20 KiB
Swift 闭包研究
方法占用对象内存吗?
实验一:
class Point {
var test = true
var age = 29
var height = 175
}
var p = Point()
print(Mems.size(ofRef: p)) // 48
为什么是48,而不是40?
Point 类前16位的前8位表示类信息,后8位表示引用计算信息,2个 Int 占2*8 = 16 Byte,Bool 占用1 Byte。所以实际占用 8 + 8 + 2 * 8 + 1 = 33 Byte。但由于存在内存对齐(内存对齐以8为 base,都是8的整数倍),但 malloc 函数分配的内存都是 16的倍数,所以占用48 Byte。
Demo:
class Person {
var age = 29
func sayHi () {
var height = 175
print("局部变量", Mems.ptr(ofVal: &height))
print("I am \(age) old")
}
}
func sayOuterHi () {
print("Hello world")
}
var p = Person()
p.sayHi()
sayOuterHi()
print("全局变量", Mems.ptr(ofVal: &p))
print("堆空间", Mems.ptr(ofRef: p))
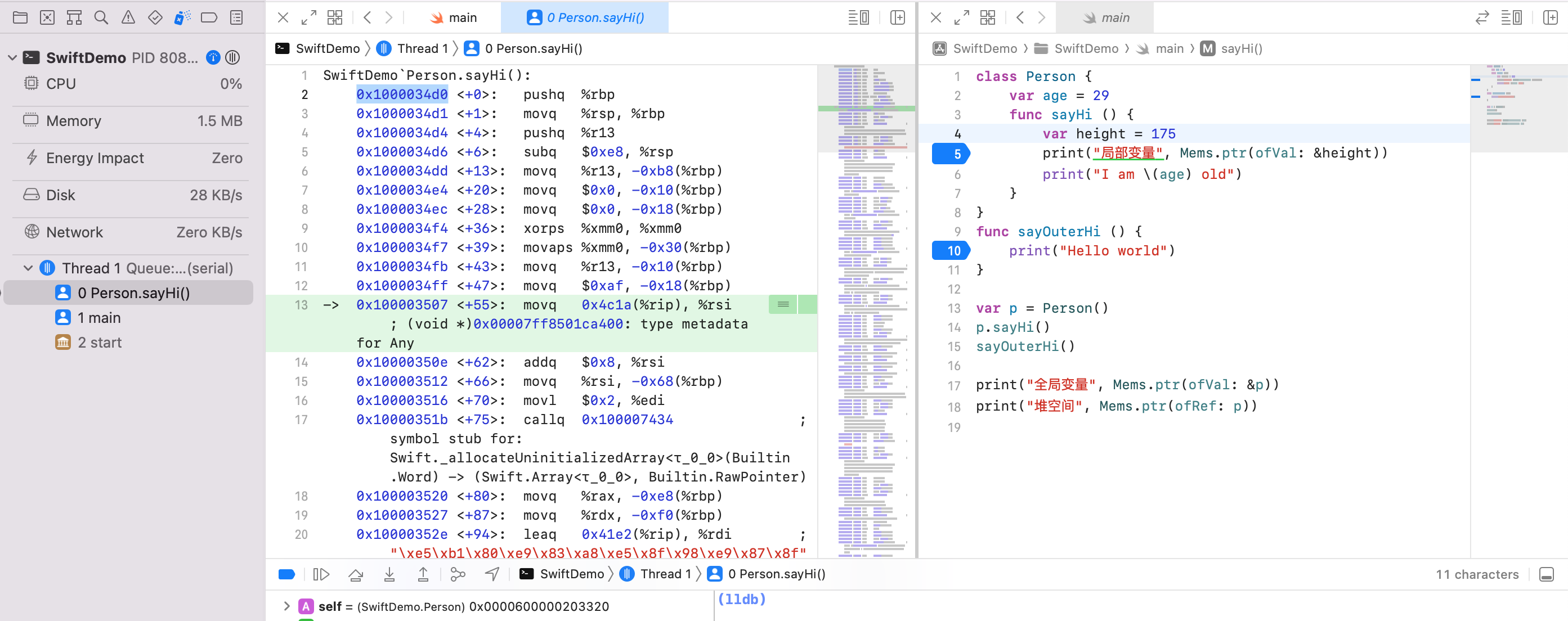
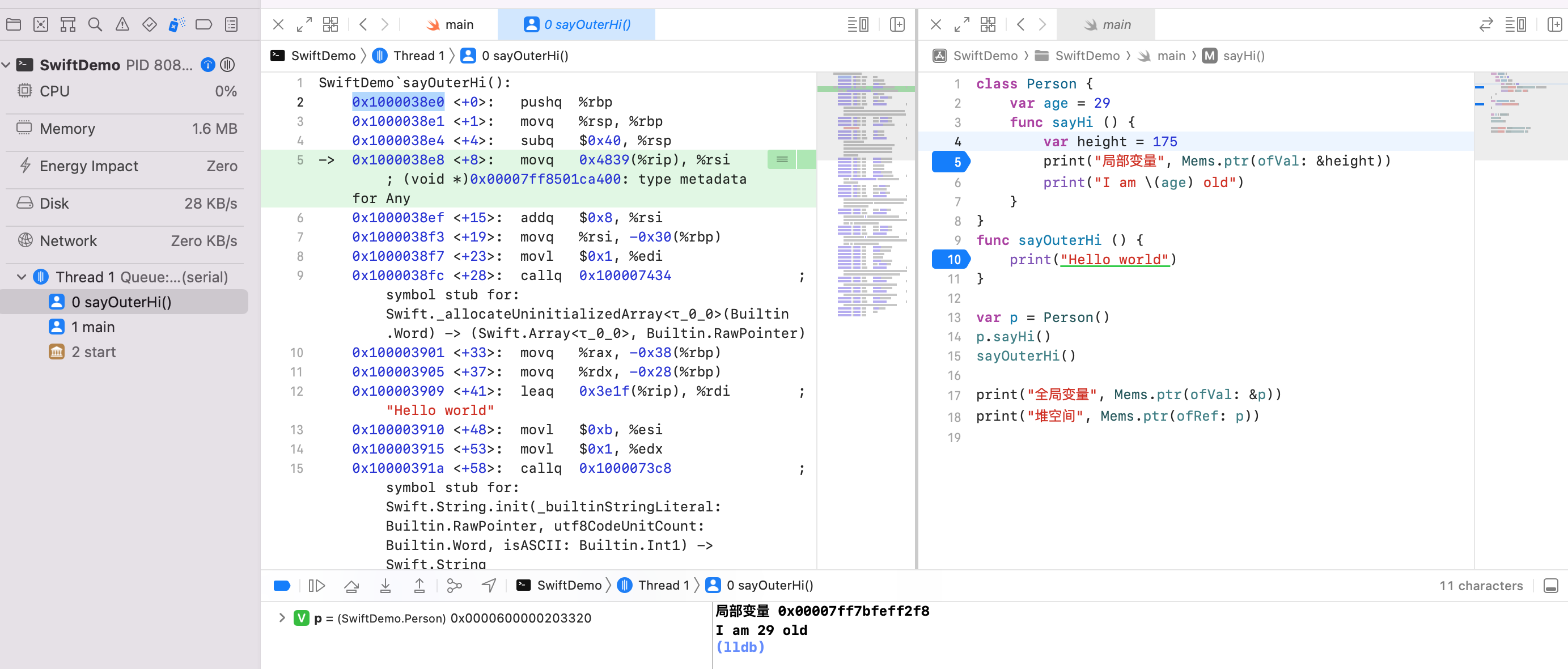
代码段:Person.sayHi 0x1000034d0
代码段:sayOuterHi 0x1000038e0
全局变量: 0x000000010000c388
堆空间: 0x20c820
局部变量(栈): 0x00007ff7bfeff2f8
可以看到写在类里面的方法地址和写在 Class 外部的方法地址差不多,都在代码段。
结论:方法不占用对象的内存。方法、函数存放于代码段。
闭包
定义
什么是闭包?一个函数和它所捕获的变量/常量环境组合起来,称为闭包。
- 一般指定义在函数内部的函数
- 一般捕获的是外层函数的局部变量、常量
原理窥探
Demo
func exec(a: Int, b: Int, fn: (Int, Int) -> Int) {
print(fn(a, b))
}
// 写法1
func sum(a: Int, b: Int) -> Int { return a + b }
exec(a: 1, b: 2, fn: sum)
// 写法2:闭包
exec(a: 1, b: 2, fn: {
(a: Int, b: Int) -> Int in
return a + b
})
// 写法3:闭包简写
exec(a: 1, b: 2, fn: {
a,b in return a + b
