feat: 浏览器渲染原理
18
Chapter1 - iOS/1.111.md
Normal file
@@ -0,0 +1,18 @@
|
||||
## 写给 iOSer 的鸿蒙开发 tips
|
||||
|
||||
## 下载问题
|
||||

|
||||
The other possible cause is that the system language of the PC is English and the region code is US. You could try to perform the following operations to change the region code to CN. Before changing the region code, close DevEco Studio.
|
||||
|
||||
|
||||
For Mac OS: ~/Library/Application Support/Huawei/DevEcoStudio3.0/options/country.region.xml
|
||||
|
||||
修改为 CN
|
||||
|
||||
```xml
|
||||
<application>
|
||||
<component name="CountryRegionSetting">
|
||||
<countryregion name="CN"/>
|
||||
</component>
|
||||
</application>
|
||||
```
|
||||
@@ -10,7 +10,7 @@ NSTimer、CADisplayLink 的 基础 API `[NSTimer scheduledTimersWithTimeInterval
|
||||
|
||||
栈、堆、BSS、数据段、代码段
|
||||
|
||||

|
||||

|
||||
|
||||
栈(stack):又称作堆栈,用来存储程序的局部变量(但不包括static声明的变量,static修饰的数据存放于数据段中)。除此之外,在函数被调用时,栈用来传递参数和返回值。栈内存地址越来越少
|
||||
|
||||
@@ -37,7 +37,7 @@ BSS段(bss segment):通常用来存储程序中未被初始化的全局变
|
||||
|
||||
代码段(code segment):编译之后的代码。通常是指用来存储程序可执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。
|
||||
|
||||
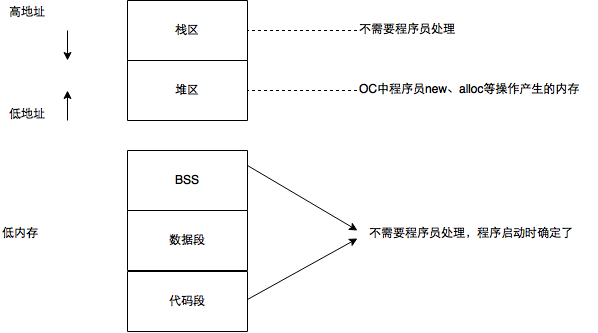
|
||||

|
||||
|
||||
上 Demo 验证
|
||||
|
||||
@@ -147,7 +147,7 @@ Demo1
|
||||
|
||||
运行该代码会 Crash,报错信息如下
|
||||
|
||||

|
||||

|
||||
|
||||
说明:一开始的报错信息只说坏内存访问,但是并没有显示具体的方法调用堆。想知道具体 Crash 原因还是需要看看堆栈比较方便。输入 bt 查看最后是由于 `objc_release` 方法造成 crash。
|
||||
|
||||
@@ -257,7 +257,7 @@ static inline bool _objc_isTaggedPointer(const void * _Nullable ptr)
|
||||
|
||||
tips:某些对象虽然是 TaggedPointer 类型,但是打印 class 发现不是,猜测可能是系统用类簇隐藏了某些实现细节。比如下面
|
||||
|
||||

|
||||

|
||||
|
||||
针对 NSNumber 的 TaggedPoniter 的 case,查看 class 打印出 `__NSCFNumber`。但根据源码和内存高地址位分析确实是 TaggedPoniter。
|
||||
|
||||
@@ -826,7 +826,7 @@ void sel_init(size_t selrefCount){
|
||||
|
||||
在 gone 处加断点,利用 runtime 查看类中的方法信息
|
||||
|
||||

|
||||

|
||||
|
||||
发现存在 `.cxx_destruct` 方法。
|
||||
|
||||
@@ -861,7 +861,7 @@ void sel_init(size_t selrefCount){
|
||||
@end
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
Tips:@property 会自动生成成员变量,另外类后面加 `{}` 在内部也可以加成员变量,假如成员变量是对象类型,比如 NSString,则叫实例变量。
|
||||
|
||||
@@ -875,7 +875,7 @@ Tips:@property 会自动生成成员变量,另外类后面加 `{}` 在内部
|
||||
|
||||
在 gone 的地方加断点,输入 `watchpoint set variable p->_name`,则会将 `_name` 实例变量加入 watchpoint,当变量被修改时会触发断点,可以看出从某个值变为 0x0,也就是 nil。此时边上调用堆栈显示在 `objc_storestrong` 方法中,被设置为 nil.
|
||||
|
||||

