mirror of
https://github.com/NohamR/knowledge-kit.git
synced 2026-07-11 22:42:17 +00:00
update: content update
This commit is contained in:
@@ -2,7 +2,7 @@
|
||||
|
||||
## TCP/UDP
|
||||
|
||||
TCP 传输的核心公式:速度 = 窗口大小/往返时间,这个公式对于理解传输本质和排查传输问题具有很强的知道意义。
|
||||
TCP 传输的核心公式:速度 = 窗口大小/往返时间,这个公式对于理解传输本质和排查传输问题具有很强的指导意义。
|
||||
|
||||
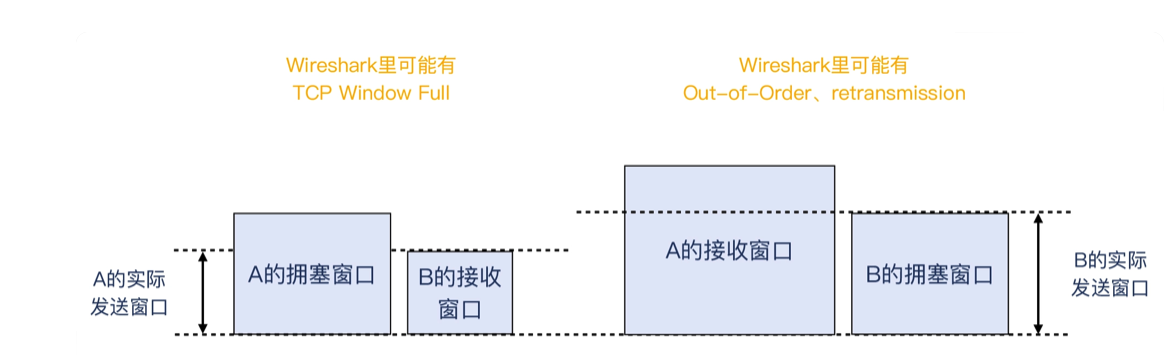
TCP 里面有三种窗口:发送窗口、接收窗口、拥塞窗口。如果没有特别说明,TCP Window 指的是接收窗口。
|
||||
|
||||
@@ -18,7 +18,7 @@ TCP 传输的起始阶段,速度都是从低到高升上来的,很少一上
|
||||
|
||||
这个机制其实就是 TCP 的拥塞控制。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -32,7 +32,7 @@ TCP 使用拥塞机制来确保传输速度和稳定性。拥塞机制是通信
|
||||
|
||||
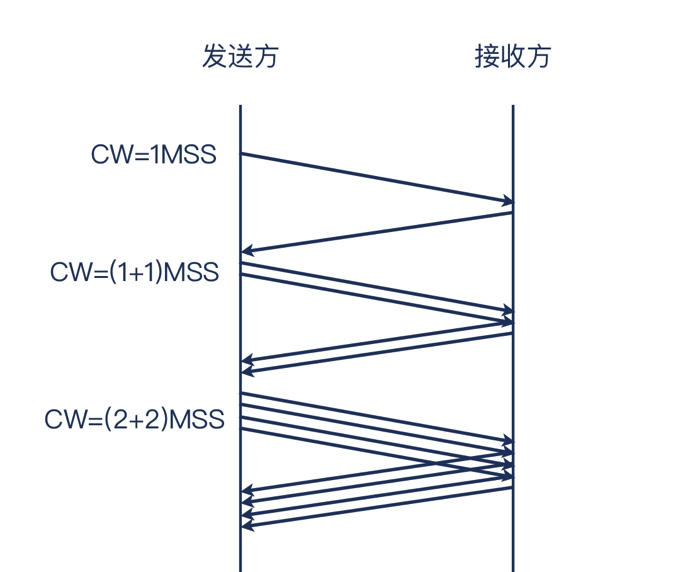
Slow start,即 TCP 传输的开始阶段是从一个相对低的速度开始的。之后拥塞窗口会翻倍方式增长。每次 TCP 收到一个确认了数据的 ACK,拥塞窗口就增加1个 MSS
|
||||
|
||||

|
||||
|
||||
|
||||
当收到重复的 ACK 报文(即确认号一样),比如收到2个 ACK,但他们的确认号一样,那么第二个 ACK 就不算是“确认数据的 ACK”,拥塞窗口就不会增加2个 MSS,只会增加1个 MSS。
|
||||
|
||||
@@ -52,11 +52,11 @@ Slow start,即 TCP 传输的开始阶段是从一个相对低的速度开始
|
||||
|
||||
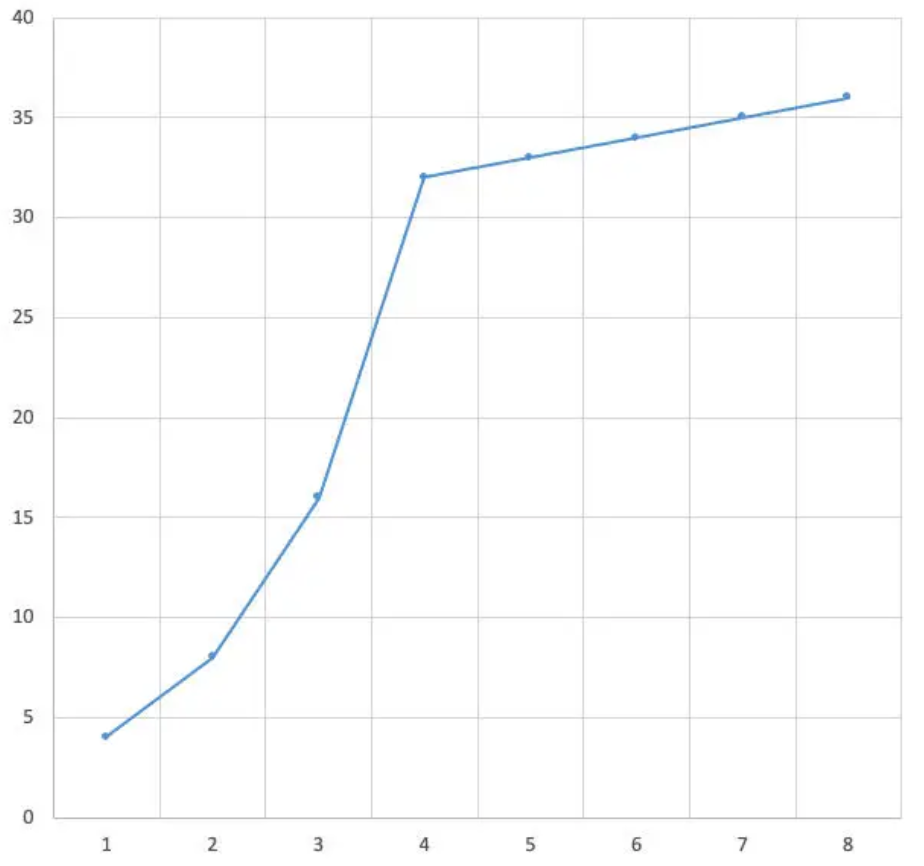
**慢启动阈值** ssthresh,过了这个阈值,拥塞窗口的增长速度就立刻变慢了,变为每过一个 RTT,拥塞窗口就增加一个 MSS(之前是没收到一个确认数据的 ACK 就增加1个 MSS)
|
||||
|
||||

|
||||
|
||||
|
||||
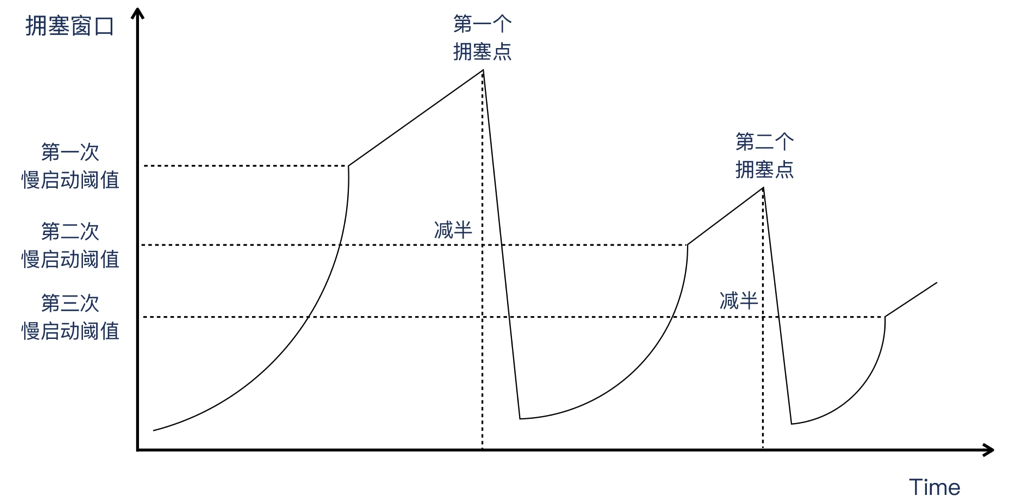
上图所示,假设 ICW 是4个 MSS,ssthresh 是32个 MSS,慢启动阶段经过1个 RTT 后,CW 扩大为8MSS、16MSS、32MSS。等到了阈值之后,TCP就进入拥塞避免阶段了。每过一个 RTT,拥塞窗口只增加1MSS,曲线就变为较为斜率较低的直线了。
|
||||
|
||||

|
||||
|
||||
|
||||
QA:如果拥塞窗口大小正好等于慢启动阈值,那么发送方这时候是需要采用拥塞避免过程(线性增长)还是继续选择慢启动过程(指数增长)?[RFC5681](https://datatracker.ietf.org/doc/html/rfc5681) 规定是说两者都可以。
|
||||
|
||||
@@ -89,7 +89,7 @@ Congestion Window,拥塞窗口,简写 CW。拥塞窗口是针对每个连接
|
||||
|
||||
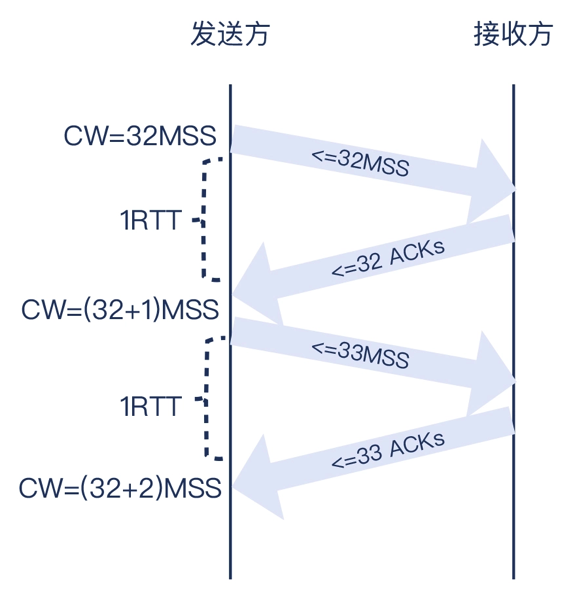
TCP 野蛮生长后当达到慢启动阈值之后,会进入拥塞避免阶段。这个阶段的特点是“和性增长乘性降低”(Addictive increase/multiplicative decrease,AIMD),解释下就是拥塞避免阶段每个RTT时间,拥塞窗口只增长1MSS,这个阶段的拥塞窗口增长是线性的(斜率比较低的直线),当探测到拥塞时,拥塞窗口就要往下降,下降是直接减半的,叫做乘性降低。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -115,7 +115,7 @@ TCP 会利用另一种机制来解决超时重传带来的时间等待问题,
|
||||
|
||||
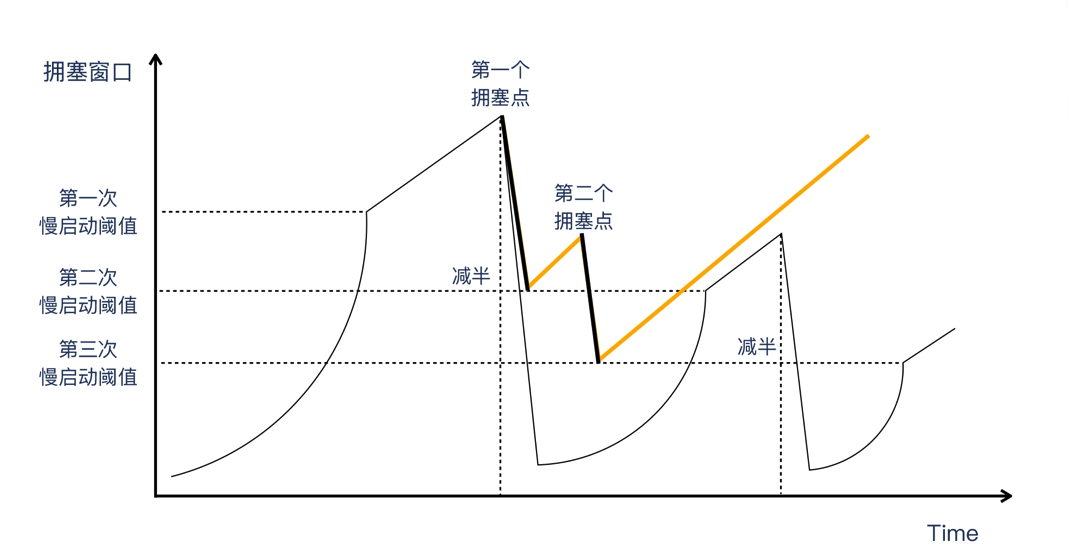
快速恢复是 TCP Reno 算法引入的一个阶段,是和“快速重传”搭配工作的。跟之前的“慢启动-拥塞避免-慢启动-拥塞避免”不同的是,当遇到拥塞点之后,通过快速重传,就不再进入慢启动了,而是从这个减半的拥塞窗口开始,保持跟拥塞避免一样的线性增长,直到遇到下一个拥塞点。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@@ -280,7 +280,7 @@ Cache-Control 中比较常用的就是 max-age,此外还有几个
|
||||
|
||||
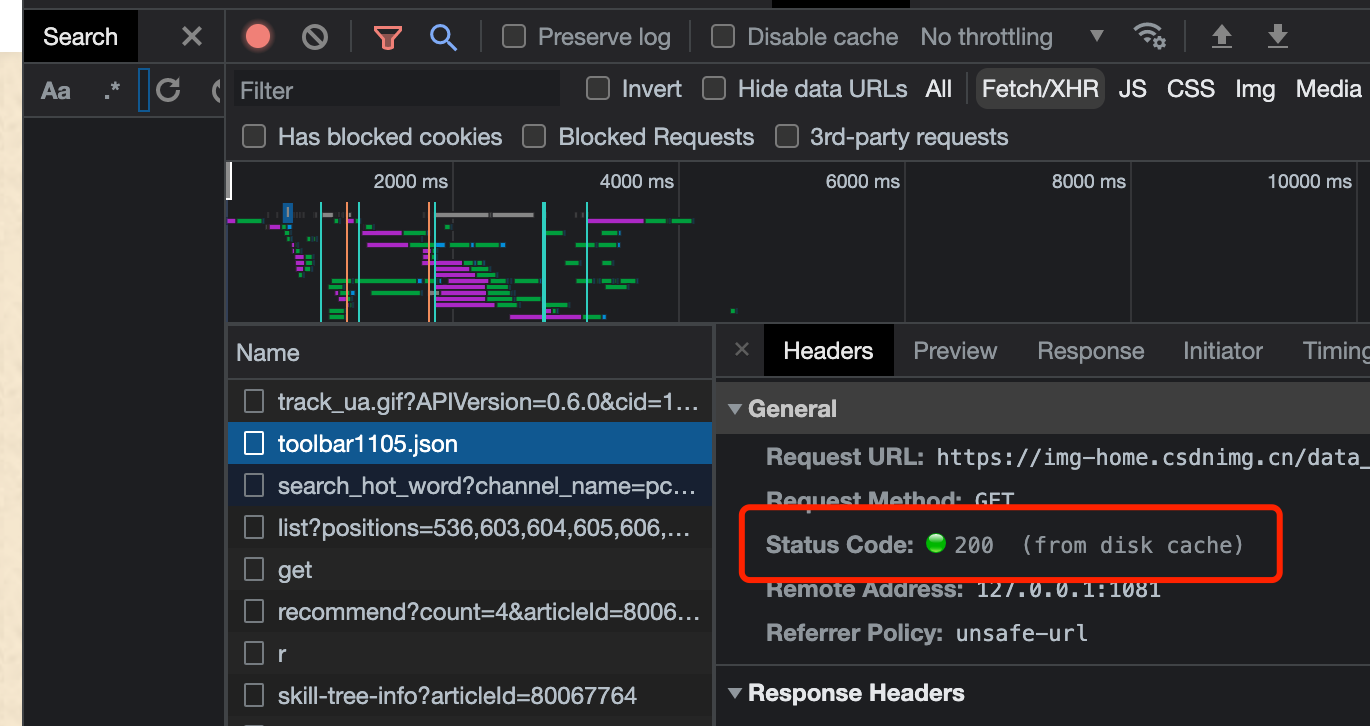
将网页点击前进、后退会发现“ Status Code:200 from disk cache”
|
||||
|
||||

