 +
+ @@ -64,7 +64,7 @@ Clang 相较于 GCC,具备下面优点:
- 设计清晰简单,容易理解,易于扩展增强
-
+
@@ -92,7 +92,7 @@ clang -ccc-print-phases main.m
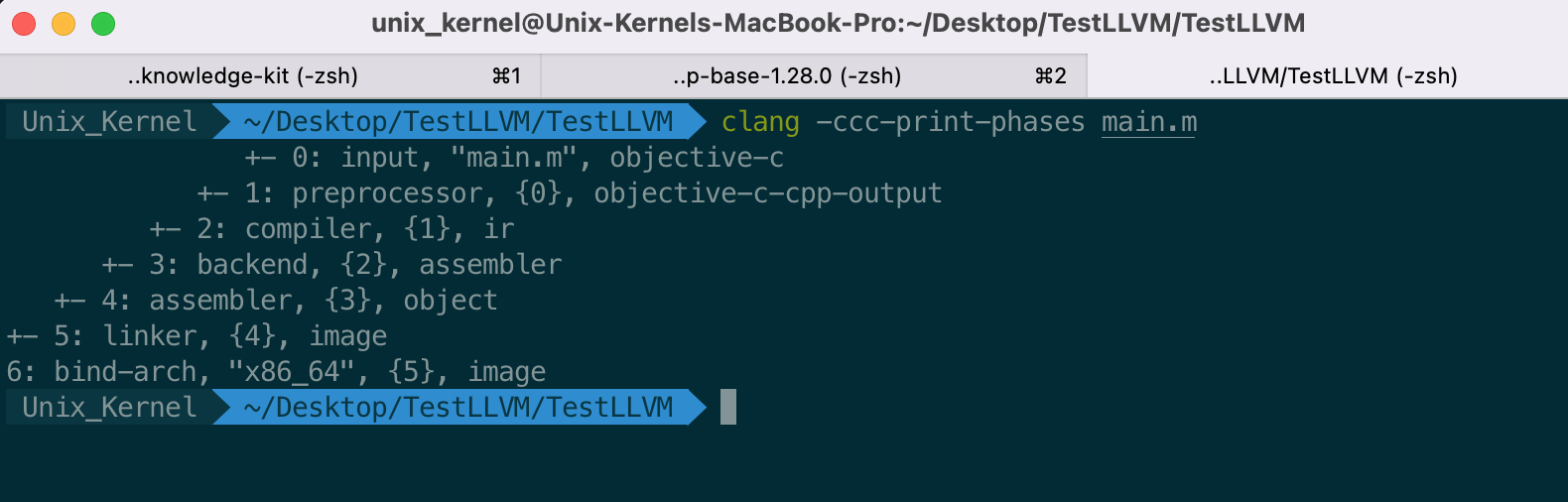
展示如下:
-
@@ -64,7 +64,7 @@ Clang 相较于 GCC,具备下面优点:
- 设计清晰简单,容易理解,易于扩展增强
-
+
@@ -92,7 +92,7 @@ clang -ccc-print-phases main.m
展示如下:
- +
+ @@ -104,7 +104,7 @@ clang -ccc-print-phases main.m
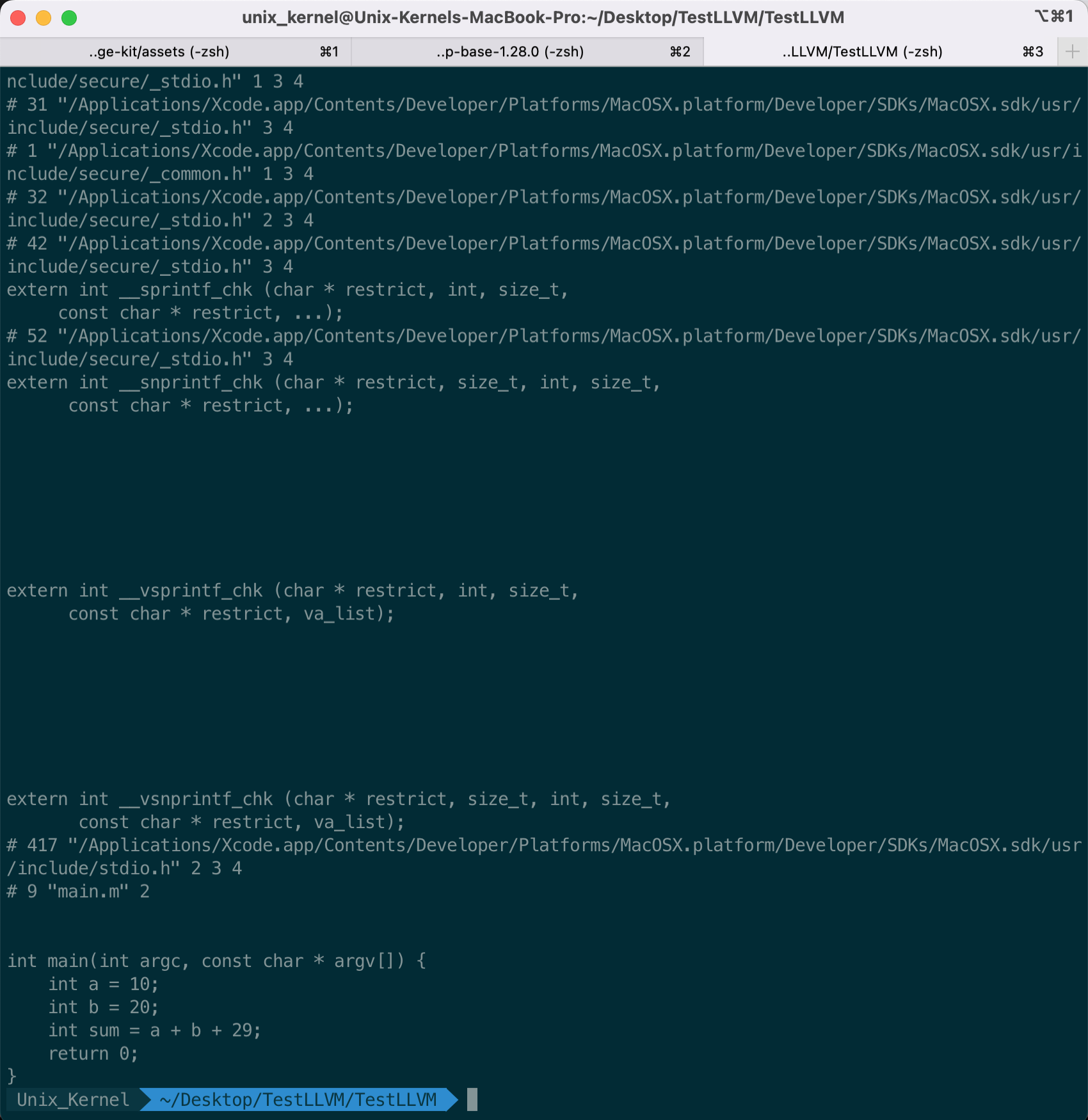
查看 preprocessor (预处理)的结果:`clang -E main.m`。预处理主要做的事情就是头文件导入( include、import)、宏定义替换等。展示如下:
-
@@ -104,7 +104,7 @@ clang -ccc-print-phases main.m
查看 preprocessor (预处理)的结果:`clang -E main.m`。预处理主要做的事情就是头文件导入( include、import)、宏定义替换等。展示如下:
- +
+ @@ -112,7 +112,7 @@ clang -ccc-print-phases main.m
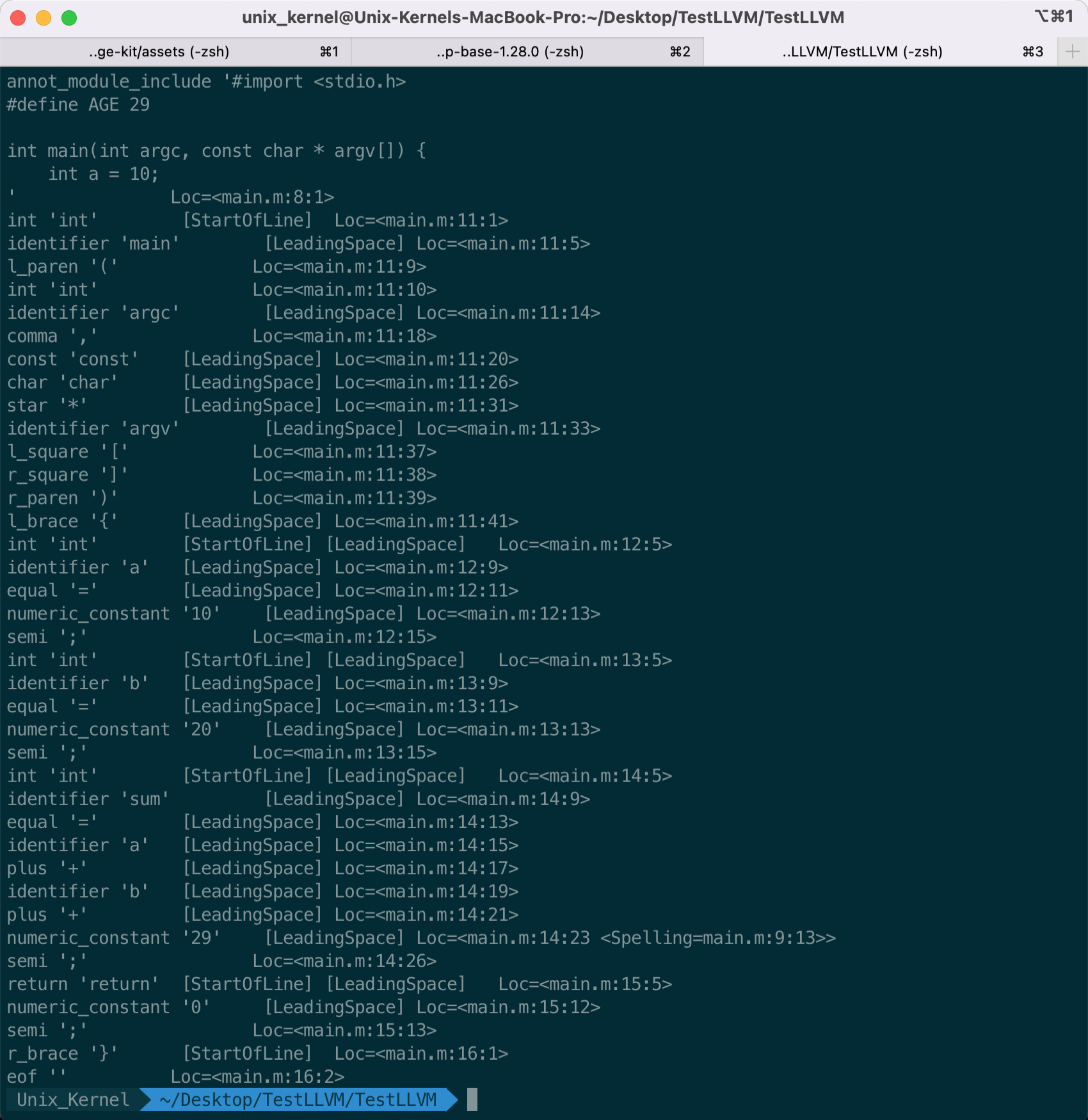
词法分析阶段,主要生成 Token。使用指令 `clang -fmodules -E -Xclang -dump-tokens main.m` 查看具体做了什么
-
@@ -112,7 +112,7 @@ clang -ccc-print-phases main.m
词法分析阶段,主要生成 Token。使用指令 `clang -fmodules -E -Xclang -dump-tokens main.m` 查看具体做了什么
- +
+ @@ -120,7 +120,7 @@ clang -ccc-print-phases main.m
语法分析阶段,生成语法树(AST,Abstract Syntax Tree)。使用指令 `clang -fmodules -fsyntax-only -Xclang -ast-dump main.m` 查看
-
@@ -120,7 +120,7 @@ clang -ccc-print-phases main.m
语法分析阶段,生成语法树(AST,Abstract Syntax Tree)。使用指令 `clang -fmodules -fsyntax-only -Xclang -ast-dump main.m` 查看
-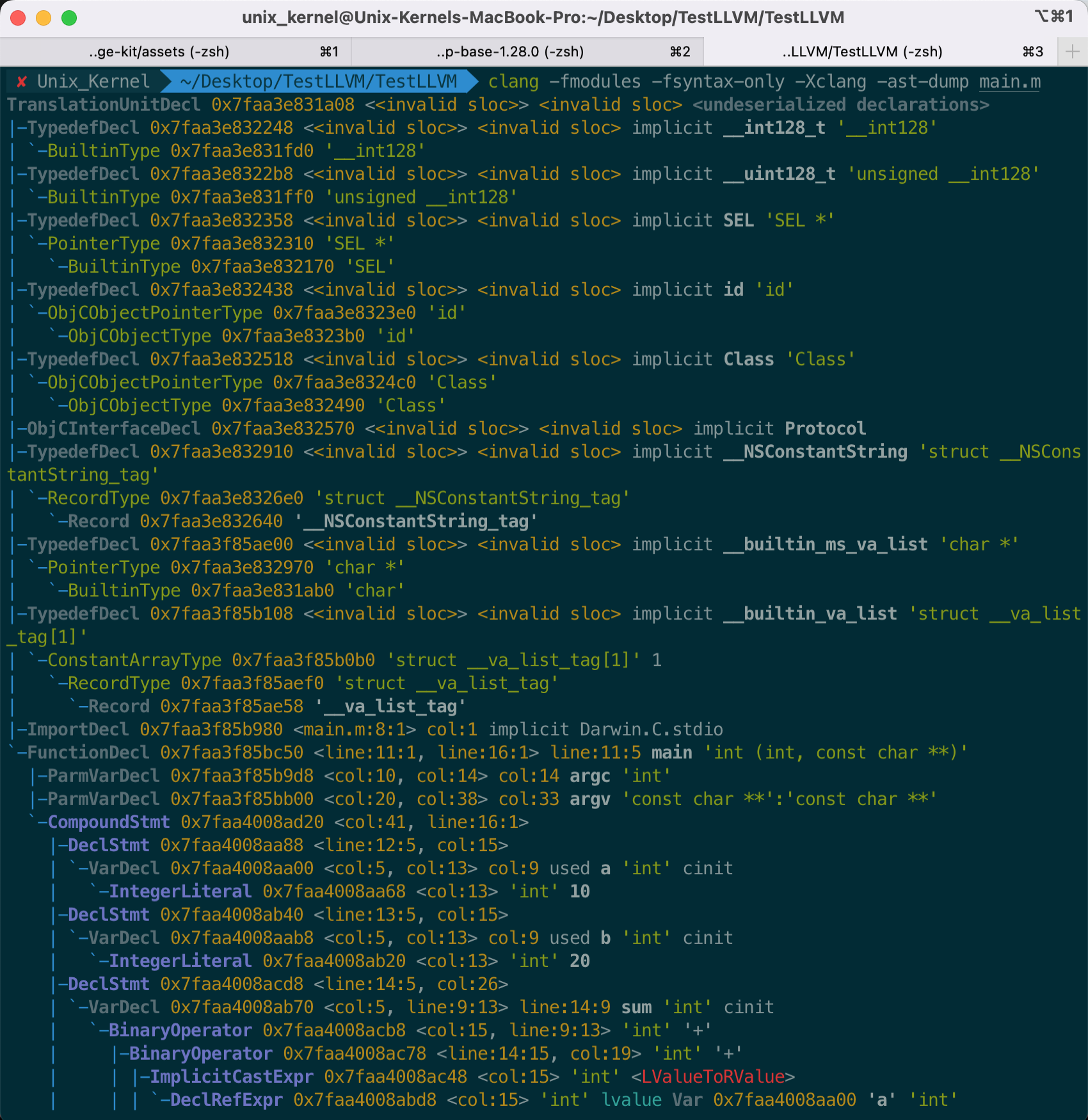 +
+ 对 main.m 的代码进行改造
@@ -142,7 +142,7 @@ void test(int a, int b) {
再次查看 AST 可以加深理解
-
对 main.m 的代码进行改造
@@ -142,7 +142,7 @@ void test(int a, int b) {
再次查看 AST 可以加深理解
-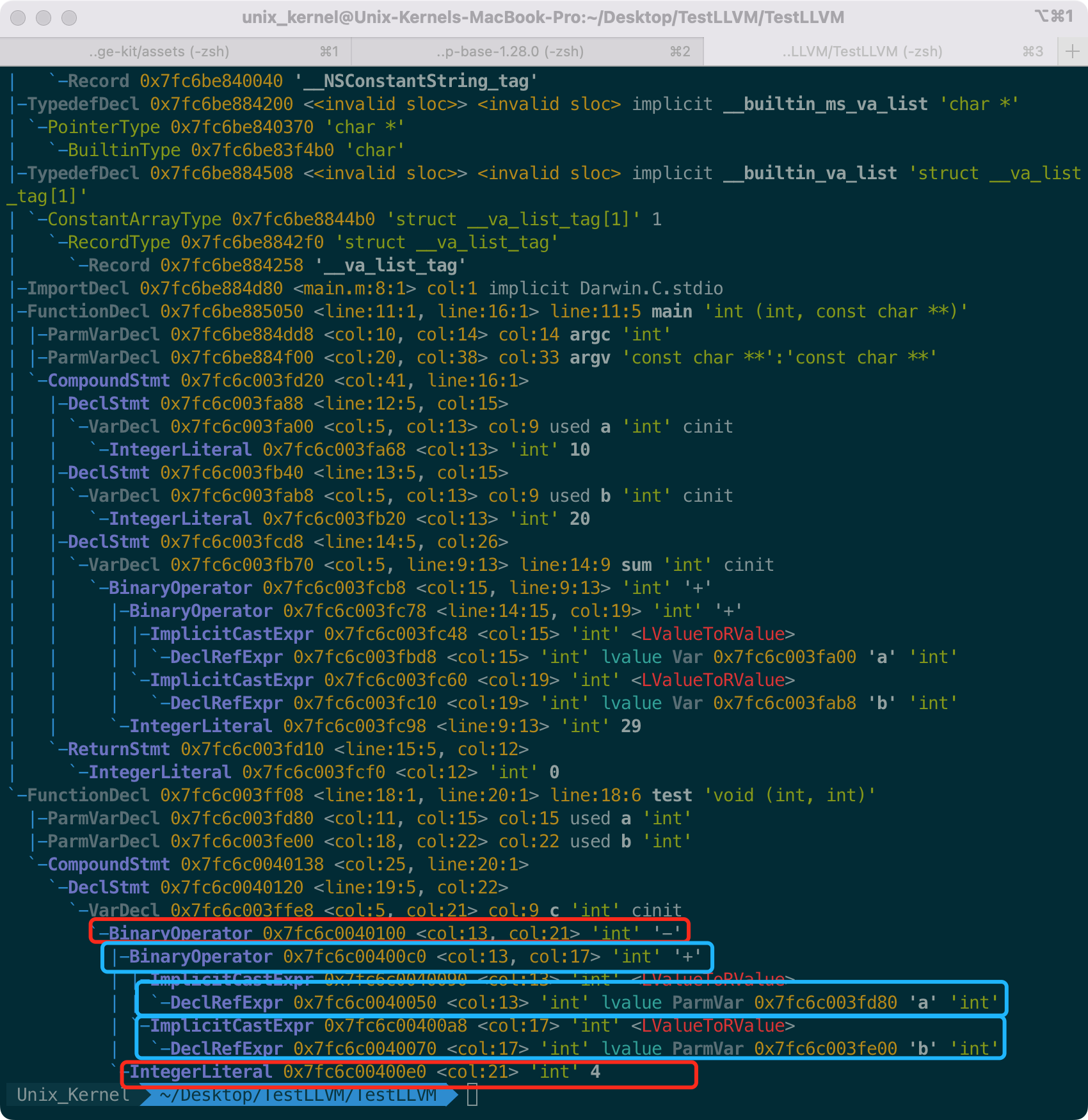 +
+ 其中:
@@ -154,7 +154,7 @@ void test(int a, int b) {
也就是先运算蓝色框内的值,然后用结果和红色框内的进行相减。所以这是很标准的树形结构。
-
其中:
@@ -154,7 +154,7 @@ void test(int a, int b) {
也就是先运算蓝色框内的值,然后用结果和红色框内的进行相减。所以这是很标准的树形结构。
- +
+ @@ -171,7 +171,7 @@ LLVM IR 有3种表示格式:
- text:便于阅读的文本格式,类似于汇编语言,推展名为 `.ll`。使用指令 `clang -S -emit-llvm main.m` 进行转换
-
@@ -171,7 +171,7 @@ LLVM IR 有3种表示格式:
- text:便于阅读的文本格式,类似于汇编语言,推展名为 `.ll`。使用指令 `clang -S -emit-llvm main.m` 进行转换
- 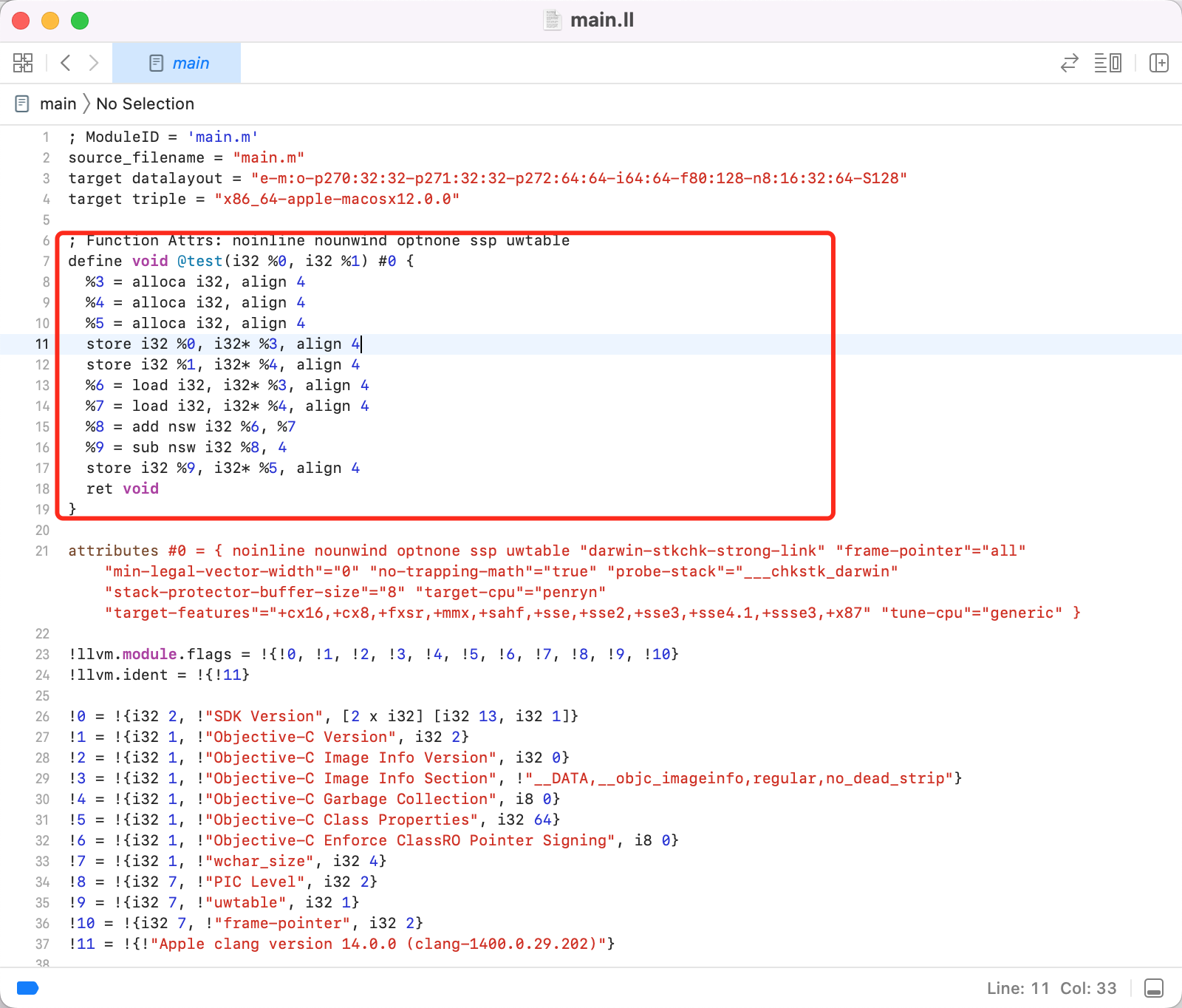 +
+  学过 arm64 汇编的话看这段 IR 很眼熟,汇编里 `load` 相关的指令都是从内存中装载数据,比如 `ldr`、`ldur` 、`ldp`。`store` 相关的指令是往内存中写入数据,比如 `str`、 `stur`、 `stp`
@@ -313,15 +313,15 @@ Tips:ninja 如果安装失败,可以直接从 [github]( https://github.com/n
```shell
mkdir llvm_xcode_build
cd llvm_xcode_build
- cmake -S .https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"
+ cmake -S ../../llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"
```
因为要编写 Clang 插件,是 c++ 代码,所以需要借助 IDE 的能力,我们选用 Xcode 进行编译。如下图所示,代表编译成功
-
学过 arm64 汇编的话看这段 IR 很眼熟,汇编里 `load` 相关的指令都是从内存中装载数据,比如 `ldr`、`ldur` 、`ldp`。`store` 相关的指令是往内存中写入数据,比如 `str`、 `stur`、 `stp`
@@ -313,15 +313,15 @@ Tips:ninja 如果安装失败,可以直接从 [github]( https://github.com/n
```shell
mkdir llvm_xcode_build
cd llvm_xcode_build
- cmake -S .https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"
+ cmake -S ../../llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"
```
因为要编写 Clang 插件,是 c++ 代码,所以需要借助 IDE 的能力,我们选用 Xcode 进行编译。如下图所示,代表编译成功
-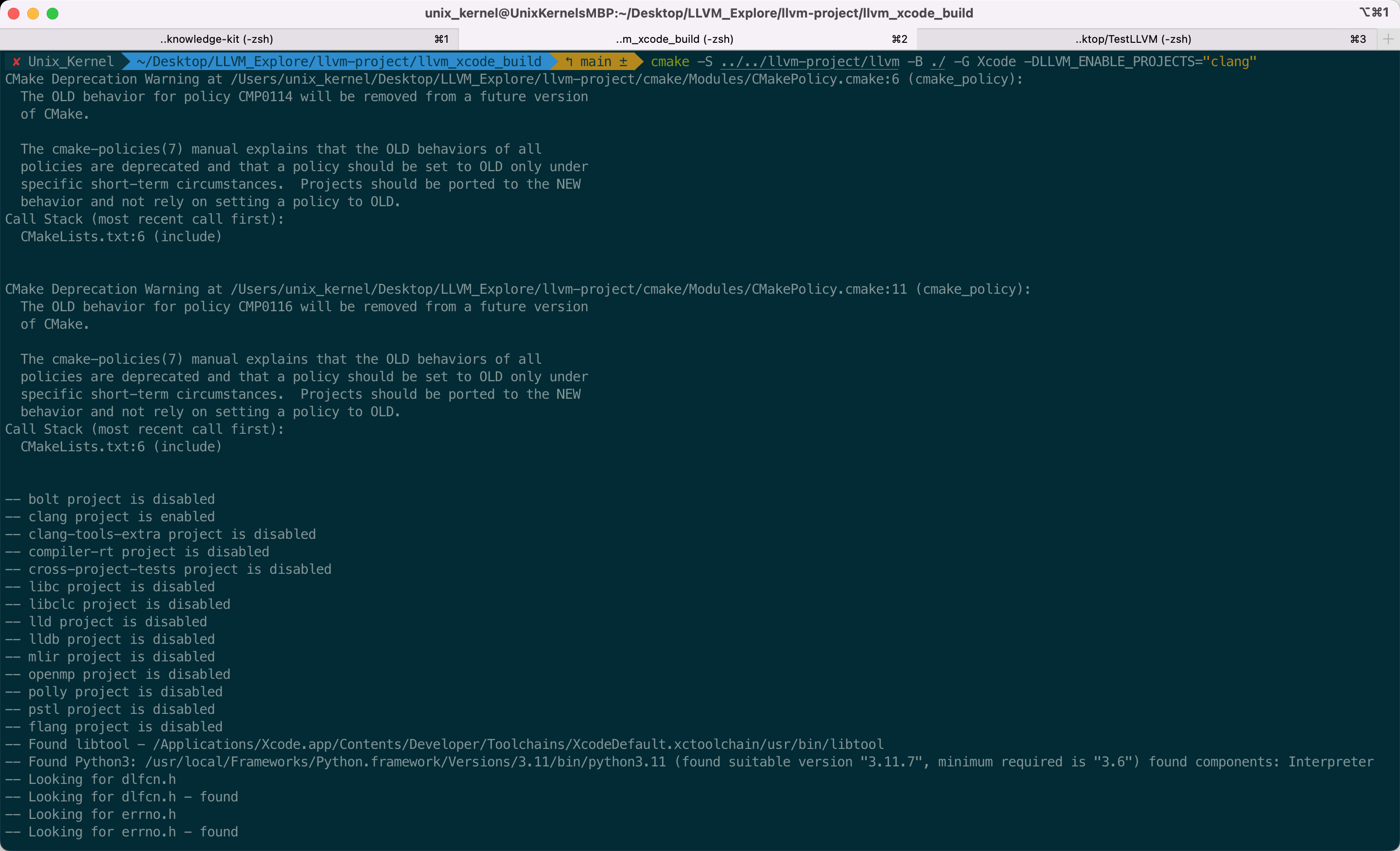 +
+ -
-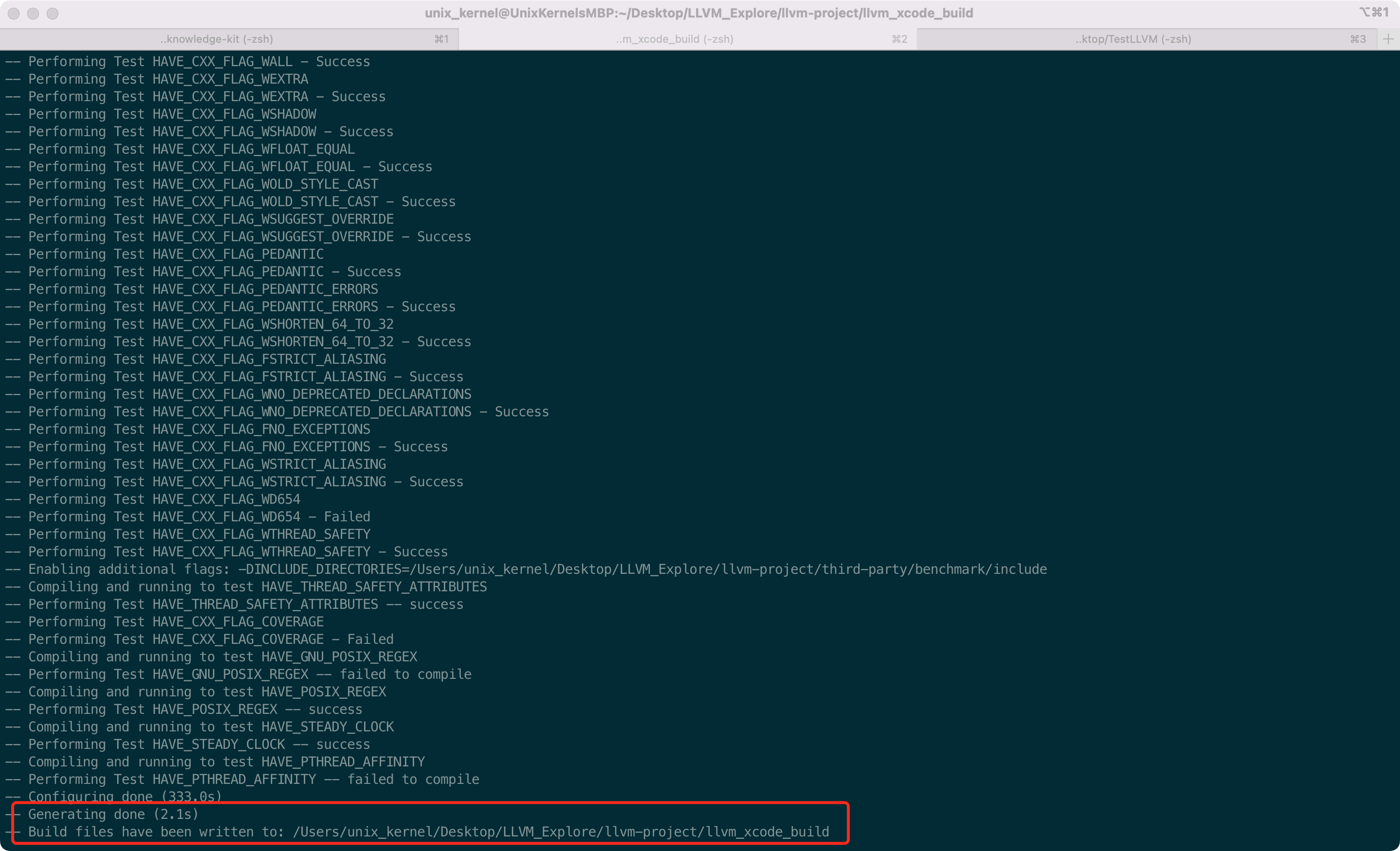 +
+ @@ -349,11 +349,11 @@ Tips:ninja 如果安装失败,可以直接从 [github]( https://github.com/n
- 先创建一个插件文件夹 `code-style-validate-plugin`
-
@@ -349,11 +349,11 @@ Tips:ninja 如果安装失败,可以直接从 [github]( https://github.com/n
- 先创建一个插件文件夹 `code-style-validate-plugin`
- 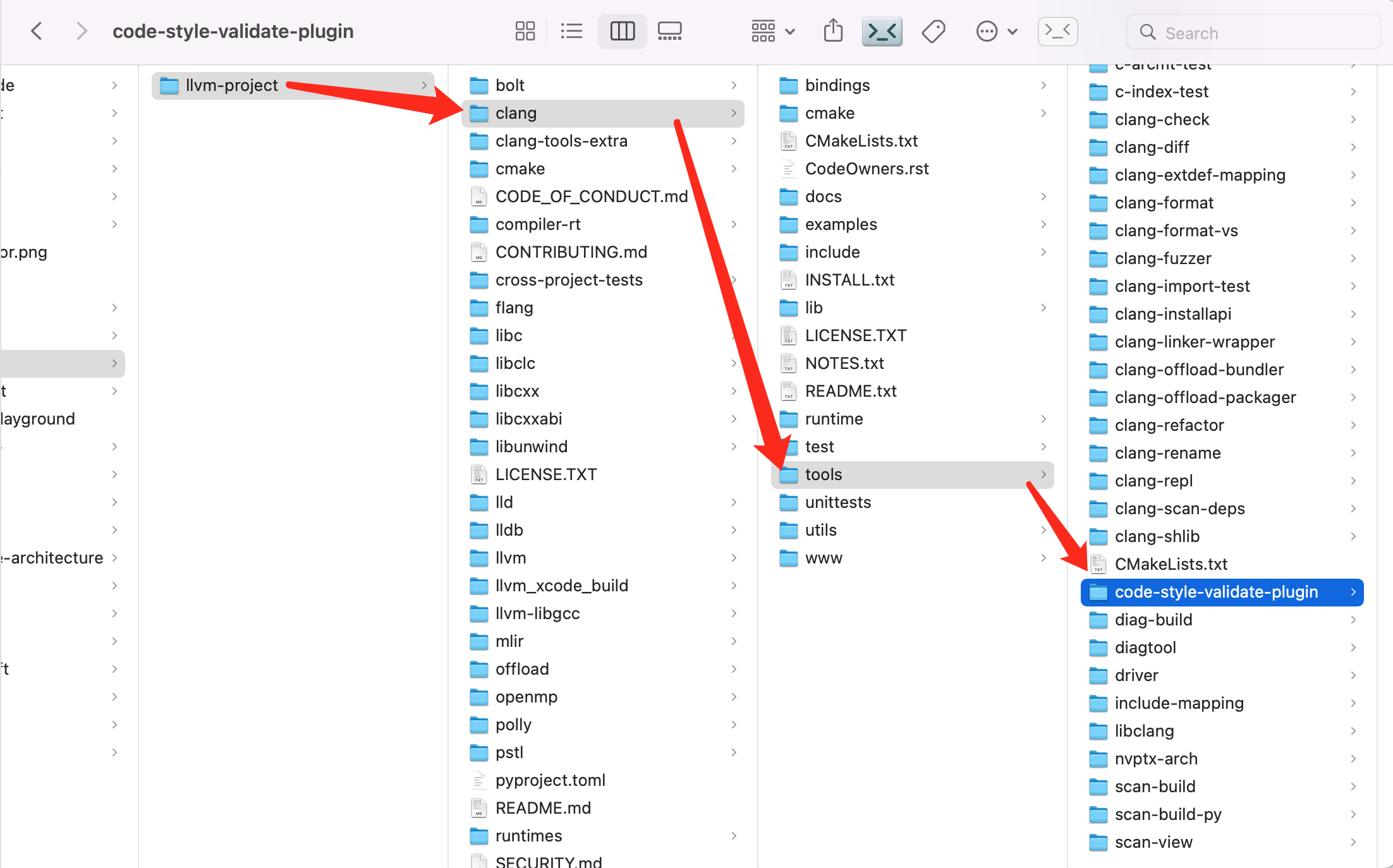 +
+  - 编辑 `CMakeLists.txt` 文件,在最后添加 `add_clang_subdirectory(code-style-validate-plugin)`
-
- 编辑 `CMakeLists.txt` 文件,在最后添加 `add_clang_subdirectory(code-style-validate-plugin)`
- 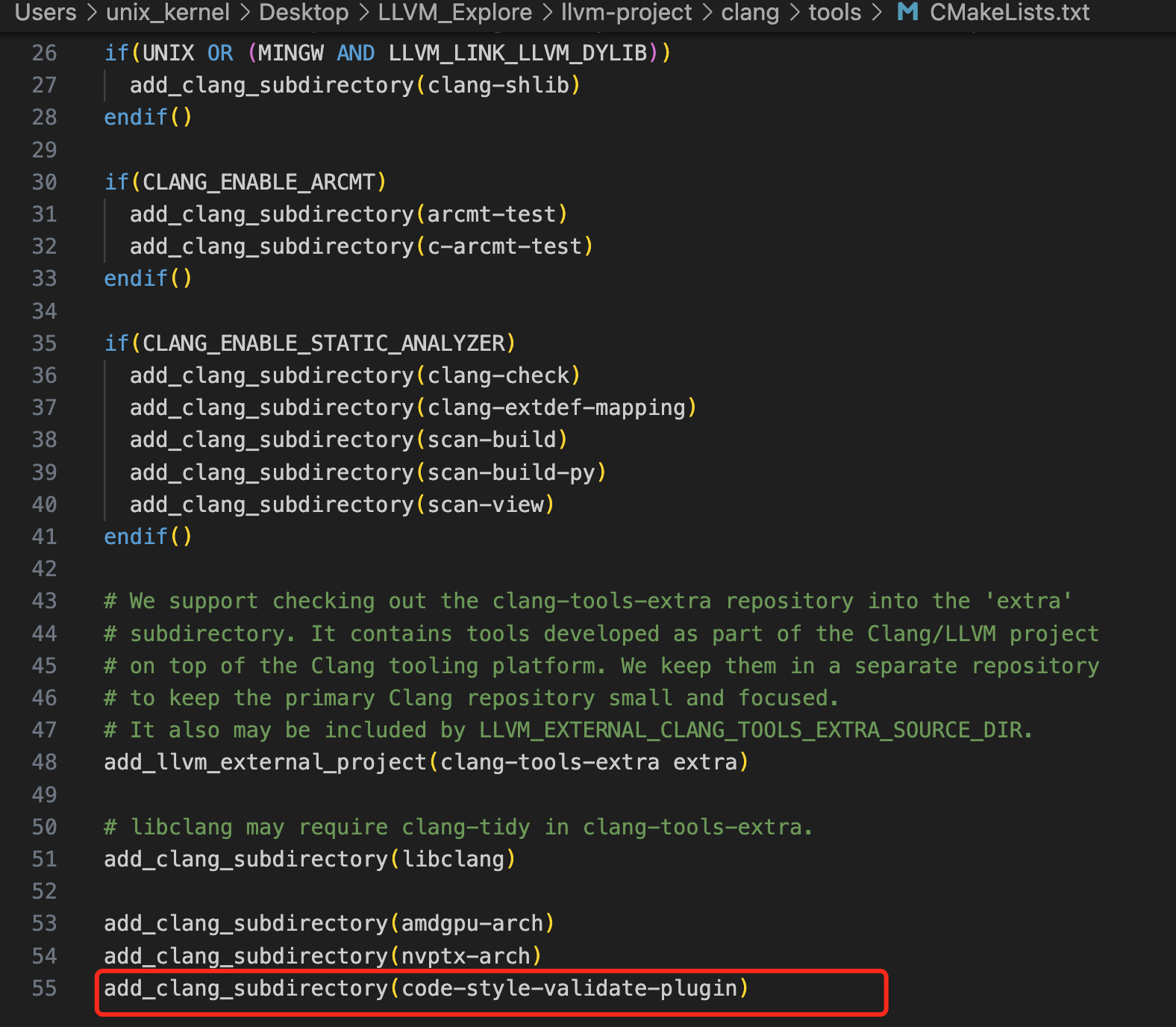 +
+  @@ -382,17 +382,17 @@ Xcode 打开项目,选择自动创建 Schemes
-
@@ -382,17 +382,17 @@ Xcode 打开项目,选择自动创建 Schemes
- +
+ 选择 Target 为 `CodeStyleValidatePlugin`,源代码所在文件夹为 `Sources/Loadable modules`,然后选中 CodeStyleValidatePlugin.cpp` 文件进行编写逻辑
-
选择 Target 为 `CodeStyleValidatePlugin`,源代码所在文件夹为 `Sources/Loadable modules`,然后选中 CodeStyleValidatePlugin.cpp` 文件进行编写逻辑
- +
+ 初步编写后 Command + B 进行编译,在 Products 下可以看到编译产物:`CodeStyleValidatePlugin.dylib` 动态库。
-
初步编写后 Command + B 进行编译,在 Products 下可以看到编译产物:`CodeStyleValidatePlugin.dylib` 动态库。
- +
+ @@ -402,7 +402,7 @@ Xcode 打开项目,选择自动创建 Schemes
此步骤的目的是:在 testLLVM 项目中,加载 `CodeStyleValidatePlugin.dylib` 插件可以成功。因为默认的 Xcode 使用的 clang/clang++ 编译器和编译 `CodeStyleValidatePlugin.dylib` 动态库不是一个版本。不做修改的话,Xcode 加载 `CodeStyleValidatePlugin.dylib` 会报错。所以需要先编译出同一个 LLVM 版本的 clang/clang++。
-
@@ -402,7 +402,7 @@ Xcode 打开项目,选择自动创建 Schemes
此步骤的目的是:在 testLLVM 项目中,加载 `CodeStyleValidatePlugin.dylib` 插件可以成功。因为默认的 Xcode 使用的 clang/clang++ 编译器和编译 `CodeStyleValidatePlugin.dylib` 动态库不是一个版本。不做修改的话,Xcode 加载 `CodeStyleValidatePlugin.dylib` 会报错。所以需要先编译出同一个 LLVM 版本的 clang/clang++。
- +
+ @@ -421,7 +421,7 @@ Xcode 打开项目,选择自动创建 Schemes
- `-Xclang`
- 插件名称
-
@@ -421,7 +421,7 @@ Xcode 打开项目,选择自动创建 Schemes
- `-Xclang`
- 插件名称
-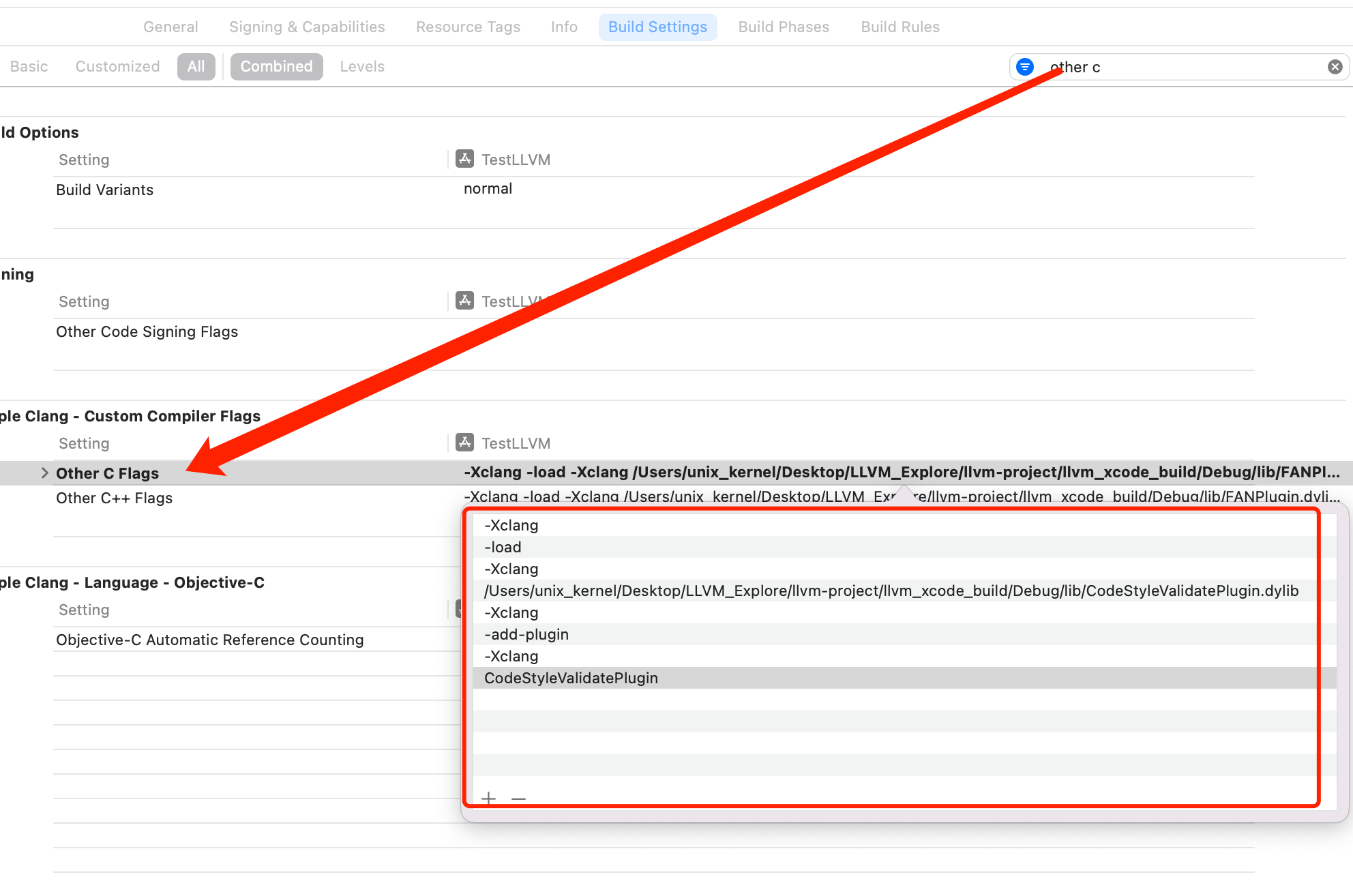 +
+ @@ -429,7 +429,7 @@ Xcode 打开项目,选择自动创建 Schemes
在新创建的 TestLLVM Xcode 项目中加载创建的 `CodeStyleValidatePlugin.dylib` 会报错。原因是:由于 Clang 插件需要使用对应的版本去加载,如果版本不一致则会导致编译错误。如下所示:
-
@@ -429,7 +429,7 @@ Xcode 打开项目,选择自动创建 Schemes
在新创建的 TestLLVM Xcode 项目中加载创建的 `CodeStyleValidatePlugin.dylib` 会报错。原因是:由于 Clang 插件需要使用对应的版本去加载,如果版本不一致则会导致编译错误。如下所示:
-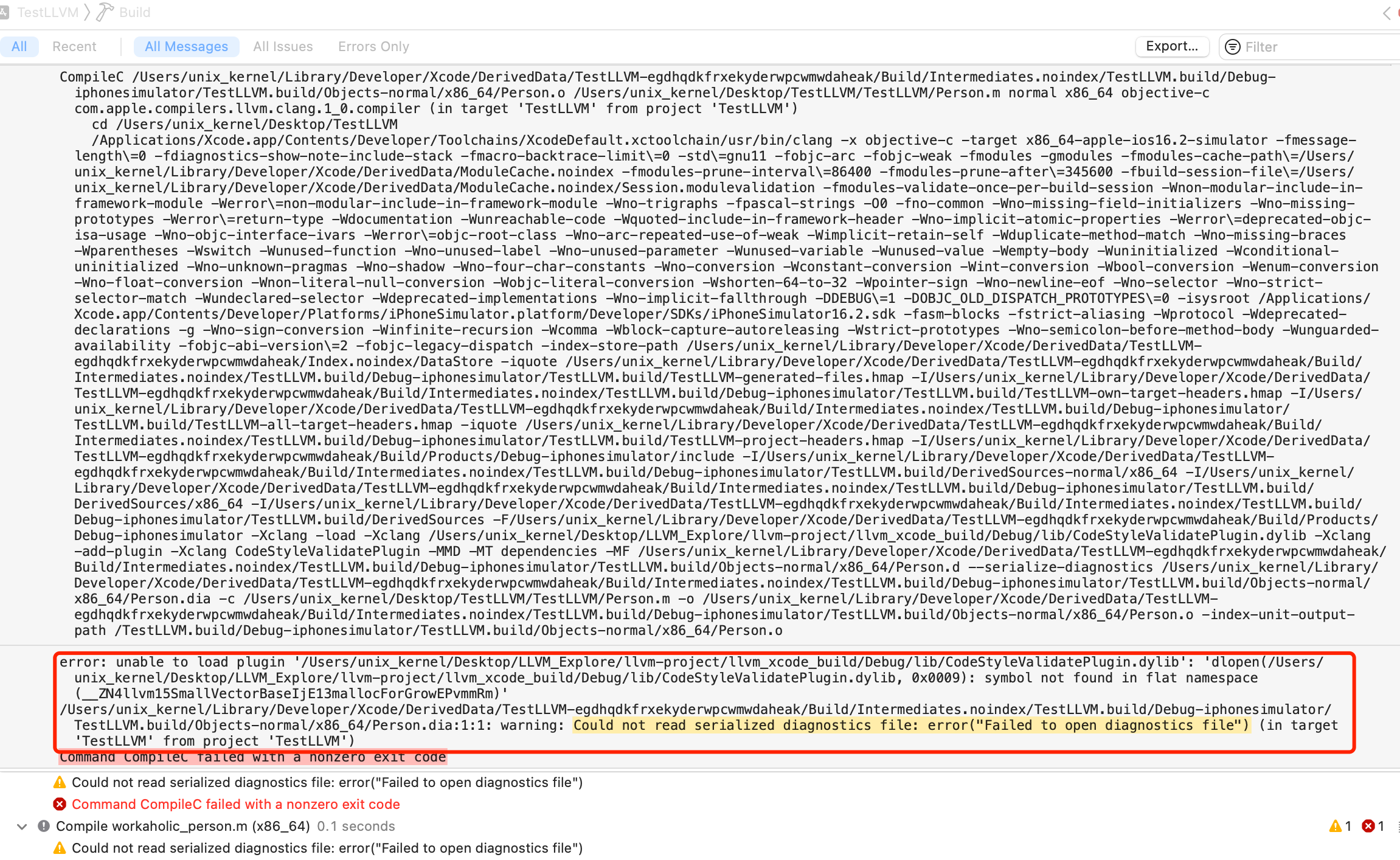 +
+ @@ -441,17 +441,17 @@ Xcode 打开项目,选择自动创建 Schemes
如下所示:
-
@@ -441,17 +441,17 @@ Xcode 打开项目,选择自动创建 Schemes
如下所示:
- +
+ 继续编译还是会报错,报错如下:
-
继续编译还是会报错,报错如下:
-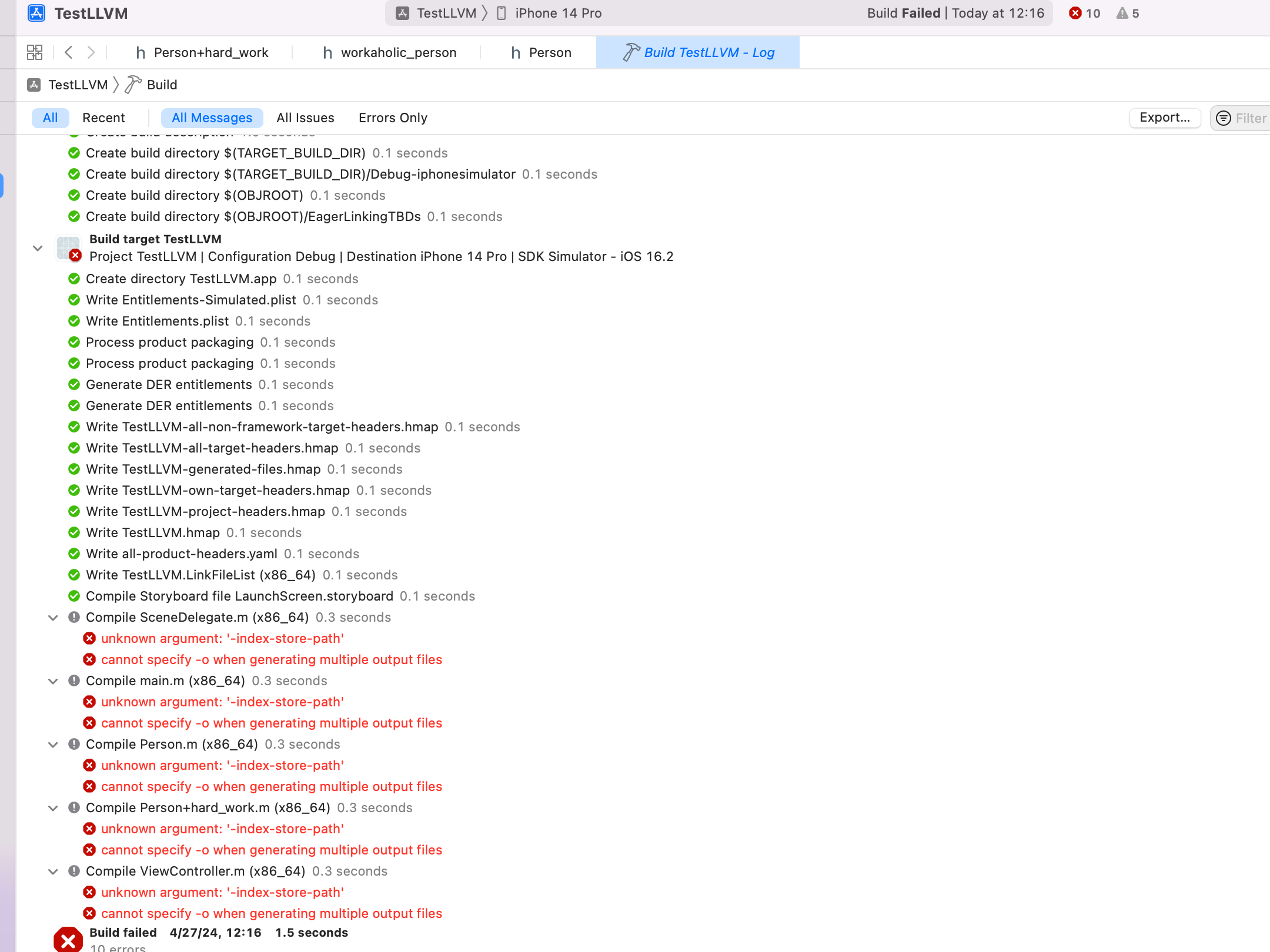 +
+ 解决方案为:在 `Build Settings` 栏目中搜索 `index`,将 `Enable Index-Wihle-Building Functionality` 的 ` Default` 改为 `NO`。
-
解决方案为:在 `Build Settings` 栏目中搜索 `index`,将 `Enable Index-Wihle-Building Functionality` 的 ` Default` 改为 `NO`。
-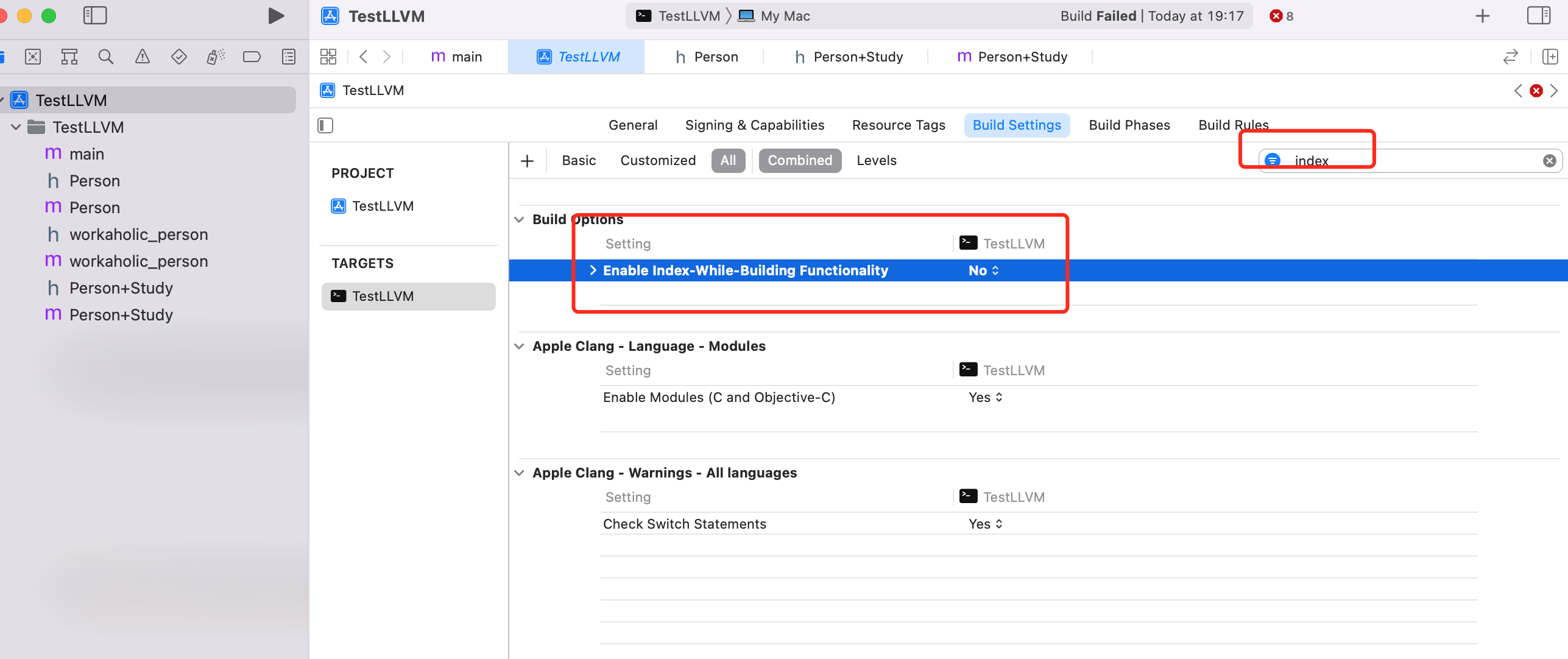 +
+ @@ -463,7 +463,7 @@ Tips: 由于重新修改了插件的源码,所以每次 Build 构建完 FANP
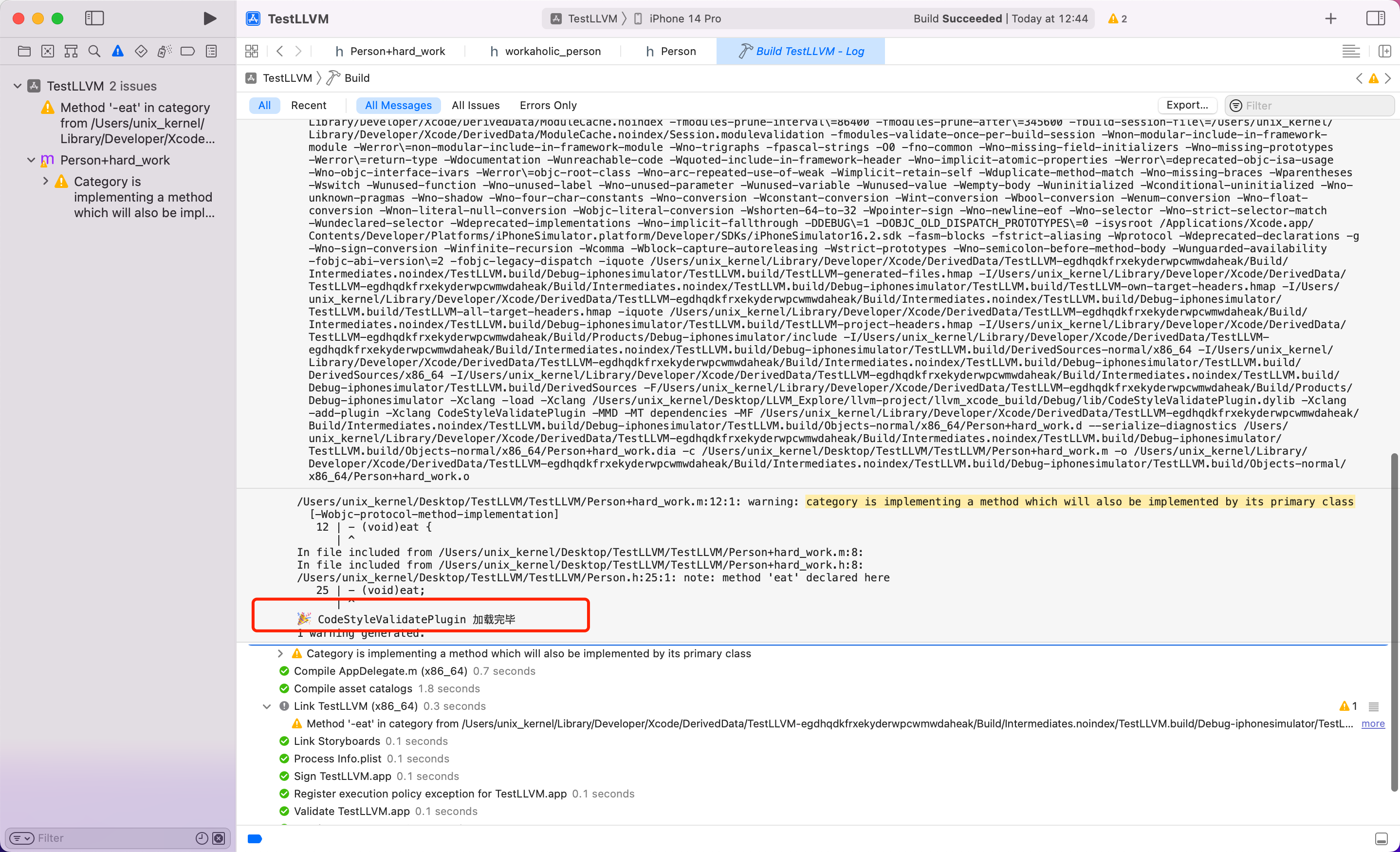
编译成功,可以看到在日志中输出了我们编写的日志信息。
-
@@ -463,7 +463,7 @@ Tips: 由于重新修改了插件的源码,所以每次 Build 构建完 FANP
编译成功,可以看到在日志中输出了我们编写的日志信息。
- +
+ @@ -496,7 +496,7 @@ NS_ASSUME_NONNULL_END
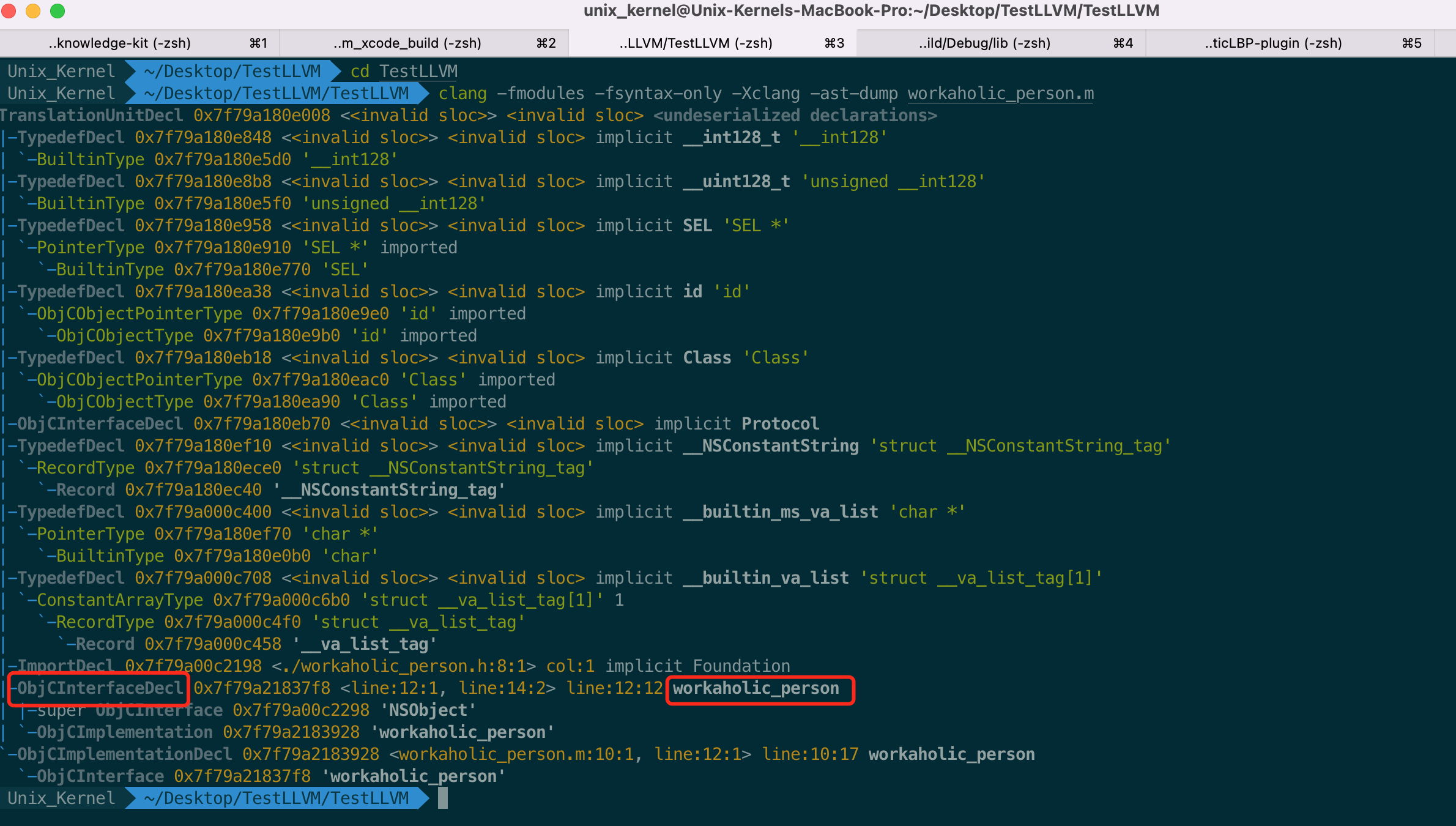
利用 Clang 查看 AST 指令为 `clang -fmodules -fsyntax-only -Xclang -ast-dump workaholic_person.m`
-
@@ -496,7 +496,7 @@ NS_ASSUME_NONNULL_END
利用 Clang 查看 AST 指令为 `clang -fmodules -fsyntax-only -Xclang -ast-dump workaholic_person.m`
- +
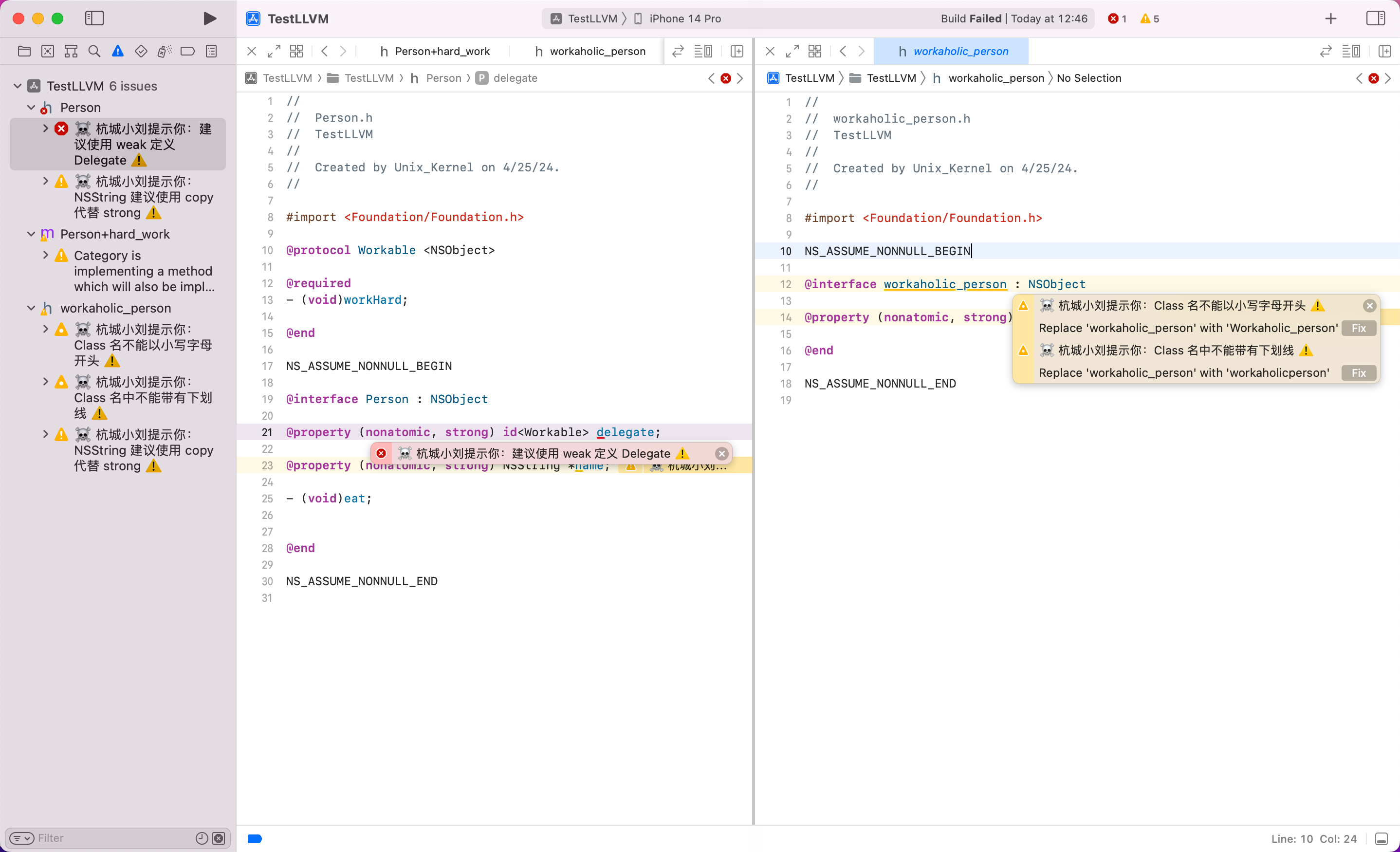
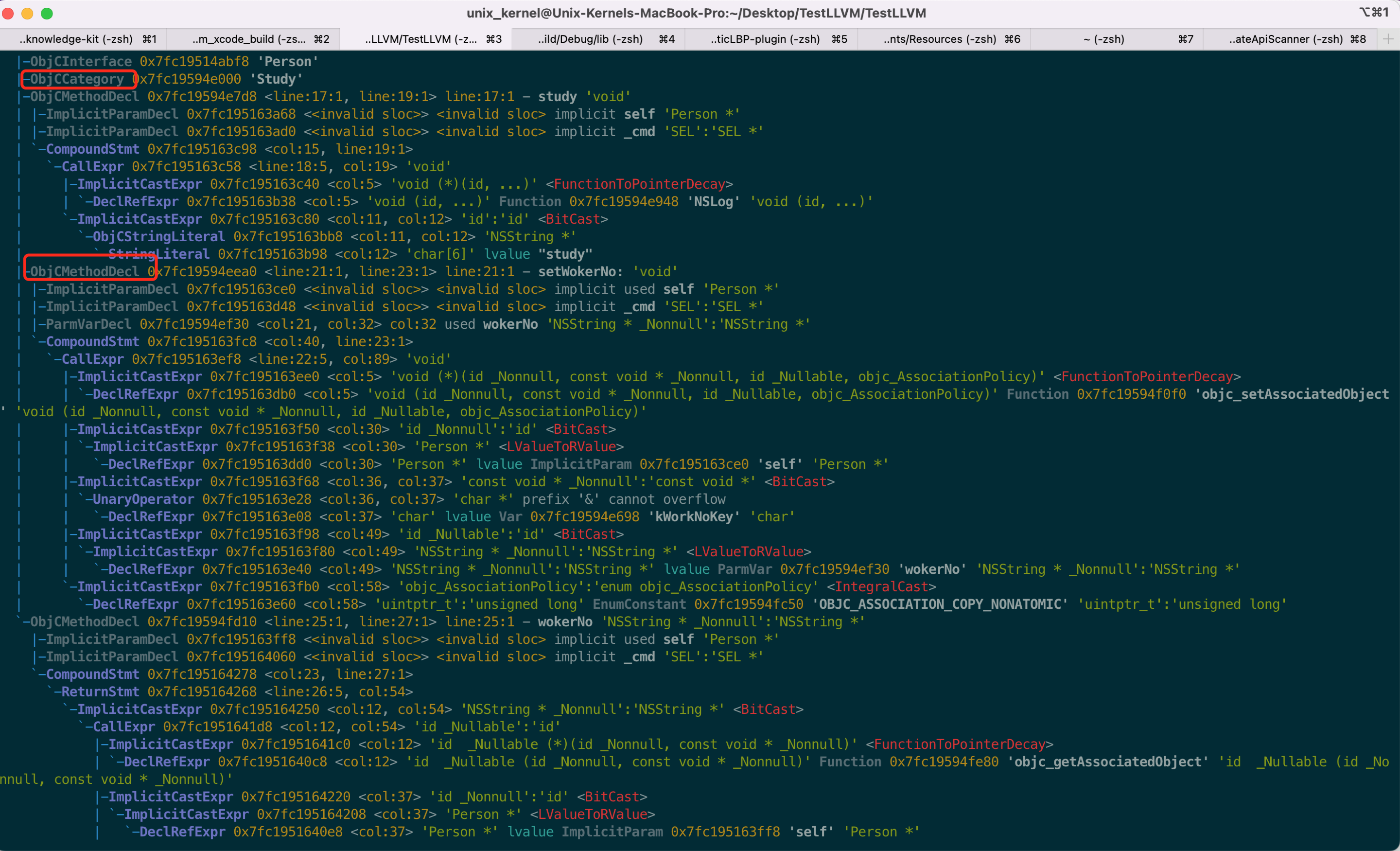
+ 核心思路为:我们要分析类名不符合规范的情况,要精确报错,首先要识别到类名,利用 AST 的能力可以办到(类名在 AST 的 `ObjCInterfaceDecl` 节点上)。然后获取到类名的行号信息,精确报错。
@@ -786,7 +786,7 @@ X("CodeStyleValidatePlugin", "This plugin is designed for scanning code styles,
- 可以对 Category 名做检测,如果带下划线,则报错提示并给出修改意见
- 编写的 `CodeStyleValidatePlugin` Demo 中对不符合规范的做了 `DiagnosticsEngine::Warning` 级别的警告。如果遇到1个警告则不影响,继续编译。如果是 `DiagnosticsEngine::Error` 级别的编译报错,遇到1个则终止编译,请注意该区别,按需编写自己的插件逻辑。
-
核心思路为:我们要分析类名不符合规范的情况,要精确报错,首先要识别到类名,利用 AST 的能力可以办到(类名在 AST 的 `ObjCInterfaceDecl` 节点上)。然后获取到类名的行号信息,精确报错。
@@ -786,7 +786,7 @@ X("CodeStyleValidatePlugin", "This plugin is designed for scanning code styles,
- 可以对 Category 名做检测,如果带下划线,则报错提示并给出修改意见
- 编写的 `CodeStyleValidatePlugin` Demo 中对不符合规范的做了 `DiagnosticsEngine::Warning` 级别的警告。如果遇到1个警告则不影响,继续编译。如果是 `DiagnosticsEngine::Error` 级别的编译报错,遇到1个则终止编译,请注意该区别,按需编写自己的插件逻辑。
- +
+ +
+ @@ -872,7 +872,7 @@ LLVM 项目中 clang 内置了一堆 checker,用于实现 lint。
- 自动调用 `[super dealloc]`
-
@@ -872,7 +872,7 @@ LLVM 项目中 clang 内置了一堆 checker,用于实现 lint。
- 自动调用 `[super dealloc]`
- 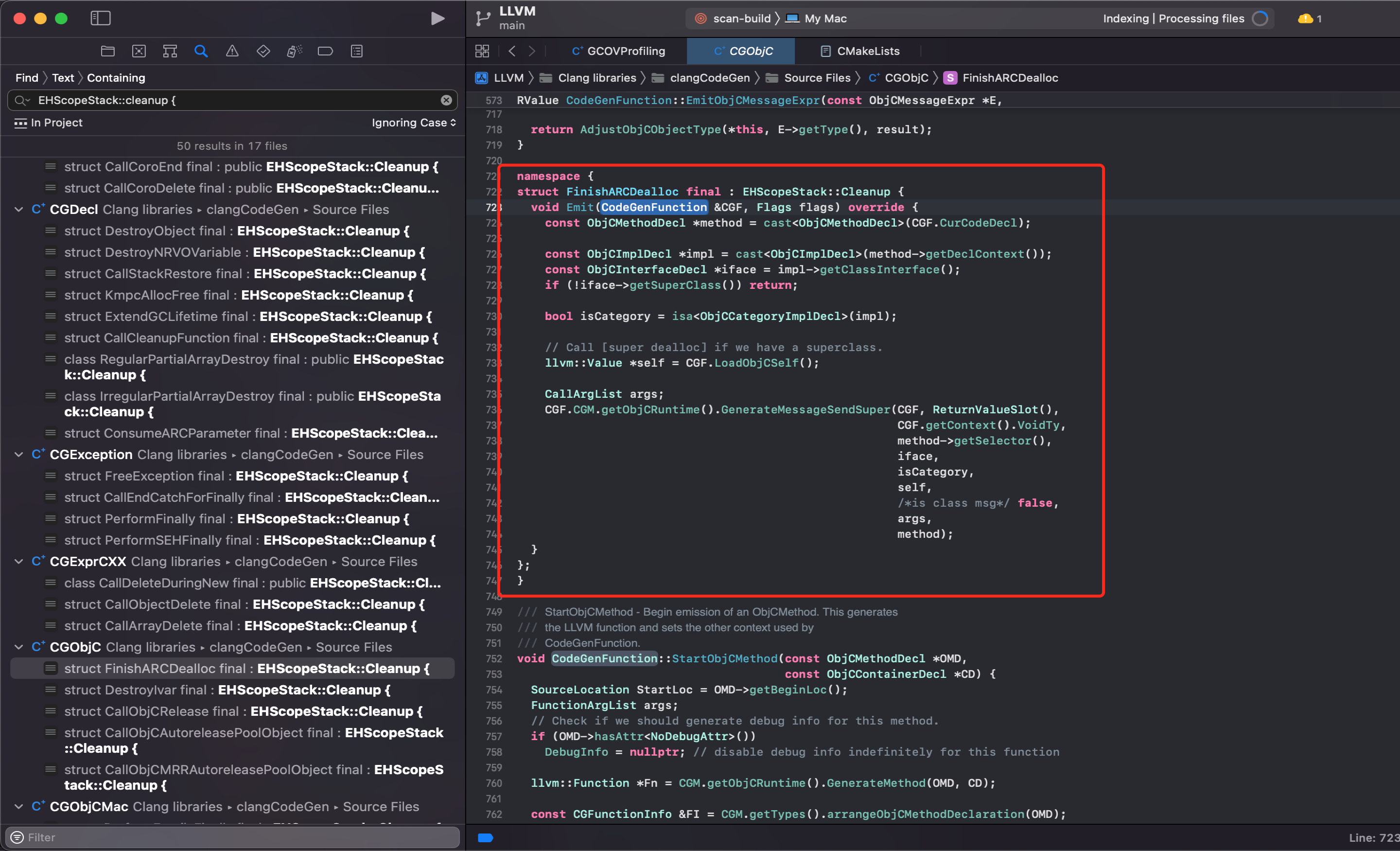 +
+  - 为每个拥有 ivar 的 Class 合成` .cxx_destructor` 方法来自动释放类的成员变量,代替 MRC 时代的 `self.xxx = nil`
diff --git a/Chapter1 - iOS/1.105.md b/Chapter1 - iOS/1.105.md
index 247abd3..60da1dc 100644
--- a/Chapter1 - iOS/1.105.md
+++ b/Chapter1 - iOS/1.105.md
@@ -18,9 +18,149 @@ UIView 绘制流程。
当调用 UIView `[UIView setNeedsDisplay]` 方法时,系统会立刻调用其 Layer 的同名方法 `[view.layer setNeedsDisplay]` 方法,之后相当于给当前 Layer 打上一个脏标记,之后会在当前 RunLoop 快要结束的时候才会调用 Layer 的 `[CALayer display]` 方法。然后进入当前 UIView 真正的绘制流程中。
-其次,会判断 CALayer 的代理,有没有实现 `displayLayer:` 方法,如果没有实现,则进入系统的绘制流程中;如果实现了,则可能是异步绘制或者自定义渲染的实现。
+其次,会判断 CALayer 的代理,有没有实现 `displayLayer:` 方法
+
+- 如果没有实现,则进入系统的绘制流程:比如:创建绘制上下文、调用 `drawInContext:`、生成内容并赋值给 `contents`
+- 如果实现了,则可能是异步绘制或者自定义渲染的实现。是**代理自定义绘制的入口**。代理可以在这个方法里直接设置`layer.contents`(比如异步绘制生成 UIImage 后赋值给`contents`),完全接管 layer 的内容渲染
+
+
+
+Demo1:
+
+自定义 View,不实现 `displayInContext` 方法
+
+```objective-c
+#import
- 为每个拥有 ivar 的 Class 合成` .cxx_destructor` 方法来自动释放类的成员变量,代替 MRC 时代的 `self.xxx = nil`
diff --git a/Chapter1 - iOS/1.105.md b/Chapter1 - iOS/1.105.md
index 247abd3..60da1dc 100644
--- a/Chapter1 - iOS/1.105.md
+++ b/Chapter1 - iOS/1.105.md
@@ -18,9 +18,149 @@ UIView 绘制流程。
当调用 UIView `[UIView setNeedsDisplay]` 方法时,系统会立刻调用其 Layer 的同名方法 `[view.layer setNeedsDisplay]` 方法,之后相当于给当前 Layer 打上一个脏标记,之后会在当前 RunLoop 快要结束的时候才会调用 Layer 的 `[CALayer display]` 方法。然后进入当前 UIView 真正的绘制流程中。
-其次,会判断 CALayer 的代理,有没有实现 `displayLayer:` 方法,如果没有实现,则进入系统的绘制流程中;如果实现了,则可能是异步绘制或者自定义渲染的实现。
+其次,会判断 CALayer 的代理,有没有实现 `displayLayer:` 方法
+
+- 如果没有实现,则进入系统的绘制流程:比如:创建绘制上下文、调用 `drawInContext:`、生成内容并赋值给 `contents`
+- 如果实现了,则可能是异步绘制或者自定义渲染的实现。是**代理自定义绘制的入口**。代理可以在这个方法里直接设置`layer.contents`(比如异步绘制生成 UIImage 后赋值给`contents`),完全接管 layer 的内容渲染
+
+
+
+Demo1:
+
+自定义 View,不实现 `displayInContext` 方法
+
+```objective-c
+#import  +
+说明:类似一个 CS 架构。
+
+- **`lldb-mi` 的角色:** 它是一个**协议适配器**,专注于将 **GDB/MI 协议** 翻译成 **LLDB API 调用**。
+- **`API` 是关键桥梁:** `lldb-mi` 几乎所有的功能都通过调用 **LLDB Public API** 来实现。
+- **Core 下的模块是 LLDB 的能力:** 图中 `Core` 下列出的 `Object Files`, `Symbols`, `Process` 等,代表了 **LLDB 调试器引擎本身提供的强大核心功能**。`lldb-mi` 依赖 API 来利用这些功能。
+- **依赖关系:** `lldb-mi` -> `API` -> (LLDB 核心引擎的) `Object Files`, `Mach-O/ELF`, `Symbols`, `DWARF`, `Disassembly`, `LLVM`, `Process`, `GDB Remote`。
+- **目的:** 这张图说明了 `lldb-mi` 是如何构建在 LLDB 强大的核心调试引擎之上,通过标准的 API 调用其功能,从而为支持 GDB/MI 协议的客户端提供调试服务。
+
+
+
+
+
+## LLDB Workflow
+
+
+
+说明:类似一个 CS 架构。
+
+- **`lldb-mi` 的角色:** 它是一个**协议适配器**,专注于将 **GDB/MI 协议** 翻译成 **LLDB API 调用**。
+- **`API` 是关键桥梁:** `lldb-mi` 几乎所有的功能都通过调用 **LLDB Public API** 来实现。
+- **Core 下的模块是 LLDB 的能力:** 图中 `Core` 下列出的 `Object Files`, `Symbols`, `Process` 等,代表了 **LLDB 调试器引擎本身提供的强大核心功能**。`lldb-mi` 依赖 API 来利用这些功能。
+- **依赖关系:** `lldb-mi` -> `API` -> (LLDB 核心引擎的) `Object Files`, `Mach-O/ELF`, `Symbols`, `DWARF`, `Disassembly`, `LLVM`, `Process`, `GDB Remote`。
+- **目的:** 这张图说明了 `lldb-mi` 是如何构建在 LLDB 强大的核心调试引擎之上,通过标准的 API 调用其功能,从而为支持 GDB/MI 协议的客户端提供调试服务。
+
+
+
+
+
+## LLDB Workflow
+
+ +
+说明:
+
+- **lldb-server**:调试服务端,`lldb-server` 作为“调试代理”,直接操控目标程序。分为两种部署方式:
+
+ - **Host 端**:调试本地程序(如 macOS 进程)。
+
+ - **Remote 端**:部署到目标设备(如手机/嵌入式设备),直接控制被调试程序
+
+- 通信层:TCP + GDB RSP 协议
+
+ - **TCP Socket**:物理传输通道,连接 Host 的 LLDB 和 Remote 的 lldb-server
+ - **GDB RSP (Remote Serial Protocol)**
+ - **基于 ASCII 的调试协议**(明文消息,如 `$m
+
+说明:
+
+- **lldb-server**:调试服务端,`lldb-server` 作为“调试代理”,直接操控目标程序。分为两种部署方式:
+
+ - **Host 端**:调试本地程序(如 macOS 进程)。
+
+ - **Remote 端**:部署到目标设备(如手机/嵌入式设备),直接控制被调试程序
+
+- 通信层:TCP + GDB RSP 协议
+
+ - **TCP Socket**:物理传输通道,连接 Host 的 LLDB 和 Remote 的 lldb-server
+ - **GDB RSP (Remote Serial Protocol)**
+ - **基于 ASCII 的调试协议**(明文消息,如 `$m版本管理
依赖安装] + B --> C[构建与测试
gym: 构建IPA
scan: 运行测试] + C --> D[应用分发
内测分发
pilot: TestFlight
第三方平台] + D --> E[商店发布
deliver: 上传元数据与二进制文件
提交审核] + E --> F[后续工作
管理测试员
Slack 通知] +``` + + + +### 1. 证书 +- iOS 数字证书是用来证明 iOS App 可执行文件的合法性和完整性的。对于想安装到真机或发布到 App Store 的 App,只有经过签名验证(Signature Validated)才能确保来源颗心,并且保证 App 内容是完整的、未经篡改的。 +- 数字证书是一个经证书授权中心数字签名的包含公开密钥拥有者信息以及公开密钥的文件。具有时效性,只在特定的时间段内有效。 + +开发证书分为2类: +- 开发证书(iOS Development):用于开发和调试应用程序,可用于真机调试 +- 发布证书(iOS Distribution):发布证书用于打包上传到 App Store,用于验证开发者身份 + +推送证书,如果项目中集成了推送功能,需要配置推送证书: +- 开发证书(Apple Development iOS Push Services) +- 发布证书(Apple Production iOS Push Services) +- 需要将生成的 p12 文件上传到服务器后台(极光、友盟、或者自己的推送服务器后台) + + +QA:存在一个情况,点击一个网页,下载 iOS App 到本地,点击启动的时候,会让你从「设置 -> 通用」中去信任证书。这个的工作原理是什么? + +这是一个典型的“无线设备管理”(MDM)注册和内部应用分发组合流程。 +原理详解: +第一步:伪装与诱导 (Phishing) + +- 接收短信:您收到一条看似普通的短信,内容可能是“刷单兼职”、“交友约会”、“彩票赌博”、“色情内容”或“高额借贷”等,并附带一个短链接(用于隐藏真实URL)。 +- 点击链接:您点击后,会跳转到一个精心设计的网页。这个网页模仿成某个 App 的下载页面,有一个非常醒目的“点击安装”或“立即跳转”按钮。 + +第二步:利用技术漏洞 (Abusing the System) +- 触发下载:点击按钮后,服务器会尝试让您的设备下载一个 .mobileconfig 文件。这是正规MDM流程的第一步,但在这里是恶意利用。 +- 系统弹窗:iOS系统会弹出标准提示框,显示“正在下载描述文件”,并询问您是否允许。这个弹窗是系统级的,无法伪造,所以具有很强的欺骗性。 + +第三步:利用信息差与恐吓 (Social Engineering) +- 引导“信任”:网页上会有非常详细的图文或视频教程,指导您下一步该怎么做。通常会编造理由,如: + - “这是为了验证您的设备安全性,防止作弊。” + - “必须完成此步骤才能使用App。” + - “这是官方要求的签名验证流程。” +- 安装描述文件:您根据指导,进入 “设置” -> “已下载的描述文件”,点击“安装”。这个描述文件里包含了一个 payload,其唯一目的就是向攻击者的服务器注册并上报您设备的UDID。 +- 信任企业证书:安装完成后,您还需要像之前了解的那样,去 “设置” -> “通用” -> “VPN与设备管理” 中,信任一个来自“某公司”的企业级应用证书。 + +第四步:达成目的 (The Payoff) +- UDID 上报:在您完成上述所有步骤的过程中,特别是安装描述文件后,您设备的 UDID (Unique Device Identifier) 以及其他一些设备信息(如型号、系统版本)已经无声无息地被发送到了灰产控制的后台服务器。 +- 白名单机制:灰产掌握着一个或多个(因为常被苹果吊销)企业证书。他们收到您的UDID后,会将其添加到他们企业开发者后台的设备白名单中。只有这样,由他们企业证书签名的最终App(赌博、色情App等)才能在您的设备上安装和打开。 +- 完成欺诈:此时,您再回到最初的网页,或者重新点击短信链接,就会发现可以正常下载那个最终的非法App了。因为您的设备UDID已经被加入白名单,企业证书已经生效。 + + + +这属于 MDM 吗?不属于真正的MDM,而是“MDM钓鱼”。 +正规MDM:目的是持续管理设备,如远程安装/卸载应用、配置策略、擦除数据等。需要用户明确知道设备被公司管理。 +灰产MDM:目的极其单一——窃取UDID。它们没有任何后续的管理意图和能力。它们只是滥用了.mobileconfig配置文件能够在安装时自动向指定服务器上报设备信息(包括UDID) 的这一功能。 +您可以理解为,骗子只偷走了MDM流程的“身份证登记处”,而完全抛弃了后面的“管理员办公室”。 + +### 2. 配置文件(Provsioning Profiles) +配置文件也分为2种: +- 开发(Development) +- 发布(Distribution) +- 配置文件(Provsioning Profiles)中包含了证书、App ID、设备(Devices),后缀名为 `.mobileprovision` +- 配置文件在开发者账号体系中扮演着配置和验证的角色。是真机调试和打包上架的必须文件 + + + +Xcode 中,对于项目是可以看到配置文件的。我们可以鼠标按住,拖动到桌面文件夹下。 +
 +此外,`mobileprovision` 文件是不可读的。可以通过 **security cms -D -i 195103db-6d6f-4da1-bd0e-66d5db88176f.mobileprovision -o profil
+e.plist** 指令,dump 成为一个 plist 格式的文件。如下图所示:
+
+此外,`mobileprovision` 文件是不可读的。可以通过 **security cms -D -i 195103db-6d6f-4da1-bd0e-66d5db88176f.mobileprovision -o profil
+e.plist** 指令,dump 成为一个 plist 格式的文件。如下图所示:
+ +
+指令解读:
+- security:是 macOS 自带的安全相关的命令行工具,用于处理证书、配置文件、密钥等的处理
+- cms:表示使用 CMD(Cryptographic Message Syntax,密码消息语法)相关功能,用于处理消息签名和加密消息
+- -i:指定输入文件
+- -o:指定输出文件
+
+重要信息:
+- DeveloperCertificates: 允许使用的开发者证书
+- Entitlements:允许使用的权限列表
+- ProvisionedDevices:允许安装的设备列表(ProvisionsAllDevices,代表授权任意设备)
+
+
+
+### 3. 授权文件(Entitlements)
+声明了 App 所需的权限
+
+
+
+### 4. 签名 codesign
+
+#### 1. 基础签名
+
+- **-s**:--sign identity 指定签名所用的证书(- 代表 ad-hoc 签名)
+- **--entitlements**:entitlements_file 指定签名所需要的 entitlements 文件
+- **-f**: --force 强制替换现有签名
+- **-preserve-metadata=identifier,entitlements**: 重用就签名的一些信息
+- **-deep**: 递归对该 bundle 内包含的其他文件签名
+
+
+注意:为什么不推荐使用 `--deep`?
+
+在没有 `--deep` 的情况下,codesign 命令只会对指定的主目标(main target)(例如 .app 包或 .framework)进行签名。它不会自动递归地签名的 .app 包内部的任何嵌套的组件(如嵌入的 .framework 或 .dylib)。
+
+--deep 选项的设计初衷是试图递归地签名一个 bundle 内部的所有嵌套代码。例如,如果你的 MyApp.app 内部嵌入了 ThirdParty.framework,使用 `codesign --deep -f -s "Your Identity" MyApp`.app 会同时签名 MyApp.app 和其内部的 ThirdParty.framework。
+
+错误的签名顺序(主要问题):
+- 代码签名不仅是对二进制文件盖章,它还计算并存储每个组件的哈希值到其 _CodeSignature/CodeResources 文件中。
+- 当你签名一个 .app 时,它也会计算其内部所有文件(包括嵌套的 .framework)的哈希值。如果这些嵌套的组件在 .app 被签名之后又被修改了,其哈希值就会改变,导致签名无效。
+- `--deep` 的工作方式是:先递归地签名最内层的组件(如 ThirdParty.framework),然后签名外层的容器(MyApp.app)。
+
+这看起来是正确的,对吗? 但实际上,在签名外层 .app 时,它记录的仍然是内层组件签名前的哈希值。而内层组件在签名后其内容(因为附加了签名信息)已经发生了变化,这就导致了内外记录不一致,从而使整个签名变得无效且不可靠。
+
+与现代构建系统不兼容:
+- Xcode 和标准的构建流程(如 xcodebuild)的正确做法是:先单独签名每一个嵌套的组件(Embedded Framework),最后再签名主应用。这确保了每个组件都有自己独立的有效签名,并且主应用在签名时记录的是所有嵌套组件的最终状态。
+- `--deep` 破坏了这种明确的、分阶段的签名流程,试图用一步代替多步,反而引入了混乱。
+
+
+
+#### 2. 动态库签名
+
+动态库可以上架,是因为对动态库可以进行签名。来一个 Demo 工程。一个 iOS 工程,以动态库的形式使用 SDWebImage
+
+##### 1. Demo1
+
+1个 iOS App 工程,使用动态库的方式,依赖了 AFNetworking。选择模拟器进行编译,查看日志:
+
+
+
+指令解读:
+- security:是 macOS 自带的安全相关的命令行工具,用于处理证书、配置文件、密钥等的处理
+- cms:表示使用 CMD(Cryptographic Message Syntax,密码消息语法)相关功能,用于处理消息签名和加密消息
+- -i:指定输入文件
+- -o:指定输出文件
+
+重要信息:
+- DeveloperCertificates: 允许使用的开发者证书
+- Entitlements:允许使用的权限列表
+- ProvisionedDevices:允许安装的设备列表(ProvisionsAllDevices,代表授权任意设备)
+
+
+
+### 3. 授权文件(Entitlements)
+声明了 App 所需的权限
+
+
+
+### 4. 签名 codesign
+
+#### 1. 基础签名
+
+- **-s**:--sign identity 指定签名所用的证书(- 代表 ad-hoc 签名)
+- **--entitlements**:entitlements_file 指定签名所需要的 entitlements 文件
+- **-f**: --force 强制替换现有签名
+- **-preserve-metadata=identifier,entitlements**: 重用就签名的一些信息
+- **-deep**: 递归对该 bundle 内包含的其他文件签名
+
+
+注意:为什么不推荐使用 `--deep`?
+
+在没有 `--deep` 的情况下,codesign 命令只会对指定的主目标(main target)(例如 .app 包或 .framework)进行签名。它不会自动递归地签名的 .app 包内部的任何嵌套的组件(如嵌入的 .framework 或 .dylib)。
+
+--deep 选项的设计初衷是试图递归地签名一个 bundle 内部的所有嵌套代码。例如,如果你的 MyApp.app 内部嵌入了 ThirdParty.framework,使用 `codesign --deep -f -s "Your Identity" MyApp`.app 会同时签名 MyApp.app 和其内部的 ThirdParty.framework。
+
+错误的签名顺序(主要问题):
+- 代码签名不仅是对二进制文件盖章,它还计算并存储每个组件的哈希值到其 _CodeSignature/CodeResources 文件中。
+- 当你签名一个 .app 时,它也会计算其内部所有文件(包括嵌套的 .framework)的哈希值。如果这些嵌套的组件在 .app 被签名之后又被修改了,其哈希值就会改变,导致签名无效。
+- `--deep` 的工作方式是:先递归地签名最内层的组件(如 ThirdParty.framework),然后签名外层的容器(MyApp.app)。
+
+这看起来是正确的,对吗? 但实际上,在签名外层 .app 时,它记录的仍然是内层组件签名前的哈希值。而内层组件在签名后其内容(因为附加了签名信息)已经发生了变化,这就导致了内外记录不一致,从而使整个签名变得无效且不可靠。
+
+与现代构建系统不兼容:
+- Xcode 和标准的构建流程(如 xcodebuild)的正确做法是:先单独签名每一个嵌套的组件(Embedded Framework),最后再签名主应用。这确保了每个组件都有自己独立的有效签名,并且主应用在签名时记录的是所有嵌套组件的最终状态。
+- `--deep` 破坏了这种明确的、分阶段的签名流程,试图用一步代替多步,反而引入了混乱。
+
+
+
+#### 2. 动态库签名
+
+动态库可以上架,是因为对动态库可以进行签名。来一个 Demo 工程。一个 iOS 工程,以动态库的形式使用 SDWebImage
+
+##### 1. Demo1
+
+1个 iOS App 工程,使用动态库的方式,依赖了 AFNetworking。选择模拟器进行编译,查看日志:
+
+ +
+日志分析:
+1. 日志中的 `--sign` 后一般接的是证书的名称,但是当前日志中是 `-`,代表使用自动签名模式(Automatic Signing)。
+ - **--sign 参数**:这是 codesign 命令的核心参数,用于指定用于签名的身份(Identity)。这个身份通常对应着钥匙串(Keychain)中的一个证书(Certificate)及其关联的私钥。
+ - **-**:这是一个特殊的标识符,在这里它不代表一个具体的证书名称。它的含义是:“使用临时生成的、匿名的 Ad-Hoc 签名身份来进行签名,而不需要指定一个具体的、来自苹果开发者账户的证书。”
+ 在模拟器(Simulator)上运行(正如你的日志中 Debug-iphonesimulator 所示):
+ 根本原因:iOS 模拟器不像真机设备那样需要验证苹果官方的代码签名证书来确保安全。模拟器的运行环境更加宽松,其主要目的是为了快速调试。为了方便:使用 Ad-Hoc 签名可以省去为模拟器编译时配置和选择开发证书的步骤,极大地加快了编译和调试的速度。Xcode 默认就会为模拟器构建采用这种方式。
+
+2. 日志中的 `--entitlements /Users/unix_kernel/Library/Developer/Xcode/DerivedData/InstallDyanmicAndStaticFramework-bmcbqvmynpdalkdhzqirbithtfwp/Build/Intermediates.noindex/InstallDyanmicAndStaticFramework.build/Debug-iphonesimulator/InstallDyanmicAndStaticFramework.build/InstallDyanmicAndStaticFramework.app.xcent` 代表 Xcode 开启的 App 能力信息。`--entitlements` 参数后面跟随的是一个 `.xcent` 文件的路径,这个文件包含了应用程序的权限(Entitlements)配置信息,也就是 “App 能力信息”
+
+对其查看,内容如下:
+
+
+日志分析:
+1. 日志中的 `--sign` 后一般接的是证书的名称,但是当前日志中是 `-`,代表使用自动签名模式(Automatic Signing)。
+ - **--sign 参数**:这是 codesign 命令的核心参数,用于指定用于签名的身份(Identity)。这个身份通常对应着钥匙串(Keychain)中的一个证书(Certificate)及其关联的私钥。
+ - **-**:这是一个特殊的标识符,在这里它不代表一个具体的证书名称。它的含义是:“使用临时生成的、匿名的 Ad-Hoc 签名身份来进行签名,而不需要指定一个具体的、来自苹果开发者账户的证书。”
+ 在模拟器(Simulator)上运行(正如你的日志中 Debug-iphonesimulator 所示):
+ 根本原因:iOS 模拟器不像真机设备那样需要验证苹果官方的代码签名证书来确保安全。模拟器的运行环境更加宽松,其主要目的是为了快速调试。为了方便:使用 Ad-Hoc 签名可以省去为模拟器编译时配置和选择开发证书的步骤,极大地加快了编译和调试的速度。Xcode 默认就会为模拟器构建采用这种方式。
+
+2. 日志中的 `--entitlements /Users/unix_kernel/Library/Developer/Xcode/DerivedData/InstallDyanmicAndStaticFramework-bmcbqvmynpdalkdhzqirbithtfwp/Build/Intermediates.noindex/InstallDyanmicAndStaticFramework.build/Debug-iphonesimulator/InstallDyanmicAndStaticFramework.build/InstallDyanmicAndStaticFramework.app.xcent` 代表 Xcode 开启的 App 能力信息。`--entitlements` 参数后面跟随的是一个 `.xcent` 文件的路径,这个文件包含了应用程序的权限(Entitlements)配置信息,也就是 “App 能力信息”
+
+对其查看,内容如下:
+ +
+`security find-identity -v -p codesigning` 指令用于 macOS 系统中用于查看可用代码签名证书的命令,主要用于开发者在进行代码签名操作前确认可用的证书信息
+
+##### 2. Demo2
+
+1个 iOS App 工程,使用动态库的方式,依赖了 AFNetworking。选择真机进行编译,查看日志:
+
+
+`security find-identity -v -p codesigning` 指令用于 macOS 系统中用于查看可用代码签名证书的命令,主要用于开发者在进行代码签名操作前确认可用的证书信息
+
+##### 2. Demo2
+
+1个 iOS App 工程,使用动态库的方式,依赖了 AFNetworking。选择真机进行编译,查看日志:
+ +日志分析:
+1. 日志中的 `Signing Identity: "Apple Development: FantasticLBP@github.com (953PZFXZFR)"` 变成了开发者证书。多了一个配置文件。
+2. 使用的动态库 AFNetworking 是如何签名的?
+选择 Pods 的 Product 里面的 AFNetworking 动态库,右击 “show in finder”。看到并没有一个 **`_CodeSignature`** 的文件夹,也就是没有签名信息。然后用指令 ` objdump --macho --private-headers /Users/unix_kernel/Library/Developer/Xcode/DerivedData/InstallDyanmicAndStaticFramework-bmcbqvmynpdalkdhzqirbithtfwp/Build/Products/Debug-iphoneos/AFNetworking/AFNetworking.framework/AFNetworking` 进行查看,发现也不存在 **`LC_CODE_SIGNATURE`** 存储签名信息的 load command。
+
+日志分析:
+1. 日志中的 `Signing Identity: "Apple Development: FantasticLBP@github.com (953PZFXZFR)"` 变成了开发者证书。多了一个配置文件。
+2. 使用的动态库 AFNetworking 是如何签名的?
+选择 Pods 的 Product 里面的 AFNetworking 动态库,右击 “show in finder”。看到并没有一个 **`_CodeSignature`** 的文件夹,也就是没有签名信息。然后用指令 ` objdump --macho --private-headers /Users/unix_kernel/Library/Developer/Xcode/DerivedData/InstallDyanmicAndStaticFramework-bmcbqvmynpdalkdhzqirbithtfwp/Build/Products/Debug-iphoneos/AFNetworking/AFNetworking.framework/AFNetworking` 进行查看,发现也不存在 **`LC_CODE_SIGNATURE`** 存储签名信息的 load command。
+ +
+可能会问,如何确定是动态库?使用 `file AFNetworking` 指令即可验证
+
+
+可能会问,如何确定是动态库?使用 `file AFNetworking` 指令即可验证
+ +
+问题:动态库 AFNetworking 没有经过签名,为什么拷贝到 App 里面后,可以上架?
+其实 Cocoapods 自动生成了脚本,在主工程的 `Build Phases -> Embed Pods Frameworks` 下。且 `Input File Lists` 配置的文件内容,就是所依赖库的文件路径。会被当作参数传递给 `Embed Pods Frameworks` 脚本。
+
+
+
+问题:动态库 AFNetworking 没有经过签名,为什么拷贝到 App 里面后,可以上架?
