mirror of
https://github.com/NohamR/knowledge-kit.git
synced 2026-07-12 07:00:07 +00:00
update: content update
This commit is contained in:
@@ -537,7 +537,7 @@ QA:优先级反转是什么?
|
||||
|
||||
举个例子:优先级:线程 A < 线程 B < 线程 C,线程A、C 都会使用共享资源 R,该资源由信号量控制进行互斥访问。
|
||||
|
||||

|
||||

|
||||
|
||||
线程 A 在 T1 时刻使用资源 R 并拿到锁。开始执行线程内的逻辑。
|
||||
|
||||
@@ -1707,6 +1707,58 @@ dispatch_barrier_async(self.queue, ^{
|
||||
|
||||
|
||||
|
||||
#### 栅栏函数拦不住全局队列
|
||||
|
||||
Demo
|
||||
|
||||
```objective-c
|
||||
- (void)testBarrierWithGlobalQueue {
|
||||
NSLog(@"%s", __func__);
|
||||
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
|
||||
for (int i = 0; i < 100; i++) {
|
||||
dispatch_async(queue, ^() {
|
||||
NSLog(@"%d", i);
|
||||
});
|
||||
}
|
||||
dispatch_barrier_async(queue, ^() {
|
||||
NSLog(@"100");
|
||||
});
|
||||
dispatch_async(queue, ^() {
|
||||
NSLog(@"101");
|
||||
});
|
||||
NSLog(@"%s", __func__);
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/GCDBarrierCannotHoldGlobalQueue.png" style="zoom:30%" />
|
||||
|
||||
|
||||
|
||||
```objective-c
|
||||
- (void)testBarrierWithCustomQueue {
|
||||
NSLog(@"%s", __func__);
|
||||
dispatch_queue_t queue = dispatch_queue_create(0, 0);
|
||||
for (int i = 0; i < 100; i++) {
|
||||
dispatch_async(queue, ^() {
|
||||
NSLog(@"%d", i);
|
||||
});
|
||||
}
|
||||
dispatch_barrier_async(queue, ^() {
|
||||
NSLog(@"100");
|
||||
});
|
||||
dispatch_async(queue, ^() {
|
||||
NSLog(@"101");
|
||||
});
|
||||
NSLog(@"%s", __func__);
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/GCDBarrierCanHoldCustomQueue.png" style="zoom:30%" />
|
||||
|
||||
结论:可以发现 GCD 的栅栏函数,拦不住全局队列,却可以拦住普通的队列。这是为什么?
|
||||
|
||||
全局队列的业务方不只是当前 App 进程,还有一些系统任务(全局并发队列中不仅有开发者的任务,还有系统的任务),如果我们用我们的任务去栏住系统的任务,可能会导致一些未知的错误。栅栏函数对全局并发队列无效,所以我们在开发的时候一定要注意
|
||||
|
||||
### dispatch_group_async
|
||||
|
||||
如何实现 A、B、C 三个任务并发执行完,再去执行任务 D ?假设需求是根据省市区下载 json,然后根据 json 数据,选中地址 picker view。
|
||||
|
||||
@@ -182,7 +182,7 @@ NSLog(@"%p %p %@", obj, &obj, obj);
|
||||
|
||||
### 为什么有 Tagged Pointer
|
||||
|
||||
现状:一般,存放 NSNumber、NSDate 这类变量的时候,本身占用的内存大小常常不需要8个字节。4字节带符号的证书可以达到2^31= 2147483648,99% 的情况都能满足了。因此为了更高效、更节省空间,用一个看似是指针的计数,来存储数据,且在 Runtime 侧判断了,节省了消息机制那一套冗长的流程,Tagged Pointer cover 一些小数据的场景,cover 不了则申请堆内存。
|
||||
现状:一般,存放 NSNumber、NSDate 这类变量的时候,本身占用的内存大小常常不需要8个字节。4字节带符号的整数可以达到2^31= 2147483648,99% 的情况都能满足了。因此为了更高效、更节省空间,用一个看似是指针的计数,来存储数据,且在 Runtime 侧判断了,节省了消息机制那一套冗长的流程,Tagged Pointer cover 一些小数据的场景,cover 不了则申请堆内存。
|
||||
|
||||
|
||||
|
||||
@@ -1505,7 +1505,7 @@ weak_table_t 结构如下:
|
||||
struct weak_entry_t {
|
||||
DisguisedPtr<objc_object> referent; // 被弱引用的对象
|
||||
|
||||
// 引用该对象的对象列表,联合。 引用个数小于4,用 inline_referrers 数组。 用个数大于4,用动态数组 weak_referrer_t *referrers
|
||||
// 引用该对象的对象列表,联合。 引用个数小于4,用 inline_referrers 数组。 个数大于4,用动态数组 weak_referrer_t *referrers
|
||||
union {
|
||||
struct {
