78 KiB
React核心技术剖析
虚拟 Dom
传统的开发方式的是关心接口请求后的数据处理以及 Dom 操作。在推出 React 和 Vue 之流后,开发者无须直接操作 Dom,而是去关心数据流动。因为在 MVVM 框架中很重要,但是在名字上没有体现出其重要性的一个角色:binder 层帮我们做好了 view 到 model 的绑定关系(底层实现类似对属性的 getter、setter 进行拦截,然后设置 watcher。然后通过指令去绑定到 Dom 和 数据。setter 的时候发现数据变动了则发送通知,然后 watcher 监听到后去自动刷新 Dom)。你只需要关心数据。
那么如何实现的呢?我们知道 Dom 操作很耗费性能,但是到底消耗在哪里,重排、重绘、渲染算一个,可以看看这篇文章。 结合实际开发步骤想想看,先声明数据,再写 jsx 模版,然后数据驱动(setState),拿到第一份的 Virtual Dom。在数据变动后 setState 拿到最新的数据和样式模版,生成最新的 Virtual Dom。然后根据 diff 算法找出变动的地方,然后该组件重新渲染其子组件也会跟着一起渲染。
虚拟 Dom 本质上来看就是 JS 对象(将一个 Dom 节点用 js 对象模拟表示出来)。直接操作 Dom 成本高,采用一种方式将 Dom 的树形结构表示出来,那么就采用了 js 对象去描述一个 Dom 结构。 然后再每次数据变动之后,根据数据和样式模版渲染生成新的虚拟 Dom。再利用 Diff 算法计算出差异部分,再去渲染。
React 性能高效的一个原因就是 Virtual Dom 的应用和 diff 之后的 Batch Update(批量处理,类比 Vue 中的 $nextTick。有 Native 开发经验的同学对于这里应该有似曾相识的感觉,和 RunLoop 很像。任何 UI 层变动的东西提交给系统,系统再下一次的运行循环到来的时候统一去渲染。)
Diff 算法
diff 算法大体上做的事情就是拿到前后2个状态的 Virtual Dom ,然后按照同层级节点去比较,发现当前的节点有差异,则不向下进行比较,直接将当前节点重新渲染。
JSX 的原理
JSX 做的事情是为了告诉 React 样式模版是什么。本质上来说 JSX 就是 React.createElement 的可读性更强的版本。React.createElement 接收三个参数。参数1:标签类型;参数2:属性;参数3:子元素。
render () {
const { content } = this.props
return <div><span>item-testing</span></div>
}
// 等价于下面的写法
render () {
const { content } = this.props
return React.createElement('div', {}, React.createElement('span', {}, 'item-testing'))
}
生命周期

状态管理
Redux 设计上是对 Flux 的改进,增加了 reducer。Flux 就不再介绍了。解决了各个组件之间数据传递的复杂问题。先看看 Redux 进行状态管理的一个流程吧。
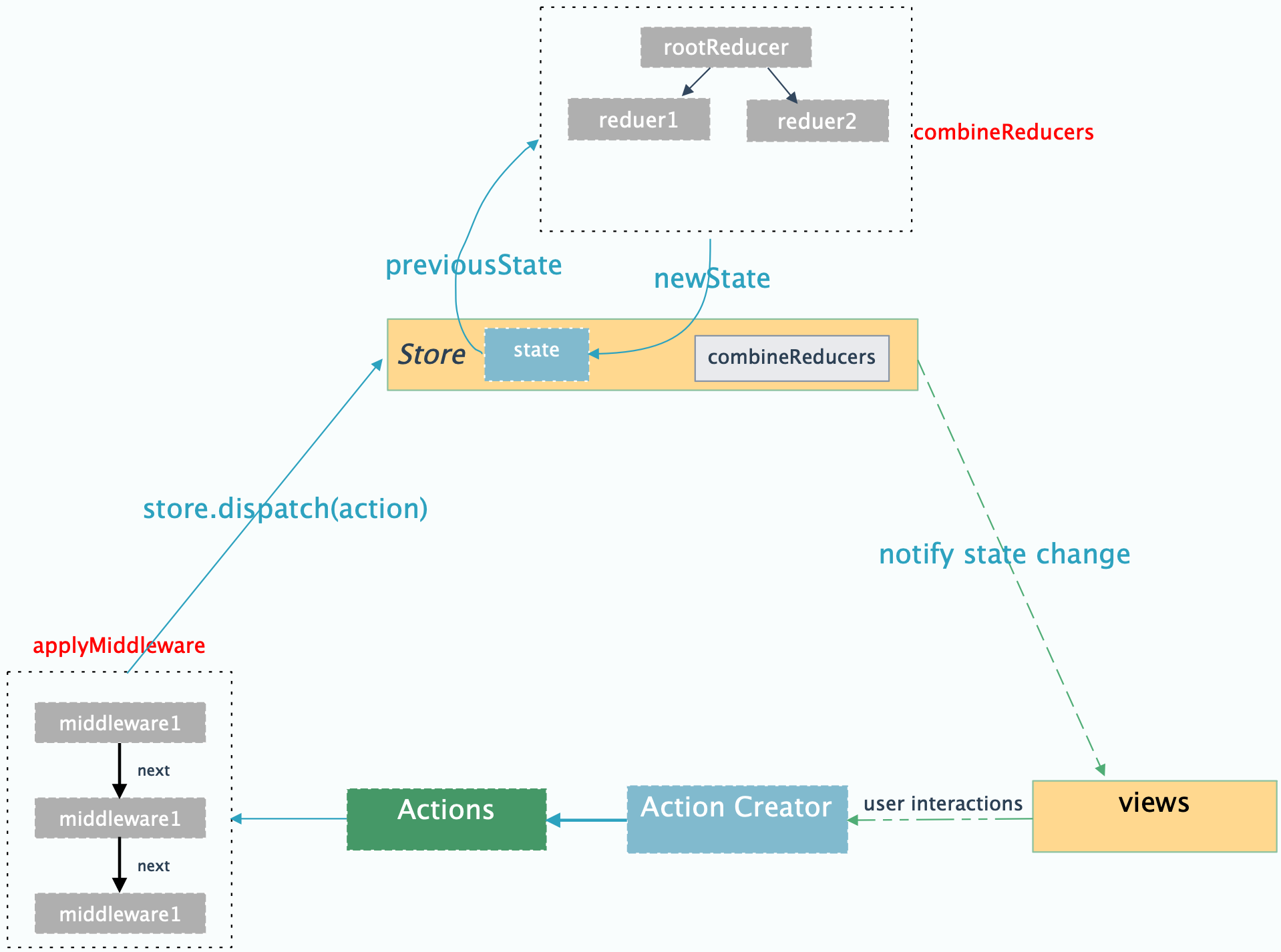
开发步骤
- 各个组件在需要修改传递数据的时候创建一个 Action
- 利用 dispatch 提交给 store
- store 本身不处理 state,所以将 action 转发给 reducer
- reducer 根据 action 的 type 判断具体如何处理数据。 reducer 中返回的函数是纯函数(输入给定的时候,输出的结果也是恒定的。且不改变输入值),函数的返回值就是 state,state 返回给 store,store 可以通过
getState()拿到最新的 state 数据。 - 各个组件如果需要知道 state 的数据变化,那么可以在组件的 constructor 中设置监听订阅(subscribe) store(代码:store.subscribe(this.handleStateChange))。订阅的地方设置一个处理函数,然后在处理函数里面根据 store 获取到最新的 state(this.setState(store.getState()))。
开发经验
-
Redux 中每次创建 action 都需要设置 type,type 为字符串,所以很容易写错,且各个组件都直接用字符串的方式创建 action 的 type 会比较分散,字符串拼写错误造成的 bug 难以排查,所以需要一个地方集中统一处理 action type。思路为在
src/store文件夹下面创建 actionTypes.js 文件夹,创建全部大写的变量,然后导出。展开示例代码
export const CHANGE_INPUT_VALUE = 'change_input_value'; export const ADD_TODO_ITEM = 'add_todo_item'; export const DELETE_TODO_ITEM = 'delete_todo_item'; export const INIT_TODO_DATA = 'init_todo_data'; export const GET_INIT_LIST = 'get_init_list' -
Redux 使用的时候全局工程会创建很多 action,所以和上面的思想一样,需要集中统一处理,符合“收口原则”、“单一原则”。做法就是在
src/store目录下创建一个 actionCreators.js 文件。然后在里面引入 actionType.js,根据业务导出几个产生 action 的函数。展开示例代码
import { CHANGE_INPUT_VALUE, ADD_TODO_ITEM, DELETE_TODO_ITEM } from './actionTypes' export const getInputChangeAction = (value) => { return { type: CHANGE_INPUT_VALUE, value } }; export const getAddTodoItemAction = () => ({ type: ADD_TODO_ITEM }); export const getDeleteTodoItemAction = (value) => ({ type: DELETE_TODO_ITEM, value }); -
store 发现 action 提交的数据是函数类型的时候,会自动执行函数
核心思想
- 单一数据源:整个应用的 state 被存储在一棵 Object tree 中,并且这个 object tree 只存在于唯一一个 store 中
- State 是只读的:唯一改变 state 的方式就是触发 action,action 是描述已发生时间的普通对象
- 使用纯函数来执行修改:为了描述 action 如何改变 state tree,你需要根据业务编写 reducer
Redux-thunk
Redux-thunk 是 redux 里面常用的一个中间件。中间件?针对谁和谁的中间?对 action 和 store 的中间件。本来 action 只可以返回一个对象,灵活性较低,但是采用了 redux-thunk 之后,action 不仅可以传递对象,还可以传递函数。 action 通过 dispatch 传递给 store。 dispatch 判断 action 的类型,如果是对象则直接传递;如果是函数则直接执行。
-
异步函数不应该放在组件的生命周期函数里面。复杂的业务逻辑和异步函数适合拆分。目前主流的解决方案有2种中间件:redux-thunk、redux-saga。采用不同的策略
- redux-thunk:将异步任务分离到 action 中。
- redux-saga:将异步任务拆分到单独的文件中,而不是 action 里面。 相比较而言,redux-saga 比 redux-thunk 功能更加强大,提供的有用的功能更多。
-
react-redux:网上经常说的 react-redux 里面既有 UI 组件、也有容器组件。connect 方法将一个 UI 组件(傻瓜组件) 和 store、dispatch 联合在一起后,connect 函数的返回结果就是一个容器组件
export default connect(mapStateToProps, mapDispatchToProps)(TodoListReactRedux)
组件的写法
// 功能组件
function Welcome (props) {
return <h2>Hello, {props.name}</h2>;
}
// 等价于下面的写法。ES6 类
class Welcome extends React.Component {
render () {
return <h2>hello, {this.props.name}</h2>;
}
}
开发tips
-
不要直接操作 state,只能通过 setState 操作数据;props 是只读的
-
setState 的时候如果依赖之前的 state 数据,那么 setState 第一个参数可以更改为函数方式,这个函数有2个参数
setState((state, props) => ({ count: state.count + props.increment })); -
路由设置的时候,我们经常会设置路径。每个路径匹配到具体的页面资源会呈现出来。但是在一开始的时候会遇到疑问,为什么我在浏览器里面输入了 “/home”。但是出来的内容还是 “/” 皮配到的页面,后来知道了还可以设置 exact 属性可以精确控制。
<Provider store={store}> <BrowserRouter> <div> <Header /> <Route path='/' exact component={Home}></Route> <Route path='/login' exact component={Login}></Route> <Route path='/write' exact component={Write}></Route> <Route path='/detail/:id' exact component={Detail}></Route> </div> </BrowserRouter> </Provider> -
