48 KiB
多线程探究
平时我们经常使用 GCD、锁、队列、block,那这些概念和本质到底是什么?线程安全如何实现?自旋锁、互斥锁区别是什么?本文来一探究竟
多线程方案
| 技术方案 | 简介 | 语言 | 线程生命周期 | 使用频率 |
|---|---|---|---|---|
| pthread | -一套通用的多线程API 适用于Unix\Linux\Windows等系统 跨平台\可移植 使用难度大 |
C | 开发者手动管理 | 很少,底层监控会用到 |
| NSThread | 使用更加面向对象 简单易用,可直接操作线程对象 |
OC | 开发者手动管理 | 偶尔 |
| GCD | 旨在替代NSThread等线程技术 充分利用设备的多核 |
C | 系统自动管理 | 经常 |
| NSOperation | 基于GCD(底层是GCD) 比GCD多了一些更简单实用的功能 使用更加面向对象 |
OC | 系统自动管理 | 经常 |
| 并发队列 | 自定义串行队列 | 主队列(串行) | |
|---|---|---|---|
| 同步(sync) | 不开新线程、串行执行任务 | 不开新线程、串行执行任务 | 不开新线程、串行执行任务 |
| 异步(async) | 开新线程、并发执行任务 | 开新线程、串行执行任务 | 不开新线程、串行执行任务 |
多线程死锁
看几个 Demo 观察下死锁情况
Demo1
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_sync(queue, ^{
NSLog(@"执行任务2");
});
NSLog(@"执行任务3");
// 死锁
分析:主队列是一个串行队列,任务3等待 dispatch_sync 内的任务执行完毕,可 dispatch_sync 内的任务等待任务3执行,互相等待,产生死锁
Demo2
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_async(queue, ^{
NSLog(@"执行任务2");
});
NSLog(@"执行任务3");
// 1 3 2
Demo3
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2")
dispatch_sync(queue, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 Crash
分析:任务4等待 dispatch_sync 内的任务3,dispatch_sync 内的任务3等待任务4执行,互相等待
Demo4
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue2 = dispatch_queue_create("myqueu2", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2");
dispatch_sync(queue2, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 3 4
分析:不会死锁。因为在存在2个任务队列。所以会按照顺序各自从队列上取任务执行。
Demo5
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2");
dispatch_sync(queue, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 3 4
总结:
-
队列决定了任务执行完是否需要等待。任务决定是否可以产生新线程
-
死锁:使用
sync函数给当前串行队列派发任务,则会卡住当前串行队列,产生死锁
Demo6
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil afterDelay:3];
NSLog(@"3");
});
}
// 1 3
分析:为什么打印1、3,没有打印2。因为 -(void)performSelector:(SEL)aSelector withObject:(nullable id)anArgument afterDelay:(NSTimeInterval)delay; 底层是开启了定时器,定时器运行需要添加到 RunLoop。上述代码是在全局并发队列上开启子线程,子线程中没有 RunLoop,所以定时器没有运行。
Demo7
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil];
NSLog(@"3");
});
}
// 1 3 2
分析:为什么现在又执行打印2了?因为 -(id)performSelector:(SEL)aSelector withObject:(id)object; 是 Runtime API,本质上就是 objc_msgSend,所以不需要 RunLoop 便可运行
查看 objc4 NSObject.m 即可
+ (id)performSelector:(SEL)sel withObject:(id)obj {
if (!sel) [self doesNotRecognizeSelector:sel];
return ((id(*)(id, SEL, id))objc_msgSend)((id)self, sel, obj);
}
iOS 底层研究宝藏
如何查看 -(void)performSelector:(SEL)aSelector withObject:(nullable id)anArgument afterDelay:(NSTimeInterval)delay; 源码。
-
未开源,但是可以设置断点查看汇编分析;
-
Apple 的 XNU 是参考 GNUstep,它将 Cocoa 的 OC 库重新实现并开源。虽然不是官方源代码,但是具有研究参考价值
查看 GUNStep 源码
- (void) performSelector: (SEL)aSelector
withObject: (id)argument
afterDelay: (NSTimeInterval)seconds
{
NSRunLoop *loop = [NSRunLoop currentRunLoop];
GSTimedPerformer *item;
item = [[GSTimedPerformer alloc] initWithSelector: aSelector
target: self
argument: argument
delay: seconds];
[[loop _timedPerformers] addObject: item];
RELEASE(item);
[loop addTimer: item->timer forMode: NSDefaultRunLoopMode];
}
可以看到底层实现就是 开启一个 Timer 并添加到 RunLoop。但是没有 Run。所以代码改下就可运行。
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil afterDelay:3];
[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];
NSLog(@"3");
});
}
// 1 2 3
所以要研究 iOS 底层的同学,看看 GUNStep 代码吧,这是宝藏
队列组
-
实现异步并发执行任务1、任务2
-
等任务1、2都执行完毕,再回到主线程执行任务3
dispatch_queue_t queue = dispatch_queue_create("concurrentQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task1: %@ - index:%zd", [NSThread currentThread], index);
}
});
dispatch_group_async(group, queue, ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task2: %@ - index:%zd", [NSThread currentThread], index);
}
});
dispatch_group_notify(group, queue, ^{
dispatch_async(dispatch_get_main_queue(), ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task3: %@ - index:%zd", [NSThread currentThread], index);
}
});
});
多线程安全问题
多线程存在资源共享问题。比如1块内存可能会被多个线程共享,同时读或者写,导致不一致,很容易引发数据错乱和数据安全问题。典型的生产者消费者问题
比如多个线程访问同一个对象、同一个变量、同一个文件
解决方案
使用线程同步技术(同步,就是协同步调,按预定的先后次序进行)
常见的线程同步技术是:加锁。
常见的锁有:
- OSSpinLock
- os_unfair_lock
- pthread_mutex
- dispatch_semaphore
- dispatch_queue(DISPATCH_QUEUE_SERIAL)
- NSLock
- NSRecursiveLock
- NSCondition
- NSConditionLock
- @synchronized
OSSpinLock
OSSpinLock 叫做”自旋锁”。
使用的时候需要导入 #import <libkern/OSAtomic.h>
OSSpinLock lock = OS_SPINLOCK_INIT 初始化
OSSpinLockLock(&lock); 加锁
OSSpinLockUnlock(&lock); 解锁
bool res = OSSpinLockTry(&lock) 尝试加锁(如果需要等待就不加锁直接返回 false,如果不需等待则加锁,返回 true)
存在问题:
-
等待锁的线程会处于忙等(busy-wait)状态,一直占用着 CPU 资源
-
不安全,可能会出现优先级反转问题
-
如果等待锁的线程优先级较高,它会一直占用着CPU资源,优先级低的线程就无法释放锁
@interface ViewController ()
@property (assign, nonatomic) OSSpinLock bankLock;
@property (nonatomic, assign) NSInteger money;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.bankLock = OS_SPINLOCK_INIT;
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self withdrawMoney];
}
});
// 100 + 10*50 - 10*10 = 500
}
- (void)saveMoney {
OSSpinLockLock(&_bankLock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
- (void)withdrawMoney {
OSSpinLockLock(&_bankLock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
@end
QA:优先级反转是什么?
