30 KiB
汇编学习
基础知识回顾
地址总线:它的宽度决定了 CPU 的寻址能力。比如8086地址总线宽度为20,则寻址能力为1M(2的20次方) 数据总线:它的宽度决定了 CPU 单次数据传送量,也就是数据传输速度。比如8086的数据总线宽度为16,所以单次最大传递2个字节的数据/ 控制总线:它的宽度决定了 CPU 对其他其间的控制能力,能有多少种控制。
内存的分段管理:起始地址+偏移地址=物理地址,计算出物理地址再去访问内存。
偏移地址为16位,16位地址的寻址能力位64kb,所以一个段的长度最大为64kb。
CPU 的典型构成
-
寄存器:信息存储
-
运算器:信息处理
-
控制器:控制其他器件进行工作
对开发同学来说,CPU 中最主要的部件就是寄存器,“可以通过改变寄存器的内容来实现对 CPU 的控制”。
不同的 CPU,寄存器个数、结构是不同的(比如8086是16为结构的 CPU,8086有14个寄存器)
说明
-
汇编中,小括号内存放的一定是内存地址。
-
指令后面的字母代表操作数长度。比如 b = byte(8-bit),s = short(16-bit integer or 32-bit floating point)、w = word(16-bit)、l=long(32-bit integer or 64-bit floating point)、q=quad(64 bit)、t=tem bytes(80-bit floating point)。比如
movq $0xa, 0x86c1(%rip)是let a:Int = 10的汇编实现。 -
rip 存储的说指令的地址。CPU 要执行的下一条指令地址就存储在 rip 中
-
rax、rdx 寄存器一般作为函数返回值使用
func getValue() -> Int { return 10 } var v = getValue()
在第5行代码加断点,第4行汇编遇到 call 函数调用,LLDB 输入
si进去,可以看到将十六进制0xa也就是10,保存到寄存器%eax也就是%rax中。SwiftDemo`getValue(): -> 0x100003b20 <+0>: pushq %rbp 0x100003b21 <+1>: movq %rsp, %rbp 0x100003b24 <+4>: movl $0xa, %eax 0x100003b29 <+9>: popq %rbp 0x100003b2a <+10>: retqLLDB 输入
finsh结束函数调用这段汇编,可以看到在汇编的第5行,将%rax保存的 10 赋值到%rip + 0x86d0地址。可以看%rip + 0x86d0是个全局变量,大概就是 v 的地址(可以继续用汇编验证,绝对是 v)。
-
rdi、rsi、rdx、rcx、r8、r9 寄存器一般用来存储函数参数。

可以看到第四行汇编的
%edi...%r9d和上面描述的寄存器顺序一致。 -
rsp、rbp 寄存器用于栈操作。栈顶指针,指向栈的顶部
-
leaq 和 movq 是有区别的。
leaq 0xd(%rip), %rax是从%rip + 0xd算出来的地址值赋值给%rax,movq 0xd(%rip), %rax是从%rip + 0xd算出来的地址值,取8个字节给%rax。 -
xorl异或运算。
寄存器的高低位兼容设计
汇编中高位对于低位寄存器的兼容性设计: %r 开头的寄存器都是64位(8 Byte) %e 开头的寄存器都是32位的(4 Byte) 那如果所有的寄存器再去分 %r、%e 那就会存在很多寄存器了,使用和记忆很难了。
同时早期的寄存器之下写的汇编代码,升级的时候要改写,成本太大了。如何设计才可以兼容升级呢?
设计很巧妙。假设一个 %rax 的64位寄存器(0~63位)
- 64位:则 all in 全部使用
- 32位:为了兼容低的32位寄存器,则拿出低的4字节(0~31位)当作 %eax 32位寄存器来使用
- 16位:为了兼容16位的寄存器,则拿出低的2个字节(0~15位)当作 %ax 16位寄存器来使用;
- 8位:为了兼容8位的寄存器,则拿出低的2个字节(0~15位)分为2段,高8位、低8位来使用,分别是 %ah、%al 寄存器。


寄存器:
- r 开头:64 bit,8 Byte
- e 开头:32 bit,4 Byte
- ax、bx、cx、dx:16 bit,2 Byte
- ah、al、bh、bl...:8 bit,1 Byte
通用寄存器
AX、BX、CX、DX 这4个寄存器通常用来存放一般性的数据,成为通用寄存器(有时候也有特定用途)
通常 CPU 会把内存中的数据存储到通用寄存器中,然后再对通用寄存器中的数据进行运算
例如:在内存中有一个内存空间a值为3,需要将它的值加1,然后将结果存储到内存空间b上。
-
mov ax, a。CPU 首先会将内存空间 a 的值放到寄存器 ax 中 -
add ax, 1。调用 add 指令,将 ax + 1 -
mov b, ax。调用 mov 将 ax 中的值赋值给内存空间 b
CS和IP
CS 为代码段,IP 为指令指针寄存器,它们代表 CPU 当前要读取指令的地址
任意时刻,8086 CPU 都会将 CS:IP 指向的指令作为下一条需要取出执行的指令。
IP 只为 CS 提供服务。
8086 CPU 工作过程如下:
-
从
CS:IP指向的内存单元读取指令,读取的指令进入指令缓冲器 -
IP = IP + 当前所读取指令的长度。从而指向 IP 指向下一条指令
-
执行指令,转到步骤1,重复执行
在8086CPU 加电启动或者复位后(即 CPU 刚开始工作时)CS 被设置位 CS=FFFFH,IP 被设置为 IP=0000H,即在8086PC 机刚启动时,CPU 从内存 FFFF0H 单元中读取指令执行,FFFF0H 单元中的指令是 8086PC 机开机后执行的第一条指令。
注意:在内存或者磁盘上,指令和数据其实没有差别,都是二进制信息。CPU 在工作时把有的信息看成指令,有些信息看数据,为同样的信息赋予了不同意义。
那么 CPU 根据什么来判断这块内存上的信息是指令还是数据?