+其实 Cocoapods 自动生成了脚本,在主工程的 `Build Phases -> Embed Pods Frameworks` 下。且 `Input File Lists` 配置的文件内容,就是所依赖库的文件路径。会被当作参数传递给 `Embed Pods Frameworks` 脚本。
+
+ +观察编译日志,会发现 「Run custom shell script '[CP] Embed Pods Frameworks'」这里,先对 Frameworks 目录进行了创建和拷贝。然后对 AFNetworking 进行签名。
+在主工程的 Products 目录下,选择 App,show in finder,然后显示包内容。查看 `Frameworks` 文件夹下的 `AFNetworking.framework` 已经存在了 `_CodeSignature` 文件夹,也就是已经签名完成。继续查看 Load Command,发现也存在了 **LC_CODE_SIGNATURE** Load Command。
+
+观察编译日志,会发现 「Run custom shell script '[CP] Embed Pods Frameworks'」这里,先对 Frameworks 目录进行了创建和拷贝。然后对 AFNetworking 进行签名。
+在主工程的 Products 目录下,选择 App,show in finder,然后显示包内容。查看 `Frameworks` 文件夹下的 `AFNetworking.framework` 已经存在了 `_CodeSignature` 文件夹,也就是已经签名完成。继续查看 Load Command,发现也存在了 **LC_CODE_SIGNATURE** Load Command。
+ +
+同时,也可以看到是先对动态库签名,再对 App 签名。
+
+#### 3. 如何查看签名信息
+
+[jtool2](https://github.com/excitedplus1s/jtool2) 工具可以方便的查看签名信息。jtool2 类似于 otool,但添加了许多 Mach-O 相关的命令,功能更完善。它支持多种运行平台
+
+安装方式为:`brew install --no-quarantine excitedplus1s/repo/jtool2`
+使用方式为:**`jtool2 --sig -vv ${MachOFile}`**
+
+
+
+同时,也可以看到是先对动态库签名,再对 App 签名。
+
+#### 3. 如何查看签名信息
+
+[jtool2](https://github.com/excitedplus1s/jtool2) 工具可以方便的查看签名信息。jtool2 类似于 otool,但添加了许多 Mach-O 相关的命令,功能更完善。它支持多种运行平台
+
+安装方式为:`brew install --no-quarantine excitedplus1s/repo/jtool2`
+使用方式为:**`jtool2 --sig -vv ${MachOFile}`**
+
+ +
+
+
+### 5. fastlane 相关概念
+
+
+
+
+
+### 5. fastlane 相关概念
+
+ +- fastlane 本质就是一套命令行工具,专为用来简化并实现我们与 Apple 交互时的自动化
+- fastlane 的每一个单独工具都是为了解决常见的 App Store 或其他问题而设计的
+- fastlane 通过脚本方式集合了一系列常见的行为,叫做 lane。也就意味着可以通过 lane 来对自己的 App 做一些量身定制的需求
+- fastlane 包含大量的 action
+- action 表示特定的应用商店或者其他开发者工作流任务
+- lane 表示工作流程
+
+- Appfile: 存储有关开发者账号相关信息
+- Fastfile:核心文件,主要用于命令行调用和处理具体的流程,lane 相对于一个方法或者函数。
+
+#### 1. action
+
+- cert: 创建和维护签名证书
+- sigh:配置文件
+- gym:构建打包应用程序
+- deliver:上传应用程序和屏幕截图到 App Store Connect
+- pilot:为 TestFlight 上传构建并处理其管理
+- scan:自动化测试
+- match:团队中同步证书和配置文件
+- boarding:测试邀请
+- pem:管理推送配置文件
+- produce:在 App Store Connect 创建新的 App
+
+
+使用方式有3种:
+- 第一种:命令行方式。比如
+ ```
+ fastlane scane --workspace "fastlaneDemo.xcworkspace" --scheme "fastlaneDemo" --device "iPhone 8" --clean
+ ```
+- 第二种:Fastfile 方式。采用 FastLane 约定的格式去编写逻辑。比如
+ ```
+ default_platform(:ios)
+
+ platform :ios do
+
+ lane :builds do
+ # 单元测试
+ scan(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ devices: ["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"],
+ clean: true,
+ code_coverage: true,
+ output_types: "html,junit",
+ output_directory: "./fastlane/test_output"
+ )
+ # 证书
+ cert
+ # 配置文件
+ sigh
+ # 打包
+ gym(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ clean: true,
+ output_directory: "./fastlane/build_output",
+ output_name: "fastlaneDemo.ipa",
+ silent: false,
+ include_symbols: true,
+ include_bitcode: true
+ )
+ end
+ end
+ ```
+- 第三种:使用特定的 Fastlane 文件。比如使用脚本 `Fastlane scan init` 会生成关于 scan 相关逻辑的脚本文件 `Scanfile`
+
+- fastlane 本质就是一套命令行工具,专为用来简化并实现我们与 Apple 交互时的自动化
+- fastlane 的每一个单独工具都是为了解决常见的 App Store 或其他问题而设计的
+- fastlane 通过脚本方式集合了一系列常见的行为,叫做 lane。也就意味着可以通过 lane 来对自己的 App 做一些量身定制的需求
+- fastlane 包含大量的 action
+- action 表示特定的应用商店或者其他开发者工作流任务
+- lane 表示工作流程
+
+- Appfile: 存储有关开发者账号相关信息
+- Fastfile:核心文件,主要用于命令行调用和处理具体的流程,lane 相对于一个方法或者函数。
+
+#### 1. action
+
+- cert: 创建和维护签名证书
+- sigh:配置文件
+- gym:构建打包应用程序
+- deliver:上传应用程序和屏幕截图到 App Store Connect
+- pilot:为 TestFlight 上传构建并处理其管理
+- scan:自动化测试
+- match:团队中同步证书和配置文件
+- boarding:测试邀请
+- pem:管理推送配置文件
+- produce:在 App Store Connect 创建新的 App
+
+
+使用方式有3种:
+- 第一种:命令行方式。比如
+ ```
+ fastlane scane --workspace "fastlaneDemo.xcworkspace" --scheme "fastlaneDemo" --device "iPhone 8" --clean
+ ```
+- 第二种:Fastfile 方式。采用 FastLane 约定的格式去编写逻辑。比如
+ ```
+ default_platform(:ios)
+
+ platform :ios do
+
+ lane :builds do
+ # 单元测试
+ scan(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ devices: ["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"],
+ clean: true,
+ code_coverage: true,
+ output_types: "html,junit",
+ output_directory: "./fastlane/test_output"
+ )
+ # 证书
+ cert
+ # 配置文件
+ sigh
+ # 打包
+ gym(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ clean: true,
+ output_directory: "./fastlane/build_output",
+ output_name: "fastlaneDemo.ipa",
+ silent: false,
+ include_symbols: true,
+ include_bitcode: true
+ )
+ end
+ end
+ ```
+- 第三种:使用特定的 Fastlane 文件。比如使用脚本 `Fastlane scan init` 会生成关于 scan 相关逻辑的脚本文件 `Scanfile`
+  +
+建议使用方式二、三,不建议使用方式一。关于 fastlane 脚本编写文档查看 [fastlane docs](http://docs.fastlane.tools)
+
+使用方式:
+Scanfile 是 专门用于配置 scan 动作(即运行测试) 的配置文件。它的唯一目的是为 scan 提供默认参数。你可以在里面设置 scheme、output_directory、code_coverage 等测试相关的选项。当你在命令行直接运行 fastlane scan 或在 Fastfile 的 lane 中调用 scan 时,它会自动读取 Scanfile 中的配置。
+
+
+
+| 文件 | 角色 | 用途 | 示例内容 |
+| :-------------- | :---------------------- | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| **`Fastfile`** | ****指挥官\**/\**剧本** | **定义 lanes(工作流)**。这是 Fastlane 的核心,你在这里组合不同的动作来创建自动化流程。 | `lane :test { scan }` `lane :beta { cert; sigh; gym; upload_to_testflight }` |
+| **`Scanfile`** | **专项配置员** | 只为 **`scan`** 动作提供默认配置参数。 | `scheme("MyApp")` `clean(true)` `output_directory("./test_results")` |
+| **`Gymfile`** | **专项配置员** | 只为 **`gym`** 动作(构建 IPA)提供默认配置参数。 | `workspace("MyApp.xcworkspace")` `export_method("app-store")` `output_directory("./builds")` |
+| **`Matchfile`** | **专项配置员** | 只为 **`match`** 动作(证书管理)提供默认配置参数。 | git_url("https://github.com/.../certs")` `app_identifier("com.yourapp") |
+
+总结:
+
+- **`Fastfile`** 就像是一个**总剧本**,里面写着:第一场戏(`lane :test`)是跑步测试,第二场戏(`lane :beta`)是打包上传。
+- **`Scanfile`**、**`Gymfile`** 等就像是每个**演员(scan, gym 动作)的个人小抄**,上面写着他们的默认表情、站位等细节。
+- 当“总剧本”喊到某个演员时,演员就会按照自己“小抄”上的默认设置来表演,除非剧本特意指定了另一种表演方式。
+
+
+
+QA:按照上面的思路和角色分工、能力边界,将下面的代码优化
+
+```ruby
+platform :ios do
+
+ lane :builds do
+ # 单元测试
+ scan(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ devices: ["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"],
+ clean: true,
+ code_coverage: true,
+ output_types: "html,junit",
+ output_directory: "./fastlane/test_output"
+ )
+ # 证书
+ cert
+ # 配置文件
+ sigh
+ # 打包
+ gym(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ clean: true,
+ output_directory: "./fastlane/build_output",
+ output_name: "fastlaneDemo.ipa",
+ silent: false,
+ include_symbols: true,
+ include_bitcode: true
+ )
+ end
+end
+```
+
+优化:
+
+- 文件一:`./fastlane/Scanfile` 只存放测试相关的配置
+
+ ```ruby
+ # Scanfile 专用配置
+ workspace("fastlaneDemo.xcworkspace")
+ scheme("fastlaneDemo")
+ devices(["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"])
+ clean(true)
+ code_coverage(true)
+ output_types("html,junit")
+ output_directory("./fastlane/test_output")
+ skip_build(true)
+ ```
+
+- 文件二:`./fastlane/Gymfile` 存放构建相关的配置
+
+ ```ruby
+ # Gymfile 专用配置
+ workspace("fastlaneDemo.xcworkspace")
+ scheme("fastlaneDemo")
+ clean(true)
+ output_directory("./fastlane/build_output")
+ include_symbols(true)
+ include_bitcode(true)
+ ```
+
+- 文件三:`./fastlane/Fastfile` 存放 lane 相关逻辑
+
+ ```ruby
+ # Fastfile - 定义 lanes
+ default_platform(:ios)
+
+ platform :ios do
+ # 定义一个名为 builds 的 lane
+ lane :builds do
+ # 运行测试,所有配置会自动从 Scanfile 读取
+ scan
+ # 管理证书
+ cert
+ sigh
+ # 构建 ipa,所有配置会自动从 Gymfile 读取
+ gym
+ end
+ end
+ ```
+
+分析:
+
+1. **清晰与模块化**:每个文件职责单一,易于维护。
+
+2. **复用性**:你可以在 `Fastfile` 中创建多个不同的 lane(如 `lane :tests`、`lane :adhoc`),它们都可以共享 `Scanfile` 和 `Gymfile` 中的通用配置,无需重复代码。
+
+3. **可覆盖性**:在 `Fastfile` 的 lane 中调用 `scan` 或 `gym` 时,你可以随时覆盖对应 `*.file` 中的默认设置。例如:
+
+ ```ruby
+ lane :special_build do
+ gym(
+ output_name: "SpecialRelease.ipa" # 覆盖 Gymfile 中的默认命名规则
+ )
+ end
+ ```
+
+
+
+#### 2. Matchfile
+
+终端使用 `fastlane match init` 指令创建 Matchfile,同时根据提示选择一些模版和输入信息。
+
+
+
+建议使用方式二、三,不建议使用方式一。关于 fastlane 脚本编写文档查看 [fastlane docs](http://docs.fastlane.tools)
+
+使用方式:
+Scanfile 是 专门用于配置 scan 动作(即运行测试) 的配置文件。它的唯一目的是为 scan 提供默认参数。你可以在里面设置 scheme、output_directory、code_coverage 等测试相关的选项。当你在命令行直接运行 fastlane scan 或在 Fastfile 的 lane 中调用 scan 时,它会自动读取 Scanfile 中的配置。
+
+
+
+| 文件 | 角色 | 用途 | 示例内容 |
+| :-------------- | :---------------------- | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| **`Fastfile`** | ****指挥官\**/\**剧本** | **定义 lanes(工作流)**。这是 Fastlane 的核心,你在这里组合不同的动作来创建自动化流程。 | `lane :test { scan }` `lane :beta { cert; sigh; gym; upload_to_testflight }` |
+| **`Scanfile`** | **专项配置员** | 只为 **`scan`** 动作提供默认配置参数。 | `scheme("MyApp")` `clean(true)` `output_directory("./test_results")` |
+| **`Gymfile`** | **专项配置员** | 只为 **`gym`** 动作(构建 IPA)提供默认配置参数。 | `workspace("MyApp.xcworkspace")` `export_method("app-store")` `output_directory("./builds")` |
+| **`Matchfile`** | **专项配置员** | 只为 **`match`** 动作(证书管理)提供默认配置参数。 | git_url("https://github.com/.../certs")` `app_identifier("com.yourapp") |
+
+总结:
+
+- **`Fastfile`** 就像是一个**总剧本**,里面写着:第一场戏(`lane :test`)是跑步测试,第二场戏(`lane :beta`)是打包上传。
+- **`Scanfile`**、**`Gymfile`** 等就像是每个**演员(scan, gym 动作)的个人小抄**,上面写着他们的默认表情、站位等细节。
+- 当“总剧本”喊到某个演员时,演员就会按照自己“小抄”上的默认设置来表演,除非剧本特意指定了另一种表演方式。
+
+
+
+QA:按照上面的思路和角色分工、能力边界,将下面的代码优化
+
+```ruby
+platform :ios do
+
+ lane :builds do
+ # 单元测试
+ scan(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ devices: ["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"],
+ clean: true,
+ code_coverage: true,
+ output_types: "html,junit",
+ output_directory: "./fastlane/test_output"
+ )
+ # 证书
+ cert
+ # 配置文件
+ sigh
+ # 打包
+ gym(
+ workspace: "fastlaneDemo.xcworkspace",
+ scheme: "fastlaneDemo",
+ clean: true,
+ output_directory: "./fastlane/build_output",
+ output_name: "fastlaneDemo.ipa",
+ silent: false,
+ include_symbols: true,
+ include_bitcode: true
+ )
+ end
+end
+```
+
+优化:
+
+- 文件一:`./fastlane/Scanfile` 只存放测试相关的配置
+
+ ```ruby
+ # Scanfile 专用配置
+ workspace("fastlaneDemo.xcworkspace")
+ scheme("fastlaneDemo")
+ devices(["iPhone 14 Pro Max", "iPhone 14", "iPhone SE (3rd generation)"])
+ clean(true)
+ code_coverage(true)
+ output_types("html,junit")
+ output_directory("./fastlane/test_output")
+ skip_build(true)
+ ```
+
+- 文件二:`./fastlane/Gymfile` 存放构建相关的配置
+
+ ```ruby
+ # Gymfile 专用配置
+ workspace("fastlaneDemo.xcworkspace")
+ scheme("fastlaneDemo")
+ clean(true)
+ output_directory("./fastlane/build_output")
+ include_symbols(true)
+ include_bitcode(true)
+ ```
+
+- 文件三:`./fastlane/Fastfile` 存放 lane 相关逻辑
+
+ ```ruby
+ # Fastfile - 定义 lanes
+ default_platform(:ios)
+
+ platform :ios do
+ # 定义一个名为 builds 的 lane
+ lane :builds do
+ # 运行测试,所有配置会自动从 Scanfile 读取
+ scan
+ # 管理证书
+ cert
+ sigh
+ # 构建 ipa,所有配置会自动从 Gymfile 读取
+ gym
+ end
+ end
+ ```
+
+分析:
+
+1. **清晰与模块化**:每个文件职责单一,易于维护。
+
+2. **复用性**:你可以在 `Fastfile` 中创建多个不同的 lane(如 `lane :tests`、`lane :adhoc`),它们都可以共享 `Scanfile` 和 `Gymfile` 中的通用配置,无需重复代码。
+
+3. **可覆盖性**:在 `Fastfile` 的 lane 中调用 `scan` 或 `gym` 时,你可以随时覆盖对应 `*.file` 中的默认设置。例如:
+
+ ```ruby
+ lane :special_build do
+ gym(
+ output_name: "SpecialRelease.ipa" # 覆盖 Gymfile 中的默认命名规则
+ )
+ end
+ ```
+
+
+
+#### 2. Matchfile
+
+终端使用 `fastlane match init` 指令创建 Matchfile,同时根据提示选择一些模版和输入信息。
+
+ +
+
+
+- `git_url`:
+
+ 是 `match` 最核心的配置,指定了存储加密证书和配置文件的 Git 仓库地址。`match` 不会将敏感的证书文件(`.cer`)、私钥文件(`.p12`)和配置文件(`.mobileprovision`)保存在本地或只留在苹果开发者门户。
+
+ 相反,它会将这些文件**加密后**推送到这个指定的 Git 仓库(`https://github.com/FantasticLBP/knowledge-kit`)中。
+
+ 当任何开发者或 CI/CD 系统需要这些文件时,`match` 会从这个仓库克隆或拉取最新的加密文件,然后在本地解密并安装到钥匙串和 Xcode 中。
+
+ 这个仓库应该是**私有的(Private)**,因为里面存储的是你应用的敏感安全凭证
+
+- `storage_mode("git")`:
+
+ 明确指定 `match` 使用 Git 作为存储后端。
+
+ match` 支持多种存储方式,`git` 是**默认且最常用**的一种。
+
+ 其他可选模式包括 `s3`(Amazon S3)和 `google_cloud`(Google Cloud Storage)。这些通常在更复杂或企业级的 CI/CD 环境中使用,以提高大文件的下载速度
+
+- `type("development")`
+
+ 设置 `match` 的**默认操作类型**为 `development`(开发证书和配置文件)
+
+ 这个参数定义了你要管理哪类证书。iOS 开发中有几种主要类型:
+
+ - `"development"`:用于开发阶段,可在真机上调试应用。
+ - `"appstore"`:用于提交到 App Store 或 TestFlight。
+ - `"adhoc"`:用于分发给有限数量的测试设备(最多 100 台)。
+ - `"enterprise"`:用于企业账号的内部分发。
+
+ 在这里设置为 `"development"` 意味着:
+
+ - 当你直接运行 `fastlane match`(而不指定类型)时,它会默认操作开发证书。
+ - 当你运行 `fastlane match development` 时,它也会使用这个配置(尽管命令行参数已经指定了类型,但其他相关配置会从这里读取)。
+
+这个 `Matchfile` 配置告诉我们:
+
+1. **存储位置**:所有加密的证书和配置文件都将被同步到 `https://github.com/FantasticLBP/knowledge-kit` 这个 Git 仓库中。
+2. **存储方式**:使用 Git 进行版本管理和同步(这是标准做法)。
+3. **默认环境**:默认情况下,操作的是用于**开发环境**的证书和配置文件。
+
+**一个典型的工作流程:**
+
+1. 团队成员 A 首次运行 `fastlane match development`。
+2. `match` 会检查指定的 Git 仓库中是否已有开发证书。
+ - 如果**没有**,它会连接到苹果开发者门户,创建新的开发证书和配置文件,加密后推送到 Git 仓库。
+ - 如果**已有**,它会将加密文件拉取到本地,解密后安装到 Xcode 和钥匙串中。
+3. 团队成员 B 加入项目,同样运行 `fastlane match development`。
+4. `match` 从同一个 Git 仓库拉取**完全相同的**证书和配置文件,确保团队环境一致。
+
+
+
+## 三、持续集成
+
+Cotinuous Integration,持续集成意味着每次代码的变更都在构建服务器上运行测试,并在指定场景下触发。这样如果开发者将测试失败的代码推送到代码库,也称为破坏构建,CI 会触发警告。
+
+- 主动式 CI:CI 提供商
+- 托管式 CI:github action
+- 手动式 CI:自己管理,Travis CI、Jenkins
+
+
+
+- Travis CI:小型开源项目,付费、简单、方便、
+- Jenkins:大型企业、丰富的自定义选项、定制化,不能做到开箱即用,免费
+
+### 1. docker
+
+> 问:为什么一定要 docker?不能在服务器上按照本地的配置安装所需的各个软件吗
+>
+> 答:在一个团队中,每个开发者的本地环境都可能略有不同(macOS 版本、Xcode 通过 App Store 安装还是手动安装、Homebrew 的使用方式等)。
+>
+> - **问题**:新同事加入,需要花费**一整天甚至更长时间**来按照文档一步步配置环境,任何一步的疏漏都会导致环境配置失败。
+> - **后果**: onboarding 成本极高,而且无法保证所有人的环境真正一致,为后续的协作埋下了隐患。
+>
+> 为什么“手动安装一下”不是最优解?它的成功依赖于:
+>
+> - **人的记忆和文档**:需要有人(或文档)准确地记录下所有依赖的**精确版本**(不仅仅是 `fastlane`,还包括它的依赖,以及依赖的依赖)。这份文档需要随着项目的每一次依赖变更而**实时更新**,这几乎是不可能的任务。
+> - **手动操作的准确性**:需要操作人员完全正确地执行安装步骤,不能有任何错漏。这是一个枯燥且容易出错的过程
+
+#### 1. 定义
+
+**Docker 概述**: Docker 是一种成熟高效的软件部署技术,利用容器化技术为应用程序封装独立的运行环境。每个运行环境即为一个**容器**,承载容器运行的计算机称为**宿主机**。
+
+容器。容器虚拟化指的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。
+
+- 镜像(image):提供容器运行时所需的程序、库、资源、配置等文件,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)
+- 容器(Container):镜像运行时的实体,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务
+- 仓库(Repository):镜像构建完成后,可以很容易的在当前容器上运行
+
+虚拟机:虚拟出一套硬件后,在其上运行一个完整的操作系统。
+
+
+
+**容器与虚拟机的区别**:
+
+* **Docker容器**: 多个容器共享同一个系统内核
+* **虚拟机**: 每个虚拟机包含一个操作系统的完整内核
+* **优势**: 所以 Docker 容器比虚拟机更轻量、占用空间更小、启动速度更快
+
+**镜像 (Image)**:
+
+* **定义**: 镜像是容器的模板,可类比为软件安装包
+* **类比**: 类似于制作糕点的模具,可用于创建多个糕点(容器),并可分享给他人
+
+**容器 (Container)**:
+
+- **定义**: 容器是基于镜像运行的应用程序实例,可类比为安装好的软件。
+- **类比**: 类似于模具制作出的糕点。
+
+**Docker仓库 (Registry)**:
+
+* **定义**: 用于存放和分享Docker镜像的场所
+* **Docker Hub**: Docker的官方公共仓库,存储了大量用户分享的Docker镜像。
+
+
+
+Docker 理解为:标准化、一摸一样的工具箱和工作环境。保证无论哪个工人来,用的工具和环境都完全一样,避免“在我这儿是好的”问题。
+
+- 环境标准化:创建一个包含特定版本 Ruby、Fastlane、Xcode 命令行工具、Cocoapods 的镜像
+- 隔离一致性:确保开发、测试、生产环境的构建完全一致,消除“环境依赖”问题
+- 快速搭建与清理:轻松为 Jenkins 提供纯净、可随时销毁和重建的构建环境。
+
+**价值:开发者需要花费大量时间排查环境差异,而不是专注于修复真正的业务逻辑 Bug,严重拖慢开发效率。**
+
+
+
+#### 2. docker 的核心角色与能力
+
+docker 在 iOS CI/CD 管道中(通常与 Jenkins、Gitlab CI、Github Actions 等工具配合)中主要负责“管理阶段”和“环境保障”
+
+1. 环境标准化与一致性
+
+ - 问题:传统的 CI 机器(无论是物理机还是虚拟机)环境复杂,不同项目所依赖的 Ruby、NodeJS、Python、Fastlane、Cocoapods 等工具版本可能冲突。造成“在我本地是好的,在 CI 机器上发布后就失败了”。(CI 机器上并不一定只部署一个 iOS 的 CI 项目,可能其他项目也部署了,可能由于 Ruby 安装了2.0,但是 iOS 的 CI 服务需要 Ruby 3.0+,这样就造成了本地 CI 服务正常,部署到 CI 服务器之后就有了问题)
+ - Docker 解决方案:构建一个专门的 Docker 镜像,预安装项目所需的所有命令行工具和依赖的特定版本,专门负责 CI 逻辑(如 Ruby 3.1.2、Fastlane 2.2.1、Cocoapods 1.22.1、Xcode 16)
+ - 结果:每一次 CI 构建都会从一个纯净、一致、已知状态的镜像环境启动,彻底消除了环境差异导致的构建失败,保证了构建结果的可靠性和可重现性。
+
+2. 依赖隔离
+
+ 多个 iOS 项目可能在同一台 CI 服务器上运行。使用 Docker 可以将每个项目需要的构建环境相互隔离。避免了项目之间的依赖冲突(例如,项目 A 需要 Cocoapods 1.10,项目 B 需要 Cocoapods 1.11)
+
+3. 快速的构建环境准备:
+
+ 相比启动一个完整的虚拟机,启动一个 Docker 容器是秒级的。这大大减少了 CI 流水线等待构建环境就绪的时间,加快了整个构建流程的反馈循环
+
+4. 版本控制与可追溯性:
+
+ DockerFile 是文本文件,可以放入 git 仓库进行版本管理。对构建环境的任何更改(例如升级 Fastlane 版本)都像代码更改一样,可以通过 Pull Request 进行审查、测试和记录,实现了基础设施即代码 (IaC)。
+
+5. 作为轻量级的“任务运行器”
+
+ 在 CI 流程中,Docker 容器通常被当做一个一次性的、执行特定任务的“沙盒”,比如:执行 pod install、执行 lint 或代码分析、运行 fastlane。
+
+
+
+#### 3. docker 的能力边界
+
+尽管 docker 很强大,但在 iOS 开发领域,它有非常明确且无法跨越的边界:
+
+1. 无法直接构建 iOS 应用(最关键的边界)
+
+ - 根本原因:iOS 最终编译、链接和打包必须依赖 MacOS 内核和 Xcode、Clang、SwiftCli
+ - Docker 局限性:标准的 Docker 容器基于 Linux 内核。它无法运行 MacOS 系统或 Xcode 这样的 GUI 应用(所以无法执行 xcodebuild 指令)
+ - 结论:无法在 linux docker 容器内编译出 `.ipa` 文件
+
+2. 无法运行 MacOS 镜像
+
+ Apple 的许可协议和硬件限制,导致不存在官方的 MacOS Docker 镜像。虽然有类似 LinuxKit 这样的非官方项目,但不够稳定,不能用于生成环境,风险较大
+
+
+
+#### 4. 最佳搭配
+
+明确了 docker 的作用和能力边界后,一个典型的 iOS CI/CD 架构就清晰了:**“在 Linux Docker 容器中准备环境和运行脚本,在 MacOS 主机/节点上进行最终编译”**
+
+- CI Server(Jenkins Controller):可以运行在任何系统上,负责任务调度
+- MacOS Build Agent/Node:一台或多台安装了 Xcode 的 MacOS 系统的电脑,它被注册到 CI Server 上,专门用于执行需要的 xcodebuild 任何
+- Docker 的使用:
+ - CI 流水线启动后,CI Server 会现在 Linux Docker 容器中完成所有它能做的工作:代码拉取、依赖安装(pod install)、运行单元测试(如果测试不依赖 MacOS 框架)、执行静态分析等
+ - 当需要进行 Xcode 的步骤(如编译、打包、签名)时,CI Server 会将工作委托给一台 MacOS Build Agent
+ - MacOS Agent:接收任务,它可能本身会通过一个 Docker 来获取一个一致的环境(用于运行 fastlane 等工具),或者直接使用本地安装的工具,然后调用 xcodebuild 和 fastlane 完成最终的构建和打包
+ -
+
+
+
+
+
+### 2. fastlane
+
+fastlane 可以理解为**专业高效的“工人”**。它精通所有 iOS 打包、签名、测试、上传的具体细节,干活又快又好。
+
+是一个自动化命令工具集。
+
+### 3. jenkins
+
+统筹全局的“项目经理”,它不亲手干活,也不提供工具,但负责安排任务、监控进度、触发流程(比如代码一来就让工人工作),并向大家汇报结果。
+
+- 调度与触发:监听 git 代码推送,定时或者其他事件触发整个流水线
+- 流程编排:定义 pipeline 流水线,决定先做什么后做什么
+- 资源管理:分配和管理执行任务的服务器(成为 Agent/Node)
+- 状态监控与报告:集中展示构建结果、测试报告、日志、并发送通知
+
+
+
+### 4. 黄金搭档
+
+```mermaid
+flowchart TD
+A[开发者推送代码] --> B[Jenkins 监听到推送事件]
+
+subgraph Jenkins_Agent_Node[Jenkins 代理节点]
+ direction TB
+ B --> C[Jenkins 触发 Pipeline]
+ C --> D[Pipeline 步骤: 准备环境]
+ D --> E["执行 Docker Run
+
+
+
+- `git_url`:
+
+ 是 `match` 最核心的配置,指定了存储加密证书和配置文件的 Git 仓库地址。`match` 不会将敏感的证书文件(`.cer`)、私钥文件(`.p12`)和配置文件(`.mobileprovision`)保存在本地或只留在苹果开发者门户。
+
+ 相反,它会将这些文件**加密后**推送到这个指定的 Git 仓库(`https://github.com/FantasticLBP/knowledge-kit`)中。
+
+ 当任何开发者或 CI/CD 系统需要这些文件时,`match` 会从这个仓库克隆或拉取最新的加密文件,然后在本地解密并安装到钥匙串和 Xcode 中。
+
+ 这个仓库应该是**私有的(Private)**,因为里面存储的是你应用的敏感安全凭证
+
+- `storage_mode("git")`:
+
+ 明确指定 `match` 使用 Git 作为存储后端。
+
+ match` 支持多种存储方式,`git` 是**默认且最常用**的一种。
+
+ 其他可选模式包括 `s3`(Amazon S3)和 `google_cloud`(Google Cloud Storage)。这些通常在更复杂或企业级的 CI/CD 环境中使用,以提高大文件的下载速度
+
+- `type("development")`
+
+ 设置 `match` 的**默认操作类型**为 `development`(开发证书和配置文件)
+
+ 这个参数定义了你要管理哪类证书。iOS 开发中有几种主要类型:
+
+ - `"development"`:用于开发阶段,可在真机上调试应用。
+ - `"appstore"`:用于提交到 App Store 或 TestFlight。
+ - `"adhoc"`:用于分发给有限数量的测试设备(最多 100 台)。
+ - `"enterprise"`:用于企业账号的内部分发。
+
+ 在这里设置为 `"development"` 意味着:
+
+ - 当你直接运行 `fastlane match`(而不指定类型)时,它会默认操作开发证书。
+ - 当你运行 `fastlane match development` 时,它也会使用这个配置(尽管命令行参数已经指定了类型,但其他相关配置会从这里读取)。
+
+这个 `Matchfile` 配置告诉我们:
+
+1. **存储位置**:所有加密的证书和配置文件都将被同步到 `https://github.com/FantasticLBP/knowledge-kit` 这个 Git 仓库中。
+2. **存储方式**:使用 Git 进行版本管理和同步(这是标准做法)。
+3. **默认环境**:默认情况下,操作的是用于**开发环境**的证书和配置文件。
+
+**一个典型的工作流程:**
+
+1. 团队成员 A 首次运行 `fastlane match development`。
+2. `match` 会检查指定的 Git 仓库中是否已有开发证书。
+ - 如果**没有**,它会连接到苹果开发者门户,创建新的开发证书和配置文件,加密后推送到 Git 仓库。
+ - 如果**已有**,它会将加密文件拉取到本地,解密后安装到 Xcode 和钥匙串中。
+3. 团队成员 B 加入项目,同样运行 `fastlane match development`。
+4. `match` 从同一个 Git 仓库拉取**完全相同的**证书和配置文件,确保团队环境一致。
+
+
+
+## 三、持续集成
+
+Cotinuous Integration,持续集成意味着每次代码的变更都在构建服务器上运行测试,并在指定场景下触发。这样如果开发者将测试失败的代码推送到代码库,也称为破坏构建,CI 会触发警告。
+
+- 主动式 CI:CI 提供商
+- 托管式 CI:github action
+- 手动式 CI:自己管理,Travis CI、Jenkins
+
+
+
+- Travis CI:小型开源项目,付费、简单、方便、
+- Jenkins:大型企业、丰富的自定义选项、定制化,不能做到开箱即用,免费
+
+### 1. docker
+
+> 问:为什么一定要 docker?不能在服务器上按照本地的配置安装所需的各个软件吗
+>
+> 答:在一个团队中,每个开发者的本地环境都可能略有不同(macOS 版本、Xcode 通过 App Store 安装还是手动安装、Homebrew 的使用方式等)。
+>
+> - **问题**:新同事加入,需要花费**一整天甚至更长时间**来按照文档一步步配置环境,任何一步的疏漏都会导致环境配置失败。
+> - **后果**: onboarding 成本极高,而且无法保证所有人的环境真正一致,为后续的协作埋下了隐患。
+>
+> 为什么“手动安装一下”不是最优解?它的成功依赖于:
+>
+> - **人的记忆和文档**:需要有人(或文档)准确地记录下所有依赖的**精确版本**(不仅仅是 `fastlane`,还包括它的依赖,以及依赖的依赖)。这份文档需要随着项目的每一次依赖变更而**实时更新**,这几乎是不可能的任务。
+> - **手动操作的准确性**:需要操作人员完全正确地执行安装步骤,不能有任何错漏。这是一个枯燥且容易出错的过程
+
+#### 1. 定义
+
+**Docker 概述**: Docker 是一种成熟高效的软件部署技术,利用容器化技术为应用程序封装独立的运行环境。每个运行环境即为一个**容器**,承载容器运行的计算机称为**宿主机**。
+
+容器。容器虚拟化指的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。
+
+- 镜像(image):提供容器运行时所需的程序、库、资源、配置等文件,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)
+- 容器(Container):镜像运行时的实体,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务
+- 仓库(Repository):镜像构建完成后,可以很容易的在当前容器上运行
+
+虚拟机:虚拟出一套硬件后,在其上运行一个完整的操作系统。
+
+
+
+**容器与虚拟机的区别**:
+
+* **Docker容器**: 多个容器共享同一个系统内核
+* **虚拟机**: 每个虚拟机包含一个操作系统的完整内核
+* **优势**: 所以 Docker 容器比虚拟机更轻量、占用空间更小、启动速度更快
+
+**镜像 (Image)**:
+
+* **定义**: 镜像是容器的模板,可类比为软件安装包
+* **类比**: 类似于制作糕点的模具,可用于创建多个糕点(容器),并可分享给他人
+
+**容器 (Container)**:
+
+- **定义**: 容器是基于镜像运行的应用程序实例,可类比为安装好的软件。
+- **类比**: 类似于模具制作出的糕点。
+
+**Docker仓库 (Registry)**:
+
+* **定义**: 用于存放和分享Docker镜像的场所
+* **Docker Hub**: Docker的官方公共仓库,存储了大量用户分享的Docker镜像。
+
+
+
+Docker 理解为:标准化、一摸一样的工具箱和工作环境。保证无论哪个工人来,用的工具和环境都完全一样,避免“在我这儿是好的”问题。
+
+- 环境标准化:创建一个包含特定版本 Ruby、Fastlane、Xcode 命令行工具、Cocoapods 的镜像
+- 隔离一致性:确保开发、测试、生产环境的构建完全一致,消除“环境依赖”问题
+- 快速搭建与清理:轻松为 Jenkins 提供纯净、可随时销毁和重建的构建环境。
+
+**价值:开发者需要花费大量时间排查环境差异,而不是专注于修复真正的业务逻辑 Bug,严重拖慢开发效率。**
+
+
+
+#### 2. docker 的核心角色与能力
+
+docker 在 iOS CI/CD 管道中(通常与 Jenkins、Gitlab CI、Github Actions 等工具配合)中主要负责“管理阶段”和“环境保障”
+
+1. 环境标准化与一致性
+
+ - 问题:传统的 CI 机器(无论是物理机还是虚拟机)环境复杂,不同项目所依赖的 Ruby、NodeJS、Python、Fastlane、Cocoapods 等工具版本可能冲突。造成“在我本地是好的,在 CI 机器上发布后就失败了”。(CI 机器上并不一定只部署一个 iOS 的 CI 项目,可能其他项目也部署了,可能由于 Ruby 安装了2.0,但是 iOS 的 CI 服务需要 Ruby 3.0+,这样就造成了本地 CI 服务正常,部署到 CI 服务器之后就有了问题)
+ - Docker 解决方案:构建一个专门的 Docker 镜像,预安装项目所需的所有命令行工具和依赖的特定版本,专门负责 CI 逻辑(如 Ruby 3.1.2、Fastlane 2.2.1、Cocoapods 1.22.1、Xcode 16)
+ - 结果:每一次 CI 构建都会从一个纯净、一致、已知状态的镜像环境启动,彻底消除了环境差异导致的构建失败,保证了构建结果的可靠性和可重现性。
+
+2. 依赖隔离
+
+ 多个 iOS 项目可能在同一台 CI 服务器上运行。使用 Docker 可以将每个项目需要的构建环境相互隔离。避免了项目之间的依赖冲突(例如,项目 A 需要 Cocoapods 1.10,项目 B 需要 Cocoapods 1.11)
+
+3. 快速的构建环境准备:
+
+ 相比启动一个完整的虚拟机,启动一个 Docker 容器是秒级的。这大大减少了 CI 流水线等待构建环境就绪的时间,加快了整个构建流程的反馈循环
+
+4. 版本控制与可追溯性:
+
+ DockerFile 是文本文件,可以放入 git 仓库进行版本管理。对构建环境的任何更改(例如升级 Fastlane 版本)都像代码更改一样,可以通过 Pull Request 进行审查、测试和记录,实现了基础设施即代码 (IaC)。
+
+5. 作为轻量级的“任务运行器”
+
+ 在 CI 流程中,Docker 容器通常被当做一个一次性的、执行特定任务的“沙盒”,比如:执行 pod install、执行 lint 或代码分析、运行 fastlane。
+
+
+
+#### 3. docker 的能力边界
+
+尽管 docker 很强大,但在 iOS 开发领域,它有非常明确且无法跨越的边界:
+
+1. 无法直接构建 iOS 应用(最关键的边界)
+
+ - 根本原因:iOS 最终编译、链接和打包必须依赖 MacOS 内核和 Xcode、Clang、SwiftCli
+ - Docker 局限性:标准的 Docker 容器基于 Linux 内核。它无法运行 MacOS 系统或 Xcode 这样的 GUI 应用(所以无法执行 xcodebuild 指令)
+ - 结论:无法在 linux docker 容器内编译出 `.ipa` 文件
+
+2. 无法运行 MacOS 镜像
+
+ Apple 的许可协议和硬件限制,导致不存在官方的 MacOS Docker 镜像。虽然有类似 LinuxKit 这样的非官方项目,但不够稳定,不能用于生成环境,风险较大
+
+
+
+#### 4. 最佳搭配
+
+明确了 docker 的作用和能力边界后,一个典型的 iOS CI/CD 架构就清晰了:**“在 Linux Docker 容器中准备环境和运行脚本,在 MacOS 主机/节点上进行最终编译”**
+
+- CI Server(Jenkins Controller):可以运行在任何系统上,负责任务调度
+- MacOS Build Agent/Node:一台或多台安装了 Xcode 的 MacOS 系统的电脑,它被注册到 CI Server 上,专门用于执行需要的 xcodebuild 任何
+- Docker 的使用:
+ - CI 流水线启动后,CI Server 会现在 Linux Docker 容器中完成所有它能做的工作:代码拉取、依赖安装(pod install)、运行单元测试(如果测试不依赖 MacOS 框架)、执行静态分析等
+ - 当需要进行 Xcode 的步骤(如编译、打包、签名)时,CI Server 会将工作委托给一台 MacOS Build Agent
+ - MacOS Agent:接收任务,它可能本身会通过一个 Docker 来获取一个一致的环境(用于运行 fastlane 等工具),或者直接使用本地安装的工具,然后调用 xcodebuild 和 fastlane 完成最终的构建和打包
+ -
+
+
+
+
+
+### 2. fastlane
+
+fastlane 可以理解为**专业高效的“工人”**。它精通所有 iOS 打包、签名、测试、上传的具体细节,干活又快又好。
+
+是一个自动化命令工具集。
+
+### 3. jenkins
+
+统筹全局的“项目经理”,它不亲手干活,也不提供工具,但负责安排任务、监控进度、触发流程(比如代码一来就让工人工作),并向大家汇报结果。
+
+- 调度与触发:监听 git 代码推送,定时或者其他事件触发整个流水线
+- 流程编排:定义 pipeline 流水线,决定先做什么后做什么
+- 资源管理:分配和管理执行任务的服务器(成为 Agent/Node)
+- 状态监控与报告:集中展示构建结果、测试报告、日志、并发送通知
+
+
+
+### 4. 黄金搭档
+
+```mermaid
+flowchart TD
+A[开发者推送代码] --> B[Jenkins 监听到推送事件]
+
+subgraph Jenkins_Agent_Node[Jenkins 代理节点]
+ direction TB
+ B --> C[Jenkins 触发 Pipeline]
+ C --> D[Pipeline 步骤: 准备环境]
+ D --> E["执行 Docker Run启动一个预先构建好的 iOS 构建镜像"] + + subgraph Docker_Container[Docker 容器内部] + direction TB + E --> F[环境内部: 代码已挂载] + F --> G[环境内部: 执行打包脚本] + G --> H["调用 Fastlane (已安装在镜像中)"] + H --> I[Fastlane 执行具体任务] + I --> I1[match 处理证书] + I --> I2[gym 打包 IPA] + I --> I3[pilot 上传 TestFlight] + end +end + +Docker_Container --> J[任务完成, 容器销毁] +J --> K[Jenkins 收集结果并报告] +``` + +上图展示了3者的协作模式:**jenkins 是大脑,负责指挥;Docker 是隔离且一致的环境,负责提供舞台;Fastlane 是主角,在这个环境里执行具体的构建任务** + +为什么需要3者结合? + +- 环境一致性问题(Docker 的核心价值) + - 问题:没有 Docker 时,Jenkins 所在的 Mac 服务器需要手动安装 Ruby、Fastlane、Xcode 版本等。一旦服务器需要重置或升级,环境配置会很麻烦,且难以保证与本地开发环境一致 + - 解决方案:使用 Docker 镜像来定义构建环境。`Dockerfile` 中明确指定了所有依赖的版本。无论是在开发者的笔记本上,还是在 Jenkins 服务器上,构建环境都是**完全一模一样的**,彻底杜绝了“环境问题”。 +- 专业化与高效(Fastlane 的核心价值) + - 问题:没有 Fastlane,你需要在 Jenkins 上编写复杂的 xcodebuild 脚本,处理代码签名等逻辑 + - 解决方案:Fastlane 用简洁的 Ruby 语法封装了所有复杂命令,提供了“开箱即用”的行动(action),极大简化了自动化脚本的编写和维护。 +- 调度与可视化(Jenkins 的核心价值) + - 问题:只有 Fastlane 和 Docker,你只能在本地手动执行指令,无法自动化出发,团队协作和监控 + - 解决方案:Jenkins 提供了强大的 Web 界面、流水线编排能力、权限管理和通知机制,让整个流程自动化、可视化、可协作 + + + +比如一个典型的场景: + +程序写好的代码提交到 github,提交了 MR: + +- 如果是合并到开发 feature 分支触发 pipeline 流水线任务,检查工程编译情况,编译成功则可以合并 +- 如果是合并到开发 develop 分支触发 pipeline 流水线任务,检查工程编译情况,编译成功后触发单元测试和精准测试 + +如果成功则给 merge request 的提交者和被 reviewer发送邮件,通知测试结果。并且 mr +3 后才可以合并。合并的结果也会通知 + +```shell +// Jenkinsfile +pipeline { + agent any + + environment { + DOCKER_IMAGE = 'your-custom-ios-builder-image:1.0' + PROJECT_URL = 'https://github.com/your/ios-project.git' + // 从环境变量获取GitHub相关信息 + GITHUB_REPO = 'your-org/your-repo' + GITHUB_API_URL = 'https://api.github.com' + } + + parameters { + // 添加参数用于手动触发时指定PR号 + string(name: 'PR_NUMBER', defaultValue: '', description: 'GitHub PR Number (for manual triggers)') + } + + stages { + stage('Checkout and Validate') { + steps { + script { + // 检出代码 + checkout scm + + // 获取当前分支信息 + env.BRANCH_NAME = env.BRANCH_NAME ?: sh(script: 'git rev-parse --abbrev-ref HEAD', returnStd: true).trim() + + echo "Building branch: ${env.BRANCH_NAME}" + + // 检查MR审批状态(如果是PR构建) + if (env.CHANGE_ID) { + checkMRApproval() + } else if (params.PR_NUMBER) { + env.CHANGE_ID = params.PR_NUMBER + checkMRApproval() + } + } + } + } + + stage('Build') { + steps { + script { + docker.image(env.DOCKER_IMAGE).inside { + sh 'fastlane ios build' + } + } + } + } + + stage('Test') { + when { + // 只在develop分支上运行测试 + expression { + return env.BRANCH_NAME == 'develop' || env.BRANCH_NAME.startsWith('release/') + } + } + steps { + script { + docker.image(env.DOCKER_IMAGE).inside { + // 运行单元测试 + sh 'fastlane ios run_unit_tests' + // 运行精准测试 + sh 'fastlane ios run_precision_tests' + } + } + } + } + } + + post { + always { + script { + // 记录构建结果 + currentBuild.description = "Branch: ${env.BRANCH_NAME}, Result: ${currentBuild.currentResult}" + + // 保存测试报告(如果有) + junit 'fastlane/test_output/report.xml' allowEmptyResults: true + } + } + + success { + script { + // 根据不同分支类型发送不同通知 + if (env.BRANCH_NAME == 'develop' || env.BRANCH_NAME.startsWith('release/')) { + // develop/release分支 - 发送详细测试报告 + sendTestSuccessNotification() + } else if (env.BRANCH_NAME.startsWith('feature/')) { + // feature分支 - 发送构建成功通知 + sendBuildSuccessNotification() + } + + // 如果是PR构建,更新PR状态 + if (env.CHANGE_ID) { + updateGitHubStatus('success', 'CI/CD pipeline completed successfully') + } + } + } + + failure { + script { + // 发送失败通知 + sendFailureNotification() + + // 如果是PR构建,更新PR状态 + if (env.CHANGE_ID) { + updateGitHubStatus('failure', 'CI/CD pipeline failed') + } + } + } + } +} + +// 检查MR是否已获得足够审批 +def checkMRApproval() { + echo "Checking MR approval status for PR #${env.CHANGE_ID}" + + // 使用GitHub API检查PR审批状态 + def approvalResponse = sh(script: """ + curl -s -H "Authorization: token \${GITHUB_TOKEN}" \ + -H "Accept: application/vnd.github.v3+json" \ + ${env.GITHUB_API_URL}/repos/${env.GITHUB_REPO}/pulls/${env.CHANGE_ID}/reviews + """, returnStd: true) + + def reviews = readJSON text: approvalResponse + def approvedCount = 0 + + // 计算批准的评审数量 + reviews.each { review -> + if (review.state == 'APPROVED') { + approvedCount++ + } + } + + echo "Found ${approvedCount} approvals (need at least 3)" + + // 如果审批不足,则失败构建 + if (approvedCount < 3) { + error "PR #${env.CHANGE_ID} does not have enough approvals (${approvedCount}/3)" + } +} + +// 发送测试成功通知 +def sendTestSuccessNotification() { + def changeAuthor = env.CHANGE_AUTHOR ?: "提交者" + def reviewers = env.CHANGE_TARGET ?: "评审者" + + // 获取测试覆盖率报告 + def coverageReport = sh(script: "cat fastlane/test_output/coverage.txt 2>/dev/null || echo '无覆盖率数据'", returnStd: true).trim() + + emailext ( + subject: "✅ 测试通过: ${env.JOB_NAME} #${env.BUILD_NUMBER}", + body: """ +
测试通过通知
+项目 ${env.JOB_NAME} 的测试已通过。
+ +构建详情:
+-
+
- 构建编号: ${env.BUILD_NUMBER} +
- 分支: ${env.BRANCH_NAME} +
- 构建结果: ${currentBuild.currentResult} +
- 构建日志: 查看详情 +
测试覆盖率:
+${coverageReport}
+
+ 此MR已获得足够审批,可以合并。
+ """, + to: "${changeAuthor},${reviewers}", + mimeType: 'text/html' + ) +} + +// 发送构建成功通知 +def sendBuildSuccessNotification() { + emailext ( + subject: "✅ 构建成功: ${env.JOB_NAME} #${env.BUILD_NUMBER}", + body: """ +项目 ${env.JOB_NAME} 的构建已成功完成。
+构建详情:
+-
+
- 构建编号: ${env.BUILD_NUMBER} +
- 分支: ${env.BRANCH_NAME} +
- 构建结果: ${currentBuild.currentResult} +
- 构建日志: 查看详情 +
编译检查通过,可以继续代码审查流程。
+ """, + to: env.CHANGE_AUTHOR ?: 'team@example.com', + mimeType: 'text/html' + ) +} + +// 发送失败通知 +def sendFailureNotification() { + def recipients = env.CHANGE_AUTHOR ? "${env.CHANGE_AUTHOR},team@example.com" : 'team@example.com' + + emailext ( + subject: "❌ 构建失败: ${env.JOB_NAME} #${env.BUILD_NUMBER}", + body: """ +项目 ${env.JOB_NAME} 的构建失败。
+构建详情:
+-
+
- 构建编号: ${env.BUILD_NUMBER} +
- 分支: ${env.BRANCH_NAME} +
- 构建结果: ${currentBuild.currentResult} +
- 构建日志: 查看详情 +
确保新提交的代码能够与主线代码成功合并、正常工作 | **快速、可靠地将测试通过的代码持续交付给用户**
自动发布流程、减少手动操作带来的错误和延迟 | +| **关注点** | **构建和测试**
- 代码能否编译成功?
- 单元测试能否通过?
- UI 测试能否通过?
- 代码风格是否规范 | **分发和部署**
- 如何打包成 IPA 文件?
- 如何分发给 QA?
- 如何提交到 TestFlight 或 App Store? | +| **典型任务** | - 触发时机:代码推送(git push)或提 PR 时
- 编译项目
- 运行单元测试
- 运行 UI 测试
- 执行 Lint 工具(如 SwiftLint)
- 生成代码覆盖率报告 | - 触发时机:CI 阶段通过后,或定时触发,或手动触发
- 生成签名证书和配置文件(`match`)
- 打包生成 IPA 文件(`gym`)
- 分发到测试平台(如 `firebase`、`testflight`)
- 提交到 App Store Connect(`deliver`) | +| **产出物** | **测试报告、精准测试覆盖率**
告诉你代码质量、工程健康度 | **可安装的 IPA 包、发布提交结果**
一个可交付给用户的产品 | +| **比喻** | **一个自动化的质量检测流水线**
每提交一个零件,就检查尺寸、规格是否合格(每一段代码) | **一个自动化的包装和物流系统**
将合格的零件包装成产品,打包、运输、分发到商店。 | + +总结:**CI 和 CD 是软件开发生命周期的2个部分。先 CI 再 CD。CI 是 CD 的基础,代码必须先经过 CI 的各类测试(编译成功、单测试覆盖率保证、精准测试覆盖率保证、Lint 成功)保证质量,才可以交给 CD 流程,进行打包和分发(实现价值)**。 + + + +### 4. CI 和 CD 的能力边界是什么? + +用个例子来描述: + +CI 是质检车间: + +- 输入:新来的原材料(代码提交) +- 过程:自动化流水线进行一系列的质量检查(编译、测试、扫描) +- 输出:通过质检的半成品(编译通过的、测试覆盖率达标的可工作的代码)和一份质检报告 +- 边界:一旦产品贴上“质检合格”的标签,CI 阶段就结束了。不再关心这个半成品接下来的任何状态 + + + +CD 是包装与物流中心: + +- 输入:(CI 车间的输出作为输入)从 CI 车间送来的“合格半成品” +- 过程:将其打包成最终产品(签名、打包 IPA)、贴标签(版本号),然后根据指令分发到不同的目的地(TestFlight、App Store) +- 输出:交付到用户(QA、用户)手中的产品 +- 边界:假设所有的输入都是合格的。核心价值是高效、可靠、无差错地完成分发流程。 + + + +整体流程为: + +```mermaid +graph LR +A[代码提交] --> B[CI流水线] +B --> C{所有检查是否通过?} +C -- 否 --> D[反馈失败 拒绝合并] +C -- 是 --> E[生成合格产物] +E --> F[CD流水线] +F --> G[部署到测试环境] +G --> H[自动化烟雾测试] +H --> I{是否通过?} +I -- 否 --> J[自动回滚] +I -- 是 --> K[人工审批?] +K -- 是 --> L[等待批准] +L -- 批准 --> M[部署到生产环境] +K -- 否 --> M +M --> N[完成交付/部署] +``` + +总结: + +**CI 和 CD 是软件开发生命周期的2个部分。先 CI 再 CD。CI 是 CD 的基础,代码必须先经过 CI 的各类测试(编译成功、单测试覆盖率保证、精准测试覆盖率保证、Lint 成功)保证质量,才可以交给 CD 流程,进行打包和分发(实现价值)** + +**CI 是质量的守门员,其边界在于代码集成阶段的验证和保证;CD 是价值的输送带,其边界在于发布流程的自动化。2者职责分明,先后衔接,各司其职。共同构建了现代软件工程的敏捷、高效的交付流程** + + + + + + + + + + + + + + + diff --git a/Chapter1 - iOS/1.143.md b/Chapter1 - iOS/1.143.md new file mode 100644 index 0000000..31c01c8 --- /dev/null +++ b/Chapter1 - iOS/1.143.md @@ -0,0 +1,461 @@ +# AI 对端上的赋能 + + +## 一、实时特征回流 +传统智能的问题、弊端是什么? + + +- 推荐系统需要收集用户的行为,将这些行为作为用户的意图表征,表征他的偏好,回流到服务端。 +- 服务端拿到这个数据,在发起一次实时请求的时候,会根据用户的行为特征,去商品池里面召回一批用户喜欢的商品,再返回给端上,给用户做展示 +- 同时,这个用户的行为数据,还会作为训练模型的一个样本 + + + +可以发现传统的推荐系统存在一些瓶颈: +- 实时性不足 + 行为数据回流的时效性,会影响算法对于用户意图变化的感知,会影响推荐的准确性。 + 现有的系统,在手淘这种亿级用户体量下面,想要做到用户数据的实时回流,技术上面挑战很大。 + 另外涉及到用户隐私方面的风险考虑,以及在服务端的存储瓶颈相关的考虑,是不能把用户所有的行为都回流到云端 +- 数据丰富度有限 + 在服务端,整个用户行为数据的丰富度非常有限的。 + 同时我们的一次推荐内容的更新,也是受限于一次新的请求时机的发起。 + 即使我们发现用户的意图,通过数据发现了意图的变化,但是也很难实时对用户的前台界面去做一次干预,去及时调整推荐的内容 +- 但用户算力/存储瓶颈 +- 千人一面的模型 + 目前服务端的算法模型更多的还是千人一面。受到算力和存储的瓶颈,很难针对每一个用户去建立一个属于他自己的模型。 + 去做更加精准的预测。 + +针对上面的这些问题,就是端上的智能可以去发挥的空间所在。 + + + +前面说过,用户的数据回流时效性会影响推荐的准确度。那么是不是可以把用户的特征、用户的数据,做到最实时的回流? +这里,我们做了一些这样的尝试: + + +- 首先可以把用户的最原始的行为数据回流。比如用户在逛手淘的过程中产生的一些浏览、点击等行为回流到服务端 +- 同时,也可以把用户的这些原始行为数据做一定的聚合,生成一个信息量含量更高,但是数据量更小的用户特征数据(数据聚合) +比如把用户在商品详情页的一系列的特征,聚合成用户对商品详情的更精炼的一些数据,比如用户有没有对商品点击过收藏、有没有点击过加购,聚合成 +一条商品详情的浏览特征 +- 也可以对这个特征继续做精加工处理,变成一个算法模型可直接使用的特征向量。当然了,它也可以表征用户的行为和意图 +- 还可以把这个向量做进一步精加工处理,生成一些用户的意图打分。比如用户对于某个商品详情的意图分,是强还是弱,用分数去表明。 + +比如用户在手淘里面浏览的过程当中,用户逛着逛着是不是不感兴趣了?是不是疲劳了?这也可以用来表征用户的一个“跳失意图”。 + +这几种数据都可以回流到服务端的,图上数据可以看到: +- 从左往右:数据的加工度越来越高的、数据量是越来越少的 +- 从右往左:数据量大,信息密度低 + +回流到服务端的时候,对于这4种不同类型的数据,一一做过尝试: +- 首先,如果直接回流用户的原始数据,那么这个数据量会非常大,服务端的存储存在压力。另一方面也会涉及到用户的隐私风险 +- 其次,我们也尝试过,将用户的行为数据聚合成一条向量直接回流到服务端,数据量虽然小了,但是会丢失一些信息。另外向量这种数据格式,通用性会非常的受限。智能针对特定的模型去回流特定的向量。 +- 另外,也尝试过直接回流用户的意图分,比如回流一条对于商品详情页的意图分,在整个手淘的流失的意图,这个数据是有效的,但是它丢失的信息也是非常多的 + +所以最后选择的是将用户的数据在端上做一定的标准的加工化处理,聚合成特征回流到服务端,这是实践过比较好的,既能保证数据的有效性又能保证实时性的一种方式。 + + +### 1. 实时特征回流 + +- 数据本地加工,做标准化处理,然后按照需要将需要的那部分数据回传到服务端 + +解决了什么问题? +- 提升了数据的丰富度,能够在服务端拿到用户更多的、更细粒度的一些行为数据。能够让服务端的数据输入变得更丰富 +- 通过对数据加工之后,建立一条实时的特征回流通道,保证了从端到云上的数据实时性 + +遗留了什么问题? +- 通过实时的回流方式,解决了用户实时感知的在实时性方面的问题 +- 但即使感知到了用户意图发生了变化,,也缺少一个实时在前台去干预用户的方式 + + +### 2. 信息流的“回退推荐” +针对实时特征无法具备实时干预能力的问题,在信息流方面做了一种叫“回退推荐的策略” + +想象这样一个场景:用户在商品列表页,对某个商品感兴趣,点击某个商品到达详情页,在详情页看了一番之后,用户点击了收藏或者加入到购物车了。有收藏、加购行为表示用户对这个商品是很感兴趣的。 + +此时,从商品详情页到回退到外面这个商品列表页的时候,会根据用户刚刚的浏览、加购行为,推荐一个相似的商品。 + + + +会根据用户刚刚浏览的这些行为,去给他推荐一个相似的商品。这个过程会发生很多行为,通过滚动、曝光等行为可以推测用户在信息流的浏览意图是逐渐从逛切换到了买。 + +如果页面回退,我们不做干预的情况下,他可能继续往下去浏览,购买这个行为的意图差“临门一脚”就可以转换为一次成交购买。如果不加以干预,可能逛着逛着就丧失购买意愿了,流失一笔潜在交易。 + +选择的策略是:在页面回退的时候,在原来的商品卡片周围,立即推荐一个相似的商品,希望能继续促成,希望能够留住他刚刚这次对商品购买的强意图。这个就是回退推荐。 + +本质上就是抓住了用户从逛到买的这个强意图聚焦。针对强意图的聚焦,做了一次成交转换的促成。 + +商品卡片的回退推荐策略落地上线后,效果是非常好的。比普通商品卡片的转换率高五六倍左右。 + + + + +存在什么问题? +类似程序员和产品设计沟通出的一种机制,可以理解为命令式编程,是人为先验地找到了一个能够代表用户意图的时机,也就是在回退时机。这种时机靠人去发现梳理,往往是很难覆盖全面的。依赖于对于用户强意图的梳理、选择。那么有没有一种方式可以自动的去预测用户意图的变化? + + + +## 二、应用场景 + +### 1. 信息流的端侧重排 + +在信息流上面做了另外一个尝试:在本地进行了一次端上的重排。 + + + + +一个用户在逛信息流的过程中,会产生滚动、曝光、点击、加购、收藏、停留、回退、滚动这些行为。从用户的实时的行为序列中,其实是表征了用户背后的一个隐式的意图表达。 + +可以把用户的实时行为序列去输入到一个意图的模型当中,去计算用户当前的意图是什么?他偏好哪些、不喜欢哪些?得到用户的正负一些意图反馈。去判断用户当前是不是正在一个疲劳的状态,去计算他即将要跳失的可能性。 + +然后将这些用户意图,输入到一个本地的实时决策模型中去,去决定接下去要给这个用户去做什么事情。例如用户是不是对于接下来要滚动浏览的商品兴趣是不是发生了变化的时候,能够根据用户的实时意图,去做一次实时的调整,永远把用户最喜欢的内容放在他排序更靠前的位置。 + +或者当发现对这批商品都不感兴趣的时候,就理解去重新更新一次商品。或者当发现用户即将跳失之前,去做一些强干预,去挽留他继续留在这个页面上。比如通过一些权益去做挽留。 + +做完决策后,就可以将这个决策结果通知到前台,去做相应的响应。 + +还存在一些问题: + + +决策选择还是受限于产品策略。程序员还需要和产品去约定设计产品策略。开发和产品共同约定,在用户的某一时机之下,接下来对应的一个处理是什么。它的整个呈现形式和所处业务域还是存在紧密关系的。 + +这种应用形式,应用在信息流上是非常好的,但是很难迁移到其他业务域。 + +### 2. 智能 Push + +在这样的背景之下,接下来开始下一个尝试,去做一个更加通用的、端上的智能应用。去 Push 业务。 + +传统业务上,Push 是服务端发起的。服务端存在一个任务,不断计算:我需要给什么样的一批用户、推送一批什么内容。服务端跑了这个任务后,会圈选一批人群,定一个任务,给这些人要去发一个推送。客户端收到这个推送,展示这个推送的消息内容。 + +服务端发起的 Push 有啥问题? +- 缺乏感知能力,难以精细化运营 + 服务端不知道用户当前 App 的状态,用户在手淘内还是不在。没有办法知道用户的实时状态,很难针对用户的实时状态去做精细化运营。 +- 被动触达,错失最佳营销时机 + 更希望的是针对用户的某一个精细化行为,去做一次响应的时候,服务端 Push 是做不到的。 + + +完整流程: + + +用户进入手淘后,会不断收集端上的行为(滚动、曝光、点击、加购、收藏、停留)数据,然后会把行为数据输入到另一个意图模型中,去判断他当前的一些实时意图。不断的根据行为做分析。也会输入到另一个决策模型中去,但这个(智能 Push)场景下的决策模型和前面的端上重排场景的决策模型是不一样的。这个决策模型会**判断用户当前的状态适不适合接受一次干预**,或者适不适合接受某一次营销的推荐。当我们发现用户当前处于一个相对空闲的状态,这个时机更适合接受一条干预的时候,我们就会把这个信号通知到服务端。这时候服务端在海量的内容中去筛选出一条对应着用户当前的意图,有效的一条信息,再推送给客户端。 + +这种从客户端发起的 Push 推送相比于服务端推送来说,对于用户当前的实时状态有着非常强的感知的,用户发生的任何一个行为在端上的决策模型中,可以以毫秒级的速度获取到,当我们真的需要去对用户做一次精准的干预的时候,这种方式相比于服务端推送来说,是有着非常大的优势的。 + +- 从“平台视角”向“用户视角”的转变 + 传统的服务端推送是站在平台视角,来去筛选内容、筛选用户去发送消息的。而“端智能 Push”更多站在用户视角,去分析用户在什么时机下适合接受干预。 +- 解决了什么问题 + 对端上单用户的算力空间的充分利用;同时智能 Push 分离了用户的感知决策。用户的感知可以作为一个独立的模块存在。用户的决策:接下来要做什么响应。也是一个比较独立的模块。在应用性上具备初步的可移植性。可以在多个应用场景,不只是信息流这样一个较为垂直的业务域上去使用。 +- 没有解决什么问题? + 决策依然需要先验制定。 + +我们对于 AI 的期待是美好的,期望 AI 可以帮助我们决定下一步做什么。然而通过这些案例可以发现,现阶段,我们还是只能做到在一个已经决策好的产品框架下面去做。是需要先有一系列的决定(在什么样的情况下面,可以有哪些响应),那么 AI 是帮助这样一个决策的结果更加精准。 + +### 3. 智能预加载 + +根据用户身份、角色、常见行为路径,预测接下去要使用的功能,对可能要进入的页面进行预热、预加载,在用户访问这个页面之前,把页面准备好,来做到秒开的效果。 + +也就是说,如果能精准预测用户下一步将要去往哪里,对于性能来说,提升是会非常明显的。 + +那么最关键问题就是:**如何预测用户下一步将要去往哪里**? + +### 4. 手势热点识别 + +判断用户热点的操作区域是什么?针对这块区域来做一些定制化的特定推荐。 + +### 5.智能营销投放 + +用算法的更加精准的预测,去替代 以往的业务规则的人群圈选。 + + +对于端智能来时,它属于基础能力。它用在哪里,才是能不能用好的一个关键,也就是业务价值能不能提升。 + +从过去的应用来说,我们认为端智能对于客户端的改变主要体现在: + +- 更多的数据 + 在端上做算法模型的预测,可以拿到用户在端上更富丰富、更细粒度的数据,去避免在服务端取不到这样丰富数据的缺陷。 +- 更实时的响应 + 相比于服务端,很多系统称具有小时、分钟、秒级别的实时响应,在端上的实时性是带来本质性的变化。 +- 更低的消耗 + 闲置算力去运算和存储资源,带来本质上的实时性的提升。同时也节约了服务端资源的消耗。 + + +## 三、端智能整体架构 +要素:算法、数据、调度框架、运行环境 +架构如下: + + +1. 围绕着端上的算法分为2种模型: +- 用户意图计算模型:不断分析用户当前所处状态 +- 决策模型:会根据用户意图计算的结果,去判断下一步要做什么样的处理。比如一次本地重排、还是去做一次数据的重新刷新 + +2. 作为端上的算法输入,建立了一个端上的特征中心,用来提供给端上的算法使用:提供标准的用户行为数据、以及一些特征服务。 + +3. 还建立了端上的用户决策框架:接受用户的每条行为数据,然后根据这些行为去决定接下来什么时机要去唤起一个什么样的模型。拿到这个模型的响应结果后再一路回传到我们的客户端应用层。应用层根据这个结果来做前台界面上的渲染。 + +4. 围绕着端上的算法所在的执行环境,是在底层有一个端计算的容器,提供 Python 的运行环境以及 MNN 轻量级的推理引擎 + +5. 对于整个算法研发的 workflow,配套的做了一个端计算的一体化研发平台。算法同学在这个平台完成开发到发布、再到 AB 实验以及模型训练的一系列工作。 + +模型从这个平台发布后,是会下发到客户端,然后在端上跑。 + +### 1. 端上算法方案 + + + +- Algorhitms Solution On Edge: + - 提供了模型、特征和样本这三大机器学习算法基础组件的端上通用方案 +- Business Solution On Edge: + - 端上推荐算法解决方案,提供了端上实时用户感知和端上智能决策2大模块 + - 通过多任务学习,端上智能决策支持了端上重排、端上智能刷新、端上会话式推荐和端上跳失点预测等任务 +- 千人千模: + - 每个用户训练和部署自己的个人化模型 + - Meta-learning + Federated Learning + +### 2. 端上特征中心 +为端智能应用而设计,提供端侧算法所使用的标准化的全域用户行为数据和特征服务 + +- 定义端侧用户行为标准 + 该特征中心会定义端上用户的行为标准,产生什么样的用户行为,比如用户的浏览行为。这个浏览行为会有一些我的浏览区域、浏览停留时长等等标准化属性。其次,也会有一些像用户手势行为。比如滚动、点击等等。 +- 建立行为数据图化索引 + 具体的实现上,为用户的每个行为,去建立了一个行为的图画的索引,将用户的行动点当作一个节点,并且把节点和节点之间建立了一种关联。这样子能够在端上,让算法可以快速拿到这个数据。 +- 数据标准化 + 同时,采集到这个数据之后。也会对数据做标准化处理。把它经过标准化的字段解析和我们的特征加工,给算法提供简单、易用、可用的数据 +- 通用特征接口服务 + + + +数据分层架构: + + +- 存储层:将采集到的用户行为数据按照约定的标准,在客户端本地做持久化存储。同时对用户数据进行一次加工处理,生成一份信息密度比较高的基础特征表。比如对详情页的浏览行为、App 页面间操作路径的数据、页面浏览的时序特征,这些数据都会存储在客户端本地。 +- 接口层:实时接口层,提供了 Python 层面的接口服务,给算法侧使用。可以做到数据的实时查询,将下层的通用数据、用户行为数据、环境信息等打包好给算法侧使用。 + 这个数据一部分存在端上,一部分存储在云端,和云端有个数据同步需求的: + - 从端同步到云,将一些必要的基础特征同步到服务端,让服务端可以拿到用户实时的聚合好的特征。 + - 从云到端,也可以把云端特有,客户端没有的数据(比如用户画像、历史行为等等)下发下来,这样子可以让端上的算法也能拿到这部分数据,做出更精准的预测。 + + +### 3. 端上的决策中心 + +比如:用户在:我的淘宝 -> 我的订单 -> 订单详情页查看了某个订单详情,然后回退到“我的淘宝”页,这时候会对用户的意图进行分析,判断当前是不是处于一个空闲的状态。如果发现是空闲状态,则给他发送一条 Push 消息,引导进入双11主会场。这个就是一个智能 Push 的案例。 + +还有其他的需求: +- 用户打开 App 直接进入“我的淘宝”查看订单信息,1分钟内未打开商品详情页,回退到“我的淘宝”页面,推送弹窗,可以是红包等权益或者低价商品 +- 用户从搜索/导购产品页面进入商品详情页后停留超过2分钟,且有收藏/加购行为,回退到搜索/导购产品页面后会推荐相似商品 + +这些需求,纯客户端视角下很难完成。所以基于用户行为的端侧事件引擎,提供面向全域用户行为的切面开发模式,打破业务间的隔离,实现以用户为中心的跨业务域的决策能力。 + +这样一个切面能力的好处就是: +- 业务开发同学不需要去关心前面的这一串行为是啥时候触发的、怎么发生的。这个行为的匹配由端上的决策框架去做。 +- 实际的开发同学,只需要去关注在切面发生的时候,我需要去做哪些处理。比如:弹层 + + +这种面向用户行为的切面的编程方式,既可以用在运营规则上,也可以用在算法模型上。后续的响应,可以是弹出弹层、发送 Push、发送1次请求等。 + +### 4. 端计算容器 + +端上的算法模型需要跑在容器里,手淘用的是一个轻量级的推理引擎 MNN。MNN 提供了算法在端上跑模型所需要的算子。 + +## 四、云端一体协同 + +上图是端计算的优势和云计算的劣势。 +未来的端计算并不是完全割裂的。端和云协同才可以迸发最大的效果。 + + +可以看到端和云拥有各自擅长的领域。 + +在做云端协同的过程中,会遇到不少问题。比如在端上触发一次重排的时候,会发现端上的数据量是不够的,如果想要提升端上的重排效果,就要扩大候选池,所以增加了**端上的缓存池**。在端上的模型在本地运行过程中,由于模型本身是在服务端训练的,它的模型和特征向量的同步一致性是需要细节方面处理好的。 +同时由于在端上选择用户时机去做一些干预,实际上对于服务端是带来一些 QPS 增量,如何解决处理使其不是负担也需要处理。 + +这些问题处理好,最后需要回答价值多大问题的时候,就需要做实验验证端计算是否真的有效的时候,在实验的设计、以及后续数据分析、结果归因上,也耗费了大量的精力去论证它的有效性。这些是踩坑之处。 + + + +QA: 决策框架与 MNN 推理引擎的区别是什么? + +| 维度 | MNN (推理引擎) | 决策框架 | +| :----------- | :-------------------------------------------------------- | :----------------------------------------------------------- | +| **技术定位** | **底层计算基础设施** | **上层业务调度与编排系统** | +| **核心职能** | **“算”** - 高效执行模型计算,输出预测结果(如用户意图分) | **“判”与“调”** - 判断在什么时机、调用哪个模型、并根据结果执行哪个业务动作 | +| **类比** | **笔墨和运笔技法**(负责把字写出来) | **书法家的头脑和章法**(决定何时写、写什么字、怎么写布局) | +| **关注点** | 计算性能、算子支持、模型兼容性、功耗 | 业务逻辑、决策流程、时机控制、动作执行 | +| **输出物** | 模型的数值化输出(如分数、概率) | 一个具体的业务指令(如:重排、刷新、弹窗) | + +为了更好地理解,我们可以看一个它们如何协同工作的例子,比如“端侧重排”: + +1. **决策框架感知时机**:决策框架监控到用户发生了一系列行为(滑动、点击、停留),判断**此时需要重新计算用户意图**。 +2. **决策框架调用MNN**:决策框架**调度**“用户意图计算模型”开始工作,并将必要的特征数据准备好。 +3. **MNN执行计算**:**MNN引擎**加载并运行该模型,进行高速数学计算,最终输出一个**用户当前的意图分数**。 +4. **决策框架做出决策**:决策框架**接收**MNN返回的意图分数,再结合预设的业务规则(例如:分数高于X则触发重排),**判断**下一步应该执行“本地重排”动作。 +5. **决策框架执行响应**:决策框架**通知**前端的渲染模块,对商品列表进行重新排序。 + + + +## 五、AI 在有赞落地了什么场景 + +### 1. 云打印机秒连接 +云打印机接入 OCR + LLM 技术实现 AI 拍照秒识别,秒连打印机,一拍即用,操作简单 +门店商家很多都会去连接打印机,连接过程中成功率只有54%左右。分析了相关原因,发现有2个主要原因: +- 商家找不到打印机的连接入口 +- 打印机的配置过程中需要输入相关的编号和密钥。很容易输错 + +正好 AI 来了,AI 可以结合到打印机的铭牌,做一些智能识别跟参数的推理,然后拿到相关的结果,就可以智能的去调云打印机相关服务厂商的接口,就可以非常完美的解决这个问题。 + +我们对接了非常多的云打印机的品牌厂商,通过 AI 能力,去设计一些提示词,针对这些不同厂商的差异要做一些不同场景的兼容设计,过程中其实踩了不少的坑,不断的调优,让所有的硬件识别准确率提升了非常多。 + +我们的产品改造完之后,在商家平台网页端,硬件添加入口,让商家上传铭牌照片就可以了。原来的十步变成1步。连接成功率也从原来的不到70%提升到97%。 +思路,以后的业务需求,可以尝试跳出 Web 前端能力、Native 能力,从 AI 侧看看有没有更多的可能和思路。 + + +### 2. 基于图像识别算法的零售移动智能收银方案 + +#### 1. 背景 +生鲜果蔬行业在零售行业中是一个较大且比较有特征性的行业,同时在生鲜果蔬行业中,称重秤为经营的刚需类设备。目前商家主要使用条码秤,通过 PLU(Price Lookup Code) 码进行商品的管理,每个 PLU 码对应一个商品,我们可以想象下在超市购买水果的时候会碰到下面这个流程: + + + +所以在门店商品种类比较多时(一个典型生鲜果蔬类商家商品种类大多超过 200 个,随机调研了 5 家有赞果蔬商家,平均 SKU 数量 500+),PLU 码较难记忆清楚,在打秤时需临时查询,称重耗时比较长,为了避免高峰时期排队现象,需在门店增加秤台和打称员,导致商家人力成本较高。 + +因此就前面所提到的场景,我们需要通过更加智能的方式帮助商家加购,那么基于机器学习的图像识别能力就被提上了议程。我们通过条码秤关联的摄像头进行实时拍摄,基于机器学习技术和图像识别技术,将店员放置在秤盘上的商品进行识别,并给出相关商品的列表,减少收银员收银场景中的操作次数,减少商家对新收银员的PLU码的培训并降低熟悉相关商品的培训成本,从而在整体上降低收银员的门槛以及商家的人力成本。所以我们可以得到我们期望的购买流程: + + + +#### 2. 架构设计 +我们针对于商家的痛点和可行的解决方案绘制了下面的流程图: + + +整个流程中的基础能力: +- 实现摄像头对于商品的拍摄 +- 针对于拍摄能力支持图像转换成为商品的能力 +- 将识别结果进行列表化展示 +- 将用户点击之后的结果进行上报,用于商家个性化画像的绘制,以及机器学习模型的加深 +- 支持机器学习模型的动态下发 + + +#### 3. 框架选择 +首先是整个环节的核心点,对于商家商品的关联以及数据模型进行机器学习并完成定时的增量更新流程。通过对比市面上已有的框架,因为 TensorFlow 有 lite 版本单独支持移动端能力,同时结合有赞算法团队已有的技术沉淀,所以敲定使用 TensorFlow 作为机器学习的基础框架。完成了框架的确定,就需要考虑业务场景上的实现了。 + + +#### 4. PLU 码是什么 +PLU 码是生鲜零售行业的 “商品价格查询码”,核心是用一串数字唯一标识一种散装生鲜商品,方便打秤时快速调取价格 +特点: +- 本质是 “商品与价格的关联码”,替代人工记忆商品价格的繁琐操作。 +- 通常由 4-5 位数字组成,可分为行业通用码和商家自定义码。 +- 仅用于散装生鲜(如蔬菜水果、散装零食),预包装商品多用地条码。 + +比如我买了10斤红富士苹果,怎么体现?PLU码会携带重量、价格信息吗?收银员拿到这个 PLU 码之后的处理流程是什么样的? +PLU 码不只为生鲜类目(主要服务散装非标品),本身不携带重量/价格信息,仅关联 “商品 + 单价”信息。10 斤红富士需通过 PLU 码调单价 + 秤称重算总价,收银员核心流程是 “输码 - 调价 - 称重 - 结算”。 + +##### 1. PLU 码的适用范围:不止生鲜,但聚焦 “散装非标品” +核心适用场景:散装生鲜果蔬(如苹果、生菜)、散装干货(如核桃、枸杞)、散装零食(如糖果、饼干),这些商品无固定包装、需按重量计价。 +非适用场景:预包装商品(如盒装牛奶、袋装面包),这类商品有固定重量 / 价格,用地条码(EAN 码)而非 PLU 码。 +简单说:PLU 码是 “散装称重商品的专属身份码”,生鲜是主要使用场景,但不是唯一场景。 + +##### 2. 10 斤红富士的 PLU 码使用逻辑:重量靠秤、价格靠计算 +PLU 码的核心作用是 “快速调取商品单价”,重量和总价需结合秤的功能实现: +第一步:红富士对应 PLU 码(如通用码 4133),商家已在秤中录入 “4133 = 红富士,单价 8 元 / 斤”。 +第二步:你买 10 斤红富士,打秤员将苹果放在秤上,输入 PLU 码 4133。 +第三步:秤自动读取 “10 斤” 重量,按 “单价 8 元 / 斤 ×10 斤” 算出总价 80 元。 + +关键:PLU 码只负责 “告诉秤这是什么商品、多少钱一斤”,重量是秤测量的,总价是系统实时计算的,三者独立但联动。 + +##### 3. 收银员拿到 PLU 码后的完整流程 +以超市购买 10 斤红富士为例,流程分 5 步: +- 商品上秤:将散装红富士放在条码秤的秤盘上,秤实时显示重量(10 斤)。 +- 输入 PLU 码:收银员手动输入 4133(红富士 PLU 码),或通过扫码枪扫预存的 PLU 码贴纸。 +- 系统调参计算:秤通过 PLU 码调取预设单价(8 元 / 斤),自动计算总价(8×10=80 元)。 +- 打印价签:秤打印含 “PLU 码、商品名、重量、单价、总价、日期” 的价签,贴在商品上。 +- 收银结算:你拿着贴有价签的商品到收银台,收银员扫价签上的条码(或手动输入 PLU 码),收银系统确认价格后完成支付。 + +#### 5. 商品关联 +完成了框架选择,接下来就需要确定如何将商品关联到数据模型上了。 + +有赞的商品有很多的字段,比如说:编码、条码、规格、属性等等。“有赞商品的编码、条码等唯一标识字段,零售场景已支持识别,但这类标识仍需人工关联 PLU 码才能完成称重结算,未能解决‘PLU 码难记忆、打秤查询耗时’的核心痛点。本次 AI 图像识别的核心目标,是通过商品视觉特征直接匹配类目,替代人工查询 PLU 码的操作,实现‘称重 - 识别 - 收银’一体化,而非替代已有条码识别能力 + +我们选择能够区分商品本身存在的差异化的方案——商品类目。 + +有赞的商品类目最大为 4 级,最后基本上已经能够细分到水果的某一个种类中。举个例子:一个苹果,在有赞类目中的选择需要被选择成为 `食品酒水 > 水产肉类/新鲜蔬果/熟食/现做食品 > 新鲜水果 > 苹果`,同时考虑到苹果中仍然存在不同的品种。所以我们在商品类目中追加了水果种类用于区分不同的苹果品种,比如说:金帅、国光、冰糖心…… + + +#### 6. 反馈闭环 +在确定了核心能力的解决方案后,接下来需要解决的是如何将商家本地的数据进行上传,并对于已有模型进行强化。为了更加及时的获得用户本地的选择情况,我们选择了有赞埋点平台作为技术支撑,通过离线缓存,并结合闲时上报的能力,将用户选择图片的整体筛选情况,基于店铺/角色等维护进行拆分,并将最终的选择数据导入 ODS 库中。并在算法前结合用户选择时机的拍摄图片上传 + 用户选择商品情况进行结合,进一步针对于对应店铺的模型进行加强。从而在不断的强化商家模型,从而提高用户准确性。 + + + +#### 7. 流程优化 +要达到好用的程度。所以我们需要对于数据统计流程/用户交互流程进行更加深入的优化 + +##### 1. 自动化类目关联 +考虑到许多商家在使用零售的过程中,如果需要挂载到对应的类目中成本较高,为了减少商家的操作成本。我们基于商家的商品标题 + 图片提供了默认类目和种类的选择。极大程度上降低了用户的操作成本。 + + +##### 2. 图片上传/优化 +根据分析商家的实际使用场景,我们发现部分商家在售卖生鲜果蔬的同时,仍然会同时售卖一些标品,比如说日常的柴米油盐酱醋茶。所以导致商家在正常选择商品时候,设备相机仍然会采集相关照片。从而导致商家返回中会存在一部分无效图片,从而影响后续的数据分析,所以我们需要在进行机器学习算法前进行空盘图片的判断,从而避免无效数据对于数据集的影响。 + +同时由于电子秤的硬件特性:当物品放置到称上的时候,电子秤中的读数从 0 变化到物品实际重量的流程是非线形的,这就导致了,如果我们在这过程中进行数据采集,可能会采集物品非稳定的状态。所以我们约定在电子秤的读数停止变化的时候才进行数据采集,从而保证数据的有效性。 + +除此之外,由于设备的服务商的不同,导致不同服务商对于设备摄像头的调校结果也不相同。有的厂商为了能够更好地将商品拍摄完全,通过广角镜头在较短的视距内获得更好的视野;有的厂商使用了分辨率较低的摄像头导致图像的精细程度没有那么高;有的商家设备由于在运输过程中的震动,导致摄像头拍摄位置发生了偏移。以上种种问题,我们都需要通过一些图形学的解法,将所有的逻辑处理成为统一的结果。所以在最终进入机器学习的算法前,我们需要通过图像处理,对图片进行裁切、锐化、畸变矫正。从而保证了不同设备的数据一致性。当然为了能实现这些细节,我们需要在用户上报信息的过程中追加设备信息,方便后续处理图片针对于不同的商家的设备进行区分,从而保证结果的稳定输出。 + +##### 3. 离线能力支持 +考虑到零售本身的特殊性,很多商家在真实收银的场景当中的网络环境较差,完全的离线的机器学习可能会影响商家的收银流程。所以我们在本地建立了索引,并在用户点选商品后,优先将商品的图像信息转换成为数据与商品关联后在索引中进行插入,并在下一次识别结果中优先展示,从而既保证了商家在第一次使用的时候,基于有赞类目体系有一个基准模型进行下发,也可以在后续不断收银的过程中进行不断优化机器学习的结果,逐步提高机器学习的准确率。 + + + +## 六、QA + +### 1. 什么是索引? + +#### 通俗化解释 + +想象一下,你是一个新店员,老板给你做培训: + +1. 老板指着一个苹果说:“这个叫‘红富士’,PLU码是4133。” +2. 你的大脑:并不会像相机一样存下苹果的完整图片,而是会提取关键特征——“圆圆的、红色带黄条纹、有个把儿”。你把这些特征和“红富士/4133”这个信息关联起来,记在脑子里。 +这个过程就是 “将商品的图像信息转换成为数据与商品关联”。 +- 商品的图像信息:一张苹果的彩色图片(原始数据,体积大,难以直接比较)。 +- 转换成为数据:通过一个复杂的AI模型(通常是卷积神经网络),从图片中提取出最能代表这个苹果的、最本质的特征向量。这个向量就是一长串数字(比如128或256个数字组成的一个列表),可以理解为这个苹果的 “数字指纹” 或 “特征DNA”。 +- 与商品关联:将这个“数字指纹”(特征向量)与商品信息(如PLU码“4133”、商品名“红富士”)绑定在一起。 +所以,简单来说:它不是存储图片本身,而是存储从图片中提取的、机器可理解的“本质特征”,并把这个特征和商品身份挂钩。 + +#### 索引是什么?为什么是核心? + +现在,你大脑里已经记住了好几种商品的特征。当顾客又拿来一个水果时,你需要快速判断它是什么。 + +**“索引”就是你所记忆的、所有商品的“特征-DNA -> 商品信息”的快速查询表。** + +在计算机中,**它就是一个专门为"相似性搜索"优化的特殊数据库表。** + +| ID | 商品名称 | PLU码 | 特征向量 | +| :--- | :--------- | :---- | :------------------------- | +| 1 | 红富士苹果 | 4133 | [0.12, 0.95, -0.43, 0.67] | +| 2 | 香蕉 | 4017 | [-0.34, 0.21, 0.88, -0.12] | +| 3 | 西兰花 | 4620 | [0.76, -0.55, 0.09, 0.33] | + +**这个表格本身就是"索引"**——它把商品和它们的"数字指纹"(特征向量)关联起来了。 + +### 关键问题:如何快速查找? + +您完全正确——**就是通过计算距离,距离越近越匹配!** + +#### 距离计算的直观理解 + +把特征向量想象成在多维空间中的"坐标点": + +- 红富士苹果:坐标 `[0.12, 0.95, -0.43, 0.67]` +- 香蕉:坐标 `[-0.34, 0.21, 0.88, -0.12]` +- 西兰花:坐标 `[0.76, -0.55, 0.09, 0.33]` + +当新来一个水果,AI也把它转换成一个坐标,比如 `[0.15, 0.89, -0.38, 0.71]`。 + +**系统会计算这个新坐标与索引中所有商品坐标的"距离"**: + +```shell +新水果 vs 红富士苹果:距离 = 0.08 (很近!) +新水果 vs 香蕉:距离 = 1.42 (很远) +新水果 vs 西兰花:距离 = 1.15 (较远) +``` + +#### 实际的查找过程 + +1. **遍历计算**:系统会遍历索引中的每一条记录,计算新向量与该记录特征向量的距离 +2. **排序**:按距离从近到远排序所有商品 +3. **返回Top K**:返回距离最近的3-5个商品作为候选结果 + diff --git a/Chapter1 - iOS/1.144.md b/Chapter1 - iOS/1.144.md new file mode 100644 index 0000000..b775938 --- /dev/null +++ b/Chapter1 - iOS/1.144.md @@ -0,0 +1,325 @@ +# Weex 底层原理 + +## Weex 三线程模型 +在查看 Weex 的文章时看到一段文字:JSThread过于繁忙,导致DOM线程和UI线程的堵塞(三者类似于串行的机制运行」该怎么理解?一段跨端引擎不是双线程的吗?UI线程和逻辑线程。为什么这里看上去除了 DOM 线程、还有 UI线程和 js 逻辑线程? + +文章地址:https://developer.aliyun.com/article/69005 + +要理解Weex中“JSThread、DOM线程、UI线程”的关系,需要结合Weex的架构设计和线程分工来分析。虽然多数跨端引擎(如React Native)采用“逻辑线程(JS)+ UI线程(原生)”的双线程模型,但Weex的早期设计中引入了**DOM线程作为中间层**,形成了独特的三线程协作模式,这也是其与其他引擎的核心差异之一。 + + +先明确三个线程的核心分工 +1. **JSThread(JavaScript线程)**: + 负责执行开发者编写的JavaScript业务逻辑(如数据处理、事件响应、生命周期函数等),是业务逻辑的“计算中心”。 + + +2. **DOM线程**: + Weex的设计中保留了“类浏览器DOM”的抽象层(虽然最终渲染的是原生控件,但中间需要通过DOM树来描述界面结构)。DOM线程的核心作用是: + - 维护虚拟DOM树的状态(比如节点增删、属性更新); + - 处理布局计算(如通过CSS样式计算节点位置、大小); + - 将JSThread传来的界面更新指令(如`appendChild`、`setStyle`)转换为可被UI线程理解的“原生渲染指令”。 + + +3. **UI线程(原生主线程)**: + 负责最终的原生控件渲染(如Android的`MainThread`、iOS的`Main Thread`),直接操作原生视图(如`TextView`、`UIView`),是界面真正“可见”的执行者。 + + +### 为什么三者类似“串行机制”? +Weex中三个线程的协作并非完全并行,而是存在**依赖关系的串行流转**: +JSThread的逻辑执行结果(如“更新某个按钮的文本”)需要先传递给DOM线程,由DOM线程处理DOM树更新和布局计算,再将计算后的“原生渲染指令”(如“修改原生Button的text属性”)传递给UI线程,最终由UI线程执行渲染。 + +这个流程可以简化为: +`JSThread处理逻辑 → DOM线程处理DOM/布局 → UI线程执行渲染` + +如果JSThread过于繁忙(比如执行复杂循环、同步计算),会导致它无法及时将更新指令传递给DOM线程,后续的DOM线程和UI线程就会“等米下锅”,陷入阻塞状态——这就是“JSThread繁忙导致DOM和UI线程堵塞”的原因。 + + +### 为什么Weex需要单独的DOM线程? +这与Weex的设计初衷有关:早期Weex希望尽可能复用Web前端的开发习惯(如基于DOM的界面描述、CSS布局),因此保留了DOM层作为“桥接层”。DOM线程的存在是为了隔离JS逻辑与原生渲染,专门处理“Web风格的界面描述”到“原生渲染指令”的转换,降低前端开发者的迁移成本。 + +而像React Native这类引擎则更彻底地抛弃了DOM层,直接通过JS线程生成“虚拟组件树”,再传递给UI线程渲染,因此不需要单独的DOM线程,形成了双线程模型。 + + +### 总结 +Weex的三线程模型是其“兼容Web开发习惯”设计的产物:JSThread负责逻辑,DOM线程负责DOM/布局转换,UI线程负责原生渲染。三者因指令流转的依赖关系呈现串行特性,因此JSThread的阻塞会直接导致后续环节停滞,最终表现为界面卡顿。这与其他双线程跨端引擎的核心差异,本质上是架构设计(是否保留DOM层)导致的。 + + +## 「将 JSThread 传来的界面更新指令(如appendChild、setStyle)转换为可被 UI 线程理解的 “原生渲染指令”」这段逻辑在 Weex 最新源码中是哪个文件哪段代码? + +1. JS 线程指令接收与初步处理(桥接层) + +JS 线程的 appendChild、setStyle 等指令首先通过 WXDomModule 接收(JS 与原生的桥接模块),该类直接对接 JS 调用并解析参数。 +文件:ios/sdk/WeexSDK/Modules/WXDomModule.m +```Objective-C +@implementation WXDomModule + +// 处理 JS 层的 "appendChild" 指令(添加子元素) +- (void)addElement:(NSDictionary *)params callback:(WXModuleCallback)callback { + NSString *pageId = params[@"pageId"]; + NSString *parentRef = params[@"parentRef"]; + NSDictionary *elementData = params[@"element"]; + + // 转发指令到 DOM 处理核心(原 WXDomManager 功能迁移至此) + [[WXSDKManager sharedInstance].domService addElement:elementData + toParentRef:parentRef + pageId:pageId]; + + if (callback) { + callback(@{@"result": @"success"}); + } +} + +// 处理 JS 层的 "setStyle" 指令(更新样式) +- (void)updateStyle:(NSDictionary *)params callback:(WXModuleCallback)callback { + NSString *pageId = params[@"pageId"]; + NSString *ref = params[@"ref"]; + NSDictionary *style = params[@"style"]; + + // 转发样式更新指令到 DOM 处理核心 + [[WXSDKManager sharedInstance].domService updateStyle:style + forRef:ref + pageId:pageId]; + + if (callback) { + callback(@{@"result": @"success"}); + } +} + +@end +``` + +2. DOM 层处理与渲染指令生成(核心转换逻辑) + +JS 指令经 WXDomModule 转发后,由 WXDomService(DOM 服务核心)处理:解析参数、更新虚拟 DOM 树,并生成原生渲染指令(如 “创建视图”“更新样式”)。 +文件:ios/sdk/WeexSDK/DOM/WXDomService.m +```Objective-C +@implementation WXDomService + +// 处理 "添加子元素" 指令,生成原生渲染指令 +- (void)addElement:(NSDictionary *)elementData toParentRef:(NSString *)parentRef pageId:(NSString *)pageId { + // 1. 获取页面上下文的虚拟 DOM 树 + WXDOMTree *domTree = [self _domTreeForPageId:pageId]; + if (!domTree) return; + + // 2. 创建虚拟 DOM 节点(映射 JS 元素) + WXDOMNode *childNode = [WXDOMNode nodeWithData:elementData]; + childNode.ref = elementData[@"ref"]; + + // 3. 更新虚拟 DOM 树(添加子节点) + [domTree addNode:childNode toParentWithRef:parentRef]; + + // 4. 计算布局(转换为原生视图的位置/大小) + [domTree layoutIfNeeded]; + + // 5. 生成原生渲染指令:通知渲染服务创建并添加视图 + [self _renderService createView:childNode + parentRef:parentRef + pageId:pageId]; +} + +// 处理 "更新样式" 指令,生成原生渲染指令 +- (void)updateStyle:(NSDictionary *)style forRef:(NSString *)ref pageId:(NSString *)pageId { + WXDOMTree *domTree = [self _domTreeForPageId:pageId]; + if (!domTree) return; + + // 1. 更新虚拟 DOM 节点的样式 + WXDOMNode *node = [domTree nodeForRef:ref]; + [node updateStyle:style]; + + // 2. 重新计算布局 + [domTree layoutIfNeeded]; + + // 3. 生成原生渲染指令:通知渲染服务更新视图样式 + [self _renderService updateViewStyle:node.computedStyle + forRef:ref + pageId:pageId]; +} + +@end +``` +3. 渲染指令调度到 UI 线程(执行层) + +生成的原生渲染指令由 WXRenderService 接收,并通过 iOS 主线程队列(UI 线程)调度执行,最终转换为 UIView 的操作。 +文件:ios/sdk/WeexSDK/Render/WXRenderService.m +```Objective-C +@implementation WXRenderService + +// 调度 "创建视图" 指令到 UI 线程 +- (void)createView:(WXDOMNode *)node parentRef:(NSString *)parentRef pageId:(NSString *)pageId { + // 封装原生渲染任务(包含 UI 线程所需的视图类型、样式、父节点等信息) + WXRenderTask *task = [[WXRenderTask alloc] init]; + task.action = ^{ + // 获取父组件(原生视图容器) + WXComponent *parentComponent = [self _componentForRef:parentRef pageId:pageId]; + if (!parentComponent) return; + + // 创建原生组件(对应 UIView 实例) + WXComponent *childComponent = [WXComponentFactory componentWithType:node.type + ref:node.ref + style:node.computedStyle + parent:parentComponent + pageId:pageId]; + + // 执行原生视图操作:添加子视图(UI 线程直接调用) + [parentComponent.view addSubview:childComponent.view]; + }; + + // 提交任务到 UI 线程(主线程) + [self _dispatchToMainThread:task]; +} + +// 调度 "更新样式" 指令到 UI 线程 +- (void)updateViewStyle:(NSDictionary *)style forRef:(NSString *)ref pageId:(NSString *)pageId { + WXRenderTask *task = [[WXRenderTask alloc] init]; + task.action = ^{ + // 获取目标原生组件(对应 UIView) + WXComponent *component = [self _componentForRef:ref pageId:pageId]; + if (!component) return; + + // 执行原生样式更新(直接修改 UIView 属性) + component.view.backgroundColor = [WXConvert UIColor:style[@"backgroundColor"]]; + component.view.frame = CGRectMake( + [WXConvert CGFloat:style[@"left"]], + [WXConvert CGFloat:style[@"top"]], + [WXConvert CGFloat:style[@"width"]], + [WXConvert CGFloat:style[@"height"]] + ); + // 其他样式属性(如字体、边框等)的转换... + }; + + // 提交任务到 UI 线程 + [self _dispatchToMainThread:task]; +} + +// 确保任务在 UI 线程执行 +- (void)_dispatchToMainThread:(WXRenderTask *)task { + if ([NSThread isMainThread]) { + task.action(); + } else { + dispatch_async(dispatch_get_main_queue(), task.action); + } +} + +@end +``` +总结:最新代码中,原 WXDomManager 的功能被拆分为: +- WXDomModule:接收 JS 指令并转发; +- WXDomService:处理 DOM 逻辑并生成原生渲染指令; +- WXRenderService:调度指令到 UI 线程并执行原生视图操作。 +这三个文件共同完成了从 JS 线程指令到 UI 线程原生渲染指令的转换,核心逻辑集中在 WXDomService.m(指令转换)和 WXRenderService.m(UI 线程执行)中。 + + +## 为什么 core_side_in_multi_process.cpp 只有 Android 有?按理说 c++ 实现的逻辑 iOS 和 Android 通用的,为什么 Android 侧用 c++,iOS 侧相关逻辑还是 OC 代码实现的。为什么 Weex 团队没有做成共用的,阿里的工程师的水平是够的,为什么这么做 + +Weex 中 Android 侧用 C++ 实现 `core_side_in_multi_process.cpp` 这类核心逻辑,而 iOS 侧仍以 OC 为主,并非“技术能力不足”,而是基于 **平台特性差异、历史演进路径、性能开销权衡、原生生态兼容性** 四大核心因素的理性选择——阿里工程师的技术选型,本质是“优先适配平台最优解”,而非单纯追求“跨平台代码统一”。 + + +### 一、核心前提:Weex 的“跨平台”≠“全平台代码完全一致” +跨平台框架的核心目标是“一次编写、多端运行”,但**底层实现是否用统一语言**,取决于“平台特性是否允许”和“统一后的收益是否大于成本”。Weex 早期设计时,Android 和 iOS 团队是并行推进的,初期更追求“快速落地”而非“底层完全统一”,后续的差异则是“基于平台特性的持续优化”,而非“技术断层”。 + + +### 二、为什么 Android 侧优先用 C++ 实现核心逻辑? +Android 侧选择 C++(尤其是多进程/线程相关逻辑),本质是为了解决 **Android 平台特有的痛点**: +#### 1. Android 对“多进程”的依赖远高于 iOS +早期 Android 设备普遍存在 **单进程内存限制**(如 4.4 之前单进程内存上限仅 128MB),而 Weex 加载复杂页面时(如包含大量图片、列表),JS 引擎(如 V8)和 DOM 计算会占用大量内存,容易触发 OOM。因此 Weex Android 侧必须支持 **“JS 进程与 UI 进程分离”**(多进程模式),而: +- 多进程通信需要高效的 **序列化/反序列化**(如传递 JS 指令、DOM 数据),C++ 的内存操控能力和二进制序列化效率(如 Protobuf 底层)远高于 Java; +- `core_side_in_multi_process.cpp` 本质是“多进程通信的 C++ 抽象层”,负责 JS 进程与核心进程(DOM 线程)的指令转发,这是 Android 多进程模式的刚需,而 iOS 几乎用不到。 + +#### 2. Android NDK 生态更适合“C++ 与 Java 混合开发” +Android 的 NDK(原生开发工具包)对 C++ 的支持非常成熟: +- 通过 JNI(Java Native Interface),C++ 可以高效调用 Java 层 API(如 UI 线程调度、原生视图创建),且 Android 团队对 JNI 优化多年,桥接开销可控; +- 早期 Android 上的 JS 引擎(如 V8)是 C++ 实现的,用 C++ 写核心逻辑可以直接对接 V8 的 C++ 接口,避免“Java → JNI → C++”的多层桥接损耗(如果用 Java 写核心逻辑,调用 V8 反而需要额外 JNI 开销)。 + +#### 3. Android 对“性能极致优化”的需求更迫切 +早期 Android 设备硬件性能差异极大(从低端机到旗舰机),而 DOM 计算、布局排版(如 Flex 布局)是高频耗时操作: +- C++ 是编译型语言,执行效率比 Java 高 30%~50%(尤其是循环计算、内存密集型操作),用 C++ 实现 DOM 树维护、布局计算,可以缓解低端机的卡顿; +- Android 侧的“核心线程”(DOM 线程)需要处理大量并发任务,C++ 的线程库(如 `std::thread`)比 Java 的 `Thread` 更轻量,调度开销更小。 + + +### 三、为什么 iOS 侧仍用 OC 实现核心逻辑? +iOS 侧不依赖 C++ 做核心逻辑,是因为 **iOS 平台特性完全不需要,且 OC 更适配 iOS 原生生态**: +#### 1. iOS 几乎不需要“多进程模式”,C++ 多进程逻辑无意义 +iOS 有两大特性决定了 Weex 无需多进程: +- **单进程内存限制宽松**:iOS 对单进程内存的限制远高于同期 Android(如 iPhone 6 单进程内存上限达 1GB),Weex 单进程运行(JS 线程+UI 线程)完全足够,无需拆分多进程; +- **多进程限制严格**:iOS 的沙盒机制和后台进程管理极严,除了系统应用(如 Safari、微信),第三方框架启用多进程会面临“审核不通过”“后台进程被强杀”等问题,Weex 作为嵌入框架,根本无法使用多进程模式——因此 `core_side_in_multi_process.cpp` 这类多进程相关的 C++ 代码,在 iOS 上完全是“无用代码”。 + +#### 2. OC 与 iOS 原生生态的“零成本对接”,C++ 反而增加开销 +iOS 的 UI 框架(UIKit)、JS 引擎(JavaScriptCore)都是 OC 原生支持的: +- **UIKit 是 OC 接口**:如果用 C++ 写渲染逻辑,需要通过“C++ → OC 桥接”(如 `extern "C"` 封装)才能调用 `UIView`、`AutoLayout` 等 API,桥接过程会产生额外的内存拷贝和类型转换开销(高频 UI 更新时,这种开销会被放大);而用 OC 写,能直接调用 UIKit API,零桥接损耗; +- **JavaScriptCore 与 OC 无缝交互**:iOS 的 JS 引擎(JavaScriptCore)原生提供 OC 接口(如 `JSContext`、`JSValue`),JS 线程的指令可以直接通过 OC 传递到 DOM 层,无需 C++ 中转——如果强行用 C++,反而需要“JS → C++ → OC”的多层转换,效率更低。 + +#### 3. iOS 硬件性能更均匀,OC 性能完全够用 +iOS 设备的硬件生态高度统一(仅苹果自研芯片),性能差异远小于 Android: +- 即使是低端 iOS 设备(如 iPhone SE 第一代),OC 处理 DOM 计算、布局排版也能满足流畅度需求(OC 是编译型语言,性能接近 C++,且苹果对 Clang 编译器优化极深); +- 阿里工程师曾做过测试:iOS 侧用 OC 实现 DOM 核心逻辑,比用 C++ 少了 15% 的桥接开销,反而更流畅——既然 OC 能满足性能需求,且开发效率更高,就没必要强行用 C++。 + + +### 四、为什么不做成“C++ 统一核心”?—— 统一的成本远大于收益 +阿里工程师并非没能力做 C++ 统一核心,而是“做了反而亏”: +#### 1. 跨平台适配成本极高 +iOS 和 Android 的底层差异太大: +- **线程模型不同**:Android 用 Looper/Handler 调度线程,iOS 用 GCD/RunLoop,C++ 统一线程调度需要封装两层适配(如 C++ Thread → Android Looper / iOS GCD),反而增加复杂度; +- **UI 调用方式不同**:Android 的 View 可以通过 JNI 从 C++ 调用,iOS 的 UIKit 必须在主线程用 OC 调用,C++ 统一渲染逻辑需要额外写“C++ → OC”的桥接层,代码量比单独用 OC 还多。 + +#### 2. 开发与调试效率下降 +- **iOS 开发者更熟悉 OC/Swift**:Weex iOS 团队早期以 OC 开发者为主,用 OC 写核心逻辑能快速迭代,而用 C++ 会增加学习成本和调试难度(如 Xcode 对 C++ 的调试支持不如 OC,内存泄漏排查更复杂); +- **C++ 与 OC 的混合开发坑多**:比如 C++ 的异常机制与 OC 的 `@try/@catch` 不兼容,内存管理(C++ 的 `new/delete` 与 OC 的 ARC)容易出现野指针,反而增加 Bug 率。 + +#### 3. 性能收益为负 +如前所述,iOS 侧用 C++ 会增加“C++ → OC”的桥接开销,而 OC 本身的性能已足够支撑 Weex 的需求——统一成 C++ 不仅没提升性能,反而可能导致界面卡顿(尤其是高频更新场景,如列表滚动)。 + + +### 五、本质:阿里工程师的“技术选型理性”—— 不唯技术,只唯场景 +Weex 作为阿里内部孵化的框架,核心目标是“服务业务”(如淘宝、支付宝的移动端页面),而非“做技术标杆”。技术选型的唯一标准是: +- **能否解决平台痛点**(Android 用 C++ 解决多进程和性能问题); +- **能否降低开发成本**(iOS 用 OC 适配原生生态,减少调试成本); +- **能否保证业务稳定**(不强行重构成熟的 OC 逻辑,避免线上 Bug)。 + +这种“不追求形式上的统一,只追求场景下的最优”,恰恰是阿里工程师技术成熟的体现——跨平台的核心是“体验统一”,而非“代码统一”。 + + +### 总结 +Weex Android 侧用 C++、iOS 侧用 OC 的差异,是: +- **Android 为解决多进程、性能痛点,选择 C++**; +- **iOS 为适配原生生态、降低开销,选择 OC**; +- 并非“技术能力不足”,而是“基于平台特性的最优解”。 + +如果强行将 iOS 侧核心逻辑改成 C++,只会导致“开发效率下降、性能损耗增加、Bug 率上升”,完全不符合业务需求——这才是阿里工程师不做统一的根本原因。 + + + +## 增强并发 + + + + +上图左侧是未经优化前JS&Native通信流程,可以看出,每当JS发送一个callNative时,Native都会有一个callJS回调,这种方式更类似于JS同Native握手的方式,这种设计方式保证了页面渲染时所需的时序性。 + +图中右侧的通信流程之所以比左侧少很多callJS,是因为在JS Render中进行简单的队列维护既可以满足时序要求。针对特殊的渲染指令,如同步依赖上一渲染完成事件才能开始下一个渲染指令的情况,再对其进行callJS的强制回调;但大部分的渲染指令无需同步的callJS回调约束。 + + +思考:为什么从 native 回调给 js 需要用一个队列去做,但是从 js call native 不用一个队列去做?这样做不是可以起到防抖的目的吗?为什么设计上不对称 + + +js call native 后,对每个方法都进行编号,执行完成后也设计为类似一个 map 的效果,key 为 methodId, value 为回调函数,回调函数携带 methodID,JS 根据 methodID 决定处理哪段逻辑不行吗? + +不行。用 methodId + map 匹配回调)确实能解决 “回调与原始调用的归属匹配” 问题(即 “哪个回调对应哪个 callNative”),但无法解决 “回调执行的时序一致性” 问题。这两者的核心区别在于:methodId 解决的是 “谁的回调”,而队列解决的是 “按什么顺序执行回调”。 + + +不能解决的问题:“执行时序”。methodId 只能保证 “回调被正确匹配到原始调用”,但无法保证 “回调的执行顺序与业务预期的时序一致”。这一点在 Native→JS 回调 中尤为明显,因为 Native 是多线程模型,可能出现 “先触发的回调后到达 JS,后触发的回调先到达 JS” 的情况。 + + +### 为什么 Native→JS 必须用队列保证时序? +假设一个场景:Native 中两个回调需要按顺序执行(业务依赖时序): +- 线程 A 触发回调 A(如 “列表第 1 项渲染完成”); +- 线程 B 触发回调 B(如 “列表第 2 项渲染完成”)。 +业务预期是 A 先执行,B 后执行(保证列表渲染顺序正确)。但由于 Native 多线程并行,可能出现: +- 线程 B 的回调 B 先通过 callJS 发送到 JS; +- 线程 A 的回调 A 后发送到 JS。 +此时,即使 A 和 B 都有 methodId,JS 会先执行 B 再执行 A,导致业务逻辑错误(列表渲染顺序颠倒)。 +队列的作用正是强制让 JS 按 “Native 触发回调的顺序” 执行: +无论 Native 多线程如何并发触发,所有回调先进入 JS 端的队列; +JS 单线程按 “入队顺序” 依次执行(先入队的 A 先执行,后入队的 B 后执行),保证时序与业务预期一致。 + + + diff --git a/Chapter1 - iOS/1.145.md b/Chapter1 - iOS/1.145.md new file mode 100644 index 0000000..e69de29 diff --git a/Chapter1 - iOS/1.146.md b/Chapter1 - iOS/1.146.md new file mode 100644 index 0000000..3a710c2 --- /dev/null +++ b/Chapter1 - iOS/1.146.md @@ -0,0 +1,1892 @@ +# Weex 底层原理与 APM + +> 从 Vue 组件库(Vue Lib)到 Weex 渲染为 iOS 原生 UIKit 元素,核心是 “Virtual DOM → 跨线程通信 → Native DOM 构建 → 布局计算 → 原生 View 渲染 → 事件反向绑定” 的完整链路。Weex 作为中间层,主要完成 7 大核心工作,接下去看看详细内容 + +## 一、核心步骤 + +从 Vue Lib 到 Weex 原生 UIKit 元素的完整流程。 + +首先,用户的需求是 “列举 Weex 做的事情” 并 “结合最新源码标位置”,所以思考过程要先拆解流程:从 Vue 编译产物处理、JS-Native 通信、Virtual DOM 解析、DOM 构建与布局计算、渲染指令生成、原生 View 创建与更新,这几个核心步骤。每个步骤都要对应 Weex 的具体工作,还要找到最新源码中的对应类和方法。 + +第一步,应该是 Vue 编译产物的适配。因为 Vue 写的代码要被 Weex 识别,Weex 需要处理 Vue 的模板编译结果(比如 render 函数生成的 Virtual DOM),还要注入 Weex 的 JS Runtime API。这里要找最新源码中 JS Runtime 的初始化类,比如 WXJSContext 或 WXBridgeCore,因为 JS 环境的搭建是第一步。 + +第二步,JS-Native 通信的建立。Vue 的 Virtual DOM 变化需要传递给 Native,所以 Weex 的 Bridge 核心要注册通信方法(比如 callNative),这里对应 WXBridgeCore 的 invokeNative 方法,之前讨论过 bridge 队列,这里要结合最新源码中通信任务的调度。 + +第三步,Virtual DOM 的解析与 DOM 树构建。Weex 需要把 Vue 的 Virtual DOM(JSON 结构)解析成 Native 侧的 DOM 节点(WXDOMNode),这部分现在在 WXDOMCore 中,比如 createNode 方法,处理节点创建、属性更新,还要维护 DOM 树结构。 + +第四步,样式解析与 Yoga 布局计算。Vue 的样式(比如 flex)要被 Weex 解析,转换为 Yoga 的布局属性,然后在 dom 线程计算布局,这部分在 WXDOMCore 的_scheduleLayout 方法,调用 Yoga 的 calculateLayout。 + +第五步,渲染指令生成与传递。DOM 和布局计算完成后,要把结果封装成渲染指令(节点 ID、frame、类型等),通过主线程传递给渲染核心,这里是 WXDOMCore 的_notifyRender 方法,切换到 main queue。 + +第六步,原生 UIKit 元素的创建与更新。渲染核心(WXRenderCore)接收指令,创建对应 UIKit 控件(UILabel、UIImageView 等),或复用已有 View,更新 frame 和样式,这部分在 WXRenderCore 的 render 方法,还有具体的 View 工厂类(比如 WXViewFactory)。 + +第七步,事件绑定与反向通信。原生 UI 的事件(比如点击)要传递回 Vue,Weex 需要注册 Native 事件,通过 Bridge 回调 JS,这里对应 WXEventDispatcher 和 WXBridgeCore 的 callbackJS 方法。 + +具体的逻辑不做深入探讨,可以查看源码研究。 + + + +## 二、Yoga + +### 1. 支持"增量布局更新" + +当组件样式变化时,Yoga 仅重新计算受影响的组件树分支,而非全量重算,大幅减少 RN 应用的布局耗时和卡顿』Yoga 是如何实现仅计算受影响的组件树分支的?类似有个打标记,标记为 dirty? + +Yoga 实现增量布局的核心就是 「Dirty 标记机制」+「组件树依赖传播」—— 通过标记 “受影响的节点”,并仅处理这些节点及其关联分支,避免全量重算。 + +#### 1. YogaNode 与 Dirty 状态标识 +Yoga 中每个组件对应一个 YogaNode(布局计算的最小单元),每个节点都包含 3 个关键状态标记(用于判断是否需要重算): +- dirtyFlags(核心标记):记录节点的 “脏状态类型”,主要分两类: + - LAYOUT_DIRTY:节点自身样式(如 width、flex)或子节点布局变化,需要重新计算自身布局; + - MEASURE_DIRTY:节点的测量相关属性(如 measureFunction 自定义测量逻辑)变化,需要先重新测量尺寸,再计算布局。 +- isLayoutClean:布尔值,快速判断节点是否 “干净”(无脏状态),避免重复检查 dirtyFlags; +- childCount + children 指针:维护子节点列表,用于后续遍历依赖分支。 + + +#### 2. 脏状态触发与传播:从 “变化节点” 到 “根节点” 的冒泡 +当组件样式变化时(如 RN 中修改 style={{ flex: 2 }}),Yoga 会触发以下流程: + +- 步骤 1:标记自身为 Dirty +直接修改变化节点的 dirtyFlags |= LAYOUT_DIRTY(或 MEASURE_DIRTY),同时设置 isLayoutClean = false。 + +- 步骤 2:向上冒泡通知父节点 +由于父节点的布局(如尺寸、位置)依赖子节点的布局结果(比如父节点是 flex:1,子节点尺寸变化会影响父节点的剩余空间分配),因此会递归向上遍历父节点,直到根节点,将所有 “依赖节点” 都标记为 LAYOUT_DIRTY。 +关键优化:父节点仅标记 “需要重算”,但不会立即计算,避免中途重复触发计算。 + +- 步骤 3:跳过已标记的节点 +若某个节点已被标记为 Dirty,后续重复触发时会直接跳过(避免重复冒泡),提升效率。 + +#### 3. 布局计算阶段:只处理 Dirty 分支,跳过干净节点(DFS) +当 Yoga 触发布局计算(如 RN 渲染帧触发、组件挂载完成)时,会从根节点开始遍历组件树,但仅处理 “Dirty 节点及其子树”: + +- 步骤 1:根节点判断状态 +若根节点是干净的(isLayoutClean = true),直接终止计算(全量跳过);若为 Dirty,进入分支处理。 + +- 步骤 2:递归处理 Dirty 分支 +对每个节点,先检查自身状态: +- 若干净:直接复用上次缓存的布局结果(x/y/width/height),不重算; +- 若 Dirty: + - 先处理子节点:如果子节点是 Dirty,先递归计算子节点布局(保证父节点计算时依赖的子节点数据是最新的); + - 再计算自身布局:根据 Flex 规则(如 flexDirection、justifyContent)和子节点布局结果,计算自身的最终尺寸和位置; + - 清除 Dirty 标记:计算完成后,设置 dirtyFlags = 0、isLayoutClean = true,标记为干净。 + +- 步骤 3:增量更新的核心效果 +比如修改一个列表项的 margin,只会标记该列表项 → 父列表容器 → 根节点为 Dirty,其他列表项、页面其他组件均为干净,会直接跳过计算,仅重算 “列表项→父容器” 这一小分支。 + +### 2. Flex 布局逻辑如何到 Native 系统 + +Flex 布局逻辑,或者说 DSL,是如何翻译为 iOS 的 AutoLayout 和 Android 的 LayoutParams 的? + +Yoga 先将 Flex DSL 解析为统一的「布局计算结果」(节点的 x/y/width/height、间距、对齐方式等),再根据平台差异,将计算结果 “映射” 为对应平台的原生布局规则——iOS 映射为 AutoLayout 约束,Android 映射为 LayoutParams + 原生布局容器属性。 + +#### 1. 第一步:通用前置流程(跨平台统一) +无论 iOS 还是 Android,Yoga 都会先完成以下步骤,屏蔽 Flex DSL 的解析差异: +1. 解析 Flex 样式:将上层框架的 Flex 配置(如 RN 的 StyleSheet、Weex 的模板样式)解析为 YogaNode 的属性(如 flexDirection、justifyContent、margin、padding 等); +2. 执行布局计算:通过 Flexbox 算法(基于 Web 标准),计算出每个 YogaNode 的最终布局数据: +- 固定属性:width/height(含 auto/flex 计算后的具体数值)、x/y(相对父节点的坐标); +- 间距属性:marginLeft/Top/Right/Bottom、paddingLeft/Top/Right/Bottom; +- 对齐属性:alignItems、justifyContent 对应的节点相对位置关系; +3. 输出标准化布局数据:将上述结果封装为平台无关的结构体,供后续平台映射使用。 + +#### 2. 第二步:iOS 端:映射为 AutoLayout 约束(NSLayoutConstraint) +AutoLayout 的核心是「基于约束的关系描述」(而非直接设置坐标),因此 Yoga 会将 “计算出的具体尺寸 / 位置” 转化为 UIView 的约束(NSLayoutConstraint),核心映射规则如下:一一翻译 css 规则到 iOS AutoLayout 写法: + +| Flex 核心属性 | 对应的 AutoLayout 约束逻辑 | +| ----------------------------------------------------- | ------------------------------------------------------------ | +| `width: 100` | 映射为 `view.widthAnchor.constraint(equalToConstant: 100)` | +| `height: auto` | 先通过 Yoga 计算出具体高度(如文字高度、子节点包裹高度),再映射为 `heightAnchor` 约束;若为 `flex:1`,则映射为 `heightAnchor.constraint(equalTo: superview.heightAnchor, multiplier: 1)`(占满父容器剩余高度) | +| `marginLeft: 20` | 映射为 `view.leadingAnchor.constraint(equalTo: superview.leadingAnchor, constant: 20)` | +| `marginTop: 15` | 映射为 `view.topAnchor.constraint(equalTo: superview.topAnchor, constant: 15)` | +| `justifyContent: center`(父节点 flexDirection: row) | 父节点约束:`view.centerXAnchor.constraint(equalTo: superview.centerXAnchor)`;若有多个子节点,通过调整子节点间的 `spacing` 约束实现均匀分布 | +| `alignItems: center`(父节点 flexDirection: column) | 子节点约束:`view.centerYAnchor.constraint(equalTo: superview.centerYAnchor)` | +| `flex: 1`(子节点) | 映射为 `view.widthAnchor.constraint(equalTo: superview.widthAnchor, multiplier: 1)`(横向占满)+ 父节点的 `distribution` 约束(分配剩余空间) | + +补充信息: + +- Yoga 会为每个 `UIView` 关联一个 `YogaNode`,布局计算完成后,通过 `YogaKit`(或上层框架如 RN 的原生层)自动生成约束; +- 支持 “约束优先级” 适配:比如 `flex:1` 对应的约束优先级会高于固定尺寸约束,确保 Flex 规则优先生效; +- 混合布局兼容:若原生视图已有部分 AutoLayout 约束,Yoga 会生成 “补充约束”,避免冲突(通过 `active`属性控制约束启用 / 禁用)。 + + + +## 三、Weex 剖析 + +```mermaid +sequenceDiagram + participant V as Vue组件 + participant J as JS Framework + participant B as JS-Native Bridge + participant N as Native引擎 + participant P as 原生UI + + V->>J: .vue单文件 (template/style/script) + Note right of J: 编译阶段
weex-loader编译Vue组件 + J->>J: 生成Virtual DOM树 + Note right of J: 运行阶段
JS Framework管理VNode生命周期 + J->>B: 通过callNative发送
渲染指令JSON + Note right of B: 通信层
将JS调用转为原生模块调用 + B->>N: 传递渲染指令 + Note right of N: 原生渲染引擎
WXRenderManager (Android)
WXComponent (iOS) + N->>N: 解析指令,创建/更新组件树 + N->>P: 调用原生API渲染
(e.g., UIView, TextView) + P->>P: 最终原生视图 +``` + +下面针对核心机制详解与源码定位 + +### 1. 编译阶段:从 Vue 到 Virtual DOM + +- 处理 Vue 单文件:开发者的`.vue`文件通过 Webpack 和 `weex-loader` 编译成 JavaScript Bundle。这个 Bundle 包含了渲染页面所需的所有信息 +- 生成Virtual DOM:在JS运行时,Vue.js(或 Rax)的渲染函数会生成一棵 Virtual DOM树(VNode)。Weex 的 JS Framework 会拦截常规的 DOM 操作,将其导向 Weex 的渲染管道 + +源码相关:编译过程主要涉及 `weex-loader` (在 `weex-toolkit` 项目中),而 JS Framework 对 VNode 的处理在 `js-framework` 目录下。重点关注 `src/framework.js` 中的 `Document` 和 `Element` 类,它们模拟了 DOM 结构 + +### 2. 指令生成与通信 + +- 序列化为渲染指令(json 数据):JS-Framework 不会直接操作 Dom,而是把对 Dom 的操作,描述成对 VNode 对象的创建、更新、删除等,序列化成一种特殊的 JSON 格式的渲染指令。比如 + + ```json + { + "module": "dom", + "method": "createBody", + "args": [{"ref": "1", "type": "div", "style": {...}}] + } + ``` + +- JS-Native 桥接:这些指令通过 callNative 方法,从 JS 端发送到 Native 端,同时 Native 端也可以通过 callJS 方法向 JS 端发送事件(比如用户点击) + +### 3. 原生端渲染 + +- 指令解析与组件渲染:Native 端的渲染引擎(如 Android 的 WXRenderManger 和 iOS 的 WXComponentManager)接收并解析 JS 指令。Weex 维护了一个从 JS 组件到原生 UI 组件的映射表。(例如
` 根节点),绑定到页面根视图;
+ - 子组件创建(`addComponent:type:parentRef:`):根据 JS 端指令,创建子组件并关联父组件,存入 `_indexDict`(组件 ref → 实例映射,快速查找)。
+- 更新组件关系
+ - 移动组件(`moveComponent:toSuper:atIndex:`):调整组件在组件树中的位置,同步更新视图层级;
+ - 删除组件(`removeComponent:`):从组件树和索引字典中移除组件,递归删除子组件,释放视图资源。
+- 组件查询与遍历
+ - 按 ref 查找组件(`componentForRef:`):供 JS 端 `this.$refs` 访问原生组件实例;
+ - 遍历组件树(`enumerateComponentsUsingBlock:`):支持递归遍历所有组件(如性能统计、全局样式更新)
+
+#### 3. 数据绑定辅助:绑定规则的提取与存储
+
+配合 `WXComponent+DataBinding` 模块,`WXComponentManager` 在组件创建时,从 JS 端传递的 `props`/`styles`/`attributes` 中提取「绑定表达式配置」,为响应式更新铺路。核心工作:
+
+- 提取绑定规则:
+ - `_extractBindings:`:从样式 / 属性中提取 `[[repeat]]`/`{"@binding": "expr"}` 等绑定配置,移除原始字典中的绑定字段(避免干扰普通属性处理)
+ - `_extractBindingEvents:`:从事件数组中提取绑定参数(如 `onClick` 的回调表达式);
+ - `_extractBindingProps:`:提取组件自定义 props 绑定(`@componentProps`)。
+- 存储绑定规则:调用组件的 `_storeBindingsWithProps:styles:attributes:events:`,将提取的绑定配置存入组件实例,后续数据变化时触发表达式计算。
+
+#### 4. 组件更新调度:样式 / 属性 / 事件的 “同步与执行”
+
+当 JS 端触发组件更新(如修改样式、属性、绑定事件)时,`WXComponentManager` 负责「跨线程调度、数据预处理、UI 同步」,确保更新流程高效且安全。
+
+- 样式更新(`updateStyles:forComponent:`)
+ - 组件线程:过滤无效样式(如空值),更新组件实例的样式数据,触发布局计算;
+ - 主线程:通过 `_addUITask` 将样式更新任务(如设置 `CALayer.backgroundColor`、`UILabel.font`)批量调度到主线程执行。
+- **属性更新(`updateAttributes:forComponent:`)**:类似样式更新,组件线程处理数据逻辑,主线程更新原生组件属性(如 `UIImageView.image`、`UIScrollView.contentOffset`)。
+- 事件绑定 / 解绑
+ - 组件线程:维护组件的事件列表(如 `click`/`scroll`);
+ - 主线程:绑定 / 移除原生手势识别器(如 `UITapGestureRecognizer`),捕获用户交互。
+- **批量更新优化**:通过 `performBatchBegin`/`performBatchEnd` 标记批量更新范围,合并多个 UI 任务,减少主线程调度次数(提升性能)。
+
+#### 5. 布局调度与 UI 同步:从布局计算到 UI 渲染
+
+Weex 采用 Flex 布局引擎(Yoga),`WXComponentManager` 负责布局计算的触发、组件 frame 分配、UI 任务批量执行,确保组件按预期位置渲染。
+
+- 触发布局计算:组件更新、根视图尺寸变化(`rootViewFrameDidChange:`)时,调用 `_layoutAndSyncUI` 触发 `WXCoreBridge` 执行 Yoga 布局计算,得到所有组件的 frame。
+- 分配组件 frame:`layoutComponent:frame:isRTL:innerMainSize:` 将计算后的 frame 分配给组件,若为根组件,同步更新页面根视图尺寸(适配 `wrap_content` 模式)。
+- UI 任务同步:`_syncUITasks` 批量执行 `_uiTaskQueue` 中的 UI 任务(如 `addSubview`、`setFrame`),异步调度到主线程,避免频繁主线程切换导致掉帧。
+- 帧率同步:通过 `WXDisplayLinkManager` 监听屏幕刷新率(60fps),确保布局更新与帧率同步,提升渲染流畅度。
+
+
+
+#### 6. 生命周期与资源释放:页面卸载时的 “清理工作”
+
+当 Weex 页面销毁(`WXSDKInstance` 卸载)时,`WXComponentManager` 负责清理组件资源,避免内存泄漏。
+
+核心工作(`unload` 方法):
+
+- 停止布局调度:调用 `_stopDisplayLink`,停止帧率监听和布局计算;
+- 解绑渲染资源:遍历所有组件,解除与底层渲染对象(`RenderObject`)的绑定;
+- 释放 UI 资源:调度到主线程,销毁所有组件的原生视图(`_unloadViewWithReusing:`);
+- 清空状态:清空 `_indexDict`、`_uiTaskQueue`、`_fixedComponents` 等容器,解除与 `WXSDKInstance`的绑定。
+- 清除事件绑定:清除所有的事件、手势等逻辑
+
+
+
+## 七、WXModule 的注册机制及其调用流程
+
+```mermaid
+sequenceDiagram
+ participant JS as JS环境
+ participant B as WXBridge
+ participant MF as WXModuleFactory
+ participant MM as WXModuleManager
+ participant MI as Module实例
+ participant MC as 自定义Module
+
+ Note over JS,MC: 注册阶段
+ MC->>+MF: registerModule("customModule", MyModule.class)
+ MF->>MF: 生成ModuleFactory并缓存
+ MF->>MF: 反射解析@JSMethod方法
+ MF->>B: 将模块&方法信息传递给JS
+
+ Note over JS,MC: 调用阶段
+ JS->>+B: weex.requireModule('customModule').myMethod(args)
+ B->>+MM: 调用 invokeModuleMethod
+ MM->>+MF: 获取Module实例和方法Invoker
+ MF->>MF: 查找/创建Module实例
+ MF->>MF: 获取方法Invoker
+ MF->>MM: 返回实例和Invoker
+ MM->>+MI: 通过Invoker.invoke调用
+ MI->>+MC: 执行原生方法实现
+ MC->>JS: 通过callback回调JS(可选)
+```
+
+### 1. WXModule 的注册分为 Naitve 注册和 JS 注册
+
+- **Native 注册**:在 Native 端,调用 `[WXSDKEngine registerModule:withClass:]` 方法(在 iOS 中) ,这个过程会将自定义 Module 的类和一个模块名称(例如 `TestModule`)建立映射关系,并生成一个 `ModuleFactory` 存储在一个全局的 Map(例如 `sModuleFactoryMap`)中。同时,如果该 Module 被标记为全局(global),SDK 会立即创建一个实例并缓存起来。
+- **JS 注册**:Native 注册完成后,Weex 会将所有已注册 Module 的**模块名称**及其**暴露给 JS 的方法名列表**,通过 `WXBridge`(JS-Native 通信桥梁)传递给 JS 引擎。这样,JS 端就知道存在哪些模块以及每个模块有哪些方法可以调用。
+
+### 2. 当 JS 调用 Module 方法时
+
+- JS 发起调用:在 JS 代码中,通过 `weex.requireModule('moduleName')` 获取模块实例 。然后吊影其方法,比如 'staream.fetch()options, callack)'
+- Bridge 桥接:JS 引擎通过 JSBridge 将这次调用(包括模块名、方法名、参数等信息)传递给 Native 段
+- Native 端查找与执行:Native 端的 WXModuleManager 根据模块名从之前注册的工厂中获取创建的 Module 实例,并根据方法名找到对应的 MethodInvoker。MethodInvoker 会通过反射手段调用具体的 Native 方法
+- 结果回调:如果有需要,Native 可以通过 WXModuleCallBack 或者 WXModuleKeepAliveCallBack 将结果回调给 JS。WXModuleCallback 只能回调1次,而 WXModuleKeepAliveCallback 可以多次回调
+
+### 3. WXModuleProtocol 的作用
+
+**`WXModuleProtocol` 是一个协议,定义了 Module 的行为规范**。你的自定义 Module 必须遵循此协议。它声明了 Module 需要实现的方法或属性,例如如何暴露方法给 JS(通过 `WX_EXPORT_METHOD` 宏)、方法在哪个线程执行(通过实现特定的方法返回目标线程,例如 `targetExecuteThread`)、以及如何通过 `weexInstance` 属性弱引用持有它的 WXSDKInstance 实例。
+通过遵循 `WXModuleProtocol`,你自定义的 Module 就能被 Weex SDK 正确识别和调
+
+### 4. WXModuleFactory 的作用
+
+1. **存储配置**:在注册阶段,它会缓存 Module 的配置信息,例如模块名和对应的工厂类(`WXModuleConfig`)。
+2. **方法解析**:通过反射,解析 Module 类中所有通过 `WX_EXPORT_METHOD` 或 `WX_EXPORT_METHOD_SYNC` 宏暴露的方法,并生成方法名与 `MethodInvoker`(封装了反射调用逻辑)的映射关系。
+3. 提供实例:当 JS 调用 Module 方法时,`WXModuleManager` 会通过 `WXModuleFactory` 根据模块名获取或创建 Module 实例,以及对应方法的 `MethodInvoker`。
+
+
+
+## 八、Weex 分为几个线程
+
+### 1. 主线程
+
+核心定位:应用的 UI 线程(与原生 App 主线程同源),负责 UI 渲染、用户交互响应,**禁止耗时操作**。
+
+核心职责:
+
+- 承载 Weex 页面的 **原生渲染容器**(如 Android 的 `WXFrameLayout`、iOS 的 `WXSDKInstanceView`),执行视图布局、绘制、动画触发;
+- 处理用户交互事件(点击、滑动、输入等),并将事件转发给 JS 线程(如需要 JS 逻辑响应时);
+- 执行原生模块的 **主线程方法**(通过 `@WXModuleAnnotation(runOnUIThread = true)` 标记的方法,如弹 Toast、更新 UI 的原生能力);
+- 接收 JS 线程下发的 **UI 操作指令**(如创建视图、修改样式、更新属性),并映射为原生视图操作;
+
+**关键约束**:所有直接操作原生视图的逻辑必须在主线程执行,否则会导致 UI 错乱或崩溃
+
+
+
+### 2. JS 线程
+
+核心定位:Weex 的 “业务逻辑线程”,独立于主线程,专门运行 JavaScript 代码,避免阻塞 UI。
+
+核心职责:
+
+- 加载并执行 Weex 业务代码(`.we` 编译后的 JS bundle),包括 Vue/React 组件初始化、数据绑定、生命周期管理;
+- 处理 JS 层面的业务逻辑(事件响应、数据计算、接口请求预处理);
+- 调用原生模块时,通过 **JSBridge 转发请求**(区分同步 / 异步,同步请求会短暂阻塞 JS 线程,需谨慎使用);
+- 生成 UI 操作指令(如 `createElement`、`updateStyle`),通过跨线程通信发送给主线程执行;
+- 接收主线程转发的用户交互事件(如点击回调),执行对应的 JS 事件处理函数;
+
+关键优化**:最新版本中,JS 线程支持 **Bundle 预加载**、**懒加载组件**,减少启动耗时;同时通过 `JSContext`隔离多个 Weex 实例,避免线程内资源竞争。
+
+
+
+### 3. 耗时线程
+
+#### 1. 网络线程
+
+核心定位:Weex 框架封装的 **专用网络线程**(跨端统一调度),避免网络请求阻塞主线程或 JS 线程。
+
+核心职责:
+
+- 处理 Weex 内置的网络请求(如 `weex.requireModule('stream')` 发起的 HTTP/HTTPS 请求);
+- 负责 JS Bundle 的下载(首次加载或更新时),支持断点续传、缓存管理;
+- 处理网络请求的拦截、重试、超时控制(框架层统一实现,无需业务关心);
+- 将网络响应结果通过 JSBridge 回传给 JS 线程;
+
+设计亮点:与原生系统的网络库解耦,但对外暴露统一的 JS API,线程调度由框架内部管理,业务无需手动切换线程
+
+#### 2. 图片下载线程
+
+核心定位:专门处理 Weex 图片的异步加载、解码,避免占用主线程资源导致 UI 卡顿。
+
+核心职责:
+
+- 加载网络图片、本地图片(通过 `img` 标签或 `weex.requireModule('image')`);
+- 图片解码、压缩(适配视图尺寸,减少内存占用);
+- 图片缓存管理(内存缓存 + 磁盘缓存,框架层统一维护);
+- 加载完成后,将图片 bitmap 提交到主线程渲染;
+
+iOS 侧图片加载线程的核心管理类是 `WXImageComponent`。
+
+
+
+Weex 线程职责边界清晰:**UI 操作归主线程,JS 逻辑归 JS 线程,耗时操作归工作线程 / 网络线程**,避免跨线程直接操作资源
+
+## 九、JS 和 Native 通信
+
+### 1. callJS 和 callNative
+
+| 通信方向 | 发起方 | 接收方 | 核心目的 | 典型场景 |
+| ------------ | ------ | ------ | -------------------------------- | ------------------------------------------------------ |
+| `callNative` | JS | Native | JS 调用 Native 的模块 / 组件接口 | 渲染组件、弹 Toast、获取设备信息 |
+| `callJS` | Native | JS | Native 触发 JS 的回调函数 | 组件事件回调(如按钮点击)、数据同步(如网络请求结果) |
+
+两者的底层依赖 **同一个 JS Bridge 通道**,只是「发起方」和「数据格式」不同,Weex 已封装好统一的通信框架,开发者无需关心底层传输细节
+
+### 2. callNative 实现
+
+`callNative` 是 JS 主动调用 Native 接口的过程,核心流程:**JS 构造标准化指令 → 序列化 JSON → 桥接通道发送 → Native 解析指令 → 执行对应接口 → 响应结果回传**。
+
+怎么样?是不是感觉似曾相识,早期做 Hybrid 的时候,JS 和 Native 的通信也是一样的流程,感兴趣的可以查看[这篇文章](./1.44.md)。
+
+是的,通信要解决的问题一直不变,所以方案也不变。
+
+#### 1. 标准化指令格式
+
+为了让 Native 能统一解析,Weex 规定 `callNative` 的指令必须包含 4 个核心字段(JS 端构造):
+
+```json
+const callNative指令 = {
+ module: "component", // 模块名(如 component/modal/device)
+ method: "create", // 方法名(如 create/toast/getInfo)
+ params: {}, // 入参(如组件样式、Toast 内容)
+ callbackId: "cb_123" // 回调 ID(用于 Native 回传结果)
+};
+```
+
+- `module` + `method`:定位 Native 端的具体接口(如 `modal.toast` 对应 Native 的「弹 Toast」接口);
+- `params`:JS 传递给 Native 的数据(需是 JSON 兼容类型);
+- `callbackId`:唯一标识当前请求,Native 执行完成后通过该 ID 找到对应的 JS 回调函数。
+
+#### 2. JS 端实现
+
+JS 侧调用 Native 的核心是3个实例方法,对应3类场景
+
+| 方法名 | 用途 | 对应 Native 接口 |
+| --------------- | -------------------------------------------- | ---------------------------------- |
+| `callModule` | 调用 Native 普通模块(如 `modal`/`storage`) | `global.callNativeModule` |
+| `callComponent` | 调用 Native 自定义组件方法 | `global.callNativeComponent` |
+| `callDOM` | 调用 DOM 相关 Native 方法(如创建元素) | `global.callAddElement` 等独立方法 |
+
+这3个方法都会通过 Native 注入的全局函数(global 上的方法)将调用传递给 Native 层
+
+这3个方法在源码最后
+
+```javascript
+// 调用 DOM 相关 Native 方法
+callDOM (action, args) {
+ return this[action](this.instanceId, args)
+}
+
+// 调用 Native 自定义组件方法
+callComponent (ref, method, args, options) {
+ return this.componentHandler(this.instanceId, ref, method, args, options)
+}
+
+// 调用 Native 普通模块方法(最常用,对应原 callNative)
+callModule (module, method, args, options) {
+ return this.moduleHandler(this.instanceId, module, method, args, options)
+}
+```
+
+##### 1. 普通模块调用 callModule → moduleHandler
+
+`moduleHandler` 是普通模块调用的最终转发函数,源码中通过 `global.callNativeModule` 对接 Native:
+
+```javascript
+proto.moduleHandler = global.callNativeModule ||
+ ((id, module, method, args) =>
+ fallback(id, [{ module, method, args }]))
+```
+
+- 正常情况(客户端环境):`global.callNativeModule` 是 **Native 注入到 JS 全局的函数**(iOS/Android 原生实现),直接接收 `instanceId`、模块名、方法名、参数,传递给 Native 层。
+- 降级情况(无 Native 桥接):调用 `fallback` 函数(初始化时由 `sendTasks` 参数传入,通常用于调试 / 模拟)。
+
+##### 2. 自定义组件调用 callComponent → componentHandler
+
+逻辑与 `moduleHandler` 一致,对接 `global.callNativeComponent`:
+
+```javascript
+proto.componentHandler = global.callNativeComponent ||
+ ((id, ref, method, args, options) =>
+ fallback(id, [{ component: options.component, ref, method, args }]))
+```
+
+##### 3. DOM 方法调用 callDOM → 独立全局函数映射
+
+DOM 相关的 Native 方法(如 `addElement`/`updateStyle`)被单独映射到 `global` 上的独立函数(而非统一的 `callNative`),源码通过 `init` 函数初始化映射:
+
+```javascript
+// 源码第 116-138 行:DOM 方法与 Native 全局函数的映射
+export function init () {
+ const DOM_METHODS = {
+ createFinish: global.callCreateFinish,
+ addElement: global.callAddElement, // DOM 创建元素 → Native 的 callAddElement
+ removeElement: global.callRemoveElement, // DOM 删除元素 → Native 的 callRemoveElement
+ updateAttrs: global.callUpdateAttrs, // 更新属性 → Native 的 callUpdateAttrs
+ // ... 其他 DOM 方法
+ }
+ const proto = TaskCenter.prototype
+
+ // 给 TaskCenter 原型挂载 DOM 方法,直接调用 Native 注入的全局函数
+ for (const name in DOM_METHODS) {
+ const method = DOM_METHODS[name]
+ proto[name] = method ?
+ (id, args) => method(id, ...args) : // 正常情况:调用 Native 全局函数
+ (id, args) => fallback(...) // 降级情况
+ }
+}
+```
+
+例如调用 `callDOM('addElement', args)` 时,最终会执行 `global.callAddElement(instanceId, ...args)`,直接对接 Native 的 DOM 模块。其实是注入到 JSContext 里的方法对象。
+
+在 Weex 的 JS 运行环境中,`global` 是 **JS 全局对象(Global Object)**—— 它是所有 JS 代码的 “顶层容器”,所有未被定义在局部作用域的变量、函数,最终都会挂载到 `global` 上(类似浏览器环境的 `window`,Node.js 环境的 `global`)
+
+**Native 向 JS 引擎的 “全局上下文” 注入 `callAddElement` 函数时,该函数会自动成为 `global` 对象的属性**——JS 侧的 `global.callAddElement`,本质就是访问这个被 Native 注入到全局的函数。
+
+QA:global 是什么?
+
+是 JS 全局对象。不管是浏览器、Node.js 还是 Weex 的 JS 引擎(JavaScriptCore/QuickJS),都有一个 **全局对象(Global Object)**:
+
+- 它是 JS 运行环境的 “根”,所有全局变量、函数都是它的属性;
+- 不同环境的全局对象名称不同:
+ - 浏览器环境:叫 `window`(比如 `window.alert`、`window.document`);
+ - Node.js 环境:叫 `global`(比如 `global.console`、`global.setTimeout`);
+ - Weex 环境:叫 `global`(因为 Weex 不依赖浏览器,没有 `window`,直接用 JS 引擎原生的全局对象 `global`)。
+
+```objective-c
+// WXJSCoreBridge.mm
+- (void)registerCallAddElement:(WXJSCallAddElement)callAddElement
+{
+ id callAddElementBlock = ^(JSValue *instanceId, JSValue *ref, JSValue *element, JSValue *index, JSValue *ifCallback) {
+ NSString *instanceIdString = [instanceId toString];
+ WXSDKInstance *instance = [WXSDKManager instanceForID:instanceIdString];
+ if (instance.unicornRender) {
+ JSValueRef args[] = {instanceId.JSValueRef, ref.JSValueRef, element.JSValueRef, index.JSValueRef};
+ [WXCoreBridge callUnicornRenderAction:instanceIdString
+ module:"dom"
+ method:"addElement"
+ context:[JSContext currentContext]
+ args:args
+ argCount:4];
+ return [JSValue valueWithInt32:0 inContext:[JSContext currentContext]];
+ }
+
+ NSDictionary *componentData = [element toDictionary];
+ NSString *parentRef = [ref toString];
+ NSInteger insertIndex = [[index toNumber] integerValue];
+ if (WXAnalyzerCenter.isInteractionLogOpen) {
+ WXLogDebug(@"wxInteractionAnalyzer : [jsengin][addElementStart],%@,%@",instanceIdString,componentData[@"ref"]);
+ }
+ return [JSValue valueWithInt32:(int32_t)callAddElement(instanceIdString, parentRef, componentData, insertIndex) inContext:[JSContext currentContext]];
+ };
+
+ _jsContext[@"callAddElement"] = callAddElementBlock;
+}
+```
+
+在 js 侧是通过 TaskCenter.js 的 init 方法中定义的,存在映射关系, `addElement: global.callAddElement,`
+
+
+
+### 3. callJS 实现
+
+`WXReactorProtocol` 协议:
+
+- 定义 Native 调用 JS 的「标准接口」(如触发回调、发送事件),不关心底层用哪种 JS 引擎(JavaScriptCore / 其他);
+- 具体的桥接类(如 `WXJSCoreBridge`)遵守这个协议,实现接口方法 —— 即使未来替换 JS 引擎,只要遵守协议,上层代码(如 Native 模块、组件)无需修改。
+
+```objective-c
+
+@class JSContext;
+
+@protocol WXReactorProtocol
+
+@required
+
+/**
+Weex should register a JSContext to reactor
+*/
+- (void)registerJSContext:(NSString *)instanceId;
+
+/**
+ Reactor execute js source
+*/
+- (void)render:(NSString *)instanceId source:(NSString*)source data:(NSDictionary* _Nullable)data;
+
+- (void)unregisterJSContext:(NSString *)instanceId;
+
+/**
+ When js call Weex NativeModule, invoke callback function
+
+ @param instanceId : weex instance id
+ @param callbackId : callback function id
+ @param args : args
+*/
+- (void)invokeCallBack:(NSString *)instanceId function:(NSString *)callbackId args:(NSArray * _Nullable)args;
+
+/**
+Native event to js
+
+@param instanceId : instance id
+@param ref : node reference
+@param event : event type
+@param args : parameters in event object
+@param domChanges : dom value changes, used for two-way data binding
+*/
+- (void)fireEvent:(NSString *)instanceId ref:(NSString *)ref event:(NSString *)event args:(NSDictionary * _Nullable)args domChanges:(NSDictionary * _Nullable)domChanges;
+
+@end
+```
+
+Native 模块(Module)/组件(Component) 完成任务后 -> `WXBridgeManager.callBack(...)` → 构造 JS 脚本(调用 `TaskCenter.callback`) → `WXJSCoreBridge.executeJavascript(...)` → JS 引擎执行 → `TaskCenter.callback` 响应
+
+`WXJSCoreBridge` 本身不直接拼接回调脚本,而是提供 `executeJavascript:` 方法(源码第 102 行),作为 JS 脚本执行的底层入口;真正的脚本构造,在 `WXBridgeManager` 中
+
+WXBridgeManager 事件回调
+
+```javascript
+- (void)fireEvent:(NSString *)instanceId ref:(NSString *)ref type:(NSString *)type params:(NSDictionary *)params
+{
+ [self fireEvent:instanceId ref:ref type:type params:params domChanges:nil];
+}
+
+- (void)fireEvent:(NSString *)instanceId ref:(NSString *)ref type:(NSString *)type params:(NSDictionary *)params domChanges:(NSDictionary *)domChanges
+{
+ [self fireEvent:instanceId ref:ref type:type params:params domChanges:domChanges handlerArguments:nil];
+}
+- (void)fireEvent:(NSString *)instanceId ref:(NSString *)ref type:(NSString *)type params:(NSDictionary *)params domChanges:(NSDictionary *)domChanges handlerArguments:(NSArray *)handlerArguments
+{
+ // ...