})
// 写法4:闭包简写
exec(a: 1, b: 2, fn: {
a,b in a + b
})
// 写法5:闭包简写。用$0、$1来获取参数。
exec(a: 1, b: 2, fn: { $0 + $1 })
// 写法5:闭包简写。用 + 来代表操作,让编译器进行推断
exec(a: 1, b: 2, fn: + )
如果将一个很长的闭包表达式作为函数的最后一个实参,使用尾随闭包可以增强函数的可读性。尾随闭包是一个被书写在函数调用括号外面(后面)的闭包表达式
上面的写法等价于
// 写法6:尾随闭包
exec(a: 1, b: 2) {
$0 + $1
}
如果闭包表达式是函数的唯一实参,而且使用饿尾随闭包的语法,那就不需要在函数名后面写圆括号
func exec(fn: (Int, Int) -> Int) {
print(fn(1, 2))
}
exec(fn: { $0 + $1 }) // 3
exec() { $0 + $1 } // 3
exec{ $0 + $1 } // 3
来个 Demo 看看系统数组的排序
var array = [1, 8, 9, 12, 32, 2]
//array.sort()
func compare(a: Int, b: Int) -> Bool {
return a < b
}
// 写法1
//array.sort(by: compare)
// 写法2
// array.sort { $0 < $1 }
// 写法3
//array.sort { a, b in
// return a < b
//}
// 写法4
//array.sort(by: {
// (a: Int, b: Int) -> Bool in
// return a < b
//})
// 写法5
//array.sort(by: <)
// 写法6
array.sort() { $0 < $1 }
print(array) // [1, 2, 8, 9, 12, 32]
Demo2
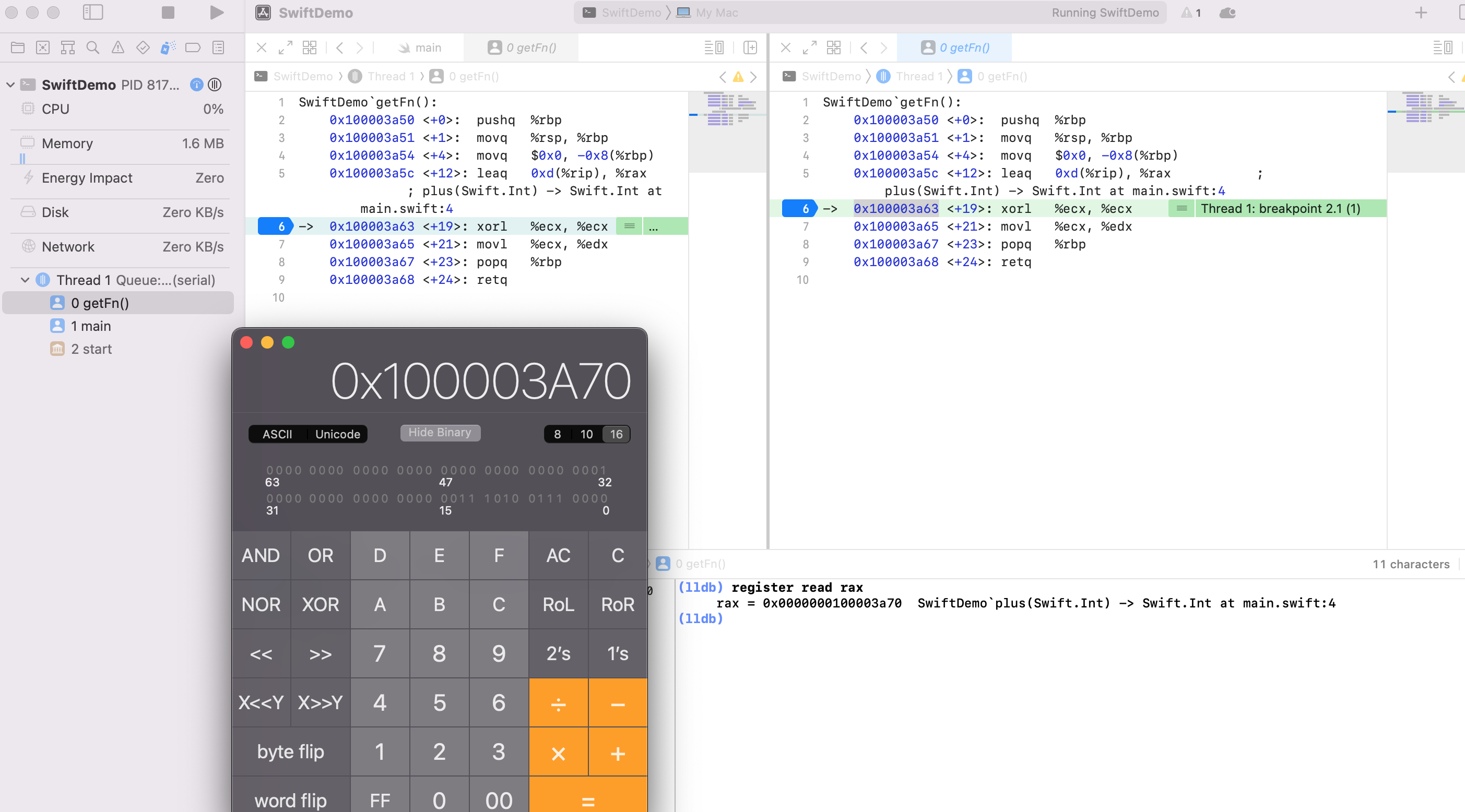
闭包的变量捕获
typealias Fn = (Int) -> Int
func getFn() -> Fn {
var num = 0
func plus(_ i: Int) -> Int {
return i
}
return plus
}
var fn = getFn()
print(fn(1)) // 1
print(fn(2)) // 2
print(fn(3)) // 3
简单修改下代码
typealias Fn = (Int) -> Int
func getFn() -> Fn {
var num = 0
func plus(_ i: Int) -> Int {
num += i
return num
}
return plus
}
var fn = getFn()
