# 剖析 Swift String
带着问题研究下 Swift 中的 String
- 1个 String 变量占用多少内存?
- String 存放在什么位置?

## 字符串的创建过程
```swift
var str1: String = "0123456789"
```
实验很简单,就一行代码。来窥探下 String 的初始化和内存结构。出发断点看到下面汇编:
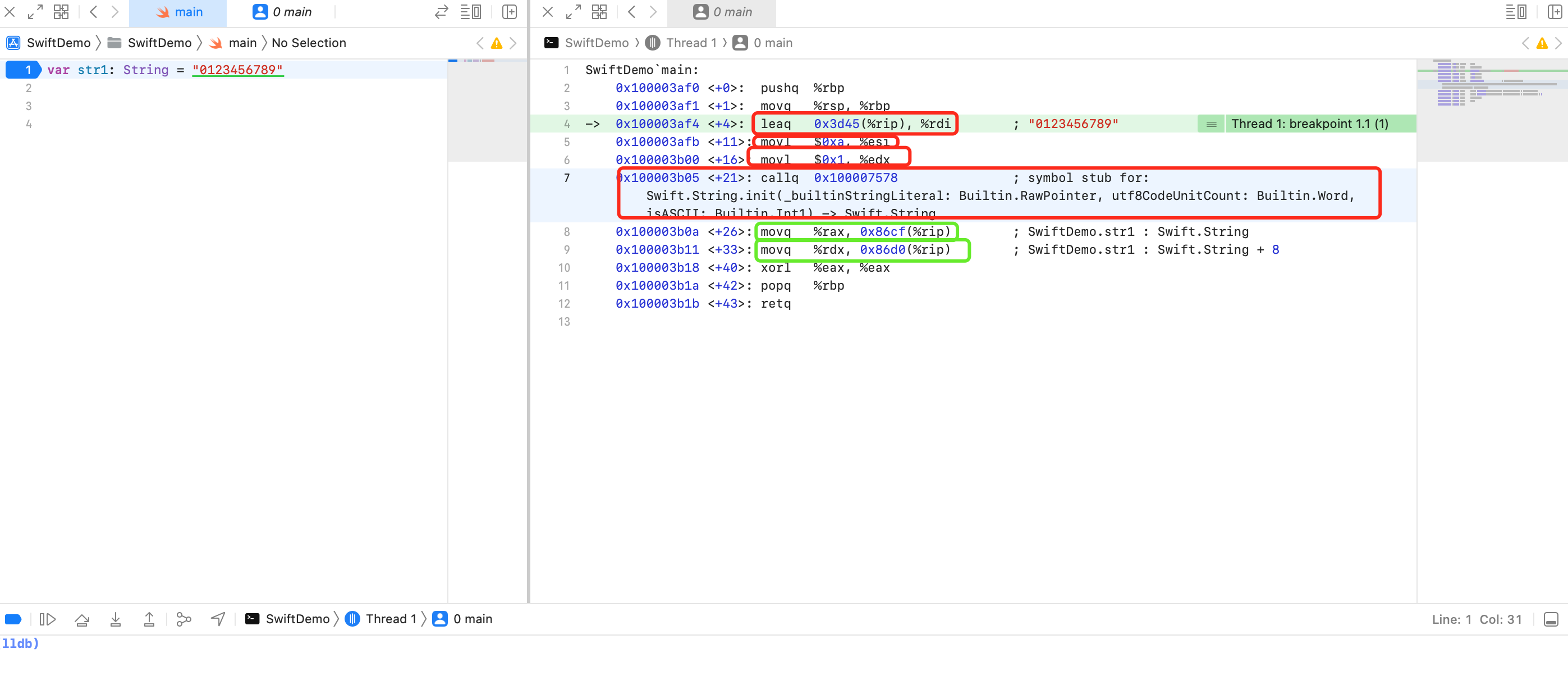 简单分析下:
- 第4行 `leaq 0x3d45(%rip), %rdi` 将 `rip + 0x3d45` 计算出的地址值赋值给寄存器 `rdi`
- 第5行 `movl $0xa, %esi` 将 10 赋值给寄存器 `esi`,也就是 `rsi`
- 第6行 `movl $0x1, %edx` 将 1 赋值给寄存器 `edx`,也就是 `rdx `
- 第7行 `callq 0x100007578 ; symbol stub for: Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String `
- 调用完第7行的方法有2个返回值,保存到寄存器 `rax` 、`rdx` 中
- 第8行 `movq %rax, 0x86cf(%rip)` 将 `rax` 的值赋值给 `rip + 0x86cf `
- 第8行 `movq %rdx, 0x86d0(%rip) ` 将 `rdx` 的值赋值给 `rip + 0x86d0 `
可以看到 String 指针占用8 + 8 = 16个字节.
QA:这个10是什么东西?1是什么东西?
结合调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1)` 方法猜测,10 应该是 `utf8CodeUnitCount` 即 utf8格式的字符个数,1 应该是 `isASCII` 即是 ASCII
做个实验验证下
```swift
var str1: String = "01234"
```
简单分析下:
- 第4行 `leaq 0x3d45(%rip), %rdi` 将 `rip + 0x3d45` 计算出的地址值赋值给寄存器 `rdi`
- 第5行 `movl $0xa, %esi` 将 10 赋值给寄存器 `esi`,也就是 `rsi`
- 第6行 `movl $0x1, %edx` 将 1 赋值给寄存器 `edx`,也就是 `rdx `
- 第7行 `callq 0x100007578 ; symbol stub for: Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String `
- 调用完第7行的方法有2个返回值,保存到寄存器 `rax` 、`rdx` 中
- 第8行 `movq %rax, 0x86cf(%rip)` 将 `rax` 的值赋值给 `rip + 0x86cf `
- 第8行 `movq %rdx, 0x86d0(%rip) ` 将 `rdx` 的值赋值给 `rip + 0x86d0 `
可以看到 String 指针占用8 + 8 = 16个字节.
QA:这个10是什么东西?1是什么东西?
结合调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1)` 方法猜测,10 应该是 `utf8CodeUnitCount` 即 utf8格式的字符个数,1 应该是 `isASCII` 即是 ASCII
做个实验验证下
```swift
var str1: String = "01234"
```
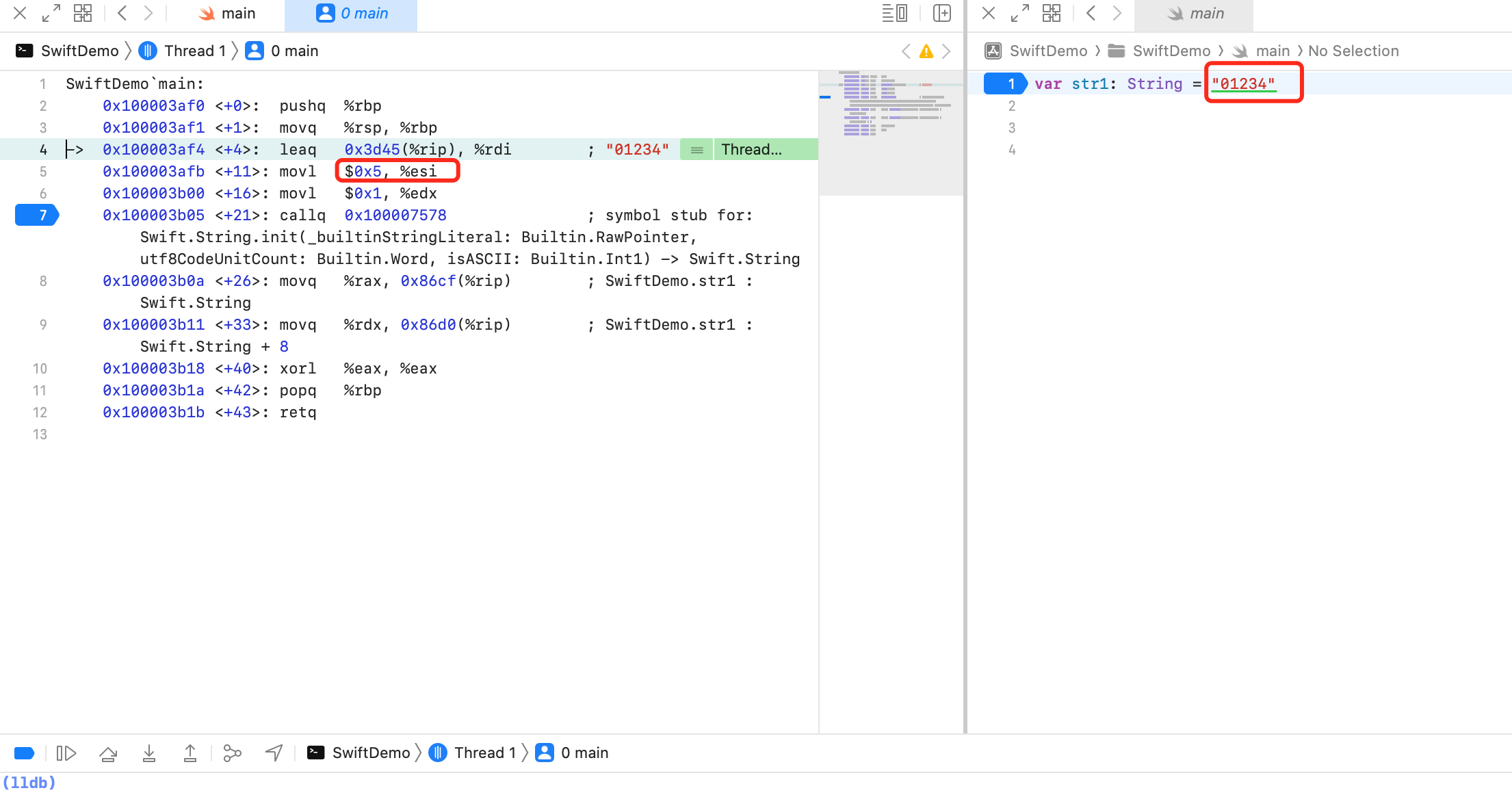 可以看到其他和上面的没变化,唯一不同的是 `movl $0x5, %esi` 将5赋值给寄存器 `esi`,即寄存器 `rsi`。实验的字符串 "01234" UTF8 字符个数为5
继续改变
```swift
var str1: String = "01234😄"
```
可以看到其他和上面的没变化,唯一不同的是 `movl $0x5, %esi` 将5赋值给寄存器 `esi`,即寄存器 `rsi`。实验的字符串 "01234" UTF8 字符个数为5
继续改变
```swift
var str1: String = "01234😄"
```
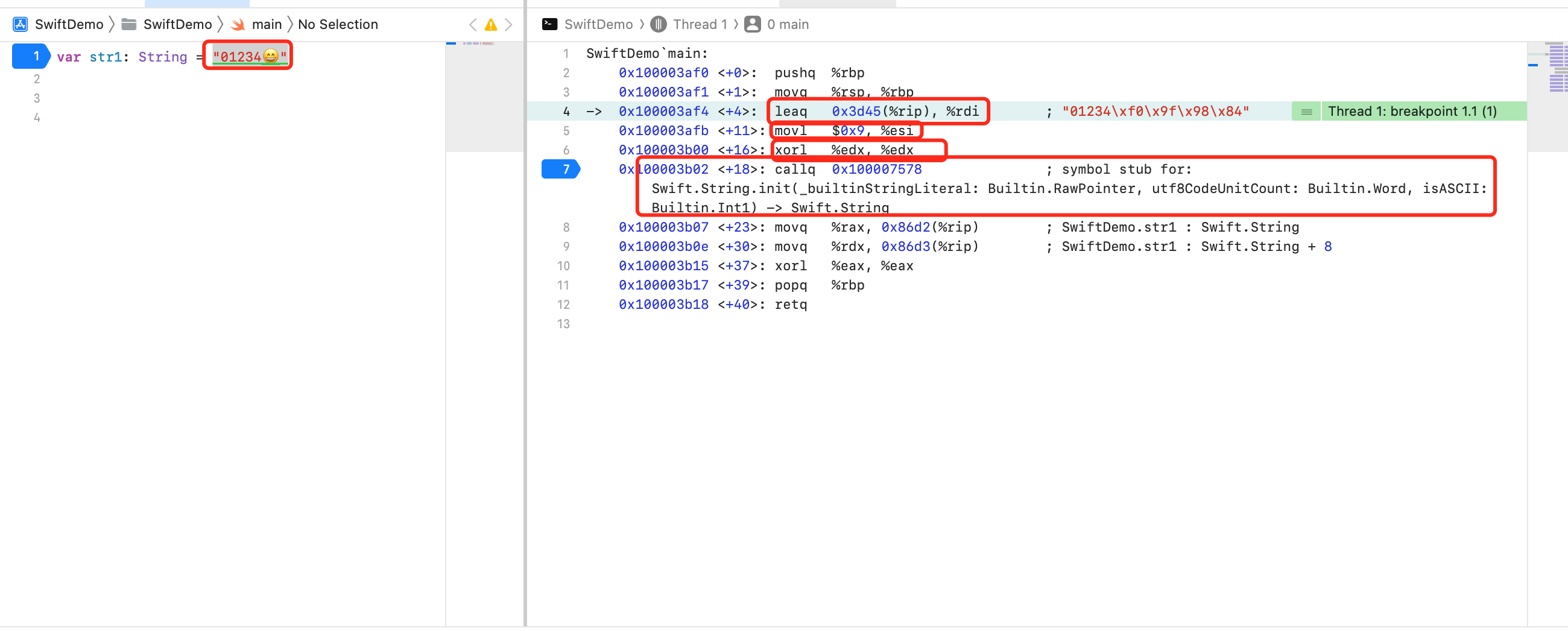 可以看到将9赋值给寄存器 `esi` 即 `rsi`,字符串赋值给寄存器 `rdi`,`xorl %edx, %edx` 异或运算结果 0 赋值给寄存器 `edx` 即 `rdx`,也就是不纯粹为