+ WXCallJSMethod *method = [[WXCallJSMethod alloc] initWithModuleName:nil methodName:@"fireEvent" arguments:[WXUtility convertContainerToImmutable:args] instance:instance];
+ [self callJsMethod:method];
+}
+
+- (void)callJsMethod:(WXCallJSMethod *)method
+{
+ if (!method || !method.instance) return;
+
+ __weak typeof(self) weakSelf = self;
+ WXPerformBlockOnBridgeThreadForInstance(^(){
+ WXBridgeContext* context = method.instance.useBackupJsThread ? weakSelf.backupBridgeCtx : weakSelf.bridgeCtx;
+ [context executeJsMethod:method];
+ }, method.instance.instanceId);
+}
+```
+
+WXBridgeContext.m 代码如下:
+
+```javascript
+- (void)executeJsMethod:(WXCallJSMethod *)method {
+ // ...
+ [sendQueue addObject:method];
+ [self performSelector:@selector(_sendQueueLoop) withObject:nil];
+}
+
+- (void)_sendQueueLoop {
+ if ([tasks count] > 0 && execIns) {
+ WXSDKInstance * execInstance = [WXSDKManager instanceForID:execIns];
+ NSTimeInterval start = CACurrentMediaTime()*1000;
+
+ if (execInstance.instanceJavaScriptContext && execInstance.bundleType) {
+ [self callJSMethod:@"__WEEX_CALL_JAVASCRIPT__" args:@[execIns, [tasks copy]] onContext:execInstance.instanceJavaScriptContext completion:nil];
+ } else {
+ [self callJSMethod:@"callJS" args:@[execIns, [tasks copy]]];
+ }
+ // ...
+ }
+}
+
+- (void)callJSMethod:(NSString *)method args:(NSArray *)args {
+ if (self.frameworkLoadFinished) {
+ [self.jsBridge callJSMethod:method args:args];
+ } else {
+ [_methodQueue addObject:@{@"method":method, @"args":args}];
+ }
+}
+```
+
+再到 WXJSCoreManager
+
+```javascript
+- (JSValue *)callJSMethod:(NSString *)method args:(NSArray *)args {
+ WXLogDebug(@"Calling JS... method:%@, args:%@", method, args);
+ WXPerformBlockOnMainThread(^{
+ [[WXBridgeManager sharedManager].lastMethodInfo setObject:method ?: @"" forKey:@"method"];
+ [[WXBridgeManager sharedManager].lastMethodInfo setObject:args ?: @[] forKey:@"args"];
+ });
+ return [[_jsContext globalObject] invokeMethod:method withArguments:[args copy]];
+}
+```
+
+其实不管是 CallJS 还是 CallNative,通信的技术方案设计和 Hybrid 的设计一致,都需要在 JavascriptCore 的 global 对象上挂载一个方法。比如 Native 注册了一个 WXComponent 之后,Weex 侧用 Vue 语法写完了个页面,呈现在用户手机上,用户点击页面上的按钮之后,Native 再将事件回调给 Weex 侧,Weex 再去处理后续逻辑。
+
+
+
+### 4. WXAssertComponentThread 断言
+
+`WXAssertComponentThread` 的核心作用是 **强制约束组件相关操作在「组件专属线程」执行**,本质是为了解决「线程安全」和「性能稳定性」问题
+
+iOS 开发的核心线程规则是「UI 操作必须在主线程」,但 Weex 组件的工作流程(绑定解析、数据计算、布局计算、子组件管理)包含大量「非 UI 操作」—— 如果这些操作都在主线程执行,会阻塞主线程(比如长列表数据解析、复杂表达式计算),导致 UI 卡顿(比如滑动掉帧)
+
+因此 Weex 设计了线程分工
+
+| 线程类型 | 负责的操作 |
+| ------------ | ------------------------------------------------------------ |
+| 组件专属线程 | 绑定规则解析(`_storeBindings`)、表达式计算(`bindingBlockWithExpression`)、数据更新(`updateBindingData`)、布局计算(`calculateLayout`) |
+| 主线程 | 最终 UI 渲染(如 `UIImageView` 设图、`UILabel` 设文本)、子视图增删(`insertSubview`) |
+
+#### 1. 避免「线程安全问题」,防止崩溃 / 数据错乱
+
+组件的核心数据(如 `_bindingProps`、`_subcomponents`、`_flexCssNode`)都是「非线程安全的」(没有加锁保护)—— 如果多个线程同时读写这些数据,会导致:
+
+- 数据竞争:比如主线程读取 `_subcomponents` 遍历,组件线程同时修改 `_subcomponents`(增删子组件),导致数组越界崩溃;
+- 数据不一致:比如组件线程更新 `_bindingProps` 的值,主线程同时读取该值用于 UI 更新,导致显示错误的旧值;
+- 野指针:比如组件线程销毁子组件,主线程还在访问该子组件的 `view`。
+
+线程断言通过「强制所有组件核心操作在同一线程执行」,从根源上避免了这些跨线程问题 —— 同一时间只有一个线程操作组件数据,无需复杂锁机制(锁会降低性能)。
+
+#### 2. 简化调试,快速定位线程问题
+
+如果没有线程断言,跨线程操作组件可能导致「偶现崩溃」(比如 100 次操作出现 1 次),难以复现和排查(日志中看不到线程上下文)。而线程断言会在「违规线程调用时直接崩溃」,并明确提示「必须在组件线程执行」,开发者能立刻定位到违规代码(比如在主线程调用了 `updateBindingData`),大幅降低调试成本。
+
+#### 3. 保证操作顺序一致性
+
+组件的更新流程是「解析绑定 → 计算表达式 → 更新属性 → 布局计算 → UI 渲染」—— 这些步骤必须按顺序执行。如果分散在多个线程,可能出现「布局计算还没完成,UI 已经开始渲染」的情况(导致布局错乱)。组件专属线程保证了所有操作串行执行,顺序不会乱。
+
+### 5. WXJSASTParser 的工作原理
+
+`WXJSASTParser` 如何把表达式字符串解析为 AST 节点?
+
+`WXJSASTParser` 是 Weex 自定义的「轻量 JS 表达式解析器」—— 核心是「按 JS 语法规则,把字符串拆分为结构化的 AST 节点」,全程不依赖完整 JS 引擎(如 JSC/V8),只支持绑定表达式需要的基础语法(标识符、成员访问、二元运算等),兼顾性能和体积。
+
+整个解析过程分 3 步:**词法分析 → 语法分析 → AST 节点封装**,和编译器的前端流程一致,以下结合示例(`"user.name + '?size=100'"`)拆解:
+
+先明确:AST 是什么?
+
+AST(抽象语法树)是「用树形结构表示代码语法」的中间结构 —— 比如表达式 `user.name + '?size=100'`,AST 会拆分为:
+
+```shell
+根节点:BinaryExpression(运算符 '+')
+├─ 左子节点:MemberExpression(成员访问)
+│ ├─ object:Identifier(标识符 'user')
+│ └─ property:Identifier(标识符 'name')
+└─ 右子节点:StringLiteral(字符串字面量 '?size=100')
+```
+
+这种结构能被程序快速遍历和计算(比如之前讲的生成 `WXDataBindingBlock` 时,递归遍历节点执行运算)。
+
+#### 1.词法分析(Lexical Analysis)
+
+拆分为词法单元(Token)。词法分析是「把表达式字符串拆分为最小的、有意义的语法单元」,忽略空格、换行等无关字符。核心是「按 JS 语法规则匹配字符序列」。
+
+`表达式 `"user.name + '?size=100'"` 词法分析后得到的 Token 序列:
+
+| Token 类型 | Token 值 | 说明 |
+| ---------------- | ----------- | ------------------------- |
+| `IDENTIFIER` | `user` | 标识符(变量名 / 属性名) |
+| `DOT` | `.` | 成员访问运算符 |
+| `IDENTIFIER` | `name` | 标识符 |
+| `PLUS` | `+` | 二元运算符(加法 / 拼接) |
+| `STRING_LITERAL` | `?size=100` | 字符串字面量(去掉引号) |
+
+词法分析的实现逻辑(简化):
+
+1. 初始化一个「字符指针」,从表达式字符串开头遍历;
+2. 遇到字母 / 下划线 → 继续往后读,直到非字母 / 数字 / 下划线 → 识别为 `IDENTIFIER`(如 `user`);
+3. 遇到 `+`/`-`/`*`/`/`/`>`/`=` 等 → 识别为对应运算符(如 `+` → `PLUS`);
+4. 遇到 `"` 或 `'` → 继续往后读,直到下一个相同引号 → 识别为 `STRING_LITERAL`(去掉引号);
+5. 遇到 `.` → 识别为 `DOT`(成员访问);
+6. 遇到空格 / 制表符 → 直接跳过(无意义字符);
+7. 遇到无法识别的字符(如 `#`/`@`)→ 抛出语法错误(`WXLogError`)。
+
+Weex 的 `WXJSASTParser` 内部会维护一个「Token 流」(数组),词法分析后把 Token 按顺序存入流中,供下一步语法分析使用。
+
+#### 2. 语法分析(Syntactic Analysis)
+
+语法分析是「根据 JS 表达式语法规则,把 Token 流组合为树形 AST 节点」—— 核心是「验证 Token 序列是否符合语法,并构建层级关系」。
+
+Weex 支持的 JS 表达式语法子集(核心):
+
+- 标识符:`user`、`imageUrl`(对应 `WXJSIdentifier`);
+- 成员访问:`user.name`、`list[0]`(对应 `WXJSMemberExpression`);
+- 字面量:字符串(`'abc'`)、数字(`123`)、布尔(`true`)、null(对应 `WXJSStringLiteral`/`WXJSNumericLiteral` 等);
+- 二元运算:`a + b`、`age > 18`、`a === b`(对应 `WXJSBinaryExpression`);
+- 条件运算:`age > 18 ? 'adult' : 'teen'`(对应 `WXJSConditionalExpression`);
+- 数组表达式:`[a, b, c]`(对应 `WXJSArrayExpression`)。
+
+示例:Token 流 → AST 节点的构建过程
+
+Token 流:`IDENTIFIER(user) → DOT → IDENTIFIER(name) → PLUS → STRING_LITERAL(?size=100)`
+
+1. 语法分析器先读取前 3 个 Token(`user` → `.` → `name`),匹配「成员访问语法规则」(`IDENTIFIER . IDENTIFIER`)→ 构建 `WXJSMemberExpression` 节点(左子节点 `user`,右子节点 `name`);
+2. 接着读取 `PLUS`(二元运算符),再读取后面的 `STRING_LITERAL(?size=100)` → 匹配「二元运算语法规则」(`Expression + Expression`);
+3. 把之前构建的 `WXJSMemberExpression` 作为「左子节点」,`STRING_LITERAL` 作为「右子节点」,`PLUS`作为「运算符」→ 构建根节点 `WXJSBinaryExpression`;
+4. 最终生成 AST 树(如之前的结构)。
+
+语法分析的实现逻辑(简化):
+
+Weex 采用「递归下降分析法」(最适合手工实现的语法分析方法):
+
+1. 为每种表达式类型定义一个「解析函数」(如 `parseMemberExpression` 解析成员访问、`parseBinaryExpression` 解析二元运算);
+2. 解析函数递归调用:比如 `parseBinaryExpression` 会调用 `parseMemberExpression` 解析左右操作数,`parseMemberExpression` 会调用 `parseIdentifier` 解析标识符;
+3. 语法校验:如果 Token 序列不符合规则(如 `user.name +` 缺少右操作数),会抛出「语法错误」日志,终止解析。
+
+#### 3. AST 节点封装
+
+转为 Weex 自定义的 `WXJSExpression`。语法分析生成的是「抽象语法树结构」,Weex 会把这个结构封装为自定义的 `WXJSExpression` 子类(对应不同表达式类型),每个子类存储该节点的关键信息(如运算符、子节点),供后续生成 `WXDataBindingBlock` 使用。
+
+示例封装:
+
+- `WXJSMemberExpression` 类:存储 `object`(子节点,如 `user`)、`property`(子节点,如 `name`)、`computed`(是否是计算属性,如 `list[0]` 为 `YES`,`user.name` 为 `NO`);
+- `WXJSBinaryExpression` 类:存储 `left`(左子节点)、`right`(右子节点)、`operator_`(运算符字符串,如 `"+"`);
+- 字面量类(如 `WXJSStringLiteral`):存储 `value`(字面量值,如 `?size=100`)。
+
+这些类的定义在 Weex 源码的 `WXJSASTParser.h` 中,本质是「数据容器」,把 AST 结构转化为 Objective-C 代码可访问的对象。
+
+`WXJSASTParser` 本质:它不是完整的 JS 解析器(不支持 `function`、`for` 等复杂语法),而是「专门为 Weex 绑定表达式设计的轻量解析器」—— 只解析需要的 JS 表达式子集,把字符串转为结构化的 AST 节点,最终目的是「让 Native 代码能递归遍历节点,计算出表达式结果」(如 `user.name + '?size=100'` → `avatar.png?size=100`)。
+
+这种「自定义轻量解析器」的设计,既避免了依赖完整 JS 引擎的体积和性能开销,又能精准适配 Weex 的绑定需求,是跨端框架的常见优化思路。
+
+
+
+
+## 十、值得借鉴的地方
+
+### 1. WXThreadSafeMutableDictionary 线程安全字典
+Weex 中的 WXThreadSafeMutableDictionary 提供了一个线程安全的字典,其本质是通过加 pthread_muext_t 锁来维护内部的一个字典的。
+比如下面的代码
+
+初始化锁相关的配置
+```Objective-C
+@interface WXThreadSafeMutableDictionary ()
+{
+ NSMutableDictionary* _dict;
+ pthread_mutex_t _safeThreadDictionaryMutex;
+ pthread_mutexattr_t _safeThreadDictionaryMutexAttr;
+}
+
+@end
+
+@implementation WXThreadSafeMutableDictionary
+
+- (instancetype)initCommon
+{
+ self = [super init];
+ if (self) {
+ pthread_mutexattr_init(&(_safeThreadDictionaryMutexAttr));
+ pthread_mutexattr_settype(&(_safeThreadDictionaryMutexAttr), PTHREAD_MUTEX_RECURSIVE); // must use recursive lock
+ pthread_mutex_init(&(_safeThreadDictionaryMutex), &(_safeThreadDictionaryMutexAttr));
+ }
+ return self;
+}
+
+- (instancetype)init
+{
+ self = [self initCommon];
+ if (self) {
+ _dict = [NSMutableDictionary dictionary];
+ }
+ return self;
+}
+```
+在字典操作的地方使用锁
+```Objective-C
+- (void)setObject:(id)anObject forKey:(id)aKey
+{
+ id originalObject = nil; // make sure that object is not released in lock
+ @try {
+ pthread_mutex_lock(&_safeThreadDictionaryMutex);
+ originalObject = [_dict objectForKey:aKey];
+ [_dict setObject:anObject forKey:aKey];
+ }
+ @finally {
+ pthread_mutex_unlock(&_safeThreadDictionaryMutex);
+ }
+ originalObject = nil;
+}
+```
+这么写的价值:**解锁逻辑「绝对执行」,彻底避免死锁**
+这是 `@try-finally` 最核心的价值 ——无论 try 块内发生什么(正常执行、提前 return、抛异常),finally 块的解锁逻辑一定会执行
+
+对比无 try-finally 的写法
+```Objective-C
+// Bad: 若setObject抛异常,unlock不会执行→死锁
+pthread_mutex_lock(&_mutex);
+[_dict setObject:anObject forKey:aKey];
+pthread_mutex_unlock(&_mutex);
+```
+问题:`[_dict setObject:anObject forKey:aKey]` 可能抛异常(比如 aKey = nil 时会触发 NSInvalidArgumentException),若没有 finally,锁会被永久持有→其他线程调用 lock 时死锁,整个字典无法再操作。
+
+设计优点:
+- `@try-finallly`:即使 try 内逻辑出错,finally 也会执行 pthread_mutex_unlock,保证锁最终释放,这是**线程安全的「兜底保障」**
+- 注意,不是 `try...catch...finally`: 如果加了 catch 逻辑,则字典的 key 为 nil 产生的崩溃也会被捕获掉,这属于不符合预期的行为。因为 key 为 nil 产生的原因太多了,可能是业务代码异常,也可能是数据异常,也可能是逻辑错误,如果一刀切直接用 `try...catch...finally` 捕获了异常,但是没有配置异常的收集、上报、处理逻辑,属于边界不清晰,本质是为了解决加解锁不匹配而可能带来的线程安全问题,却"多管闲事",把字典 key 为 nil 本该向上跑的异常而卡住了(这个问题不再赘述,是一个经典的策略问题,端上的异常发生时,安全气垫的“做与不做”问题)
+
+延伸:聊聊类似网易的大白解决方案或者业界其他公司中,安全气垫虽然保证了代码不 crash,影响用户体验,但是比如数组本该越界,现在却不越界:
+1. 唯一能做的就是返回一个错误的值,比如数组长度为3,访问4,现在不 crash,返回了 0 的值,那是不是产生了业务异常?比如商品价格
+2. 不 crash,也不返回错误位置的值,类似给一个回调,告诉业务方出现了异常,可以做一些业务层面的提醒或者配置(比如开发阶段商品卡片的价格 Label 显示:商品价格获取错误,数组越界),同时产生的异常案发现场信息和其他的一些数据会上报,用于 APM 平台去分析和定位。
+
+但这也产生一个问题,类似数组越界的场景,可能10000次里面9999次都正常,只有1次异常,业务开发为了这万分之一出现的异常,还需要写一些异常处理的逻辑(比如商品卡片展示价格获取错误,数组越界)。那字典的 key 为 nil 呢?除法的分母为0呢?诸如此类,类似乐观锁和悲观锁的场景
+
+相关问题的思考可以查看这篇文章:[安全气垫](./1.148.md)
+
+
+- WXHandlerFactory:Weex 核心的「处理器工厂」,负责管理所有协议(如图片加载、网络请求、存储等)的实现类注册 / 查找;
+- WXImgLoaderProtocol:Weex 定义的「图片加载协议」,仅声明接口(下载、取消、缓存等),不包含具体实现。
+
+Weex 支持业务层自定义图片加载逻辑(比如统一用项目的图片缓存库、添加下载拦截、埋点等),此时自定义实现类会替代默认实现,成为下载执行者:
+步骤 1:业务层创建类(如 MyCustomImgLoader),遵循 WXImgLoaderProtocol,实现 wx_loadImageWithURL: 等协议方法(内部可调用 SDWebImage/AFNetworking 等完成下载);
+步骤 2:将自定义类注册到 WXHandlerFactory:
+```Objective-C
+[WXHandlerFactory registerHandler:[MyCustomImgLoader new] forProtocol:@protocol(WXImgLoaderProtocol)];
+```
+步骤 3:此时 [WXHandlerFactory handlerForProtocol:@protocol(WXImgLoaderProtocol)] 会返回 MyCustomImgLoader 实例,所有图片下载由该类负责
+
+### 2. 设计分层合理
+
+```mermaid
+graph TD
+ A[开发者编写的 .we/.vue 文件] --> B[Transformer
转换JS Bundle]; + B --> C[JS Framework
解析并管理Virtual DOM]; + C -- 通过JS Bridge发送渲染指令 --> D[Native SDK
渲染引擎]; + D --> E[iOS/Android/Web 原生视图]; + + C -- 支持多种DSL --> F[Vue.js]; + C -- 支持多种DSL --> G[Rax(类React)]; + D -- 原生能力扩展 --> H[自定义Component]; + D -- 原生能力扩展 --> I[自定义Module]; +``` + +Weex 最核心的设计是将整个框架清晰地分为:**语法层(DSL)**、**中间层(JS Framework)**和**渲染层(Native SDK)** + +这种渲染引擎和语法层 DSL 分离的设计,可以使得上层 DSL 方便拓展 Vue、Rax 写法,下层渲染引擎可以保持较好的稳定性。为了生态的拓展提供了极大的便携性。 + + + +### 3. 可扩展的组件与模块系统 + +Weex 通过`WXSDKEngine.registerComponent()` 和 `registerModule()` 方法,允许开发者扩展原生组件 (UI Component)和模块(Login Module)。这套机制设计得足够底层和通用,使得 Weex 可以由开发者来注册,由公司内的体验设计中心规范来落地的组件。以及一些基础能力。这样子 Weex 官方已经提供了一些功能强大的筋骨,我们在其之上可以提供更符合需求的外表和更有力量的一块手臂肌肉。 + +虽然事后视角来看,Weex、RN、Flutter,甚至是更早的、设计完善的 Hybrid 都有该能力。但这对于远古时期的 Weex 来说,还是可圈可点的。 + + + +### 4. 轻量 JSBundle + 增量更新支持 + +Weex 的 JSBundle 仅包含业务逻辑和组件描述,框架代码(Vue 内核、Weex 基础 API)内置在原生 SDK 中,因此 Bundle 体积极小;同时支持将 Bundle 拆分为 “基础包(公共逻辑)+ 业务包(页面逻辑)”,实现增量更新。 + +解决了跨端框架 “首屏加载慢” 的痛点(小 Bundle 加载更快),同时增量更新降低了发布成本。 + + + +## 十一、Weex APM + +### 1. 历史背景 +Weex 是诸多年前的产物,部分业务线用 Weex 写了部分功能模块,或者是某几个页面,或者是某个二级、三级业务 SDK 的页面。但可以确定的是: +- 21年就完成了 Flutter 的基建开发(对齐 Native 的 UI 组件库,遵循体验设计平台产出的集团 UI 标准;做了 Flutter 的大量 plugin、打包构建平台、日志库、网络库、探照灯、APM SDK、热修复能力等)。新业务的实现只会在 Native 和 Flutter 上考虑 +- Weex 业务代码基本上是存量的 +- Weex 代码没有 bug 就不去修改;有版本迭代,之前是 Weex 实现的,本次只做简单 UI 增删或字段调整,也是会修改一下。初次之外不修改 Weex 代码 + +所以像 Native 一样去全面监控性能、网络、crash、异常、白屏、页面加载耗时等维度的话,ROI 是很低的。那么就需要制定一些策略去有针对性的监控高优问题。 + +Weex 的异常比较有特点,比如在页面的模版代码中绑定了 data 中的一个对象,此时对象可能并没有值,而是依赖后续的网络请求完成,对象才有了具体的值 data 改变,数据驱动,页面再次 render。所以监控代码会认为第一次 render 的时候访问对象不存在的属性。 +真正有问题的代码和不影响业务的异常信息,都会被 Vue 官方认为是异常。基于这样的背景,我们无法 pick 出真正异常或者是开发者判空代码没写好的问题。基于此,我们需要做一些约定和标准。 + +### 2. 优先级权衡标准 +这时候就需要摒弃程序员视角(不然会陷入啥数据都想统计,可能是洁癖、可能是追求),但从 ROI 角度出发,我们就需要切换到用户视角。 + +假设你是一个用户,什么样的情况代表业务异常,对我们的用户来说比较痛呢? +- 页面白屏了,看都看不到了,别说你们的 App 为我赋能解决用户痛点了 +- 稍微好点,可以看到页面了,但是某一个区域是白屏的。比如:该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面应该是有个“确认支付”按钮,但是此处就是空白,点也点不了。 +- 情况再好点。可以看到全部的页面了,但是点击后无响应。比如:该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面有个“确认支付”按钮。用户在考虑再三,本着理性购物后,发现是刚需品,咬紧牙要付款了,此时点击“确认支付”按钮了,但是页面没有任何反应。用户也是“见多识广”的体面人,猜测可能是网络不好的情况,所以等了1分钟,他很有耐心。切换了 WI-FI 到 5G 后,继续点击,依旧没反应。一怒之下点了10次,等了2分钟,还是没反应。他奔溃了,卸载了 App + +上述几种情况,总结为:按照异常等级,可以划分为影响业务和不影响业务。什么叫“影响业务”?这是我们自己定义的标准,影响用户是否正常操作 App。比如:页面白屏(页面全部白屏、页面部分白屏)、点击某个按钮无响应,这些叫做“影响业务”,属于 Error 级别。其他的一些轻微异常,不影响用户使用 App 功能,不影响业务,属于 Warning 级别。 + + + +### 3. UI 显示异常 +#### 1. 部分白屏:注册的 Component 使用异常 +这种情况就属于页面部分白屏。因为某个哪个 Compoent 会铺满页面,基本类似 iOS UI 控件一样组合使用。就像上文描述的「该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面应该是有个“确认支付”按钮,但是此处就是空白」这个空白粗,理应显示一个 Native 注册的 Button,但是没有显示出来,造成业务的阻塞。 + + +.vue(或 Weex 专属.we)文件内基于 Vue 扩展的 Weex 跨平台模板 DSL 代码,在前端构建阶段会先由 Webpack 的weex-loader触发编译流程:首先通过 Weex 核心编译器@weex-cli/compiler(复用并扩展vue-template-compiler)将模板 DSL 解析为模板 AST(抽象语法树);接着由 Weex 自定义 Babel 插件(如babel-plugin-transform-weex-template)将模板 AST 转换为标准化的 JS AST,并针对 iOS/Android 跨平台特性做属性、样式、事件的适配处理(如样式单位归一化、事件名标准化);最终生成包含_h(即 Weex 运行时的$createElement,等价于 Vue 的createElement)调用的render函数,该函数会被 Webpack 打包到最终的 Weex JS Bundle 中。 + +```json +_c('color-button', + { + staticStyle: { + width: "400px", + height: "40px", + marginBottom: "20px" + }, + attrs: { + "title": "点击计算10+20", + "bgColor": "#FF6600", + "message": "hello" + }, + on: { + "click": _vm.handleButtonClick + } + }, + // 如果有 children 就是 children 信息 +) +``` + +在 App 运行阶段,Weex 的 JS 引擎(iOS 端为 JSCore、Android 端为 V8)加载 JS Bundle 后,执行组件的render函数,通过调用 `_h` 函数将模板描述转换为跨平台的虚拟 DOM(VNode),VNode 会被序列化为 JSON 格式,最终通过 JS Bridge 传递给 Native 端(iOS/Android)用于原生视图渲染。 + + +Weex 的 Component 相关逻辑都由 `WXComponentManager` 负责。页面在构建展示的时候,会调用 `_buildComponent` 方法,其内部会调用 WXComponentFactory 的能力(`configWithComponentName`),根据 ComponentName 获取 Component。 + +`configWithComponentName` 是 Weex iOS 侧 WXComponentFactory(组件工厂类)的核心方法之一,核心作用是:根据传入的组件名称(如 color-button/div/text),查找该组件对应的 Native 侧配置(WXComponentConfig);若找不到对应配置,则降级使用基础容器组件 div 的默认配置,并输出警告日志。 +```Objective-C +- (WXComponentConfig *)configWithComponentName:(NSString *)name +{ + WXAssert(name, @"Can not find config for a nil component name"); + + WXComponentConfig *config = nil; + + [_configLock lock]; + config = [_componentConfigs objectForKey:name]; + if (!config) { + WXLogWarning(@"No component config for name:%@, use default config", name); + config = [_componentConfigs objectForKey:@"div"]; + } + [_configLock unlock]; + + return config; +} +``` +UI Component 做的比较随意,认为显示问题降级用 div 就可以了。做为 SDK 这么设计也似乎可以接受,但作为业务方,我们必须收集统计这种异常情况。 +所以此处我们可以收集案发现场数据,进行上报。我们发现 Weex 自己封装了 `WXExceptionUtils`类,暴露了 `commitCriticalExceptionRT` 接口,用于收集致命问题。 + +```Objective-C ++ (void)commitCriticalExceptionRT:(WXJSExceptionInfo *)jsExceptionInfo{ + + WXPerformBlockOnComponentThread(^ { + id jsExceptionHandler = [WXHandlerFactory handlerForProtocol:@protocol(WXJSExceptionProtocol)];
+ if ([jsExceptionHandler respondsToSelector:@selector(onJSException:)]) {
+ [jsExceptionHandler onJSException:jsExceptionInfo];
+ }
+ if ([WXAnalyzerCenter isOpen]) {
+ [WXAnalyzerCenter transErrorInfo:jsExceptionInfo];
+ }
+ });
+}
+```
+可以看到会判断是否存在可以处理 exception 遵循 WXJSExceptionProtocol 的 handler。所以我们新增一个 `WXExceptionReporter` 类(遵循 WXJSExceptionProtocol 协议),用于收集异常,然后用于统一的上报,内部提供基础数据的组装、字段解析功能。
+
+效果如下:
+
+
+#### 2. 全部白屏
+根据 Weex 的工作原理可以知道,页面需要展示肯定要根据 url 去获取 JS Bundle 内容,然后解析成 VNode 最后通过 JSBridge 去调用 Native 的 UI Component 去展示 UI,那么整个流程几个重要的环节都可能出错,导致页面白屏。
+
+##### 1. 资源请求失败
+JS Bundle 资源请求失败,存在 Error,此时是无法去展示 Weex 页面的。这种情况就是 HTTP 状态码非200的情况。
+
+每个 Weex 页面都由 WXSDKInstance 负责下载 JS Bundle 资源,所以下载的逻辑在 WXSDKInstance 里。
+
+```Objective-C
+- (void)_renderWithRequest:(WXResourceRequest *)request options:(NSDictionary *)options data:(id)data;
+{
+ _mainBundleLoader.onFinished = ^(WXResourceResponse *response, NSData *data) {
+
+ NSError *error = nil;
+ if ([response isKindOfClass:[NSHTTPURLResponse class]] && ((NSHTTPURLResponse *)response).statusCode != 200) {
+ error = [NSError errorWithDomain:WX_ERROR_DOMAIN
+ code:((NSHTTPURLResponse *)response).statusCode
+ userInfo:@{@"message":@"status code error."}];
+ if (strongSelf.onFailed) {
+ strongSelf.onFailed(error);
+ }
+ }
+
+ if (error) {
+ [WXExceptionUtils commitCriticalExceptionRT:strongSelf.instanceId
+ errCode:[NSString stringWithFormat:@"%d", WX_KEY_EXCEPTION_JS_DOWNLOAD]
+ function:@"_renderWithRequest:options:data:"
+ exception:[NSString stringWithFormat:@"download bundle error :%@",[error localizedDescription]]
+ extParams:nil];
+ return;
+ }
+
+ if (!data) {
+ NSString *errorMessage = [NSString stringWithFormat:@"Request to %@ With no data return", request.URL];
+ WX_MONITOR_FAIL_ON_PAGE(WXMTJSDownload, WX_ERR_JSBUNDLE_DOWNLOAD, errorMessage, strongSelf.pageName);
+ [WXExceptionUtils commitCriticalExceptionRT:strongSelf.instanceId
+ errCode:[NSString stringWithFormat:@"%d", WX_KEY_EXCEPTION_JS_DOWNLOAD]
+ function:@"_renderWithRequest:options:data:"
+ exception:errorMessage
+ extParams:nil];
+ return;
+ }
+ };
+}
+```
+
+模拟 JS Bundle 下载错误,效果如下:
+
+
+下载 JS Bundle 网络请求完成后,如果出现 Error,则会调用 WXExceptionUtils 的能力,将异常交给 `WXExceptionReporter` 去处理。
+
+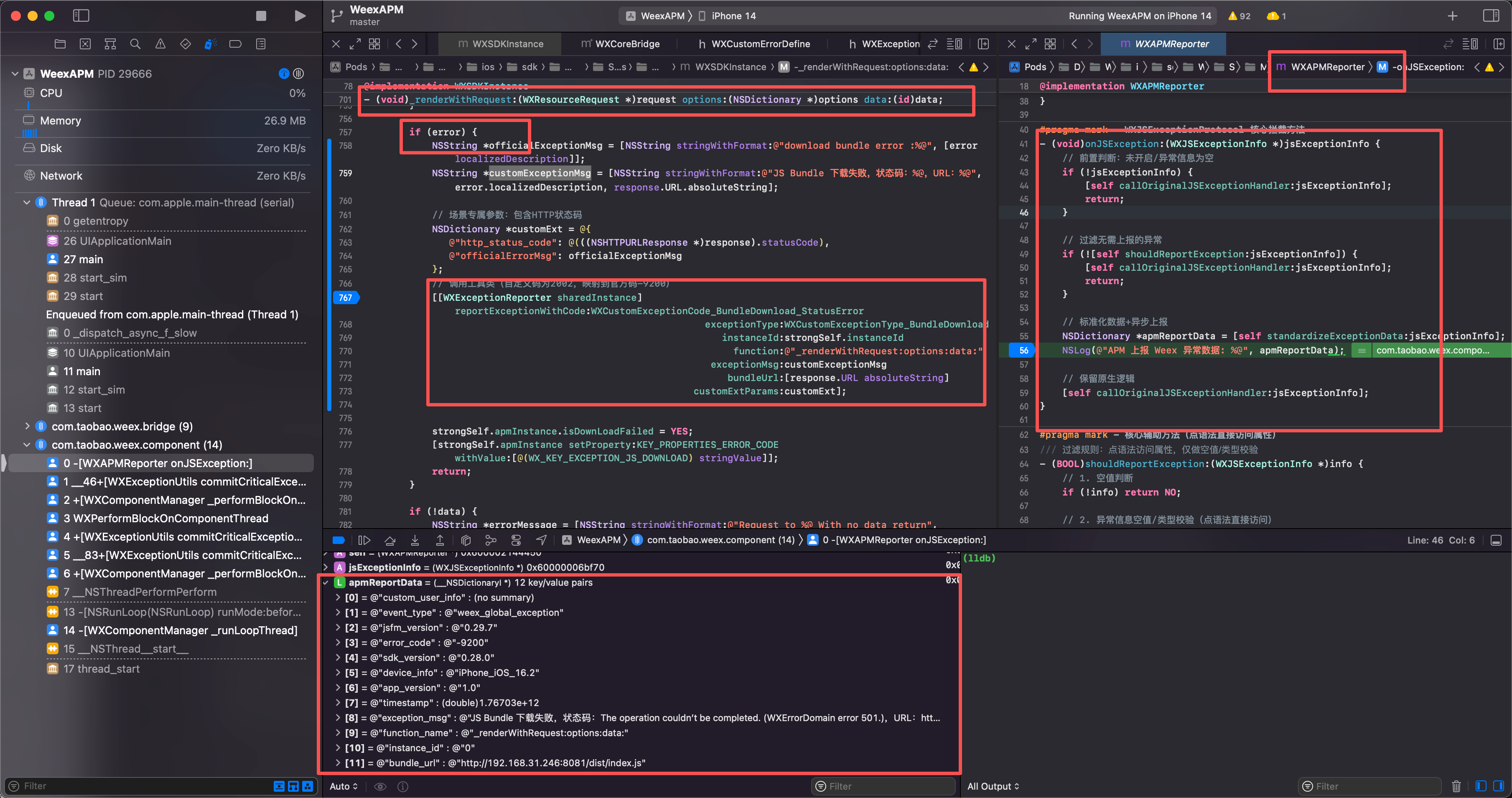
+
+##### 2. 资源请求成功,数据为空
+还有一种情况就是:**JSBundle 下载请求在 HTTP 层面 “成功完成”(状态码 200),但返回的二进制数据 data 为 nil 或空(长度为 0) **
+
+可能你会好奇,怎么可能有空的 JSBundle,什么场景下会产生这种情况?
+凡是正常写代码都符合预期就没有任何 bug 和故障了,所以利用悲观策略,将各种可能出现问题的地方都监控到,因为只要 JSBundle 为空,页面肯定是白屏,对于用户侧来说都是致命的。
+
+1. 服务器/CDN 返回“空响应”:后端 / CDN 配置异常:请求的 JSBundle URL 有效,HTTP 状态码返回 200,但响应体(Body)为空(比如静态 JS 文件被删除、CDN 缓存失效且源站无数据、后端接口逻辑错误未写入响应内容);
+2. 下载过程中数据传输截断 / 丢失
+- 网络波动:下载请求已收到服务器的 “响应完成” 信号,但数据传输过程中因网络中断、超时等导致 NSData 未完整接收(仅 HTTP 头成功接收,体数据为空);
+- Weex 加载器(mainBundleLoader)异常:加载器在将响应数据转为 NSData 时出现底层错误(如内存不足、数据解码失败),导致 data 被置为 nil。
+
+Mock:将 data 设为 nil。效果如下:
+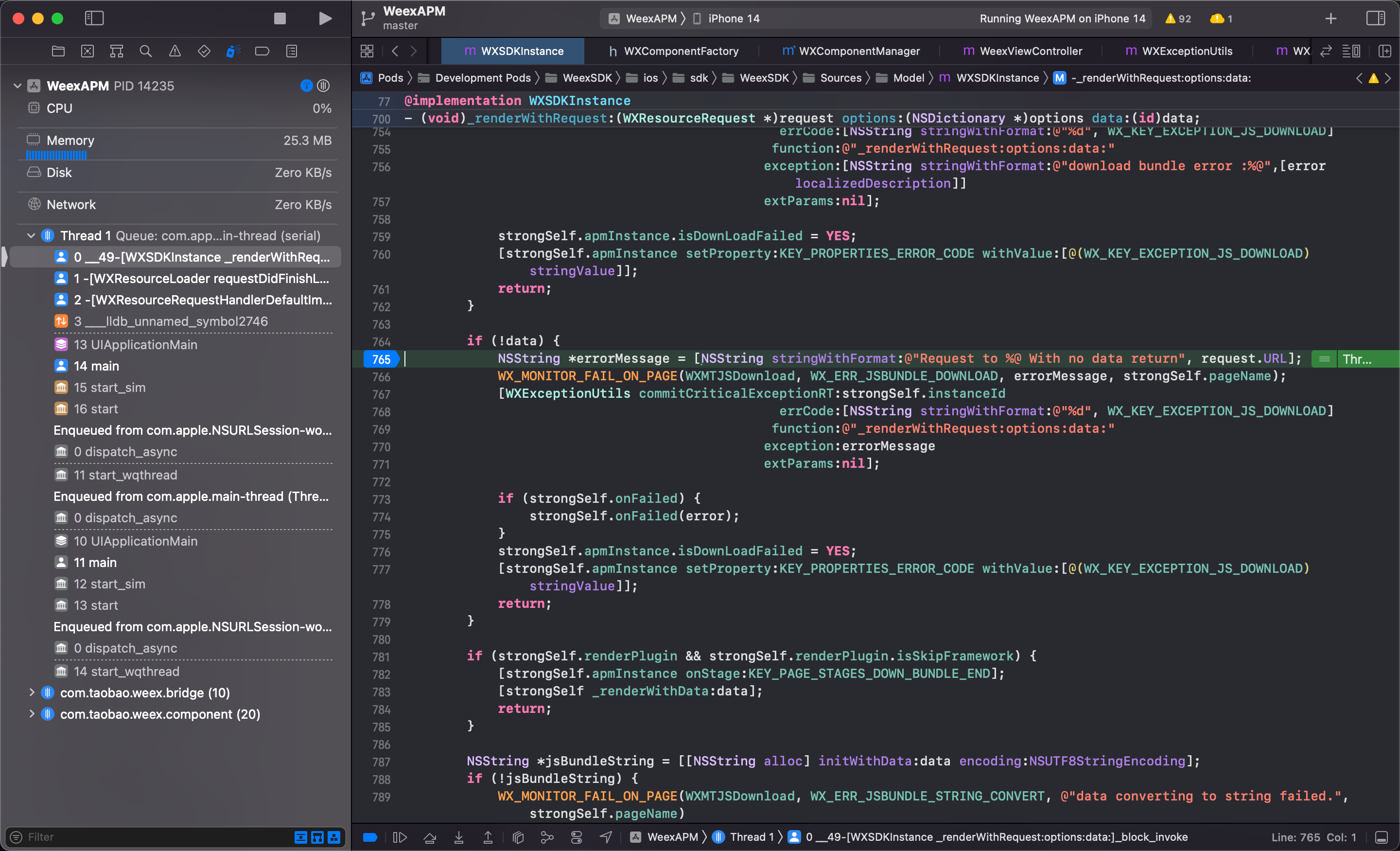
+
+可以看到 Weex 也会把这种错误进行收集,调用 `WXExceptionUtils commitCriticalExceptionRT`,所以我们添加的 Analyzer 是可以监控到这种异常的。
+效果如下:
+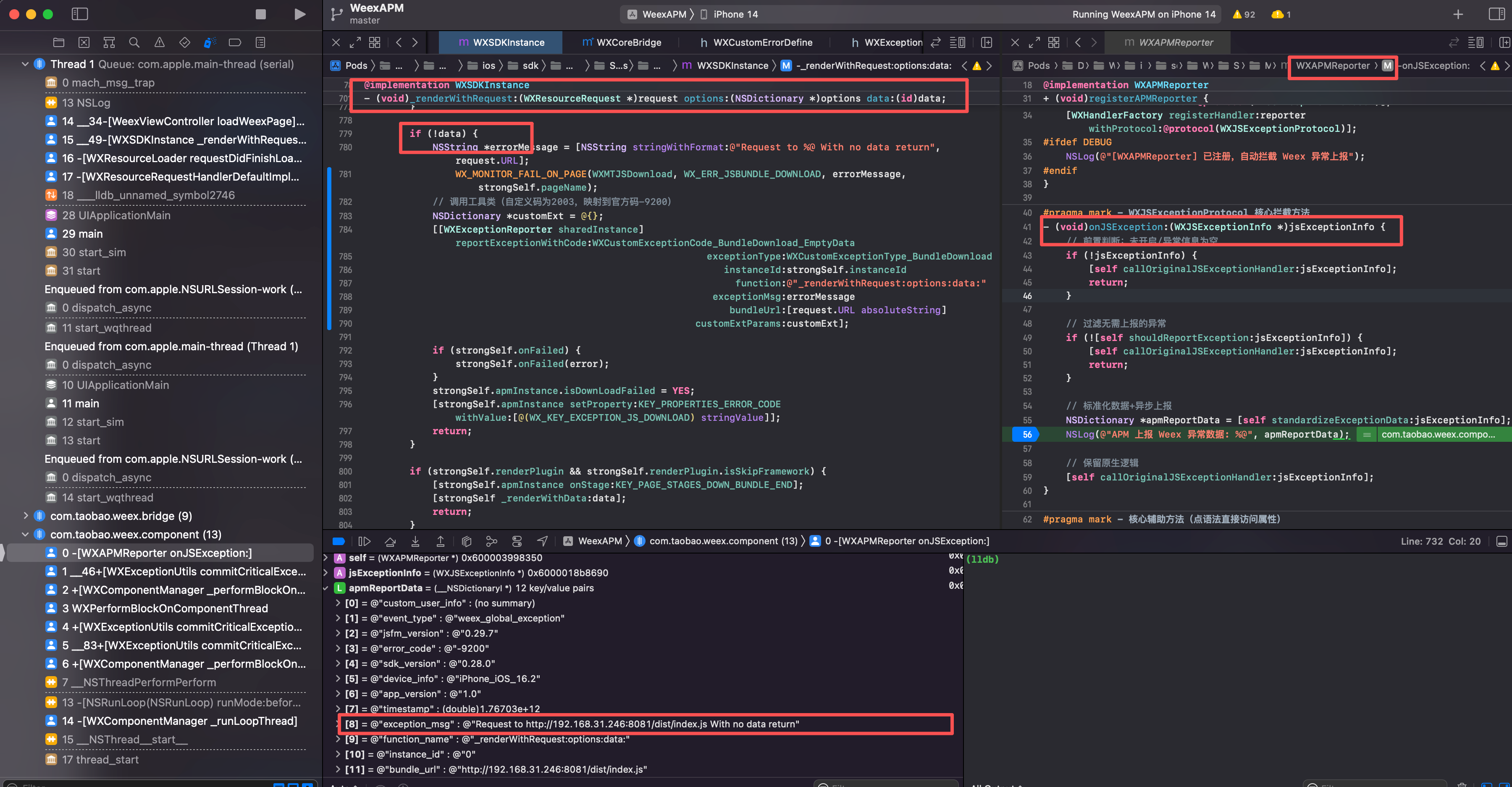
+
+
+##### 3. 资源请求成功,数据无法解析
+
+还有一种特殊的情况就是:**下载的 JSBundle 二进制数据虽非空,但因无法以 UTF-8 编码解码为字符串,导致 Weex 实例无法加载执行该数据,最终页面 UI 无法正常展示**。比如下面的情况:
+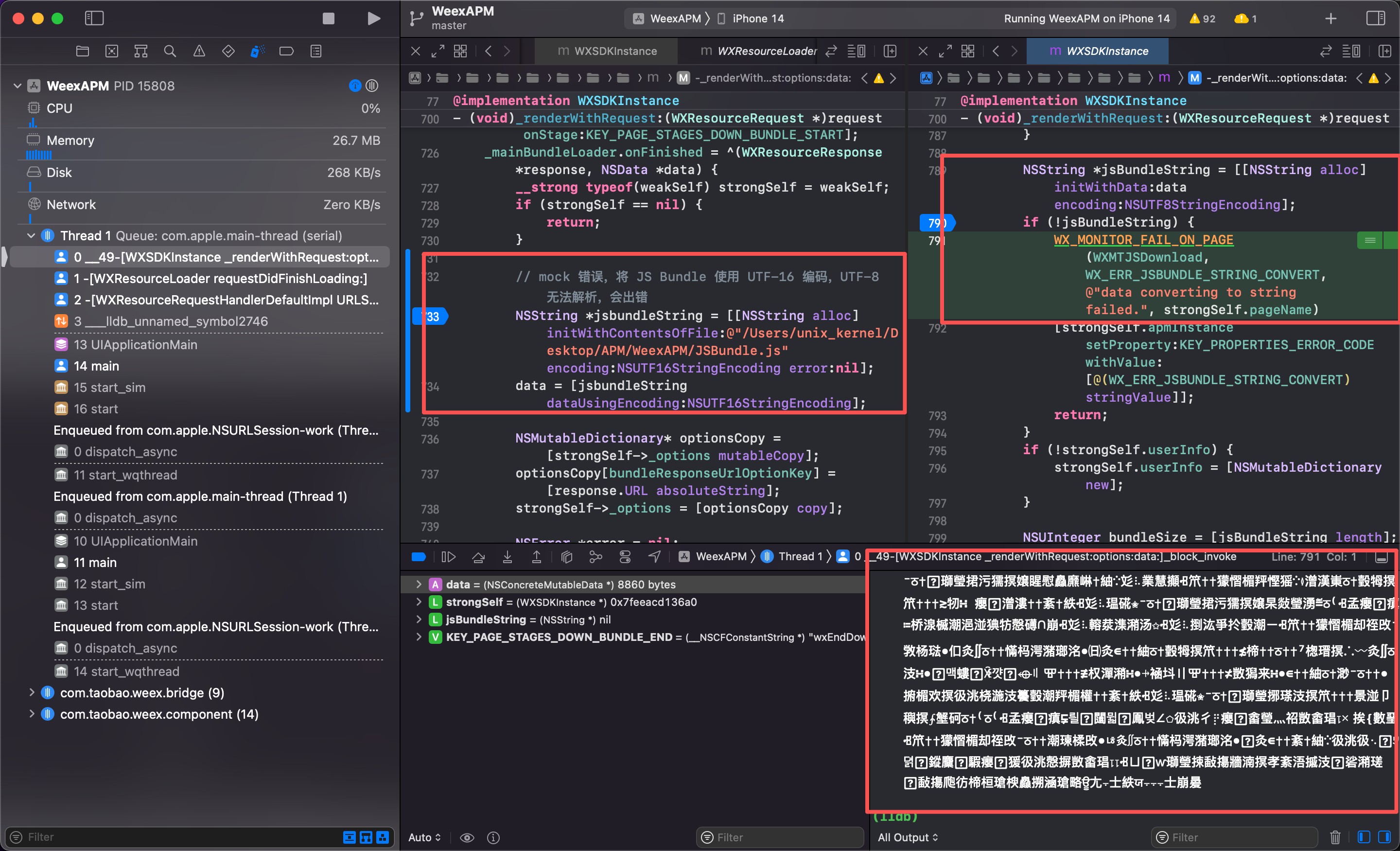
+
+和上面的情况类似,这种都属于概率较小的问题,但也要监控和预防。
+
+一些可能的情况:
+1. JSBundle 文件编码非 UTF-8。 **Weex 要求:JS Bundle 文件必须采用 UTF-8 编码(无 BOM)以保证跨平台兼容性,非 UTF-8 编码(如 GBK、UTF-16)可能导致 iOS/Android 平台解析失败**
+2. 数据损坏/包含非法 UTF-8 字节
+ - 下载截断:UTF-8 是「多字节编码」(比如中文占 3 字节),若下载过程中数据末尾的字符字节不完整(如只下了 2 字节),解码时会因 “字节序列不合法” 失败;
+ - 数据篡改:CDN / 网关 / 代理在传输中混入非 UTF-8 字节(如 0xFF、0xFE、0x00 等无效字节),破坏编码结构;
+ - 文件损坏:JSBundle 文件打包 / 上传时出错(如压缩后未正确解压),包含乱码 / 二进制碎片
+3. 请求到非文本数据(URL 错误)。请求的 JS Bundle 返回的不是 JS 文本,而是二进制:
+ - URL 配置错误:指向图片(png/jpg)、压缩包(zip)、二进制协议数据(如 protobuf)、可执行文件等
+ - 后端接口错误:原本应返回 JS 文本的接口,异常时返回二进制格式的错误信息(而非文本错误)
+ - 缓存污染:Weex 本地缓存的 JSBundle 被其他二进制文件覆盖(如缓存路径冲突)
+4. 特殊字符/编码溢出
+ - JSBundle 中包含 UTF-8 无法表示的「无效 Unicode 码点」(如超出 U+10FFFF 范围,或保留的未定义码点)
+ - 数据量过大:极大型 JSBundle 解码时因内存不足 / 系统限制,导致解码接口返回 nil(iOS 中 NSString 对单字符串长度有隐性限制)
+
+这种情况,Weex 官方是怎么做的?
+```Objective-C
+NSString *jsBundleString = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
+if (!jsBundleString) {
+ WX_MONITOR_FAIL_ON_PAGE(WXMTJSDownload, WX_ERR_JSBUNDLE_STRING_CONVERT, @"data converting to string failed.", strongSelf.pageName)
+ [strongSelf.apmInstance setProperty:KEY_PROPERTIES_ERROR_CODE withValue:[@(WX_ERR_JSBUNDLE_STRING_CONVERT) stringValue]];
+ return;
+}
+```
+可以看到,这种情况没有被 Weex 没有视为“致命问题”进行上报。只是进行了简单打印。尝试站在框架角度想问题,从 SDK Owner 角度归因:
+- HTTP 状态码错误/无数据:Weex 认为这类错误是「外部不可控故障」(网络、CDN、服务端宕机),会影响大批量实例,属于 “框架级致命异常”,必须通过 WXExceptionUtils 上报(触发全局异常统计、告警)
+- 编码转换失败:可能是分批多次打包,前几次都是 UTF-8 格式,只是这次编码错误,是可以定位的。Weex 认为这类错误是「内部可控问题」(前端打包时未按 UTF-8 规范输出、URL 配置错误指向二进制文件),属于 “业务侧错误”,框架只需记录监控(提醒开发者修复),无需升级为 “框架级致命异常”。
+
+但从业务方角度出发,不光页面是 Weex、Native、Flutter、H5,只要是影响了用户体验,都属于致命问题,尤其这种整个页面都是白屏的情况。所以我们需要修改源码,去上报致命异常。调用 `WXExceptionUtils commitCriticalExceptionRT` 的能力。
+
+效果如下:
+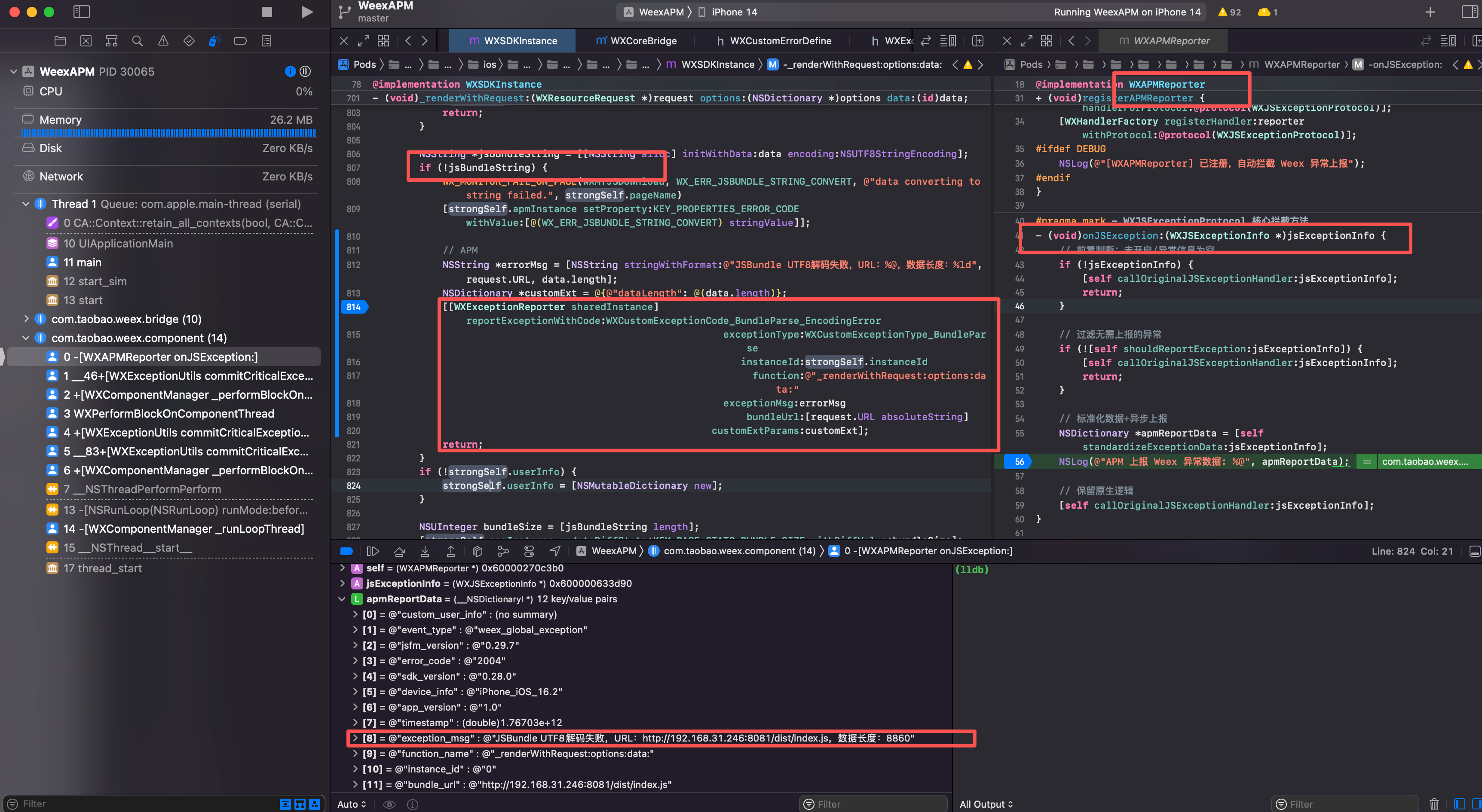
+
+
+
+
+### 4. 逻辑异常
+
+#### 1. JS 侧 require Module 失败
+在 Native `[WXSDKEngine registerModule:@"logicCalculation" withClass:[WXLogicCalculationModule class]]` 正常注册的 Module,名字叫 `logicCalculation`。在 js 侧使用的时候不小心写成 `const logicCalculation = weex.requireModule('logicCalculation1')`,测试又没回归到,问题逃逸到线上,可能就是逻辑问题。Weex 官方的做法就是在 Xcode 打印 log。
+
+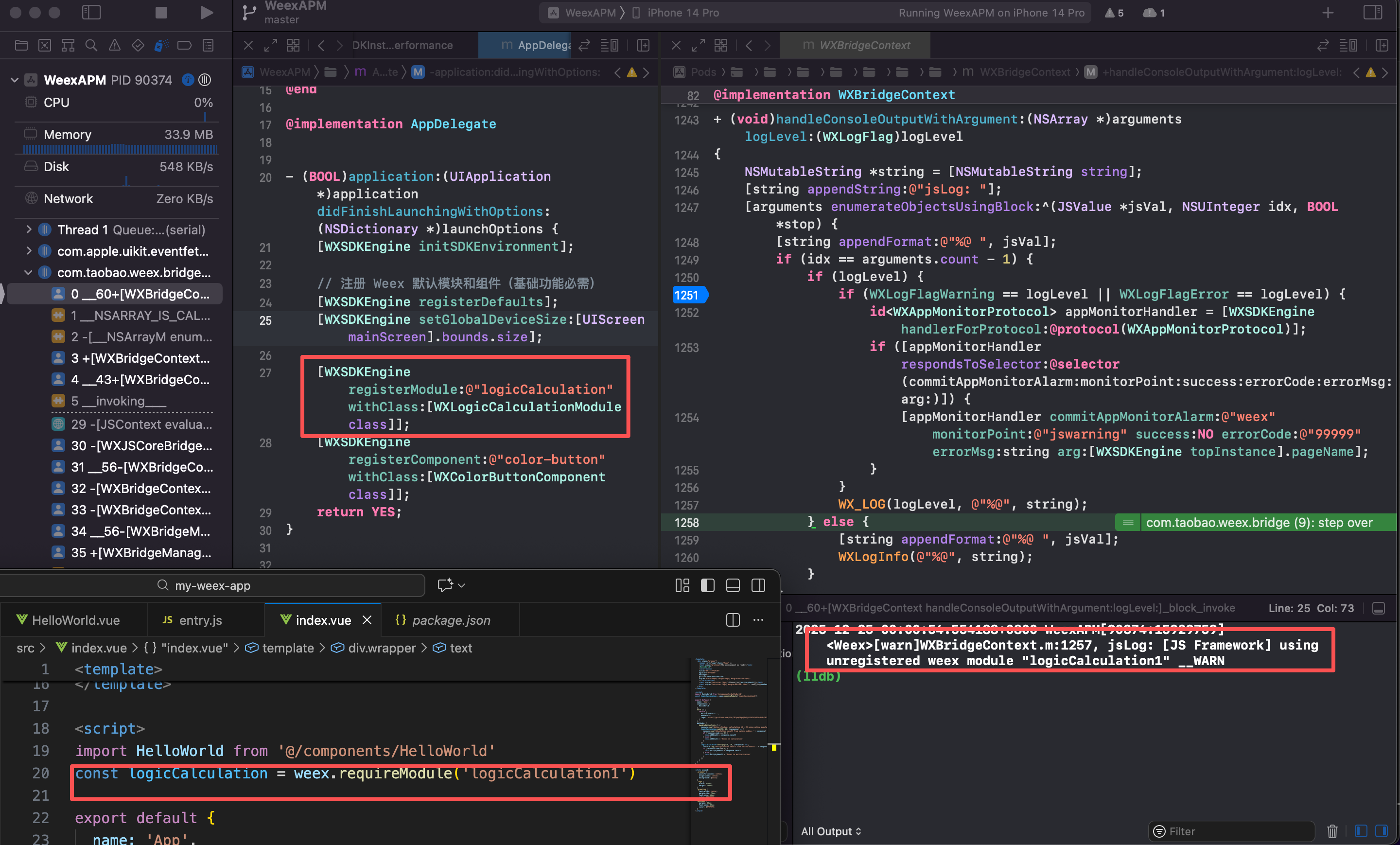
+
+所以作为 APM 侧,我们要定位和收集到该问题,进行问题上报。
+
+想办法知道哪里报错,requireModule 不是原生写法,这肯定是 JS 侧封装的,查看 Weex 源码
+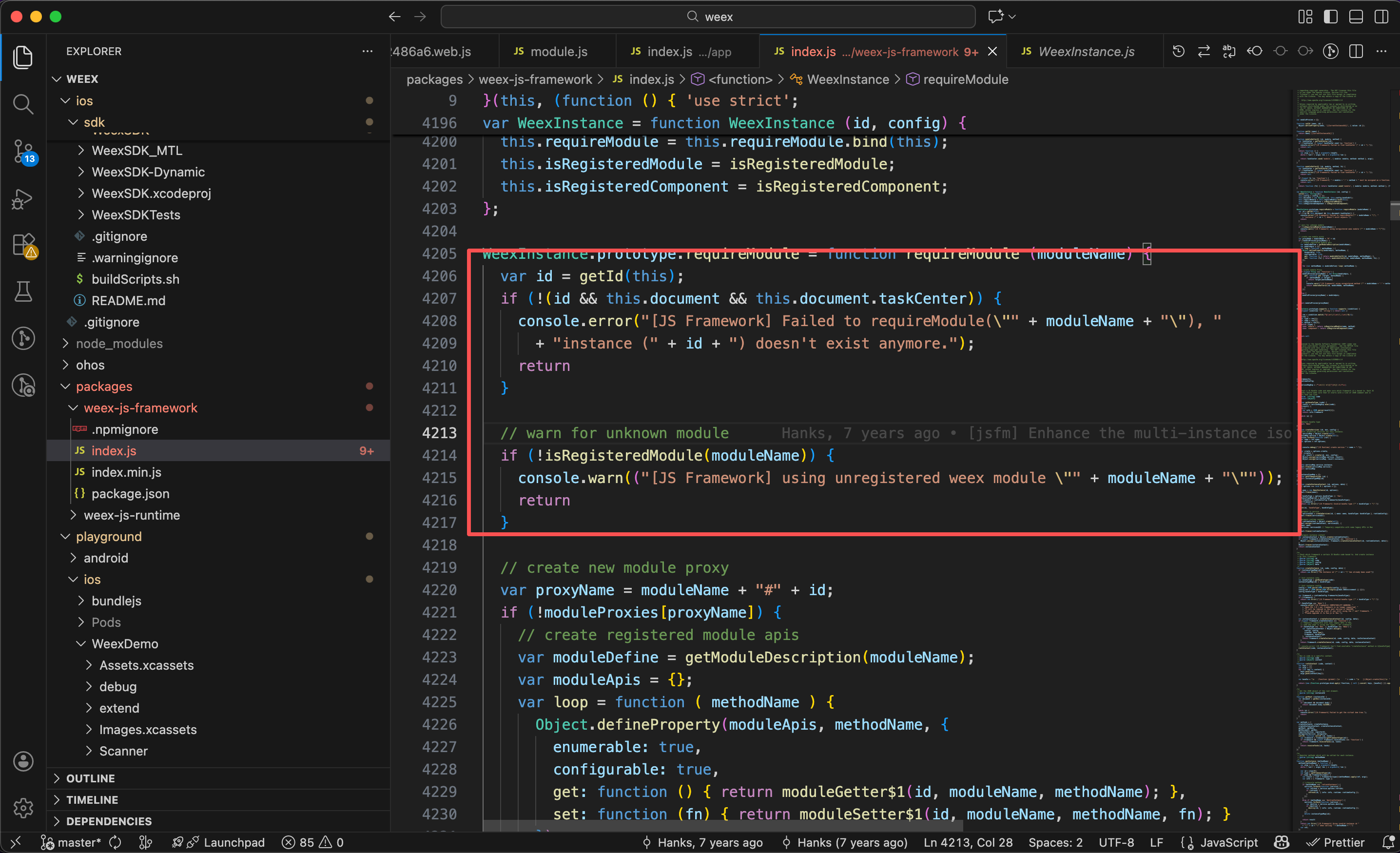
+```JS
+// Weex JS Framework 核心源码(简化)
+WeexInstance.prototype.requireModule = function requireModule(moduleName) {
+ // 1. 基础校验:Weex实例是否有效(比如是否已销毁)
+ var id = getId(this); // 获取当前Weex实例ID
+ if (!(id && this.document && this.document.taskCenter)) {
+ console.error("[JS Framework] Failed to requireModule(\"" + moduleName + "\"), instance doesn't exist.");
+ return;
+ }
+
+ // 2. 关键校验:检查Module是否在Native侧注册过
+ if (!isRegisteredModule(moduleName)) {
+ console.warn("[JS Framework] using unregistered weex module \"" + moduleName + "\"");
+ return;
+ }
+
+ // 3. 核心:创建Module代理对象(并非真实对象,仅封装桥接调用)
+ var moduleProxy = {};
+ // 获取该Module在Native侧注册的所有方法(提前从Native同步到JS的方法映射表)
+ var moduleMethods = getRegisteredMethods(moduleName);
+
+ // 4. 为代理对象绑定方法:调用方法时触发JS-Native桥接
+ moduleMethods.forEach(function(methodName) {
+ moduleProxy[methodName] = function() {
+ // 封装调用参数:实例ID、Module名、方法名、参数、回调
+ var args = Array.prototype.slice.call(arguments);
+ var callback = null;
+ // 提取最后一个参数作为回调(Weex约定)
+ if (typeof args[args.length - 1] === 'function') {
+ callback = args.pop();
+ }
+
+ // 5. 核心:通过taskCenter(桥接核心)调用Native
+ this.document.taskCenter.sendNative('callNative', {
+ instanceId: id,
+ module: moduleName,
+ method: methodName,
+ params: args,
+ callback: callback ? generateCallbackId(callback) : null
+ });
+ }.bind(this);
+ }, this);
+
+ // 6. 返回代理对象给JS侧使用
+ return moduleProxy;
+};
+```
+
+- 返回的不是真实的 Module 实例,而是代理对象(Proxy) —— 所有方法调用都会被拦截,转而通过桥接发送到 Native;
+- isRegisteredModule 校验:JS 侧会缓存一份「Native 已注册 Module 列表」(Native 初始化时同步到 JS),避免无效桥接。
+
+方案一:Weex 由于安全设计,没办法直接注入 JS。也就是说想通过“切面”思想,hook JS 侧 requireModule 是行不通的。这种方案,代码如下
+
+```JS
+// 备份原生requireModule方法
+const originalRequireModule = WeexInstance.prototype.requireModule;
+
+// 重写requireModule,在错误触发时主动上报Native
+WeexInstance.prototype.requireModule = function (moduleName) {
+ // 先执行原生判断逻辑
+ const id = getId(this);
+ if (!(id && this.document && this.document.taskCenter)) {
+ const errorMsg = "[JS Framework] Failed to requireModule(\"" + moduleName + "\"), instance (" + id + ") doesn't exist anymore.";
+ // 主动上报“实例不存在”错误到Native
+ this.document.taskCenter.sendNative('__weex_apm_report', {
+ type: 'module_require_failed',
+ subType: 'instance_not_exist',
+ moduleName: moduleName,
+ message: errorMsg,
+ instanceId: id
+ });
+ console.error(errorMsg);
+ return;
+ }
+
+ // 核心:拦截“未注册Module”判断
+ if (!isRegisteredModule(moduleName)) {
+ const warnMsg = "[JS Framework] using unregistered weex module \"" + moduleName + "\"";
+ // 主动上报“Module未注册”错误到Native(关键)
+ this.document.taskCenter.sendNative('__weex_apm_report', {
+ type: 'module_not_registered',
+ moduleName: moduleName,
+ message: warnMsg,
+ instanceId: id,
+ timestamp: Date.now()
+ });
+ // 保留原生warn日志(不影响原有逻辑)
+ console.warn(warnMsg);
+ return;
+ }
+
+ // 执行原生逻辑
+ return originalRequireModule.call(this, moduleName);
+};
+```
+
+方案二:Native 侧拦截 JS 的 console.warn 调用(无 JS 侵入)
+
+写法1:Weex JS 侧的 `console.warn` 最终会通过 WXBridgeContext 的 `handleJSLog` 方法传递到 Native,无需解析最终日志,直接 Hook 该方法拦截 warn 信息,精准匹配 Module 未注册错误
+
+```Objective-C
+#import
+
+@implementation NSObject (WXJSLogHook)
++ (void)load {
+ static dispatch_once_t onceToken;
+ dispatch_once(&onceToken, ^{
+ // 获取WXBridgeContext类(无需头文件)
+ Class bridgeContextClass = NSClassFromString(@"WXBridgeContext");
+ if (!bridgeContextClass) return;
+
+ // Hook处理JS日志的核心方法:handleJSLog:
+ SEL handleJSLogSel = NSSelectorFromString(@"handleJSLog:");
+ Method originalMethod = class_getInstanceMethod(bridgeContextClass, handleJSLogSel);
+ if (!originalMethod) return;
+
+ SEL swizzledSel = NSSelectorFromString(@"weex_apm_handleJSLog:");
+ Method swizzledMethod = class_getInstanceMethod(self, swizzledSel);
+ class_addMethod(bridgeContextClass, swizzledSel, method_getImplementation(swizzledMethod), method_getTypeEncoding(swizzledMethod));
+ method_exchangeImplementations(originalMethod, swizzledMethod);
+ });
+}
+
+// Hook后的handleJSLog方法:拦截JS侧的warn日志
+- (void)weex_apm_handleJSLog:(NSDictionary *)logInfo {
+ // 1. 先执行原方法,保留原有日志输出逻辑
+ [self weex_apm_handleJSLog:logInfo];
+
+ // 2. 解析JS日志信息(logInfo格式:{level: 'warn', msg: 'xxx', ...})
+ NSString *logLevel = logInfo[@"level"];
+ NSString *logMsg = logInfo[@"msg"];
+
+ // 3. 精准匹配“未注册Module”的warn
+ if ([logLevel isEqualToString:@"warn"] && [logMsg containsString:@"using unregistered weex module"]) {
+ // 提取Module名称
+ NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:@"using unregistered weex module \"(.*?)\"" options:0 error:nil];
+ NSTextCheckingResult *match = [regex firstMatchInString:logMsg options:0 range:NSMakeRange(0, logMsg.length)];
+ NSString *moduleName = match ? [logMsg substringWithRange:match.rangeAtIndex(1)] : @"";
+
+ // 4. 构造APM数据上报
+ NSDictionary *apmData = @{
+ @"error_type": @"weex_module_not_registered",
+ @"module_name": moduleName,
+ @"message": logMsg,
+ @"source": @"js_console_warn", // 标记来源:JS console.warn
+ @"timestamp": @([[NSDate date] timeIntervalSince1970] * 1000)
+ };
+
+ // 调用 APM SDK 接口,数据先落库,后续统一按照数据上报策略,从本地 DB 捞取、聚合、上报
+ // [YourAPMManager reportWeexError:apmData];
+ }
+}
+@end
+```
+核心优势
+- 无侵入:无需修改 / 注入 JS 代码,纯 Native 侧实现;
+- 精准:拦截的是 JS 侧传递到 Native 的原始日志数据(而非最终打印的字符串),无格式误差;
+- 覆盖全:所有 JS 侧的console.warn都会经过此方法,100% 覆盖 Module 未注册场景
+
+写法二:由于 Weex 代码是大量的存量业务代码,很稳定。而且 Weex 官方好几年不更新,所以我们内部私有化 Weex SDK,也就没有采取 Hook 手段。而是直接修改源码,`WXBridgeContext.m` 的 `+ (void)handleConsoleOutputWithArgument:(NSArray *)arguments logLevel:(WXLogFlag)logLevel` 方法。比如:
+
+```Objective-C
++ (void)handleConsoleOutputWithArgument:(NSArray *)arguments logLevel:(WXLogFlag)logLevel
+{
+ NSMutableString *string = [NSMutableString string];
+ [string appendString:@"jsLog: "];
+ [arguments enumerateObjectsUsingBlock:^(JSValue *jsVal, NSUInteger idx, BOOL *stop) {
+ [string appendFormat:@"%@ ", jsVal];
+ if (idx == arguments.count - 1) {
+ if (logLevel) {
+ if (WXLogFlagWarning == logLevel || WXLogFlagError == logLevel) {
+ if ([string containsString:@"using unregistered weex module"]) {
+ // 提取Module名称
+ NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:@"using unregistered weex module \"(.*?)\"" options:0 error:nil];
+ NSTextCheckingResult *match = [regex firstMatchInString:string options:0 range:NSMakeRange(0, string.length)];
+ NSString *moduleName = match ? [string substringWithRange:[match rangeAtIndex:1]] : @"";
+
+ // 接入收口工具类
+ NSString *exceptionMsg = [NSString stringWithFormat:@"JS require未注册模块:%@,原始日志:%@", moduleName, string];
+ NSDictionary *customExt = @{@"moduleName": moduleName};
+ NSString *instanceId = [WXSDKEngine topInstance].instanceId ?: @"";
+ NSString *bundleUrl = [WXSDKEngine topInstance].scriptURL.absoluteString ?: @"";
+ [[WXExceptionReporter sharedInstance] reportExceptionWithCode:WXCustomExceptionCode_Module_NotRegistered
+ exceptionType:WXCustomExceptionType_Module
+ instanceId:instanceId
+ function:@"handleConsoleOutputWithArgument:logLevel:"
+ exceptionMsg:exceptionMsg
+ bundleUrl:bundleUrl
+ customExtParams:customExt];
+ }
+
+ id appMonitorHandler = [WXSDKEngine handlerForProtocol:@protocol(WXAppMonitorProtocol)];
+ if ([appMonitorHandler respondsToSelector:@selector(commitAppMonitorAlarm:monitorPoint:success:errorCode:errorMsg:arg:)]) {
+ [appMonitorHandler commitAppMonitorAlarm:@"weex" monitorPoint:@"jswarning" success:NO errorCode:@"99999" errorMsg:string arg:[WXSDKEngine topInstance].pageName];
+ }
+ }
+ WX_LOG(logLevel, @"%@", string);
+ } else {
+ [string appendFormat:@"%@ ", jsVal];
+ WXLogInfo(@"%@", string);
+ }
+ }
+ }];
+}
+```
+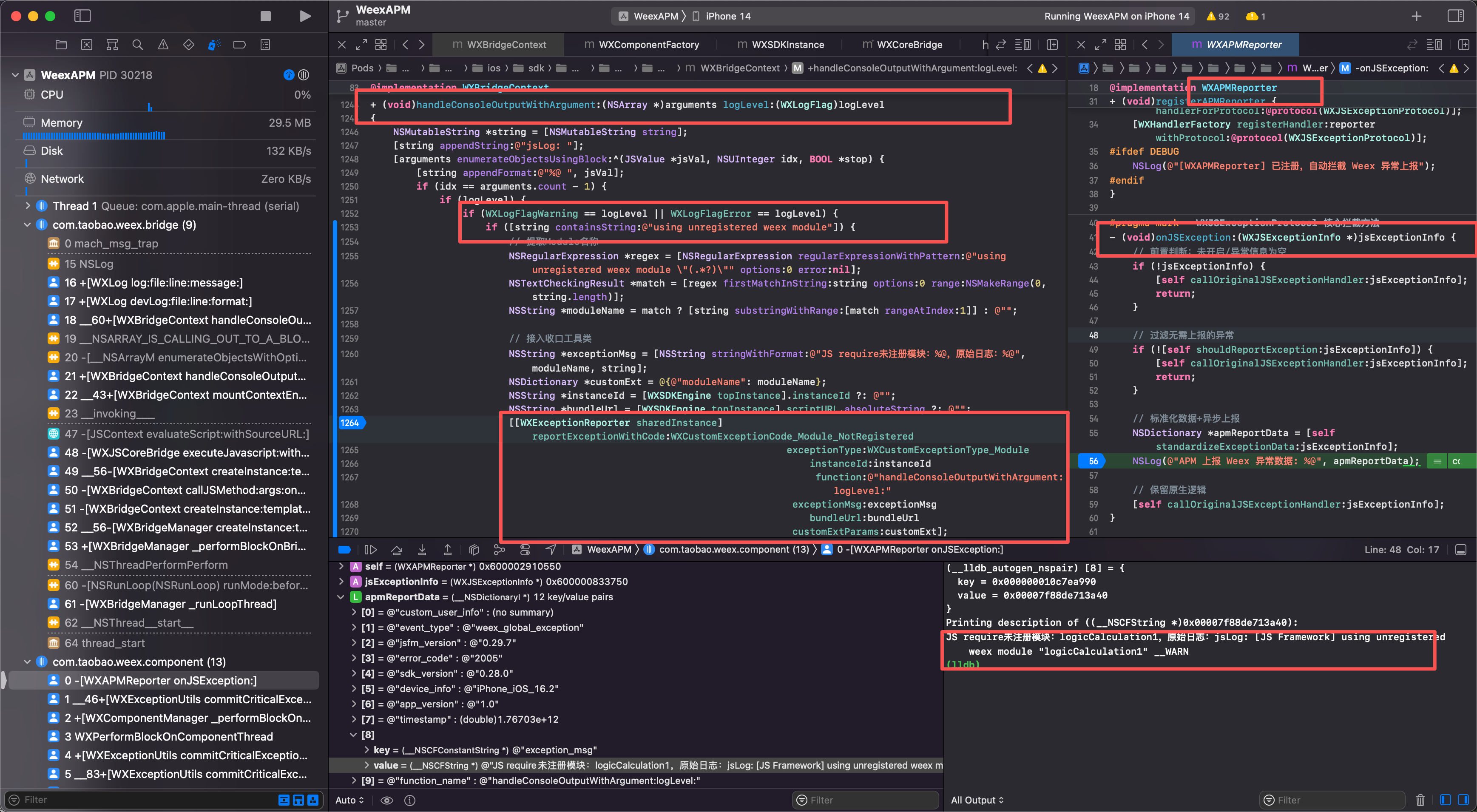
+
+
+#### 2. JS 调用 Moudle 方法失败
+Native 注册了一个负责逻辑的 Module,但是在 JS 侧使用的时候,要么方法名写错了,要么参数少传了,都可能导致预期的逻辑执行错误,发生不符合预期的行为。
+
+##### 1. 点击事件工作原理
+核心问题:点击事件发生时,如何根据 Component 的点击事件定位到该 Component 在 Vue DSL 中声明的事件?
+
+第一步:页面初始化时,JS 侧构建**事件映射表**。
+Weex 页面渲染时,会为每个组件做2件事情:
+- 生成组件唯一标识:每个组件都有 `ref/componentId/docId`,类似组件身份证
+- 绑定事件与方法:解析 `@click="handleButtonClick"` 时,JS 会将「组件 ID + 事件类型(click)」作为 key,`handleButtonClick` 作为 value,一起存进组件实例的映射表里,(对应下面的 `this.event[type]`)
+
+第二步:Native 侧捕获点击,携带关键信息调用 fireEvent。
+Native 侧能拿到 componentId,是因为渲染组件时,JS 侧会把组件 ID 同步给 Native 渲染引擎(WXComponent),Native 控件和 JS 组件实例通过 ID 一一绑定
+
+第三步:JS 侧调用 `fireEvent` 方法,其内部通过 `ID + 事件类型` 找方法。
+- 定位组件实例:JS 通过 componentID(代码里的 this.ref)找到组件实例。
+- 查找事件映射:从组件实例的 `this.event` 里根据 type (如 click)找到具体的 eventDesc(包含具体的 handler)
+- 发起调用 `handler.call`
+
+```js
+/**
+ * Fire an event manually.
+ * @param {string} type type
+ * @param {function} event handler
+ * @param {boolean} isBubble whether or not event bubble
+ * @param {boolean} options
+ * @return {} anything returned by handler function
+ */
+ Element.prototype.fireEvent = function fireEvent (type, event, isBubble, options) {
+ var result = null;
+ var isStopPropagation = false;
+ var eventDesc = this.event[type];
+ if (eventDesc && event) {
+ var handler = eventDesc.handler;
+ event.stopPropagation = function () {
+ isStopPropagation = true;
+ };
+ if (options && options.params) {
+ result = handler.call.apply(handler, [ this ].concat( options.params, [event] ));
+ }
+ else {
+ result = handler.call(this, event);
+ }
+ }
+
+ if (!isStopPropagation
+ && isBubble
+ && (BUBBLE_EVENTS.indexOf(type) !== -1)
+ && this.parentNode
+ && this.parentNode.fireEvent) {
+ event.currentTarget = this.parentNode;
+ this.parentNode.fireEvent(type, event, isBubble); // no options
+ }
+
+ return result
+ };
+```
+
+##### 2. JS 调用 module 方法,方法名错误
+Native 注册的 Module 方法名为 `multiply:num2:callback:`,而在 JS 侧调用的时候方法名多加了几个字符,造成方法名对不上,方法调用失败的问题。
+
+用户点击屏幕上的 UI 控件(此处就是注册 Component `[WXSDKEngine registerComponent:@"color-button" withClass:[WXColorButtonComponent class]]`)。
+
+Weex 统一给 Comonent 添加了分类来负责事件的处理。`WXComponent+Events`。源码中 `addClickEvent` 就是添加了点击事件的监听。当发生点击后会计算点击事件的坐标和时间戳信息,最后封装一个 `WXCallJSMethod` 对象,方法名固定为 `fireEvent`。如下堆栈所示:
+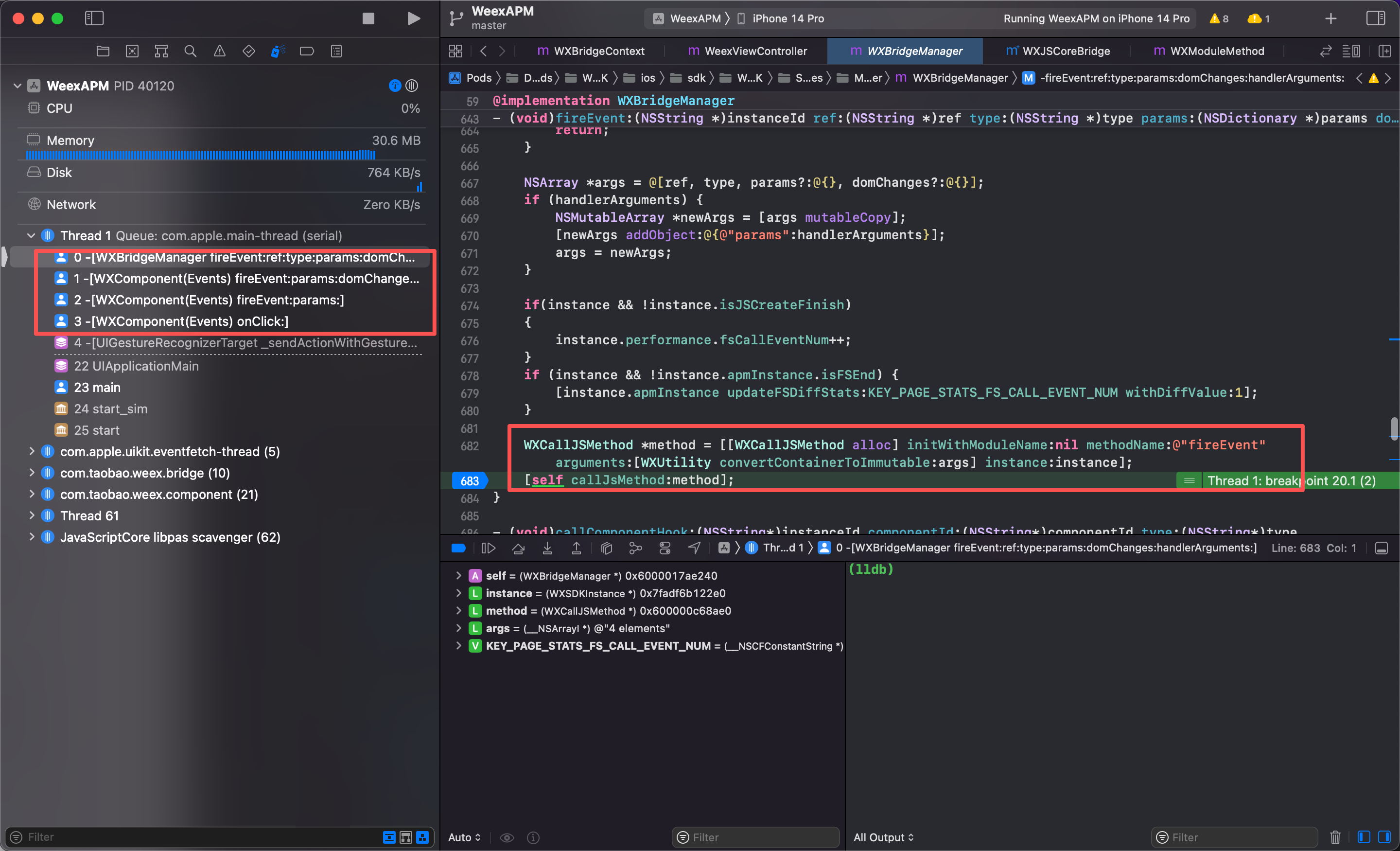
+
+由于 `logicCalculation` 没有对应的 `multiplyWith` 方法,所以会报错,被 JS 的 `try...catch...` 捕获后,通过 `console.error` 的方式输出异常信息。但是 `console.error` 被 Native 接管了。所以我们可以在 Native 接管的地方统一拦截处理。只要日志包含 `Failed to invoke the event handler` 就可以认为是因为方法名问题,导致调用方法出错
+
+代码如下:
+```Objective-c
++ (void)handleConsoleOutputWithArgument:(NSArray *)arguments logLevel:(WXLogFlag)logLevel
+{
+ // ...
+ if ([string containsString:@"Failed to invoke the event handler"]) {
+ // 原有解析逻辑保留
+ NSString *errorMethodName = @"";
+ NSString *eventType = @"";
+ NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:@"'\\.\\.\\.(?:logicCalculation\\.)([a-zA-Z0-9_]+)\\.\\.\\." options:0 error:nil];
+ NSTextCheckingResult *match = [regex firstMatchInString:string options:0 range:NSMakeRange(0, string.length)];
+ if (match) {
+ errorMethodName = [string substringWithRange:[match rangeAtIndex:1]];
+ }
+ NSRegularExpression *eventRegex = [NSRegularExpression regularExpressionWithPattern:@"event handler of \"([^\"]+)\"" options:0 error:nil];
+ NSTextCheckingResult *eventMatch = [eventRegex firstMatchInString:string options:0 range:NSMakeRange(0, string.length)];
+ if (eventMatch) {
+ eventType = [string substringWithRange:[eventMatch rangeAtIndex:1]];
+ }
+
+ // 接入收口工具类
+ NSString *exceptionMsg = [NSString stringWithFormat:@"Module方法名错误:%@,事件类型:%@,原始日志:%@", errorMethodName, eventType, string];
+ NSDictionary *customExt = @{
+ @"moduleName": @"logicCalculation",
+ @"methodName": errorMethodName,
+ @"eventType": eventType
+ };
+ NSString *instanceId = [WXSDKEngine topInstance].instanceId ?: @"";
+ NSString *bundleUrl = [WXSDKEngine topInstance].scriptURL.absoluteString ?: @"";
+ [[WXExceptionReporter sharedInstance] reportExceptionWithCode:WXCustomExceptionCode_Module_MethodNotFound
+ exceptionType:WXCustomExceptionType_Module
+ instanceId:instanceId
+ function:@"handleConsoleOutputWithArgument:logLevel:"
+ exceptionMsg:exceptionMsg
+ bundleUrl:bundleUrl
+ customExtParams:customExt];
+ }
+ // ...
+}
+```
+
+效果如下
+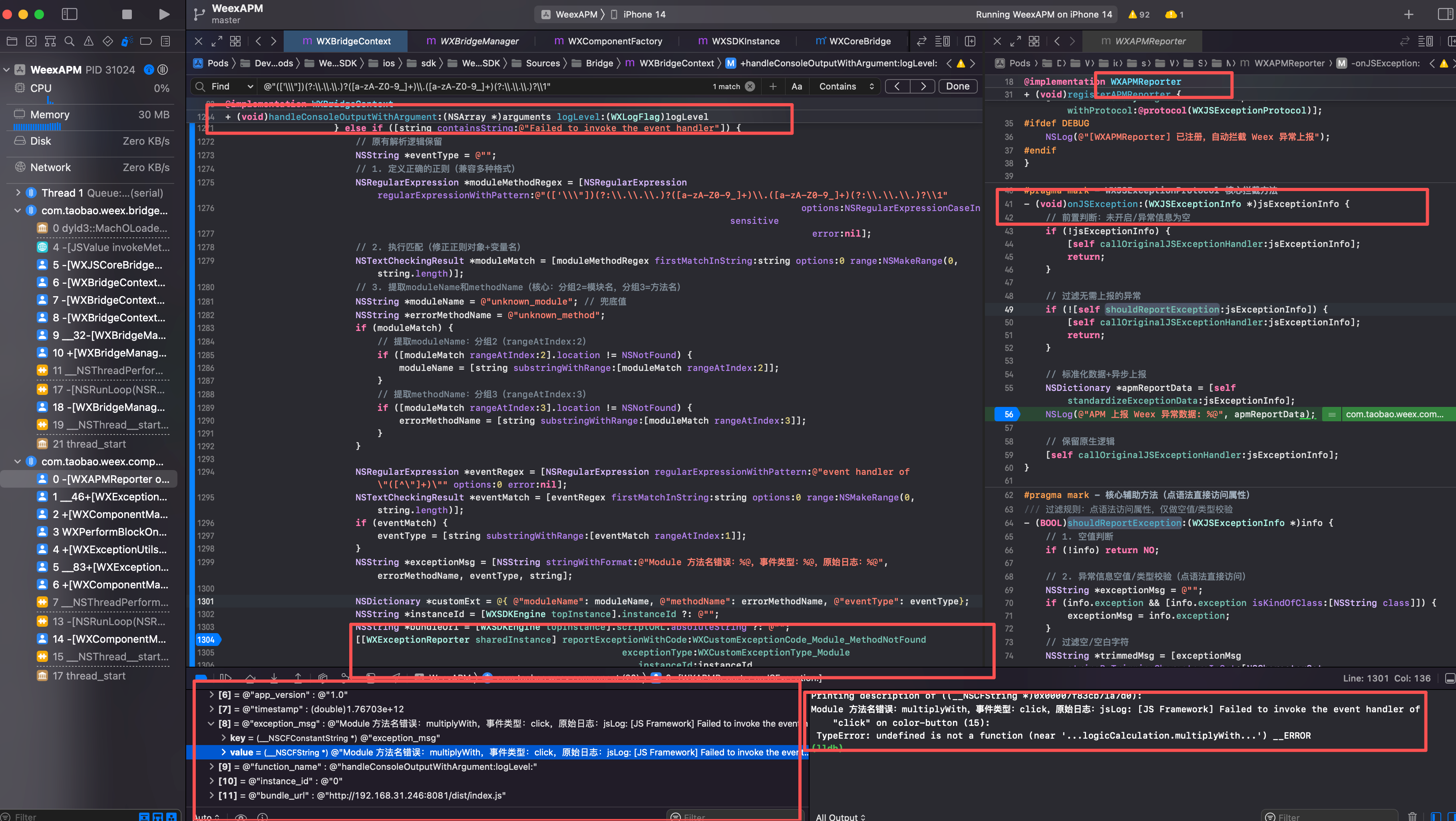
+
+
+##### 3. JS 调用 module 方法,方法参数个数不匹配
+上面已经讲了点击事件的工作流程,调用方法时,除了调用了不存在的方法或者方法名写错了,还有一种情况就是参数个数不匹配。
+
+这种情况如何识别并监控?
+JS 的事件处理函数里,调用注册的 Module 和对应的方法,会统一走到 `WXJSCoreBridge.mm` 的 `- (void)registerCallNativeModule:(WXJSCallNativeModule)callNativeModuleBlock` 给当前的 JSContext 注册好的 `callNativeModule` 回调里。`_jsContext[@"callNativeModule"] = ^JSValue *(JSValue *instanceId, JSValue *moduleName, JSValue *methodName, JSValue *args, JSValue *options)` 可以拿到模块名、方法名、参数个数、instanceID 等。拿到实际传递的方法参数列表,再通过模块名根据 `ModuleFactory` 找到模块类对象,然后利用 runtime 能力,遍历类对象的方法列表,找到对应的 SEL,判断其预期的方法参数个数,然后再和实际传递过来的方法参数个数做比较即可
+
+```Objective-c
+- (void)registerCallNativeModule:(WXJSCallNativeModule)callNativeModuleBlock
+{
+ // JS 调用 Native 的方法都会走这里。可以解析到:模块名、方法名、参数数组等信息。可以在这里判断方法参数个数是否相同。
+ _jsContext[@"callNativeModule"] = ^JSValue *(JSValue *instanceId, JSValue *moduleName, JSValue *methodName, JSValue *args, JSValue *options) {
+ // ...
+ };
+}
+```
+
+在其 `callNativeModule` 的 block 里,增加一个方法,专门用来判断和检查方法参数个数是否匹配的问题
+```Objective-C
+// 辅助方法:校验Module方法参数个数
+- (void)checkModuleParamCount:(NSString *)moduleName
+ methodName:(NSString *)methodName
+ actualParams:(NSArray *)actualParams
+ instanceId:(NSString *)instanceId {
+ // 1. 跳过空值/系统模块(避免无意义校验)
+ if (!moduleName || !methodName || actualParams.count < 0) return;
+ Class moduleClass = [WXModuleFactory classWithModuleName:moduleName];
+ if (!moduleClass) return;
+
+ // 2. 拼接完整的方法选择器(Weex Module方法名带冒号,需补全,如multiply→multiply:num2:callback:)
+ // 注:若方法名规则固定,可通过模块类的方法列表获取所有selector,匹配前缀
+ SEL targetSel = nil;
+ unsigned int methodCount = 0;
+ Method *methods = class_copyMethodList(moduleClass, &methodCount);
+ for (int i = 0; i < methodCount; i++) {
+ Method method = methods[i];
+ SEL sel = method_getName(method);
+ NSString *selStr = NSStringFromSelector(sel);
+ // 匹配前缀(如multiply开头的方法)
+ if ([selStr hasPrefix:methodName]) {
+ targetSel = sel;
+ break;
+ }
+ }
+ free(methods);
+ if (!targetSel) return;
+
+ // 3. 解析方法签名,计算预期参数个数(减self/_cmd)
+ NSMethodSignature *methodSig = [moduleClass instanceMethodSignatureForSelector:targetSel];
+ NSInteger weexParamCount = methodSig.numberOfArguments - 2;
+
+ // 4. 判断参数个数是否不匹配
+ if (actualParams.count != weexParamCount) {
+ // 构造错误信息
+ NSString *errorMsg = [NSString stringWithFormat:@"Module:%@ 方法:%@ 参数个数不匹配,预期%ld个,实际%ld个",
+ moduleName, methodName, weexParamCount, actualParams.count];
+ WXLogError(@"[WeexParamError] %@", errorMsg);
+
+ // 5. 上报APM(核心:生产环境监控)
+ NSDictionary *apmData = @{
+ @"error_type": @"weex_module_param_count_mismatch",
+ @"module_name": moduleName,
+ @"method_name": methodName,
+ @"expected_count": @(weexParamCount),
+ @"actual_count": @(actualParams.count),
+ @"actual_params": actualParams,
+ @"instance_id": instanceId ?: @"",
+ @"timestamp": @([[NSDate date] timeIntervalSince1970] * 1000),
+ @"message": errorMsg
+ };
+
+ // APM:异步上报,避免阻塞JS桥接
+ NSLog(@"APM 数据上报通道,【JS 通过 Module 调用 Native 方法,参数个数不匹配】:%@", apmData);
+ }
+}
+```
+效果如下:
+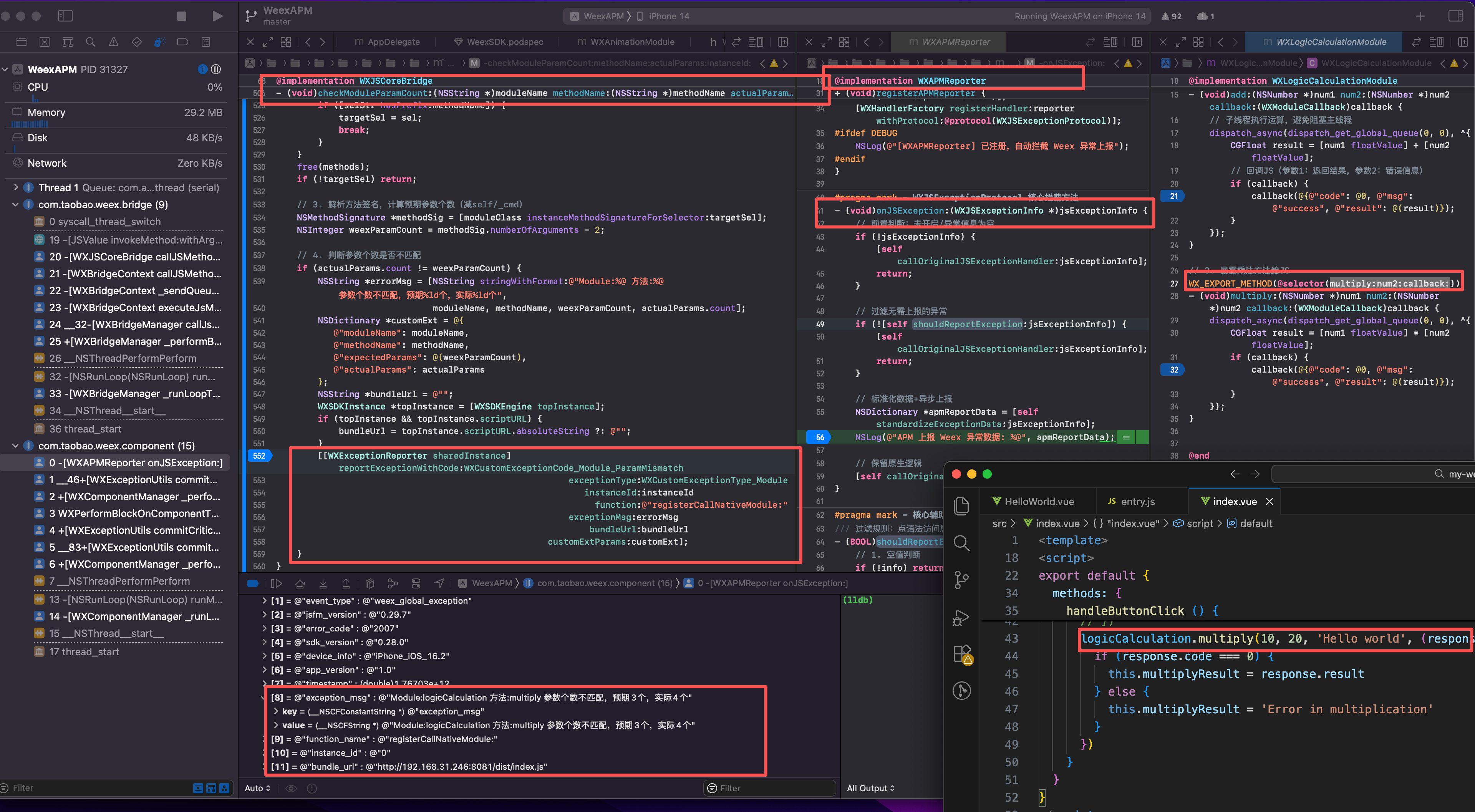
+
+
+#### 5. Vue 层面异常
+Weex 底层依靠 Vue 实现,差异化就是 VM 去通过 Bridge 在 WeexSDK Native 去做绘制。异常方面除了常规的 JS 运行时异常(如语法错误、类型错误等 7 种),Vue 框架自身的逻辑层、编译层、响应式系统、组件生命周期 等环节会抛出专属异常,这些异常必须通过 Vue.config.errorHandler 兜底。
+
+分析 Weex 源码中:`packages/weex-js-framework/index.js/`
+
+```js
+function handleError (err, vm, info) {
+ if (vm) {
+ var cur = vm;
+ while ((cur = cur.$parent)) {
+ var hooks = cur.$options.errorCaptured;
+ if (hooks) {
+ for (var i = 0; i < hooks.length; i++) {
+ try {
+ var capture = hooks[i].call(cur, err, vm, info) === false;
+ if (capture) { return }
+ } catch (e) {
+ globalHandleError(e, cur, 'errorCaptured hook');
+ }
+ }
+ }
+ }
+ }
+ globalHandleError(err, vm, info);
+}
+
+function globalHandleError (err, vm, info) {
+ if (config.errorHandler) {
+ try {
+ return config.errorHandler.call(null, err, vm, info)
+ } catch (e) {
+ logError(e, null, 'config.errorHandler');
+ }
+ }
+ logError(err, vm, info);
+}
+```
+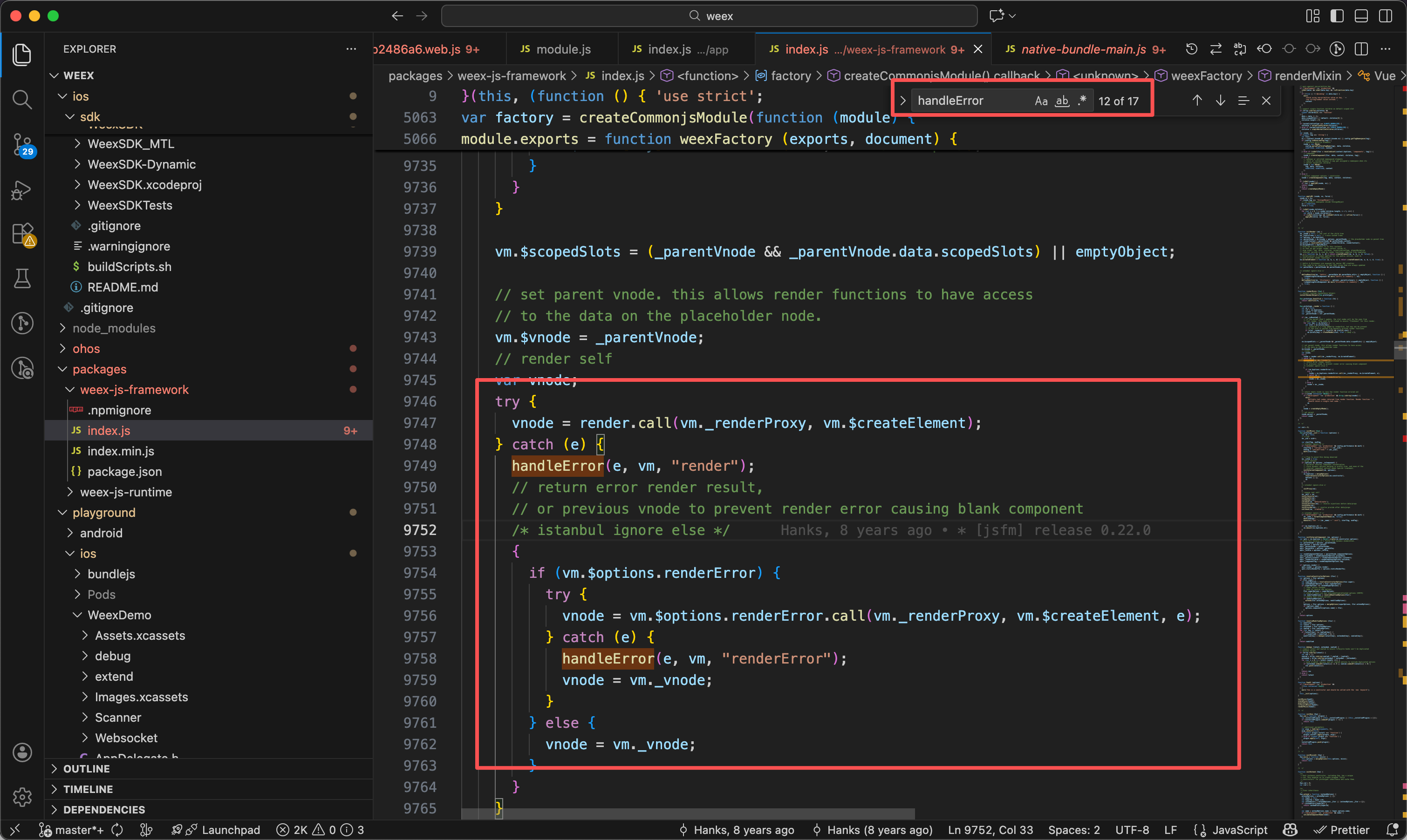
+
+源码中 nextTick、Vue.prototype.$emit、callHook、Watcher.prototype.get、Watcher.prototype.run、renderRecyclableComponentTemplate、Vue.prototype._render 等等都调用了 handleError 方法。
+Vue 内部对部分异常做了封装/拦截,避免直接冒泡到全局(防止阻断应用整体运行),但会通过 errorHandler 暴露出来。
+
+举个例子,WeexAPM 类可以封装为:
+```JS
+/**
+ * APM
+ */
+class WeexAPM {
+ /**
+ * 获取当前的叶子节点
+ * @param {*} Vue vm
+ * @returns 当前组件名称
+ */
+ formatComponentName (vm) {
+ if (vm.$root === vm) return 'root'
+ var name = vm._isVue
+ ? (vm.$options && vm.$options.name) ||
+ (vm.$options && vm.$options._componentTag)
+ : vm.name
+ return (
+ (name ? 'component <' + name + '>' : 'anonymous component') +
+ (vm._isVue && vm.$options && vm.$options.__file
+ ? ' at ' + (vm.$options && vm.$options.__file)
+ : '')
+ )
+ }
+
+ /**
+ * 处理Vue错误提示
+ */
+ monitor (Vue) {
+ if (!Vue) {
+ return
+ }
+ // 错误处理
+ Vue.config.errorHandler = (err, vm, info) => {
+ let componentName = 'unknown'
+ if (vm) {
+ componentName = this.formatComponentName(vm)
+ }
+ let errorInfo = {
+ name: err.name,
+ reason: err.message,
+ callStack: err.stack,
+ componentName: componentName,
+ info: info,
+ level: 'VUE_ERROR'
+ }
+ try {
+ const weexAPMUploader = weex.requireModule('weexAPMUploader')
+ weexAPMUploader.uploadException(errorInfo)
+ } catch (error) {
+ console.error('APMMonitor 能力有问题,请检查是否注册了weexAPMUploader模块' + error)
+ }
+ }
+ }
+}
+
+export default WeexAPM
+```
+在捕获到 Vue 层面的异常时,可以调用注册好的 weexAPMUploader module 能力,将数据传输到 Native 侧,由 Native 侧进行统一的参数组装,最后调用 APM SDK 的能力进行数据写入数据库、按照策略上报到 APM 服务端进行消费。
+
+模拟产生 Vue 层级的错误:给一个字符串类型的数据,在计算属性里调用 `toFixed` 方法。按钮的点击事件里将数据改为字符串,则会报错。
+可以看到被 `Vue.config.errorHandler` 捕获了,后续交给 Native 处理即可。
+
+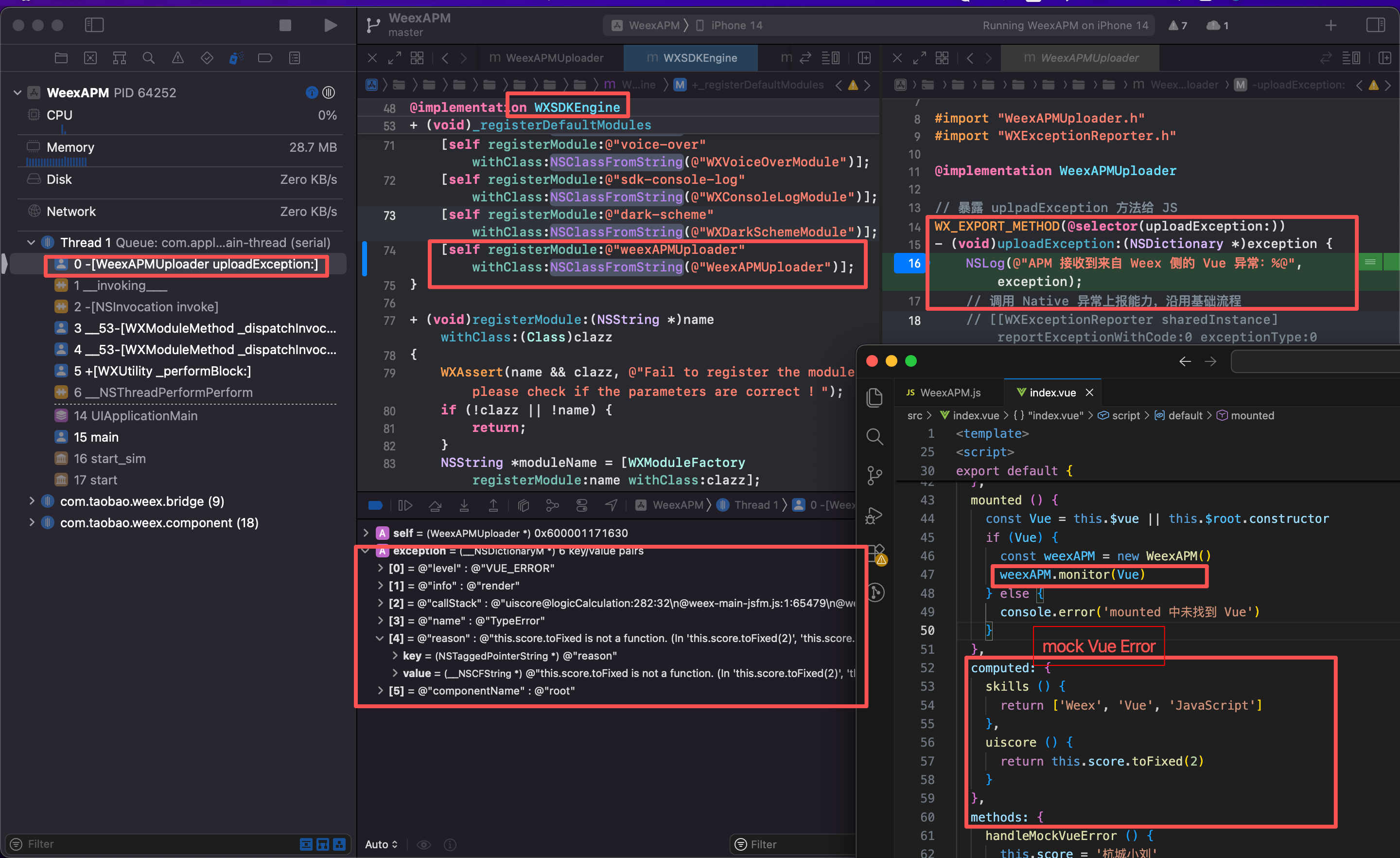
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.147.md b/Chapter1 - iOS/1.147.md
new file mode 100644
index 0000000..f2cae13
--- /dev/null
+++ b/Chapter1 - iOS/1.147.md
@@ -0,0 +1,278 @@
+# Rust 在移动端可以做什么
+
+> uniffi 的思路,和早期类似营销计算的逻辑用 ts 写好,端上 js 引擎加速,Android、iOS 再去使用是一个思路。
+
+## 一、Uniffi 在移动端能做什么?
+
+### 1. uniffi 是什么?
+
+uniffi(全称 “Uniffi-rs”)是 Mozilla 开发的一个跨语言绑定生成工具,核心作用是让 Rust 代码能被其他编程语言(如 Swift、Kotlin、Python、JavaScript 等)无缝调用,通过自动生成类型安全的绑定层,大幅简化跨语言 FFI(Foreign Function Interface)开发的复杂度。
+
+### 2. 为什么营销计算的逻辑适合用 ts 写?
+
+纯函数,给定恒定的输入,输出不变。这非常适合 ts、rust 去实现。所以可以说,纯函数、纯逻辑适合用 Rust 去开发。区别在于即使采用类似 Wasm、JS 引擎预热、预加载等技术手段,Rust 天然比 JS 效率高。
+
+### 3. ffi 能做什么?
+
+早期 Flutter 和 Native 交互走 method channel 效率低,所以腾讯的同学开发了 Dart Native 方案,就是基于 ffi 的思路。
+
+
+所以可以回答 Uniffi 能做什么的问题了:
+
+uniffi 的核心是 “让 Rust 成为跨语言共享逻辑的‘通用语言’”,尤其在移动端,它解决了 iOS 和 Android 逻辑重复开发的问题,同时借助 Rust 的安全和性能优势,提升核心模块的可靠性。它更适合 “业务逻辑层” 而非 “UI 层”(UI 仍需依赖各平台原生框架),是移动端跨平台开发的重要补充工具
+
+
+
+uniffi 的核心价值是跨语言复用 Rust 代码,因此它适合开发 “需要在多平台 / 多语言间共享的核心逻辑”,尤其适合以下场景:
+
+1. 跨平台共享的业务逻辑当同一套逻辑需要在多个平台(如移动端 iOS/Android、桌面端、后端服务)实现时,用 Rust 编写一次核心逻辑,再通过 uniffi 生成各平台对应的绑定(如 Swift 绑定供 iOS 调用,Kotlin 绑定供 Android 调用、桌面端 Electron js 去调用、小程序 js 去调用),避免重复开发,保证逻辑一致性。
+2. 对安全性、性能要求高的模块 Rust 自带内存安全和零成本抽象特性,适合处理敏感逻辑(如加密解密、用户认证、支付流程)或性能敏感操作(如数据解析、复杂计算、实时处理)。uniffi 能让这些 Rust 模块被其他语言(如动态语言)安全调用,兼顾安全性与开发效率。
+3. 需要跨语言交互的中间层例如,在一个混合技术栈的项目中(如前端用 JavaScript、后端用 Python、移动端用 Kotlin/Swift),可以用 Rust 编写通用的数据处理或协议解析逻辑,再通过 uniffi 生成多语言绑定,作为各层之间的 “桥梁”。
+4. 替代手动 FFI 开发传统跨语言调用需要手动编写 FFI 绑定(如用 extern "C" 暴露 Rust 接口,再在其他语言中手动适配类型),容易出错且维护成本高。uniffi 可自动生成类型安全的绑定,大幅降低开发和维护成本。
+
+## 二、移动端中 uniffi 可以做什么?