print(fn(1)) // 1
print(fn(2)) // 3
print(fn(3)) // 6
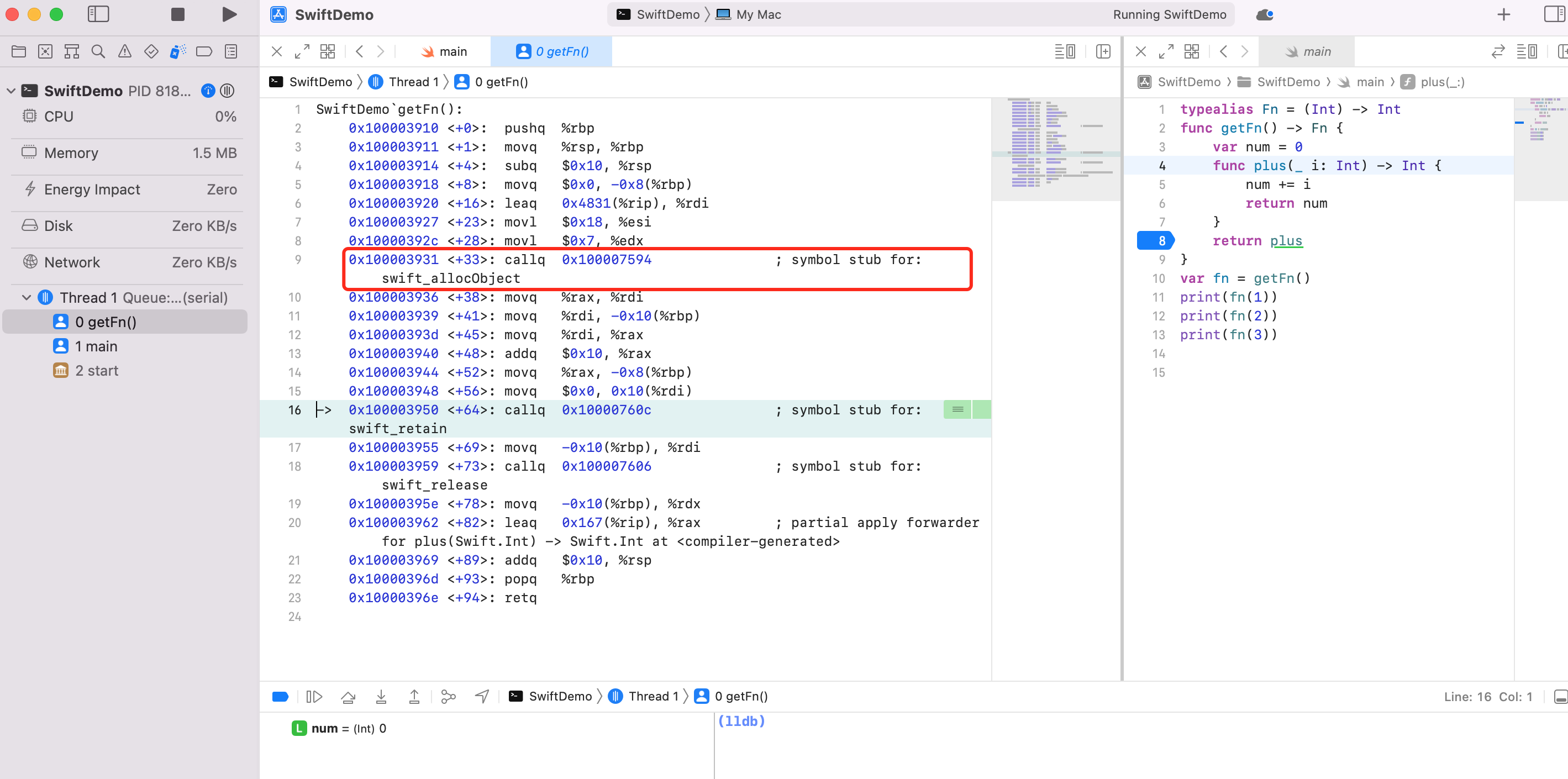
可以看到上面有 allocObject 方法调用,说明产生了堆空间对象,用于存放 num 。是由 var fn = getFn() 造成的,调用1次 getFn 则产生1次堆空间分配,用于保存 num。
也就是说如果一个内层函数访问了外层函数的局部变量,也就会发生变量捕获,做法就是延长局部变量的生命周期,在堆空间申请一段内存,用户保存局部变量。
对代码进行修改
typealias Fn = (Int) -> Int
func getFn() -> Fn {
var num = 1
func plus(_ i: Int) -> Int {
num += i
return num
}
return plus
}
var fn1 = getFn()
var fn2 = getFn()
var fn3 = getFn()
print(fn1(1)) // 2
print(fn2(2)) // 3
print(fn3(3)) // 4
我们在汇编 swift_allocObject 下面下个断点
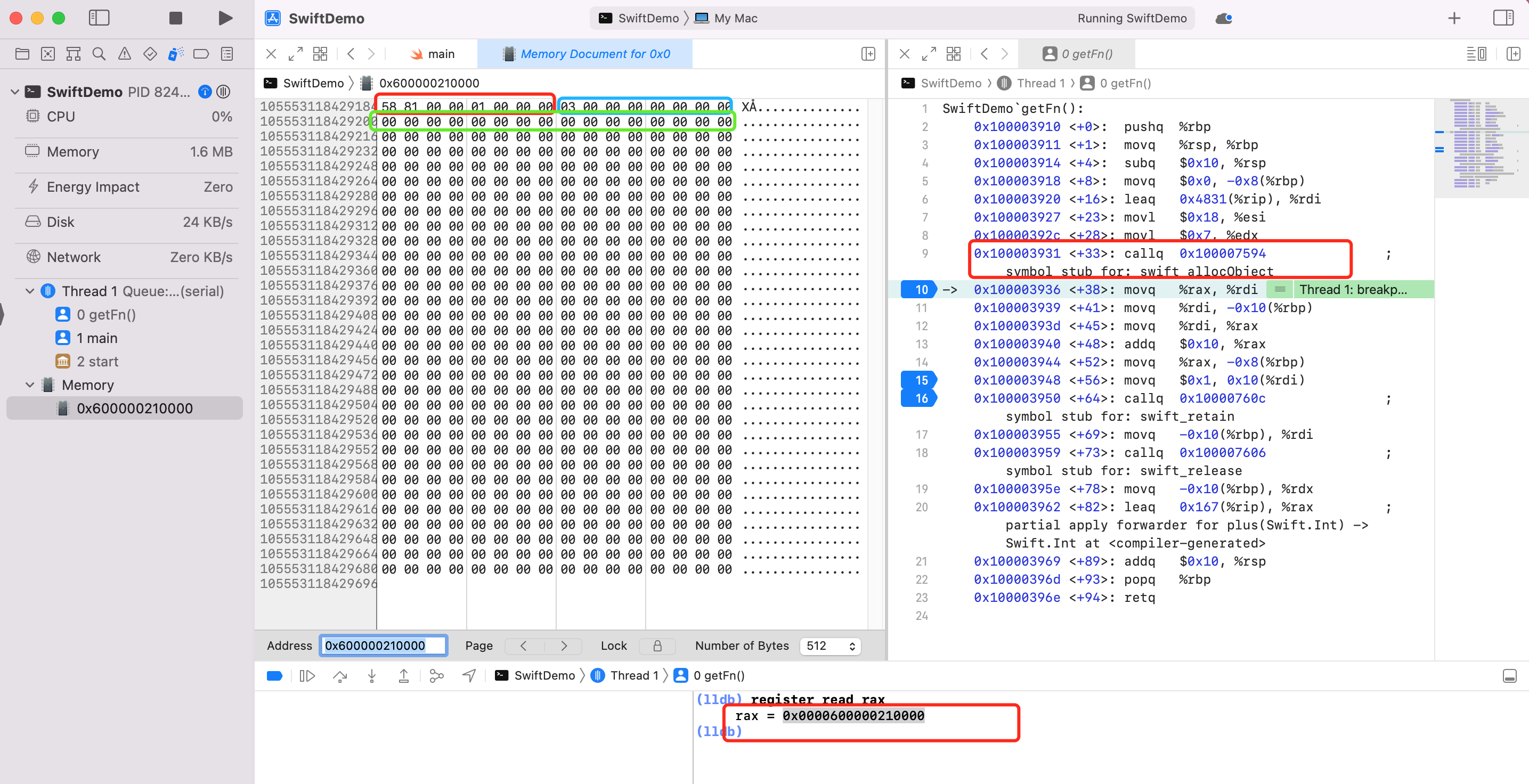
第一次:可以看到 alloc 在堆空间申请后的内存被存放到寄存器 rax 中,此时只是申请内存,没有赋值的。利用 Debug -> Debug Workflow -> View Memory 查看内存信息0x0000600000210000。此时还没值。
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
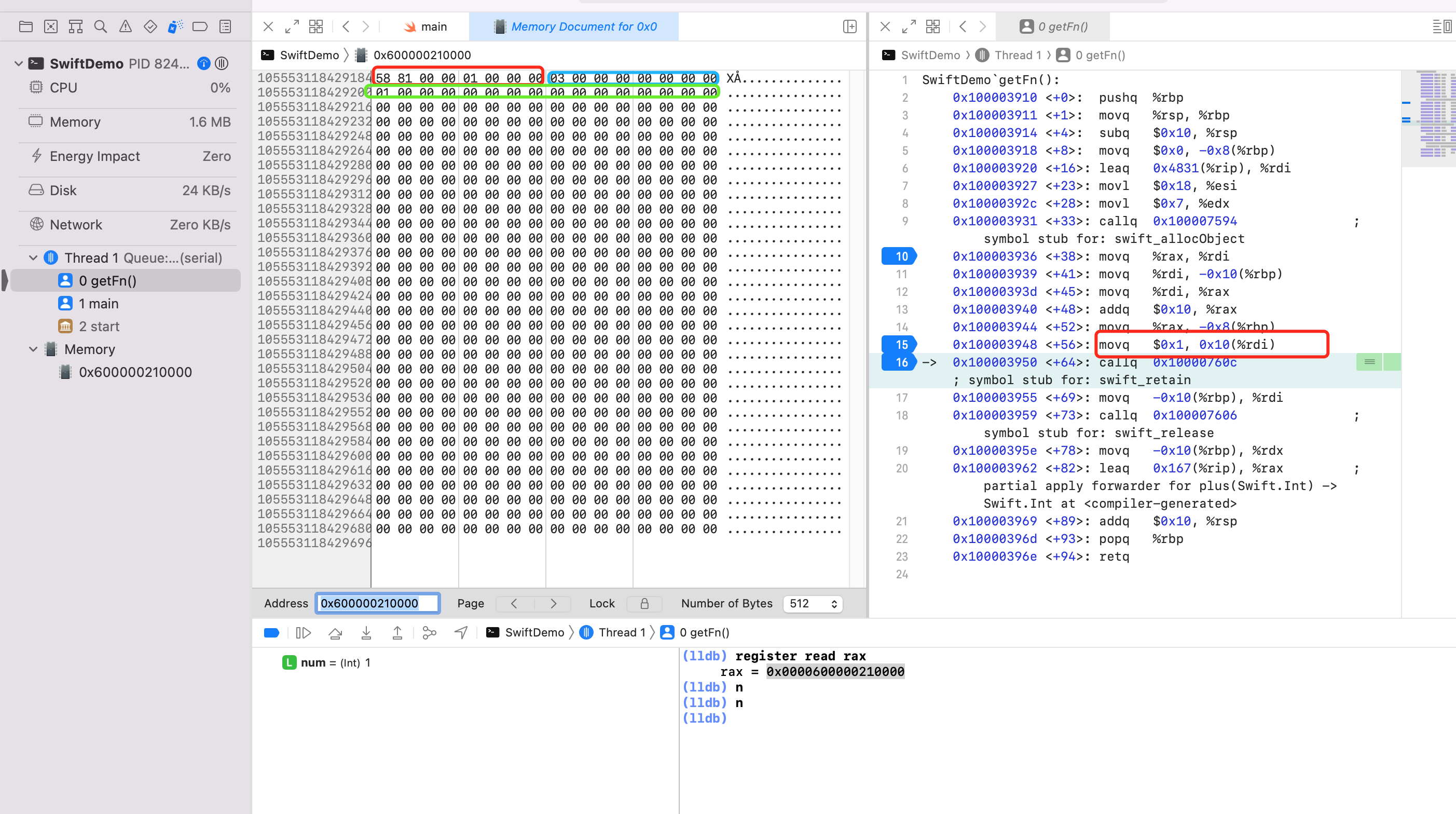
可以看到内存数据发生了改变。绿色框内有了值1。
第二次:可以看到 alloc 在堆空间申请后的内存被存放到寄存器 rax 中,此时只是申请内存,没有赋值的。利用 Debug -> Debug Workflow -> View Memory 查看内存信息0x00006000002042c0。此时还没值。
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
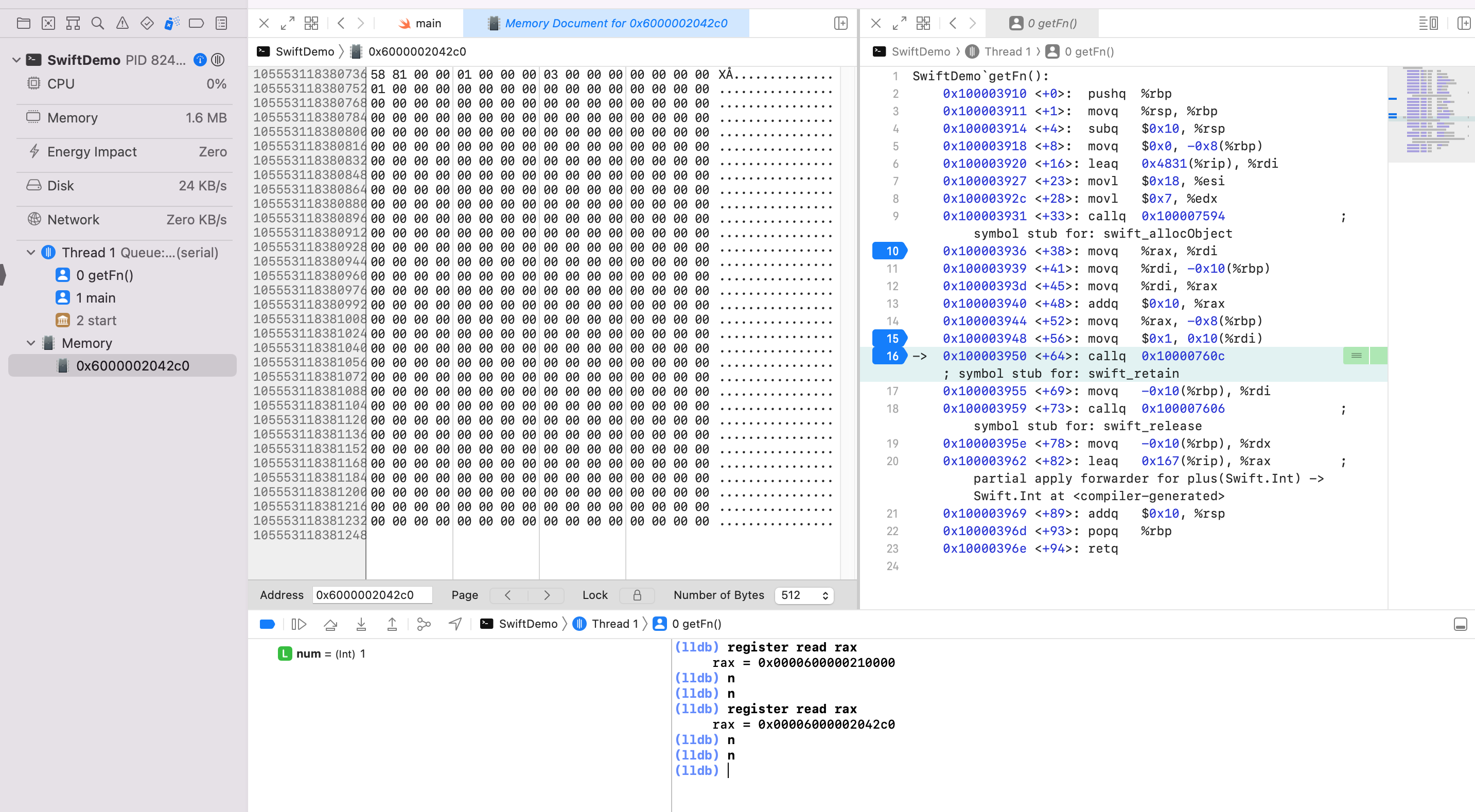
第三次:可以看到 alloc 在堆空间申请后的内存被存放到寄存器 rax 中,此时只是申请内存,没有赋值的。利用 Debug -> Debug Workflow -> View Memory 查看内存信息0x000060000020d460。此时还没值。
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
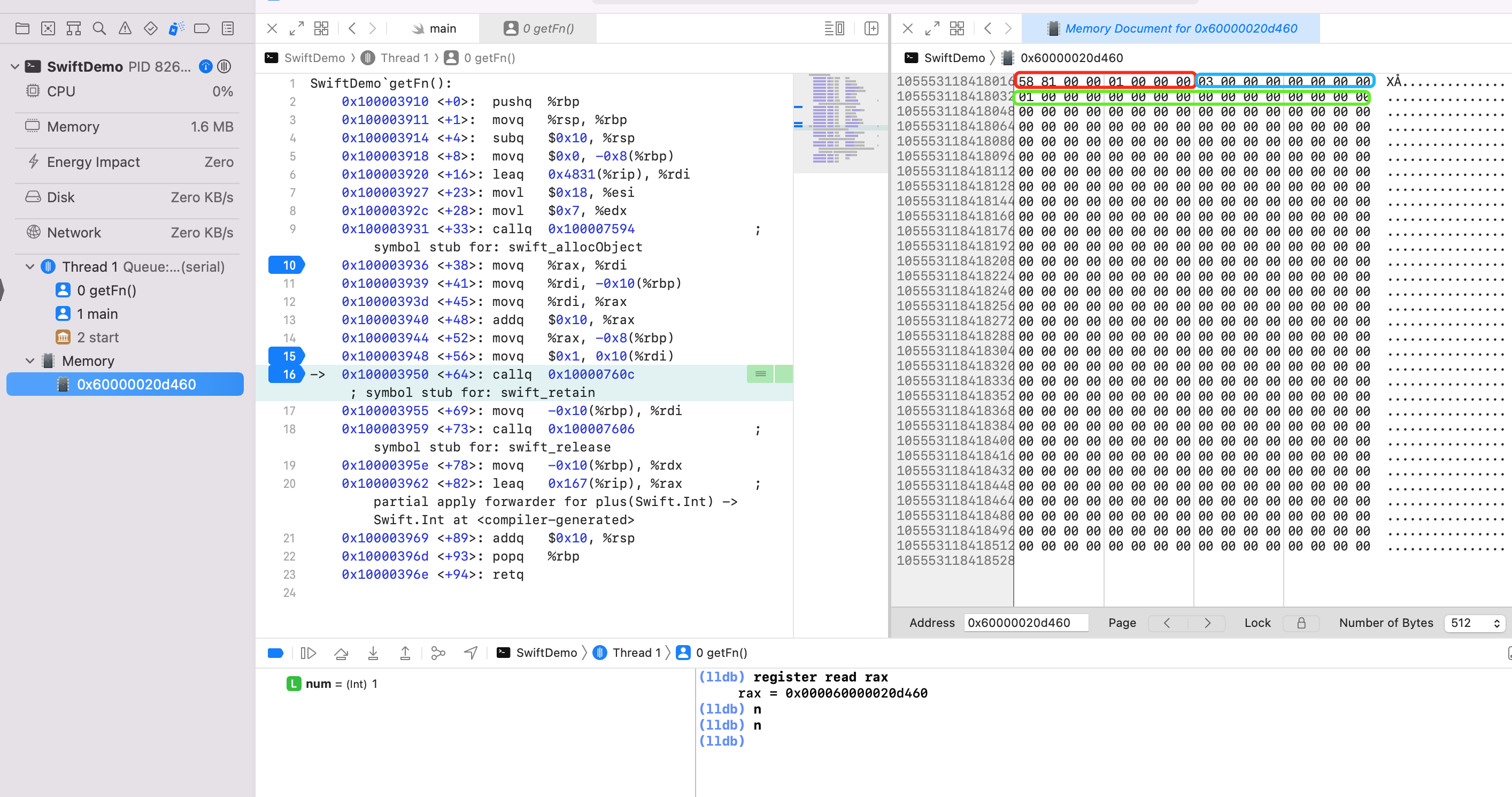