所以猜想正确。具体字符串创建过程可以查看 [Swift String 源码](https://github.com/apple/swift/blob/81812eaf2a6589610054a5db655bf7de3f3c8de6/stdlib/public/core/String.swift#L774)
```swift
// stdlib/public/core/String.swift
extension String: _ExpressibleByBuiltinStringLiteral {
@inlinable @inline(__always)
@_effects(readonly) @_semantics("string.makeUTF8")
public init(
_builtinStringLiteral start: Builtin.RawPointer,
utf8CodeUnitCount: Builtin.Word,
isASCII: Builtin.Int1
) {
let bufPtr = UnsafeBufferPointer(
start: UnsafeRawPointer(start).assumingMemoryBound(to: UInt8.self),
count: Int(utf8CodeUnitCount))
if let smol = _SmallString(bufPtr) {
self = String(_StringGuts(smol))
return
}
self.init(_StringGuts(bufPtr, isASCII: Bool(isASCII)))
}
}
```
也就是说 String 本身会占用16个字节长度,会调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String` 方法,该方法传递3个参数:字符串真实地址、字符串 UTF8 格式的个数、是否是 ASCII 。
### 字符串长度小于15位的创建
继续探索:
可以看到将9赋值给寄存器 `esi` 即 `rsi`,字符串赋值给寄存器 `rdi`,`xorl %edx, %edx` 异或运算结果 0 赋值给寄存器 `edx` 即 `rdx`,也就是不纯粹为
所以猜想正确。具体字符串创建过程可以查看 [Swift String 源码](https://github.com/apple/swift/blob/81812eaf2a6589610054a5db655bf7de3f3c8de6/stdlib/public/core/String.swift#L774)
```swift
// stdlib/public/core/String.swift
extension String: _ExpressibleByBuiltinStringLiteral {
@inlinable @inline(__always)
@_effects(readonly) @_semantics("string.makeUTF8")
public init(
_builtinStringLiteral start: Builtin.RawPointer,
utf8CodeUnitCount: Builtin.Word,
isASCII: Builtin.Int1
) {
let bufPtr = UnsafeBufferPointer(
start: UnsafeRawPointer(start).assumingMemoryBound(to: UInt8.self),
count: Int(utf8CodeUnitCount))
if let smol = _SmallString(bufPtr) {
self = String(_StringGuts(smol))
return
}
self.init(_StringGuts(bufPtr, isASCII: Bool(isASCII)))
}
}
```
也就是说 String 本身会占用16个字节长度,会调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String` 方法,该方法传递3个参数:字符串真实地址、字符串 UTF8 格式的个数、是否是 ASCII 。
### 字符串长度小于15位的创建
继续探索:
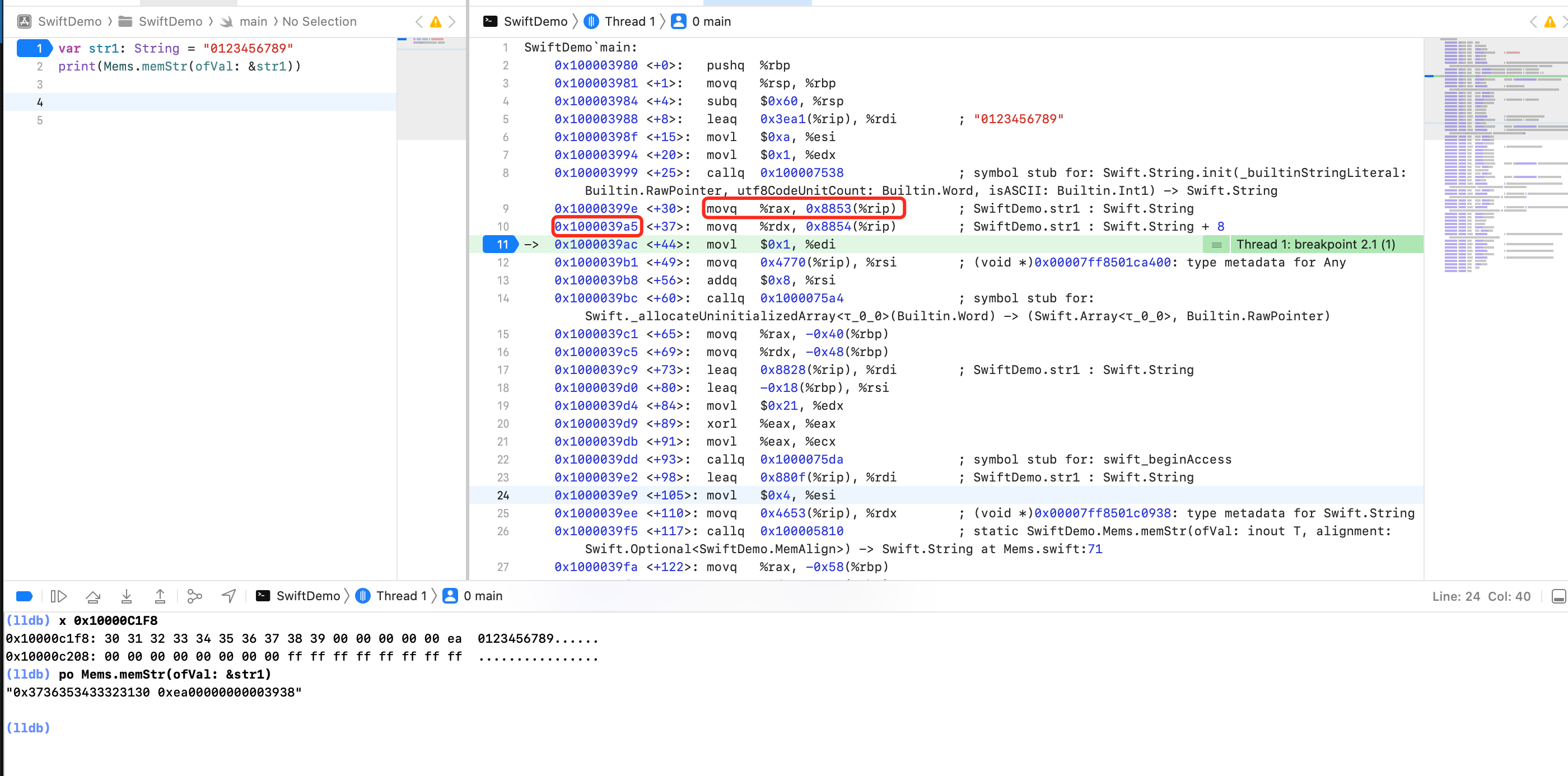 可以看到 `str1` 地址为 `rip + 0x8853 = 0x1000039a5 + 0x8853 = 0x10000C1F8 `,然后读取对应堆上的内容为:
```shell
0x10000c1f8: 30 31 32 33 34 35 36 37 38 39 00 00 00 00 00 ea 0123456789......