+
+移动端开发的核心痛点之一是 “iOS(Swift/Objective-C)和 Android(Kotlin/Java)需要重复实现相同逻辑”,而 uniffi 恰好能通过 Rust 实现跨平台逻辑复用,具体应用场景包括:共享核心业务逻辑例如:用户登录流程、权限验证、数据校验规则、业务状态管理等。用 Rust 编写一次,通过 uniffi 生成 Swift 绑定(供 iOS)和 Kotlin 绑定(供 Android),两端直接调用,避免 “同一逻辑两套代码” 的冗余和不一致问题。
+
+高性能数据处理移动端涉及的复杂数据处理(如 JSON/Protobuf 解析、大数据集合过滤 / 排序、二进制协议编解码),用 Rust 实现可获得比 Kotlin/Swift 更高的性能,uniffi 可让两端高效调用这些逻辑。
+
+安全敏感操作如加密(AES、RSA)、解密、签名验证、敏感数据(密码、Token)存储逻辑等,Rust 的内存安全特性可减少传统 C/C++ 调用可能带来的内存漏洞风险,uniffi 则确保调用过程的类型安全。
+
+跨平台工具类例如:日期时间处理、字符串工具、设备信息计算(如唯一标识生成)等通用工具,用 Rust 实现后,通过 uniffi 让 iOS 和 Android 共享,减少重复开发。
+
+与现有跨平台框架配合即使项目使用 Flutter、React Native 等跨平台 UI 框架,也可通过 uniffi 将 Rust 逻辑作为 “原生能力扩展”:例如 Flutter 中通过 Platform Channel 调用 uniffi 生成的 Rust 绑定,处理 Flutter 难以高效实现的复杂计算。
+
+
+
+### 三、Rust 中使用 Unifii 实现与 Swift 高效互操作性
+UniFFI(Universal Foreign Function Interface)是一个工具集,旨在帮助开发者轻松生成适用于多个编程语言(如 Swift、Kotlin 和 Python)的外部函数接口 (FFI) 绑定。它允许你通过定义一个接口描述语言 (UDL) 文件,自动生成跨语言的绑定代码,从而简化 Rust 代码与其他语言之间的交互。
+
+#### 1. 必要工具
+开始之前,你需要确保已经安装了以下工具:
+- Rust 和 Cargo:Rust 是一种系统编程语言,强调安全性和性能。Cargo 是 Rust 的包管理器和构建系统。
+验证安装:运行以下命令确保 Rust 和 Cargo 已正确安装。
+```shell
+rustc --version
+cargo --version
+```
+- UniFFI CLI 工具:UniFFI 提供了一个命令行工具,用于生成绑定代码。安装 UniFFI:你可以通过 Cargo 安装 UniFFI。
+```shell
+cargo install uniffi_bindgen
+```
+验证安装:运行以下命令确保 UniFFI 已正确安装。
+```shell
+uniffi-bindgen --version
+```
+
+#### 2. 项目设置
+1. 创建 Rust 项目
+- 打开终端并运行以下命令创建一个新的 Rust 库项目:
+```shell
+cargo new my_rust_library --lib
+cd my_rust_library
+```
+- 编辑Cargo.toml文件,添加 Uniffi 依赖项
+```shell
+[dependencies]
+uniffi = "0.27.0"
+serde = { version = "1.0", features = ["derive"] }
+```
+- 配置Cargo.toml文件中的lib部分,设置 crate 类型为 cdylib:
+```shell
+[lib]
+crate-type = ["cdylib"]
+```
+
+2. 创建名为 `MySwiftApp` 的Swift 项目
+
+#### 3. Rust 库的创建
+我们将创建一个简单的 Rust 库,并配置它以便与 Swift 互操作。我们将定义一个数据结构和一些基本的功能,使用 UniFFI 来生成绑定。
+1. 设置 Cargo.toml
+首先,我们需要在 Cargo.toml 文件中配置项目依赖和库类型:
+```rs
+[package]
+name = "my_rust_library"
+version = "0.1.0"
+edition = "2018"
+
+[dependencies]
+uniffi = "0.27.0" # 检查最新版本
+serde = { version = "1.0", features = ["derive"] }
+
+[lib]
+crate-type = ["cdylib"]
+```
+2. 编写 Rust 代码
+在 src/lib.rs 文件中编写 Rust 代码。我们将定义一个简单的结构体 Greeting 和相关的方法。
+```rs
+// src/lib.rs
+use serde::{Serialize, Deserialize};
+use uniffi_macros::include_scaffolding;
+
+#[derive(Debug, Clone, Serialize, Deserialize)]
+pub struct Greeting {
+ pub message: String,
+}
+
+impl Greeting {
+ pub fn new(name: String) -> Greeting {
+ Greeting {
+ message: format!("Hello, {}!", name),
+ }
+ }
+
+ pub fn greet(&self) -> String {
+ self.message.clone()
+ }
+}
+
+include_scaffolding!("my_library");
+```
+3. 编写 UDL 文件
+在项目根目录下创建一个新的文件 src/my_library.udl,用于定义接口描述语言 (UDL)。
+```rs
+namespace my_library {
+ struct Greeting {
+ message: string;
+ }
+
+ Greeting {
+ static Greeting new(string name);
+ string greet();
+ }
+}
+```
+这个 UDL 文件描述了 Greeting 结构体及其方法。
+
+#### 4. 生成 Uniffi 绑定
+使用 UniFFI 工具生成 Swift 绑定文件。确保你在项目根目录下,然后运行以下命令:
+```shell
+uniffi-bindgen generate src/my_library.udl --language swift --out-dir gen/
+```
+该命令将生成必要的 Swift 文件,并保存在gen/目录下。
+
+#### 5. 构建 Rust 库
+使用以下命令构建 Rust 库:
+```shell
+cargo build --release
+```
+生成的动态库文件将位于 target/release 目录下,文件名为 libmy_rust_library.dylib(在 macOS 上)。
+
+通过上述步骤,我们创建了一个简单的 Rust 库,并配置了 Uniffi 以生成 Swift 绑定文件。在下一部分中,我们将把生成的 Swift 文件集成到 Swift 项目中,并编写代码调用 Rust 库。
+
+#### 6. 生成 UniFFI 绑定
+在这一部分,我们将使用 UniFFI 工具生成 Swift 绑定代码。这将使得我们可以在 Swift 项目中调用 Rust 库的功能。
+
+1. 编写 UDL 文件
+首先,我们需要编写一个 UniFFI 接口描述语言 (UDL) 文件。这个文件描述了我们希望暴露给 Swift 的数据结构和函数接口。
+在项目根目录的 src 文件夹中创建一个名为 my_library.udl 的文件,并添加以下内容:
+```rs
+namespace my_library {
+ struct Greeting {
+ message: string;
+ }
+
+ Greeting {
+ static Greeting new(string name);
+ string greet();
+ }
+}
+```
+这个 UDL 文件定义了一个名为 Greeting 的结构体及其两个方法:new 和 greet
+
+
+2. 生成 Swift 绑定
+在终端中导航到项目根目录,并运行以下命令生成 Swift 绑定:
+```shell
+uniffi-bindgen generate src/my_library.udl --language swift --out-dir gen/
+```
+这个命令会根据 my_library.udl 文件生成 Swift 绑定代码,并将其放在 `gen/` 目录下。生成的文件包括:
+- my_library.swift:包含 Swift 代码,用于调用 Rust 库。
+- my_libraryFFI.h:C 头文件,用于描述 Rust 和 Swift 之间的接口。
+- my_libraryFFI.swift:内部使用的 Swift 文件,处理底层的 FFI 调用。
+
+下是生成的 my_library.swift 文件的示例内容:
+
+```swift
+import Foundation
+
+public struct Greeting {
+ public let message: String
+
+ public init(name: String) {
+ self = Greeting.new(name: name)
+ }
+
+ public func greet() -> String {
+ return greeting_greet(self)
+ }
+}
+```
+
+my_libraryFFI.h 文件的示例内容:
+```c
+#ifndef MY_LIBRARY_FFI_H
+#define MY_LIBRARY_FFI_H
+
+#include
+#include
+
+typedef struct {
+ char* message;
+} Greeting;
+
+Greeting* greeting_new(const char* name);
+const char* greeting_greet(const Greeting* self);
+void greeting_free(Greeting* self);
+
+#endif // MY_LIBRARY_FFI_H
+```
+
+3. 构建 Rust 库
+在继续之前,确保 Rust 库可以成功构建。运行以下命令:
+```shell
+cargo build --release
+```
+生成的动态库文件位于 `target/release` 目录下,文件名为 libmy_rust_library.dylib(在 macOS 上)。这个文件将被 Swift 项目使用。
+通过以上步骤,你已经成功生成了用于 Swift 调用的 Rust 绑定文件。在下一部分中,我们将这些文件集成到 Swift 项目中,并编写代码调用 Rust 库。
+
+#### 集成到 Swift 项目
+1. 打开 Finder,导航到 Rust 项目中的 `gen/` 目录,选择 my_library.swift、my_libraryFFI.h、my_libraryFFI.swift 文件。
+拖动这些文件到 Xcode 项目导航器中的项目目录下。在弹出的对话框中,确保选中 "Copy items if needed" 选项,然后点击 "Finish"。
+
+2. 添加 Rust 动态库
+为了让 Swift 项目能够找到并使用 Rust 动态库,需要将动态库文件添加到 Xcode 项目中:
+- 在 Finder 中,导航到 Rust 项目的target/release目录。
+- 找到生成的动态库文件libmy_rust_library.dylib(在 macOS 上)。
+- 拖动这个文件到 Xcode 项目导航器中的项目目录下。在弹出的对话框中,确保选中 "Copy items if needed" 选项,然后点击 "Finish"。
+
+3. 配置 Xcode 项目
+为了让 Xcode 项目能够正确地链接和加载 Rust 动态库,需要进行一些配置:
+- 选择项目文件,在左侧的 "TARGETS" 列表中选择你的应用目标。
+- 选择 "Build Phases" 选项卡。
+- 展开 "Link Binary With Libraries" 部分,点击 "+" 按钮,添加刚才拖动到项目中的 libmy_rust_library.dylib 文件。
+
+4. 配置动态库加载路径
+选择项目文件,在左侧的 "TARGETS" 列表中选择你的应用目标。
+- 选择 "Build Settings" 选项卡。
+- 搜索 "Runpath Search Paths"。
+- 添加以下路径到 "Runpath Search Paths" 配置项中:`@executable_path/../Frameworks`
+
+5. 编写 Swift 调用代码
+在 ViewController.swift 文件中,编写代码调用 Rust 库:
+```swift
+import UIKit
+
+class ViewController: UIViewController {
+
+ override func viewDidLoad() {
+ super.viewDidLoad()
+
+ // 调用 Rust 库
+ let greeting = Greeting(name: "World")
+ print(greeting.greet())
+ }
+}
+```
+
+通过这些步骤,已经掌握了如何在 Swift 项目中高效地使用 Rust 库,并了解了相关的高级技术。这种跨语言的集成不仅能利用 Rust 的性能优势,还能享受 Swift 的便捷开发体验。
diff --git a/Chapter1 - iOS/1.148.md b/Chapter1 - iOS/1.148.md
new file mode 100644
index 0000000..59f15f6
--- /dev/null
+++ b/Chapter1 - iOS/1.148.md
@@ -0,0 +1,585 @@
+# 安全气垫
+
+> 安全气垫是端上一个老生常谈的话题,技术方案已经是好多年前的产物。唯一的问题是不同公司对于安全气垫在拦截到异常的时候,“做与不做”策略的判断不同。比如数组索引越界的时候要返回一个错误位置的值吗?会不会产生业务异常?要一刀切吗?那么本文就尝试回答下这个问题
+
+## 一、一个经典的场景
+Weex 源码中,设计了一个 `WXThreadSafeMutableDictionary`。在字典操作的地方使用锁:
+```Objective-C
+- (void)setObject:(id)anObject forKey:(id)aKey
+{
+ id originalObject = nil; // make sure that object is not released in lock
+ @try {
+ pthread_mutex_lock(&_safeThreadDictionaryMutex);
+ originalObject = [_dict objectForKey:aKey];
+ [_dict setObject:anObject forKey:aKey];
+ }
+ @finally {
+ pthread_mutex_unlock(&_safeThreadDictionaryMutex);
+ }
+ originalObject = nil;
+}
+```
+这么写的价值:**解锁逻辑「绝对执行」,彻底避免死锁**
+这是 `@try-finally` 最核心的价值 ——无论 try 块内发生什么(正常执行、提前 return、抛异常),finally 块的解锁逻辑一定会执行
+
+对比无 try-finally 的写法
+```Objective-C
+// Bad: 若setObject抛异常,unlock不会执行→死锁
+pthread_mutex_lock(&_mutex);
+[_dict setObject:anObject forKey:aKey];
+pthread_mutex_unlock(&_mutex);
+```
+问题:`[_dict setObject:anObject forKey:aKey]` 可能抛异常(比如 aKey = nil 时会触发 NSInvalidArgumentException),若没有 finally,锁会被永久持有→其他线程调用 lock 时死锁,整个字典无法再操作。
+
+设计优点:
+- `@try-finallly`:即使 try 内逻辑出错,finally 也会执行 pthread_mutex_unlock,保证锁最终释放,这是**线程安全的「兜底保障」**
+- 注意,不是 `try...catch...finally`: 如果加了 catch 逻辑,则字典的 key 为 nil 产生的崩溃也会被捕获掉,这属于不符合预期的行为。因为 key 为 nil 产生的原因太多了,可能是业务代码异常,也可能是数据异常,也可能是逻辑错误,如果一刀切直接用 `try...catch...finally` 捕获了异常,但是没有配置异常的收集、上报、处理逻辑,属于边界不清晰,本质是为了解决加解锁不匹配而可能带来的线程安全问题,却"多管闲事",把字典 key 为 nil 本该向上跑的异常而卡住了。
+
+这是一个经典的策略问题,端上的异常发生时,安全气垫的“做与不做”问题
+聊聊类似网易的大白解决方案或者业界其他公司中,安全气垫虽然保证了代码不 crash,影响用户体验,但是比如数组本该越界,现在却不越界:
+1. 唯一能做的就是返回一个错误的值,比如数组长度为3,访问4,现在不 crash,返回了 0 的值,那是不是产生了业务异常?比如商品价格
+2. 不 crash,也不返回错误位置的值,类似给一个回调,告诉业务方出现了异常,可以做一些业务层面的提醒或者配置(比如开发阶段商品卡片的价格 Label 显示:商品价格获取错误,数组越界),同时产生的异常案发现场信息和其他的一些数据会上报,用于 APM 平台去分析和定位。
+
+但这也产生一个问题,类似数组越界的场景,可能10000次里面9999次都正常,只有1次异常,业务开发为了这万分之一出现的异常,还需要写一些异常处理的逻辑(比如商品卡片展示价格获取错误,数组越界)。那字典的 key 为 nil 呢?除法的分母为0呢?诸如此类,类似乐观锁和悲观锁的场景
+
+## 二、核心原则
+要解决「安全气垫防崩溃但引发隐性业务异常」「低概率异常导致业务开发冗余逻辑」的核心矛盾,业界的优雅方案核心思路是:「环境差异化策略」+「分层兜底 + 语义化默认值」+「可观测驱动的轻量处理」,既避免线上 Crash,又最小化业务侵入,同时保证问题可被发现和修复。
+
+**开发阶段让问题 “炸出来”,生产阶段让问题 “软落地”**。从源头减少线上低概率异常的发生,业务开发无需为 “万分之一” 的异常写冗余逻辑
+
+| 环境 | 核心目标 | 策略 |
+| ----------- | ---------------------------------- | ----------------------------------- |
+| 开发 / 测试 | 提前暴露问题,杜绝上线 | 「零容忍」:直接 Crash + 详细上下文 |
+| 生产 | 避免 Crash + 可观测 + 最小业务影响 | 「软兜底」:语义化默认值 + 全量上报 |
+
+
+
+## 三、多个方案
+
+### 方案1:环境差异化 + 开发强感知(网易大白/腾讯 Bugly 核心思路)
+
+对 NSArray、NSDictionary、NSNumber 等基础类做运行时 Hook,区分环境处理异常:
+NSArray+DWSafeHook.m
+
+```Objective-C
+// 核心逻辑:
+// 1. Method Swizzling Hook数组核心读写方法
+// 2. Debug环境:越界直接Crash+详细上下文,强制研发修复
+// 3. Release环境:拦截崩溃+上报异常+返回语义化空值,避免用户感知
+//
+#import "NSArray+DWSafeHook.h"
+#import
+#import "DWEnvironmentUtils.h" // 环境判断工具类(自研)
+#import "DWCrashReporter.h" // 崩溃上报工具类(自研)
+
+@implementation NSArray (DWSafeHook)
+
+#pragma mark - 对外入口:初始化Hook
++ (void)dw_setupSafeHook {
+ // 防止重复Hook
+ static dispatch_once_t onceToken;
+ dispatch_once(&onceToken, ^{
+ // Hook 只读数组核心方法
+ [self dw_swizzleInstanceMethod:@selector(objectAtIndex:)
+ withNewMethod:@selector(dw_safe_objectAtIndex:)];
+ [self dw_swizzleInstanceMethod:@selector(objectAtIndexedSubscript:)
+ withNewMethod:@selector(dw_safe_objectAtIndexedSubscript:)];
+
+ // Hook 可变数组核心方法(写操作)
+ [NSMutableArray dw_swizzleInstanceMethod:@selector(addObject:)
+ withNewMethod:@selector(dw_safe_addObject:)];
+ [NSMutableArray dw_swizzleInstanceMethod:@selector(insertObject:atIndex:)
+ withNewMethod:@selector(dw_safe_insertObject:atIndex:)];
+ [NSMutableArray dw_swizzleInstanceMethod:@selector(removeObjectAtIndex:)
+ withNewMethod:@selector(dw_safe_removeObjectAtIndex:)];
+ });
+}
+
+#pragma mark - 私有工具:Method Swizzling封装
+/// 通用Swizzling方法(避免重复代码)
+/// @param originalSEL 原方法SEL
+/// @param newSEL 替换后的方法SEL
++ (void)dw_swizzleInstanceMethod:(SEL)originalSEL withNewMethod:(SEL)newSEL {
+ Class cls = [self class];
+
+ // 获取原方法和新方法
+ Method originalMethod = class_getInstanceMethod(cls, originalSEL);
+ Method newMethod = class_getInstanceMethod(cls, newSEL);
+ if (!originalMethod || !newMethod) {
+ NSLog(@"[DWCrashGuard] Swizzling失败:方法不存在 originalSEL: %@, class: %@",
+ NSStringFromSelector(originalSEL), NSStringFromClass(cls));
+ return;
+ }
+
+ // 尝试添加新方法(防止原方法未实现)
+ BOOL isAdded = class_addMethod(cls,
+ originalSEL,
+ method_getImplementation(newMethod),
+ method_getTypeEncoding(newMethod));
+ if (isAdded) {
+ // 替换原方法实现
+ class_replaceMethod(cls,
+ newSEL,
+ method_getImplementation(originalMethod),
+ method_getTypeEncoding(originalMethod));
+ } else {
+ // 交换方法实现
+ method_exchangeImplementations(originalMethod, newMethod);
+ }
+}
+
+#pragma mark - Hook实现:只读数组读操作(核心防越界)
+/// 拦截 [array objectAtIndex:] 越界
+- (id)dw_safe_objectAtIndex:(NSUInteger)index {
+ // 安全校验:索引越界判断
+ if (index >= self.count) {
+ [self dw_handleArrayOutOfBoundsWithIndex:index method:@"objectAtIndex:"];
+ return [NSNull null]; // Release环境返回语义化空值(而非0)
+ }
+
+ // 正常逻辑:调用原方法(Swizzle后,此处实际是原objectAtIndex:)
+ return [self dw_safe_objectAtIndex:index];
+}
+
+/// 拦截 array[index] 下标访问越界
+- (id)dw_safe_objectAtIndexedSubscript:(NSUInteger)index {
+ if (index >= self.count) {
+ [self dw_handleArrayOutOfBoundsWithIndex:index method:@"objectAtIndexedSubscript:"];
+ return [NSNull null];
+ }
+
+ return [self dw_safe_objectAtIndexedSubscript:index];
+}
+
+#pragma mark - 私有工具:数组越界统一处理
+/// 数组越界异常处理(区分环境)
+/// @param index 访问的索引
+/// @param method 触发异常的方法名
+- (void)dw_handleArrayOutOfBoundsWithIndex:(NSUInteger)index method:(NSString *)method {
+ // 1. 构建异常上下文(用于上报/调试)
+ NSDictionary *context = @{
+ @"crashType": @"NSArrayOutOfBounds",
+ @"method": method,
+ @"arrayCount": @(self.count),
+ @"accessIndex": @(index),
+ @"arrayDescription": [self description], // 数组内容(便于定位)
+ @"callStack": [NSThread callStackSymbols], // 完整调用栈
+ @"timestamp": @([[NSDate date] timeIntervalSince1970]),
+ @"deviceInfo": [DWEnvironmentUtils deviceInfo] // 设备型号/系统版本等
+ };
+
+ // 2. 区分环境处理
+ if ([DWEnvironmentUtils isDebugEnvironment]) {
+ // Debug环境:直接Crash+详细日志,强制研发修复
+ NSString *errorMsg = [NSString stringWithFormat:
+ @"【网易大白】NSArray越界崩溃!\n"
+ @"方法:%@\n"
+ @"数组长度:%lu,访问索引:%lu\n"
+ @"数组内容:%@\n"
+ @"调用栈:%@",
+ method, self.count, index, self, [NSThread callStackSymbols]];
+ NSAssert(NO, @"%@", errorMsg);
+ abort(); // 确保Crash(NSAssert在Release下失效)
+ } else {
+ // Release环境:拦截崩溃+上报APM平台
+ [DWCrashReporter reportCrashWithType:@"NSArrayOutOfBounds"
+ context:context
+ severity:DWCrashSeverityLow]; // 低优先级(万分之一概率)
+ NSLog(@"[DWCrashGuard] 拦截NSArray越界:%@, count:%lu, index:%lu", method, self.count, index);
+ }
+}
+
+@end
+
+#pragma mark - 可变数组Hook实现(写操作防护)
+@implementation NSMutableArray (DWSafeHook)
+
+/// 拦截 addObject:nil 崩溃
+- (void)dw_safe_addObject:(id)anObject {
+ if (anObject == nil) {
+ // 构建异常上下文
+ NSDictionary *context = @{
+ @"crashType": @"NSMutableArrayAddNil",
+ @"callStack": [NSThread callStackSymbols],
+ @"timestamp": @([[NSDate date] timeIntervalSince1970])
+ };
+
+ if ([DWEnvironmentUtils isDebugEnvironment]) {
+ // Debug环境:Crash+提示
+ NSAssert(NO, @"【网易大白】NSMutableArray添加nil对象!调用栈:%@", [NSThread callStackSymbols]);
+ abort();
+ } else {
+ // Release环境:拦截+上报,忽略nil添加
+ [DWCrashReporter reportCrashWithType:@"NSMutableArrayAddNil"
+ context:context
+ severity:DWCrashSeverityLow];
+ NSLog(@"[DWCrashGuard] 拦截NSMutableArray添加nil对象");
+ return;
+ }
+ }
+
+ // 正常逻辑:调用原方法
+ [self dw_safe_addObject:anObject];
+}
+
+/// 拦截 insertObject:atIndex: 越界/nil
+- (void)dw_safe_insertObject:(id)anObject atIndex:(NSUInteger)index {
+ // 1. 校验nil
+ if (anObject == nil) {
+ [self dw_handleMutableArrayNilObjectWithMethod:@"insertObject:atIndex:"];
+ return;
+ }
+
+ // 2. 校验越界
+ if (index > self.count) { // insert允许index == count(追加)
+ [self dw_handleArrayOutOfBoundsWithIndex:index method:@"insertObject:atIndex:"];
+ return;
+ }
+
+ // 正常逻辑
+ [self dw_safe_insertObject:anObject atIndex:index];
+}
+
+/// 拦截 removeObjectAtIndex: 越界
+- (void)dw_safe_removeObjectAtIndex:(NSUInteger)index {
+ if (index >= self.count) {
+ [self dw_handleArrayOutOfBoundsWithIndex:index method:@"removeObjectAtIndex:"];
+ return;
+ }
+
+ // 正常逻辑
+ [self dw_safe_removeObjectAtIndex:index];
+}
+
+#pragma mark - 私有工具:可变数组nil处理
+- (void)dw_handleMutableArrayNilObjectWithMethod:(NSString *)method {
+ NSDictionary *context = @{
+ @"crashType": @"NSMutableArrayInsertNil",
+ @"method": method,
+ @"callStack": [NSThread callStackSymbols]
+ };
+
+ if ([DWEnvironmentUtils isDebugEnvironment]) {
+ NSAssert(NO, @"【网易大白】NSMutableArray插入nil对象!方法:%@,调用栈:%@", method, [NSThread callStackSymbols]);
+ abort();
+ } else {
+ [DWCrashReporter reportCrashWithType:@"NSMutableArrayInsertNil"
+ context:context
+ severity:DWCrashSeverityLow];
+ NSLog(@"[DWCrashGuard] 拦截NSMutableArray插入nil对象:%@", method);
+ }
+}
+@end
+```
+
+简化下,逻辑基本为:
+
+```Objective-C
+// 伪代码:Hook NSArray的objectAtIndex:
+- (id)safe_objectAtIndex:(NSUInteger)index {
+ if (index >= self.count) {
+ // 开发环境:Crash + 打印完整的案发现场信息 + 调用栈 + 上下文(数组内容、访问索引、业务模块)
+ #ifdef DEBUG
+ NSAssert(NO, @"数组越界:数组长度%lu,访问索引%lu,调用栈:%@", self.count, index, [NSThread callStackSymbols]);
+ abort();
+ #else
+ // 生产环境:返回语义化空值(而非0)+ 上报APM
+ [APMManager reportExceptionWithType:@"数组越界"
+ context:@{@"arrayCount": @(self.count), @"index": @(index), @"callStack": [NSThread callStackSymbols]}];
+ return [NSNull null]; // 而非0,业务层可统一识别,比如价格展示为: '--'
+ #endif
+ }
+ return [self original_objectAtIndex:index];
+}
+```
+核心优势:
+- 开发环境:不仅 Crash,还打印「业务数据上下文」(比如当前是商品详情页、数组是价格数组),开发一眼定位问题
+- 生产环境:返回NSNull(而非无意义的 0),业务层只需做一次全局 UI 处理(比如所有 Label 展示时,判断值为NSNull则显示 “--”),无需为每个场景写逻辑
+覆盖场景:
+- 数组越界:返回NSNull;
+- 字典 key 为 nil:setObject:forKey:时忽略 nil key 并上报,objectForKey:时返回NSNull;
+- 分母为 0:返回INFINITY(全局工具类判断isinf(),统一返回 “--”);
+- 字符串转数字失败:返回NSNull而非 0
+
+### 方案2:声明式全局兜底 + 业务按需关注(阿里/字节)
+避免业务层 “零散处理异常”,而是**全局统一兜底 + 业务选择性注册关注的异常类型**。
+- 全局层面:所有基础类异常返回 NSNull,UI 层统一处理 NSNull 为 “--”/“获取失败”;
+- 业务层面:仅对 “核心场景”(如商品价格、支付金额)注册异常回调,非核心场景无需处理:
+
+WXExceptionManager.h
+```Objective-C
+#import
+
+NS_ASSUME_NONNULL_BEGIN
+
+/// 异常类型枚举(替代字符串,避免硬编码)
+typedef NS_ENUM(NSUInteger, WXExceptionType) {
+ WXExceptionTypeArrayOutOfBounds, // 数组越界
+ WXExceptionTypeDictionaryNilKey, // 字典nil key
+ WXExceptionTypeDivideByZero, // 分母为0
+};
+
+/// 异常上下文Key定义(统一常量,避免拼写错误)
+FOUNDATION_EXTERN NSString *const WXExceptionContextBizModuleKey; // 业务模块
+FOUNDATION_EXTERN NSString *const WXExceptionContextArrayCountKey;// 数组长度
+FOUNDATION_EXTERN NSString *const WXExceptionContextAccessIndexKey;// 访问索引
+FOUNDATION_EXTERN NSString *const WXExceptionContextCallStackKey; // 调用栈
+FOUNDATION_EXTERN NSString *const WXExceptionContextExtraKey; // 扩展信息
+
+@interface WXExceptionManager : NSObject
+
+/// 单例(全局唯一)
++ (instancetype)sharedManager;
+
+/// 注册异常回调
+/// @param type 异常类型
+/// @param handler 回调(主线程执行,避免UI操作崩溃)
+- (void)registerCallbackForType:(WXExceptionType)type handler:(void(^)(NSDictionary *context))handler;
+
+/// 上报异常(内部Hook调用,业务层无需调用)
+/// @param type 异常类型
+/// @param context 异常上下文
+- (void)reportExceptionWithType:(WXExceptionType)type context:(NSDictionary *)context;
+
+@end
+
+NS_ASSUME_NONNULL_END
+```
+WXExceptionManager.m
+```Objective-C
+#import "WXExceptionManager.h"
+#import
+
+// 上下文Key常量定义
+NSString *const WXExceptionContextBizModuleKey = @"bizModule";
+NSString *const WXExceptionContextArrayCountKey = @"arrayCount";
+NSString *const WXExceptionContextAccessIndexKey = @"accessIndex";
+NSString *const WXExceptionContextCallStackKey = @"callStack";
+NSString *const WXExceptionContextExtraKey = @"extra";
+
+@interface WXExceptionManager ()
+/// 存储不同异常类型的回调(key: WXExceptionType的NSNumber,value: 回调数组)
+@property (nonatomic, strong) NSMutableDictionary *> *callbackDict;
+/// 线程安全锁
+@property (nonatomic, assign) pthread_mutex_t mutex;
+@end
+
+@implementation WXExceptionManager
+
++ (instancetype)sharedManager {
+ static WXExceptionManager *instance = nil;
+ static dispatch_once_t onceToken;
+ dispatch_once(&onceToken, ^{
+ instance = [[self alloc] init];
+ });
+ return instance;
+}
+
+- (instancetype)init {
+ self = [super init];
+ if (self) {
+ _callbackDict = [NSMutableDictionary dictionary];
+ // 初始化线程锁
+ pthread_mutex_init(&_mutex, NULL);
+ }
+ return self;
+}
+
+/// 注册异常回调
+- (void)registerCallbackForType:(WXExceptionType)type handler:(void (^)(NSDictionary *))handler {
+ if (!handler) return;
+
+ pthread_mutex_lock(&_mutex);
+ // 按异常类型分组存储回调
+ NSNumber *typeKey = @(type);
+ if (!_callbackDict[typeKey]) {
+ _callbackDict[typeKey] = [NSMutableArray array];
+ }
+ [_callbackDict[typeKey] addObject:handler];
+ pthread_mutex_unlock(&_mutex);
+}
+
+/// 上报异常(触发回调+APM上报)
+- (void)reportExceptionWithType:(WXExceptionType)type context:(NSDictionary *)context {
+ // 1. APM平台上报(模拟:实际对接公司APM,如Bugly/云监控)
+ NSLog(@"【APM上报】异常类型:%lu,上下文:%@", type, context);
+
+ // 2. 触发注册的回调(主线程执行,避免UI操作崩溃)
+ dispatch_async(dispatch_get_main_queue(), ^{
+ pthread_mutex_lock(&self->_mutex);
+ NSNumber *typeKey = @(type);
+ NSArray *handlers = self->_callbackDict[typeKey];
+ pthread_mutex_unlock(&self->_mutex);
+
+ for (void(^handler)(NSDictionary *) in handlers) {
+ if (handler) {
+ handler(context);
+ }
+ }
+ });
+}
+
+- (void)dealloc {
+ pthread_mutex_destroy(&_mutex);
+}
+
+#pragma mark - 类方法封装(简化调用)
++ (void)registerCallbackForType:(WXExceptionType)type handler:(void (^)(NSDictionary *))handler {
+ [[self sharedManager] registerCallbackForType:type handler:handler];
+}
+
++ (void)reportExceptionWithType:(WXExceptionType)type context:(NSDictionary *)context {
+ [[self sharedManager] reportExceptionWithType:type context:context];
+}
+
+@end
+```
+使用的地方
+```Objective-C
+- (void)viewDidLoad {
+ [super viewDidLoad];
+ self.view.backgroundColor = [UIColor whiteColor];
+
+ // 1. 初始化价格标签
+ self.priceLabel = [[UILabel alloc] initWithFrame:CGRectMake(100, 200, 200, 40)];
+ self.priceLabel.font = [UIFont systemFontOfSize:18];
+ [self.view addSubview:self.priceLabel];
+
+ // 2. 模拟业务数据:价格数组(长度3,索引0-2)
+ self.priceArray = @[@"99.9", @"199.9", @"299.9"];
+ // 标记数组所属业务模块(关键:用于回调筛选)
+ self.priceArray.bizModule = @"goodsPrice";
+
+ // 3. 注册数组越界异常回调(仅关注价格模块)
+ [WXExceptionManager registerCallbackForType:WXExceptionTypeArrayOutOfBounds handler:^(NSDictionary *context) {
+ // 筛选:仅处理“价格数组”的越界异常
+ if ([context[WXExceptionContextBizModuleKey] isEqualToString:@"goodsPrice"]) {
+ NSLog(@"【业务降级】商品价格数组越界,触发UI兜底");
+ // 生产环境:展示友好提示(而非错误值)
+ self.priceLabel.text = @"价格获取失败";
+ // 可选:触发其他降级逻辑(如隐藏价格、显示默认价)
+ [self triggerPriceFallback];
+ }
+ }];
+
+ // 4. 模拟异常场景:访问索引3(越界)
+ [self testPriceArrayOutOfBounds];
+}
+
+/// 模拟价格数组越界访问
+- (void)testPriceArrayOutOfBounds {
+ // 访问索引3(数组长度3,正常索引0-2)
+ id price = [self.priceArray objectAtIndex:3];
+ // 正常场景:显示价格;异常场景:price是NSNull,显示兜底
+ if ([price isKindOfClass:[NSNull class]]) {
+ self.priceLabel.text = @"价格获取失败";
+ } else {
+ self.priceLabel.text = [NSString stringWithFormat:@"¥%@", price];
+ }
+}
+
+/// 价格降级逻辑(可选)
+- (void)triggerPriceFallback {
+ // 比如:隐藏优惠券、显示默认包邮等
+ NSLog(@"【降级】隐藏优惠券模块,显示默认包邮文案");
+}
+
+@end
+```
+核心优势:
+- 99% 的低概率异常由全局兜底处理(返回 NSNull+UI 显示 --)
+- 仅核心业务场景(价格、支付)需写少量回调逻辑,避免冗余
+效果,类似针对核心的业务场景做专项化监控和优化。
+
+
+### 方案 3:静态分析 + CI/CD 前置拦截(从源头消灭异常)
+比运行时 Hook 更优雅的是 **“提前拦截”**。通过静态分析工具(Clang Static Analyzer、OCLint、自定义 LLVM 插件),在代码提交/编译阶段检测出:
+- 数组越界风险(如array[index]中 index 未做长度校验)
+- 字典 key 为 nil(如dict[nil])
+- 分母为 0(如a / b中 b 未判 0)
+- 强制类型转换风险(如(NSNumber *)nil)
+
+落地方式:
+- 集成到 CI/CD Pipeline,代码提交时触发静态分析,有风险则阻断合入
+- 通过编写 LLVM 插件,就可以在 Xcode 有问题的代码上实时提示 “数组越界风险”“字典 key 可能为 nil”。比如
+ +
+效果:线上低概率异常的根源被提前消灭,问题无法逃逸到现线上,业务层几乎无需处理这类异常(因为代码本身就没有漏洞)
+
+关于如何编写 LLVM 插件,做到在 Xcode 中实时展示代码中存在的问题,可以查看:[LLVM 插件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.102.md) 这篇文章。
+
+
+
+### 方案 4:轻量级熔断 / 降级(适合核心业务场景)
+
+对于 “万分之一” 但影响大的异常(如支付金额计算、商品价格),采用「熔断策略」:
+第一次出现异常:上报 + 降级为默认值(如价格显示 “--”);
+短时间内多次出现(如 1 分钟内 > 3 次):触发熔断,建议:展示兜底 UI,提示安抚用户,稍等片刻后尝试(起码不会发生稳定的 crash 或者业务异常)
+熔断状态上报 APM,研发收到告警后优先修复。
+
+### 方案 5:语义化默认值 + 业务无感知适配(美团 / 饿了么实践)
+
+返回**业务可识别的语义化空值**,并在 UI 层做统一适配:
+
+| 异常场景 | 兜底值 | UI 层统一处理 | 业务层感知 |
+| ---------------- | -------- | --------------- | ---------- |
+| 数组越界 | NSNull | 显示 “--” | 无 |
+| 字典 key 为 nil | NSNull | 显示 “暂无数据” | 无 |
+| 分母为 0 | INFINITY | 显示 “计算异常” | 无 |
+| 字符串转数字失败 | NSNull | 显示 “--” | 无 |
+
+**实现方式**:
+
+- 封装全局 UI 工具类(如`WXUILabel+Safe.h`),重写`setText:`方法:
+
+```objective-c
+- (void) safe_setText:(id)text {
+ if (text == [NSNull null] || text == nil) {
+ self.text = @"--";
+ } else if ([text isKindOfClass:[NSNumber class]] && isinf([text doubleValue])) {
+ self.text = @"计算异常";
+ } else {
+ self.text = [text description];
+ }
+}
+```
+
+业务层只需使用`safe_setText:`,无需为每个异常场景写判断逻辑。
+
+
+
+## 四、最佳实践
+
+1. **开发环境零容忍**:通过静态分析、自定义 LLVM 插件 + 运行时 Hook,让问题在测试阶段暴露,比如异常发生时,通过日志打印案发现场数据,或者在 Xcode 面板上可视化的在有问题的代码地方显示 error,及时 crash 掉,阻塞正常流程,以防止开发偷懒不去及时修复,产生技术债,同时也防止问题逃逸到线上。
+2. **生产环境软兜底**:不要一刀切,做到可配置。业务方在配置平台可以针对不同业务域的配置,决定是否开启兜底展示(某些业务域的架构师可能更严格,需要开发在 debug 阶段解决这些问题,线上如果出现就统计为 crash)。如果开启,那么安全气垫就返回语义化默认值(而非无意义的 0),全局 UI 统一处理,业务层零侵入;
+3. **可观测驱动修复**:APM 平台统计异常频率 / 影响度,优先处理高频高影响的异常;
+4. **核心场景按需关注**:仅对价格、支付等核心场景注册回调,非核心场景无需处理。
+
+虽然机制和策略已经制定了,但是执行还是靠人,难以保证100%解决问题。所以开发解决通过 lint 和 crash 可以拦截到大部分问题,但是逃逸到线上的部分问题,还是需要安全气垫去 cover,线下无限毕竟去清空问题 + 少数逃逸到线上的问题通过安全气垫去 cover 就可以保证相对全面的安全守护。
+
+
+
+## 五、平台做些什么
+
+获取到 问题数据是第一步,获取之后问题需要及时上报,需要有一个数据上报系统,数据及时准确、高效的上传到服务端(这就是另一个命题,可以查看这篇文章:[打造一个通用、可配置、多句柄的数据上报 SDK](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md)),到 APM 后台。后台产生工单,根据业务模块分配到对应的责任人、群组。根据问题的紧急程度,报警策略和提醒频次也不一样,比如**波动报警、自定义报警策略等(这也是另一个命题:智能报警策略、波动报警策略、业务线自定义可配置责任人等)**。责任人及时解决问题、修改工单状态、热修复或者发布新版本,问题闭环。
+
+线上异常上报后,APM 平台需提供:
+
+- 异常频率(如 “数组越界” 仅 1/10000);
+- 影响用户数(如仅影响 10 个用户);
+- 业务上下文(如 “商品详情页 - 价格数组”);
+- 调用栈 + 设备信息。
+
+**核心逻辑**:
+
+- 低频率、低影响的异常(如 1/10000,影响 10 用户):暂时无需业务层处理,研发排期修复即可;
+- 高频率、高影响的异常(如 1/100,影响 1000 用户):触发告警,研发紧急修复,业务层临时加兜底。
+
+这样业务开发无需为 “万分之一” 的异常写逻辑,仅需处理 “高频高影响” 的异常。
+
+
+
+## 总结
+
+“最佳实践”部分选择的方案既避免了 “安全气垫返回错误值导致业务异常”,又解决了 “业务开发为低概率异常写冗余逻辑” 的问题,是网易、腾讯、阿里等大厂的通用实践 ——**优雅的方案不是 “兜底所有异常”,而是 “让异常可被提前发现、可被观测、最小化影响”**,即使少数逃逸到线上的,再由安全气垫去兜底解决(解决了展示问题、异常上报和案发现场还原问题),一个好的 APM 平台不光是告诉你又问题,还会告诉你哪里有问题。
+
diff --git a/Chapter1 - iOS/1.38.md b/Chapter1 - iOS/1.38.md
index b187121..46fb552 100644
--- a/Chapter1 - iOS/1.38.md
+++ b/Chapter1 - iOS/1.38.md
@@ -35,7 +35,7 @@
先附上一张总结的非常棒的RunLoop图
-
+
+效果:线上低概率异常的根源被提前消灭,问题无法逃逸到现线上,业务层几乎无需处理这类异常(因为代码本身就没有漏洞)
+
+关于如何编写 LLVM 插件,做到在 Xcode 中实时展示代码中存在的问题,可以查看:[LLVM 插件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.102.md) 这篇文章。
+
+
+
+### 方案 4:轻量级熔断 / 降级(适合核心业务场景)
+
+对于 “万分之一” 但影响大的异常(如支付金额计算、商品价格),采用「熔断策略」:
+第一次出现异常:上报 + 降级为默认值(如价格显示 “--”);
+短时间内多次出现(如 1 分钟内 > 3 次):触发熔断,建议:展示兜底 UI,提示安抚用户,稍等片刻后尝试(起码不会发生稳定的 crash 或者业务异常)
+熔断状态上报 APM,研发收到告警后优先修复。
+
+### 方案 5:语义化默认值 + 业务无感知适配(美团 / 饿了么实践)
+
+返回**业务可识别的语义化空值**,并在 UI 层做统一适配:
+
+| 异常场景 | 兜底值 | UI 层统一处理 | 业务层感知 |
+| ---------------- | -------- | --------------- | ---------- |
+| 数组越界 | NSNull | 显示 “--” | 无 |
+| 字典 key 为 nil | NSNull | 显示 “暂无数据” | 无 |
+| 分母为 0 | INFINITY | 显示 “计算异常” | 无 |
+| 字符串转数字失败 | NSNull | 显示 “--” | 无 |
+
+**实现方式**:
+
+- 封装全局 UI 工具类(如`WXUILabel+Safe.h`),重写`setText:`方法:
+
+```objective-c
+- (void) safe_setText:(id)text {
+ if (text == [NSNull null] || text == nil) {
+ self.text = @"--";
+ } else if ([text isKindOfClass:[NSNumber class]] && isinf([text doubleValue])) {
+ self.text = @"计算异常";
+ } else {
+ self.text = [text description];
+ }
+}
+```
+
+业务层只需使用`safe_setText:`,无需为每个异常场景写判断逻辑。
+
+
+
+## 四、最佳实践
+
+1. **开发环境零容忍**:通过静态分析、自定义 LLVM 插件 + 运行时 Hook,让问题在测试阶段暴露,比如异常发生时,通过日志打印案发现场数据,或者在 Xcode 面板上可视化的在有问题的代码地方显示 error,及时 crash 掉,阻塞正常流程,以防止开发偷懒不去及时修复,产生技术债,同时也防止问题逃逸到线上。
+2. **生产环境软兜底**:不要一刀切,做到可配置。业务方在配置平台可以针对不同业务域的配置,决定是否开启兜底展示(某些业务域的架构师可能更严格,需要开发在 debug 阶段解决这些问题,线上如果出现就统计为 crash)。如果开启,那么安全气垫就返回语义化默认值(而非无意义的 0),全局 UI 统一处理,业务层零侵入;
+3. **可观测驱动修复**:APM 平台统计异常频率 / 影响度,优先处理高频高影响的异常;
+4. **核心场景按需关注**:仅对价格、支付等核心场景注册回调,非核心场景无需处理。
+
+虽然机制和策略已经制定了,但是执行还是靠人,难以保证100%解决问题。所以开发解决通过 lint 和 crash 可以拦截到大部分问题,但是逃逸到线上的部分问题,还是需要安全气垫去 cover,线下无限毕竟去清空问题 + 少数逃逸到线上的问题通过安全气垫去 cover 就可以保证相对全面的安全守护。
+
+
+
+## 五、平台做些什么
+
+获取到 问题数据是第一步,获取之后问题需要及时上报,需要有一个数据上报系统,数据及时准确、高效的上传到服务端(这就是另一个命题,可以查看这篇文章:[打造一个通用、可配置、多句柄的数据上报 SDK](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md)),到 APM 后台。后台产生工单,根据业务模块分配到对应的责任人、群组。根据问题的紧急程度,报警策略和提醒频次也不一样,比如**波动报警、自定义报警策略等(这也是另一个命题:智能报警策略、波动报警策略、业务线自定义可配置责任人等)**。责任人及时解决问题、修改工单状态、热修复或者发布新版本,问题闭环。
+
+线上异常上报后,APM 平台需提供:
+
+- 异常频率(如 “数组越界” 仅 1/10000);
+- 影响用户数(如仅影响 10 个用户);
+- 业务上下文(如 “商品详情页 - 价格数组”);
+- 调用栈 + 设备信息。
+
+**核心逻辑**:
+
+- 低频率、低影响的异常(如 1/10000,影响 10 用户):暂时无需业务层处理,研发排期修复即可;
+- 高频率、高影响的异常(如 1/100,影响 1000 用户):触发告警,研发紧急修复,业务层临时加兜底。
+
+这样业务开发无需为 “万分之一” 的异常写逻辑,仅需处理 “高频高影响” 的异常。
+
+
+
+## 总结
+
+“最佳实践”部分选择的方案既避免了 “安全气垫返回错误值导致业务异常”,又解决了 “业务开发为低概率异常写冗余逻辑” 的问题,是网易、腾讯、阿里等大厂的通用实践 ——**优雅的方案不是 “兜底所有异常”,而是 “让异常可被提前发现、可被观测、最小化影响”**,即使少数逃逸到线上的,再由安全气垫去兜底解决(解决了展示问题、异常上报和案发现场还原问题),一个好的 APM 平台不光是告诉你又问题,还会告诉你哪里有问题。
+
diff --git a/Chapter1 - iOS/1.38.md b/Chapter1 - iOS/1.38.md
index b187121..46fb552 100644
--- a/Chapter1 - iOS/1.38.md
+++ b/Chapter1 - iOS/1.38.md
@@ -35,7 +35,7 @@
先附上一张总结的非常棒的RunLoop图
- +
+ @@ -138,7 +138,7 @@ struct __CFRunLoopMode {
Demo:
-
@@ -138,7 +138,7 @@ struct __CFRunLoopMode {
Demo:
- +
+ @@ -178,11 +178,11 @@ Source0:
Demo1:给屏幕点击事件加断点,查看堆栈可以看到是 Source0 触发的。
-
@@ -178,11 +178,11 @@ Source0:
Demo1:给屏幕点击事件加断点,查看堆栈可以看到是 Source0 触发的。
- +
+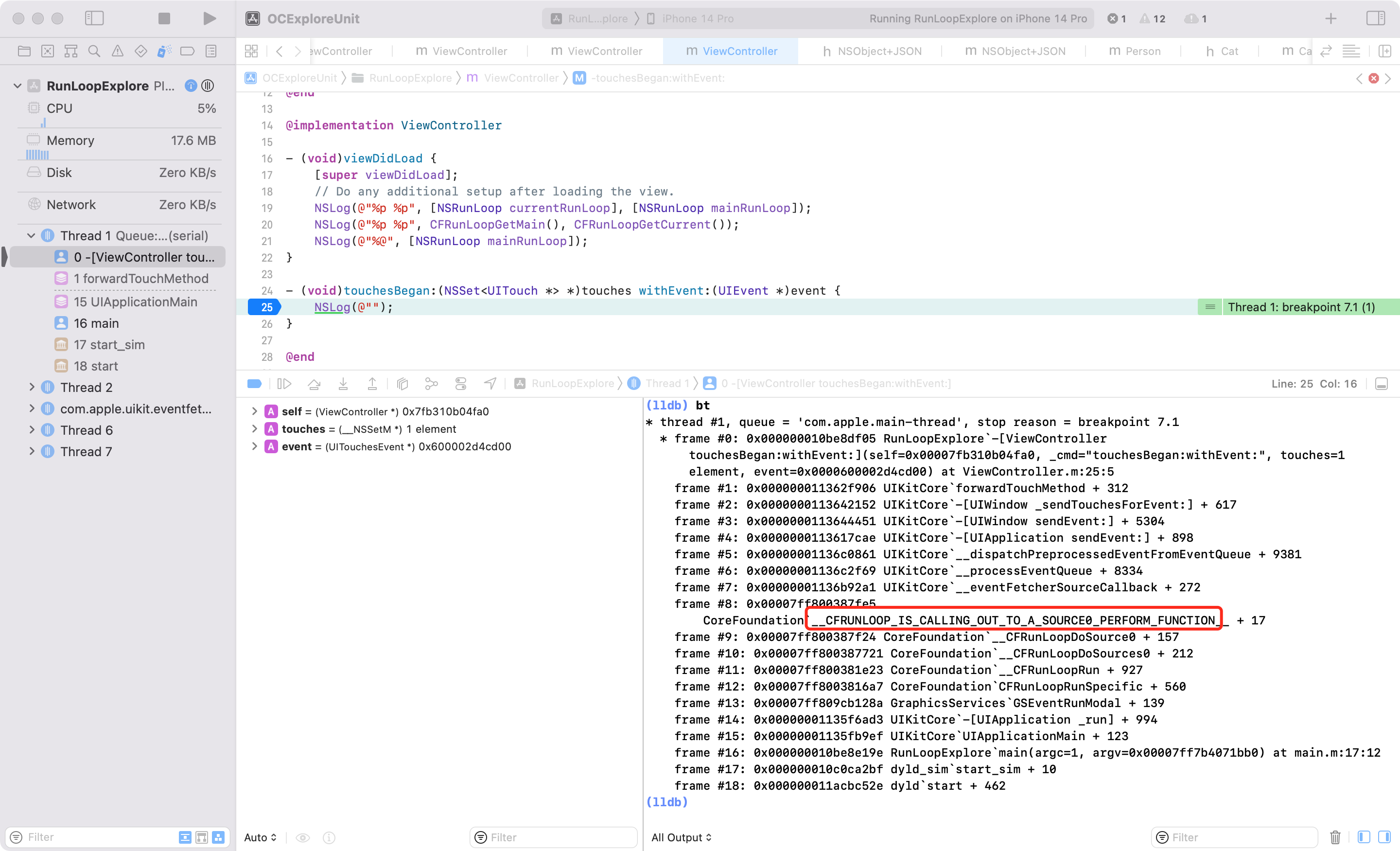 Demo2: `- (void)performSelector:(SEL)aSelector onThread:(NSThread *)thr withObject:(nullable id)arg waitUntilDone:(BOOL)wait` 该 API 的底层就是:向目标线程的 RunLoop 添加一个 Source0 事件,标记后唤醒线程执行对应的事件。
-
Demo2: `- (void)performSelector:(SEL)aSelector onThread:(NSThread *)thr withObject:(nullable id)arg waitUntilDone:(BOOL)wait` 该 API 的底层就是:向目标线程的 RunLoop 添加一个 Source0 事件,标记后唤醒线程执行对应的事件。
- +
+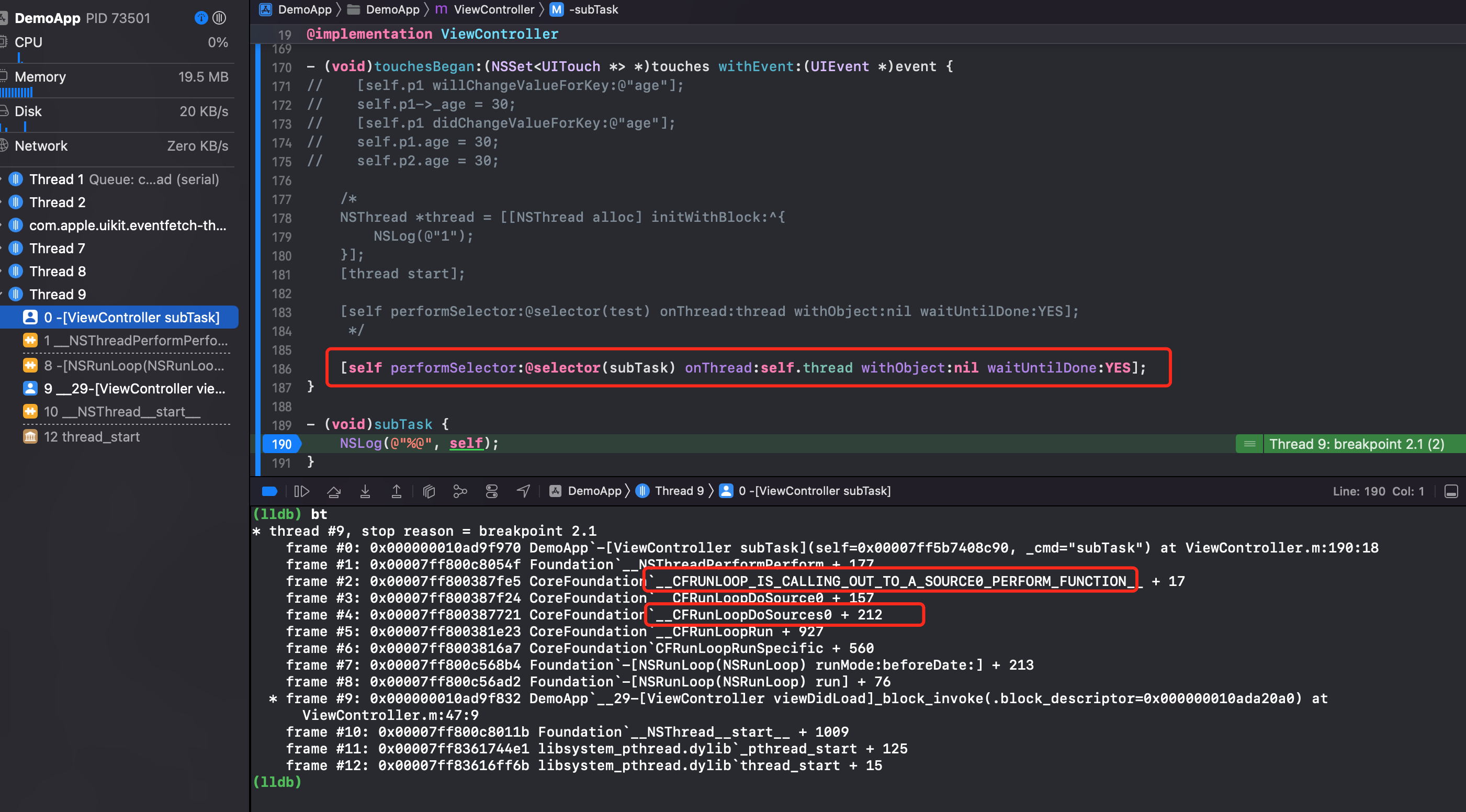 Source1:
@@ -221,7 +221,7 @@ CFRunLoopSourceRef 事件源(输入源)
### 一对多的关系
-
Source1:
@@ -221,7 +221,7 @@ CFRunLoopSourceRef 事件源(输入源)
### 一对多的关系
- +
+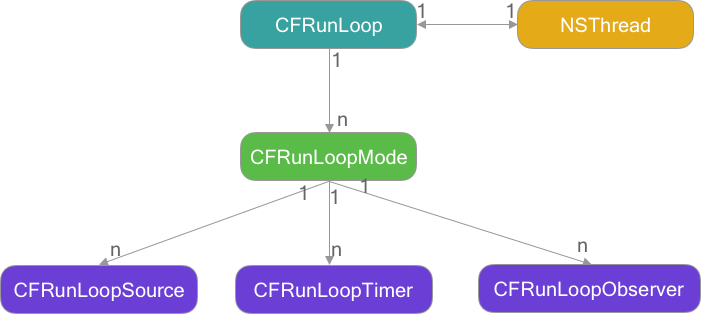 @@ -434,7 +434,7 @@ CFRelease(obersver);
*/
```
-
+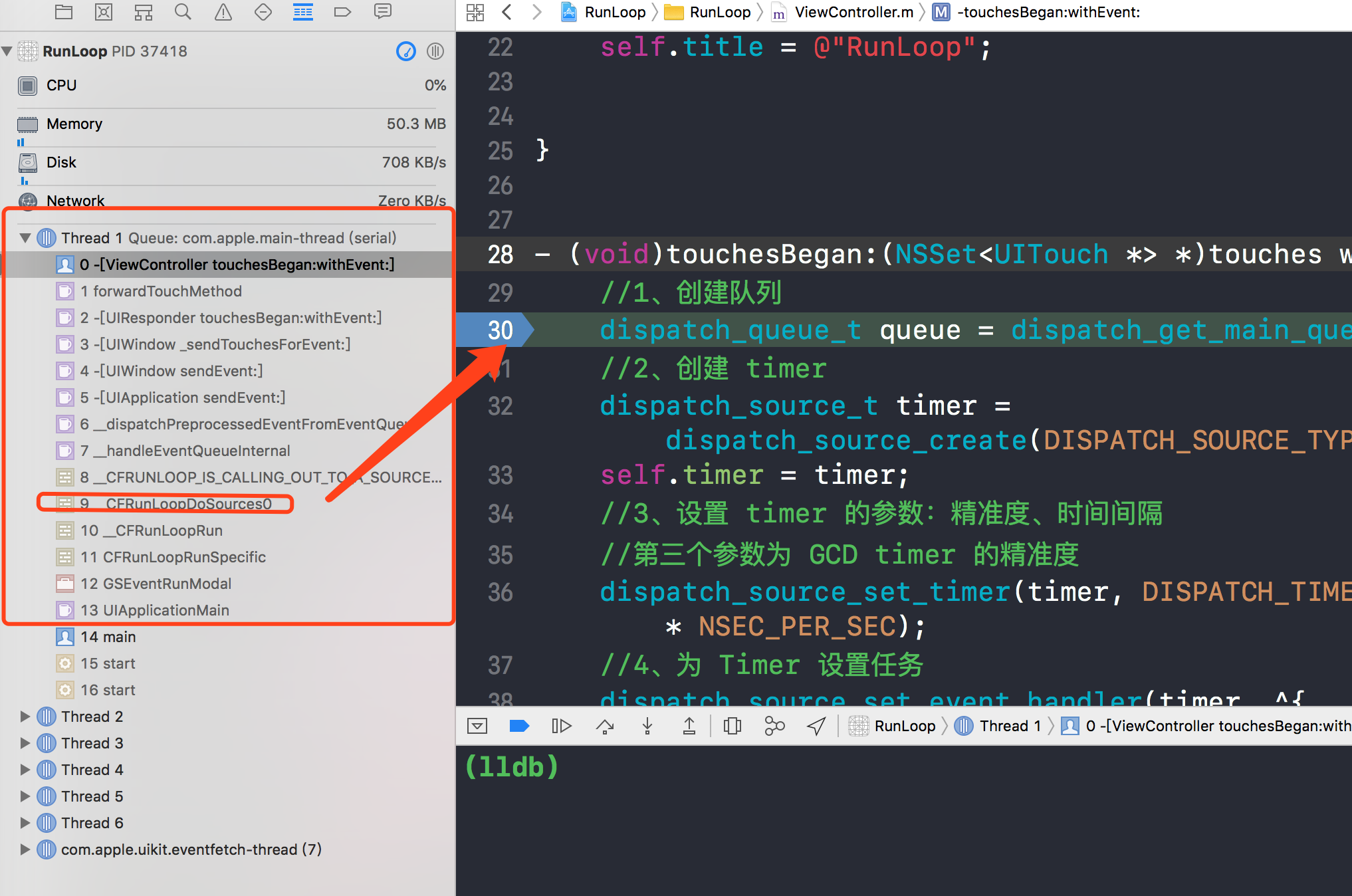
上个实验是在主线程对 RunLoop 进行的监听,但是由于是主线程是由系统创建的,所以系统也创建了对应的主 RunLoop,所以我们看不到 RunLoop 创建的状态,为了模拟完整的状态,我们开启子线程,在子线程中模拟
@@ -510,7 +510,7 @@ CFRelease(obersver);
### 运行原概要
-
+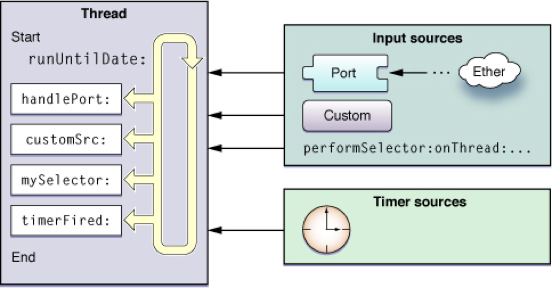
- 图上左上角的 Input source 是早期 RunLoop 的分法,现在分法为:Source0 和 Source1。
- Source0:非基于 port 的,用户主动触发的事件。
@@ -527,7 +527,7 @@ CFRelease(obersver);
但是如何直到系统是运行 RunLoop 的哪个函数?给 viewDidLoad 设置断点,在 lldb 模式输入 `bt` 查看堆栈
-
+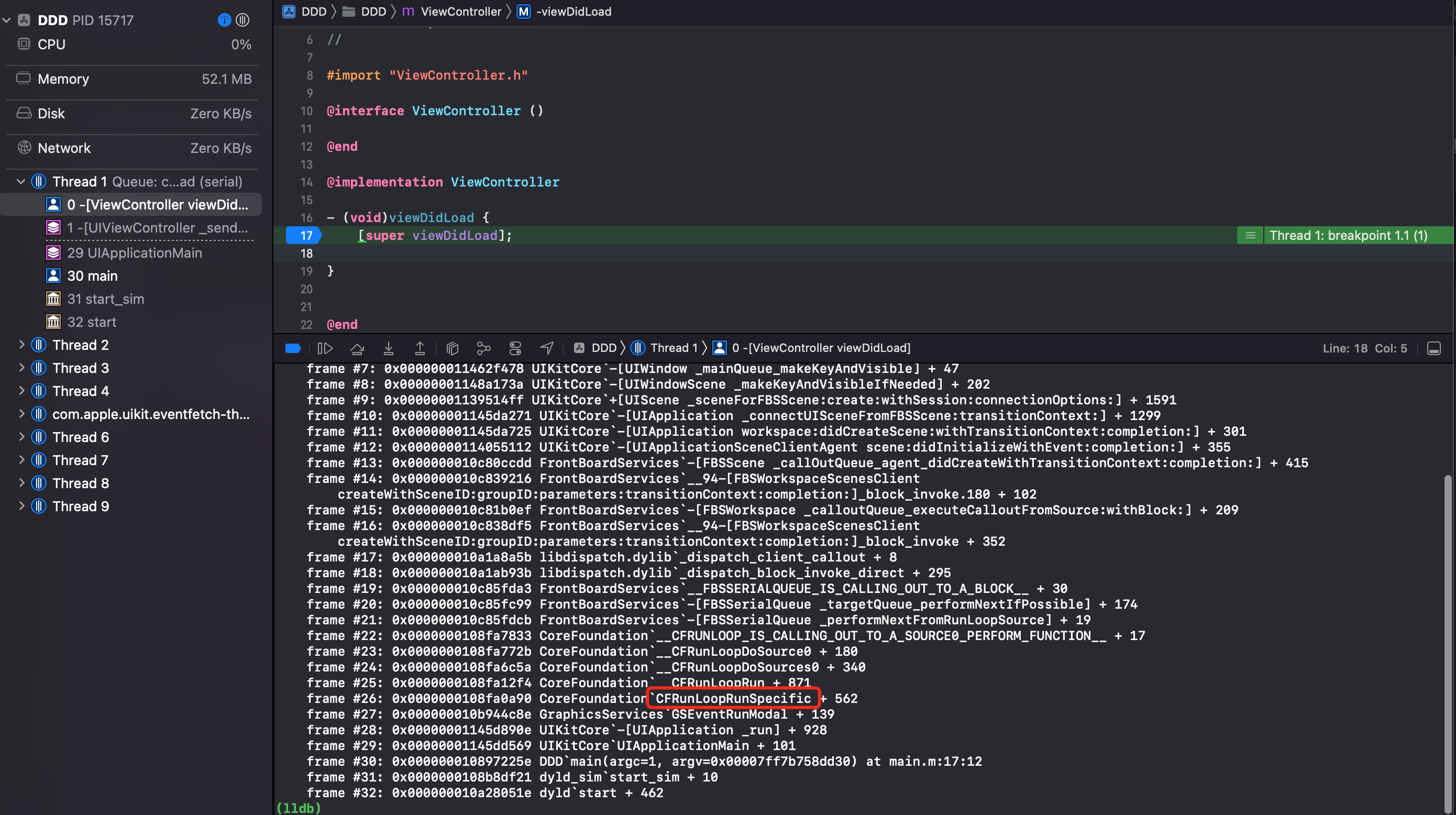
查看 CF 中 `CFRunLoop.c`源码。方法比较复杂,做了精简摘要
@@ -1137,7 +1137,7 @@ RunLoop 内部几个核心的动作:`__CFRunLoopDoObservers`、`__CFRunLoopSer
上面结合源码看了 Runloop 是怎么运行的。下面通过图片看看 RunLoop 各个状态运行切换的完整流程。
-
@@ -434,7 +434,7 @@ CFRelease(obersver);
*/
```
-
+
上个实验是在主线程对 RunLoop 进行的监听,但是由于是主线程是由系统创建的,所以系统也创建了对应的主 RunLoop,所以我们看不到 RunLoop 创建的状态,为了模拟完整的状态,我们开启子线程,在子线程中模拟
@@ -510,7 +510,7 @@ CFRelease(obersver);
### 运行原概要
-
+
- 图上左上角的 Input source 是早期 RunLoop 的分法,现在分法为:Source0 和 Source1。
- Source0:非基于 port 的,用户主动触发的事件。
@@ -527,7 +527,7 @@ CFRelease(obersver);
但是如何直到系统是运行 RunLoop 的哪个函数?给 viewDidLoad 设置断点,在 lldb 模式输入 `bt` 查看堆栈
-
+
查看 CF 中 `CFRunLoop.c`源码。方法比较复杂,做了精简摘要
@@ -1137,7 +1137,7 @@ RunLoop 内部几个核心的动作:`__CFRunLoopDoObservers`、`__CFRunLoopSer
上面结合源码看了 Runloop 是怎么运行的。下面通过图片看看 RunLoop 各个状态运行切换的完整流程。
- +
+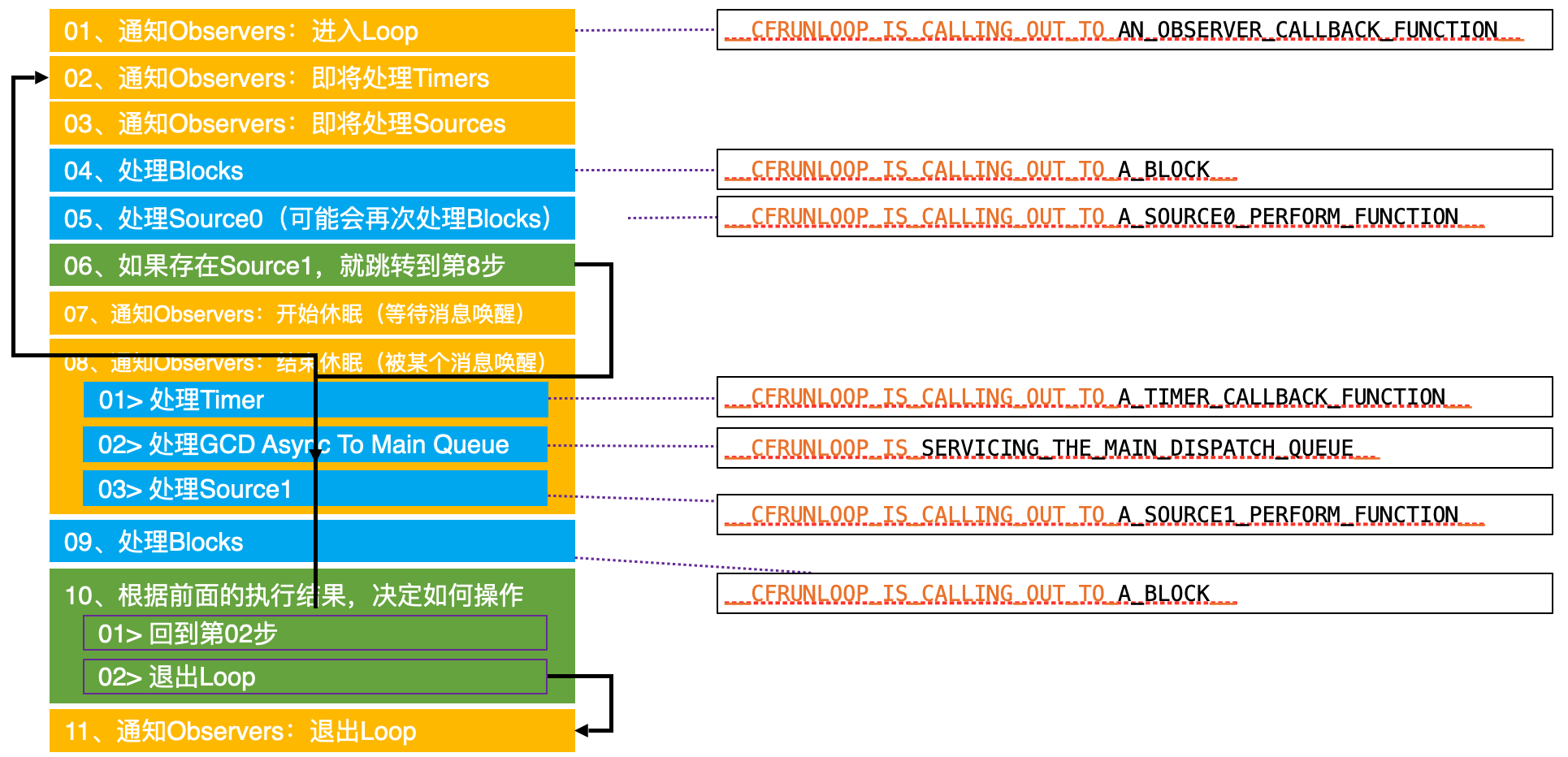 Demo:
@@ -1151,7 +1151,7 @@ Demo:
2. 上面8>2,Runloop 处理 GCD Async To Main Quque
-
Demo:
@@ -1151,7 +1151,7 @@ Demo:
2. 上面8>2,Runloop 处理 GCD Async To Main Quque
-  +
+ 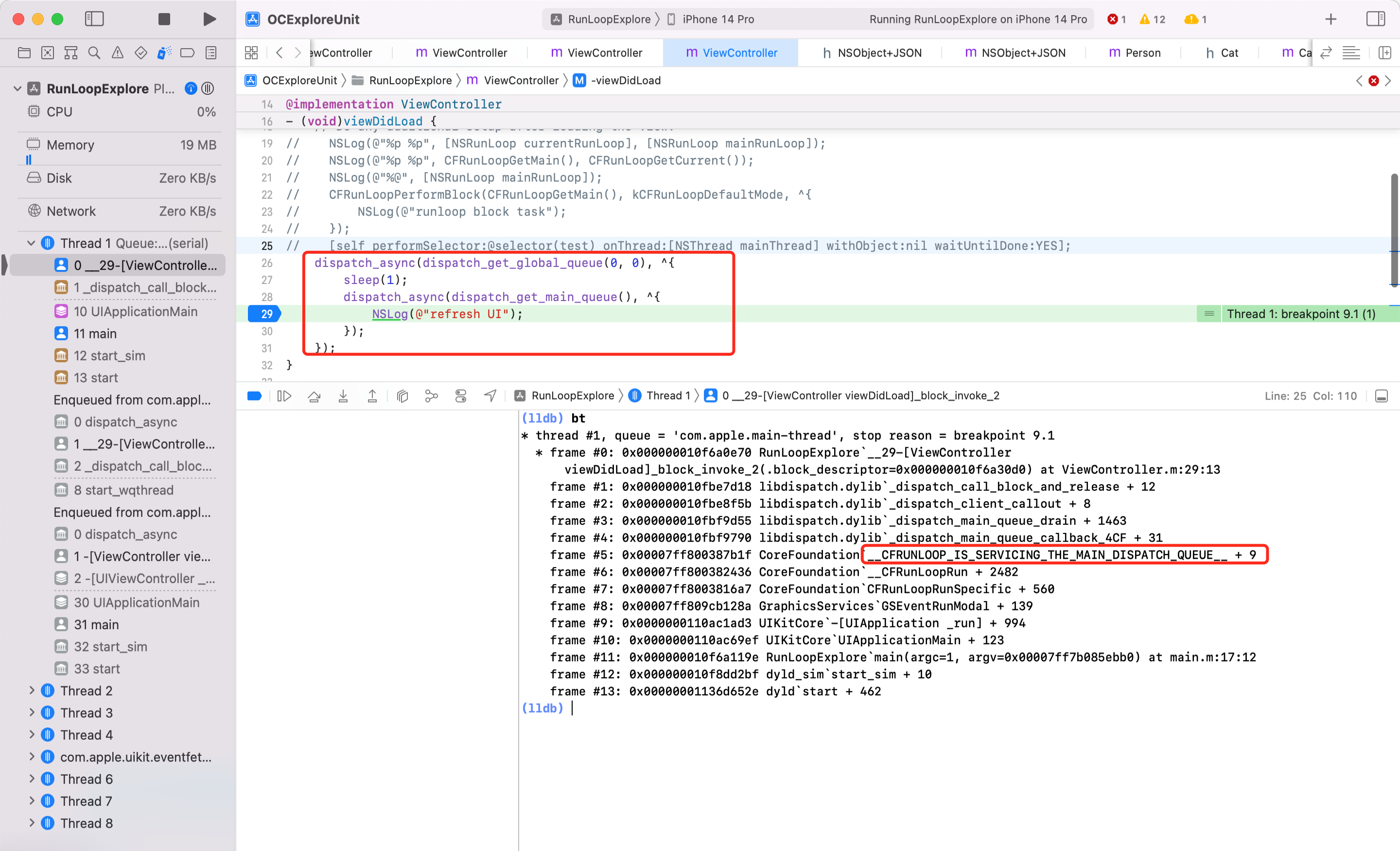 @@ -1165,7 +1165,7 @@ Demo:
可以在 App 运行过程中,点击 Xcode 左下角的 debug 暂停按钮,可以看到 App 堆栈存在系统调用
-
@@ -1165,7 +1165,7 @@ Demo:
可以在 App 运行过程中,点击 Xcode 左下角的 debug 暂停按钮,可以看到 App 堆栈存在系统调用
- +
+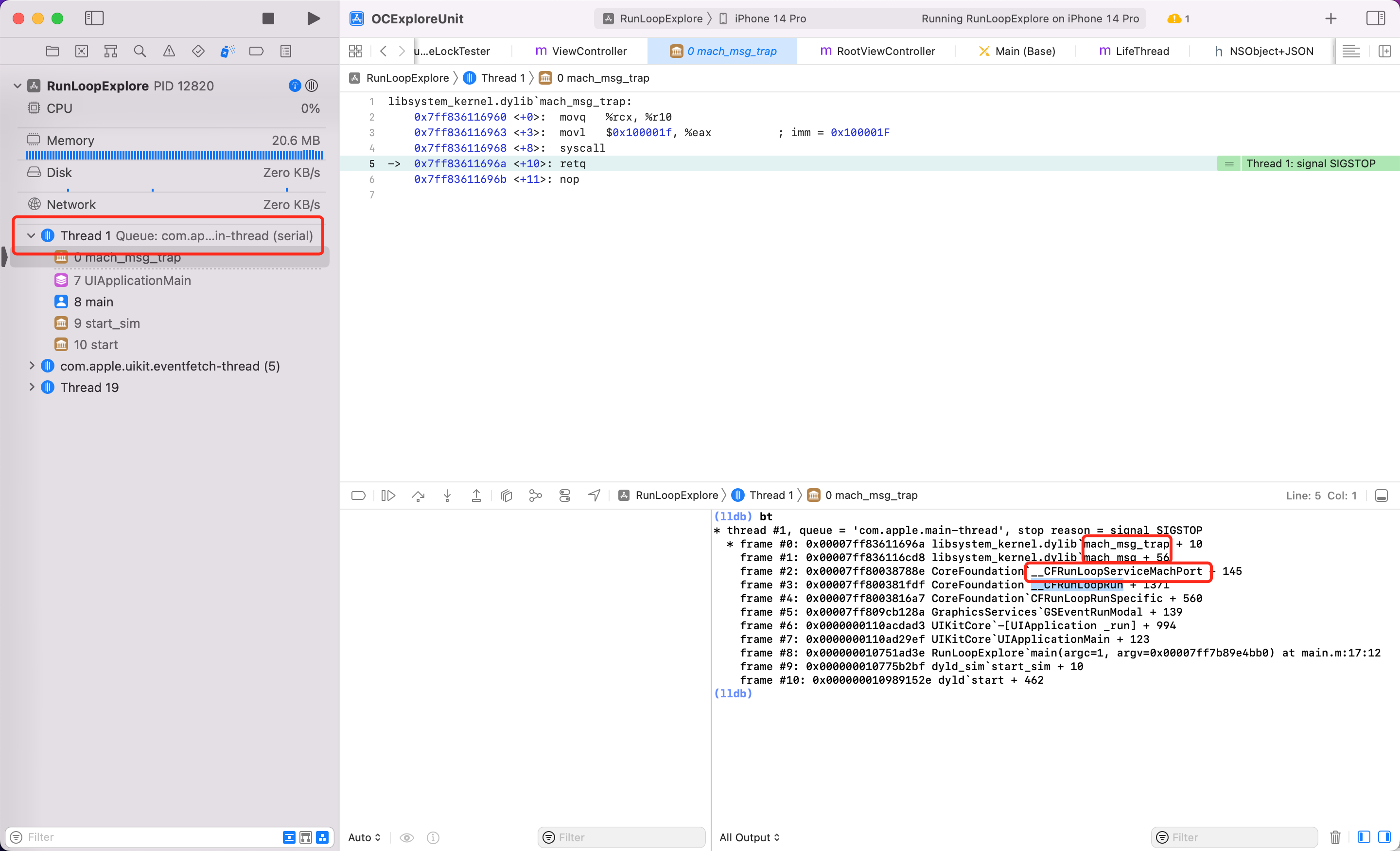 @@ -1647,7 +1647,7 @@ App 启动后,主线程 RunLoop 里注册了2个 Observer,其回调都是 `_
当界面的 Frame 改变,或者更改 UIView、CALayer 的层次时,或者调用了 UIView、CALayer 的 setNeedsLayout、setNeedsDisplay 方法后,这个 UIView、CALayer 会被标记为待处理(类比前端的 Virtual Dom Diff,标记为 dirty),并被提交到一个全局容器中。
-苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Obserger 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
+苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Observer 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
@@ -1887,7 +1887,7 @@ main 方法内其实就是在执行 _selector。也就是在 NSThread 的初始
2. `[[NSRunLoop currentRunLoop] run]` api 换掉。查看系统说明,底层其实就是一个无限循环,循环内部不断调用 `runMode:beforeDate:`。下面也有建议,建议我们想销毁 RunLoop,可以替换 API,比如设置一个变量,标记是否需要结束 RunLoop
-
@@ -1647,7 +1647,7 @@ App 启动后,主线程 RunLoop 里注册了2个 Observer,其回调都是 `_
当界面的 Frame 改变,或者更改 UIView、CALayer 的层次时,或者调用了 UIView、CALayer 的 setNeedsLayout、setNeedsDisplay 方法后,这个 UIView、CALayer 会被标记为待处理(类比前端的 Virtual Dom Diff,标记为 dirty),并被提交到一个全局容器中。
-苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Obserger 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
+苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Observer 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
@@ -1887,7 +1887,7 @@ main 方法内其实就是在执行 _selector。也就是在 NSThread 的初始
2. `[[NSRunLoop currentRunLoop] run]` api 换掉。查看系统说明,底层其实就是一个无限循环,循环内部不断调用 `runMode:beforeDate:`。下面也有建议,建议我们想销毁 RunLoop,可以替换 API,比如设置一个变量,标记是否需要结束 RunLoop
-  +
+  改进代码如下
@@ -1995,7 +1995,7 @@ self.thread = [[LifeThread alloc] initWithBlock:^{
效果如下:
-
改进代码如下
@@ -1995,7 +1995,7 @@ self.thread = [[LifeThread alloc] initWithBlock:^{
效果如下:
- +
+ diff --git a/Chapter1 - iOS/1.39.md b/Chapter1 - iOS/1.39.md
index 33ad89e..c9cb0fb 100644
--- a/Chapter1 - iOS/1.39.md
+++ b/Chapter1 - iOS/1.39.md
@@ -1079,6 +1079,169 @@ QA:互斥递归锁,可以在不同线程中加锁吗?
+#### 使用注意事项
+##### 加解锁必须成对
+加解锁必须成对出现,否则容易出现多线程性能问题。提供一种思路,利用 `@try-finally` 来保证加解锁必须成对存在,这个写法也是 Weex 官方的实现。
+Weex 中的 WXThreadSafeMutableDictionary 提供了一个线程安全的字典,其本质是通过加 pthread_muext_t 锁来维护内部的一个字典的。
+比如下面的代码
+
+初始化锁相关的配置
+```Objective-C
+@interface WXThreadSafeMutableDictionary ()
+{
+ NSMutableDictionary* _dict;
+ pthread_mutex_t _safeThreadDictionaryMutex;
+ pthread_mutexattr_t _safeThreadDictionaryMutexAttr;
+}
+
+@end
+
+@implementation WXThreadSafeMutableDictionary
+
+- (instancetype)initCommon
+{
+ self = [super init];
+ if (self) {
+ pthread_mutexattr_init(&(_safeThreadDictionaryMutexAttr));
+ pthread_mutexattr_settype(&(_safeThreadDictionaryMutexAttr), PTHREAD_MUTEX_RECURSIVE); // must use recursive lock
+ pthread_mutex_init(&(_safeThreadDictionaryMutex), &(_safeThreadDictionaryMutexAttr));
+ }
+ return self;
+}
+
+- (instancetype)init
+{
+ self = [self initCommon];
+ if (self) {
+ _dict = [NSMutableDictionary dictionary];
+ }
+ return self;
+}
+```
+在字典操作的地方使用锁
+```Objective-C
+- (void)setObject:(id)anObject forKey:(id
diff --git a/Chapter1 - iOS/1.39.md b/Chapter1 - iOS/1.39.md
index 33ad89e..c9cb0fb 100644
--- a/Chapter1 - iOS/1.39.md
+++ b/Chapter1 - iOS/1.39.md
@@ -1079,6 +1079,169 @@ QA:互斥递归锁,可以在不同线程中加锁吗?
+#### 使用注意事项
+##### 加解锁必须成对
+加解锁必须成对出现,否则容易出现多线程性能问题。提供一种思路,利用 `@try-finally` 来保证加解锁必须成对存在,这个写法也是 Weex 官方的实现。
+Weex 中的 WXThreadSafeMutableDictionary 提供了一个线程安全的字典,其本质是通过加 pthread_muext_t 锁来维护内部的一个字典的。
+比如下面的代码
+
+初始化锁相关的配置
+```Objective-C
+@interface WXThreadSafeMutableDictionary ()
+{
+ NSMutableDictionary* _dict;
+ pthread_mutex_t _safeThreadDictionaryMutex;
+ pthread_mutexattr_t _safeThreadDictionaryMutexAttr;
+}
+
+@end
+
+@implementation WXThreadSafeMutableDictionary
+
+- (instancetype)initCommon
+{
+ self = [super init];
+ if (self) {
+ pthread_mutexattr_init(&(_safeThreadDictionaryMutexAttr));
+ pthread_mutexattr_settype(&(_safeThreadDictionaryMutexAttr), PTHREAD_MUTEX_RECURSIVE); // must use recursive lock
+ pthread_mutex_init(&(_safeThreadDictionaryMutex), &(_safeThreadDictionaryMutexAttr));
+ }
+ return self;
+}
+
+- (instancetype)init
+{
+ self = [self initCommon];
+ if (self) {
+ _dict = [NSMutableDictionary dictionary];
+ }
+ return self;
+}
+```
+在字典操作的地方使用锁
+```Objective-C
+- (void)setObject:(id)anObject forKey:(id)aKey
+{
+ id originalObject = nil; // make sure that object is not released in lock
+ @try {
+ pthread_mutex_lock(&_safeThreadDictionaryMutex);
+ originalObject = [_dict objectForKey:aKey];
+ [_dict setObject:anObject forKey:aKey];
+ }
+ @finally {
+ pthread_mutex_unlock(&_safeThreadDictionaryMutex);
+ }
+ originalObject = nil;
+}
+```
+这么写的价值:**解锁逻辑「绝对执行」,彻底避免死锁**
+这是 `@try-finally` 最核心的价值 ——无论 try 块内发生什么(正常执行、提前 return、抛异常),finally 块的解锁逻辑一定会执行
+
+对比无 try-finally 的写法
+```Objective-C
+// Bad: 若setObject抛异常,unlock不会执行→死锁
+pthread_mutex_lock(&_mutex);
+[_dict setObject:anObject forKey:aKey];
+pthread_mutex_unlock(&_mutex);
+```
+问题:`[_dict setObject:anObject forKey:aKey]` 可能抛异常(比如 aKey = nil 时会触发 NSInvalidArgumentException),若没有 finally,锁会被永久持有→其他线程调用 lock 时死锁,整个字典无法再操作。
+
+设计优点:
+- `@try-finallly`:即使 try 内逻辑出错,finally 也会执行 pthread_mutex_unlock,保证锁最终释放,这是**线程安全的「兜底保障」**
+- 注意,不是 `try...catch...finally`: 如果加了 catch 逻辑,则字典的 key 为 nil 产生的崩溃也会被捕获掉,这属于不符合预期的行为。因为 key 为 nil 产生的原因太多了,可能是业务代码异常,也可能是数据异常,也可能是逻辑错误,如果一刀切直接用 `try...catch...finally` 捕获了异常,但是没有配置异常的收集、上报、处理逻辑,属于边界不清晰,本质是为了解决加解锁不匹配而可能带来的线程安全问题,却"多管闲事",把字典 key 为 nil 本该向上跑的异常而卡住了(这个问题不再赘述,是一个经典的策略问题,端上的异常发生时,安全气垫的“做与不做”问题)
+
+##### `pthread_mutex_t` 的加解锁函数返回值处理
+「加解锁函数都有返回值,需要对返回值进行判断和处理」这个是意识也业务场景问题,先告诉你有返回值,看你的场景需要严格处理还是松散处理。类似 JS 的 `use strict`
+iOS 系统开源组件(如 libdispatch/GCD)、Apple 官方开源代码,以及知名第三方开源库(AFNetworking、SDWebImage 等)都会严格检查 pthread 锁相关函数的返回值—— 因为系统 / 核心库需要保证鲁棒性,避免锁操作失败导致的死锁、崩溃或线程安全漏洞
+
+1. GCD 的处理(libdispatch)
+核心文件:dispatch/src/queue.c(队列的线程安全实现)
+```c
+// libdispatch 中 pthread_mutex_lock 返回值检查的典型写法
+static inline void _dispatch_mutex_lock(pthread_mutex_t *m) {
+ int ret = pthread_mutex_lock(m);
+ // 严格检查返回值,仅允许「成功(0)」或「递归锁重复加锁(EDEADLK)」(针对递归锁场景)
+ if (ret != 0 && ret != EDEADLK) {
+ // 系统级库会触发 crash 并打印错误,避免静默失败
+ dispatch_fatal("pthread_mutex_lock failed: %d", ret);
+ }
+}
+
+static inline void _dispatch_mutex_unlock(pthread_mutex_t *m) {
+ int ret = pthread_mutex_unlock(m);
+ if (ret != 0) {
+ dispatch_fatal("pthread_mutex_unlock failed: %d", ret);
+ }
+}
+```
+说明:
+- 加锁
+ - 对 pthread_mutex_lock,除了「成功(0)」,仅允许递归锁的「重复加锁(EDEADLK)」(递归锁场景下 EDEADLK 是预期行为);
+ - 非预期返回值直接触发 dispatch_fatal(系统级崩溃),避免锁异常导致的隐性问题;
+- 解锁操作(pthread_mutex_unlock)仅接受「成功(0)」,失败则崩溃
+
+思考:为什么 GCD 要这么做?
+系统库是「基础设施」,锁操作失败(如 EINVAL/ENOMEM)意味着系统资源耗尽或参数错误,属于「致命错误」—— 与其静默运行导致更严重的线程安全问题,不如直接崩溃并暴露问题。
+
+2. AFNetworking(网络库,线程安全的缓存 / 队列实现)
+AFNetworking 的 AFURLSessionManager.m 中,对锁操作的返回值检查:
+```Objective-C
+// AFNetworking 中锁操作的返回值检查
+- (void)lock {
+ int lockResult = pthread_mutex_lock(&_lock);
+ NSAssert(lockResult == 0, @"Failed to lock mutex with error: %d", lockResult);
+}
+
+- (void)unlock {
+ int unlockResult = pthread_mutex_unlock(&_lock);
+ NSAssert(unlockResult == 0, @"Failed to unlock mutex with error: %d", unlockResult);
+}
+```
+说明:
+- 用 NSAssert 检查返回值(Debug 模式下断言失败会崩溃,Release 模式下跳过);
+- 兼顾「调试阶段暴露问题」和「Release 阶段不影响运行」;
+- 符合第三方库的「友好调试 + 线上稳定性」平衡原则。
+
+
+3. CocoaLumberjack(日志库,线程安全的日志队列)
+CocoaLumberjack 的 DDLog.m 中,锁返回值检查的严谨写法:
+```Objective-C
+- (void)initLock {
+ pthread_mutexattr_t attr;
+ int ret = pthread_mutexattr_init(&attr);
+ if (ret != 0) {
+ DDLogError(@"pthread_mutexattr_init failed: %d", ret);
+ return;
+ }
+
+ ret = pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
+ if (ret != 0) {
+ DDLogError(@"pthread_mutexattr_settype failed: %d", ret);
+ pthread_mutexattr_destroy(&attr);
+ return;
+ }
+
+ ret = pthread_mutex_init(&_lock, &attr);
+ if (ret != 0) {
+ DDLogError(@"pthread_mutex_init failed: %d", ret);
+ pthread_mutexattr_destroy(&attr);
+ return;
+ }
+
+ pthread_mutexattr_destroy(&attr);
+}
+```
+说明:
+- 「初始化→设置属性→创建锁」全链路检查返回值
+- 失败时「回滚操作」(如销毁已初始化的 attr),避免资源泄漏
+- 打错误日志,便于问题排查
+
+总结:
+核心原则:锁操作的返回值检查不是 “可选的”,而是 “必须的”,区别仅在于「失败后是崩溃、打日志还是抛异常」,需根据组件的核心程度选择。
+- 系统级开源库(如 libdispatch):严格检查返回值,非预期失败直接崩溃(保证系统稳定性);
+- 第三方开源库(AFNetworking/SDWebImage):调试阶段断言 + Release 阶段日志(平衡调试和线上稳定性);
+- 业务组件(如你的字典):推荐「断言 + 日志」模式 ——Debug 暴露问题,Release 不崩溃且留痕;
+
#### 互斥锁的条件变量 pthread_cond_t
多线程环境下,很多时候没办法确保先有数据再消费,比如生产者-消费者问题,这时候就有互斥锁的另一个 API 了,即条件变量`pthread_cond_t`
@@ -2543,4 +2706,8 @@ APIClient.fetchData(...).then().onFailure();
- GCD:简单的任务处理,以及多读单写、读写锁、dispatch_group_async
- NSOperationQueue、NSOperation:AFNetworking、SDWebImage ,可以方便对 Operation 的状态管理和依赖管理
- NSThread,主要用于实现常驻线程
-- NSOperation Finished 之后如何移除?KVO
\ No newline at end of file
+- NSOperation Finished 之后如何移除?KVO
+- 锁操作的返回值检查不是 “可选的”,而是 “必须的”,区别仅在于「失败后是崩溃、打日志还是抛异常」,需根据组件的核心程度选择。
+ - 系统级开源库(如 libdispatch):严格检查返回值,非预期失败直接崩溃(保证系统稳定性);
+ - 第三方开源库(AFNetworking/SDWebImage):调试阶段断言 + Release 阶段日志(平衡调试和线上稳定性);
+ - 业务组件(如你的字典):推荐「断言 + 日志」模式 ——Debug 暴露问题,Release 不崩溃且留痕;
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.44.md b/Chapter1 - iOS/1.44.md
index d5a7569..98d24cb 100644
--- a/Chapter1 - iOS/1.44.md
+++ b/Chapter1 - iOS/1.44.md
@@ -45,9 +45,15 @@ Hybrid 架构设计的第一要考虑的问题就是如何设计前端与 Native
### 2. 账号信息设计
-账号系统是重要且无法避免的,Native 需要设计良好安全的身份验证机制,保证这块对业务开发者足够透明,打通账户体系
+账号系统是重要且无法避免的,Native 需要设计良好安全的身份验证机制,保证这块对业务开发者足够透明,打通账户体系。
+举个例子,客户端提供了一个 WebView 容器,Native 侧的个人中心,用户是登陆态。但用户去访问 A 业务,A 业务的实现是前端实现的。访问页面时,页面内容都可以看到了,但是某个接口需要用户登录态,然后忽然跳转到登陆页,对于用户体验很不好。用户一脸懵逼,我不是登陆了吗?为什么还跳转到登陆页面,管你页面的技术实现是 Native 还是前端,对于用户来说,用户不是专业技术人员,不会判断是 Native 还是跨端方案,也不需要判断。
+所以解决方案是 Native 和 Hybrid 打通账号体系,通过 WebView 去访问 H5 的时候,应该保持同样的登陆态,用户账号信息是打通的。
+Todo:
+WebView 的鉴权
+
+举个例子:携程的动态化很高现在 RN 居多,前几年的时候大部分页面还是 Hybrid 架构。假设用户在浏览器里面访问了一个页面 A,输入手机号登陆成功了,也在页面 A 上完成了自己的业务。此时
### 3. Hybrid 开发调试
@@ -830,4 +836,12 @@ NSURLProtocol能够让你去重新定义苹果的URL加载系统(URL Loading Sys
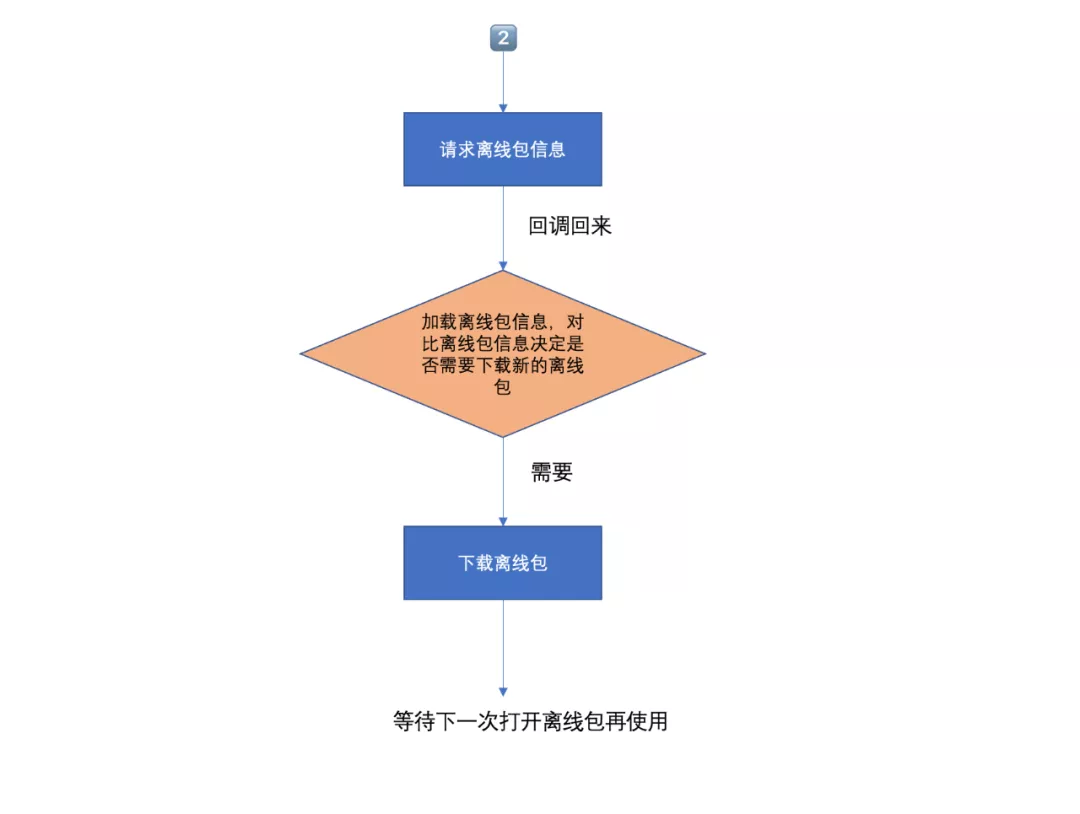
-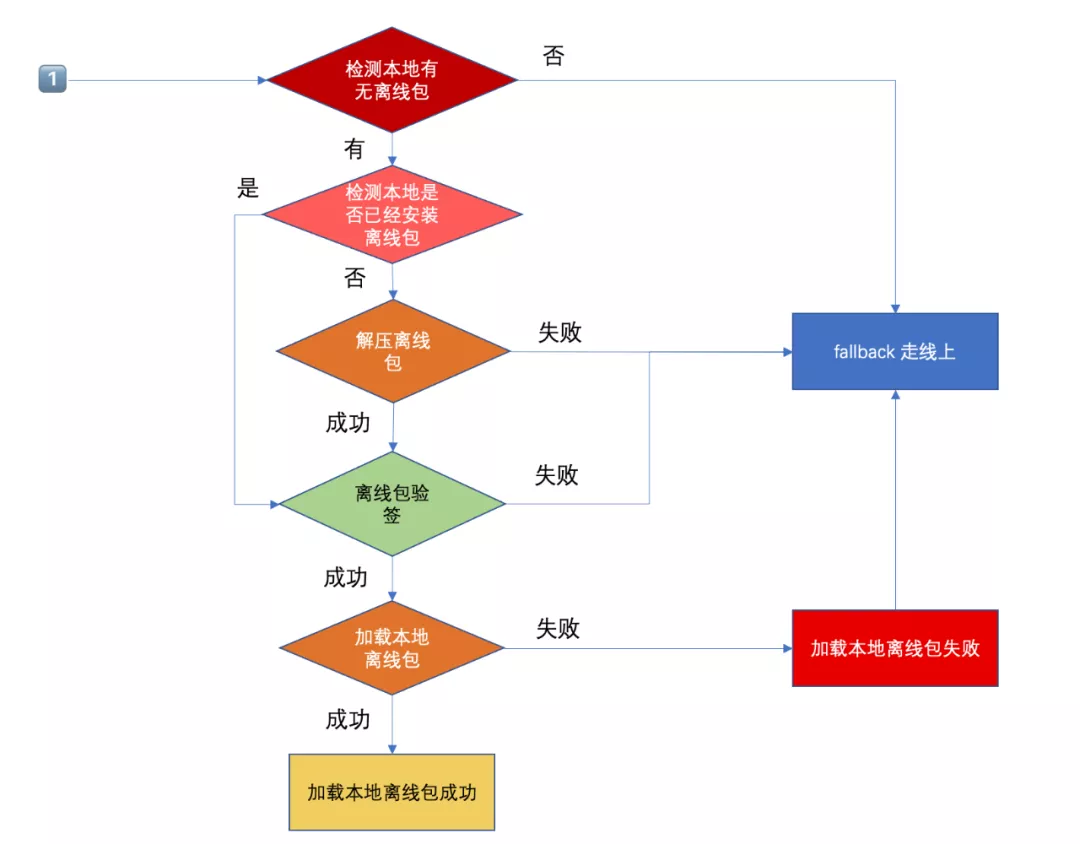
\ No newline at end of file
+
+
+## 十一、如何落地和推进
+如果开展 Hybrid 就存在一个问题,很多业务在迭代或者新开的时候就会选择用 H5 前端技术去实现了,但是如果团队内的客户端同学不懂前端或者不是很懂的时候,就会存在一个抵触的心理,觉得是前端在“侵占”、“蚕食”客户端的领地。所以我们做 Hybrid 跨端项目的时候就需要诚恳一些,抱着“双赢”的出发点去聊、去推进。
+- 你在咱们公司当前的项目1中不选择 Hyrbid 技术,将来的项目2、项目3,其他合作的同学可能就会拥抱 Hybrid 技术来水岸
+- 多端融合能力、跨端是趋势,即使在我们公司一直不做,你离开公司去新的公司,肯定也会遇到用跨端去写业务的场景,这是趋势,尽早拥抱吧
+- 你如果只做 Native 以后新的项目或者新的机会给你,你抓不住,不如趁此机和我合作,或者分配一些前端开发的小任务给你,趁此学会前端技术和 Hybrid 的设计,成为一个跨端工程师,点亮、丰富自己的技能树,日后项目的技术选型方面,类似小程序、Weex/RN/Flutter 方案等,上手就会很方便了,也在做技术方案调研、评估方面多一个可选项。
+
+客户端同学都是程序员,都比较爱学习,拥抱新技术、新设计,早点拥抱技术红利,享受 Hybrid 设计哲学带来的思维增益。我们要实现的效果并不是前端去侵占、蚕食 Native 领地的效果,而是拥抱优雅的、高效的技术方案,去拓展业务上更多的可能性,也在技术方面增加更多的视野维度
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.5.md b/Chapter1 - iOS/1.5.md
index d71fa93..0fcbb0b 100644
--- a/Chapter1 - iOS/1.5.md
+++ b/Chapter1 - iOS/1.5.md
@@ -11,13 +11,13 @@
-```
+```objective-c
//BaseView
#import "BaseView.h"
@implementation BaseView
-(void)touchesBegan:(NSSet *)touches withEvent:(UIEvent *)event{
-NSLog(@"%@",[self class]);
+ NSLog(@"%@",[self class]);
}
```
diff --git a/Chapter1 - iOS/1.55.md b/Chapter1 - iOS/1.55.md
index 84c8e98..508294a 100644
--- a/Chapter1 - iOS/1.55.md
+++ b/Chapter1 - iOS/1.55.md
@@ -292,89 +292,89 @@ static char *ua_viewController_close_time = "ua_viewController_close_time";
当然有解决方案啦。
-- 找出当前元素在父层同类型元素中的索引。根据当前的元素遍历当前元素的父级元素的子元素,如果出现相同的元素,则需要判断当前元素是所在层级的第几个元素
+找出当前元素在父层同类型元素中的索引。根据当前的元素遍历当前元素的父级元素的子元素,如果出现相同的元素,则需要判断当前元素是所在层级的第几个元素
- 对当前的控件元素的父视图的全部子视图进行遍历,如果存在和当前的控件元素同类型的控件,那么需要判断当前控件元素在同类型控件元素中的所处的位置,那么则可以唯一定位。举例:`GoodsCell-3.GoodsTableView.GoodsViewController.xxApp`
+对当前的控件元素的父视图的全部子视图进行遍历,如果存在和当前的控件元素同类型的控件,那么需要判断当前控件元素在同类型控件元素中的所处的位置,那么则可以唯一定位。举例:`GoodsCell-3.GoodsTableView.GoodsViewController.xxApp`
- ```Objective-c
+```Objective-c
//UIResponder分类
- - (NSString *)ua_identifierKa
- {
- // if (self.xq_identifier_ka == nil) {
- if ([self isKindOfClass:[UIView class]]) {
- UIView *view = (id)self;
- NSString *sameViewTreeNode = [view obtainSameSuperViewSameClassViewTreeIndexPath];
- NSMutableString *str = [NSMutableString string];
- //特殊的 加减购 因为带有spm但是要区分加减 需要带TreeNode
- NSString *className = [NSString stringWithUTF8String:object_getClassName(view)];
- if (!view.accessibilityIdentifier || [className isEqualToString:@"uaButton"]) {
- [str appendString:sameViewTreeNode];
- [str appendString:@","];
- }
- while (view.nextResponder) {
- [str appendFormat:@"%@,", NSStringFromClass(view.class)];
- if ([view.class isSubclassOfClass:[UIViewController class]]) {
- break;
- }
- view = (id)view.nextResponder;
- }
- self.xq_identifier_ka = [self md5String:[NSString stringWithFormat:@"%@",str]];
- // self.xq_identifier_ka = [NSString stringWithFormat:@"%@",str];
- }
- // }
- return self.xq_identifier_ka;
- }
-
- // UIView 分类
- - (NSString *)obtainSameSuperViewSameClassViewTreeIndexPat
- {
- NSString *classStr = NSStringFromClass([self class]);
- //cell的子view
- //UITableView 特殊的superview (UITableViewContentView)
- //UICollectionViewCell
- BOOL shouldUseSuperView =
- ([classStr isEqualToString:@"UITableViewCellContentView"]) ||
- ([[self.superview class] isKindOfClass:[UITableViewCell class]])||
- ([[self.superview class] isKindOfClass:[UICollectionViewCell class]]);
- if (shouldUseSuperView) {
- return [self obtainIndexPathByView:self.superview];
- }else {
- return [self obtainIndexPathByView:self];
- }
- }
-
- - (NSString *)obtainIndexPathByView:(UIView *)view
- {
- NSInteger viewTreeNodeDepth = NSIntegerMin;
- NSInteger sameViewTreeNodeDepth = NSIntegerMin;
-
- NSString *classStr = NSStringFromClass([view class]);
-
- NSMutableArray *sameClassArr = [[NSMutableArray alloc]init];
- //所处父view的全部subviews根节点深度
- for (NSInteger index =0; index < view.superview.subviews.count; index ++) {
- //同类型
- if ([classStr isEqualToString:NSStringFromClass([view.superview.subviews[index] class])]){
- [sameClassArr addObject:view.superview.subviews[index]];
- }
- if (view == view.superview.subviews[index]) {
- viewTreeNodeDepth = index;
- break;
- }
- }
- //所处父view的同类型subviews根节点深度
- for (NSInteger index =0; index < sameClassArr.count; index ++) {
- if (view == sameClassArr[index]) {
- sameViewTreeNodeDepth = index;
- break;
- }
- }
- return [NSString stringWithFormat:@"%ld",sameViewTreeNodeDepth];
-
- }
- ```
-
- 
+- (NSString *)ua_identifierKa
+{
+// if (self.xq_identifier_ka == nil) {
+ if ([self isKindOfClass:[UIView class]]) {
+ UIView *view = (id)self;
+ NSString *sameViewTreeNode = [view obtainSameSuperViewSameClassViewTreeIndexPath];
+ NSMutableString *str = [NSMutableString string];
+ //特殊的 加减购 因为带有spm但是要区分加减 需要带TreeNode
+ NSString *className = [NSString stringWithUTF8String:object_getClassName(view)];
+ if (!view.accessibilityIdentifier || [className isEqualToString:@"uaButton"]) {
+ [str appendString:sameViewTreeNode];
+ [str appendString:@","];
+ }
+ while (view.nextResponder) {
+ [str appendFormat:@"%@,", NSStringFromClass(view.class)];
+ if ([view.class isSubclassOfClass:[UIViewController class]]) {
+ break;
+ }
+ view = (id)view.nextResponder;
+ }
+ self.xq_identifier_ka = [self md5String:[NSString stringWithFormat:@"%@",str]];
+ // self.xq_identifier_ka = [NSString stringWithFormat:@"%@",str];
+ }
+// }
+ return self.xq_identifier_ka;
+}
+
+// UIView 分类
+- (NSString *)obtainSameSuperViewSameClassViewTreeIndexPat
+{
+ NSString *classStr = NSStringFromClass([self class]);
+ //cell的子view
+ //UITableView 特殊的superview (UITableViewContentView)
+ //UICollectionViewCell
+ BOOL shouldUseSuperView =
+ ([classStr isEqualToString:@"UITableViewCellContentView"]) ||
+ ([[self.superview class] isKindOfClass:[UITableViewCell class]])||
+ ([[self.superview class] isKindOfClass:[UICollectionViewCell class]]);
+ if (shouldUseSuperView) {
+ return [self obtainIndexPathByView:self.superview];
+ }else {
+ return [self obtainIndexPathByView:self];
+ }
+}
+
+- (NSString *)obtainIndexPathByView:(UIView *)view
+{
+ NSInteger viewTreeNodeDepth = NSIntegerMin;
+ NSInteger sameViewTreeNodeDepth = NSIntegerMin;
+
+ NSString *classStr = NSStringFromClass([view class]);
+
+ NSMutableArray *sameClassArr = [[NSMutableArray alloc]init];
+ //所处父view的全部subviews根节点深度
+ for (NSInteger index =0; index < view.superview.subviews.count; index ++) {
+ //同类型
+ if ([classStr isEqualToString:NSStringFromClass([view.superview.subviews[index] class])]){
+ [sameClassArr addObject:view.superview.subviews[index]];
+ }
+ if (view == view.superview.subviews[index]) {
+ viewTreeNodeDepth = index;
+ break;
+ }
+ }
+ //所处父view的同类型subviews根节点深度
+ for (NSInteger index =0; index < sameClassArr.count; index ++) {
+ if (view == sameClassArr[index]) {
+ sameViewTreeNodeDepth = index;
+ break;
+ }
+ }
+ return [NSString stringWithFormat:@"%ld",sameViewTreeNodeDepth];
+
+}
+```
+
+
diff --git a/Chapter1 - iOS/1.73.md b/Chapter1 - iOS/1.73.md
index a0cf032..651de85 100644
--- a/Chapter1 - iOS/1.73.md
+++ b/Chapter1 - iOS/1.73.md
@@ -1,10 +1,775 @@
# Ruby
-> 为了 iOS 工程化开展,自己最近开始了 Ruby 的学习,本篇博文就用来记录 Ruby 的学习心得和体验。
+> 为了 iOS 工程化开展,自己最近开始了 Ruby 的学习,本篇博文就用来记录 Ruby 的学习心得和体验。本文作为切入点,展开聊聊原理、组件、脚本
+
+
+## 一. Ruby VS Python
+- Python 的解析器实现更成熟,第三方库质量高。但是 Ruby 包管理更简单、方便。
+- Python 的应用领域广泛。而Ruby目前主要局限在在 Web 领域与精致项目。
+- Python语法简单,Ruby更强大、灵活
+
+
+
+## 二. Ruby 语法
+
+### 1. 注释
+单行注释
+```
+# 单行注释
+puts "Hello, ruby!"
+```
+
+多行注释
+```Ruby
+=begin
+多行注释:第1行
+多行注释:第2行
+多行注释:第3行
+=end
+print("Hello world!\n")
+```
+
+### 2. 打印
+- puts:打印后自动换行
+- print:打印后不会自动换行
+
+- 另外如果打印内容携带变量格式的话,必须用双引号。比如
+ ```Ruby
+ name = "@FantasticLBP"
+ puts "hello, #{name}!"
+ puts 'hello,#{name}!'
+
+ # 输出
+ hello, @FantasticLBP!
+ hello,#{name}!
+ ```
+- 如果要直接 shell,则需要用 ``
+ ```Ruby
+ puts `ruby --version`
+ # 输出
+ ruby 2.6.10p210 (2022-04-12 revision 67958) [universal.x86_64-darwin21]
+ ```
+
+### 3. 万物皆对象
+```Ruby
+puts 3.class
+puts 'FantasticLBP'.class
+puts nil.class
+puts true.class
+# 输出
+Integer
+String
+NilClass
+TrueClass
+```
+
+
+### 4. Symbol
+- Ruby 是一个强大的面向对象脚本语言,一切皆是对象
+- 在 Ruby 中 Symbol 表示“名字”,比如字符串的名字,标识符的名字。
+- 创建一个 Symbol 对象的方法是在名字或者字符串前面加上冒号:
+- 在 Ruby 中每一个对象都有唯一的对象标识符(Object Identifier)
+- 对于 Symbol 对象,一个名字唯一确定一个 Symbol 对象
+- Ruby 内部一直在使用 Symbol,Ruby内部也存在符号表
+- Symbol 本质上是一个数字,这个数字和创建 Symbol 的名字形成一对一的映射;而String 对象是一个重量级的 用C结构体表示的家伙,因此使用 Symbol 和 String 的开销相差很大。
+- 符号表是一个全局数据结构,它存放了所有 Symbol 的(数字ID,名字)。 Ruby 不会从中删除 Symbol ,因此 当你创建一个 Symbol 对象后,它将一直存在,直到程序结束。
+
+## 三. 安装篇
+
+### 1. rvm & rbenv
+
+- rvm & rbenv 是一种命令行工具,可让您轻松地安装,管理和使用多个Ruby环境。
+- 这两个工具本质都是 PATH 上做手脚,一个在执行前,一个在执行中
+- 如果你不需要维护特定版本的 Ruby 项目,那么只需要装一个比较新的 Ruby 版本 就行了。`brew install ruby`
+
+### 2. gem
+
+- 与大多数的编程语言一样,Ruby 也受益于海量的第三方代码库
+- 这些代码库大部分都以 Gem 形式发布。 RubyGems 是设计用来帮助创建,分享和安装 这些代码库的
+ - `gem search -r/-f `
+ - `gem install --version `
+ - `gem list`
+ 有没有发现 gem search、install、list 和 cocoapods 的 pod 指令一样
+
+### 3. Bundler
+
+Bundler 能够跟踪并安装所需的特定版本的 gem,以此来为 Ruby 项目提供一致的运行环境
+ +
+```
+source 'https://rubygems.org' gem 'rails', '4.1.0.rc2'
+gem ‘rack-cache'
+gem 'nokogiri', '~> 1.6.1'
+```
+
+- 读取 Gemfile:Bundler 首先会读取当前目录下的 Gemfile 文件,解析其中声明的所有依赖项及其版本约束
+- 解析依赖关系:
+ - 分析每个 gem 的版本要求,确定满足所有约束的最佳版本组合
+ - 处理依赖的依赖(传递依赖),确保整个依赖树的兼容性
+- 检查本地缓存:
+ - 查看本地是否已缓存所需版本的 gem
+ - 如果有,直接使用本地缓存,跳过下载步骤
+- 从源下载 gem:
+ - 对于本地没有的 gem,从 source 'https://rubygems.org' 指定的源下载
+ - 默认源是 RubyGems 官方仓库,国内用户可能需要切换到镜像源以提高速度
+- 安装 gem 到项目目录:
+ - 默认情况下,gem 会被安装到项目根目录下的 vendor/bundle 目录
+ - 这种方式可以避免污染系统级的 gem 安装,实现项目间的依赖隔离
+- 生成 Gemfile.lock:
+ - 安装完成后,Bundler 会生成 Gemfile.lock 文件
+ - 该文件记录了实际安装的每个 gem 的精确版本,确保团队协作或部署时使用完全相同的依赖版本
+
+思考:怎么样,是不是发现 Ruby Bundler 工作流程和 iOS Cocoapods 的工作过程一致?是的,iOS Cocoapods 的设计就是参考 Ruby Bundler 的设计。甚至连 pod search、install、list API 设计也和 gem 一致
+
+
+
+## 四. Cocoapods
+
+### 1. cocoapods-binary
+- cocoapods-binary 通过开关,在 pod insatll 的过程中进行 library 的预编译,生成 framework,并自动集成到项目中。
+- 整个预编译工作分成了三个阶段来完成:
+ - binary pod 的安装
+ - binary pod 的预编译
+ - binary pod 的集成
+
+### 2. Hook
+- pre_install:Pod 下载之后,但在安装之前可以有时机对 Pod 进行任何更改
+- post_install:当所需依赖安装完成,但此时生成的 XcodeProj 项目在写入磁盘前,我们可以对其进行最后的更改
+
+
+### 3. Cocoapods 工程拆解
+#### 1. cocoapods.gemspec 文件
+```Ruby
+# encoding: UTF-8
+require File.expand_path('../lib/cocoapods/gem_version', __FILE__)
+require 'date'
+
+Gem::Specification.new do |s|
+ s.name = "cocoapods"
+ s.version = Pod::VERSION
+ s.date = Date.today
+ s.license = "MIT"
+ s.email = ["eloy.de.enige@gmail.com", "fabiopelosin@gmail.com", "kyle@fuller.li", "segiddins@segiddins.me"]
+ s.homepage = "https://github.com/CocoaPods/CocoaPods"
+ s.authors = ["Eloy Duran", "Fabio Pelosin", "Kyle Fuller", "Samuel Giddins"]
+
+ s.summary = "The Cocoa library package manager."
+ s.description = "CocoaPods manages library dependencies for your Xcode project.\n\n" \
+ "You specify the dependencies for your project in one easy text file. " \
+ "CocoaPods resolves dependencies between libraries, fetches source " \
+ "code for the dependencies, and creates and maintains an Xcode " \
+ "workspace to build your project.\n\n" \
+ "Ultimately, the goal is to improve discoverability of, and engagement " \
+ "in, third party open-source libraries, by creating a more centralized " \
+ "ecosystem."
+
+ s.files = Dir["lib/**/*.rb"] + %w{ bin/pod bin/sandbox-pod README.md LICENSE CHANGELOG.md }
+
+ s.executables = %w{ pod sandbox-pod }
+ s.require_paths = %w{ lib }
+
+ # Link with the version of CocoaPods-Core
+ s.add_runtime_dependency 'cocoapods-core', "= #{Pod::VERSION}"
+
+ s.add_runtime_dependency 'claide', '>= 1.0.2', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-deintegrate', '>= 1.0.3', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-downloader', '>= 2.1', '< 3.0'
+ s.add_runtime_dependency 'cocoapods-plugins', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-search', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-trunk', '>= 1.6.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-try', '>= 1.1.0', '< 2.0'
+ s.add_runtime_dependency 'molinillo', '~> 0.8.0'
+ s.add_runtime_dependency 'xcodeproj', '>= 1.27.0', '< 2.0'
+
+ s.add_runtime_dependency 'colored2', '~> 3.1'
+ s.add_runtime_dependency 'escape', '~> 0.0.4'
+ s.add_runtime_dependency 'fourflusher', '>= 2.3.0', '< 3.0'
+ s.add_runtime_dependency 'gh_inspector', '~> 1.0'
+ s.add_runtime_dependency 'nap', '~> 1.0'
+ s.add_runtime_dependency 'ruby-macho', '~> 4.1.0'
+
+ s.add_runtime_dependency 'addressable', '~> 2.8'
+
+ s.add_development_dependency 'bacon', '~> 1.1'
+ s.add_development_dependency 'bundler', '~> 2.0'
+ s.add_development_dependency 'rake', '~> 12.3'
+
+ s.required_ruby_version = '>= 2.6'
+end
+
+```
+
+`cocoapods.gemspec` 作为 Cocoapods 工程的配置文件,类似 iOS 组件库的 Podspec 文件一样。
+Cocospods 工程本身就是一个 Ruby gem,所以 `cocoapods.gemspec` 用于描述这个 gem 包的元数据,包括作者、版本、描述信息,包括一些导入的文件。
+
+也声明了该 gem 包含的源代码文件、资源文件,以及它所依赖的其他 Ruby gem(比如 xcodeProj 等)和版本要求,确保安装时能正确解析依赖关系。
+
+
+
+#### 2. cocoapods-core
+
+1. CocoaPods 核心模块,用来支持:
+
+ - Pod::specification(podspec)
+
+ - Pod::Podfile(Podfile)
+
+ - Pod::Source(Spec repo)
+
+2. cocoapods-deintergrate: 用于从项目中删除和取消集成 CocoaPods,指令为 `pod deintegrate`
+
+3. Xcodeproj:
+
+ 来操作 Xcode 项目的创建和编辑等。同时支持 Xcode 项目的脚本管理和 libraries 构建,以及 Xcode 工作空间(.xcworkspace) 和配置文件 .xcconfig 的管理
+
+4. cocospods-downloader:用于下载和管理引入的源码
+
+5. cocoapods-plugins: 插件管理功能
+
+6. cocoapods-try:可以快速体验该 pod 的 Demo 项目
+
+7. CLAide:命令行解释器
+
+8. ruby-macho:一个用于检查和修改 Mach-O 文件的 Ruby 库
+
+
+
+#### 3. Podfile
+
+Podfile 是一个文件,以 DSL 来描述依赖关系,用于描述项目所需要的第三方库。
+
+
+
+### 4. VSCode 调试 Cocoapods
+
+1. 新创建文件夹 `RubyDemos`
+2. 从 git clone Cocoapods 源码到本地目录
+3. 进入到 Cocoapods 文件夹,将分支切换到和本机安全的 pod 版本一致的分支,指令为: **git checkout `pod --version`**
+4. `RubyDemos` 根目录下创建一个 Xcode iOS 工程,并为其编写 Podfile 文件。目的是为了调试 Cocoapods
+5. `RubyDemos` 根目录下创建一个 **Gemfile** 文件。内容如下:
+ ```Ruby
+ source 'https://rubygems.org'
+
+ gem 'cocoapods', path: './Cocoapods' # 指向本地源码
+ gem 'debug', '~> 1.9.0' # 调试用
+ ```
+6. 终端执行 `bundle install` 指令
+7. 此时,项目文件夹为:
+ ```
+ .
+ ├── CocoaPods
+ ├── Demos
+ ├── Gemfile
+ ├── Gemfile.lock
+ └── StaticLibConflictsDemo
+ ```
+8. 用 VSCode 打开工程。进入 Run and Debug 面板 → 点击 create a launch.json file → 选择 Ruby → 选 Debug Local File。
+9. 修改 launch.json 内容。
+ ```json
+ {
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "name": "Debug CocoaPods",
+ "type": "rdbg", // 必须为 rdbg(debug 工具类型)
+ "request": "launch",
+ "script": "${workspaceFolder}/CocoaPods/bin/pod", // 源码中的 pod 入口
+ "args": ["install", "--verbose"], // 执行 pod install
+ "cwd": "${workspaceFolder}/StaticLibConflictsDemo", // 测试工程目录(Podfile 所在目录)
+ "useBundler": true, // 强制通过 bundle 执行
+ "askParameters": false // 关闭参数询问(避免干扰)
+ }
+ ]
+ }
+ ```
+10. VSCode 插件市场安装:VSCode rdbg Ruby Debugger、Ruby LSP
+11. VSCode 面板中,点击左侧的调试按钮。便可调试。要是看到下面的图,说明可以正常 Debug 了
+
+
+```
+source 'https://rubygems.org' gem 'rails', '4.1.0.rc2'
+gem ‘rack-cache'
+gem 'nokogiri', '~> 1.6.1'
+```
+
+- 读取 Gemfile:Bundler 首先会读取当前目录下的 Gemfile 文件,解析其中声明的所有依赖项及其版本约束
+- 解析依赖关系:
+ - 分析每个 gem 的版本要求,确定满足所有约束的最佳版本组合
+ - 处理依赖的依赖(传递依赖),确保整个依赖树的兼容性
+- 检查本地缓存:
+ - 查看本地是否已缓存所需版本的 gem
+ - 如果有,直接使用本地缓存,跳过下载步骤
+- 从源下载 gem:
+ - 对于本地没有的 gem,从 source 'https://rubygems.org' 指定的源下载
+ - 默认源是 RubyGems 官方仓库,国内用户可能需要切换到镜像源以提高速度
+- 安装 gem 到项目目录:
+ - 默认情况下,gem 会被安装到项目根目录下的 vendor/bundle 目录
+ - 这种方式可以避免污染系统级的 gem 安装,实现项目间的依赖隔离
+- 生成 Gemfile.lock:
+ - 安装完成后,Bundler 会生成 Gemfile.lock 文件
+ - 该文件记录了实际安装的每个 gem 的精确版本,确保团队协作或部署时使用完全相同的依赖版本
+
+思考:怎么样,是不是发现 Ruby Bundler 工作流程和 iOS Cocoapods 的工作过程一致?是的,iOS Cocoapods 的设计就是参考 Ruby Bundler 的设计。甚至连 pod search、install、list API 设计也和 gem 一致
+
+
+
+## 四. Cocoapods
+
+### 1. cocoapods-binary
+- cocoapods-binary 通过开关,在 pod insatll 的过程中进行 library 的预编译,生成 framework,并自动集成到项目中。
+- 整个预编译工作分成了三个阶段来完成:
+ - binary pod 的安装
+ - binary pod 的预编译
+ - binary pod 的集成
+
+### 2. Hook
+- pre_install:Pod 下载之后,但在安装之前可以有时机对 Pod 进行任何更改
+- post_install:当所需依赖安装完成,但此时生成的 XcodeProj 项目在写入磁盘前,我们可以对其进行最后的更改
+
+
+### 3. Cocoapods 工程拆解
+#### 1. cocoapods.gemspec 文件
+```Ruby
+# encoding: UTF-8
+require File.expand_path('../lib/cocoapods/gem_version', __FILE__)
+require 'date'
+
+Gem::Specification.new do |s|
+ s.name = "cocoapods"
+ s.version = Pod::VERSION
+ s.date = Date.today
+ s.license = "MIT"
+ s.email = ["eloy.de.enige@gmail.com", "fabiopelosin@gmail.com", "kyle@fuller.li", "segiddins@segiddins.me"]
+ s.homepage = "https://github.com/CocoaPods/CocoaPods"
+ s.authors = ["Eloy Duran", "Fabio Pelosin", "Kyle Fuller", "Samuel Giddins"]
+
+ s.summary = "The Cocoa library package manager."
+ s.description = "CocoaPods manages library dependencies for your Xcode project.\n\n" \
+ "You specify the dependencies for your project in one easy text file. " \
+ "CocoaPods resolves dependencies between libraries, fetches source " \
+ "code for the dependencies, and creates and maintains an Xcode " \
+ "workspace to build your project.\n\n" \
+ "Ultimately, the goal is to improve discoverability of, and engagement " \
+ "in, third party open-source libraries, by creating a more centralized " \
+ "ecosystem."
+
+ s.files = Dir["lib/**/*.rb"] + %w{ bin/pod bin/sandbox-pod README.md LICENSE CHANGELOG.md }
+
+ s.executables = %w{ pod sandbox-pod }
+ s.require_paths = %w{ lib }
+
+ # Link with the version of CocoaPods-Core
+ s.add_runtime_dependency 'cocoapods-core', "= #{Pod::VERSION}"
+
+ s.add_runtime_dependency 'claide', '>= 1.0.2', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-deintegrate', '>= 1.0.3', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-downloader', '>= 2.1', '< 3.0'
+ s.add_runtime_dependency 'cocoapods-plugins', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-search', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-trunk', '>= 1.6.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-try', '>= 1.1.0', '< 2.0'
+ s.add_runtime_dependency 'molinillo', '~> 0.8.0'
+ s.add_runtime_dependency 'xcodeproj', '>= 1.27.0', '< 2.0'
+
+ s.add_runtime_dependency 'colored2', '~> 3.1'
+ s.add_runtime_dependency 'escape', '~> 0.0.4'
+ s.add_runtime_dependency 'fourflusher', '>= 2.3.0', '< 3.0'
+ s.add_runtime_dependency 'gh_inspector', '~> 1.0'
+ s.add_runtime_dependency 'nap', '~> 1.0'
+ s.add_runtime_dependency 'ruby-macho', '~> 4.1.0'
+
+ s.add_runtime_dependency 'addressable', '~> 2.8'
+
+ s.add_development_dependency 'bacon', '~> 1.1'
+ s.add_development_dependency 'bundler', '~> 2.0'
+ s.add_development_dependency 'rake', '~> 12.3'
+
+ s.required_ruby_version = '>= 2.6'
+end
+
+```
+
+`cocoapods.gemspec` 作为 Cocoapods 工程的配置文件,类似 iOS 组件库的 Podspec 文件一样。
+Cocospods 工程本身就是一个 Ruby gem,所以 `cocoapods.gemspec` 用于描述这个 gem 包的元数据,包括作者、版本、描述信息,包括一些导入的文件。
+
+也声明了该 gem 包含的源代码文件、资源文件,以及它所依赖的其他 Ruby gem(比如 xcodeProj 等)和版本要求,确保安装时能正确解析依赖关系。
+
+
+
+#### 2. cocoapods-core
+
+1. CocoaPods 核心模块,用来支持:
+
+ - Pod::specification(podspec)
+
+ - Pod::Podfile(Podfile)
+
+ - Pod::Source(Spec repo)
+
+2. cocoapods-deintergrate: 用于从项目中删除和取消集成 CocoaPods,指令为 `pod deintegrate`
+
+3. Xcodeproj:
+
+ 来操作 Xcode 项目的创建和编辑等。同时支持 Xcode 项目的脚本管理和 libraries 构建,以及 Xcode 工作空间(.xcworkspace) 和配置文件 .xcconfig 的管理
+
+4. cocospods-downloader:用于下载和管理引入的源码
+
+5. cocoapods-plugins: 插件管理功能
+
+6. cocoapods-try:可以快速体验该 pod 的 Demo 项目
+
+7. CLAide:命令行解释器
+
+8. ruby-macho:一个用于检查和修改 Mach-O 文件的 Ruby 库
+
+
+
+#### 3. Podfile
+
+Podfile 是一个文件,以 DSL 来描述依赖关系,用于描述项目所需要的第三方库。
+
+
+
+### 4. VSCode 调试 Cocoapods
+
+1. 新创建文件夹 `RubyDemos`
+2. 从 git clone Cocoapods 源码到本地目录
+3. 进入到 Cocoapods 文件夹,将分支切换到和本机安全的 pod 版本一致的分支,指令为: **git checkout `pod --version`**
+4. `RubyDemos` 根目录下创建一个 Xcode iOS 工程,并为其编写 Podfile 文件。目的是为了调试 Cocoapods
+5. `RubyDemos` 根目录下创建一个 **Gemfile** 文件。内容如下:
+ ```Ruby
+ source 'https://rubygems.org'
+
+ gem 'cocoapods', path: './Cocoapods' # 指向本地源码
+ gem 'debug', '~> 1.9.0' # 调试用
+ ```
+6. 终端执行 `bundle install` 指令
+7. 此时,项目文件夹为:
+ ```
+ .
+ ├── CocoaPods
+ ├── Demos
+ ├── Gemfile
+ ├── Gemfile.lock
+ └── StaticLibConflictsDemo
+ ```
+8. 用 VSCode 打开工程。进入 Run and Debug 面板 → 点击 create a launch.json file → 选择 Ruby → 选 Debug Local File。
+9. 修改 launch.json 内容。
+ ```json
+ {
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "name": "Debug CocoaPods",
+ "type": "rdbg", // 必须为 rdbg(debug 工具类型)
+ "request": "launch",
+ "script": "${workspaceFolder}/CocoaPods/bin/pod", // 源码中的 pod 入口
+ "args": ["install", "--verbose"], // 执行 pod install
+ "cwd": "${workspaceFolder}/StaticLibConflictsDemo", // 测试工程目录(Podfile 所在目录)
+ "useBundler": true, // 强制通过 bundle 执行
+ "askParameters": false // 关闭参数询问(避免干扰)
+ }
+ ]
+ }
+ ```
+10. VSCode 插件市场安装:VSCode rdbg Ruby Debugger、Ruby LSP
+11. VSCode 面板中,点击左侧的调试按钮。便可调试。要是看到下面的图,说明可以正常 Debug 了
+ +
+接下来就可以愉快的调试了。
+说明:
+- pod 的每个指令,分别对应 Cocoapods 工程中一个代码文件
+
+
+接下来就可以愉快的调试了。
+说明:
+- pod 的每个指令,分别对应 Cocoapods 工程中一个代码文件
+  +- 同时根据观察,发现 `target do` 的代码比 pre_install、post_install 执行更早。所以我们可以做一些脚本化的操作。
+比如下面,增加了一段自定义的脚本
+
+- 同时根据观察,发现 `target do` 的代码比 pre_install、post_install 执行更早。所以我们可以做一些脚本化的操作。
+比如下面,增加了一段自定义的脚本
+ +
+
+
+## 五、体验核心依赖库能力
+
+### 1. ruby-macho
+
+#### 1. 操作 Mach-O 文件
+
+读取 Mach-O 文件,并用操作对象的方式去读区、增加、删除信息。
+
+分别对 Mach-O 增加了一个 `LC_RPATH` 类型的 Load Command
+
+```ruby
+lc_rpath = MachO::LoadCommands::LoadCommand.create(:LC_RPATH, 'test_rpath')
+file_exec.add_command lc_rpath
+```
+
+
+
+
+
+## 五、体验核心依赖库能力
+
+### 1. ruby-macho
+
+#### 1. 操作 Mach-O 文件
+
+读取 Mach-O 文件,并用操作对象的方式去读区、增加、删除信息。
+
+分别对 Mach-O 增加了一个 `LC_RPATH` 类型的 Load Command
+
+```ruby
+lc_rpath = MachO::LoadCommands::LoadCommand.create(:LC_RPATH, 'test_rpath')
+file_exec.add_command lc_rpath
+```
+
+ +
+对 Mach-O 文件中删除了类型为 `LC_LINKER_OPTION` 的 Load Command
+
+
+
+对 Mach-O 文件中删除了类型为 `LC_LINKER_OPTION` 的 Load Command
+
+ +
+#### 2. 操作动态库
+
+`ruby-macho` 还可以读取动态库信息,下面演示几个能力:
+
+- 读取动态库所依赖的动态库信息
+
+ ```ruby
+ # 打印出当前 Mach-O 文件使用的所有动态库
+ macho_dylibs = MachO::Tools.dylibs(macho_filepath)
+ macho_dylibs.each do | dylib |
+ puts dylib
+ end
+ ```
+
+- 修改动态库的 id
+
+ ```ruby
+ # 修改动态库的 id
+ MachO::Tools.change_dylib_id(macho_copy_filepath, 'test_selfdefined_dylib')
+ ```
+
+ 修改后在终端用指令 **objdump --macho --private-headers ./macho/libAFNetworking_copy.dylib | grep 'LC_ID_DYLIB' -A 5** 验证效果,如下图所示:
+
+
+
+#### 2. 操作动态库
+
+`ruby-macho` 还可以读取动态库信息,下面演示几个能力:
+
+- 读取动态库所依赖的动态库信息
+
+ ```ruby
+ # 打印出当前 Mach-O 文件使用的所有动态库
+ macho_dylibs = MachO::Tools.dylibs(macho_filepath)
+ macho_dylibs.each do | dylib |
+ puts dylib
+ end
+ ```
+
+- 修改动态库的 id
+
+ ```ruby
+ # 修改动态库的 id
+ MachO::Tools.change_dylib_id(macho_copy_filepath, 'test_selfdefined_dylib')
+ ```
+
+ 修改后在终端用指令 **objdump --macho --private-headers ./macho/libAFNetworking_copy.dylib | grep 'LC_ID_DYLIB' -A 5** 验证效果,如下图所示:
+
+  +
+ 也可以直接查看动态库的 id
+
+ ```ruby
+ original_dylib_id = MachO::MachOFile.new(macho_filepath)
+ copyed_dylib_id = MachO::MachOFile.new(macho_copy_filepath)
+
+ # 也可以直接查看动态库的 id
+ puts "before change dylib id: #{original_dylib_id.dylib_id}"
+ puts "after change dylib id: #{copyed_dylib_id.dylib_id}"
+ ```
+
+- 修改动态库 rpath
+
+ ```ruby
+ MachO::Tools.change_rpath(macho_copy_filepath, '@loader_path/Frameworks', '@loader_path/Frameworks/FantasicLBP')
+ ```
+
+
+
+ 也可以直接查看动态库的 id
+
+ ```ruby
+ original_dylib_id = MachO::MachOFile.new(macho_filepath)
+ copyed_dylib_id = MachO::MachOFile.new(macho_copy_filepath)
+
+ # 也可以直接查看动态库的 id
+ puts "before change dylib id: #{original_dylib_id.dylib_id}"
+ puts "after change dylib id: #{copyed_dylib_id.dylib_id}"
+ ```
+
+- 修改动态库 rpath
+
+ ```ruby
+ MachO::Tools.change_rpath(macho_copy_filepath, '@loader_path/Frameworks', '@loader_path/Frameworks/FantasicLBP')
+ ```
+
+  +
+#### 3. 合并动态库到胖二进制
+
+ruby-macho 有很多丰富的 API,基本上开发阶段所遇到的问题,都有现成的 API 解决。比如二进制指令集的合并
+
+```ruby
+filenames = [dylib_merged_filepath, dylib_arm_filepath]
+# # 第一个参数为合并之后的动态库名称,第二个参数为需要合并的一堆动态库
+MachO::Tools.merge_machos(dylib_merged_filepath, *filenames)
+```
+
+合并后用 `otool -f ./macho/libAFNetworking_merged.dylib` 指令查看指令集
+
+
+
+#### 3. 合并动态库到胖二进制
+
+ruby-macho 有很多丰富的 API,基本上开发阶段所遇到的问题,都有现成的 API 解决。比如二进制指令集的合并
+
+```ruby
+filenames = [dylib_merged_filepath, dylib_arm_filepath]
+# # 第一个参数为合并之后的动态库名称,第二个参数为需要合并的一堆动态库
+MachO::Tools.merge_machos(dylib_merged_filepath, *filenames)
+```
+
+合并后用 `otool -f ./macho/libAFNetworking_merged.dylib` 指令查看指令集
+
+ +
+
+
+### 2. Xcodeproj
+
+通过 xcodeproject 路径构建 xcodeproj 对象 `app_project = Xcodeproj::Project.new(app_project_path)`
+
+通过 xcworkspace 路径构建 xcworkspace 对象 `app_workspace = Xcodeproj::Workspace.new_from_xcworkspace(app_workspace_project_path)`
+
+然后通过对象的方式访问 xcworkspace 的信息。比如 schemes
+
+```ruby
+app_workspace.schemes.each do | scheme |
+ puts scheme
+end
+```
+
+
+
+
+
+### 2. Xcodeproj
+
+通过 xcodeproject 路径构建 xcodeproj 对象 `app_project = Xcodeproj::Project.new(app_project_path)`
+
+通过 xcworkspace 路径构建 xcworkspace 对象 `app_workspace = Xcodeproj::Workspace.new_from_xcworkspace(app_workspace_project_path)`
+
+然后通过对象的方式访问 xcworkspace 的信息。比如 schemes
+
+```ruby
+app_workspace.schemes.each do | scheme |
+ puts scheme
+end
+```
+
+ +
+也可以针对特定的 target 修改 xcconfig
+
+```ruby
+# 修改 targets 中第一个对应 configurations 为指定的 xcconfig 文件
+configuration_path = File.dirname(__FILE__) + '/xcodeproject/AFNetworkingMock/xcodeproj-testing.debug.xcconfig'
+# 转换为 xcode 的 file
+xc_file = app_project.new_file(configuration_path)
+
+app_project.targets.first.build_configurations.first.base_configuration_reference = xc_file
+```
+
+效果如下:
+
+
+
+也可以针对特定的 target 修改 xcconfig
+
+```ruby
+# 修改 targets 中第一个对应 configurations 为指定的 xcconfig 文件
+configuration_path = File.dirname(__FILE__) + '/xcodeproject/AFNetworkingMock/xcodeproj-testing.debug.xcconfig'
+# 转换为 xcode 的 file
+xc_file = app_project.new_file(configuration_path)
+
+app_project.targets.first.build_configurations.first.base_configuration_reference = xc_file
+```
+
+效果如下:
+
+ +
+也可以对特定的 target 修改 buildSetting 中的信息,比如 bundle id
+
+```ruby
+# 修改 target 的 bundle id
+app_project.targets.each do | target |
+ target.build_configurations.each do | config |
+ config.build_settings['PRODUCT_BUNDLE_IDENTIFIER'] = 'com.github.FantasticLBP.AFNetworkingMock' if config.name == 'Debug'
+ end
+end
+```
+
+
+
+也可以对特定的 target 修改 buildSetting 中的信息,比如 bundle id
+
+```ruby
+# 修改 target 的 bundle id
+app_project.targets.each do | target |
+ target.build_configurations.each do | config |
+ config.build_settings['PRODUCT_BUNDLE_IDENTIFIER'] = 'com.github.FantasticLBP.AFNetworkingMock' if config.name == 'Debug'
+ end
+end
+```
+
+ +
+
+
+## 六、自定义 cocoapods 插件
+
+### 1. 自定义 gem 库
+
+
+
+#### 1. 初始化创建
+
+输入指令 `bundle gem cocoapods-hmap` 自定义一个名为 `cocoapods-hmap` 的 gem 库
+
+#### 2. 工程结构说明
+
+得到的工程结构是:
+
+```shell
+.