|
||||
|
||||
|
||||
### 条件请求
|
||||
|
||||
@@ -290,7 +290,7 @@ Cache-Control 中比较常用的就是 max-age,此外还有几个
|
||||
|
||||
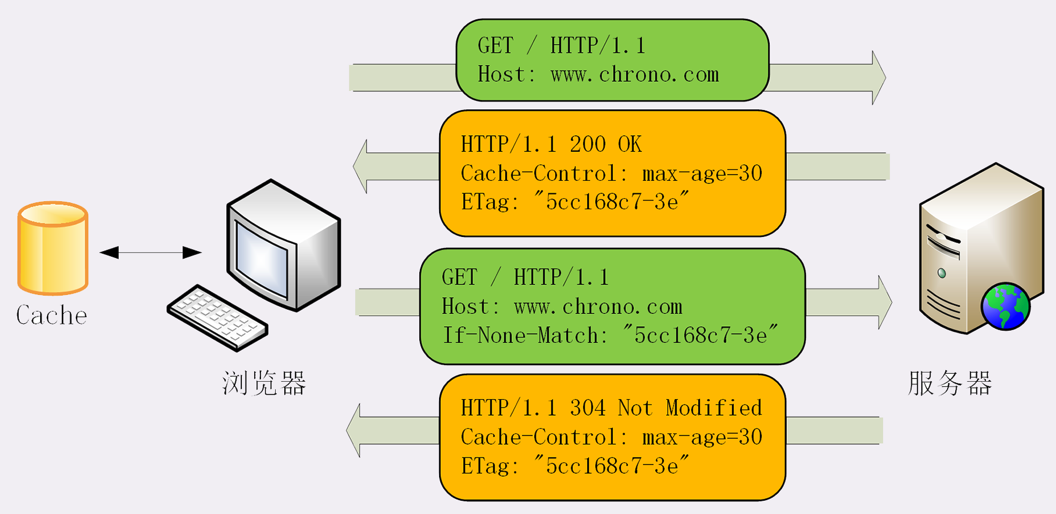
条件请求共5个头字段,常用的是 `If-Modified-Since` + `Last-modified` 和 `If-None-Match` + `ETag`这两个(需要搭配使用)。需要在第一次响应报文预先提供 `Last-modified` 和 `ETag`,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。如果服务端资源没有更新,则返回 “304 Not Modified”,表示缓存有效, 浏览器只需要更新缓存日期便可继续使用本地缓存
|
||||
|
||||

|
||||
|
||||
|
||||
Last Modified 代表资源的最后修改时间
|
||||
|
||||
@@ -401,7 +401,7 @@ HTTP 传输链路上,不只是客户端有缓存,服务器上的缓存也是
|
||||
|
||||
### 客户端的缓存控制
|
||||
|
||||

|
||||
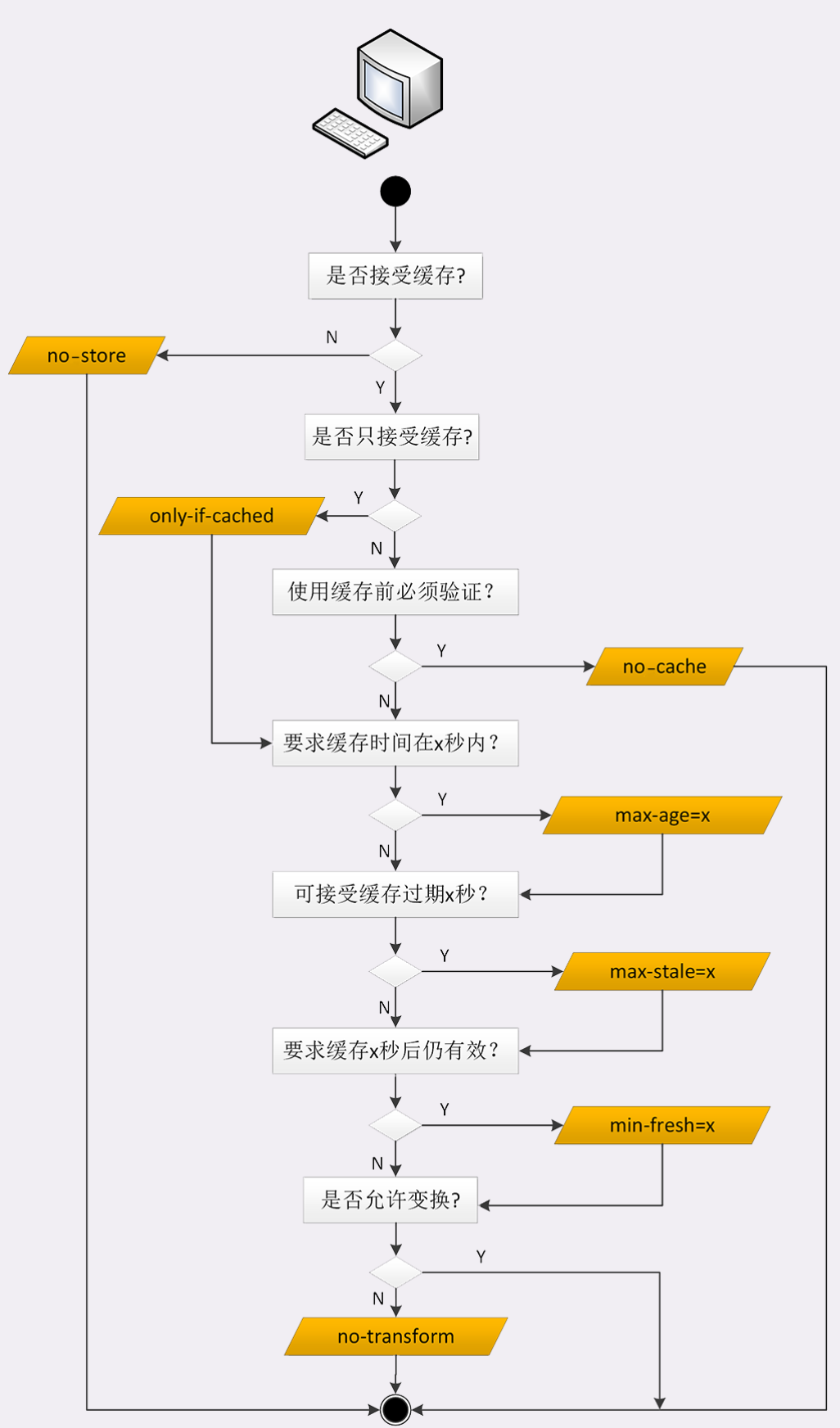
|
||||
|
||||
- max-stale:如果代理上的缓存过期了也可以接受,但不能过期太多,超过 x 秒也会不要
|
||||
|
||||
@@ -593,7 +593,7 @@ HTTPS 其实是一个“非常简单”的协议,RFC 只有短短的 7 页
|
||||
|
||||
HTTPS 的核心在于 `s` ,也就是把 HTTP 下层传输协议由 TCP/IP 换为了 SSL/TLS,从 "HTTP Over TCP/IP" 变为 "HTTP Over SSL/TLS"。让 HTTP 运行在了安全的 SSL/TLS 协议上,收发报文不再使用 Socket API,而是调用专门的安全接口。
|
||||
|
||||

|
||||
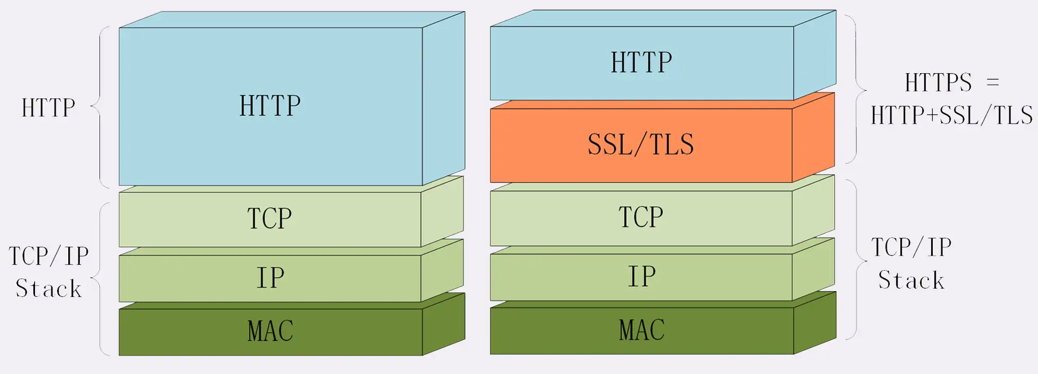
|
||||
|
||||
SSL(Secure Sockets Layer),安全套接字层,在 OSI 模型中第五层会话层,由网景公司在1994年发明,有 V2、V3 版本,V1 因为有严重缺陷从未公开过。SSL 发展到 V3 被证明是一个非常好的安全通信协议,于是互联网工程组 IEFT 在1999年更名为 TLS(Transport Layer Security)传输层安全,正式标准化,版本号从1.0计数,所以 TLS1.0 也就是 SSL V3.1/
|
||||
|
||||
@@ -695,7 +695,7 @@ SHA-2 其实是一系列摘要算法的统称,包含6中,常用的是 SHA224
|
||||
|
||||
知道问题症结所在,也比较好解,真正的完整性必须建立在“机密性”基础上。使用混合加密系统中用会话密钥加密消息和摘要,这样中间人无法得知明文。这个过程叫做“哈希消息认证码”(HMAC)
|
||||
|
||||