0x10000c208: 00 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff ................
```
打印出 `0x3736353433323130 0xea00000000003938`。怎么理解呢?
从 [ASCII 码表](https://www.ascii-code.com) 可以看出 0 对应 `0x30`,1 对应 `0x31`,所以字符串`0123456789` 从 `0x30` 到 `0x39`
`ea` 代表什么?
a 即10,代表10个字符。最大为 f,只能存储15个字符。e 代表字符串类型。
```swift
var str1: String = "0123456789ABCDE"
print(Mems.memStr(ofVal: &str1)) // "0x3736353433323130 0xef45444342413938"
```
当把字符改为15个时,输出的内存上的值为 `0x3736353433323130 0xef45444342413938`。
也就是说:当字符串长度小于16位的时候,通常会使用内联存储来存储字符串的内容。内联存储意味着字符串的实际内容会直接存储在字符串对象本身的内存空间中,而不需要额外的内存分配。类似 OC `NSString` 的 `NSTaggedPointerString`
### 字符串长度大于15位
```swift
var str1: String = "0123456789ABCDEF"
print(Mems.memStr(ofVal: &str1))
```
可以看到 `str1` 地址为 `rip + 0x8853 = 0x1000039a5 + 0x8853 = 0x10000C1F8 `,然后读取对应堆上的内容为:
```shell
0x10000c1f8: 30 31 32 33 34 35 36 37 38 39 00 00 00 00 00 ea 0123456789......
0x10000c208: 00 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff ................
```
打印出 `0x3736353433323130 0xea00000000003938`。怎么理解呢?
从 [ASCII 码表](https://www.ascii-code.com) 可以看出 0 对应 `0x30`,1 对应 `0x31`,所以字符串`0123456789` 从 `0x30` 到 `0x39`
`ea` 代表什么?
a 即10,代表10个字符。最大为 f,只能存储15个字符。e 代表字符串类型。
```swift
var str1: String = "0123456789ABCDE"
print(Mems.memStr(ofVal: &str1)) // "0x3736353433323130 0xef45444342413938"
```
当把字符改为15个时,输出的内存上的值为 `0x3736353433323130 0xef45444342413938`。
也就是说:当字符串长度小于16位的时候,通常会使用内联存储来存储字符串的内容。内联存储意味着字符串的实际内容会直接存储在字符串对象本身的内存空间中,而不需要额外的内存分配。类似 OC `NSString` 的 `NSTaggedPointerString`
### 字符串长度大于15位
```swift
var str1: String = "0123456789ABCDEF"
print(Mems.memStr(ofVal: &str1))
```
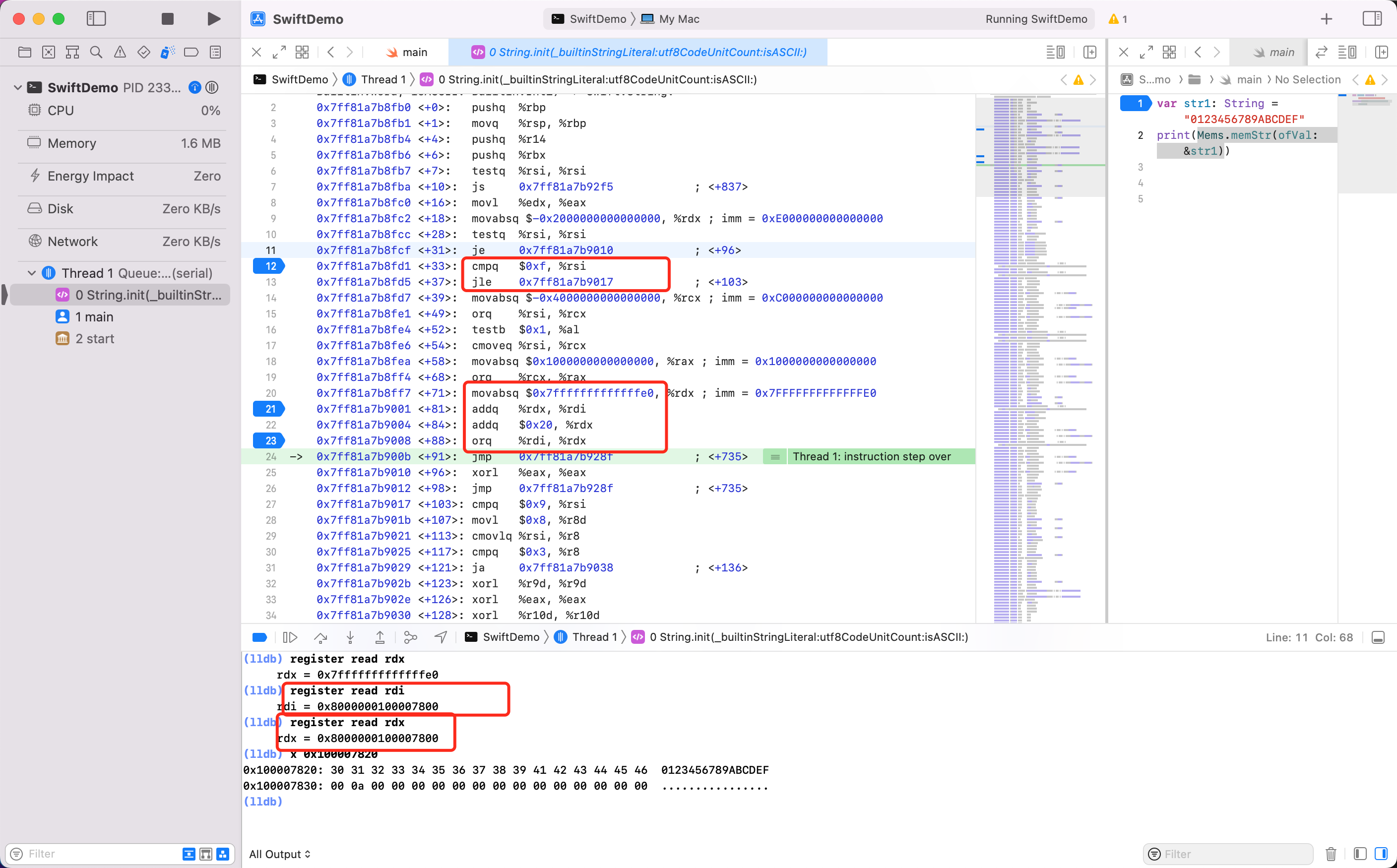 分析下:
- 第12行 `cmpq $0xf, %rsi` 拿 `0xf` 15 和寄存器 `rsi` 的值进行比较。上面已经分析过了,`rsi` 里面存放的是字符串的长度
- 第13行 `jle 0x7ff81a7b9017 ` 如果12行比较结果为真,则跳转到 `0x7ff81a7b9017`
- 实际发现,字符串长度大于15,则继续向下执行
- 第20行 `movabsq $0x7fffffffffffffe0, %rdx` 则会把立即数 `0x7fffffffffffffe0` 移动到寄存器 `rdx`
- 第21行 `addq %rdx, %rdi` 将 `rdx` + ` rdi` 的值赋值给 `rdi`,也就是 `rdi` 存放了: 字符串的真实地址 + `0x7fffffffffffffe0 相加后的值。`
所以字符串真实地址 = `rdx 的地址` - `0x7fffffffffffffe0`。
寄存器 `rdi` 读取出地址为 `0x8000000100007800` 。所以字符串真实地址为:`0x8000000100007800` - `0x7fffffffffffffe0` = `0x100007820`。
LLDB 读取下 `x 0x100007820 ` 看到 30、31...46刚好是字符串 `0123456789ABCDEF` 的 ASCII 值。
所以 **`字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`**,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
- 经过23行后 `orq %rdi, %rdx` 可以看到 `rdx` 、`rdi` 里面存储的都是:`字符串真实地址` + `0x7fffffffffffffe0`
- LLDB 输入 finish 结束函数细节,外部可以看到第10行 `movq %rdx, 0x8864(%rip) ` 将 `rdx` 寄存器里的值(也就是:`字符串真实地址` + `0x7fffffffffffffe0` )赋值给 `str1` 指针的后8个字节
分析下:
- 第12行 `cmpq $0xf, %rsi` 拿 `0xf` 15 和寄存器 `rsi` 的值进行比较。上面已经分析过了,`rsi` 里面存放的是字符串的长度
- 第13行 `jle 0x7ff81a7b9017 ` 如果12行比较结果为真,则跳转到 `0x7ff81a7b9017`
- 实际发现,字符串长度大于15,则继续向下执行
- 第20行 `movabsq $0x7fffffffffffffe0, %rdx` 则会把立即数 `0x7fffffffffffffe0` 移动到寄存器 `rdx`
