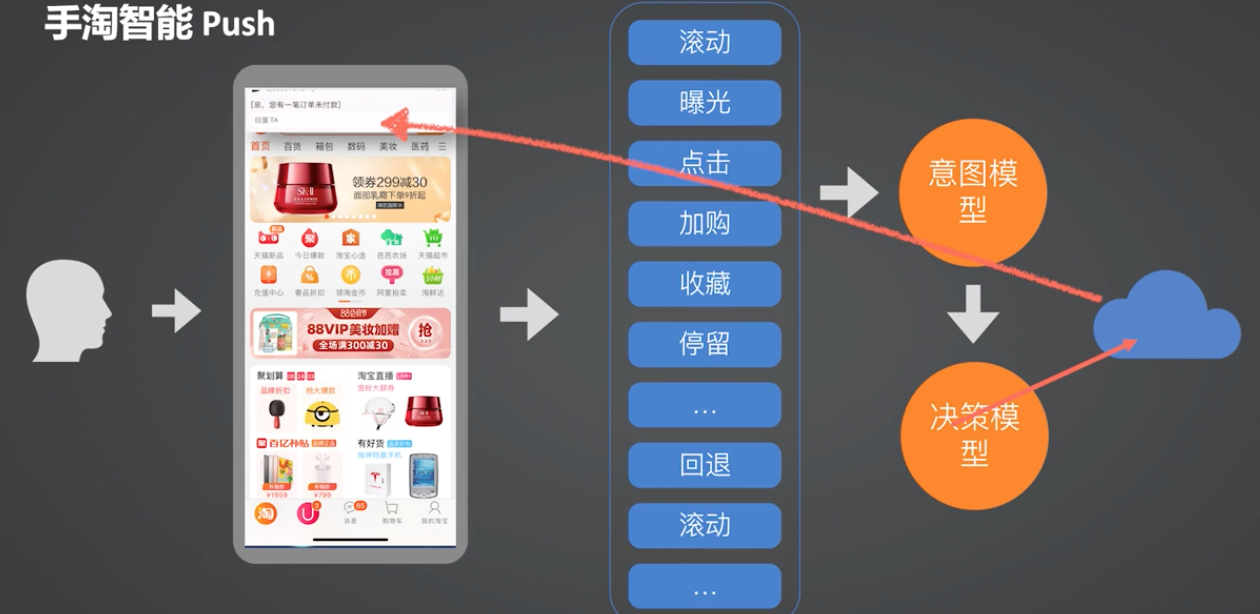
完整流程:
|
||||

|
||||
|
||||
|
||||
用户进入手淘后,会不断收集端上的行为(滚动、曝光、点击、加购、收藏、停留)数据,然后会把行为数据输入到另一个意图模型中,去判断他当前的一些实时意图。不断的根据行为做分析。也会输入到另一个决策模型中去,但这个(智能 Push)场景下的决策模型和前面的端上重排场景的决策模型是不一样的。这个决策模型会**判断用户当前的状态适不适合接受一次干预**,或者适不适合接受某一次营销的推荐。当我们发现用户当前处于一个相对空闲的状态,这个时机更适合接受一条干预的时候,我们就会把这个信号通知到服务端。这时候服务端在海量的内容中去筛选出一条对应着用户当前的意图,有效的一条信息,再推送给客户端。