|
||||
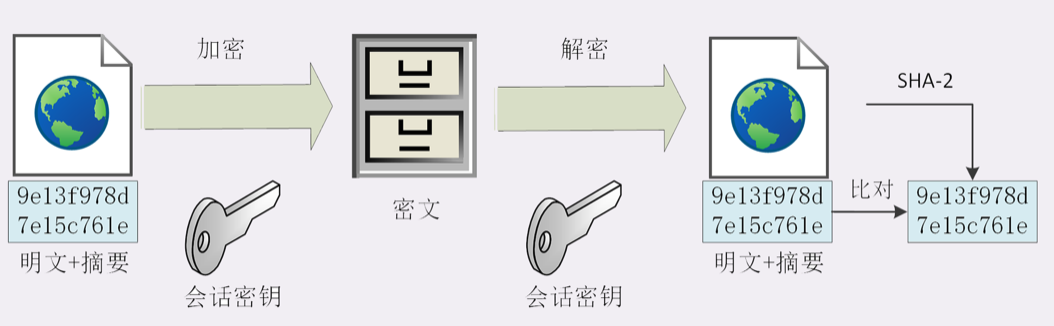
|
||||
|
||||
#### 数字签名
|
||||
|
||||
@@ -707,7 +707,7 @@ SHA-2 其实是一系列摘要算法的统称,包含6中,常用的是 SHA224
|
||||
|
||||
非对称加密效率太低,所以私钥只加密原报文的摘要,这样运算量小,速度也快。得到的数字签名也很小,方便传输和保管。
|
||||
|
||||

|
||||
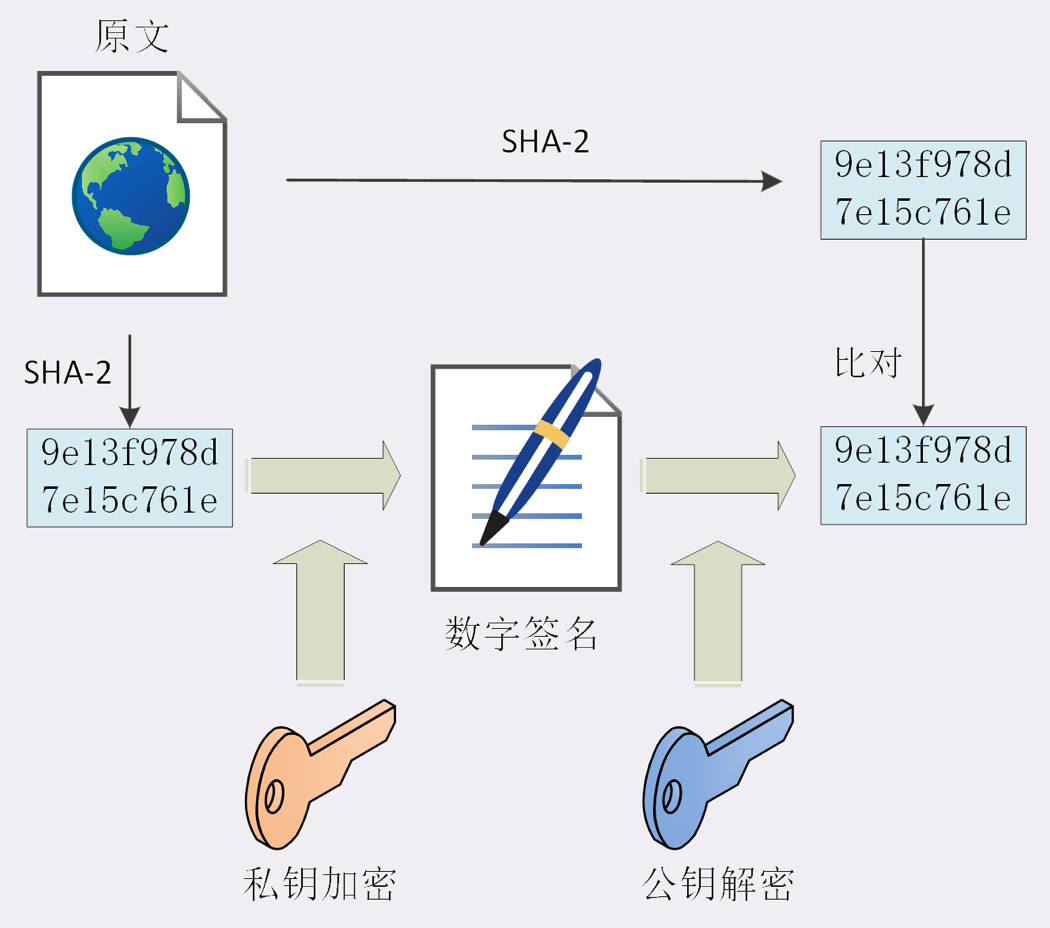
|
||||
|
||||
这个过程被叫做“签名”、“验签”。
|
||||
|
||||
@@ -725,7 +725,7 @@ CA 如何自证?
|
||||
|
||||
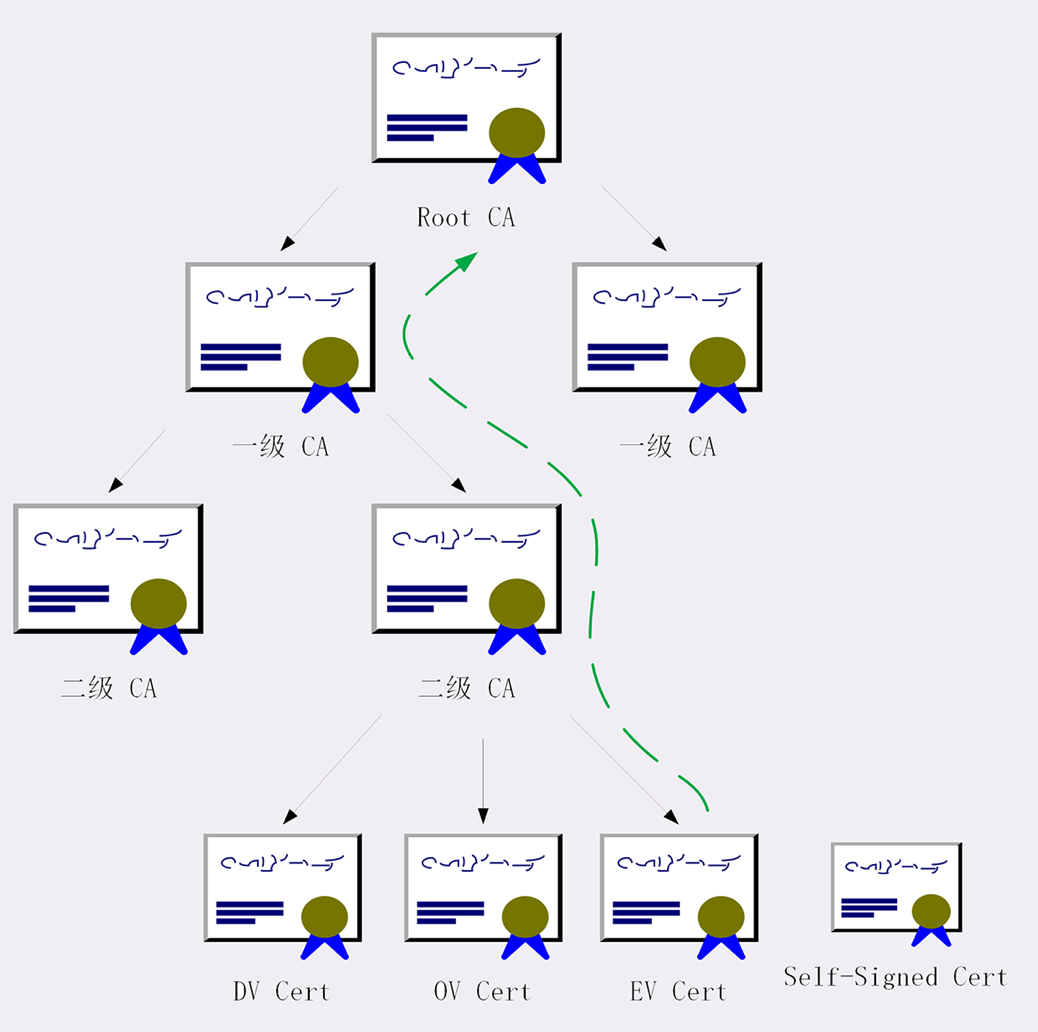
信任链。小一点的 CA 可以让大 CA 签名认证,但链条的最后,也就是 Root CA,就只能自己证明自己了,这个就叫“自签名证书”(Self-Signed Certificate)或者“根证书”(Root Certificate)。你必须相信,否则整个证书信任链就走不下去了。
|
||||
|
||||

|
||||
|
||||
|
||||
浏览器内置各大 CA 的根证书,上网的时候只要服务器发过来它的证书,就可以验证证书里的签名,顺着证书链(Certificate Chain)一层层地验证,直到找到根证书,就能够确定证书是可信的,从而里面的公钥也是可信的。
|
||||
|
||||
@@ -759,7 +759,7 @@ TLS 包含多个子协议,每个协议都有各自的职责,比较常用的
|
||||
|
||||
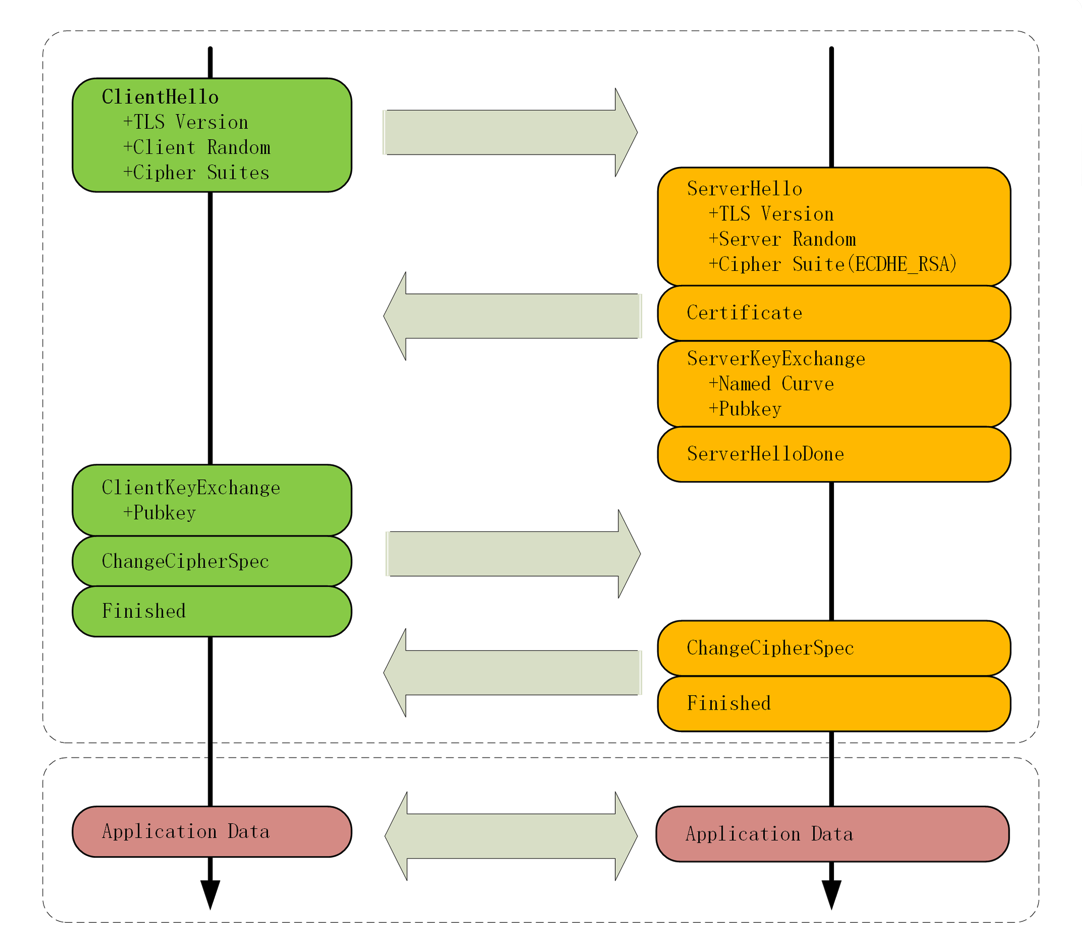
关于记录可以用下图解释
|
||||
|
||||