线程本质上就是 CPU 高速切换,看上去是同时在做多个线程内的事情。操作系统会使用基于优先级抢占式调度算法。高优先级的线程始终在低优先级线程前执行。

线程 A 在 T1 时刻拿到锁,并处理数据。
线程 C 在 T2 时刻被唤醒,但是此时锁被线程 A 使用,所以线程 C 放弃 CPU 进入阻塞状态,而线程 A 继续占据 CPU,执行任务
目前来看一切正常。
但是在 T3 时刻,线程 B 被唤醒,由于优先级比较高,所以会立即抢占 CPU,此时线程 A 被迫进入 READY 状态等待。
T4 时刻,线程 B 放弃 CPU,此时线程 A (优先级10)是唯一处于 READY 状态的线程,所以再次占据 CPU 去执行任务,在 T5 时刻释放锁。
在 T5 时刻,线程 A 解锁瞬间,线程 C 立即获取锁,并在优先级20上等待 CPU,因为优先级比较高,所以系统会立刻调度线程 C 的任务执行。此时线程 A 进入 READY 状态。
线程 B 从 T3 到 T4 这个时间段占据 CPU 资源的行为叫做优先级反转。一个优先级 15 的线程B,通过压制优线级10的线程 A,而事实上导致高优先级线程 C 无法正确得到 CPU。这段时间是不可控的,因为线程 B 可以长时间占据 CPU(即使轮转时间片到时,线程 A 和 B 都处于可执行态,但是因为B的优先级高,它依然可以占据 CPU),其结果就是高优先级线程 C 可能长时间无法得到 CPU。
上面的代码改进下
- (void)saveMoney {
if (OSSpinLockLock(&_bankLock)) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
}
- (void)withdrawMoney {
if (OSSpinLockLock(&_bankLock)) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
}
os_unfair_lock
os_unfair_lock 用于取代不安全的 OSSpinLock ,从iOS10开始才支持。使用的时候需要导入头文件 #import <os/lock.h>
从底层调用看,等待 os_unfair_lock 锁的线程会处于休眠状态,并非忙等(自旋锁会忙等)
初始化 os_unfair_lock moneylock = OS_UNFAIR_LOCK_INIT;
加锁 os_unfair_lock_lock(&_moneylock);
解锁 os_unfair_lock_unlock(&_moneylock);
尝试加锁 os_unfair_lock_trylock(&_moneylock)
继续对存取钱 Demo 用 os_unfair_lock 实现
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, assign) os_unfair_lock moneylock;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.moneylock = OS_UNFAIR_LOCK_INIT;
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self withdrawMoney];
}
});
// 100 + 10*50 - 10*10 = 500
}
int cursorr = 1;
- (void)saveMoney {
NSLog(@"current cursor %d", cursorr);
cursorr++;
os_unfair_lock_lock(&_moneylock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
os_unfair_lock_unlock(&_moneylock);
}
- (void)withdrawMoney {
os_unfair_lock_lock(&_moneylock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
os_unfair_lock_unlock(&_moneylock);
}
@end
假如对存钱过程,忘记解锁怎么办?产生死锁,如下

添加 cursor 标记死锁是发生在 saveMoney 方法执行的第几次。发现是第二次。因为第一次锁没有任何使用方,所以加锁成功,当第二次加锁的时候发现锁没有释放,所以产生死锁。
这时候使用尝试加锁 API os_unfair_lock_trylock 即可成功如下

pthread_mutex
mutex 叫做”互斥锁”,等待锁的线程会处于休眠状态。使用时需要引入 #import <pthread.h>
使用:
// 初始化属性
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_DEFAULT);
// 初始化锁
pthread_mutex_init(&_moneyLock, &attr);
// 释放属性内存
pthread_mutexattr_destroy(&attr);
// 加锁
pthread_mutex_lock(&_moneyLock);
// 解锁
pthread_mutex_unlock(&_moneyLock);
// 释放锁内存
pthread_mutex_destroy(&_moneyLock);
其中 pthread_mutexattr_settype(pthread_mutexattr_t *, int); 第二个参数有4个枚举值
/*
* Mutex type attributes
*/
#define PTHREAD_MUTEX_NORMAL 0
#define PTHREAD_MUTEX_ERRORCHECK 1
#define PTHREAD_MUTEX_RECURSIVE 2
#define PTHREAD_MUTEX_DEFAULT PTHREAD_MUTEX_NORMAL
如果类型选 PTHREAD_MUTEX_DEFAULT 或者 PTHREAD_MUTEX_NORMAL 则可以省略 pthread_mutexattr_t 的创建,直接传 NULL,即 pthread_mutex_init(&_moneyLock, NULL)
使用如下
- (void)saveMoney {
pthread_mutex_lock(&_moneyLock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
pthread_mutex_unlock(&_moneyLock);
}
如果在某个方法内部递归调用自身怎么实现,好像挺简单的,直接内部调用即可。
int cursor = 0;
- (void)sayHi {
if (cursor<10) {
pthread_mutex_lock(&_moneyLock);
cursor++;
NSLog(@"Hi %d", cursor);
[self sayHi];
pthread_mutex_unlock(&_moneyLock);
}
}
// Hi 1
只打印了 1。为什么?因为第一次调用正常加锁,然后递归调用自身,第二次调用的时候尝试加锁,但是这时候第一次调用时候锁还没释放。
互斥锁提供 API 实现该功能。只需要在互斥锁初始化地方将属性修改为 PTHREAD_MUTEX_RECURSIVE。即 pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);在同一个线程中可以多次获取同一把锁。并且不会死锁。
互斥条件锁 pthread_cond_t
初始化互斥锁条件 pthread_cond_init(&_condition, NULL);
等待条件进入休眠,放开 mutex 锁,被唤醒后会再次对 mutex 加锁 pthread_cond_wait(&_condition, &_moneyLock);
激活一个等待该条件的线程 pthread_cond_signal(&_condition)
激活所有等待该条件的线程 pthread_cond_broadcast(&_condition)
@interface ViewController ()
@property (nonatomic, assign) pthread_mutex_t moneyLock;
@property (nonatomic, assign) pthread_cond_t condition;
@property (nonatomic, strong) NSMutableArray *array;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_DEFAULT);
// 初始化锁
pthread_mutex_init(&_moneyLock, &attr);
// 释放属性内存
pthread_mutexattr_destroy(&attr);
// 加锁
pthread_mutex_lock(&_moneyLock);
// 解锁
pthread_mutex_unlock(&_moneyLock);
// 初始化互斥锁条件
pthread_cond_init(&_condition, NULL);
[self test];
self.array = [NSMutableArray array];
}
- (void)test{
[[[NSThread alloc] initWithTarget:self selector:@selector(delete) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(add) object:nil] start];
}
- (void)add{
NSLog(@"add beign");
pthread_mutex_lock(&_moneyLock);
[self.array addObject:@"bb"];
NSLog(@"加元素 %zd", self.array.count);
pthread_cond_signal(&_condition);
pthread_mutex_unlock(&_moneyLock);
NSLog(@"add beign");
}
- (void)delete{
NSLog(@"delete beign");
pthread_mutex_lock(&_moneyLock);
if (self.array.count == 0) {
pthread_cond_wait(&_condition, &_moneyLock);
}
[self.array removeLastObject];
NSLog(@"减元素 %zd", self.array.count);
pthread_mutex_unlock(&_moneyLock);
NSLog(@"delete end");
}
@end
// delete beign
// add beign
// 加元素 1
// add beign
// 减元素 0
// delete end
可以看到同时调用 delete、add 方法
-
执行 delete 方法先加锁,但是由于数组为空,这时候就不需要执行删除元素,然后执行 add 方法
-
add 方法要加锁,发现锁被 delete 方法占用了
-
delete 方法为了等有元素再去执行 delete 引入了互斥锁条件
pthread_cond_t,调用pthread_cond_wait。此时线程进入休眠,同时会释放锁。 -
add 方法内加完元素会调用
pthread_cond_signal来激活等待该条件的线程
从汇编角度分析 os_unfair_lock 属于什么锁(教你如何用汇编分析源码)
属于互斥锁。自旋锁是指在等锁的时候通过类似 while 循环的代码,让线程忙碌等到锁的到来。
Low-level lock that allows waiters to block efficiently on contention.