-
CPU 将
CS:IP所指向的内存单元的内容看作指令 -
如果内存中的某段内容曾被 CPU 执行过,那么它所在的内存单元肯定被
CS:IP指向过
jmp 指令
mov 指令不能用于设置 CS、IP 的值,8086没有提供该功能。可以通过 jmp 指令来实现修改 CS、IP 的值,这些指令被成为转移指令。
jmp 段地址:偏移地址 可以实现同时修改 CS、IP 的值,表示用指令中给出的段地址修改 CS,偏移地址 IP。
jmp 2AE3:3 执行后表示:CS=2AE3H,IP=0003H,CPU 将从2AE33H处读取指令。
QA:下面3条指令执行完毕后,CPU 修改了几次 IP 寄存器?
mov ax, bx
sub ax, ax
jmp ax
修改了4次。每执行一条指令,IP 都会被修改1次(IP=IP+该条指令的长度),最后一条指令执行后,IP 寄存器的值也会被修改1次,共3+1=4次。
jmp *%rax jmp 后面如果跟寄存器地址,则一定要加 *,地址存放在 %rax 中
ds 寄存器
CPU 要读写一个内存单元时,必须要给出这个内存单元的地址,在8086中,内存地址由段地址和偏移地址组成。
8086中有一个 DS 段寄存器,通常用来存放要访问数据的段地址
mov bx, 1000H
mov ds, bx
mov al, [0]
上面3条指令的意思是将 10000H (1000:0)中的内存数据,赋值到 al 寄存器中。
mov al, [address] 的意思是将 DS:address 该地址中的内存数据赋值到 al 寄存器中。
由于 al 是8位寄存器,所以上述命令是将一个字节的数据赋值给 al 寄存器。
tips:8086 不支持将数据直接送入段寄存器,所以 mov ds, 1000H 是错误的。
QA:写指令来实现将 al 中的数据写入到内存单元 10000H 中
mov ax, 1000
mov ds, ax
mov [0], al
QA:内存中有如下数据,写出下面指令执行后寄存器 ax 的值?
| 10000H | 23 |
|---|---|
| 10001H | 11 |
| 10002H | 22 |
| 10003H | 66 |
mov ax, 1000H
mov ds, ax
mov ax, [2]
代码分析:
-
第一条指令,ax 寄存器存放了 1000H 这个地址
-
第二条指令,将访问 ds 数据段,在 1000H 这个地址出访问
-
第三条指令,将数据段中 1000H 这个地址处,偏移 2,也就是内存中 10002H 这个的值22写入到 ax 中,由于 ax 寄存器是16位,所以会取2个单位的数据,22和66。所以 ax 的值为2266。
8086 CPU 下,AX、BX、CX、DX 等通用寄存器均被分为高位和低位,AX = AH + AL,其中高位寄存器和低位寄存器。高位和低位都是16位。所以会从10002H 开始取2个16位的数据赋值给 ax。
思考:如果代码改变下呢,如下
mov ax, 1000H
mov ds, ax
mov al, [2]
此时 al 的值为多少?al 和 ax 的区别在于 ax = ah + al,所以 al 的情况下直接从 10002H 开始取1个16位的数据,所以 al 为 0022。
大小端序
小端序,指的是数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中
大端序,指的是数据的高字节保存在内存的低地址中,数据的低字节保存在内存的高地址中。
注意:这里的大小端序还存在网络大小端序 NBO 和主机大小端序 HBO,详细可以查看我这篇文章
Big Endian:PowerPC、IBM、Sun
Little Endian:x86、DEC