|
||||
|
||||
@@ -181,7 +181,7 @@
|
||||
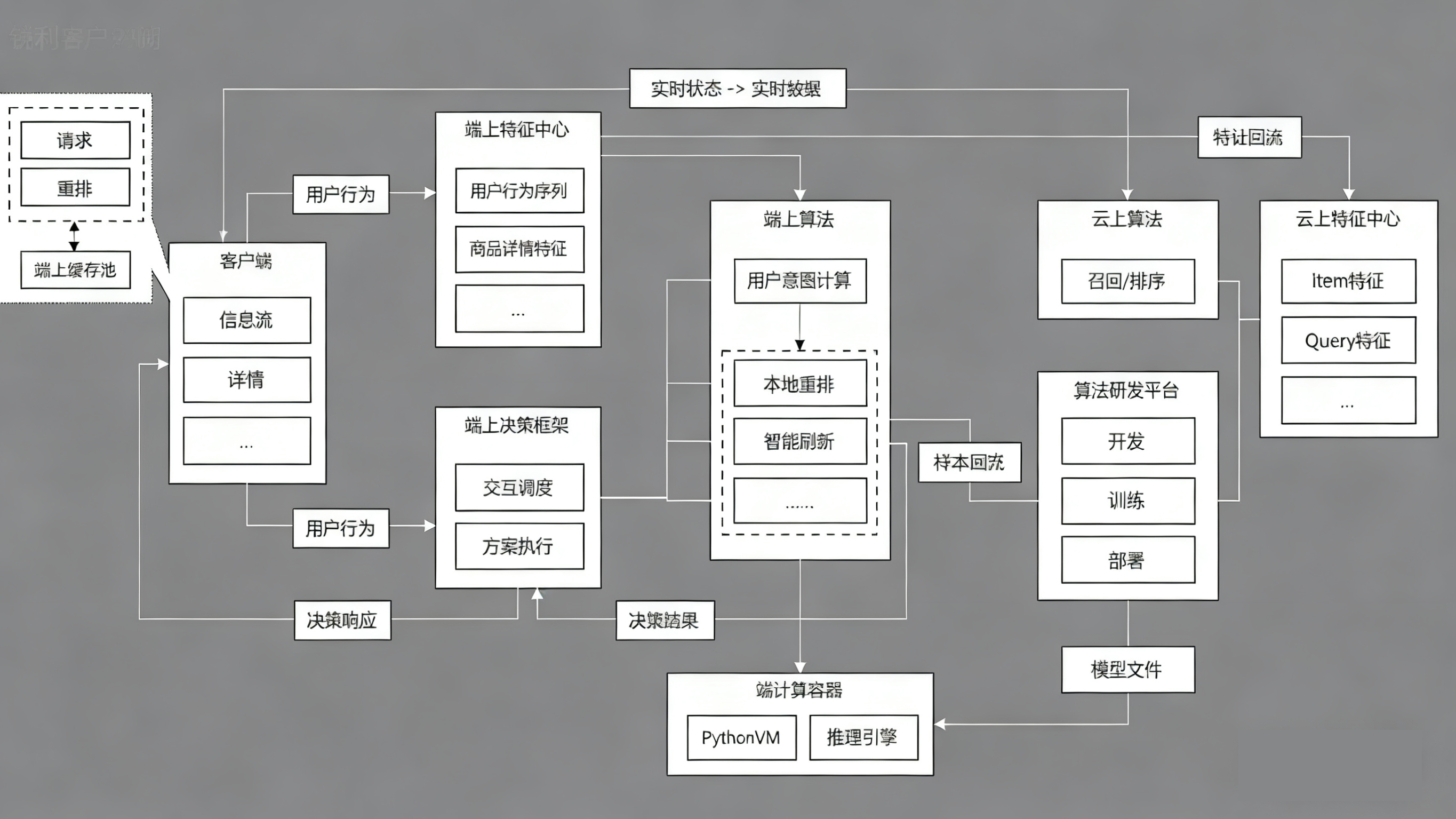
## 三、端智能整体架构
|
||||
要素:算法、数据、调度框架、运行环境
|
||||
架构如下:
|
||||

|
||||
|
||||
|
||||
1. 围绕着端上的算法分为2种模型:
|
||||
- 用户意图计算模型:不断分析用户当前所处状态
|
||||
@@ -199,7 +199,7 @@
|
||||
|
||||
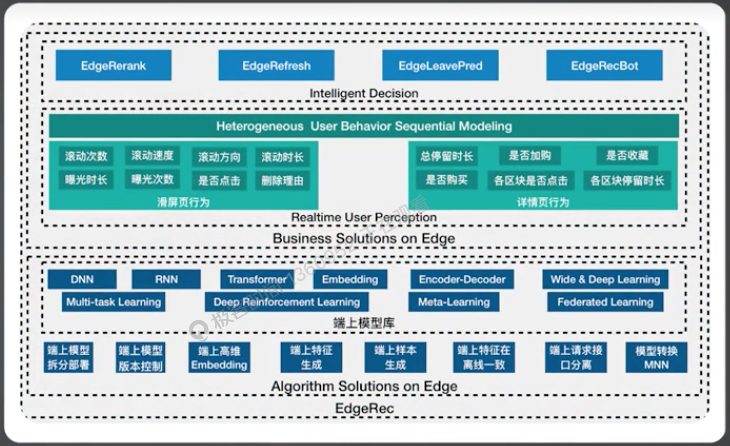
### 1. 端上算法方案
|
||||
|
||||