|
||||
weak_referrer_t *referrers; // 弱引用该对象的对象指针地址的hash数组
|
||||
@@ -1551,10 +1551,32 @@ struct weak_entry_t {
|
||||
|
||||
#### 存 weak 对象
|
||||
|
||||
声明一个 `__weak` 对象
|
||||
|
||||
```objective-c
|
||||
{
|
||||
id __weak obj = strongObj;
|
||||
}
|
||||
```
|
||||
|
||||
LLVM转换成对应的代码
|
||||
|
||||
```objective-c
|
||||
id __attribute__((objc_ownership(none))) obj1 = strongObj;
|
||||
```
|
||||
|
||||
相应的会调用
|
||||
|
||||
```objective-c
|
||||
id obj ;
|
||||
objc_initWeak(&obj,strongObj);
|
||||
objc_destoryWeak(&obj);
|
||||
```
|
||||
|
||||
上 Demo
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/ObjcStoreWeakWhenUseWeak.png" style="zoom:30%" />
|
||||
|
||||
|
||||
|
||||
可以看到当一个 weak 指针被赋值的时候,底层调用了 `objc_initWeak`,跟踪查看 objc 源码
|
||||
|
||||
```c++
|
||||
@@ -2273,7 +2295,7 @@ weak_clear_no_lock(weak_table_t *weak_table, id referent_id)
|
||||
|
||||
- object_remove_assocations(obj):去除该对象相关的关联属性(Category 添加的)
|
||||
|
||||
- obj->clearDeallocating():清空引用技术表和弱引用表,将 weak 引用设置为 nil
|
||||
- obj->clearDeallocating():清空引用计数表和弱引用表,将 weak 引用设置为 nil
|
||||
|
||||
继续看看 object_cxxDestruct 方法内部细节。
|
||||
|
||||
@@ -2574,7 +2596,7 @@ struct FinishARCDealloc : EHScopeStack::Cleanup {
|
||||
|
||||
#### LLVM + Runtime 共同协作的结果
|
||||
|
||||
LLVM 编译器前端 clang 在编译阶段,自动帮我们给对象加了 release、retain、autorelease 的代码(比如在一个大括号内的代码,生命的对象,在大括号将要结束的时候会自动加 `[person release] 之类的代码`)。
|
||||
LLVM 编译器前端 clang 在编译阶段,自动帮我们给对象加了 release、retain、autorelease 的代码(比如在一个大括号内的代码,声明的对象,在大括号将要结束的时候会自动加 `[person release] 之类的代码`)。
|
||||
|
||||
ARC 中禁止手动调用 retain/release/retainCount/dealloc 方法。
|
||||
|
||||
@@ -4093,6 +4115,27 @@ IMP Caching 比其他方法快2倍。
|
||||
|
||||
## 典型的内存问题
|
||||
|
||||
### 使用NSArray 保存weak对象,会有什么问题?
|
||||
Foundation 中数组在元素被添加的时候(这里的数组 指平常使用的 NSArray 和 NSMutableArray )会强引用持有,就算使用 `__weak` 修饰也没有用,导致一些奇特的内存泄漏和循环引用问题。
|
||||
|
||||
`-(NSValue *)valueWithNonretainedObject:(nullable id)anObject;`
|
||||
|
||||
`NSPointerArray` 提供 `strongObjectsPointerArray` 和 `weakObjectsPointerArray`工厂,weakObjectsPointerArray 就是我们需要的弱引用数组方法。
|
||||
|
||||
NSHashTable 和 NSMapTable
|
||||
|
||||
```
|
||||
// 弱应用对象
|
||||
NSMapTable *map = [NSMapTable weakToWeakObjectsMapTable];
|
||||
[map setObject:dog forKey:@"first"];
|
||||
|
||||
// 弱应用对象
|
||||
NSHashTable *hashTable = [NSHashTable weakObjectsHashTable];
|
||||
[hashTable addObject:dog];
|
||||
```
|
||||
|
||||
|
||||
|
||||
### OC 中有没有不对内存进行强持有的集合类型?
|
||||
|
||||
`NSHashMap`、`NSMapTable` 都可以描述 key、value 的内存修饰。
|
||||
|
||||
@@ -573,7 +573,7 @@ void map_images_nolock(unsigned mhCount, const char * const mhPaths[],
|
||||
}
|
||||
```
|
||||
|
||||
`map_images_nolock` 会调用 `_read_images` 方法,用于初始化 map 后的 `image`,这里面干了很多的事情,像 load所 有的类、协议和 category,著名的`+ load` 方法就是这一步调用的。如下:
|
||||
`map_images_nolock` 会调用 `_read_images` 方法,用于初始化 map 后的 `image`,这里面干了很多的事情,像 load所有的类、协议和 category,著名的 `+ load` 方法就是这一步调用的。如下:
|
||||
|
||||
```c++
|
||||
void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses)
|
||||
@@ -1278,7 +1278,7 @@ Demo: 为 Person 类创建2个 Category,分别存在同名方法 study,具
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryMethodOrderExplore.png" style="zoom:25%">
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/OCCategoryMethodOrderExplore.png" style="zoom:25%">
|
||||
|
||||
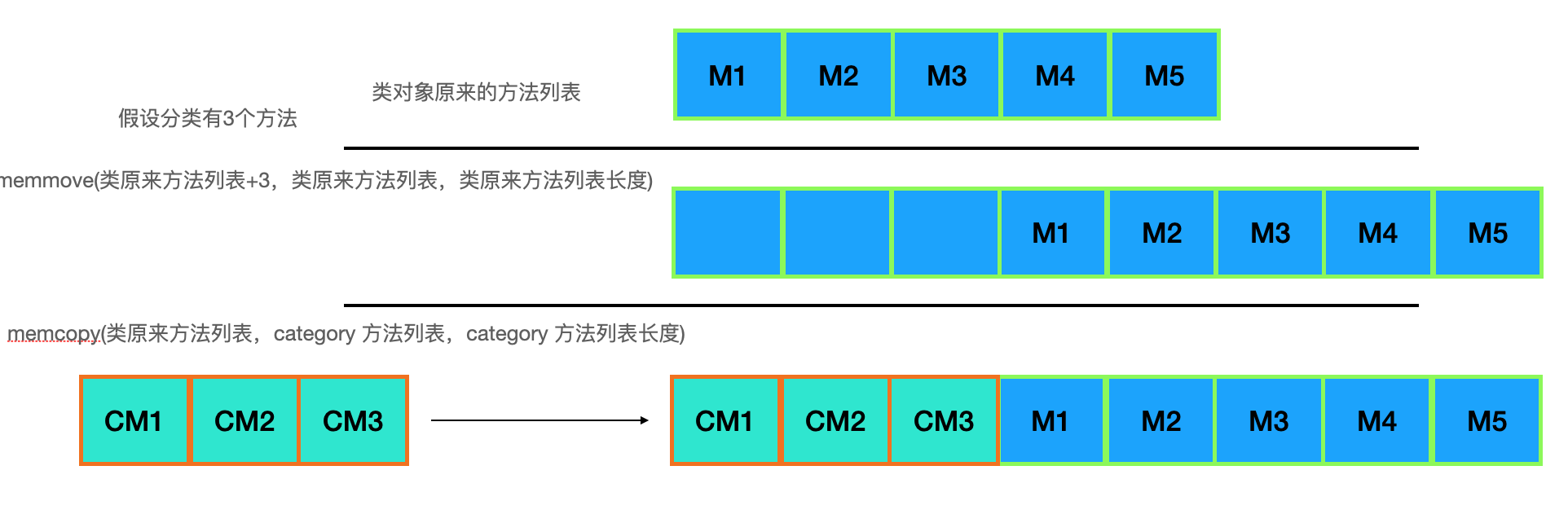
可以看到 sayHi 方法存在多个,但是由于 Category 同名的方法在方法列表的前面,所以类自身的方法实现”被覆盖了“(根据 isa 查找方法实现的时候,优先查找到 Category 的方法实现,则停止查找了)
|
||||
|
||||
@@ -1291,17 +1291,17 @@ Demo: 为 Person 类创建2个 Category,分别存在同名方法 study,具
|
||||
|
||||
Demo: 为 Person 类创建2个 Category,分别存在同名方法 study,具有不同实现。探索编译顺序决定方法实现
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo1.png" style="zoom:25%">
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/OCCategoryBuildOrderDemo1.png" style="zoom:25%">
|
||||
|
||||
2个对比实验:
|
||||
|
||||
让 `Person+Study` 参与后编译
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo2.png" style="zoom:25%">
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/OCCategoryBuildOrderDemo2.png" style="zoom:25%">
|
||||
|
||||
让 `Person+Learn` 参与后编译
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo3.png" style="zoom:25%">
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/OCCategoryBuildOrderDemo3.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
@@ -1765,7 +1765,7 @@ static void call_class_loads(void)
|
||||
if (PrintLoading) {
|
||||
_objc_inform("LOAD: +[%s load]\n", cls->nameForLogging());
|
||||
}
|
||||
// 直接调用 +load 方法,而不是采用发消息的形式
|
||||
// 方法指针。直接调用 +load 方法,而不是采用发消息的形式
|
||||
(*load_method)(cls, @selector(load));
|
||||
}
|
||||
|
||||
@@ -2160,7 +2160,7 @@ Person +load
|
||||
|
||||
查看分类在 Runtime 加载类信息时候的调用原理可以知道,分类中的类方法、对象方法都会被加载原始类的前面去(initialize 是类方法)如下图:
|
||||
|
||||

|
||||
|
||||
|
||||
### 为什么给子类发消息,父类和子类的 +initialize 都会被调用?且父类的先调用
|
||||
|
||||
@@ -2743,8 +2743,6 @@ NS_ASSUME_NONNULL_END
|
||||
void objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy) {
|
||||
_object_set_associative_reference(object, (void *)key, value, policy);
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
简化版
|
||||
|
||||
@@ -68,3 +68,26 @@ NSLog(@"%@",[self class]);
|
||||
|
||||
|
||||
|
||||
## 手饰事件和点击事件的响应顺序
|
||||
|
||||
假如给某个 view 所在的父视图添加了手饰识别器。
|
||||
|
||||
**手势识别器的优先级**:如果你将 `UITapGestureRecognizer` 添加到了视图上,UIKit 会首先尝试识别手势。如果视图上添加了多个手势识别器,它们的识别顺序将根据它们被添加到视图的顺序或者它们的 `delaysTouchesBegan` 和 `delaysTouchesEnded` 属性来决定。
|
||||
|
||||
|
||||
|
||||
想要子 view 响应事件而不是被根视图拦截,则需要给手势识别器添加代理,实现代理方法
|
||||
|
||||
```objective-c
|
||||
UIGestureRecognizer *gesture;
|
||||
gesture.delegate = self;
|
||||
|
||||
- (BOOL)gestureRecognizerShouldBegin:(UIGestureRecognizer *)gestureRecognizer {
|
||||