ARM:大小端序模式下均可工作。
16bit 宽的数0x1234 分别在大小端序模式的 CPU 内存存放形式为
| 内存地址 | 小端序 | 大端序 |
|---|---|---|
| 0x4000 | 0x34 | 0x12 |
| 0x4001 | 0x12 | 0x34 |
32bit宽的 0x12345678 分别在大小端序模式的 CPU 内存存放形式为
| 内存地址 | 小端序 | 大端序 |
|---|---|---|
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
QA:将 0x1122 存放在 0x40002 中,如何存储?
分析 0x1122需要2个字节,0x40002 是1个字节,所以肯定需要在 0x40002和向后的一个字节中存储。然后考虑主机序的大小端情况。假设小端模式下:
0x40000
0x40001
0x40002 0x22
0x40003 0x11
指令操作明确 CPU 操作的内存
mov ax, 1000H
mov ds, ax
mov word ptr [0], 66h
上述代码先把 1000H 写入 ax 寄存器,然后访问数据段的 1000H 内存,然后将66h写入到数据段的0位置,但是 word 告诉了 CPU 需要操作2个字节,也就是 00 66
指令执行前:1000: 0000 11 22 00 00 00 00 00 00
指令执行后:1000: 0000 00 66 00 00 00 00 00 00
如果将第三行代码改为 mov byte ptr [0], 66h,意味着明确告诉计算机需要操作1个字节,也就是66 。
指令执行前:1000: 0000 11 22 00 00 00 00 00 00
指令执行后:1000: 0000 66 22 00 00 00 00 00 00
栈
栈是一种后进先出特点的数据存储空间(LIFO)
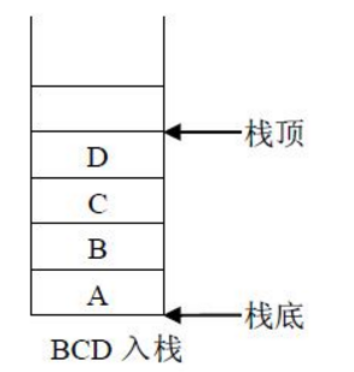
-
8086 会将 CS 作为代码段的段地址,将
CS:IP指向的指令作为下一条需要取出执行的指令 -
8060会将 DS 作为数据段的段地址,
mov ax, [address]就是取出DS:address内存区域上的数据放到 ax 寄存器中 -
8086会将 SS 作为栈段的段地址,
SS:SP指向栈顶元素 -
8086提供了 PUSH 指令用来入栈,POP 出栈。PUSH ax 是将 ax 的数据入栈,pop ax 是将栈顶的数据送入 ax
SS: 栈的段地址
SP:堆栈寄存器存放栈的偏移地址
push
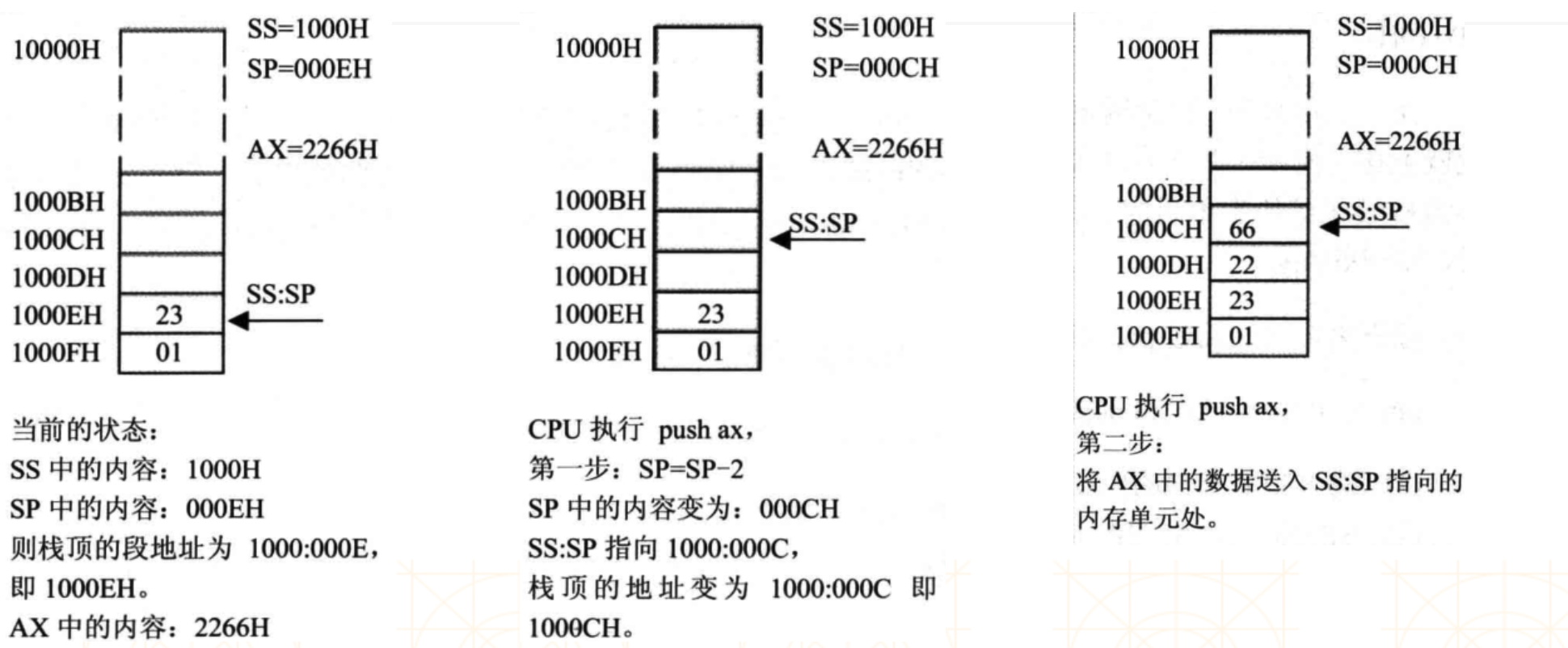
push ax 指令执行,会拆解为:
-
SP = SP-2,SS:SP指向当前栈顶前面的单元,更新栈顶指针 -
将 ax 中的数据送入到
SS:SP所指向的内存单元处
ax = ah + al,所以 ax 中的数据入栈需要占据2个单位(sp = sp - 2)
pop
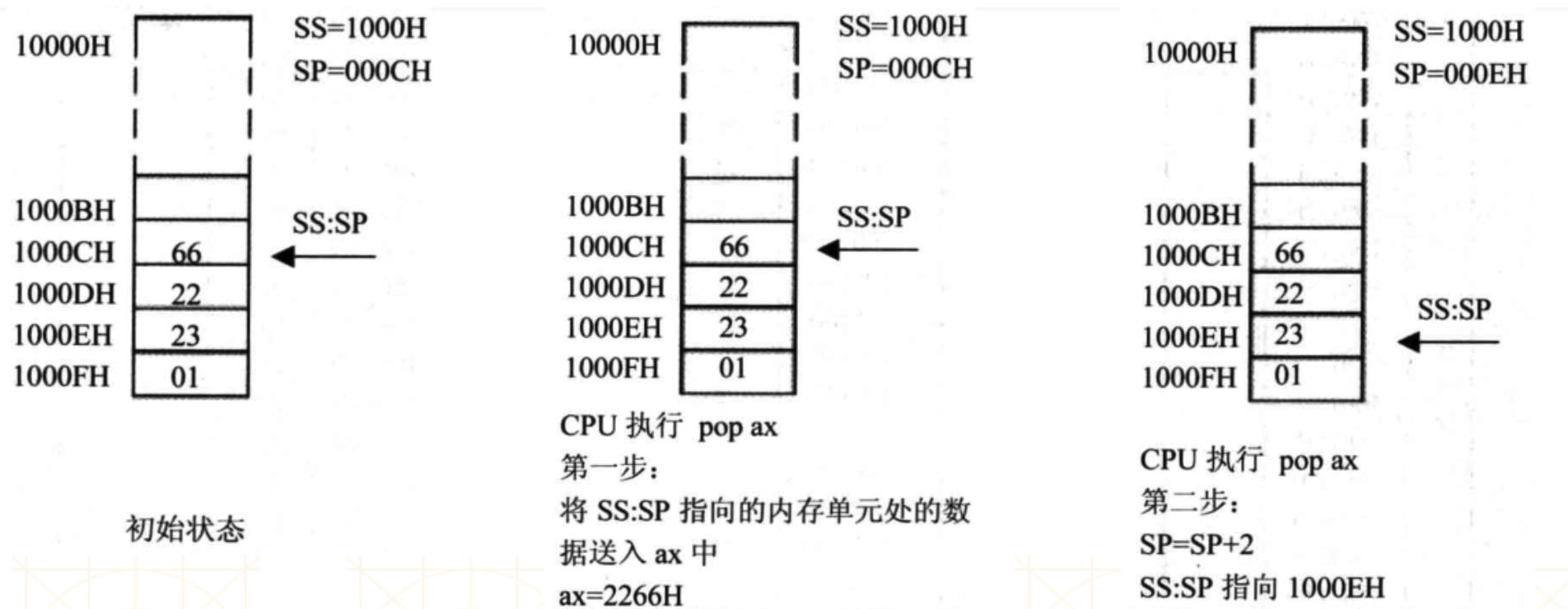
pop ax 指令执行,会拆解为:
-
将
SS:SP栈顶指向的内存单元中的数据(2个单位)写入到 ax 寄存器中 -
SP = SP + 2,更新SS:SP栈顶的地址
注意:
当一个栈空间是空的时候,SS:SP 指向栈空间最高地址单元的下一个单元。
![]()
当一个栈空或者满的时候,执行 PUSH、POP 指令需要注意,因为 SP = SP + 2、SP = SP - 2 都会导致将错误的数据入栈或者错误的数据出栈,导致发生不可预期的事情。
QA:将10000H~1000FH 这段空间当作栈,初始栈为空,AX = 001AH,BX=001BH,利用栈,交换 AX、BX 中的数据