|
||||
|
||||
|
||||
- Algorhitms Solution On Edge:
|
||||
- 提供了模型、特征和样本这三大机器学习算法基础组件的端上通用方案
|
||||
@@ -212,7 +212,7 @@
|
||||
|
||||
### 2. 端上特征中心
|
||||
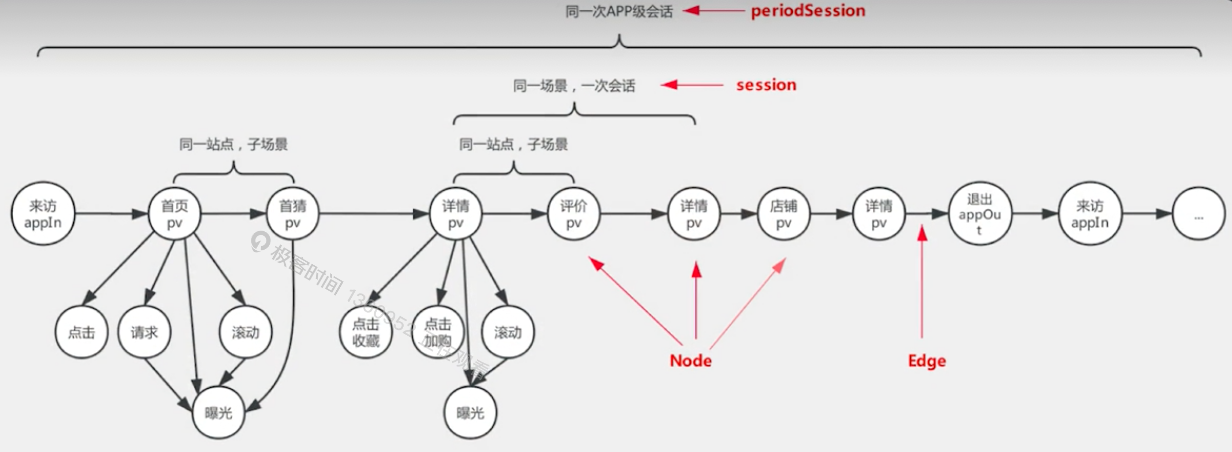
为端智能应用而设计,提供端侧算法所使用的标准化的全域用户行为数据和特征服务
|
||||

|
||||
|
||||
- 定义端侧用户行为标准
|
||||
该特征中心会定义端上用户的行为标准,产生什么样的用户行为,比如用户的浏览行为。这个浏览行为会有一些我的浏览区域、浏览停留时长等等标准化属性。其次,也会有一些像用户手势行为。比如滚动、点击等等。
|
||||
- 建立行为数据图化索引
|
||||
@@ -224,7 +224,7 @@
|
||||
|
||||
|
||||
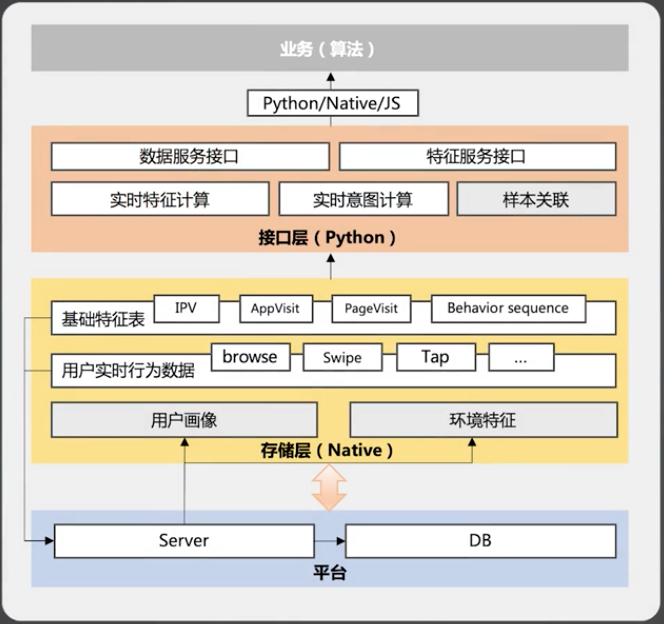
数据分层架构:
|
||||