- 第21行 `addq %rdx, %rdi` 将 `rdx` + ` rdi` 的值赋值给 `rdi`,也就是 `rdi` 存放了: 字符串的真实地址 + `0x7fffffffffffffe0 相加后的值。`
所以字符串真实地址 = `rdx 的地址` - `0x7fffffffffffffe0`。
寄存器 `rdi` 读取出地址为 `0x8000000100007800` 。所以字符串真实地址为:`0x8000000100007800` - `0x7fffffffffffffe0` = `0x100007820`。
LLDB 读取下 `x 0x100007820 ` 看到 30、31...46刚好是字符串 `0123456789ABCDEF` 的 ASCII 值。
所以 **`字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`**,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
- 经过23行后 `orq %rdi, %rdx` 可以看到 `rdx` 、`rdi` 里面存储的都是:`字符串真实地址` + `0x7fffffffffffffe0`
- LLDB 输入 finish 结束函数细节,外部可以看到第10行 `movq %rdx, 0x8864(%rip) ` 将 `rdx` 寄存器里的值(也就是:`字符串真实地址` + `0x7fffffffffffffe0` )赋值给 `str1` 指针的后8个字节
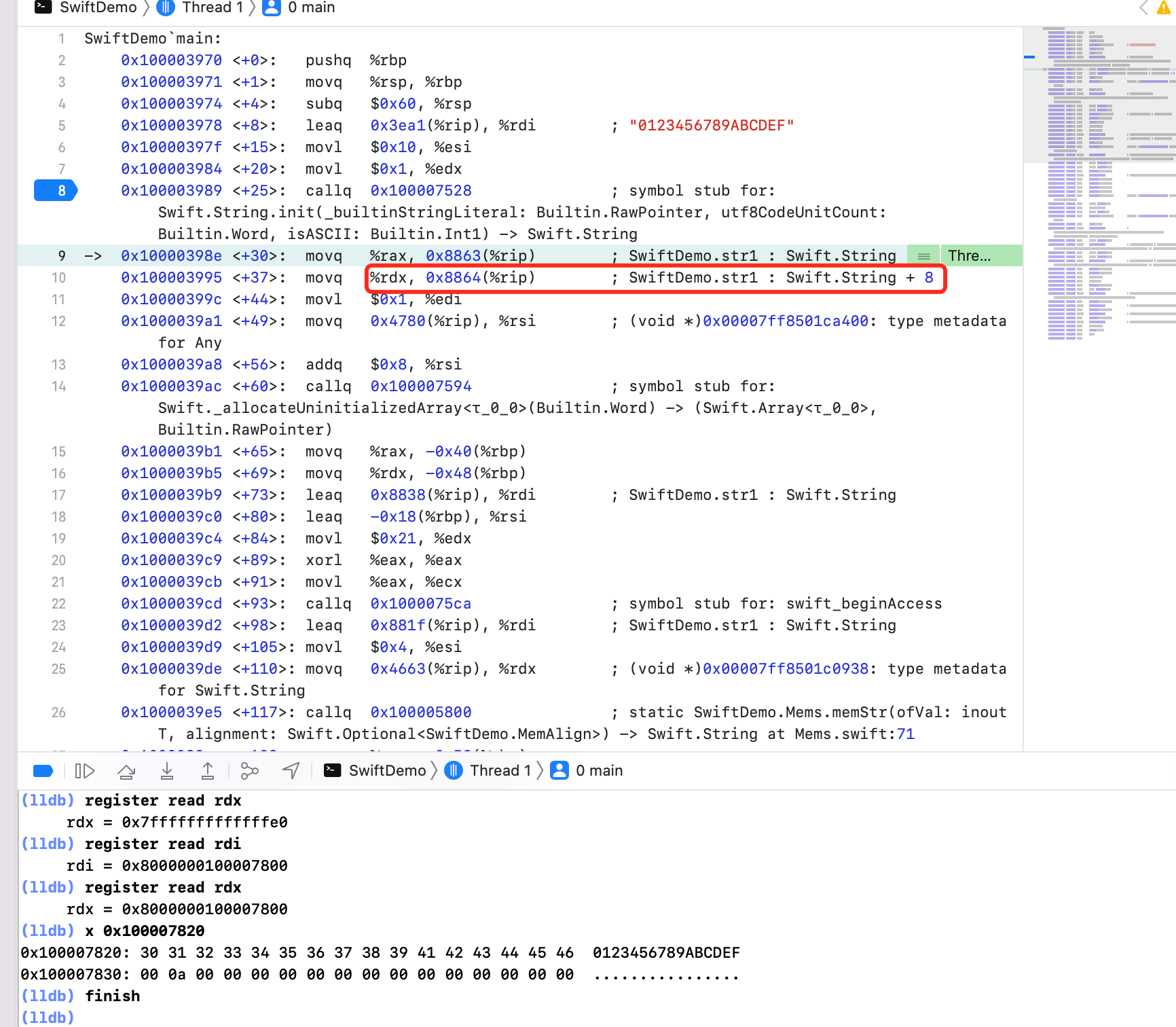 `字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
### 字符串存储在内存中什么地方
```swift
var str1: String = "0123456789ABCDEF"
```
字符串地址为 ` 0x10000397f + 0x3ea1 = 0x100007820`,看着像全局变量、也有可能是常量区?字符串内容写死的情况下,编译器编译后内存地址应该可以确定,那到底在什么地方呢?利用 `MachOView` 窥探下 `MachO` 文件吧
`字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
### 字符串存储在内存中什么地方
```swift
var str1: String = "0123456789ABCDEF"
```
字符串地址为 ` 0x10000397f + 0x3ea1 = 0x100007820`,看着像全局变量、也有可能是常量区?字符串内容写死的情况下,编译器编译后内存地址应该可以确定,那到底在什么地方呢?利用 `MachOView` 窥探下 `MachO` 文件吧
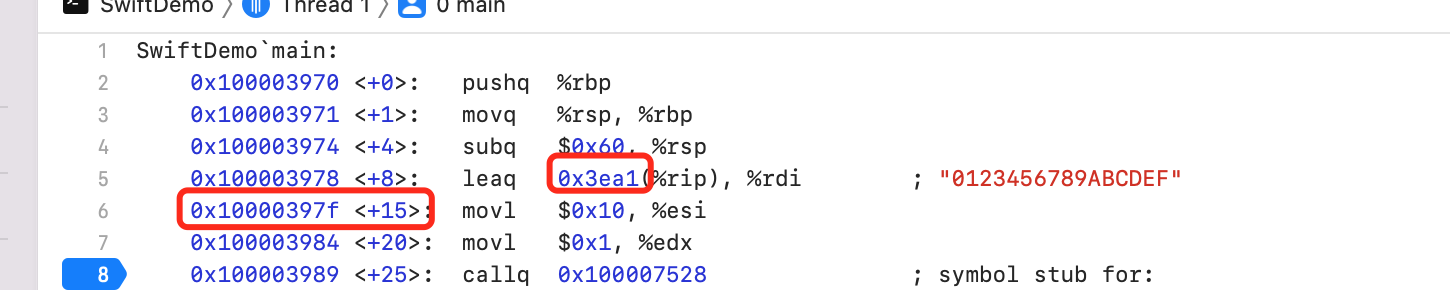 利用 MachOView 打开如下
利用 MachOView 打开如下
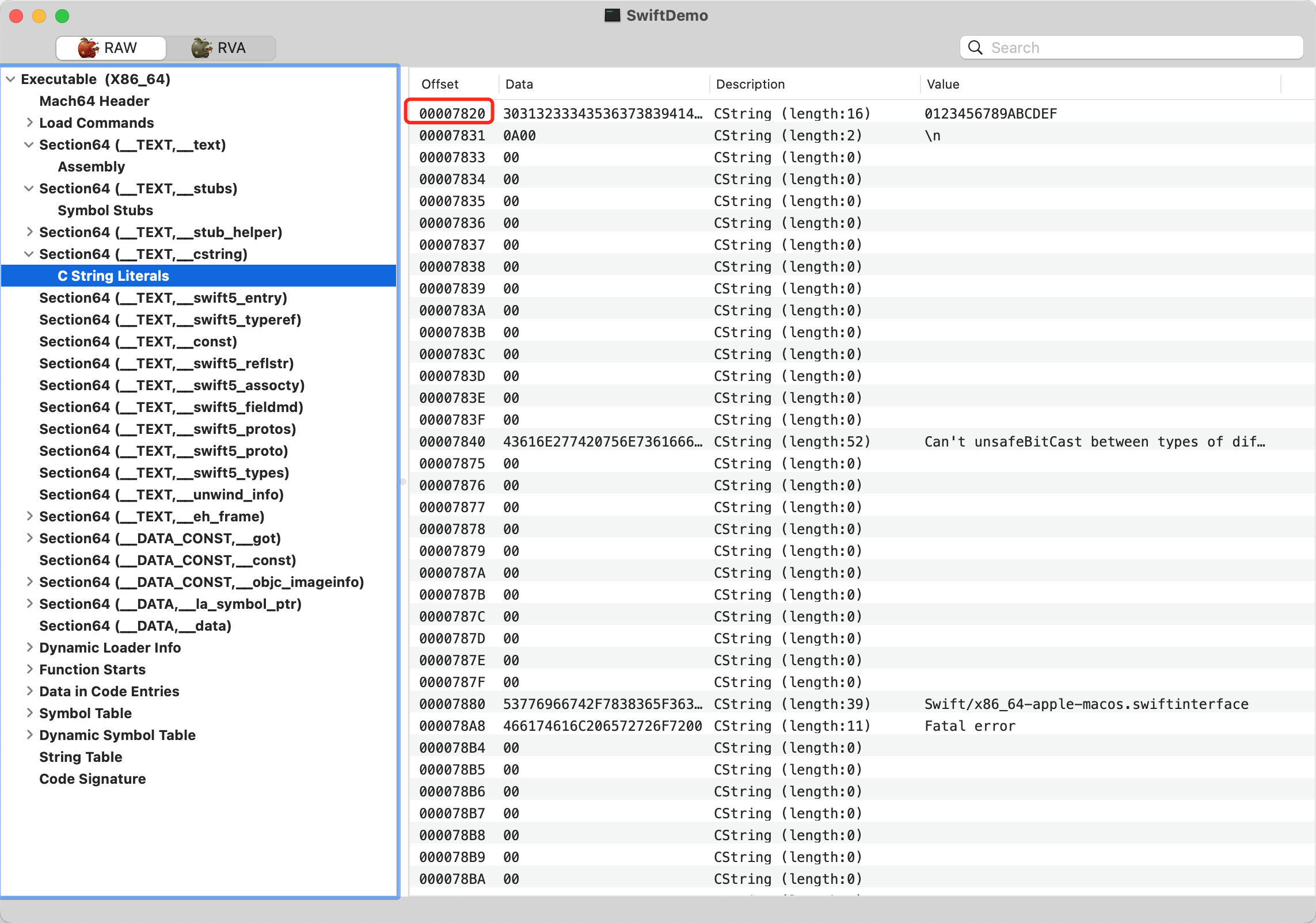 X86_64 架构下,我们在 MachOView 看到的地址,真实对应地址为: `0x10000000 + 00007820 = 0x10007820` 好巧啊,发现计算出的值刚好就是字符串 `str1` 的真实地址。MachOView 右侧也显示了字符串的内容,刚好就是 str1
解释下:
在 macOS 和 iOS 的二进制文件(如 Mach-O 格式的可执行文件或动态库)中,`Section64` 是一个结构体,用于描述二进制文件中的一个段(section)。每个段包含特定类型的数据或代码,并且具有特定的属性,比如是否可写、是否可执行等。
`Section64(__TEXT,__cstring)` 中:
- `__TEXT` 是段的段名(segment name),存储**只读且可执行**的内容,包括代码和只读数据。**典型节(Sections)**:
- `__text`:存放机器指令(代码段)。
- `__cstring`:存放字符串常量。
- `__const`:存放其他常量数据。
- **`__DATA` 段**:存储**可读写**的数据(如全局变量、静态变量)。
- `__cstring` 节:
- **功能**:`_cstring` 专门存储硬编码的字符串常量(如 `"Hello, World!"`)。
- **内存权限**:映射到内存时,`__TEXT` 段整体为**只读**(`r--` 或 `r-x`),但 `_cstring` 本身**不可执行**,仅用于数据存储
- **所属区域**:
- 逻辑上属于**常量区**(类似 ELF 格式的 `.rodata`)。
- 物理上可能与代码段(`__text`)同属 `__TEXT` 段,但用途和权限不同。
因此,`Section64(__TEXT,__cstring)` 描述的是二进制文件中存储 C 字符串字面量的一个节。这个节位于 `__TEXT__` 段中,并且包含的是只读数据。
再做下调整
```swift
var str1: String = "0123456789ABCDEF"
var str2: String = "012345"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
```
X86_64 架构下,我们在 MachOView 看到的地址,真实对应地址为: `0x10000000 + 00007820 = 0x10007820` 好巧啊,发现计算出的值刚好就是字符串 `str1` 的真实地址。MachOView 右侧也显示了字符串的内容,刚好就是 str1
解释下:
在 macOS 和 iOS 的二进制文件(如 Mach-O 格式的可执行文件或动态库)中,`Section64` 是一个结构体,用于描述二进制文件中的一个段(section)。每个段包含特定类型的数据或代码,并且具有特定的属性,比如是否可写、是否可执行等。
`Section64(__TEXT,__cstring)` 中:
- `__TEXT` 是段的段名(segment name),存储**只读且可执行**的内容,包括代码和只读数据。**典型节(Sections)**:
- `__text`:存放机器指令(代码段)。
- `__cstring`:存放字符串常量。
- `__const`:存放其他常量数据。
- **`__DATA` 段**:存储**可读写**的数据(如全局变量、静态变量)。
- `__cstring` 节:
- **功能**:`_cstring` 专门存储硬编码的字符串常量(如 `"Hello, World!"`)。