系统说它是低级锁,等不到锁就休眠。
测试代码
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i < 10; i++) {
[[[NSThread alloc] initWithTarget:self selector:@selector(saveMoney) object:nil] start];
}
- (void)saveMoney {
OSSpinLockLock(&_bankLock);
NSInteger previousMoney = self.money;
sleep(600);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
为了调试方便,开启10个线程去执行 saveMoney 方法,为了查看自旋锁的等是什么实现。我们给里面休眠600s。同时 Xcode - Debug - DebugWorkflow - Always Show Disassembly
lldb 模式下调试汇编有几个指令
c: 代表 continue,
si:step instruction,简写为 stepi,si。当你在 Xcode 汇编面板看到某个认识或者可疑符号,断点在这一行的时候,在下方 lldb 面板,属于 si,即可进入内部实现。
第一步:当第二次调用 saveMoney 方法,开启汇编调试

看到可疑方法 OSSpinLockLock,给它加断点,看到第10行高亮了。lldb 模式输入 c,敲回车。次数输入 si 即可进入 OSSpinLockLock 方法内部调试
第二步:继续输入 si,敲回车

第三步:看到可疑方法 _OSSpinLockLockSlow,给它加断点,lldb 输入 C。此时断点到这一行了,继续输入 si。

第四步:在 OSSpinLockLockSlow 方法内部调试,不断输入 si。

发现不断 si 最终一直会在第6行到第19行之间执行。懂汇编的会发现这其实是一个 while 循环。便可以证明自旋锁 OSSpinLock 在等锁的时候,底层实现是执行 while 循环,忙等,太浪费性能了。
同样方式看看 ,按照上述调试汇编代码的步骤,我将关键步骤截图如下
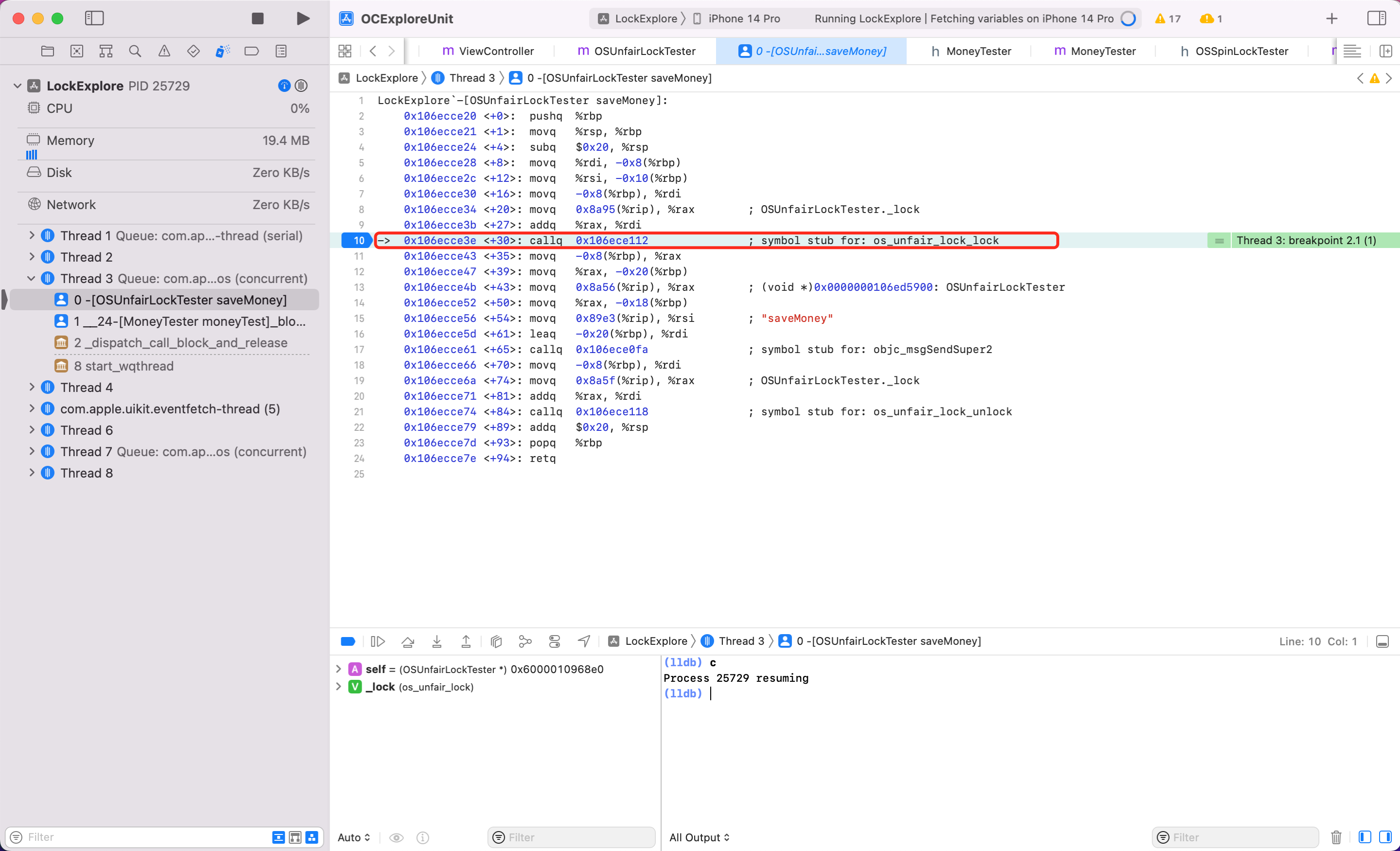
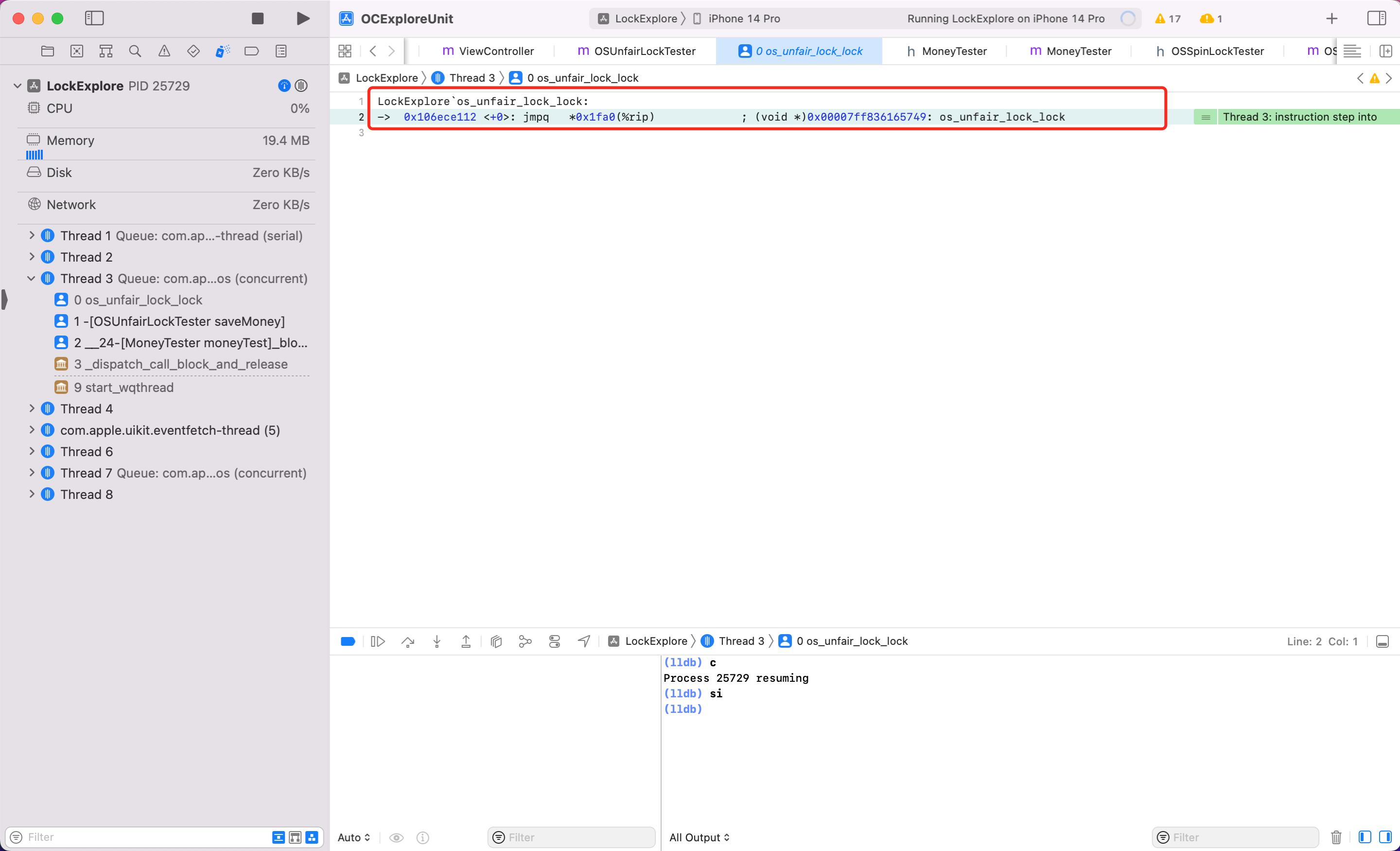
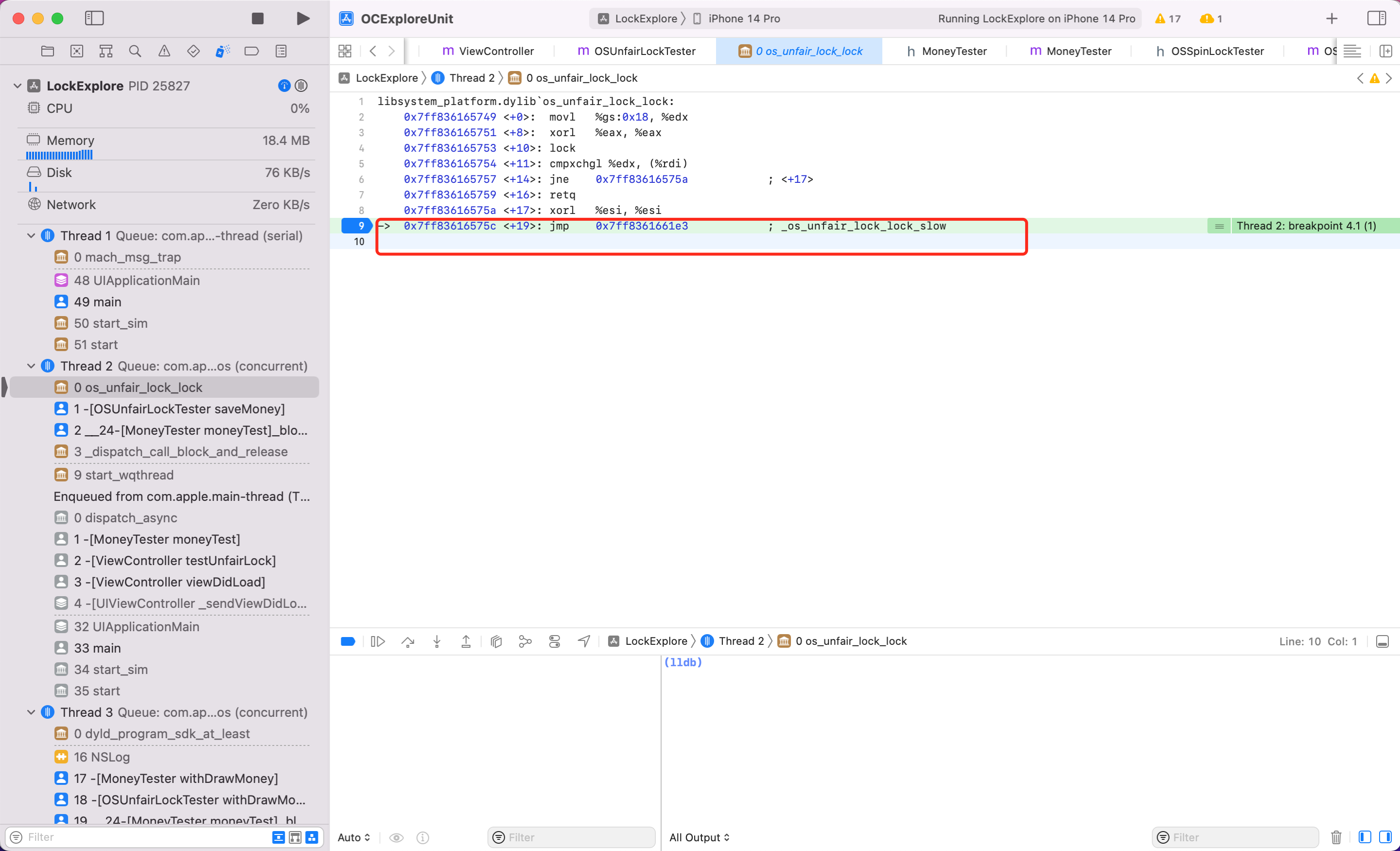