打印结果也说明了问题,因为调用3次 getFn() 所以会在堆上 alloc 3块内存,用于保存捕获的变量。所以调用 fn1 得到 2,调用 fn2 得到 3,调用 fn3 得到 4。
BTW,堆空间分配的内存,如果没有 init 或者赋特定的值,数据会是随机的。因为有可能是之前别的地方使用过的内存。
闭包内存结构
先来个简单的函数,看看指针内存结构
func sum(_ a: Int, _ b: Int) -> Int { return a + b }
var fn = sum
print(fn(1, 2)) // 3
在 var fn = sum 处下断点,可以看到下面汇编
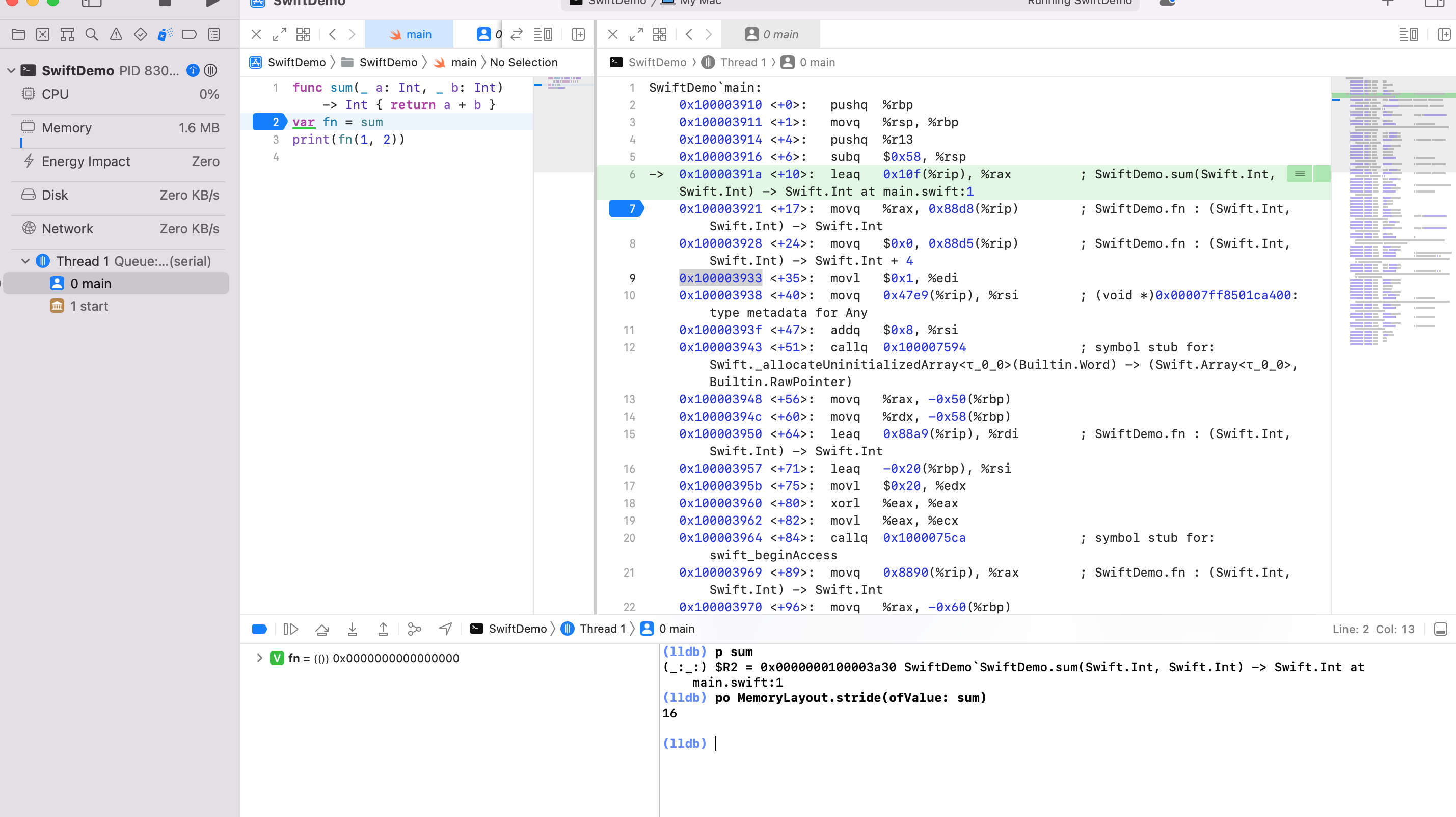
我们知道 leaq 是从 %rip + 0x10f 算出来的地址,赋值给 %rax。所以大概可以推测 %rip + 0x10f 就是 sum 函数地址。LLDM p 打印 sum 地址为 0x0000000100003a30。
%rip 是下一条指令的地址 0x100003921,%rip + 0x10f 也就是 0x0000000100003a30。和猜想一致。
第六行汇编的意思就是将 sum 函数的地址赋值给 %rax。
第七行汇编的意思是将保存在 %rax 内的地址,从 %rip + 0x88d8 处,取8个字节用来保存 %rax 的地址。0x100003928 + 0x88d8 = 0x10000C200
第八行汇编的意思是将保存在 %rax 内的地址,从 %rip + 0x88d85 处,取8个字节用来保存 $0x0 。0x100003933 + 0x88d5 = 0x10000C208
0x10000C200 到 0x10000C208 差8位,也是连续的。说明分配了一个函数指针,长度为16位。通过MemoryLayout.stride(ofValue: sum) 看到也是16位。符合猜想。
直奔主题,研究闭包内存
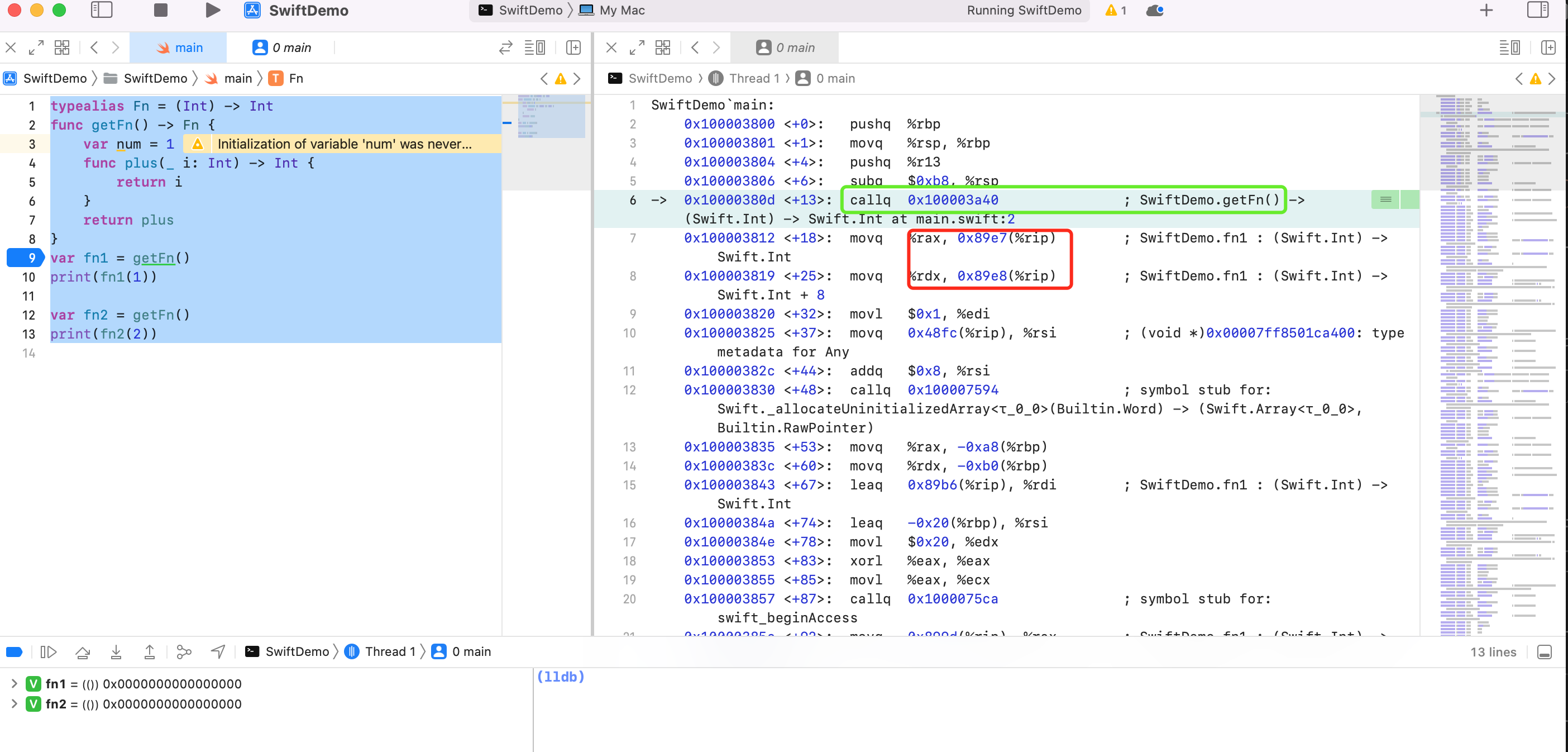
可以看到在调用完第六行的函数后将寄存器 rax、rdx 里的值取出来使用了。进入函数内部看看发生了什么,LLDB 输入 si
可以看到 rax 里面存放了 plus 函数地址。第7行汇编是异或运算,2个 ecx 异或,结果为0,写入到 ecx 里。然后第8行汇编将 ecx 里的0写入到 edx,edx 也就是 rdx。走完第6行的汇编,继续看第7、8行
将第6行函数的返回结果 rax 里的函数地址赋值给 rip +0x89e7 = 0x100003819 + 0x89e7 = 0x10000C200 , 第7行的rdx 的值赋值个给 rip +0x89e8 = 0x100003820 + 0x89e8 = 0x10000C208。
也就是 fn1 前8个字节存放 plus 的函数地址,后8个字节存放0.