- **内存权限**:映射到内存时,`__TEXT` 段整体为**只读**(`r--` 或 `r-x`),但 `_cstring` 本身**不可执行**,仅用于数据存储
- **所属区域**:
- 逻辑上属于**常量区**(类似 ELF 格式的 `.rodata`)。
- 物理上可能与代码段(`__text`)同属 `__TEXT` 段,但用途和权限不同。
因此,`Section64(__TEXT,__cstring)` 描述的是二进制文件中存储 C 字符串字面量的一个节。这个节位于 `__TEXT__` 段中,并且包含的是只读数据。
再做下调整
```swift
var str1: String = "0123456789ABCDEF"
var str2: String = "012345"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
```
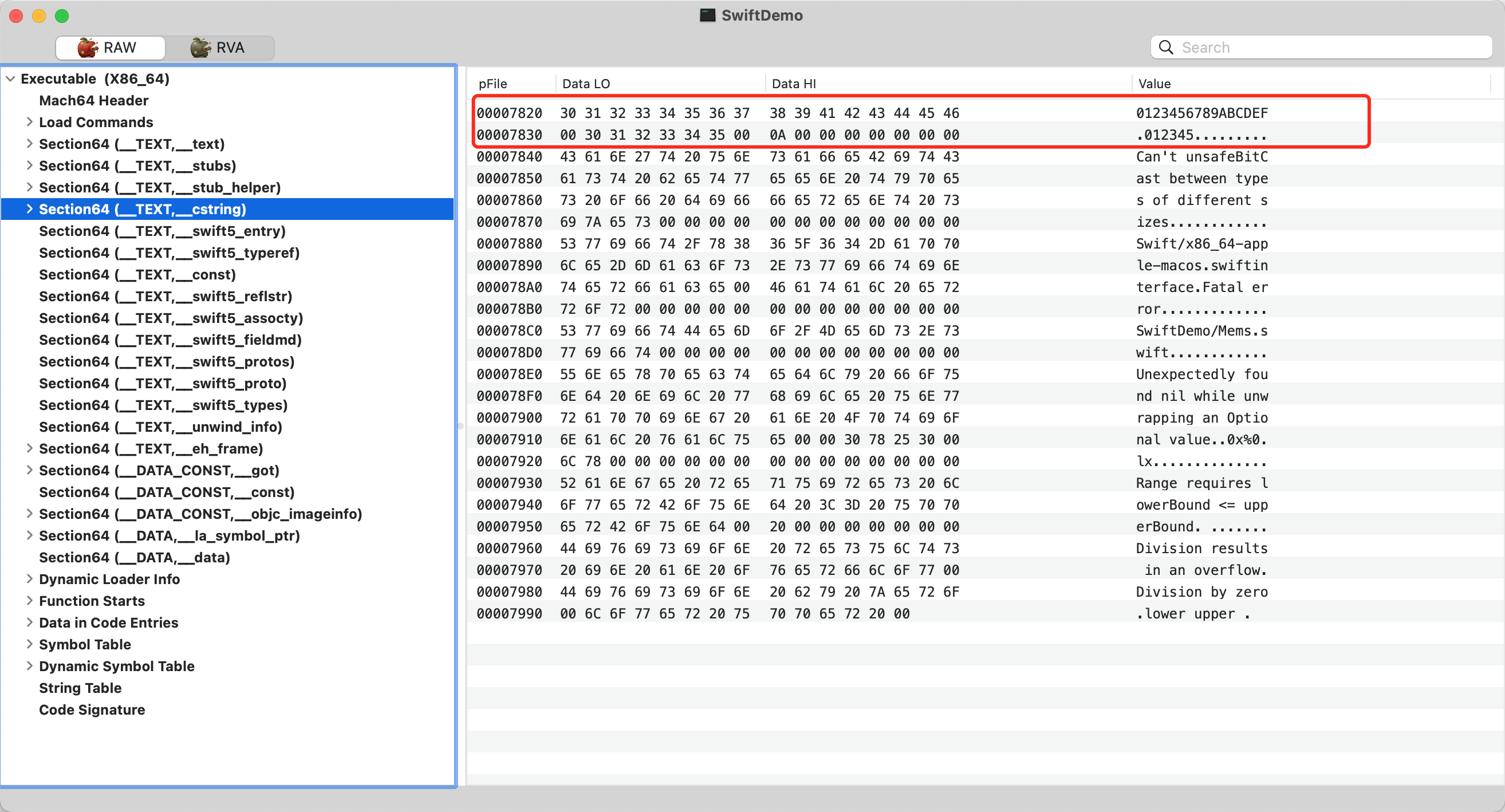 可以看到:
- str1、str2 指针长度为均为16个字节,且内存连续 `00007820`、`00007830`
- 字符串长度小于15的时候,打印出 str2 的内存值的前8个字节存储的就是字符串本身 `0x0000353433323130`,后8个字节 `0xe600000000000000` e 代表字符串类型,6代表字符串长度
- 字符串长度大于15的时候,内存值的前8位 `0xd000000000000010` 最后的10也就是16,代表字符串长度。内存的后8位代表字符串计算后的地址(`字符串真实地址` + `0x7fffffffffffffe0` )
- 字符串是存储在 `__TEXT__` 段的 `__cstring` 节中,属于常量区。
做了调整,可以看到 str3 内存值的前8个字节 `0xd000000000000015` 中的15也就是21位字符串,符合预期。
```swift
var str1: String = "0123456789ABCDEF"
var str2: String = "012345"
var str3: String = "0123456789ABCDEFGHIJK"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x80000001000077e0
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
print(Mems.memStr(ofVal: &str3)) // 0xd000000000000015 0x8000000100007800
```
### Swift 字符串存储本质
Swift 字符串存储的两种模式:
- **内联存储(Small String Optimization,SSO)**:
- **条件**:字符串长度 ≤15 个 **ASCII 字符**(或 ≤7 个 **UTF-16 字符**)。
- **特点**:字符串内容直接存储在 `StringObject` 的 16 字节内存中,无需堆分配。有点类似 Objective-C 的 **Tagged Pointer**
- **堆存储(Heap-Allocated)**:
- **条件**:字符串长度超过上述限制(字符串长度 > 15 个 **ASCII 字符** 或 > 7 个 **UTF-16 字符**)
- **特点**:字符串内容存储在堆内存。其指针结构是一个 16 字节的 `StringObject`,`StringObject` 存储堆地址和元数据
#### 内联存储(SSO)的具体实现
内存布局:前8个字节(元数据 + 部分字符) + 后8个字节(剩余字符 + 填充)
元数据编码:
最低有效位(LSB)用于标识存储模式:
- **0**:内联存储
- **1**:堆存储
其余位存储字符串长度和编码信息(ASCII 或 UTF-16)
Demo
````Swift
let str = "Hello" // 5 个 ASCII 字符
内存布局如下:
0x0000000000000a05 // 元数据(长度=5, ASCII, 内联标志位=0)
0x48656c6c6f000000 // ASCII 字符 "Hello" 的十六进制表示 + 填充
````
与 Objective-C Tagged Pointer 的区别
| **特性** | **Swift 内联存储 (SSO)** | **Objective-C Tagged Pointer** |
| :----------- | :------------------------- | :------------------------------ |
| **存储位置** | 字符串对象的 16 字节内存中 | 指针值本身(64 位) |
| **标识方式** | 元数据的最低有效位 (LSB) | 指针的最高有效位 (MSB) |
| **兼容性** | 需考虑 Unicode 编码复杂性 | 仅支持有限类型(如短 NSString) |
| **内存安全** | 完全由编译器管理 | 需运行时特殊处理 |
## 字符串拼接
### 长度小于15的字符串拼接
```swift
var str1: String = "012345"
print(Mems.memStr(ofVal: &str1)) // 0x0000353433323130 0xe600000000000000
str1.append("ABC")
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xe900000000000043
str1.append("DEFGHI")
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xef49484746454443
```
可以看到不管字符串怎么拼接,只要拼接后的内容小于小于等于15,则依旧是在字符串的内容存放在自身的16个字节中。
### 长度大于15的字符串拼接
```swift
var str1: String = "0123456789ABCDEF"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
str1.append("G")
print(Mems.memStr(ofVal: &str1)) // 0xf000000000000011 0x0000600001700440
print("explore")
```
可以看到:长度为16的字符串拼接后