|
||||
|
||||
|
||||
可以看出:
|
||||
|
||||
@@ -773,19 +773,19 @@ TLS 包含多个子协议,每个协议都有各自的职责,比较常用的
|
||||
|
||||
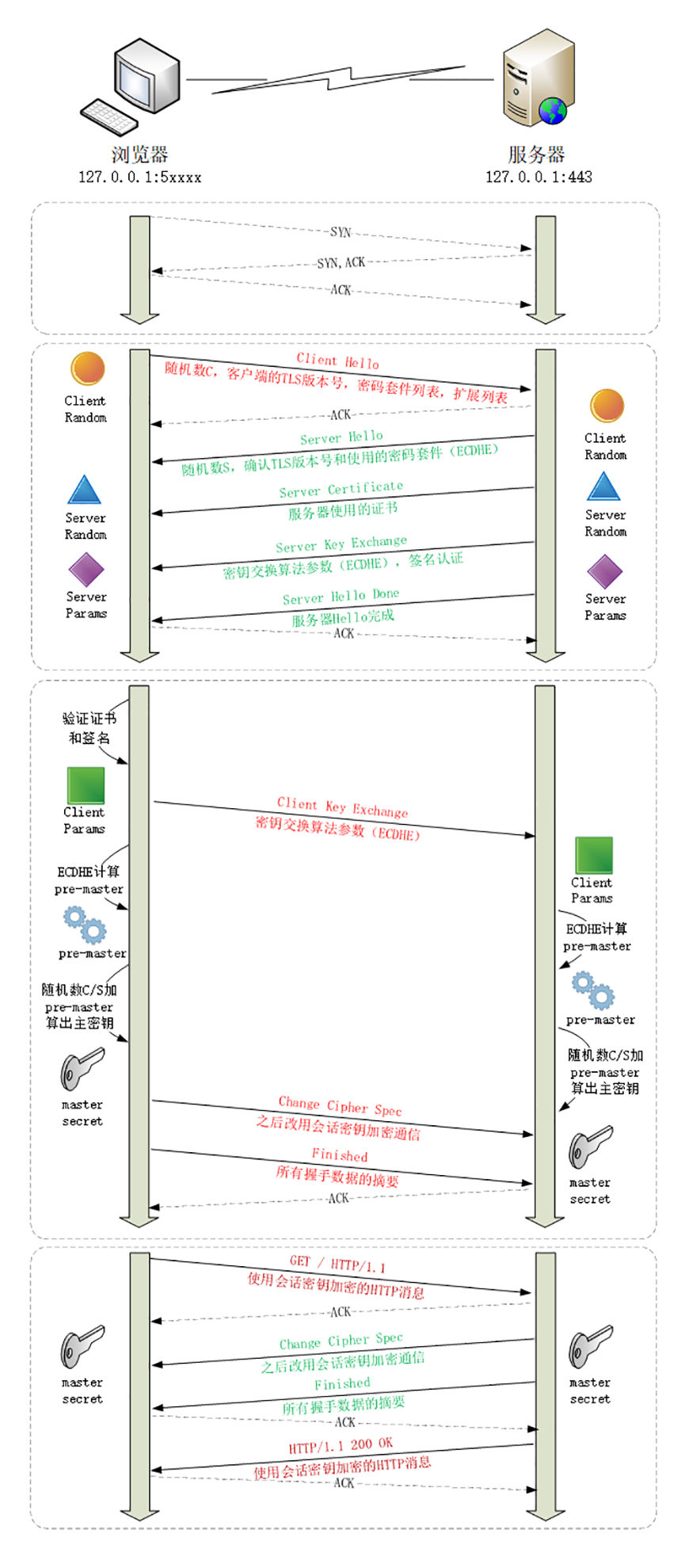
下图是 TLS 完整的流程
|
||||
|
||||

|
||||
|
||||
|
||||
上 Demo,以 Mac 上 wireshark 抓取 `https://github.com` 为例。
|
||||
|
||||
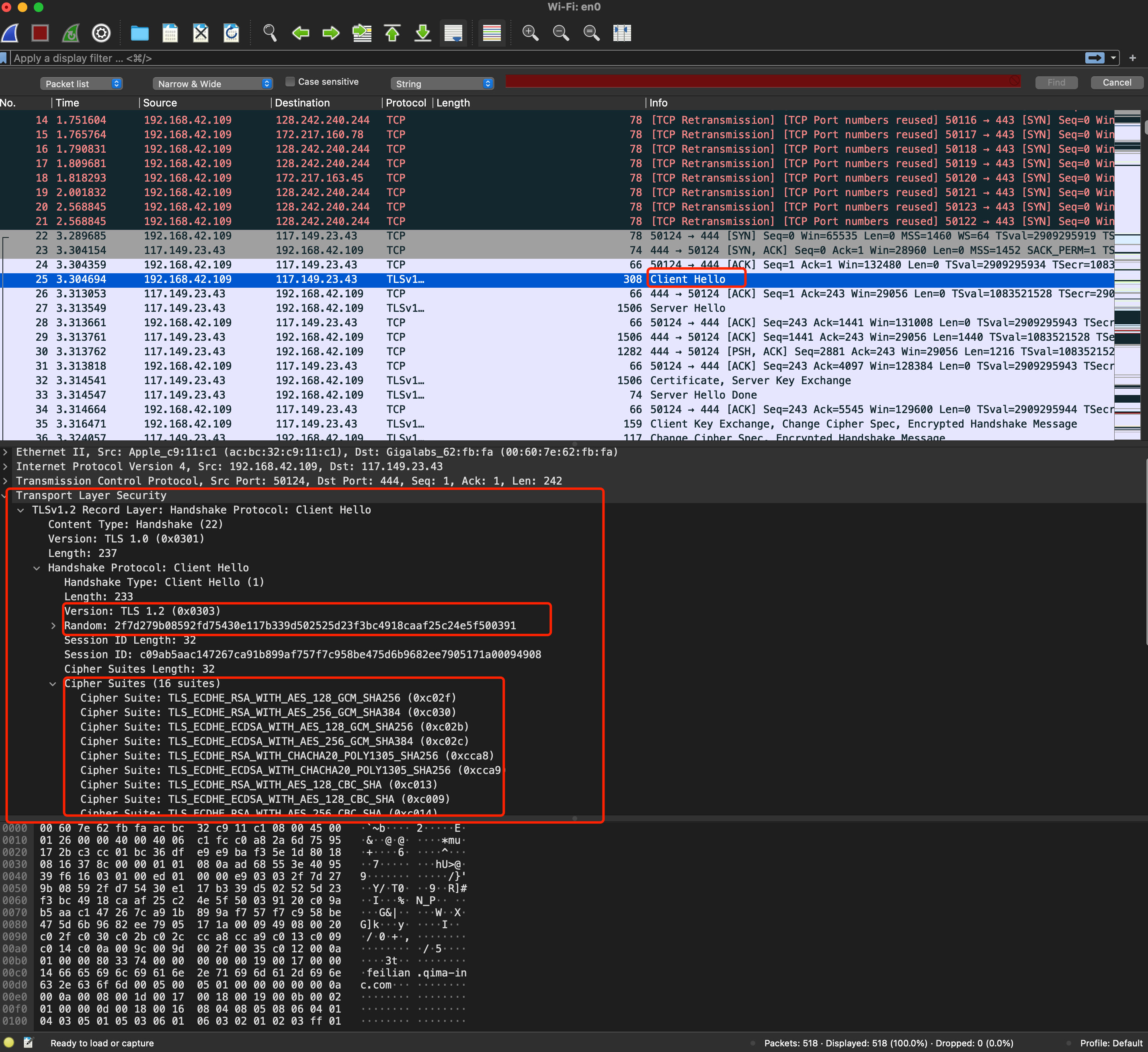
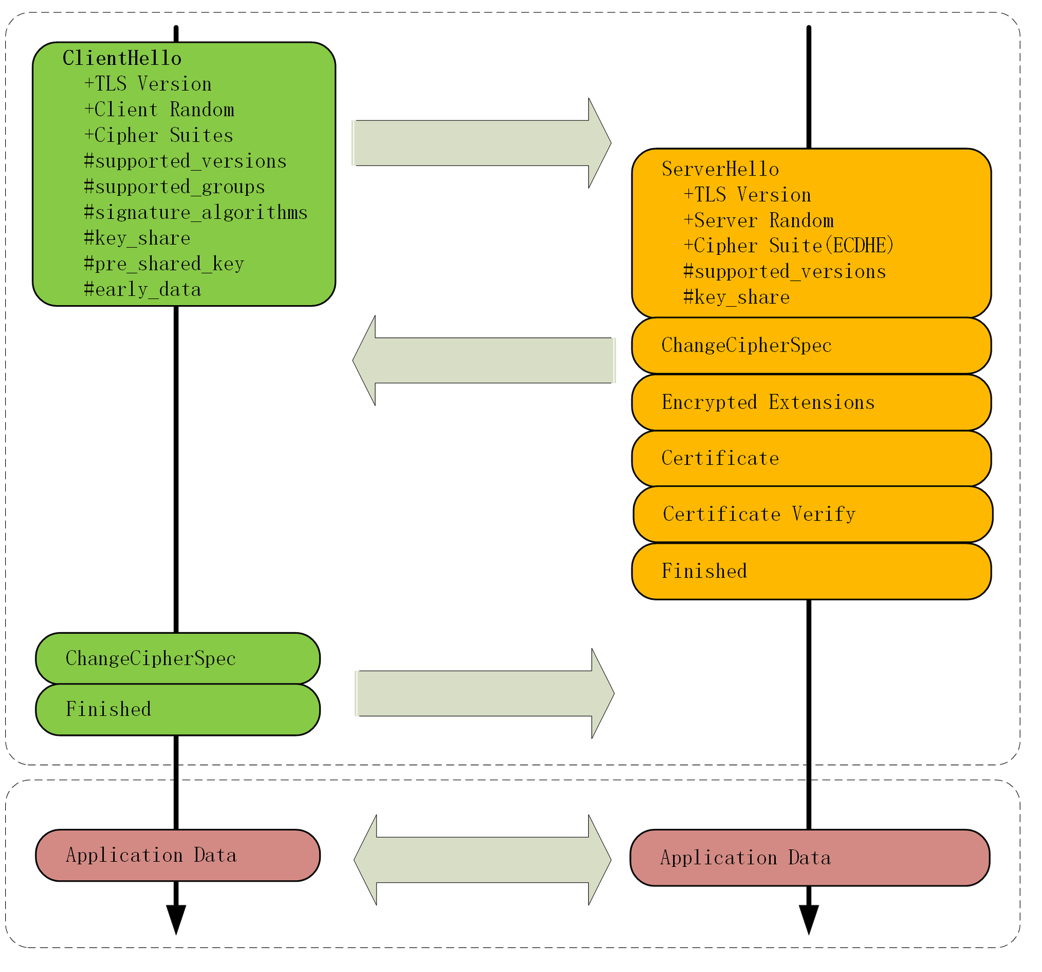
第一步:在 TCP 3次握手建立连接后,客户端发送一个 “Client Hello“ 的消息,表示开始和服务器沟通。包含客户端的 TLS 版本号、支持的密码套件、随机数,这些信息用于后续生成会话密钥。
|
||||
|
||||

|
||||
|
||||
|
||||
其实,这些信息的作用都是**协商**,客户端告诉浏览器我这边的 TLS 协议是什么版本,我本地支持的加密套件都有哪些,你后续从我支持的列表中选一个。
|
||||
|
||||
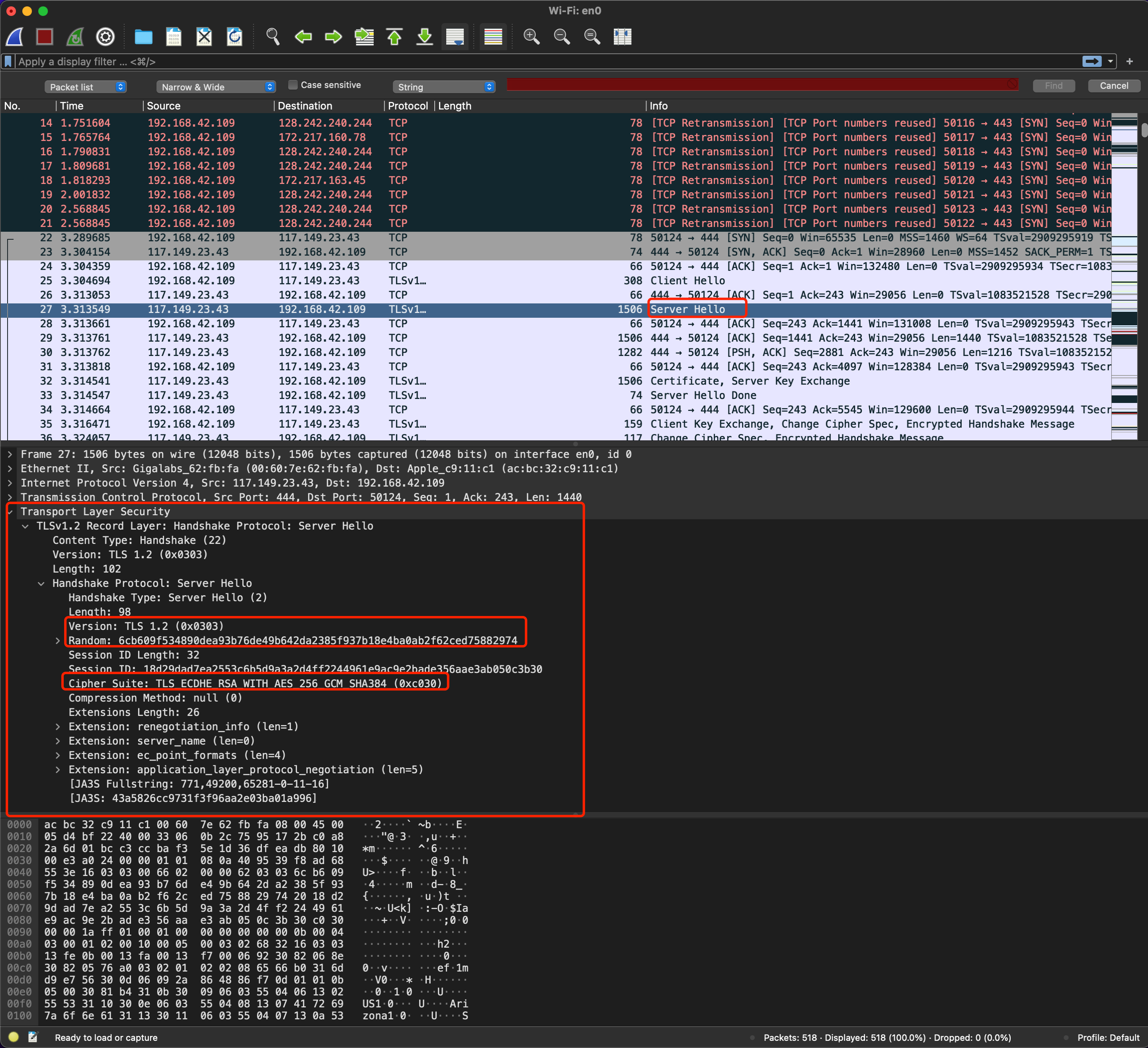
第二步:服务端收到 “Client Hello” 的消息后,会返回一个 “Server Hello” 的消息。核对版本号,同时也会生成一个随机数,然后从客户端的加密套件中选择一个作为本次通信使用的密码套件。
|
||||
|
||||