push ax
push bx
pop ax
pop bx
段总结
数据段:存放数据的段
代码段:存放代码的段
栈段:将一个段当作栈
对于数据段,将它的段地址放在 DS 中,用 mov、add、sub 等访问内存单元的指令时,CPU 则认为数据段中的内容是数据来访问
对于代码段,将它的段地址存放在 CS 中,将段中的第一条指令的偏移地址放在 IP 中,这样 CPU 就将执行我们定义的代码段的指令(每执行一条指令之前,就会将 IP 的值更新,规则为 IP = IP + 当前指令的长度,以保证该条指令执行完可以根据 段地址 + 偏移地址获取到下条指令的地址)
对于栈段,将它的段地址存放在 SS 中,将栈顶单元的偏移地址存放在 SP 中,这样 CPU 在进行栈操作(LIFO)的时候比如 push、pop 指令,就可以操作 SP,将我们定义的栈段当作栈空间来使用
中断
中断是由于软件或者硬件的信号,使得 CPU 暂停当前的任务,转而去执行另一段子程序。
在程序运行过程中,系统出现了一个必须由 CPU 立即处理的情况,此时,CPU 暂时终止当前程序的执行转而处理这个新情况的过程就叫中断。
中断分为:
-
硬中断(外中断):由外部设备(网卡、硬盘)随机引发的,比如当网卡收到数据包的时候,就会发出一个中断
-
软中断(内中断):由执行中断指令产生,可以通过程序控制触发
汇编中主要指的是软中断,可以通过指令 int n 产生中断,其中 n 表示中断码,内存中有一张中断向量表,用来存放中断码对应中断处理程序的入口地址。
Demo:写一个打印 Hello World 的汇编代码
; 提醒开发者每个段的定义(增加可读性)
assume cs:code, ds:data
;------ 数据段 begin --------
data segment
age db 20h
no dw 30h
db 10 dup(6) ; 生成连续10个6
string db 'Hello world!$'
data ends
;------ 数据段 end --------
;------ 代码段 begin --------
code sgement
start:
; 设置 ds 的值
mov ax, data
mov ds, ax
mov ax, no
mov bl, age
; 打印字符串
mov dx, offset string ; offset string 代表 string 的偏移地址(将地址赋值给 dx)
mov ah, 9h
int 21h ; 打印字符串其实也是一次中断
; 退出程序
mov ax, 4c00h
int 21h
code ends
end start
;------ 代码段 end --------
-
start 代表汇编程序的入口
-
mov ax, 4c00h和int 21h代表程序正常中断
QA:“全局变量的地址在编译那一刻就确定好了”怎么理解?
全局变量存放在数据段,我们开发者写的代码存放在代码段,位置不一样,编译期就可以确定全局变量的地址。
call 和 ret 指令
实现打印3次 "Hello"
方法1
assume ds:data, ss: stack, cs: code
; 栈段
stack segment
ends stack
; 数据段
data segment
ends data
; 代码段
code segment
start:
; 设置 ds、ss
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
; 业务逻辑
; 打印
; ds:dx 告诉字符串地址
mov dx, offset string
mov ah, 9h
int 21h
mov dx, offset string