|
||||

|
||||
|
||||
### 深入 .cxx_destruct
|
||||
|
||||
@@ -1123,7 +1123,7 @@ class AutoreleasePoolPage {
|
||||
- 每个 AutoreleasePoolPage 对象占用 4096 字节内存,除了用来存放它内部的成员变量,剩下的空间用来存放 autorelease 对象的地址
|
||||
- 所有的 AutoreleasePoolPage 对象通过**双向链表**的形式连接在一起。child 指向下一个对象,parent 指向上一个对象
|
||||
|
||||

|
||||

|
||||
|
||||
```objectivec
|
||||
id * begin() {
|
||||
@@ -1181,7 +1181,7 @@ int main(int argc, const char * argv[]) {
|
||||
|
||||
main 方法内部3个 autoreleasepool 底层怎么样工作的?
|
||||
|
||||

|
||||

|
||||
|
||||
3个@auto releasepool, 系统遇到第一个的时候底层就是初始化一个结构体 `__AtAutoreleasePool`,结构体构造方法内部调用 `AutoreleasePoolPage::push` 方法,系统给 AutoreleasePoolPage 真正保存 autorelease 对象的地方存储进一个 `POOL_BOUNDARY` 对象,然后储存 P1、P2 对象地址,遇到第二个则继续初始化结构体,调用 push 方法,存储一个` POOL_BOUNDARY` 对象,继续保存 P3,遇到第三个则继续初始化结构体,调用 push 方法,存储一个 `POOL_BOUNDARY` 对象,继续保存 P4。
|
||||
|
||||
@@ -1963,7 +1963,7 @@ static inline id *autoreleaseFast(id obj) {
|
||||
|
||||
每当进行一次`objc_autoreleasePoolPush`调用时,runtime 向当前的 AutoreleasePoolPage 中 add 进一个`哨兵对象`,值为0(也就是个nil),那么这一个page就变成了下面的样子:
|
||||
|
||||

|
||||

|
||||
|
||||
`objc_autoreleasePoolPush`的返回值正是这个哨兵对象的地址,被`objc_autoreleasePoolPop(哨兵对象)`作为入参,于是:
|
||||
|
||||
@@ -1981,7 +1981,7 @@ iOS 在主线程的 Runloop 中注册了2个 Observer
|
||||
|
||||
结合 RunLoop 运行图
|
||||
|
||||

|
||||

|
||||
|
||||
- 01 通知 Observer 进入 Loop 会调用 `objc_autoreleasePoolPush`
|
||||
|
||||
@@ -2070,7 +2070,7 @@ NSHashMap、NSMapTable 都可以描述 key、value 的内存修饰。
|
||||
|
||||
这段代码运行会 crash,信息如下
|
||||
|
||||

|
||||

|
||||
|
||||
原因是 NSError 构造方法内部会加 autorelease。源码如下
|
||||
|
||||
@@ -2133,7 +2133,7 @@ MRC 下的 `[(id)(object) autorelease]` 等价于 ARC 下的 `id __autoreleasing
|
||||
|
||||
我写了个僵尸对象检测工具,效果如下
|
||||
|
||||

|
||||

|
||||
|
||||
可以定位僵尸对象,并且打印出具体堆栈,并模拟系统行为调用 `abort` 。对监控原理和工具实现感兴趣的可以查看这里[带你打造一套 APM 监控系统-内存监控之野指针/内存泄漏监控](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.74.md#zombieSniffer)
|
||||
|
||||
|
||||
@@ -1,2 +1,235 @@
|
||||
# 浏览器布局与DOM绘制
|
||||
# 事件循环
|
||||
|
||||
|
||||
## 浏览器多进程架构
|
||||