- 内存的前8个字节,从 `0xd000000000000010` 变到了 `0xf000000000000011`,最后2位代表字符串长度,16进制的10就是16。从16位变成17位。
- 内存的后8个字节,字符串的地址改变了
上面可知, `字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
可以看到:
- str1、str2 指针长度为均为16个字节,且内存连续 `00007820`、`00007830`
- 字符串长度小于15的时候,打印出 str2 的内存值的前8个字节存储的就是字符串本身 `0x0000353433323130`,后8个字节 `0xe600000000000000` e 代表字符串类型,6代表字符串长度
- 字符串长度大于15的时候,内存值的前8位 `0xd000000000000010` 最后的10也就是16,代表字符串长度。内存的后8位代表字符串计算后的地址(`字符串真实地址` + `0x7fffffffffffffe0` )
- 字符串是存储在 `__TEXT__` 段的 `__cstring` 节中,属于常量区。
做了调整,可以看到 str3 内存值的前8个字节 `0xd000000000000015` 中的15也就是21位字符串,符合预期。
```swift
var str1: String = "0123456789ABCDEF"
var str2: String = "012345"
var str3: String = "0123456789ABCDEFGHIJK"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x80000001000077e0
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
print(Mems.memStr(ofVal: &str3)) // 0xd000000000000015 0x8000000100007800
```
### Swift 字符串存储本质
Swift 字符串存储的两种模式:
- **内联存储(Small String Optimization,SSO)**:
- **条件**:字符串长度 ≤15 个 **ASCII 字符**(或 ≤7 个 **UTF-16 字符**)。
- **特点**:字符串内容直接存储在 `StringObject` 的 16 字节内存中,无需堆分配。有点类似 Objective-C 的 **Tagged Pointer**
- **堆存储(Heap-Allocated)**:
- **条件**:字符串长度超过上述限制(字符串长度 > 15 个 **ASCII 字符** 或 > 7 个 **UTF-16 字符**)
- **特点**:字符串内容存储在堆内存。其指针结构是一个 16 字节的 `StringObject`,`StringObject` 存储堆地址和元数据
#### 内联存储(SSO)的具体实现
内存布局:前8个字节(元数据 + 部分字符) + 后8个字节(剩余字符 + 填充)
元数据编码:
最低有效位(LSB)用于标识存储模式:
- **0**:内联存储
- **1**:堆存储
其余位存储字符串长度和编码信息(ASCII 或 UTF-16)
Demo
````Swift
let str = "Hello" // 5 个 ASCII 字符
内存布局如下:
0x0000000000000a05 // 元数据(长度=5, ASCII, 内联标志位=0)
0x48656c6c6f000000 // ASCII 字符 "Hello" 的十六进制表示 + 填充
````
与 Objective-C Tagged Pointer 的区别
| **特性** | **Swift 内联存储 (SSO)** | **Objective-C Tagged Pointer** |
| :----------- | :------------------------- | :------------------------------ |
| **存储位置** | 字符串对象的 16 字节内存中 | 指针值本身(64 位) |
| **标识方式** | 元数据的最低有效位 (LSB) | 指针的最高有效位 (MSB) |
| **兼容性** | 需考虑 Unicode 编码复杂性 | 仅支持有限类型(如短 NSString) |
| **内存安全** | 完全由编译器管理 | 需运行时特殊处理 |
## 字符串拼接
### 长度小于15的字符串拼接
```swift
var str1: String = "012345"
print(Mems.memStr(ofVal: &str1)) // 0x0000353433323130 0xe600000000000000
str1.append("ABC")
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xe900000000000043
str1.append("DEFGHI")
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xef49484746454443
```
可以看到不管字符串怎么拼接,只要拼接后的内容小于小于等于15,则依旧是在字符串的内容存放在自身的16个字节中。
### 长度大于15的字符串拼接
```swift
var str1: String = "0123456789ABCDEF"
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
str1.append("G")
print(Mems.memStr(ofVal: &str1)) // 0xf000000000000011 0x0000600001700440
print("explore")
```
可以看到:长度为16的字符串拼接后
- 内存的前8个字节,从 `0xd000000000000010` 变到了 `0xf000000000000011`,最后2位代表字符串长度,16进制的10就是16。从16位变成17位。
- 内存的后8个字节,字符串的地址改变了
上面可知, `字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
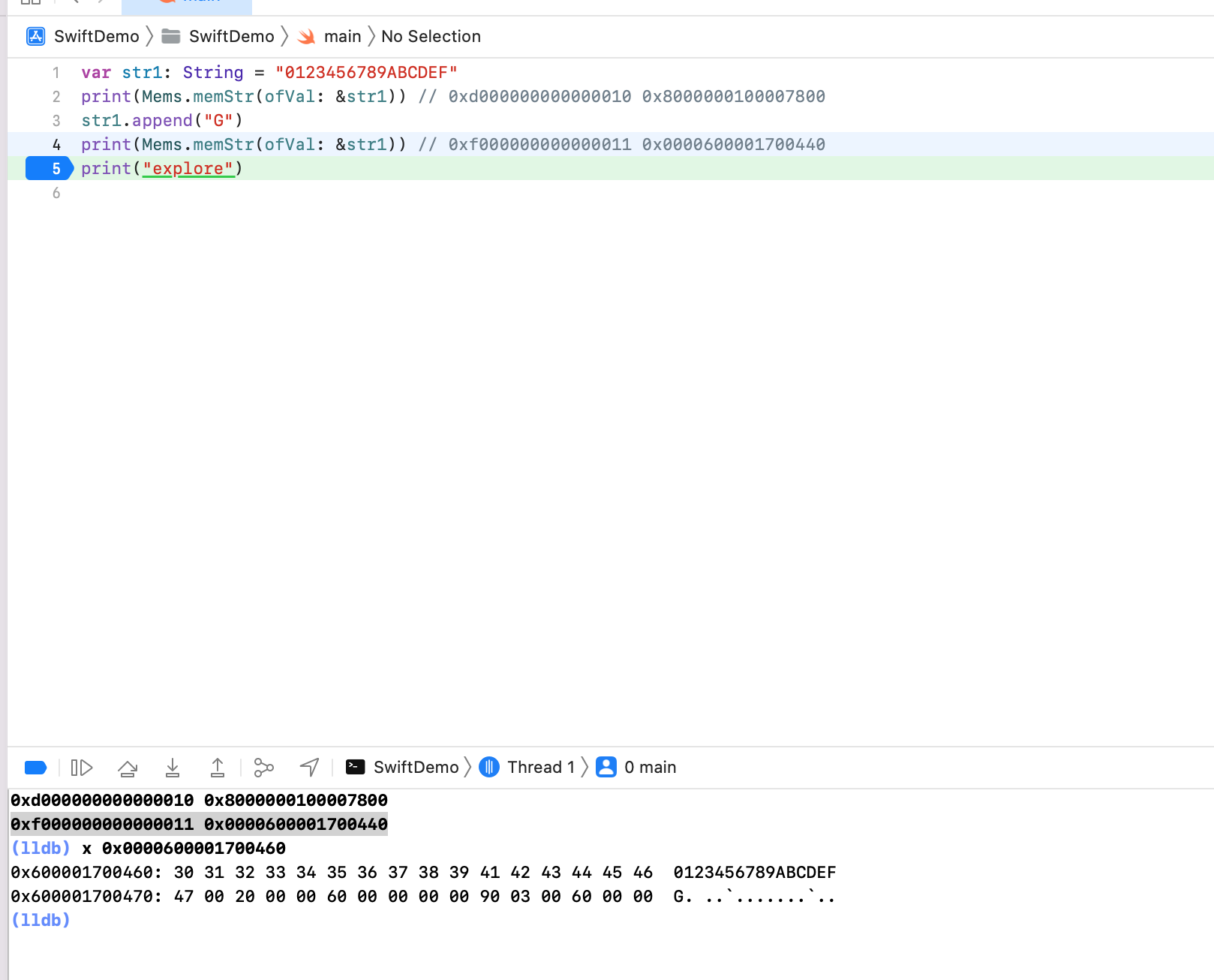 字符串真实地址:`0x0000600001700440 + 0x20 = 0x0000600001700460`,LLDB `x 0x0000600001700460 ` 可以看到字符串拼接后的结果。看上去是存储在堆上。如何验证?