在 React 的开发中,有2个名字会很熟悉:傻瓜组件、容器组件。假如一个 TodoList 的 UI 部分和逻辑处理部分都在 一个 TodoList 组件里面进行解决,那么代码将会冗余且不易测试,为了解决此问题,我们常常会将 UI 部分单独抽离出去,只负责显示出 UI,这种组件叫做傻瓜组件(UI组件)。页面需要的数据或者点击事件的处理函数都通过 props 的形式由父组件传递下来。父组件在渲染的时候只负责逻辑的展示,在自身的 render 函数里面调用之前分离出去的傻瓜组件(UI组件)。为了保证代码的健壮性和安全性,UI 组件需要的数据和函数都通过 props 传递,且加一个 propTypes 安全校验。
-
无状态组件:当一个组件只有 render 函数的时候,这样的组件被叫做无状态组件。做法就是将
class TodoList extends React.Dom修改成一个函数。函数形式的无状态组件效率比较高。因为类形式的组件,会有生命周期等函数,效率会低一些。const TodoListUI = (props) => { return <div>props.name</div>; } -
export default 在一个模块里面只可以存在一个,使用的时候不需要
{};export 可以存在多个,使用的时候需要使用{}export const person = { name: 'lbp', age: 22 } export const testing = 'testing' export default store; import store from './store' import { person, testing } from './store'
React 和 Vue 的对比
-
React 是单向数据流,数据是不可变的。Vue 是双向数据流,数据是可以变的。什么意思?看下面的例子 Vue.js
<input type="text" maxlength="11" autocomplete="off" class="form-control input-lg input-flat input-flat-user" placeholder="请输入手机号码" name="resetmobile" v-validate="'required|resetmobile'" v-model="resetmobile">React.js
constructor(props) { super(props); this.state = store.getState() // 函数的 this 绑定放在顶部对 React 性能提升有好处 this.handleInputChange = this.handleInputChange.bind(this) store.subscribe(this.handleStateChange); } <input placeholder="things to do..." style={ { width: 300, marginRight: 20 } } value={props.inputValue} onChange={props.handleInputChange} /> handleInputChange(e) { /* // 方式1 this.setState({ inputValue: this.inputRef.value }) */ //方式2:redux:先创建 action,然后 dispatch 给 store,然后 store 转发给 reducer、reducer处理完后给 store、依赖的组件设置监听,然后在监听的回调里面拿到最新的数据去 render UI const action = getInputChangeAction(e.target.value); store.dispatch(action); } // 负责订阅 store 里面 state 的改变;感知到 store 里面的 state 改变,则在当前组件里面 setState handleStateChange () { this.setState(store.getState()); }可以看出来,Vue 通过简单的一个内置命令
v-model将 model 和 view 双向绑定了起来,数据是双向的。model 改变 view 自动刷新;用户在 input 写了文字,model 的值也自动改变。React 先设置一个 input 组件,监听用户的输入事件(onChange),然后在 onChange 里面拿到当前输入框里面的数据,然后你可以直接 setState 去操作数据,setState 后才会触发 render 函数,dom 才会跟着更新。 -
React 比 Vue 更加适合构建大型项目。 什么是大型项目?这句话没什么意义,那就说一些区别吧。通过上面的说明知道 Vue 在内部做了双向绑定,对于数据的处理更加方便。React 对于数据变动还需要自己手动去调用 setState。假如有多个数据,按照 Vue 的原理会启动 n 个 watcher 去监听,所以性能会有一些问题。React 性能相关都需要开发者去处理。
-
Vue 设计思想:How easy it can be。React:How corrct it can be 和 all in js(css写法也在用 js 控制,比如 styled-component)
在 React、React Native、Vue、Weex、Flutter 等声明式开发思想的框架下,UI = F(state)。一个状态唯一对应一个 UI(但一个 UI 不一定对应一个 state),关心 state 即可
React 核心渲染流程 Fiber 架构
React 在 16 之后引入了 Fiber 架构,旨在解决长列表的渲染卡顿问题。几个关键问题
hostRenderFiber 里的 updateQueue.shared.pending 怎么理解?为什么需要 shared 属性?
在 React 的 Fiber 架构中,hostRenderFiber.updateQueue.shared.pending 涉及更新队列的核心设计,尤其是为了支持并发渲染和多优先级更新。我们可以分两部分理解:
- 先拆解概念:
hostRenderFiber.updateQueue.shared.pending
hostRenderFiber:指「宿主环境渲染 Fiber 节点」(如对应 DOM 元素的 Fiber),负责管理该节点的渲染和更新状态。updateQueue:Fiber 节点上的「更新队列」,用于存储待处理的更新(如setState、useState产生的更新)。React 通过更新队列实现更新的合并、优先级排序和批量处理。shared:更新队列中「共享部分」的容器,用于在多场景下共享更新数据(核心是支持并发模式)。pending:shared中存储「待处理更新」的链表(环形链表),指向当前等待被处理的更新队列尾部。
pending的作用pending是更新队列中未被处理的更新链表,本质是一个「环形单向链表」。其设计目的是高效地收集和处理更新:
- 当产生新更新(如调用
setState)时,React 会创建一个Update对象,并将其添加到pending链表的尾部(通过指针调整形成环形)。 - 在「协调阶段(Reconciliation)」,React 会从
pending中取出所有待处理更新,进行合并(如多个相同状态的更新合并为一个),最终计算出最新的状态。
环形链表的设计能让更新的添加和取出操作更高效(时间复杂度 O(1)),避免频繁的数组操作开销。
- 为什么需要
shared属性?shared(共享)是为了支持 React 的并发渲染机制而设计的,核心解决「多场景下更新队列的共享与同步」问题:
在并发模式中,React 可能同时存在多个「更新任务」(如高优先级的用户输入更新和低优先级的列表渲染更新),且这些任务可能在不同的「调度阶段」(如主线程、后台任务)中被处理。此时需要一个「共享的更新容器」,让不同的调度逻辑、优先级任务能访问到同一份待处理更新,避免更新丢失或冲突。
具体来说,shared 的核心作用是:
- 跨优先级共享更新:高优先级更新和低优先级更新可以共用同一个
pending队列,确保低优先级更新不会被高优先级任务覆盖。 - 跨 Fiber 共享更新:在
current Fiber(当前渲染树的 Fiber)和workInProgress Fiber(正在构建的新 Fiber)交替工作时,shared确保两者能访问到相同的待处理更新,避免状态不一致。 - 支持中断与恢复:并发渲染中,低优先级任务可能被高优先级任务中断,
shared.pending中的更新不会因中断而丢失,恢复时可继续处理。
总结
hostRenderFiber.updateQueue.shared.pending是宿主 Fiber 节点上「共享更新队列中待处理的更新链表」,用于收集和暂存未处理的更新。shared属性是为了适配并发渲染的多优先级、多阶段调度需求,确保更新队列能在不同场景(如不同优先级任务、不同 Fiber 树)中被安全共享和同步,避免更新丢失或冲突。
注意:「在并发模式中,React 可能同时存在多个更新任务」并不是说明 React 在渲染的时候存在多个线程,JS 是单线程模型这一客观事实没有改变,这里说的是更新任务,是任务队列,并不是任务线程。
- JS 单线程的限制是 “同一时间只能执行一个任务”,但可以通过任务队列(如宏任务、微任务)控制任务的执行时机。
- React 并发模式下,不同更新任务(如用户输入、列表渲染)会被标记不同的优先级(通过 Scheduler 包实现)。高优先级任务(如点击事件)可以打断低优先级任务(如长列表渲染)的执行 —— 此时低优先级任务的中间状态不会提交到 DOM,而是被暂停,等高优先级任务完成后,低优先级任务再从暂停处恢复执行。
这种 “中断 - 恢复” 机制让开发者感觉 “多个任务在同时处理”,但本质上仍是主线程按优先级依次执行,没有多线程参与。而 shared.pending 正是为了在这种 “中断 - 恢复” 中,确保低优先级任务被打断时,其未处理的更新不会丢失(因为更新存在共享队列中,恢复时可继续读取)。
shared 与双缓冲机制(current/WIP 切换)的关系
shared(共享)是为了支持 React 的并发渲染机制而设计的」可以理解为 React Fiber 架构为了解决长列表渲染问题,借鉴 iOS、Android 设计了双缓冲机制,系统在 current 和 WIP 之间切换,从而避免长时间阻塞主线程,提升用户体验吗?