+├── CHANGELOG.md
+├── CODE_OF_CONDUCT.md
+├── Gemfile
+├── LICENSE.txt
+├── README.md
+├── Rakefile
+├── bin
+│ ├── console
+│ └── setup
+├── cocoapods-hmap.gemspec
+├── lib
+│ └── cocoapods
+│ ├── hmap
+│ │ └── version.rb
+│ └── hmap.rb
+└── sig
+ └── cocoapods
+ └── hmap.rbs
+```
+
+说明:
+
+- **cocoapods-hmap.gemspec**:
+
+ - gem 的核心配置文件,定义了 gem 的名称、版本、作者、依赖、描述、文件包含规则等关键信息。
+ - 用于打包和发布 gem 到 RubyGems 仓库,是 gem 工程的 “身份证
+
+- **Rakefile**:
+
+ - 定义自动化任务(如测试、打包、发布等),通过 `rake <任务名>` 执行(类似 `Makefile`)。
+ - 常见任务:`rake spec`(运行测试)、`rake build`(打包 gem)、`rake release`(发布到 RubyGems)
+
+- **Gemfile**:
+
+ - 定义 gem 开发 / 测试阶段的依赖(如测试框架 `rspec`、打包工具等),类似前端的 `package.json`。
+ - 通过 `bundle install` 安装依赖,依赖版本由 `Gemfile.lock`(自动生成)锁定
+
+- **源代码目录:lib/ **
+
+ - gem 的核心功能代码存放目录,Ruby 会自动加载该目录下的文件
+
+ - `lib/cocoapods/hmap.rb`:gem 的主入口文件,定义了 `CocoaPods::Hmap` 模块的核心逻辑,是功能实现的主要载体(如与 CocoaPods 集成的逻辑、头文件映射相关功能等)
+ - `lib/cocoapods/hmap/version.rb`: 单独存放版本号的文件,通常定义 `CocoaPods::Hmap::VERSION` 常量,便于统一管理版本(在 `gemspec`中会引用该常量)。
+
+
+
+#### 3. 改造并 run 起来
+
+- 修改 gemspec 文件中带有 url、uri 的字段,开发阶段可以修改为任何一个 url 字符串
+
+- 修改自带的工程结构,比如 `cocoapods/hmap` 改为 `cocoapods-hmap`,将对应的文件也移动位置
+
+- 我们预期的效果是:在终端输入 **pod hmap** 就可以将工程中的静态库 Header Search Path 传统查找模式改为 hmap 文件配置模式。所以需要的的步骤就是在 **bin 目录下创建 hmap.rb**,然后通过 **bin 目录下的代码调用 lib 目录下的 HMap.rb** 能力。
+
+- 为此,需要:
+
+ - 在 lib 目录下创建 HMap.rb 文件
+
+ ```ruby
+ require_relative "version"
+
+ module CocoapodsHmap
+ class HMap
+ def initialize
+ puts "Cocoapods HMap initialized"
+ end
+
+ def self.run
+ puts "Running Cocoapods HMap..."
+ end
+
+ end
+ end
+
+ ```
+
+ - 在 bin 目录下创建 hmap.rb 文件
+
+ ```ruby
+ #!/usr/bin/env ruby
+ require "bundler/setup"
+ require "cocoapods-hmap/hmap"
+
+ # 打印携带的参数
+ puts ARGV
+
+ CocoapodsHmap::HMap.run
+ ```
+
+- 为了在 VSCode 中测试,需要在 Gemfile 中添加一行 **gem 'debug', '~> 1.9.0' # 调试用**
+
+- 工程根目录创建 `.vscode` 文件夹,创建 launch.json 文件。内容如下:
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ "script": "${workspaceFolder}/bin/hmap",
+ "args": ["hmap"], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+VSCode 中运行效果如下:
+
+
+
+
+
+## 六、自定义 cocoapods 插件
+
+### 1. 自定义 gem 库
+
+
+
+#### 1. 初始化创建
+
+输入指令 `bundle gem cocoapods-hmap` 自定义一个名为 `cocoapods-hmap` 的 gem 库
+
+#### 2. 工程结构说明
+
+得到的工程结构是:
+
+```shell
+.
+├── CHANGELOG.md
+├── CODE_OF_CONDUCT.md
+├── Gemfile
+├── LICENSE.txt
+├── README.md
+├── Rakefile
+├── bin
+│ ├── console
+│ └── setup
+├── cocoapods-hmap.gemspec
+├── lib
+│ └── cocoapods
+│ ├── hmap
+│ │ └── version.rb
+│ └── hmap.rb
+└── sig
+ └── cocoapods
+ └── hmap.rbs
+```
+
+说明:
+
+- **cocoapods-hmap.gemspec**:
+
+ - gem 的核心配置文件,定义了 gem 的名称、版本、作者、依赖、描述、文件包含规则等关键信息。
+ - 用于打包和发布 gem 到 RubyGems 仓库,是 gem 工程的 “身份证
+
+- **Rakefile**:
+
+ - 定义自动化任务(如测试、打包、发布等),通过 `rake <任务名>` 执行(类似 `Makefile`)。
+ - 常见任务:`rake spec`(运行测试)、`rake build`(打包 gem)、`rake release`(发布到 RubyGems)
+
+- **Gemfile**:
+
+ - 定义 gem 开发 / 测试阶段的依赖(如测试框架 `rspec`、打包工具等),类似前端的 `package.json`。
+ - 通过 `bundle install` 安装依赖,依赖版本由 `Gemfile.lock`(自动生成)锁定
+
+- **源代码目录:lib/ **
+
+ - gem 的核心功能代码存放目录,Ruby 会自动加载该目录下的文件
+
+ - `lib/cocoapods/hmap.rb`:gem 的主入口文件,定义了 `CocoaPods::Hmap` 模块的核心逻辑,是功能实现的主要载体(如与 CocoaPods 集成的逻辑、头文件映射相关功能等)
+ - `lib/cocoapods/hmap/version.rb`: 单独存放版本号的文件,通常定义 `CocoaPods::Hmap::VERSION` 常量,便于统一管理版本(在 `gemspec`中会引用该常量)。
+
+
+
+#### 3. 改造并 run 起来
+
+- 修改 gemspec 文件中带有 url、uri 的字段,开发阶段可以修改为任何一个 url 字符串
+
+- 修改自带的工程结构,比如 `cocoapods/hmap` 改为 `cocoapods-hmap`,将对应的文件也移动位置
+
+- 我们预期的效果是:在终端输入 **pod hmap** 就可以将工程中的静态库 Header Search Path 传统查找模式改为 hmap 文件配置模式。所以需要的的步骤就是在 **bin 目录下创建 hmap.rb**,然后通过 **bin 目录下的代码调用 lib 目录下的 HMap.rb** 能力。
+
+- 为此,需要:
+
+ - 在 lib 目录下创建 HMap.rb 文件
+
+ ```ruby
+ require_relative "version"
+
+ module CocoapodsHmap
+ class HMap
+ def initialize
+ puts "Cocoapods HMap initialized"
+ end
+
+ def self.run
+ puts "Running Cocoapods HMap..."
+ end
+
+ end
+ end
+
+ ```
+
+ - 在 bin 目录下创建 hmap.rb 文件
+
+ ```ruby
+ #!/usr/bin/env ruby
+ require "bundler/setup"
+ require "cocoapods-hmap/hmap"
+
+ # 打印携带的参数
+ puts ARGV
+
+ CocoapodsHmap::HMap.run
+ ```
+
+- 为了在 VSCode 中测试,需要在 Gemfile 中添加一行 **gem 'debug', '~> 1.9.0' # 调试用**
+
+- 工程根目录创建 `.vscode` 文件夹,创建 launch.json 文件。内容如下:
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ "script": "${workspaceFolder}/bin/hmap",
+ "args": ["hmap"], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+VSCode 中运行效果如下:
+
+ +
+#### 4. 如何将自定义的指令加入到 cocoapods 中
+
+- 在 Command 目录下创建 `hmap` 文件,不带任何拓展名。rake 处理后,最后会变为 `/Users/unix_kernel/.rbenv/versions/3.2.2/lib/ruby/gems/3.2.0/gems/cocoapods-hmap-0.1.0/bin/hmap: Ruby script text executable, ASCII text`
+
+- 在 lib 目录下,创建 `cocoapods-hmap` 文件夹。
+ - 在 `cocoapods-hmap` 文件夹内创建 `command` 文件夹,在 `command` 文件夹内创建 `hmap.rb` 文件
+ - class 继承自 Pod::Command,并实现相关方法。比如 initialize、validate!、run
+- 在 lib 目录下,创建 `cocoapods-plugin.rb` 文件
+ - 暴露继承自 Pod::Command 的 hmap command
+
+调试运行后的效果如下:
+
+
+
+#### 4. 如何将自定义的指令加入到 cocoapods 中
+
+- 在 Command 目录下创建 `hmap` 文件,不带任何拓展名。rake 处理后,最后会变为 `/Users/unix_kernel/.rbenv/versions/3.2.2/lib/ruby/gems/3.2.0/gems/cocoapods-hmap-0.1.0/bin/hmap: Ruby script text executable, ASCII text`
+
+- 在 lib 目录下,创建 `cocoapods-hmap` 文件夹。
+ - 在 `cocoapods-hmap` 文件夹内创建 `command` 文件夹,在 `command` 文件夹内创建 `hmap.rb` 文件
+ - class 继承自 Pod::Command,并实现相关方法。比如 initialize、validate!、run
+- 在 lib 目录下,创建 `cocoapods-plugin.rb` 文件
+ - 暴露继承自 Pod::Command 的 hmap command
+
+调试运行后的效果如下:
+
+ +
+类名小写,和类文件关联起来
+
+比如 install.rb 中,类名为 `class Install` ,内部会记录为 **{"install": "install.rb"}**
+
+
+
+#### 5. 打包安装到本地
+
+在终端项目目录下,执行指令 **rake install:local** ,主要用于**在本地构建并安装当前开发的 gem 包**,方便开发者进行本地测试和调试。
+
+一开始有报错,如下图所示。按照提示修改 `cocoapods-hmap.gemspec` 中的配置,然后就可以成功安装了。然后输入 **gem list** 查看:
+
+
+
+类名小写,和类文件关联起来
+
+比如 install.rb 中,类名为 `class Install` ,内部会记录为 **{"install": "install.rb"}**
+
+
+
+#### 5. 打包安装到本地
+
+在终端项目目录下,执行指令 **rake install:local** ,主要用于**在本地构建并安装当前开发的 gem 包**,方便开发者进行本地测试和调试。
+
+一开始有报错,如下图所示。按照提示修改 `cocoapods-hmap.gemspec` 中的配置,然后就可以成功安装了。然后输入 **gem list** 查看:
+
+ +
+输入: **gem info cocoapods-hmap** 查看安装信息
+
+
+
+输入: **gem info cocoapods-hmap** 查看安装信息
+
+ +
+
+
+就目前的功能进行测试:
+
+| 条件 | 预期 | 结果 |
+| ----------------------------------- | --------------------------------------- | -------- |
+| 随便一个工程目录,没有 Podfile 文件 | 执行 `pod hmap` 会报错 | 符合预期 |
+| 存在 Podfile 文件的目录 | 正常执行 run 方法里面的逻辑(打印逻辑) | 符合预期 |
+
+
+
+
+
+就目前的功能进行测试:
+
+| 条件 | 预期 | 结果 |
+| ----------------------------------- | --------------------------------------- | -------- |
+| 随便一个工程目录,没有 Podfile 文件 | 执行 `pod hmap` 会报错 | 符合预期 |
+| 存在 Podfile 文件的目录 | 正常执行 run 方法里面的逻辑(打印逻辑) | 符合预期 |
+
+ +
+
+
+#### 6. Hook 能力
+
+##### 1. post_install
+
+- 修改插件入口文件 (cocoapods_plugin.rb)
+
+ 先在 `lib/cocoapods-plugin.rb` 中注册插件和对应的 hook 能力。利用 API:**Pod::HooksManager.register('cocoapods-hmap', :post_install)**,其文档说明如下:
+
+ >register(plugin_name, hook_name, &block)
+ >
+ >**Definitions**: [hooks_manager.rb](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-browser/workbench/workbench.html)
+ >
+ >Registers a block for the hook with the given name.
+ >
+ >@param [String] plugin_name The name of the plugin the hook comes from.
+ >
+ >@param [Symbol] hook_name The name of the notification.
+ >
+ >@param [Proc] block The block.
+
+ ```ruby
+ Pod::HooksManager.register('cocoapods-hmap', :post_install) do |context, options|
+ argv = CLAide::ARGV.new([]) # 创建一个空的参数数组
+ command = Pod::Command::HMap.new(argv)
+ command.run_post_install(context, options)
+ end
+ ```
+
+- 完善 HMap 命令类
+
+ 修改 `lib/cocoapods-hmap/command/hmap.rb`,增加 `run_post_install` 方法
+
+ ```ruby
+ module Pod
+ class Command
+ class HMap < Command
+ // ...
+
+ # Post-install 钩子执行的方法
+ def run_post_install(context, options = {})
+ puts "[Cocoapods hmap] Running HMap command in post_install hook..."
+ end
+ end
+ end
+ end
+ ```
+
+- 测试配置
+
+ 修改测试项目的 Podfile 文件,声明 **plugin 'cocoapods-hmap'**
+
+ ```ruby
+ platform :ios, '9.0'
+ plugin 'cocoapods-hmap'
+
+ post_install do | installer |
+ puts "Self defined post_install hook"
+ end
+
+ target 'StaticLibConflictsDemo' do
+ # Comment the next line if you don't want to use dynamic frameworks
+ # AFNetworking 以静态库的形式被依赖
+ pod 'AFNetworking'
+ # 脚本化
+ script_phase :name => 'Run Self-defined Script',
+ :script => "echo 'This is a self-defined script phase'",
+ :input_files => [],
+ :execution_position => :after_compile
+ end
+ ```
+
+- 修改 `cocoapods-hmap` 工程的 VSCode 的 launch.json 文件
+
+ 因为 cocoapods-hmap 工程和 iOS Pods 工程不在一个目录,所以可以在 args 的第二个参数设置为测试工程路径
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ // "script": "${workspaceFolder}/bin/hmap",
+ "script": " /Users/unix_kernel/.rbenv/versions/3.2.2/bin/pod",
+ "args": [
+ "install",
+ "--project-directory=${workspaceFolder}/../StaticLibConflictsDemo"
+ ], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+- 测试:存在2种方法
+
+ - 第一种:在 cocospods-hmap 工程中测试,如下图
+
+
+
+
+
+#### 6. Hook 能力
+
+##### 1. post_install
+
+- 修改插件入口文件 (cocoapods_plugin.rb)
+
+ 先在 `lib/cocoapods-plugin.rb` 中注册插件和对应的 hook 能力。利用 API:**Pod::HooksManager.register('cocoapods-hmap', :post_install)**,其文档说明如下:
+
+ >register(plugin_name, hook_name, &block)
+ >
+ >**Definitions**: [hooks_manager.rb](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-browser/workbench/workbench.html)
+ >
+ >Registers a block for the hook with the given name.
+ >
+ >@param [String] plugin_name The name of the plugin the hook comes from.
+ >
+ >@param [Symbol] hook_name The name of the notification.
+ >
+ >@param [Proc] block The block.
+
+ ```ruby
+ Pod::HooksManager.register('cocoapods-hmap', :post_install) do |context, options|
+ argv = CLAide::ARGV.new([]) # 创建一个空的参数数组
+ command = Pod::Command::HMap.new(argv)
+ command.run_post_install(context, options)
+ end
+ ```
+
+- 完善 HMap 命令类
+
+ 修改 `lib/cocoapods-hmap/command/hmap.rb`,增加 `run_post_install` 方法
+
+ ```ruby
+ module Pod
+ class Command
+ class HMap < Command
+ // ...
+
+ # Post-install 钩子执行的方法
+ def run_post_install(context, options = {})
+ puts "[Cocoapods hmap] Running HMap command in post_install hook..."
+ end
+ end
+ end
+ end
+ ```
+
+- 测试配置
+
+ 修改测试项目的 Podfile 文件,声明 **plugin 'cocoapods-hmap'**
+
+ ```ruby
+ platform :ios, '9.0'
+ plugin 'cocoapods-hmap'
+
+ post_install do | installer |
+ puts "Self defined post_install hook"
+ end
+
+ target 'StaticLibConflictsDemo' do
+ # Comment the next line if you don't want to use dynamic frameworks
+ # AFNetworking 以静态库的形式被依赖
+ pod 'AFNetworking'
+ # 脚本化
+ script_phase :name => 'Run Self-defined Script',
+ :script => "echo 'This is a self-defined script phase'",
+ :input_files => [],
+ :execution_position => :after_compile
+ end
+ ```
+
+- 修改 `cocoapods-hmap` 工程的 VSCode 的 launch.json 文件
+
+ 因为 cocoapods-hmap 工程和 iOS Pods 工程不在一个目录,所以可以在 args 的第二个参数设置为测试工程路径
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ // "script": "${workspaceFolder}/bin/hmap",
+ "script": " /Users/unix_kernel/.rbenv/versions/3.2.2/bin/pod",
+ "args": [
+ "install",
+ "--project-directory=${workspaceFolder}/../StaticLibConflictsDemo"
+ ], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+- 测试:存在2种方法
+
+ - 第一种:在 cocospods-hmap 工程中测试,如下图
+
+  +
+ - 第二种:
+
+ - 在终端 cocoapods-hmap 目录下执行 **rake install:local** ,将插件安装到本地
+ - 然后切换到 iOS 被测工程目录下,执行 `pod install`
+
+ 效果如下:
+
+
+
+ - 第二种:
+
+ - 在终端 cocoapods-hmap 目录下执行 **rake install:local** ,将插件安装到本地
+ - 然后切换到 iOS 被测工程目录下,执行 `pod install`
+
+ 效果如下:
+
+  +
+
+
+##### 2. pre_install
+
+
+
+
+
+
+
+### 2. CocoaPods 插件系统设计
+
+CocoaPods 通过严格的目录结构约定来加载插件:
+
+```shell
+lib/
+├── cocoapods-plugin.rb # 插件主入口文件(必需)
+└── cocoapods-hmap/ # 插件命名空间目录
+ └── command/ # 命令目录
+ └── hmap.rb # 命令实现文件(必需)
+```
+
+#### 1. 自动加载机制
+
+CocoaPods 启动时会自动执行以下操作:
+
+1. 扫描已安装的 gem
+2. 查找所有以 `cocoapods-` 为前缀的 gem
+3. 加载这些 gem 中的 `lib/cocoapods-plugin.rb` 文件
+4. 通过该文件加载插件功能
+
+#### 2. 关键文件
+
+- 插件入口文件 (`lib/cocoapods-plugin.rb`)
+
+ ```ruby
+ require 'cocoapods-hmap/command/hmap'
+ ```
+
+- 命令实现文件 (lib/cocoapods-hmap/command/hmap.rb)
+
+-
+
+
+
+
-- block 最后一行是返回值,不需要指定 return
-- ruby 脚本语言在编写好代码后也想像其他 GPL 语言一样断点可以,需要安装依赖和相应的代码调整
- - `gem install pry`
- - 文件引入 `require 'pry'`
- - 需要 debug 的地方加上 `binding.pry`
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.74.md b/Chapter1 - iOS/1.74.md
index 0730290..98d39c4 100644
--- a/Chapter1 - iOS/1.74.md
+++ b/Chapter1 - iOS/1.74.md
@@ -1,8 +1,8 @@
## 带你打造一套 APM 监控系统
-> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的纬度谈谈如何精确监控以及数据如何上报等技术点
+> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的维度谈谈如何精确监控以及数据如何上报等技术点
-App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
+App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:卡顿、Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大、Weex/RN/Flutter 页面白屏等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
本篇文章着重总结了 APM 的原因以及如何收集数据。APM 数据收集后结合数据上报机制,按照一定策略上传数据到服务端。服务端消费这些信息并产出报告。请结合[姊妹篇](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md), 总结了如何打造一款灵活可配置、功能强大的数据上报组件。
@@ -8094,6 +8094,52 @@ runZoned
+
+
+
+##### 2. pre_install
+
+
+
+
+
+
+
+### 2. CocoaPods 插件系统设计
+
+CocoaPods 通过严格的目录结构约定来加载插件:
+
+```shell
+lib/
+├── cocoapods-plugin.rb # 插件主入口文件(必需)
+└── cocoapods-hmap/ # 插件命名空间目录
+ └── command/ # 命令目录
+ └── hmap.rb # 命令实现文件(必需)
+```
+
+#### 1. 自动加载机制
+
+CocoaPods 启动时会自动执行以下操作:
+
+1. 扫描已安装的 gem
+2. 查找所有以 `cocoapods-` 为前缀的 gem
+3. 加载这些 gem 中的 `lib/cocoapods-plugin.rb` 文件
+4. 通过该文件加载插件功能
+
+#### 2. 关键文件
+
+- 插件入口文件 (`lib/cocoapods-plugin.rb`)
+
+ ```ruby
+ require 'cocoapods-hmap/command/hmap'
+ ```
+
+- 命令实现文件 (lib/cocoapods-hmap/command/hmap.rb)
+
+-
+
+
+
+
-- block 最后一行是返回值,不需要指定 return
-- ruby 脚本语言在编写好代码后也想像其他 GPL 语言一样断点可以,需要安装依赖和相应的代码调整
- - `gem install pry`
- - 文件引入 `require 'pry'`
- - 需要 debug 的地方加上 `binding.pry`
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.74.md b/Chapter1 - iOS/1.74.md
index 0730290..98d39c4 100644
--- a/Chapter1 - iOS/1.74.md
+++ b/Chapter1 - iOS/1.74.md
@@ -1,8 +1,8 @@
## 带你打造一套 APM 监控系统
-> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的纬度谈谈如何精确监控以及数据如何上报等技术点
+> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的维度谈谈如何精确监控以及数据如何上报等技术点
-App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
+App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:卡顿、Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大、Weex/RN/Flutter 页面白屏等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
本篇文章着重总结了 APM 的原因以及如何收集数据。APM 数据收集后结合数据上报机制,按照一定策略上传数据到服务端。服务端消费这些信息并产出报告。请结合[姊妹篇](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md), 总结了如何打造一款灵活可配置、功能强大的数据上报组件。
@@ -8094,6 +8094,52 @@ runZoned>(() async {
## 十、子线程 UI 监控
+### 为什么不能在子线程操作 UI
+UI 必须在主线程(UI 线程)执行,核心原因是 **UI 框架的单线程模型**设计,为了保证 UI 操作的线程安全、状态一致性和渲染效率,几乎所有的主流 UI 框架(Android、iOS、Web、Windows、Web 前端、Flutter、Weex、RN)都限制:只有主线程才可以访问和修改 UI 控件。
+
+#### 核心原因:解决“线程安全”与“状态一致性”问题
+UI 控件(如按钮、文本框)是**共享资源**,且设计时**没有内置线程同步机制(比如锁)**,如果允许多线程直接操作 UI,会引发2个致命问题:
+
+##### 1. 竞态条件(Race Condition):UI 状态错乱
+多线程同时修改同一个 UI 控件的属性,会导致 UI 状态“冲突”,比如:
+- 线程 A 设置 UILabel 的文本为“加载中,正在获取服务端数据...”
+- 线程 B,设置 UILabel 文字颜色为蓝色
+- 线程 C,设置 UILabel 为隐藏(此时 UILabel 的文字可能还没更改完,状态不对,但立马被设置为隐藏了)
+最终出现了 UILabel 的显示错乱,UI 控件卡死,界面闪烁问题
+
+##### 2. 渲染流程混乱:绘制结果不可预期
+UI 渲染是个连续的流水线:先计算控件布局(Measure/Layout) -> 绘制控件(Draw) -> 刷新屏幕(Compose)。这个流程需要顺序执行、状态稳定,如果多线程介入:
+- 线程 A 正在计算布局(比如调整 UILabel 的位置)
+- 线程 B 突然修改 Frame 大小,导致布局计算结果失效
+- 最终绘制出界面可能是“按钮位置偏移”、“控件重叠”等异常
+
+#### 为什么不设计线程安全的 UI 控件?
+##### 1. 性能暴跌:UI 操作便卡顿
+UI 操作是非常高频的场景(比如列表在滑动的时候,每秒可能刷新几十次),而加锁会导致性能问题(比如线程 A 给 UILabel 加了锁,线程 B 想要修改文字大小,此时必须等待线程 A 释放锁)。频繁的锁竞争会让 UI 的变化延迟响应,甚至出现“滑动掉帧”问题,或者“点击无响应”-这违背了 UI 对流畅性的核心要求
+##### 2. 复杂度爆炸:容易引发死锁
+UI 控件存在依赖关系(比如父子组件、UI 组件树),多线程操作时,可能出现“锁顺序错乱”
+- 线程 A 锁父控件 -> 再尝试锁子控件
+- 线程 B 锁子控件 -> 再尝试锁父控件
+2者相互等待出现死锁
+
+因此,UI 框架必须满足“牺牲多线程灵活性”,以确保“单线程的简单性、安全性和高效性”,索性一刀切,**所有的 UI 操作必须在主线程上执行**,从根源上避免不符合预期的行为出现
+
+##### GUI 平台的单线程模型
+所有主流平台、框架都遵循这一原则,且会主动拦截“子线程操作 UI” 的行为:
+1. Android
+ - 主线程(UI 线程)通过 Looper 循环处理 MessageQueue 的 UI 消息
+ - 子线程操作 UI 会直接弹出 `CalledFromWrongThreadException`(只有创建视图层次的原始线程才可以触摸其视图)
+ - 必须通过 Handler、runOnUiThread、Croutine(Dispatch.Main)等方式更新 UI
+2. iOS
+ - 主线程(UI 线程)通过绑定主 RunLoop,负责处理 UI 事件(点击、触摸、滑动)和渲染
+ - 子线程操作 UI 可能导致界面异常(比如 UILabel 文本不更新)、甚至 crash
+ - 必须通过 dispatch.async 来向主队列派发可以用于主线程执行的任务
+3. Web 前端
+ - 浏览器的 DOM 操作是单线程的(主线程负责 DOM 渲染、事件处理)
+ - 子线程(如 Web Worker)无法直接操作 DOM,必须通过 postMessage 通知主线程操作 UI 更新
+
+总结:UI 必须在主线程上更新是因为:UI 控件没有设计线程同步机制(比如加锁),所以框架为了保证线程安全、状态一致、渲染高效,一刀切直接采用了单线程模型。
+
### 1. 背景介绍
@@ -8263,27 +8309,8 @@ runZoned>(() async {
## 十四、未来规划
-- 监控能力继续完善
-
-- 技术持续研究,提升监控准确度、案发第一现场数据,便于排查问题
-
+- 监控能力继续完善、提升监控准确度
- APM 新方向的研究。UI 自动化结合 iOS Instrucments Server 中的性能数据(DTXMessage 通信)
-
-- 开源 SDK + 桌面端 App 查看性能数据(产品侧)
-
-## 参考资料
-
-- [iOS 保持界面流畅的技巧](https://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/)
-- [Call Stack](https://en.wikipedia.org/wiki/Call_stack)
-- [iOS 启动时间优化](https://www.zoomfeng.com/blog/launch-time.html)
-- [WWDC2019 之启动时间与 Dyld3](https://www.zoomfeng.com/blog/launch-optimize-from-wwdc2019.html)
-- [Apple-libmalloc](https://opensource.apple.com/tarballs/libmalloc/)
-- [Apple-XNU](https://opensource.apple.com/tarballs/xnu/)
-- [OOM 探究:XNU 内存状态管理](https://www.jianshu.com/p/4458700a8ba8)
-- [Reducing FOOMs in the Facebook iOS app](https://engineering.fb.com/ios/reducing-fooms-in-the-facebook-ios-app/)
-- [iOS 内存 abort(Jetsam) 原理探究](https://satanwoo.github.io/2017/10/18/abort/)
-- [iOS 微信内存监控](https://wetest.qq.com/lab/view/367.html?from=coop_gad)
-- [iOS 堆栈信息解析(函数地址与符号关联)](https://www.jianshu.com/p/df5b08330afd)
-- [Apple-CFNetwork Programming Guide](https://developer.apple.com/library/archive/documentation/Networking/Conceptual/CFNetwork/Introduction/Introduction.html#//apple_ref/doc/uid/TP30001132-CH1-DontLinkElementID_30)
-- [MDN-HTTP Messages](https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages)
-- [DWARF 和符号化](https://junyixie.github.io/2018/09/30/dwarf和符号化/)
+- 产品侧:开源 SDK + mPaaS 平台(或者 Electron 写一款 桌面端 App 查看性能数据)
+- AI 赋能:根据特征数据做到智能化归因
+- 报警平台已具备波动报警、业务域 Owner 报警策略可配置。未来需利用 AI 能力做更多畅想
diff --git a/Chapter1 - iOS/1.75.md b/Chapter1 - iOS/1.75.md
index ad72ae2..171c46f 100644
--- a/Chapter1 - iOS/1.75.md
+++ b/Chapter1 - iOS/1.75.md
@@ -1177,6 +1177,45 @@ SPEC_END
## 五、UI 测试
+### 概念
+UI 测试:属于端到端测试,是从应用程序启动到结束的测试过程。完全按照用户与应用程序交互的方式来复制与应用程序的交互。比但愿测试慢得多,运行起来更消耗资源。
+
+### 测试原则
+
+FIRST
+- Fast:测试模块应该是快速高效的
+- Independent/Isolated:测试模块应该是独立、互相不影响的
+- Repeatable:测试实例应该是可以重复使用的,测试结果应该是相同的
+- Self-validating:测试应完全自动化。输出结果要么成功、要么失败
+- Timely:理想情况下,应该在编写要测试的生产代码之前编写测试(测试驱动开发)
+
+### 需要测试什么?
+- 视觉表现验证
+ - 元素渲染:控件尺寸、颜色、字体、图标资源(accessibilityIdentifier 定位)
+ - 布局规则:动态布局(Auto Layout 约束断裂检测)、横竖屏适配、多语言截断
+ - 动效完整性:转场动画时长、交互反馈(如按钮点击态)
+
+- 交互行为验证
+
+ | 交互类型 | 测试要点 | 工具示例 |
+ | :----------- | :----------------------------------------------- | :------------------------------------- |
+ | **手势操作** | 滑动/长按/捏合等触发事件 | `XCUITest: swipeUp()` |
+ | **表单输入** | 键盘类型切换、输入校验(正则)、自动填充 | `typeText("test@email.com")` |
+ | **导航流** | 页面跳转栈深度、返回逻辑(物理返回 vs 程序返回) | `navigationBars.buttons["Back"].tap()` |
+ | **异步状态** | 加载中/空状态/错误页的显示与隐藏 | `waitForExistence(timeout: 5)` |
+
+- 数据驱动验证
+ - API 数据映射:Mock 不同 API 响应(200/404/500),检查 UI 渲染正确性
+ - 本地数据同步:Core Data/Realm 更新后 UI 即时刷新
+ - 动态内容:富文本(含超链接)、图片懒加载、视频播放器状态
+- 边界场景验证(Edge Cases)
+ - 设备兼容:从 iPhone SE 到 iPad Pro 的适配
+ - 系统版本:iOS 14~17 的关键行为差异(如权限弹窗样式)
+ - 极端操作:快速连续点击、低内存告警恢复
+ - 无障碍支持:VoiceOver 焦点顺序、Dynamic Type 超大字体布局
+
+
+
### 基础使用
上面文章大篇幅的讲了单元测试相关的话题,单元测试十分适合代码质量、逻辑、网络等内容的测试,但是针对最终产物 App 来说单元测试就不太适合了,如果测试 UI 界面的正确性、功能是否正确显然就不太适合了。Apple 在 Xcode 7 开始推出的 `UI Testing` 就是苹果自己的 UI 测试框架。
@@ -1339,16 +1378,194 @@ int main(int argc, char * argv[]) {
-### 探索
+### 单元测试的原理窥探
开发的单元测试代码,运行的背后也是一个可执行文件。查看内部,可以发现一堆和测试相关的 framework。
 -思考:一个工程中,只要写好了测试代码,是不是加载这几个动态库就可以运行测试用例了?
+思考:一个非 UI 测试工程(正常的 App 工程),是不是加载这几个测试相关的动态库,写好测试代码,就可以运行测试用例了?
+
+细节不贴了。Demo App 引入 `XCTest.framework` 后业务代码里即可引入 `#import
-思考:一个工程中,只要写好了测试代码,是不是加载这几个动态库就可以运行测试用例了?
+思考:一个非 UI 测试工程(正常的 App 工程),是不是加载这几个测试相关的动态库,写好测试代码,就可以运行测试用例了?
+
+细节不贴了。Demo App 引入 `XCTest.framework` 后业务代码里即可引入 `#import ` 然后就可以编写测试代码了。
+
+写法1:
+
+```objective-c
+- (void)touchesBegan:(NSSet *)touches withEvent:(UIEvent *)event {
+ // 测试管理集
+ XCTestSuite *suite = [XCTestSuite defaultTestSuite];
+ // 初始化 TestCase
+ LoginUITests *loginTest = [LoginUITests testCaseWithSelector:@selector(testDidClickLoginAction)];
+
+ // 添加测试用例到当前 suite
+ [suite addTest:loginTest];
+
+ // 遍历并运行测试用例
+ for (XCTest *test in suite.tests) {
+ [test runTest];
+ }
+}
+```
+
+写法2:
+
+```objective-c
+- (void)touchesBegan:(NSSet *)touches withEvent:(UIEvent *)event {
+ // 测试管理集
+ XCTestSuite *suite = [XCTestSuite testSuiteForTestCaseClass:LoginUITests.class];
+ // 初始化 TestCase
+ LoginUITests *loginTest = [LoginUITests new];
+
+ // 添加测试用例到当前 suite
+ [suite addTest:loginTest];
+
+ // 遍历并运行测试用例
+ for (XCTest *test in suite.tests) {
+ [test runTest];
+ }
+}
+```
+#### 执行时机
+
+这种情况下,整体流程为:
+
+```mermaid
+graph TD
+ A[测试套件启动] --> B[创建测试类实例]
+ B --> C1[执行 testMethod1]
+ C1 --> D1[调用 setUp]
+ D1 --> E1[执行 testMethod1 本体]
+ E1 --> F1[调用 tearDown]
+
+ B --> C2[执行 testMethod2]
+ C2 --> D2[调用 setUp]
+ D2 --> E2[执行 testMethod2 本体]
+ E2 --> F2[调用 tearDown]
+
+ B --> C3[执行 testMethod3]
+ C3 --> D3[调用 setUp]
+ D3 --> E3[执行 testMethod3 本体]
+ E3 --> F3[调用 tearDown]
+```
+
+分析:
+
+- 当有多个测试方法时,XCTest 会为**每个测试方法创建单独的类实例**
+
+- 每个测试方法执行时都会触发完整的生命周期
+
+ ```objective-c
+ // 伪代码展示 XCTest 内部执行流程
+ for (XCTest *test in allTests) {
+ [test invokeTest]; // 实际执行入口
+ }
+
+ // invokeTest 内部实现:
+ - (void)invokeTest {
+ [self setUp]; // 每次测试前调用
+ [self performTest]; // 执行测试方法本体
+ [self tearDown]; // 每次测试后调用
+ }
+ ```
+
+- 三个测试方法的执行示例
+
+ 测试代码:
+
+ ```objective-c
+ - (void)testValidLogin { ... }
+ - (void)testInvalidPassword { ... }
+ - (void)testNetworkErrorHandling { ... }
+ ```
+
+ 实际执行顺序
+
+ ```objective-c
+ // 测试1
+ [LoginUITests setUp];
+ [LoginUITests testValidLogin];
+ [LoginUITests tearDown];
+
+ // 测试2
+ [LoginUITests setUp]; // 全新状态!
+ [LoginUITests testInvalidPassword];
+ [LoginUITests tearDown];
+
+ // 测试3
+ [LoginUITests setUp]; // 再次重置状态
+ [LoginUITests testNetworkErrorHandling];
+ [LoginUITests tearDown];
+ ```
+
+思考:为什么需要每次重置?
+
+1. **测试隔离原则**
+ - 防止测试间的状态污染
+ - 确保每个测试都是独立可重复的
+2. **资源管理**
+ - 每次 `tearDown` 释放测试占用的资源
+ - 避免内存泄漏累积
+3. **环境一致性**
+ - `setUp` 确保每次测试初始条件相同
+ - 不受前次测试副作用影响
+
+QA:单独执行每个测试方法,都会走 setup 和 teardown。按了快捷键 command + u,运行所有的测试 case,会执行几次 setup?比如 Login 有3个测试 case。点击后执行流程是什么样的?
+
+```mermaid
+sequenceDiagram
+ participant X as XCTestRunner
+ participant C as LoginUITests Class
+ participant I1 as 实例1 (testA)
+ participant I2 as 实例2 (testB)
+ participant I3 as 实例3 (testC)
+
+ X->>C: 调用 +[LoginUITests setUp] (类方法)
+ activate C
+
+ X->>I1: 创建实例1 (testA)
+ activate I1
+ I1->>I1: -setUp (实例方法)
+ I1->>I1: -testA (测试方法)
+ I1->>I1: -tearDown (实例方法)
+ deactivate I1
+
+ X->>I2: 创建实例2 (testB)
+ activate I2
+ I2->>I2: -setUp (实例方法)
+ I2->>I2: -testB (测试方法)
+ I2->>I2: -tearDown (实例方法)
+ deactivate I2
+
+ X->>I3: 创建实例3 (testC)
+ activate I3
+ I3->>I3: -setUp (实例方法)
+ I3->>I3: -testC (测试方法)
+ I3->>I3: -tearDown (实例方法)
+ deactivate I3
+
+ X->>C: 调用 +[LoginUITests tearDown] (类方法)
+ deactivate C
+```
+
+分析:
+
+- 类级别初始化(只执行一次)。`+[LoginUITests setUp]` 类方法
+ - 在**所有测试开始前**执行一次
+ - 适合做全局初始化(如启动模拟服务器)
+ - 执行频率:1次/测试类
+- 每个测试方法的独立执行。对于每个测试方法(testA, testB, testC):
+ - 创建**新的测试类实例**
+ - **-setUp** 实例方法(每个测试方法前执行)
+ - 执行测试方法(如 **-testA**)
+ - **-tearDown** 实例方法(每个测试方法后执行)
+- 类级别清理(只执行一次)。`+[LoginUITests tearDown]` 类方法
+ - 在**所有测试结束后**执行一次
+ - 适合做全局清理(如关闭模拟服务器)
+ - 执行频率:1次/测试类
+
## 六、精准测试
@@ -1369,7 +1586,7 @@ int main(int argc, char * argv[]) {
下面是之前在有赞,开发完精准测试系统后,落地到一个业务项目中取得的价值,帮助2位 QA 发现漏测的代码,倒逼 QA 去设计更完善的测试 case、分析覆盖率低是开发者的兜底代码太多还是真的漏掉了业务 case。
-
 +
+
 精准测试助力业务,质量更加稳定。
@@ -1394,3 +1611,5 @@ UITesting 还是建议在核心逻辑且长时间没有改动的情况下去做
WWDC 这张图也很清楚,UI 其实需要的占比较小,还是要靠单测驱动。
+
+##
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.89.md b/Chapter1 - iOS/1.89.md
index dfb663e..dbd4224 100644
--- a/Chapter1 - iOS/1.89.md
+++ b/Chapter1 - iOS/1.89.md
@@ -11,9 +11,9 @@
-## block 本质探索
+## 一、block 本质探索
-### 实验探索
+### 1. 实验探索
Demo
@@ -244,7 +244,7 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-### 结论
+### 2. 结论
通过探索发现:
@@ -260,9 +260,9 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-## block 变量捕获
+## 二、block 变量捕获
-### auto 变量捕获
+### 1. auto 变量捕获
> 在 C 和 Objective-C 编程语言中,`auto` 关键字用于声明自动存储期的变量。自动存储期的变量会在定义它们的块(block)或作用域(scope)中自动创建,并在退出该作用域时自动销毁。这是变量存储期的默认行为,因此 `auto` 关键字实际上是可选的,但有时候为了清晰起见,开发者可能会显式使用它。
@@ -322,7 +322,7 @@ c++ 中,在函数内部定义的变量,默认用 **auto** 修饰,叫做自
-### static 变量捕获
+### 2. static 变量捕获
```objective-c
auto NSInteger age = 27;
@@ -354,7 +354,7 @@ printInfoBlock();
-### 全局变量捕获
+### 3. 全局变量捕获
```objective-c
NSInteger age = 27;
@@ -405,7 +405,7 @@ QA:为什么局部变量存在捕获,全局变量不需要捕获?
-### 变量捕获总结
+### 4. 变量捕获总结
block 截获变量可以分为:
@@ -576,9 +576,9 @@ static void __Person__testBlockCapture_block_func_0(struct __Person__testBlockCa
-## block 类型
+## 三、block 类型
-### 类型划分
+### 1. 类型划分
我们知道 block 可以看成是一个 oc 对象,所以它有类型,写个 Demo1 验证下
@@ -619,7 +619,7 @@ block 的类型可以通过 isa 或者 class 方法查看,最终都是继承
-### 如何判断 block 属于什么类型
+### 2. 如何判断 block 属于什么类型
Demo:
@@ -651,7 +651,7 @@ Demo 也同时发现,当对 `__NSGlobalBlock__` 调用 copy ,不会变为 `
-### 总结
+### 3. 总结
| block 类型 | 环境 |
| ------------------- | ------------------------------ |
@@ -691,9 +691,9 @@ int main(int argc, const char * argv[]) {
-## 内存管理
+## 四、内存管理
-### ARC 针对 block 的优化
+### 1. ARC 针对 block 的优化
#### 1. block 作为函数返回值,并且捕获了 auto 变量
@@ -905,7 +905,7 @@ static struct __main_block_desc_0 {
-### block 的 copy、dispose
+### 2. block 的 copy、dispose
```c++
static struct __main_block_desc_0 {
@@ -1004,9 +1004,319 @@ NSLog(@"-touchesBegan:withEvent:");
2024-08-13 20:59:54.313367+0800 BlockExplore[29889:968688] (null)
```
-### block 如何修改变量
+### 3. _Block_release 和 _Block_copy
-#### __block 修饰基本数据类型
+Demo1
+
+```objective-c
+void test(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ void(^ __weak weakInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ weakBlock = weakInnerBlock;
+ }
+ weakBlock();
+}
+```
+
+- 定义了一个局部变量 weakBlock
+
+- 在 `{}` 内定义了一个栈上的 block **__NSStackBlock__** ,block 内访问了定义在 block 外部的 b
+
+- 将 weakInnerBlock 赋值给 weakBlock
+
+- 出了 `{}`,也意味着栈上的 block 作用域结束了。block 会调用 block_release 方法
+
+- 由于出了局部作用域,栈上的 block 被释放了。所以在 `{}` 外调用 weakBlock 则存在野指针风险。编译器也会报警告:`Assigning block literal to a weak variable; object will be released after assignment` 。但可能不崩溃:栈内存虽回收但未被新数据覆盖
+
+
+
+我们来看看 **block_release** 源码
+
+```c++
+void
+_Block_release(const void *src)
+{
+ struct StackBlockClass *self = (struct StackBlockClass *)src;
+ extern const void _NSConcreteStackBlock;
+
+ if (self->isa == &_NSConcreteStackBlock // 必须是栈块类型
+ // A Global block doesn't need to be released
+ && self->flags & BLOCK_HAS_DESCRIPTOR // 必须有描述符结构
+ // Should always be true...
+ && self->reserved > 0) // 引用计数大于0
+ // If false, then it's not allocated on the heap, we won't release auto memory !
+ {
+ self->reserved--;
+ if (self->reserved == 0)
+ {
+ if (self->flags & BLOCK_HAS_COPY_DISPOSE)
+ self->descriptor->dispose_helper(self);
+ free(self);
+ }
+ }
+}
+```
+
+说明:
+
+- `StackBlockClass` 表示栈 block 结构,包含:
+ - isa:指向块类型的指针(栈块为 `__NSConcreteStackBlock`)
+ - flag: 标志位( BLOCK_HAS_DESCRIPTOR 表示有描述符)
+ - reserved:引用计数器
+ - descriptor:包含析构函数 dispose_helper。当 block 捕获了 OC、C++ 对象后,编译器会自动设置此标志
+- 释放条件:
+ - 排除全局 block 和堆 block:全局block `__NSConcreteGlobalBlock` 和堆上的 block 无需释放。
+ - **栈块**:
+ 存储在栈内存中,生命周期与函数作用域绑定。
+ **需要手动管理**:通过 `_Block_copy()` 复制到堆时,需用 `_Block_release()` 平衡引用计数。
+ - **堆块**:
+ 由 `_Block_copy()` 动态分配在堆内存,受 ARC 管理。
+ **自动管理**:ARC 会自动插入 `objc_release()` 调用,使用标准 Objective-C 对象释放机制。
+ - 有效性检验:确保块结构完整且引用计数有效
+- 引用计数管理:
+ - `self->reserved--` 引用计数减 1
+ - 引用计数归0的时候,调用 dispose_helper 方法。释放 block 捕获的对象、内存
+ - 释放 block 结构体内存
+- 一般来说 block 由栈管理,但是被 copy、strong 等强引用作为属性或者参数,则会调用 **_Block_copy** 拷贝到堆上。本函数管理堆化后栈 block 的引用计数
+
+
+
+Demo2
+
+```c++
+void test2(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ // 栈 block 赋值给一个 strong或copy 修饰的强引用变量,则会调用 _Block_copy 方法拷贝到堆上,变成堆 block
+ void(^ __strong strongInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ // 结构体赋值,也就是此时 a 是一个堆上的 block
+ weakBlock = strongInnerBlock;
+ } // 离开作用域,堆上的 block 会自动调用 _Block_release 方法,内部会 free 掉,此时再去调用释放的内存,系统机制会为已经释放的内存填充 0xDEADBEEF 标记,MMU 也会触发缺页异常,发送 crash
+ weakBlock();
+}
+```
+
+现象:上面的代码会稳定 crash。报错:`Thread 1: EXC_BAD_ACCESS (code=1, address=0x10)`
+
+分析:
+
+- 在 `{}` 内定义初始化了一个栈 block
+- 赋值给一个由强指针指向的 strongInnerBlock 变量时,自动触发 `_Block_copy` 方法,复制到堆上,变为堆 block **__NSConcreteMallocBlock**
+- 然后通过结构体赋值的方式,赋值给 `weakBlock`
+- 要出 `{}` 作用域时,则会调用 `_block_release` 方法。堆块的引用计数清零。释放后,堆内存表记为不可访问
+- 此时调用 `weakBlock()` 则会 crash。访问已经释放的堆内存。系统在释放的堆内存上添加保护(如 `EXC_BAD_ACCESS`)
+
+test 和 test2 的本质区别
+
+| 函数 | 内存类型 | 内存回收机制 | 崩溃原因 |
+| :------ | :------- | :---------------------- | :--------------- |
+| `test` | 栈内存 | 系统自动回收(无保护) | 内存可能未被覆盖 |
+| `test2` | 堆内存 | `free()` + 内存保护标记 | 强制触发访问异常 |
+
+
+
+Demo3
+
+
精准测试助力业务,质量更加稳定。
@@ -1394,3 +1611,5 @@ UITesting 还是建议在核心逻辑且长时间没有改动的情况下去做

WWDC 这张图也很清楚,UI 其实需要的占比较小,还是要靠单测驱动。
+
+##
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.89.md b/Chapter1 - iOS/1.89.md
index dfb663e..dbd4224 100644
--- a/Chapter1 - iOS/1.89.md
+++ b/Chapter1 - iOS/1.89.md
@@ -11,9 +11,9 @@
-## block 本质探索
+## 一、block 本质探索
-### 实验探索
+### 1. 实验探索
Demo
@@ -244,7 +244,7 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-### 结论
+### 2. 结论
通过探索发现:
@@ -260,9 +260,9 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-## block 变量捕获
+## 二、block 变量捕获
-### auto 变量捕获
+### 1. auto 变量捕获
> 在 C 和 Objective-C 编程语言中,`auto` 关键字用于声明自动存储期的变量。自动存储期的变量会在定义它们的块(block)或作用域(scope)中自动创建,并在退出该作用域时自动销毁。这是变量存储期的默认行为,因此 `auto` 关键字实际上是可选的,但有时候为了清晰起见,开发者可能会显式使用它。
@@ -322,7 +322,7 @@ c++ 中,在函数内部定义的变量,默认用 **auto** 修饰,叫做自
-### static 变量捕获
+### 2. static 变量捕获
```objective-c
auto NSInteger age = 27;
@@ -354,7 +354,7 @@ printInfoBlock();
-### 全局变量捕获
+### 3. 全局变量捕获
```objective-c
NSInteger age = 27;
@@ -405,7 +405,7 @@ QA:为什么局部变量存在捕获,全局变量不需要捕获?
-### 变量捕获总结
+### 4. 变量捕获总结
block 截获变量可以分为:
@@ -576,9 +576,9 @@ static void __Person__testBlockCapture_block_func_0(struct __Person__testBlockCa
-## block 类型
+## 三、block 类型
-### 类型划分
+### 1. 类型划分
我们知道 block 可以看成是一个 oc 对象,所以它有类型,写个 Demo1 验证下
@@ -619,7 +619,7 @@ block 的类型可以通过 isa 或者 class 方法查看,最终都是继承
-### 如何判断 block 属于什么类型
+### 2. 如何判断 block 属于什么类型
Demo:
@@ -651,7 +651,7 @@ Demo 也同时发现,当对 `__NSGlobalBlock__` 调用 copy ,不会变为 `
-### 总结
+### 3. 总结
| block 类型 | 环境 |
| ------------------- | ------------------------------ |
@@ -691,9 +691,9 @@ int main(int argc, const char * argv[]) {
-## 内存管理
+## 四、内存管理
-### ARC 针对 block 的优化
+### 1. ARC 针对 block 的优化
#### 1. block 作为函数返回值,并且捕获了 auto 变量
@@ -905,7 +905,7 @@ static struct __main_block_desc_0 {
-### block 的 copy、dispose
+### 2. block 的 copy、dispose
```c++
static struct __main_block_desc_0 {
@@ -1004,9 +1004,319 @@ NSLog(@"-touchesBegan:withEvent:");
2024-08-13 20:59:54.313367+0800 BlockExplore[29889:968688] (null)
```
-### block 如何修改变量
+### 3. _Block_release 和 _Block_copy
-#### __block 修饰基本数据类型
+Demo1
+
+```objective-c
+void test(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ void(^ __weak weakInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ weakBlock = weakInnerBlock;
+ }
+ weakBlock();
+}
+```
+
+- 定义了一个局部变量 weakBlock
+
+- 在 `{}` 内定义了一个栈上的 block **__NSStackBlock__** ,block 内访问了定义在 block 外部的 b
+
+- 将 weakInnerBlock 赋值给 weakBlock
+
+- 出了 `{}`,也意味着栈上的 block 作用域结束了。block 会调用 block_release 方法
+
+- 由于出了局部作用域,栈上的 block 被释放了。所以在 `{}` 外调用 weakBlock 则存在野指针风险。编译器也会报警告:`Assigning block literal to a weak variable; object will be released after assignment` 。但可能不崩溃:栈内存虽回收但未被新数据覆盖
+
+
+
+我们来看看 **block_release** 源码
+
+```c++
+void
+_Block_release(const void *src)
+{
+ struct StackBlockClass *self = (struct StackBlockClass *)src;
+ extern const void _NSConcreteStackBlock;
+
+ if (self->isa == &_NSConcreteStackBlock // 必须是栈块类型
+ // A Global block doesn't need to be released
+ && self->flags & BLOCK_HAS_DESCRIPTOR // 必须有描述符结构
+ // Should always be true...
+ && self->reserved > 0) // 引用计数大于0
+ // If false, then it's not allocated on the heap, we won't release auto memory !
+ {
+ self->reserved--;
+ if (self->reserved == 0)
+ {
+ if (self->flags & BLOCK_HAS_COPY_DISPOSE)
+ self->descriptor->dispose_helper(self);
+ free(self);
+ }
+ }
+}
+```
+
+说明:
+
+- `StackBlockClass` 表示栈 block 结构,包含:
+ - isa:指向块类型的指针(栈块为 `__NSConcreteStackBlock`)
+ - flag: 标志位( BLOCK_HAS_DESCRIPTOR 表示有描述符)
+ - reserved:引用计数器
+ - descriptor:包含析构函数 dispose_helper。当 block 捕获了 OC、C++ 对象后,编译器会自动设置此标志
+- 释放条件:
+ - 排除全局 block 和堆 block:全局block `__NSConcreteGlobalBlock` 和堆上的 block 无需释放。
+ - **栈块**:
+ 存储在栈内存中,生命周期与函数作用域绑定。
+ **需要手动管理**:通过 `_Block_copy()` 复制到堆时,需用 `_Block_release()` 平衡引用计数。
+ - **堆块**:
+ 由 `_Block_copy()` 动态分配在堆内存,受 ARC 管理。
+ **自动管理**:ARC 会自动插入 `objc_release()` 调用,使用标准 Objective-C 对象释放机制。
+ - 有效性检验:确保块结构完整且引用计数有效
+- 引用计数管理:
+ - `self->reserved--` 引用计数减 1
+ - 引用计数归0的时候,调用 dispose_helper 方法。释放 block 捕获的对象、内存
+ - 释放 block 结构体内存
+- 一般来说 block 由栈管理,但是被 copy、strong 等强引用作为属性或者参数,则会调用 **_Block_copy** 拷贝到堆上。本函数管理堆化后栈 block 的引用计数
+
+
+
+Demo2
+
+```c++
+void test2(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ // 栈 block 赋值给一个 strong或copy 修饰的强引用变量,则会调用 _Block_copy 方法拷贝到堆上,变成堆 block
+ void(^ __strong strongInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ // 结构体赋值,也就是此时 a 是一个堆上的 block
+ weakBlock = strongInnerBlock;
+ } // 离开作用域,堆上的 block 会自动调用 _Block_release 方法,内部会 free 掉,此时再去调用释放的内存,系统机制会为已经释放的内存填充 0xDEADBEEF 标记,MMU 也会触发缺页异常,发送 crash
+ weakBlock();
+}
+```
+
+现象:上面的代码会稳定 crash。报错:`Thread 1: EXC_BAD_ACCESS (code=1, address=0x10)`
+
+分析:
+
+- 在 `{}` 内定义初始化了一个栈 block
+- 赋值给一个由强指针指向的 strongInnerBlock 变量时,自动触发 `_Block_copy` 方法,复制到堆上,变为堆 block **__NSConcreteMallocBlock**
+- 然后通过结构体赋值的方式,赋值给 `weakBlock`
+- 要出 `{}` 作用域时,则会调用 `_block_release` 方法。堆块的引用计数清零。释放后,堆内存表记为不可访问
+- 此时调用 `weakBlock()` 则会 crash。访问已经释放的堆内存。系统在释放的堆内存上添加保护(如 `EXC_BAD_ACCESS`)
+
+test 和 test2 的本质区别
+
+| 函数 | 内存类型 | 内存回收机制 | 崩溃原因 |
+| :------ | :------- | :---------------------- | :--------------- |
+| `test` | 栈内存 | 系统自动回收(无保护) | 内存可能未被覆盖 |
+| `test2` | 堆内存 | `free()` + 内存保护标记 | 强制触发访问异常 |
+
+
+
+Demo3
+
+ +
+为什么上面的代码会 crash?
+
+- weakBlock 是一个栈 block(__NSConcreteStackBlock)
+- GCD 代码以 block 的形式将延迟任务添加到主队列中
+- `dispatch_block_t` 内部捕获了 block,但捕获的是原始指针,未复制 block
+- GCD 不会阻塞,函数会结束,同时栈 block 会被回收,栈帧销毁。此时 `dispatch_block_t` 内持有其悬挂指针。
+- 3s 后开始执行 dispatch_block_t 所指向的 weakBlock
+- 发现 weakBlock 所指向的栈内存被回收,调用无效指针导致 **EXC_BAD_ACCESS** 崩溃(访问野指针)。
+
+
+
+解决方案:
+
+1. 将栈 block 改为堆 block。block 修饰改为 strong
+
+ ````objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__strong block)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ block();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ }
+ ````
+
+2. 复制 block 到堆
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), [weakBlock copy]);
+ }
+ ```
+
+3. 栈帧不要回收。开启一个 RunLoop 晚退出3秒
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ weakBlock();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ [[NSRunLoop currentRunLoop] runUntilDate:[NSDate dateWithTimeIntervalSinceNow:3]];
+ }
+ ```
+
+
+
+Demo4
+
+
+
+为什么上面的代码会 crash?
+
+- weakBlock 是一个栈 block(__NSConcreteStackBlock)
+- GCD 代码以 block 的形式将延迟任务添加到主队列中
+- `dispatch_block_t` 内部捕获了 block,但捕获的是原始指针,未复制 block
+- GCD 不会阻塞,函数会结束,同时栈 block 会被回收,栈帧销毁。此时 `dispatch_block_t` 内持有其悬挂指针。
+- 3s 后开始执行 dispatch_block_t 所指向的 weakBlock
+- 发现 weakBlock 所指向的栈内存被回收,调用无效指针导致 **EXC_BAD_ACCESS** 崩溃(访问野指针)。
+
+
+
+解决方案:
+
+1. 将栈 block 改为堆 block。block 修饰改为 strong
+
+ ````objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__strong block)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ block();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ }
+ ````
+
+2. 复制 block 到堆
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), [weakBlock copy]);
+ }
+ ```
+
+3. 栈帧不要回收。开启一个 RunLoop 晚退出3秒
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ weakBlock();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ [[NSRunLoop currentRunLoop] runUntilDate:[NSDate dateWithTimeIntervalSinceNow:3]];
+ }
+ ```
+
+
+
+Demo4
+
+ +
+分析:
+
+- block 本质就是结构体
+
+- `void (^__strong strongBlock)(void) = weakBlock;` 看上去左侧是一个 `__strong` 修饰,其实就是结构体,所以不会像对象一样,底层调用 setter 方法。所以 block 的赋值本就是按照结构体的成员变量一个个字段简单赋值而已。
+
+ ```c++
+ struct __block_impl {
+ void *isa; // 指向 Block 类 (栈上)
+ int flags; // 标志位 (栈上)
+ int reserved; // 保留字段 (栈上)
+ void (*invoke)(void); // 函数指针 (代码段)
+ struct __block_descriptor *descriptor; // 描述符指针 (栈上)
+ };
+
+ struct __block_descriptor {
+ unsigned long reserved; // 保留字段 (栈上)
+ unsigned long size; // Block 大小 (栈上)
+ void (*copy)(void); // copy 辅助函数 (代码段)
+ void (*dispose)(void); // dispose 辅助函数 (代码段)
+ };
+ ```
+
+- 当把结构体 block 的 invoke 设为 nil,由于是简单赋值,所以原来的 weakblock 的 invoke 也为 nil
+
+- 所以 strongblock 的 invoke 也为 nil,所以执行 block 底层就是先判断 block 的 isa、然后根据 invoke 指针,找到代码段的函数去执行。此时已经为 nil,再去执行就会 crash
+
+解决方案:将 weakblock copy 一下,即 `void (^__strong strongBlock)(void) = [weakBlock copy];`
+
+
+
+### 4. 栈内存、堆内存保护机制
+
+通过上面 test 和 test2 知道,栈内存、堆内存在释放后继续访问存在不同的表现
+
+#### 1. 栈内存
+
+##### 1. 栈内存的本质上是:
+
+- **线性结构**:栈是连续的内存区域,通过栈指针(SP)管理
+- **自动回收**:函数退出时,只需移动栈指针即可"释放"内存
+- **物理内存不变**:移动栈指针不会立即清除数据,原内存内容保持不变
+
+##### 2. 访问已释放的内存为何可能不崩溃?
+
+- 无硬件保护:CPU 和 MMU(内存管理单元)不跟踪栈帧生命周期
+- 内存数据保留:除非被新的栈帧覆盖,否则数据仍可被读取
+
+##### 3. 不崩溃的深层原因:
+
+- 无页表标记:栈内存页始终标记为:可读写 (PROT_READ|PORT_WRITE)
+- 无隔离机制:不同函数的栈帧共享同一内存页
+- 延迟覆盖:新栈帧写入前,元数据保持有效
+
+
+
+
+
+#### 2. 堆内存
+
+##### 1. 堆内存管理的核心机制:
+
+- malloc -> 向内核申请内存页 -> 设置页表属性 -> 分配内存块
+- free -> 标记内存页属性 -> 加入空闲链表 -> 触发内存页回收
+
+##### 2. free 后的关键操作
+
+内存标记
+
+````objective-c
+// 典型内存分配器实现
+void free(void *ptr) {
+ // 1. 在内存块头部写入魔数(如0xDEADBEEF)
+ *(uint32_t*)(ptr - 4) = 0xDEADBEEF;
+
+ // 2. 通过 mprotect 设置内存页不可访问
+ mprotect(ALIGN_PAGE(ptr), PAGE_SIZE, PROT_NONE);
+}
+````
+
+页表更新
+
+| 状态 | 页表项标志位 | 访问后果 |
+| :--- | :-------------- | :----------- |
+| 正常 | PRESENT+RW+USER | 允许访问 |
+| 释放 | ~PRESENT | 触发缺页异常 |
+
+稳定崩溃的硬件基础:
+
+MMU 介入:当访问 `PROT_NONE` 内存页时:
+
+1. 触发缺页一场(Page Fault)
+2. 内核检查异常地址
+3. 发送 `SIGSEGV` 信号
+4. 进程终止(崩溃)
+
+#### 3. iOS/Macos 优化
+
+##### 1. 堆内存保护优化
+
+- Malloc Scribble:释放后填充`0x55`(调试模式默认启用)
+
+- Zone-based Protection:
+
+ ```objective-c
+ malloc_zone_t *zone = malloc_create_zone(0, 0);
+ malloc_set_zone_name(zone, "Protected Zone");
+ malloc_zone_protect(zone, 1); // 启用保护
+ ```
+
+##### 2. 栈内存的刻意放松
+
+- **性能优先**:避免栈操作时的权限检查
+- **安全边界**:仅防止栈溢出,不保护栈帧间访问
+
+
+
+### 5. block 如何修改变量
+
+#### 1. __block 修饰基本数据类型
```objectivec
typedef void(^MyBlock)(void);
@@ -1178,7 +1488,7 @@ __attribute__((__blocks__(byref))) __Block_byref_num2_0 num2 = {(void*)0,(__Bloc
-#### __block 修饰对象
+#### 2. __block 修饰对象
对` __block` 修饰的对象,clang 转换为 c++ 后如下:
@@ -1307,13 +1617,13 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-#### 什么情况下需要 __block
+#### 3. 什么情况下需要 __block
局部变量:基本数据类型、对象数据类型
-#### 什么情况下不需要 __block
+#### 4. 什么情况下不需要 __block
- 全局变量(不截获)
- 静态全局变量(不截获)
@@ -1323,7 +1633,7 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-## `__forwarding` 的设计
+## 五、`__forwarding` 的设计
Demo1
@@ -1587,7 +1897,7 @@ Tips:实现 block 拷贝及其捕获对象的函数是 `_Block_copy`,工作
-## Block 内存引用
+## 六、Block 内存引用
对于` __block` 修饰的变量进行研究
@@ -1803,7 +2113,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
-## 循环引用
+## 七. 循环引用
self 是一个局部变量,block 访问 self,即存在捕获变量的效果。
@@ -1817,7 +2127,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
可以看到 Person 对象的 dealloc 方法没有执行,里面的打印信息没有输出。
-### ARC 下
+### 1. ARC 下
`__weak`、`__unsafe_unretained` 修饰 `__block` 所修饰的变量。区别在于:
@@ -1880,7 +2190,7 @@ p.block();
-### MRC 下
+### 2. MRC 下
方法1: `__unsafe_retained` 修饰。`__unsafe_unretained typeof(self) weakself = self;`
@@ -1888,7 +2198,7 @@ p.block();
-## 为什么加 weakself、strongself
+## 八、为什么加 weakself、strongself
weakSelf 是为了使 block 不持有 self,避免 Retain Circle 循环引用。在 Block 内如果需要访问 self 的方法、变量,建议使用 weakSelf。
@@ -1922,7 +2232,9 @@ block 执行完后这个 strongSelf 会自动释放,没有不会存在循环
});
```
-## 总结
+
+
+## 九、总结
1. block 本质是什么?封装了函数调用及其调用环境的 OC 对象。本质实现是一个结构体。
2. `__block` 的作用是什么?可以对 block 外部的变量进行捕获,可以修改。但是需要注意内存管理相关问题。比如`__weak`、`__unsafe_unretained`、`__block`
diff --git a/Chapter1 - iOS/1.91.md b/Chapter1 - iOS/1.91.md
index aef2391..2d9a590 100644
--- a/Chapter1 - iOS/1.91.md
+++ b/Chapter1 - iOS/1.91.md
@@ -1,10 +1,10 @@
# DYLD 及 Mach-O
-> 动态库还是静态库对包体积影响大?
+> 链接动态库还是静态库对 App l包体积影响大?
>
> 动态库、静态库编译链接都做了哪些事情?链接的要素是什么?
>
-> Moudle 是什么?
+> Module 是什么?
>
> 如果这些问题不是很清楚,可以带着问题看看本文。
@@ -1149,6 +1149,44 @@ clang 编译、链接的参数解释如下:
-framework
+
+分析:
+
+- block 本质就是结构体
+
+- `void (^__strong strongBlock)(void) = weakBlock;` 看上去左侧是一个 `__strong` 修饰,其实就是结构体,所以不会像对象一样,底层调用 setter 方法。所以 block 的赋值本就是按照结构体的成员变量一个个字段简单赋值而已。
+
+ ```c++
+ struct __block_impl {
+ void *isa; // 指向 Block 类 (栈上)
+ int flags; // 标志位 (栈上)
+ int reserved; // 保留字段 (栈上)
+ void (*invoke)(void); // 函数指针 (代码段)
+ struct __block_descriptor *descriptor; // 描述符指针 (栈上)
+ };
+
+ struct __block_descriptor {
+ unsigned long reserved; // 保留字段 (栈上)
+ unsigned long size; // Block 大小 (栈上)
+ void (*copy)(void); // copy 辅助函数 (代码段)
+ void (*dispose)(void); // dispose 辅助函数 (代码段)
+ };
+ ```
+
+- 当把结构体 block 的 invoke 设为 nil,由于是简单赋值,所以原来的 weakblock 的 invoke 也为 nil
+
+- 所以 strongblock 的 invoke 也为 nil,所以执行 block 底层就是先判断 block 的 isa、然后根据 invoke 指针,找到代码段的函数去执行。此时已经为 nil,再去执行就会 crash
+
+解决方案:将 weakblock copy 一下,即 `void (^__strong strongBlock)(void) = [weakBlock copy];`
+
+
+
+### 4. 栈内存、堆内存保护机制
+
+通过上面 test 和 test2 知道,栈内存、堆内存在释放后继续访问存在不同的表现
+
+#### 1. 栈内存
+
+##### 1. 栈内存的本质上是:
+
+- **线性结构**:栈是连续的内存区域,通过栈指针(SP)管理
+- **自动回收**:函数退出时,只需移动栈指针即可"释放"内存
+- **物理内存不变**:移动栈指针不会立即清除数据,原内存内容保持不变
+
+##### 2. 访问已释放的内存为何可能不崩溃?
+
+- 无硬件保护:CPU 和 MMU(内存管理单元)不跟踪栈帧生命周期
+- 内存数据保留:除非被新的栈帧覆盖,否则数据仍可被读取
+
+##### 3. 不崩溃的深层原因:
+
+- 无页表标记:栈内存页始终标记为:可读写 (PROT_READ|PORT_WRITE)
+- 无隔离机制:不同函数的栈帧共享同一内存页
+- 延迟覆盖:新栈帧写入前,元数据保持有效
+
+
+
+
+
+#### 2. 堆内存
+
+##### 1. 堆内存管理的核心机制:
+
+- malloc -> 向内核申请内存页 -> 设置页表属性 -> 分配内存块
+- free -> 标记内存页属性 -> 加入空闲链表 -> 触发内存页回收
+
+##### 2. free 后的关键操作
+
+内存标记
+
+````objective-c
+// 典型内存分配器实现
+void free(void *ptr) {
+ // 1. 在内存块头部写入魔数(如0xDEADBEEF)
+ *(uint32_t*)(ptr - 4) = 0xDEADBEEF;
+
+ // 2. 通过 mprotect 设置内存页不可访问
+ mprotect(ALIGN_PAGE(ptr), PAGE_SIZE, PROT_NONE);
+}
+````
+
+页表更新
+
+| 状态 | 页表项标志位 | 访问后果 |
+| :--- | :-------------- | :----------- |
+| 正常 | PRESENT+RW+USER | 允许访问 |
+| 释放 | ~PRESENT | 触发缺页异常 |
+
+稳定崩溃的硬件基础:
+
+MMU 介入:当访问 `PROT_NONE` 内存页时:
+
+1. 触发缺页一场(Page Fault)
+2. 内核检查异常地址
+3. 发送 `SIGSEGV` 信号
+4. 进程终止(崩溃)
+
+#### 3. iOS/Macos 优化
+
+##### 1. 堆内存保护优化
+
+- Malloc Scribble:释放后填充`0x55`(调试模式默认启用)
+
+- Zone-based Protection:
+
+ ```objective-c
+ malloc_zone_t *zone = malloc_create_zone(0, 0);
+ malloc_set_zone_name(zone, "Protected Zone");
+ malloc_zone_protect(zone, 1); // 启用保护
+ ```
+
+##### 2. 栈内存的刻意放松
+
+- **性能优先**:避免栈操作时的权限检查
+- **安全边界**:仅防止栈溢出,不保护栈帧间访问
+
+
+
+### 5. block 如何修改变量
+
+#### 1. __block 修饰基本数据类型
```objectivec
typedef void(^MyBlock)(void);
@@ -1178,7 +1488,7 @@ __attribute__((__blocks__(byref))) __Block_byref_num2_0 num2 = {(void*)0,(__Bloc
-#### __block 修饰对象
+#### 2. __block 修饰对象
对` __block` 修饰的对象,clang 转换为 c++ 后如下:
@@ -1307,13 +1617,13 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-#### 什么情况下需要 __block
+#### 3. 什么情况下需要 __block
局部变量:基本数据类型、对象数据类型
-#### 什么情况下不需要 __block
+#### 4. 什么情况下不需要 __block
- 全局变量(不截获)
- 静态全局变量(不截获)
@@ -1323,7 +1633,7 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-## `__forwarding` 的设计
+## 五、`__forwarding` 的设计
Demo1
@@ -1587,7 +1897,7 @@ Tips:实现 block 拷贝及其捕获对象的函数是 `_Block_copy`,工作
-## Block 内存引用
+## 六、Block 内存引用
对于` __block` 修饰的变量进行研究
@@ -1803,7 +2113,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
-## 循环引用
+## 七. 循环引用
self 是一个局部变量,block 访问 self,即存在捕获变量的效果。
@@ -1817,7 +2127,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
可以看到 Person 对象的 dealloc 方法没有执行,里面的打印信息没有输出。
-### ARC 下
+### 1. ARC 下
`__weak`、`__unsafe_unretained` 修饰 `__block` 所修饰的变量。区别在于:
@@ -1880,7 +2190,7 @@ p.block();
-### MRC 下
+### 2. MRC 下
方法1: `__unsafe_retained` 修饰。`__unsafe_unretained typeof(self) weakself = self;`
@@ -1888,7 +2198,7 @@ p.block();
-## 为什么加 weakself、strongself
+## 八、为什么加 weakself、strongself
weakSelf 是为了使 block 不持有 self,避免 Retain Circle 循环引用。在 Block 内如果需要访问 self 的方法、变量,建议使用 weakSelf。
@@ -1922,7 +2232,9 @@ block 执行完后这个 strongSelf 会自动释放,没有不会存在循环
});
```
-## 总结
+
+
+## 九、总结
1. block 本质是什么?封装了函数调用及其调用环境的 OC 对象。本质实现是一个结构体。
2. `__block` 的作用是什么?可以对 block 外部的变量进行捕获,可以修改。但是需要注意内存管理相关问题。比如`__weak`、`__unsafe_unretained`、`__block`
diff --git a/Chapter1 - iOS/1.91.md b/Chapter1 - iOS/1.91.md
index aef2391..2d9a590 100644
--- a/Chapter1 - iOS/1.91.md
+++ b/Chapter1 - iOS/1.91.md
@@ -1,10 +1,10 @@
# DYLD 及 Mach-O
-> 动态库还是静态库对包体积影响大?
+> 链接动态库还是静态库对 App l包体积影响大?
>
> 动态库、静态库编译链接都做了哪些事情?链接的要素是什么?
>
-> Moudle 是什么?
+> Module 是什么?
>
> 如果这些问题不是很清楚,可以带着问题看看本文。
@@ -1149,6 +1149,44 @@ clang 编译、链接的参数解释如下:
-framework 指定链接的framework名称 other link flags -framework AFNetworking
```
+说明:
+
+- `-I` 参数
+
+ ```shell
+ # Xcode
+ Header Search Paths: /path/Headers
+ # 等价于 Clang
+ clang -I/path/Headers
+ ```
+
+- `-I` + 通配符:
+
+ ```shell
+ # Xcode
+ Header Search Paths: /path/libs/**
+ # 等价于 Clang
+ clang -I/path/libs/subdir1 -I/path/libs/subdir2 ...
+ ```
+
+- 系统头文件参数:`-isystem`
+
+ ```shell
+ # Xcode
+ Header Search Paths: system /path/system_headers
+ # 等价于 Clang
+ clang -isystem /path/system_headers ...
+ ```
+
+- `-framework` 参数
+
+ ```shell
+ # Xcode
+ Framework Search Paths: /path/framework/Headers
+ # 等价于 Clang
+ clang -F /path/framework/Headers
+ ```
+
### 2. 静态库就是 .o 文件的合集
@@ -1269,25 +1307,283 @@ clang -target x86_64-apple-macos13.1 \
-## 六、 Strip 流程
+### 6. 静态库冲突
+
+#### 1. 情景模拟
+
+##### 1. Demo1
+一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库。再将另一个 `libAFNetworking.a` 以静态库的形式引入了 AFNetworking。
+
+ +
+
+现象:工程编译成功。编译链接后,运行输出打印信息。
+问题:为什么2个同样的静态库,没有链接失败?
+分析:
+- 直接在 Xcode 中手动拖入一个静态库/动态库,本质是将库的路径写到 OTHER_LDFLAGS 后面。Xcode 会按照指定的路径去加载静态库/动态库。
+ ```shell
+ OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking" "/Users/unix_kernel/Desktop/编译链接/LDAndFramework/StaticLibConflictsSolution/StaticLibConflictsDemo/AFNetworking"`
+ ```
+- 但链接器很聪明,当发现同名的库的时候,会优先链接找到的第一个库库,第二个库不会被链接。
+- 即使将 `OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking"` 中的 `-ObjC` 改为 `-all_load` 也不会存在链接问题。本质是链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题
+
+
+
+##### 2. Demo2
+
+一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库,再将另一个 `libAFNetworking.a` 静态库改名为 `libAFNetworkingCopy.a`,然后引入 Xcode 工程。
+
+
+
+
+现象:工程编译成功。编译链接后,运行输出打印信息。
+问题:为什么2个同样的静态库,没有链接失败?
+分析:
+- 直接在 Xcode 中手动拖入一个静态库/动态库,本质是将库的路径写到 OTHER_LDFLAGS 后面。Xcode 会按照指定的路径去加载静态库/动态库。
+ ```shell
+ OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking" "/Users/unix_kernel/Desktop/编译链接/LDAndFramework/StaticLibConflictsSolution/StaticLibConflictsDemo/AFNetworking"`
+ ```
+- 但链接器很聪明,当发现同名的库的时候,会优先链接找到的第一个库库,第二个库不会被链接。
+- 即使将 `OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking"` 中的 `-ObjC` 改为 `-all_load` 也不会存在链接问题。本质是链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题
+
+
+
+##### 2. Demo2
+
+一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库,再将另一个 `libAFNetworking.a` 静态库改名为 `libAFNetworkingCopy.a`,然后引入 Xcode 工程。
+
+ +
+ +
+现象:工程链接失败。报错:`Issues223 duplicate symbols for architecture x86_64`
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+##### 3. Demo3
+
+- 一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库
+- 然后 Xcode 新创建一个静态库,选择 `Static Library`
+- 新创建的静态库就1个 `AFNetworkingMock` 文件。不过类里面还存在一个类 `AFURLSessionManager` 和一个全局函数 `global_function`
+
+现象:工程链接失败。报错:`error: duplicate interface definition for class 'AFURLSessionManager'`
+
+
+现象:工程链接失败。报错:`Issues223 duplicate symbols for architecture x86_64`
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+##### 3. Demo3
+
+- 一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库
+- 然后 Xcode 新创建一个静态库,选择 `Static Library`
+- 新创建的静态库就1个 `AFNetworkingMock` 文件。不过类里面还存在一个类 `AFURLSessionManager` 和一个全局函数 `global_function`
+
+现象:工程链接失败。报错:`error: duplicate interface definition for class 'AFURLSessionManager'`
+ +
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+#### 2. 解决方案
+
+2个静态库有符号冲突怎么办?且一个静态库没有源码。[llvm-objcopy](https://llvm.org/docs/CommandGuide/llvm-objcopy.html) 这个工具刚好有能力在静态库基础上直接修改符号名称。
+
+##### 1. 收集需要重命名的符号
+通过 **objdump --macho -t ${MACH_PATH}** 就可以输出符号信息。Demo 中需要重命名的符号如下:
+
+
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+#### 2. 解决方案
+
+2个静态库有符号冲突怎么办?且一个静态库没有源码。[llvm-objcopy](https://llvm.org/docs/CommandGuide/llvm-objcopy.html) 这个工具刚好有能力在静态库基础上直接修改符号名称。
+
+##### 1. 收集需要重命名的符号
+通过 **objdump --macho -t ${MACH_PATH}** 就可以输出符号信息。Demo 中需要重命名的符号如下:
+ +
+
+
+
+
+##### 2. 编译 llvm-objcopy 产出工具
+
+关于 LLVM 如何编译运行,或者开发 pass 可以查看 [LLVM 编译运行](./1.102.md#编写-xcode-插件)
+
+打开 LLVM 工程,Scheme 切换为 `llvm-objcopy` 然后编译运行,从 Products 目录下将产物拷贝到个人电脑的 CustomTools 文件夹,后续就可以在终端访问 llvm-objcopy 指令。(因为在 `.zshrc` 文件里配置过 `export PATH=~/CustomTools:$PATH`)
+
+
+
+
+
+
+##### 2. 编译 llvm-objcopy 产出工具
+
+关于 LLVM 如何编译运行,或者开发 pass 可以查看 [LLVM 编译运行](./1.102.md#编写-xcode-插件)
+
+打开 LLVM 工程,Scheme 切换为 `llvm-objcopy` 然后编译运行,从 Products 目录下将产物拷贝到个人电脑的 CustomTools 文件夹,后续就可以在终端访问 llvm-objcopy 指令。(因为在 `.zshrc` 文件里配置过 `export PATH=~/CustomTools:$PATH`)
+ +这样就说明已经成功了
+
+这样就说明已经成功了
+ +
+
+然后改造 Demo 工程静态库的脚本为 **llvm-objcopy --prefix-symbols=FantasticLBP_ ${MACH_PATH}** 去给冲突的符号加前缀 `FantasticLBP_`(当然这个前缀名字可以是 SDK 名称简写、业务线简写,我这里是 Github ID ,验证问题而已)。
+
+结果:但发现运行报错,提示 `llvm-objcopy: command not found`
+
+
+
+然后改造 Demo 工程静态库的脚本为 **llvm-objcopy --prefix-symbols=FantasticLBP_ ${MACH_PATH}** 去给冲突的符号加前缀 `FantasticLBP_`(当然这个前缀名字可以是 SDK 名称简写、业务线简写,我这里是 Github ID ,验证问题而已)。
+
+结果:但发现运行报错,提示 `llvm-objcopy: command not found`
+ +
+改进:将 `llvm-objcopy` 移动到源码根目录下,现在 `Command not found` 的问题解决了,但是报错: **error: option is not supported for MachO**
+
+
+改进:将 `llvm-objcopy` 移动到源码根目录下,现在 `Command not found` 的问题解决了,但是报错: **error: option is not supported for MachO**
+ +说明 `--prefix-symbols` 并不支持 MachO 格式。而 `--redefine-sym` 符合要求。
+
+打开 llvm 源码进行调试,配置启动参数。
+
+说明 `--prefix-symbols` 并不支持 MachO 格式。而 `--redefine-sym` 符合要求。
+
+打开 llvm 源码进行调试,配置启动参数。
+ +发现修改成功
+
+发现修改成功
+ +
+上面演示了单个修改符号名称的过程。llvm-objcopy 可以批量修改。
+- 指令改为 `--redefine-syms`。
+- 用一个文件,格式为空格和换行来区别。
+ ```
+ _OBJC_CLASS_$_AFURLSessionManager FantasticLBP__OBJC_CLASS_$_AFURLSessionManager
+ _OBJC_METACLASS_$_AFURLSessionManager FantasticLBP__OBJC_METACLASS_$_AFURLSessionManager
+ _OBJC_IVAR_$_AFURLSessionManager._session FantasticLBP__OBJC_IVAR_$_AFURLSessionManager._session
+ ```
+ 修改后运行,发现批量符号修改成功。
+
+
+上面演示了单个修改符号名称的过程。llvm-objcopy 可以批量修改。
+- 指令改为 `--redefine-syms`。
+- 用一个文件,格式为空格和换行来区别。
+ ```
+ _OBJC_CLASS_$_AFURLSessionManager FantasticLBP__OBJC_CLASS_$_AFURLSessionManager
+ _OBJC_METACLASS_$_AFURLSessionManager FantasticLBP__OBJC_METACLASS_$_AFURLSessionManager
+ _OBJC_IVAR_$_AFURLSessionManager._session FantasticLBP__OBJC_IVAR_$_AFURLSessionManager._session
+ ```
+ 修改后运行,发现批量符号修改成功。
+  +
+
+
+##### 3. 使用工具修改符号名称
+
+利用 llvm-objcopy 的能力,修改重名的符号后测试下。
+
+
+
+
+##### 3. 使用工具修改符号名称
+
+利用 llvm-objcopy 的能力,修改重名的符号后测试下。
+ +
+可以看到:
+
+- 符号冲突的问题解决了
+- 但同一个符号存在2处实现,当两个同名类被加载时,运行时随机选择一个
+
+
+
+##### 4. 为什么存在2处类定义?
+
+```mermaid
+graph LR
+A[AFURLSessionManager] --> B[_OBJC_CLASS_$_AFURLSessionManager]
+A --> C[_OBJC_METACLASS_$_AFURLSessionManager]
+A --> D[“__objc_classname” 段中的字符串]
+```
+
+**通过 llvm-objcopy 只是修改了 `_OBJC_CLASS_$` 符号而忽略 `_OBJC_METACLASS_$` 和类名字符串,运行时仍会看到两个类定义,导致冲突未解决**
+而且和运行时系统相关的所有功能都会受影响,比如:Category、KVC/KVO 内部使用类名字符串查找、Archive/Unarchive 崩溃等。
+
+所以这种方式存在巨大风险,这里只是从技术研究角度出发,证明可以这么做,但是影响面太大。
+另外一种方式:2个不同名的静态库,但存在相同符号。可以通过 cocoapods 的配置,将某个静态库改为动态库。因为动态库存在二级命名空间,就可以避免符号重复的问题。
+关于动态库二级命名空间的细节,可以查看[这里](#twoLevelNamespace)
+
+方案 1:单个库转为动态库
+```ruby
+# Podfile
+use_frameworks! # 启用框架支持
+
+target 'YourApp' do
+ pod 'AFNetworking', '~> 4.0' # 默认静态库
+
+ # 将冲突库转为动态框架
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+end
+```
+方案 2:指定模块为动态框架
+```ruby
+dynamic_frameworks = ['ConflictingLib']
+
+target 'YourApp' do
+ # 先声明所有库
+ pods = [
+ 'AFNetworking',
+ 'ConflictingLib',
+ 'OtherLib'
+ ]
+
+ # 动态处理
+ pods.each do |pod|
+ if dynamic_frameworks.include?(pod)
+ pod pod, :modular_headers => true, :linkage => :dynamic
+ else
+ pod pod
+ end
+ end
+end
+```
+实验:我的电脑 cocoapods 版本较低,采用下面写法
+```ruby
+platform :ios, '9.0'
+use_frameworks! # 确保启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 动态链接 AFNetworking(兼容所有版本)
+ pod 'AFNetworking', :modular_headers => true
+
+ # 添加后安装钩子脚本
+ post_install do |installer|
+ # 将 AFNetworking 设为动态框架
+ installer.pods_project.targets.each do |target|
+ if target.name == 'AFNetworking'
+ # 设置 Mach-O 类型为动态库
+ target.build_configurations.each do |config|
+ config.build_settings['MACH_O_TYPE'] = 'mh_dylib'
+ config.build_settings['DYLIB_INSTALL_NAME_BASE'] = '@rpath'
+ config.build_settings['LD_RUNPATH_SEARCH_PATHS'] = ['$(FRAMEWORK_SEARCH_PATHS)']
+ end
+ end
+ end
+
+ # 确保框架被正确嵌入
+ installer.pods_project.build_configurations.each do |config|
+ config.build_settings['EMBEDDED_CONTENT_CONTAINS_SWIFT'] = 'YES'
+ end
+ end
+end
+```
+效果:
+
+
+可以看到:
+
+- 符号冲突的问题解决了
+- 但同一个符号存在2处实现,当两个同名类被加载时,运行时随机选择一个
+
+
+
+##### 4. 为什么存在2处类定义?
+
+```mermaid
+graph LR
+A[AFURLSessionManager] --> B[_OBJC_CLASS_$_AFURLSessionManager]
+A --> C[_OBJC_METACLASS_$_AFURLSessionManager]
+A --> D[“__objc_classname” 段中的字符串]
+```
+
+**通过 llvm-objcopy 只是修改了 `_OBJC_CLASS_$` 符号而忽略 `_OBJC_METACLASS_$` 和类名字符串,运行时仍会看到两个类定义,导致冲突未解决**
+而且和运行时系统相关的所有功能都会受影响,比如:Category、KVC/KVO 内部使用类名字符串查找、Archive/Unarchive 崩溃等。
+
+所以这种方式存在巨大风险,这里只是从技术研究角度出发,证明可以这么做,但是影响面太大。
+另外一种方式:2个不同名的静态库,但存在相同符号。可以通过 cocoapods 的配置,将某个静态库改为动态库。因为动态库存在二级命名空间,就可以避免符号重复的问题。
+关于动态库二级命名空间的细节,可以查看[这里](#twoLevelNamespace)
+
+方案 1:单个库转为动态库
+```ruby
+# Podfile
+use_frameworks! # 启用框架支持
+
+target 'YourApp' do
+ pod 'AFNetworking', '~> 4.0' # 默认静态库
+
+ # 将冲突库转为动态框架
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+end
+```
+方案 2:指定模块为动态框架
+```ruby
+dynamic_frameworks = ['ConflictingLib']
+
+target 'YourApp' do
+ # 先声明所有库
+ pods = [
+ 'AFNetworking',
+ 'ConflictingLib',
+ 'OtherLib'
+ ]
+
+ # 动态处理
+ pods.each do |pod|
+ if dynamic_frameworks.include?(pod)
+ pod pod, :modular_headers => true, :linkage => :dynamic
+ else
+ pod pod
+ end
+ end
+end
+```
+实验:我的电脑 cocoapods 版本较低,采用下面写法
+```ruby
+platform :ios, '9.0'
+use_frameworks! # 确保启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 动态链接 AFNetworking(兼容所有版本)
+ pod 'AFNetworking', :modular_headers => true
+
+ # 添加后安装钩子脚本
+ post_install do |installer|
+ # 将 AFNetworking 设为动态框架
+ installer.pods_project.targets.each do |target|
+ if target.name == 'AFNetworking'
+ # 设置 Mach-O 类型为动态库
+ target.build_configurations.each do |config|
+ config.build_settings['MACH_O_TYPE'] = 'mh_dylib'
+ config.build_settings['DYLIB_INSTALL_NAME_BASE'] = '@rpath'
+ config.build_settings['LD_RUNPATH_SEARCH_PATHS'] = ['$(FRAMEWORK_SEARCH_PATHS)']
+ end
+ end
+ end
+
+ # 确保框架被正确嵌入
+ installer.pods_project.build_configurations.each do |config|
+ config.build_settings['EMBEDDED_CONTENT_CONTAINS_SWIFT'] = 'YES'
+ end
+ end
+end
+```
+效果:
+ +可以看到不光是解决了符号重复的问题,也解决了同一个类,存在2处实现的问题。
+
+
+```mermaid
+graph LR
+A[主可执行文件] --> B[静态库A]
+A --> C[动态库B]
+C --> D[私有符号空间]
+```
+
+- 静态库:符号直接合并到主可执行文件的全局符号表
+- 动态库:拥有独立的符号空间(LC_ID_DYLIB 标识)
+ - 动态库内部符号相互可见
+ - 外部通过导出符号表(LC_DYSYMTAB)访问
+
+
+##### 5. 符号冲突总结
+###### 1. 最佳实践方案:动态库隔离
+
+利用动态库的二级命名空间特性,将冲突的静态库转换为动态库,实现符号隔离
+
+```ruby
+# Podfile
+use_frameworks! # 关键:启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 将冲突库转为动态 framework
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+
+ # 其他静态库
+ pod 'NonConflictingLib'
+end
+```
+
+静态库的 xcconfig 为
+
+
+可以看到不光是解决了符号重复的问题,也解决了同一个类,存在2处实现的问题。
+
+
+```mermaid
+graph LR
+A[主可执行文件] --> B[静态库A]
+A --> C[动态库B]
+C --> D[私有符号空间]
+```
+
+- 静态库:符号直接合并到主可执行文件的全局符号表
+- 动态库:拥有独立的符号空间(LC_ID_DYLIB 标识)
+ - 动态库内部符号相互可见
+ - 外部通过导出符号表(LC_DYSYMTAB)访问
+
+
+##### 5. 符号冲突总结
+###### 1. 最佳实践方案:动态库隔离
+
+利用动态库的二级命名空间特性,将冲突的静态库转换为动态库,实现符号隔离
+
+```ruby
+# Podfile
+use_frameworks! # 关键:启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 将冲突库转为动态 framework
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+
+ # 其他静态库
+ pod 'NonConflictingLib'
+end
+```
+
+静态库的 xcconfig 为
+
+ +
+动态库的 xcconfig 为
+
+
+
+动态库的 xcconfig 为
+
+ +
+###### 2. 源码级解决方案:添加类前缀
+
+```objective-c
+// 原始类名
+@interface AFURLSessionManager : NSObject
+
+// 修改后
+@interface ABC_AFURLSessionManager : NSObject
+```
+
+###### 3. 构建系统级解决方案:Bazel 命名空间
+
+```shell
+objc_library(
+ name = "AFNetworking",
+ namespace = "ABC", # 自动添加前缀
+ srcs = glob(["*.m"]),
+ hdrs = glob(["*.h"]),
+)
+```
+
+
+
+## 六、Strip 流程
静态库/ .o 文件 Strip 流程: 处理 `_DWARF` 段
-
+
+###### 2. 源码级解决方案:添加类前缀
+
+```objective-c
+// 原始类名
+@interface AFURLSessionManager : NSObject
+
+// 修改后
+@interface ABC_AFURLSessionManager : NSObject
+```
+
+###### 3. 构建系统级解决方案:Bazel 命名空间
+
+```shell
+objc_library(
+ name = "AFNetworking",
+ namespace = "ABC", # 自动添加前缀
+ srcs = glob(["*.m"]),
+ hdrs = glob(["*.h"]),
+)
+```
+
+
+
+## 六、Strip 流程
静态库/ .o 文件 Strip 流程: 处理 `_DWARF` 段
- +
Strip 的过程,就是在修改 Mach-O 文件中的内容。
-
-
动态库
-
+
Strip 的过程,就是在修改 Mach-O 文件中的内容。
-
-
动态库
- +
All Symbols
-
+
All Symbols
- +
@@ -1295,7 +1591,7 @@ Non-Global Symbols(非全局符号):
-
+
@@ -1295,7 +1591,7 @@ Non-Global Symbols(非全局符号):
- +
@@ -1400,7 +1696,7 @@ test.o -o test
Mach header 包括一些基础信息,所以 Mach header 存在冗余(大小端序、CPU 类型等),这也就是为什么静态库比动态库体积大的原因之一。
-
+
@@ -1400,7 +1696,7 @@ test.o -o test
Mach header 包括一些基础信息,所以 Mach header 存在冗余(大小端序、CPU 类型等),这也就是为什么静态库比动态库体积大的原因之一。
- +
```shell
Unix_Kernel ~/Desktop/OCExplore/OCExplore file Person.o
@@ -1416,7 +1712,7 @@ Mach header
动态库在 Mach header 这里有改进,AFNetworking 动态库格式如下:
-
+
```shell
Unix_Kernel ~/Desktop/OCExplore/OCExplore file Person.o
@@ -1416,7 +1712,7 @@ Mach header
动态库在 Mach header 这里有改进,AFNetworking 动态库格式如下:
- +
将公共的信息放到一起,公用一个 Mach header。
@@ -2258,6 +2554,141 @@ otool -l Person | grep 'ID' -A 5
+
将公共的信息放到一起,公用一个 Mach header。
@@ -2258,6 +2554,141 @@ otool -l Person | grep 'ID' -A 5
 +
+### 6. 二级命名空间
+在 iOS 系统中,动态库的二级命名空间是一种关键的符号管理机制,它解决了不同库之间可能发生的符号冲突问题。这个机制是 macOS 和 iOS 平台动态链接的核心特性。
+
+
+#### 1. 核心原理
+二级命名空间通过2个维度来唯一标识符号:
+- 符号名称(Symbol Name)
+- 动态库名称(Dylib Identity)
+```
+graph TD
+ A[符号解析] --> B{是否在二级命名空间?}
+ B -->|是| C[符号名称 + 库标识符]
+ B -->|否| D[仅符号名称]
+ C --> E[唯一符号]
+ D --> F[可能冲突]
+```
+
+##### 1. 库标识符(Dylib Identity)
+每个动态库都有一个唯一标识符,通常包含:
+- 安装路径(Install Name)
+- 当前版本号(Current Version)
+- 兼容版本号(Compatibility Version)
+```shell
+# 查看库标识符
+otool -l libExample.dylib | grep -A 3 LC_ID_DYLIB
+
+# 输出示例:
+# cmd LC_ID_DYLIB
+# cmdsize 56
+# name @rpath/libExample.dylib (offset 24)
+# time stamp 1 Wed Dec 31 19:00:01 1969
+# current version 1.0.0
+# compatibility version 1.0.0
+```
+
+##### 2. 使用过程
+当动态链接器(dyld)加载符号的时候:
+- 解析符号引用
+- 确定定义该符号的动态库
+- 使用(符号名、动态库ID)作为唯一键
+- 在符号表中查找唯一匹配
+```mermaid
+sequenceDiagram
+ participant App as 应用程序
+ participant dyld as 动态链接器
+ participant LibA as 库A
+ participant LibB as 库B
+
+ App->>dyld: 请求符号 foo
+ dyld->>LibA: 检查 foo@LibA
+ dyld->>LibB: 检查 foo@LibB
+ dyld-->>App: 返回 foo@LibA
+```
+
+##### 3. 符号表结构
+在二级命名空间下,符号表使用分层结构
+```shell
+Symbol Table
+├── LibA Symbols
+│ ├── foo
+│ ├── bar
+│ └── baz
+├── LibB Symbols
+│ ├── foo
+│ ├── xyz
+│ └── abc
+└── ...
+```
+
+#### 2. 应用场景
+##### 1. 解决符号冲突
+当两个库定义同名符号时:
+```shell
+// libNetwork.dylib
+void process_data() {
+ // 网络处理实现
+}
+
+// libAudio.dylib
+void process_data() {
+ // 音频处理实现
+}
+```
+在二级命名空间作用下:
+- process_data@libNetwork
+- process_data@libAudio
+所以,可以安全的使用2个库,而不会发生符号冲突问题
+
+
+
+##### 2. Xcode 配置
+
+- 启用二级命名空间(默认):`OTHER_LDFLAGS = $(inherited) -twolevel_namespace`
+- 禁用二级命名空间:`OTHER_LDFLAGS = $(inherited) -flat_namespace`
+查看命名空间状态:
+```shell
+# 检查二进制是否使用二级命名空间
+otool -lv YourApp | grep TWOLEVEL
+
+# 输出示例:
+# flags TWOLEVEL
+```
+
+
+
+#### 3. 动态库开发 tips
+
+##### 1. 动态库设计原则
+- 使用唯一前缀命名符号
+ ```c++
+ // 良好的命名实践
+ void TaoBaoNetwork_processData() {
+ // 实现
+ }
+ ```
+- 限制导出符号数量
+- 明确声明依赖关系
+- 符号可见性控制
+ ```c++
+ // 只导出必要的符号
+ __attribute__((visibility("default")))
+ void public_api();
+
+ // 隐藏内部实现
+ __attribute__((visibility("hidden")))
+ void internal_function();
+ ```
+
+##### 2. 运行时路径管理
+使用适当的路径变量:
+- `@executable_path`: 可执行文件所在目录
+- `@loader_path`: 当前加载模块所在目录
+- `@rpath`: 运行时搜索路径
+
## 九、xcframework
@@ -2787,15 +3218,103 @@ end
### 1. 定义
+在 iOS/macOS 开发领域的编译链接体系中,Module 是一项由 Clang/LLVM 提供的**语义化头文件封装**技术,其核心目标是**通过强隔离的预编译单元解决传统 `#include` 机制的头文件污染与低效问题**
+
+编译器实现:
+
+```mermaid
+graph LR
+ A[Module] --> B[Clang Module]
+ A --> C[Swift Module]
+ B --> D[.modulemap 描述文件]
+ B --> E[.pcm 预编译二进制]
+ C --> F[.swiftmodule 接口文件]
+```
+
+特征:
+
+- **原子性**:头文件集合的编译边界(不可部分导入)
+- **自包含性**:显式声明导出符号(`export`)与依赖(`requires`)
+- **隔离性**:宏定义(`#define`)不泄漏到导入方
+- **预编译能力**:可序列化为 `.pcm`(Precompiled Module)加速编译
+
+
+
一个 Module 是机器代码和数据的最小单位,可以独立于其他代码单元进行链接。
通常,Module 是通过编译单个源文件生成的目标文件。例如,当前的 `test.m` 被编译成目标文件 `test.o` 时,当前的目标文件就代表了一个 Module 。
-但是,Module 在调用的时候会产生**开销**,比如我们在使用一个静态库的时候。(这个开销是什么接下去会讲)
+但是,Module 在调用的时候会产生**开销**,比如我们在使用一个**静态库**的时候。
+
+
+
+### 2. .pcm 文件
+
+#### 1. 结构
+
+Module 生成的 `.pcm`(Precompiled Module)文件是 Clang 对 C++ Module 的**预编译二进制表示**,其内容远非简单的头文件文本封装,而是包含编译器所需的完整语义信息。
+
+`.pcm` 文件包含:
+
+- 模块元数据
+
+ - **模块标识**:模块名、导出符号列表(`export` 声明的函数/类)
+
+ - **编译环境指纹**:
+
+ ```shell
+ Target: x86_64-apple-darwin22.4.0
+ SDK: MacOSX13.3.sdk
+ Language: C++17
+ ```
+
+ - **时间戳与版本号**:确保与源码版本一致
+
+- AST 抽象语法树:**完整语法树序列化**:将头文件解析后的 AST 以二进制形式存储,通常占 `.pcm` 文件的 **60-70%**(主要膨胀源)
+
+- 语义信息:
+
+ - 符号可见性
+ - 内联函数代码生成
+ - ...
+
+- 依赖关系图
+
+ - **显式依赖**:通过 `import` 直接导入的其他模块(如 `import std.core;`)
+ - **隐式依赖**:递归包含的所有头文件(如 `
+
+### 6. 二级命名空间
+在 iOS 系统中,动态库的二级命名空间是一种关键的符号管理机制,它解决了不同库之间可能发生的符号冲突问题。这个机制是 macOS 和 iOS 平台动态链接的核心特性。
+
+
+#### 1. 核心原理
+二级命名空间通过2个维度来唯一标识符号:
+- 符号名称(Symbol Name)
+- 动态库名称(Dylib Identity)
+```
+graph TD
+ A[符号解析] --> B{是否在二级命名空间?}
+ B -->|是| C[符号名称 + 库标识符]
+ B -->|否| D[仅符号名称]
+ C --> E[唯一符号]
+ D --> F[可能冲突]
+```
+
+##### 1. 库标识符(Dylib Identity)
+每个动态库都有一个唯一标识符,通常包含:
+- 安装路径(Install Name)
+- 当前版本号(Current Version)
+- 兼容版本号(Compatibility Version)
+```shell
+# 查看库标识符
+otool -l libExample.dylib | grep -A 3 LC_ID_DYLIB
+
+# 输出示例:
+# cmd LC_ID_DYLIB
+# cmdsize 56
+# name @rpath/libExample.dylib (offset 24)
+# time stamp 1 Wed Dec 31 19:00:01 1969
+# current version 1.0.0
+# compatibility version 1.0.0
+```
+
+##### 2. 使用过程
+当动态链接器(dyld)加载符号的时候:
+- 解析符号引用
+- 确定定义该符号的动态库
+- 使用(符号名、动态库ID)作为唯一键
+- 在符号表中查找唯一匹配
+```mermaid
+sequenceDiagram
+ participant App as 应用程序
+ participant dyld as 动态链接器
+ participant LibA as 库A
+ participant LibB as 库B
+
+ App->>dyld: 请求符号 foo
+ dyld->>LibA: 检查 foo@LibA
+ dyld->>LibB: 检查 foo@LibB
+ dyld-->>App: 返回 foo@LibA
+```
+
+##### 3. 符号表结构
+在二级命名空间下,符号表使用分层结构
+```shell
+Symbol Table
+├── LibA Symbols
+│ ├── foo
+│ ├── bar
+│ └── baz
+├── LibB Symbols
+│ ├── foo
+│ ├── xyz
+│ └── abc
+└── ...
+```
+
+#### 2. 应用场景
+##### 1. 解决符号冲突
+当两个库定义同名符号时:
+```shell
+// libNetwork.dylib
+void process_data() {
+ // 网络处理实现
+}
+
+// libAudio.dylib
+void process_data() {
+ // 音频处理实现
+}
+```
+在二级命名空间作用下:
+- process_data@libNetwork
+- process_data@libAudio
+所以,可以安全的使用2个库,而不会发生符号冲突问题
+
+
+
+##### 2. Xcode 配置
+
+- 启用二级命名空间(默认):`OTHER_LDFLAGS = $(inherited) -twolevel_namespace`
+- 禁用二级命名空间:`OTHER_LDFLAGS = $(inherited) -flat_namespace`
+查看命名空间状态:
+```shell
+# 检查二进制是否使用二级命名空间
+otool -lv YourApp | grep TWOLEVEL
+
+# 输出示例:
+# flags TWOLEVEL
+```
+
+
+
+#### 3. 动态库开发 tips
+
+##### 1. 动态库设计原则
+- 使用唯一前缀命名符号
+ ```c++
+ // 良好的命名实践
+ void TaoBaoNetwork_processData() {
+ // 实现
+ }
+ ```
+- 限制导出符号数量
+- 明确声明依赖关系
+- 符号可见性控制
+ ```c++
+ // 只导出必要的符号
+ __attribute__((visibility("default")))
+ void public_api();
+
+ // 隐藏内部实现
+ __attribute__((visibility("hidden")))
+ void internal_function();
+ ```
+
+##### 2. 运行时路径管理
+使用适当的路径变量:
+- `@executable_path`: 可执行文件所在目录
+- `@loader_path`: 当前加载模块所在目录
+- `@rpath`: 运行时搜索路径
+
## 九、xcframework
@@ -2787,15 +3218,103 @@ end
### 1. 定义
+在 iOS/macOS 开发领域的编译链接体系中,Module 是一项由 Clang/LLVM 提供的**语义化头文件封装**技术,其核心目标是**通过强隔离的预编译单元解决传统 `#include` 机制的头文件污染与低效问题**
+
+编译器实现:
+
+```mermaid
+graph LR
+ A[Module] --> B[Clang Module]
+ A --> C[Swift Module]
+ B --> D[.modulemap 描述文件]
+ B --> E[.pcm 预编译二进制]
+ C --> F[.swiftmodule 接口文件]
+```
+
+特征:
+
+- **原子性**:头文件集合的编译边界(不可部分导入)
+- **自包含性**:显式声明导出符号(`export`)与依赖(`requires`)
+- **隔离性**:宏定义(`#define`)不泄漏到导入方
+- **预编译能力**:可序列化为 `.pcm`(Precompiled Module)加速编译
+
+
+
一个 Module 是机器代码和数据的最小单位,可以独立于其他代码单元进行链接。
通常,Module 是通过编译单个源文件生成的目标文件。例如,当前的 `test.m` 被编译成目标文件 `test.o` 时,当前的目标文件就代表了一个 Module 。
-但是,Module 在调用的时候会产生**开销**,比如我们在使用一个静态库的时候。(这个开销是什么接下去会讲)
+但是,Module 在调用的时候会产生**开销**,比如我们在使用一个**静态库**的时候。
+
+
+
+### 2. .pcm 文件
+
+#### 1. 结构
+
+Module 生成的 `.pcm`(Precompiled Module)文件是 Clang 对 C++ Module 的**预编译二进制表示**,其内容远非简单的头文件文本封装,而是包含编译器所需的完整语义信息。
+
+`.pcm` 文件包含:
+
+- 模块元数据
+
+ - **模块标识**:模块名、导出符号列表(`export` 声明的函数/类)
+
+ - **编译环境指纹**:
+
+ ```shell
+ Target: x86_64-apple-darwin22.4.0
+ SDK: MacOSX13.3.sdk
+ Language: C++17
+ ```
+
+ - **时间戳与版本号**:确保与源码版本一致
+
+- AST 抽象语法树:**完整语法树序列化**:将头文件解析后的 AST 以二进制形式存储,通常占 `.pcm` 文件的 **60-70%**(主要膨胀源)
+
+- 语义信息:
+
+ - 符号可见性
+ - 内联函数代码生成
+ - ...
+
+- 依赖关系图
+
+ - **显式依赖**:通过 `import` 直接导入的其他模块(如 `import std.core;`)
+ - **隐式依赖**:递归包含的所有头文件(如 `` 依赖 ``)
+ - **依赖树序列化**:以邻接表存储,支持快速增量编译检查
+
+- 编译器配置快照
+
+ - **编译标志**:`-D` 宏定义、`-I` 包含路径、`-std=c++20` 等
+ - **ABI 配置**:`-mabi=sysv`、`-fPIC` 等影响二进制兼容性的参数
+ - **诊断设置**:`-Werror`、`-fno-exceptions` 等策略
+
+
+
+#### 2. 技术特性
+
+- 平台强耦合性:`.pcm` 文件与以下环境绑定,**不可跨平台/编译器/配置复用**:
+
+ ```shell
+ // 不同配置生成不同 .pcm
+ -arch arm64 ≠ -arch x86_64
+ -O2 ≠ -O0
+ -DDEBUG ≠ -DRELEASE
+ ```
+
+- 内容敏感性
+
+ - **头文件内容哈希**:即使注释修改也会使 `.pcm` 失效(因 AST 变化)
+ - **编译参数敏感性**:`-I` 路径顺序变化即触发重新生成
+
+- 反序列化开销:加载 `.pcm` 本质是 AST 的反序列化过程
+
+
-### 2. 场景
+### 3. 场景
说人话,平时什么情况下使用的最多?导入库文件的时候,就是 module 的主战场。
@@ -2839,7 +3358,7 @@ module 是 clang 提供的能力。可以把头文件编译成二进制文件,
-### 3. modulemap 编写规范
+### 4. modulemap 编写规范
- 开启 module 能力:Xcode 默认开启了 module 能力,开启或者关闭步骤:选择项目中的 target,进入 Build Settings 页面,搜索 “Enable Modules (C and Objective-C)”,将其设置为 NO,即可关闭 Module
- 配置 Module Map File 路径:Xcode -> Build Settings -> Module Map File 中配置 moduleMapFile 路径。
@@ -3044,7 +3563,7 @@ framework module AsyncDisplayKit { // 定义了一个名为 AsyncDisplayKit 的
-### 4. 实战:Framework 使用 modulemap
+### 5. 实战:Framework 使用 modulemap
第一步:创建动态库 `PersonFramework`,创建一个 iOS App Demo 工程。
@@ -3111,7 +3630,7 @@ framework module AsyncDisplayKit { // 定义了一个名为 AsyncDisplayKit 的
-### 5. Swift Framework modulemap
+### 6. Swift Framework modulemap
背景:探索 Swift Framework 中,没有桥接文件,Swift 如何访问 OC?如何处理 modulemap 导出文件?
@@ -3159,7 +3678,7 @@ module 提供 private modle 的能力。
-### 6. Swift module - Swift 静态库的合并
+### 7. Swift module - Swift 静态库的合并
#### 1. Swift module 概念
@@ -3258,11 +3777,27 @@ Swift 库引入了一个全新的文件 `.swiftmodule`,其包含序列化过
+### 8. 静态库使用 Module 带来的问题
+
+#### 1. 存储与 I/O 开销显著增加
+
+- **`.pcm` 文件体积膨胀**
+
+ Module 预编译生成的 `.pcm` 文件包含头文件的完整 AST(抽象语法树)及依赖元数据,其体积通常达原始头文件的 **30–40 倍**(例如 `` 头文件 20 KB → `.pcm` 800 KB)。大型项目累积 `.pcm` 可达 GB 级(如 LLVM 编译超 10 GB),加剧存储压力与 I/O 延迟(机械硬盘随机读写性能骤降)。
+
+- 缓存管理复杂度上升
+
+ 需维护全局 `.pcm` 缓存路径(`-fmodules-cache-path`),多版本编译环境易因缓存失效导致重复生成,消耗额外磁盘与计算资源
+
+#### 2. 编译效率降低
+
+
+
## 十二、hmap文件与 Header Maps
### 1. 头文件导入技术发展历史
-#### 1. 思考
+#### 1. 头文件查找流程
引入头文件的方式:
@@ -3271,19 +3806,60 @@ Swift 库引入了一个全新的文件 `.swiftmodule`,其包含序列化过
思考:平时 Xcode 写代码的时候 `#import "ViewController.h"` 背后是怎么工作的?是如何找到具体的文件内容的
-1. **本地引用**:当你使用双引号 `"ViewController.h"` 进行导入时,编译器会首先在当前文件的本地目录(即当前 `.m` 或 `.mm` 文件所在的目录)查找头文件。
-2. **递归搜索**:如果在当前目录找不到 `ViewController.h`,编译器会递归地搜索所有子目录。
-3. **项目设置**:如果本地目录中没有找到文件,编译器会根据 Xcode 项目的设置中的 "Header Search Paths" 来确定接下来搜索的目录。这些路径通常包括:
- - 项目的其他部分,如其他目标的目录。
- - 项目依赖的库或框架的路径。
- - 用户或系统级别的额外头文件目录。
-4. **相对路径**:在 "Header Search Paths" 中设置的路径可以是相对路径,Xcode 会将其相对于项目文件(`.xcodeproj`)的位置来解析。
-5. **绝对路径**:也可以使用绝对路径指定头文件的位置。
-6. **环境变量**:有时,Header Search Paths 会包含环境变量,这些变量在编译时会被系统的实际路径替换。
-7. **Framework和Library**:如果 `ViewController.h` 是某个框架或库的一部分,编译器还会在 "Framework Search Paths" 中指定的目录下查找。
-8. **Header Maps**:为了提高查找效率,项目可能使用 Header Maps。这些是预先生成的文件,列出了目录中所有头文件的索引,帮助编译器快速定位。
-9. **编译器缓存**:编译器可能会缓存头文件的查找结果,以避免在后续编译中重复搜索。
-10. **错误报告**:如果编译器在所有指定的搜索路径中都没有找到 `ViewController.h`,它会报错指出找不到文件。
+##### 阶段1:基础路径搜索
+
+1. **本地目录优先搜索**:
+ - 当你使用双引号 `"ViewController.h"` 进行导入时,编译器会首先在当前源文件所在的本地目录(即当前 `.m` 或 `.mm` 文件所在的目录)查找头文件
+ - 示例:`AppDelegate.m` 中导入 `ViewController.h` 时,优先在 `AppDelegate.m` 同级目录查找
+2. **递归子目录搜索**
+ - 如果在当前目录找不到 `ViewController.h`,编译器会自动递归地搜索所有子目录
+ - 搜索深度由 Xcode 设置决定(默认无限制)
+ - 可通过 `-I-` 编译选项禁用递归
+
+##### 阶段2:工程配置路径搜索
+
+3. **Header Search Paths 遍历**
+
+ 如果本地目录中没有找到文件,编译器会根据 Xcode 项目的设置中的 "Header Search Paths" 来确定接下来搜索的目录。这些路径通常包括:
+
+ - 项目的其他部分,如其他目标的目录
+ - 项目依赖的库或框架的路径
+ - 用户或系统级别的额外头文件目录
+
+ 路径类型:
+
+ - **相对路径**:在 "Header Search Paths" 中设置的路径可以是相对路径,Xcode 会将其相对于项目文件(`.xcodeproj`)的位置来解析
+ - **绝对路径**:也可以使用绝对路径指定头文件的位置
+ - **环境变量**:有时 Header Search Paths 会包含环境变量,这些变量在编译时会被系统的实际路径替换。
+
+4. **Framework Search Paths 遍历**
+
+ 如果 `ViewController.h` 是某个框架或库的一部分,编译器还会在 "Framework Search Paths" 中指定的目录下查找。
+
+##### 阶段3:高级优化机制
+
+5. **Header Maps(hmap) 加速**
+
+ 为了提高查找效率,项目可能使用 Header Maps。这些是预先生成的文件,列出了目录中所有头文件的索引,帮助编译器快速定位。
+
+6. **编译器缓存优化**
+
+ 编译器可能会缓存头文件的查找结果,以避免在后续编译中重复搜索
+
+##### 阶段4:错误处理机制
+
+7. **文件未找到处理**
+
+ 如果编译器在所有指定的搜索路径中都没有找到 `ViewController.h`,它会报错指出找不到文件。
+
+ ```objective-c
+ fatal error: 'ViewController.h' file not found
+ #import "ViewController.h"
+ ^~~~~~~~~~~~~~~~~~
+ 1 error generated.
+ ```
+
+
@@ -3398,7 +3974,7 @@ import 举个例子吧。在 `Person.m`
相关的一些使用,可以查看上面的 section。
-还是存在问题,因此诞生了 Use Header Maps 技术。
+还是存在问题,因此诞生了 Use Header Maps 技术
@@ -3408,6 +3984,17 @@ import 举个例子吧。在 `Person.m`
基于此,诞生了 Header Maps 技术,通过 hmap 文件,让 Xcode 在查找头文件的时候更快速。
+编译器 -I 参数可以跟 Header Search Paths 也可以跟 hmap 文件路径。
+
+
+
+QA:Xcode 自己会生成 hmap 文件,为什么我们还需要自己生成?
+
+- **Xcode默认行为**:虽然 Xcode 可以自己生成 hmap 文件。首次编译时动态生成hmap(耗时),后续编译复用。但清理工程后需重新生成。
+- **优化策略**:通过 CocoaPods 插件或自定义脚本在 pod install 阶段提前生成好 hmap 文件,避免动态生成的开销。工程化阶段,修改 xcconfig 文件,给编译器 `-I` 参数提供 hmap 文件路径。来享受编译加速带来的红利。
+
+
+
### 3. hmap 结构
创建一个 iOS App,默认模版的基础上添加一个 Person 类,一个继承自 Person 的 Student 类。然后编译
@@ -3437,25 +4024,105 @@ import 举个例子吧。在 `Person.m`
-### 4. 编写工具分析 hmap 文件
+### 4. why hmap?
-其结构、工作原理都类似 Mach-O 文件。参考 Mach-O 文件结构和 [LLVM:HeaderMap.cpp](https://github.com/llvm/llvm-project/blob/main/clang/lib/Lex/HeaderMap.cpp) 的实现,编写一个读取 hmap 文件的代码。
+不就是1个文件依赖4个头文件吗?为什么设计成 hMap 这么复杂的结构?要表示路径的话,可以有很多种方式,比如最基础的 Map。hMap 有啥优点?
-具体代码可以在这个 Repo 中查看并运行 [BlogDemos:HMapDump](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapDump)
+```json
+{
+ "ViewController.m": ['a.h', 'b.h', 'c.h', 'd.h']
+}
+```
+
+#### 1. 文本映射方案的致命缺陷
+
+内存占用对比(10,000 头文件场景)
+
+| 方案 | 存储量 | 内存占用 | 问题 |
+| :-------------- | :-------- | :------- | :---------------- |
+| 文本映射 (JSON) | 约 5 MB | 50+ MB | 解析耗时 + 碎片化 |
+| HMap 二进制 | 约 800 KB | 2 MB | **直接内存映射** |
+
+查找性能对比(单次查找)
+
+| 操作 | JSON 方案 | HMap 方案 |
+| :------- | :----------------- | :---------------------- |
+| 加载文件 | 5 ms (读5MB) | 0.01 ms (mmap) |
+| 解析数据 | 15 ms (JSON parse) | **0 ms** (直接访问) |
+| 查找键值 | 0.5 ms (遍历) | **0.001 ms** (哈希计算) |
+| 总耗时 | ~20 ms | **~0.01 ms** |
+
+> **2000倍差距**:当 ViewController.m 引入 4 个头文件时,仅查找就相差 **80ms vs 0.04ms**
+
+#### 2. HMap 的优点
+
+##### 1. 零解析内存映射
+
+```mermaid
+graph LR
+ A[磁盘 HMap] --> |mmap 系统调用|B[虚拟内存]
+ B --> C[CPU 直接访问]
+```
+
+- **传统文本方案**:读取 → 解析 → 构建哈希表(三重开销)
+- **HMap 方案**:操作系统自动映射,编译器直接访问。HMap 利用操作系统提供的 **内存映射文件 (mmap)** 技术,让编译器能够像访问内存一样直接操作 HMap 文件,无需传统的数据加载和解析过程。这是 HMap 高性能的核心秘密。
+
+##### 2. 路径压缩艺术
+
+假设 100 个头文件在相同目录:
+
+```shell
+// 文本方案存储:
+{"File1.h": "/path/to/project/Sources/File1.h", ...} // 重复100次"/path/to/project/Sources/"
+
+// HMap 存储:
+前缀: "/path/to/project/Sources/" (存储1次)
+后缀: "File1.h", "File2.h" ... (只存文件名)
+```
+
+有事:**空间节省**,目录路径节省 **99%** 存储。类似 Trie 树。
+
+##### 3. CPU 缓存友好
+
+- HMap 的桶数组是**连续内存块**(12字节/桶)
+- 现代 CPU 缓存行(通常 64 字节)可一次加载 **5个桶**
+
+
+
+### 5. 编写工具分析 hmap 文件
+
+#### 1. 读取 HMap 文件的代码
+
+其结构、工作原理都类似 Mach-O 文件。读取思路为:
+
+```
+二进制数据
+sizeOf(HMapHeader)
+
+从二进制数据中读取出:header -----> 根据 Header 信息,按照 Bucket 格式,读取出 Bucket 信息 ------> 再根据 Bucket 的 Key、prefix、suffix 去 String Payload 区域读取数据
+```
+
+参考 Mach-O 文件结构和 LLVM 源码中对于 HMap 的处理 [LLVM:HeaderMap.cpp](https://github.com/llvm/llvm-project/blob/main/clang/lib/Lex/HeaderMap.cpp) 的实现,编写一个读取 hmap 文件的代码。
+
+具体可以运行的代码可以在 github 这个 Repo 中查看并运行 [BlogDemos:HMapDump](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapDump)
运行调试的时候,把需要读取的 HMapFile 拷贝到项目根目录。然后 Edit Scheme - Run - Arguments Passed On Launch
+这里我把 [github Textture](https://github.com/texturegroup/texture/) 编译日志中的 hmap 拖到项目的根目录下了
+

 -如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
+#### 2. 变成终端可使用的能力
+
+QA:如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
- 在电脑根目录新建 `CustomTools` 文件夹
- 将上面编译后的产物复制进去
- 在 `.zshrc` 文件里将路径添加进去。`export PATH=~/CustomTools:$PATH`
- 编辑 `.zshrc` 文件后,在终端执行 `souce .zshrc`
-- 即可使用
+- 即可使用,在终端输入: **hmapdump ${hmapFileFullPath}**
效果如下:
@@ -3530,29 +4197,100 @@ LLVM 真是好东西,把 Xcode 编译、链接等一些幕后的事情变成
### 6. hmap 助力提升 iOS 项目编译速度
-已经编写好生成 `.hmap` 文件的能力了,那如何使用生成的 `.hmap` 文件?
+本节讨论:**如何为静态库自定义 hmap 开启编译加速**?
-- Xcode `Build Setting` 中 `Use Header Maps` 为 NO
-- `Header Search Path` 设置生成的 hmap 文件路径
+为了方便观察,开启2组对照实验。
-实践操作下。把上面静态库无法走 Header Maps 带来的问题解决掉。
+#### 1. 实验一:静态库 + Header Search Paths + App 编译
-第一步,编写 hmap 所需要的 json 信息。
+##### 1. 静态库设置
-第二步,利用 `HMapWriter` 能力,根据 json 生成静态库所需要的 `StaticLibUsage.hmap`
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderSearchPath**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
-第三步,在静态库 Xcode 项目中,关闭 `Use Header Maps`(设置为 NO),同时修改 `Header Search Paths` 为生成 `StaticLibUsage.hmap` 路径。
+整体目录结构和设置如下:
-第四步,编译使用静态库的 App 工程。最后比较静态库走自定义 `.hmap` 前后的编译耗时。
-
-
-如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
+#### 2. 变成终端可使用的能力
+
+QA:如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
- 在电脑根目录新建 `CustomTools` 文件夹
- 将上面编译后的产物复制进去
- 在 `.zshrc` 文件里将路径添加进去。`export PATH=~/CustomTools:$PATH`
- 编辑 `.zshrc` 文件后,在终端执行 `souce .zshrc`
-- 即可使用
+- 即可使用,在终端输入: **hmapdump ${hmapFileFullPath}**
效果如下:
@@ -3530,29 +4197,100 @@ LLVM 真是好东西,把 Xcode 编译、链接等一些幕后的事情变成
### 6. hmap 助力提升 iOS 项目编译速度
-已经编写好生成 `.hmap` 文件的能力了,那如何使用生成的 `.hmap` 文件?
+本节讨论:**如何为静态库自定义 hmap 开启编译加速**?