return NO;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果 `UITapGestureRecognizer` 识别了一个手势,它可以通过设置 `cancelsTouchesInView` 属性为 `YES` 来取消视图上的触摸事件,这样点击事件就不会被进一步传递到视图控制器的 `touchesBegan` 或 `touchesEnded` 方法。
|
||||
|
||||
|
||||
@@ -28,7 +28,7 @@ _displayLink = [CADisplayLink displayLinkWithTarget:self selector:@selector(p_di
|
||||
|
||||
|
||||
|
||||
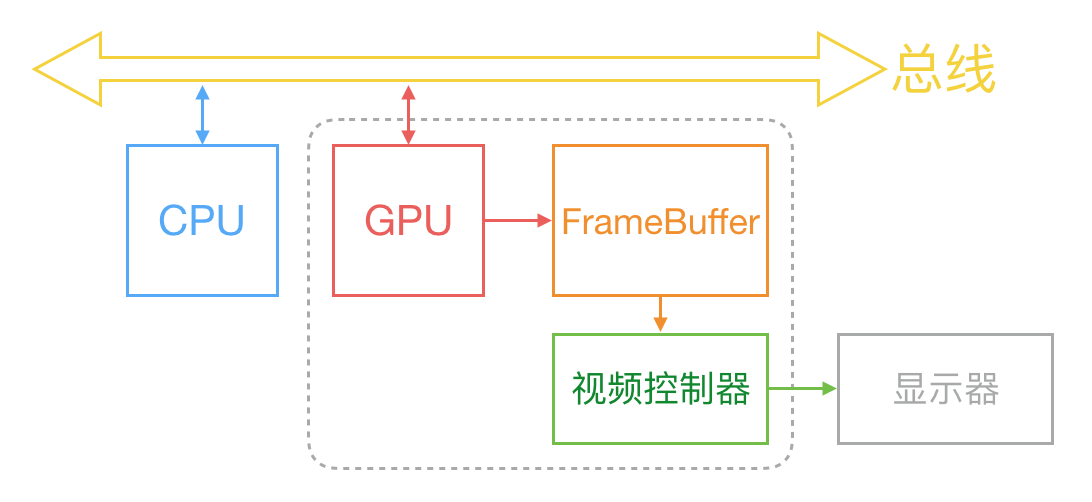
通常,屏幕上一张画面的显示是由 CPU、GPU 和显示器是按照上图的方式协同工作的。CPU 根据工程师写的代码计算好需要现实的内容(比如视图创建、布局计算、图片解码、文本绘制等),然后把计算结果提交到 GPU,GPU 负责图层合成、纹理渲染,随后 GPU 将渲染结果提交到帧缓冲区。随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过数模转换传递给显示器显示。
|
||||
通常,屏幕上一张画面的显示是由 CPU、GPU 和显示器是按照上图的方式协同工作的。CPU 根据工程师写的代码计算好需要显实的内容(比如视图创建、布局计算、图片解码、文本绘制等),然后把计算结果提交到 GPU,GPU 负责图层合成、纹理渲染,随后 GPU 将渲染结果提交到帧缓冲区。随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过数模转换传递给显示器显示。
|
||||
|
||||
在帧缓冲区只有一个的情况下,帧缓冲区的读取和刷新都存在效率问题,为了解决效率问题,显示系统会引入 2 个缓冲区,即双缓冲机制。在这种情况下,GPU 会预先渲染好一帧放入帧缓冲区,让视频控制器来读取,当下一帧渲染好后,GPU 直接把视频控制器的指针指向第二个缓冲区。提升了效率。
|
||||
|
||||
@@ -44,7 +44,7 @@ _displayLink = [CADisplayLink displayLinkWithTarget:self selector:@selector(p_di
|
||||
|
||||
设想一个显示器显示第一帧图像和第二帧图像的过程。首先在双缓冲区的情况下,GPU 首先渲染好一帧图像存入到帧缓冲区,然后让视频控制器的指针直接直接这个缓冲区,显示第一帧图像。第一帧图像的内容显示完成后,视频控制器发送 V-Sync 信号,GPU 收到 V-Sync 信号后渲染第二帧图像并将视频控制器的指针指向第二个帧缓冲区。
|
||||
|
||||
**看上去第二帧图像是在等第一帧显示后的视频控制器发送 V-Sync 信号。是吗?真是这样的吗? 😭 想啥呢,当然不是。 🐷 不然双缓冲区就没有存在的意义了**
|
||||
**看上去第二帧图像是在等第一帧显示后的视频控制器发送 V-Sync 信号。是吗?真是这样的吗? 当然不是,不然双缓冲区就没有存在的意义了**
|
||||
|
||||
揭秘。请看下图
|
||||
|
||||
@@ -2131,7 +2131,7 @@ OC 语言:指针指向的内存对象已经被释放或回收了,但是指
|
||||
|
||||
#### 什么是僵尸对象?
|
||||
|
||||
僵尸对象就是指一个 OC 对象释放后所占用的内存还没被复写(重新分配给其他对象)前被称为僵尸对象。此时僵尸对象内存很不稳定,内存随时可能被系统分配给其他对象所使用。所以此时僵尸对象不应该访问和使用(调用对象的方法等)
|
||||
僵尸对象就是指一个 OC 对象释放后所占用的内存还没被覆写(重新分配给其他对象)前被称为僵尸对象。此时僵尸对象内存很不稳定,内存随时可能被系统分配给其他对象所使用。所以此时僵尸对象不应该访问和使用(调用对象的方法等)
|
||||
|
||||
#### 为什么 OC 野指针 Crash 很多?
|
||||
|
||||
@@ -7930,6 +7930,8 @@ runZoned<Future<Null>>(() async {
|
||||
|
||||
|
||||
|
||||
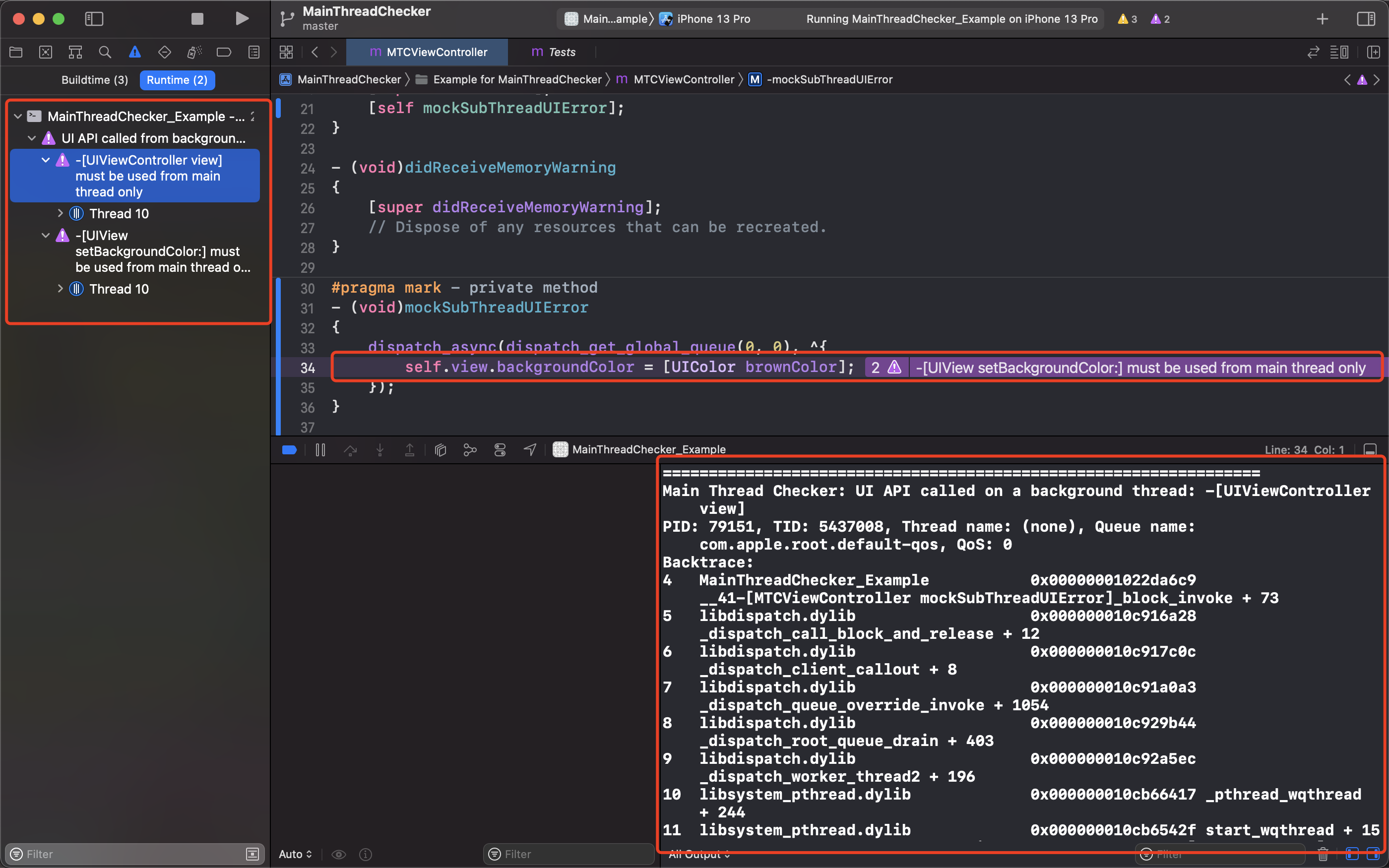
本来常见的开发都会规避这些写法,没机会看到子线程操作 UI 的问题,但是 Weex 的业务代码,检测出存在子线程操作 UI 的问题,所以还是有必要增加这个能力的。
|
||||
|
||||
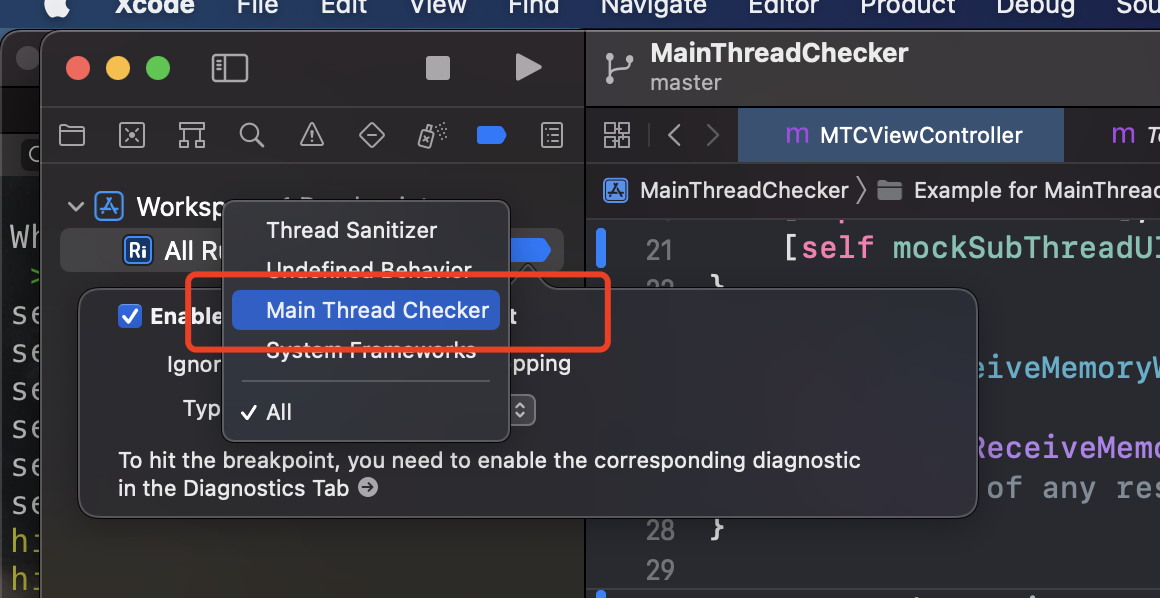
其实我们可以给 Xcode 打个 `Runtime Issue Breakpoint` ,type 选择 `Main Thread Checker`, 在发生子线程操作 UI 的时候就会被系统检测到并触发断点,同时可以看到堆栈情况
|
||||
|
||||
|
||||
@@ -7956,7 +7958,7 @@ runZoned<Future<Null>>(() async {
|
||||
|
||||
对 [dlopen](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man3/dlopen.3.html)、[dlsym](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man3/dlsym.3.html) 陌生的小伙伴可以直接看 Apple 官方文档,这里不做展开。
|
||||
|
||||
具体可以参考这个 [saDemo](https://github.com/FantasticLBP/MainThreadChecker)
|
||||
具体可以参考这个 [Demo](https://github.com/FantasticLBP/MainThreadChecker)
|
||||
|
||||
## 十一、页面渲染时长统计
|
||||
|
||||
|
||||
@@ -502,7 +502,7 @@ dispatch_queue_t group1 = dispatch_group_create();
|
||||
|
||||
下断点后可以看到 `dispatch_group_create` 是位于 `libdispatch.dylib` 库中的。
|
||||
|
||||