双缓冲机制(current 与 workInProgress Fiber 树):这是 React Fiber 架构的核心设计之一,类似 iOS/Android 的双缓冲(前台显示缓冲区、后台绘制缓冲区)。
- current Fiber:当前已渲染到 DOM 的 Fiber 树,代表 “当前屏幕上的 UI”。
- workInProgress Fiber(WIP):正在内存中构建的新 Fiber 树,用于计算更新后的 UI。 当 WIP 树构建完成后,React 会通过切换 current 指针(指向 WIP 树)完成更新,避免直接修改 current 树导致的 UI 闪烁或不完整(因为构建过程可能被中断)。 这一机制的核心是避免渲染过程中的中间状态暴露给用户,解决 “长时间阻塞主线程导致的 UI 卡顿”。
shared 的作用:支持双缓冲中的更新共享双缓冲机制中,current 和 WIP 是两棵独立的 Fiber 树,但它们需要共享同一份更新队列—— 否则如果更新只存在于 current 树,WIP 树构建时会丢失更新;反之如果只存在于 WIP 树,若 WIP 树被中断丢弃(高优先级任务抢占后可能重新构建),更新也会丢失。
- shared 正是为这两棵树提供了一个 “共享的更新容器”:
- 无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列。
- 当需要构建 WIP 树时,会从 shared.pending 中读取所有待处理更新,确保不遗漏。 即使 WIP 树被中断重建,新的 WIP 树仍能从 shared.pending 中获取最新更新。 简单说:双缓冲机制解决 “渲染过程不阻塞 UI”,shared 解决 “双缓冲切换时更新不丢失”,二者配合支撑了并发渲染的可靠性。
「无论更新是在 current 树还是 WIP 树中产生,都会被添加到 shared.pending 队列」那么是不是 update 任务会有个标记用于区分当前任务是 current Fiber 树的任务还是 WIP Fiber 树的任务?请分别列举,WIP和 Current 不同的任务提交后,后续是如何执行的
在 React 中,Update 任务(即更新对象)并没有专门的标记区分其来自 current Fiber 树还是 workInProgress Fiber 树。这是因为 shared.pending 队列的设计目标就是 “消除来源差异”—— 无论更新来自哪个 Fiber 树,最终都需要被统一处理,确保状态的一致性。一言以蔽之就是:update 任务不管是 WIP Fiber tree 产生的,还是 Current Fiber Tree 产生的,只用于服务于下一次(也就是 WIP Fiber Tree),类似双缓冲机制,用于构建下一次需要显示的内容
- current 树是 “只读的”:它代表当前屏幕上的 UI,任何更新都不会直接修改 current 树(否则会导致用户看到中间态、闪烁或不一致)。
- WIP 树是 “可写的构建区”:所有更新(无论来自 current 树的用户交互,还是 WIP 树构建中的嵌套逻辑)最终都会被收集到 shared.pending 队列,然后在 WIP 树的构建过程中被统一处理(计算新状态、生成新的 Fiber 节点)
“挂载”和“插入”
React 中经常会看到挂载和插入2个术语。2者有啥区别呢?
| 概念 | 含义 | 发生阶段 | 操作对象 | 是否触发浏览器重排 |
|---|---|---|---|---|
| 挂载(mounting) | 在内存中构建DOM节点间的父子关系 | Render阶段 | React Element 对象parentElement.appendChild(childElement)(仅在内存中) |
否 |
| 插入文档(insert) | 将DOM树实际添加到浏览器的文档流中 | Commit阶段 | 标准的 DOM 对象document.getElementById('root').appendChild(domTree) |
是 |
举个例子:
function Counter() {
return (
<div>
<button>Click</button>
<span>Text</span>
</div>
);
}
"将button的DOM节点挂载到父div的DOM节点下(但不插入文档)",这其实说的是在 React 的 Render 阶段做的事情
// 在内存中的操作(伪代码):
const divElement = document.createElement('div');
const buttonElement = document.createElement('button');
// ✅ "挂载":建立父子关系(仅在内存中)
divElement.appendChild(buttonElement); // 此时button成为div的子节点
// ❌ 但还没有插入到实际文档中:
// document.body.appendChild(divElement); // 这个操作还没发生
为什么要做这些区分?为的是性能优化,用代价更小的 Virtual Dom 来模拟真实的 Dom。利用 diff 之后的结果,提交到 queue 里,采用类似 iOS、Android 的双缓冲机制,将 Render 阶段的计算结果 commit 到真实的 Dom 上,以此来减少 Dom 的实际操作,达到性能优化的目的。
| 层级 | 职责 | 性能代价 | 更新频率 |
|---|---|---|---|
| Element | 描述UI应该长什么样 | 极低(纯 JS 对象) | 每次 render 都创建,用于后续 diff 比较 |
| Fiber | 协调更新、调度任务 | 中等(可中断计算) | 渲染期间持续存在 |
| DOM | 实际渲染、触发重排 | 极高(浏览器操作) | 最小化更新 |
效果就是 :
JSX → Element → Fiber协调 → 副作用标记 → 双缓冲切换 → 批量DOM更新
↓ ↓ ↓ ↓ ↓
声明式UI 轻量对象 可中断计算 无闪烁切换 最小化重排
// 不好的做法(传统):
document.body.appendChild(div); // 1. 插入div(触发重排)
document.body.appendChild(button); // 2. 插入button(再次触发重排)
document.body.appendChild(span); // 3. 插入span(第三次重排)
// React的做法(优化):
// Render阶段:在内存中构建完整的DOM树
div.appendChild(button);
div.appendChild(span);
// Commit阶段:一次性插入整个树
document.getElementById('root').appendChild(div); // 只触发一次重排
一个小例子
// 详细流程示例:
// 阶段1: Render(协调/构建)
function renderPhase() {
// 创建所有DOM节点(但独立存在)
const div = document.createElement('div');
const button = document.createElement('button');
const span = document.createElement('span');
// ✅ 挂载操作:建立节点间的关系
div.appendChild(button); // button成为div的子节点
div.appendChild(span); // span成为div的子节点
// 此时:div - button - span 形成了完整的DOM树结构
// 但整个div树还没有插入到文档中!
return div; // 返回构建好的完整DOM树
}
// 阶段2: Commit(提交)
function commitPhase(domTree) {
const container = document.getElementById('root');
// ✅ 插入文档:一次性将整棵树插入
container.appendChild(domTree);
// 此时用户才能在浏览器中看到内容
}
// 使用示例:
const completeDOMTree = renderPhase(); // 构建
commitPhase(completeDOMTree); // 插入
这样做的好处(效果)是什么?
// 性能优势对比:
// ❌ 传统方式(多次重排):
for (let i = 0; i < 100; i++) {
const element = document.createElement('div');
document.body.appendChild(element); // 100次重排!
}
// ✅ React方式(一次重排):
const fragment = document.createDocumentFragment();
for (let i = 0; i < 100; i++) {
const element = document.createElement('div');
fragment.appendChild(element); // 在内存中构建
}
document.body.appendChild(fragment); // 一次重排!
问题:
1.Fiber 节点和 Element和Dom 节点,3者之间的对应关系是什么?
| 层面 | 角色 | 生命周期 | 示例 |
|---|---|---|---|
| React Element | 描述 UI 的 JS 对象 | 每次 render 都重新创建 | {type: 'div', props: {...}} |
| Fiber 节点 | 协调的工作单元 | 在多次渲染间持续存在 | FiberNode {tag: HostComponent, ...} |
| DOM 节点 | 浏览器渲染单元 | 从创建到销毁 | <div class="container">Hello</div> |
看上去 React Element 对象和 JSX 都是做“描述 UI” 这个事儿的,那有啥区别?
JSX 是 React 的语法糖(不是标准的、有效的 js),如果开发者写的代码都用 React.createElement 代替的话,很耗费时间、效率很低。
比如下面的例子,Babel 编译器会把 JSX 编译为真正的 JS 代码。
// 编译前 (JSX)
const App = () => (
<div className="container">
<h1>Hello {name}</h1>
<Button onClick={handleClick}>Click me</Button>
</div>
);
// 编译后 (JavaScript)
const App = () =>
React.createElement(
'div',
{ className: 'container' },
React.createElement(
'h1',
null,
'Hello ',
name
),
React.createElement(
Button,
{ onClick: handleClick },
'Click me'
)
);
2.Fiber 对象的 stateNode 属性是做什么的?