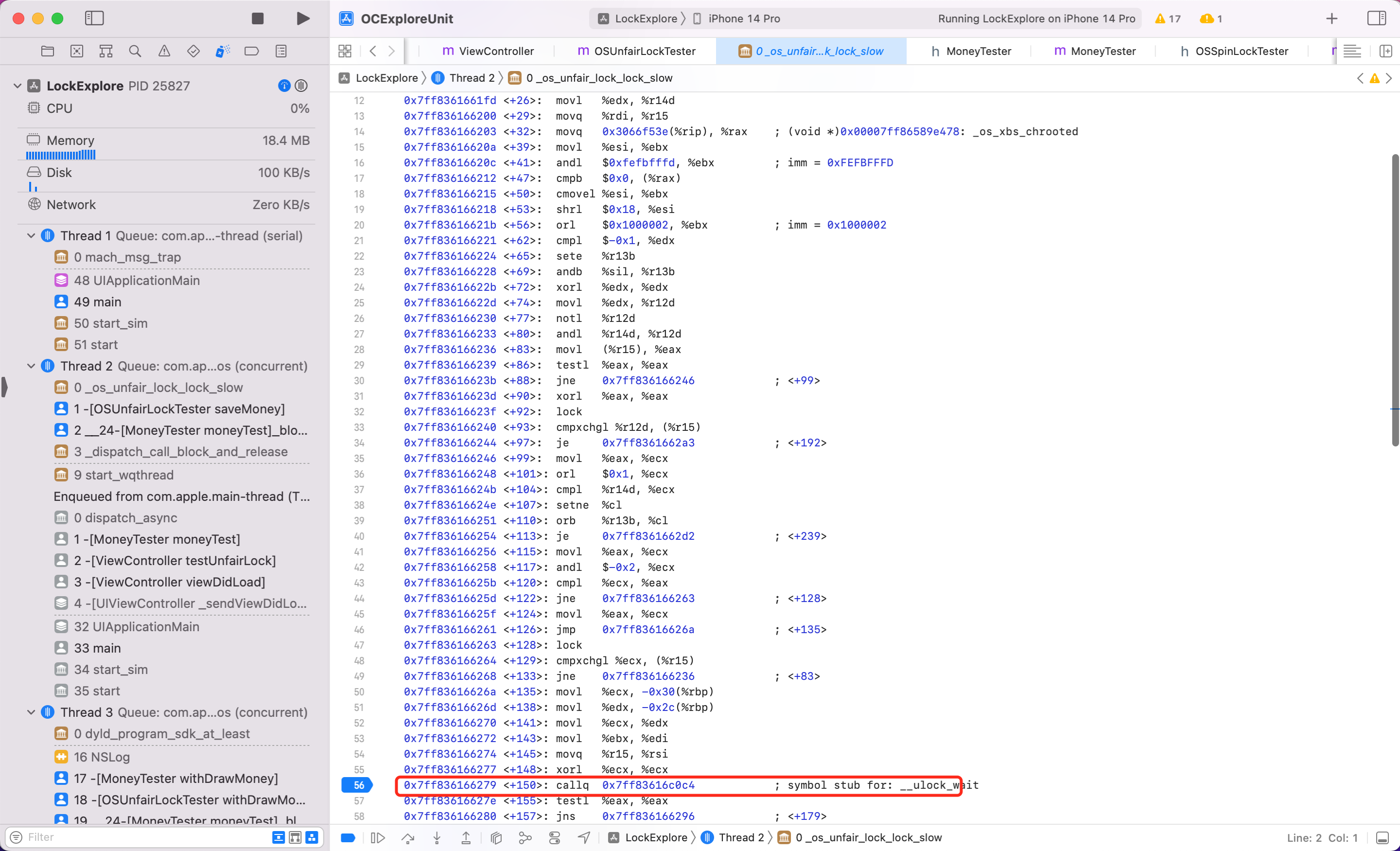
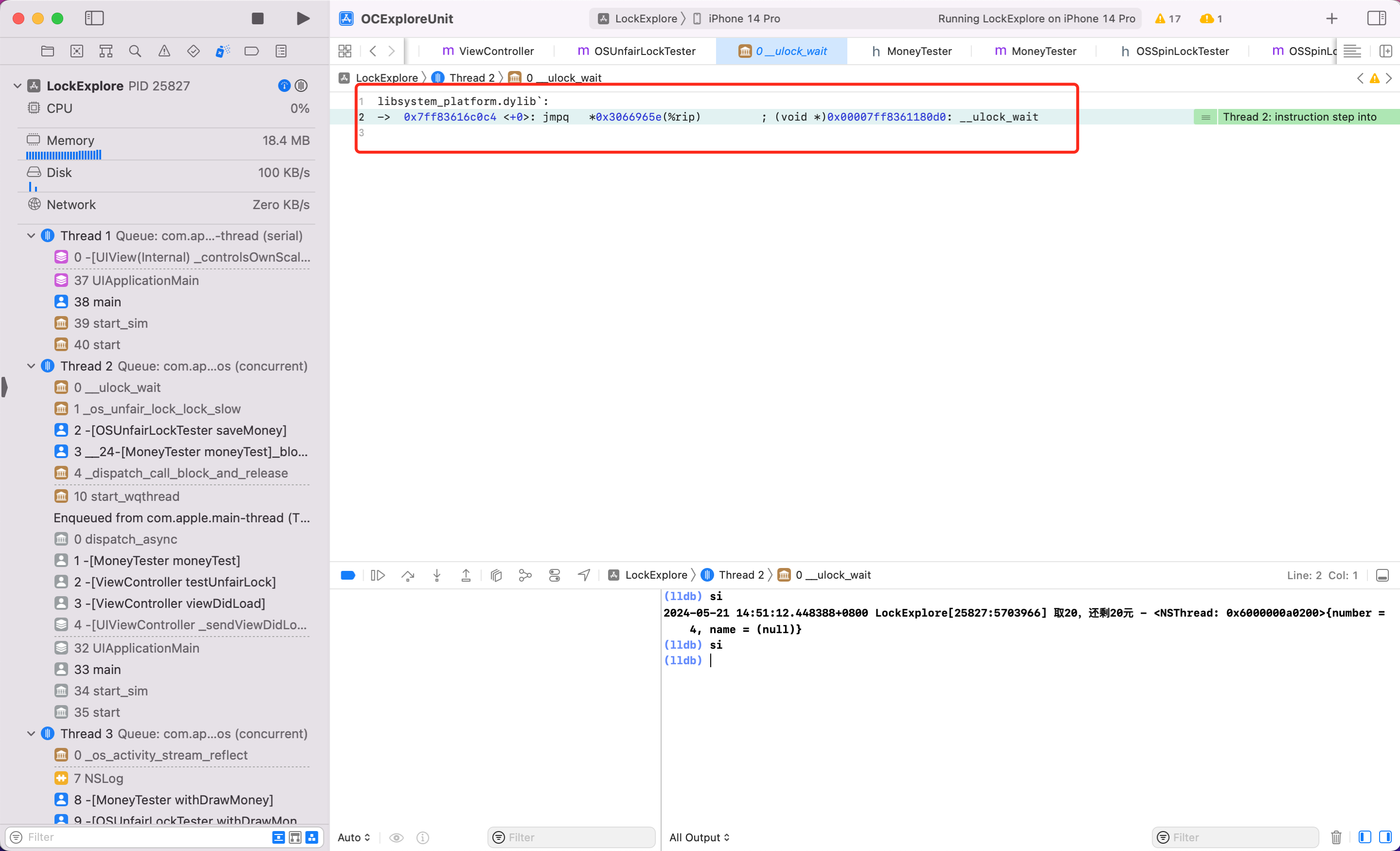 可以看到最后一步调用到了
可以看到最后一步调用到了 syscall,当这一步执行后会发现后续代码都不执行了,也就是调用系统底层能力,线程真正休眠了
同样的步骤研究 pthread_mutex_t 会发现最后也是调用 syscall 做到线程休眠,不像自旋锁一样,在底层实现是 while 循环一样忙等,浪费资源。
NSLock、NSRecursiveLock
NSLock 是对 mutex 普通锁(pthread_mutex_t)的封装
NSRecursiveLock 是对 mutex 递归锁(pthread_mutex_t ,且 attr 为 PTHREAD_MUTEX_RECURSIVE)的封装,API 跟 NSLock 基本一致
查看 GUN 源码可以看看到底是如何实现的
+ (void) initialize{
static BOOL beenHere = NO;
if (beenHere == NO){
beenHere = YES;
/* Initialise attributes for the different types of mutex.