-- Xcode `Build Setting` 中 `Use Header Maps` 为 NO
-- `Header Search Path` 设置生成的 hmap 文件路径
+为了方便观察,开启2组对照实验。
-实践操作下。把上面静态库无法走 Header Maps 带来的问题解决掉。
+#### 1. 实验一:静态库 + Header Search Paths + App 编译
-第一步,编写 hmap 所需要的 json 信息。
+##### 1. 静态库设置
-第二步,利用 `HMapWriter` 能力,根据 json 生成静态库所需要的 `StaticLibUsage.hmap`
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderSearchPath**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
-第三步,在静态库 Xcode 项目中,关闭 `Use Header Maps`(设置为 NO),同时修改 `Header Search Paths` 为生成 `StaticLibUsage.hmap` 路径。
+整体目录结构和设置如下:
-第四步,编译使用静态库的 App 工程。最后比较静态库走自定义 `.hmap` 前后的编译耗时。
-
- -
-可以看到静态库使用了自定义的 Header Maps 文件后,使用静态的 App 前后,编译耗时减少了1.1s,节省了57%。
+
-
-可以看到静态库使用了自定义的 Header Maps 文件后,使用静态的 App 前后,编译耗时减少了1.1s,节省了57%。
+ -Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLibApp) 和 [HMapStaticLib](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib)。
+##### 2. App 以 Header Search Paths 方式编译链接静态库
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderSearchPath** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderSearchPath/StaticLib/HMapStaticLib-HeaderSearchPath/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderSearchPath.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+
-Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLibApp) 和 [HMapStaticLib](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib)。
+##### 2. App 以 Header Search Paths 方式编译链接静态库
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderSearchPath** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderSearchPath/StaticLib/HMapStaticLib-HeaderSearchPath/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderSearchPath.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+ +
+解决办法:
+- 方法1: 创建不同的 Xcode 工程
+- 方法2: 还是同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+
+
+解决办法:
+- 方法1: 创建不同的 Xcode 工程
+- 方法2: 还是同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+ +
+问题修复完,最终编译链接效果如下:
+
+
+问题修复完,最终编译链接效果如下:
+ +编译日志里时间先放着。等以 HeaderMap 编译链接实现结束一起对比看看时间节省了多少。
+
+
+
+
+#### 2. 实验二:静态库 + HeaderMap + App 编译
+
+##### 1. 静态库设置
+
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderMap**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:根据源码中头文件目录,创建一个 **HMapFile.json** 文件。以数组的形式写入信息,3个元素,分别为:Key、Prefix、Suffix。利用 LLVM 开发的 hmapmaker 能力,将 json 转换为 hmap 文件
+
+编译日志里时间先放着。等以 HeaderMap 编译链接实现结束一起对比看看时间节省了多少。
+
+
+
+
+#### 2. 实验二:静态库 + HeaderMap + App 编译
+
+##### 1. 静态库设置
+
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderMap**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:根据源码中头文件目录,创建一个 **HMapFile.json** 文件。以数组的形式写入信息,3个元素,分别为:Key、Prefix、Suffix。利用 LLVM 开发的 hmapmaker 能力,将 json 转换为 hmap 文件
+  +- 第六步:**Build Settings - Use Header Maps** 中设为 **NO**,**Header Search Paths** 设为:`${SRCROOT}/HMapStaticLib-HeaderMap/hmap`(hmap 文件所在目录)
+- 第七步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第八步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
+
+整体目录结构和设置如下:
+
+
+- 第六步:**Build Settings - Use Header Maps** 中设为 **NO**,**Header Search Paths** 设为:`${SRCROOT}/HMapStaticLib-HeaderMap/hmap`(hmap 文件所在目录)
+- 第七步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第八步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
+
+整体目录结构和设置如下:
+
+ +
+
+
+##### 2. App 以 HeaderMap 方式编译链接静态库
+
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderMap** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderMap/StaticLib/HMapStaticLib-HeaderMap/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderMap.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+
+
+解决办法:同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+
+
+最终编译链接效果如下:
+
+
+
+
+##### 2. App 以 HeaderMap 方式编译链接静态库
+
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderMap** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderMap/StaticLib/HMapStaticLib-HeaderMap/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderMap.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+
+
+解决办法:同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+
+
+最终编译链接效果如下:
+ +
+
+
+#### 3. 数据分析及结论
+
+
+
+
+#### 3. 数据分析及结论
+ +**可以看到静态库先用 Header Search Paths 的方式,App 编译耗时6.5s。使用了自定义的 Header Map 文件后,App 编译耗时6.1s。编译耗时减少了0.4s,节省了6.6%。这是只有1个静态库且只有7个头文件的情况下测试得到的数据。真实项目中,如果静态库数量越多、项目文件目录长且嵌套复杂、头文件数量越多,以自定义 hmap 的方式将会在编译阶段节省更多的时间**
+
+
+
+源码查看:
+- 静态库 + HeaderSearchPath:[HMapStaticLib-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderSearchPath) 和 [HMapBenchMark-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderSearchPath)
+
+- 静态库 + hmap:[HMapStaticLib-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderMap) 和 [HMapBenchMark-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderMap)
### 7. 工程化问题
@@ -3562,6 +4300,18 @@ Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/Bl
- 生成后的 hmap 文件如何使用
如果每个工程项目都这么做,效率有点低,所以需要站在工程化的角度去设计,如何优化?
+完整流程如下:
+```mermaid
+graph TD
+ A[Podfile] --> B[post_install Hook]
+ B --> C[遍历所有 Pod]
+ C --> D[收集头文件映射]
+ D --> E[生成 hmap 文件]
+ E --> F[修改 xcconfig]
+ F --> G[关闭默认 hmap]
+ G --> H[App 编译加速]
+```
+
Cocoapods 提供了很多钩子,可以自定义编写 Ruby 脚本。
- HooksManager 注册 cocoapods 的 `post_install` 钩子
- 通过 `header_mappings_by_file_accessor` 遍历所有头文件和 `header_dir`,由header_dir/header.h和header.h为key,以头文件搜索路径为value,组装成一个Hash
+**可以看到静态库先用 Header Search Paths 的方式,App 编译耗时6.5s。使用了自定义的 Header Map 文件后,App 编译耗时6.1s。编译耗时减少了0.4s,节省了6.6%。这是只有1个静态库且只有7个头文件的情况下测试得到的数据。真实项目中,如果静态库数量越多、项目文件目录长且嵌套复杂、头文件数量越多,以自定义 hmap 的方式将会在编译阶段节省更多的时间**
+
+
+
+源码查看:
+- 静态库 + HeaderSearchPath:[HMapStaticLib-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderSearchPath) 和 [HMapBenchMark-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderSearchPath)
+
+- 静态库 + hmap:[HMapStaticLib-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderMap) 和 [HMapBenchMark-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderMap)
### 7. 工程化问题
@@ -3562,6 +4300,18 @@ Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/Bl
- 生成后的 hmap 文件如何使用
如果每个工程项目都这么做,效率有点低,所以需要站在工程化的角度去设计,如何优化?
+完整流程如下:
+```mermaid
+graph TD
+ A[Podfile] --> B[post_install Hook]
+ B --> C[遍历所有 Pod]
+ C --> D[收集头文件映射]
+ D --> E[生成 hmap 文件]
+ E --> F[修改 xcconfig]
+ F --> G[关闭默认 hmap]
+ G --> H[App 编译加速]
+```
+
Cocoapods 提供了很多钩子,可以自定义编写 Ruby 脚本。
- HooksManager 注册 cocoapods 的 `post_install` 钩子
- 通过 `header_mappings_by_file_accessor` 遍历所有头文件和 `header_dir`,由header_dir/header.h和header.h为key,以头文件搜索路径为value,组装成一个Hash,生成所有组件pod头文件的json文件,再通过hmap工具将json文件转成hmap文件。
@@ -3570,6 +4320,16 @@ Cocoapods 提供了很多钩子,可以自定义编写 Ruby 脚本。
+完整步骤:
+
+1. Hook `pod install` 执行过程;
+2. 扫描所有Pod组件的头文件路径;
+3. 为**每个Pod**生成专属hmap文件(如`Pods-MainApp-prebuilt.hmap`);
+4. 修改xcconfig:删除原始头文件搜索路径,替换为hmap路径(`HEADER_SEARCH_PATHS = ${PODS_ROOT}/Headers/HMap/Pods-MainApp-prebuilt.hmap`);
+5. 关闭Xcode默认hmap生成(`USE_HEADERMAP = NO`)。
+
+
+
## 十一、dyld 及其工作流程
### 1. DYLD(dyld shared cache) 动态库共享缓存
@@ -4464,13 +5224,13 @@ iOS 是小端序,从右向左看,`b2 ff ff ff` 可以看到后4位是 ff,
完整的
- +
#### 2. 如何找到全局变量地址
第一步,先用指令查看全局变量的地址值。 `objdump --macho -s main`,可以看到地址值为 `0x100008000`
-
+
#### 2. 如何找到全局变量地址
第一步,先用指令查看全局变量的地址值。 `objdump --macho -s main`,可以看到地址值为 `0x100008000`
- +
diff --git a/Chapter2 - Web FrontEnd/2.32.md b/Chapter2 - Web FrontEnd/2.32.md
index aa36ba6..8911ee2 100644
--- a/Chapter2 - Web FrontEnd/2.32.md
+++ b/Chapter2 - Web FrontEnd/2.32.md
@@ -37,13 +37,13 @@ render () {
## 生命周期
-
+
## 状态管理
Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍了。解决了各个组件之间数据传递的复杂问题。先看看 Redux 进行状态管理的一个流程吧。
-
+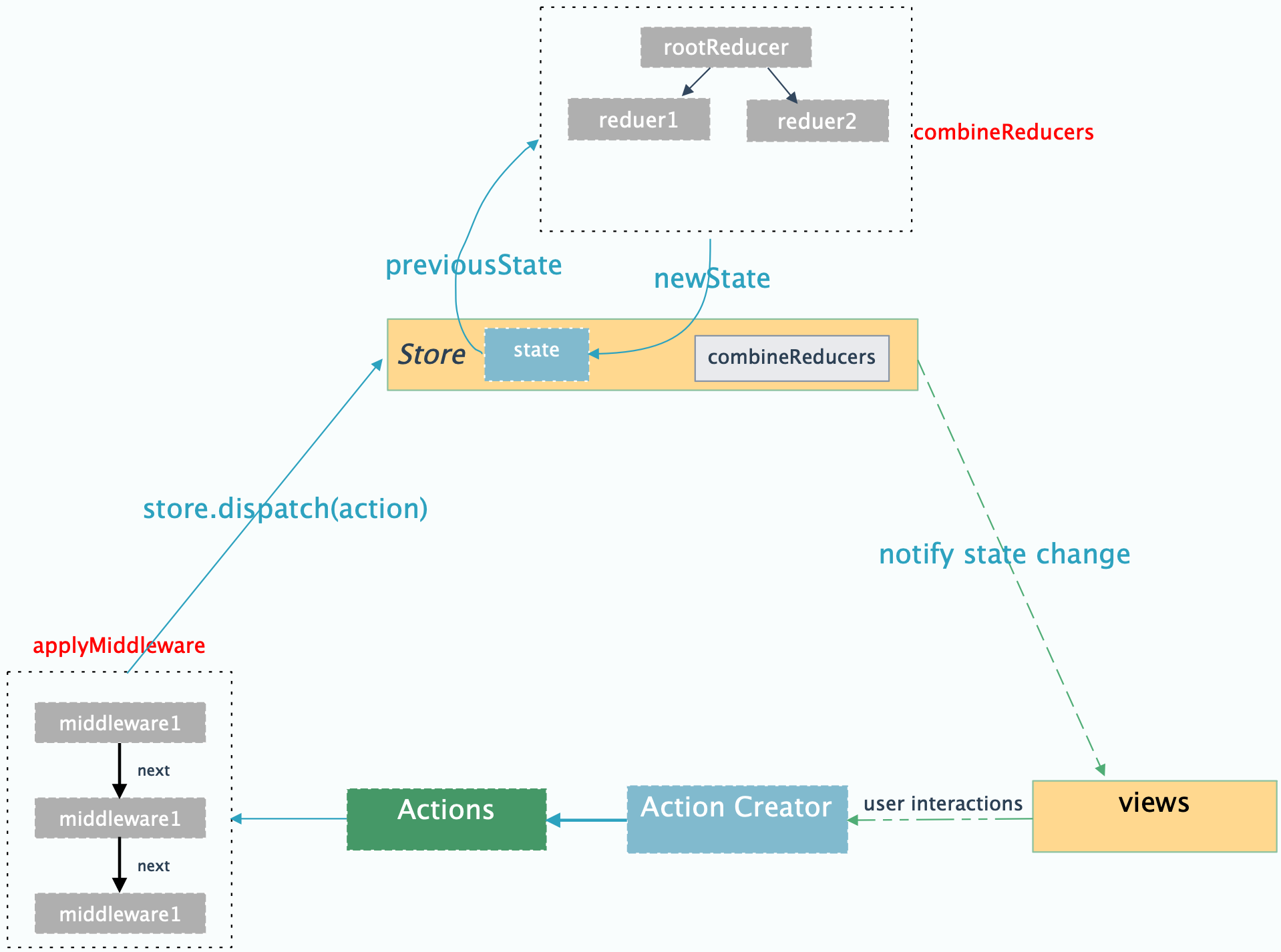
### 开发步骤
@@ -109,7 +109,7 @@ Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍
Redux-thunk 是 redux 里面常用的一个中间件。中间件?针对谁和谁的中间?对 action 和 store 的中间件。本来 action 只可以返回一个对象,灵活性较低,但是采用了 redux-thunk 之后,action 不仅可以传递对象,还可以传递函数。 action 通过 dispatch 传递给 store。 dispatch 判断 action 的类型,如果是对象则直接传递;如果是函数则直接执行。
-
+
- 异步函数不应该放在组件的生命周期函数里面。复杂的业务逻辑和异步函数适合拆分。目前主流的解决方案有2种中间件:redux-thunk、redux-saga。采用不同的策略
@@ -237,4 +237,1481 @@ class Welcome extends React.Component {
- Vue 设计思想:How easy it can be。React:How corrct it can be 和 all in js(css写法也在用 js 控制,比如 styled-component)
-在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
\ No newline at end of file
+在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
+
+
+
+
+
+## React 核心渲染流程 Fiber 架构
+
+React 在 16 之后引入了 Fiber 架构,旨在解决长列表的渲染卡顿问题。几个关键问题
+
+### hostRenderFiber 里的 updateQueue.shared.pending 怎么理解?为什么需要 shared 属性?
+
+
+在 React 的 Fiber 架构中,`hostRenderFiber.updateQueue.shared.pending` 涉及更新队列的核心设计,尤其是为了支持并发渲染和多优先级更新。我们可以分两部分理解:
+
+
+1. 先拆解概念:`hostRenderFiber.updateQueue.shared.pending`
+- **`hostRenderFiber`**:指「宿主环境渲染 Fiber 节点」(如对应 DOM 元素的 Fiber),负责管理该节点的渲染和更新状态。
+- **`updateQueue`**:Fiber 节点上的「更新队列」,用于存储待处理的更新(如 `setState`、`useState` 产生的更新)。React 通过更新队列实现更新的合并、优先级排序和批量处理。
+- **`shared`**:更新队列中「共享部分」的容器,用于在多场景下共享更新数据(核心是支持并发模式)。
+- **`pending`**:`shared` 中存储「待处理更新」的链表(环形链表),指向当前等待被处理的更新队列尾部。
+
+
+2. `pending` 的作用
+`pending` 是更新队列中**未被处理的更新链表**,本质是一个「环形单向链表」。其设计目的是高效地收集和处理更新:
+- 当产生新更新(如调用 `setState`)时,React 会创建一个 `Update` 对象,并将其添加到 `pending` 链表的尾部(通过指针调整形成环形)。
+- 在「协调阶段(Reconciliation)」,React 会从 `pending` 中取出所有待处理更新,进行合并(如多个相同状态的更新合并为一个),最终计算出最新的状态。
+
+环形链表的设计能让更新的添加和取出操作更高效(时间复杂度 O(1)),避免频繁的数组操作开销。
+
+
+3. 为什么需要 `shared` 属性?
+`shared`(共享)是为了支持 React 的**并发渲染机制**而设计的,核心解决「多场景下更新队列的共享与同步」问题:
+
+在并发模式中,React 可能同时存在多个「更新任务」(如高优先级的用户输入更新和低优先级的列表渲染更新),且这些任务可能在不同的「调度阶段」(如主线程、后台任务)中被处理。此时需要一个「共享的更新容器」,让不同的调度逻辑、优先级任务能访问到同一份待处理更新,避免更新丢失或冲突。
+
+
+具体来说,`shared` 的核心作用是:
+- **跨优先级共享更新**:高优先级更新和低优先级更新可以共用同一个 `pending` 队列,确保低优先级更新不会被高优先级任务覆盖。
+- **跨 Fiber 共享更新**:在 `current Fiber`(当前渲染树的 Fiber)和 `workInProgress Fiber`(正在构建的新 Fiber)交替工作时,`shared` 确保两者能访问到相同的待处理更新,避免状态不一致。
+- **支持中断与恢复**:并发渲染中,低优先级任务可能被高优先级任务中断,`shared.pending` 中的更新不会因中断而丢失,恢复时可继续处理。
+
+
+总结
+- `hostRenderFiber.updateQueue.shared.pending` 是宿主 Fiber 节点上「共享更新队列中待处理的更新链表」,用于收集和暂存未处理的更新。
+- `shared` 属性是为了适配并发渲染的多优先级、多阶段调度需求,确保更新队列能在不同场景(如不同优先级任务、不同 Fiber 树)中被安全共享和同步,避免更新丢失或冲突。
+
+
+注意:「在并发模式中,React 可能同时存在多个更新任务」并不是说明 React 在渲染的时候存在多个线程,**JS 是单线程模型**这一客观事实没有改变,这里说的是更新任务,是任务队列,并不是任务线程。
+
+- JS 单线程的限制是 “同一时间只能执行一个任务”,但可以通过任务队列(如宏任务、微任务)控制任务的执行时机。
+- React 并发模式下,不同更新任务(如用户输入、列表渲染)会被标记不同的优先级(通过 Scheduler 包实现)。高优先级任务(如点击事件)可以打断低优先级任务(如长列表渲染)的执行 —— 此时低优先级任务的中间状态不会提交到 DOM,而是被暂停,等高优先级任务完成后,低优先级任务再从暂停处恢复执行。
+
+
+这种 “中断 - 恢复” 机制让开发者感觉 “多个任务在同时处理”,但本质上仍是主线程按优先级依次执行,没有多线程参与。而 shared.pending 正是为了在这种 “中断 - 恢复” 中,确保低优先级任务被打断时,其未处理的更新不会丢失(因为更新存在共享队列中,恢复时可继续读取)。
+
+
+
+### shared 与双缓冲机制(current/WIP 切换)的关系
+shared(共享)是为了支持 React 的并发渲染机制而设计的」可以理解为 React Fiber 架构为了解决长列表渲染问题,借鉴 iOS、Android 设计了双缓冲机制,系统在 current 和 WIP 之间切换,从而避免长时间阻塞主线程,提升用户体验吗?
+
+双缓冲机制(current 与 workInProgress Fiber 树):这是 React Fiber 架构的核心设计之一,类似 iOS/Android 的双缓冲(前台显示缓冲区、后台绘制缓冲区)。
+- current Fiber:当前已渲染到 DOM 的 Fiber 树,代表 “当前屏幕上的 UI”。
+- workInProgress Fiber(WIP):正在内存中构建的新 Fiber 树,用于计算更新后的 UI。
+当 WIP 树构建完成后,React 会通过切换 current 指针(指向 WIP 树)完成更新,避免直接修改 current 树导致的 UI 闪烁或不完整(因为构建过程可能被中断)。
+这一机制的核心是避免渲染过程中的中间状态暴露给用户,解决 “长时间阻塞主线程导致的 UI 卡顿”。
+
+shared 的作用:支持双缓冲中的更新共享双缓冲机制中,current 和 WIP 是两棵独立的 Fiber 树,但它们需要共享同一份更新队列—— 否则如果更新只存在于 current 树,WIP 树构建时会丢失更新;反之如果只存在于 WIP 树,若 WIP 树被中断丢弃(高优先级任务抢占后可能重新构建),更新也会丢失。
+- shared 正是为这两棵树提供了一个 “共享的更新容器”:
+- 无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列。
+- 当需要构建 WIP 树时,会从 shared.pending 中读取所有待处理更新,确保不遗漏。
+即使 WIP 树被中断重建,新的 WIP 树仍能从 shared.pending 中获取最新更新。
+简单说:双缓冲机制解决 “渲染过程不阻塞 UI”,shared 解决 “双缓冲切换时更新不丢失”,二者配合支撑了并发渲染的可靠性。
+
+### 「无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列」那么是不是 update 任务会有个标记用于区分当前任务是 current Fiber 树的任务还是 WIP Fiber 树的任务?请分别列举,WIP和 Current 不同的任务提交后,后续是如何执行的
+
+在 React 中,Update 任务(即更新对象)并没有专门的标记区分其来自 current Fiber 树还是 workInProgress Fiber 树。这是因为 shared.pending 队列的设计目标就是 “消除来源差异”—— 无论更新来自哪个 Fiber 树,最终都需要被统一处理,确保状态的一致性。一言以蔽之就是:**update 任务不管是 WIP Fiber tree 产生的,还是 Current Fiber Tree 产生的,只用于服务于下一次(也就是 WIP Fiber Tree),类似双缓冲机制,用于构建下一次需要显示的内容**
+
+- current 树是 “只读的”:它代表当前屏幕上的 UI,任何更新都不会直接修改 current 树(否则会导致用户看到中间态、闪烁或不一致)。
+- WIP 树是 “可写的构建区”:所有更新(无论来自 current 树的用户交互,还是 WIP 树构建中的嵌套逻辑)最终都会被收集到 shared.pending 队列,然后在 WIP 树的构建过程中被统一处理(计算新状态、生成新的 Fiber 节点)
+
+### “挂载”和“插入”
+
+React 中经常会看到挂载和插入2个术语。2者有啥区别呢?
+
+| 概念 | 含义 | 发生阶段 | 操作对象 | 是否触发浏览器重排 |
+| :--------------------- | :-------------------------------- | :--------- | :----------------------------------------------------------- | ------------------ |
+| **挂载(mounting)** | 在内存中构建DOM节点间的父子关系 | Render阶段 | React Element 对象
+
diff --git a/Chapter2 - Web FrontEnd/2.32.md b/Chapter2 - Web FrontEnd/2.32.md
index aa36ba6..8911ee2 100644
--- a/Chapter2 - Web FrontEnd/2.32.md
+++ b/Chapter2 - Web FrontEnd/2.32.md
@@ -37,13 +37,13 @@ render () {
## 生命周期
-
+
## 状态管理
Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍了。解决了各个组件之间数据传递的复杂问题。先看看 Redux 进行状态管理的一个流程吧。
-
+
### 开发步骤
@@ -109,7 +109,7 @@ Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍
Redux-thunk 是 redux 里面常用的一个中间件。中间件?针对谁和谁的中间?对 action 和 store 的中间件。本来 action 只可以返回一个对象,灵活性较低,但是采用了 redux-thunk 之后,action 不仅可以传递对象,还可以传递函数。 action 通过 dispatch 传递给 store。 dispatch 判断 action 的类型,如果是对象则直接传递;如果是函数则直接执行。
-
+
- 异步函数不应该放在组件的生命周期函数里面。复杂的业务逻辑和异步函数适合拆分。目前主流的解决方案有2种中间件:redux-thunk、redux-saga。采用不同的策略
@@ -237,4 +237,1481 @@ class Welcome extends React.Component {
- Vue 设计思想:How easy it can be。React:How corrct it can be 和 all in js(css写法也在用 js 控制,比如 styled-component)
-在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
\ No newline at end of file
+在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
+
+
+
+
+
+## React 核心渲染流程 Fiber 架构
+
+React 在 16 之后引入了 Fiber 架构,旨在解决长列表的渲染卡顿问题。几个关键问题
+
+### hostRenderFiber 里的 updateQueue.shared.pending 怎么理解?为什么需要 shared 属性?
+
+
+在 React 的 Fiber 架构中,`hostRenderFiber.updateQueue.shared.pending` 涉及更新队列的核心设计,尤其是为了支持并发渲染和多优先级更新。我们可以分两部分理解:
+
+
+1. 先拆解概念:`hostRenderFiber.updateQueue.shared.pending`
+- **`hostRenderFiber`**:指「宿主环境渲染 Fiber 节点」(如对应 DOM 元素的 Fiber),负责管理该节点的渲染和更新状态。
+- **`updateQueue`**:Fiber 节点上的「更新队列」,用于存储待处理的更新(如 `setState`、`useState` 产生的更新)。React 通过更新队列实现更新的合并、优先级排序和批量处理。
+- **`shared`**:更新队列中「共享部分」的容器,用于在多场景下共享更新数据(核心是支持并发模式)。
+- **`pending`**:`shared` 中存储「待处理更新」的链表(环形链表),指向当前等待被处理的更新队列尾部。
+
+
+2. `pending` 的作用
+`pending` 是更新队列中**未被处理的更新链表**,本质是一个「环形单向链表」。其设计目的是高效地收集和处理更新:
+- 当产生新更新(如调用 `setState`)时,React 会创建一个 `Update` 对象,并将其添加到 `pending` 链表的尾部(通过指针调整形成环形)。
+- 在「协调阶段(Reconciliation)」,React 会从 `pending` 中取出所有待处理更新,进行合并(如多个相同状态的更新合并为一个),最终计算出最新的状态。
+
+环形链表的设计能让更新的添加和取出操作更高效(时间复杂度 O(1)),避免频繁的数组操作开销。
+
+
+3. 为什么需要 `shared` 属性?
+`shared`(共享)是为了支持 React 的**并发渲染机制**而设计的,核心解决「多场景下更新队列的共享与同步」问题:
+
+在并发模式中,React 可能同时存在多个「更新任务」(如高优先级的用户输入更新和低优先级的列表渲染更新),且这些任务可能在不同的「调度阶段」(如主线程、后台任务)中被处理。此时需要一个「共享的更新容器」,让不同的调度逻辑、优先级任务能访问到同一份待处理更新,避免更新丢失或冲突。
+
+
+具体来说,`shared` 的核心作用是:
+- **跨优先级共享更新**:高优先级更新和低优先级更新可以共用同一个 `pending` 队列,确保低优先级更新不会被高优先级任务覆盖。
+- **跨 Fiber 共享更新**:在 `current Fiber`(当前渲染树的 Fiber)和 `workInProgress Fiber`(正在构建的新 Fiber)交替工作时,`shared` 确保两者能访问到相同的待处理更新,避免状态不一致。
+- **支持中断与恢复**:并发渲染中,低优先级任务可能被高优先级任务中断,`shared.pending` 中的更新不会因中断而丢失,恢复时可继续处理。
+
+
+总结
+- `hostRenderFiber.updateQueue.shared.pending` 是宿主 Fiber 节点上「共享更新队列中待处理的更新链表」,用于收集和暂存未处理的更新。
+- `shared` 属性是为了适配并发渲染的多优先级、多阶段调度需求,确保更新队列能在不同场景(如不同优先级任务、不同 Fiber 树)中被安全共享和同步,避免更新丢失或冲突。
+
+
+注意:「在并发模式中,React 可能同时存在多个更新任务」并不是说明 React 在渲染的时候存在多个线程,**JS 是单线程模型**这一客观事实没有改变,这里说的是更新任务,是任务队列,并不是任务线程。
+
+- JS 单线程的限制是 “同一时间只能执行一个任务”,但可以通过任务队列(如宏任务、微任务)控制任务的执行时机。
+- React 并发模式下,不同更新任务(如用户输入、列表渲染)会被标记不同的优先级(通过 Scheduler 包实现)。高优先级任务(如点击事件)可以打断低优先级任务(如长列表渲染)的执行 —— 此时低优先级任务的中间状态不会提交到 DOM,而是被暂停,等高优先级任务完成后,低优先级任务再从暂停处恢复执行。
+
+
+这种 “中断 - 恢复” 机制让开发者感觉 “多个任务在同时处理”,但本质上仍是主线程按优先级依次执行,没有多线程参与。而 shared.pending 正是为了在这种 “中断 - 恢复” 中,确保低优先级任务被打断时,其未处理的更新不会丢失(因为更新存在共享队列中,恢复时可继续读取)。
+
+
+
+### shared 与双缓冲机制(current/WIP 切换)的关系
+shared(共享)是为了支持 React 的并发渲染机制而设计的」可以理解为 React Fiber 架构为了解决长列表渲染问题,借鉴 iOS、Android 设计了双缓冲机制,系统在 current 和 WIP 之间切换,从而避免长时间阻塞主线程,提升用户体验吗?
+
+双缓冲机制(current 与 workInProgress Fiber 树):这是 React Fiber 架构的核心设计之一,类似 iOS/Android 的双缓冲(前台显示缓冲区、后台绘制缓冲区)。
+- current Fiber:当前已渲染到 DOM 的 Fiber 树,代表 “当前屏幕上的 UI”。
+- workInProgress Fiber(WIP):正在内存中构建的新 Fiber 树,用于计算更新后的 UI。
+当 WIP 树构建完成后,React 会通过切换 current 指针(指向 WIP 树)完成更新,避免直接修改 current 树导致的 UI 闪烁或不完整(因为构建过程可能被中断)。
+这一机制的核心是避免渲染过程中的中间状态暴露给用户,解决 “长时间阻塞主线程导致的 UI 卡顿”。
+
+shared 的作用:支持双缓冲中的更新共享双缓冲机制中,current 和 WIP 是两棵独立的 Fiber 树,但它们需要共享同一份更新队列—— 否则如果更新只存在于 current 树,WIP 树构建时会丢失更新;反之如果只存在于 WIP 树,若 WIP 树被中断丢弃(高优先级任务抢占后可能重新构建),更新也会丢失。
+- shared 正是为这两棵树提供了一个 “共享的更新容器”:
+- 无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列。
+- 当需要构建 WIP 树时,会从 shared.pending 中读取所有待处理更新,确保不遗漏。
+即使 WIP 树被中断重建,新的 WIP 树仍能从 shared.pending 中获取最新更新。
+简单说:双缓冲机制解决 “渲染过程不阻塞 UI”,shared 解决 “双缓冲切换时更新不丢失”,二者配合支撑了并发渲染的可靠性。
+
+### 「无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列」那么是不是 update 任务会有个标记用于区分当前任务是 current Fiber 树的任务还是 WIP Fiber 树的任务?请分别列举,WIP和 Current 不同的任务提交后,后续是如何执行的
+
+在 React 中,Update 任务(即更新对象)并没有专门的标记区分其来自 current Fiber 树还是 workInProgress Fiber 树。这是因为 shared.pending 队列的设计目标就是 “消除来源差异”—— 无论更新来自哪个 Fiber 树,最终都需要被统一处理,确保状态的一致性。一言以蔽之就是:**update 任务不管是 WIP Fiber tree 产生的,还是 Current Fiber Tree 产生的,只用于服务于下一次(也就是 WIP Fiber Tree),类似双缓冲机制,用于构建下一次需要显示的内容**
+
+- current 树是 “只读的”:它代表当前屏幕上的 UI,任何更新都不会直接修改 current 树(否则会导致用户看到中间态、闪烁或不一致)。
+- WIP 树是 “可写的构建区”:所有更新(无论来自 current 树的用户交互,还是 WIP 树构建中的嵌套逻辑)最终都会被收集到 shared.pending 队列,然后在 WIP 树的构建过程中被统一处理(计算新状态、生成新的 Fiber 节点)
+
+### “挂载”和“插入”
+
+React 中经常会看到挂载和插入2个术语。2者有啥区别呢?
+
+| 概念 | 含义 | 发生阶段 | 操作对象 | 是否触发浏览器重排 |
+| :--------------------- | :-------------------------------- | :--------- | :----------------------------------------------------------- | ------------------ |
+| **挂载(mounting)** | 在内存中构建DOM节点间的父子关系 | Render阶段 | React Element 对象
`parentElement.appendChild(childElement)`
(仅在内存中) | 否 | +| **插入文档(insert)** | 将DOM树实际添加到浏览器的文档流中 | Commit阶段 | 标准的 DOM 对象
`document.getElementById('root').appendChild(domTree)` | 是 | + +举个例子: + +```react +function Counter() { + return ( +
转换JS Bundle]; + B --> C[JS Framework
解析并管理Virtual DOM]; + C -- 通过JS Bridge发送渲染指令 --> D[Native SDK
渲染引擎]; + D --> E[iOS/Android/Web 原生视图]; + + C -- 支持多种DSL --> F[Vue.js]; + C -- 支持多种DSL --> G[Rax(类React)]; + D -- 原生能力扩展 --> H[自定义Component]; + D -- 原生能力扩展 --> I[自定义Module]; +``` + +Weex 最核心的设计是将整个框架清晰地分为:**语法层(DSL)**、**中间层(JS Framework)**和**渲染层(Native SDK)** + +这种渲染引擎和语法层 DSL 分离的设计,可以使得上层 DSL 方便拓展 Vue、Rax 写法,下层渲染引擎可以保持较好的稳定性。为了生态的拓展提供了极大的便携性。 + + + +### 3. 可扩展的组件与模块系统 + +Weex 通过`WXSDKEngine.registerComponent()` 和 `registerModule()` 方法,允许开发者扩展原生组件 (UI Component)和模块(Login Module)。这套机制设计得足够底层和通用,使得 Weex 可以由开发者来注册,由公司内的体验设计中心规范来落地的组件。以及一些基础能力。这样子 Weex 官方已经提供了一些功能强大的筋骨,我们在其之上可以提供更符合需求的外表和更有力量的一块手臂肌肉。 + +虽然事后视角来看,Weex、RN、Flutter,甚至是更早的、设计完善的 Hybrid 都有该能力。但这对于远古时期的 Weex 来说,还是可圈可点的。 + + + +### 4. 轻量 JSBundle + 增量更新支持 + +Weex 的 JSBundle 仅包含业务逻辑和组件描述,框架代码(Vue 内核、Weex 基础 API)内置在原生 SDK 中,因此 Bundle 体积极小;同时支持将 Bundle 拆分为 “基础包(公共逻辑)+ 业务包(页面逻辑)”,实现增量更新。 + +解决了跨端框架 “首屏加载慢” 的痛点(小 Bundle 加载更快),同时增量更新降低了发布成本。 + + + +## 十一、Weex APM + +### 1. 历史背景 +Weex 是诸多年前的产物,部分业务线用 Weex 写了部分功能模块,或者是某几个页面,或者是某个二级、三级业务 SDK 的页面。但可以确定的是: +- 21年就完成了 Flutter 的基建开发(对齐 Native 的 UI 组件库,遵循体验设计平台产出的集团 UI 标准;做了 Flutter 的大量 plugin、打包构建平台、日志库、网络库、探照灯、APM SDK、热修复能力等)。新业务的实现只会在 Native 和 Flutter 上考虑 +- Weex 业务代码基本上是存量的 +- Weex 代码没有 bug 就不去修改;有版本迭代,之前是 Weex 实现的,本次只做简单 UI 增删或字段调整,也是会修改一下。初次之外不修改 Weex 代码 + +所以像 Native 一样去全面监控性能、网络、crash、异常、白屏、页面加载耗时等维度的话,ROI 是很低的。那么就需要制定一些策略去有针对性的监控高优问题。 + +Weex 的异常比较有特点,比如在页面的模版代码中绑定了 data 中的一个对象,此时对象可能并没有值,而是依赖后续的网络请求完成,对象才有了具体的值 data 改变,数据驱动,页面再次 render。所以监控代码会认为第一次 render 的时候访问对象不存在的属性。 +真正有问题的代码和不影响业务的异常信息,都会被 Vue 官方认为是异常。基于这样的背景,我们无法 pick 出真正异常或者是开发者判空代码没写好的问题。基于此,我们需要做一些约定和标准。 + +### 2. 优先级权衡标准 +这时候就需要摒弃程序员视角(不然会陷入啥数据都想统计,可能是洁癖、可能是追求),但从 ROI 角度出发,我们就需要切换到用户视角。 + +假设你是一个用户,什么样的情况代表业务异常,对我们的用户来说比较痛呢? +- 页面白屏了,看都看不到了,别说你们的 App 为我赋能解决用户痛点了 +- 稍微好点,可以看到页面了,但是某一个区域是白屏的。比如:该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面应该是有个“确认支付”按钮,但是此处就是空白,点也点不了。 +- 情况再好点。可以看到全部的页面了,但是点击后无响应。比如:该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面有个“确认支付”按钮。用户在考虑再三,本着理性购物后,发现是刚需品,咬紧牙要付款了,此时点击“确认支付”按钮了,但是页面没有任何反应。用户也是“见多识广”的体面人,猜测可能是网络不好的情况,所以等了1分钟,他很有耐心。切换了 WI-FI 到 5G 后,继续点击,依旧没反应。一怒之下点了10次,等了2分钟,还是没反应。他奔溃了,卸载了 App + +上述几种情况,总结为:按照异常等级,可以划分为影响业务和不影响业务。什么叫“影响业务”?这是我们自己定义的标准,影响用户是否正常操作 App。比如:页面白屏(页面全部白屏、页面部分白屏)、点击某个按钮无响应,这些叫做“影响业务”,属于 Error 级别。其他的一些轻微异常,不影响用户使用 App 功能,不影响业务,属于 Warning 级别。 + + + +### 3. UI 显示异常 +#### 1. 部分白屏:注册的 Component 使用异常 +这种情况就属于页面部分白屏。因为某个哪个 Compoent 会铺满页面,基本类似 iOS UI 控件一样组合使用。就像上文描述的「该页面大部分在展示商品价格、商品数量、商品折扣价、商品折扣信息、下面应该是有个“确认支付”按钮,但是此处就是空白」这个空白粗,理应显示一个 Native 注册的 Button,但是没有显示出来,造成业务的阻塞。 + + +.vue(或 Weex 专属.we)文件内基于 Vue 扩展的 Weex 跨平台模板 DSL 代码,在前端构建阶段会先由 Webpack 的weex-loader触发编译流程:首先通过 Weex 核心编译器@weex-cli/compiler(复用并扩展vue-template-compiler)将模板 DSL 解析为模板 AST(抽象语法树);接着由 Weex 自定义 Babel 插件(如babel-plugin-transform-weex-template)将模板 AST 转换为标准化的 JS AST,并针对 iOS/Android 跨平台特性做属性、样式、事件的适配处理(如样式单位归一化、事件名标准化);最终生成包含_h(即 Weex 运行时的$createElement,等价于 Vue 的createElement)调用的render函数,该函数会被 Webpack 打包到最终的 Weex JS Bundle 中。 + +```json +_c('color-button', + { + staticStyle: { + width: "400px", + height: "40px", + marginBottom: "20px" + }, + attrs: { + "title": "点击计算10+20", + "bgColor": "#FF6600", + "message": "hello" + }, + on: { + "click": _vm.handleButtonClick + } + }, + // 如果有 children 就是 children 信息 +) +``` + +在 App 运行阶段,Weex 的 JS 引擎(iOS 端为 JSCore、Android 端为 V8)加载 JS Bundle 后,执行组件的render函数,通过调用 `_h` 函数将模板描述转换为跨平台的虚拟 DOM(VNode),VNode 会被序列化为 JSON 格式,最终通过 JS Bridge 传递给 Native 端(iOS/Android)用于原生视图渲染。 + + +Weex 的 Component 相关逻辑都由 `WXComponentManager` 负责。页面在构建展示的时候,会调用 `_buildComponent` 方法,其内部会调用 WXComponentFactory 的能力(`configWithComponentName`),根据 ComponentName 获取 Component。 + +`configWithComponentName` 是 Weex iOS 侧 WXComponentFactory(组件工厂类)的核心方法之一,核心作用是:根据传入的组件名称(如 color-button/div/text),查找该组件对应的 Native 侧配置(WXComponentConfig);若找不到对应配置,则降级使用基础容器组件 div 的默认配置,并输出警告日志。 +```Objective-C +- (WXComponentConfig *)configWithComponentName:(NSString *)name +{ + WXAssert(name, @"Can not find config for a nil component name"); + + WXComponentConfig *config = nil; + + [_configLock lock]; + config = [_componentConfigs objectForKey:name]; + if (!config) { + WXLogWarning(@"No component config for name:%@, use default config", name); + config = [_componentConfigs objectForKey:@"div"]; + } + [_configLock unlock]; + + return config; +} +``` +UI Component 做的比较随意,认为显示问题降级用 div 就可以了。做为 SDK 这么设计也似乎可以接受,但作为业务方,我们必须收集统计这种异常情况。 +所以此处我们可以收集案发现场数据,进行上报。我们发现 Weex 自己封装了 `WXExceptionUtils`类,暴露了 `commitCriticalExceptionRT` 接口,用于收集致命问题。 + +```Objective-C ++ (void)commitCriticalExceptionRT:(WXJSExceptionInfo *)jsExceptionInfo{ + + WXPerformBlockOnComponentThread(^ { + id
+
+效果:线上低概率异常的根源被提前消灭,问题无法逃逸到现线上,业务层几乎无需处理这类异常(因为代码本身就没有漏洞)
+
+关于如何编写 LLVM 插件,做到在 Xcode 中实时展示代码中存在的问题,可以查看:[LLVM 插件](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.102.md) 这篇文章。
+
+
+
+### 方案 4:轻量级熔断 / 降级(适合核心业务场景)
+
+对于 “万分之一” 但影响大的异常(如支付金额计算、商品价格),采用「熔断策略」:
+第一次出现异常:上报 + 降级为默认值(如价格显示 “--”);
+短时间内多次出现(如 1 分钟内 > 3 次):触发熔断,建议:展示兜底 UI,提示安抚用户,稍等片刻后尝试(起码不会发生稳定的 crash 或者业务异常)
+熔断状态上报 APM,研发收到告警后优先修复。
+
+### 方案 5:语义化默认值 + 业务无感知适配(美团 / 饿了么实践)
+
+返回**业务可识别的语义化空值**,并在 UI 层做统一适配:
+
+| 异常场景 | 兜底值 | UI 层统一处理 | 业务层感知 |
+| ---------------- | -------- | --------------- | ---------- |
+| 数组越界 | NSNull | 显示 “--” | 无 |
+| 字典 key 为 nil | NSNull | 显示 “暂无数据” | 无 |
+| 分母为 0 | INFINITY | 显示 “计算异常” | 无 |
+| 字符串转数字失败 | NSNull | 显示 “--” | 无 |
+
+**实现方式**:
+
+- 封装全局 UI 工具类(如`WXUILabel+Safe.h`),重写`setText:`方法:
+
+```objective-c
+- (void) safe_setText:(id)text {
+ if (text == [NSNull null] || text == nil) {
+ self.text = @"--";
+ } else if ([text isKindOfClass:[NSNumber class]] && isinf([text doubleValue])) {
+ self.text = @"计算异常";
+ } else {
+ self.text = [text description];
+ }
+}
+```
+
+业务层只需使用`safe_setText:`,无需为每个异常场景写判断逻辑。
+
+
+
+## 四、最佳实践
+
+1. **开发环境零容忍**:通过静态分析、自定义 LLVM 插件 + 运行时 Hook,让问题在测试阶段暴露,比如异常发生时,通过日志打印案发现场数据,或者在 Xcode 面板上可视化的在有问题的代码地方显示 error,及时 crash 掉,阻塞正常流程,以防止开发偷懒不去及时修复,产生技术债,同时也防止问题逃逸到线上。
+2. **生产环境软兜底**:不要一刀切,做到可配置。业务方在配置平台可以针对不同业务域的配置,决定是否开启兜底展示(某些业务域的架构师可能更严格,需要开发在 debug 阶段解决这些问题,线上如果出现就统计为 crash)。如果开启,那么安全气垫就返回语义化默认值(而非无意义的 0),全局 UI 统一处理,业务层零侵入;
+3. **可观测驱动修复**:APM 平台统计异常频率 / 影响度,优先处理高频高影响的异常;
+4. **核心场景按需关注**:仅对价格、支付等核心场景注册回调,非核心场景无需处理。
+
+虽然机制和策略已经制定了,但是执行还是靠人,难以保证100%解决问题。所以开发解决通过 lint 和 crash 可以拦截到大部分问题,但是逃逸到线上的部分问题,还是需要安全气垫去 cover,线下无限毕竟去清空问题 + 少数逃逸到线上的问题通过安全气垫去 cover 就可以保证相对全面的安全守护。
+
+
+
+## 五、平台做些什么
+
+获取到 问题数据是第一步,获取之后问题需要及时上报,需要有一个数据上报系统,数据及时准确、高效的上传到服务端(这就是另一个命题,可以查看这篇文章:[打造一个通用、可配置、多句柄的数据上报 SDK](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md)),到 APM 后台。后台产生工单,根据业务模块分配到对应的责任人、群组。根据问题的紧急程度,报警策略和提醒频次也不一样,比如**波动报警、自定义报警策略等(这也是另一个命题:智能报警策略、波动报警策略、业务线自定义可配置责任人等)**。责任人及时解决问题、修改工单状态、热修复或者发布新版本,问题闭环。
+
+线上异常上报后,APM 平台需提供:
+
+- 异常频率(如 “数组越界” 仅 1/10000);
+- 影响用户数(如仅影响 10 个用户);
+- 业务上下文(如 “商品详情页 - 价格数组”);
+- 调用栈 + 设备信息。
+
+**核心逻辑**:
+
+- 低频率、低影响的异常(如 1/10000,影响 10 用户):暂时无需业务层处理,研发排期修复即可;
+- 高频率、高影响的异常(如 1/100,影响 1000 用户):触发告警,研发紧急修复,业务层临时加兜底。
+
+这样业务开发无需为 “万分之一” 的异常写逻辑,仅需处理 “高频高影响” 的异常。
+
+
+
+## 总结
+
+“最佳实践”部分选择的方案既避免了 “安全气垫返回错误值导致业务异常”,又解决了 “业务开发为低概率异常写冗余逻辑” 的问题,是网易、腾讯、阿里等大厂的通用实践 ——**优雅的方案不是 “兜底所有异常”,而是 “让异常可被提前发现、可被观测、最小化影响”**,即使少数逃逸到线上的,再由安全气垫去兜底解决(解决了展示问题、异常上报和案发现场还原问题),一个好的 APM 平台不光是告诉你又问题,还会告诉你哪里有问题。
+
diff --git a/Chapter1 - iOS/1.38.md b/Chapter1 - iOS/1.38.md
index b187121..46fb552 100644
--- a/Chapter1 - iOS/1.38.md
+++ b/Chapter1 - iOS/1.38.md
@@ -35,7 +35,7 @@
先附上一张总结的非常棒的RunLoop图
-
+
@@ -138,7 +138,7 @@ struct __CFRunLoopMode {
Demo:
-
+
@@ -178,11 +178,11 @@ Source0:
Demo1:给屏幕点击事件加断点,查看堆栈可以看到是 Source0 触发的。
-
+
Demo2: `- (void)performSelector:(SEL)aSelector onThread:(NSThread *)thr withObject:(nullable id)arg waitUntilDone:(BOOL)wait` 该 API 的底层就是:向目标线程的 RunLoop 添加一个 Source0 事件,标记后唤醒线程执行对应的事件。
-
+
Source1:
@@ -221,7 +221,7 @@ CFRunLoopSourceRef 事件源(输入源)
### 一对多的关系
-
+
@@ -434,7 +434,7 @@ CFRelease(obersver);
*/
```
-
+
上个实验是在主线程对 RunLoop 进行的监听,但是由于是主线程是由系统创建的,所以系统也创建了对应的主 RunLoop,所以我们看不到 RunLoop 创建的状态,为了模拟完整的状态,我们开启子线程,在子线程中模拟
@@ -510,7 +510,7 @@ CFRelease(obersver);
### 运行原概要
-
+
- 图上左上角的 Input source 是早期 RunLoop 的分法,现在分法为:Source0 和 Source1。
- Source0:非基于 port 的,用户主动触发的事件。
@@ -527,7 +527,7 @@ CFRelease(obersver);
但是如何直到系统是运行 RunLoop 的哪个函数?给 viewDidLoad 设置断点,在 lldb 模式输入 `bt` 查看堆栈
-
+
查看 CF 中 `CFRunLoop.c`源码。方法比较复杂,做了精简摘要
@@ -1137,7 +1137,7 @@ RunLoop 内部几个核心的动作:`__CFRunLoopDoObservers`、`__CFRunLoopSer
上面结合源码看了 Runloop 是怎么运行的。下面通过图片看看 RunLoop 各个状态运行切换的完整流程。
-
+
Demo:
@@ -1151,7 +1151,7 @@ Demo:
2. 上面8>2,Runloop 处理 GCD Async To Main Quque
-
+
@@ -1165,7 +1165,7 @@ Demo:
可以在 App 运行过程中,点击 Xcode 左下角的 debug 暂停按钮,可以看到 App 堆栈存在系统调用
-
+
@@ -1647,7 +1647,7 @@ App 启动后,主线程 RunLoop 里注册了2个 Observer,其回调都是 `_
当界面的 Frame 改变,或者更改 UIView、CALayer 的层次时,或者调用了 UIView、CALayer 的 setNeedsLayout、setNeedsDisplay 方法后,这个 UIView、CALayer 会被标记为待处理(类比前端的 Virtual Dom Diff,标记为 dirty),并被提交到一个全局容器中。
-苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Obserger 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
+苹果设计 UI 更新也是 RunLoop 的业务方,所以会注册一个 Observer 监控 `kCFRunLoopBeforeWaiting`(将要休眠)和 `kCFRunLoopExit` (即将退出 RunLoop)状态,然后会执行 `_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()` 回调。内部会遍历所有待处理的 UIView、CALayer 以执行实际的绘制和渲染,更新 UI
@@ -1887,7 +1887,7 @@ main 方法内其实就是在执行 _selector。也就是在 NSThread 的初始
2. `[[NSRunLoop currentRunLoop] run]` api 换掉。查看系统说明,底层其实就是一个无限循环,循环内部不断调用 `runMode:beforeDate:`。下面也有建议,建议我们想销毁 RunLoop,可以替换 API,比如设置一个变量,标记是否需要结束 RunLoop
-
+
改进代码如下
@@ -1995,7 +1995,7 @@ self.thread = [[LifeThread alloc] initWithBlock:^{
效果如下:
-
+
diff --git a/Chapter1 - iOS/1.39.md b/Chapter1 - iOS/1.39.md
index 33ad89e..c9cb0fb 100644
--- a/Chapter1 - iOS/1.39.md
+++ b/Chapter1 - iOS/1.39.md
@@ -1079,6 +1079,169 @@ QA:互斥递归锁,可以在不同线程中加锁吗?
+#### 使用注意事项
+##### 加解锁必须成对
+加解锁必须成对出现,否则容易出现多线程性能问题。提供一种思路,利用 `@try-finally` 来保证加解锁必须成对存在,这个写法也是 Weex 官方的实现。
+Weex 中的 WXThreadSafeMutableDictionary 提供了一个线程安全的字典,其本质是通过加 pthread_muext_t 锁来维护内部的一个字典的。
+比如下面的代码
+
+初始化锁相关的配置
+```Objective-C
+@interface WXThreadSafeMutableDictionary ()
+{
+ NSMutableDictionary* _dict;
+ pthread_mutex_t _safeThreadDictionaryMutex;
+ pthread_mutexattr_t _safeThreadDictionaryMutexAttr;
+}
+
+@end
+
+@implementation WXThreadSafeMutableDictionary
+
+- (instancetype)initCommon
+{
+ self = [super init];
+ if (self) {
+ pthread_mutexattr_init(&(_safeThreadDictionaryMutexAttr));
+ pthread_mutexattr_settype(&(_safeThreadDictionaryMutexAttr), PTHREAD_MUTEX_RECURSIVE); // must use recursive lock
+ pthread_mutex_init(&(_safeThreadDictionaryMutex), &(_safeThreadDictionaryMutexAttr));
+ }
+ return self;
+}
+
+- (instancetype)init
+{
+ self = [self initCommon];
+ if (self) {
+ _dict = [NSMutableDictionary dictionary];
+ }
+ return self;
+}
+```
+在字典操作的地方使用锁
+```Objective-C
+- (void)setObject:(id)anObject forKey:(id
+
+```
+source 'https://rubygems.org' gem 'rails', '4.1.0.rc2'
+gem ‘rack-cache'
+gem 'nokogiri', '~> 1.6.1'
+```
+
+- 读取 Gemfile:Bundler 首先会读取当前目录下的 Gemfile 文件,解析其中声明的所有依赖项及其版本约束
+- 解析依赖关系:
+ - 分析每个 gem 的版本要求,确定满足所有约束的最佳版本组合
+ - 处理依赖的依赖(传递依赖),确保整个依赖树的兼容性
+- 检查本地缓存:
+ - 查看本地是否已缓存所需版本的 gem
+ - 如果有,直接使用本地缓存,跳过下载步骤
+- 从源下载 gem:
+ - 对于本地没有的 gem,从 source 'https://rubygems.org' 指定的源下载
+ - 默认源是 RubyGems 官方仓库,国内用户可能需要切换到镜像源以提高速度
+- 安装 gem 到项目目录:
+ - 默认情况下,gem 会被安装到项目根目录下的 vendor/bundle 目录
+ - 这种方式可以避免污染系统级的 gem 安装,实现项目间的依赖隔离
+- 生成 Gemfile.lock:
+ - 安装完成后,Bundler 会生成 Gemfile.lock 文件
+ - 该文件记录了实际安装的每个 gem 的精确版本,确保团队协作或部署时使用完全相同的依赖版本
+
+思考:怎么样,是不是发现 Ruby Bundler 工作流程和 iOS Cocoapods 的工作过程一致?是的,iOS Cocoapods 的设计就是参考 Ruby Bundler 的设计。甚至连 pod search、install、list API 设计也和 gem 一致
+
+
+
+## 四. Cocoapods
+
+### 1. cocoapods-binary
+- cocoapods-binary 通过开关,在 pod insatll 的过程中进行 library 的预编译,生成 framework,并自动集成到项目中。
+- 整个预编译工作分成了三个阶段来完成:
+ - binary pod 的安装
+ - binary pod 的预编译
+ - binary pod 的集成
+
+### 2. Hook
+- pre_install:Pod 下载之后,但在安装之前可以有时机对 Pod 进行任何更改
+- post_install:当所需依赖安装完成,但此时生成的 XcodeProj 项目在写入磁盘前,我们可以对其进行最后的更改
+
+
+### 3. Cocoapods 工程拆解
+#### 1. cocoapods.gemspec 文件
+```Ruby
+# encoding: UTF-8
+require File.expand_path('../lib/cocoapods/gem_version', __FILE__)
+require 'date'
+
+Gem::Specification.new do |s|
+ s.name = "cocoapods"
+ s.version = Pod::VERSION
+ s.date = Date.today
+ s.license = "MIT"
+ s.email = ["eloy.de.enige@gmail.com", "fabiopelosin@gmail.com", "kyle@fuller.li", "segiddins@segiddins.me"]
+ s.homepage = "https://github.com/CocoaPods/CocoaPods"
+ s.authors = ["Eloy Duran", "Fabio Pelosin", "Kyle Fuller", "Samuel Giddins"]
+
+ s.summary = "The Cocoa library package manager."
+ s.description = "CocoaPods manages library dependencies for your Xcode project.\n\n" \
+ "You specify the dependencies for your project in one easy text file. " \
+ "CocoaPods resolves dependencies between libraries, fetches source " \
+ "code for the dependencies, and creates and maintains an Xcode " \
+ "workspace to build your project.\n\n" \
+ "Ultimately, the goal is to improve discoverability of, and engagement " \
+ "in, third party open-source libraries, by creating a more centralized " \
+ "ecosystem."
+
+ s.files = Dir["lib/**/*.rb"] + %w{ bin/pod bin/sandbox-pod README.md LICENSE CHANGELOG.md }
+
+ s.executables = %w{ pod sandbox-pod }
+ s.require_paths = %w{ lib }
+
+ # Link with the version of CocoaPods-Core
+ s.add_runtime_dependency 'cocoapods-core', "= #{Pod::VERSION}"
+
+ s.add_runtime_dependency 'claide', '>= 1.0.2', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-deintegrate', '>= 1.0.3', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-downloader', '>= 2.1', '< 3.0'
+ s.add_runtime_dependency 'cocoapods-plugins', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-search', '>= 1.0.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-trunk', '>= 1.6.0', '< 2.0'
+ s.add_runtime_dependency 'cocoapods-try', '>= 1.1.0', '< 2.0'
+ s.add_runtime_dependency 'molinillo', '~> 0.8.0'
+ s.add_runtime_dependency 'xcodeproj', '>= 1.27.0', '< 2.0'
+
+ s.add_runtime_dependency 'colored2', '~> 3.1'
+ s.add_runtime_dependency 'escape', '~> 0.0.4'
+ s.add_runtime_dependency 'fourflusher', '>= 2.3.0', '< 3.0'
+ s.add_runtime_dependency 'gh_inspector', '~> 1.0'
+ s.add_runtime_dependency 'nap', '~> 1.0'
+ s.add_runtime_dependency 'ruby-macho', '~> 4.1.0'
+
+ s.add_runtime_dependency 'addressable', '~> 2.8'
+
+ s.add_development_dependency 'bacon', '~> 1.1'
+ s.add_development_dependency 'bundler', '~> 2.0'
+ s.add_development_dependency 'rake', '~> 12.3'
+
+ s.required_ruby_version = '>= 2.6'
+end
+
+```
+
+`cocoapods.gemspec` 作为 Cocoapods 工程的配置文件,类似 iOS 组件库的 Podspec 文件一样。
+Cocospods 工程本身就是一个 Ruby gem,所以 `cocoapods.gemspec` 用于描述这个 gem 包的元数据,包括作者、版本、描述信息,包括一些导入的文件。
+
+也声明了该 gem 包含的源代码文件、资源文件,以及它所依赖的其他 Ruby gem(比如 xcodeProj 等)和版本要求,确保安装时能正确解析依赖关系。
+
+
+
+#### 2. cocoapods-core
+
+1. CocoaPods 核心模块,用来支持:
+
+ - Pod::specification(podspec)
+
+ - Pod::Podfile(Podfile)
+
+ - Pod::Source(Spec repo)
+
+2. cocoapods-deintergrate: 用于从项目中删除和取消集成 CocoaPods,指令为 `pod deintegrate`
+
+3. Xcodeproj:
+
+ 来操作 Xcode 项目的创建和编辑等。同时支持 Xcode 项目的脚本管理和 libraries 构建,以及 Xcode 工作空间(.xcworkspace) 和配置文件 .xcconfig 的管理
+
+4. cocospods-downloader:用于下载和管理引入的源码
+
+5. cocoapods-plugins: 插件管理功能
+
+6. cocoapods-try:可以快速体验该 pod 的 Demo 项目
+
+7. CLAide:命令行解释器
+
+8. ruby-macho:一个用于检查和修改 Mach-O 文件的 Ruby 库
+
+
+
+#### 3. Podfile
+
+Podfile 是一个文件,以 DSL 来描述依赖关系,用于描述项目所需要的第三方库。
+
+
+
+### 4. VSCode 调试 Cocoapods
+
+1. 新创建文件夹 `RubyDemos`
+2. 从 git clone Cocoapods 源码到本地目录
+3. 进入到 Cocoapods 文件夹,将分支切换到和本机安全的 pod 版本一致的分支,指令为: **git checkout `pod --version`**
+4. `RubyDemos` 根目录下创建一个 Xcode iOS 工程,并为其编写 Podfile 文件。目的是为了调试 Cocoapods
+5. `RubyDemos` 根目录下创建一个 **Gemfile** 文件。内容如下:
+ ```Ruby
+ source 'https://rubygems.org'
+
+ gem 'cocoapods', path: './Cocoapods' # 指向本地源码
+ gem 'debug', '~> 1.9.0' # 调试用
+ ```
+6. 终端执行 `bundle install` 指令
+7. 此时,项目文件夹为:
+ ```
+ .
+ ├── CocoaPods
+ ├── Demos
+ ├── Gemfile
+ ├── Gemfile.lock
+ └── StaticLibConflictsDemo
+ ```
+8. 用 VSCode 打开工程。进入 Run and Debug 面板 → 点击 create a launch.json file → 选择 Ruby → 选 Debug Local File。
+9. 修改 launch.json 内容。
+ ```json
+ {
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "name": "Debug CocoaPods",
+ "type": "rdbg", // 必须为 rdbg(debug 工具类型)
+ "request": "launch",
+ "script": "${workspaceFolder}/CocoaPods/bin/pod", // 源码中的 pod 入口
+ "args": ["install", "--verbose"], // 执行 pod install
+ "cwd": "${workspaceFolder}/StaticLibConflictsDemo", // 测试工程目录(Podfile 所在目录)
+ "useBundler": true, // 强制通过 bundle 执行
+ "askParameters": false // 关闭参数询问(避免干扰)
+ }
+ ]
+ }
+ ```
+10. VSCode 插件市场安装:VSCode rdbg Ruby Debugger、Ruby LSP
+11. VSCode 面板中,点击左侧的调试按钮。便可调试。要是看到下面的图,说明可以正常 Debug 了
+
+
+接下来就可以愉快的调试了。
+说明:
+- pod 的每个指令,分别对应 Cocoapods 工程中一个代码文件
+
+- 同时根据观察,发现 `target do` 的代码比 pre_install、post_install 执行更早。所以我们可以做一些脚本化的操作。
+比如下面,增加了一段自定义的脚本
+
+
+
+
+## 五、体验核心依赖库能力
+
+### 1. ruby-macho
+
+#### 1. 操作 Mach-O 文件
+
+读取 Mach-O 文件,并用操作对象的方式去读区、增加、删除信息。
+
+分别对 Mach-O 增加了一个 `LC_RPATH` 类型的 Load Command
+
+```ruby
+lc_rpath = MachO::LoadCommands::LoadCommand.create(:LC_RPATH, 'test_rpath')
+file_exec.add_command lc_rpath
+```
+
+
+
+对 Mach-O 文件中删除了类型为 `LC_LINKER_OPTION` 的 Load Command
+
+
+
+#### 2. 操作动态库
+
+`ruby-macho` 还可以读取动态库信息,下面演示几个能力:
+
+- 读取动态库所依赖的动态库信息
+
+ ```ruby
+ # 打印出当前 Mach-O 文件使用的所有动态库
+ macho_dylibs = MachO::Tools.dylibs(macho_filepath)
+ macho_dylibs.each do | dylib |
+ puts dylib
+ end
+ ```
+
+- 修改动态库的 id
+
+ ```ruby
+ # 修改动态库的 id
+ MachO::Tools.change_dylib_id(macho_copy_filepath, 'test_selfdefined_dylib')
+ ```
+
+ 修改后在终端用指令 **objdump --macho --private-headers ./macho/libAFNetworking_copy.dylib | grep 'LC_ID_DYLIB' -A 5** 验证效果,如下图所示:
+
+
+
+ 也可以直接查看动态库的 id
+
+ ```ruby
+ original_dylib_id = MachO::MachOFile.new(macho_filepath)
+ copyed_dylib_id = MachO::MachOFile.new(macho_copy_filepath)
+
+ # 也可以直接查看动态库的 id
+ puts "before change dylib id: #{original_dylib_id.dylib_id}"
+ puts "after change dylib id: #{copyed_dylib_id.dylib_id}"
+ ```
+
+- 修改动态库 rpath
+
+ ```ruby
+ MachO::Tools.change_rpath(macho_copy_filepath, '@loader_path/Frameworks', '@loader_path/Frameworks/FantasicLBP')
+ ```
+
+
+
+#### 3. 合并动态库到胖二进制
+
+ruby-macho 有很多丰富的 API,基本上开发阶段所遇到的问题,都有现成的 API 解决。比如二进制指令集的合并
+
+```ruby
+filenames = [dylib_merged_filepath, dylib_arm_filepath]
+# # 第一个参数为合并之后的动态库名称,第二个参数为需要合并的一堆动态库
+MachO::Tools.merge_machos(dylib_merged_filepath, *filenames)
+```
+
+合并后用 `otool -f ./macho/libAFNetworking_merged.dylib` 指令查看指令集
+
+
+
+
+
+### 2. Xcodeproj
+
+通过 xcodeproject 路径构建 xcodeproj 对象 `app_project = Xcodeproj::Project.new(app_project_path)`
+
+通过 xcworkspace 路径构建 xcworkspace 对象 `app_workspace = Xcodeproj::Workspace.new_from_xcworkspace(app_workspace_project_path)`
+
+然后通过对象的方式访问 xcworkspace 的信息。比如 schemes
+
+```ruby
+app_workspace.schemes.each do | scheme |
+ puts scheme
+end
+```
+
+
+
+也可以针对特定的 target 修改 xcconfig
+
+```ruby
+# 修改 targets 中第一个对应 configurations 为指定的 xcconfig 文件
+configuration_path = File.dirname(__FILE__) + '/xcodeproject/AFNetworkingMock/xcodeproj-testing.debug.xcconfig'
+# 转换为 xcode 的 file
+xc_file = app_project.new_file(configuration_path)
+
+app_project.targets.first.build_configurations.first.base_configuration_reference = xc_file
+```
+
+效果如下:
+
+
+
+也可以对特定的 target 修改 buildSetting 中的信息,比如 bundle id
+
+```ruby
+# 修改 target 的 bundle id
+app_project.targets.each do | target |
+ target.build_configurations.each do | config |
+ config.build_settings['PRODUCT_BUNDLE_IDENTIFIER'] = 'com.github.FantasticLBP.AFNetworkingMock' if config.name == 'Debug'
+ end
+end
+```
+
+
+
+
+
+## 六、自定义 cocoapods 插件
+
+### 1. 自定义 gem 库
+
+
+
+#### 1. 初始化创建
+
+输入指令 `bundle gem cocoapods-hmap` 自定义一个名为 `cocoapods-hmap` 的 gem 库
+
+#### 2. 工程结构说明
+
+得到的工程结构是:
+
+```shell
+.
+├── CHANGELOG.md
+├── CODE_OF_CONDUCT.md
+├── Gemfile
+├── LICENSE.txt
+├── README.md
+├── Rakefile
+├── bin
+│ ├── console
+│ └── setup
+├── cocoapods-hmap.gemspec
+├── lib
+│ └── cocoapods
+│ ├── hmap
+│ │ └── version.rb
+│ └── hmap.rb
+└── sig
+ └── cocoapods
+ └── hmap.rbs
+```
+
+说明:
+
+- **cocoapods-hmap.gemspec**:
+
+ - gem 的核心配置文件,定义了 gem 的名称、版本、作者、依赖、描述、文件包含规则等关键信息。
+ - 用于打包和发布 gem 到 RubyGems 仓库,是 gem 工程的 “身份证
+
+- **Rakefile**:
+
+ - 定义自动化任务(如测试、打包、发布等),通过 `rake <任务名>` 执行(类似 `Makefile`)。
+ - 常见任务:`rake spec`(运行测试)、`rake build`(打包 gem)、`rake release`(发布到 RubyGems)
+
+- **Gemfile**:
+
+ - 定义 gem 开发 / 测试阶段的依赖(如测试框架 `rspec`、打包工具等),类似前端的 `package.json`。
+ - 通过 `bundle install` 安装依赖,依赖版本由 `Gemfile.lock`(自动生成)锁定
+
+- **源代码目录:lib/ **
+
+ - gem 的核心功能代码存放目录,Ruby 会自动加载该目录下的文件
+
+ - `lib/cocoapods/hmap.rb`:gem 的主入口文件,定义了 `CocoaPods::Hmap` 模块的核心逻辑,是功能实现的主要载体(如与 CocoaPods 集成的逻辑、头文件映射相关功能等)
+ - `lib/cocoapods/hmap/version.rb`: 单独存放版本号的文件,通常定义 `CocoaPods::Hmap::VERSION` 常量,便于统一管理版本(在 `gemspec`中会引用该常量)。
+
+
+
+#### 3. 改造并 run 起来
+
+- 修改 gemspec 文件中带有 url、uri 的字段,开发阶段可以修改为任何一个 url 字符串
+
+- 修改自带的工程结构,比如 `cocoapods/hmap` 改为 `cocoapods-hmap`,将对应的文件也移动位置
+
+- 我们预期的效果是:在终端输入 **pod hmap** 就可以将工程中的静态库 Header Search Path 传统查找模式改为 hmap 文件配置模式。所以需要的的步骤就是在 **bin 目录下创建 hmap.rb**,然后通过 **bin 目录下的代码调用 lib 目录下的 HMap.rb** 能力。
+
+- 为此,需要:
+
+ - 在 lib 目录下创建 HMap.rb 文件
+
+ ```ruby
+ require_relative "version"
+
+ module CocoapodsHmap
+ class HMap
+ def initialize
+ puts "Cocoapods HMap initialized"
+ end
+
+ def self.run
+ puts "Running Cocoapods HMap..."
+ end
+
+ end
+ end
+
+ ```
+
+ - 在 bin 目录下创建 hmap.rb 文件
+
+ ```ruby
+ #!/usr/bin/env ruby
+ require "bundler/setup"
+ require "cocoapods-hmap/hmap"
+
+ # 打印携带的参数
+ puts ARGV
+
+ CocoapodsHmap::HMap.run
+ ```
+
+- 为了在 VSCode 中测试,需要在 Gemfile 中添加一行 **gem 'debug', '~> 1.9.0' # 调试用**
+
+- 工程根目录创建 `.vscode` 文件夹,创建 launch.json 文件。内容如下:
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ "script": "${workspaceFolder}/bin/hmap",
+ "args": ["hmap"], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+VSCode 中运行效果如下:
+
+
+
+#### 4. 如何将自定义的指令加入到 cocoapods 中
+
+- 在 Command 目录下创建 `hmap` 文件,不带任何拓展名。rake 处理后,最后会变为 `/Users/unix_kernel/.rbenv/versions/3.2.2/lib/ruby/gems/3.2.0/gems/cocoapods-hmap-0.1.0/bin/hmap: Ruby script text executable, ASCII text`
+
+- 在 lib 目录下,创建 `cocoapods-hmap` 文件夹。
+ - 在 `cocoapods-hmap` 文件夹内创建 `command` 文件夹,在 `command` 文件夹内创建 `hmap.rb` 文件
+ - class 继承自 Pod::Command,并实现相关方法。比如 initialize、validate!、run
+- 在 lib 目录下,创建 `cocoapods-plugin.rb` 文件
+ - 暴露继承自 Pod::Command 的 hmap command
+
+调试运行后的效果如下:
+
+
+
+类名小写,和类文件关联起来
+
+比如 install.rb 中,类名为 `class Install` ,内部会记录为 **{"install": "install.rb"}**
+
+
+
+#### 5. 打包安装到本地
+
+在终端项目目录下,执行指令 **rake install:local** ,主要用于**在本地构建并安装当前开发的 gem 包**,方便开发者进行本地测试和调试。
+
+一开始有报错,如下图所示。按照提示修改 `cocoapods-hmap.gemspec` 中的配置,然后就可以成功安装了。然后输入 **gem list** 查看:
+
+
+
+输入: **gem info cocoapods-hmap** 查看安装信息
+
+
+
+
+
+就目前的功能进行测试:
+
+| 条件 | 预期 | 结果 |
+| ----------------------------------- | --------------------------------------- | -------- |
+| 随便一个工程目录,没有 Podfile 文件 | 执行 `pod hmap` 会报错 | 符合预期 |
+| 存在 Podfile 文件的目录 | 正常执行 run 方法里面的逻辑(打印逻辑) | 符合预期 |
+
+
+
+
+
+#### 6. Hook 能力
+
+##### 1. post_install
+
+- 修改插件入口文件 (cocoapods_plugin.rb)
+
+ 先在 `lib/cocoapods-plugin.rb` 中注册插件和对应的 hook 能力。利用 API:**Pod::HooksManager.register('cocoapods-hmap', :post_install)**,其文档说明如下:
+
+ >register(plugin_name, hook_name, &block)
+ >
+ >**Definitions**: [hooks_manager.rb](vscode-file://vscode-app/Applications/Visual Studio Code.app/Contents/Resources/app/out/vs/code/electron-browser/workbench/workbench.html)
+ >
+ >Registers a block for the hook with the given name.
+ >
+ >@param [String] plugin_name The name of the plugin the hook comes from.
+ >
+ >@param [Symbol] hook_name The name of the notification.
+ >
+ >@param [Proc] block The block.
+
+ ```ruby
+ Pod::HooksManager.register('cocoapods-hmap', :post_install) do |context, options|
+ argv = CLAide::ARGV.new([]) # 创建一个空的参数数组
+ command = Pod::Command::HMap.new(argv)
+ command.run_post_install(context, options)
+ end
+ ```
+
+- 完善 HMap 命令类
+
+ 修改 `lib/cocoapods-hmap/command/hmap.rb`,增加 `run_post_install` 方法
+
+ ```ruby
+ module Pod
+ class Command
+ class HMap < Command
+ // ...
+
+ # Post-install 钩子执行的方法
+ def run_post_install(context, options = {})
+ puts "[Cocoapods hmap] Running HMap command in post_install hook..."
+ end
+ end
+ end
+ end
+ ```
+
+- 测试配置
+
+ 修改测试项目的 Podfile 文件,声明 **plugin 'cocoapods-hmap'**
+
+ ```ruby
+ platform :ios, '9.0'
+ plugin 'cocoapods-hmap'
+
+ post_install do | installer |
+ puts "Self defined post_install hook"
+ end
+
+ target 'StaticLibConflictsDemo' do
+ # Comment the next line if you don't want to use dynamic frameworks
+ # AFNetworking 以静态库的形式被依赖
+ pod 'AFNetworking'
+ # 脚本化
+ script_phase :name => 'Run Self-defined Script',
+ :script => "echo 'This is a self-defined script phase'",
+ :input_files => [],
+ :execution_position => :after_compile
+ end
+ ```
+
+- 修改 `cocoapods-hmap` 工程的 VSCode 的 launch.json 文件
+
+ 因为 cocoapods-hmap 工程和 iOS Pods 工程不在一个目录,所以可以在 args 的第二个参数设置为测试工程路径
+
+ ```json
+ {
+ // Use IntelliSense to learn about possible attributes.
+ // Hover to view descriptions of existing attributes.
+ // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "type": "rdbg",
+ "name": "Debug current file with rdbg",
+ "request": "launch",
+ // "script": "${workspaceFolder}/bin/hmap",
+ "script": " /Users/unix_kernel/.rbenv/versions/3.2.2/bin/pod",
+ "args": [
+ "install",
+ "--project-directory=${workspaceFolder}/../StaticLibConflictsDemo"
+ ], // pod 命令的参数
+ "askParameters": true,
+ "cwd": "${workspaceFolder}", // pod 执行命令的路径
+ },
+ {
+ "type": "rdbg",
+ "name": "Attach with rdbg",
+ "request": "attach"
+ }
+ ]
+ }
+ ```
+
+- 测试:存在2种方法
+
+ - 第一种:在 cocospods-hmap 工程中测试,如下图
+
+
+
+ - 第二种:
+
+ - 在终端 cocoapods-hmap 目录下执行 **rake install:local** ,将插件安装到本地
+ - 然后切换到 iOS 被测工程目录下,执行 `pod install`
+
+ 效果如下:
+
+
+
+
+
+##### 2. pre_install
+
+
+
+
+
+
+
+### 2. CocoaPods 插件系统设计
+
+CocoaPods 通过严格的目录结构约定来加载插件:
+
+```shell
+lib/
+├── cocoapods-plugin.rb # 插件主入口文件(必需)
+└── cocoapods-hmap/ # 插件命名空间目录
+ └── command/ # 命令目录
+ └── hmap.rb # 命令实现文件(必需)
+```
+
+#### 1. 自动加载机制
+
+CocoaPods 启动时会自动执行以下操作:
+
+1. 扫描已安装的 gem
+2. 查找所有以 `cocoapods-` 为前缀的 gem
+3. 加载这些 gem 中的 `lib/cocoapods-plugin.rb` 文件
+4. 通过该文件加载插件功能
+
+#### 2. 关键文件
+
+- 插件入口文件 (`lib/cocoapods-plugin.rb`)
+
+ ```ruby
+ require 'cocoapods-hmap/command/hmap'
+ ```
+
+- 命令实现文件 (lib/cocoapods-hmap/command/hmap.rb)
+
+-
+
+
+
+
-- block 最后一行是返回值,不需要指定 return
-- ruby 脚本语言在编写好代码后也想像其他 GPL 语言一样断点可以,需要安装依赖和相应的代码调整
- - `gem install pry`
- - 文件引入 `require 'pry'`
- - 需要 debug 的地方加上 `binding.pry`
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.74.md b/Chapter1 - iOS/1.74.md
index 0730290..98d39c4 100644
--- a/Chapter1 - iOS/1.74.md
+++ b/Chapter1 - iOS/1.74.md
@@ -1,8 +1,8 @@
## 带你打造一套 APM 监控系统
-> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的纬度谈谈如何精确监控以及数据如何上报等技术点
+> APM 是 Application Performance Monitoring 的缩写,监视和管理软件应用程序的性能和可用性。应用性能管理对一个应用的持续稳定运行至关重要。所以这篇文章就从一个 iOS App 的性能管理的维度谈谈如何精确监控以及数据如何上报等技术点
-App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
+App 的性能问题是影响用户体验的重要因素之一。性能问题主要包含:卡顿、Crash、网络请求错误或者超时、UI 响应速度慢、主线程卡顿、CPU 和内存使用率高、耗电量大、Weex/RN/Flutter 页面白屏等等。大多数的问题原因在于开发者错误地使用了线程锁、系统函数、编程规范问题、数据结构等等。解决问题的关键在于尽早的发现和定位问题。
本篇文章着重总结了 APM 的原因以及如何收集数据。APM 数据收集后结合数据上报机制,按照一定策略上传数据到服务端。服务端消费这些信息并产出报告。请结合[姊妹篇](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.80.md), 总结了如何打造一款灵活可配置、功能强大的数据上报组件。
@@ -8094,6 +8094,52 @@ runZoned
-思考:一个工程中,只要写好了测试代码,是不是加载这几个动态库就可以运行测试用例了?
+思考:一个非 UI 测试工程(正常的 App 工程),是不是加载这几个测试相关的动态库,写好测试代码,就可以运行测试用例了?
+
+细节不贴了。Demo App 引入 `XCTest.framework` 后业务代码里即可引入 `#import
+
精准测试助力业务,质量更加稳定。
@@ -1394,3 +1611,5 @@ UITesting 还是建议在核心逻辑且长时间没有改动的情况下去做

WWDC 这张图也很清楚,UI 其实需要的占比较小,还是要靠单测驱动。
+
+##
\ No newline at end of file
diff --git a/Chapter1 - iOS/1.89.md b/Chapter1 - iOS/1.89.md
index dfb663e..dbd4224 100644
--- a/Chapter1 - iOS/1.89.md
+++ b/Chapter1 - iOS/1.89.md
@@ -11,9 +11,9 @@
-## block 本质探索
+## 一、block 本质探索
-### 实验探索
+### 1. 实验探索
Demo
@@ -244,7 +244,7 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-### 结论
+### 2. 结论
通过探索发现:
@@ -260,9 +260,9 @@ struct __ViewController__viewDidLoad_block_desc_0 {
-## block 变量捕获
+## 二、block 变量捕获
-### auto 变量捕获
+### 1. auto 变量捕获
> 在 C 和 Objective-C 编程语言中,`auto` 关键字用于声明自动存储期的变量。自动存储期的变量会在定义它们的块(block)或作用域(scope)中自动创建,并在退出该作用域时自动销毁。这是变量存储期的默认行为,因此 `auto` 关键字实际上是可选的,但有时候为了清晰起见,开发者可能会显式使用它。
@@ -322,7 +322,7 @@ c++ 中,在函数内部定义的变量,默认用 **auto** 修饰,叫做自
-### static 变量捕获
+### 2. static 变量捕获
```objective-c
auto NSInteger age = 27;
@@ -354,7 +354,7 @@ printInfoBlock();
-### 全局变量捕获
+### 3. 全局变量捕获
```objective-c
NSInteger age = 27;
@@ -405,7 +405,7 @@ QA:为什么局部变量存在捕获,全局变量不需要捕获?
-### 变量捕获总结
+### 4. 变量捕获总结
block 截获变量可以分为:
@@ -576,9 +576,9 @@ static void __Person__testBlockCapture_block_func_0(struct __Person__testBlockCa
-## block 类型
+## 三、block 类型
-### 类型划分
+### 1. 类型划分
我们知道 block 可以看成是一个 oc 对象,所以它有类型,写个 Demo1 验证下
@@ -619,7 +619,7 @@ block 的类型可以通过 isa 或者 class 方法查看,最终都是继承
-### 如何判断 block 属于什么类型
+### 2. 如何判断 block 属于什么类型
Demo:
@@ -651,7 +651,7 @@ Demo 也同时发现,当对 `__NSGlobalBlock__` 调用 copy ,不会变为 `
-### 总结
+### 3. 总结
| block 类型 | 环境 |
| ------------------- | ------------------------------ |
@@ -691,9 +691,9 @@ int main(int argc, const char * argv[]) {
-## 内存管理
+## 四、内存管理
-### ARC 针对 block 的优化
+### 1. ARC 针对 block 的优化
#### 1. block 作为函数返回值,并且捕获了 auto 变量
@@ -905,7 +905,7 @@ static struct __main_block_desc_0 {
-### block 的 copy、dispose
+### 2. block 的 copy、dispose
```c++
static struct __main_block_desc_0 {
@@ -1004,9 +1004,319 @@ NSLog(@"-touchesBegan:withEvent:");
2024-08-13 20:59:54.313367+0800 BlockExplore[29889:968688] (null)
```
-### block 如何修改变量
+### 3. _Block_release 和 _Block_copy
-#### __block 修饰基本数据类型
+Demo1
+
+```objective-c
+void test(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ void(^ __weak weakInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ weakBlock = weakInnerBlock;
+ }
+ weakBlock();
+}
+```
+
+- 定义了一个局部变量 weakBlock
+
+- 在 `{}` 内定义了一个栈上的 block **__NSStackBlock__** ,block 内访问了定义在 block 外部的 b
+
+- 将 weakInnerBlock 赋值给 weakBlock
+
+- 出了 `{}`,也意味着栈上的 block 作用域结束了。block 会调用 block_release 方法
+
+- 由于出了局部作用域,栈上的 block 被释放了。所以在 `{}` 外调用 weakBlock 则存在野指针风险。编译器也会报警告:`Assigning block literal to a weak variable; object will be released after assignment` 。但可能不崩溃:栈内存虽回收但未被新数据覆盖
+
+
+
+我们来看看 **block_release** 源码
+
+```c++
+void
+_Block_release(const void *src)
+{
+ struct StackBlockClass *self = (struct StackBlockClass *)src;
+ extern const void _NSConcreteStackBlock;
+
+ if (self->isa == &_NSConcreteStackBlock // 必须是栈块类型
+ // A Global block doesn't need to be released
+ && self->flags & BLOCK_HAS_DESCRIPTOR // 必须有描述符结构
+ // Should always be true...
+ && self->reserved > 0) // 引用计数大于0
+ // If false, then it's not allocated on the heap, we won't release auto memory !
+ {
+ self->reserved--;
+ if (self->reserved == 0)
+ {
+ if (self->flags & BLOCK_HAS_COPY_DISPOSE)
+ self->descriptor->dispose_helper(self);
+ free(self);
+ }
+ }
+}
+```
+
+说明:
+
+- `StackBlockClass` 表示栈 block 结构,包含:
+ - isa:指向块类型的指针(栈块为 `__NSConcreteStackBlock`)
+ - flag: 标志位( BLOCK_HAS_DESCRIPTOR 表示有描述符)
+ - reserved:引用计数器
+ - descriptor:包含析构函数 dispose_helper。当 block 捕获了 OC、C++ 对象后,编译器会自动设置此标志
+- 释放条件:
+ - 排除全局 block 和堆 block:全局block `__NSConcreteGlobalBlock` 和堆上的 block 无需释放。
+ - **栈块**:
+ 存储在栈内存中,生命周期与函数作用域绑定。
+ **需要手动管理**:通过 `_Block_copy()` 复制到堆时,需用 `_Block_release()` 平衡引用计数。
+ - **堆块**:
+ 由 `_Block_copy()` 动态分配在堆内存,受 ARC 管理。
+ **自动管理**:ARC 会自动插入 `objc_release()` 调用,使用标准 Objective-C 对象释放机制。
+ - 有效性检验:确保块结构完整且引用计数有效
+- 引用计数管理:
+ - `self->reserved--` 引用计数减 1
+ - 引用计数归0的时候,调用 dispose_helper 方法。释放 block 捕获的对象、内存
+ - 释放 block 结构体内存
+- 一般来说 block 由栈管理,但是被 copy、strong 等强引用作为属性或者参数,则会调用 **_Block_copy** 拷贝到堆上。本函数管理堆化后栈 block 的引用计数
+
+
+
+Demo2
+
+```c++
+void test2(void) {
+
+ int a = 0;
+ void(^__weak weakBlock)(void) = nil;
+ {
+ int b = 2;
+ // 栈 block 赋值给一个 strong或copy 修饰的强引用变量,则会调用 _Block_copy 方法拷贝到堆上,变成堆 block
+ void(^ __strong strongInnerBlock)(void) = ^{
+ NSLog(@"%d", b);
+ };
+ a = b;
+ // 结构体赋值,也就是此时 a 是一个堆上的 block
+ weakBlock = strongInnerBlock;
+ } // 离开作用域,堆上的 block 会自动调用 _Block_release 方法,内部会 free 掉,此时再去调用释放的内存,系统机制会为已经释放的内存填充 0xDEADBEEF 标记,MMU 也会触发缺页异常,发送 crash
+ weakBlock();
+}
+```
+
+现象:上面的代码会稳定 crash。报错:`Thread 1: EXC_BAD_ACCESS (code=1, address=0x10)`
+
+分析:
+
+- 在 `{}` 内定义初始化了一个栈 block
+- 赋值给一个由强指针指向的 strongInnerBlock 变量时,自动触发 `_Block_copy` 方法,复制到堆上,变为堆 block **__NSConcreteMallocBlock**
+- 然后通过结构体赋值的方式,赋值给 `weakBlock`
+- 要出 `{}` 作用域时,则会调用 `_block_release` 方法。堆块的引用计数清零。释放后,堆内存表记为不可访问
+- 此时调用 `weakBlock()` 则会 crash。访问已经释放的堆内存。系统在释放的堆内存上添加保护(如 `EXC_BAD_ACCESS`)
+
+test 和 test2 的本质区别
+
+| 函数 | 内存类型 | 内存回收机制 | 崩溃原因 |
+| :------ | :------- | :---------------------- | :--------------- |
+| `test` | 栈内存 | 系统自动回收(无保护) | 内存可能未被覆盖 |
+| `test2` | 堆内存 | `free()` + 内存保护标记 | 强制触发访问异常 |
+
+
+
+Demo3
+
+
+
+为什么上面的代码会 crash?
+
+- weakBlock 是一个栈 block(__NSConcreteStackBlock)
+- GCD 代码以 block 的形式将延迟任务添加到主队列中
+- `dispatch_block_t` 内部捕获了 block,但捕获的是原始指针,未复制 block
+- GCD 不会阻塞,函数会结束,同时栈 block 会被回收,栈帧销毁。此时 `dispatch_block_t` 内持有其悬挂指针。
+- 3s 后开始执行 dispatch_block_t 所指向的 weakBlock
+- 发现 weakBlock 所指向的栈内存被回收,调用无效指针导致 **EXC_BAD_ACCESS** 崩溃(访问野指针)。
+
+
+
+解决方案:
+
+1. 将栈 block 改为堆 block。block 修饰改为 strong
+
+ ````objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__strong block)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ block();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ }
+ ````
+
+2. 复制 block 到堆
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), [weakBlock copy]);
+ }
+ ```
+
+3. 栈帧不要回收。开启一个 RunLoop 晚退出3秒
+
+ ```objective-c
+ void test3(void) {
+ int a = 10;
+ void(^__weak weakBlock)(void) = ^ {
+ NSLog(@"%d", a);
+ };
+
+ dispatch_block_t dispatch_block = ^{
+ weakBlock();
+ };
+ dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), dispatch_block);
+ [[NSRunLoop currentRunLoop] runUntilDate:[NSDate dateWithTimeIntervalSinceNow:3]];
+ }
+ ```
+
+
+
+Demo4
+
+
+
+分析:
+
+- block 本质就是结构体
+
+- `void (^__strong strongBlock)(void) = weakBlock;` 看上去左侧是一个 `__strong` 修饰,其实就是结构体,所以不会像对象一样,底层调用 setter 方法。所以 block 的赋值本就是按照结构体的成员变量一个个字段简单赋值而已。
+
+ ```c++
+ struct __block_impl {
+ void *isa; // 指向 Block 类 (栈上)
+ int flags; // 标志位 (栈上)
+ int reserved; // 保留字段 (栈上)
+ void (*invoke)(void); // 函数指针 (代码段)
+ struct __block_descriptor *descriptor; // 描述符指针 (栈上)
+ };
+
+ struct __block_descriptor {
+ unsigned long reserved; // 保留字段 (栈上)
+ unsigned long size; // Block 大小 (栈上)
+ void (*copy)(void); // copy 辅助函数 (代码段)
+ void (*dispose)(void); // dispose 辅助函数 (代码段)
+ };
+ ```
+
+- 当把结构体 block 的 invoke 设为 nil,由于是简单赋值,所以原来的 weakblock 的 invoke 也为 nil
+
+- 所以 strongblock 的 invoke 也为 nil,所以执行 block 底层就是先判断 block 的 isa、然后根据 invoke 指针,找到代码段的函数去执行。此时已经为 nil,再去执行就会 crash
+
+解决方案:将 weakblock copy 一下,即 `void (^__strong strongBlock)(void) = [weakBlock copy];`
+
+
+
+### 4. 栈内存、堆内存保护机制
+
+通过上面 test 和 test2 知道,栈内存、堆内存在释放后继续访问存在不同的表现
+
+#### 1. 栈内存
+
+##### 1. 栈内存的本质上是:
+
+- **线性结构**:栈是连续的内存区域,通过栈指针(SP)管理
+- **自动回收**:函数退出时,只需移动栈指针即可"释放"内存
+- **物理内存不变**:移动栈指针不会立即清除数据,原内存内容保持不变
+
+##### 2. 访问已释放的内存为何可能不崩溃?
+
+- 无硬件保护:CPU 和 MMU(内存管理单元)不跟踪栈帧生命周期
+- 内存数据保留:除非被新的栈帧覆盖,否则数据仍可被读取
+
+##### 3. 不崩溃的深层原因:
+
+- 无页表标记:栈内存页始终标记为:可读写 (PROT_READ|PORT_WRITE)
+- 无隔离机制:不同函数的栈帧共享同一内存页
+- 延迟覆盖:新栈帧写入前,元数据保持有效
+
+
+
+
+
+#### 2. 堆内存
+
+##### 1. 堆内存管理的核心机制:
+
+- malloc -> 向内核申请内存页 -> 设置页表属性 -> 分配内存块
+- free -> 标记内存页属性 -> 加入空闲链表 -> 触发内存页回收
+
+##### 2. free 后的关键操作
+
+内存标记
+
+````objective-c
+// 典型内存分配器实现
+void free(void *ptr) {
+ // 1. 在内存块头部写入魔数(如0xDEADBEEF)
+ *(uint32_t*)(ptr - 4) = 0xDEADBEEF;
+
+ // 2. 通过 mprotect 设置内存页不可访问
+ mprotect(ALIGN_PAGE(ptr), PAGE_SIZE, PROT_NONE);
+}
+````
+
+页表更新
+
+| 状态 | 页表项标志位 | 访问后果 |
+| :--- | :-------------- | :----------- |
+| 正常 | PRESENT+RW+USER | 允许访问 |
+| 释放 | ~PRESENT | 触发缺页异常 |
+
+稳定崩溃的硬件基础:
+
+MMU 介入:当访问 `PROT_NONE` 内存页时:
+
+1. 触发缺页一场(Page Fault)
+2. 内核检查异常地址
+3. 发送 `SIGSEGV` 信号
+4. 进程终止(崩溃)
+
+#### 3. iOS/Macos 优化
+
+##### 1. 堆内存保护优化
+
+- Malloc Scribble:释放后填充`0x55`(调试模式默认启用)
+
+- Zone-based Protection:
+
+ ```objective-c
+ malloc_zone_t *zone = malloc_create_zone(0, 0);
+ malloc_set_zone_name(zone, "Protected Zone");
+ malloc_zone_protect(zone, 1); // 启用保护
+ ```
+
+##### 2. 栈内存的刻意放松
+
+- **性能优先**:避免栈操作时的权限检查
+- **安全边界**:仅防止栈溢出,不保护栈帧间访问
+
+
+
+### 5. block 如何修改变量
+
+#### 1. __block 修饰基本数据类型
```objectivec
typedef void(^MyBlock)(void);
@@ -1178,7 +1488,7 @@ __attribute__((__blocks__(byref))) __Block_byref_num2_0 num2 = {(void*)0,(__Bloc
-#### __block 修饰对象
+#### 2. __block 修饰对象
对` __block` 修饰的对象,clang 转换为 c++ 后如下:
@@ -1307,13 +1617,13 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-#### 什么情况下需要 __block
+#### 3. 什么情况下需要 __block
局部变量:基本数据类型、对象数据类型
-#### 什么情况下不需要 __block
+#### 4. 什么情况下不需要 __block
- 全局变量(不截获)
- 静态全局变量(不截获)
@@ -1323,7 +1633,7 @@ block 内部对变量的值修改其实就是对 block 内部自定义结构体
-## `__forwarding` 的设计
+## 五、`__forwarding` 的设计
Demo1
@@ -1587,7 +1897,7 @@ Tips:实现 block 拷贝及其捕获对象的函数是 `_Block_copy`,工作
-## Block 内存引用
+## 六、Block 内存引用
对于` __block` 修饰的变量进行研究
@@ -1803,7 +2113,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
-## 循环引用
+## 七. 循环引用
self 是一个局部变量,block 访问 self,即存在捕获变量的效果。
@@ -1817,7 +2127,7 @@ __attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
可以看到 Person 对象的 dealloc 方法没有执行,里面的打印信息没有输出。
-### ARC 下
+### 1. ARC 下
`__weak`、`__unsafe_unretained` 修饰 `__block` 所修饰的变量。区别在于:
@@ -1880,7 +2190,7 @@ p.block();
-### MRC 下
+### 2. MRC 下
方法1: `__unsafe_retained` 修饰。`__unsafe_unretained typeof(self) weakself = self;`
@@ -1888,7 +2198,7 @@ p.block();
-## 为什么加 weakself、strongself
+## 八、为什么加 weakself、strongself
weakSelf 是为了使 block 不持有 self,避免 Retain Circle 循环引用。在 Block 内如果需要访问 self 的方法、变量,建议使用 weakSelf。
@@ -1922,7 +2232,9 @@ block 执行完后这个 strongSelf 会自动释放,没有不会存在循环
});
```
-## 总结
+
+
+## 九、总结
1. block 本质是什么?封装了函数调用及其调用环境的 OC 对象。本质实现是一个结构体。
2. `__block` 的作用是什么?可以对 block 外部的变量进行捕获,可以修改。但是需要注意内存管理相关问题。比如`__weak`、`__unsafe_unretained`、`__block`
diff --git a/Chapter1 - iOS/1.91.md b/Chapter1 - iOS/1.91.md
index aef2391..2d9a590 100644
--- a/Chapter1 - iOS/1.91.md
+++ b/Chapter1 - iOS/1.91.md
@@ -1,10 +1,10 @@
# DYLD 及 Mach-O
-> 动态库还是静态库对包体积影响大?
+> 链接动态库还是静态库对 App l包体积影响大?
>
> 动态库、静态库编译链接都做了哪些事情?链接的要素是什么?
>
-> Moudle 是什么?
+> Module 是什么?
>
> 如果这些问题不是很清楚,可以带着问题看看本文。
@@ -1149,6 +1149,44 @@ clang 编译、链接的参数解释如下:
-framework
+
+
+现象:工程编译成功。编译链接后,运行输出打印信息。
+问题:为什么2个同样的静态库,没有链接失败?
+分析:
+- 直接在 Xcode 中手动拖入一个静态库/动态库,本质是将库的路径写到 OTHER_LDFLAGS 后面。Xcode 会按照指定的路径去加载静态库/动态库。
+ ```shell
+ OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking" "/Users/unix_kernel/Desktop/编译链接/LDAndFramework/StaticLibConflictsSolution/StaticLibConflictsDemo/AFNetworking"`
+ ```
+- 但链接器很聪明,当发现同名的库的时候,会优先链接找到的第一个库库,第二个库不会被链接。
+- 即使将 `OTHER_LDFLAGS = $(inherited) -ObjC -l"AFNetworking"` 中的 `-ObjC` 改为 `-all_load` 也不会存在链接问题。本质是链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题
+
+
+
+##### 2. Demo2
+
+一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库,再将另一个 `libAFNetworking.a` 静态库改名为 `libAFNetworkingCopy.a`,然后引入 Xcode 工程。
+
+
+
+
+现象:工程链接失败。报错:`Issues223 duplicate symbols for architecture x86_64`
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+##### 3. Demo3
+
+- 一个 cocoapods 组织的工程,以 pod 的形式引入了 AFNetworking 库
+- 然后 Xcode 新创建一个静态库,选择 `Static Library`
+- 新创建的静态库就1个 `AFNetworkingMock` 文件。不过类里面还存在一个类 `AFURLSessionManager` 和一个全局函数 `global_function`
+
+现象:工程链接失败。报错:`error: duplicate interface definition for class 'AFURLSessionManager'`
+
+
+问题:为什么上次的链接成功,这次却链接失败了,报符号重复的错误?
+分析:
+
+- 不同名称的静态库,就不存在「链接器对于同名的库,找到第一个后,后面的就停止查找,不会被链接了,所以不存在符号重复相关的问题」,也就是会发生冲突
+
+
+
+#### 2. 解决方案
+
+2个静态库有符号冲突怎么办?且一个静态库没有源码。[llvm-objcopy](https://llvm.org/docs/CommandGuide/llvm-objcopy.html) 这个工具刚好有能力在静态库基础上直接修改符号名称。
+
+##### 1. 收集需要重命名的符号
+通过 **objdump --macho -t ${MACH_PATH}** 就可以输出符号信息。Demo 中需要重命名的符号如下:
+
+
+
+
+
+
+##### 2. 编译 llvm-objcopy 产出工具
+
+关于 LLVM 如何编译运行,或者开发 pass 可以查看 [LLVM 编译运行](./1.102.md#编写-xcode-插件)
+
+打开 LLVM 工程,Scheme 切换为 `llvm-objcopy` 然后编译运行,从 Products 目录下将产物拷贝到个人电脑的 CustomTools 文件夹,后续就可以在终端访问 llvm-objcopy 指令。(因为在 `.zshrc` 文件里配置过 `export PATH=~/CustomTools:$PATH`)
+
+这样就说明已经成功了
+
+
+
+然后改造 Demo 工程静态库的脚本为 **llvm-objcopy --prefix-symbols=FantasticLBP_ ${MACH_PATH}** 去给冲突的符号加前缀 `FantasticLBP_`(当然这个前缀名字可以是 SDK 名称简写、业务线简写,我这里是 Github ID ,验证问题而已)。
+
+结果:但发现运行报错,提示 `llvm-objcopy: command not found`
+
+
+改进:将 `llvm-objcopy` 移动到源码根目录下,现在 `Command not found` 的问题解决了,但是报错: **error: option is not supported for MachO**
+
+说明 `--prefix-symbols` 并不支持 MachO 格式。而 `--redefine-sym` 符合要求。
+
+打开 llvm 源码进行调试,配置启动参数。
+
+发现修改成功
+
+
+上面演示了单个修改符号名称的过程。llvm-objcopy 可以批量修改。
+- 指令改为 `--redefine-syms`。
+- 用一个文件,格式为空格和换行来区别。
+ ```
+ _OBJC_CLASS_$_AFURLSessionManager FantasticLBP__OBJC_CLASS_$_AFURLSessionManager
+ _OBJC_METACLASS_$_AFURLSessionManager FantasticLBP__OBJC_METACLASS_$_AFURLSessionManager
+ _OBJC_IVAR_$_AFURLSessionManager._session FantasticLBP__OBJC_IVAR_$_AFURLSessionManager._session
+ ```
+ 修改后运行,发现批量符号修改成功。
+
+
+
+
+##### 3. 使用工具修改符号名称
+
+利用 llvm-objcopy 的能力,修改重名的符号后测试下。
+
+
+可以看到:
+
+- 符号冲突的问题解决了
+- 但同一个符号存在2处实现,当两个同名类被加载时,运行时随机选择一个
+
+
+
+##### 4. 为什么存在2处类定义?
+
+```mermaid
+graph LR
+A[AFURLSessionManager] --> B[_OBJC_CLASS_$_AFURLSessionManager]
+A --> C[_OBJC_METACLASS_$_AFURLSessionManager]
+A --> D[“__objc_classname” 段中的字符串]
+```
+
+**通过 llvm-objcopy 只是修改了 `_OBJC_CLASS_$` 符号而忽略 `_OBJC_METACLASS_$` 和类名字符串,运行时仍会看到两个类定义,导致冲突未解决**
+而且和运行时系统相关的所有功能都会受影响,比如:Category、KVC/KVO 内部使用类名字符串查找、Archive/Unarchive 崩溃等。
+
+所以这种方式存在巨大风险,这里只是从技术研究角度出发,证明可以这么做,但是影响面太大。
+另外一种方式:2个不同名的静态库,但存在相同符号。可以通过 cocoapods 的配置,将某个静态库改为动态库。因为动态库存在二级命名空间,就可以避免符号重复的问题。
+关于动态库二级命名空间的细节,可以查看[这里](#twoLevelNamespace)
+
+方案 1:单个库转为动态库
+```ruby
+# Podfile
+use_frameworks! # 启用框架支持
+
+target 'YourApp' do
+ pod 'AFNetworking', '~> 4.0' # 默认静态库
+
+ # 将冲突库转为动态框架
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+end
+```
+方案 2:指定模块为动态框架
+```ruby
+dynamic_frameworks = ['ConflictingLib']
+
+target 'YourApp' do
+ # 先声明所有库
+ pods = [
+ 'AFNetworking',
+ 'ConflictingLib',
+ 'OtherLib'
+ ]
+
+ # 动态处理
+ pods.each do |pod|
+ if dynamic_frameworks.include?(pod)
+ pod pod, :modular_headers => true, :linkage => :dynamic
+ else
+ pod pod
+ end
+ end
+end
+```
+实验:我的电脑 cocoapods 版本较低,采用下面写法
+```ruby
+platform :ios, '9.0'
+use_frameworks! # 确保启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 动态链接 AFNetworking(兼容所有版本)
+ pod 'AFNetworking', :modular_headers => true
+
+ # 添加后安装钩子脚本
+ post_install do |installer|
+ # 将 AFNetworking 设为动态框架
+ installer.pods_project.targets.each do |target|
+ if target.name == 'AFNetworking'
+ # 设置 Mach-O 类型为动态库
+ target.build_configurations.each do |config|
+ config.build_settings['MACH_O_TYPE'] = 'mh_dylib'
+ config.build_settings['DYLIB_INSTALL_NAME_BASE'] = '@rpath'
+ config.build_settings['LD_RUNPATH_SEARCH_PATHS'] = ['$(FRAMEWORK_SEARCH_PATHS)']
+ end
+ end
+ end
+
+ # 确保框架被正确嵌入
+ installer.pods_project.build_configurations.each do |config|
+ config.build_settings['EMBEDDED_CONTENT_CONTAINS_SWIFT'] = 'YES'
+ end
+ end
+end
+```
+效果:
+
+可以看到不光是解决了符号重复的问题,也解决了同一个类,存在2处实现的问题。
+
+
+```mermaid
+graph LR
+A[主可执行文件] --> B[静态库A]
+A --> C[动态库B]
+C --> D[私有符号空间]
+```
+
+- 静态库:符号直接合并到主可执行文件的全局符号表
+- 动态库:拥有独立的符号空间(LC_ID_DYLIB 标识)
+ - 动态库内部符号相互可见
+ - 外部通过导出符号表(LC_DYSYMTAB)访问
+
+
+##### 5. 符号冲突总结
+###### 1. 最佳实践方案:动态库隔离
+
+利用动态库的二级命名空间特性,将冲突的静态库转换为动态库,实现符号隔离
+
+```ruby
+# Podfile
+use_frameworks! # 关键:启用框架支持
+
+target 'StaticLibConflictsDemo' do
+ # 将冲突库转为动态 framework
+ pod 'ConflictingLib', :modular_headers => true, :linkage => :dynamic
+
+ # 其他静态库
+ pod 'NonConflictingLib'
+end
+```
+
+静态库的 xcconfig 为
+
+
+
+动态库的 xcconfig 为
+
+
+
+###### 2. 源码级解决方案:添加类前缀
+
+```objective-c
+// 原始类名
+@interface AFURLSessionManager : NSObject
+
+// 修改后
+@interface ABC_AFURLSessionManager : NSObject
+```
+
+###### 3. 构建系统级解决方案:Bazel 命名空间
+
+```shell
+objc_library(
+ name = "AFNetworking",
+ namespace = "ABC", # 自动添加前缀
+ srcs = glob(["*.m"]),
+ hdrs = glob(["*.h"]),
+)
+```
+
+
+
+## 六、Strip 流程
静态库/ .o 文件 Strip 流程: 处理 `_DWARF` 段
-
+
Strip 的过程,就是在修改 Mach-O 文件中的内容。
-
-
动态库
-
+
All Symbols
-
+
@@ -1295,7 +1591,7 @@ Non-Global Symbols(非全局符号):
-
+
@@ -1400,7 +1696,7 @@ test.o -o test
Mach header 包括一些基础信息,所以 Mach header 存在冗余(大小端序、CPU 类型等),这也就是为什么静态库比动态库体积大的原因之一。
-
+
```shell
Unix_Kernel ~/Desktop/OCExplore/OCExplore file Person.o
@@ -1416,7 +1712,7 @@ Mach header
动态库在 Mach header 这里有改进,AFNetworking 动态库格式如下:
-
+
将公共的信息放到一起,公用一个 Mach header。
@@ -2258,6 +2554,141 @@ otool -l Person | grep 'ID' -A 5
+
+### 6. 二级命名空间
+在 iOS 系统中,动态库的二级命名空间是一种关键的符号管理机制,它解决了不同库之间可能发生的符号冲突问题。这个机制是 macOS 和 iOS 平台动态链接的核心特性。
+
+
+#### 1. 核心原理
+二级命名空间通过2个维度来唯一标识符号:
+- 符号名称(Symbol Name)
+- 动态库名称(Dylib Identity)
+```
+graph TD
+ A[符号解析] --> B{是否在二级命名空间?}
+ B -->|是| C[符号名称 + 库标识符]
+ B -->|否| D[仅符号名称]
+ C --> E[唯一符号]
+ D --> F[可能冲突]
+```
+
+##### 1. 库标识符(Dylib Identity)
+每个动态库都有一个唯一标识符,通常包含:
+- 安装路径(Install Name)
+- 当前版本号(Current Version)
+- 兼容版本号(Compatibility Version)
+```shell
+# 查看库标识符
+otool -l libExample.dylib | grep -A 3 LC_ID_DYLIB
+
+# 输出示例:
+# cmd LC_ID_DYLIB
+# cmdsize 56
+# name @rpath/libExample.dylib (offset 24)
+# time stamp 1 Wed Dec 31 19:00:01 1969
+# current version 1.0.0
+# compatibility version 1.0.0
+```
+
+##### 2. 使用过程
+当动态链接器(dyld)加载符号的时候:
+- 解析符号引用
+- 确定定义该符号的动态库
+- 使用(符号名、动态库ID)作为唯一键
+- 在符号表中查找唯一匹配
+```mermaid
+sequenceDiagram
+ participant App as 应用程序
+ participant dyld as 动态链接器
+ participant LibA as 库A
+ participant LibB as 库B
+
+ App->>dyld: 请求符号 foo
+ dyld->>LibA: 检查 foo@LibA
+ dyld->>LibB: 检查 foo@LibB
+ dyld-->>App: 返回 foo@LibA
+```
+
+##### 3. 符号表结构
+在二级命名空间下,符号表使用分层结构
+```shell
+Symbol Table
+├── LibA Symbols
+│ ├── foo
+│ ├── bar
+│ └── baz
+├── LibB Symbols
+│ ├── foo
+│ ├── xyz
+│ └── abc
+└── ...
+```
+
+#### 2. 应用场景
+##### 1. 解决符号冲突
+当两个库定义同名符号时:
+```shell
+// libNetwork.dylib
+void process_data() {
+ // 网络处理实现
+}
+
+// libAudio.dylib
+void process_data() {
+ // 音频处理实现
+}
+```
+在二级命名空间作用下:
+- process_data@libNetwork
+- process_data@libAudio
+所以,可以安全的使用2个库,而不会发生符号冲突问题
+
+
+
+##### 2. Xcode 配置
+
+- 启用二级命名空间(默认):`OTHER_LDFLAGS = $(inherited) -twolevel_namespace`
+- 禁用二级命名空间:`OTHER_LDFLAGS = $(inherited) -flat_namespace`
+查看命名空间状态:
+```shell
+# 检查二进制是否使用二级命名空间
+otool -lv YourApp | grep TWOLEVEL
+
+# 输出示例:
+# flags TWOLEVEL
+```
+
+
+
+#### 3. 动态库开发 tips
+
+##### 1. 动态库设计原则
+- 使用唯一前缀命名符号
+ ```c++
+ // 良好的命名实践
+ void TaoBaoNetwork_processData() {
+ // 实现
+ }
+ ```
+- 限制导出符号数量
+- 明确声明依赖关系
+- 符号可见性控制
+ ```c++
+ // 只导出必要的符号
+ __attribute__((visibility("default")))
+ void public_api();
+
+ // 隐藏内部实现
+ __attribute__((visibility("hidden")))
+ void internal_function();
+ ```
+
+##### 2. 运行时路径管理
+使用适当的路径变量:
+- `@executable_path`: 可执行文件所在目录
+- `@loader_path`: 当前加载模块所在目录
+- `@rpath`: 运行时搜索路径
+
## 九、xcframework
@@ -2787,15 +3218,103 @@ end
### 1. 定义
+在 iOS/macOS 开发领域的编译链接体系中,Module 是一项由 Clang/LLVM 提供的**语义化头文件封装**技术,其核心目标是**通过强隔离的预编译单元解决传统 `#include` 机制的头文件污染与低效问题**
+
+编译器实现:
+
+```mermaid
+graph LR
+ A[Module] --> B[Clang Module]
+ A --> C[Swift Module]
+ B --> D[.modulemap 描述文件]
+ B --> E[.pcm 预编译二进制]
+ C --> F[.swiftmodule 接口文件]
+```
+
+特征:
+
+- **原子性**:头文件集合的编译边界(不可部分导入)
+- **自包含性**:显式声明导出符号(`export`)与依赖(`requires`)
+- **隔离性**:宏定义(`#define`)不泄漏到导入方
+- **预编译能力**:可序列化为 `.pcm`(Precompiled Module)加速编译
+
+
+
一个 Module 是机器代码和数据的最小单位,可以独立于其他代码单元进行链接。
通常,Module 是通过编译单个源文件生成的目标文件。例如,当前的 `test.m` 被编译成目标文件 `test.o` 时,当前的目标文件就代表了一个 Module 。
-但是,Module 在调用的时候会产生**开销**,比如我们在使用一个静态库的时候。(这个开销是什么接下去会讲)
+但是,Module 在调用的时候会产生**开销**,比如我们在使用一个**静态库**的时候。
+
+
+
+### 2. .pcm 文件
+
+#### 1. 结构
+
+Module 生成的 `.pcm`(Precompiled Module)文件是 Clang 对 C++ Module 的**预编译二进制表示**,其内容远非简单的头文件文本封装,而是包含编译器所需的完整语义信息。
+
+`.pcm` 文件包含:
+
+- 模块元数据
+
+ - **模块标识**:模块名、导出符号列表(`export` 声明的函数/类)
+
+ - **编译环境指纹**:
+
+ ```shell
+ Target: x86_64-apple-darwin22.4.0
+ SDK: MacOSX13.3.sdk
+ Language: C++17
+ ```
+
+ - **时间戳与版本号**:确保与源码版本一致
+
+- AST 抽象语法树:**完整语法树序列化**:将头文件解析后的 AST 以二进制形式存储,通常占 `.pcm` 文件的 **60-70%**(主要膨胀源)
+
+- 语义信息:
+
+ - 符号可见性
+ - 内联函数代码生成
+ - ...
+
+- 依赖关系图
+
+ - **显式依赖**:通过 `import` 直接导入的其他模块(如 `import std.core;`)
+ - **隐式依赖**:递归包含的所有头文件(如 `
-如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
+#### 2. 变成终端可使用的能力
+
+QA:如何做到该工具做到像系统自带的 `objdump` 一样,在终端命令行使用:
- 在电脑根目录新建 `CustomTools` 文件夹
- 将上面编译后的产物复制进去
- 在 `.zshrc` 文件里将路径添加进去。`export PATH=~/CustomTools:$PATH`
- 编辑 `.zshrc` 文件后,在终端执行 `souce .zshrc`
-- 即可使用
+- 即可使用,在终端输入: **hmapdump ${hmapFileFullPath}**
效果如下:
@@ -3530,29 +4197,100 @@ LLVM 真是好东西,把 Xcode 编译、链接等一些幕后的事情变成
### 6. hmap 助力提升 iOS 项目编译速度
-已经编写好生成 `.hmap` 文件的能力了,那如何使用生成的 `.hmap` 文件?
+本节讨论:**如何为静态库自定义 hmap 开启编译加速**?
-- Xcode `Build Setting` 中 `Use Header Maps` 为 NO
-- `Header Search Path` 设置生成的 hmap 文件路径
+为了方便观察,开启2组对照实验。
-实践操作下。把上面静态库无法走 Header Maps 带来的问题解决掉。
+#### 1. 实验一:静态库 + Header Search Paths + App 编译
-第一步,编写 hmap 所需要的 json 信息。
+##### 1. 静态库设置
-第二步,利用 `HMapWriter` 能力,根据 json 生成静态库所需要的 `StaticLibUsage.hmap`
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderSearchPath**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
-第三步,在静态库 Xcode 项目中,关闭 `Use Header Maps`(设置为 NO),同时修改 `Header Search Paths` 为生成 `StaticLibUsage.hmap` 路径。
+整体目录结构和设置如下:
-第四步,编译使用静态库的 App 工程。最后比较静态库走自定义 `.hmap` 前后的编译耗时。
-
-
-
-可以看到静态库使用了自定义的 Header Maps 文件后,使用静态的 App 前后,编译耗时减少了1.1s,节省了57%。
+
-Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLibApp) 和 [HMapStaticLib](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib)。
+##### 2. App 以 Header Search Paths 方式编译链接静态库
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderSearchPath** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderSearchPath/StaticLib/HMapStaticLib-HeaderSearchPath/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderSearchPath.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+
+
+解决办法:
+- 方法1: 创建不同的 Xcode 工程
+- 方法2: 还是同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+
+
+问题修复完,最终编译链接效果如下:
+
+编译日志里时间先放着。等以 HeaderMap 编译链接实现结束一起对比看看时间节省了多少。
+
+
+
+
+#### 2. 实验二:静态库 + HeaderMap + App 编译
+
+##### 1. 静态库设置
+
+- 第一步:Xcode 新建项目,选择 **Static Library **。为了方便对照,命名为:**HMapStaticLib-HeaderMap**
+- 第二步:根目录下创建 **Sources** 文件夹,多创建几个存在继承关系的类
+- 第三步:把这几个类的头文件导入到静态库头文件中
+- 第四步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第五步:根据源码中头文件目录,创建一个 **HMapFile.json** 文件。以数组的形式写入信息,3个元素,分别为:Key、Prefix、Suffix。利用 LLVM 开发的 hmapmaker 能力,将 json 转换为 hmap 文件
+
+- 第六步:**Build Settings - Use Header Maps** 中设为 **NO**,**Header Search Paths** 设为:`${SRCROOT}/HMapStaticLib-HeaderMap/hmap`(hmap 文件所在目录)
+- 第七步:**Build Phases - Headers** 中设置静态库头文件为 **Public**,允许外部直接访问。其他几个头文件设为 **Private**
+- 第八步:为了方便操作,不用每次创建文件夹,手动拖 **.a** 文件和 **.h** 文件很低效。编写 shell 脚本处理。指定到 **Build Phases - Run Script** 中
+
+整体目录结构和设置如下:
+
+
+
+
+
+##### 2. App 以 HeaderMap 方式编译链接静态库
+
+- 新建 App 工程。在工程目录下创建 **StaticLib** 文件夹
+- 将上面脚本得到静态库产物 **HMapStaticLib-HeaderMap** 拷贝到 **StaticLib** 文件夹下
+- App 工程打开,Build Settings - Header Search Paths** 中配置:`${SRCROOT}/HMapBenchMark-HeaderMap/StaticLib/HMapStaticLib-HeaderMap/Headers`
+- App 工程的 `ViewController.m` 中,`#import "HMapStaticLib_HeaderMap.h"` 引入静态库的公共头文件,然后使用里面的类
+- 编译运行,导出编译日志。查看编译时间.
+
+注意:因为我的 Demo 都是在一个 Xcode 工程,不同的 **TARGETS**,所以即使打包好的静态库产物,复制到 App 工程 **StaticLib** 文件夹下,系统在编译的时候还是会以源码的形式编译。
+会看到以下的编译日志。
+
+
+解决办法:同一个 Project,不同的 Targets,选中当前的 Target,**Edit Scheme**,在 **Build** 下取消勾选 **Find Implicit Depedencies**
+
+
+最终编译链接效果如下:
+
+
+
+
+#### 3. 数据分析及结论
+
+**可以看到静态库先用 Header Search Paths 的方式,App 编译耗时6.5s。使用了自定义的 Header Map 文件后,App 编译耗时6.1s。编译耗时减少了0.4s,节省了6.6%。这是只有1个静态库且只有7个头文件的情况下测试得到的数据。真实项目中,如果静态库数量越多、项目文件目录长且嵌套复杂、头文件数量越多,以自定义 hmap 的方式将会在编译阶段节省更多的时间**
+
+
+
+源码查看:
+- 静态库 + HeaderSearchPath:[HMapStaticLib-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderSearchPath) 和 [HMapBenchMark-HeaderSearchPath](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderSearchPath)
+
+- 静态库 + hmap:[HMapStaticLib-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapStaticLib-HeaderMap) 和 [HMapBenchMark-HeaderMap](https://github.com/FantasticLBP/BlogDemos/tree/master/HMapBenchMark-HeaderMap)
### 7. 工程化问题
@@ -3562,6 +4300,18 @@ Demo 及其演示代码见 [HMapStaticLibApp](https://github.com/FantasticLBP/Bl
- 生成后的 hmap 文件如何使用
如果每个工程项目都这么做,效率有点低,所以需要站在工程化的角度去设计,如何优化?
+完整流程如下:
+```mermaid
+graph TD
+ A[Podfile] --> B[post_install Hook]
+ B --> C[遍历所有 Pod]
+ C --> D[收集头文件映射]
+ D --> E[生成 hmap 文件]
+ E --> F[修改 xcconfig]
+ F --> G[关闭默认 hmap]
+ G --> H[App 编译加速]
+```
+
Cocoapods 提供了很多钩子,可以自定义编写 Ruby 脚本。
- HooksManager 注册 cocoapods 的 `post_install` 钩子
- 通过 `header_mappings_by_file_accessor` 遍历所有头文件和 `header_dir`,由header_dir/header.h和header.h为key,以头文件搜索路径为value,组装成一个Hash
+
#### 2. 如何找到全局变量地址
第一步,先用指令查看全局变量的地址值。 `objdump --macho -s main`,可以看到地址值为 `0x100008000`
-
+
diff --git a/Chapter2 - Web FrontEnd/2.32.md b/Chapter2 - Web FrontEnd/2.32.md
index aa36ba6..8911ee2 100644
--- a/Chapter2 - Web FrontEnd/2.32.md
+++ b/Chapter2 - Web FrontEnd/2.32.md
@@ -37,13 +37,13 @@ render () {
## 生命周期
-
+
## 状态管理
Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍了。解决了各个组件之间数据传递的复杂问题。先看看 Redux 进行状态管理的一个流程吧。
-
+
### 开发步骤
@@ -109,7 +109,7 @@ Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍
Redux-thunk 是 redux 里面常用的一个中间件。中间件?针对谁和谁的中间?对 action 和 store 的中间件。本来 action 只可以返回一个对象,灵活性较低,但是采用了 redux-thunk 之后,action 不仅可以传递对象,还可以传递函数。 action 通过 dispatch 传递给 store。 dispatch 判断 action 的类型,如果是对象则直接传递;如果是函数则直接执行。
-
+
- 异步函数不应该放在组件的生命周期函数里面。复杂的业务逻辑和异步函数适合拆分。目前主流的解决方案有2种中间件:redux-thunk、redux-saga。采用不同的策略
@@ -237,4 +237,1481 @@ class Welcome extends React.Component {
- Vue 设计思想:How easy it can be。React:How corrct it can be 和 all in js(css写法也在用 js 控制,比如 styled-component)
-在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
\ No newline at end of file
+在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
+
+
+
+
+
+## React 核心渲染流程 Fiber 架构
+
+React 在 16 之后引入了 Fiber 架构,旨在解决长列表的渲染卡顿问题。几个关键问题
+
+### hostRenderFiber 里的 updateQueue.shared.pending 怎么理解?为什么需要 shared 属性?
+
+
+在 React 的 Fiber 架构中,`hostRenderFiber.updateQueue.shared.pending` 涉及更新队列的核心设计,尤其是为了支持并发渲染和多优先级更新。我们可以分两部分理解:
+
+
+1. 先拆解概念:`hostRenderFiber.updateQueue.shared.pending`
+- **`hostRenderFiber`**:指「宿主环境渲染 Fiber 节点」(如对应 DOM 元素的 Fiber),负责管理该节点的渲染和更新状态。
+- **`updateQueue`**:Fiber 节点上的「更新队列」,用于存储待处理的更新(如 `setState`、`useState` 产生的更新)。React 通过更新队列实现更新的合并、优先级排序和批量处理。
+- **`shared`**:更新队列中「共享部分」的容器,用于在多场景下共享更新数据(核心是支持并发模式)。
+- **`pending`**:`shared` 中存储「待处理更新」的链表(环形链表),指向当前等待被处理的更新队列尾部。
+
+
+2. `pending` 的作用
+`pending` 是更新队列中**未被处理的更新链表**,本质是一个「环形单向链表」。其设计目的是高效地收集和处理更新:
+- 当产生新更新(如调用 `setState`)时,React 会创建一个 `Update` 对象,并将其添加到 `pending` 链表的尾部(通过指针调整形成环形)。
+- 在「协调阶段(Reconciliation)」,React 会从 `pending` 中取出所有待处理更新,进行合并(如多个相同状态的更新合并为一个),最终计算出最新的状态。
+
+环形链表的设计能让更新的添加和取出操作更高效(时间复杂度 O(1)),避免频繁的数组操作开销。
+
+
+3. 为什么需要 `shared` 属性?
+`shared`(共享)是为了支持 React 的**并发渲染机制**而设计的,核心解决「多场景下更新队列的共享与同步」问题:
+
+在并发模式中,React 可能同时存在多个「更新任务」(如高优先级的用户输入更新和低优先级的列表渲染更新),且这些任务可能在不同的「调度阶段」(如主线程、后台任务)中被处理。此时需要一个「共享的更新容器」,让不同的调度逻辑、优先级任务能访问到同一份待处理更新,避免更新丢失或冲突。
+
+
+具体来说,`shared` 的核心作用是:
+- **跨优先级共享更新**:高优先级更新和低优先级更新可以共用同一个 `pending` 队列,确保低优先级更新不会被高优先级任务覆盖。
+- **跨 Fiber 共享更新**:在 `current Fiber`(当前渲染树的 Fiber)和 `workInProgress Fiber`(正在构建的新 Fiber)交替工作时,`shared` 确保两者能访问到相同的待处理更新,避免状态不一致。
+- **支持中断与恢复**:并发渲染中,低优先级任务可能被高优先级任务中断,`shared.pending` 中的更新不会因中断而丢失,恢复时可继续处理。
+
+
+总结
+- `hostRenderFiber.updateQueue.shared.pending` 是宿主 Fiber 节点上「共享更新队列中待处理的更新链表」,用于收集和暂存未处理的更新。
+- `shared` 属性是为了适配并发渲染的多优先级、多阶段调度需求,确保更新队列能在不同场景(如不同优先级任务、不同 Fiber 树)中被安全共享和同步,避免更新丢失或冲突。
+
+
+注意:「在并发模式中,React 可能同时存在多个更新任务」并不是说明 React 在渲染的时候存在多个线程,**JS 是单线程模型**这一客观事实没有改变,这里说的是更新任务,是任务队列,并不是任务线程。
+
+- JS 单线程的限制是 “同一时间只能执行一个任务”,但可以通过任务队列(如宏任务、微任务)控制任务的执行时机。
+- React 并发模式下,不同更新任务(如用户输入、列表渲染)会被标记不同的优先级(通过 Scheduler 包实现)。高优先级任务(如点击事件)可以打断低优先级任务(如长列表渲染)的执行 —— 此时低优先级任务的中间状态不会提交到 DOM,而是被暂停,等高优先级任务完成后,低优先级任务再从暂停处恢复执行。
+
+
+这种 “中断 - 恢复” 机制让开发者感觉 “多个任务在同时处理”,但本质上仍是主线程按优先级依次执行,没有多线程参与。而 shared.pending 正是为了在这种 “中断 - 恢复” 中,确保低优先级任务被打断时,其未处理的更新不会丢失(因为更新存在共享队列中,恢复时可继续读取)。
+
+
+
+### shared 与双缓冲机制(current/WIP 切换)的关系
+shared(共享)是为了支持 React 的并发渲染机制而设计的」可以理解为 React Fiber 架构为了解决长列表渲染问题,借鉴 iOS、Android 设计了双缓冲机制,系统在 current 和 WIP 之间切换,从而避免长时间阻塞主线程,提升用户体验吗?
+
+双缓冲机制(current 与 workInProgress Fiber 树):这是 React Fiber 架构的核心设计之一,类似 iOS/Android 的双缓冲(前台显示缓冲区、后台绘制缓冲区)。
+- current Fiber:当前已渲染到 DOM 的 Fiber 树,代表 “当前屏幕上的 UI”。
+- workInProgress Fiber(WIP):正在内存中构建的新 Fiber 树,用于计算更新后的 UI。
+当 WIP 树构建完成后,React 会通过切换 current 指针(指向 WIP 树)完成更新,避免直接修改 current 树导致的 UI 闪烁或不完整(因为构建过程可能被中断)。
+这一机制的核心是避免渲染过程中的中间状态暴露给用户,解决 “长时间阻塞主线程导致的 UI 卡顿”。
+
+shared 的作用:支持双缓冲中的更新共享双缓冲机制中,current 和 WIP 是两棵独立的 Fiber 树,但它们需要共享同一份更新队列—— 否则如果更新只存在于 current 树,WIP 树构建时会丢失更新;反之如果只存在于 WIP 树,若 WIP 树被中断丢弃(高优先级任务抢占后可能重新构建),更新也会丢失。
+- shared 正是为这两棵树提供了一个 “共享的更新容器”:
+- 无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列。
+- 当需要构建 WIP 树时,会从 shared.pending 中读取所有待处理更新,确保不遗漏。
+即使 WIP 树被中断重建,新的 WIP 树仍能从 shared.pending 中获取最新更新。
+简单说:双缓冲机制解决 “渲染过程不阻塞 UI”,shared 解决 “双缓冲切换时更新不丢失”,二者配合支撑了并发渲染的可靠性。
+
+### 「无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列」那么是不是 update 任务会有个标记用于区分当前任务是 current Fiber 树的任务还是 WIP Fiber 树的任务?请分别列举,WIP和 Current 不同的任务提交后,后续是如何执行的
+
+在 React 中,Update 任务(即更新对象)并没有专门的标记区分其来自 current Fiber 树还是 workInProgress Fiber 树。这是因为 shared.pending 队列的设计目标就是 “消除来源差异”—— 无论更新来自哪个 Fiber 树,最终都需要被统一处理,确保状态的一致性。一言以蔽之就是:**update 任务不管是 WIP Fiber tree 产生的,还是 Current Fiber Tree 产生的,只用于服务于下一次(也就是 WIP Fiber Tree),类似双缓冲机制,用于构建下一次需要显示的内容**
+
+- current 树是 “只读的”:它代表当前屏幕上的 UI,任何更新都不会直接修改 current 树(否则会导致用户看到中间态、闪烁或不一致)。
+- WIP 树是 “可写的构建区”:所有更新(无论来自 current 树的用户交互,还是 WIP 树构建中的嵌套逻辑)最终都会被收集到 shared.pending 队列,然后在 WIP 树的构建过程中被统一处理(计算新状态、生成新的 Fiber 节点)
+
+### “挂载”和“插入”
+
+React 中经常会看到挂载和插入2个术语。2者有啥区别呢?