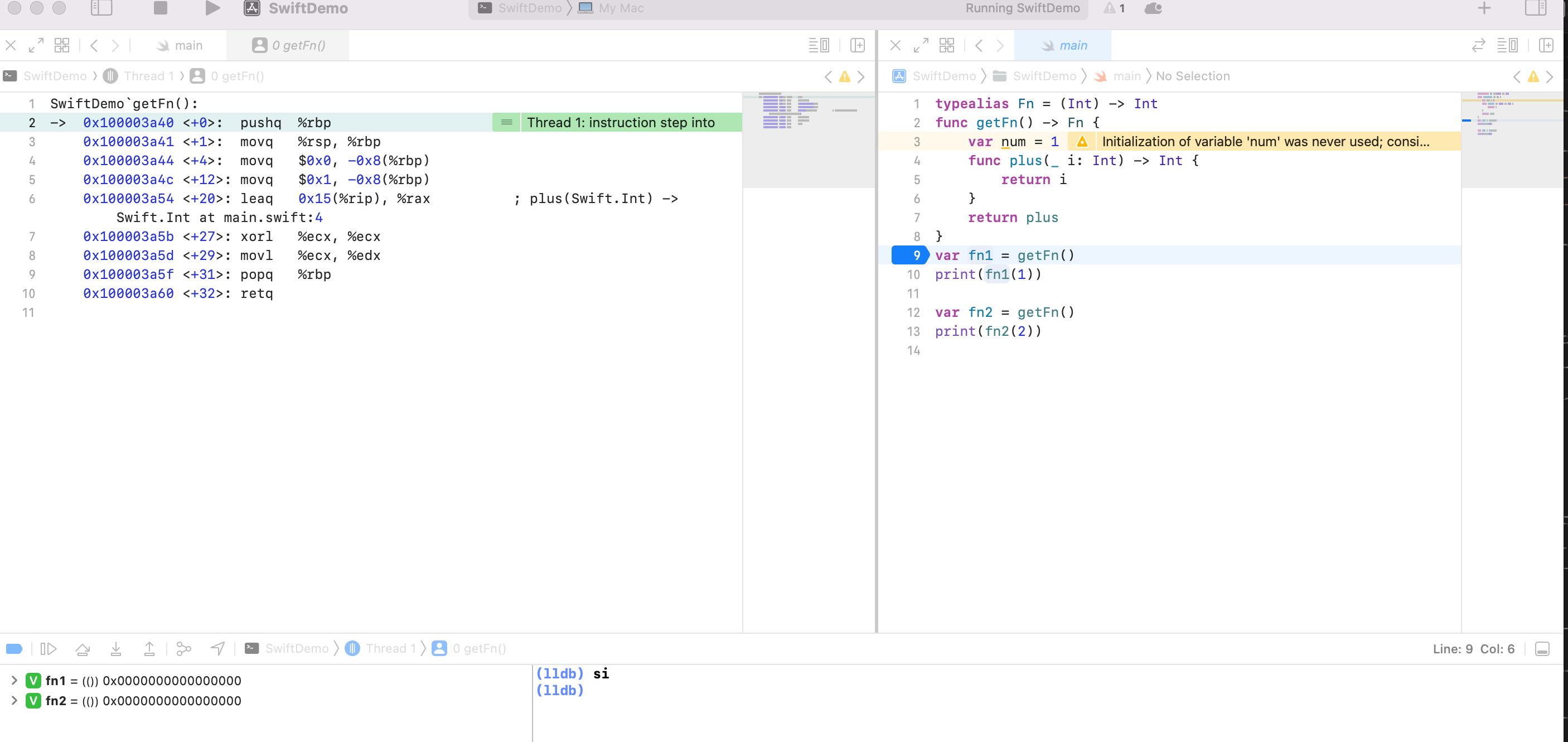
继续对比实验,查看闭包放了什么东西(注意和上面的实验不同,下面存在闭包)
基本可以断定:函数会返回一个长度为16 Byte 的内存。分别保存在 rax 和 rdx上。所以针对性的研究 rdx 和 rax
汇编第10行,经过在堆上为捕获的变量 alloc 内存后,将内存保存到 rax 中,然后赋值给 rdi,第11行,将 rdi 再赋值给 rbp - 0x10 的地址。所以汇编19行的 rbp - 0x10 保存的也就是堆内存,赋值给 rdx 了。
20行的 rax 保存了一个看似是 plus 的函数地址。具体是:rip + 0x167 = 0x100003969 + 0x167= 0x100003C37
继续走,走到真正的 plus 方法内,可以看到函数地址是 0x100003970 。所以返回的 rax 里面可能是间接调用真正的 plus 函数的。
问题变得微妙起来了,getFn 方法返回一个地址,占用16个字节,但是前8个字节存储 plus 方法地址,后8个字节存储闭包捕获后在堆上申请内存存放的数据地址。那如何根据一个地址的前8位去真正调用方法?
Tips:由于地址是动态生成的,所以真正去调用 plus 的时候一定不是写死的地址,一定是动态生成的。这种属于间接调用。
- call 后面直接加一个函数地址,属于直接调用。类似
callq 0x100003970 - call 后面的函数地址不是固定的,而是动态生成的叫间接调用。在
at&t汇编里面,间接调用前面要加*。类似callq *%rax,意思是从%rax里面取出一个地址值出来,当成函数地址,去调用