在 React 的 Fiber 架构中,stateNode 是 Fiber 对象的核心属性之一,其作用是关联 Fiber 节点对应的“实际运行时实体”(如 DOM 元素、组件实例、根节点容器等)。简单来说,stateNode 是 Fiber 节点与真实世界实体(如 DOM 树、组件实例)之间的“桥梁”。
不同类型 Fiber 节点的 stateNode 含义
stateNode 的具体类型取决于 Fiber 节点的 tag(标签,标识节点类型),不同类型的 Fiber 节点对应不同的 stateNode:
-
HostComponent(原生 DOM 标签,如<div>、<span>)
stateNode指向该 Fiber 节点对应的真实 DOM 元素。
例如:<div>对应的 Fiber 节点,其stateNode就是document.createElement('div')创建的 DOM 元素。
(在你提供的代码中,HostComponent的stateNode会被赋值为创建的 DOM 元素:workInProgress.stateNode = instance)。 -
HostText(文本节点,如Hello World)
stateNode指向对应的文本 DOM 节点(Text类型的 DOM 对象)。
例如:文本 “Hello” 对应的 Fiber 节点,其stateNode是document.createTextNode('Hello')创建的文本节点。 -
ClassComponent(类组件,如class MyComponent extends React.Component)
stateNode指向该类组件的实例对象(即new MyComponent(...)创建的实例)。
通过stateNode可以访问组件实例的state、props或方法(如this.setState)。 -
HostRoot(根节点,对应ReactDOM.render()的根容器)
stateNode指向根容器相关的对象(通常是FiberRoot或与根 DOM 容器关联的信息),用于管理整个应用的根节点状态。 -
其他类型(如
FunctionComponent、Fragment、MemoComponent等)
这些类型的 Fiber 节点通常没有实际的运行时实体,因此stateNode可能为null或undefined。
例如:函数组件(FunctionComponent)没有实例,其Fiber.stateNode为null;Fragment只是逻辑分组,无实际 DOM 节点,stateNode也为null。
stateNode 的核心作用
-
连接虚拟 Fiber 树与真实 DOM 树
在提交阶段(Commit),React 需要通过 Fiber 节点的stateNode找到对应的 DOM 元素,才能执行实际的 DOM 操作(如插入、删除、更新属性等)。例如:- 更新
<div>的className时,通过fiber.stateNode拿到真实 DOM 元素,再修改其className属性。
- 更新
-
保存组件实例状态
对于类组件,stateNode保存组件实例,React 可以通过它访问实例的state、refs或生命周期方法(如componentDidMount),确保组件状态的正确维护。 -
标识节点唯一性
stateNode是 Fiber 节点与实际实体的唯一关联,在 Fiber 树的遍历、更新、复用过程中,通过stateNode可以快速定位到对应的实际对象,避免重复创建或错误操作。
stateNode 是 Fiber 节点的“实体指针”,其类型随 Fiber 节点的类型而变化,核心作用是将虚拟的 Fiber 树与真实的运行时实体(DOM 元素、组件实例等)关联起来,使得 React 能够基于 Fiber 树的计算结果,高效地操作真实对象(如更新 DOM、管理组件状态)。
Fiber 树渲染按照深度优先遍历顺序
React 的渲染分为 Render 阶段(协调/构建 Fiber 树)和 Commit 阶段(应用 DOM 更新)。在 Render 阶段,React 采用 深度优先遍历(DFS) 构建或更新 Fiber 树,遍历顺序遵循:
优先处理当前节点的 子节点(child 指针)。 若无子节点,则处理 兄弟节点(sibling 指针)。 若无兄弟节点,则 回溯父节点(return 指针)。
flags 和 subTreeFlags 有啥区别?
Fiber 架构中 flags 和 subTreeFlags 是用于标记节点更新状态的核心字段,二者的核心区别在于作用范围和职责定位,共同服务于 React 的协调(Reconciliation)和提交(Commit)阶段,以高效处理更新。
1. 核心区别:作用范围
flags:仅针对当前 Fiber 节点自身的更新标记,记录当前节点需要执行的操作(如更新、插入、删除等)。subTreeFlags:针对当前 Fiber 节点的整个子树(所有后代节点)的更新标记,记录子树中是否存在需要处理的更新(聚合了所有后代节点的flags)。
2. 各自的职责
flags:标记当前节点的具体更新操作
flags 是一个位掩码(bitmask),用于标识当前 Fiber 节点自身需要执行的具体操作。React 定义了一系列枚举值(如 Update、Placement、Deletion 等),每个值对应一种操作,多个操作可以通过位运算组合。
常见的 flags 类型:
Update:当前节点需要更新(如 props 变化、状态变化等)。Placement:当前节点需要插入到 DOM 中。Deletion:当前节点需要从 DOM 中删除。ChildDeletion:当前节点的子节点中有需要删除的节点(用于优化删除逻辑)。Ref:当前节点的 ref 需要更新。
职责:在协调阶段标记当前节点的更新类型,在提交阶段指导 React 执行具体的 DOM 操作(如更新属性、插入节点、删除节点等)。
subTreeFlags:标记子树中是否存在更新:
subTreeFlags 同样是位掩码,但其作用是聚合当前节点所有后代节点的 flags,用于快速判断“当前节点的子树中是否存在需要处理的更新”。
职责:优化 Fiber 树的遍历效率。在协调阶段,React 遍历 Fiber 树时,会先检查当前节点的 subTreeFlags:
- 如果
subTreeFlags为0,说明子树中没有任何更新,可直接跳过对子树的遍历,减少不必要的计算。 - 如果
subTreeFlags不为0,说明子树中存在更新,需要继续深入遍历子节点处理具体更新。
传播逻辑:当子节点的 flags 发生变化时,React 会向上“冒泡”更新父节点的 subTreeFlags(即父节点的 subTreeFlags 会包含子节点的 flags),确保上层节点能感知到子树的更新状态。
| 字段 | 作用范围 | 核心职责 |
|---|---|---|
flags |
当前 Fiber 节点自身 | 标记当前节点需要执行的具体操作(如更新、插入、删除),指导提交阶段的 DOM 操作。 |
subTreeFlags |
当前节点的整个子树 | 聚合子树中所有节点的更新标记,用于快速判断子树是否有更新,优化遍历效率。 |
简单来说,flags 关注“当前节点要做什么”,subTreeFlags 关注“子树里有没有活要干”,二者配合让 React 能高效地定位和处理更新,避免不必要的计算和 DOM 操作。
类比 iOS 类对象的 isa,采用了 bitmask 的技术。高效访问,不需要挨个关心里面的各个子节点构成子树的状态
fiber 树深度优先遍历
在 Fiber 树的深度优先遍历(DFS)过程中,subTreeFlags 的赋值遵循**“自底向上聚合”**的逻辑——即先递归处理完所有子节点,再基于子节点的更新状态(flags 和 subTreeFlags)向上合并,最终形成当前节点的 subTreeFlags。这一过程主要发生在 React 协调阶段的 completeWork 阶段(子节点处理完成后对父节点的“收尾”工作)。
具体处理流程(结合 DFS 遍历)
深度优先遍历的核心是“先深入子树,再回溯父节点”。subTreeFlags 的赋值正是利用了这一特性,在子树完全处理后才聚合其更新状态。具体步骤如下:
- 遍历进入子节点(向下递归)
当遍历到某个 Fiber 节点(记为
parent)时,DFS 会先处理其子节点(通过child指针访问第一个子节点,再通过sibling指针遍历所有兄弟子节点)。
- 对每个子节点(记为
child),会递归执行相同的遍历逻辑:先处理child自身的更新(beginWork阶段),再继续深入child的子节点(child.child),直到触及叶子节点(没有子节点的节点)。
- 子节点处理完成(回溯阶段)
当一个子节点
child的所有后代节点(子树)都处理完毕后,遍历会回溯到child自身,进入completeWork阶段。此时:
child的flags已确定(自身需要的更新操作,如Update、Placement等);child的subTreeFlags也已确定(通过聚合child所有后代节点的flags和subTreeFlags得到)。
- 父节点聚合子节点的更新状态(核心赋值逻辑)
当
child处理完成后,遍历回到其父节点parent的处理流程。此时,parent会通过位运算(OR 操作) 将child的flags和subTreeFlags合并到自己的subTreeFlags中。
公式可简化为:
parent.subTreeFlags |= child.flags | child.subTreeFlags;
- 原因:
child.flags包含child自身的更新,child.subTreeFlags包含child子树的所有更新,二者的合并结果就是child整个子树(含自身)的全部更新状态。 - 作用:
parent通过这种方式“感知”到子树中存在的更新,无需深入遍历即可知道子树是否有活要干。
- 处理所有兄弟子节点
如果
parent有多个子节点(通过sibling指针连接),则会对每个子节点重复步骤 1-3:
- 先处理第一个子节点
child1,合并child1.flags | child1.subTreeFlags到parent.subTreeFlags; - 再处理第二个子节点
child2,合并child2.flags | child2.subTreeFlags到parent.subTreeFlags; - 以此类推,直到所有子节点处理完毕。
- 父节点自身的
subTreeFlags最终确定 当parent的所有子节点及其子树都处理完毕后,parent.subTreeFlags已聚合了所有后代节点(含所有子节点、孙节点等) 的更新状态。此时,parent的subTreeFlags赋值完成。
关键特点总结
- 自底向上:
subTreeFlags的赋值依赖子树的处理结果,必须在所有子节点处理完成后才会计算,符合 DFS“先深入后回溯”的特性。 - 位运算聚合:通过
|(或运算)合并子节点的更新状态,确保父节点能“继承”子树中所有类型的更新(如Update、Deletion等不会丢失)。 - 优化遍历效率:最终父节点的
subTreeFlags若为0,则说明整个子树无任何更新,上层节点遍历到此时可直接跳过,避免无效计算。
举例来说:
- 若叶子节点
leaf有flags = Update,则其subTreeFlags = 0(无后代); leaf的父节点parent会合并leaf.flags | leaf.subTreeFlags,即parent.subTreeFlags = Update;parent的父节点grandparent会合并parent.flags | parent.subTreeFlags,若parent自身无更新(flags=0),则grandparent.subTreeFlags = Update,以此类推。
通过这种方式,subTreeFlags 像“信号”一样从子树向上传递,让 React 能高效定位需要更新的区域。
伪代码为:
// 核心:bubbleProperties 逻辑(将当前节点的更新状态冒泡到父节点)
const parentFiber = workInProgress.return;
if (parentFiber) {
// 合并当前节点的 flags 和 subTreeFlags 到父节点的 subTreeFlags
// 位或运算(|)确保父节点能包含所有子树更新类型
parentFiber.subTreeFlags |= workInProgress.flags | workInProgress.subTreeFlags;
}
举个例子说明下 flags 和 subTreeFlags 的变化过程:
我们通过一个具体的组件树更新场景,来直观展示 flags 和 subTreeFlags 的更新过程。假设我们有如下组件结构:
// 组件树结构
function Parent() {
return <Child />;
}
function Child() {
return <div>Hello, <span>World</span></div>;
}
对应的 Fiber 树结构(简化)为:
ParentFiber → ChildFiber → DivFiber → SpanFiber → TextFiber(内容为"World")
初始状态:
所有 Fiber 节点的 flags 和 subTreeFlags 均为 NoFlags(假设值为 0,表示无任何更新)。
场景:更新 TextFiber 的内容为"React"
当 TextFiber 的内容从"World"变为"React"时,React 会触发协调阶段,我们逐步分析各节点的 flags 和 subTreeFlags 变化:
- TextFiber(叶子节点,标签为
HostText)
-
flags更新:
在beginWork阶段(处理当前节点更新),React 发现 TextFiber 的内容变化,将其flags标记为Update(假设Update = 1 << 0 = 1)。
→TextFiber.flags = Update (1)。 -
subTreeFlags更新:
由于 TextFiber 是叶子节点(无任何子节点),其subTreeFlags始终为NoFlags(没有子树需要聚合)。
→TextFiber.subTreeFlags = NoFlags (0)。
- SpanFiber(父节点,标签为
HostComponent,对应<span>)
-
flags更新:
SpanFiber 自身的 props/内容未变化(仅子节点 TextFiber 变化),因此flags保持NoFlags。
→SpanFiber.flags = NoFlags (0)。 -
subTreeFlags更新:
在completeWork阶段(子树处理完成后回溯),SpanFiber 会聚合子节点 TextFiber 的flags和subTreeFlags:
SpanFiber.subTreeFlags |= TextFiber.flags | TextFiber.subTreeFlags
→0 | (1 | 0) = 1(即Update)。
→SpanFiber.subTreeFlags = Update (1)。
- DivFiber(祖父节点,标签为
HostComponent,对应<div>)
-
flags更新:
DivFiber 自身的 props/结构未变化(仅子树 SpanFiber 及其后代变化),因此flags保持NoFlags。
→DivFiber.flags = NoFlags (0)。 -
subTreeFlags更新:
在completeWork阶段,DivFiber 聚合子节点 SpanFiber 的flags和subTreeFlags:
DivFiber.subTreeFlags |= SpanFiber.flags | SpanFiber.subTreeFlags
→0 | (0 | 1) = 1(即Update)。
→DivFiber.subTreeFlags = Update (1)。
- ChildFiber(曾祖父节点,标签为
FunctionComponent,对应Child组件)
-
flags更新:
Child 组件自身的逻辑未变化(仅渲染的子树 DivFiber 变化),因此flags保持NoFlags。
→ChildFiber.flags = NoFlags (0)。 -
subTreeFlags更新:
在completeWork阶段,ChildFiber 聚合子节点 DivFiber 的flags和subTreeFlags:
ChildFiber.subTreeFlags |= DivFiber.flags | DivFiber.subTreeFlags
→0 | (0 | 1) = 1(即Update)。
→ChildFiber.subTreeFlags = Update (1)。
- ParentFiber(根节点,标签为
FunctionComponent,对应Parent组件)
-
flags更新:
Parent 组件自身未变化,flags保持NoFlags。
→ParentFiber.flags = NoFlags (0)。 -
subTreeFlags更新:
在completeWork阶段,ParentFiber 聚合子节点 ChildFiber 的flags和subTreeFlags:
ParentFiber.subTreeFlags |= ChildFiber.flags | ChildFiber.subTreeFlags
→0 | (0 | 1) = 1(即Update)。
→ParentFiber.subTreeFlags = Update (1)。
最终状态总结
| Fiber 节点 | flags(自身更新) |
subTreeFlags(子树更新) |
说明 |
|---|---|---|---|
| TextFiber | Update (1) |
NoFlags (0) |
自身内容更新 |
| SpanFiber | NoFlags (0) |
Update (1) |
子树(TextFiber)有更新 |
| DivFiber | NoFlags (0) |
Update (1) |
子树(SpanFiber)有更新 |
| ChildFiber | NoFlags (0) |
Update (1) |
子树(DivFiber)有更新 |
| ParentFiber | NoFlags (0) |
Update (1) |
子树(ChildFiber)有更新 |
另一种场景:同时更新 SpanFiber 和 TextFiber
如果不仅 TextFiber 内容更新(Update),SpanFiber 还需要添加 className(自身 Update),则:
- SpanFiber 的
flags会被标记为Update (1); - SpanFiber 的
subTreeFlags聚合 TextFiber 的Update (1),结果为1 | 1 = 1(仍为Update); - 上层节点(DivFiber、ChildFiber 等)的
subTreeFlags依然会聚合为Update(因为位运算|不会重复计算相同标记)。
核心结论
flags只关注自身是否有更新(如内容、props 变化),仅当前节点有操作时才会被标记。subTreeFlags关注子树是否有更新(无论自身是否更新),通过“自底向上”的位运算聚合所有后代节点的flags,让上层节点无需遍历子树即可快速判断是否有更新,从而优化性能
渲染核心流程
- 创建初始化 WIP
- 进入“递归”的“递”流程
主要是 beginWork 函数逻辑:
- 处理 Fiber 节点的父子、兄弟节点的关系,涉及:child、return、sibling
- 给 Fiber 节点打标记 flags、subTreeFlags
- 进入“递归”的“归”流程
- 处理真实 Dom 节点关系
- 解析 flags 标记、合并处理 subTreeFlags
- 处理父子 Dom 真实的节点关系,将子节点插入父节点中
- 进入 commit 流程,进行真实的 Dom 渲染
递归的“递”阶段做了哪些事情?
渲染阶段(构建 workInProgress 树)
// 开始渲染时,创建 workInProgress 树
function prepareFreshStack(root: FiberRoot, lanes: Lanes) {
// 从 current 树克隆出 workInProgress 树
root.workInProgress = createWorkInProgress(root.current, null);
}
// 协调过程在 workInProgress 树上进行
function renderRootSync(root: FiberRoot, lanes: Lanes) {
// 在 workInProgress 树上执行协调
workLoopSync();
// 协调完成,workInProgress 树构建完毕
const finishedWork: FiberNode = root.current.alternate;
root.finishedWork = finishedWork;
}
递归的“归”阶段做了哪些事情?
提交阶段(树切换)
function commitRoot(root: FiberRoot) {
const finishedWork = root.finishedWork;
if (finishedWork !== null) {
// === 准备提交 ===
root.finishedWork = null;
// === 执行 DOM 操作 ===
commitMutationEffects(root, finishedWork);
// === 关键:切换 current 指针 ===
root.current = finishedWork; // 🎯 双缓冲切换!
// === 执行 layout 效果 ===
commitLayoutEffects(root, finishedWork);
}
}
变更前 commitBeforeMutationEffects
React 的 commitRoot 分为3个阶段
function commitRoot(root: FiberRoot) {
// 完整版本,包含所有三个阶段
commitBeforeMutationEffects(root, finishedWork); // 阶段1
commitMutationEffects(root, finishedWork); // 阶段2
commitLayoutEffects(root, finishedWork); // 阶段3
// 注意:树切换在内部处理
}
变更前执行 commitBeforeMutationEffects。主要负责在 DOM 发生变更(mutation)之前 执行一系列必要的准备工作,为后续的 DOM 操作(如插入、删除、更新节点)铺路。
function commitBeforeMutationEffects(root: FiberRoot, finishedWork: Fiber) {
// 读取 DOM 状态快照(如滚动位置)
// 调用 getSnapshotBeforeUpdate 生命周期
// 不涉及 DOM 修改
}
核心作用:commitBeforeMutationEffects 的核心目标是:在真正修改 DOM 结构之前,处理一些依赖于「当前 DOM 状态」的逻辑,确保这些逻辑能获取到 DOM 变更前的状态,同时完成一些前置准备。
变更 commitMutationEffects
function commitMutationEffects(root: FiberRoot, finishedWork: Fiber) {
// 遍历并执行所有 DOM 操作:
recursivelyTraverseMutationEffects(root, finishedWork);
commitReconciliationEffects(finishedWork);
}
DOM 操作:
function commitReconciliationEffects(finishedWork: Fiber) {
const flags = finishedWork.flags;
if (flags & Placement) {
// 🎯 插入 DOM 节点到父节点
commitPlacement(finishedWork);
}
if (flags & Update) {
// 🎯 更新 DOM 属性和内容
commitUpdate(finishedWork);
}
if (flags & Deletion) {
// 🎯 删除 DOM 节点
commitDeletion(finishedWork);
}
}
布局阶段 commitLayoutEffects
function commitLayoutEffects(root: FiberRoot, finishedWork: Fiber) {
// DOM 已经更新完成,执行:
// - componentDidMount / componentDidUpdate
// - useLayoutEffect 回调
// - refs 的赋值和清理
// - 调度 useEffect
}
commitLayoutEffects 是 DOM 变更(mutation)之后的关键步骤,核心作用是:在 DOM 已经完成更新后,处理所有依赖于「最新 DOM 布局状态」的逻辑(比如读取元素尺寸、位置,更新 refs,触发布局相关的生命周期等)
虽然浏览器还没自动触发 layout,但在 commitLayoutEffects 阶段,如果你主动读取 DOM 的布局信息(如 offsetHeight、getBoundingClientRect() 等),浏览器会被 “强制” 立即执行 layout 计算(因为需要返回最新的结果)。 这正是 commitLayoutEffects 的设计用意: 此时 DOM 已更新,读取布局信息能拿到最新结果; 强制 layout 后,你可以同步修改 DOM 样式(如调整位置、尺寸),这些修改会被浏览器合并到后续的绘制中,不会导致额外的 layout 开销(避免 “布局抖动”)
比如
useLayoutEffect(() => {
// 1. 读取 offsetHeight:强制浏览器立即计算 layout(因为 DOM 已更新但未 layout)
const height = ref.current.offsetHeight;
// 2. 同步修改样式:此时修改会被浏览器合并,不会触发二次 layout
ref.current.style.marginTop = `${100 - height}px`;
}, []);
双缓冲切换的详细过程
React 采用了类似 iOS/Android 中图形渲染的双缓冲机制来实现无撕裂的 UI 更新
// React 同时维护两棵 Fiber 树:
let current: FiberNode; // 当前显示在屏幕上的树(前缓冲区)
let workInProgress: FiberNode; // 正在构建的新树(后缓冲区)
切换前的状态
// 切换前:
FiberRoot {
current: FiberNode_A, // 屏幕上显示的是树A