<img src="./../assets/DispatchGroupTSourceLocation.png" style="zoom:30%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/DispatchGroupTSourceLocation.png" style="zoom:30%" />
|
||||
|
||||
打开 `libdispatch.dylib` 搜索 `dispatch_group_create`。可以看到源码实现。
|
||||
|
||||
@@ -526,7 +526,7 @@ _dispatch_group_create_with_count(uint32_t n)
|
||||
|
||||
`dispatch_group_create` 调用 `_dispatch_group_create_with_count`, `_dispatch_group_create_with_count` 调用 `_dispatch_object_alloc`,有2个参数:`DISPATCH_VTABLE(group)` 和 `sizeof(struct dispatch_group_s)`
|
||||
|
||||
<img src="./../assets/DispatchGroupCreateSourceCode.png" style="zoom:30%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/DispatchGroupCreateSourceCode.png" style="zoom:30%" />
|
||||
|
||||
在汇编调试模式下,对其打印输出,对于 x86 架构的汇编,第一个参数存放在 rdi,第二个参数存放在 rsi 中。
|
||||
|
||||
@@ -538,7 +538,7 @@ _dispatch_group_create_with_count(uint32_t n)
|
||||
|
||||
然后顺着源码看看,左侧可以看到内部就是调用 `calloc` 分配的内存。
|
||||
|
||||
<img src="./../assets/DispatchGroupTAllocObject.png" style="zoom:30%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/DispatchGroupTAllocObject.png" style="zoom:30%" />
|
||||
|
||||
那 `dispatch_group_t` 是什么就很明显了。和 id 一样,是一个结构体指针。
|
||||
|
||||
@@ -568,7 +568,7 @@ struct dispatch_group_s {
|
||||
|
||||
对 `dispach_group_enter` 下断点,可以看到如下图
|
||||
|
||||
<img src="./../assets/DispatchGroupEnterSourceCode.png" style="zoom:30%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/DispatchGroupEnterSourceCode.png" style="zoom:30%" />
|
||||
|
||||
一进断点就查看寄存器的值,因为 dispatch_group_enter 函数就一个参数,所以直接读取寄存器 rdi 的值,可以看到就是 `dispatch_group_t` 对象。其中 count 为0.
|
||||
|
||||
@@ -794,7 +794,7 @@ _dispatch_group_wait_slow(dispatch_group_t dg, dispatch_time_t timeout)
|
||||
|
||||
线程的生命周期分为5种:新建 -> 就绪 -> 运行 -> 阻塞 -> 死亡
|
||||
|
||||
<img src="./../assets/ThreadLifeCycle.png" style="zoom:30%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/ThreadLifeCycle.png" style="zoom:30%" />
|
||||
|
||||
- 新建:使用 `new` 实例化一个线程对象,但该线程对象还未使用 `start()` 方法启动线程这个阶段,该阶段只在内存的堆中为该对象的实例变量分配了内存空间,但线程还**无法参与抢夺CPU的使用权**
|
||||
- 就绪:一个线程对象调用 `start()` 方法将线程加入到 **可调度线程池**,同时也变成就绪状态,等待 CPU 来调度执行
|
||||
@@ -808,7 +808,7 @@ _dispatch_group_wait_slow(dispatch_group_t dg, dispatch_time_t timeout)
|
||||
|
||||
## 可调度线程池
|
||||
|
||||
<img src="./../assets/DispatchableThreadPool.png" style="zoom:40%" />
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/DispatchableThreadPool.png" style="zoom:40%" />
|
||||
|
||||
有新任务过来,会先判断线程池是否都在执行任务:
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
>
|
||||
> - block 原理是什么,系统是如何实现的?
|
||||
> - __block 的作用是什么?
|
||||
> - block 作为属性时,为什么用 copu 修饰?
|
||||
> - block 作为属性时,为什么用 copy 修饰?
|
||||
> - block 在修改 NSMutableArray 的时候,需要加 __block 吗?
|
||||
>
|
||||
> 带着问题探究本文。
|
||||
@@ -19,11 +19,11 @@ Demo
|
||||
|
||||
```objective-c
|
||||
NSInteger age = 27;
|
||||
void(^block)(NSInteger, NSInteger) = ^(NSInteger a, NSInteger b) {