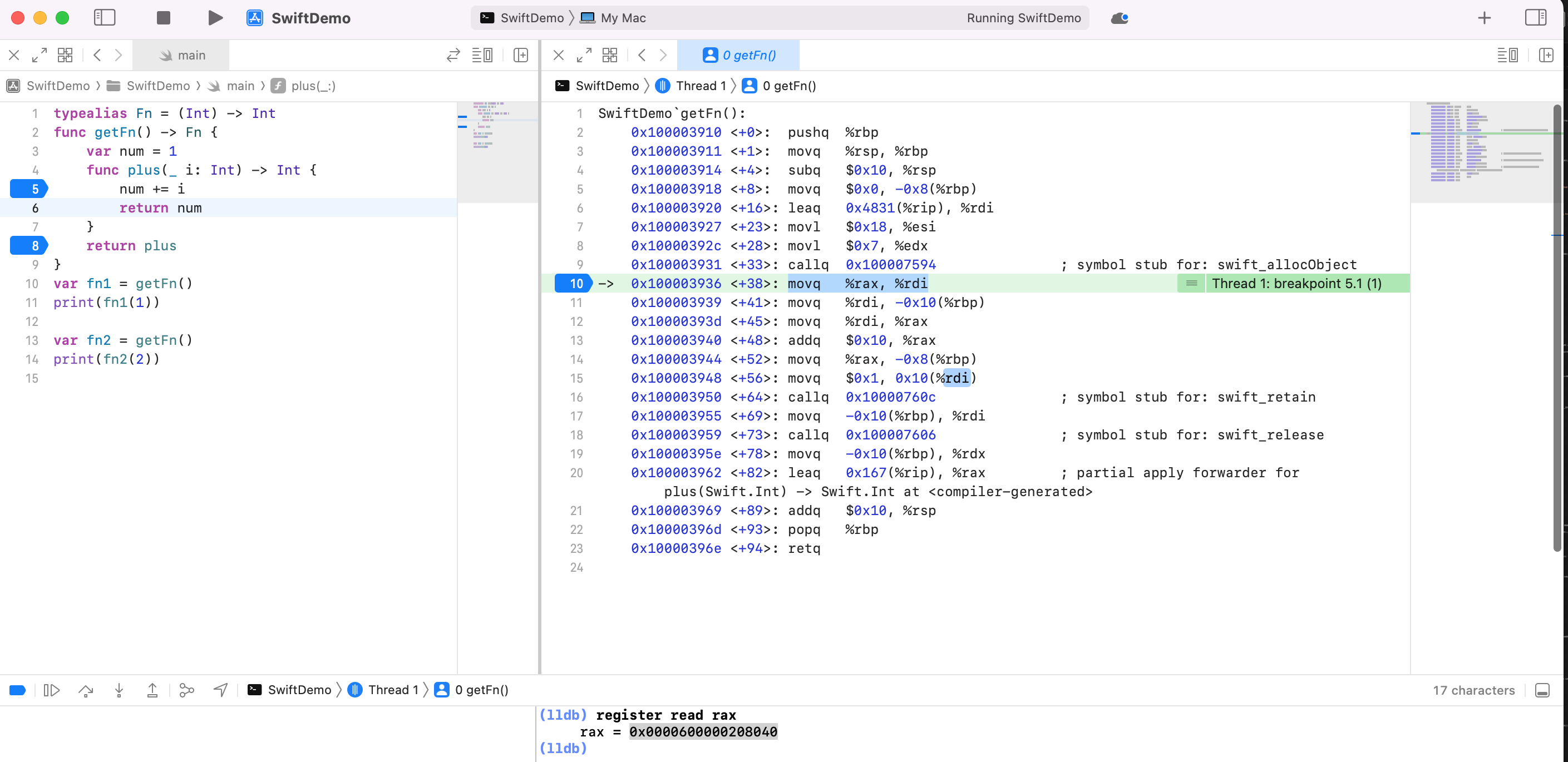
顺着思路,分析下汇编:
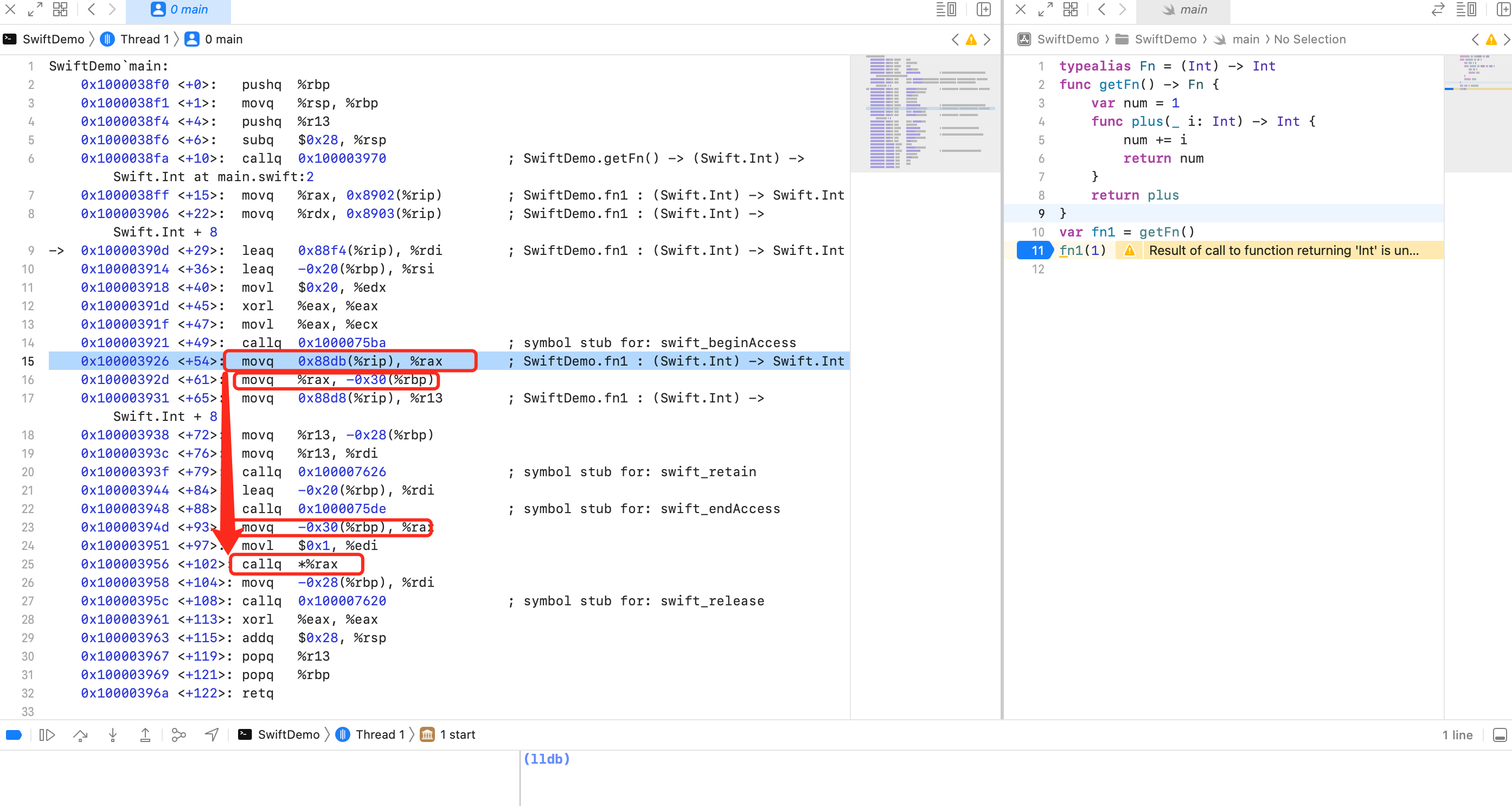
我们看到25行 callq *%rax 存在动态调用,所以需要找到 %rax 里的值是哪里来的。然后顺着向上找,找到23行 movq -0x30(%rbp), %rax。然后继续向上看到16行 movq %rax, -0x30(%rbp)。继续向上看到15行 movq 0x88db(%rip), %rax。相当于就是在 rip + 0x88db 处取出8个字节出来,当作函数地址调用(汇编代码的右边写了,fn1 ),地址为:0x88db(%rip) = rip + 0x88db = 0x10000392d + 0x88db = 0x10000C208 。
断点继续放开,在汇编25行处加断点 callq *%rax
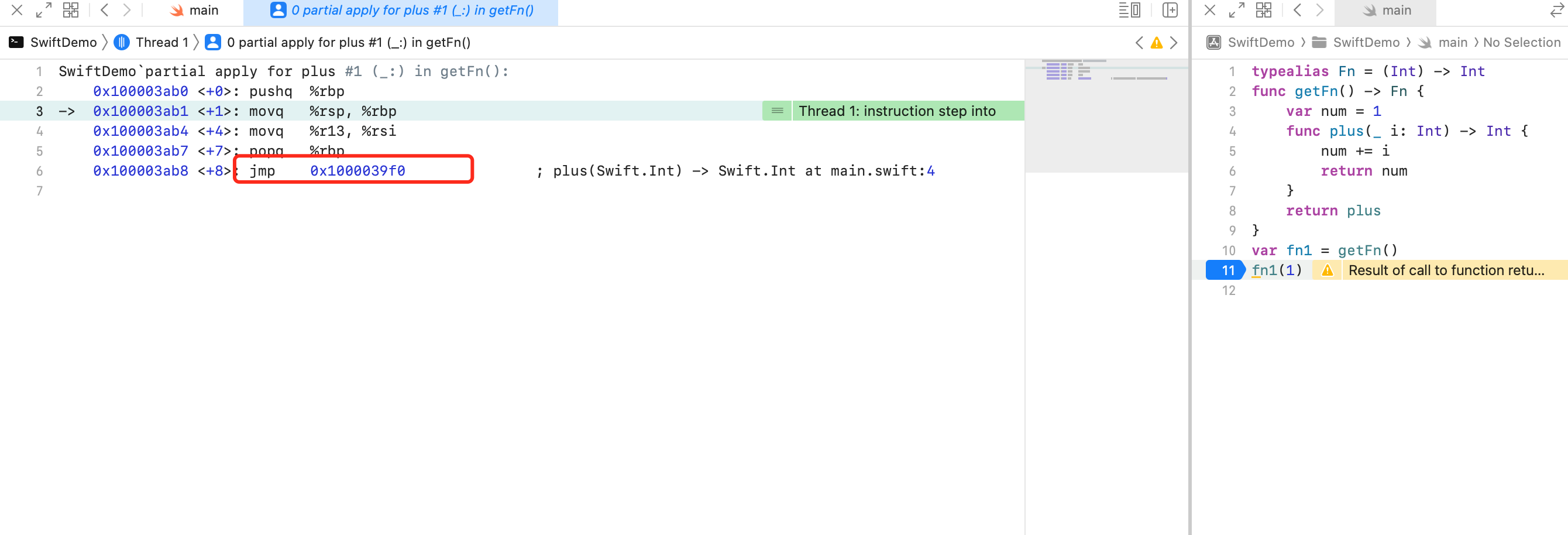
可以看到在方法内部,第6行汇编处,直接调用一个代码段的函数地址 jmp 0x1000039f0
指令 jmp、call 的区别在于:
jmp指令控制程序直接跳转到目标地址执行程序,程序总是顺序执行,指令本身无堆栈操作过程。call指令跳转到指定目标地址执行子程序,执行完子程序后,会返回call指令的下一条指令处执行程序,执行call指令有堆栈操作过程
LLDB 输入 si,可以看到是 plus 函数真正的地址
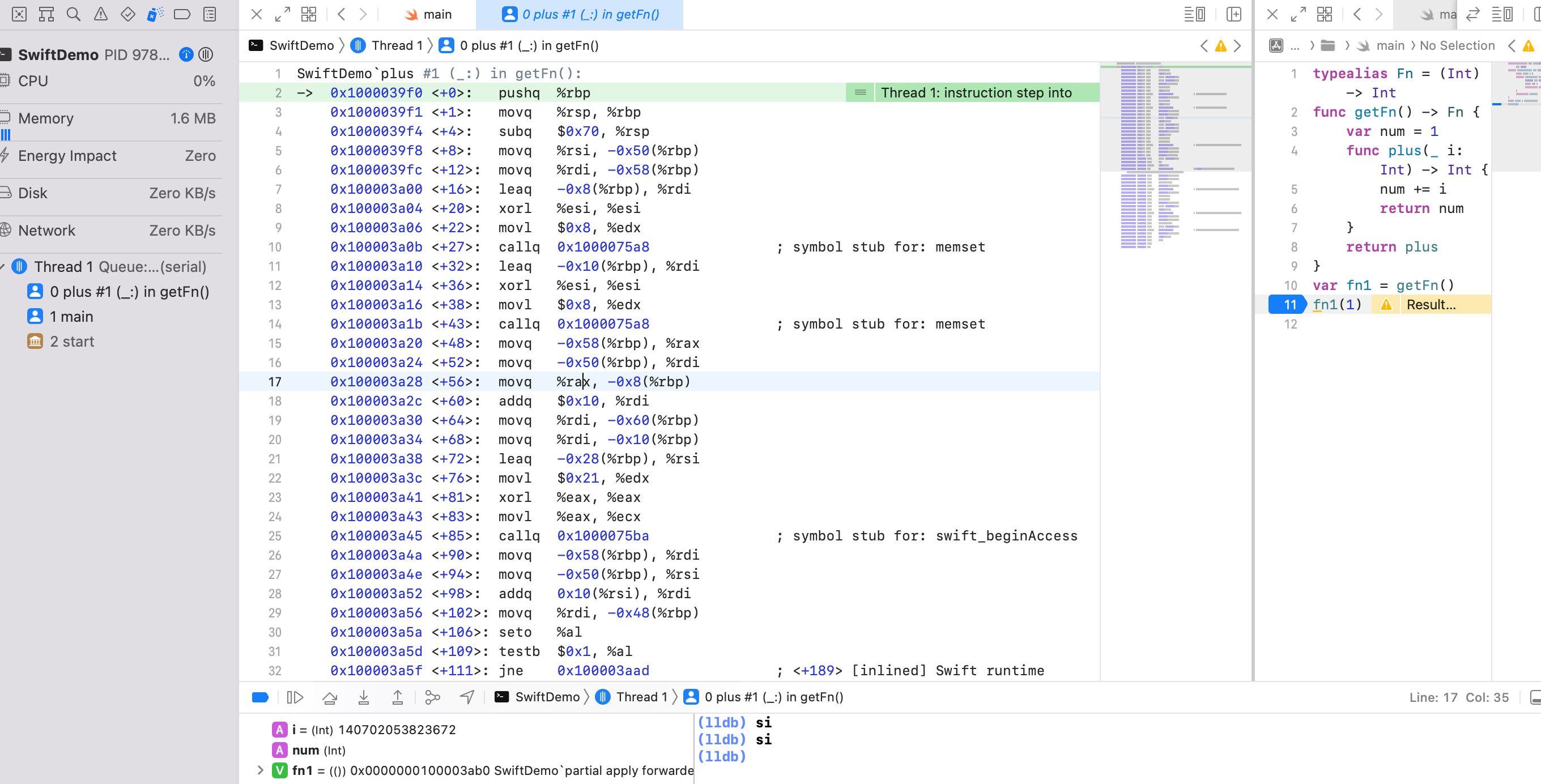
fn1 函数调用的时候,参数如何传递?