finishedWork: FiberNode_B, // 刚构建完的树B
}
// 两棵树通过 alternate 互相引用:
FiberNode_A.alternate = FiberNode_B;
FiberNode_B.alternate = FiberNode_A;
切换后的状态
// 切换 current 指针。类似 iOS 双缓冲机制,视频控制器在收到 V-Sync 信号后,GPU 切换画面
root.current = root.finishedWork
// 切换后
FiberRoot {
current: FiberNode_B, // 现在屏幕上显示树B
finishedWork: null // 准备下一轮构建
}
双缓冲好处
无撕裂更新
没有双缓冲的问题:用户可能看到部分更新的UI(比如旧的 header + 新的 content) 有双缓冲:所有 DOM 操作在后台完成,然后一次性切换到新树。用户看到的是完整的、一致的 UI
可中断渲染
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
// 如果被打断,下次可以从断点继续
// workInProgress 树保持中间状态,不影响 current 树
}
状态一致性
- 在渲染过程中,current 树始终保持不变
- 用户可以继续与当前UI交互
实际例子
// 假设我们有这样的组件更新:
function App() {
const [count, setCount] = useState(0);
return (
<div>
<button onClick={() => setCount(c => c + 1)}>
Count: {count}
</button>
<span>Current: {count}</span>
</div>
);
}
点击事件触发后的完整流程伪代码为:
// 1. 开始渲染
const root = FiberRootNode;
root.current = Tree_A; // 当前显示Tree_A
// 2. 准备workInProgress树
root.workInProgress = createWorkInProgress(Tree_A, null);
// 现在有:Tree_A (current) 和 Tree_B (workInProgress)
// 3. 在Tree_B上执行协调
// - 更新button的文本
// - 更新span的文本
// - 计算DOM变更
// 4. 协调完成
root.finishedWork = Tree_B;
// 5. 提交阶段
commitRoot(root);
// - 执行DOM更新(修改文本内容)
// - 🎯 root.current = Tree_B; // 切换到新树
// - Tree_B现在成为current树
// 6. 准备下一轮更新
root.workInProgress = null;
// 下次更新时,会从Tree_B克隆出新的workInProgress树
React 的合成事件
React 将事件统一绑定在根节点(React 17 之前是 document,React 17 及之后是 React 应用挂载的根 DOM 节点)上,主要是基于性能优化、兼容性处理和架构设计等方面的综合考虑。这个机制被称为 “合成事件(SyntheticEvent)” 和 “事件委托(Event Delegation)
深入了解事件委托机制
在 React 中,你通过 JSX 编写的事件处理函数(如 onClick、onChange)并不会直接绑定到对应的 DOM 元素上。React 实际做的事情是:
- 统一监听:在应用的根节点(React 17+ 是你挂载 React 应用的 DOM 节点,如 ReactDOM.createRoot(document.getElementById('root')) 中的 #root;之前是 document)上设置一个统一的事件监听器。
- 事件触发:当任何子元素发生事件(比如点击),由于事件冒泡机制,这个事件会最终冒泡到根节点。
- 映射处理:根节点上的统一监听器捕获事件后,React 会根据事件触发的源 DOM 元素和事件类型,在自己的映射关系中找到对应组件的事件处理函数并执行。
React 17 的变化提醒:需要注意的是,在 React 17 及之后的版本中,事件委托的节点从 document 变为了你渲染 React 树的根 DOM 容器。这个改动使得多个 React 版本共存时事件系统可以更好地隔离。
好处:
- 简化事件处理:开发者无需手动管理事件的绑定 (addEventListener) 和解绑 (removeEventListener),React 已在内部处理,降低了代码复杂度和内存泄漏风险。
- 功能增强:合成事件提供了与浏览器原生事件相同的接口,并在某些情况下进行了增强,确保在不同浏览器中有一致的行为
你在某个组件上写的事件代码,本质上都是添加到根 Dom 节点上的。
// 你在组件中写的:
function Button() {
const handleClick = () => console.log('Clicked!');
return <button onClick={handleClick}>Click me</button>;
}
// 🔧 React实际做的事情:
// 1. 只在根元素上绑定一个真实的事件监听器
rootElement.addEventListener('click', (nativeEvent) => {
// 2. 找到实际被点击的DOM元素
const targetElement = nativeEvent.target;
// 3. 根据DOM元素找到对应的React组件和事件处理函数
const syntheticEvent = createSyntheticEvent(nativeEvent);
dispatchEvent(targetElement, 'click', syntheticEvent);
});
setState 是单向循环链表结构
跟随源码来看看执行流程
// 递归中的递阶段
export const beginWork = (wip: FiberNode, renderLane: Lane) => {
// 比较,返回子fiberNode
switch (wip.tag) {
case HostRoot:
return updateHostRoot(wip, renderLane);
// ...
};
会调用 updateHostRoot 方法
function updateHostRoot(wip: FiberNode, renderLane: Lane) {
const baseState = wip.memoizedState;
const updateQueue = wip.updateQueue as UpdateQueue<Element>;
const pending = updateQueue.shared.pending;
updateQueue.shared.pending = null;
const prevChildren = wip.memoizedState;
const { memoizedState } = processUpdateQueue(baseState, pending, renderLane);
wip.memoizedState = memoizedState;
const current = wip.alternate;
// 考虑RootDidNotComplete的情况,需要复用memoizedState
if (current !== null) {
if (!current.memoizedState) {
current.memoizedState = memoizedState;
}
}
const nextChildren = wip.memoizedState;
if (prevChildren === nextChildren) {
return bailoutOnAlreadyFinishedWork(wip, renderLane);
}
reconcileChildren(wip, nextChildren);
return wip.child;
}
接着会调用 processUpdateQueue 方法
export const processUpdateQueue = <State>(
baseState: State,
pendingUpdate: Update<State> | null,
renderLane: Lane,
onSkipUpdate?: <State>(update: Update<State>) => void
): {
memoizedState: State;
baseState: State;
baseQueue: Update<State> | null;
} => {
const result: ReturnType<typeof processUpdateQueue<State>> = {
memoizedState: baseState,
baseState,
baseQueue: null
};
if (pendingUpdate !== null) {
// 第一个update
const first = pendingUpdate.next;
let pending = pendingUpdate.next as Update<any>;
let newBaseState = baseState;
let newBaseQueueFirst: Update<State> | null = null;
let newBaseQueueLast: Update<State> | null = null;
let newState = baseState;
do {
const updateLane = pending.lane;
if (!isSubsetOfLanes(renderLane, updateLane)) {
// 跳过低优先级更新,但保留在链表中(优先级不够 被跳过)
const clone = createUpdate(pending.action, pending.lane);
onSkipUpdate?.(clone);
// 是不是第一个被跳过的
if (newBaseQueueFirst === null) {
// first u0 last = u0
newBaseQueueFirst = clone;
newBaseQueueLast = clone;
newBaseState = newState;
} else {
// first u0 -> u1 -> u2
// last u2
(newBaseQueueLast as Update<State>).next = clone;
newBaseQueueLast = clone;
}
} else {
// 优先级足够
if (newBaseQueueLast !== null) {
const clone = createUpdate(pending.action, NoLane);
newBaseQueueLast.next = clone;
newBaseQueueLast = clone;
}
const action = pending.action;
if (pending.hasEagerState) {
newState = pending.eagerState;
} else {
newState = basicStateReducer(baseState, action);
}
}
pending = pending.next as Update<any>;
} while (pending !== first);
if (newBaseQueueLast === null) {
// 本次计算没有update被跳过
newBaseState = newState;
} else {
newBaseQueueLast.next = newBaseQueueFirst;
}
result.memoizedState = newState;
result.baseState = newBaseState;
result.baseQueue = newBaseQueueLast;
}
return result;
};
pending !== first 设计为一个单向循环链表来方便遍历,为什么设计为双向循环链表?
前置知识:循环链表相比数组,在插入和删除方面更加高效。因为数组在插入和删除方面需要时间复杂度为 O(n)
React 的并发特性允许高优先级更新中断低优先级更新,使用循环链表数据结构可以满足:
- 保存中断点(记住当前节点)
- 从中断处继续执行
- 插入高优先级更新找到合适位置 使用其他的数据结构也能做,就是效率很低,循环链表更适合做这个事。
QA:什么是高优先级更新、什么是低优先级更新? 高优先级更新(同步/用户阻塞)
- 用户交互:点击、输入、滚动
- 动画:CSS transitions/animations
- 生命周期方法:componentDidMount等
低优先级更新(并发/可中断)
- 数据获取:API调用结果
- 懒加载:非关键内容加载
- 大计算量:复杂数据处理
React Hooks 链表结构
在 React 中,所有 Hooks(包括 useState、useEffect、useRef 等)都是通过一个单向链表结构来管理的,并非只有 useState 如此。这个链表是 React 内部用于追踪组件中 Hooks 调用顺序和状态的核心机制。
为什么用链表管理 Hooks?