从安全性、高性能等原因出发,目前浏览器已经是多进程架构模式,至于演进历史,本文不再展开,感兴趣的可以查看这篇[“Electron” 一个可圈可点的 PC 多端融合方案]()文章。
|
||||
|
||||
现在的架构设计如下:
|
||||

|
||||
|
||||
一个页面最少包括:1个网络进程、1个浏览器进程、1个 GPU 进程、多个渲染进程、多个插件进程
|
||||
|
||||
- 浏览器进程:负责界面展示、用户交互(比如滚动条)、子进程管理协作、同时提供存储功能。同时内部会启动多个线程处理不同的任务
|
||||
- 渲染进程:核心任务是将 HTML、CSS、Javascript 转换为用户可以与之的网页,排版引擎 Blink 和 Javascript 引擎 V8 都是运行在该进程中。默认情况下,Chrome 为每个 tab 标签页创建一个新的渲染进程。出于安全考虑,渲染进程都是运行在沙箱机制下的。渲染进程启动后,会开启一个渲染主线程,主线程负责执行 HTML、CSS、JS 代码。
|
||||
- GPU 进程:最早 Chrome 刚发布的时候是没有 GPU 进程的,而 GPU 的使用初衷是实现 css 3D 效果。随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍需求。最后 Chrome 多进程架构中也引入了 GPU 进程。
|
||||
- 网络进程:主要负责页面的网络资源请求加载。早期是作为一个模块运行在浏览器进程里面的,最近才独立出来作为一个单独的进程。网络进程内部会启动多个线程来处理不同的网路任务
|
||||
- 插件进程:主要负责插件的运行。因插件代码由普通开发者书写,所以在 QA 方面可能不是那么完善,代码质量参差不齐,插件容易奔溃,所以需要通过插件进程来隔离,以保证插件进程的奔溃不会对浏览器和页面造成影响。
|
||||
|
||||
所以,你会发现打开一个页面,查看进程发现有4个进程。凡事具有两面性,上面说了多进程架构带来浏览器稳定性、安全性、流畅性,但是也带来一些问题:
|
||||
|
||||
- 更高资源占用:每个进程都会包含公共基础结构的副本(如 Javascript 运行环境),这意味着浏览器将会消耗更多的资源
|
||||
- 更复杂的体系结构:浏览器各模块之间耦合度高、拓展性差,会导致现在的架构很难适应新需求。
|
||||
|
||||
|
||||
|
||||
## 渲染主线程是如何工作的
|
||||
|
||||
渲染主线程是浏览器中最繁忙的线程,需要它处理的任务包括但不限于:
|
||||
|
||||
- HTML 解析和构建 DOM 树:渲染主线程会解析 HTML 代码,并构建 DOM(文档对象模型)树。DOM 树是网页的结构化表示,它描述了网页中的元素、标签和它们之间的关系。
|
||||
- CSS 解析和构建样式树:渲染主线程会解析 CSS 样式表,并构建样式树。样式树表示了网页中的元素和它们的样式信息,包括颜色、字体、布局等属性。
|
||||
- 布局(Layout):渲染主线程会根据 DOM 树和样式树计算元素在页面中的位置和大小,确定它们的布局。布局过程也被称为回流(reflow)或重排(relayout)。
|
||||
- 绘制(Painting):渲染主线程会将布局后的元素绘制到屏幕上,形成可见的网页内容。这个过程包括生成绘制命令、将命令发送给图形系统,并最终在屏幕上绘制出来。
|
||||
- JavaScript 执行:渲染主线程会执行网页中的 JavaScript 代码,处理交互、动画和事件等。JavaScript 的执行可能会引起 DOM 树和样式树的变化,进而触发布局和绘制。
|
||||
- 处理用户输入:渲染主线程会监听用户的输入事件,如鼠标点击、键盘输入等,并根据用户的操作进行相应的处理。这包括响应用户的点击、滚动、拖拽等操作,以及处理表单提交和页面跳转等事件。
|
||||
|
||||
渲染主线程是渲染进程中的核心部分,它负责将网页的结构、样式和交互转化为可视化的网页内容。通过优化渲染主线程的性能和效率,可以提高网页的渲染速度和用户体验。同时,渲染主线程也需要与其他线程(如网络线程、合成线程等)进行协作,以实现流畅的页面渲染和交互效果。
|
||||
|
||||
|
||||
|
||||
## 主线程如何有条不紊工作
|
||||
|
||||
浏览器主线程很繁忙,遇到以下情况该怎么处理:
|
||||
|
||||
- 正在执行某个方法,此时用户点击了按钮触发了事件,该立即去执行点击事件的处理函数吗?
|
||||