* We do it once, since attributes can be shared between multiple
* mutexes.
* If we had a pthread_mutexattr_t instance for each mutex, we would
* either have to store it as an ivar of our NSLock (or similar), or
* we would potentially leak instances as we couldn't destroy them
* when destroying the NSLock. I don't know if any implementation
* of pthreads actually allocates memory when you call the
* pthread_mutexattr_init function, but they are allowed to do so
* (and deallocate the memory in pthread_mutexattr_destroy).
*/
pthread_mutexattr_init(&attr_normal);
pthread_mutexattr_settype(&attr_normal, PTHREAD_MUTEX_NORMAL);
pthread_mutexattr_init(&attr_reporting);
pthread_mutexattr_settype(&attr_reporting, PTHREAD_MUTEX_ERRORCHECK);
pthread_mutexattr_init(&attr_recursive);
pthread_mutexattr_settype(&attr_recursive, PTHREAD_MUTEX_RECURSIVE);
/* To emulate OSX behavior, we need to be able both to detect deadlocks
* (so we can log them), and also hang the thread when one occurs.
* the simple way to do that is to set up a locked mutex we can
* force a deadlock on.
*/
pthread_mutex_init(&deadlock, &attr_normal);
pthread_mutex_lock(&deadlock);
baseConditionClass = [NSCondition class];
baseConditionLockClass = [NSConditionLock class];
baseLockClass = [NSLock class];
baseRecursiveLockClass = [NSRecursiveLock class];
tracedConditionClass = [GSTracedCondition class];
tracedConditionLockClass = [GSTracedConditionLock class];
tracedLockClass = [GSTracedLock class];
tracedRecursiveLockClass = [GSTracedRecursiveLock class];
untracedConditionClass = [GSUntracedCondition class];
untracedConditionLockClass = [GSUntracedConditionLock class];
untracedLockClass = [GSUntracedLock class];
untracedRecursiveLockClass = [GSUntracedRecursiveLock class];
}
}
可以看到 NSLock 底层就是 pthread_mutex_t。
再看看 NSRecursiveLock
@implementation NSRecursiveLock
- (id) init{
if (nil != (self = [super init])) {
if (0 != pthread_mutex_init(&_mutex, &attr_recursive)){
DESTROY(self);
}
}
return self;
}
底层就是 pthread_mutex_init。参数 attr_recursive 其实就是一个递归锁的属性。
pthread_mutexattr_init(&attr_recursive);
pthread_mutexattr_settype(&attr_recursive, PTHREAD_MUTEX_RECURSIVE);
NSRecursiveLock 不能在多线程下递归调用。@synchronized 可以在多线程下递归调用。底层原因是 TLS 有关。
NSCondition
NSCondition 是对 mutex 和 cond 的封装。
- (id) init {
if (nil != (self = [super init])) {
if (0 != pthread_cond_init(&_condition, NULL)){
DESTROY(self);
} else if (0 != pthread_mutex_init(&_mutex, &attr_reporting)) {
pthread_cond_destroy(&_condition);
DESTROY(self);
}
}
return self;
}
因为 NSCondtion 已经封装好锁和条件,所以直接使即可。pthread_mutex_t 需要搭配 pthread_cond_t 一起使用
Demo
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, strong) NSCondition *condition;
@property (nonatomic, strong) NSMutableArray *array;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.condition = [[NSCondition alloc] init];
[self test];
self.array = [NSMutableArray array];
}
- (void)test{
[[[NSThread alloc] initWithTarget:self selector:@selector(delete) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(add) object:nil] start];
}
- (void)add{
NSLog(@"add beign");
[self.condition lock];
[self.array addObject:@"bb"];
NSLog(@"加元素 %zd", self.array.count);
[self.condition unlock];
[self.condition signal];
NSLog(@"add beign");
}
- (void)delete{
NSLog(@"delete beign");
[self.condition lock];
if (self.array.count == 0) {
[self.condition wait];
}
[self.array removeLastObject];
NSLog(@"减元素 %zd", self.array.count);
[self.condition unlock];
NSLog(@"delete end");
}
@end
存在 虚假唤醒 的问题。则可以将后续的 if 判断换为 while。比如某一时刻发送了一次 signal,然后可能有多个线程收到唤醒的信号,则可能还是会存在问题。所以 if 换为 while。
NSCondtionLock
NSConditionLock 是对 NSCondition 的进一步封装,可以设置具体的条件值。
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, strong) NSConditionLock *condition;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.condition = [[NSConditionLock alloc] initWithCondition:1];
[self test];
}
- (void)test{
[[[NSThread alloc] initWithTarget:self selector:@selector(task1) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(task2) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(task3) object:nil] start];
}
- (void)task1{
[self.condition lockWhenCondition:1];
NSLog(@"task1");
[self.condition unlockWithCondition:2];
}
- (void)task2{
[self.condition lockWhenCondition:2];
NSLog(@"task2");
[self.condition unlockWithCondition:3];
}
- (void)task3{
[self.condition lockWhenCondition:3];
NSLog(@"task3");
[self.condition unlock];
}
@end
通过 NSCondtionLock 可以控制线程的执行顺序。
dispatch_queue
使用 GCD 的串行队列,也是可以实现线程同步。
线程同步的本质就是多线程的任务是顺序执行
dispatch_semaphore
semaphore 叫做”信号量”
信号量的初始值,可以用来控制线程并发访问的最大数量
信号量的初始值为1,代表同时只允许1条线程访问资源,保证线程同步
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, strong) dispatch_semaphore_t semaphore;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
// 控制线程最大并发量
self.semaphore = dispatch_semaphore_create(5);
[self test];
}
- (void)test{
for (NSInteger index = 0; index<20; index++) {
[[[NSThread alloc] initWithTarget:self selector:@selector(task) object:nil] start];
}
}
- (void)task{
dispatch_semaphore_wait(self.semaphore, DISPATCH_TIME_FOREVER);
NSLog(@"task %@", [NSThread currentThread]);
sleep(5);
dispatch_semaphore_signal(self.semaphore);
}
@end
dispatch_semaphore_wait 函数的本质
-
如果信号量的值 > 0,则会让信号量的值 -1,然后继续向下执行代码
-
如果信号量的值 <= 0,则线程休眠等待。等待多久取决于第二个参数。直到信号量的值 > 0,此时会让信号量的值 -1,然后继续向下执行代码
dispatch_semaphore_signal 函数的本质:让信号量的值 + 1
所以如何让线程同步?设置信号量的值=1即可。保证同一时间只有一个线程任务在执行
NSCache 扩容策略。x86 3/4,arm7/8.