|
||||
|
||||
|
||||
- 存储层:将采集到的用户行为数据按照约定的标准,在客户端本地做持久化存储。同时对用户数据进行一次加工处理,生成一份信息密度比较高的基础特征表。比如对详情页的浏览行为、App 页面间操作路径的数据、页面浏览的时序特征,这些数据都会存储在客户端本地。
|
||||
- 接口层:实时接口层,提供了 Python 层面的接口服务,给算法侧使用。可以做到数据的实时查询,将下层的通用数据、用户行为数据、环境信息等打包好给算法侧使用。
|
||||
@@ -234,7 +234,7 @@
|
||||
|
||||
|
||||
### 3. 端上的决策中心
|
||||

|
||||
|
||||
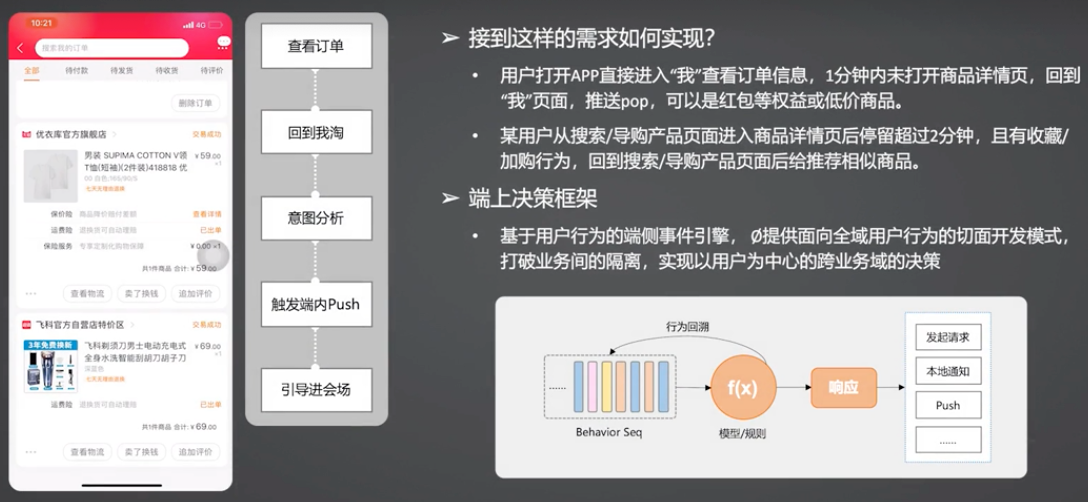
比如:用户在:我的淘宝 -> 我的订单 -> 订单详情页查看了某个订单详情,然后回退到“我的淘宝”页,这时候会对用户的意图进行分析,判断当前是不是处于一个空闲的状态。如果发现是空闲状态,则给他发送一条 Push 消息,引导进入双11主会场。这个就是一个智能 Push 的案例。
|
||||
|
||||
还有其他的需求:
|
||||
@@ -251,15 +251,15 @@
|
||||
这种面向用户行为的切面的编程方式,既可以用在运营规则上,也可以用在算法模型上。后续的响应,可以是弹出弹层、发送 Push、发送1次请求等。
|
||||
|
||||
### 4. 端计算容器
|
||||