|
||||
NSLog(@"age is %zd", age);
|
||||
NSLog(@"a is %zd, b is %zd", a, b);
|
||||
};
|
||||
block(1, 2);
|
||||
void(^block)(NSInteger, NSInteger) = ^(NSInteger a, NSInteger b) {
|
||||
NSLog(@"age is %zd", age);
|
||||
NSLog(@"a is %zd, b is %zd", a, b);
|
||||
};
|
||||
block(1, 2);
|
||||
```
|
||||
|
||||
用指令`xcrun --sdk iphoneos clang -arch arm64 ViewController.m -rewrite-objc -o ViewController-arm64.cpp` 转为 c++
|
||||
@@ -224,6 +224,8 @@ struct __ViewController__viewDidLoad_block_desc_0 {
|
||||
|
||||
### auto 变量捕获
|
||||
|
||||
> 在 C 和 Objective-C 编程语言中,`auto` 关键字用于声明自动存储期的变量。自动存储期的变量会在定义它们的块(block)或作用域(scope)中自动创建,并在退出该作用域时自动销毁。这是变量存储期的默认行为,因此 `auto` 关键字实际上是可选的,但有时候为了清晰起见,开发者可能会显式使用它。
|
||||
|
||||
Demo1:
|
||||
|
||||
一个最简单的 block,参数和返回值都是 void,内部仅一条打印语句。
|
||||
@@ -248,11 +250,13 @@ printBlock();
|
||||
Demo2: 捕获外部变量
|
||||
|
||||
```objective-c
|
||||
age = 27;
|
||||
void(^printAgeBlock)(void) = ^ {
|
||||
NSLog(@"age is %zd", age);
|
||||
};
|
||||
age = 28;
|
||||
printAgeBlock();
|
||||
// 27
|
||||
```
|
||||
|
||||
用指令 `xcrun --sdk iphoneos clang -arch arm64 ViewController.m -rewrite-objc -o ViewController-arm64.cpp` 转换为 c++ 代码
|
||||
@@ -289,6 +293,7 @@ void(^printInfoBlock)(void) = ^ {
|
||||
age = 28;
|
||||
height = 176;
|
||||
printInfoBlock();
|
||||
// age is 27, height is 176
|
||||
```
|
||||
|
||||
用指令 `xcrun --sdk iphoneos clang -arch arm64 ViewController.m -rewrite-objc -o ViewController-arm64.cpp` 转换为 c++ 代码
|
||||
@@ -301,7 +306,7 @@ printInfoBlock();
|
||||
|
||||
- 可以看到我们编写的 block 被声明为一个 `__ViewController__viewDidLoad_block_impl_0` 类型的结构体
|
||||
- 结构体内有个构造函数,见50774行代码。
|
||||
- c++ 中,构造方法中 `age(_age) `的写法,表明传入的 `_age` 会被赋值给结构体内的 age,age 为值传递;`height(_height)` 写法,表明传入的 `_height` 会被复制给结构体内的 height,height 为引用传递
|
||||
- c++ 中,构造方法中 `age(_age) `的写法,表明传入的 `_age` 会被赋值给结构体内的 age,`NSInteger _age` 则 age 为值传递;`height(_height)` 写法,表明传入的 `_height` 会被复制给结构体内的 height,`NSInteger *_height` 则 height 为引用传递
|
||||
- 50797行代码,调用结构体的构造方法,age 以值传递的方式传入参数,结构体构造方法内部将 参数 age 的值保存到结构体内部的 age 中。height 以引用传递的方式传入参数,结构体构造方法内,将参数 height 的引用保存起来
|
||||
- 因为 age 是值传递。所以即使在 50798 行代码对 age 进行了修改,结构体内部的 age 值不变
|
||||
- 因为 height 是引用传递。所以在 50799 行代码对 height 进行了修改,结构体内部的 height 值跟着改变
|
||||
@@ -352,6 +357,12 @@ QA:为什么局部变量存在捕获,全局变量不需要捕获?
|
||||
|
||||
全局变量到哪都可以访问,所以没必要捕获。局部变量因为作用域的问题,所以需要捕获到哪步,以便后续使用。
|
||||
|
||||
理解 block 的本质和意义:
|
||||
|
||||
- block 本质上就是一个 oc 对象,也有 isa 指针
|
||||
|
||||
- block 是封装了函数调用和函数调用环境的 OC 对象
|
||||
|
||||
|
||||
|
||||
### 变量捕获总结
|
||||
@@ -752,6 +763,46 @@ Demo4
|
||||
|
||||
|
||||
|
||||
|
||||
block 嵌套。多个 block 存在先后关系时
|
||||
- 看看最晚的一个 block 是什么修饰的。如果是 strong,早期的是 weak,则也不会释放。
|
||||
- 看看最晚的一个 block 是什么修饰的。如果是 weak,早起是 strong,则第一个 block 内部的可以正常访问,之后调用对象的 dealloc 方法,最后的 block 访问因为对象释放了,所以访问为 null
|
||||
|
||||
|
||||
```objective-c
|
||||
Person *p = [[Person alloc] init];