有趣的实验:
self.semaphore = dispatch_semaphore_create(1);
dispatch_semaphore_wait(self.semaphore, DISPATCH_TIME_FOREVER);
上面的代码会 crash。因为创建出来信号量为1,但是经过 dispatch_semaphore_wait 之后信号量变为0,底层会调用到 _dispatch_semaphore_dispose。内部会做判断,就是原始的信号量
void _dispatch_semaphore_dispose(dispatch_object_t dou,
DISPATCH_UNUSED bool *allow_free){
dispatch_semaphore_t dsema = dou._dsema;
if (dsema->dsema_value < dsema->dsema_orig) {
DISPATCH_CLIENT_CRASH(dsema->dsema_orig - dsema->dsema_value,
"Semaphore object deallocated while in use");
}
_dispatch_sema4_dispose(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
}
@synchronized
@synchronized 可递归重入的原理分析/线程缓存空间
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self withdrawMoney];
}
});
// 100 + 10*50 - 10*10 = 500
}
- (void)saveMoney {
@synchronized (self) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
}
}
- (void)withdrawMoney {
@synchronized (self) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
}
}
@end
@synchronized 使用很方便,它是对 pthread_mutex_t 递归锁的封装
为了探究下实现,开启汇编调试

可以查看 objc4 的源码,查找 objc_sync_enter
int objc_sync_enter(id obj){
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, ACQUIRE);
assert(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
}
return result;
}
typedef struct SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
} SyncData;
可以看到 @synchronized 的本质是一个互斥递归锁 recursive_mutex_t.
传递一个参数 obj,经过 id2data 方法得到一个结构体对象,访问结构体对象的成员变量
mutex,然后调用 lock 方法。
如何根据 obj 获取对象,继续查看 id2data 方法。
#define LOCK_FOR_OBJ(obj) sDataLists[obj].lock
#define LISTFOR_OBJ(obj) sDataLists[obj].data
static StripedMap<SyncList> sDataLists;
static SyncData* id2data(id object, enum usage why)
{
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
// ...
}
class recursive_mutex_tt : nocopy_t {
pthread_mutex_t mLock;
public:
recursive_mutex_tt() : mLock(PTHREAD_RECURSIVE_MUTEX_INITIALIZER) {
lockdebug_remember_recursive_mutex(this);
}
recursive_mutex_tt(const fork_unsafe_lock_t unsafe)
: mLock(PTHREAD_RECURSIVE_MUTEX_INITIALIZER)
{ }
void lock()
{
lockdebug_recursive_mutex_lock(this);
int err = pthread_mutex_lock(&mLock);
if (err) _objc_fatal("pthread_mutex_lock failed (%d)", err);
}
void unlock()
{
lockdebug_recursive_mutex_unlock(this);
int err = pthread_mutex_unlock(&mLock);
if (err) _objc_fatal("pthread_mutex_unlock failed (%d)", err);
}
void forceReset()
{
lockdebug_recursive_mutex_unlock(this);
bzero(&mLock, sizeof(mLock));
mLock = pthread_mutex_t PTHREAD_RECURSIVE_MUTEX_INITIALIZER;
}
bool tryUnlock()
{
int err = pthread_mutex_unlock(&mLock);
if (err == 0) {
lockdebug_recursive_mutex_unlock(this);
return true;
} else if (err == EPERM) {
return false;
} else {
_objc_fatal("pthread_mutex_unlock failed (%d)", err);
}
}
void assertLocked() {
lockdebug_recursive_mutex_assert_locked(this);
}
void assertUnlocked() {
lockdebug_recursive_mutex_assert_unlocked(this);
}
};
可以看到是一个哈希表 StripedMap,哈希表工作原理就是传递一个 key,经过哈希算法生成索引,然后获取对应的值。
内部维护了一个哈希表,一个对象一个锁。
另外 recursive_mutex_tt 在初始化的时候传入 PTHREAD_RECURSIVE_MUTEX_INITIALIZER,看起来也支持递归。所以 @synchronized 是一个递归互斥锁的封装。
封装
有的时候我们需要在方法内部创建 semaphore ,则可以创建宏
#define SemaphoreBegin \
static dispatch_semaphore_t semaphore; \
static dispatch_once_t onceToken; \
dispatch_once(&onceToken, ^{ \
semaphore = dispatch_semaphore_create(1); \
}); \
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
#define SemaphoreEnd \
dispatch_semaphore_signal(semaphore);
自旋锁、互斥锁对比
什么情况使用自旋锁比较划算?
-
预计线程等待锁的时间很短
-
加锁的代码(临界区)经常被调用,但竞争情况很少发生
-
CPU资源不紧张
-
多核处理器
什么情况使用互斥锁比较划算?
-
预计线程等待锁的时间较长
-
单核处理器
-
临界区有IO操作(IO一般占用 CPU 资源较多。互斥锁本身就占用 CPU,所以不适合)
-
临界区代码复杂或者循环量大
-
临界区竞争非常激烈
atomic
atomic 用于保证属性 setter、getter 的原子性操作,相当于在 getter 和 setter 内部加了线程同步的锁。
可以参考源码 objc4 的 objc-accessors.mm
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
if (offset == 0) {
return object_getClass(self);
}
// Retain release world
id *slot = (id*) ((char*)self + offset);
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
id value = objc_retain(*slot);
slotlock.unlock();
// for performance, we (safely) issue the autorelease OUTSIDE of the spinlock.
return objc_autoreleaseReturnValue(value);
}
可以看到在获取属性值的时候,判断是不是 atomic
-
不是 atomic 则直接 return
-
如果是 atomic,则调用自旋锁
slotlock加锁,取值,解锁,return
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
if (offset == 0) {
object_setClass(self, newValue);
return;
}
id oldValue;
id *slot = (id*) ((char*)self offset);
if (copy) {
newValue = [newValue copyWithZone:nil];
} else if (mutableCopy) {
newValue = [newValue mutableCopyWithZone:nil];
} else {
if (*slot == newValue) return;
newValue = objc_retain(newValue);
}
if (!atomic) {
oldValue = *slot;
*slot = newValue;
} else {
spinlock_t& slotlock = PropertyLocks[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
objc_release(oldValue);
}
void objc_setProperty(id self, SEL _cmd, ptrdiff_t offset, id newValue, BOOL atomic, signed char shouldCopy)
{
bool copy = (shouldCopy && shouldCopy != MUTABLE_COPY);
bool mutableCopy = (shouldCopy == MUTABLE_COPY);
reallySetProperty(self, _cmd, newValue, offset, atomic, copy, mutableCopy);
}
void lock() {
lockdebug_mutex_lock(this);
// <rdar://problem/50384154>
uint32_t opts = OS_UNFAIR_LOCK_DATA_SYNCHRONIZATION | OS_UNFAIR_LOCK_ADAPTIVE_SPIN;
os_unfair_lock_lock_with_options_inline(&mLock, (os_unfair_lock_options_t)opts);
}
可以看到设置属性的时候会判断是不是 atomic
-
atomic 类型,则直接赋值
-
非 atomic 类型,则先自旋锁加锁、赋值、解锁
它并不能保证使用属性的过程是线程安全的。
QA:为什么在 iOS 上几乎没有使用?
因为属性 getter、setter 使用太高频,另外 atomic 内部实现是自旋锁,自旋锁是忙等,所以太耗费性能了。
atomic 并不能保证使用属性的过程是线程安全的?