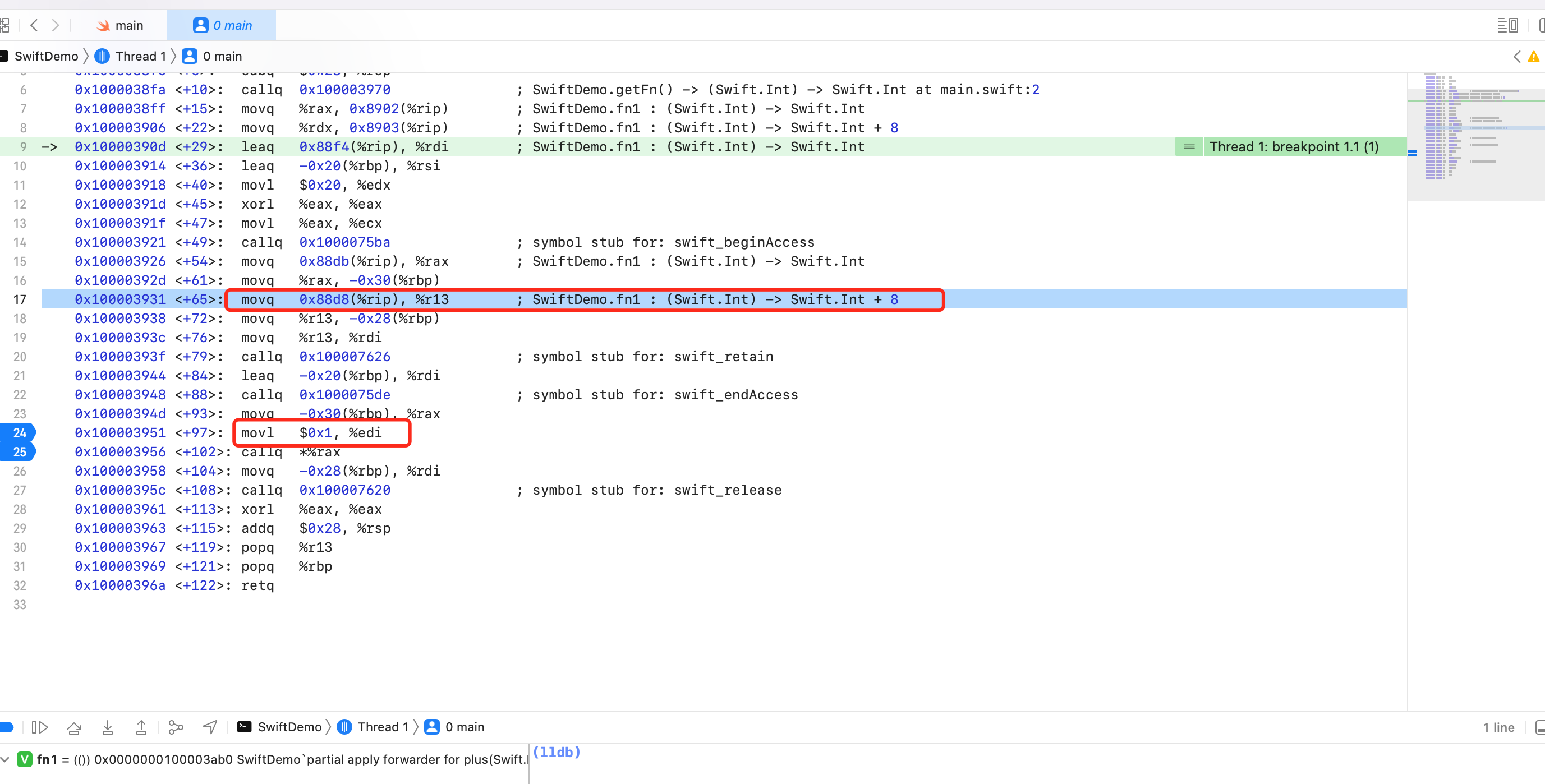
汇编17行 movq 0x88d8(%rip), %r13 ; SwiftDemo.fn1 : (Swift.Int) -> Swift.Int + 8可以看到将返回的 fn1 本身16字节的后8个字节,也就是堆地址空间值,保存到寄存器 edi 也就是寄存器 rdi 上了。
汇编24行 movl $0x1, %edi 将参数1传给寄存器 rdi 了。
然后 LLDB 输入 si 去分析 callq 内部
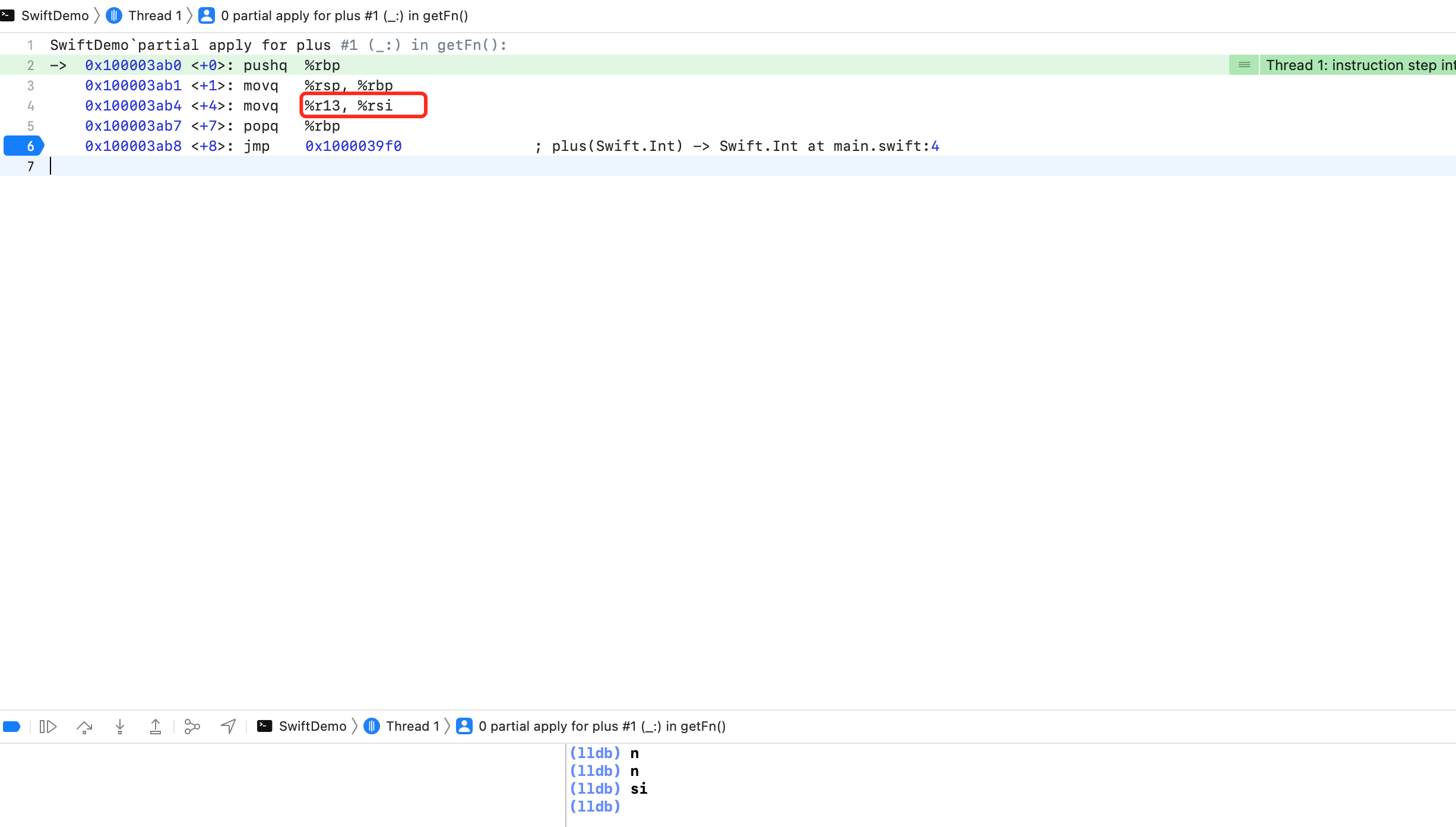
可以看到 movq %r13, %rsi 将寄存器 r13 的值写入到 rsi 了。目前为止:rdi 保存参数1,rsi 保存堆地址值。
继续输入 si
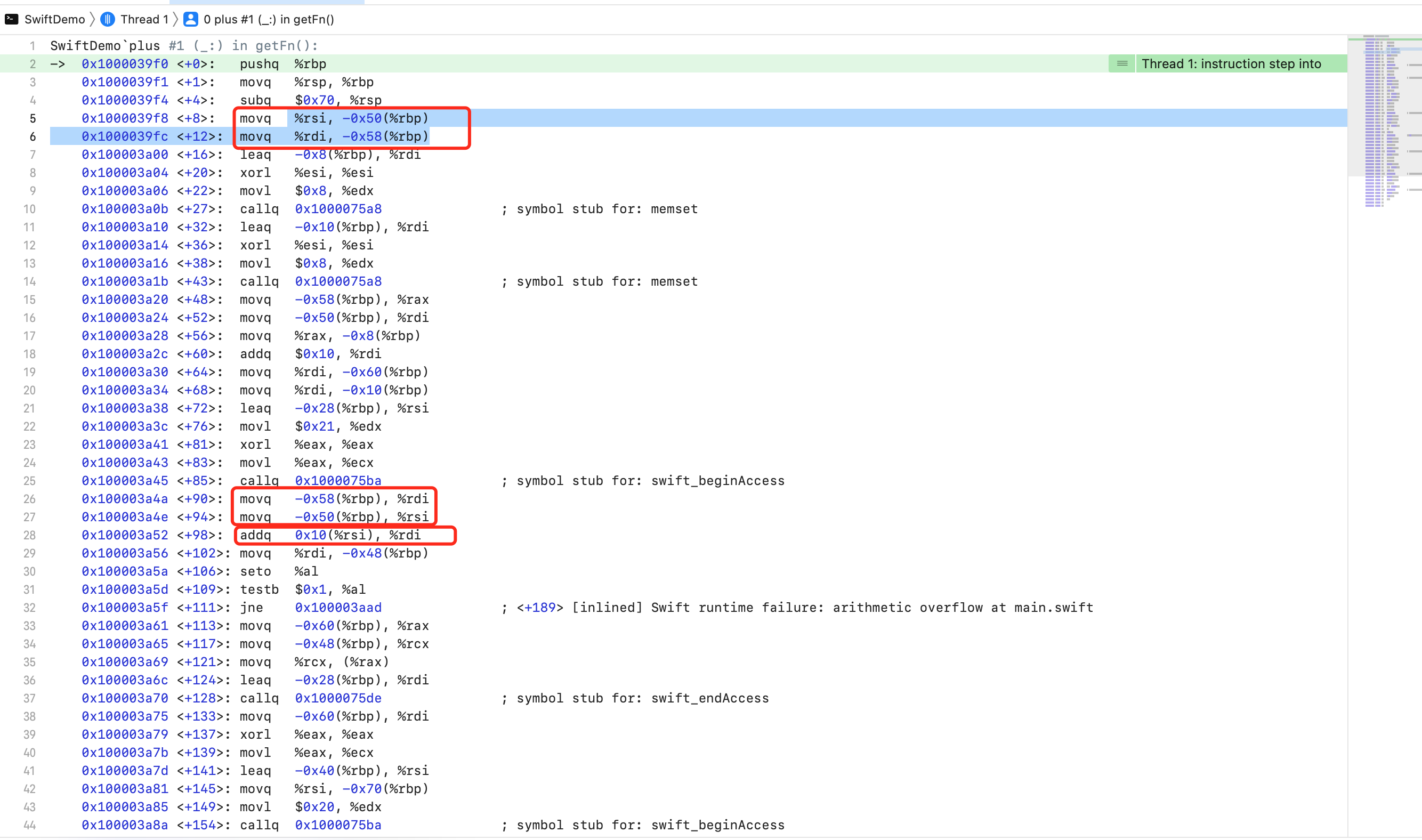
可以看到汇编的第5行 movq %rsi, -0x50(%rbp) 将 rsi 里的1,保存到 rbp - 0x50 处。第6行汇编 movq %rdi, -0x58(%rbp) 将 rdi 堆地址值保存到 rbp - 0x58 处。
汇编26行 movq -0x58(%rbp), %rdi 将 rbp - 0x58 的值写入到 rdi,也就是堆地址值。第27行 movq -0x50(%rbp), %rsi 将 rbp - 0x50 的值写入到 rsi,也就是参数值1。
然后真正做 plus 加法运算的就是28行的 addq 0x10(%rsi), %rdi, 从 rsi 堆地址值的第16个字节的地方取出8个字节的值,也就是捕获的外部变量 num 再和参数1相加。
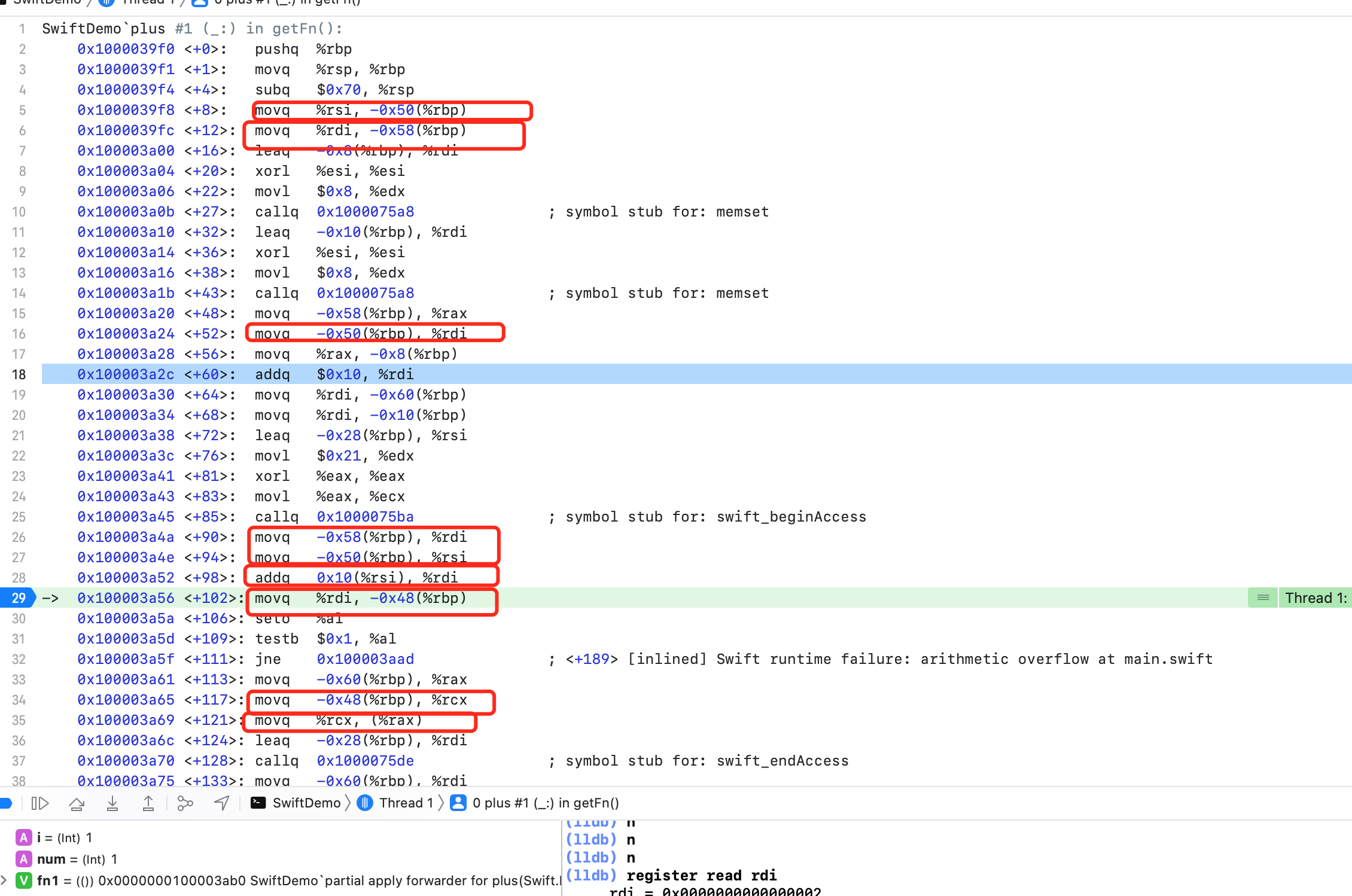
可以看到第6行堆地址空间的值写入到 rbp -0x58 ,第26行又将 rbp -0x58 写入到 rdi,29行将 rdi 的值,写入到 rbp - 0x48,34行将 rbp - 0x48 写入到 rcx,35行将 rcx 的地址值,写入到 rax 对应的存储空间。也就是堆上的 num 值已经修改,被覆盖了。
总结:当 getFn 内部没有发生闭包的时候,fn1 的地址就是16 Byte,前8 Byte就是 plus 的函数地址。当发生函数闭包的时候,fn1 的16 Byte,前8 Byte 存储间接调用 plus 函数的中转函数,后8 Byte 存储着捕获的且在堆上分配内存的地址值。真正调用 plus 的时候会通过寄存器传递2个参数:1个是 fn1 函数的参数,1个是堆空间的地址值。
var fn1 = getFn()
fn1(1) // 2
fn1(3) //4
因为只调用1次 getFn 所以堆内存分配了1个被捕获的变量地址,调用过1次 fn1 后,堆地址所指向的内存上的数被修改了。当第二次调用的时候操作的还是同一块堆内存地址,也就是同一个被捕获的堆地址所指向的变量。
var fn1 = getFn()
fn1(1) // 2
fn1(3) //4
var fn2 = getFn()
fn2(2) // 3
fn2(4) // 5
因为调用了2次 getFn 所以堆内存分配了2个被捕获的变量地址,调用过1次 fn1 后,堆地址所指向的内存上的数被修改了。当第二次调用的时候操作的还是同一块堆内存地址,也就是同一个被捕获的堆地址所指向的变量。当调用 fn2 的时候操作的是被捕获的新的一个堆地址空间所指向的变量。
且 fn1 所占用的16个字节,fn2 所占用16个字节。2者的前8字节内容相同,都是包装了 plus 函数的一个地址。
“闭包就是对象”
捕获了外部变量的闭包类似于一个类,里面存在存储属性和方法
class {
var num: Int
func fn(_ i: Int) -> Int {
return i + num
}
}
自动闭包
自动闭包是一种自动创建的,用来把作为实际参数传递给函数的表达式打包的闭包。它不接受任何实际参数,并且当它被调用时,它会返回内部打包的表达式的值
这个语法的好处在于通过写普通表达式代替显示闭包,而使你省略包围函数的形式参数的括号.
比如系统的断言 assert
public func assert(_ condition: @autoclosure () -> Bool, _ message: @autoclosure () -> String = String(), file: StaticString = #file, line: UInt = #line)
// 语法糖。自动闭包
func getPositiveValue(_ v1: Int, _ v2: @autoclosure () -> Int) -> Int {