|
||||
|
||||
|
||||
可以看到此时,服务端选择了 `Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)`这个加密套件。服务端返回给客户端的这些信息也就代表“TLS 版本号对上了,你这边给的加密套件很多,我选了一个最合适的,椭圆曲线 + RSA + AES + SHA384。另外我给了你一个随机数,你需要保存后续使用”
|
||||
|
||||
@@ -799,13 +799,13 @@ TLS 是建立在 TCP 的上层协议,因此要先按照 TCP 的规则来,也
|
||||
|
||||
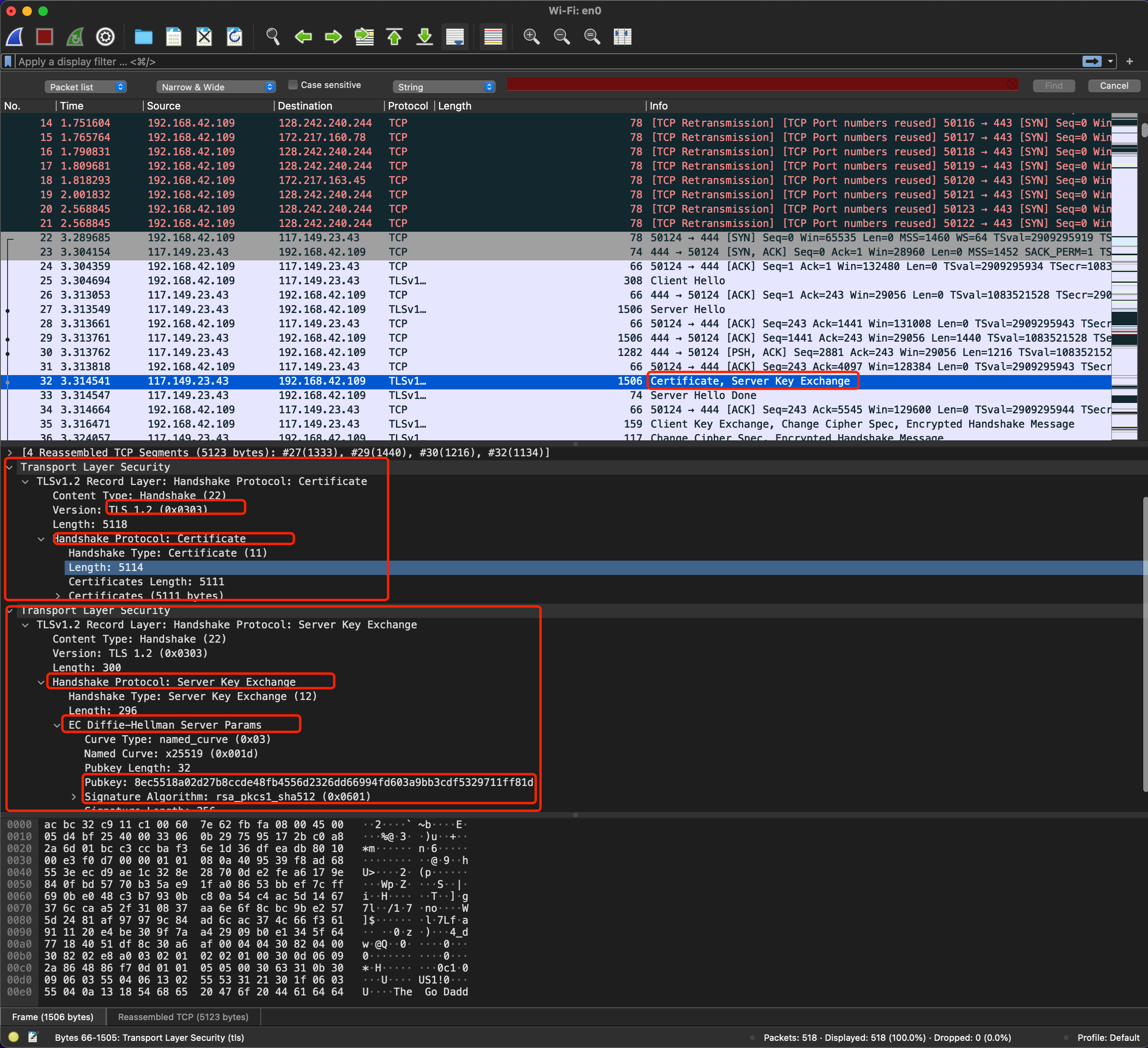
同时服务器选择了 ECDHE 算法,所以在发送了服务器证书后马上发送“Server Key Exchange”消息。里面是椭圆曲线的公钥(Server Params),用来实现密钥的交换算法,再加上自己的私钥签名认证(用私钥对椭圆曲线的 public key 做了签名认证生成了 Signature)
|
||||
|
||||

|
||||
|
||||
|
||||
意味着,服务器告诉客户端,我这边选择的加密套件有点复杂,所以再给你一个算法的参数,和随机数一样,先保存后续使用。为了保证我就是我,我给参数 public key 做了签名。
|
||||
|
||||
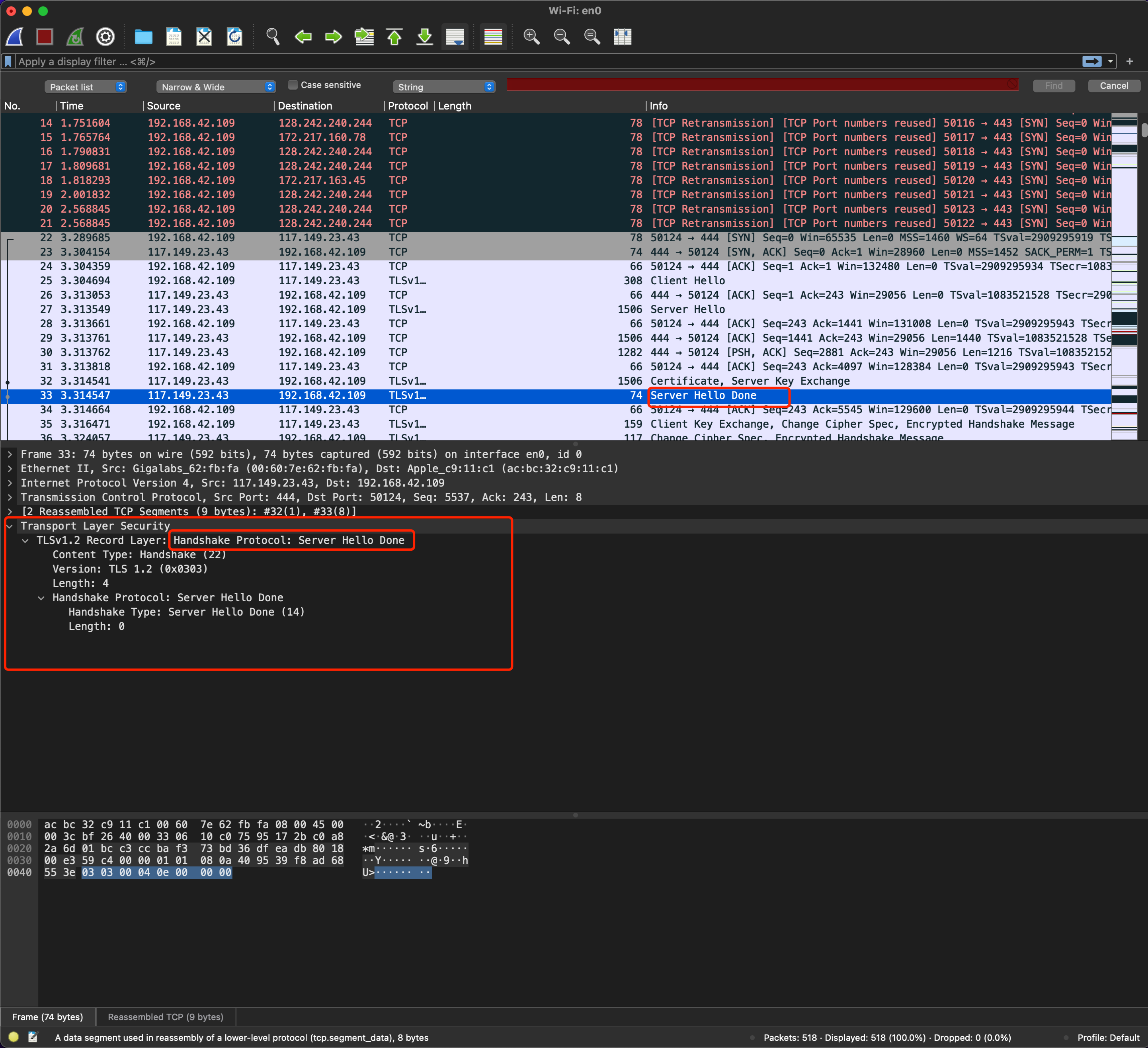
第四步:服务端发送“Server Hello Done”消息。告诉客户端,我的基础信息就是这些,打招呼阶段结束
|
||||
|
||||

|
||||
|
||||
|
||||
至此,第一个消息往返就结束了(2个TCP包),客户端和服务端通过**明文**共享了:Client Random、Server Random、Server Params。
|
||||
|
||||
@@ -813,7 +813,7 @@ TLS 是建立在 TCP 的上层协议,因此要先按照 TCP 的规则来,也
|
||||
|
||||
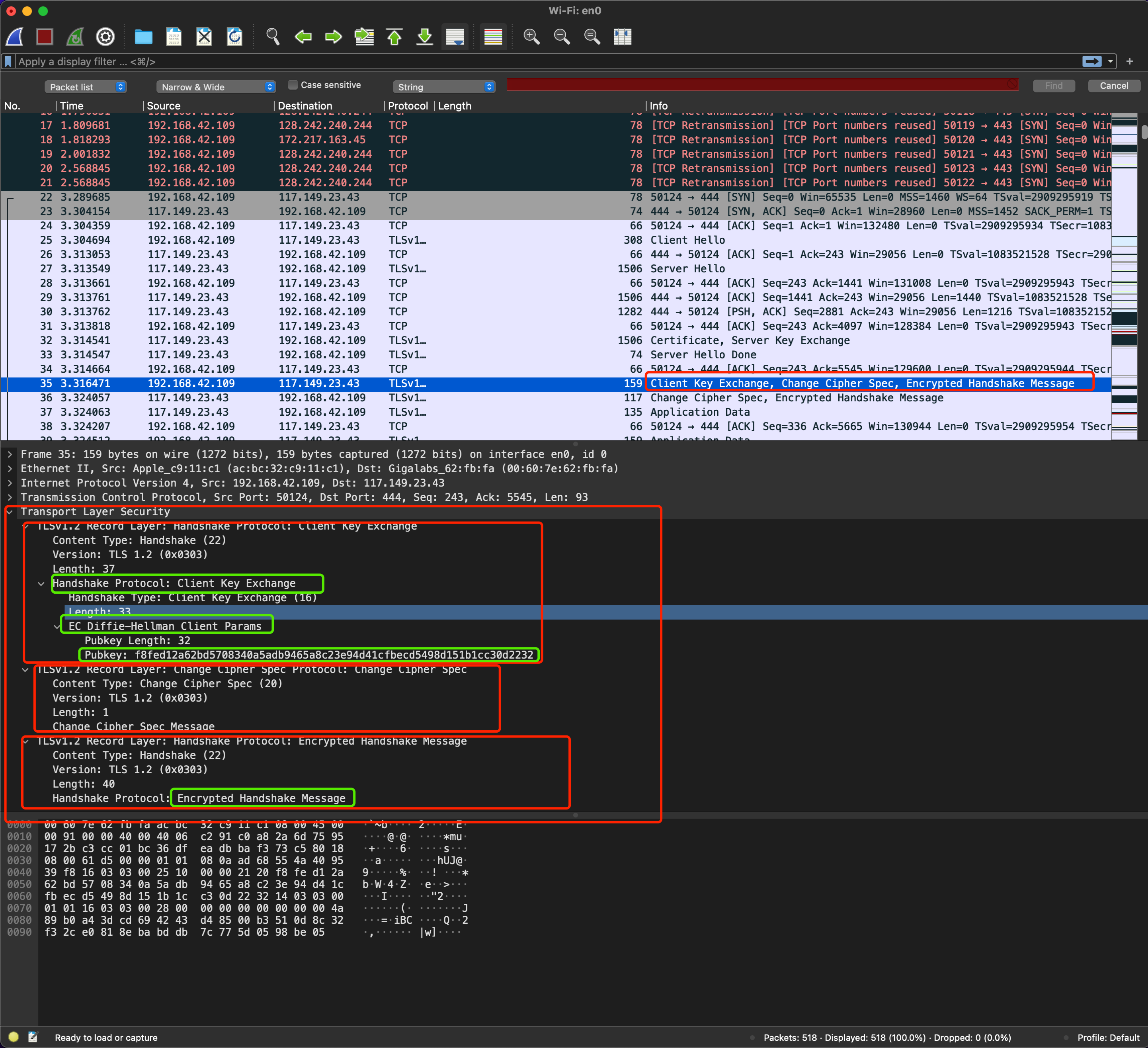
第五步:客户端按照加密套件的要求,也生成了一个椭圆曲线的公钥(Client Params),用“Client Key Exchange”消息发送给服务器
|
||||
|
||||