我们知道堆上的内存初始化在 Swift 侧,关键方法为 `swift_allocObject ` -> `swift_slowAlloc` -> `malloc `。给 malloc 下断点,然后在断点出查看调用堆栈,可以看到在 `string.append()` 后有堆分配内存
字符串真实地址:`0x0000600001700440 + 0x20 = 0x0000600001700460`,LLDB `x 0x0000600001700460 ` 可以看到字符串拼接后的结果。看上去是存储在堆上。如何验证?
我们知道堆上的内存初始化在 Swift 侧,关键方法为 `swift_allocObject ` -> `swift_slowAlloc` -> `malloc `。给 malloc 下断点,然后在断点出查看调用堆栈,可以看到在 `string.append()` 后有堆分配内存
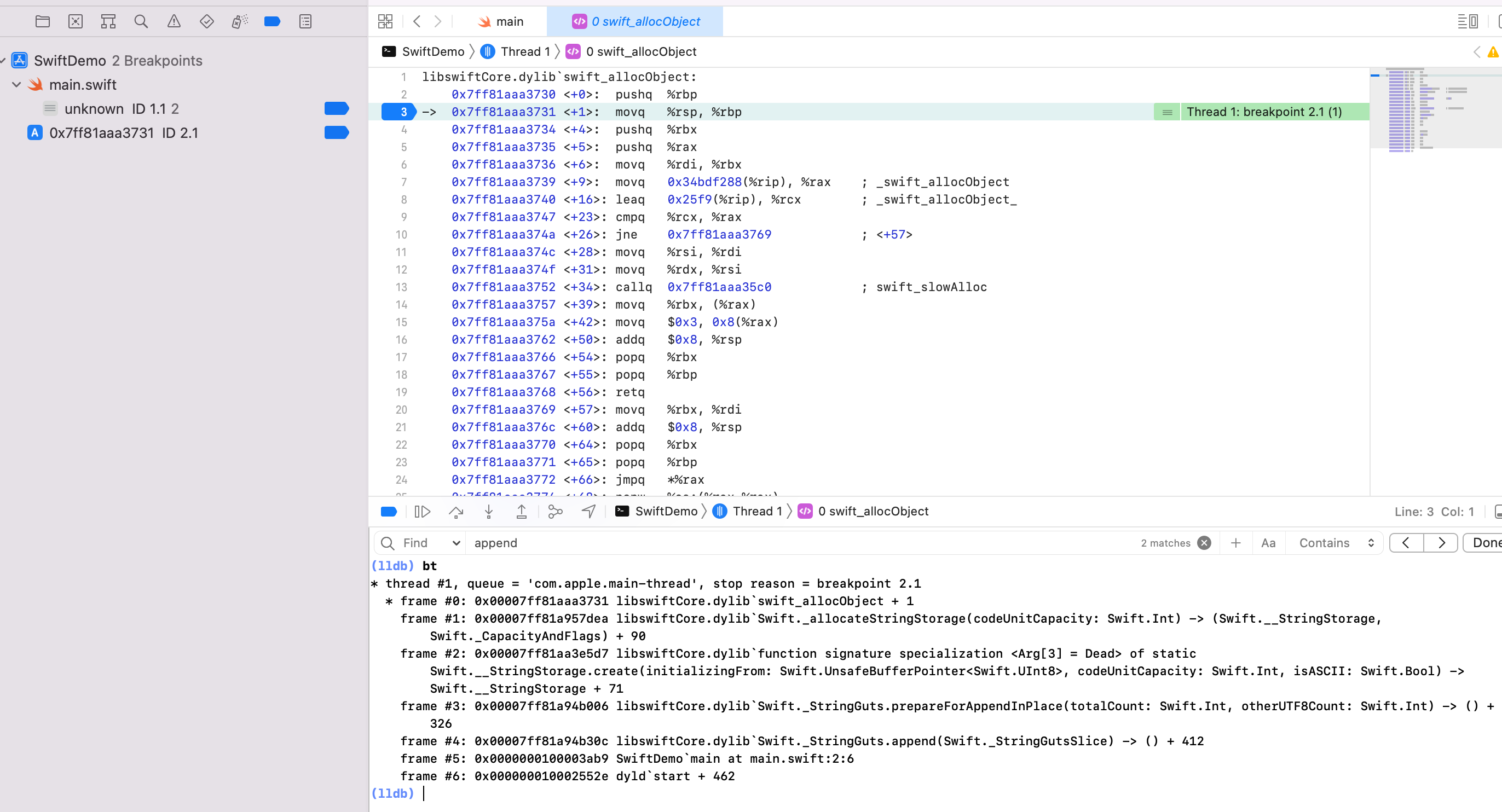 结束当前函数调用,在外层可以看到 str2 地址值的后8个字节为 `0x000060000170410`,再 + `0x20` 就是字符串真实地址,打印如下。
结束当前函数调用,在外层可以看到 str2 地址值的后8个字节为 `0x000060000170410`,再 + `0x20` 就是字符串真实地址,打印如下。
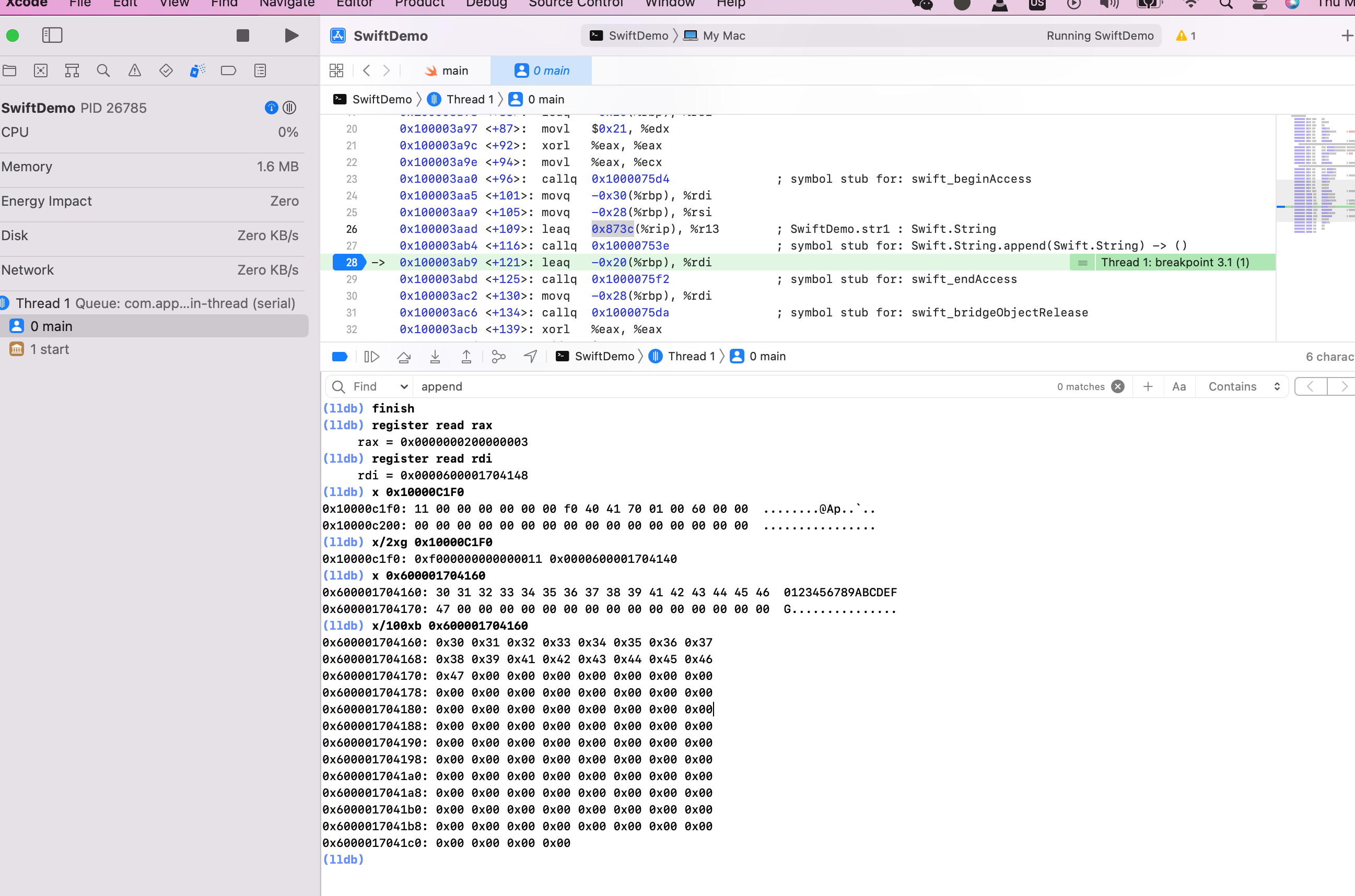 0x20 是什么?这32个字节存放了什么信息?存储字符串的描述信息,比如:引用计数、字符串长度等信息。
总结:
- 当字符串长度小于等于 0xF(也就是15),字符串内容直接存放在指针变量对应的内存中
- 当字符拼接时候,拼接后字符串长度小于等于15,则字符串内容依旧存储在指针变量的内存中
- 当字符串长度大于 0xF(也就是15),字符串的内容存放在 `__TEXT,__cstring` 中(常量区)。字符串的地址值信息存放在指针变量的后8个字节中,且真正的地址值为 (`后8个字节值` + `0x20` ),前32字节存储字符串的基础信息(长度、引用计数等)
## dyld_stub_binder
`__TEXT` 是 Mach-O 文件中通常包含代码和只读数据的段。这个段包含了程序的主要执行代码,以及常量字符串、符号表等。
`dyld_stub_binder` 是一个由动态链接器(dyld)在运行时生成和使用的函数。它的主要目的是在首次调用某个动态链接的符号(如函数或方法)时,将该符号的实际地址绑定到调用点
Swift 中 `String` 类型的初始化方法(`init`)的地址是否采用延迟绑定(Lazy Binding),取决于 **编译环境、优化级别和具体方法实现**
### 延迟绑定的基本原理
在编译时,对于动态链接的符号,编译器会生成一个桩(stub),而不是直接调用该符号。桩是一个小段的代码,当被首次执行时,它会触发 `dyld_stub_binder` 的调用。`dyld_stub_binder` 的任务就是找到该符号的实际地址,并将其写入桩中,从而替换桩的原始代,这样,下一次调用该符号时,就可以直接跳转到实际的地址,而无需再次通过桩和 `dyld_stub_binder`。
延迟绑定(Lazy Binding)是动态链接的机制,用于推迟符号(如函数、方法)地址的解析到首次调用时。其核心步骤为:
1. **编译阶段**:生成存根(Stub),指向符号占位地址。
2. **启动阶段**:存根指向动态链接器(如 `dyld`)的解析函数(如 `dyld_stub_binder`)。
3. **首次调用**:触发符号解析,动态链接器填充真实地址到存根。