+
+| 概念 | 含义 | 发生阶段 | 操作对象 | 是否触发浏览器重排 |
+| :--------------------- | :-------------------------------- | :--------- | :----------------------------------------------------------- | ------------------ |
+| **挂载(mounting)** | 在内存中构建DOM节点间的父子关系 | Render阶段 | React Element 对象`parentElement.appendChild(childElement)`
(仅在内存中) | 否 | +| **插入文档(insert)** | 将DOM树实际添加到浏览器的文档流中 | Commit阶段 | 标准的 DOM 对象
`document.getElementById('root').appendChild(domTree)` | 是 | + +举个例子: + +```react +function Counter() { + return ( +
+
+ Text
+
+ );
+}
+```
+
+"将button的DOM节点挂载到父div的DOM节点下(但不插入文档)",这其实说的是在 React 的 Render 阶段做的事情
+
+```react
+// 在内存中的操作(伪代码):
+const divElement = document.createElement('div');
+const buttonElement = document.createElement('button');
+
+// ✅ "挂载":建立父子关系(仅在内存中)
+divElement.appendChild(buttonElement); // 此时button成为div的子节点
+
+// ❌ 但还没有插入到实际文档中:
+// document.body.appendChild(divElement); // 这个操作还没发生
+```
+
+为什么要做这些区分?为的是性能优化,用代价更小的 Virtual Dom 来模拟真实的 Dom。利用 diff 之后的结果,提交到 queue 里,采用类似 iOS、Android 的双缓冲机制,将 Render 阶段的计算结果 commit 到真实的 Dom 上,以此来减少 Dom 的实际操作,达到性能优化的目的。
+
+| 层级 | 职责 | 性能代价 | 更新频率 |
+| :---------- | :----------------- | :----------------- | :------------------------------------- |
+| **Element** | 描述UI应该长什么样 | 极低(纯 JS 对象) | 每次 render 都创建,用于后续 diff 比较 |
+| **Fiber** | 协调更新、调度任务 | 中等(可中断计算) | 渲染期间持续存在 |
+| **DOM** | 实际渲染、触发重排 | 极高(浏览器操作) | 最小化更新 |
+
+效果就是 :
+
+```shell
+JSX → Element → Fiber协调 → 副作用标记 → 双缓冲切换 → 批量DOM更新
+ ↓ ↓ ↓ ↓ ↓
+ 声明式UI 轻量对象 可中断计算 无闪烁切换 最小化重排
+```
+
+```react
+// 不好的做法(传统):
+document.body.appendChild(div); // 1. 插入div(触发重排)
+document.body.appendChild(button); // 2. 插入button(再次触发重排)
+document.body.appendChild(span); // 3. 插入span(第三次重排)
+
+// React的做法(优化):
+// Render阶段:在内存中构建完整的DOM树
+div.appendChild(button);
+div.appendChild(span);
+
+// Commit阶段:一次性插入整个树
+document.getElementById('root').appendChild(div); // 只触发一次重排
+```
+
+一个小例子
+
+```react
+// 详细流程示例:
+
+// 阶段1: Render(协调/构建)
+function renderPhase() {
+ // 创建所有DOM节点(但独立存在)
+ const div = document.createElement('div');
+ const button = document.createElement('button');
+ const span = document.createElement('span');
+
+ // ✅ 挂载操作:建立节点间的关系
+ div.appendChild(button); // button成为div的子节点
+ div.appendChild(span); // span成为div的子节点
+
+ // 此时:div - button - span 形成了完整的DOM树结构
+ // 但整个div树还没有插入到文档中!
+
+ return div; // 返回构建好的完整DOM树
+}
+
+// 阶段2: Commit(提交)
+function commitPhase(domTree) {
+ const container = document.getElementById('root');
+
+ // ✅ 插入文档:一次性将整棵树插入
+ container.appendChild(domTree);
+
+ // 此时用户才能在浏览器中看到内容
+}
+
+// 使用示例:
+const completeDOMTree = renderPhase(); // 构建
+commitPhase(completeDOMTree); // 插入
+```
+
+这样做的好处(效果)是什么?
+
+```react
+// 性能优势对比:
+// ❌ 传统方式(多次重排):
+for (let i = 0; i < 100; i++) {
+ const element = document.createElement('div');
+ document.body.appendChild(element); // 100次重排!
+}
+
+// ✅ React方式(一次重排):
+const fragment = document.createDocumentFragment();
+for (let i = 0; i < 100; i++) {
+ const element = document.createElement('div');
+ fragment.appendChild(element); // 在内存中构建
+}
+document.body.appendChild(fragment); // 一次重排!
+```
+
+
+
+问题:
+
+1.Fiber 节点和 Element和Dom 节点,3者之间的对应关系是什么?
+
+| 层面 | 角色 | 生命周期 | 示例 |
+| :---------------- | :----------------- | :--------------------- | :------------------------------------ |
+| **React Element** | 描述 UI 的 JS 对象 | 每次 render 都重新创建 | `{type: 'div', props: {...}}` |
+| **Fiber 节点** | 协调的工作单元 | 在多次渲染间持续存在 | `FiberNode {tag: HostComponent, ...}` |
+| **DOM 节点** | 浏览器渲染单元 | 从创建到销毁 | `Hello
` |
+
+看上去 React Element 对象和 JSX 都是做“描述 UI” 这个事儿的,那有啥区别?
+
+JSX 是 React 的语法糖(不是标准的、有效的 js),如果开发者写的代码都用 `React.createElement` 代替的话,很耗费时间、效率很低。
+
+比如下面的例子,Babel 编译器会把 JSX 编译为真正的 JS 代码。
+
+```react
+// 编译前 (JSX)
+const App = () => (
+
+
+);
+
+// 编译后 (JavaScript)
+const App = () =>
+ React.createElement(
+ 'div',
+ { className: 'container' },
+ React.createElement(
+ 'h1',
+ null,
+ 'Hello ',
+ name
+ ),
+ React.createElement(
+ Button,
+ { onClick: handleClick },
+ 'Click me'
+ )
+ );
+```
+
+2.Fiber 对象的 stateNode 属性是做什么的?
+
+在 React 的 Fiber 架构中,`stateNode` 是 Fiber 对象的核心属性之一,其作用是**关联 Fiber 节点对应的“实际运行时实体”**(如 DOM 元素、组件实例、根节点容器等)。简单来说,`stateNode` 是 Fiber 节点与真实世界实体(如 DOM 树、组件实例)之间的“桥梁”。
+
+
+不同类型 Fiber 节点的 `stateNode` 含义
+`stateNode` 的具体类型取决于 Fiber 节点的 `tag`(标签,标识节点类型),不同类型的 Fiber 节点对应不同的 `stateNode`:
+
+1. **`HostComponent`(原生 DOM 标签,如 `Hello {name}
+ +`、``)**
+ `stateNode` 指向该 Fiber 节点对应的**真实 DOM 元素**。
+ 例如:`
` 对应的 Fiber 节点,其 `stateNode` 就是 `document.createElement('div')` 创建的 DOM 元素。
+ (在你提供的代码中,`HostComponent` 的 `stateNode` 会被赋值为创建的 DOM 元素:`workInProgress.stateNode = instance`)。
+
+2. **`HostText`(文本节点,如 `Hello World`)**
+ `stateNode` 指向对应的**文本 DOM 节点**(`Text` 类型的 DOM 对象)。
+ 例如:文本 “Hello” 对应的 Fiber 节点,其 `stateNode` 是 `document.createTextNode('Hello')` 创建的文本节点。
+
+3. **`ClassComponent`(类组件,如 `class MyComponent extends React.Component`)**
+ `stateNode` 指向该类组件的**实例对象**(即 `new MyComponent(...)` 创建的实例)。
+ 通过 `stateNode` 可以访问组件实例的 `state`、`props` 或方法(如 `this.setState`)。
+
+4. **`HostRoot`(根节点,对应 `ReactDOM.render()` 的根容器)**
+ `stateNode` 指向**根容器相关的对象**(通常是 `FiberRoot` 或与根 DOM 容器关联的信息),用于管理整个应用的根节点状态。
+
+5. **其他类型(如 `FunctionComponent`、`Fragment`、`MemoComponent` 等)**
+ 这些类型的 Fiber 节点通常**没有实际的运行时实体**,因此 `stateNode` 可能为 `null` 或 `undefined`。
+ 例如:函数组件(`FunctionComponent`)没有实例,其 `Fiber.stateNode` 为 `null`;`Fragment` 只是逻辑分组,无实际 DOM 节点,`stateNode` 也为 `null`。
+
+
+`stateNode` 的核心作用
+1. **连接虚拟 Fiber 树与真实 DOM 树**
+ 在提交阶段(Commit),React 需要通过 Fiber 节点的 `stateNode` 找到对应的 DOM 元素,才能执行实际的 DOM 操作(如插入、删除、更新属性等)。例如:
+ - 更新 `
` 的 `className` 时,通过 `fiber.stateNode` 拿到真实 DOM 元素,再修改其 `className` 属性。
+
+2. **保存组件实例状态**
+ 对于类组件,`stateNode` 保存组件实例,React 可以通过它访问实例的 `state`、`refs` 或生命周期方法(如 `componentDidMount`),确保组件状态的正确维护。
+
+3. **标识节点唯一性**
+ `stateNode` 是 Fiber 节点与实际实体的唯一关联,在 Fiber 树的遍历、更新、复用过程中,通过 `stateNode` 可以快速定位到对应的实际对象,避免重复创建或错误操作。
+
+
+`stateNode` 是 Fiber 节点的“实体指针”,其类型随 Fiber 节点的类型而变化,核心作用是**将虚拟的 Fiber 树与真实的运行时实体(DOM 元素、组件实例等)关联起来**,使得 React 能够基于 Fiber 树的计算结果,高效地操作真实对象(如更新 DOM、管理组件状态)。
+
+
+### Fiber 树渲染按照深度优先遍历顺序
+React 的渲染分为 Render 阶段(协调/构建 Fiber 树)和 Commit 阶段(应用 DOM 更新)。在 Render 阶段,React 采用 深度优先遍历(DFS) 构建或更新 Fiber 树,遍历顺序遵循:
+
+优先处理当前节点的 子节点(child 指针)。
+若无子节点,则处理 兄弟节点(sibling 指针)。
+若无兄弟节点,则 回溯父节点(return 指针)。
+
+
+
+### flags 和 subTreeFlags 有啥区别?
+
+Fiber 架构中 `flags` 和 `subTreeFlags` 是用于标记节点更新状态的核心字段,二者的核心区别在于**作用范围**和**职责定位**,共同服务于 React 的协调(Reconciliation)和提交(Commit)阶段,以高效处理更新。
+
+
+#### 1. 核心区别:作用范围
+- **`flags`**:仅针对**当前 Fiber 节点自身**的更新标记,记录当前节点需要执行的操作(如更新、插入、删除等)。
+- **`subTreeFlags`**:针对**当前 Fiber 节点的整个子树**(所有后代节点)的更新标记,记录子树中是否存在需要处理的更新(聚合了所有后代节点的 `flags`)。
+
+
+#### 2. 各自的职责
+`flags`:标记当前节点的具体更新操作
+`flags` 是一个位掩码(bitmask),用于标识当前 Fiber 节点自身需要执行的具体操作。React 定义了一系列枚举值(如 `Update`、`Placement`、`Deletion` 等),每个值对应一种操作,多个操作可以通过位运算组合。
+
+**常见的 `flags` 类型**:
+- `Update`:当前节点需要更新(如 props 变化、状态变化等)。
+- `Placement`:当前节点需要插入到 DOM 中。
+- `Deletion`:当前节点需要从 DOM 中删除。
+- `ChildDeletion`:当前节点的子节点中有需要删除的节点(用于优化删除逻辑)。
+- `Ref`:当前节点的 ref 需要更新。
+
+**职责**:在协调阶段标记当前节点的更新类型,在提交阶段指导 React 执行具体的 DOM 操作(如更新属性、插入节点、删除节点等)。
+
+
+`subTreeFlags`:标记子树中是否存在更新:
+`subTreeFlags` 同样是位掩码,但其作用是**聚合当前节点所有后代节点的 `flags`**,用于快速判断“当前节点的子树中是否存在需要处理的更新”。
+
+**职责**:优化 Fiber 树的遍历效率。在协调阶段,React 遍历 Fiber 树时,会先检查当前节点的 `subTreeFlags`:
+- 如果 `subTreeFlags` 为 `0`,说明子树中没有任何更新,可直接跳过对子树的遍历,减少不必要的计算。
+- 如果 `subTreeFlags` 不为 `0`,说明子树中存在更新,需要继续深入遍历子节点处理具体更新。
+
+**传播逻辑**:当子节点的 `flags` 发生变化时,React 会向上“冒泡”更新父节点的 `subTreeFlags`(即父节点的 `subTreeFlags` 会包含子节点的 `flags`),确保上层节点能感知到子树的更新状态。
+
+
+| 字段 | 作用范围 | 核心职责 |
+|---------------|------------------------|--------------------------------------------------------------------------|
+| `flags` | 当前 Fiber 节点自身 | 标记当前节点需要执行的具体操作(如更新、插入、删除),指导提交阶段的 DOM 操作。 |
+| `subTreeFlags`| 当前节点的整个子树 | 聚合子树中所有节点的更新标记,用于快速判断子树是否有更新,优化遍历效率。 |
+
+
+简单来说,`flags` 关注“当前节点要做什么”,`subTreeFlags` 关注“子树里有没有活要干”,二者配合让 React 能高效地定位和处理更新,避免不必要的计算和 DOM 操作。
+
+类比 iOS 类对象的 isa,采用了 bitmask 的技术。高效访问,不需要挨个关心里面的各个子节点构成子树的状态
+
+#### fiber 树深度优先遍历
+在 Fiber 树的深度优先遍历(DFS)过程中,`subTreeFlags` 的赋值遵循**“自底向上聚合”**的逻辑——即先递归处理完所有子节点,再基于子节点的更新状态(`flags` 和 `subTreeFlags`)向上合并,最终形成当前节点的 `subTreeFlags`。这一过程主要发生在 React 协调阶段的 **`completeWork` 阶段**(子节点处理完成后对父节点的“收尾”工作)。
+
+
+具体处理流程(结合 DFS 遍历)
+深度优先遍历的核心是“先深入子树,再回溯父节点”。`subTreeFlags` 的赋值正是利用了这一特性,在子树完全处理后才聚合其更新状态。具体步骤如下:
+
+
+1. 遍历进入子节点(向下递归)
+当遍历到某个 Fiber 节点(记为 `parent`)时,DFS 会先处理其**子节点**(通过 `child` 指针访问第一个子节点,再通过 `sibling` 指针遍历所有兄弟子节点)。
+- 对每个子节点(记为 `child`),会递归执行相同的遍历逻辑:先处理 `child` 自身的更新(`beginWork` 阶段),再继续深入 `child` 的子节点(`child.child`),直到触及叶子节点(没有子节点的节点)。
+
+
+2. 子节点处理完成(回溯阶段)
+当一个子节点 `child` 的所有后代节点(子树)都处理完毕后,遍历会回溯到 `child` 自身,进入 `completeWork` 阶段。此时:
+- `child` 的 `flags` 已确定(自身需要的更新操作,如 `Update`、`Placement` 等);
+- `child` 的 `subTreeFlags` 也已确定(通过聚合 `child` 所有后代节点的 `flags` 和 `subTreeFlags` 得到)。
+
+3. 父节点聚合子节点的更新状态(核心赋值逻辑)
+当 `child` 处理完成后,遍历回到其父节点 `parent` 的处理流程。此时,`parent` 会通过**位运算(OR 操作)** 将 `child` 的 `flags` 和 `subTreeFlags` 合并到自己的 `subTreeFlags` 中。
+
+公式可简化为:
+```javascript
+parent.subTreeFlags |= child.flags | child.subTreeFlags;
+```
+
+- 原因:`child.flags` 包含 `child` 自身的更新,`child.subTreeFlags` 包含 `child` 子树的所有更新,二者的合并结果就是 `child` 整个子树(含自身)的全部更新状态。
+- 作用:`parent` 通过这种方式“感知”到子树中存在的更新,无需深入遍历即可知道子树是否有活要干。
+
+4. 处理所有兄弟子节点
+如果 `parent` 有多个子节点(通过 `sibling` 指针连接),则会对每个子节点重复步骤 1-3:
+- 先处理第一个子节点 `child1`,合并 `child1.flags | child1.subTreeFlags` 到 `parent.subTreeFlags`;
+- 再处理第二个子节点 `child2`,合并 `child2.flags | child2.subTreeFlags` 到 `parent.subTreeFlags`;
+- 以此类推,直到所有子节点处理完毕。
+
+5. 父节点自身的 `subTreeFlags` 最终确定
+当 `parent` 的所有子节点及其子树都处理完毕后,`parent.subTreeFlags` 已聚合了**所有后代节点(含所有子节点、孙节点等)** 的更新状态。此时,`parent` 的 `subTreeFlags` 赋值完成。
+
+
+### 关键特点总结
+1. **自底向上**:`subTreeFlags` 的赋值依赖子树的处理结果,必须在所有子节点处理完成后才会计算,符合 DFS“先深入后回溯”的特性。
+2. **位运算聚合**:通过 `|`(或运算)合并子节点的更新状态,确保父节点能“继承”子树中所有类型的更新(如 `Update`、`Deletion` 等不会丢失)。
+3. **优化遍历效率**:最终父节点的 `subTreeFlags` 若为 `0`,则说明整个子树无任何更新,上层节点遍历到此时可直接跳过,避免无效计算。
+
+
+举例来说:
+- 若叶子节点 `leaf` 有 `flags = Update`,则其 `subTreeFlags = 0`(无后代);
+- `leaf` 的父节点 `parent` 会合并 `leaf.flags | leaf.subTreeFlags`,即 `parent.subTreeFlags = Update`;
+- `parent` 的父节点 `grandparent` 会合并 `parent.flags | parent.subTreeFlags`,若 `parent` 自身无更新(`flags=0`),则 `grandparent.subTreeFlags = Update`,以此类推。
+
+通过这种方式,`subTreeFlags` 像“信号”一样从子树向上传递,让 React 能高效定位需要更新的区域。
+
+伪代码为:
+```javascript
+// 核心:bubbleProperties 逻辑(将当前节点的更新状态冒泡到父节点)
+const parentFiber = workInProgress.return;
+if (parentFiber) {
+ // 合并当前节点的 flags 和 subTreeFlags 到父节点的 subTreeFlags
+ // 位或运算(|)确保父节点能包含所有子树更新类型
+ parentFiber.subTreeFlags |= workInProgress.flags | workInProgress.subTreeFlags;
+}
+```
+
+举个例子说明下 flags 和 subTreeFlags 的变化过程:
+
+我们通过一个具体的组件树更新场景,来直观展示 `flags` 和 `subTreeFlags` 的更新过程。假设我们有如下组件结构:
+```jsx
+// 组件树结构
+function Parent() {
+ return
Hello, World
;
+}
+```
+
+对应的 Fiber 树结构(简化)为:
+`ParentFiber → ChildFiber → DivFiber → SpanFiber → TextFiber(内容为"World")`
+
+
+初始状态:
+所有 Fiber 节点的 `flags` 和 `subTreeFlags` 均为 `NoFlags`(假设值为 `0`,表示无任何更新)。
+
+
+场景:更新 TextFiber 的内容为"React"
+当 `TextFiber` 的内容从"World"变为"React"时,React 会触发协调阶段,我们逐步分析各节点的 `flags` 和 `subTreeFlags` 变化:
+
+
+1. TextFiber(叶子节点,标签为 `HostText`)
+- **`flags` 更新**:
+ 在 `beginWork` 阶段(处理当前节点更新),React 发现 TextFiber 的内容变化,将其 `flags` 标记为 `Update`(假设 `Update = 1 << 0 = 1`)。
+ → `TextFiber.flags = Update (1)`。
+
+- **`subTreeFlags` 更新**:
+ 由于 TextFiber 是叶子节点(无任何子节点),其 `subTreeFlags` 始终为 `NoFlags`(没有子树需要聚合)。
+ → `TextFiber.subTreeFlags = NoFlags (0)`。
+
+
+2. SpanFiber(父节点,标签为 `HostComponent`,对应 ``)
+- **`flags` 更新**:
+ SpanFiber 自身的 props/内容未变化(仅子节点 TextFiber 变化),因此 `flags` 保持 `NoFlags`。
+ → `SpanFiber.flags = NoFlags (0)`。
+
+- **`subTreeFlags` 更新**:
+ 在 `completeWork` 阶段(子树处理完成后回溯),SpanFiber 会聚合子节点 TextFiber 的 `flags` 和 `subTreeFlags`:
+ `SpanFiber.subTreeFlags |= TextFiber.flags | TextFiber.subTreeFlags`
+ → `0 | (1 | 0) = 1`(即 `Update`)。
+ → `SpanFiber.subTreeFlags = Update (1)`。
+
+
+3. DivFiber(祖父节点,标签为 `HostComponent`,对应 ``)
+- **`flags` 更新**:
+ DivFiber 自身的 props/结构未变化(仅子树 SpanFiber 及其后代变化),因此 `flags` 保持 `NoFlags`。
+ → `DivFiber.flags = NoFlags (0)`。
+
+- **`subTreeFlags` 更新**:
+ 在 `completeWork` 阶段,DivFiber 聚合子节点 SpanFiber 的 `flags` 和 `subTreeFlags`:
+ `DivFiber.subTreeFlags |= SpanFiber.flags | SpanFiber.subTreeFlags`
+ → `0 | (0 | 1) = 1`(即 `Update`)。
+ → `DivFiber.subTreeFlags = Update (1)`。
+
+
+4. ChildFiber(曾祖父节点,标签为 `FunctionComponent`,对应 `Child` 组件)
+- **`flags` 更新**:
+ Child 组件自身的逻辑未变化(仅渲染的子树 DivFiber 变化),因此 `flags` 保持 `NoFlags`。
+ → `ChildFiber.flags = NoFlags (0)`。
+
+- **`subTreeFlags` 更新**:
+ 在 `completeWork` 阶段,ChildFiber 聚合子节点 DivFiber 的 `flags` 和 `subTreeFlags`:
+ `ChildFiber.subTreeFlags |= DivFiber.flags | DivFiber.subTreeFlags`
+ → `0 | (0 | 1) = 1`(即 `Update`)。
+ → `ChildFiber.subTreeFlags = Update (1)`。
+
+
+5. ParentFiber(根节点,标签为 `FunctionComponent`,对应 `Parent` 组件)
+- **`flags` 更新**:
+ Parent 组件自身未变化,`flags` 保持 `NoFlags`。
+ → `ParentFiber.flags = NoFlags (0)`。
+
+- **`subTreeFlags` 更新**:
+ 在 `completeWork` 阶段,ParentFiber 聚合子节点 ChildFiber 的 `flags` 和 `subTreeFlags`:
+ `ParentFiber.subTreeFlags |= ChildFiber.flags | ChildFiber.subTreeFlags`
+ → `0 | (0 | 1) = 1`(即 `Update`)。
+ → `ParentFiber.subTreeFlags = Update (1)`。
+
+
+最终状态总结
+| Fiber 节点 | `flags`(自身更新) | `subTreeFlags`(子树更新) | 说明 |
+|--------------|---------------------|---------------------------|--------------------------|
+| TextFiber | `Update (1)` | `NoFlags (0)` | 自身内容更新 |
+| SpanFiber | `NoFlags (0)` | `Update (1)` | 子树(TextFiber)有更新 |
+| DivFiber | `NoFlags (0)` | `Update (1)` | 子树(SpanFiber)有更新 |
+| ChildFiber | `NoFlags (0)` | `Update (1)` | 子树(DivFiber)有更新 |
+| ParentFiber | `NoFlags (0)` | `Update (1)` | 子树(ChildFiber)有更新 |
+
+
+另一种场景:同时更新 SpanFiber 和 TextFiber
+如果不仅 TextFiber 内容更新(`Update`),SpanFiber 还需要添加 `className`(自身 `Update`),则:
+- SpanFiber 的 `flags` 会被标记为 `Update (1)`;
+- SpanFiber 的 `subTreeFlags` 聚合 TextFiber 的 `Update (1)`,结果为 `1 | 1 = 1`(仍为 `Update`);
+- 上层节点(DivFiber、ChildFiber 等)的 `subTreeFlags` 依然会聚合为 `Update`(因为位运算 `|` 不会重复计算相同标记)。
+
+
+核心结论
+- `flags` 只关注**自身是否有更新**(如内容、props 变化),仅当前节点有操作时才会被标记。
+- `subTreeFlags` 关注**子树是否有更新**(无论自身是否更新),通过“自底向上”的位运算聚合所有后代节点的 `flags`,让上层节点无需遍历子树即可快速判断是否有更新,从而优化性能
+
+## 渲染核心流程
+- 创建初始化 WIP
+- 进入“递归”的“递”流程
+ 主要是 beginWork 函数逻辑:
+ - 处理 Fiber 节点的父子、兄弟节点的关系,涉及:child、return、sibling
+ - 给 Fiber 节点打标记 flags、subTreeFlags
+- 进入“递归”的“归”流程
+ - 处理真实 Dom 节点关系
+ - 解析 flags 标记、合并处理 subTreeFlags
+ - 处理父子 Dom 真实的节点关系,将子节点插入父节点中
+- 进入 commit 流程,进行真实的 Dom 渲染
+
+### 递归的“递”阶段做了哪些事情?
+#### 渲染阶段(构建 workInProgress 树)
+```javascript
+// 开始渲染时,创建 workInProgress 树
+function prepareFreshStack(root: FiberRoot, lanes: Lanes) {
+ // 从 current 树克隆出 workInProgress 树
+ root.workInProgress = createWorkInProgress(root.current, null);
+}
+
+// 协调过程在 workInProgress 树上进行
+function renderRootSync(root: FiberRoot, lanes: Lanes) {
+ // 在 workInProgress 树上执行协调
+ workLoopSync();
+
+ // 协调完成,workInProgress 树构建完毕
+ const finishedWork: FiberNode = root.current.alternate;
+ root.finishedWork = finishedWork;
+}
+```
+
+### 递归的“归”阶段做了哪些事情?
+#### 提交阶段(树切换)
+```javascript
+function commitRoot(root: FiberRoot) {
+ const finishedWork = root.finishedWork;
+
+ if (finishedWork !== null) {
+ // === 准备提交 ===
+ root.finishedWork = null;
+
+ // === 执行 DOM 操作 ===
+ commitMutationEffects(root, finishedWork);
+
+ // === 关键:切换 current 指针 ===
+ root.current = finishedWork; // 🎯 双缓冲切换!
+
+ // === 执行 layout 效果 ===
+ commitLayoutEffects(root, finishedWork);
+ }
+}
+```
+
+#### 变更前 commitBeforeMutationEffects
+React 的 commitRoot 分为3个阶段
+```javascript
+function commitRoot(root: FiberRoot) {
+ // 完整版本,包含所有三个阶段
+ commitBeforeMutationEffects(root, finishedWork); // 阶段1
+ commitMutationEffects(root, finishedWork); // 阶段2
+ commitLayoutEffects(root, finishedWork); // 阶段3
+ // 注意:树切换在内部处理
+}
+```
+
+变更前执行 commitBeforeMutationEffects。主要负责在 DOM 发生变更(mutation)之前 执行一系列必要的准备工作,为后续的 DOM 操作(如插入、删除、更新节点)铺路。
+```javascript
+function commitBeforeMutationEffects(root: FiberRoot, finishedWork: Fiber) {
+ // 读取 DOM 状态快照(如滚动位置)
+ // 调用 getSnapshotBeforeUpdate 生命周期
+ // 不涉及 DOM 修改
+}
+```
+
+核心作用:commitBeforeMutationEffects 的核心目标是:在真正修改 DOM 结构之前,处理一些依赖于「当前 DOM 状态」的逻辑,确保这些逻辑能获取到 DOM 变更前的状态,同时完成一些前置准备。
+
+#### 变更 commitMutationEffects
+```javascript
+function commitMutationEffects(root: FiberRoot, finishedWork: Fiber) {
+ // 遍历并执行所有 DOM 操作:
+ recursivelyTraverseMutationEffects(root, finishedWork);
+ commitReconciliationEffects(finishedWork);
+}
+```
+DOM 操作:
+```javascript
+function commitReconciliationEffects(finishedWork: Fiber) {
+ const flags = finishedWork.flags;
+
+ if (flags & Placement) {
+ // 🎯 插入 DOM 节点到父节点
+ commitPlacement(finishedWork);
+ }
+
+ if (flags & Update) {
+ // 🎯 更新 DOM 属性和内容
+ commitUpdate(finishedWork);
+ }
+
+ if (flags & Deletion) {
+ // 🎯 删除 DOM 节点
+ commitDeletion(finishedWork);
+ }
+}
+```
+
+#### 布局阶段 commitLayoutEffects
+```javascript
+function commitLayoutEffects(root: FiberRoot, finishedWork: Fiber) {
+ // DOM 已经更新完成,执行:
+ // - componentDidMount / componentDidUpdate
+ // - useLayoutEffect 回调
+ // - refs 的赋值和清理
+ // - 调度 useEffect
+}
+```
+commitLayoutEffects 是 DOM 变更(mutation)之后的关键步骤,核心作用是:在 DOM 已经完成更新后,处理所有依赖于「最新 DOM 布局状态」的逻辑(比如读取元素尺寸、位置,更新 refs,触发布局相关的生命周期等)
+
+虽然浏览器还没自动触发 layout,但在 commitLayoutEffects 阶段,如果你主动读取 DOM 的布局信息(如 offsetHeight、getBoundingClientRect() 等),浏览器会被 “强制” 立即执行 layout 计算(因为需要返回最新的结果)。
+这正是 commitLayoutEffects 的设计用意:
+此时 DOM 已更新,读取布局信息能拿到最新结果;
+强制 layout 后,你可以同步修改 DOM 样式(如调整位置、尺寸),这些修改会被浏览器合并到后续的绘制中,不会导致额外的 layout 开销(避免 “布局抖动”)
+
+比如
+```javascript
+useLayoutEffect(() => {
+ // 1. 读取 offsetHeight:强制浏览器立即计算 layout(因为 DOM 已更新但未 layout)
+ const height = ref.current.offsetHeight;
+ // 2. 同步修改样式:此时修改会被浏览器合并,不会触发二次 layout
+ ref.current.style.marginTop = `${100 - height}px`;
+}, []);
+```
+
+### 双缓冲切换的详细过程
+React 采用了类似 iOS/Android 中图形渲染的双缓冲机制来实现无撕裂的 UI 更新
+```javascript
+// React 同时维护两棵 Fiber 树:
+let current: FiberNode; // 当前显示在屏幕上的树(前缓冲区)
+let workInProgress: FiberNode; // 正在构建的新树(后缓冲区)
+```
+
+#### 切换前的状态
+```javascript
+// 切换前:
+FiberRoot {
+ current: FiberNode_A, // 屏幕上显示的是树A
+ finishedWork: FiberNode_B, // 刚构建完的树B
+}
+
+// 两棵树通过 alternate 互相引用:
+FiberNode_A.alternate = FiberNode_B;
+FiberNode_B.alternate = FiberNode_A;
+```
+
+#### 切换后的状态
+```javascript
+// 切换 current 指针。类似 iOS 双缓冲机制,视频控制器在收到 V-Sync 信号后,GPU 切换画面
+root.current = root.finishedWork
+
+// 切换后
+FiberRoot {
+ current: FiberNode_B, // 现在屏幕上显示树B
+ finishedWork: null // 准备下一轮构建
+}
+```
+
+### 双缓冲好处
+
+#### 无撕裂更新
+没有双缓冲的问题:用户可能看到部分更新的UI(比如旧的 header + 新的 content)
+有双缓冲:所有 DOM 操作在后台完成,然后一次性切换到新树。用户看到的是完整的、一致的 UI
+
+#### 可中断渲染
+```javascript
+function workLoopConcurrent() {
+ while (workInProgress !== null && !shouldYield()) {
+ performUnitOfWork(workInProgress);
+ }
+
+ // 如果被打断,下次可以从断点继续
+ // workInProgress 树保持中间状态,不影响 current 树
+}
+```
+
+#### 状态一致性
+- 在渲染过程中,current 树始终保持不变
+- 用户可以继续与当前UI交互
+
+#### 实际例子
+```javascript
+// 假设我们有这样的组件更新:
+function App() {
+ const [count, setCount] = useState(0);
+
+ return (
+ ;
+ const pending = updateQueue.shared.pending;
+ updateQueue.shared.pending = null;
+
+ const prevChildren = wip.memoizedState;
+
+ const { memoizedState } = processUpdateQueue(baseState, pending, renderLane);
+ wip.memoizedState = memoizedState;
+
+ const current = wip.alternate;
+ // 考虑RootDidNotComplete的情况,需要复用memoizedState
+ if (current !== null) {
+ if (!current.memoizedState) {
+ current.memoizedState = memoizedState;
+ }
+ }
+
+ const nextChildren = wip.memoizedState;
+ if (prevChildren === nextChildren) {
+ return bailoutOnAlreadyFinishedWork(wip, renderLane);
+ }
+ reconcileChildren(wip, nextChildren);
+ return wip.child;
+}
+```
+接着会调用 processUpdateQueue 方法
+```javascript
+export const processUpdateQueue = (
+ baseState: State,
+ pendingUpdate: Update | null,
+ renderLane: Lane,
+ onSkipUpdate?: (update: Update) => void
+): {
+ memoizedState: State;
+ baseState: State;
+ baseQueue: Update | null;
+} => {
+ const result: ReturnType> = {
+ memoizedState: baseState,
+ baseState,
+ baseQueue: null
+ };
+
+ if (pendingUpdate !== null) {
+ // 第一个update
+ const first = pendingUpdate.next;
+ let pending = pendingUpdate.next as Update;
+
+ let newBaseState = baseState;
+ let newBaseQueueFirst: Update | null = null;
+ let newBaseQueueLast: Update | null = null;
+ let newState = baseState;
+
+ do {
+ const updateLane = pending.lane;
+ if (!isSubsetOfLanes(renderLane, updateLane)) {
+ // 跳过低优先级更新,但保留在链表中(优先级不够 被跳过)
+ const clone = createUpdate(pending.action, pending.lane);
+
+ onSkipUpdate?.(clone);
+
+ // 是不是第一个被跳过的
+ if (newBaseQueueFirst === null) {
+ // first u0 last = u0
+ newBaseQueueFirst = clone;
+ newBaseQueueLast = clone;
+ newBaseState = newState;
+ } else {
+ // first u0 -> u1 -> u2
+ // last u2
+ (newBaseQueueLast as Update).next = clone;
+ newBaseQueueLast = clone;
+ }
+ } else {
+ // 优先级足够
+ if (newBaseQueueLast !== null) {
+ const clone = createUpdate(pending.action, NoLane);
+ newBaseQueueLast.next = clone;
+ newBaseQueueLast = clone;
+ }
+
+ const action = pending.action;
+ if (pending.hasEagerState) {
+ newState = pending.eagerState;
+ } else {
+ newState = basicStateReducer(baseState, action);
+ }
+ }
+ pending = pending.next as Update;
+ } while (pending !== first);
+
+ if (newBaseQueueLast === null) {
+ // 本次计算没有update被跳过
+ newBaseState = newState;
+ } else {
+ newBaseQueueLast.next = newBaseQueueFirst;
+ }
+ result.memoizedState = newState;
+ result.baseState = newBaseState;
+ result.baseQueue = newBaseQueueLast;
+ }
+ return result;
+};
+```
+
+`pending !== first` 设计为一个单向循环链表来方便遍历,为什么设计为双向循环链表?
+前置知识:循环链表相比数组,在插入和删除方面更加高效。因为数组在插入和删除方面需要时间复杂度为 O(n)
+React 的并发特性允许高优先级更新中断低优先级更新,使用循环链表数据结构可以满足:
+- 保存中断点(记住当前节点)
+- 从中断处继续执行
+- 插入高优先级更新找到合适位置
+使用其他的数据结构也能做,就是效率很低,循环链表更适合做这个事。
+
+QA:什么是高优先级更新、什么是低优先级更新?
+高优先级更新(同步/用户阻塞)
+- 用户交互:点击、输入、滚动
+- 动画:CSS transitions/animations
+- 生命周期方法:componentDidMount等
+
+低优先级更新(并发/可中断)
+- 数据获取:API调用结果
+- 懒加载:非关键内容加载
+- 大计算量:复杂数据处理
+
+
+## React Hooks 链表结构
+在 React 中,**所有 Hooks(包括 useState、useEffect、useRef 等)都是通过一个单向链表结构来管理的**,并非只有 useState 如此。这个链表是 React 内部用于追踪组件中 Hooks 调用顺序和状态的核心机制。
+
+### 为什么用链表管理 Hooks?
+React Hooks 的设计要求“必须在组件顶层调用”(不能在条件、循环、嵌套函数中调用),这正是因为 Hooks 的状态依赖于**调用顺序**。链表结构天然适合按顺序记录和访问 Hooks 的信息(如状态值、更新函数、依赖项等),确保每次渲染时 Hooks 的顺序与首次渲染一致,从而正确匹配对应的状态。
+
+### Hooks 链表的工作流程
+React 会为每个组件实例维护一个独立的 Hooks 链表,其核心工作流程可分为**首次渲染**和**重新渲染**两个阶段:
+
+#### 1. 首次渲染(Mount 阶段)
+- 当组件首次渲染时,React 会初始化一个 `workInProgressHook` 指针(指向当前处理的 Hook 节点),并创建一个空的 Hooks 链表。
+- 每调用一个 Hook(如 `useState`),React 会创建一个对应的 **Hook 节点**(包含该 Hook 的状态、更新函数、依赖项等信息),并将其添加到链表的末尾。
+- 同时,`workInProgressHook` 指针会向后移动,指向新创建的节点,确保下一个 Hook 按顺序衔接。
+
+ 例如,组件中调用两个 Hooks:
+ ```jsx
+ function MyComponent() {
+ const [count, setCount] = useState(0); // 第一个 Hook 节点
+ useEffect(() => {}, []); // 第二个 Hook 节点
+ return
+
+ );
+}
+
+export default App;
+```
+上面的代码会输出:
+```javascript
+Effect 3(B组件的副作用逻辑1)
+Effect 4(B组件的副作用逻辑2)
+Effect 1(A组件的副作用逻辑1)
+Effect 2(A组件的副作用逻辑2)
+```
+为什么会这样输出??
+
+### 源码探究
+```javascript
+// 递归中的递阶段
+export const beginWork = (wip: FiberNode, renderLane: Lane) => {
+ // bailout策略
+ didReceiveUpdate = false;
+ const current = wip.alternate;
+
+ if (current !== null) {
+ const oldProps = current.memoizedProps;
+ const newProps = wip.pendingProps;
+ // 四要素~ props type
+ // {num: 0, name: 'cpn2'}
+ // {num: 0, name: 'cpn2'}
+ if (oldProps !== newProps || current.type !== wip.type) {
+ didReceiveUpdate = true;
+ } else {
+ // state context
+ const hasScheduledStateOrContext = checkScheduledUpdateOrContext(
+ current,
+ renderLane
+ );
+ if (!hasScheduledStateOrContext) {
+ // 四要素~ state context
+ // 命中bailout
+ didReceiveUpdate = false;
+
+ switch (wip.tag) {
+ case ContextProvider:
+ const newValue = wip.memoizedProps.value;
+ const context = wip.type._context;
+ pushProvider(context, newValue);
+ break;
+ // TODO Suspense
+ }
+
+ return bailoutOnAlreadyFinishedWork(wip, renderLane);
+ }
+ }
+ }
+
+ wip.lanes = NoLanes;
+
+ // 比较,返回子fiberNode
+ switch (wip.tag) {
+ case HostRoot:
+ return updateHostRoot(wip, renderLane);
+ case HostComponent:
+ return updateHostComponent(wip);
+ case HostText:
+ return null;
+ case FunctionComponent:
+ return updateFunctionComponent(wip, wip.type, renderLane);
+ case Fragment:
+ return updateFragment(wip);
+ case ContextProvider:
+ return updateContextProvider(wip, renderLane);
+ case SuspenseComponent:
+ return updateSuspenseComponent(wip);
+ case OffscreenComponent:
+ return updateOffscreenComponent(wip);
+ case LazyComponent:
+ return mountLazyComponent(wip, renderLane);
+ case MemoComponent:
+ return updateMemoComponent(wip, renderLane);
+ default:
+ if (__DEV__) {
+ console.warn('beginWork未实现的类型');
+ }
+ break;
+ }
+ return null;
+};
+```
+判断 fiber 节点的 tag 为 FunctionComponent 则执行 updateFunctionComponent 流程
+```javascript
+function updateFunctionComponent(
+ wip: FiberNode,
+ Component: FiberNode['type'],
+ renderLane: Lane
+) {
+ prepareToReadContext(wip, renderLane);
+ // render
+ const nextChildren = renderWithHooks(wip, Component, renderLane);
+
+ const current = wip.alternate;
+ if (current !== null && !didReceiveUpdate) {
+ bailoutHook(wip, renderLane);
+ return bailoutOnAlreadyFinishedWork(wip, renderLane);
+ }
+
+ reconcileChildren(wip, nextChildren);
+ return wip.child;
+}
+```
+可以看到在 updateFunctionComponent 内部执行了 renderWithHooks 函数
+```javascript
+export function renderWithHooks(
+ wip: FiberNode,
+ Component: FiberNode['type'],
+ lane: Lane
+) {
+ // 赋值操作
+ currentlyRenderingFiber = wip;
+ // 重置 hooks链表
+ wip.memoizedState = null;
+ // 重置 effect链表
+ wip.updateQueue = null;
+ renderLane = lane;
+
+ const current = wip.alternate;
+
+ if (current !== null) {
+ // update
+ currentDispatcher.current = HooksDispatcherOnUpdate;
+ } else {
+ // mount
+ currentDispatcher.current = HooksDispatcherOnMount;
+ }
+
+ const props = wip.pendingProps;
+ // FC render
+ const children = Component(props);
+
+ // 重置操作
+ currentlyRenderingFiber = null;
+ workInProgressHook = null;
+ currentHook = null;
+ renderLane = NoLane;
+ return children;
+}
+```
+
+### useState 循环链表
+对 useState 下断点会走到 pushEffect 的逻辑里,核心代码如下
+```javascript
+function pushEffect(
+ hookFlags: Flags,
+ create: EffectCallback | void,
+ destroy: EffectCallback | void,
+ deps: HookDeps
+): Effect {
+ const effect: Effect = {
+ tag: hookFlags,
+ create,
+ destroy,
+ deps,
+ next: null
+ };
+ const fiber = currentlyRenderingFiber as FiberNode;
+ const updateQueue = fiber.updateQueue as FCUpdateQueue;
+ if (updateQueue === null) {
+ // 创建一个新的 effect 循环
+ const updateQueue = createFCUpdateQueue();
+ // 将新创建的循环队列赋值给当前的 fiber
+ fiber.updateQueue = updateQueue;
+ // 由于是循环链表,链表为空的情况下,当前节点的下一个节点指向自己,next 指针指向自己
+ effect.next = effect;
+ // lastEffect 指向最后一个节点。有了 lastEffect 就可以很方便的找到第一个节点。只一个节点的情况下,lastEffect 就是自己
+ updateQueue.lastEffect = effect;
+ } else {
+ // 插入effect
+ const lastEffect = updateQueue.lastEffect;
+ if (lastEffect === null) {
+ effect.next = effect;
+ updateQueue.lastEffect = effect;
+ } else {
+ const firstEffect = lastEffect.next;
+ lastEffect.next = effect;
+ effect.next = firstEffect;
+ updateQueue.lastEffect = effect;
+ }
+ }
+ return effect;
+}
+```
+其中会调用 createUpdateQueue 方法。用于创建一个循环链表用于存储 effect
+```javascript
+function createFCUpdateQueue() {
+ const updateQueue = createUpdateQueue() as FCUpdateQueue;
+ updateQueue.lastEffect = null;
+ return updateQueue;
+}
+```
+如果有多个 effect,则都会被添加到循环链表中,产生类似右侧的结构: effect1 -> effect2 -> effect1
+
+### useEffect 回调的执行时机
+- **渲染阶段收集副作用**
+- **提交阶段执行副作用**
+
+针对上面的 Demo 逐步进行分析:
+
+#### 1. 渲染阶段(Reconciliation Phase):收集副作用,构建循环链表
+当组件首次渲染时,React 会遍历组件树(从父到子),为每个组件创建 Fiber 节点,并收集其内部的 useEffect 副作用,存储到 Fiber 节点的副作用队列(updateQueue)中,队列底层是 循环链表(如之前分析的 pushEffect 逻辑)。
+
+- 父组件 A 先进入渲染阶段:解析 A 组件的 useEffect 时,React 会调用 pushEffect 函数,将该 useEffect 的回调(包含 effect1、effect2 调用)封装为一个 Effect 对象,添加到 A 的 Fiber 节点的副作用队列(循环链表)中。此时 A 的队列中只有一个 Effect 节点(指向自身的循环链表)。
+- 子组件 B 后进入渲染阶段:由于 B 是 A 的子组件,React 会先完成 A 的渲染框架,再递归渲染 B。解析 B 组件的 useEffect 时,同样通过 pushEffect 创建 Effect 对象,添加到 B 的 Fiber 节点的副作用队列(循环链表)中。
+
+QA:假设一个页面存在3个自定义组件,每个组件内部存在一些 Dom 节点,那么会创建多少个 Fiber 节点,存在多少个 Fiber Tree?
+
+#### 2. 提交阶段(Commit Phase):遍历 Fiber 树,执行副作用
+渲染阶段完成后,React 进入提交阶段,此时会遍历整个 Fiber 树,按 “先子后父” 的顺序执行所有收集到的副作用(useEffect 的回调函数)。
+递归的“归”阶段。Fiber Tree 的 DFS 过程。
+
+##### 为什么是 “先子后父”?
+组件挂载的逻辑是 “父组件挂载依赖子组件挂载完成”(父组件的 DOM 节点需要包含子组件的 DOM 节点)。因此,只有子组件完全挂载后,父组件才算真正挂载完成。副作用 (如 DOM 操作、数据请求)需要在组件挂载完成后执行,因此子组件的副作用先于父组件执行。
+具体执行顺序:
+- 遍历到 B 的 Fiber 节点,取出其副作用队列(循环链表)中的 Effect 对象,执行其 create 回调(即 useEffect 的回调),依次调用 effect3()、effect4(),输出 Effect 3、Effect 4。
+- 遍历到 A 的 Fiber 节点,取出其副作用队列中的 Effect 对象,执行其 create 回调,依次调用 effect1()、effect2(),输出 Effect 1、Effect 2。
+
+
+几个关键函数:
+- flushPassiveEffects
+- commitHookEffectList
+
+
+```javascript
+export function commitHookEffectListCreate(flags: Flags, lastEffect: Effect) {
+ commitHookEffectList(flags, lastEffect, (effect) => {
+ const create = effect.create;
+ if (typeof create === 'function') {
+ effect.destroy = create();
+ }
+ });
+}
+```
+
+```javascript
+function commitHookEffectList(
+ flags: Flags,
+ lastEffect: Effect,
+ callback: (effect: Effect) => void
+) {
+ let effect = lastEffect.next as Effect;
+
+ do {
+ if ((effect.tag & flags) === flags) {
+ callback(effect);
+ }
+ effect = effect.next as Effect;
+ } while (effect !== lastEffect.next);
+}
+```
+
+pendingPassiveEffects
+
+在 commitRoot 方法中不断调用会走到 commitPassiveEffect 方法中。
+```javascript
+function commitRoot(root: FiberRootNode) {
+ // ...
+ if (subtreeHasEffect || rootHasEffect) {
+ // beforeMutation
+ // mutation Placement
+ commitMutationEffects(finishedWork, root);
+
+ root.current = finishedWork;
+
+ // 阶段3/3:Layout
+ commitLayoutEffects(finishedWork, root);
+ } else {
+ root.current = finishedWork;
+ }
+}
+
+function commitPassiveEffect(
+ fiber: FiberNode,
+ root: FiberRootNode,
+ type: keyof PendingPassiveEffects
+) {
+ // update unmount
+ if (
+ fiber.tag !== FunctionComponent ||
+ (type === 'update' && (fiber.flags & PassiveEffect) === NoFlags)
+ ) {
+ return;
+ }
+ const updateQueue = fiber.updateQueue as FCUpdateQueue;
+ if (updateQueue !== null) {
+ if (updateQueue.lastEffect === null && __DEV__) {
+ console.error('当FC存在PassiveEffect flag时,不应该不存在effect');
+ }
+ root.pendingPassiveEffects[type].push(updateQueue.lastEffect as Effect);
+ }
+}
+```
+可以看到 React 在 commitRoot 提交阶段会遍历所有收集到的副作用 (useEffect 属于此类),
+**root.pendingPassiveEffects[type].push(updateQueue.lastEffect as Effect)** 通过这段代码,React 会将每个组件的副作用循环链表的“入口节点”(updateQueuee.lastEffect) 推入全局队列,而收集顺序是从 Fiber 叶子节点到父 Fiber 节点(DFS)
+- 遍历到 BComponent 的 Fiber 节点时:
+ - 取 BComponent.updateQueue.lastEffect(即 EffectB,B 的循环链表入口节点)
+ - 将 EffectB 推入 root.pendingPassiveEffects.mount 数组。此时全局的队列为:[EffectB]
+- 遍历到 AComponent 的 Fiber 节点时:
+ - 取 AComponent.updateQueue.lastEffect(即 EffectA,A 的循环链表入口节点)
+ - 将 EffectA 推入 root.pendingPassiveEffects.mount 数组。此时全局的队列为:[EffectB、EffectA]
+
+在 commitRoot 阶段,会调用 `flushPassiveEffects` 方法。
+```javascript
+function commitRoot(root: FiberRootNode) {
+ // ...
+ if (
+ (finishedWork.flags & PassiveMask) !== NoFlags ||
+ (finishedWork.subtreeFlags & PassiveMask) !== NoFlags
+ ) {
+ if (!rootDoesHasPassiveEffects) {
+ rootDoesHasPassiveEffects = true;
+ // 调度副作用
+ scheduleCallback(NormalPriority, () => {
+ // 执行副作用
+ flushPassiveEffects(root.pendingPassiveEffects);
+ return;
+ });
+ }
+ }
+ // ...
+}
+```
+flushPassiveEffects 方法实现如下
+```javascript
+function flushPassiveEffects(pendingPassiveEffects: PendingPassiveEffects) {
+ let didFlushPassiveEffect = false;
+ pendingPassiveEffects.unmount.forEach((effect) => {
+ didFlushPassiveEffect = true;
+ commitHookEffectListUnmount(Passive, effect);
+ });
+ pendingPassiveEffects.unmount = [];
+
+ pendingPassiveEffects.update.forEach((effect) => {
+ didFlushPassiveEffect = true;
+ commitHookEffectListDestroy(Passive | HookHasEffect, effect);
+ });
+ pendingPassiveEffects.update.forEach((effect) => {
+ didFlushPassiveEffect = true;
+ commitHookEffectListCreate(Passive | HookHasEffect, effect);
+ });
+ pendingPassiveEffects.update = [];
+ flushSyncCallbacks();
+ return didFlushPassiveEffect;
+}
+```
+可以看到内部分别处理了 pendingPassiveEffects.unmount、pendingPassiveEffects.update 托管的 effect。
+```javascript
+export function commitHookEffectListCreate(flags: Flags, lastEffect: Effect) {
+ commitHookEffectList(flags, lastEffect, (effect) => {
+ const create = effect.create;
+ if (typeof create === 'function') {
+ effect.destroy = create();
+ }
+ });
+}
+```
+通过 commitHookEffectListCreate 的实现可以知道,内部是封装调用了 commitHookEffectList 方法。
+```javascript
+function commitHookEffectList(
+ flags: Flags,
+ lastEffect: Effect,
+ callback: (effect: Effect) => void
+) {
+ let effect = lastEffect.next as Effect;
+
+ do {
+ if ((effect.tag & flags) === flags) {
+ callback(effect);
+ }
+ effect = effect.next as Effect;
+ } while (effect !== lastEffect.next);
+}
+```
+commitHookEffectList 的核心职责是:
+- 遍历 effect 循环链表,根据 flags 筛选出需要处理的 effect
+- 然后调用 callback 对这些 effect 执行具体操作(比如执行 effect 的销毁函数 destroy 或创建函数 create)
+它是 React 处理 Hook 副作用的「通用遍历器」,在不同阶段(如 layout 阶段处理 useLayoutEffect,passive 阶段处理 useEffect)会被传入不同的 flags 和 callback,以实现对不同类型副作用的精准处理。
+
+
+QA:flushPassiveEffects 源码中,在执行 pendingPassiveEffects.update 相关的 effect 的时候,会先调用 destory,再去执行 create,为什么要这么做?
+核心是**保证副作用的正确性、避免资源泄漏,以及确保副作用与当前组件状态的一致性。**
+本质原因是:副作用的生命周期同步问题。React 的 effect 本质是「与组件状态关联的副作用」,它会随着组件的渲染(或依赖变化)而更新。当组件重新渲染(或依赖项变化)时,旧的 effect 可能已经基于「旧的状态 /props」,如果不先销毁旧的副作用,直接创建新的副作用,会导致:
+- 旧的副作用与新状态的冲突:旧的副作用可能还在使用旧的 State,而新的副作用基于新的 State,两者并存会导致逻辑混乱(比如重复监听、数据不一致)
+- 资源泄漏:如果副作用涉及资源占用(如事件监听、定时器、网络连接等),不销毁旧的副作用会导致这些资源无法释放,长期积累会引发**内存泄漏或性能问题**
+
+对于 useEffect(异步执行的 effect),虽然执行时机在浏览器绘制后,但同样需要先销毁旧的副作用(基于旧状态),再创建新的(基于新状态),否则会导致副作用与组件当前状态脱节
+
+举个例子:
+```javascript
+function TimerDemo() {
+ // 计数器状态(会影响UI)
+ const [count, setCount] = useState(0);
+ // 定时器间隔(用户可修改)
+ const [delay, setDelay] = useState(1000); // 初始1秒
+
+ useEffect(() => {
+ // 创建定时器:每隔delay毫秒更新一次count
+ const timer = setInterval(() => {
+ // 用函数式更新确保获取最新的count(避免闭包问题)
+ setCount(prevCount => prevCount + 1);
+ }, delay);
+
+ // 销毁函数:清除当前定时器
+ return () => {
+ clearInterval(timer);
+ };
+ }, [delay]); // 依赖delay:当delay变化时,重新执行effect
+
+ return (
+  +
+git 存在3个区域:
+
+| **区域** | **别名** | **存储位置** | **核心功能** | **操作命令** |
+| :--------- | :---------- | :---------------- | :----------------- | :----------- |
+| **工作区** | Workspace | 本地目录 | 开发者直接编辑文件 | 手动编辑文件 |
+| **暂存区** | Index/Stage | `.git/index` 文件 | 准备下次提交的变更 | `git add` |
+| **版本库** | Repository | `.git/objects` | 永久存储的提交历史 | `git commit` |
+
+代码回滚用的是 git reset 指令。区别在于参数:
+
+- git reset --hard commitId:将代码回滚到工作区,本次代码(文件)的变动都会被舍弃。
+- git reset --soft commitId:将代码回滚到暂存区,本次代码(文件)的变动不会被舍弃,也就是相当于执行了 `git add` 的操作
+
+一般而言,为了安全和灵活,都采用 `git reset --soft commitId` 指令。
+
+
+
+HEAD:用来指向分支的最后一次提交对象。
+
+如果想要回到上一步,可以用 `HEAD~1` 代替具体的 commitID。
+
+如果想要丢弃还需要进一步处理:
+
+- git reset HEAD .`:则将暂存区的提交回滚掉。相当于没有执行 `git add`(只有本地新改动的数据)
+- `git checkout -- .`: 将本地新改动的数据丢弃掉。
+
+
+
+git checkout:
+
+- 切换分支,例如:`git checkout master`
+- 重新存储工作区文件。例如:`git checkout -- .`
+
+
+
+## git 原理
+
+- git 以 key、value 的形式存储。
+- 二进制仓库的底层数据结构为树
+- 本次修改文件的 hash 值为 key
+- 本次修改文件的压缩版本为 value
+
+
+
+### 1. git 对象存储
+
+git 将存储对象的40位 HASH 分为2部分:
+
+- 头2位作为文件夹
+
+- 后38位作为对象文件名。结构为:`.git/objects/hash[0:2]/hash[2:40]`
+
+
+
+git 存在3个区域:
+
+| **区域** | **别名** | **存储位置** | **核心功能** | **操作命令** |
+| :--------- | :---------- | :---------------- | :----------------- | :----------- |
+| **工作区** | Workspace | 本地目录 | 开发者直接编辑文件 | 手动编辑文件 |
+| **暂存区** | Index/Stage | `.git/index` 文件 | 准备下次提交的变更 | `git add` |
+| **版本库** | Repository | `.git/objects` | 永久存储的提交历史 | `git commit` |
+
+代码回滚用的是 git reset 指令。区别在于参数:
+
+- git reset --hard commitId:将代码回滚到工作区,本次代码(文件)的变动都会被舍弃。
+- git reset --soft commitId:将代码回滚到暂存区,本次代码(文件)的变动不会被舍弃,也就是相当于执行了 `git add` 的操作
+
+一般而言,为了安全和灵活,都采用 `git reset --soft commitId` 指令。
+
+
+
+HEAD:用来指向分支的最后一次提交对象。
+
+如果想要回到上一步,可以用 `HEAD~1` 代替具体的 commitID。
+
+如果想要丢弃还需要进一步处理:
+
+- git reset HEAD .`:则将暂存区的提交回滚掉。相当于没有执行 `git add`(只有本地新改动的数据)
+- `git checkout -- .`: 将本地新改动的数据丢弃掉。
+
+
+
+git checkout:
+
+- 切换分支,例如:`git checkout master`
+- 重新存储工作区文件。例如:`git checkout -- .`
+
+
+
+## git 原理
+
+- git 以 key、value 的形式存储。
+- 二进制仓库的底层数据结构为树
+- 本次修改文件的 hash 值为 key
+- 本次修改文件的压缩版本为 value
+
+
+
+### 1. git 对象存储
+
+git 将存储对象的40位 HASH 分为2部分:
+
+- 头2位作为文件夹
+
+- 后38位作为对象文件名。结构为:`.git/objects/hash[0:2]/hash[2:40]`
+
+  +
+ 比如:`gitDemo/.git/objects/22/13d05bf4b8cfc7ee323af3ac427ad2fa14da88`
+
+
+
+QA: 为什么要设计这样的目录结构(Hash 值总40位,前2位为文件夹名称,后38为文件名称),而不直接用40位 hash 值作为文件名?
+
+- 部分文件系统对目录下的文件数量有限制。例如,FAT32 限制单目录下的最大文件数量位 65535 个
+- 部分文件系统查找文件属于线性查找,目录下的文件越多,查找越慢
+
+
+
+### 2. git add 的本质
+
+
+
+ 比如:`gitDemo/.git/objects/22/13d05bf4b8cfc7ee323af3ac427ad2fa14da88`
+
+
+
+QA: 为什么要设计这样的目录结构(Hash 值总40位,前2位为文件夹名称,后38为文件名称),而不直接用40位 hash 值作为文件名?
+
+- 部分文件系统对目录下的文件数量有限制。例如,FAT32 限制单目录下的最大文件数量位 65535 个
+- 部分文件系统查找文件属于线性查找,目录下的文件越多,查找越慢
+
+
+
+### 2. git add 的本质
+
+  +
+`git ls-files -s` 指令查看暂存区文件 。
+
+git add 的本质就是内容哈希化。
+
+- 输入:文件内容(二进制流)
+- 处理:
+ - 添加头部信息:**"blob " + 内容字节数 + "\0"**
+ - 计算 SHA-1: **SHA1(header + content)**
+- 输出:40位十六进制的哈希值
+
+比如对 “Hello” 进行哈希计算:
+
+1. 原始内容:`b"Hello"`
+2. 添加头部
+ - 内容长度:5字节
+ - 构造头部:`b"blob 5\0"`
+3. 完整数据:`b"blob 5\0Hello"`
+4. SHA-1 计算。`HashUtils.sha1(data).hexdigest()`
+
+### 3. 如何计算 git 哈希
+
+使用指令 **git hash-object -w ./index.txt** 即可。
+
+将得到的40位长度的哈希,拆为2部分,前2位为文件夹名称,后38位为文件名。
+
+
+
+Demo1:
+
+对 `index.txt` 文件使用 `git hash-object -w index.txt` 指令计算哈希。
+
+
+
+`git ls-files -s` 指令查看暂存区文件 。
+
+git add 的本质就是内容哈希化。
+
+- 输入:文件内容(二进制流)
+- 处理:
+ - 添加头部信息:**"blob " + 内容字节数 + "\0"**
+ - 计算 SHA-1: **SHA1(header + content)**
+- 输出:40位十六进制的哈希值
+
+比如对 “Hello” 进行哈希计算:
+
+1. 原始内容:`b"Hello"`
+2. 添加头部
+ - 内容长度:5字节
+ - 构造头部:`b"blob 5\0"`
+3. 完整数据:`b"blob 5\0Hello"`
+4. SHA-1 计算。`HashUtils.sha1(data).hexdigest()`
+
+### 3. 如何计算 git 哈希
+
+使用指令 **git hash-object -w ./index.txt** 即可。
+
+将得到的40位长度的哈希,拆为2部分,前2位为文件夹名称,后38位为文件名。
+
+
+
+Demo1:
+
+对 `index.txt` 文件使用 `git hash-object -w index.txt` 指令计算哈希。
+
+ +
+Demo2:
+
+ `index.txt`文件内容没有改变, 继续计算哈希。发现哈希值一致
+
+结论:
+
+- **只要文件内容不变,hash 值不变。**
+- **每次计算一次哈希,都会在 `.git/objects/` 文件夹下多出一个子文件夹。**
+
+Demo3:
+
+对 `index.txt` 文件内容进行调整,`git hash-object -w index.txt` 指令计算哈希
+
+
+
+Demo2:
+
+ `index.txt`文件内容没有改变, 继续计算哈希。发现哈希值一致
+
+结论:
+
+- **只要文件内容不变,hash 值不变。**
+- **每次计算一次哈希,都会在 `.git/objects/` 文件夹下多出一个子文件夹。**
+
+Demo3:
+
+对 `index.txt` 文件内容进行调整,`git hash-object -w index.txt` 指令计算哈希
+
+ +
+结论:
+
+- **文件内容改变了,hash 值变了。**
+- **文件内容改变后,生成新的 hash 值,同时会在 `.git/objects/` 文件夹下多出一个新的文件夹**。文件夹名称为新的哈希值的前2位,文件夹内文件名称为新的哈希值的后38位。
+
+
+
+### 4. 模拟 git add
+
+利用指令 **`git update-index --add --cacheinfo 100644 {FileHashValue} index.txt`** 将工作区的文件添加到缓存区
+
+- `--add`: 强制将指定文件添加到暂存区(即使文件不存在于工作目录中)
+- `--cacheinfo`: 手动指定文件的「模式(mode)+ 哈希值(hash)+ 路径(path)」来更新暂存区,用于添加那些不在工作目录中的文件
+- `100644`: 文件模式(file mode),表示这是一个普通文件(非执行文件、非符号链接等)。Git 中常见模式:`100644`(普通文件)、`100755`(可执行文件)、`120000`(符号链接)等
+- `{FileHashValue}`: 文件内容的 SHA-1 哈希值(40 位字符串),对应 Git 数据库(`.git/objects`)中存储的文件内容
+- `index.txt`:最终在暂存区中记录的文件名(路径)
+
+Demo:
+
+- 为了模拟 `git add` 的效果,先把仓库中的 `.git` 文件夹删掉
+- 利用指令 `git hash-object -w index.txt` 计算出 index.txt 的哈希值
+- 利用指令 `git update-index --add --cacheinfo 100644 2213d05bf4b8cfc7ee323af3ac427ad2fa14da88 index.txt` 将 `index.txt` 和计算出来的哈希值写入到暂存区
+- 利用指令 `git status` 查看是否成功写入到暂存区
+- 继续按照上述2个流程(git hash-object 和 git update-index)将剩余2个文件进行模拟添加到暂存区
+
+整体效果如下图:
+
+
+
+结论:
+
+- **文件内容改变了,hash 值变了。**
+- **文件内容改变后,生成新的 hash 值,同时会在 `.git/objects/` 文件夹下多出一个新的文件夹**。文件夹名称为新的哈希值的前2位,文件夹内文件名称为新的哈希值的后38位。
+
+
+
+### 4. 模拟 git add
+
+利用指令 **`git update-index --add --cacheinfo 100644 {FileHashValue} index.txt`** 将工作区的文件添加到缓存区
+
+- `--add`: 强制将指定文件添加到暂存区(即使文件不存在于工作目录中)
+- `--cacheinfo`: 手动指定文件的「模式(mode)+ 哈希值(hash)+ 路径(path)」来更新暂存区,用于添加那些不在工作目录中的文件
+- `100644`: 文件模式(file mode),表示这是一个普通文件(非执行文件、非符号链接等)。Git 中常见模式:`100644`(普通文件)、`100755`(可执行文件)、`120000`(符号链接)等
+- `{FileHashValue}`: 文件内容的 SHA-1 哈希值(40 位字符串),对应 Git 数据库(`.git/objects`)中存储的文件内容
+- `index.txt`:最终在暂存区中记录的文件名(路径)
+
+Demo:
+
+- 为了模拟 `git add` 的效果,先把仓库中的 `.git` 文件夹删掉
+- 利用指令 `git hash-object -w index.txt` 计算出 index.txt 的哈希值
+- 利用指令 `git update-index --add --cacheinfo 100644 2213d05bf4b8cfc7ee323af3ac427ad2fa14da88 index.txt` 将 `index.txt` 和计算出来的哈希值写入到暂存区
+- 利用指令 `git status` 查看是否成功写入到暂存区
+- 继续按照上述2个流程(git hash-object 和 git update-index)将剩余2个文件进行模拟添加到暂存区
+
+整体效果如下图:
+
+ +
+
+
+### 5. git 只有文件,没有目录
+
+为什么进一步强调 **git 只有文件,没有目录**的概念,做一个实验。
+
+第一步:上述步骤生成了3份 git hash,分别保存在 `.git/objects/` 目录下。
+
+
+
+
+
+### 5. git 只有文件,没有目录
+
+为什么进一步强调 **git 只有文件,没有目录**的概念,做一个实验。
+
+第一步:上述步骤生成了3份 git hash,分别保存在 `.git/objects/` 目录下。
+
+ +
+第二步:接下去将暂存区的文件生成一颗树。使用指令 **git write-tree**
+
+第三步:查看生成的树信息。使用指令 `git cat-file -p {TreeHash}`
+
+
+
+第二步:接下去将暂存区的文件生成一颗树。使用指令 **git write-tree**
+
+第三步:查看生成的树信息。使用指令 `git cat-file -p {TreeHash}`
+
+ +
+第四步:使用指令 **`git read-tree --prefix=FantasticLBP/ 7f7bbe6285c9c767aeaa1aedba6dcf5324774bc8`** 将指定的 tree 对象内容读取到当前索引中,并将其所有文件放在名为 `FantasticLBP/` 的目录下。
+
+此时文件目录为:
+
+
+
+第四步:使用指令 **`git read-tree --prefix=FantasticLBP/ 7f7bbe6285c9c767aeaa1aedba6dcf5324774bc8`** 将指定的 tree 对象内容读取到当前索引中,并将其所有文件放在名为 `FantasticLBP/` 的目录下。
+
+此时文件目录为:
+
+ +
+第五步:此时的效果为,暂存区里面存在另一份目录名为 `FantasticLBP/` 的暂存区信息。但是此时实体文件夹下并不存在。使用指令 `git checkout -- .` 便可以从暂存区恢复。
+
+恢复后的目录结构为:
+
+
+
+第五步:此时的效果为,暂存区里面存在另一份目录名为 `FantasticLBP/` 的暂存区信息。但是此时实体文件夹下并不存在。使用指令 `git checkout -- .` 便可以从暂存区恢复。
+
+恢复后的目录结构为:
+
+ +
+
+
+结论:
+
+- 通过在暂存区里面重新构建一颗树,便可以使用 checkout 恢复出来
+- 所以在使用代码重置功能的时候,最好使用 `git reset --soft head~1 ` 的方式进行,因为更加灵活。使用 `--hard` 就没有暂存区的记录了。
+
+### 6. git commit 的本质
+
+上述步骤:
+
+- 生成了3份文件的 git hash
+- 同时又将3份文件写入到暂存区,得到一个暂存区 tree 的哈希: `ce8045cf527ef892b8ad19c7b0bbac889fc44c59`。
+
+接下去为了探索 git commit 的本质,我们用 **`echo 'init commit' | git commit-tree ce8045cf527ef892b8ad19c7b0bbac889fc44c59`** 来完成提交。
+
+**`git commit-tree`**:Git 底层命令,用于创建一个新的提交对象(commit object)。它需要一个 tree 对象作为基础,并通过标准输入接收提交信息。命令执行成功后,会输出新创建的提交对象的 SHA-1 哈希值。
+
+
+
+
+
+结论:
+
+- 通过在暂存区里面重新构建一颗树,便可以使用 checkout 恢复出来
+- 所以在使用代码重置功能的时候,最好使用 `git reset --soft head~1 ` 的方式进行,因为更加灵活。使用 `--hard` 就没有暂存区的记录了。
+
+### 6. git commit 的本质
+
+上述步骤:
+
+- 生成了3份文件的 git hash
+- 同时又将3份文件写入到暂存区,得到一个暂存区 tree 的哈希: `ce8045cf527ef892b8ad19c7b0bbac889fc44c59`。
+
+接下去为了探索 git commit 的本质,我们用 **`echo 'init commit' | git commit-tree ce8045cf527ef892b8ad19c7b0bbac889fc44c59`** 来完成提交。
+
+**`git commit-tree`**:Git 底层命令,用于创建一个新的提交对象(commit object)。它需要一个 tree 对象作为基础,并通过标准输入接收提交信息。命令执行成功后,会输出新创建的提交对象的 SHA-1 哈希值。
+
+ +
+可以看到:
+
+git commit 提交后也是会生成一个新的提交对象(commit object),新的提交对象也会在 `.git/objects/` 目录下存在。
+
+
+
+### 7. git rebase
+
+假如当前在分支 featureA 上,执行 `git rebase master` 后的效果,等价于将寻找到 featureA 和 master 的最近公共祖先节点,然后从 最近公共祖先节点到 featureA 的最新节点之间的 commit 都会被拆开,拼接到 master 分支最后面的 commit 上,重新组合成一个新的 commit。
+
+也就是搞清楚2个对象:
+
+- 当前在什么分之上?featureA
+- git rebase 指令后跟什么分之?master
+
+执行完的效果就是:master + featureA(从 master 和 featureA 的最近公共祖先处截断、拼接在后面)
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1 <--- A2 <--- A3 [featureA, HEAD]
+```
+
+- 寻找公共祖先
+
+ ```shell
+ LCA = git merge-base featureA maste` # 返回 C1
+ ```
+
+- 提取提交差异
+
+ ```shell
+ commits = git log C1..featureA --pretty=format:"%H` # 获取从 C1 到 featureA 的 commit 差异,得到: [A1, A2, A3]
+ ```
+
+- 重置到目标基点
+
+ ```shell
+ git reset --hard M2 # featureA分支指针临时指向M2
+ ```
+
+- 按顺序重新重置提交
+
+ ```shell
+ git cherry-pick A1 # 创建新提交A1' (父提交=C1)
+ git cherry-pick A2 # 创建新提交A2' (父提交=A1)
+ git cherry-pick A3 # 创建新提交A3' (父提交=A2)
+ ```
+
+最终结果
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1' <--- A2' <--- A3' [featureA, HEAD]
+```
+
+
+
+git rebase 还可以用于一些提交信息的处理,比如 `git rebase -i {CommitHash}`
+
+
+
+可以看到:
+
+git commit 提交后也是会生成一个新的提交对象(commit object),新的提交对象也会在 `.git/objects/` 目录下存在。
+
+
+
+### 7. git rebase
+
+假如当前在分支 featureA 上,执行 `git rebase master` 后的效果,等价于将寻找到 featureA 和 master 的最近公共祖先节点,然后从 最近公共祖先节点到 featureA 的最新节点之间的 commit 都会被拆开,拼接到 master 分支最后面的 commit 上,重新组合成一个新的 commit。
+
+也就是搞清楚2个对象:
+
+- 当前在什么分之上?featureA
+- git rebase 指令后跟什么分之?master
+
+执行完的效果就是:master + featureA(从 master 和 featureA 的最近公共祖先处截断、拼接在后面)
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1 <--- A2 <--- A3 [featureA, HEAD]
+```
+
+- 寻找公共祖先
+
+ ```shell
+ LCA = git merge-base featureA maste` # 返回 C1
+ ```
+
+- 提取提交差异
+
+ ```shell
+ commits = git log C1..featureA --pretty=format:"%H` # 获取从 C1 到 featureA 的 commit 差异,得到: [A1, A2, A3]
+ ```
+
+- 重置到目标基点
+
+ ```shell
+ git reset --hard M2 # featureA分支指针临时指向M2
+ ```
+
+- 按顺序重新重置提交
+
+ ```shell
+ git cherry-pick A1 # 创建新提交A1' (父提交=C1)
+ git cherry-pick A2 # 创建新提交A2' (父提交=A1)
+ git cherry-pick A3 # 创建新提交A3' (父提交=A2)
+ ```
+
+最终结果
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1' <--- A2' <--- A3' [featureA, HEAD]
+```
+
+
+
+git rebase 还可以用于一些提交信息的处理,比如 `git rebase -i {CommitHash}`
+
+ +
+git rebase 还可以将多次 commit 合并为1次,也可以修改某次 commit 的信息等等,具体的可以看指令后面的注释。
+
+
+
+### 8. 冲突展示
+
+#### 1. 双路展示策略
+
+git 在 merge 或者 rebase 都会存在冲突的可能,关于文件内容冲突默认是按照双路合并的形式进行展示的。这样子信息有限
+
+可以通过下面指令,查看当前的冲突展示规则:
+
+```shell
+git config merge.conflictstyle
+```
+
+如果没有任何输出,则说明没有任何设置,默认就是**双路展示策略**。
+
+冲突标记仅显示**当前分支**(`<<<<<<< HEAD`)和**合并分支**(`>>>>>>>
+
+git rebase 还可以将多次 commit 合并为1次,也可以修改某次 commit 的信息等等,具体的可以看指令后面的注释。
+
+
+
+### 8. 冲突展示
+
+#### 1. 双路展示策略
+
+git 在 merge 或者 rebase 都会存在冲突的可能,关于文件内容冲突默认是按照双路合并的形式进行展示的。这样子信息有限
+
+可以通过下面指令,查看当前的冲突展示规则:
+
+```shell
+git config merge.conflictstyle
+```
+
+如果没有任何输出,则说明没有任何设置,默认就是**双路展示策略**。
+
+冲突标记仅显示**当前分支**(`<<<<<<< HEAD`)和**合并分支**(`>>>>>>> `)的内容,例如:
+
+```shell
+<<<<<<< HEAD
+当前分支的修改
+=======
+合并分支的修改
+>>>>>>> feature
+```
+
+
+
+#### 2. 三路展示策略
+
+可以通过下面指令,将冲突展示策略改为**三路合并**进行展示:
+
+```shell
+git config merge.conflictstyle diff3
+```
+
+该指令用于配置 Git 合并冲突的展示格式,**`diff3` 模式会在冲突标记中增加「共同祖先版本」**,相比默认的 `merge` 模式提供更完整的冲突上下文,在决策时,提供更多的上下文信息。
+
+这个公共祖先,指的就是**最近公共祖先(Lowest Common Ancestor, LCA)**。
+
+展示如下:
+
+```shell
+<<<<<<< HEAD
+当前分支内容 (ours)
+||||||| merged common ancestors
+共同祖先版本内容 (base)
+=======
+要合并的分支内容 (theirs)
+>>>>>>> branch-name
+```
+
+结论:**配置为三路展示策略,会在冲突时展示最近公共祖先节点的信息,在代码冲突分析决策的时候提供更多的上下文,所以推荐大家通过 git config --global merge.conflictstyle diff3 配置为三路展示策略**。
+
+
+
+#### 3. 相关指令
+
+```shell
+# 检查全局配置(无输出表示未设置)
+git config --global merge.conflictStyle
+
+# 检查仓库级配置(无输出表示未设置)
+git config --local merge.conflictStyle
+
+# 查看实际生效值(输出默认值 'merge')
+git config --get merge.conflictStyle
+
+# 配置全局为三路展示策略
+git config --global merge.conflictstyle diff3
+
+# 配置当前仓库为三路展示策略
+git config merge.conflictstyle diff3
+```
+
+
+
+#### 4. 配置冲突解决工具
+
+要将 `git mergetool` 配置为使用 Xcode 自带的 diff 工具(FileMerge)
+
+- 确保已安装 Xcode 命令行工具
+
+ ```shell
+ xcode-select --install
+ ```
+
+- 配置 git 使用 opendiff 作为冲突解决工具
+
+ ```shell
+ # 设置 mergetool 为 opendiff
+ git config --global merge.tool opendiff
+
+ # 指定 opendiff 的调用参数
+ git config --global mergetool.opendiff.cmd \
+ "opendiff \"\$LOCAL\" \"\$REMOTE\" -ancestor \"\$BASE\" -merge \"\$MERGED\""
+ ```
+
+- 不建议配置这个 `git config --global mergetool.trustExitCode true`,保持默认或者设置为 false,有助于进行最后一次的确认
+
+配置后的使用方式:
+
+`git mergetool` 使用指令将会启动 Xcode 的 FileMerge 工具。
+
+比如,我模拟了文件冲突,调用 `git mergetool` 使用 opendiff 打开了文件冲突展示能力
+
+ +
+当前 case 下,我需要选择左侧为结果,所以点击了 "Choose left"。下面区域为合并后的结果。在终端还有来一次确认过程。做到 double check。
+
+
+
+当前 case 下,我需要选择左侧为结果,所以点击了 "Choose left"。下面区域为合并后的结果。在终端还有来一次确认过程。做到 double check。
+
+ +
+属于 y 后,相当于选择了结果,接下去再进行 add、commit 等操作。
+
+
+
+### 9. git log -p
+
+#### 1. 基础指令
+
+**`git log -p commitId`** 是一个组合命令,用于**详细展示特定提交及其之前的提交历史,并显示每个提交的代码差异**
+
+说明:从指定的 `commitId` **开始回溯**,按时间倒序列出其**祖先提交**
+
+示例如下
+
+
+
+属于 y 后,相当于选择了结果,接下去再进行 add、commit 等操作。
+
+
+
+### 9. git log -p
+
+#### 1. 基础指令
+
+**`git log -p commitId`** 是一个组合命令,用于**详细展示特定提交及其之前的提交历史,并显示每个提交的代码差异**
+
+说明:从指定的 `commitId` **开始回溯**,按时间倒序列出其**祖先提交**
+
+示例如下
+
+ +
+
+
+#### 2. 输出信息结构
+
+每个提交显示2块信息:
+
+- 提交元信息
+
+ 比如
+
+ ```shell
+ commit 0d614db5d3ba7ae2606de696a3627819b2368378 # 提交哈希
+ Author: FantasticLBP
+
+
+
+#### 2. 输出信息结构
+
+每个提交显示2块信息:
+
+- 提交元信息
+
+ 比如
+
+ ```shell
+ commit 0d614db5d3ba7ae2606de696a3627819b2368378 # 提交哈希
+ Author: FantasticLBP # 作者信息
+ Date: Sat Jul 26 19:25:59 2025 +0800 # 提交时间
+
+ Line5 # 提交日志(提交说明)
+ ```
+
+- 代码差异
+
+ 以 diff 格式展示修改内容。比如:
+
+ ```shell
+ diff --git a/index.txt b/index.txt
+ index 2213d05..67124b1 100644
+ --- a/index.txt
+ +++ b/index.txt
+ @@ -1,3 +1,5 @@
+ 1: Line1
+ 2: Line2
+ -3: Line3
+ \ No newline at end of file
+ +3: Line3
+ +4: Line4
+ +5: Line5
+ ```
+
+
+
+#### 3. 常用指令
+
+| 目的 | 指令格式 | 指令效果 |
+| ------------------ | ------------------------------------- | ----------------------- |
+| 限制输出数量 | git log -p -2 d3adb33f | 仅显示最近 2 个提交 |
+| 过滤文件 | git log -p d3adb33f -- path/to/file | 只查看该文件的修改历史 |
+| **图形化显示分支** | git log -p --graph --oneline d3adb33f | 用 ASCII 图展示分支结构 |
+
+
+
+
+
+### 10. git stash
+
+`git stash` 是 Git 中一个强大的工作流工具,用于**临时保存未提交的更改**,让您可以清理工作目录并切换到其他任务
+
+```
+git stash push [-m "描述信息"] [其他选项]
+```
+
+使用上述指令:将当前**工作目录修改**和**暂存区修改**存入储藏栈
+
+
+
+Demo:
+
+- 故意在当前分支进行随意修改,用来模拟需要 stash 的场景。
+
+- 使用指令 `git stash push -m 'commitMessage'` 将当前**工作目录修改**和**暂存区修改**存入储藏栈
+
+- 使用 `git stash list` 用于**查看当前所有存储条目**的核心命令,展示的信息从时间上由近到远
+
+  +
+ - 使用 `git stash show -p stash@{0}` 查看**存储修改内容**。其中 `-p` 是 `--patch` 的缩写,显示完整差异(补丁格式),`stash{0}` 指定要查看的储藏引用(0 表示最近一次储藏)
+
+
+
+ - 使用 `git stash show -p stash@{0}` 查看**存储修改内容**。其中 `-p` 是 `--patch` 的缩写,显示完整差异(补丁格式),`stash{0}` 指定要查看的储藏引用(0 表示最近一次储藏)
+
+  +
+
+
+ - 也可以使用 `git stash` 指令,会自动生成默认消息,包含清晰的 WIP 日志。也是标准推荐做法。
+
+ ```shell
+ # 标准命令
+ git stash
+ # 等价于
+ git stash push "WIP on $(git branch --show-current): $(git log -1 --format=%s)"
+ ```
+
+ - 使用 `git stash apply stash@{1}` 来应用某次具体的 stash 栈里的信息。注意:新 stash 的 序号更早,早期的由近到远依次+1
+
+
+
+
+
+ - 也可以使用 `git stash` 指令,会自动生成默认消息,包含清晰的 WIP 日志。也是标准推荐做法。
+
+ ```shell
+ # 标准命令
+ git stash
+ # 等价于
+ git stash push "WIP on $(git branch --show-current): $(git log -1 --format=%s)"
+ ```
+
+ - 使用 `git stash apply stash@{1}` 来应用某次具体的 stash 栈里的信息。注意:新 stash 的 序号更早,早期的由近到远依次+1
+
+  +
+ - 如果从 stash 里取出的代码不满意,如何恢复到 之前的状态?使用组合命令 **git stash show -p stash@{1} | git apply -R`** 来达到反向应用补丁的效果。
+
+
+
+ - 如果从 stash 里取出的代码不满意,如何恢复到 之前的状态?使用组合命令 **git stash show -p stash@{1} | git apply -R`** 来达到反向应用补丁的效果。
+
+  +
+ 管道符 `|` ,将前一个命令的输出作为后一个命令的输入。比如:
+
+ ```shell
+ # 应用了错误的存储
+ git stash apply stash@{1}
+
+ # 发现需要撤销
+ git stash show -p stash@{1} | git apply -R
+ ```
+
+ - stash 由于是栈,所以有 push、pop 能力。push 就是往栈里加,pop 就是移除。完整指令为 **`git stash pop stash@{0}`**
+
+
+
+### 11. git ignore
+
+在开发中经常会遇到有些类型的文件不需要提交到远端进行多人协作,比如 iOS 开发中的 cocoapods install 后的 pods 目录,或者 NodeJS 开发中的 node_modules 目录,git 也设计了该口子,允许使用 **.gitignore ** 文件用于指定 Git 版本控制系统应忽略的文件和目录,避免将临时文件、编译产物或敏感信息纳入版本控制。
+
+#### 1. 核心规则
+
+- 每行一个规则,支持通配符:
+ - `*` 匹配任意字符(除路径分隔符外)
+ - `**` 匹配任意层级目录
+ - `?` 匹配单个字符
+ - `[abc]` 匹配指定字符
+- 路径规则:
+ - 以 `/` 开头:仅匹配项目根目录(如 `/temp.log`)
+ - 以 `/` 结尾:仅匹配目录(如 `build/`)
+- 取反规则:用 `!` 取消忽略(如 `!src/important.log`
+
+
+
+#### 2. 最佳实践
+
+- 在项目根目录创建 ``.gitignore` 文件
+
+- 根据项目和语言类型,搜索一个标准的 `.gitignore` 模版,将内容复制进去
+
+- 如果项目初始化的时候没有添加完全部的 `.gitignore` 文件内容。再到后来开发的过程中,给 `.gitignore` 里面添加了内容,但后来添加的 `.gitignore` 已经比较晚了,当前提示不允许追踪的文件,还是会被 git 追踪。并且已经提交到暂存区了。
+
+ 因为都存在于本地暂存区了,所以可以使用指令 **`git update-index --assume-unchanged {FileName}`** 来告诉 git,不要追踪暂存区的 FileName 该文件
+
+
+
+ 管道符 `|` ,将前一个命令的输出作为后一个命令的输入。比如:
+
+ ```shell
+ # 应用了错误的存储
+ git stash apply stash@{1}
+
+ # 发现需要撤销
+ git stash show -p stash@{1} | git apply -R
+ ```
+
+ - stash 由于是栈,所以有 push、pop 能力。push 就是往栈里加,pop 就是移除。完整指令为 **`git stash pop stash@{0}`**
+
+
+
+### 11. git ignore
+
+在开发中经常会遇到有些类型的文件不需要提交到远端进行多人协作,比如 iOS 开发中的 cocoapods install 后的 pods 目录,或者 NodeJS 开发中的 node_modules 目录,git 也设计了该口子,允许使用 **.gitignore ** 文件用于指定 Git 版本控制系统应忽略的文件和目录,避免将临时文件、编译产物或敏感信息纳入版本控制。
+
+#### 1. 核心规则
+
+- 每行一个规则,支持通配符:
+ - `*` 匹配任意字符(除路径分隔符外)
+ - `**` 匹配任意层级目录
+ - `?` 匹配单个字符
+ - `[abc]` 匹配指定字符
+- 路径规则:
+ - 以 `/` 开头:仅匹配项目根目录(如 `/temp.log`)
+ - 以 `/` 结尾:仅匹配目录(如 `build/`)
+- 取反规则:用 `!` 取消忽略(如 `!src/important.log`
+
+
+
+#### 2. 最佳实践
+
+- 在项目根目录创建 ``.gitignore` 文件
+
+- 根据项目和语言类型,搜索一个标准的 `.gitignore` 模版,将内容复制进去
+
+- 如果项目初始化的时候没有添加完全部的 `.gitignore` 文件内容。再到后来开发的过程中,给 `.gitignore` 里面添加了内容,但后来添加的 `.gitignore` 已经比较晚了,当前提示不允许追踪的文件,还是会被 git 追踪。并且已经提交到暂存区了。
+
+ 因为都存在于本地暂存区了,所以可以使用指令 **`git update-index --assume-unchanged {FileName}`** 来告诉 git,不要追踪暂存区的 FileName 该文件
+
+  +
+#### 3. 进阶玩法
+
+- 文件已经被追踪,此时再配置到 `.gitigore` 文件中,还是会被追踪。此时需手动删除缓存:
+
+ ```shell
+ git rm --cached {fileName}
+ ```
+
+- 验证忽略规则
+
+ ```shell
+ git check-ignore -v {fileName}
+ ```
+
+
+
+### 12. git revert
+
+`git revert` 是 Git 中用于安全撤销已提交更改的命令,它通过创建一个**新的反向提交**来撤销指定提交的更改,**不会重写历史**
+
+比如
+
+```shell
+# 撤销最近一次提交
+git revert HEAD
+
+# 撤销指定提交(按 commit hash)
+git revert a1b2c3d
+
+# 撤销多个提交(从旧到新依次撤销)
+git revert commit1 commit2
+```
+
+最佳实践:
+
+- 撤销公共提交:用 revert
+
+- 复杂撤销:用 `-n` 组合多个撤销后再提交
+
+ ````shell
+ git revert -n commit1 commit2
+ # 手动调整后提交
+ git commit -m "Batch revert"
+ ````
+
+- 撤销文件,优先使用 `git checkout {commitId} -- {fileName}`
+
+
+
+### 13. git reflog
+
+> git-reflog - Manage reflog information
+
+`git reflog`(引用日志)是 Git 的**安全网**,它记录了本地仓库中所有分支和 HEAD 指针的变更历史,主要用于恢复误操作(如错误重置、删除分支等)
+
+一些常见的操作无法解决的问题,一些不符合预期的行为发生时,我们可以根据 reflog 来“恢复”之前的状态。
+
+核心用途
+
+- 找回丢失的提交:恢复被 `reset`/`rebase` 删除的提交
+- 恢复误删分支:找回已删除的分支指针
+- 追踪操作历史:查看所有 HEAD 和分支的移动记录
+- 灾难恢复:当 `git log` 无法显示提交时(如分支被覆盖)
+
+
+
+##### 1. 一些实际场景
+
+- 恢复误删的操作:
+
+ ```shell
+ # 错误重置了提交
+ git reset --hard HEAD~3
+
+ # 查看 reflog 找到被删提交的哈希
+ git reflog
+ # f45e678 HEAD@{1}: commit: Important feature
+
+ # 恢复到指定位置
+ git reset --hard f45e678
+ ```
+
+- 找回被删除的分支
+
+ ```shell
+ # 误删分支
+ git branch -D feature/login
+ # 根据 reflog 日志,匹配找到 'feature/login' 信息
+ git reflog | grep 'feature/login'
+ # c9d8a7b HEAD@{2}: checkout: moving from main to feature/login
+ # 重建分支
+ git breanch feature/login c9d8a7b
+ ```
+
+
+
+### 14. git hook
+
+Git Hook 是 Git 提供的自动化脚本机制,可在特定 Git 操作(如提交、推送、合并等)前后触发自定义任务,从而优化开发流程、提升代码质量和协作效率。结合脚本能力广泛用于 CI/CD 领域。
+
+
+
+一个项目如果是 git init 之后的,会在 `.git/hooks` 目录下存在一堆 hooks 模版,如下图
+
+
+
+#### 3. 进阶玩法
+
+- 文件已经被追踪,此时再配置到 `.gitigore` 文件中,还是会被追踪。此时需手动删除缓存:
+
+ ```shell
+ git rm --cached {fileName}
+ ```
+
+- 验证忽略规则
+
+ ```shell
+ git check-ignore -v {fileName}
+ ```
+
+
+
+### 12. git revert
+
+`git revert` 是 Git 中用于安全撤销已提交更改的命令,它通过创建一个**新的反向提交**来撤销指定提交的更改,**不会重写历史**
+
+比如
+
+```shell
+# 撤销最近一次提交
+git revert HEAD
+
+# 撤销指定提交(按 commit hash)
+git revert a1b2c3d
+
+# 撤销多个提交(从旧到新依次撤销)
+git revert commit1 commit2
+```
+
+最佳实践:
+
+- 撤销公共提交:用 revert
+
+- 复杂撤销:用 `-n` 组合多个撤销后再提交
+
+ ````shell
+ git revert -n commit1 commit2
+ # 手动调整后提交
+ git commit -m "Batch revert"
+ ````
+
+- 撤销文件,优先使用 `git checkout {commitId} -- {fileName}`
+
+
+
+### 13. git reflog
+
+> git-reflog - Manage reflog information
+
+`git reflog`(引用日志)是 Git 的**安全网**,它记录了本地仓库中所有分支和 HEAD 指针的变更历史,主要用于恢复误操作(如错误重置、删除分支等)
+
+一些常见的操作无法解决的问题,一些不符合预期的行为发生时,我们可以根据 reflog 来“恢复”之前的状态。
+
+核心用途
+
+- 找回丢失的提交:恢复被 `reset`/`rebase` 删除的提交
+- 恢复误删分支:找回已删除的分支指针
+- 追踪操作历史:查看所有 HEAD 和分支的移动记录
+- 灾难恢复:当 `git log` 无法显示提交时(如分支被覆盖)
+
+
+
+##### 1. 一些实际场景
+
+- 恢复误删的操作:
+
+ ```shell
+ # 错误重置了提交
+ git reset --hard HEAD~3
+
+ # 查看 reflog 找到被删提交的哈希
+ git reflog
+ # f45e678 HEAD@{1}: commit: Important feature
+
+ # 恢复到指定位置
+ git reset --hard f45e678
+ ```
+
+- 找回被删除的分支
+
+ ```shell
+ # 误删分支
+ git branch -D feature/login
+ # 根据 reflog 日志,匹配找到 'feature/login' 信息
+ git reflog | grep 'feature/login'
+ # c9d8a7b HEAD@{2}: checkout: moving from main to feature/login
+ # 重建分支
+ git breanch feature/login c9d8a7b
+ ```
+
+
+
+### 14. git hook
+
+Git Hook 是 Git 提供的自动化脚本机制,可在特定 Git 操作(如提交、推送、合并等)前后触发自定义任务,从而优化开发流程、提升代码质量和协作效率。结合脚本能力广泛用于 CI/CD 领域。
+
+
+
+一个项目如果是 git init 之后的,会在 `.git/hooks` 目录下存在一堆 hooks 模版,如下图
+
+ +
+- 顾名思义,pre-push、post-push 分别是在 push 之前、push 之后触发的钩子。所以其他几个钩子类似
+
+- 本次演示继续在之前的 Demo 上演示,使用 Pre-Commit 钩子,去掉拓展名。注释掉其他代码,添加一句打印输出
+
+
+
+- 顾名思义,pre-push、post-push 分别是在 push 之前、push 之后触发的钩子。所以其他几个钩子类似
+
+- 本次演示继续在之前的 Demo 上演示,使用 Pre-Commit 钩子,去掉拓展名。注释掉其他代码,添加一句打印输出
+
+  +
+注意:这里可以使用 shell、也可以使用 python、JS、Ruby 等脚本
+
+
+
+
+
+#### 1. 代码格式与静态检查
+
+- 钩子:`pre-commit`
+
+- 作用:提交前自动运行 ESLint、Prettier、Flake8 等工具,检查语法错误、代码风格或安全漏洞。若检查失败,则阻止提交
+
+ ```shell
+ # pre-commit 脚本片段
+ eslint --fix --ext .js,.ts src/ # 自动修复并检查JS/TS文件
+ ```
+
+
+
+#### 2. git 日志规范化
+
+- 钩子:`commit-msg`
+
+- 作用:检查提交信息是否符合约定格式(如必须包含前缀 `[Feat]`、`[Fix]` 或关联问题编号)。违规时终止提交
+
+ ```shell
+ # commit-msg 脚本片段
+ if ! grep -qE "^(FEAT|FIX|DOC):" "$1"; then
+ echo "提交信息必须以 FEAT/FIX/DOC 开头!"
+ exit 1
+ fi
+ ```
+
+#### 3. 单元测试与代码覆盖率
+
+- 钩子:`pre-push`
+- 作用:推送前运行测试套件(不管是单元测试也好,还是精准测试也好),必须保证全部的测试 case 通过,且代码覆盖率达到95%以上才可以合并。确保新代码不破坏现有功能。测试失败则阻止推送。
+
+
+
+#### 4. 自动部署测试环境
+
+- 钩子:`post-receive`(服务端)
+- 作用:代码推送到远程仓库后,自动将代码同步至服务器目录,触发部署流程(如更新网站文件)
+
+
+
+#### 5. CI/CD 流程
+
+- 钩子:`post-receive`(服务端)
+- 作用:推送完成后通知 CI 工具(如 Jenkins、GitLab CI)执行流水线任务(构建、测试、部署)
+
+
+
+### 15. 本地仓库对应远端仓库是1对多的关系
+
+为了模拟本地和远端是1对多的关系:
+
+- 将之前的 Demo 的 `.git` 文件夹删掉。模拟一个干净的文件夹,没有 git 信息
+- 创建2个文件夹,模拟 git 远端服务器的 repo 信息。分别为 gitDemoServer1、gitDemoServer2
+- 分别在 gitDemoServer1、gitDemoServer2 文件夹执行 `git init --bare` ,**在服务器文件夹初始化裸仓库**
+- 在 gitDemo 终端路径下,执行 `git init` 初始化本地仓库
+- 继续在 gitDemo 终端路径下分别执行 **`git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1` **和** `git remote add origin2 /Users/unix_kernel/Desktop/gitDemoServer2`** ,为了给当前的 repo 配置多个远端仓库
+- 最后执行 `git remote -v` 指令查看当前 repo 的 remote 信息
+
+
+
+注意:这里可以使用 shell、也可以使用 python、JS、Ruby 等脚本
+
+
+
+
+
+#### 1. 代码格式与静态检查
+
+- 钩子:`pre-commit`
+
+- 作用:提交前自动运行 ESLint、Prettier、Flake8 等工具,检查语法错误、代码风格或安全漏洞。若检查失败,则阻止提交
+
+ ```shell
+ # pre-commit 脚本片段
+ eslint --fix --ext .js,.ts src/ # 自动修复并检查JS/TS文件
+ ```
+
+
+
+#### 2. git 日志规范化
+
+- 钩子:`commit-msg`
+
+- 作用:检查提交信息是否符合约定格式(如必须包含前缀 `[Feat]`、`[Fix]` 或关联问题编号)。违规时终止提交
+
+ ```shell
+ # commit-msg 脚本片段
+ if ! grep -qE "^(FEAT|FIX|DOC):" "$1"; then
+ echo "提交信息必须以 FEAT/FIX/DOC 开头!"
+ exit 1
+ fi
+ ```
+
+#### 3. 单元测试与代码覆盖率
+
+- 钩子:`pre-push`
+- 作用:推送前运行测试套件(不管是单元测试也好,还是精准测试也好),必须保证全部的测试 case 通过,且代码覆盖率达到95%以上才可以合并。确保新代码不破坏现有功能。测试失败则阻止推送。
+
+
+
+#### 4. 自动部署测试环境
+
+- 钩子:`post-receive`(服务端)
+- 作用:代码推送到远程仓库后,自动将代码同步至服务器目录,触发部署流程(如更新网站文件)
+
+
+
+#### 5. CI/CD 流程
+
+- 钩子:`post-receive`(服务端)
+- 作用:推送完成后通知 CI 工具(如 Jenkins、GitLab CI)执行流水线任务(构建、测试、部署)
+
+
+
+### 15. 本地仓库对应远端仓库是1对多的关系
+
+为了模拟本地和远端是1对多的关系:
+
+- 将之前的 Demo 的 `.git` 文件夹删掉。模拟一个干净的文件夹,没有 git 信息
+- 创建2个文件夹,模拟 git 远端服务器的 repo 信息。分别为 gitDemoServer1、gitDemoServer2
+- 分别在 gitDemoServer1、gitDemoServer2 文件夹执行 `git init --bare` ,**在服务器文件夹初始化裸仓库**
+- 在 gitDemo 终端路径下,执行 `git init` 初始化本地仓库
+- 继续在 gitDemo 终端路径下分别执行 **`git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1` **和** `git remote add origin2 /Users/unix_kernel/Desktop/gitDemoServer2`** ,为了给当前的 repo 配置多个远端仓库
+- 最后执行 `git remote -v` 指令查看当前 repo 的 remote 信息
+
+ +
+说明:
+
+- 裸仓库特点:
+
+ - 没有工作目录(不能直接编辑文件)
+ - 目录内容直接包含 Git 内部文件(无 `.git` 隐藏文件夹)
+
+- `git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1`
+
+ - `origin` 和 `origin2` 是远程仓库的别名
+ - 路径可以是绝对路径(推荐)或相对路径
+
+- 本地只有1个分支,远端分支名也不一定相同。所以需要告诉 git 本地分支如何与远端进行关联
+
+ ````shell
+ git remote add -t main origin https://github.com/FantasticLBP/GitDemo
+ ````
+
+ - `git remote add` :想本地仓库添加要 track 的远程仓库
+ - `-t main` : 指定本地要 track 远程仓库中的哪个分支
+ - `origin`: 远程仓库的名字
+ - `https://github.com/FantasticLBP/GitDemo`: 远程仓库的地址
+
+
diff --git a/Chapter8 - Algorithm/8.1.md b/Chapter8 - Algorithm/8.1.md
new file mode 100644
index 0000000..c8be63f
--- /dev/null
+++ b/Chapter8 - Algorithm/8.1.md
@@ -0,0 +1,190 @@
+## leetcode 968. 监控二叉树
+
+## 题目描述
+给定一个二叉树,我们在树的节点上安装监控。
+
+节点上的每个摄影头都可以监视其父对象、自身及其直接子对象
+
+计算监控树的所有节点所需的最小监控数量。
+
+2个例子:
+
+case1:
+
+``` shell
+ 1
+ |
+ 2 监控
+ / \
+ 3 4
+
+```
+
+Case2:
+
+```shell
+ 1
+ /
+ 2 监控
+ /
+ 3
+ /
+ 4 监控
+ \
+ 5
+```
+
+## 分析
+
+- 一颗监控可以覆盖:当前节点、当前节点的父节点、当前节点的所有子节点3层
+
+- 本题目要求使用最小数量的监控解决问题。那么也就是贪心思维的体现,那么问题来了,什么策略才可以使用最小数量的监控?
+
+ - 一棵二叉树中,叶子节点数量肯定是最多的。所以要想最小数量安装监控,优先选择非叶子节点上安装监控。这也是本题中贪心思维的体现。
+ - 如果最后一层叶子节点不安装监控,那么肯定是叶子节点的父节点安装监控,同理叶子节点的父节点的父节点,也会被监控覆盖到,所以叶子节点的父节点的父节点不用安装监控。于是
+ 叶子节点的父节点的父节点的父节点就必须安装监控。
+
+
+
+- 对于二叉树一定是采用递归法或者迭代法解决,本题选择递归法。
+
+- 因为要根据叶子节点的状态来反推父节点的状态,所以采用后续遍历。
+
+- 另外需要根据左右子树的返回值来判断,所以递归函数需要返回值
+
+- 为了方便定义3个状态。
+
+ - 未设置监控 NotCovered = 0
+ - 被监控覆盖 IsCoverd = 1
+ - 设置监控 SetCamera = 2
+
+- 如何定义递归函数?
+
+ - 返回值就是数字,存在3种情况,也就是上面定义的3种状态
+ - 递归函数的终止条件是什么?遇到叶子节点的左右空子树的情况下,该选用什么状态?思考下:共3种情况
+ - 空节点选用 “未覆盖 NotCovered”?
+ ❌ 问题 :叶子节点必须安装监控来覆盖空节点
+ 如果空节点是 NotCovered,那么空节点的父节点,也就是叶子节点,必须设置监控,才可以保证叶子节点的左右子节点才可以被监控覆盖到。
+ ❌ 结果:摄像头数量过多,不符合最小化原则
+ 这和题目要求的最小监控数量不契合
+ - 空节点选用 “安装监控 SetCamera”?
+ ❌ 问题:叶子节点自动变为被覆盖状态 (IsCovered = 1)
+ 如果空节点是 SetCamera,那么空节点的父节点,也就是叶子节点,状态一定是被覆盖 IsCoverd,如果叶子节点是 IsCoverd,
+ ❌ 结果:叶子节点的父节点不需要安装监控,破坏了"叶子节点的父节点安装监控"的最优策略
+ 反推叶子节点的父节点就不需要安装监控了(因为监控必须间隔设置,覆盖 - 监控 - 覆盖 - 监控 这样的形式),那这个情况也和题目的预设条件不满足。
+ - 所以空节点应该选用 “被监控覆盖 IsCoverd” 这个状态
+ ✅ 正确:叶子节点为未覆盖状态 (NotCovered = 0)
+ 空节点被监控覆盖 IsCoverd,那么空节点的父节点,也就是叶子节点就不需要设置监控,
+ ✅ 结果:叶子节点的父节点必须安装监控,符合贪心策略
+ 也就是未设置监控 NotCovered = 0,那么叶子节点的父节点才需要设置监控 SetCamera
+
+## 状态转换情况
+说明:
+- 未设置监控 NotCovered = 0
+- 被监控覆盖 IsCoverd = 1
+- 设置监控 SetCamera = 2
+
+| leftChild | rightChild | root | count=0 | 说明 |
+| --------- | ---------- | ---- | ------- | ------------------------------------------------------------ |
+| 1 | 1 | 0 | +0 | 空节点(叶子节点的子节点)必须同时处于被覆盖状态 |
+| | | | | |
+| 0 | 0 | 2 | +1 | 普通节点不管 left、right 只要有1个处于未覆盖状态,那么父节点一定要设置监控才可以“罩着”下面的子节点 |
+| 0 | 1 | 2 | +1 | |
+| 1 | 0 | 2 | +1 | |
+| 2 | 0 | 2 | +1 | |
+| 0 | 2 | 2 | +1 | |
+| | | | | |
+| 2 | 2 | 1 | +0 | 其他情况,父节点都是处于被监控覆盖的状态,不需要增加监控 |
+| 2 | 1 | 0 | +0 | |
+| 1 | 2 | 1 | +0 | |
+| 2 | 1 | 1 | +0 | |
+
+
+
+## 贪心思想
+
+本题目贪心体现在(监控数量 count = 0):
+- 空节点(叶子节点的子节点):处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- 叶子节点:不设置监控,处于 NotCovered 状态。需要父节点罩着。count 不变
+- 叶子节点的父节点:安装监控,处于 SetCamera 状态,count++
+- 叶子节点的爷爷节点:处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- ♻️ 循环往复
+
+
+
+## 代码实现(JS 为例)
+
+```js
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var minCameraCover = function(root) {
+ let count = 0
+ const Mode_NotCovered = 0 // 未设置监控
+ const Mode_IsCovered = 1 // 被监控覆盖
+ const Mode_SetCamera = 2 // 设置监控
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return Mode_IsCovered
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === Mode_NotCovered || right === Mode_NotCovered) {
+ count++
+ return Mode_SetCamera
+ }
+ // 如果左孩子和右孩子都是覆盖状态,那么父节点处于非覆盖状态
+ if (left === Mode_IsCovered && right === Mode_IsCovered) {
+ return Mode_NotCovered
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === Mode_SetCamera || right === Mode_SetCamera) {
+ return Mode_IsCovered
+ }
+ return Mode_NotCovered
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === Mode_NotCovered) count++
+ return count
+};
+```
+提交后发现空间复杂度一般,去掉定义的状态和更加清楚的 if 分支,代码如下
+
+```js
+var minCameraCover = function(root) {
+ let count = 0
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return 1
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === 0 || right === 0) {
+ count++
+ return 2
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === 2 || right === 2) {
+ return 1
+ }
+ return 0
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === 0) count++
+ return count
+};
+```
+
diff --git a/Chapter8 - Algorithm/8.2.md b/Chapter8 - Algorithm/8.2.md
new file mode 100644
index 0000000..c9c13f4
--- /dev/null
+++ b/Chapter8 - Algorithm/8.2.md
@@ -0,0 +1,161 @@
+# 《剑指 Offer》字符串“左旋”、“右旋”里的数学秘密
+
+> 为什么要写本篇文章?看上去这是 easy 级别的题目。但“点是面的缩影,面是点的抽象”,单独一道题似乎很简单,我们可以比较轻松做出来。但是这一类题目的本质是什么?不要处于混沌的状态解决了题目,但下次遇到类似的,还是要迟疑思考一会儿。本篇文章带你吃透问题的本质和背后的数学推导。
+
+
+
+## 题目描述
+字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。
+
+请定义一个函数实现字符串左旋转操作的功能。比如:
+- 输入字符串 "abcdefg" 和数字 2
+- 该函数将返回左旋转 2 位后的结果 "cdefgab"
+
+请实现该函数
+
+## 结论
+只要是字符串的左旋、右旋,都用整体逆序 + 部分逆序的方法,也可以是部分逆序 + 整体逆序。
+
+## 分析
+关于反转(也就是逆序),有2个 feature:
+- 反转的可逆性:反转(反转(x)) = x
+ - 类似负负得正。比如:'123' 经过一次反转后为 '321', '321' 再经过一次反转为 '123'
+- 反转的可组合性:反转 (A + B) = 反转(B) + 反转(A)
+ - '123456' 按照长度为3进行拆分为2部分,s1 + s2。s1 = '123', s2 = '456
+ - 先对后面的 s2,也就是'456' 反转得到 '654',即 s2' = '654'
+ - 再对前面的 s1,也就是'123' 反转得到 '321',即 s1' = '321'
+ - 再对 s1' 和 s2' 进行拼接, s1' + s2' = '654321'
+ - 观察发现 s1' + s2' 就等于对整体 s1 + s2 逆序后的结果。
+
+再来观察看看:左旋、右旋题目要求的是什么?
+
+前提:假设一个逆序函数,可以将 x 作为输入,输出是 x'。这个共识、前提成立,我们再进行后续的推导:
+1. 原始字符串通过 k 为分割,可以拆分为: A + B。题目求的是什么? B + A
+2. 思考:根据上面的2个特性,通过什么变化可以从 A + B,得到 B + A 呢?
+不难得出结论,有2个方案:
+- 先整体逆序,`逆序 (A + B) = 逆序(B) + 逆序(A) = B' + A'`
+- 再局部逆序,`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求。所以这些方法都是有迹可循的,符合数学群论中的 **“逆运算”** 和 **“运算律”** 的思想
+
+
+## 方法1:先整体逆序,再局部逆序
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先整体逆序。`逆序(A) = A' 逆序(B) = B'。大的结构还是逆序(A + B) = B' + A'`
+3. 再局部逆序:`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法1: 先整体,再部分
+ const rotateLeft = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 2. 再局部逆序
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, length - k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, length - k, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+## 方法2:先部分逆序,再整体逆序
+思考:能不能先局部逆序,再整体逆序?
+分析:继续用上面的思路推导下
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先局部逆序:`逆序(A) + 逆序(B) = A' + B'`
+3. 再整体逆序。`逆序(A + B) = 逆序(B) + 逆序(A)`。但是此刻我们的输入为: A' + B',
+
+所以等价于:`逆序(A' + B') = 逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法2: 先部分,再整体
+ const rotateLeft1 = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 再局部逆序
+
+ // abcdefg -> gfedc ba ->
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, k, length - 1)
+
+ // 2. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/Chapter8 - Algorithm/chapter8.md b/Chapter8 - Algorithm/chapter8.md
new file mode 100644
index 0000000..e69de29
diff --git a/SUMMARY.md b/SUMMARY.md
index cd36511..d74a057 100644
--- a/SUMMARY.md
+++ b/SUMMARY.md
@@ -117,6 +117,8 @@
* [112、Swift 枚举值内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.112.md)
* [113、Swift 结构体和类的内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.113.md)
* [114、Swift 优化](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.114.md)
+ * [115、AI 对端上的赋能](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.115.md)
+ * [147. Rust 在移动端可以做什么](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.147.md)
* [Chapter2 - Web FrontEnd](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/chapter2.md)
* [1、-last-child与-last-of-type你只是会用,有研究过区别吗?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.1.md)
* [2、正则表达式](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.2.md)
@@ -162,6 +164,9 @@
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
* [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
+ * [45、内存管理之垃圾回收与内存泄漏](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.46.md)
+
+
* [Chapter3 - Server](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/chapter3.md)
* [1、利用分页和模糊查询技术实现一个App接口](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.1.md)
* [2、网页端扫码登录实现原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.2.md)
@@ -246,4 +251,6 @@
* [24、短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.25.md)
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
* [26、敏捷软件开发和 Scurm Master](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.27.md)
- * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
\ No newline at end of file
+ * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
+* [Chapter8 - Algorithm](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/chapter8.md)
+ * [1、Leetcode968. 监控二叉树](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/8.1.md)
\ No newline at end of file
diff --git a/assets/AFNetworkingIsDynamicLib.png b/assets/AFNetworkingIsDynamicLib.png
new file mode 100644
index 0000000..8653c33
Binary files /dev/null and b/assets/AFNetworkingIsDynamicLib.png differ
diff --git a/assets/APM-CoreAnimationPipeline.png b/assets/APM-CoreAnimationPipeline.png
new file mode 100644
index 0000000..b36eed4
Binary files /dev/null and b/assets/APM-CoreAnimationPipeline.png differ
diff --git a/assets/AddStaticLibIntoApp.png b/assets/AddStaticLibIntoApp.png
new file mode 100644
index 0000000..0dd8197
Binary files /dev/null and b/assets/AddStaticLibIntoApp.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderMap.png b/assets/AppCompileStaticLibWithHeaderMap.png
new file mode 100644
index 0000000..155a6f2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderMap.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderSearchPath.png b/assets/AppCompileStaticLibWithHeaderSearchPath.png
new file mode 100644
index 0000000..393d7b2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderSearchPath.png differ
diff --git a/assets/AppLinkDynamicLibNotSign.png b/assets/AppLinkDynamicLibNotSign.png
new file mode 100644
index 0000000..c5f147f
Binary files /dev/null and b/assets/AppLinkDynamicLibNotSign.png differ
diff --git a/assets/BlockAssignIsValueAssign.png b/assets/BlockAssignIsValueAssign.png
new file mode 100644
index 0000000..50a9f77
Binary files /dev/null and b/assets/BlockAssignIsValueAssign.png differ
diff --git a/assets/CocdSignIphoneLog.png b/assets/CocdSignIphoneLog.png
new file mode 100644
index 0000000..ac4dce3
Binary files /dev/null and b/assets/CocdSignIphoneLog.png differ
diff --git a/assets/CocoapodsCommandWithSciptFile.png b/assets/CocoapodsCommandWithSciptFile.png
new file mode 100644
index 0000000..3d5ea65
Binary files /dev/null and b/assets/CocoapodsCommandWithSciptFile.png differ
diff --git a/assets/CocoapodsHMapInfo.png b/assets/CocoapodsHMapInfo.png
new file mode 100644
index 0000000..8132397
Binary files /dev/null and b/assets/CocoapodsHMapInfo.png differ
diff --git a/assets/CocoapodsHMapLocalInstall.png b/assets/CocoapodsHMapLocalInstall.png
new file mode 100644
index 0000000..479bf21
Binary files /dev/null and b/assets/CocoapodsHMapLocalInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall.png b/assets/CocoapodsHMapPostInstall.png
new file mode 100644
index 0000000..349dbf4
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall2.png b/assets/CocoapodsHMapPostInstall2.png
new file mode 100644
index 0000000..3cab6fe
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall2.png differ
diff --git a/assets/CocoapodsHMapV1.png b/assets/CocoapodsHMapV1.png
new file mode 100644
index 0000000..5c73744
Binary files /dev/null and b/assets/CocoapodsHMapV1.png differ
diff --git a/assets/CocoapodsHMapV2.png b/assets/CocoapodsHMapV2.png
new file mode 100644
index 0000000..5b25a8f
Binary files /dev/null and b/assets/CocoapodsHMapV2.png differ
diff --git a/assets/CocoapodsHMapV2Test.png b/assets/CocoapodsHMapV2Test.png
new file mode 100644
index 0000000..f808bfd
Binary files /dev/null and b/assets/CocoapodsHMapV2Test.png differ
diff --git a/assets/CocoapodsScriptCodeSignDetails.png b/assets/CocoapodsScriptCodeSignDetails.png
new file mode 100644
index 0000000..ff7fbd0
Binary files /dev/null and b/assets/CocoapodsScriptCodeSignDetails.png differ
diff --git a/assets/CocoapodsSelfDefinedScript.png b/assets/CocoapodsSelfDefinedScript.png
new file mode 100644
index 0000000..e9cf916
Binary files /dev/null and b/assets/CocoapodsSelfDefinedScript.png differ
diff --git a/assets/CodeSignAppWithDynamicLibLog.png b/assets/CodeSignAppWithDynamicLibLog.png
new file mode 100644
index 0000000..d91d7c2
Binary files /dev/null and b/assets/CodeSignAppWithDynamicLibLog.png differ
diff --git a/assets/CodeSignByCocoapodsScripts.png b/assets/CodeSignByCocoapodsScripts.png
new file mode 100644
index 0000000..c782400
Binary files /dev/null and b/assets/CodeSignByCocoapodsScripts.png differ
diff --git a/assets/CodeSignEntitlements.png b/assets/CodeSignEntitlements.png
new file mode 100644
index 0000000..1341ecb
Binary files /dev/null and b/assets/CodeSignEntitlements.png differ
diff --git a/assets/DumpProvisionProfile.png b/assets/DumpProvisionProfile.png
new file mode 100644
index 0000000..a84866a
Binary files /dev/null and b/assets/DumpProvisionProfile.png differ
diff --git a/assets/DuplicateSymbolWhenLinkTwoStaticLib.png b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..06c65db
Binary files /dev/null and b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png differ
diff --git a/assets/FastlaneMatchfile.png b/assets/FastlaneMatchfile.png
new file mode 100644
index 0000000..e8eab68
Binary files /dev/null and b/assets/FastlaneMatchfile.png differ
diff --git a/assets/FastlaneScriptCodeGen.png b/assets/FastlaneScriptCodeGen.png
new file mode 100644
index 0000000..5380457
Binary files /dev/null and b/assets/FastlaneScriptCodeGen.png differ
diff --git a/assets/FastlaneStructure.png b/assets/FastlaneStructure.png
new file mode 100644
index 0000000..04d5192
Binary files /dev/null and b/assets/FastlaneStructure.png differ
diff --git a/assets/GitHash.png b/assets/GitHash.png
new file mode 100644
index 0000000..7557ced
Binary files /dev/null and b/assets/GitHash.png differ
diff --git a/assets/GitHooksTemplate.png b/assets/GitHooksTemplate.png
new file mode 100644
index 0000000..33a093c
Binary files /dev/null and b/assets/GitHooksTemplate.png differ
diff --git a/assets/GitLogPCommand.png b/assets/GitLogPCommand.png
new file mode 100644
index 0000000..67ec5ac
Binary files /dev/null and b/assets/GitLogPCommand.png differ
diff --git a/assets/GitOpenDiffPanel.png b/assets/GitOpenDiffPanel.png
new file mode 100644
index 0000000..fe4e4da
Binary files /dev/null and b/assets/GitOpenDiffPanel.png differ
diff --git a/assets/GitOpenDiffResult.png b/assets/GitOpenDiffResult.png
new file mode 100644
index 0000000..1f35373
Binary files /dev/null and b/assets/GitOpenDiffResult.png differ
diff --git a/assets/GitPreCommitHook.png b/assets/GitPreCommitHook.png
new file mode 100644
index 0000000..bfbe0c0
Binary files /dev/null and b/assets/GitPreCommitHook.png differ
diff --git a/assets/GitRebaseCommand.png b/assets/GitRebaseCommand.png
new file mode 100644
index 0000000..cc6ba7e
Binary files /dev/null and b/assets/GitRebaseCommand.png differ
diff --git a/assets/GitRemoveTrackingWithIgnore.png b/assets/GitRemoveTrackingWithIgnore.png
new file mode 100644
index 0000000..85c7037
Binary files /dev/null and b/assets/GitRemoveTrackingWithIgnore.png differ
diff --git a/assets/GitStashApply.png b/assets/GitStashApply.png
new file mode 100644
index 0000000..06bd2bb
Binary files /dev/null and b/assets/GitStashApply.png differ
diff --git a/assets/GitStashApplyRevert.png b/assets/GitStashApplyRevert.png
new file mode 100644
index 0000000..aad4b24
Binary files /dev/null and b/assets/GitStashApplyRevert.png differ
diff --git a/assets/GitStashCommand.png b/assets/GitStashCommand.png
new file mode 100644
index 0000000..cabb549
Binary files /dev/null and b/assets/GitStashCommand.png differ
diff --git a/assets/GitStashPCommand.png b/assets/GitStashPCommand.png
new file mode 100644
index 0000000..5b157b9
Binary files /dev/null and b/assets/GitStashPCommand.png differ
diff --git a/assets/GitWorkFlow.png b/assets/GitWorkFlow.png
new file mode 100644
index 0000000..b7ddd52
Binary files /dev/null and b/assets/GitWorkFlow.png differ
diff --git a/assets/HMapDumpRes.png b/assets/HMapDumpRes.png
index 89807d3..6fb2ae8 100644
Binary files a/assets/HMapDumpRes.png and b/assets/HMapDumpRes.png differ
diff --git a/assets/HMapDumpSystemTools.png b/assets/HMapDumpSystemTools.png
index 29e0b3a..34b6f5f 100644
Binary files a/assets/HMapDumpSystemTools.png and b/assets/HMapDumpSystemTools.png differ
diff --git a/assets/HMapDumpXcodeConfig.png b/assets/HMapDumpXcodeConfig.png
index 8c50a0a..36ddbeb 100644
Binary files a/assets/HMapDumpXcodeConfig.png and b/assets/HMapDumpXcodeConfig.png differ
diff --git a/assets/LLDBArchitecture.png b/assets/LLDBArchitecture.png
new file mode 100644
index 0000000..6830834
Binary files /dev/null and b/assets/LLDBArchitecture.png differ
diff --git a/assets/LLDBWorkflow.png b/assets/LLDBWorkflow.png
new file mode 100644
index 0000000..270597f
Binary files /dev/null and b/assets/LLDBWorkflow.png differ
diff --git a/assets/LLVMObjCopyBuildSuccess.png b/assets/LLVMObjCopyBuildSuccess.png
new file mode 100644
index 0000000..4e09abb
Binary files /dev/null and b/assets/LLVMObjCopyBuildSuccess.png differ
diff --git a/assets/LLVMObjCopyCommandNotFound.png b/assets/LLVMObjCopyCommandNotFound.png
new file mode 100644
index 0000000..b07b762
Binary files /dev/null and b/assets/LLVMObjCopyCommandNotFound.png differ
diff --git a/assets/LLVMObjCopyHelp.png b/assets/LLVMObjCopyHelp.png
new file mode 100644
index 0000000..e3d3eef
Binary files /dev/null and b/assets/LLVMObjCopyHelp.png differ
diff --git a/assets/LLVMObjcCopySuccess.png b/assets/LLVMObjcCopySuccess.png
new file mode 100644
index 0000000..2fe4ce0
Binary files /dev/null and b/assets/LLVMObjcCopySuccess.png differ
diff --git a/assets/LVMObjCopyBatchSuccess.png b/assets/LVMObjCopyBatchSuccess.png
new file mode 100644
index 0000000..a944963
Binary files /dev/null and b/assets/LVMObjCopyBatchSuccess.png differ
diff --git a/assets/LVMObjCopyLaunchOptions.png b/assets/LVMObjCopyLaunchOptions.png
new file mode 100644
index 0000000..85a235e
Binary files /dev/null and b/assets/LVMObjCopyLaunchOptions.png differ
diff --git a/assets/LVMObjCopyOptionNotSupportIssue.png b/assets/LVMObjCopyOptionNotSupportIssue.png
new file mode 100644
index 0000000..294d141
Binary files /dev/null and b/assets/LVMObjCopyOptionNotSupportIssue.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib.png b/assets/LinkFailedWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..a42e60f
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib2.png b/assets/LinkFailedWhenLinkTwoStaticLib2.png
new file mode 100644
index 0000000..b91fad8
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib2.png differ
diff --git a/assets/LinkSuccessWhenLinkTwoStaticLib.png b/assets/LinkSuccessWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..018a9da
Binary files /dev/null and b/assets/LinkSuccessWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkTwoStaticLibBefore.png b/assets/LinkTwoStaticLibBefore.png
new file mode 100644
index 0000000..55dfb60
Binary files /dev/null and b/assets/LinkTwoStaticLibBefore.png differ
diff --git a/assets/MobileDeviceAI-AlgorithmModel.png b/assets/MobileDeviceAI-AlgorithmModel.png
new file mode 100644
index 0000000..56906c7
Binary files /dev/null and b/assets/MobileDeviceAI-AlgorithmModel.png differ
diff --git a/assets/MobileDeviceAI-ComputeContainer.png b/assets/MobileDeviceAI-ComputeContainer.png
new file mode 100644
index 0000000..3f9bfe1
Binary files /dev/null and b/assets/MobileDeviceAI-ComputeContainer.png differ
diff --git a/assets/MobileDeviceAI-DataCapture.png b/assets/MobileDeviceAI-DataCapture.png
new file mode 100644
index 0000000..7ca9aea
Binary files /dev/null and b/assets/MobileDeviceAI-DataCapture.png differ
diff --git a/assets/MobileDeviceAI-DataGraphIndex.png b/assets/MobileDeviceAI-DataGraphIndex.png
new file mode 100644
index 0000000..9f18f57
Binary files /dev/null and b/assets/MobileDeviceAI-DataGraphIndex.png differ
diff --git a/assets/MobileDeviceAI-DataLevel.png b/assets/MobileDeviceAI-DataLevel.png
new file mode 100644
index 0000000..7c54c74
Binary files /dev/null and b/assets/MobileDeviceAI-DataLevel.png differ
diff --git a/assets/MobileDeviceAI-Disadvantage.png b/assets/MobileDeviceAI-Disadvantage.png
new file mode 100644
index 0000000..f661aa4
Binary files /dev/null and b/assets/MobileDeviceAI-Disadvantage.png differ
diff --git a/assets/MobileDeviceAI-JudgeCenter.png b/assets/MobileDeviceAI-JudgeCenter.png
new file mode 100644
index 0000000..b1b0960
Binary files /dev/null and b/assets/MobileDeviceAI-JudgeCenter.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff.png b/assets/MobileDeviceAI-LocalAndServerDiff.png
new file mode 100644
index 0000000..5f7771c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff2.png b/assets/MobileDeviceAI-LocalAndServerDiff2.png
new file mode 100644
index 0000000..ae65f7c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff2.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommended.png b/assets/MobileDeviceAI-PageBackRecommended.png
new file mode 100644
index 0000000..e991b3b
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommended.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommendedIssue.png b/assets/MobileDeviceAI-PageBackRecommendedIssue.png
new file mode 100644
index 0000000..b3a3b96
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommendedIssue.png differ
diff --git a/assets/MobileDeviceAI-Push.png b/assets/MobileDeviceAI-Push.png
new file mode 100644
index 0000000..f40cbd0
Binary files /dev/null and b/assets/MobileDeviceAI-Push.png differ
diff --git a/assets/MobileDeviceAI-UserDataFlow.png b/assets/MobileDeviceAI-UserDataFlow.png
new file mode 100644
index 0000000..dd1faf7
Binary files /dev/null and b/assets/MobileDeviceAI-UserDataFlow.png differ
diff --git a/assets/MobileDeviceAI-reLayout.png b/assets/MobileDeviceAI-reLayout.png
new file mode 100644
index 0000000..19b5e6d
Binary files /dev/null and b/assets/MobileDeviceAI-reLayout.png differ
diff --git a/assets/MobileDeviceAI-reLayoutIssue.png b/assets/MobileDeviceAI-reLayoutIssue.png
new file mode 100644
index 0000000..20a9366
Binary files /dev/null and b/assets/MobileDeviceAI-reLayoutIssue.png differ
diff --git a/assets/MobileDeviceAIArch.png b/assets/MobileDeviceAIArch.png
new file mode 100644
index 0000000..08822dc
Binary files /dev/null and b/assets/MobileDeviceAIArch.png differ
diff --git a/assets/RubyGemProcess.png b/assets/RubyGemProcess.png
new file mode 100644
index 0000000..af25cb6
Binary files /dev/null and b/assets/RubyGemProcess.png differ
diff --git a/assets/RubyMachoAddLoadCommand.png b/assets/RubyMachoAddLoadCommand.png
new file mode 100644
index 0000000..9817a91
Binary files /dev/null and b/assets/RubyMachoAddLoadCommand.png differ
diff --git a/assets/RubyMachoChangeIDOnDylib.png b/assets/RubyMachoChangeIDOnDylib.png
new file mode 100644
index 0000000..763707c
Binary files /dev/null and b/assets/RubyMachoChangeIDOnDylib.png differ
diff --git a/assets/RubyMachoChangeRPath.png b/assets/RubyMachoChangeRPath.png
new file mode 100644
index 0000000..da5c254
Binary files /dev/null and b/assets/RubyMachoChangeRPath.png differ
diff --git a/assets/RubyMachoDeleteLoadCommand.png b/assets/RubyMachoDeleteLoadCommand.png
new file mode 100644
index 0000000..1343391
Binary files /dev/null and b/assets/RubyMachoDeleteLoadCommand.png differ
diff --git a/assets/RubyMachoMergeMach.png b/assets/RubyMachoMergeMach.png
new file mode 100644
index 0000000..c3d95ef
Binary files /dev/null and b/assets/RubyMachoMergeMach.png differ
diff --git a/assets/StaticConflictsframework.png b/assets/StaticConflictsframework.png
new file mode 100644
index 0000000..612126c
Binary files /dev/null and b/assets/StaticConflictsframework.png differ
diff --git a/assets/StaticConflictslibrary.png b/assets/StaticConflictslibrary.png
new file mode 100644
index 0000000..f548039
Binary files /dev/null and b/assets/StaticConflictslibrary.png differ
diff --git a/assets/StaticLibCompileTimeCompare.png b/assets/StaticLibCompileTimeCompare.png
new file mode 100644
index 0000000..e992395
Binary files /dev/null and b/assets/StaticLibCompileTimeCompare.png differ
diff --git a/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png
new file mode 100644
index 0000000..c4f30fb
Binary files /dev/null and b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png differ
diff --git a/assets/StaticLibHMapGenerate.png b/assets/StaticLibHMapGenerate.png
new file mode 100644
index 0000000..029d6d9
Binary files /dev/null and b/assets/StaticLibHMapGenerate.png differ
diff --git a/assets/StaticLibLinkErrorWhenSameSymbol.png b/assets/StaticLibLinkErrorWhenSameSymbol.png
new file mode 100644
index 0000000..f21ea92
Binary files /dev/null and b/assets/StaticLibLinkErrorWhenSameSymbol.png differ
diff --git a/assets/StaticLibNeedRenamedSymbol.png b/assets/StaticLibNeedRenamedSymbol.png
new file mode 100644
index 0000000..6beb6d7
Binary files /dev/null and b/assets/StaticLibNeedRenamedSymbol.png differ
diff --git a/assets/StaticLibraryHeaderMapSettings.png b/assets/StaticLibraryHeaderMapSettings.png
new file mode 100644
index 0000000..78aa292
Binary files /dev/null and b/assets/StaticLibraryHeaderMapSettings.png differ
diff --git a/assets/StaticLibraryHeaderSearchPathSettings.png b/assets/StaticLibraryHeaderSearchPathSettings.png
new file mode 100644
index 0000000..c7710f0
Binary files /dev/null and b/assets/StaticLibraryHeaderSearchPathSettings.png differ
diff --git a/assets/VSCodeDebugCocoapods.png b/assets/VSCodeDebugCocoapods.png
new file mode 100644
index 0000000..49285ad
Binary files /dev/null and b/assets/VSCodeDebugCocoapods.png differ
diff --git a/assets/VegetablesGoodsAIDataUpload.png b/assets/VegetablesGoodsAIDataUpload.png
new file mode 100644
index 0000000..6e0a92a
Binary files /dev/null and b/assets/VegetablesGoodsAIDataUpload.png differ
diff --git a/assets/VegetablesPurchaseViaAIArch.png b/assets/VegetablesPurchaseViaAIArch.png
new file mode 100644
index 0000000..bc6ae0b
Binary files /dev/null and b/assets/VegetablesPurchaseViaAIArch.png differ
diff --git a/assets/VegetablesPurchaseWorkflowViaAI.png b/assets/VegetablesPurchaseWorkflowViaAI.png
new file mode 100644
index 0000000..c2da339
Binary files /dev/null and b/assets/VegetablesPurchaseWorkflowViaAI.png differ
diff --git a/assets/VisitReleasedStackBlockWillCrash.png b/assets/VisitReleasedStackBlockWillCrash.png
new file mode 100644
index 0000000..789cea0
Binary files /dev/null and b/assets/VisitReleasedStackBlockWillCrash.png differ
diff --git a/assets/Weex-ConcurrencyEnhancement.png b/assets/Weex-ConcurrencyEnhancement.png
new file mode 100644
index 0000000..df5cbfb
Binary files /dev/null and b/assets/Weex-ConcurrencyEnhancement.png differ
diff --git a/assets/WeexCallModuleMethodNameMismatch.png b/assets/WeexCallModuleMethodNameMismatch.png
new file mode 100644
index 0000000..c5f0f87
Binary files /dev/null and b/assets/WeexCallModuleMethodNameMismatch.png differ
diff --git a/assets/WeexCallNativeModuleParamsError.png b/assets/WeexCallNativeModuleParamsError.png
new file mode 100644
index 0000000..a1f743e
Binary files /dev/null and b/assets/WeexCallNativeModuleParamsError.png differ
diff --git a/assets/WeexCaptureVueError.png b/assets/WeexCaptureVueError.png
new file mode 100644
index 0000000..fa50bc9
Binary files /dev/null and b/assets/WeexCaptureVueError.png differ
diff --git a/assets/WeexComponentBuildFlow.png b/assets/WeexComponentBuildFlow.png
new file mode 100644
index 0000000..dc68ca6
Binary files /dev/null and b/assets/WeexComponentBuildFlow.png differ
diff --git a/assets/WeexComponentClickLogic.png b/assets/WeexComponentClickLogic.png
new file mode 100644
index 0000000..1d9871e
Binary files /dev/null and b/assets/WeexComponentClickLogic.png differ
diff --git a/assets/WeexComponentRegisterError.png b/assets/WeexComponentRegisterError.png
new file mode 100644
index 0000000..0da7907
Binary files /dev/null and b/assets/WeexComponentRegisterError.png differ
diff --git a/assets/WeexJSBundleDownloadFailed.png b/assets/WeexJSBundleDownloadFailed.png
new file mode 100644
index 0000000..cfa756e
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailed.png differ
diff --git a/assets/WeexJSBundleDownloadFailedAPM.png b/assets/WeexJSBundleDownloadFailedAPM.png
new file mode 100644
index 0000000..45aae06
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailedAPM.png differ
diff --git a/assets/WeexJSBundleEncodingAPM.png b/assets/WeexJSBundleEncodingAPM.png
new file mode 100644
index 0000000..47aa961
Binary files /dev/null and b/assets/WeexJSBundleEncodingAPM.png differ
diff --git a/assets/WeexJSBundleParseErrorAPM.png b/assets/WeexJSBundleParseErrorAPM.png
new file mode 100644
index 0000000..ed24ebe
Binary files /dev/null and b/assets/WeexJSBundleParseErrorAPM.png differ
diff --git a/assets/WeexJSBundleParseFailed.png b/assets/WeexJSBundleParseFailed.png
new file mode 100644
index 0000000..6f6a2ac
Binary files /dev/null and b/assets/WeexJSBundleParseFailed.png differ
diff --git a/assets/WeexJSbundleEncodingError.png b/assets/WeexJSbundleEncodingError.png
new file mode 100644
index 0000000..04e2a06
Binary files /dev/null and b/assets/WeexJSbundleEncodingError.png differ
diff --git a/assets/WeexMockVueAPM.png b/assets/WeexMockVueAPM.png
new file mode 100644
index 0000000..656ed6e
Binary files /dev/null and b/assets/WeexMockVueAPM.png differ
diff --git a/assets/WeexModuleRequireError.png b/assets/WeexModuleRequireError.png
new file mode 100644
index 0000000..d87b69c
Binary files /dev/null and b/assets/WeexModuleRequireError.png differ
diff --git a/assets/WeexRequireModuleError.png b/assets/WeexRequireModuleError.png
new file mode 100644
index 0000000..ae99068
Binary files /dev/null and b/assets/WeexRequireModuleError.png differ
diff --git a/assets/WeexRequireModuleErrorAPM.png b/assets/WeexRequireModuleErrorAPM.png
new file mode 100644
index 0000000..66ff520
Binary files /dev/null and b/assets/WeexRequireModuleErrorAPM.png differ
diff --git a/assets/XcodeProvisionProfile.png b/assets/XcodeProvisionProfile.png
new file mode 100644
index 0000000..89231f1
Binary files /dev/null and b/assets/XcodeProvisionProfile.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png
new file mode 100644
index 0000000..8fb3864
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png
new file mode 100644
index 0000000..debfba6
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png differ
diff --git a/assets/Youzan-VegetablesGoodsWorkflow.png b/assets/Youzan-VegetablesGoodsWorkflow.png
new file mode 100644
index 0000000..46eaf17
Binary files /dev/null and b/assets/Youzan-VegetablesGoodsWorkflow.png differ
diff --git a/assets/fastlaneScreentshotConfig.png b/assets/fastlaneScreentshotConfig.png
new file mode 100644
index 0000000..e5e4ae6
Binary files /dev/null and b/assets/fastlaneScreentshotConfig.png differ
diff --git a/assets/gitAddMocking.png b/assets/gitAddMocking.png
new file mode 100644
index 0000000..90c046d
Binary files /dev/null and b/assets/gitAddMocking.png differ
diff --git a/assets/gitCommitTree.png b/assets/gitCommitTree.png
new file mode 100644
index 0000000..bdb5d3f
Binary files /dev/null and b/assets/gitCommitTree.png differ
diff --git a/assets/gitFileTreeAfter.png b/assets/gitFileTreeAfter.png
new file mode 100644
index 0000000..7db5ab1
Binary files /dev/null and b/assets/gitFileTreeAfter.png differ
diff --git a/assets/gitFileTreeBefore.png b/assets/gitFileTreeBefore.png
new file mode 100644
index 0000000..ab0ab49
Binary files /dev/null and b/assets/gitFileTreeBefore.png differ
diff --git a/assets/gitRemoteAdd.png b/assets/gitRemoteAdd.png
new file mode 100644
index 0000000..88c4c67
Binary files /dev/null and b/assets/gitRemoteAdd.png differ
diff --git a/assets/gitTreeRecoverAfter.png b/assets/gitTreeRecoverAfter.png
new file mode 100644
index 0000000..0f08f22
Binary files /dev/null and b/assets/gitTreeRecoverAfter.png differ
diff --git a/assets/gitTreeRecoverBefore.png b/assets/gitTreeRecoverBefore.png
new file mode 100644
index 0000000..fddb97d
Binary files /dev/null and b/assets/gitTreeRecoverBefore.png differ
diff --git a/assets/githashChange.png b/assets/githashChange.png
new file mode 100644
index 0000000..db2372e
Binary files /dev/null and b/assets/githashChange.png differ
diff --git a/assets/githashCommand.png b/assets/githashCommand.png
new file mode 100644
index 0000000..860e056
Binary files /dev/null and b/assets/githashCommand.png differ
diff --git a/assets/githashDemo.png b/assets/githashDemo.png
new file mode 100644
index 0000000..e7dc1a0
Binary files /dev/null and b/assets/githashDemo.png differ
diff --git a/assets/jtool2WatchSignature.png b/assets/jtool2WatchSignature.png
new file mode 100644
index 0000000..4776b2b
Binary files /dev/null and b/assets/jtool2WatchSignature.png differ
diff --git a/assets/wechat_2025-08-20_235658_762.png b/assets/wechat_2025-08-20_235658_762.png
new file mode 100644
index 0000000..bee616c
Binary files /dev/null and b/assets/wechat_2025-08-20_235658_762.png differ
diff --git a/assets/xcodeprojChangeBuildSettings.png b/assets/xcodeprojChangeBuildSettings.png
new file mode 100644
index 0000000..71738dc
Binary files /dev/null and b/assets/xcodeprojChangeBuildSettings.png differ
diff --git a/assets/xcodeprojSetXcconfig.png b/assets/xcodeprojSetXcconfig.png
new file mode 100644
index 0000000..66b9c48
Binary files /dev/null and b/assets/xcodeprojSetXcconfig.png differ
diff --git a/assets/xcodeprojVisitScheme.png b/assets/xcodeprojVisitScheme.png
new file mode 100644
index 0000000..4aace85
Binary files /dev/null and b/assets/xcodeprojVisitScheme.png differ
+
+说明:
+
+- 裸仓库特点:
+
+ - 没有工作目录(不能直接编辑文件)
+ - 目录内容直接包含 Git 内部文件(无 `.git` 隐藏文件夹)
+
+- `git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1`
+
+ - `origin` 和 `origin2` 是远程仓库的别名
+ - 路径可以是绝对路径(推荐)或相对路径
+
+- 本地只有1个分支,远端分支名也不一定相同。所以需要告诉 git 本地分支如何与远端进行关联
+
+ ````shell
+ git remote add -t main origin https://github.com/FantasticLBP/GitDemo
+ ````
+
+ - `git remote add` :想本地仓库添加要 track 的远程仓库
+ - `-t main` : 指定本地要 track 远程仓库中的哪个分支
+ - `origin`: 远程仓库的名字
+ - `https://github.com/FantasticLBP/GitDemo`: 远程仓库的地址
+
+
diff --git a/Chapter8 - Algorithm/8.1.md b/Chapter8 - Algorithm/8.1.md
new file mode 100644
index 0000000..c8be63f
--- /dev/null
+++ b/Chapter8 - Algorithm/8.1.md
@@ -0,0 +1,190 @@
+## leetcode 968. 监控二叉树
+
+## 题目描述
+给定一个二叉树,我们在树的节点上安装监控。
+
+节点上的每个摄影头都可以监视其父对象、自身及其直接子对象
+
+计算监控树的所有节点所需的最小监控数量。
+
+2个例子:
+
+case1:
+
+``` shell
+ 1
+ |
+ 2 监控
+ / \
+ 3 4
+
+```
+
+Case2:
+
+```shell
+ 1
+ /
+ 2 监控
+ /
+ 3
+ /
+ 4 监控
+ \
+ 5
+```
+
+## 分析
+
+- 一颗监控可以覆盖:当前节点、当前节点的父节点、当前节点的所有子节点3层
+
+- 本题目要求使用最小数量的监控解决问题。那么也就是贪心思维的体现,那么问题来了,什么策略才可以使用最小数量的监控?