React Hooks 的设计要求“必须在组件顶层调用”(不能在条件、循环、嵌套函数中调用),这正是因为 Hooks 的状态依赖于调用顺序。链表结构天然适合按顺序记录和访问 Hooks 的信息(如状态值、更新函数、依赖项等),确保每次渲染时 Hooks 的顺序与首次渲染一致,从而正确匹配对应的状态。
Hooks 链表的工作流程
React 会为每个组件实例维护一个独立的 Hooks 链表,其核心工作流程可分为首次渲染和重新渲染两个阶段:
1. 首次渲染(Mount 阶段)
-
当组件首次渲染时,React 会初始化一个
workInProgressHook指针(指向当前处理的 Hook 节点),并创建一个空的 Hooks 链表。 -
每调用一个 Hook(如
useState),React 会创建一个对应的 Hook 节点(包含该 Hook 的状态、更新函数、依赖项等信息),并将其添加到链表的末尾。 -
同时,
workInProgressHook指针会向后移动,指向新创建的节点,确保下一个 Hook 按顺序衔接。例如,组件中调用两个 Hooks:
function MyComponent() { const [count, setCount] = useState(0); // 第一个 Hook 节点 useEffect(() => {}, []); // 第二个 Hook 节点 return <div>{count}</div>; }首次渲染后,链表结构为:
useState 节点 -> useEffect 节点 -> null。
2. 重新渲染(Update 阶段)
-
当组件因状态更新(如调用
setCount)重新渲染时,React 会重置workInProgressHook指针到链表的头部。 -
再次按顺序调用 Hooks 时,React 会通过指针依次访问链表中已有的节点,直接复用或更新节点中的信息(而非重新创建节点)。
- 对于
useState:直接读取节点中保存的最新状态值,并返回更新函数。 - 对于
useEffect:检查当前依赖项与节点中保存的旧依赖项是否一致,决定是否执行副作用回调。
这种“按顺序复用节点”的机制,正是 Hooks 能在多次渲染中保持状态的核心原因。
- 对于
关键注意点
- 顺序必须严格一致:如果在条件语句中调用 Hook(如
if (condition) { useState() }),会导致重新渲染时 Hooks 调用顺序与首次渲染不一致,链表指针无法正确匹配节点,最终引发状态错乱或报错。 - 每个组件独立维护链表:不同组件的 Hooks 链表是隔离的,互不影响(通过组件的 Fiber 节点关联各自的 Hooks 链表)。
总结:所有 Hooks 共同组成一个单向链表,React 通过维护这个链表并严格遵循调用顺序,实现了 Hooks 在组件多次渲染中的状态追踪和复用。这一机制是 Hooks 设计的底层基础。
useEffect 工作原理
实验说明
AComponent
import { useEffect } from "react"; // 注意:是 useEffect 而非 use
export default function AComponent(props) {
// 普通函数:仅在 useEffect 回调中被调用,不是独立副作用
const effect1 = () => {
console.log("Effect 1(A组件的副作用逻辑1)");
return () => console.log("clean effect 1(A组件的清理逻辑1)");
};
const effect2 = () => {
console.log("Effect 2(A组件的副作用逻辑2)");
return () => console.log("clean effect 2(A组件的清理逻辑2)");
};
// A组件的唯一 useEffect 调用(生成1个 Effect 对象)
useEffect(() => {
// 回调中依次执行普通函数(属于该 Effect 对象的逻辑)
effect1();
effect2();
}, []);
return (
<div>
<h3>AComponent(父组件)</h3>
{props.children} {/* 渲染子组件B */}
</div>
);
}
BComponent
// BComponent.jsx
import { useEffect } from "react";
export default function BComponent() {
const effect3 = () => {
console.log("Effect 3(B组件的副作用逻辑1)");
return () => console.log("clean effect 3(B组件的清理逻辑1)");
};
const effect4 = () => {
console.log("Effect 4(B组件的副作用逻辑2)");
return () => console.log("clean effect 4(B组件的清理逻辑2)");
};
// B组件的唯一 useEffect 调用(生成1个 Effect 对象)
useEffect(() => {
effect3();
effect4();
}, []);
return <div>BComponent(子组件)</div>;
}
App.js
// App.jsx
import AComponent from "./AComponent";
import BComponent from "./BComponent";
function App() {
// 渲染结构:A是父组件,B是A的子组件
return (
<AComponent>
<BComponent />
</AComponent>
);
}
export default App;
上面的代码会输出:
Effect 3(B组件的副作用逻辑1)
Effect 4(B组件的副作用逻辑2)
Effect 1(A组件的副作用逻辑1)
Effect 2(A组件的副作用逻辑2)
为什么会这样输出??
源码探究
// 递归中的递阶段
export const beginWork = (wip: FiberNode, renderLane: Lane) => {
// bailout策略
didReceiveUpdate = false;
const current = wip.alternate;
if (current !== null) {
const oldProps = current.memoizedProps;
const newProps = wip.pendingProps;
// 四要素~ props type
// {num: 0, name: 'cpn2'}
// {num: 0, name: 'cpn2'}
if (oldProps !== newProps || current.type !== wip.type) {
didReceiveUpdate = true;
} else {
// state context
const hasScheduledStateOrContext = checkScheduledUpdateOrContext(
current,
renderLane
);
if (!hasScheduledStateOrContext) {
// 四要素~ state context
// 命中bailout
didReceiveUpdate = false;
switch (wip.tag) {
case ContextProvider:
const newValue = wip.memoizedProps.value;
const context = wip.type._context;
pushProvider(context, newValue);
break;
// TODO Suspense
}
return bailoutOnAlreadyFinishedWork(wip, renderLane);
}
}
}
wip.lanes = NoLanes;
// 比较,返回子fiberNode
switch (wip.tag) {
case HostRoot:
return updateHostRoot(wip, renderLane);
case HostComponent:
return updateHostComponent(wip);
case HostText:
return null;
case FunctionComponent:
return updateFunctionComponent(wip, wip.type, renderLane);
case Fragment:
return updateFragment(wip);
case ContextProvider:
return updateContextProvider(wip, renderLane);
case SuspenseComponent:
return updateSuspenseComponent(wip);
case OffscreenComponent:
return updateOffscreenComponent(wip);
case LazyComponent:
return mountLazyComponent(wip, renderLane);
case MemoComponent:
return updateMemoComponent(wip, renderLane);
default:
if (__DEV__) {
console.warn('beginWork未实现的类型');
}
break;
}
return null;
};
判断 fiber 节点的 tag 为 FunctionComponent 则执行 updateFunctionComponent 流程
function updateFunctionComponent(
wip: FiberNode,
Component: FiberNode['type'],
renderLane: Lane
) {
prepareToReadContext(wip, renderLane);
// render
const nextChildren = renderWithHooks(wip, Component, renderLane);
const current = wip.alternate;
if (current !== null && !didReceiveUpdate) {
bailoutHook(wip, renderLane);
return bailoutOnAlreadyFinishedWork(wip, renderLane);
}
reconcileChildren(wip, nextChildren);
return wip.child;
}
可以看到在 updateFunctionComponent 内部执行了 renderWithHooks 函数
export function renderWithHooks(
wip: FiberNode,
Component: FiberNode['type'],
lane: Lane
) {
// 赋值操作
currentlyRenderingFiber = wip;
// 重置 hooks链表
wip.memoizedState = null;
// 重置 effect链表
wip.updateQueue = null;
renderLane = lane;
const current = wip.alternate;
if (current !== null) {
// update
currentDispatcher.current = HooksDispatcherOnUpdate;
} else {
// mount
currentDispatcher.current = HooksDispatcherOnMount;
}
const props = wip.pendingProps;
// FC render
const children = Component(props);
// 重置操作
currentlyRenderingFiber = null;
workInProgressHook = null;
currentHook = null;
renderLane = NoLane;
return children;
}
useState 循环链表
对 useState 下断点会走到 pushEffect 的逻辑里,核心代码如下
function pushEffect(
hookFlags: Flags,
create: EffectCallback | void,
destroy: EffectCallback | void,
deps: HookDeps
): Effect {
const effect: Effect = {
tag: hookFlags,
create,
destroy,
deps,
next: null
};
const fiber = currentlyRenderingFiber as FiberNode;
const updateQueue = fiber.updateQueue as FCUpdateQueue<any>;
if (updateQueue === null) {
// 创建一个新的 effect 循环
const updateQueue = createFCUpdateQueue();
// 将新创建的循环队列赋值给当前的 fiber
fiber.updateQueue = updateQueue;
// 由于是循环链表,链表为空的情况下,当前节点的下一个节点指向自己,next 指针指向自己
effect.next = effect;
// lastEffect 指向最后一个节点。有了 lastEffect 就可以很方便的找到第一个节点。只一个节点的情况下,lastEffect 就是自己
updateQueue.lastEffect = effect;
} else {
// 插入effect
const lastEffect = updateQueue.lastEffect;
if (lastEffect === null) {
effect.next = effect;
updateQueue.lastEffect = effect;
} else {
const firstEffect = lastEffect.next;
lastEffect.next = effect;
effect.next = firstEffect;
updateQueue.lastEffect = effect;
}
}
return effect;
}
其中会调用 createUpdateQueue 方法。用于创建一个循环链表用于存储 effect
function createFCUpdateQueue<State>() {
const updateQueue = createUpdateQueue<State>() as FCUpdateQueue<State>;
updateQueue.lastEffect = null;
return updateQueue;
}
如果有多个 effect,则都会被添加到循环链表中,产生类似右侧的结构: effect1 -> effect2 -> effect1
useEffect 回调的执行时机
- 渲染阶段收集副作用
- 提交阶段执行副作用
针对上面的 Demo 逐步进行分析:
1. 渲染阶段(Reconciliation Phase):收集副作用,构建循环链表
当组件首次渲染时,React 会遍历组件树(从父到子),为每个组件创建 Fiber 节点,并收集其内部的 useEffect 副作用,存储到 Fiber 节点的副作用队列(updateQueue)中,队列底层是 循环链表(如之前分析的 pushEffect 逻辑)。
- 父组件 A 先进入渲染阶段:解析 A 组件的 useEffect 时,React 会调用 pushEffect 函数,将该 useEffect 的回调(包含 effect1、effect2 调用)封装为一个 Effect 对象,添加到 A 的 Fiber 节点的副作用队列(循环链表)中。此时 A 的队列中只有一个 Effect 节点(指向自身的循环链表)。
- 子组件 B 后进入渲染阶段:由于 B 是 A 的子组件,React 会先完成 A 的渲染框架,再递归渲染 B。解析 B 组件的 useEffect 时,同样通过 pushEffect 创建 Effect 对象,添加到 B 的 Fiber 节点的副作用队列(循环链表)中。
QA:假设一个页面存在3个自定义组件,每个组件内部存在一些 Dom 节点,那么会创建多少个 Fiber 节点,存在多少个 Fiber Tree?