|
||||
|
||||
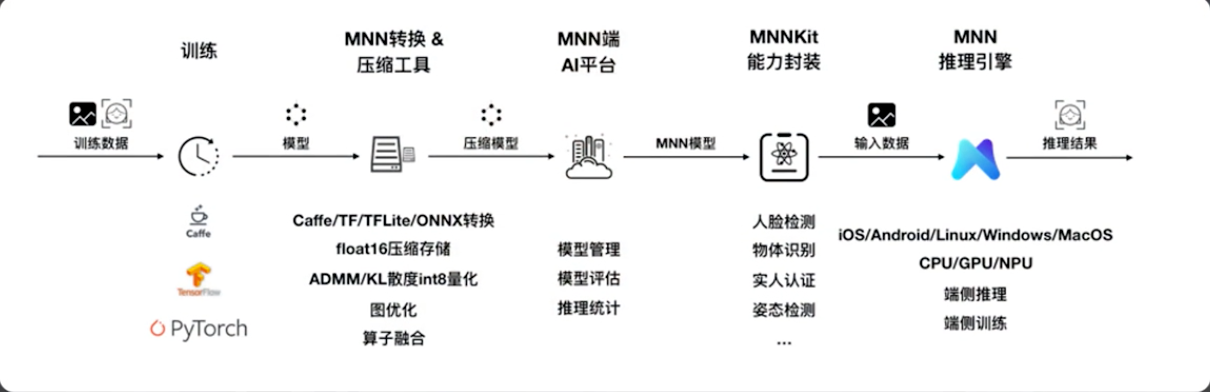
端上的算法模型需要跑在容器里,手淘用的是一个轻量级的推理引擎 MNN。MNN 提供了算法在端上跑模型所需要的算子。
|
||||
|
||||
## 四、云端一体协同
|
||||

|
||||
|
||||
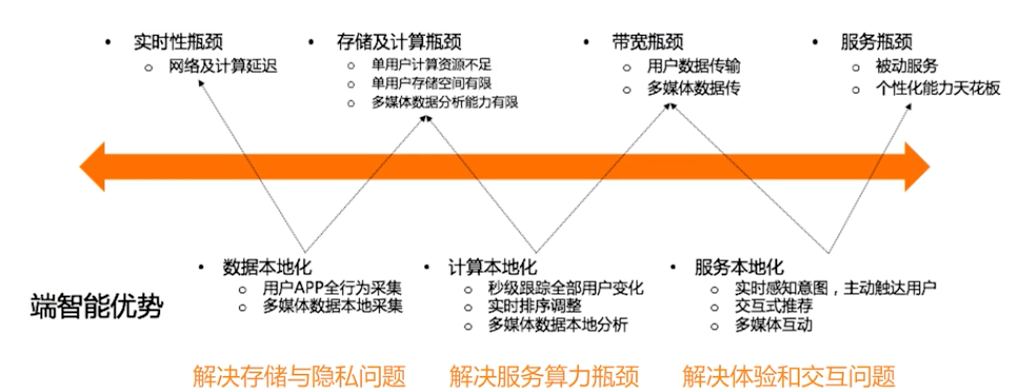
上图是端计算的优势和云计算的劣势。
|
||||
未来的端计算并不是完全割裂的。端和云协同才可以迸发最大的效果。
|
||||
|
||||

|
||||

|
||||
可以看到端和云拥有各自擅长的领域。
|
||||
|
||||
在做云端协同的过程中,会遇到不少问题。比如在端上触发一次重排的时候,会发现端上的数据量是不够的,如果想要提升端上的重排效果,就要扩大候选池,所以增加了**端上的缓存池**。在端上的模型在本地运行过程中,由于模型本身是在服务端训练的,它的模型和特征向量的同步一致性是需要细节方面处理好的。
|
||||
@@ -310,17 +310,17 @@ QA: 决策框架与 MNN 推理引擎的区别是什么?
|
||||
#### 1. 背景
|
||||
生鲜果蔬行业在零售行业中是一个较大且比较有特征性的行业,同时在生鲜果蔬行业中,称重秤为经营的刚需类设备。目前商家主要使用条码秤,通过 PLU(Price Lookup Code) 码进行商品的管理,每个 PLU 码对应一个商品,我们可以想象下在超市购买水果的时候会碰到下面这个流程:
|
||||
|
||||

|
||||

|
||||
|
||||
所以在门店商品种类比较多时(一个典型生鲜果蔬类商家商品种类大多超过 200 个,随机调研了 5 家有赞果蔬商家,平均 SKU 数量 500+),PLU 码较难记忆清楚,在打秤时需临时查询,称重耗时比较长,为了避免高峰时期排队现象,需在门店增加秤台和打称员,导致商家人力成本较高。
|
||||
|
||||
因此就前面所提到的场景,我们需要通过更加智能的方式帮助商家加购,那么基于机器学习的图像识别能力就被提上了议程。我们通过条码秤关联的摄像头进行实时拍摄,基于机器学习技术和图像识别技术,将店员放置在秤盘上的商品进行识别,并给出相关商品的列表,减少收银员收银场景中的操作次数,减少商家对新收银员的PLU码的培训并降低熟悉相关商品的培训成本,从而在整体上降低收银员的门槛以及商家的人力成本。所以我们可以得到我们期望的购买流程:
|
||||
|
||||