@property (atomic,copy) NSString *name;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
@synchronized(self){
for (int i = 0; i<100; i++) {
self.name = @"杭城小刘";
NSLog(@"线程1 : %@",self.name);
}
}
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
@synchronized(self){
for (int i = 0; i<100; i++) {
self.name = @"魅影";
NSLog(@"线程2 : %@",self.name);
}
}
});
预期:线程 A 打印出来一定是杭城小刘,线程 B 打印出来是魅影。但事实上可能存在乱序。
atomic 是原子属性,它内部实现是针对属性的 setter、getter 进行加锁(早期实现是自旋旋,因为存在问题,后续替换为了 os_unfair_lock)。但是事实上在进行多线程编程的时候,我们针对数据的操作并不是修改指针本身(思考 NSString 的 getter、setter),而是操作类似 NSArray、NSDictionary 这样的 case。比如 @property(atomic, strong)NSMutableArray *hobbies; 如果在多线程情况下进行处理,一边生产者添加数据,一边消费者消费数据,则会产生内存问题。
所以多线程并发编程来说,推荐使用锁是一个合理的方案。此外自旋锁不推荐使用,互斥锁中 pthread_mutex 等性能高一些的锁推荐使用。
读写安全
- 同一时间,只能有1个线程进行写的操作
- 同一时间,允许有多个线程进行读的操作
- 同一时间,不允许既有写的操作,又有读的操作
“多读单写”问题,经常用于文件、数据的读写操作。iOS 主流方案有:
-
pthread_rwlock:读写锁
-
dispatch_barrier_async:异步栅栏调用
pthread_rwlock
初始化
pthread_rwlock_t lock
pthread_rwlock_init(&_lock, NULL)
读操作-加锁 pthread_rwlock_rdlock(&_lock)
读操作-尝试加锁 pthread_rwlock_tryrdlock(&_lock);
写操作-加锁 pthread_rwlock_wrlock(&_lock);
写操作-尝试加锁 pthread_rwlock_trywrlock(&_lock);
解锁 pthread_rwlock_unlock(&_lock);
销毁 pthread_rwlock_destroy(&_lock);
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, assign) pthread_rwlock_t lock;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
pthread_rwlock_init(&_lock, NULL); // 初始化读写锁
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self read];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 4; i++) {
[self write];
}
});
}
- (void)read {
pthread_rwlock_rdlock(&_lock);
NSLog(@"read %zd", self.money);
pthread_rwlock_unlock(&_lock);
}
- (void)write {
pthread_rwlock_wrlock(&_lock);
self.money += 25;
NSLog(@"write %zd", self.money);
pthread_rwlock_unlock(&_lock);
}
@end
2022-04-09 22:25:25.042853+0800 DDD[13652:333135] read 100
2022-04-09 22:25:25.043058+0800 DDD[13652:333126] write 125
2022-04-09 22:25:25.043269+0800 DDD[13652:333135] read 125
2022-04-09 22:25:25.043445+0800 DDD[13652:333126] write 150
2022-04-09 22:25:25.043586+0800 DDD[13652:333135] read 150
2022-04-09 22:25:25.043724+0800 DDD[13652:333126] write 175
2022-04-09 22:25:25.043895+0800 DDD[13652:333135] read 175
2022-04-09 22:25:25.044037+0800 DDD[13652:333126] write 200
2022-04-09 22:25:25.044226+0800 DDD[13652:333135] read 200
2022-04-09 22:25:25.044393+0800 DDD[13652:333135] read 200
2022-04-09 22:25:25.044557+0800 DDD[13652:333135] read 200
2022-04-09 22:25:25.044713+0800 DDD[13652:333135] read 200
2022-04-09 22:25:25.044869+0800 DDD[13652:333135] read 200
2022-04-09 22:25:25.045020+0800 DDD[13652:333135] read 200
dispatch_barrier_async
// 初始化队列
self.queue = dispatch_queue_create("rwqueue", DISPATCH_QUEUE_CONCURRENT);
// 读
dispatch_async(self.queue, ^{
});
// 写
dispatch_barrier_async(self.queue, ^{
});
注意:
- 这个函数传入的并发队列必须是自己通过dispatch_queue_cretate创建的
- 如果传入的是一个串行或是一个全局的并发队列,那这个函数便等同于dispatch_async函数的效果
上 Demo
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, strong) dispatch_queue_t queue;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.queue = dispatch_queue_create("rwqueue", DISPATCH_QUEUE_CONCURRENT);
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self read];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 4; i++) {
[self write];
}
});
}
- (void)read {
dispatch_async(self.queue, ^{
NSLog(@"read %zd", self.money);
});
}
- (void)write {
dispatch_barrier_async(self.queue, ^{
self.money += 25;
NSLog(@"write %zd", self.money);
});
}
@end
2022-04-09 22:37:26.476134+0800 DDD[14019:343934] read 100
2022-04-09 22:37:26.476134+0800 DDD[14019:343932] read 100
2022-04-09 22:37:26.476317+0800 DDD[14019:343932] write 125
2022-04-09 22:37:26.476489+0800 DDD[14019:343932] read 125
2022-04-09 22:37:26.476629+0800 DDD[14019:343932] write 150
2022-04-09 22:37:26.476766+0800 DDD[14019:343932] read 150
2022-04-09 22:37:26.476905+0800 DDD[14019:343932] write 175
2022-04-09 22:37:26.477033+0800 DDD[14019:343932] write 200
2022-04-09 22:37:26.477199+0800 DDD[14019:343932] read 200
2022-04-09 22:37:26.477216+0800 DDD[14019:343934] read 200
2022-04-09 22:37:26.477233+0800 DDD[14019:343936] read 200
2022-04-09 22:37:26.477247+0800 DDD[14019:343937] read 200
2022-04-09 22:37:26.477267+0800 DDD[14019:343938] read 200
2022-04-09 22:37:26.477269+0800 DDD[14019:343933] read 200
其他常见的多线程编程模式
Promise
Promise 在多线程解决方案中比较常见,比如在前端中 Promise 就是一个标准解决方案。同样的,iOS 界也有三方开发者写的 PromiseKit。也有对应的 AFNetworking Promise 版本。
Promise 解决了什么问题?
-
在需要多个操作的时候,我们可能会设置多个回调参数嵌套,导致代码很长,也就是传说中的“回调地狱”(Callback Hell)
-
丧失了 return 特性
Promise 就是一个对象,用来传递异步操作的消息。代表了某个未来才会知道结果的事件(也就是异步操作),并且这个事件提供统一的 API,可以供进一步处理
对象的状态不受外界影响。Promise 对象代表一个异步操作,有三种状态:Pending(进行中,又称 Incomplete)、Resolved(已完成,又称 Fulfilled)和 Rejected (已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是 Promise 这个名字的由来,它的英语意思就是「承诺」,表示其他手段无法改变。
一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从 Pending 变为 Resolved 和从 Pending 变为 Rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果。就算改变已经发生了,你再对 Promise 对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
APIClient.fetchData(...).then().onFailure();
Pipeline
将一个任务分解为若干个阶段(Stage),前阶段的输出为下阶段的输入,各个阶段由不同的工
作者线程负责执行。
各个任务的各个阶段是并行(Parallel)处理的。
具体任务的处理是串行的,即完成一个任务要依次执行各个阶段,但从整体任务上看,不同任务的各个阶段的执行是并行的。
Master-Slave
将一个任务分解为若干个语义等同的子任务,并由专门的工作者线程来并行执行这些子任务,既 提高计算效率,又实现了信息隐藏。
比如 Jekins
Serial Thread Confinement
如果并发任务的执行涉及某个非线程安全对象,而很多时候我们又不希望因此而引入锁。
通过将多个并发的任务存入队列实现任务的串行化,并为这些串行化任务创建唯一的工作者线程进行处理。
比如 FMDB 的设计,内部就是一个串行队列。