mov ah, 9h
int 21h
mov dx, offset string
mov ah, 9h
int 21h
; 程序正常退出
mov ax, 4c00h
int 21h
code ends
end start
有没有问题?重复出现2次以及以上,需要封装为函数,汇编也遵循这个原则
方法2
assume ds:data, ss: stack, cs: code
; 栈段
stack segment
ends stack
; 数据段
data segment
ends data
; 代码段
code segment
start:
; 设置 ds、ss
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
; 业务逻辑
call print
call print
call print
; 程序正常退出
mov ax, 4c00h
int 21h
print:
; 打印
; ds:dx 告诉字符串地址
mov dx, offset string
mov ah, 9h
int 21h
; 函数正常退出
ret
code ends
end start
说明:
call 会将下一条指令的偏移地址入栈;会转到标号(print:) 处执行指令
ret 会将栈顶的值出栈,赋值给 CS:IP ,ret 即 return
函数调用的本质
函数的3要素:参数、返回值、局部变量
返回值
函数运算的结果,一般是放在 ax 通用寄存器中。可以拿 Xcode 将下面的代码执行下,断点开启在 test 方法内的 return 处(Debug - Debug WorkFlow - Always show Disassembly)
#import <Foundation/Foundation.h>
int test (void) {
return 9;
}
int main(int argc, const char * argv[]) {
int res = test();
printf("%d", res);
return 0;
}
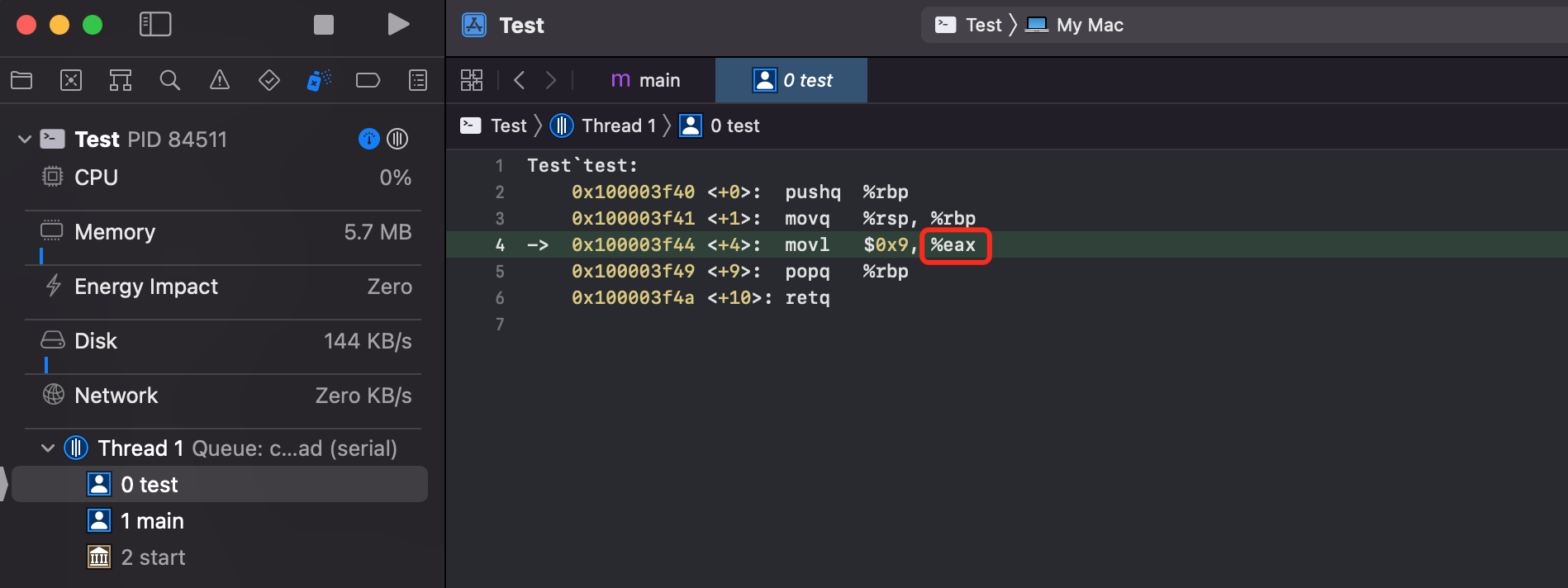
可以看到 return 的值是保存在 eax 寄存器中。为什么是 e,e是32位的意思(环境:老款 MBP 电脑运行)。
参数
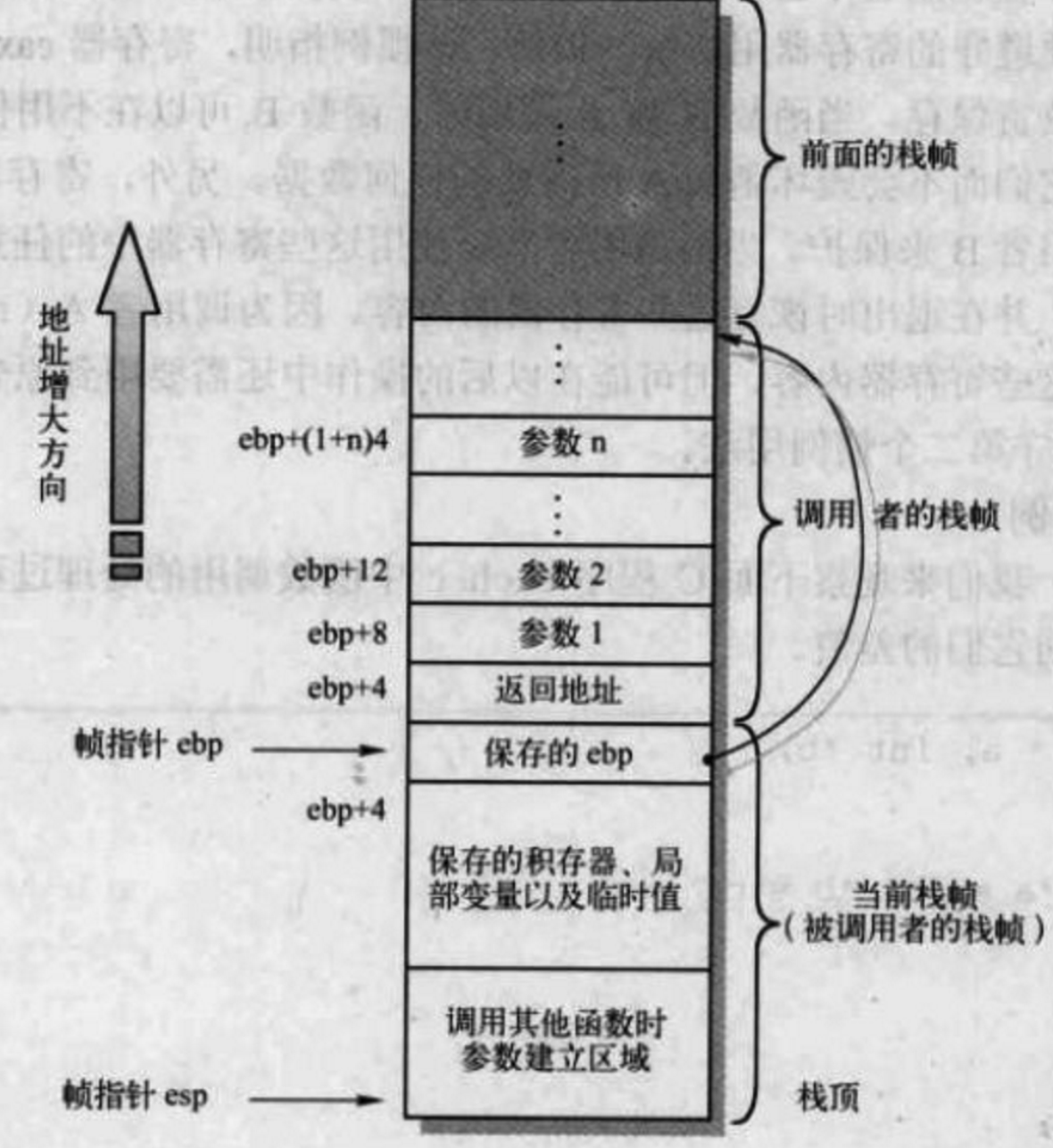
需要用的时候 push,最后不用则 pop,所以用栈来传参。
注意利用栈传递参数,在函数内部计算之后(return出来),需要保证栈平衡,也就是函数调用前后的栈顶指针要一致。
栈不平衡会导致栈空间迟早溢出,发生不可预期的错误。
Demo
push 1122h
push 2233h
call sum
add sp, 4
sum:
; 访问栈中的参数
mov bp, sp
mov ax, ss:[bp + 2]
add ax, ss:[bp + 4]
ret
-
上面代码调用2次 push 将方法参数入栈,调用 sum 方法(call sum),call 本质会将下一行指令的地址压入栈,所以目前栈有3个元素。
-
函数执行完毕,调用 ret 指令会将栈顶的指令 pop 出来,更改
CS:IP然后马上执行 -
访问栈中的参数的时候,由于 call 指令会将下一条指令地址也入栈,所以访问需要 +2
-
访问栈中参数 +2 的时候不能直接
sp + 2,需要用 bp
但目前函数调用结束了,栈里面还存在2个局部变量,导致空间浪费了,会存在“栈平衡”问题。所以在函数调用完毕,需要告诉内存,将栈顶指针恢复原位 sp = sp + 4(类比程序员告诉计算机,这块内存我不用了,后续其他人的代码可以用这块内存存某个值)
QA:stack overflow?