|
||||
|
||||
|
||||
至此,客户端和服务器都拿到了密钥交换算法的2个参数(Client Params、Server Params),然后用 ECDHE 算法计算出一个随机数,叫“Pre-Master”,也叫做“预主密钥”。
|
||||
|
||||
@@ -842,7 +842,7 @@ master_secret = PRF(pre_master_secret, "master secret",
|
||||
|
||||
第六步:服务器发送“Change Cipher Spec” 和 “Encrypted Handshake Message” 消息,双方都解密 OK,握手正式结束。后续请求就收发被加密的 HTTP 数据了。
|
||||
|
||||

|
||||
|
||||
|
||||
#### RSA 握手
|
||||
|
||||
@@ -926,7 +926,7 @@ HTTPS 建立连接时除了要做 TCP 握手,还要做 TLS 握手,在 1.2
|
||||
|
||||
做法:利用了扩展。客户端在 “Client Hello” 消息里直接用 “supported_groups” 带上支持的曲线,比如 P-256、x25519,用“key_share”带上曲线对应的客户端公钥参数,用 “signature_algorithms” 带上签名算法。服务器收到后在这些扩展里选定一个曲线和参数,再用 “key_share” 扩展返回服务器这边的公钥参数,就实现了双方的密钥交换,后面的流程就和 1.2 基本一样了。
|
||||
|
||||

|
||||
|
||||
|
||||
### HTTPS 加速
|
||||
|
||||
@@ -946,7 +946,7 @@ HTTPS 连接大致上可以划分为两个部分:建立连接时的非对称
|
||||
|
||||
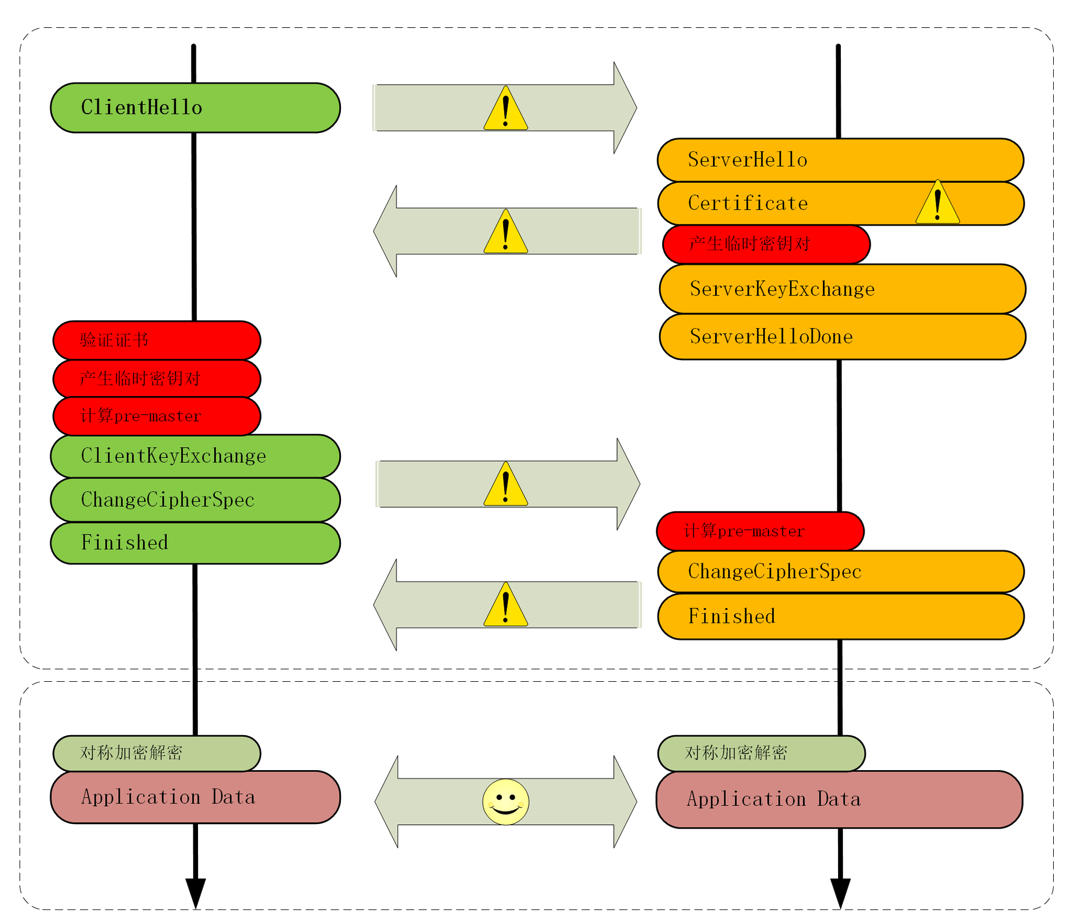
下图是存在改进空间的地方。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 硬件优化
|
||||
|
||||
@@ -1006,7 +1006,7 @@ Session Ticket 方案需要使用一个固定密钥文件(ticket_key)来加密 T
|
||||
|
||||
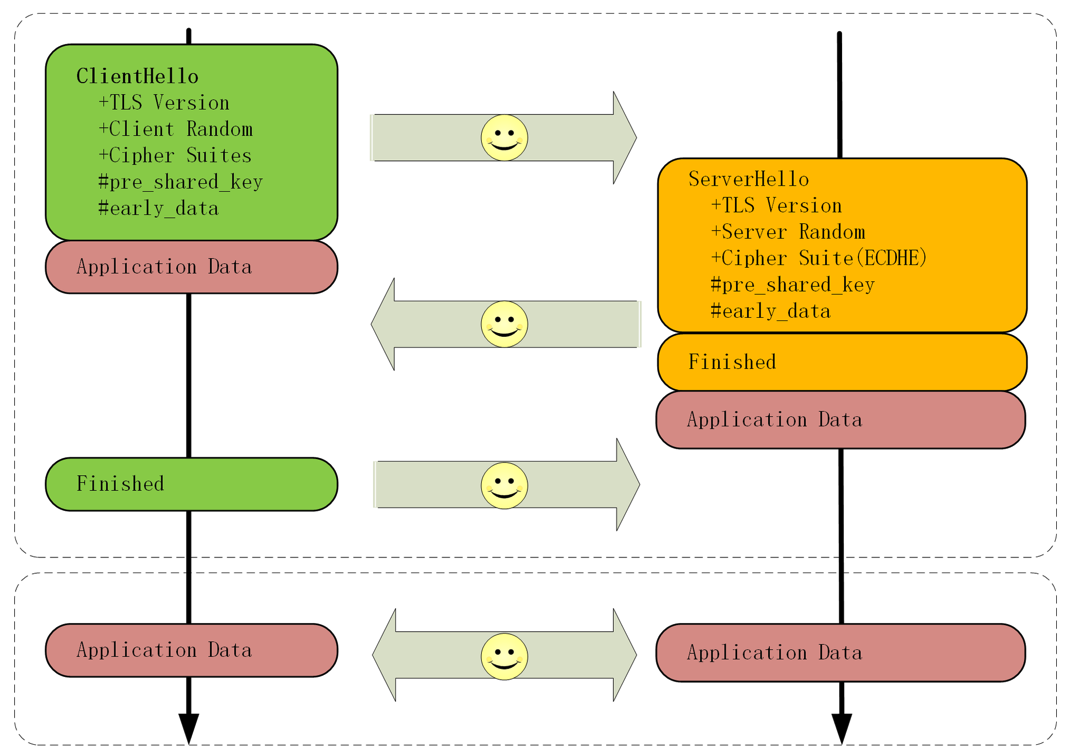
`False Start` 、`Session ID`、 `Session Ticket`等方式只能实现 1-RTT,而 TLS1.3 更进一步实现了 0-RTT,原理和 `Session Ticket` 差不多,但在发送 Ticket 的同时会带上应用数据(Early Data),免去了 1.2 里的服务器确认步骤,这种方式叫 `Pre-shared Key`,简称为“PSK”。
|
||||
|
||||

|
||||
|
||||
|
||||
PSK 存在缺点,为了追求效率而降低一些安全性,容易收到“重放攻击”,黑客截获 PSK 后,原封不动的向服务器发出去。解决办法是只允许安全的 HTTP 请求方法,如 HEAD/GET,在消息中增加时间戳、nonce 验证。
|
||||
|
||||
@@ -1040,7 +1040,7 @@ PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
但在 wireshark 抓包中,HTTP/2 连接前言被称为 “Magic“。
|
||||
|
||||

|
||||
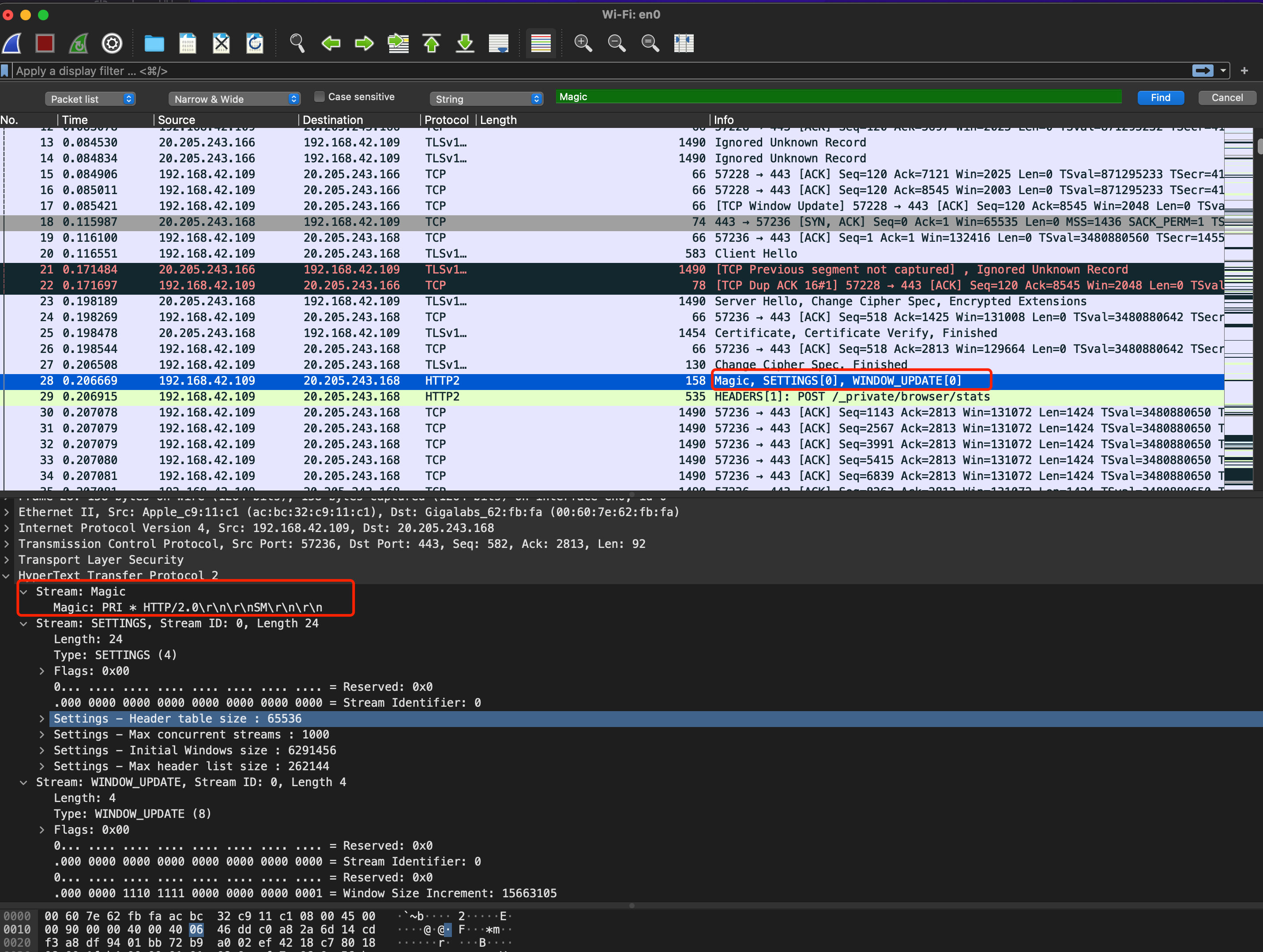
|
||||
|
||||
### 头部压缩
|
||||
|
||||
@@ -1054,13 +1054,13 @@ HTTP/1 使用头部字段“Content-Encoding” 指定 Body 的编码方式,
|
||||
|
||||
现在 HTTP 报文头就简单了,全都是 `Key-Value` 形式的字段,于是 HTTP/2 就为一些最常用的头字段定义了一个只读的“静态表”(Static Table)。
|
||||
|
||||