- 正在执行某个方法,此时某个计时器到达了时间,该立即去执行它的回调吗?
|
||||
- Input 输入框内容改变了,触发了 `oninput` 事件 ,此时刚好某个计时器也到达了时间,回调函数和 oninput 事件如何调度?
|
||||
|
||||
熟悉其他系统设计的同学可能会立马想到用**队列**来解决问题。浏览器对这个 case 也采用队列,叫做事件队列。
|
||||
|
||||
<img src="./../assets/JSMainThreadEventLoop.png" style="zoom:30%;">
|
||||
|
||||
|
||||
|
||||
解释下这个事件队列:
|
||||
|
||||
1. 一开始,渲染主线程开启一个事件循环(也可以认为是死循环一直在跑)
|
||||
2. 每一次循环会检查消息队列中是否有任务存在。如果有,就取出第一个任务执行,执行完一个后进入下一次循环;如果没有,则进入休眠状态
|
||||
3. 其他所有线程(包括浏览器其他进程中的线程)都可以向这个事件队列中添加任务,新任务会被添加到队列尾部。添加新任务时,如果主线程是休眠的,则会唤醒主线程,继续从事件队列头部读取任务并不断执行
|
||||
4. 持续这个流程
|
||||
|
||||
当然,这个解释是相对宏观宽泛的,具包括哪些队列、不同任务里的任务优先级是怎么样的下面会逐步展开。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
1. 执行当前的同步任务:JS 引擎每次执行当前的同步任务,将其推入调用栈中执行。同步任务是按照代码顺序执行的,知道遇到异步任务
|
||||
2. 执行微任务队列:在执行同步任务的过程中,如果遇到微任务(Microtask)如 Promise 的回调函数、MutationObserver 的回调函数则被添加到微任务队列(Microtask Queue)中。当前的同步任务执行完毕后,在进入下一轮事件循环之前,JS 引擎会按照顺序执行微任务队列中的事件。
|
||||
3.
|
||||
|
||||
1. 每次循环都会检查消息队列中是否存在任务,如果存在,就取出第一个任务执行,执行完一个后进入另一个
|
||||
|
||||
|
||||
|
||||
## 异步任务
|
||||
|
||||
### 何为异步
|
||||
|
||||
代码在执行的过程中会遇到一些无法立即处理的逻辑,比如:
|
||||
|
||||
- 计时器完成之后需要执行的任务:setTimeout、setInterval
|
||||
- 网络通信完成后需要执行的任务:XHR、Fetch
|
||||
- 用户交互后需要执行的任务:addEventListener
|
||||
|
||||
如果渲染主线程遇到这些任务时等待的话,就会让主线程处于等待的状态,对于用户而言,就是浏览器的「卡死」。
|
||||
|
||||
应对这种情况,浏览器采用异步的设计来解决,如下图
|
||||
|
||||
<img src="./../assets/JSEventloop.png" style="zoom:40%;">
|
||||
|
||||
使用异步的方案,可以使得主线程不等待、不阻塞,高效有序的执行逻辑。
|
||||
|
||||
何为异步?异步(Asynchronous)是指一种非阻塞的执行方式,允许同时执行多个任务而不会阻塞主线程。异步任务是指那些不会立即执行或不会阻塞代码执行的任务。
|
||||
|
||||
以下是常见的异步操作和写法:
|
||||
|
||||
1. 回调函数:使用回调函数是一种常见的处理异步操作的方式。在执行异步操作时,可以提供一个回调函数,在操作完成后调用回调函数来处理结果。
|
||||
2. Promise:ES6 引入的一种处理异步操作的机制。它可以用于处理异步操作的成功和失败,并支持链式调用。
|
||||
3. async/await:ES8 引入的一种更直观处理异步操作的语法。通过在函数前面加上 `async` 关键字,可以在函数内部使用 `await` 关键字来等待异步操作的结果。
|
||||
4. 定时器函数:JavaScript 提供了一些定时器函数,如 `setTimeout` 和 `setInterval`,它们可以用来延迟执行代码或定期执行代码
|
||||
5. XHR 和 Fetch:通过使用 AJAX 或 Fetch API,可以发送异步请求并获取服务器返回的数据。
|
||||
6. 交互事件:当事件发生时,注册好的回调函数通过异步来处理事件,而不会阻塞主线程的执行
|
||||
|