清楚函数调用原理 call、ret、stack 就知道函数调用函数,常见的递归或者循环,其实函数都在 stack 上进行操作,比如函数参数、函数下一条指令也会入栈,在递归或者函数内不断调用函数的过程中,stack 不及时”栈平衡“,很容易出现栈溢出的情况,也就是 stack overflow。
内平栈/外平栈
外平栈
push 1122h
push 2233h
call sum
add sp, 4
sum:
; 访问栈中的参数
mov bp, sp
mov ax, ss:[bp + 2]
add ax, ss:[bp + 4]
ret
内平栈
push 1122h
push 2233h
call sum
sum:
; 访问栈中的参数
mov bp, sp
mov ax, ss:[bp + 2]
add ax, ss:[bp + 4]
ret 4
内平栈的好处是函数调用者不用去处理“栈平衡”
函数调用的约定
__cdecl 外平栈,参数从右到左入栈
_stdcall 内平栈,参数从右到左入栈
_fastcall 内平栈,ecx、edx 分别传递前面2个参数,其他参数从右到左入栈
寄存器传递参数效率更高,速度更快,iOS 平台函数采用6到8个 寄存器传参,剩余的从右到左入栈。
c 代码可与汇编混合开发
验证函数的返回值是存放在 eax 寄存器中(eax 和 ax 区别在于位数)
#import <Foundation/Foundation.h>
int test (int a, int b) {
return a + b;
}
int main(int argc, const char * argv[]) {
test(2, 8);
int c = 0;
__asm {
mov c, eax
}
printf("%d", c);
return 0;
}
// 10
函数局部变量
大多数情况下函数内部会存在局部变量,但是不知道局部变量到底有多少,如何保证局部变量不会被污染呢?
CPU 会在栈内部,将局部变量的地方,临时分配10字节大小空间用来存储局部变量。这个怎么实现呢?SP = SP - 10 这条指令用来将栈顶指针改变,留出10字节大小空间。但是留出的空间是空的,万一 CS:IP 指向这块区域会把里面的数据当作指令去执行,则可能发生一些不可预知的错误。Windows 平台,针对预留的局部变量空间,会走动填充 cc,也就是 int 3 断点中断,只要 CS:IP 去执行就会断点中断,更安全。
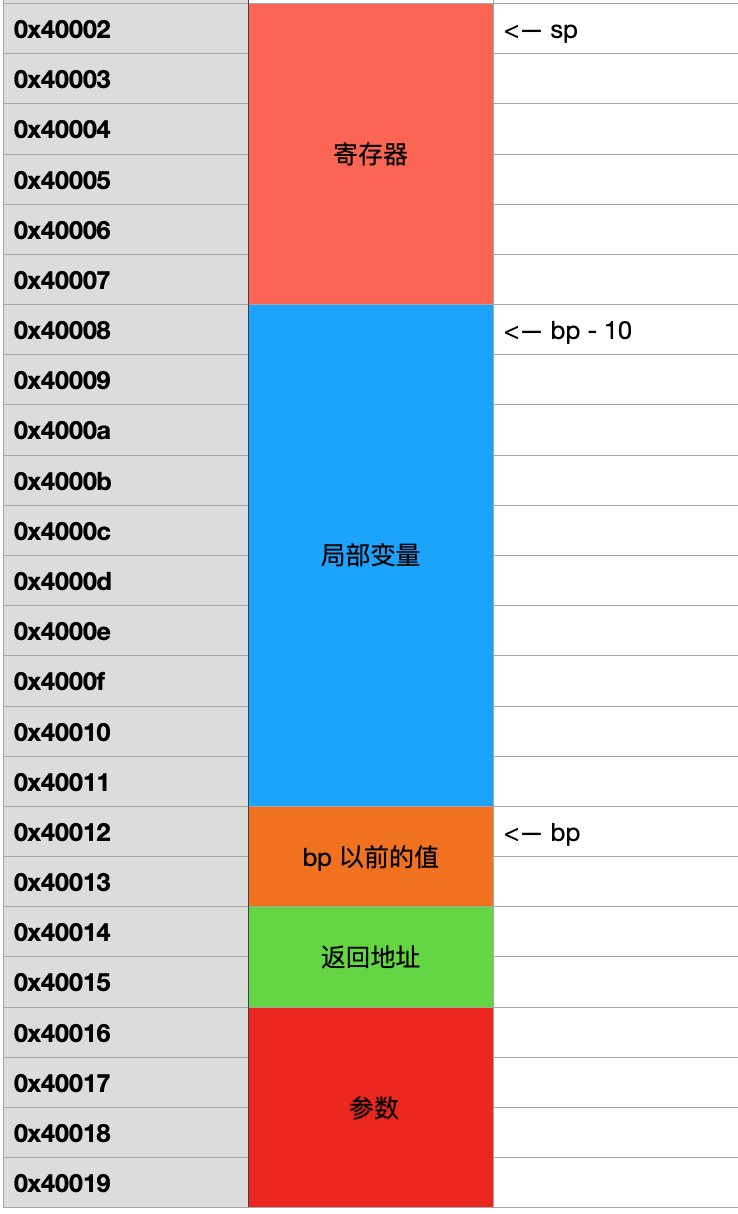
关键代码如下:
; 返回值放在 ax 寄存器中
; 传递2个参数(放入栈中)
sum:
; 保护 bp
push bp
; 保存 sp 之前的值;指向 bp 以前的值
mov bp, sp
; 预留10个字节的空间用来存放局部变量(栈,内部是高地址向)
sub sp, 10
; 保护可能用到的寄存器
push si
push di
push bx
; 给局部变量空间填充 int 3(cccc):调试中断,以增加 `CS:IP` 安全性
; stosw 的作用:将 ax 的值拷贝到 es:di 中
mov ax, 0cccch
; 让 es 等于 ss
mov es, ss
mov es, bx
; 让 di = bp - 10(局部变量地址的最小处)
mov di, bp
sub di, 10
; cx 的值决定了 rep 的执行次数
mov cx, 5
; rep 重复执行某条指令(次数由 cx 的值决定)
rep stosw
; 业务逻辑
; 定义2个局部变量
mov word ptr ss:[bp-2], 3
mov word ptr ss:[bp-4], 4
mov ax, ss:[bp-2]
add ax, ss:[bp-4]
mov ss:[bp-6], ax
; 访问栈中的参数
mov ax, ss:[bp+4]
add ax, ss:[bp+6]
add ax, ss:[bp-6]