|
||||
p.name = @"杭城小刘";
|
||||
__weak Person *weakPerson = p;
|
||||
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(1 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
|
||||
NSLog(@"%@", weakPerson.name);
|
||||
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(2 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
|
||||
NSLog(@"%@", p.name);
|
||||
});
|
||||
});
|
||||
NSLog(@"-touchesBegan:withEvent:");
|
||||
|
||||
2024-08-13 20:58:46.500553+0800 BlockExplore[29848:967516] -touchesBegan:withEvent:
|
||||
2024-08-13 20:58:47.549486+0800 BlockExplore[29848:967516] 杭城小刘
|
||||
2024-08-13 20:58:49.550015+0800 BlockExplore[29848:967516] 杭城小刘
|
||||
2024-08-13 20:58:49.550315+0800 BlockExplore[29848:967516] -[Person dealloc]
|
||||
|
||||
Person *p = [[Person alloc] init];
|
||||
p.name = @"杭城小刘";
|
||||
__weak Person *weakPerson = p;
|
||||
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(1 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
|
||||
NSLog(@"%@", p.name);
|
||||
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(2 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
|
||||
NSLog(@"%@", weakPerson.name);
|
||||
});
|
||||
});
|
||||
NSLog(@"-touchesBegan:withEvent:");
|
||||
|
||||
2024-08-13 20:59:51.265796+0800 BlockExplore[29889:968688] -touchesBegan:withEvent:
|
||||
2024-08-13 20:59:52.313063+0800 BlockExplore[29889:968688] 杭城小刘
|
||||
2024-08-13 20:59:52.313265+0800 BlockExplore[29889:968688] -[Person dealloc]
|
||||
2024-08-13 20:59:54.313367+0800 BlockExplore[29889:968688] (null)
|
||||
```
|
||||
|
||||
### block 如何修改变量
|
||||
|
||||
#### __block 修饰基本数据类型
|
||||
@@ -949,7 +1000,7 @@ __attribute__((__blocks__(byref))) __Block_byref_num2_0 num2 = {(void*)0,(__Bloc
|
||||
|
||||
- block 外定义的 NSMutableArray,block 内只是使用数组则不需要` __block`
|
||||
|
||||
- 如果在 block 利操作指针,则需要加 `__block`
|
||||
- 如果在 block 里操作指针,则需要加 `__block`
|
||||
|
||||
注意:`__weak` 只可以用来修饰对象,(终端用 clang 处理)否则 clang 会报错 `warning: 'objc_ownership' only applies to Objective-C object or block pointer types; type here is 'int' [-Wignored-attributes]`
|
||||
|
||||
@@ -1160,7 +1211,7 @@ in block: age = 28, address is 0x600000464938
|
||||
|
||||
**一言以蔽之,`__forwarding` 指针是为了在 `__block` 变量从栈复制到堆上后,在 block 外对 `__block` 变量的修改也可以同步到堆上实际存储的 `__block` 变量的结构体上。也就是抹平栈、堆上对变量操作的差异。**
|
||||
|
||||
不论在
|
||||
|
||||
|
||||
## Block 内存引用
|
||||
|
||||
@@ -1221,10 +1272,9 @@ __Block_byref_p_0 *__forwarding; 8
|
||||
int __size; 4
|
||||
void (*__Block_byref_id_object_copy)(void*, void*); 8
|
||||
void (*__Block_byref_id_object_dispose)(void*); 8
|
||||
Person *p;
|
||||
Person *p; 8
|
||||
};
|
||||
|
||||
|
||||
__attribute__((__blocks__(byref))) __Block_byref_p_0 p = {
|
||||
0,
|
||||
&p,
|
||||
@@ -1316,6 +1366,14 @@ p.block();
|
||||
|
||||
|
||||
|
||||
## 为什么加 weakself、strongself
|
||||
|
||||