|
||||
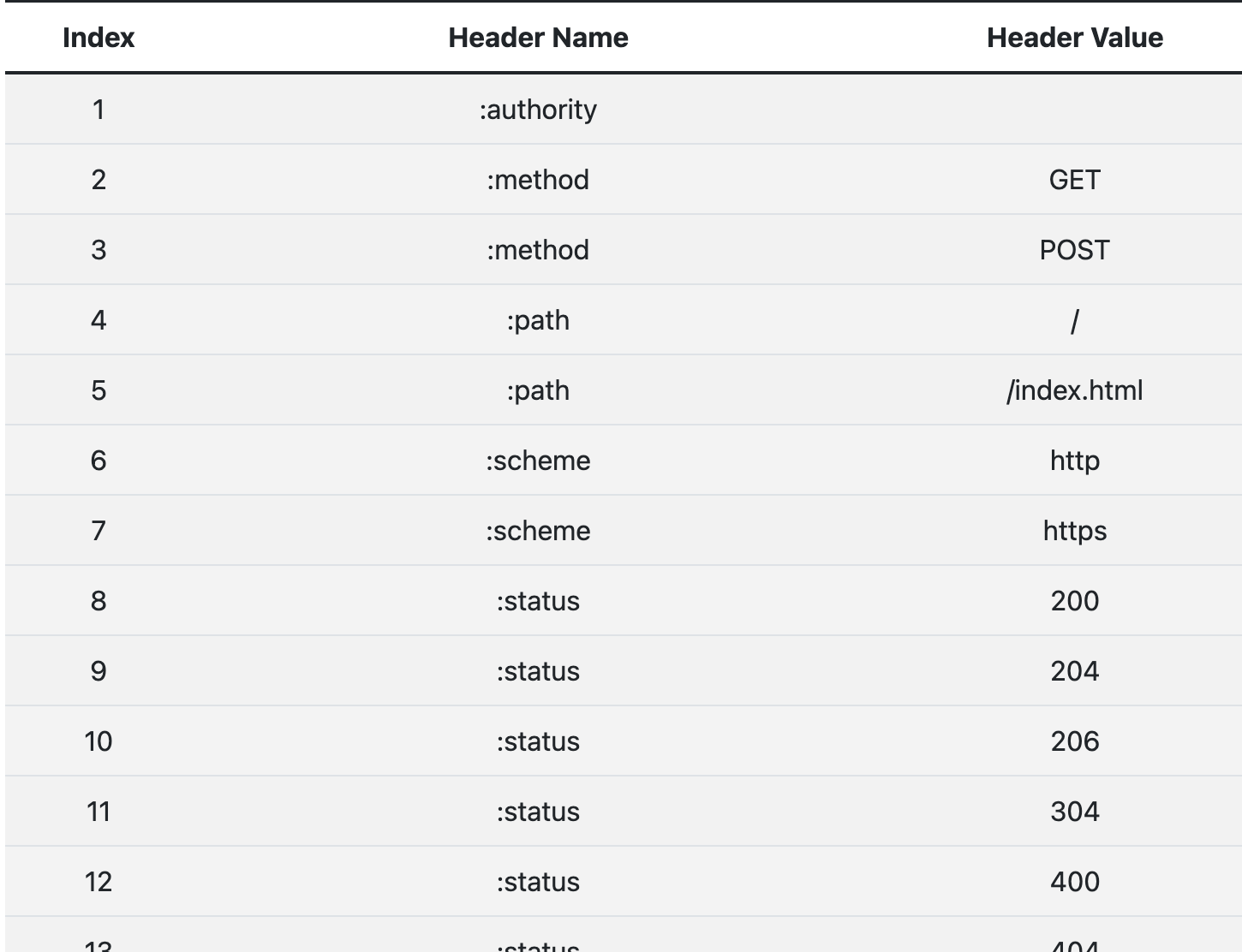
|
||||
|
||||
完整的静态表可以查看[RFC 7541 - HPACK: Header Compression for HTTP/2](https://httpwg.org/specs/rfc7541.html#static.table.definition)
|
||||
|
||||
假设使用了自定义字段怎么办?动态表(Dynamic Table) 添加在静态表后面,结构相同,在编码的时候随时更新。
|
||||
|
||||

|
||||
|
||||
|
||||
在 HTTP/2 连接上发送的报文越来越多,客户端、服务器的“字典”也会越来越丰富,最终每次的头部字段都会变成一两个字节的代码,原来上千字节的头用几十个字节就可以表示了,压缩效果比 gzip 要好得多。
|
||||
|
||||
@@ -1074,11 +1074,11 @@ HTTP/2 以前采用纯文本格式的报文(ASCII 码),但 HTTP/2 向 TCP/IP
|
||||
|
||||
这种策略有点像 `Chunked` 分块编码的方式,化整为零,但 HTTP/2 数据分帧后 “Header + Body” 的报文结构就没了,协议看到的是一个个碎片。
|
||||
|
||||

|
||||
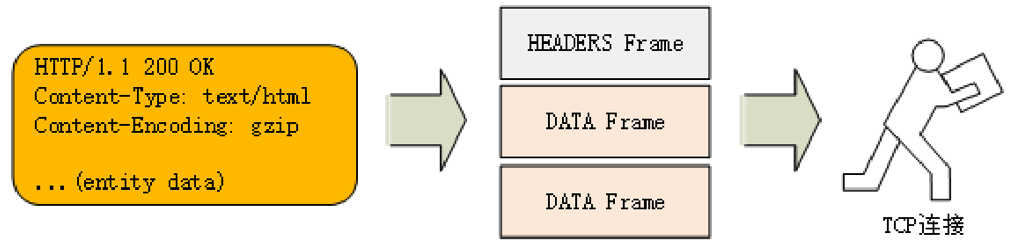
|
||||
|
||||
HTTP/2 的帧结构有点类似 TCP 的段或者 TLS 里的记录,但报头很小,只有 9 字节,非常地节省(可以对比一下 TCP 头,它最少是 20 个字节)。
|
||||
|
||||

|
||||

|
||||
|
||||
帧开头是 3 个字节的长度(但不包括头的 9 个字节),默认上限是 2^14,最大是 2^24,也就是说 HTTP/2 的帧通常不超过 16K,最大是 16M。
|
||||
|
||||
@@ -1098,7 +1098,7 @@ HTTP/2 总共定义了 10 种类型的帧,但一个字节可以表示最多 25
|
||||
|
||||
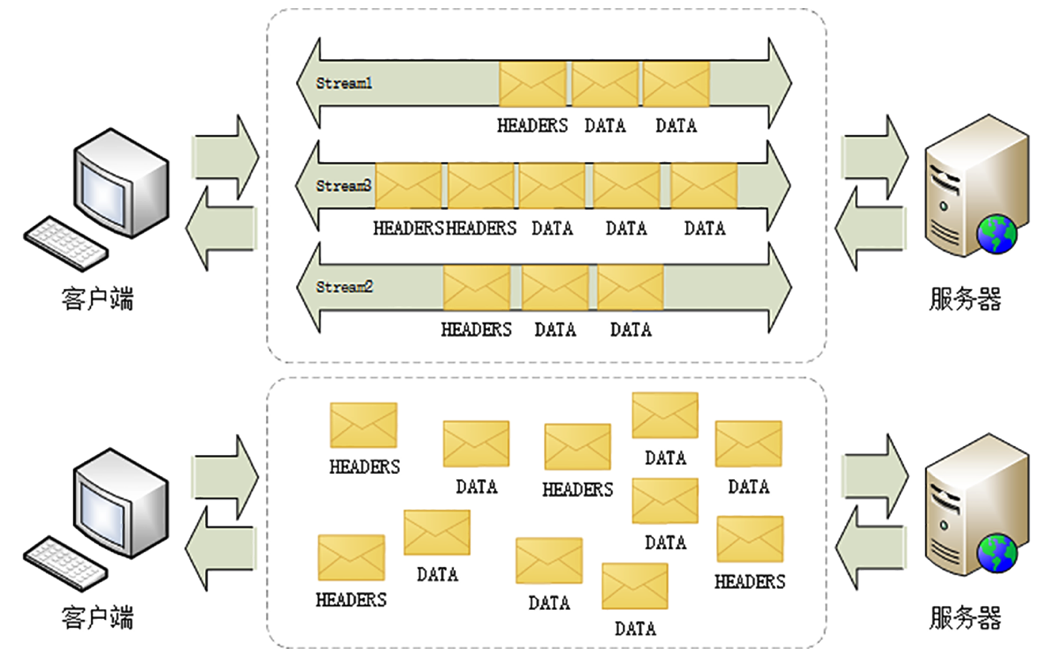
从“流”的层面上看,消息是一些有序的“帧”序列,而在“连接”的层面上看,消息却是乱序收发的“帧”。多个请求 / 响应之间没有了顺序关系,不需要排队等待,也就不会再出现“队头阻塞”问题,降低了延迟,大幅度提高了连接的利用率。
|
||||
|
||||

|
||||
|
||||
|
||||
HTTP/1 中请求-响应报文来回一次是一次 HTTP 通信,HTTP/2中一个流也做了类似的事情。
|
||||
|
||||
@@ -1120,7 +1120,7 @@ HTTP/2流的特点:
|
||||
|
||||
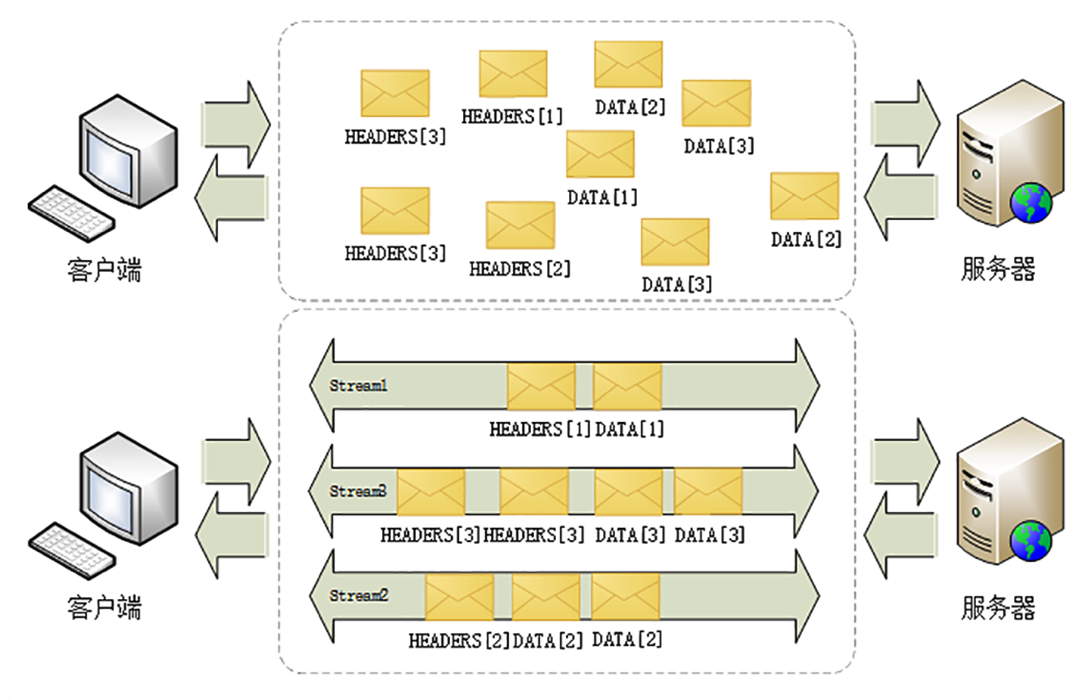
- 第 0 号流比较特殊,不能关闭,也不能发送数据帧,只能发送控制帧,用于流量控制
|
||||
|
||||