|
||||

|
||||
|
||||
#### 2. 架构设计
|
||||
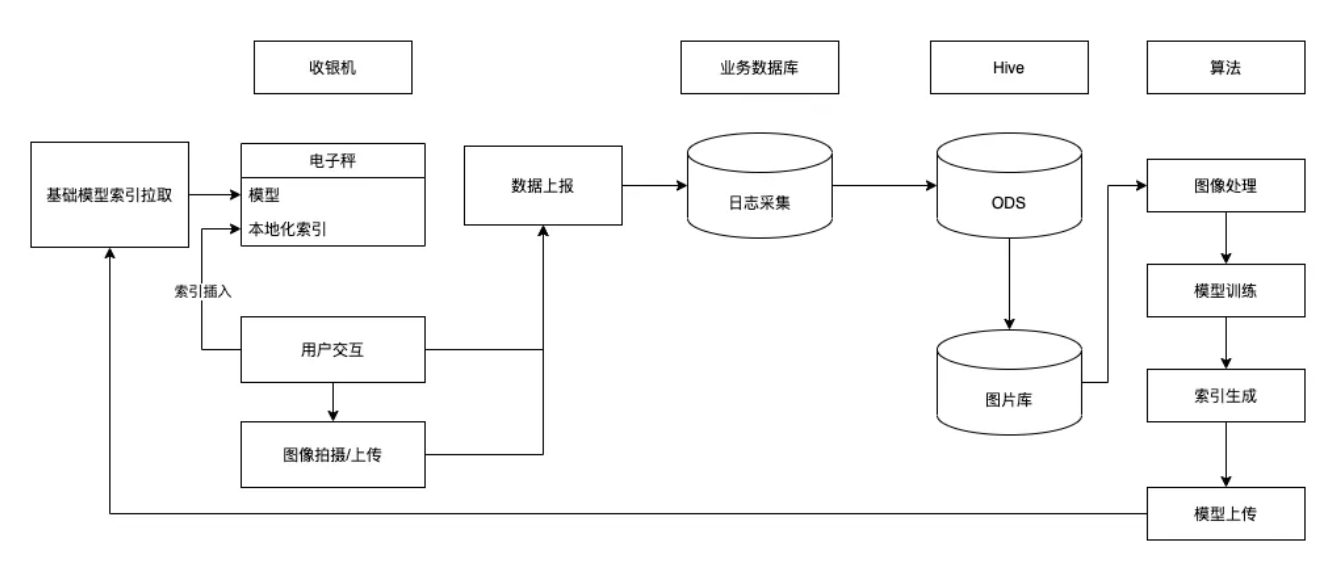
我们针对于商家的痛点和可行的解决方案绘制了下面的流程图:
|
||||

|
||||
|
||||
|
||||
整个流程中的基础能力:
|
||||
- 实现摄像头对于商品的拍摄
|
||||
@@ -378,7 +378,7 @@ PLU 码的核心作用是 “快速调取商品单价”,重量和总价需结
|
||||
#### 6. 反馈闭环
|
||||
在确定了核心能力的解决方案后,接下来需要解决的是如何将商家本地的数据进行上传,并对于已有模型进行强化。为了更加及时的获得用户本地的选择情况,我们选择了有赞埋点平台作为技术支撑,通过离线缓存,并结合闲时上报的能力,将用户选择图片的整体筛选情况,基于店铺/角色等维护进行拆分,并将最终的选择数据导入 ODS 库中。并在算法前结合用户选择时机的拍摄图片上传 + 用户选择商品情况进行结合,进一步针对于对应店铺的模型进行加强。从而在不断的强化商家模型,从而提高用户准确性。
|
||||
|
||||

|
||||

|
||||
|
||||
#### 7. 流程优化
|
||||
要达到好用的程度。所以我们需要对于数据统计流程/用户交互流程进行更加深入的优化
|
||||
|
||||
Reference in New Issue
Block a user