weakSelf 是为了使 block 不持有 self,避免 Retain Circle 循环引用。在 Block 内如果需要访问 self 的方法、变量,建议使用 weakSelf。
|
||||
|
||||
strongSelf 的目的是因为一旦进入 block 执行,假设不允许 self 在这个执行过程中释放,就需要加入 strongSelf。
|
||||
|
||||
block 执行完后这个 strongSelf 会自动释放,没有不会存在循环引用问题。如果在 Block 内需要多次 访问 self,则需要使用 strongSelf。
|
||||
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
@@ -2425,7 +2425,7 @@ import 举个例子吧。在 `Person.m`
|
||||
|
||||
### 编写工具生成 hmap 文件
|
||||
|
||||
#### 为什么要编写 hmap 文件
|
||||
#### 为什么要生成 hmap 文件
|
||||
|
||||
如果2个 `.m` 文件有相同的头文件代码,造成编译浪费。
|
||||
|
||||
@@ -2458,7 +2458,7 @@ Xcode 会主动生成 `.hmap` 文件,那为什么还需要研究生成 `hmap`
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/StaticLibUseHeaderMapOnlyQuoteMethod.png" style="zoom:30%" />
|
||||
|
||||
分析:在 App 使用 Static Library 的情况下,假设开启了 `Use Header Map`,静态库中所有头文件类型为 `Project`(只有 Project、Private、Public 3种类型,public 就是字面意思的公开,p r)的情况,最终生成的 `.hmap` 文件中只会包含类似 `#import "Student.h"` 的键值引用。也就是说使用的地方,只有 `#import "Student.h"` 的这种方式才会走 hmap 策略,否则还是走 `Header Search Path` 来寻找头文件路径。
|
||||
分析:在 App 使用 Static Library 的情况下,假设开启了 `Use Header Map`,静态库中所有头文件类型为 `Project`(只有 Project、Private、Public 3种类型,public 就是字面意思的公开,private 则代表 In Progress, project 才是通常意义上的 Private 含义)的情况,最终生成的 `.hmap` 文件中只会包含类似 `#import "Student.h"` 的键值引用。也就是说使用的地方,只有 `#import "Student.h"` 的这种方式才会走 hmap 策略,否则还是走 `Header Search Path` 来寻找头文件路径。
|
||||
|
||||
组件、库使用 `#import <SomeFramework/SomeFrameworkExportedHeader.h>` 是访问的标准做法。好处有3点:
|
||||
1. 明确头文件的由来,避免歧义
|
||||
@@ -2505,7 +2505,7 @@ LLVM 真是好东西,把 Xcode 编译、链接等一些幕后的事情变成
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/StaticLibUseHeaderMapEffect.png" style="zoom:30%" />
|
||||
|
||||
可以看到静态库使用了自定义的 Header Maps 文件后,使用静态的 App 前后,编译耗时减少了0.1s。
|
||||
可以看到静态库使用了自定义的 Header Maps 文件后,使用静态的 App 前后,编译耗时减少了1.1s,节省了57%。
|
||||
|
||||
|
||||
|
||||
@@ -2696,6 +2696,37 @@ objdump --macho --private-headers DSYMDemo
|
||||
|
||||
|
||||
|
||||
### main 函数
|
||||
|
||||
实验一:
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/MainFuncHasNoDifferenceWithOthers.png" style="zoom:30%" />
|
||||
|
||||
编写2个函数,main 函数和 test 函数,除了方法名不同,在汇编侧是一样的。
|
||||
|
||||
实验二:
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/CanNotLinkWithoutMainFunc.png" style="zoom:30%" />
|
||||
|
||||
可以看到创建的 `test.c` 文件中,只有一个 `test` 方法。没有 `main` 方法,然后用 gcc 发现链接报错。
|
||||
|
||||
然后利用 gcc 指令 ` gcc -nostartfiles -e_test test.c` 发现可以编译通过,运行也没问题。
|
||||
|
||||
当然除了 gcc,很多嵌入式平台,可以在代码中指定 c 程序的起点。
|
||||
|
||||
比如 STM32,专门有个汇编文件,用于系统的初始化。
|
||||
|
||||
总结一下:
|
||||
|
||||
- main 函数和其他普通函数并无区别
|
||||
- main 函数是很多程序的默认起点,但绝不是非它不可,任何函数都可以被设置成程序起点。
|
||||
|
||||
|
||||
|
||||
iOS 侧,dyld 默认以 main 函数作为函数起点。
|
||||
|
||||
|
||||
|
||||
### dyld 加载过程
|
||||
|
||||
<img src="https://raw.githubusercontent.com/FantasticLBP/knowledge-kit/master/assets/dyldFullProcess.png" style="zoom:40%" />
|
||||
|
||||
Reference in New Issue
Block a user