||||
|
||||
|
||||
### 异步的意义
|
||||
|
||||
浏览器是一个多进程架构,包含诸多进程,不同进程核心处理的问题不一样。浏览器进程负责界面展示、用户交互(比如滚动条)等。JS 是一门单线程语言,因为运行在浏览器渲染主线程中。然而这个浏览器主线程工作特别繁忙,渲染页面、执行 JS、负责用户交互等,如果采用同步的方式,很有可能会导致主线程阻塞,从而导致消息队列 中的很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白 白的消耗时间,另一方面导致⻚面无法及时更新,给用户造成卡死现象。
|
||||
|
||||
为了解决同步带来的问题,浏览器采用异步的设计。做法是渲染主线程存在一个事件队列,当某些任务(上述描述的异步任务)发生时,主线程会将该任务派发给其他线程处理(比如定时任务交给计时器线程处理),自身立即结束该任务的执行,转而执行后续逻辑。当派发给其他线程的异步任务执行完毕后,该异步事件的回调函数将被包装成任务,添加到消息队列的尾部,待主线程调度执行。
|
||||
|
||||
这种设计使得即使是单线程的 JS,运行也不会卡顿,渲染主线程有条不紊、高效的执行,保证了浏览器的流畅性。
|
||||
|
||||
**通过使用异步,可以更好地处理耗时的操作、网络请求、文件读写等任务,提高程序的性能和用户体验。**
|
||||
|
||||
|
||||
|
||||
## JS 为何会阻塞渲染?
|
||||
|
||||
由于 JS 可以操作 DOM,如果在修改 DOM 元素属性的同时渲染界面(JS 线程与 UI 线程同时运行),那么可能会发生一些不符合预期的结果了,渲染线程前后获得的元素数据不一致。
|
||||
|
||||
因此为了防止产生渲染产生不符合预期的结果,**浏览器设置 GUI 渲染线程和 JS 引擎为互斥关系**。当 JS 引擎执行时 GUI 线程会被挂起。GUI 的更新会被保存在一个队列中,等到 JS 引擎线程空闲时立即被执行。
|
||||
|
||||
因为互斥,所以可以推导出,JS 如果执行时间过长就会阻塞页面。
|
||||
|
||||
举个例子:
|
||||
|
||||
```
|
||||
<h1>你好</h1>
|
||||
<button>问好</button>
|
||||
<script>
|
||||
let h1 = document.querySelector('h1');
|
||||
let btn = document.querySelector('button');
|
||||
let delay = function(duration) {
|
||||
let startTime = Date.now();
|
||||
while (Date.now() - startTime < duration) {}
|
||||
}
|
||||
btn.onclick = function () {
|
||||
h1.textContent = '早上好,小刘';
|
||||
delay(3000);
|
||||
};
|
||||
</script>
|
||||
```
|
||||
|
||||
效果就是:点击按钮修改 h1 标签内的文本。但是在点击后停了3秒后才开始执行。那这个现象如何解释呢?
|
||||
|
||||
T0 时刻:最开始的时候,主线程没有任务任务需要执行。但是主线程告诉交互线程,你需要监听用户的点击事件,点击后需要执行 callback
|
||||
|
||||
<img src="./../assets/JS-UIClickLag1.png" style="zoom:60%;">
|
||||
|
||||
T1时刻:当用户点击后,交互线程会把 callback 封装成一个任务,添加到事件循环队列的尾部。此时主线程依旧没有任务,所以主线程事件循环将被唤醒,从事件队列的头部取出一个任务去执行。大的一个任务里包含2个子事件:修改 DOM 和 延迟3秒。修改 DOM 这句指令执行后,浏览器要想看的见,需要内部会产生一个绘制任务(硬件设备显示图形的画家算法)。绘制任务被添加到事件队列尾部后,立马执行延迟3秒的事件。
|
||||
|
||||
<img src="./../assets/JS-UIClickLag2.png" style="zoom:60%;">
|
||||
|
||||
T2时刻:到达T2时刻后,主线程又空了,此时从事件队列中读取绘制任务。进而去显示出 DOM 文本修改后的结果(但此时前面已经等待了3秒钟,所以体感上会有一种卡顿的现象)