|
||||
|
||||
|
||||
可以看到:
|
||||
|
||||
@@ -1132,7 +1132,7 @@ HTTP/2流的特点:
|
||||
|
||||
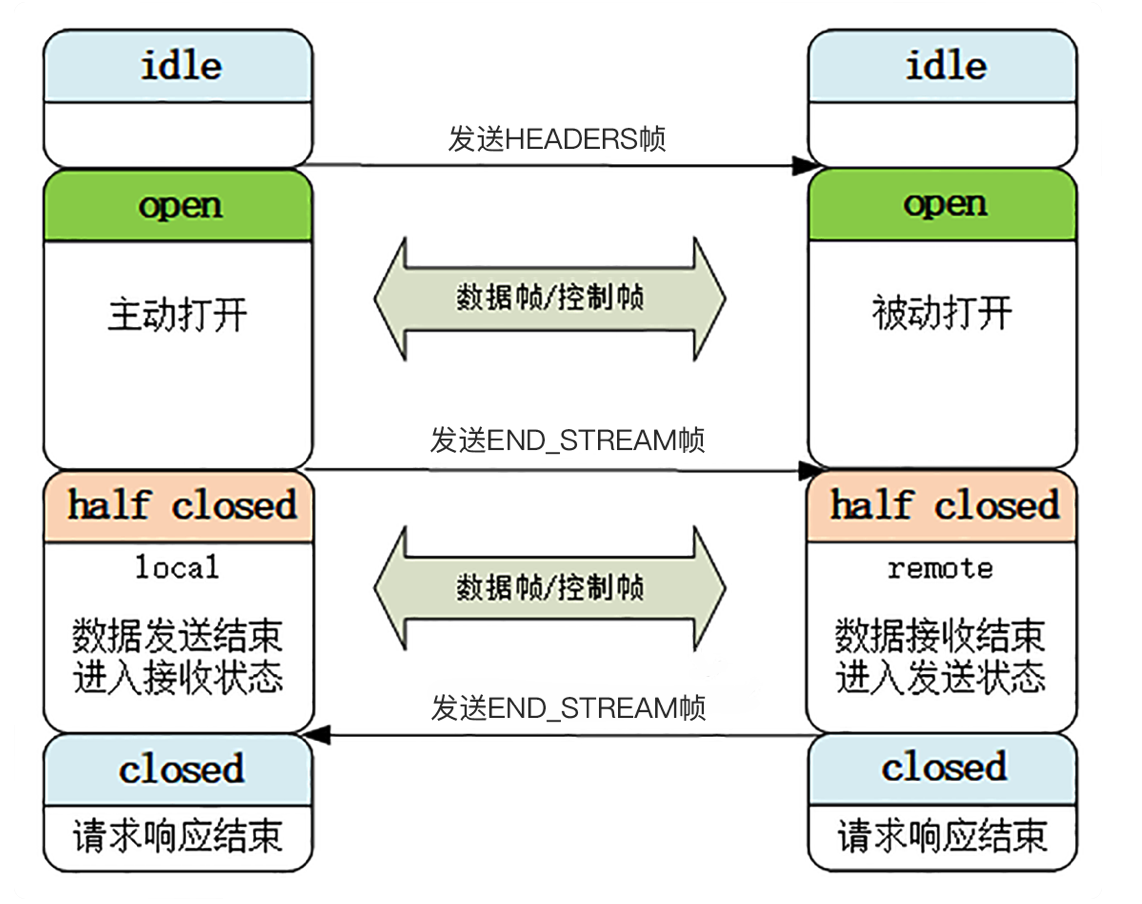
### 流状态转换
|
||||
|
||||

|
||||
|
||||
|
||||
上图对应到标准的 HTTP 请求应答。
|
||||
|
||||
@@ -1170,7 +1170,7 @@ HTTP/2 还在一定程度上改变了传统的“请求 - 应答”工作模式
|
||||
|
||||
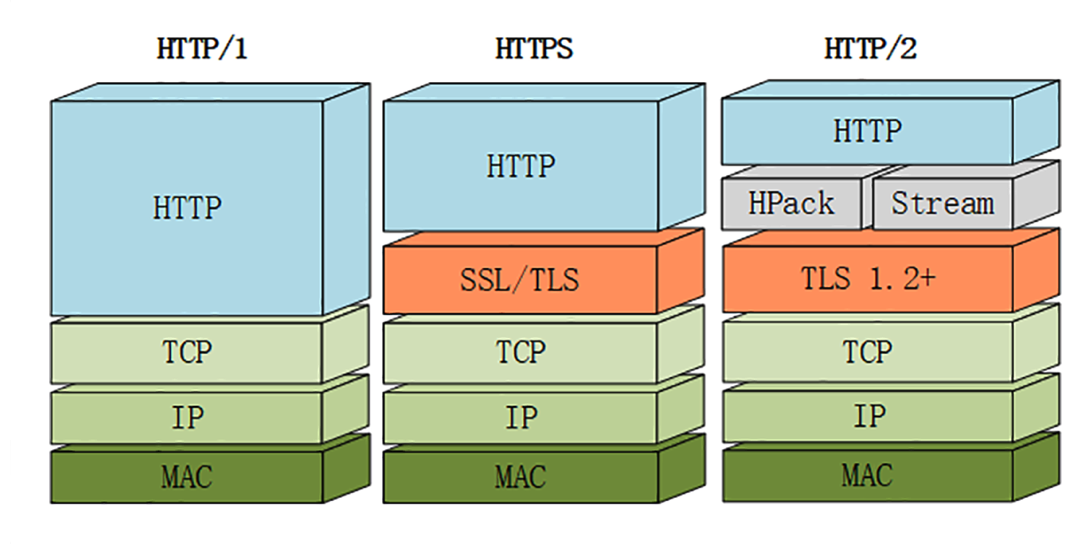
HTTP/2 是建立在 HPack + Stream + TLS1.2 之上的。
|
||||
|
||||

|
||||
|
||||
|
||||
QA:明文形式的 HTTP/2(h2c)有什么好处,应该如何使用呢?
|
||||
|
||||
@@ -1236,7 +1236,7 @@ HTTP Over QUIC 就是 HTTP3,完美解决队头阻塞问题。
|
||||
|
||||
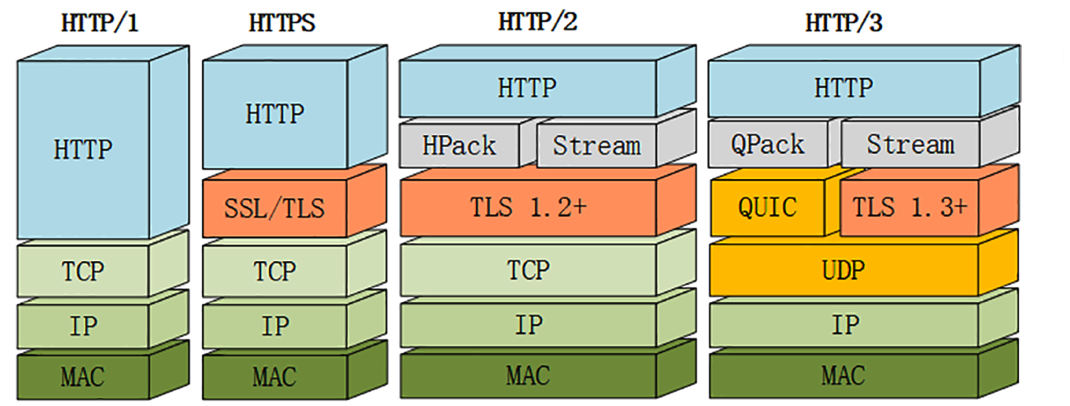
### QUIC 协议
|
||||
|
||||

|
||||
|
||||
|
||||
可以看到 HTTP3 对比 HTTP2 将 TCP 换为 UDP,因为 UDP 无序,包之间没有依赖关系,所以从根本上解决了“队头阻塞”问题
|
||||
|
||||
@@ -1260,7 +1260,7 @@ QUIC 的基本数据传输单位是包(packet)和帧(frame),一个包
|
||||
|
||||
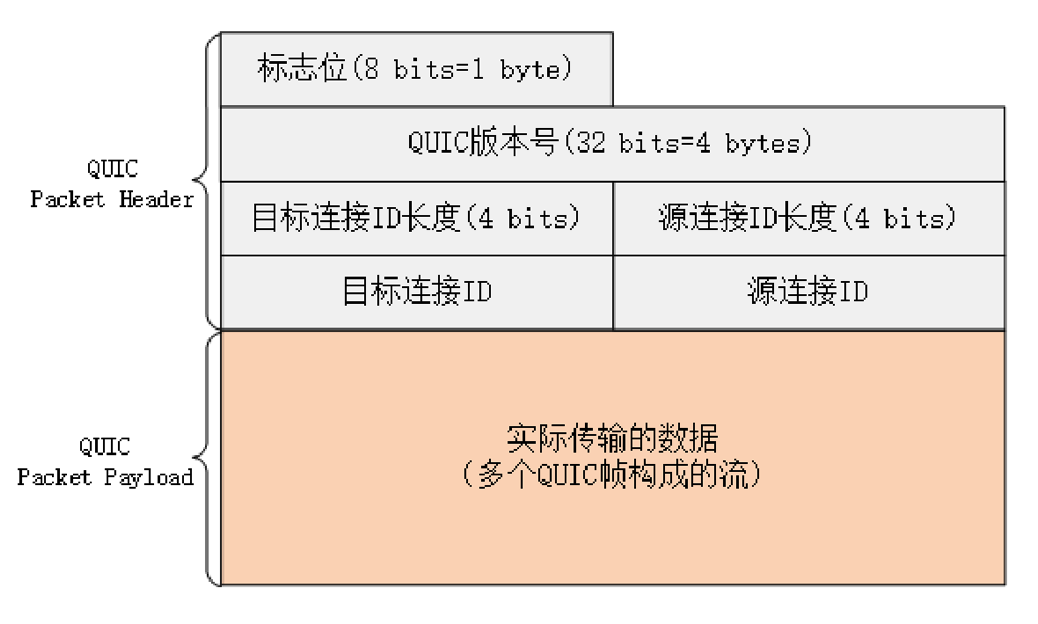
QUIC 使用不透明的 “**连接 ID**” 来标记通信的两个端点,客户端和服务器可以自行选择一组 ID 来标记自己,这样就解除了 TCP 里连接对“IP 地址 + 端口”(即常说的四元组)的强绑定,支持“连接迁移”(Connection Migration)
|
||||
|
||||

|
||||
|
||||
|
||||
比如从外面玩回到家,手机会自动由 4G 切换到 WiFi。这时 IP 地址会发生变化,TCP 就必须重新建立连接。而 QUIC 连接里的两端连接 ID 不会变,所以连接在“逻辑上”没有中断,它就可以在新的 IP 地址上继续使用之前的连接,消除重连的成本,实现连接的无缝迁移。
|
||||
|
||||
@@ -1268,7 +1268,7 @@ QUIC 的帧里有多种类型,PING、ACK 等帧用于管理连接,而 STREAM
|
||||
|
||||
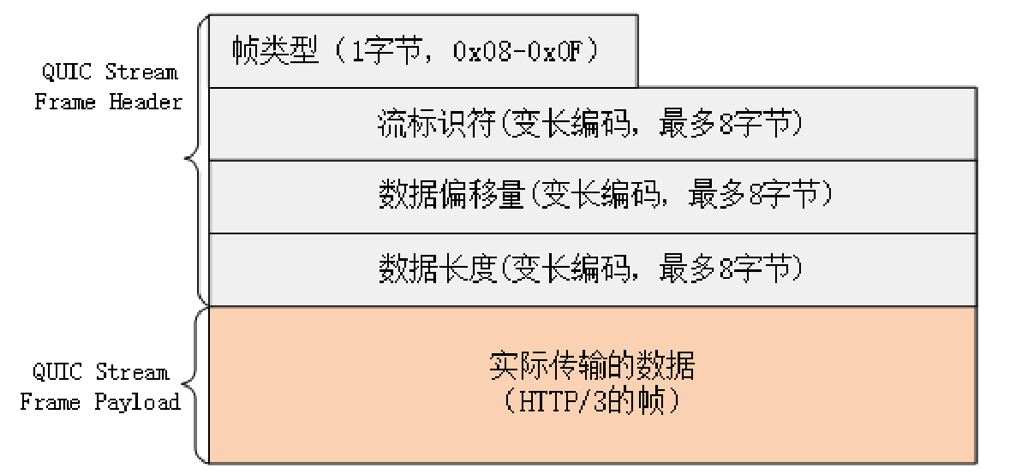
QUIC 里的流与 HTTP/2 的流非常相似,也是帧的序列。但 HTTP/2 里的流都是双向的,而 QUIC 则分为双向流和单向流。
|
||||
|
||||

|
||||
|
||||
|
||||
QUIC 帧普遍采用变长编码,最少只要 1 个字节,最多有 8 个字节。流 ID 的最大可用位数是 62,数量上比 HTTP/2 的 2^31 大大增加。
|
||||
|
||||
@@ -1282,7 +1282,7 @@ HTTP/3 里仍然使用流来发送“请求 - 响应”,但它自身不需要
|
||||
|
||||
HTTP/3 里的“双向流”可以完全对应到 HTTP/2 的流,而“单向流”在 HTTP/3 里用来实现控制和推送,近似地对应 HTTP/2 的 0 号流。由于流管理被“下放”到了 QUIC,所以 HTTP/3 里帧的结构也变简单了。帧头只有两个字段:类型和长度,而且同样都采用变长编码,最小只需要两个字节。
|
||||
|
||||

|
||||

|
||||
|
||||
HTTP/3 里的帧仍然分成数据帧和控制帧两类,HEADERS 帧和 DATA 帧传输数据,但其他一些帧因为在下层的 QUIC 里有了替代,所以在 HTTP/3 里就都消失了,比如 RST_STREAM、WINDOW_UPDATE、PING 等。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user