+
+ - 一棵二叉树中,叶子节点数量肯定是最多的。所以要想最小数量安装监控,优先选择非叶子节点上安装监控。这也是本题中贪心思维的体现。
+ - 如果最后一层叶子节点不安装监控,那么肯定是叶子节点的父节点安装监控,同理叶子节点的父节点的父节点,也会被监控覆盖到,所以叶子节点的父节点的父节点不用安装监控。于是
+ 叶子节点的父节点的父节点的父节点就必须安装监控。
+
+
+
+- 对于二叉树一定是采用递归法或者迭代法解决,本题选择递归法。
+
+- 因为要根据叶子节点的状态来反推父节点的状态,所以采用后续遍历。
+
+- 另外需要根据左右子树的返回值来判断,所以递归函数需要返回值
+
+- 为了方便定义3个状态。
+
+ - 未设置监控 NotCovered = 0
+ - 被监控覆盖 IsCoverd = 1
+ - 设置监控 SetCamera = 2
+
+- 如何定义递归函数?
+
+ - 返回值就是数字,存在3种情况,也就是上面定义的3种状态
+ - 递归函数的终止条件是什么?遇到叶子节点的左右空子树的情况下,该选用什么状态?思考下:共3种情况
+ - 空节点选用 “未覆盖 NotCovered”?
+ ❌ 问题 :叶子节点必须安装监控来覆盖空节点
+ 如果空节点是 NotCovered,那么空节点的父节点,也就是叶子节点,必须设置监控,才可以保证叶子节点的左右子节点才可以被监控覆盖到。
+ ❌ 结果:摄像头数量过多,不符合最小化原则
+ 这和题目要求的最小监控数量不契合
+ - 空节点选用 “安装监控 SetCamera”?
+ ❌ 问题:叶子节点自动变为被覆盖状态 (IsCovered = 1)
+ 如果空节点是 SetCamera,那么空节点的父节点,也就是叶子节点,状态一定是被覆盖 IsCoverd,如果叶子节点是 IsCoverd,
+ ❌ 结果:叶子节点的父节点不需要安装监控,破坏了"叶子节点的父节点安装监控"的最优策略
+ 反推叶子节点的父节点就不需要安装监控了(因为监控必须间隔设置,覆盖 - 监控 - 覆盖 - 监控 这样的形式),那这个情况也和题目的预设条件不满足。
+ - 所以空节点应该选用 “被监控覆盖 IsCoverd” 这个状态
+ ✅ 正确:叶子节点为未覆盖状态 (NotCovered = 0)
+ 空节点被监控覆盖 IsCoverd,那么空节点的父节点,也就是叶子节点就不需要设置监控,
+ ✅ 结果:叶子节点的父节点必须安装监控,符合贪心策略
+ 也就是未设置监控 NotCovered = 0,那么叶子节点的父节点才需要设置监控 SetCamera
+
+## 状态转换情况
+说明:
+- 未设置监控 NotCovered = 0
+- 被监控覆盖 IsCoverd = 1
+- 设置监控 SetCamera = 2
+
+| leftChild | rightChild | root | count=0 | 说明 |
+| --------- | ---------- | ---- | ------- | ------------------------------------------------------------ |
+| 1 | 1 | 0 | +0 | 空节点(叶子节点的子节点)必须同时处于被覆盖状态 |
+| | | | | |
+| 0 | 0 | 2 | +1 | 普通节点不管 left、right 只要有1个处于未覆盖状态,那么父节点一定要设置监控才可以“罩着”下面的子节点 |
+| 0 | 1 | 2 | +1 | |
+| 1 | 0 | 2 | +1 | |
+| 2 | 0 | 2 | +1 | |
+| 0 | 2 | 2 | +1 | |
+| | | | | |
+| 2 | 2 | 1 | +0 | 其他情况,父节点都是处于被监控覆盖的状态,不需要增加监控 |
+| 2 | 1 | 0 | +0 | |
+| 1 | 2 | 1 | +0 | |
+| 2 | 1 | 1 | +0 | |
+
+
+
+## 贪心思想
+
+本题目贪心体现在(监控数量 count = 0):
+- 空节点(叶子节点的子节点):处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- 叶子节点:不设置监控,处于 NotCovered 状态。需要父节点罩着。count 不变
+- 叶子节点的父节点:安装监控,处于 SetCamera 状态,count++
+- 叶子节点的爷爷节点:处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- ♻️ 循环往复
+
+
+
+## 代码实现(JS 为例)
+
+```js
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var minCameraCover = function(root) {
+ let count = 0
+ const Mode_NotCovered = 0 // 未设置监控
+ const Mode_IsCovered = 1 // 被监控覆盖
+ const Mode_SetCamera = 2 // 设置监控
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return Mode_IsCovered
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === Mode_NotCovered || right === Mode_NotCovered) {
+ count++
+ return Mode_SetCamera
+ }
+ // 如果左孩子和右孩子都是覆盖状态,那么父节点处于非覆盖状态
+ if (left === Mode_IsCovered && right === Mode_IsCovered) {
+ return Mode_NotCovered
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === Mode_SetCamera || right === Mode_SetCamera) {
+ return Mode_IsCovered
+ }
+ return Mode_NotCovered
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === Mode_NotCovered) count++
+ return count
+};
+```
+提交后发现空间复杂度一般,去掉定义的状态和更加清楚的 if 分支,代码如下
+
+```js
+var minCameraCover = function(root) {
+ let count = 0
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return 1
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === 0 || right === 0) {
+ count++
+ return 2
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === 2 || right === 2) {
+ return 1
+ }
+ return 0
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === 0) count++
+ return count
+};
+```
+
diff --git a/Chapter8 - Algorithm/8.2.md b/Chapter8 - Algorithm/8.2.md
new file mode 100644
index 0000000..c9c13f4
--- /dev/null
+++ b/Chapter8 - Algorithm/8.2.md
@@ -0,0 +1,161 @@
+# 《剑指 Offer》字符串“左旋”、“右旋”里的数学秘密
+
+> 为什么要写本篇文章?看上去这是 easy 级别的题目。但“点是面的缩影,面是点的抽象”,单独一道题似乎很简单,我们可以比较轻松做出来。但是这一类题目的本质是什么?不要处于混沌的状态解决了题目,但下次遇到类似的,还是要迟疑思考一会儿。本篇文章带你吃透问题的本质和背后的数学推导。
+
+
+
+## 题目描述
+字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。
+
+请定义一个函数实现字符串左旋转操作的功能。比如:
+- 输入字符串 "abcdefg" 和数字 2
+- 该函数将返回左旋转 2 位后的结果 "cdefgab"
+
+请实现该函数
+
+## 结论
+只要是字符串的左旋、右旋,都用整体逆序 + 部分逆序的方法,也可以是部分逆序 + 整体逆序。
+
+## 分析
+关于反转(也就是逆序),有2个 feature:
+- 反转的可逆性:反转(反转(x)) = x
+ - 类似负负得正。比如:'123' 经过一次反转后为 '321', '321' 再经过一次反转为 '123'
+- 反转的可组合性:反转 (A + B) = 反转(B) + 反转(A)
+ - '123456' 按照长度为3进行拆分为2部分,s1 + s2。s1 = '123', s2 = '456
+ - 先对后面的 s2,也就是'456' 反转得到 '654',即 s2' = '654'
+ - 再对前面的 s1,也就是'123' 反转得到 '321',即 s1' = '321'
+ - 再对 s1' 和 s2' 进行拼接, s1' + s2' = '654321'
+ - 观察发现 s1' + s2' 就等于对整体 s1 + s2 逆序后的结果。
+
+再来观察看看:左旋、右旋题目要求的是什么?
+
+前提:假设一个逆序函数,可以将 x 作为输入,输出是 x'。这个共识、前提成立,我们再进行后续的推导:
+1. 原始字符串通过 k 为分割,可以拆分为: A + B。题目求的是什么? B + A
+2. 思考:根据上面的2个特性,通过什么变化可以从 A + B,得到 B + A 呢?
+不难得出结论,有2个方案:
+- 先整体逆序,`逆序 (A + B) = 逆序(B) + 逆序(A) = B' + A'`
+- 再局部逆序,`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求。所以这些方法都是有迹可循的,符合数学群论中的 **“逆运算”** 和 **“运算律”** 的思想
+
+
+## 方法1:先整体逆序,再局部逆序
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先整体逆序。`逆序(A) = A' 逆序(B) = B'。大的结构还是逆序(A + B) = B' + A'`
+3. 再局部逆序:`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法1: 先整体,再部分
+ const rotateLeft = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 2. 再局部逆序
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, length - k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, length - k, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+## 方法2:先部分逆序,再整体逆序
+思考:能不能先局部逆序,再整体逆序?
+分析:继续用上面的思路推导下
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先局部逆序:`逆序(A) + 逆序(B) = A' + B'`
+3. 再整体逆序。`逆序(A + B) = 逆序(B) + 逆序(A)`。但是此刻我们的输入为: A' + B',
+
+所以等价于:`逆序(A' + B') = 逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法2: 先部分,再整体
+ const rotateLeft1 = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 再局部逆序
+
+ // abcdefg -> gfedc ba ->
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, k, length - 1)
+
+ // 2. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/Chapter8 - Algorithm/chapter8.md b/Chapter8 - Algorithm/chapter8.md
new file mode 100644
index 0000000..e69de29
diff --git a/SUMMARY.md b/SUMMARY.md
index cd36511..d74a057 100644
--- a/SUMMARY.md
+++ b/SUMMARY.md
@@ -117,6 +117,8 @@
* [112、Swift 枚举值内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.112.md)
* [113、Swift 结构体和类的内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.113.md)
* [114、Swift 优化](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.114.md)
+ * [115、AI 对端上的赋能](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.115.md)
+ * [147. Rust 在移动端可以做什么](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.147.md)
* [Chapter2 - Web FrontEnd](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/chapter2.md)
* [1、-last-child与-last-of-type你只是会用,有研究过区别吗?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.1.md)
* [2、正则表达式](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.2.md)
@@ -162,6 +164,9 @@
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
* [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
+ * [45、内存管理之垃圾回收与内存泄漏](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.46.md)
+
+
* [Chapter3 - Server](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/chapter3.md)
* [1、利用分页和模糊查询技术实现一个App接口](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.1.md)
* [2、网页端扫码登录实现原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.2.md)
@@ -246,4 +251,6 @@
* [24、短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.25.md)
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
* [26、敏捷软件开发和 Scurm Master](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.27.md)
- * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
\ No newline at end of file
+ * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
+* [Chapter8 - Algorithm](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/chapter8.md)
+ * [1、Leetcode968. 监控二叉树](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/8.1.md)
\ No newline at end of file
diff --git a/assets/AFNetworkingIsDynamicLib.png b/assets/AFNetworkingIsDynamicLib.png
new file mode 100644
index 0000000..8653c33
Binary files /dev/null and b/assets/AFNetworkingIsDynamicLib.png differ
diff --git a/assets/APM-CoreAnimationPipeline.png b/assets/APM-CoreAnimationPipeline.png
new file mode 100644
index 0000000..b36eed4
Binary files /dev/null and b/assets/APM-CoreAnimationPipeline.png differ
diff --git a/assets/AddStaticLibIntoApp.png b/assets/AddStaticLibIntoApp.png
new file mode 100644
index 0000000..0dd8197
Binary files /dev/null and b/assets/AddStaticLibIntoApp.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderMap.png b/assets/AppCompileStaticLibWithHeaderMap.png
new file mode 100644
index 0000000..155a6f2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderMap.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderSearchPath.png b/assets/AppCompileStaticLibWithHeaderSearchPath.png
new file mode 100644
index 0000000..393d7b2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderSearchPath.png differ
diff --git a/assets/AppLinkDynamicLibNotSign.png b/assets/AppLinkDynamicLibNotSign.png
new file mode 100644
index 0000000..c5f147f
Binary files /dev/null and b/assets/AppLinkDynamicLibNotSign.png differ
diff --git a/assets/BlockAssignIsValueAssign.png b/assets/BlockAssignIsValueAssign.png
new file mode 100644
index 0000000..50a9f77
Binary files /dev/null and b/assets/BlockAssignIsValueAssign.png differ
diff --git a/assets/CocdSignIphoneLog.png b/assets/CocdSignIphoneLog.png
new file mode 100644
index 0000000..ac4dce3
Binary files /dev/null and b/assets/CocdSignIphoneLog.png differ
diff --git a/assets/CocoapodsCommandWithSciptFile.png b/assets/CocoapodsCommandWithSciptFile.png
new file mode 100644
index 0000000..3d5ea65
Binary files /dev/null and b/assets/CocoapodsCommandWithSciptFile.png differ
diff --git a/assets/CocoapodsHMapInfo.png b/assets/CocoapodsHMapInfo.png
new file mode 100644
index 0000000..8132397
Binary files /dev/null and b/assets/CocoapodsHMapInfo.png differ
diff --git a/assets/CocoapodsHMapLocalInstall.png b/assets/CocoapodsHMapLocalInstall.png
new file mode 100644
index 0000000..479bf21
Binary files /dev/null and b/assets/CocoapodsHMapLocalInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall.png b/assets/CocoapodsHMapPostInstall.png
new file mode 100644
index 0000000..349dbf4
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall2.png b/assets/CocoapodsHMapPostInstall2.png
new file mode 100644
index 0000000..3cab6fe
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall2.png differ
diff --git a/assets/CocoapodsHMapV1.png b/assets/CocoapodsHMapV1.png
new file mode 100644
index 0000000..5c73744
Binary files /dev/null and b/assets/CocoapodsHMapV1.png differ
diff --git a/assets/CocoapodsHMapV2.png b/assets/CocoapodsHMapV2.png
new file mode 100644
index 0000000..5b25a8f
Binary files /dev/null and b/assets/CocoapodsHMapV2.png differ
diff --git a/assets/CocoapodsHMapV2Test.png b/assets/CocoapodsHMapV2Test.png
new file mode 100644
index 0000000..f808bfd
Binary files /dev/null and b/assets/CocoapodsHMapV2Test.png differ
diff --git a/assets/CocoapodsScriptCodeSignDetails.png b/assets/CocoapodsScriptCodeSignDetails.png
new file mode 100644
index 0000000..ff7fbd0
Binary files /dev/null and b/assets/CocoapodsScriptCodeSignDetails.png differ
diff --git a/assets/CocoapodsSelfDefinedScript.png b/assets/CocoapodsSelfDefinedScript.png
new file mode 100644
index 0000000..e9cf916
Binary files /dev/null and b/assets/CocoapodsSelfDefinedScript.png differ
diff --git a/assets/CodeSignAppWithDynamicLibLog.png b/assets/CodeSignAppWithDynamicLibLog.png
new file mode 100644
index 0000000..d91d7c2
Binary files /dev/null and b/assets/CodeSignAppWithDynamicLibLog.png differ
diff --git a/assets/CodeSignByCocoapodsScripts.png b/assets/CodeSignByCocoapodsScripts.png
new file mode 100644
index 0000000..c782400
Binary files /dev/null and b/assets/CodeSignByCocoapodsScripts.png differ
diff --git a/assets/CodeSignEntitlements.png b/assets/CodeSignEntitlements.png
new file mode 100644
index 0000000..1341ecb
Binary files /dev/null and b/assets/CodeSignEntitlements.png differ
diff --git a/assets/DumpProvisionProfile.png b/assets/DumpProvisionProfile.png
new file mode 100644
index 0000000..a84866a
Binary files /dev/null and b/assets/DumpProvisionProfile.png differ
diff --git a/assets/DuplicateSymbolWhenLinkTwoStaticLib.png b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..06c65db
Binary files /dev/null and b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png differ
diff --git a/assets/FastlaneMatchfile.png b/assets/FastlaneMatchfile.png
new file mode 100644
index 0000000..e8eab68
Binary files /dev/null and b/assets/FastlaneMatchfile.png differ
diff --git a/assets/FastlaneScriptCodeGen.png b/assets/FastlaneScriptCodeGen.png
new file mode 100644
index 0000000..5380457
Binary files /dev/null and b/assets/FastlaneScriptCodeGen.png differ
diff --git a/assets/FastlaneStructure.png b/assets/FastlaneStructure.png
new file mode 100644
index 0000000..04d5192
Binary files /dev/null and b/assets/FastlaneStructure.png differ
diff --git a/assets/GitHash.png b/assets/GitHash.png
new file mode 100644
index 0000000..7557ced
Binary files /dev/null and b/assets/GitHash.png differ
diff --git a/assets/GitHooksTemplate.png b/assets/GitHooksTemplate.png
new file mode 100644
index 0000000..33a093c
Binary files /dev/null and b/assets/GitHooksTemplate.png differ
diff --git a/assets/GitLogPCommand.png b/assets/GitLogPCommand.png
new file mode 100644
index 0000000..67ec5ac
Binary files /dev/null and b/assets/GitLogPCommand.png differ
diff --git a/assets/GitOpenDiffPanel.png b/assets/GitOpenDiffPanel.png
new file mode 100644
index 0000000..fe4e4da
Binary files /dev/null and b/assets/GitOpenDiffPanel.png differ
diff --git a/assets/GitOpenDiffResult.png b/assets/GitOpenDiffResult.png
new file mode 100644
index 0000000..1f35373
Binary files /dev/null and b/assets/GitOpenDiffResult.png differ
diff --git a/assets/GitPreCommitHook.png b/assets/GitPreCommitHook.png
new file mode 100644
index 0000000..bfbe0c0
Binary files /dev/null and b/assets/GitPreCommitHook.png differ
diff --git a/assets/GitRebaseCommand.png b/assets/GitRebaseCommand.png
new file mode 100644
index 0000000..cc6ba7e
Binary files /dev/null and b/assets/GitRebaseCommand.png differ
diff --git a/assets/GitRemoveTrackingWithIgnore.png b/assets/GitRemoveTrackingWithIgnore.png
new file mode 100644
index 0000000..85c7037
Binary files /dev/null and b/assets/GitRemoveTrackingWithIgnore.png differ
diff --git a/assets/GitStashApply.png b/assets/GitStashApply.png
new file mode 100644
index 0000000..06bd2bb
Binary files /dev/null and b/assets/GitStashApply.png differ
diff --git a/assets/GitStashApplyRevert.png b/assets/GitStashApplyRevert.png
new file mode 100644
index 0000000..aad4b24
Binary files /dev/null and b/assets/GitStashApplyRevert.png differ
diff --git a/assets/GitStashCommand.png b/assets/GitStashCommand.png
new file mode 100644
index 0000000..cabb549
Binary files /dev/null and b/assets/GitStashCommand.png differ
diff --git a/assets/GitStashPCommand.png b/assets/GitStashPCommand.png
new file mode 100644
index 0000000..5b157b9
Binary files /dev/null and b/assets/GitStashPCommand.png differ
diff --git a/assets/GitWorkFlow.png b/assets/GitWorkFlow.png
new file mode 100644
index 0000000..b7ddd52
Binary files /dev/null and b/assets/GitWorkFlow.png differ
diff --git a/assets/HMapDumpRes.png b/assets/HMapDumpRes.png
index 89807d3..6fb2ae8 100644
Binary files a/assets/HMapDumpRes.png and b/assets/HMapDumpRes.png differ
diff --git a/assets/HMapDumpSystemTools.png b/assets/HMapDumpSystemTools.png
index 29e0b3a..34b6f5f 100644
Binary files a/assets/HMapDumpSystemTools.png and b/assets/HMapDumpSystemTools.png differ
diff --git a/assets/HMapDumpXcodeConfig.png b/assets/HMapDumpXcodeConfig.png
index 8c50a0a..36ddbeb 100644
Binary files a/assets/HMapDumpXcodeConfig.png and b/assets/HMapDumpXcodeConfig.png differ
diff --git a/assets/LLDBArchitecture.png b/assets/LLDBArchitecture.png
new file mode 100644
index 0000000..6830834
Binary files /dev/null and b/assets/LLDBArchitecture.png differ
diff --git a/assets/LLDBWorkflow.png b/assets/LLDBWorkflow.png
new file mode 100644
index 0000000..270597f
Binary files /dev/null and b/assets/LLDBWorkflow.png differ
diff --git a/assets/LLVMObjCopyBuildSuccess.png b/assets/LLVMObjCopyBuildSuccess.png
new file mode 100644
index 0000000..4e09abb
Binary files /dev/null and b/assets/LLVMObjCopyBuildSuccess.png differ
diff --git a/assets/LLVMObjCopyCommandNotFound.png b/assets/LLVMObjCopyCommandNotFound.png
new file mode 100644
index 0000000..b07b762
Binary files /dev/null and b/assets/LLVMObjCopyCommandNotFound.png differ
diff --git a/assets/LLVMObjCopyHelp.png b/assets/LLVMObjCopyHelp.png
new file mode 100644
index 0000000..e3d3eef
Binary files /dev/null and b/assets/LLVMObjCopyHelp.png differ
diff --git a/assets/LLVMObjcCopySuccess.png b/assets/LLVMObjcCopySuccess.png
new file mode 100644
index 0000000..2fe4ce0
Binary files /dev/null and b/assets/LLVMObjcCopySuccess.png differ
diff --git a/assets/LVMObjCopyBatchSuccess.png b/assets/LVMObjCopyBatchSuccess.png
new file mode 100644
index 0000000..a944963
Binary files /dev/null and b/assets/LVMObjCopyBatchSuccess.png differ
diff --git a/assets/LVMObjCopyLaunchOptions.png b/assets/LVMObjCopyLaunchOptions.png
new file mode 100644
index 0000000..85a235e
Binary files /dev/null and b/assets/LVMObjCopyLaunchOptions.png differ
diff --git a/assets/LVMObjCopyOptionNotSupportIssue.png b/assets/LVMObjCopyOptionNotSupportIssue.png
new file mode 100644
index 0000000..294d141
Binary files /dev/null and b/assets/LVMObjCopyOptionNotSupportIssue.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib.png b/assets/LinkFailedWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..a42e60f
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib2.png b/assets/LinkFailedWhenLinkTwoStaticLib2.png
new file mode 100644
index 0000000..b91fad8
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib2.png differ
diff --git a/assets/LinkSuccessWhenLinkTwoStaticLib.png b/assets/LinkSuccessWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..018a9da
Binary files /dev/null and b/assets/LinkSuccessWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkTwoStaticLibBefore.png b/assets/LinkTwoStaticLibBefore.png
new file mode 100644
index 0000000..55dfb60
Binary files /dev/null and b/assets/LinkTwoStaticLibBefore.png differ
diff --git a/assets/MobileDeviceAI-AlgorithmModel.png b/assets/MobileDeviceAI-AlgorithmModel.png
new file mode 100644
index 0000000..56906c7
Binary files /dev/null and b/assets/MobileDeviceAI-AlgorithmModel.png differ
diff --git a/assets/MobileDeviceAI-ComputeContainer.png b/assets/MobileDeviceAI-ComputeContainer.png
new file mode 100644
index 0000000..3f9bfe1
Binary files /dev/null and b/assets/MobileDeviceAI-ComputeContainer.png differ
diff --git a/assets/MobileDeviceAI-DataCapture.png b/assets/MobileDeviceAI-DataCapture.png
new file mode 100644
index 0000000..7ca9aea
Binary files /dev/null and b/assets/MobileDeviceAI-DataCapture.png differ
diff --git a/assets/MobileDeviceAI-DataGraphIndex.png b/assets/MobileDeviceAI-DataGraphIndex.png
new file mode 100644
index 0000000..9f18f57
Binary files /dev/null and b/assets/MobileDeviceAI-DataGraphIndex.png differ
diff --git a/assets/MobileDeviceAI-DataLevel.png b/assets/MobileDeviceAI-DataLevel.png
new file mode 100644
index 0000000..7c54c74
Binary files /dev/null and b/assets/MobileDeviceAI-DataLevel.png differ
diff --git a/assets/MobileDeviceAI-Disadvantage.png b/assets/MobileDeviceAI-Disadvantage.png
new file mode 100644
index 0000000..f661aa4
Binary files /dev/null and b/assets/MobileDeviceAI-Disadvantage.png differ
diff --git a/assets/MobileDeviceAI-JudgeCenter.png b/assets/MobileDeviceAI-JudgeCenter.png
new file mode 100644
index 0000000..b1b0960
Binary files /dev/null and b/assets/MobileDeviceAI-JudgeCenter.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff.png b/assets/MobileDeviceAI-LocalAndServerDiff.png
new file mode 100644
index 0000000..5f7771c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff2.png b/assets/MobileDeviceAI-LocalAndServerDiff2.png
new file mode 100644
index 0000000..ae65f7c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff2.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommended.png b/assets/MobileDeviceAI-PageBackRecommended.png
new file mode 100644
index 0000000..e991b3b
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommended.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommendedIssue.png b/assets/MobileDeviceAI-PageBackRecommendedIssue.png
new file mode 100644
index 0000000..b3a3b96
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommendedIssue.png differ
diff --git a/assets/MobileDeviceAI-Push.png b/assets/MobileDeviceAI-Push.png
new file mode 100644
index 0000000..f40cbd0
Binary files /dev/null and b/assets/MobileDeviceAI-Push.png differ
diff --git a/assets/MobileDeviceAI-UserDataFlow.png b/assets/MobileDeviceAI-UserDataFlow.png
new file mode 100644
index 0000000..dd1faf7
Binary files /dev/null and b/assets/MobileDeviceAI-UserDataFlow.png differ
diff --git a/assets/MobileDeviceAI-reLayout.png b/assets/MobileDeviceAI-reLayout.png
new file mode 100644
index 0000000..19b5e6d
Binary files /dev/null and b/assets/MobileDeviceAI-reLayout.png differ
diff --git a/assets/MobileDeviceAI-reLayoutIssue.png b/assets/MobileDeviceAI-reLayoutIssue.png
new file mode 100644
index 0000000..20a9366
Binary files /dev/null and b/assets/MobileDeviceAI-reLayoutIssue.png differ
diff --git a/assets/MobileDeviceAIArch.png b/assets/MobileDeviceAIArch.png
new file mode 100644
index 0000000..08822dc
Binary files /dev/null and b/assets/MobileDeviceAIArch.png differ
diff --git a/assets/RubyGemProcess.png b/assets/RubyGemProcess.png
new file mode 100644
index 0000000..af25cb6
Binary files /dev/null and b/assets/RubyGemProcess.png differ
diff --git a/assets/RubyMachoAddLoadCommand.png b/assets/RubyMachoAddLoadCommand.png
new file mode 100644
index 0000000..9817a91
Binary files /dev/null and b/assets/RubyMachoAddLoadCommand.png differ
diff --git a/assets/RubyMachoChangeIDOnDylib.png b/assets/RubyMachoChangeIDOnDylib.png
new file mode 100644
index 0000000..763707c
Binary files /dev/null and b/assets/RubyMachoChangeIDOnDylib.png differ
diff --git a/assets/RubyMachoChangeRPath.png b/assets/RubyMachoChangeRPath.png
new file mode 100644
index 0000000..da5c254
Binary files /dev/null and b/assets/RubyMachoChangeRPath.png differ
diff --git a/assets/RubyMachoDeleteLoadCommand.png b/assets/RubyMachoDeleteLoadCommand.png
new file mode 100644
index 0000000..1343391
Binary files /dev/null and b/assets/RubyMachoDeleteLoadCommand.png differ
diff --git a/assets/RubyMachoMergeMach.png b/assets/RubyMachoMergeMach.png
new file mode 100644
index 0000000..c3d95ef
Binary files /dev/null and b/assets/RubyMachoMergeMach.png differ
diff --git a/assets/StaticConflictsframework.png b/assets/StaticConflictsframework.png
new file mode 100644
index 0000000..612126c
Binary files /dev/null and b/assets/StaticConflictsframework.png differ
diff --git a/assets/StaticConflictslibrary.png b/assets/StaticConflictslibrary.png
new file mode 100644
index 0000000..f548039
Binary files /dev/null and b/assets/StaticConflictslibrary.png differ
diff --git a/assets/StaticLibCompileTimeCompare.png b/assets/StaticLibCompileTimeCompare.png
new file mode 100644
index 0000000..e992395
Binary files /dev/null and b/assets/StaticLibCompileTimeCompare.png differ
diff --git a/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png
new file mode 100644
index 0000000..c4f30fb
Binary files /dev/null and b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png differ
diff --git a/assets/StaticLibHMapGenerate.png b/assets/StaticLibHMapGenerate.png
new file mode 100644
index 0000000..029d6d9
Binary files /dev/null and b/assets/StaticLibHMapGenerate.png differ
diff --git a/assets/StaticLibLinkErrorWhenSameSymbol.png b/assets/StaticLibLinkErrorWhenSameSymbol.png
new file mode 100644
index 0000000..f21ea92
Binary files /dev/null and b/assets/StaticLibLinkErrorWhenSameSymbol.png differ
diff --git a/assets/StaticLibNeedRenamedSymbol.png b/assets/StaticLibNeedRenamedSymbol.png
new file mode 100644
index 0000000..6beb6d7
Binary files /dev/null and b/assets/StaticLibNeedRenamedSymbol.png differ
diff --git a/assets/StaticLibraryHeaderMapSettings.png b/assets/StaticLibraryHeaderMapSettings.png
new file mode 100644
index 0000000..78aa292
Binary files /dev/null and b/assets/StaticLibraryHeaderMapSettings.png differ
diff --git a/assets/StaticLibraryHeaderSearchPathSettings.png b/assets/StaticLibraryHeaderSearchPathSettings.png
new file mode 100644
index 0000000..c7710f0
Binary files /dev/null and b/assets/StaticLibraryHeaderSearchPathSettings.png differ
diff --git a/assets/VSCodeDebugCocoapods.png b/assets/VSCodeDebugCocoapods.png
new file mode 100644
index 0000000..49285ad
Binary files /dev/null and b/assets/VSCodeDebugCocoapods.png differ
diff --git a/assets/VegetablesGoodsAIDataUpload.png b/assets/VegetablesGoodsAIDataUpload.png
new file mode 100644
index 0000000..6e0a92a
Binary files /dev/null and b/assets/VegetablesGoodsAIDataUpload.png differ
diff --git a/assets/VegetablesPurchaseViaAIArch.png b/assets/VegetablesPurchaseViaAIArch.png
new file mode 100644
index 0000000..bc6ae0b
Binary files /dev/null and b/assets/VegetablesPurchaseViaAIArch.png differ
diff --git a/assets/VegetablesPurchaseWorkflowViaAI.png b/assets/VegetablesPurchaseWorkflowViaAI.png
new file mode 100644
index 0000000..c2da339
Binary files /dev/null and b/assets/VegetablesPurchaseWorkflowViaAI.png differ
diff --git a/assets/VisitReleasedStackBlockWillCrash.png b/assets/VisitReleasedStackBlockWillCrash.png
new file mode 100644
index 0000000..789cea0
Binary files /dev/null and b/assets/VisitReleasedStackBlockWillCrash.png differ
diff --git a/assets/Weex-ConcurrencyEnhancement.png b/assets/Weex-ConcurrencyEnhancement.png
new file mode 100644
index 0000000..df5cbfb
Binary files /dev/null and b/assets/Weex-ConcurrencyEnhancement.png differ
diff --git a/assets/WeexCallModuleMethodNameMismatch.png b/assets/WeexCallModuleMethodNameMismatch.png
new file mode 100644
index 0000000..c5f0f87
Binary files /dev/null and b/assets/WeexCallModuleMethodNameMismatch.png differ
diff --git a/assets/WeexCallNativeModuleParamsError.png b/assets/WeexCallNativeModuleParamsError.png
new file mode 100644
index 0000000..a1f743e
Binary files /dev/null and b/assets/WeexCallNativeModuleParamsError.png differ
diff --git a/assets/WeexCaptureVueError.png b/assets/WeexCaptureVueError.png
new file mode 100644
index 0000000..fa50bc9
Binary files /dev/null and b/assets/WeexCaptureVueError.png differ
diff --git a/assets/WeexComponentBuildFlow.png b/assets/WeexComponentBuildFlow.png
new file mode 100644
index 0000000..dc68ca6
Binary files /dev/null and b/assets/WeexComponentBuildFlow.png differ
diff --git a/assets/WeexComponentClickLogic.png b/assets/WeexComponentClickLogic.png
new file mode 100644
index 0000000..1d9871e
Binary files /dev/null and b/assets/WeexComponentClickLogic.png differ
diff --git a/assets/WeexComponentRegisterError.png b/assets/WeexComponentRegisterError.png
new file mode 100644
index 0000000..0da7907
Binary files /dev/null and b/assets/WeexComponentRegisterError.png differ
diff --git a/assets/WeexJSBundleDownloadFailed.png b/assets/WeexJSBundleDownloadFailed.png
new file mode 100644
index 0000000..cfa756e
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailed.png differ
diff --git a/assets/WeexJSBundleDownloadFailedAPM.png b/assets/WeexJSBundleDownloadFailedAPM.png
new file mode 100644
index 0000000..45aae06
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailedAPM.png differ
diff --git a/assets/WeexJSBundleEncodingAPM.png b/assets/WeexJSBundleEncodingAPM.png
new file mode 100644
index 0000000..47aa961
Binary files /dev/null and b/assets/WeexJSBundleEncodingAPM.png differ
diff --git a/assets/WeexJSBundleParseErrorAPM.png b/assets/WeexJSBundleParseErrorAPM.png
new file mode 100644
index 0000000..ed24ebe
Binary files /dev/null and b/assets/WeexJSBundleParseErrorAPM.png differ
diff --git a/assets/WeexJSBundleParseFailed.png b/assets/WeexJSBundleParseFailed.png
new file mode 100644
index 0000000..6f6a2ac
Binary files /dev/null and b/assets/WeexJSBundleParseFailed.png differ
diff --git a/assets/WeexJSbundleEncodingError.png b/assets/WeexJSbundleEncodingError.png
new file mode 100644
index 0000000..04e2a06
Binary files /dev/null and b/assets/WeexJSbundleEncodingError.png differ
diff --git a/assets/WeexMockVueAPM.png b/assets/WeexMockVueAPM.png
new file mode 100644
index 0000000..656ed6e
Binary files /dev/null and b/assets/WeexMockVueAPM.png differ
diff --git a/assets/WeexModuleRequireError.png b/assets/WeexModuleRequireError.png
new file mode 100644
index 0000000..d87b69c
Binary files /dev/null and b/assets/WeexModuleRequireError.png differ
diff --git a/assets/WeexRequireModuleError.png b/assets/WeexRequireModuleError.png
new file mode 100644
index 0000000..ae99068
Binary files /dev/null and b/assets/WeexRequireModuleError.png differ
diff --git a/assets/WeexRequireModuleErrorAPM.png b/assets/WeexRequireModuleErrorAPM.png
new file mode 100644
index 0000000..66ff520
Binary files /dev/null and b/assets/WeexRequireModuleErrorAPM.png differ
diff --git a/assets/XcodeProvisionProfile.png b/assets/XcodeProvisionProfile.png
new file mode 100644
index 0000000..89231f1
Binary files /dev/null and b/assets/XcodeProvisionProfile.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png
new file mode 100644
index 0000000..8fb3864
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png
new file mode 100644
index 0000000..debfba6
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png differ
diff --git a/assets/Youzan-VegetablesGoodsWorkflow.png b/assets/Youzan-VegetablesGoodsWorkflow.png
new file mode 100644
index 0000000..46eaf17
Binary files /dev/null and b/assets/Youzan-VegetablesGoodsWorkflow.png differ
diff --git a/assets/fastlaneScreentshotConfig.png b/assets/fastlaneScreentshotConfig.png
new file mode 100644
index 0000000..e5e4ae6
Binary files /dev/null and b/assets/fastlaneScreentshotConfig.png differ
diff --git a/assets/gitAddMocking.png b/assets/gitAddMocking.png
new file mode 100644
index 0000000..90c046d
Binary files /dev/null and b/assets/gitAddMocking.png differ
diff --git a/assets/gitCommitTree.png b/assets/gitCommitTree.png
new file mode 100644
index 0000000..bdb5d3f
Binary files /dev/null and b/assets/gitCommitTree.png differ
diff --git a/assets/gitFileTreeAfter.png b/assets/gitFileTreeAfter.png
new file mode 100644
index 0000000..7db5ab1
Binary files /dev/null and b/assets/gitFileTreeAfter.png differ
diff --git a/assets/gitFileTreeBefore.png b/assets/gitFileTreeBefore.png
new file mode 100644
index 0000000..ab0ab49
Binary files /dev/null and b/assets/gitFileTreeBefore.png differ
diff --git a/assets/gitRemoteAdd.png b/assets/gitRemoteAdd.png
new file mode 100644
index 0000000..88c4c67
Binary files /dev/null and b/assets/gitRemoteAdd.png differ
diff --git a/assets/gitTreeRecoverAfter.png b/assets/gitTreeRecoverAfter.png
new file mode 100644
index 0000000..0f08f22
Binary files /dev/null and b/assets/gitTreeRecoverAfter.png differ
diff --git a/assets/gitTreeRecoverBefore.png b/assets/gitTreeRecoverBefore.png
new file mode 100644
index 0000000..fddb97d
Binary files /dev/null and b/assets/gitTreeRecoverBefore.png differ
diff --git a/assets/githashChange.png b/assets/githashChange.png
new file mode 100644
index 0000000..db2372e
Binary files /dev/null and b/assets/githashChange.png differ
diff --git a/assets/githashCommand.png b/assets/githashCommand.png
new file mode 100644
index 0000000..860e056
Binary files /dev/null and b/assets/githashCommand.png differ
diff --git a/assets/githashDemo.png b/assets/githashDemo.png
new file mode 100644
index 0000000..e7dc1a0
Binary files /dev/null and b/assets/githashDemo.png differ
diff --git a/assets/jtool2WatchSignature.png b/assets/jtool2WatchSignature.png
new file mode 100644
index 0000000..4776b2b
Binary files /dev/null and b/assets/jtool2WatchSignature.png differ
diff --git a/assets/wechat_2025-08-20_235658_762.png b/assets/wechat_2025-08-20_235658_762.png
new file mode 100644
index 0000000..bee616c
Binary files /dev/null and b/assets/wechat_2025-08-20_235658_762.png differ
diff --git a/assets/xcodeprojChangeBuildSettings.png b/assets/xcodeprojChangeBuildSettings.png
new file mode 100644
index 0000000..71738dc
Binary files /dev/null and b/assets/xcodeprojChangeBuildSettings.png differ
diff --git a/assets/xcodeprojSetXcconfig.png b/assets/xcodeprojSetXcconfig.png
new file mode 100644
index 0000000..66b9c48
Binary files /dev/null and b/assets/xcodeprojSetXcconfig.png differ
diff --git a/assets/xcodeprojVisitScheme.png b/assets/xcodeprojVisitScheme.png
new file mode 100644
index 0000000..4aace85
Binary files /dev/null and b/assets/xcodeprojVisitScheme.png differ
+
+ Current: {count}
+
+ );
+}
+```
+点击事件触发后的完整流程伪代码为:
+```javascript
+// 1. 开始渲染
+const root = FiberRootNode;
+root.current = Tree_A; // 当前显示Tree_A
+
+// 2. 准备workInProgress树
+root.workInProgress = createWorkInProgress(Tree_A, null);
+// 现在有:Tree_A (current) 和 Tree_B (workInProgress)
+
+// 3. 在Tree_B上执行协调
+// - 更新button的文本
+// - 更新span的文本
+// - 计算DOM变更
+
+// 4. 协调完成
+root.finishedWork = Tree_B;
+
+// 5. 提交阶段
+commitRoot(root);
+// - 执行DOM更新(修改文本内容)
+// - 🎯 root.current = Tree_B; // 切换到新树
+// - Tree_B现在成为current树
+
+// 6. 准备下一轮更新
+root.workInProgress = null;
+// 下次更新时,会从Tree_B克隆出新的workInProgress树
+```
+
+
+
+## React 的合成事件
+React 将事件统一绑定在根节点(React 17 之前是 document,React 17 及之后是 React 应用挂载的根 DOM 节点)上,主要是基于性能优化、兼容性处理和架构设计等方面的综合考虑。这个机制被称为 “合成事件(SyntheticEvent)” 和 “事件委托(Event Delegation)
+
+### 深入了解事件委托机制
+在 React 中,你通过 JSX 编写的事件处理函数(如 onClick、onChange)并不会直接绑定到对应的 DOM 元素上。React 实际做的事情是:
+
+- 统一监听:在应用的根节点(React 17+ 是你挂载 React 应用的 DOM 节点,如 ReactDOM.createRoot(document.getElementById('root')) 中的 #root;之前是 document)上设置一个统一的事件监听器。
+- 事件触发:当任何子元素发生事件(比如点击),由于事件冒泡机制,这个事件会最终冒泡到根节点。
+- 映射处理:根节点上的统一监听器捕获事件后,React 会根据事件触发的源 DOM 元素和事件类型,在自己的映射关系中找到对应组件的事件处理函数并执行。
+
+React 17 的变化提醒:需要注意的是,在 React 17 及之后的版本中,事件委托的节点从 document 变为了你渲染 React 树的根 DOM 容器。这个改动使得多个 React 版本共存时事件系统可以更好地隔离。
+
+好处:
+- 简化事件处理:开发者无需手动管理事件的绑定 (addEventListener) 和解绑 (removeEventListener),React 已在内部处理,降低了代码复杂度和内存泄漏风险。
+- 功能增强:合成事件提供了与浏览器原生事件相同的接口,并在某些情况下进行了增强,确保在不同浏览器中有一致的行为
+
+你在某个组件上写的事件代码,本质上都是添加到根 Dom 节点上的。
+```javascript
+// 你在组件中写的:
+function Button() {
+ const handleClick = () => console.log('Clicked!');
+ return ;
+}
+
+// 🔧 React实际做的事情:
+// 1. 只在根元素上绑定一个真实的事件监听器
+rootElement.addEventListener('click', (nativeEvent) => {
+ // 2. 找到实际被点击的DOM元素
+ const targetElement = nativeEvent.target;
+
+ // 3. 根据DOM元素找到对应的React组件和事件处理函数
+ const syntheticEvent = createSyntheticEvent(nativeEvent);
+ dispatchEvent(targetElement, 'click', syntheticEvent);
+});
+```
+
+
+
+
+
+## setState 是单向循环链表结构
+跟随源码来看看执行流程
+```javascript
+// 递归中的递阶段
+export const beginWork = (wip: FiberNode, renderLane: Lane) => {
+ // 比较,返回子fiberNode
+ switch (wip.tag) {
+ case HostRoot:
+ return updateHostRoot(wip, renderLane);
+ // ...
+};
+```
+会调用 updateHostRoot 方法
+
+```javascript
+function updateHostRoot(wip: FiberNode, renderLane: Lane) {
+ const baseState = wip.memoizedState;
+ const updateQueue = wip.updateQueue as UpdateQueue{count}
;
+ }
+ ```
+ 首次渲染后,链表结构为:`useState 节点 -> useEffect 节点 -> null`。
+
+
+#### 2. 重新渲染(Update 阶段)
+- 当组件因状态更新(如调用 `setCount`)重新渲染时,React 会重置 `workInProgressHook` 指针到链表的头部。
+- 再次按顺序调用 Hooks 时,React 会通过指针依次访问链表中已有的节点,直接复用或更新节点中的信息(而非重新创建节点)。
+ - 对于 `useState`:直接读取节点中保存的最新状态值,并返回更新函数。
+ - 对于 `useEffect`:检查当前依赖项与节点中保存的旧依赖项是否一致,决定是否执行副作用回调。
+
+ 这种“按顺序复用节点”的机制,正是 Hooks 能在多次渲染中保持状态的核心原因。
+
+
+### 关键注意点
+- **顺序必须严格一致**:如果在条件语句中调用 Hook(如 `if (condition) { useState() }`),会导致重新渲染时 Hooks 调用顺序与首次渲染不一致,链表指针无法正确匹配节点,最终引发状态错乱或报错。
+- **每个组件独立维护链表**:不同组件的 Hooks 链表是隔离的,互不影响(通过组件的 Fiber 节点关联各自的 Hooks 链表)。
+
+
+总结:**所有 Hooks 共同组成一个单向链表**,React 通过维护这个链表并严格遵循调用顺序,实现了 Hooks 在组件多次渲染中的状态追踪和复用。这一机制是 Hooks 设计的底层基础。
+
+
+## useEffect 工作原理
+### 实验说明
+AComponent
+```javascript
+import { useEffect } from "react"; // 注意:是 useEffect 而非 use
+
+export default function AComponent(props) {
+ // 普通函数:仅在 useEffect 回调中被调用,不是独立副作用
+ const effect1 = () => {
+ console.log("Effect 1(A组件的副作用逻辑1)");
+ return () => console.log("clean effect 1(A组件的清理逻辑1)");
+ };
+
+ const effect2 = () => {
+ console.log("Effect 2(A组件的副作用逻辑2)");
+ return () => console.log("clean effect 2(A组件的清理逻辑2)");
+ };
+
+ // A组件的唯一 useEffect 调用(生成1个 Effect 对象)
+ useEffect(() => {
+ // 回调中依次执行普通函数(属于该 Effect 对象的逻辑)
+ effect1();
+ effect2();
+ }, []);
+
+ return (
+
+
+ );
+}
+```
+BComponent
+```javascript
+// BComponent.jsx
+import { useEffect } from "react";
+
+export default function BComponent() {
+ const effect3 = () => {
+ console.log("Effect 3(B组件的副作用逻辑1)");
+ return () => console.log("clean effect 3(B组件的清理逻辑1)");
+ };
+
+ const effect4 = () => {
+ console.log("Effect 4(B组件的副作用逻辑2)");
+ return () => console.log("clean effect 4(B组件的清理逻辑2)");
+ };
+
+ // B组件的唯一 useEffect 调用(生成1个 Effect 对象)
+ useEffect(() => {
+ effect3();
+ effect4();
+ }, []);
+
+ return AComponent(父组件)
+ {props.children} {/* 渲染子组件B */} +BComponent(子组件)
;
+}
+```
+App.js
+```javascript
+// App.jsx
+import AComponent from "./AComponent";
+import BComponent from "./BComponent";
+
+function App() {
+ // 渲染结构:A是父组件,B是A的子组件
+ return (
+
+
+ );
+}
+```
+effect 中包含定时器,依赖于 delay 状态。input 输入框内容变化会改变 delay 的值,从而重新创建 timer。如果 React 官方的实现里面,没有在 effect 的执行前,把 effect.destory 先执行,再去执行 effect.create 就可能存在2个 timer,timer 回调里会修改 count,造成 UI 的错乱。
+
+
+## React 并发更新
diff --git a/Chapter2 - Web FrontEnd/2.42.md b/Chapter2 - Web FrontEnd/2.42.md
index 8131de6..1bf21ef 100644
--- a/Chapter2 - Web FrontEnd/2.42.md
+++ b/Chapter2 - Web FrontEnd/2.42.md
@@ -1,24 +1 @@
-# weex 优化和原理
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+# weex 优化和原理
\ No newline at end of file
diff --git a/Chapter2 - Web FrontEnd/2.46.md b/Chapter2 - Web FrontEnd/2.46.md
new file mode 100644
index 0000000..7666a7a
--- /dev/null
+++ b/Chapter2 - Web FrontEnd/2.46.md
@@ -0,0 +1,10 @@
+# 内存管理之垃圾回收与内存泄漏
+
+> 初级前端可能只是写写前端页面的话,如果没有关注过性能指标、内存情况的话,可能对于 JS 的内存管理策略、垃圾回收机制、内存泄漏等问题没有做过关注。
+
+- https://www.bilibili.com/video/BV1GZ421i7Hf/?spm_id_from=333.337.search-card.all.click&vd_source=28b2bef5a0ed844314aa1e77411ae19c
+
+
+## 垃圾回收
+
+## 内存泄漏
\ No newline at end of file
diff --git a/Chapter2 - Web FrontEnd/chapter2.md b/Chapter2 - Web FrontEnd/chapter2.md
index 084bbf6..94fa6f6 100644
--- a/Chapter2 - Web FrontEnd/chapter2.md
+++ b/Chapter2 - Web FrontEnd/chapter2.md
@@ -45,4 +45,5 @@
* [41、sourceMap 闪亮登场](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.41.md)
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
- * [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
\ No newline at end of file
+ * [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
+ * [45、内存管理之垃圾回收与内存泄漏](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.46.md)
\ No newline at end of file
diff --git a/Chapter7 - Geek Talk/7.5.md b/Chapter7 - Geek Talk/7.5.md
index b52969e..7e812ae 100644
--- a/Chapter7 - Geek Talk/7.5.md
+++ b/Chapter7 - Geek Talk/7.5.md
@@ -30,7 +30,7 @@
将全部的提交记录合并为1个
-## 删除项目中所有的提交记录
+## 删除项目中所有的提交记录
之前个人在 Github 开源了一些完整的项目,但是有些人用于商业用途,所以有了这个需求,就是将项目改动一下,删除一些重要代码提交最新的代码到仓库并且让用户不能通过提交的历史记录会滚到指定的版本看到代码。
以下为步骤
@@ -67,4 +67,741 @@
```shell
git tag -a 1.0.0 -m 'release SPM lib'
-```
\ No newline at end of file
+```
+
+
+## 代码回滚
+当前计数:{count}
+定时器间隔:{delay}ms
+ setDelay(Number(e.target.value))} + /> +修改输入框可改变间隔,观察计数变化
+
+
+git 存在3个区域:
+
+| **区域** | **别名** | **存储位置** | **核心功能** | **操作命令** |
+| :--------- | :---------- | :---------------- | :----------------- | :----------- |
+| **工作区** | Workspace | 本地目录 | 开发者直接编辑文件 | 手动编辑文件 |
+| **暂存区** | Index/Stage | `.git/index` 文件 | 准备下次提交的变更 | `git add` |
+| **版本库** | Repository | `.git/objects` | 永久存储的提交历史 | `git commit` |
+
+代码回滚用的是 git reset 指令。区别在于参数:
+
+- git reset --hard commitId:将代码回滚到工作区,本次代码(文件)的变动都会被舍弃。
+- git reset --soft commitId:将代码回滚到暂存区,本次代码(文件)的变动不会被舍弃,也就是相当于执行了 `git add` 的操作
+
+一般而言,为了安全和灵活,都采用 `git reset --soft commitId` 指令。
+
+
+
+HEAD:用来指向分支的最后一次提交对象。
+
+如果想要回到上一步,可以用 `HEAD~1` 代替具体的 commitID。
+
+如果想要丢弃还需要进一步处理:
+
+- git reset HEAD .`:则将暂存区的提交回滚掉。相当于没有执行 `git add`(只有本地新改动的数据)
+- `git checkout -- .`: 将本地新改动的数据丢弃掉。
+
+
+
+git checkout:
+
+- 切换分支,例如:`git checkout master`
+- 重新存储工作区文件。例如:`git checkout -- .`
+
+
+
+## git 原理
+
+- git 以 key、value 的形式存储。
+- 二进制仓库的底层数据结构为树
+- 本次修改文件的 hash 值为 key
+- 本次修改文件的压缩版本为 value
+
+
+
+### 1. git 对象存储
+
+git 将存储对象的40位 HASH 分为2部分:
+
+- 头2位作为文件夹
+
+- 后38位作为对象文件名。结构为:`.git/objects/hash[0:2]/hash[2:40]`
+
+
+
+ 比如:`gitDemo/.git/objects/22/13d05bf4b8cfc7ee323af3ac427ad2fa14da88`
+
+
+
+QA: 为什么要设计这样的目录结构(Hash 值总40位,前2位为文件夹名称,后38为文件名称),而不直接用40位 hash 值作为文件名?
+
+- 部分文件系统对目录下的文件数量有限制。例如,FAT32 限制单目录下的最大文件数量位 65535 个
+- 部分文件系统查找文件属于线性查找,目录下的文件越多,查找越慢
+
+
+
+### 2. git add 的本质
+
+
+
+`git ls-files -s` 指令查看暂存区文件 。
+
+git add 的本质就是内容哈希化。
+
+- 输入:文件内容(二进制流)
+- 处理:
+ - 添加头部信息:**"blob " + 内容字节数 + "\0"**
+ - 计算 SHA-1: **SHA1(header + content)**
+- 输出:40位十六进制的哈希值
+
+比如对 “Hello” 进行哈希计算:
+
+1. 原始内容:`b"Hello"`
+2. 添加头部
+ - 内容长度:5字节
+ - 构造头部:`b"blob 5\0"`
+3. 完整数据:`b"blob 5\0Hello"`
+4. SHA-1 计算。`HashUtils.sha1(data).hexdigest()`
+
+### 3. 如何计算 git 哈希
+
+使用指令 **git hash-object -w ./index.txt** 即可。
+
+将得到的40位长度的哈希,拆为2部分,前2位为文件夹名称,后38位为文件名。
+
+
+
+Demo1:
+
+对 `index.txt` 文件使用 `git hash-object -w index.txt` 指令计算哈希。
+
+
+
+Demo2:
+
+ `index.txt`文件内容没有改变, 继续计算哈希。发现哈希值一致
+
+结论:
+
+- **只要文件内容不变,hash 值不变。**
+- **每次计算一次哈希,都会在 `.git/objects/` 文件夹下多出一个子文件夹。**
+
+Demo3:
+
+对 `index.txt` 文件内容进行调整,`git hash-object -w index.txt` 指令计算哈希
+
+
+
+结论:
+
+- **文件内容改变了,hash 值变了。**
+- **文件内容改变后,生成新的 hash 值,同时会在 `.git/objects/` 文件夹下多出一个新的文件夹**。文件夹名称为新的哈希值的前2位,文件夹内文件名称为新的哈希值的后38位。
+
+
+
+### 4. 模拟 git add
+
+利用指令 **`git update-index --add --cacheinfo 100644 {FileHashValue} index.txt`** 将工作区的文件添加到缓存区
+
+- `--add`: 强制将指定文件添加到暂存区(即使文件不存在于工作目录中)
+- `--cacheinfo`: 手动指定文件的「模式(mode)+ 哈希值(hash)+ 路径(path)」来更新暂存区,用于添加那些不在工作目录中的文件
+- `100644`: 文件模式(file mode),表示这是一个普通文件(非执行文件、非符号链接等)。Git 中常见模式:`100644`(普通文件)、`100755`(可执行文件)、`120000`(符号链接)等
+- `{FileHashValue}`: 文件内容的 SHA-1 哈希值(40 位字符串),对应 Git 数据库(`.git/objects`)中存储的文件内容
+- `index.txt`:最终在暂存区中记录的文件名(路径)
+
+Demo:
+
+- 为了模拟 `git add` 的效果,先把仓库中的 `.git` 文件夹删掉
+- 利用指令 `git hash-object -w index.txt` 计算出 index.txt 的哈希值
+- 利用指令 `git update-index --add --cacheinfo 100644 2213d05bf4b8cfc7ee323af3ac427ad2fa14da88 index.txt` 将 `index.txt` 和计算出来的哈希值写入到暂存区
+- 利用指令 `git status` 查看是否成功写入到暂存区
+- 继续按照上述2个流程(git hash-object 和 git update-index)将剩余2个文件进行模拟添加到暂存区
+
+整体效果如下图:
+
+
+
+
+
+### 5. git 只有文件,没有目录
+
+为什么进一步强调 **git 只有文件,没有目录**的概念,做一个实验。
+
+第一步:上述步骤生成了3份 git hash,分别保存在 `.git/objects/` 目录下。
+
+
+
+第二步:接下去将暂存区的文件生成一颗树。使用指令 **git write-tree**
+
+第三步:查看生成的树信息。使用指令 `git cat-file -p {TreeHash}`
+
+
+
+第四步:使用指令 **`git read-tree --prefix=FantasticLBP/ 7f7bbe6285c9c767aeaa1aedba6dcf5324774bc8`** 将指定的 tree 对象内容读取到当前索引中,并将其所有文件放在名为 `FantasticLBP/` 的目录下。
+
+此时文件目录为:
+
+
+
+第五步:此时的效果为,暂存区里面存在另一份目录名为 `FantasticLBP/` 的暂存区信息。但是此时实体文件夹下并不存在。使用指令 `git checkout -- .` 便可以从暂存区恢复。
+
+恢复后的目录结构为:
+
+
+
+
+
+结论:
+
+- 通过在暂存区里面重新构建一颗树,便可以使用 checkout 恢复出来
+- 所以在使用代码重置功能的时候,最好使用 `git reset --soft head~1 ` 的方式进行,因为更加灵活。使用 `--hard` 就没有暂存区的记录了。
+
+### 6. git commit 的本质
+
+上述步骤:
+
+- 生成了3份文件的 git hash
+- 同时又将3份文件写入到暂存区,得到一个暂存区 tree 的哈希: `ce8045cf527ef892b8ad19c7b0bbac889fc44c59`。
+
+接下去为了探索 git commit 的本质,我们用 **`echo 'init commit' | git commit-tree ce8045cf527ef892b8ad19c7b0bbac889fc44c59`** 来完成提交。
+
+**`git commit-tree`**:Git 底层命令,用于创建一个新的提交对象(commit object)。它需要一个 tree 对象作为基础,并通过标准输入接收提交信息。命令执行成功后,会输出新创建的提交对象的 SHA-1 哈希值。
+
+
+
+可以看到:
+
+git commit 提交后也是会生成一个新的提交对象(commit object),新的提交对象也会在 `.git/objects/` 目录下存在。
+
+
+
+### 7. git rebase
+
+假如当前在分支 featureA 上,执行 `git rebase master` 后的效果,等价于将寻找到 featureA 和 master 的最近公共祖先节点,然后从 最近公共祖先节点到 featureA 的最新节点之间的 commit 都会被拆开,拼接到 master 分支最后面的 commit 上,重新组合成一个新的 commit。
+
+也就是搞清楚2个对象:
+
+- 当前在什么分之上?featureA
+- git rebase 指令后跟什么分之?master
+
+执行完的效果就是:master + featureA(从 master 和 featureA 的最近公共祖先处截断、拼接在后面)
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1 <--- A2 <--- A3 [featureA, HEAD]
+```
+
+- 寻找公共祖先
+
+ ```shell
+ LCA = git merge-base featureA maste` # 返回 C1
+ ```
+
+- 提取提交差异
+
+ ```shell
+ commits = git log C1..featureA --pretty=format:"%H` # 获取从 C1 到 featureA 的 commit 差异,得到: [A1, A2, A3]
+ ```
+
+- 重置到目标基点
+
+ ```shell
+ git reset --hard M2 # featureA分支指针临时指向M2
+ ```
+
+- 按顺序重新重置提交
+
+ ```shell
+ git cherry-pick A1 # 创建新提交A1' (父提交=C1)
+ git cherry-pick A2 # 创建新提交A2' (父提交=A1)
+ git cherry-pick A3 # 创建新提交A3' (父提交=A2)
+ ```
+
+最终结果
+
+```shell
+C0 <--- C1 <--- M1 <--- M2 [master]
+ \
+ \
+ A1' <--- A2' <--- A3' [featureA, HEAD]
+```
+
+
+
+git rebase 还可以用于一些提交信息的处理,比如 `git rebase -i {CommitHash}`
+
+
+
+git rebase 还可以将多次 commit 合并为1次,也可以修改某次 commit 的信息等等,具体的可以看指令后面的注释。
+
+
+
+### 8. 冲突展示
+
+#### 1. 双路展示策略
+
+git 在 merge 或者 rebase 都会存在冲突的可能,关于文件内容冲突默认是按照双路合并的形式进行展示的。这样子信息有限
+
+可以通过下面指令,查看当前的冲突展示规则:
+
+```shell
+git config merge.conflictstyle
+```
+
+如果没有任何输出,则说明没有任何设置,默认就是**双路展示策略**。
+
+冲突标记仅显示**当前分支**(`<<<<<<< HEAD`)和**合并分支**(`>>>>>>>
+
+当前 case 下,我需要选择左侧为结果,所以点击了 "Choose left"。下面区域为合并后的结果。在终端还有来一次确认过程。做到 double check。
+
+
+
+属于 y 后,相当于选择了结果,接下去再进行 add、commit 等操作。
+
+
+
+### 9. git log -p
+
+#### 1. 基础指令
+
+**`git log -p commitId`** 是一个组合命令,用于**详细展示特定提交及其之前的提交历史,并显示每个提交的代码差异**
+
+说明:从指定的 `commitId` **开始回溯**,按时间倒序列出其**祖先提交**
+
+示例如下
+
+
+
+
+
+#### 2. 输出信息结构
+
+每个提交显示2块信息:
+
+- 提交元信息
+
+ 比如
+
+ ```shell
+ commit 0d614db5d3ba7ae2606de696a3627819b2368378 # 提交哈希
+ Author: FantasticLBP
+
+ - 使用 `git stash show -p stash@{0}` 查看**存储修改内容**。其中 `-p` 是 `--patch` 的缩写,显示完整差异(补丁格式),`stash{0}` 指定要查看的储藏引用(0 表示最近一次储藏)
+
+
+
+
+
+ - 也可以使用 `git stash` 指令,会自动生成默认消息,包含清晰的 WIP 日志。也是标准推荐做法。
+
+ ```shell
+ # 标准命令
+ git stash
+ # 等价于
+ git stash push "WIP on $(git branch --show-current): $(git log -1 --format=%s)"
+ ```
+
+ - 使用 `git stash apply stash@{1}` 来应用某次具体的 stash 栈里的信息。注意:新 stash 的 序号更早,早期的由近到远依次+1
+
+
+
+ - 如果从 stash 里取出的代码不满意,如何恢复到 之前的状态?使用组合命令 **git stash show -p stash@{1} | git apply -R`** 来达到反向应用补丁的效果。
+
+
+
+ 管道符 `|` ,将前一个命令的输出作为后一个命令的输入。比如:
+
+ ```shell
+ # 应用了错误的存储
+ git stash apply stash@{1}
+
+ # 发现需要撤销
+ git stash show -p stash@{1} | git apply -R
+ ```
+
+ - stash 由于是栈,所以有 push、pop 能力。push 就是往栈里加,pop 就是移除。完整指令为 **`git stash pop stash@{0}`**
+
+
+
+### 11. git ignore
+
+在开发中经常会遇到有些类型的文件不需要提交到远端进行多人协作,比如 iOS 开发中的 cocoapods install 后的 pods 目录,或者 NodeJS 开发中的 node_modules 目录,git 也设计了该口子,允许使用 **.gitignore ** 文件用于指定 Git 版本控制系统应忽略的文件和目录,避免将临时文件、编译产物或敏感信息纳入版本控制。
+
+#### 1. 核心规则
+
+- 每行一个规则,支持通配符:
+ - `*` 匹配任意字符(除路径分隔符外)
+ - `**` 匹配任意层级目录
+ - `?` 匹配单个字符
+ - `[abc]` 匹配指定字符
+- 路径规则:
+ - 以 `/` 开头:仅匹配项目根目录(如 `/temp.log`)
+ - 以 `/` 结尾:仅匹配目录(如 `build/`)
+- 取反规则:用 `!` 取消忽略(如 `!src/important.log`
+
+
+
+#### 2. 最佳实践
+
+- 在项目根目录创建 ``.gitignore` 文件
+
+- 根据项目和语言类型,搜索一个标准的 `.gitignore` 模版,将内容复制进去
+
+- 如果项目初始化的时候没有添加完全部的 `.gitignore` 文件内容。再到后来开发的过程中,给 `.gitignore` 里面添加了内容,但后来添加的 `.gitignore` 已经比较晚了,当前提示不允许追踪的文件,还是会被 git 追踪。并且已经提交到暂存区了。
+
+ 因为都存在于本地暂存区了,所以可以使用指令 **`git update-index --assume-unchanged {FileName}`** 来告诉 git,不要追踪暂存区的 FileName 该文件
+
+
+
+- 顾名思义,pre-push、post-push 分别是在 push 之前、push 之后触发的钩子。所以其他几个钩子类似
+
+- 本次演示继续在之前的 Demo 上演示,使用 Pre-Commit 钩子,去掉拓展名。注释掉其他代码,添加一句打印输出
+
+
+
+注意:这里可以使用 shell、也可以使用 python、JS、Ruby 等脚本
+
+
+
+
+
+#### 1. 代码格式与静态检查
+
+- 钩子:`pre-commit`
+
+- 作用:提交前自动运行 ESLint、Prettier、Flake8 等工具,检查语法错误、代码风格或安全漏洞。若检查失败,则阻止提交
+
+ ```shell
+ # pre-commit 脚本片段
+ eslint --fix --ext .js,.ts src/ # 自动修复并检查JS/TS文件
+ ```
+
+
+
+#### 2. git 日志规范化
+
+- 钩子:`commit-msg`
+
+- 作用:检查提交信息是否符合约定格式(如必须包含前缀 `[Feat]`、`[Fix]` 或关联问题编号)。违规时终止提交
+
+ ```shell
+ # commit-msg 脚本片段
+ if ! grep -qE "^(FEAT|FIX|DOC):" "$1"; then
+ echo "提交信息必须以 FEAT/FIX/DOC 开头!"
+ exit 1
+ fi
+ ```
+
+#### 3. 单元测试与代码覆盖率
+
+- 钩子:`pre-push`
+- 作用:推送前运行测试套件(不管是单元测试也好,还是精准测试也好),必须保证全部的测试 case 通过,且代码覆盖率达到95%以上才可以合并。确保新代码不破坏现有功能。测试失败则阻止推送。
+
+
+
+#### 4. 自动部署测试环境
+
+- 钩子:`post-receive`(服务端)
+- 作用:代码推送到远程仓库后,自动将代码同步至服务器目录,触发部署流程(如更新网站文件)
+
+
+
+#### 5. CI/CD 流程
+
+- 钩子:`post-receive`(服务端)
+- 作用:推送完成后通知 CI 工具(如 Jenkins、GitLab CI)执行流水线任务(构建、测试、部署)
+
+
+
+### 15. 本地仓库对应远端仓库是1对多的关系
+
+为了模拟本地和远端是1对多的关系:
+
+- 将之前的 Demo 的 `.git` 文件夹删掉。模拟一个干净的文件夹,没有 git 信息
+- 创建2个文件夹,模拟 git 远端服务器的 repo 信息。分别为 gitDemoServer1、gitDemoServer2
+- 分别在 gitDemoServer1、gitDemoServer2 文件夹执行 `git init --bare` ,**在服务器文件夹初始化裸仓库**
+- 在 gitDemo 终端路径下,执行 `git init` 初始化本地仓库
+- 继续在 gitDemo 终端路径下分别执行 **`git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1` **和** `git remote add origin2 /Users/unix_kernel/Desktop/gitDemoServer2`** ,为了给当前的 repo 配置多个远端仓库
+- 最后执行 `git remote -v` 指令查看当前 repo 的 remote 信息
+
+
+
+说明:
+
+- 裸仓库特点:
+
+ - 没有工作目录(不能直接编辑文件)
+ - 目录内容直接包含 Git 内部文件(无 `.git` 隐藏文件夹)
+
+- `git remote add origin /Users/unix_kernel/Desktop/gitDemoServer1`
+
+ - `origin` 和 `origin2` 是远程仓库的别名
+ - 路径可以是绝对路径(推荐)或相对路径
+
+- 本地只有1个分支,远端分支名也不一定相同。所以需要告诉 git 本地分支如何与远端进行关联
+
+ ````shell
+ git remote add -t main origin https://github.com/FantasticLBP/GitDemo
+ ````
+
+ - `git remote add` :想本地仓库添加要 track 的远程仓库
+ - `-t main` : 指定本地要 track 远程仓库中的哪个分支
+ - `origin`: 远程仓库的名字
+ - `https://github.com/FantasticLBP/GitDemo`: 远程仓库的地址
+
+
diff --git a/Chapter8 - Algorithm/8.1.md b/Chapter8 - Algorithm/8.1.md
new file mode 100644
index 0000000..c8be63f
--- /dev/null
+++ b/Chapter8 - Algorithm/8.1.md
@@ -0,0 +1,190 @@
+## leetcode 968. 监控二叉树
+
+## 题目描述
+给定一个二叉树,我们在树的节点上安装监控。
+
+节点上的每个摄影头都可以监视其父对象、自身及其直接子对象
+
+计算监控树的所有节点所需的最小监控数量。
+
+2个例子:
+
+case1:
+
+``` shell
+ 1
+ |
+ 2 监控
+ / \
+ 3 4
+
+```
+
+Case2:
+
+```shell
+ 1
+ /
+ 2 监控
+ /
+ 3
+ /
+ 4 监控
+ \
+ 5
+```
+
+## 分析
+
+- 一颗监控可以覆盖:当前节点、当前节点的父节点、当前节点的所有子节点3层
+
+- 本题目要求使用最小数量的监控解决问题。那么也就是贪心思维的体现,那么问题来了,什么策略才可以使用最小数量的监控?
+
+ - 一棵二叉树中,叶子节点数量肯定是最多的。所以要想最小数量安装监控,优先选择非叶子节点上安装监控。这也是本题中贪心思维的体现。
+ - 如果最后一层叶子节点不安装监控,那么肯定是叶子节点的父节点安装监控,同理叶子节点的父节点的父节点,也会被监控覆盖到,所以叶子节点的父节点的父节点不用安装监控。于是
+ 叶子节点的父节点的父节点的父节点就必须安装监控。
+
+
+
+- 对于二叉树一定是采用递归法或者迭代法解决,本题选择递归法。
+
+- 因为要根据叶子节点的状态来反推父节点的状态,所以采用后续遍历。
+
+- 另外需要根据左右子树的返回值来判断,所以递归函数需要返回值
+
+- 为了方便定义3个状态。
+
+ - 未设置监控 NotCovered = 0
+ - 被监控覆盖 IsCoverd = 1
+ - 设置监控 SetCamera = 2
+
+- 如何定义递归函数?
+
+ - 返回值就是数字,存在3种情况,也就是上面定义的3种状态
+ - 递归函数的终止条件是什么?遇到叶子节点的左右空子树的情况下,该选用什么状态?思考下:共3种情况
+ - 空节点选用 “未覆盖 NotCovered”?
+ ❌ 问题 :叶子节点必须安装监控来覆盖空节点
+ 如果空节点是 NotCovered,那么空节点的父节点,也就是叶子节点,必须设置监控,才可以保证叶子节点的左右子节点才可以被监控覆盖到。
+ ❌ 结果:摄像头数量过多,不符合最小化原则
+ 这和题目要求的最小监控数量不契合
+ - 空节点选用 “安装监控 SetCamera”?
+ ❌ 问题:叶子节点自动变为被覆盖状态 (IsCovered = 1)
+ 如果空节点是 SetCamera,那么空节点的父节点,也就是叶子节点,状态一定是被覆盖 IsCoverd,如果叶子节点是 IsCoverd,
+ ❌ 结果:叶子节点的父节点不需要安装监控,破坏了"叶子节点的父节点安装监控"的最优策略
+ 反推叶子节点的父节点就不需要安装监控了(因为监控必须间隔设置,覆盖 - 监控 - 覆盖 - 监控 这样的形式),那这个情况也和题目的预设条件不满足。
+ - 所以空节点应该选用 “被监控覆盖 IsCoverd” 这个状态
+ ✅ 正确:叶子节点为未覆盖状态 (NotCovered = 0)
+ 空节点被监控覆盖 IsCoverd,那么空节点的父节点,也就是叶子节点就不需要设置监控,
+ ✅ 结果:叶子节点的父节点必须安装监控,符合贪心策略
+ 也就是未设置监控 NotCovered = 0,那么叶子节点的父节点才需要设置监控 SetCamera
+
+## 状态转换情况
+说明:
+- 未设置监控 NotCovered = 0
+- 被监控覆盖 IsCoverd = 1
+- 设置监控 SetCamera = 2
+
+| leftChild | rightChild | root | count=0 | 说明 |
+| --------- | ---------- | ---- | ------- | ------------------------------------------------------------ |
+| 1 | 1 | 0 | +0 | 空节点(叶子节点的子节点)必须同时处于被覆盖状态 |
+| | | | | |
+| 0 | 0 | 2 | +1 | 普通节点不管 left、right 只要有1个处于未覆盖状态,那么父节点一定要设置监控才可以“罩着”下面的子节点 |
+| 0 | 1 | 2 | +1 | |
+| 1 | 0 | 2 | +1 | |
+| 2 | 0 | 2 | +1 | |
+| 0 | 2 | 2 | +1 | |
+| | | | | |
+| 2 | 2 | 1 | +0 | 其他情况,父节点都是处于被监控覆盖的状态,不需要增加监控 |
+| 2 | 1 | 0 | +0 | |
+| 1 | 2 | 1 | +0 | |
+| 2 | 1 | 1 | +0 | |
+
+
+
+## 贪心思想
+
+本题目贪心体现在(监控数量 count = 0):
+- 空节点(叶子节点的子节点):处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- 叶子节点:不设置监控,处于 NotCovered 状态。需要父节点罩着。count 不变
+- 叶子节点的父节点:安装监控,处于 SetCamera 状态,count++
+- 叶子节点的爷爷节点:处于被监控状态(IsCovered 状态),没有安装监控。count 不变
+- ♻️ 循环往复
+
+
+
+## 代码实现(JS 为例)
+
+```js
+/**
+ * @param {TreeNode} root
+ * @return {number}
+ */
+var minCameraCover = function(root) {
+ let count = 0
+ const Mode_NotCovered = 0 // 未设置监控
+ const Mode_IsCovered = 1 // 被监控覆盖
+ const Mode_SetCamera = 2 // 设置监控
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return Mode_IsCovered
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === Mode_NotCovered || right === Mode_NotCovered) {
+ count++
+ return Mode_SetCamera
+ }
+ // 如果左孩子和右孩子都是覆盖状态,那么父节点处于非覆盖状态
+ if (left === Mode_IsCovered && right === Mode_IsCovered) {
+ return Mode_NotCovered
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === Mode_SetCamera || right === Mode_SetCamera) {
+ return Mode_IsCovered
+ }
+ return Mode_NotCovered
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === Mode_NotCovered) count++
+ return count
+};
+```
+提交后发现空间复杂度一般,去掉定义的状态和更加清楚的 if 分支,代码如下
+
+```js
+var minCameraCover = function(root) {
+ let count = 0
+
+ const traverse = (node) => {
+ // 空节点视为已覆盖(推到过程见上面注释部分)
+ if (node === null) return 1
+
+ // 后序遍历
+ let left = traverse(node.left)
+ let right = traverse(node.right)
+
+ // 如果左右孩子有一个未被覆盖,当前节点需要安装摄像头
+ if (left === 0 || right === 0) {
+ count++
+ return 2
+ }
+ // 如果左孩子或者右孩子是设置监控状态,那么父节点处于监控覆盖状态
+ if (left === 2 || right === 2) {
+ return 1
+ }
+ return 0
+ }
+
+ let rootResult = traverse(root)
+ // 检查根节点状态,如果未被覆盖则需要增加一个摄像头
+ if (rootResult === 0) count++
+ return count
+};
+```
+
diff --git a/Chapter8 - Algorithm/8.2.md b/Chapter8 - Algorithm/8.2.md
new file mode 100644
index 0000000..c9c13f4
--- /dev/null
+++ b/Chapter8 - Algorithm/8.2.md
@@ -0,0 +1,161 @@
+# 《剑指 Offer》字符串“左旋”、“右旋”里的数学秘密
+
+> 为什么要写本篇文章?看上去这是 easy 级别的题目。但“点是面的缩影,面是点的抽象”,单独一道题似乎很简单,我们可以比较轻松做出来。但是这一类题目的本质是什么?不要处于混沌的状态解决了题目,但下次遇到类似的,还是要迟疑思考一会儿。本篇文章带你吃透问题的本质和背后的数学推导。
+
+
+
+## 题目描述
+字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。
+
+请定义一个函数实现字符串左旋转操作的功能。比如:
+- 输入字符串 "abcdefg" 和数字 2
+- 该函数将返回左旋转 2 位后的结果 "cdefgab"
+
+请实现该函数
+
+## 结论
+只要是字符串的左旋、右旋,都用整体逆序 + 部分逆序的方法,也可以是部分逆序 + 整体逆序。
+
+## 分析
+关于反转(也就是逆序),有2个 feature:
+- 反转的可逆性:反转(反转(x)) = x
+ - 类似负负得正。比如:'123' 经过一次反转后为 '321', '321' 再经过一次反转为 '123'
+- 反转的可组合性:反转 (A + B) = 反转(B) + 反转(A)
+ - '123456' 按照长度为3进行拆分为2部分,s1 + s2。s1 = '123', s2 = '456
+ - 先对后面的 s2,也就是'456' 反转得到 '654',即 s2' = '654'
+ - 再对前面的 s1,也就是'123' 反转得到 '321',即 s1' = '321'
+ - 再对 s1' 和 s2' 进行拼接, s1' + s2' = '654321'
+ - 观察发现 s1' + s2' 就等于对整体 s1 + s2 逆序后的结果。
+
+再来观察看看:左旋、右旋题目要求的是什么?
+
+前提:假设一个逆序函数,可以将 x 作为输入,输出是 x'。这个共识、前提成立,我们再进行后续的推导:
+1. 原始字符串通过 k 为分割,可以拆分为: A + B。题目求的是什么? B + A
+2. 思考:根据上面的2个特性,通过什么变化可以从 A + B,得到 B + A 呢?
+不难得出结论,有2个方案:
+- 先整体逆序,`逆序 (A + B) = 逆序(B) + 逆序(A) = B' + A'`
+- 再局部逆序,`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求。所以这些方法都是有迹可循的,符合数学群论中的 **“逆运算”** 和 **“运算律”** 的思想
+
+
+## 方法1:先整体逆序,再局部逆序
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先整体逆序。`逆序(A) = A' 逆序(B) = B'。大的结构还是逆序(A + B) = B' + A'`
+3. 再局部逆序:`逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法1: 先整体,再部分
+ const rotateLeft = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 2. 再局部逆序
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, length - k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, length - k, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+## 方法2:先部分逆序,再整体逆序
+思考:能不能先局部逆序,再整体逆序?
+分析:继续用上面的思路推导下
+1. 原始字符串通过 k 拆分为: A + B 的结构,左旋后变为 B + A
+2. 先局部逆序:`逆序(A) + 逆序(B) = A' + B'`
+3. 再整体逆序。`逆序(A + B) = 逆序(B) + 逆序(A)`。但是此刻我们的输入为: A' + B',
+
+所以等价于:`逆序(A' + B') = 逆序(B') + 逆序(A') = B + A`
+
+结论:我们发现这时候的结果刚好满足题目要求,不管是先局部再整体,还是先整体再局部,效果是等价的。
+
+```javascript
+ // 方法2: 先部分,再整体
+ const rotateLeft1 = (message, k) => {
+ const length = message.length
+ let datasource = Array.from(message)
+
+
+ const reverse = (datasource, fromIndex, toIndex) => {
+ for (; fromIndex < toIndex; fromIndex++, toIndex--) {
+ let temp = datasource[fromIndex]
+ datasource[fromIndex] = datasource[toIndex]
+ datasource[toIndex] = temp
+ }
+ }
+
+ // 1. 再局部逆序
+
+ // abcdefg -> gfedc ba ->
+ // 先对左半部分逆序
+ /*
+ 已知:leftTo = k,leftLength = fullLength - k,求 leftTo?
+ 注意:此时的 length 不等于 k,因为左旋的前半段为 k,剩余的后半段 length 为完整的 length - k
+ leftTo - leftFrom + 1 = leftLength
+ leftTo = leftLength + leftFrom - 1
+ 代入得到:
+ leftTo = (fullLength - k) + 0 - 1 = length - k - 1
+ */
+ reverse(datasource, 0, k - 1)
+ // 再对右半部分逆序
+ /*
+ 已知:rightTo = fullLength - 1,rightLength = k,求 rightFrom?
+ rightTo - rightFrom + 1 = rightLength
+ rightFrom = rightTo - rightLength + 1
+ 代入得到:
+ rightFrom = (length - 1) - k + 1 = length - k
+ */
+ reverse(datasource, k, length - 1)
+
+ // 2. 先整体逆序
+ reverse(datasource, 0, length - 1)
+
+ // 3. 字符串数组拼接为结果
+ return datasource.join('')
+ }
+```
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/Chapter8 - Algorithm/chapter8.md b/Chapter8 - Algorithm/chapter8.md
new file mode 100644
index 0000000..e69de29
diff --git a/SUMMARY.md b/SUMMARY.md
index cd36511..d74a057 100644
--- a/SUMMARY.md
+++ b/SUMMARY.md
@@ -117,6 +117,8 @@
* [112、Swift 枚举值内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.112.md)
* [113、Swift 结构体和类的内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.113.md)
* [114、Swift 优化](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.114.md)
+ * [115、AI 对端上的赋能](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.115.md)
+ * [147. Rust 在移动端可以做什么](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.147.md)
* [Chapter2 - Web FrontEnd](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/chapter2.md)
* [1、-last-child与-last-of-type你只是会用,有研究过区别吗?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.1.md)
* [2、正则表达式](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.2.md)
@@ -162,6 +164,9 @@
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
* [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
+ * [45、内存管理之垃圾回收与内存泄漏](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.46.md)
+
+
* [Chapter3 - Server](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/chapter3.md)
* [1、利用分页和模糊查询技术实现一个App接口](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.1.md)
* [2、网页端扫码登录实现原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.2.md)
@@ -246,4 +251,6 @@
* [24、短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.25.md)
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
* [26、敏捷软件开发和 Scurm Master](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.27.md)
- * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
\ No newline at end of file
+ * [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
+* [Chapter8 - Algorithm](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/chapter8.md)
+ * [1、Leetcode968. 监控二叉树](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/8.1.md)
\ No newline at end of file
diff --git a/assets/AFNetworkingIsDynamicLib.png b/assets/AFNetworkingIsDynamicLib.png
new file mode 100644
index 0000000..8653c33
Binary files /dev/null and b/assets/AFNetworkingIsDynamicLib.png differ
diff --git a/assets/APM-CoreAnimationPipeline.png b/assets/APM-CoreAnimationPipeline.png
new file mode 100644
index 0000000..b36eed4
Binary files /dev/null and b/assets/APM-CoreAnimationPipeline.png differ
diff --git a/assets/AddStaticLibIntoApp.png b/assets/AddStaticLibIntoApp.png
new file mode 100644
index 0000000..0dd8197
Binary files /dev/null and b/assets/AddStaticLibIntoApp.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderMap.png b/assets/AppCompileStaticLibWithHeaderMap.png
new file mode 100644
index 0000000..155a6f2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderMap.png differ
diff --git a/assets/AppCompileStaticLibWithHeaderSearchPath.png b/assets/AppCompileStaticLibWithHeaderSearchPath.png
new file mode 100644
index 0000000..393d7b2
Binary files /dev/null and b/assets/AppCompileStaticLibWithHeaderSearchPath.png differ
diff --git a/assets/AppLinkDynamicLibNotSign.png b/assets/AppLinkDynamicLibNotSign.png
new file mode 100644
index 0000000..c5f147f
Binary files /dev/null and b/assets/AppLinkDynamicLibNotSign.png differ
diff --git a/assets/BlockAssignIsValueAssign.png b/assets/BlockAssignIsValueAssign.png
new file mode 100644
index 0000000..50a9f77
Binary files /dev/null and b/assets/BlockAssignIsValueAssign.png differ
diff --git a/assets/CocdSignIphoneLog.png b/assets/CocdSignIphoneLog.png
new file mode 100644
index 0000000..ac4dce3
Binary files /dev/null and b/assets/CocdSignIphoneLog.png differ
diff --git a/assets/CocoapodsCommandWithSciptFile.png b/assets/CocoapodsCommandWithSciptFile.png
new file mode 100644
index 0000000..3d5ea65
Binary files /dev/null and b/assets/CocoapodsCommandWithSciptFile.png differ
diff --git a/assets/CocoapodsHMapInfo.png b/assets/CocoapodsHMapInfo.png
new file mode 100644
index 0000000..8132397
Binary files /dev/null and b/assets/CocoapodsHMapInfo.png differ
diff --git a/assets/CocoapodsHMapLocalInstall.png b/assets/CocoapodsHMapLocalInstall.png
new file mode 100644
index 0000000..479bf21
Binary files /dev/null and b/assets/CocoapodsHMapLocalInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall.png b/assets/CocoapodsHMapPostInstall.png
new file mode 100644
index 0000000..349dbf4
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall.png differ
diff --git a/assets/CocoapodsHMapPostInstall2.png b/assets/CocoapodsHMapPostInstall2.png
new file mode 100644
index 0000000..3cab6fe
Binary files /dev/null and b/assets/CocoapodsHMapPostInstall2.png differ
diff --git a/assets/CocoapodsHMapV1.png b/assets/CocoapodsHMapV1.png
new file mode 100644
index 0000000..5c73744
Binary files /dev/null and b/assets/CocoapodsHMapV1.png differ
diff --git a/assets/CocoapodsHMapV2.png b/assets/CocoapodsHMapV2.png
new file mode 100644
index 0000000..5b25a8f
Binary files /dev/null and b/assets/CocoapodsHMapV2.png differ
diff --git a/assets/CocoapodsHMapV2Test.png b/assets/CocoapodsHMapV2Test.png
new file mode 100644
index 0000000..f808bfd
Binary files /dev/null and b/assets/CocoapodsHMapV2Test.png differ
diff --git a/assets/CocoapodsScriptCodeSignDetails.png b/assets/CocoapodsScriptCodeSignDetails.png
new file mode 100644
index 0000000..ff7fbd0
Binary files /dev/null and b/assets/CocoapodsScriptCodeSignDetails.png differ
diff --git a/assets/CocoapodsSelfDefinedScript.png b/assets/CocoapodsSelfDefinedScript.png
new file mode 100644
index 0000000..e9cf916
Binary files /dev/null and b/assets/CocoapodsSelfDefinedScript.png differ
diff --git a/assets/CodeSignAppWithDynamicLibLog.png b/assets/CodeSignAppWithDynamicLibLog.png
new file mode 100644
index 0000000..d91d7c2
Binary files /dev/null and b/assets/CodeSignAppWithDynamicLibLog.png differ
diff --git a/assets/CodeSignByCocoapodsScripts.png b/assets/CodeSignByCocoapodsScripts.png
new file mode 100644
index 0000000..c782400
Binary files /dev/null and b/assets/CodeSignByCocoapodsScripts.png differ
diff --git a/assets/CodeSignEntitlements.png b/assets/CodeSignEntitlements.png
new file mode 100644
index 0000000..1341ecb
Binary files /dev/null and b/assets/CodeSignEntitlements.png differ
diff --git a/assets/DumpProvisionProfile.png b/assets/DumpProvisionProfile.png
new file mode 100644
index 0000000..a84866a
Binary files /dev/null and b/assets/DumpProvisionProfile.png differ
diff --git a/assets/DuplicateSymbolWhenLinkTwoStaticLib.png b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..06c65db
Binary files /dev/null and b/assets/DuplicateSymbolWhenLinkTwoStaticLib.png differ
diff --git a/assets/FastlaneMatchfile.png b/assets/FastlaneMatchfile.png
new file mode 100644
index 0000000..e8eab68
Binary files /dev/null and b/assets/FastlaneMatchfile.png differ
diff --git a/assets/FastlaneScriptCodeGen.png b/assets/FastlaneScriptCodeGen.png
new file mode 100644
index 0000000..5380457
Binary files /dev/null and b/assets/FastlaneScriptCodeGen.png differ
diff --git a/assets/FastlaneStructure.png b/assets/FastlaneStructure.png
new file mode 100644
index 0000000..04d5192
Binary files /dev/null and b/assets/FastlaneStructure.png differ
diff --git a/assets/GitHash.png b/assets/GitHash.png
new file mode 100644
index 0000000..7557ced
Binary files /dev/null and b/assets/GitHash.png differ
diff --git a/assets/GitHooksTemplate.png b/assets/GitHooksTemplate.png
new file mode 100644
index 0000000..33a093c
Binary files /dev/null and b/assets/GitHooksTemplate.png differ
diff --git a/assets/GitLogPCommand.png b/assets/GitLogPCommand.png
new file mode 100644
index 0000000..67ec5ac
Binary files /dev/null and b/assets/GitLogPCommand.png differ
diff --git a/assets/GitOpenDiffPanel.png b/assets/GitOpenDiffPanel.png
new file mode 100644
index 0000000..fe4e4da
Binary files /dev/null and b/assets/GitOpenDiffPanel.png differ
diff --git a/assets/GitOpenDiffResult.png b/assets/GitOpenDiffResult.png
new file mode 100644
index 0000000..1f35373
Binary files /dev/null and b/assets/GitOpenDiffResult.png differ
diff --git a/assets/GitPreCommitHook.png b/assets/GitPreCommitHook.png
new file mode 100644
index 0000000..bfbe0c0
Binary files /dev/null and b/assets/GitPreCommitHook.png differ
diff --git a/assets/GitRebaseCommand.png b/assets/GitRebaseCommand.png
new file mode 100644
index 0000000..cc6ba7e
Binary files /dev/null and b/assets/GitRebaseCommand.png differ
diff --git a/assets/GitRemoveTrackingWithIgnore.png b/assets/GitRemoveTrackingWithIgnore.png
new file mode 100644
index 0000000..85c7037
Binary files /dev/null and b/assets/GitRemoveTrackingWithIgnore.png differ
diff --git a/assets/GitStashApply.png b/assets/GitStashApply.png
new file mode 100644
index 0000000..06bd2bb
Binary files /dev/null and b/assets/GitStashApply.png differ
diff --git a/assets/GitStashApplyRevert.png b/assets/GitStashApplyRevert.png
new file mode 100644
index 0000000..aad4b24
Binary files /dev/null and b/assets/GitStashApplyRevert.png differ
diff --git a/assets/GitStashCommand.png b/assets/GitStashCommand.png
new file mode 100644
index 0000000..cabb549
Binary files /dev/null and b/assets/GitStashCommand.png differ
diff --git a/assets/GitStashPCommand.png b/assets/GitStashPCommand.png
new file mode 100644
index 0000000..5b157b9
Binary files /dev/null and b/assets/GitStashPCommand.png differ
diff --git a/assets/GitWorkFlow.png b/assets/GitWorkFlow.png
new file mode 100644
index 0000000..b7ddd52
Binary files /dev/null and b/assets/GitWorkFlow.png differ
diff --git a/assets/HMapDumpRes.png b/assets/HMapDumpRes.png
index 89807d3..6fb2ae8 100644
Binary files a/assets/HMapDumpRes.png and b/assets/HMapDumpRes.png differ
diff --git a/assets/HMapDumpSystemTools.png b/assets/HMapDumpSystemTools.png
index 29e0b3a..34b6f5f 100644
Binary files a/assets/HMapDumpSystemTools.png and b/assets/HMapDumpSystemTools.png differ
diff --git a/assets/HMapDumpXcodeConfig.png b/assets/HMapDumpXcodeConfig.png
index 8c50a0a..36ddbeb 100644
Binary files a/assets/HMapDumpXcodeConfig.png and b/assets/HMapDumpXcodeConfig.png differ
diff --git a/assets/LLDBArchitecture.png b/assets/LLDBArchitecture.png
new file mode 100644
index 0000000..6830834
Binary files /dev/null and b/assets/LLDBArchitecture.png differ
diff --git a/assets/LLDBWorkflow.png b/assets/LLDBWorkflow.png
new file mode 100644
index 0000000..270597f
Binary files /dev/null and b/assets/LLDBWorkflow.png differ
diff --git a/assets/LLVMObjCopyBuildSuccess.png b/assets/LLVMObjCopyBuildSuccess.png
new file mode 100644
index 0000000..4e09abb
Binary files /dev/null and b/assets/LLVMObjCopyBuildSuccess.png differ
diff --git a/assets/LLVMObjCopyCommandNotFound.png b/assets/LLVMObjCopyCommandNotFound.png
new file mode 100644
index 0000000..b07b762
Binary files /dev/null and b/assets/LLVMObjCopyCommandNotFound.png differ
diff --git a/assets/LLVMObjCopyHelp.png b/assets/LLVMObjCopyHelp.png
new file mode 100644
index 0000000..e3d3eef
Binary files /dev/null and b/assets/LLVMObjCopyHelp.png differ
diff --git a/assets/LLVMObjcCopySuccess.png b/assets/LLVMObjcCopySuccess.png
new file mode 100644
index 0000000..2fe4ce0
Binary files /dev/null and b/assets/LLVMObjcCopySuccess.png differ
diff --git a/assets/LVMObjCopyBatchSuccess.png b/assets/LVMObjCopyBatchSuccess.png
new file mode 100644
index 0000000..a944963
Binary files /dev/null and b/assets/LVMObjCopyBatchSuccess.png differ
diff --git a/assets/LVMObjCopyLaunchOptions.png b/assets/LVMObjCopyLaunchOptions.png
new file mode 100644
index 0000000..85a235e
Binary files /dev/null and b/assets/LVMObjCopyLaunchOptions.png differ
diff --git a/assets/LVMObjCopyOptionNotSupportIssue.png b/assets/LVMObjCopyOptionNotSupportIssue.png
new file mode 100644
index 0000000..294d141
Binary files /dev/null and b/assets/LVMObjCopyOptionNotSupportIssue.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib.png b/assets/LinkFailedWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..a42e60f
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkFailedWhenLinkTwoStaticLib2.png b/assets/LinkFailedWhenLinkTwoStaticLib2.png
new file mode 100644
index 0000000..b91fad8
Binary files /dev/null and b/assets/LinkFailedWhenLinkTwoStaticLib2.png differ
diff --git a/assets/LinkSuccessWhenLinkTwoStaticLib.png b/assets/LinkSuccessWhenLinkTwoStaticLib.png
new file mode 100644
index 0000000..018a9da
Binary files /dev/null and b/assets/LinkSuccessWhenLinkTwoStaticLib.png differ
diff --git a/assets/LinkTwoStaticLibBefore.png b/assets/LinkTwoStaticLibBefore.png
new file mode 100644
index 0000000..55dfb60
Binary files /dev/null and b/assets/LinkTwoStaticLibBefore.png differ
diff --git a/assets/MobileDeviceAI-AlgorithmModel.png b/assets/MobileDeviceAI-AlgorithmModel.png
new file mode 100644
index 0000000..56906c7
Binary files /dev/null and b/assets/MobileDeviceAI-AlgorithmModel.png differ
diff --git a/assets/MobileDeviceAI-ComputeContainer.png b/assets/MobileDeviceAI-ComputeContainer.png
new file mode 100644
index 0000000..3f9bfe1
Binary files /dev/null and b/assets/MobileDeviceAI-ComputeContainer.png differ
diff --git a/assets/MobileDeviceAI-DataCapture.png b/assets/MobileDeviceAI-DataCapture.png
new file mode 100644
index 0000000..7ca9aea
Binary files /dev/null and b/assets/MobileDeviceAI-DataCapture.png differ
diff --git a/assets/MobileDeviceAI-DataGraphIndex.png b/assets/MobileDeviceAI-DataGraphIndex.png
new file mode 100644
index 0000000..9f18f57
Binary files /dev/null and b/assets/MobileDeviceAI-DataGraphIndex.png differ
diff --git a/assets/MobileDeviceAI-DataLevel.png b/assets/MobileDeviceAI-DataLevel.png
new file mode 100644
index 0000000..7c54c74
Binary files /dev/null and b/assets/MobileDeviceAI-DataLevel.png differ
diff --git a/assets/MobileDeviceAI-Disadvantage.png b/assets/MobileDeviceAI-Disadvantage.png
new file mode 100644
index 0000000..f661aa4
Binary files /dev/null and b/assets/MobileDeviceAI-Disadvantage.png differ
diff --git a/assets/MobileDeviceAI-JudgeCenter.png b/assets/MobileDeviceAI-JudgeCenter.png
new file mode 100644
index 0000000..b1b0960
Binary files /dev/null and b/assets/MobileDeviceAI-JudgeCenter.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff.png b/assets/MobileDeviceAI-LocalAndServerDiff.png
new file mode 100644
index 0000000..5f7771c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff.png differ
diff --git a/assets/MobileDeviceAI-LocalAndServerDiff2.png b/assets/MobileDeviceAI-LocalAndServerDiff2.png
new file mode 100644
index 0000000..ae65f7c
Binary files /dev/null and b/assets/MobileDeviceAI-LocalAndServerDiff2.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommended.png b/assets/MobileDeviceAI-PageBackRecommended.png
new file mode 100644
index 0000000..e991b3b
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommended.png differ
diff --git a/assets/MobileDeviceAI-PageBackRecommendedIssue.png b/assets/MobileDeviceAI-PageBackRecommendedIssue.png
new file mode 100644
index 0000000..b3a3b96
Binary files /dev/null and b/assets/MobileDeviceAI-PageBackRecommendedIssue.png differ
diff --git a/assets/MobileDeviceAI-Push.png b/assets/MobileDeviceAI-Push.png
new file mode 100644
index 0000000..f40cbd0
Binary files /dev/null and b/assets/MobileDeviceAI-Push.png differ
diff --git a/assets/MobileDeviceAI-UserDataFlow.png b/assets/MobileDeviceAI-UserDataFlow.png
new file mode 100644
index 0000000..dd1faf7
Binary files /dev/null and b/assets/MobileDeviceAI-UserDataFlow.png differ
diff --git a/assets/MobileDeviceAI-reLayout.png b/assets/MobileDeviceAI-reLayout.png
new file mode 100644
index 0000000..19b5e6d
Binary files /dev/null and b/assets/MobileDeviceAI-reLayout.png differ
diff --git a/assets/MobileDeviceAI-reLayoutIssue.png b/assets/MobileDeviceAI-reLayoutIssue.png
new file mode 100644
index 0000000..20a9366
Binary files /dev/null and b/assets/MobileDeviceAI-reLayoutIssue.png differ
diff --git a/assets/MobileDeviceAIArch.png b/assets/MobileDeviceAIArch.png
new file mode 100644
index 0000000..08822dc
Binary files /dev/null and b/assets/MobileDeviceAIArch.png differ
diff --git a/assets/RubyGemProcess.png b/assets/RubyGemProcess.png
new file mode 100644
index 0000000..af25cb6
Binary files /dev/null and b/assets/RubyGemProcess.png differ
diff --git a/assets/RubyMachoAddLoadCommand.png b/assets/RubyMachoAddLoadCommand.png
new file mode 100644
index 0000000..9817a91
Binary files /dev/null and b/assets/RubyMachoAddLoadCommand.png differ
diff --git a/assets/RubyMachoChangeIDOnDylib.png b/assets/RubyMachoChangeIDOnDylib.png
new file mode 100644
index 0000000..763707c
Binary files /dev/null and b/assets/RubyMachoChangeIDOnDylib.png differ
diff --git a/assets/RubyMachoChangeRPath.png b/assets/RubyMachoChangeRPath.png
new file mode 100644
index 0000000..da5c254
Binary files /dev/null and b/assets/RubyMachoChangeRPath.png differ
diff --git a/assets/RubyMachoDeleteLoadCommand.png b/assets/RubyMachoDeleteLoadCommand.png
new file mode 100644
index 0000000..1343391
Binary files /dev/null and b/assets/RubyMachoDeleteLoadCommand.png differ
diff --git a/assets/RubyMachoMergeMach.png b/assets/RubyMachoMergeMach.png
new file mode 100644
index 0000000..c3d95ef
Binary files /dev/null and b/assets/RubyMachoMergeMach.png differ
diff --git a/assets/StaticConflictsframework.png b/assets/StaticConflictsframework.png
new file mode 100644
index 0000000..612126c
Binary files /dev/null and b/assets/StaticConflictsframework.png differ
diff --git a/assets/StaticConflictslibrary.png b/assets/StaticConflictslibrary.png
new file mode 100644
index 0000000..f548039
Binary files /dev/null and b/assets/StaticConflictslibrary.png differ
diff --git a/assets/StaticLibCompileTimeCompare.png b/assets/StaticLibCompileTimeCompare.png
new file mode 100644
index 0000000..e992395
Binary files /dev/null and b/assets/StaticLibCompileTimeCompare.png differ
diff --git a/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png
new file mode 100644
index 0000000..c4f30fb
Binary files /dev/null and b/assets/StaticLibConflictsSolvedByDynamicLibNamespace.png differ
diff --git a/assets/StaticLibHMapGenerate.png b/assets/StaticLibHMapGenerate.png
new file mode 100644
index 0000000..029d6d9
Binary files /dev/null and b/assets/StaticLibHMapGenerate.png differ
diff --git a/assets/StaticLibLinkErrorWhenSameSymbol.png b/assets/StaticLibLinkErrorWhenSameSymbol.png
new file mode 100644
index 0000000..f21ea92
Binary files /dev/null and b/assets/StaticLibLinkErrorWhenSameSymbol.png differ
diff --git a/assets/StaticLibNeedRenamedSymbol.png b/assets/StaticLibNeedRenamedSymbol.png
new file mode 100644
index 0000000..6beb6d7
Binary files /dev/null and b/assets/StaticLibNeedRenamedSymbol.png differ
diff --git a/assets/StaticLibraryHeaderMapSettings.png b/assets/StaticLibraryHeaderMapSettings.png
new file mode 100644
index 0000000..78aa292
Binary files /dev/null and b/assets/StaticLibraryHeaderMapSettings.png differ
diff --git a/assets/StaticLibraryHeaderSearchPathSettings.png b/assets/StaticLibraryHeaderSearchPathSettings.png
new file mode 100644
index 0000000..c7710f0
Binary files /dev/null and b/assets/StaticLibraryHeaderSearchPathSettings.png differ
diff --git a/assets/VSCodeDebugCocoapods.png b/assets/VSCodeDebugCocoapods.png
new file mode 100644
index 0000000..49285ad
Binary files /dev/null and b/assets/VSCodeDebugCocoapods.png differ
diff --git a/assets/VegetablesGoodsAIDataUpload.png b/assets/VegetablesGoodsAIDataUpload.png
new file mode 100644
index 0000000..6e0a92a
Binary files /dev/null and b/assets/VegetablesGoodsAIDataUpload.png differ
diff --git a/assets/VegetablesPurchaseViaAIArch.png b/assets/VegetablesPurchaseViaAIArch.png
new file mode 100644
index 0000000..bc6ae0b
Binary files /dev/null and b/assets/VegetablesPurchaseViaAIArch.png differ
diff --git a/assets/VegetablesPurchaseWorkflowViaAI.png b/assets/VegetablesPurchaseWorkflowViaAI.png
new file mode 100644
index 0000000..c2da339
Binary files /dev/null and b/assets/VegetablesPurchaseWorkflowViaAI.png differ
diff --git a/assets/VisitReleasedStackBlockWillCrash.png b/assets/VisitReleasedStackBlockWillCrash.png
new file mode 100644
index 0000000..789cea0
Binary files /dev/null and b/assets/VisitReleasedStackBlockWillCrash.png differ
diff --git a/assets/Weex-ConcurrencyEnhancement.png b/assets/Weex-ConcurrencyEnhancement.png
new file mode 100644
index 0000000..df5cbfb
Binary files /dev/null and b/assets/Weex-ConcurrencyEnhancement.png differ
diff --git a/assets/WeexCallModuleMethodNameMismatch.png b/assets/WeexCallModuleMethodNameMismatch.png
new file mode 100644
index 0000000..c5f0f87
Binary files /dev/null and b/assets/WeexCallModuleMethodNameMismatch.png differ
diff --git a/assets/WeexCallNativeModuleParamsError.png b/assets/WeexCallNativeModuleParamsError.png
new file mode 100644
index 0000000..a1f743e
Binary files /dev/null and b/assets/WeexCallNativeModuleParamsError.png differ
diff --git a/assets/WeexCaptureVueError.png b/assets/WeexCaptureVueError.png
new file mode 100644
index 0000000..fa50bc9
Binary files /dev/null and b/assets/WeexCaptureVueError.png differ
diff --git a/assets/WeexComponentBuildFlow.png b/assets/WeexComponentBuildFlow.png
new file mode 100644
index 0000000..dc68ca6
Binary files /dev/null and b/assets/WeexComponentBuildFlow.png differ
diff --git a/assets/WeexComponentClickLogic.png b/assets/WeexComponentClickLogic.png
new file mode 100644
index 0000000..1d9871e
Binary files /dev/null and b/assets/WeexComponentClickLogic.png differ
diff --git a/assets/WeexComponentRegisterError.png b/assets/WeexComponentRegisterError.png
new file mode 100644
index 0000000..0da7907
Binary files /dev/null and b/assets/WeexComponentRegisterError.png differ
diff --git a/assets/WeexJSBundleDownloadFailed.png b/assets/WeexJSBundleDownloadFailed.png
new file mode 100644
index 0000000..cfa756e
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailed.png differ
diff --git a/assets/WeexJSBundleDownloadFailedAPM.png b/assets/WeexJSBundleDownloadFailedAPM.png
new file mode 100644
index 0000000..45aae06
Binary files /dev/null and b/assets/WeexJSBundleDownloadFailedAPM.png differ
diff --git a/assets/WeexJSBundleEncodingAPM.png b/assets/WeexJSBundleEncodingAPM.png
new file mode 100644
index 0000000..47aa961
Binary files /dev/null and b/assets/WeexJSBundleEncodingAPM.png differ
diff --git a/assets/WeexJSBundleParseErrorAPM.png b/assets/WeexJSBundleParseErrorAPM.png
new file mode 100644
index 0000000..ed24ebe
Binary files /dev/null and b/assets/WeexJSBundleParseErrorAPM.png differ
diff --git a/assets/WeexJSBundleParseFailed.png b/assets/WeexJSBundleParseFailed.png
new file mode 100644
index 0000000..6f6a2ac
Binary files /dev/null and b/assets/WeexJSBundleParseFailed.png differ
diff --git a/assets/WeexJSbundleEncodingError.png b/assets/WeexJSbundleEncodingError.png
new file mode 100644
index 0000000..04e2a06
Binary files /dev/null and b/assets/WeexJSbundleEncodingError.png differ
diff --git a/assets/WeexMockVueAPM.png b/assets/WeexMockVueAPM.png
new file mode 100644
index 0000000..656ed6e
Binary files /dev/null and b/assets/WeexMockVueAPM.png differ
diff --git a/assets/WeexModuleRequireError.png b/assets/WeexModuleRequireError.png
new file mode 100644
index 0000000..d87b69c
Binary files /dev/null and b/assets/WeexModuleRequireError.png differ
diff --git a/assets/WeexRequireModuleError.png b/assets/WeexRequireModuleError.png
new file mode 100644
index 0000000..ae99068
Binary files /dev/null and b/assets/WeexRequireModuleError.png differ
diff --git a/assets/WeexRequireModuleErrorAPM.png b/assets/WeexRequireModuleErrorAPM.png
new file mode 100644
index 0000000..66ff520
Binary files /dev/null and b/assets/WeexRequireModuleErrorAPM.png differ
diff --git a/assets/XcodeProvisionProfile.png b/assets/XcodeProvisionProfile.png
new file mode 100644
index 0000000..89231f1
Binary files /dev/null and b/assets/XcodeProvisionProfile.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png
new file mode 100644
index 0000000..8fb3864
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProject.png differ
diff --git a/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png
new file mode 100644
index 0000000..debfba6
Binary files /dev/null and b/assets/XcodeWillCompileStaticLibUseSourceCodeWhenInSameProjectIssue.png differ
diff --git a/assets/Youzan-VegetablesGoodsWorkflow.png b/assets/Youzan-VegetablesGoodsWorkflow.png
new file mode 100644
index 0000000..46eaf17
Binary files /dev/null and b/assets/Youzan-VegetablesGoodsWorkflow.png differ
diff --git a/assets/fastlaneScreentshotConfig.png b/assets/fastlaneScreentshotConfig.png
new file mode 100644
index 0000000..e5e4ae6
Binary files /dev/null and b/assets/fastlaneScreentshotConfig.png differ
diff --git a/assets/gitAddMocking.png b/assets/gitAddMocking.png
new file mode 100644
index 0000000..90c046d
Binary files /dev/null and b/assets/gitAddMocking.png differ
diff --git a/assets/gitCommitTree.png b/assets/gitCommitTree.png
new file mode 100644
index 0000000..bdb5d3f
Binary files /dev/null and b/assets/gitCommitTree.png differ
diff --git a/assets/gitFileTreeAfter.png b/assets/gitFileTreeAfter.png
new file mode 100644
index 0000000..7db5ab1
Binary files /dev/null and b/assets/gitFileTreeAfter.png differ
diff --git a/assets/gitFileTreeBefore.png b/assets/gitFileTreeBefore.png
new file mode 100644
index 0000000..ab0ab49
Binary files /dev/null and b/assets/gitFileTreeBefore.png differ
diff --git a/assets/gitRemoteAdd.png b/assets/gitRemoteAdd.png
new file mode 100644
index 0000000..88c4c67
Binary files /dev/null and b/assets/gitRemoteAdd.png differ
diff --git a/assets/gitTreeRecoverAfter.png b/assets/gitTreeRecoverAfter.png
new file mode 100644
index 0000000..0f08f22
Binary files /dev/null and b/assets/gitTreeRecoverAfter.png differ
diff --git a/assets/gitTreeRecoverBefore.png b/assets/gitTreeRecoverBefore.png
new file mode 100644
index 0000000..fddb97d
Binary files /dev/null and b/assets/gitTreeRecoverBefore.png differ
diff --git a/assets/githashChange.png b/assets/githashChange.png
new file mode 100644
index 0000000..db2372e
Binary files /dev/null and b/assets/githashChange.png differ
diff --git a/assets/githashCommand.png b/assets/githashCommand.png
new file mode 100644
index 0000000..860e056
Binary files /dev/null and b/assets/githashCommand.png differ
diff --git a/assets/githashDemo.png b/assets/githashDemo.png
new file mode 100644
index 0000000..e7dc1a0
Binary files /dev/null and b/assets/githashDemo.png differ
diff --git a/assets/jtool2WatchSignature.png b/assets/jtool2WatchSignature.png
new file mode 100644
index 0000000..4776b2b
Binary files /dev/null and b/assets/jtool2WatchSignature.png differ
diff --git a/assets/wechat_2025-08-20_235658_762.png b/assets/wechat_2025-08-20_235658_762.png
new file mode 100644
index 0000000..bee616c
Binary files /dev/null and b/assets/wechat_2025-08-20_235658_762.png differ
diff --git a/assets/xcodeprojChangeBuildSettings.png b/assets/xcodeprojChangeBuildSettings.png
new file mode 100644
index 0000000..71738dc
Binary files /dev/null and b/assets/xcodeprojChangeBuildSettings.png differ
diff --git a/assets/xcodeprojSetXcconfig.png b/assets/xcodeprojSetXcconfig.png
new file mode 100644
index 0000000..66b9c48
Binary files /dev/null and b/assets/xcodeprojSetXcconfig.png differ
diff --git a/assets/xcodeprojVisitScheme.png b/assets/xcodeprojVisitScheme.png
new file mode 100644
index 0000000..4aace85
Binary files /dev/null and b/assets/xcodeprojVisitScheme.png differ