; 恢复寄存器中的值
pop bx
pop di
pop si
; 恢复 sp
mov sp, bp
; 恢复 bp
pop
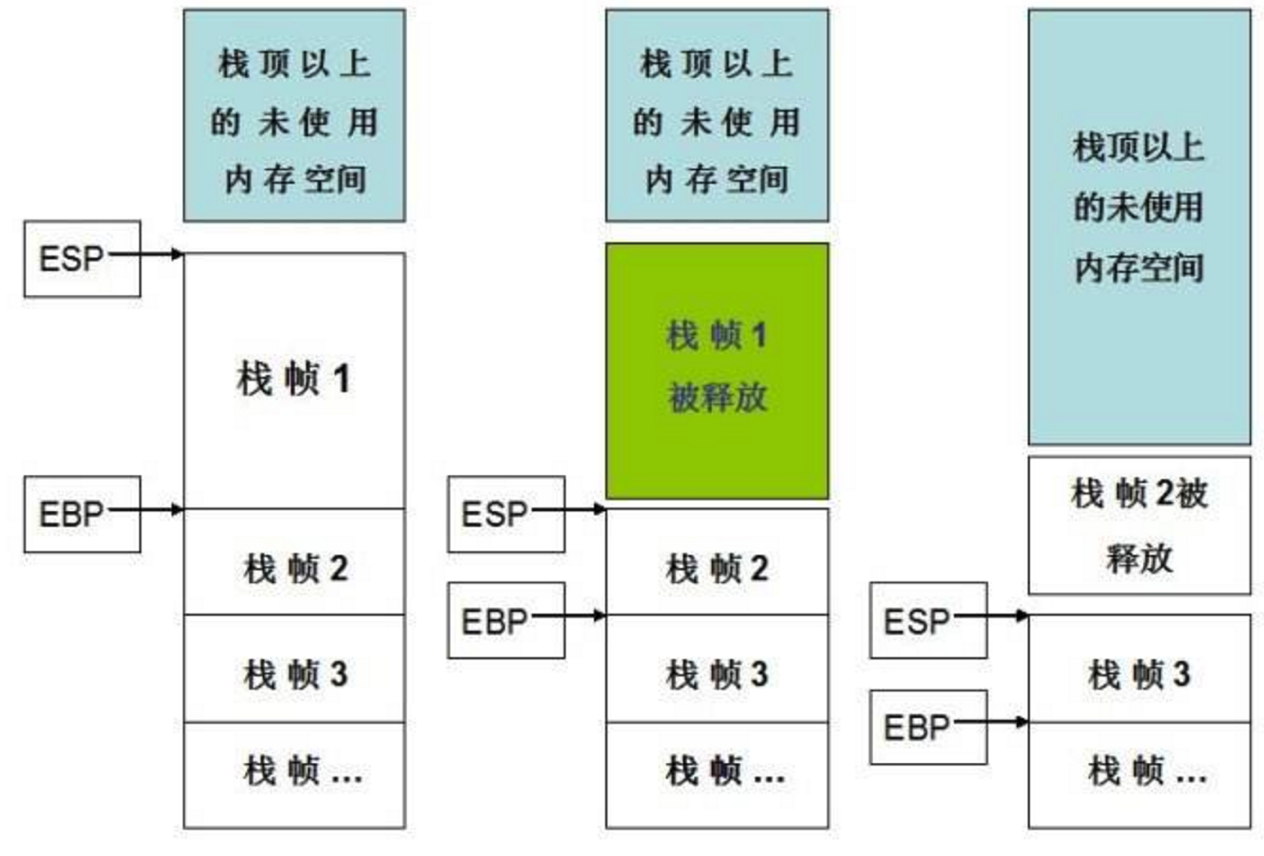
栈帧
Stack Frame Layout,代表一个函数的执行环境。包括:参数、返回地址、局部变量和包括在本函数内部执行的所有内存操作等
iOS 调用汇编
- 在 Xcode 工程中创建文件,选择 Other -> empty,保存为
.s拓展名

-
编写汇编代码
.text .global _test _test: movq $0x8, %rax; ret;创建一个名为
test的函数,内部给 rax 寄存器赋值为8,然后 ret 返回。.text是保存在 _TEXT 段上。并将函数暴露给全局,函数名为 test,暴露的时候就要写 _test -
汇编函数给外部调用,就需要声明一个头文件
Asm.h,写好需要暴露的方法声明 -
最后在使用的地方,引入暴露的汇编头文件
Asm.h,正常调用函数即可。

汇编编写“函数”
上面的例子也顺带看了汇编是如何编写“函数”的,为什么加引号,因为这个概念是不存在的,汇编只有指令,这个函数概念是方便组织代码,参考定义的。类似给一段代码打了个标签。
-
创建汇编文件
-
编写代码
.text .global _test, _add, _sub _test: movq $0x8, %rax; ret; _add: movq %rsi, %rax movq %rdi, %rbx addq %rbx, %rax retq _sub: movq %rdi, %rax movq %rsi, %rbx subq %rbx, %rax ret
说明:笔者编写平台是老款 MBP,Xcode 连接模拟器跑的代码,也就是 X86_64 架构的汇编。真机运行一般跑 arm64 汇编语法,会 X86_64 的话 arm64 类似,翻译下写法就好。
看这2个函数,都是从
rsirdi寄存器里面获取函数参数,内部调用系统指令,做了减加运算逻辑后,将函数返回值保存到rax寄存器中,直接 return。不需要显示声明return rax,汇编会自动将rax寄存器里的值,交给函数调用者。 -
汇编函数给外部调用,就需要声明一个头文件
Asm.h,写好需要暴露的方法声明 -
最后在使用的地方,引入暴露的汇编头文件
Asm.h,正常调用函数即可。
iOS 源码探索
经常需要将黑盒的 iOS 代码结合 GNU 之外,还需要将源文件编译成汇编代码去分析。格式为:
xcrun --sdk iphoneos clang -S -arch arm64 main.m -o main.s
arm64 汇编
寄存器
通用寄存器
- 64位: x0~x28
- 32位:w0~w28(属于 x0~x28 的低32位)
- x0~x7 经常用来存放函数的参数,更多的函数参数用堆栈来传递
- x0 经常用来存放函数的返回值
Demo:汇编定义加减法,OC 去调用
// Asm.s
.text
.global _add, _sub
_add:
add x0, x0, x1
ret
_sub:
sub x0, x0, x1
ret
// ViewContoller.m
#import "Asm.h"
NSInteger sum = add(2, 4) // 6
NSInteger res = sub(4, 2) // 2
程序计数器
pc(Program Counter)
堆栈指针
- sp(Stack Pointer)
- fp(Frame Pointer),也就是 x29
链接寄存器
lr(link register),也就是 x30
程序状态寄存器
- cpsr(Current Program Status Register)
- spsr(Saved Program Status Register),异常状态下使用
指令
-
ret:函数返回
-