4. **后续调用**:直接跳转到已解析的地址。
替换桩,位于 `__DATA,__la_symbol_ptr` 数据段可读可写,所以可以修改。
0x20 是什么?这32个字节存放了什么信息?存储字符串的描述信息,比如:引用计数、字符串长度等信息。
总结:
- 当字符串长度小于等于 0xF(也就是15),字符串内容直接存放在指针变量对应的内存中
- 当字符拼接时候,拼接后字符串长度小于等于15,则字符串内容依旧存储在指针变量的内存中
- 当字符串长度大于 0xF(也就是15),字符串的内容存放在 `__TEXT,__cstring` 中(常量区)。字符串的地址值信息存放在指针变量的后8个字节中,且真正的地址值为 (`后8个字节值` + `0x20` ),前32字节存储字符串的基础信息(长度、引用计数等)
## dyld_stub_binder
`__TEXT` 是 Mach-O 文件中通常包含代码和只读数据的段。这个段包含了程序的主要执行代码,以及常量字符串、符号表等。
`dyld_stub_binder` 是一个由动态链接器(dyld)在运行时生成和使用的函数。它的主要目的是在首次调用某个动态链接的符号(如函数或方法)时,将该符号的实际地址绑定到调用点
Swift 中 `String` 类型的初始化方法(`init`)的地址是否采用延迟绑定(Lazy Binding),取决于 **编译环境、优化级别和具体方法实现**
### 延迟绑定的基本原理
在编译时,对于动态链接的符号,编译器会生成一个桩(stub),而不是直接调用该符号。桩是一个小段的代码,当被首次执行时,它会触发 `dyld_stub_binder` 的调用。`dyld_stub_binder` 的任务就是找到该符号的实际地址,并将其写入桩中,从而替换桩的原始代,这样,下一次调用该符号时,就可以直接跳转到实际的地址,而无需再次通过桩和 `dyld_stub_binder`。
延迟绑定(Lazy Binding)是动态链接的机制,用于推迟符号(如函数、方法)地址的解析到首次调用时。其核心步骤为:
1. **编译阶段**:生成存根(Stub),指向符号占位地址。
2. **启动阶段**:存根指向动态链接器(如 `dyld`)的解析函数(如 `dyld_stub_binder`)。
3. **首次调用**:触发符号解析,动态链接器填充真实地址到存根。
4. **后续调用**:直接跳转到已解析的地址。
替换桩,位于 `__DATA,__la_symbol_ptr` 数据段可读可写,所以可以修改。
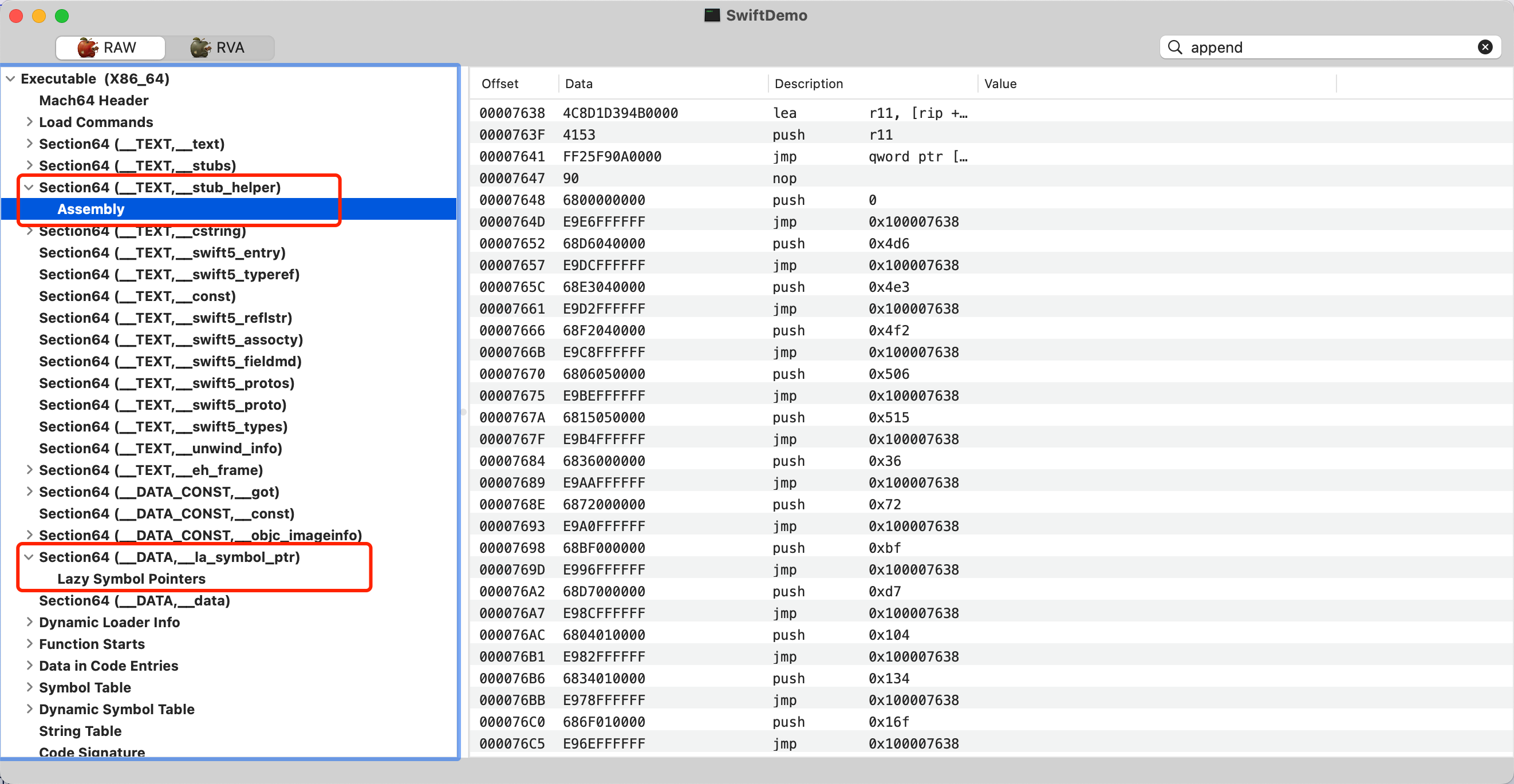 `__stub_helper` 节是 `__TEXT` 段中的一个特定节,它包含了用于处理符号懒加载的辅助函数和代码。当动态链接的符号首次被调用时,这些辅助函数会被触发,以解析符号并将其地址绑定到调用点。
这个过程也叫 `Lazy_binding`。懒加载是一种优化技术,允许程序在启动时不必立即解析和绑定所有动态链接的符号。相反,这些符号的解析和绑定被推迟到它们实际被使用时进行。这种延迟可以减少应用程序启动时的内存和性能开销。
`__stub_helper` 节是 `__TEXT` 段中的一个特定节,它包含了用于处理符号懒加载的辅助函数和代码。当动态链接的符号首次被调用时,这些辅助函数会被触发,以解析符号并将其地址绑定到调用点。
这个过程也叫 `Lazy_binding`。懒加载是一种优化技术,允许程序在启动时不必立即解析和绑定所有动态链接的符号。相反,这些符号的解析和绑定被推迟到它们实际被使用时进行。这种延迟可以减少应用程序启动时的内存和性能开销。