|
||||
|
||||
<img src="./../assets/JS-UIClickLag3.png" style="zoom:60%;">
|
||||
|
||||
|
||||
|
||||
## 任务有优先级吗
|
||||
|
||||
任务没有优先级,因为在消息队列中,无差别从对头选出任务,给队尾添加任务。
|
||||
|
||||
**但消息队列是有优先级的。**怎么理解?因为存在多个队列
|
||||
|
||||
根据 W3C 定义:
|
||||
|
||||
- 每个任务都有一个任务类型,同一种任务类型的任务归属于同一个队列。不同任务类型的任务被派发到不同的队列中(在一次事件循环中,浏览器可以根据实际情况从不同的任务队列中取出任务并执行)
|
||||
- 浏览器必须事先准备好1个微任务队列。微队列中的任务优先所有其他任务执行,优先级最高
|
||||
|
||||
浏览器的复杂度急剧提升,W3C 不再使用宏队列的说法。
|
||||
|
||||
目前 chromium 中,至少包含以下队列:
|
||||
|
||||
- 延时队列:用于存放计时器到达后的回调任务,优先级「中」
|
||||
- 交互队列:用于存放用户操作后产生的事件处理任务,优先级「高」
|
||||
- 微队列:用户存放需要最快执行的任务,优先级「最高」
|
||||
|
||||
添加任务到微队列的主要方式主要是使用 Promise、MutationObserver。此外新加入的 [`queueMicrotask()`](https://developer.mozilla.org/zh-CN/docs/Web/API/queueMicrotask) 方法增加了一种标准的方式,可以安全的引入微任务。
|
||||
|
||||
|
||||
|
||||
## JS 事件循环
|
||||
|
||||
事件循环又叫消息循环,是指在单线程中处理任务队列的机制。
|
||||
|
||||
1. JS 引擎会创建一个全局作用域,并将其添加到调用栈中
|
||||
2. 如果有同步任务,则直接进入主线程执行该任务
|
||||
3. 若存在微任务或者用户交互事件、定时器事件等异步任务,则分门别类,添加到对应的任务队列中
|
||||
4. 当所有的同步任务执行完毕后,JS 引擎开始按照队列优先级检查任务队列是否存在未执行的任务
|
||||
- 如果微任务队列中存在任务,则优先从微任务队列对头取出1个任务执行,然后再次返回到主线程检查是否有新的同步任务。重复此过程,直到微任务队列为空
|
||||
- 如果微任务队列已经没有任务了,则从交互队列队列中判断,如果用户触发了某个事件,则把交互队列中对应的回调取出来放到主线程执行
|
||||
- 如果交互队列为空了,而定时器队列不为空,则判断定时器任务有没有到时见,如果已经达到可执行的条件,则把对应的回调事件放到主线程进行执行
|
||||
- 如果微任务队列和用户交互队列、定时器队列都为空,那么 JS 引擎会抛出一个“There are no more tasks to run.“ 的错误信息,表示事件循环结束
|
||||
|
||||
|
||||
|
||||
QA:JS 计时器准吗?
|
||||
|
||||
不准。存在以下几个原因:
|
||||
|
||||
- 计算机硬件没有原子钟,无法做到精确计时。依靠网络来和拥有原子钟的服务器进行同步
|
||||
- 操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差
|
||||
- 按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级超过 5 层,则会带有 4 毫秒的最少时间
|
||||
- 受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -29,11 +29,11 @@ GUI 架构:过程化绘制(drawLine、drawRect)-> 面向对象抽象时代
|
||||
|
||||
3天时间写了个 PC 端应用程序。先看看结果吧
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -58,7 +58,7 @@ npm install && npm start
|
||||
```
|
||||
|
||||
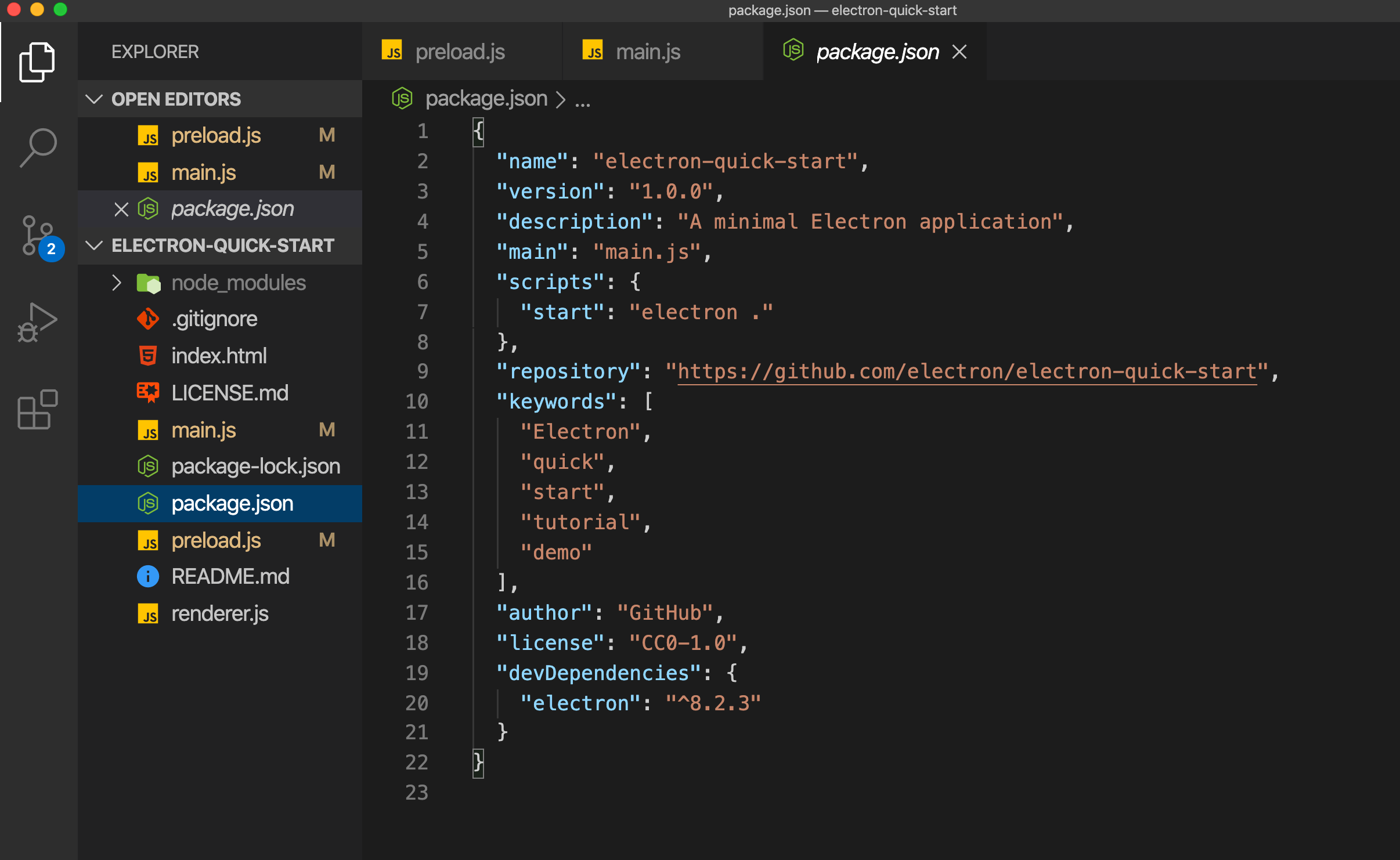
简单介绍下 Demo 工程,工程目录如下所示
|
||||
|
||||