return v1 > 0 ? v1 : v2()
}
//print(getPositiveValue(10, {20}))
//print(getPositiveValue(-10) {20})
//print(getPositiveValue(-20) {
// let a = 10
// return a + 1
//}
//)
print(getPositiveValue(-10, 22))
@autoclosure 会自动将 22 封装成闭包 { 22 }。
@autoclosure 只支持 () -> T 无参数,并且有一个返回值的闭包。
@autoclosure 并非只支持最后1个参数。
?? 函数的本质就是自动闭包
自动闭包允许延迟处理,因此任何闭包内部的代码直到你调用的时候才会运行。对于有副作用或者占用资源的代码来说很有用。因为它可以允许你控制代码何时进行求值
var group = ["zhangsan", "lisi", "wangwu"]
//print(group.count)
//let groupRemover = { group.remove(at: 0) }
//print(group.count)
//
////print("execute remove function \(groupRemover())")
//print(group.count)
func serve(customer customerProvider: @autoclosure () -> String) {
print("Now serving \(customerProvider())!")
}
serve(customer: group.remove(at: 0))
// Now serving zhangsan!
如果一个闭包作为参数,是可以去掉 {} 的,参数加了 @autoclosure 后,是会自动转换为闭包的。
但如果函数参数没有加 @autoclosure,在调用函数的时候,传参没有加 {} 编译器是会报错的
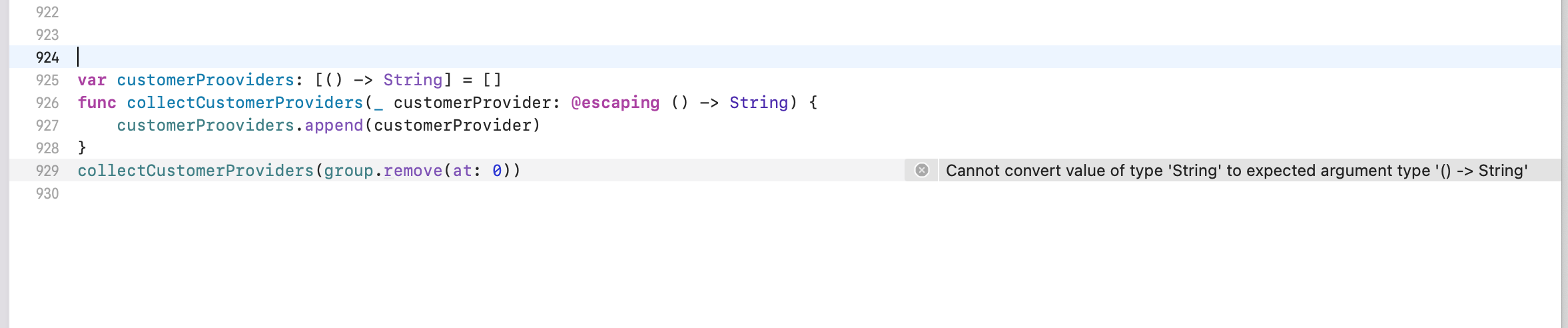
正确的做法是:要么加 @autoclosure 要么在函数调用的时候加 {}
// 改法1
func collectCustomerProviders(_ customerProvider: @escaping () -> String) {
customerProoviders.append(customerProvider)
}
collectCustomerProviders( { group.remove(at: 0) })
// 改法2
func collectCustomerProviders(_ customerProvider: @autoclosure @escaping () -> String) {
customerProoviders.append(customerProvider)
}
collectCustomerProviders(group.remove(at: 0))
如果你的自动闭包允许逃逸,就可以同时使用 @autoclosure 和 @escaping
var customerProoviders: [() -> String] = []
func collectCustomerProviders(_ customerProvider: @autoclosure @escaping () -> String) {
customerProoviders.append(customerProvider)
}
collectCustomerProviders(group.remove(at: 0))
闭包和闭包表达式的区别
闭包
定义:闭包是自包含的功能代码块,可以在代码中被传递和使用。它能捕获并存储其所在上下文的常量和变量(即“闭合”环境)
种类:
- 全局函数(有名称,不捕获任何值)
- 嵌套函数(有名称,可捕获外曾函数的变量)
- 闭包表达式(匿名,轻量语法,可以捕获上下文变量)
闭包强调的是:捕获上下文的能力。不管是函数还是闭包表达式
闭包表达式
定义:是 Swift 中一种简洁的语法格式,用于编写匿名闭包。是闭包的一种实现方式之一(函数和闭包表达式都可以实现闭包)
特点:
- 没有函数名
- 语法清凉,支持参数类型推断、隐式返回、简写参数名(如 $0、$1)等特性
- 通常用于作为函数的参数传递
总结
- 闭包是广义概念,包含所有能捕获上下文的代码块(如函数、闭包表达式)。
- 闭包表达式是闭包的一种具体实现方式,专指用轻量语法编写的匿名闭包。