cmp:将2个寄存器的值相减,结果会影响 cpsr 寄存器的标志位
-
b:跳转指令。格式为:
b{条件} 目标地址。b 指令是最简单的跳转指令,一旦遇到一个 B 指令,ARM 处理器将立即跳转到给定的目标地址,从那里继续执行。条件跳转一般搭配 cmp 使用。条件跳转对应
if...else...Demo:定义一段汇编代码一个标签,然后跳转执行。跳转前传递参数,跳转后读取并相加
.text .global _jump _jump: movq $0x1, %rsi jmp myCode myCode: movq %rsi, %rax movq $0x2, %rbx addq %rbx, %rax ret

上面是 x86_64 的汇编,
jmp跳转指令在 arm64 中对应b指令。类似下面代码.text .global _jump: _jump: // ... b myCode myCode: // ...条件跳转:
bgt conditionJump.text .global _jump _jump: mov x0, #0x5 mov x1, #0x5 cmp x0, x1 bgt conditionJump conditionJump: mov x1, #0x6 ret -
bl:带返回值的跳转指令。格式为:
bl{条件} 目标地址。bl 跳转前,会在寄存器 r14 中保存 pc 的当前内容,因此,可以通过将 r14 的内容重新加载到 pc 中,来返回到跳转指令之后的那个指令处执行。该指令是实现子程序调用的一个基本但常用的手段。在 x86_64 中就是 call 指令。
条件域
- EQ:equal 相等
- NE:not equal 不想等
- GT:great than 大于
- GE:greater equal 大于等于
- LT:less than 小于
- LE:less equal 小于等于
内存操作
-
load 从内存中装载数据
-
ldr
ldr x0, [x1]代表从地址 x1 处,取8个字节的数据,赋值给 x0(会将 x1 寄存器中存储的内存地址所指向的值加载到 x0 寄存器中)。ldr w0, [x1]代表从地址 x1 处,取4个字节的数据,赋值给 w0。一般会搭配 CPU 寻址能力一起使用。 -
ldur
和 ldr 一样,作用都是从一个寄存器中存储的内存地址所指向的值加载到某个寄存器上。ldr 搭配正数地址,如
ldr x1, [sp, #0x28],ldur 搭配负数地址,如ldur w8, [x29, #-0x8] -
ldp,
ldp w0, w1, [x2, #0x10]代表从 x2 + 0x10 计算结果对应的内存出,取出前4个字节的值赋值给寄存器 w0,后4个字节对应的值赋值给寄存器 w1
-
-
store 往内存中存储数据
-
str。
str w0, [x1, #0x5]将 w0 寄存器的值赋值给x1 + #0x5地址开始,4个字节处。str 搭配正数地址偏移 -
stur。
str w0, [x1, #-0x5]将 w0 寄存器的值赋值给x1 - #0x5地址开始,4个字节处。stur 搭配正数地址偏移 -
stp。
stp w0, w1, [x1, #0x5]将 w0 寄存器的值赋值给x1 + #0x5地址开始,前4个字节处,w1 寄存器的值赋值给后4个字节 -
零寄存器
- wzr(32bit)即 word zero register。
- xzr(64bit)
int a = 0; long b = 0;转换为 arm64 汇编就是
stur wzr, [x29, #-0x14] stur xzr, [x29, #-0x24]
-
经验小结
- 内存地址格式为:
0x7ab60(%rip)一般是全局变量 - 内存地址格式为:
-0x50(%rbp)一般是局部变量 - 源代码 -> 汇编 -> 机器码,从机器码到汇编是可逆的。但是无法做到汇编到源代码的反编译,因为不同的源代码可能生成的汇编代码是一样的。