|
||||
|
||||
在终端执行 `npm start` 执行的是 package.json 中的 `scripts` 节点下的 start 命令,也就是 `Electron .`,`.` 代表执行 main.js 中的逻辑。
|
||||
|
||||
@@ -159,7 +159,7 @@ Electron 分为**渲染进程和主进程**。和 Native 中的概念不一样
|
||||
|
||||
单进程浏览器指的是浏览器的所有功能模块都是运行在同一个进程里的,这些模块包括网络、插件、Javascript 运行环境、渲染引擎和页面等。如此复杂的功能都在一个进程内运行,所以导致浏览器出现不稳定、不安全、不流畅等问题。
|
||||
|
||||

|
||||

|
||||
|
||||
早在2007年之前,市面上的浏览器都是单进程架构。
|
||||
|
||||
@@ -194,7 +194,7 @@ Electron 分为**渲染进程和主进程**。和 Native 中的概念不一样
|
||||
|
||||
#### 1.2 早期多进程架构浏览器
|
||||
|
||||

|
||||

|
||||
|
||||
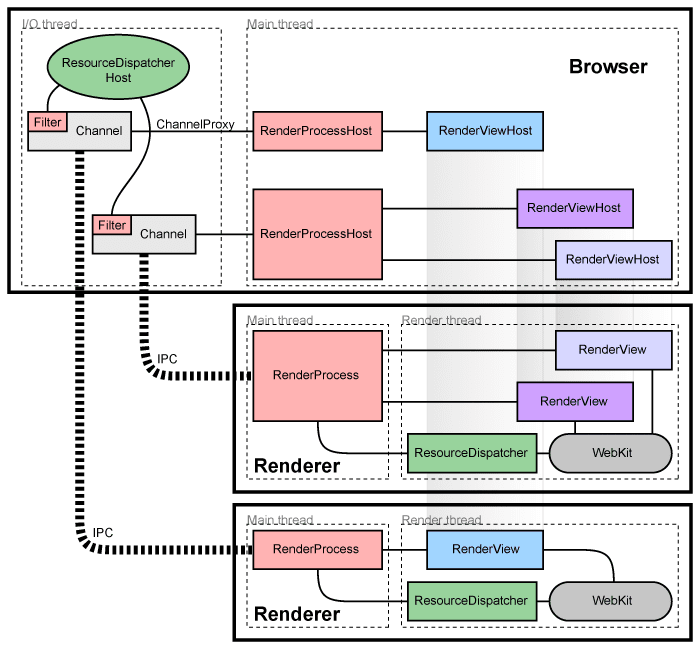
上图2008年 Chrome 发布时的进程架构图。可以看出 Chrome 的页面是运行在单独的渲染进程中,同时页面的插件也是运行在单独的插件进行中的,进程之间通过 IPC 进行通信。
|
||||
|
||||
@@ -218,7 +218,7 @@ Electron 分为**渲染进程和主进程**。和 Native 中的概念不一样
|
||||
|
||||
Chrome 团队不断发展,目前架构有了较新变化,最新 Chrome 架构图如下所示
|
||||
|
||||