2. 提交阶段(Commit Phase):遍历 Fiber 树,执行副作用
渲染阶段完成后,React 进入提交阶段,此时会遍历整个 Fiber 树,按 “先子后父” 的顺序执行所有收集到的副作用(useEffect 的回调函数)。 递归的“归”阶段。Fiber Tree 的 DFS 过程。
为什么是 “先子后父”?
组件挂载的逻辑是 “父组件挂载依赖子组件挂载完成”(父组件的 DOM 节点需要包含子组件的 DOM 节点)。因此,只有子组件完全挂载后,父组件才算真正挂载完成。副作用 (如 DOM 操作、数据请求)需要在组件挂载完成后执行,因此子组件的副作用先于父组件执行。 具体执行顺序:
- 遍历到 B 的 Fiber 节点,取出其副作用队列(循环链表)中的 Effect 对象,执行其 create 回调(即 useEffect 的回调),依次调用 effect3()、effect4(),输出 Effect 3、Effect 4。
- 遍历到 A 的 Fiber 节点,取出其副作用队列中的 Effect 对象,执行其 create 回调,依次调用 effect1()、effect2(),输出 Effect 1、Effect 2。
几个关键函数:
- flushPassiveEffects
- commitHookEffectList
export function commitHookEffectListCreate(flags: Flags, lastEffect: Effect) {
commitHookEffectList(flags, lastEffect, (effect) => {
const create = effect.create;
if (typeof create === 'function') {
effect.destroy = create();
}
});
}
function commitHookEffectList(
flags: Flags,
lastEffect: Effect,
callback: (effect: Effect) => void
) {
let effect = lastEffect.next as Effect;
do {
if ((effect.tag & flags) === flags) {
callback(effect);
}
effect = effect.next as Effect;
} while (effect !== lastEffect.next);
}
pendingPassiveEffects
在 commitRoot 方法中不断调用会走到 commitPassiveEffect 方法中。
function commitRoot(root: FiberRootNode) {
// ...
if (subtreeHasEffect || rootHasEffect) {
// beforeMutation
// mutation Placement
commitMutationEffects(finishedWork, root);
root.current = finishedWork;
// 阶段3/3:Layout
commitLayoutEffects(finishedWork, root);
} else {
root.current = finishedWork;
}
}
function commitPassiveEffect(
fiber: FiberNode,
root: FiberRootNode,
type: keyof PendingPassiveEffects
) {
// update unmount
if (
fiber.tag !== FunctionComponent ||
(type === 'update' && (fiber.flags & PassiveEffect) === NoFlags)
) {
return;
}
const updateQueue = fiber.updateQueue as FCUpdateQueue<any>;
if (updateQueue !== null) {
if (updateQueue.lastEffect === null && __DEV__) {
console.error('当FC存在PassiveEffect flag时,不应该不存在effect');
}
root.pendingPassiveEffects[type].push(updateQueue.lastEffect as Effect);
}
}
可以看到 React 在 commitRoot 提交阶段会遍历所有收集到的副作用 (useEffect 属于此类), root.pendingPassiveEffects[type].push(updateQueue.lastEffect as Effect) 通过这段代码,React 会将每个组件的副作用循环链表的“入口节点”(updateQueuee.lastEffect) 推入全局队列,而收集顺序是从 Fiber 叶子节点到父 Fiber 节点(DFS)
- 遍历到 BComponent 的 Fiber 节点时:
- 取 BComponent.updateQueue.lastEffect(即 EffectB,B 的循环链表入口节点)
- 将 EffectB 推入 root.pendingPassiveEffects.mount 数组。此时全局的队列为:[EffectB]
- 遍历到 AComponent 的 Fiber 节点时:
- 取 AComponent.updateQueue.lastEffect(即 EffectA,A 的循环链表入口节点)
- 将 EffectA 推入 root.pendingPassiveEffects.mount 数组。此时全局的队列为:[EffectB、EffectA]
在 commitRoot 阶段,会调用 flushPassiveEffects 方法。
function commitRoot(root: FiberRootNode) {
// ...
if (
(finishedWork.flags & PassiveMask) !== NoFlags ||
(finishedWork.subtreeFlags & PassiveMask) !== NoFlags
) {
if (!rootDoesHasPassiveEffects) {
rootDoesHasPassiveEffects = true;
// 调度副作用
scheduleCallback(NormalPriority, () => {
// 执行副作用
flushPassiveEffects(root.pendingPassiveEffects);
return;
});
}
}
// ...
}
flushPassiveEffects 方法实现如下
function flushPassiveEffects(pendingPassiveEffects: PendingPassiveEffects) {
let didFlushPassiveEffect = false;
pendingPassiveEffects.unmount.forEach((effect) => {
didFlushPassiveEffect = true;
commitHookEffectListUnmount(Passive, effect);
});
pendingPassiveEffects.unmount = [];
pendingPassiveEffects.update.forEach((effect) => {
didFlushPassiveEffect = true;
commitHookEffectListDestroy(Passive | HookHasEffect, effect);
});
pendingPassiveEffects.update.forEach((effect) => {
didFlushPassiveEffect = true;
commitHookEffectListCreate(Passive | HookHasEffect, effect);
});
pendingPassiveEffects.update = [];
flushSyncCallbacks();
return didFlushPassiveEffect;
}
可以看到内部分别处理了 pendingPassiveEffects.unmount、pendingPassiveEffects.update 托管的 effect。
export function commitHookEffectListCreate(flags: Flags, lastEffect: Effect) {
commitHookEffectList(flags, lastEffect, (effect) => {
const create = effect.create;
if (typeof create === 'function') {
effect.destroy = create();
}
});
}
通过 commitHookEffectListCreate 的实现可以知道,内部是封装调用了 commitHookEffectList 方法。
function commitHookEffectList(
flags: Flags,
lastEffect: Effect,
callback: (effect: Effect) => void
) {
let effect = lastEffect.next as Effect;
do {
if ((effect.tag & flags) === flags) {
callback(effect);
}
effect = effect.next as Effect;
} while (effect !== lastEffect.next);
}
commitHookEffectList 的核心职责是:
- 遍历 effect 循环链表,根据 flags 筛选出需要处理的 effect
- 然后调用 callback 对这些 effect 执行具体操作(比如执行 effect 的销毁函数 destroy 或创建函数 create) 它是 React 处理 Hook 副作用的「通用遍历器」,在不同阶段(如 layout 阶段处理 useLayoutEffect,passive 阶段处理 useEffect)会被传入不同的 flags 和 callback,以实现对不同类型副作用的精准处理。
QA:flushPassiveEffects 源码中,在执行 pendingPassiveEffects.update 相关的 effect 的时候,会先调用 destory,再去执行 create,为什么要这么做? 核心是保证副作用的正确性、避免资源泄漏,以及确保副作用与当前组件状态的一致性。 本质原因是:副作用的生命周期同步问题。React 的 effect 本质是「与组件状态关联的副作用」,它会随着组件的渲染(或依赖变化)而更新。当组件重新渲染(或依赖项变化)时,旧的 effect 可能已经基于「旧的状态 /props」,如果不先销毁旧的副作用,直接创建新的副作用,会导致:
- 旧的副作用与新状态的冲突:旧的副作用可能还在使用旧的 State,而新的副作用基于新的 State,两者并存会导致逻辑混乱(比如重复监听、数据不一致)
- 资源泄漏:如果副作用涉及资源占用(如事件监听、定时器、网络连接等),不销毁旧的副作用会导致这些资源无法释放,长期积累会引发内存泄漏或性能问题
对于 useEffect(异步执行的 effect),虽然执行时机在浏览器绘制后,但同样需要先销毁旧的副作用(基于旧状态),再创建新的(基于新状态),否则会导致副作用与组件当前状态脱节
举个例子:
function TimerDemo() {
// 计数器状态(会影响UI)
const [count, setCount] = useState(0);
// 定时器间隔(用户可修改)
const [delay, setDelay] = useState(1000); // 初始1秒
useEffect(() => {
// 创建定时器:每隔delay毫秒更新一次count
const timer = setInterval(() => {
// 用函数式更新确保获取最新的count(避免闭包问题)
setCount(prevCount => prevCount + 1);
}, delay);
// 销毁函数:清除当前定时器
return () => {
clearInterval(timer);
};
}, [delay]); // 依赖delay:当delay变化时,重新执行effect
return (
<div>
<h3>当前计数:{count}</h3>
<p>定时器间隔:{delay}ms</p>
<input
type="number"
value={delay}
onChange={(e) => setDelay(Number(e.target.value))}
/>
<p>修改输入框可改变间隔,观察计数变化</p>
</div>
);
}
effect 中包含定时器,依赖于 delay 状态。input 输入框内容变化会改变 delay 的值,从而重新创建 timer。如果 React 官方的实现里面,没有在 effect 的执行前,把 effect.destory 先执行,再去执行 effect.create 就可能存在2个 timer,timer 回调里会修改 count,造成 UI 的错乱。