|
||||

|
||||
|
||||
最新 Chrome 浏览器包括:1个网络进程、1个浏览器进程、1个 GPU 进程、多个渲染进程、多个插件进程。
|
||||
|
||||
@@ -247,7 +247,7 @@ Chrome 团队一直在寻求新的弹性方案,既可以解决资源占用较
|
||||
|
||||
Chrome 最终把 UI、数据库、文件、设备、网络等模块重构为基础服务。下图是 “Chrome 面向服务的架构”的进程模型图
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
@@ -257,7 +257,7 @@ Chrome 最终把 UI、数据库、文件、设备、网络等模块重构为基
|
||||
|
||||
Chrome 提供灵活的弹性架构,在强大性能设备上会以多进程的方式运行基础服务,但是在设备资源受限的情况下,Chrome 会将很多服务整合到一个进程中,从而节省内存占用。
|
||||
|
||||

|
||||

|
||||
|
||||
#### 1.5 小实验
|
||||
|
||||
@@ -273,7 +273,7 @@ Chrome 提供灵活的弹性架构,在强大性能设备上会以多进程的
|
||||
|
||||
实验现象:
|
||||
|
||||

|
||||

|
||||
|
||||
实验结论:
|
||||
|
||||
@@ -310,7 +310,7 @@ Chrome 的默认策略是,每个标签对应一个渲染进程。但是如果
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -331,7 +331,7 @@ Chrome 的默认策略是,每个标签对应一个渲染进程。但是如果
|
||||
|
||||
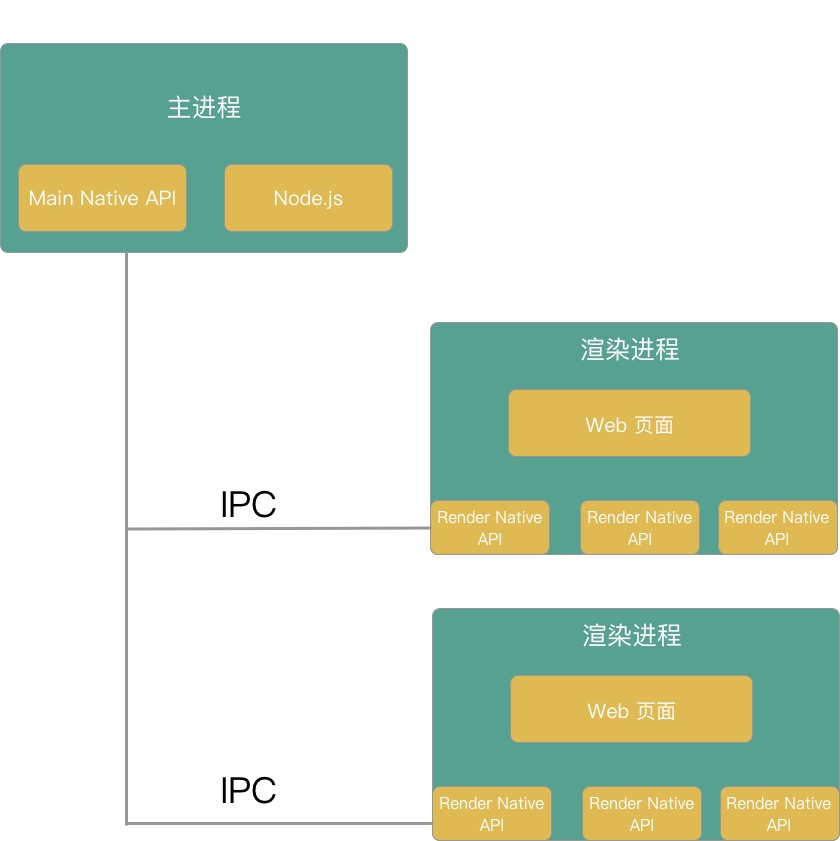
### 2. Electron 架构
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -353,7 +353,7 @@ Electron 架构和 Chromium 架构类似,也是具有1个主进程和多个渲
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
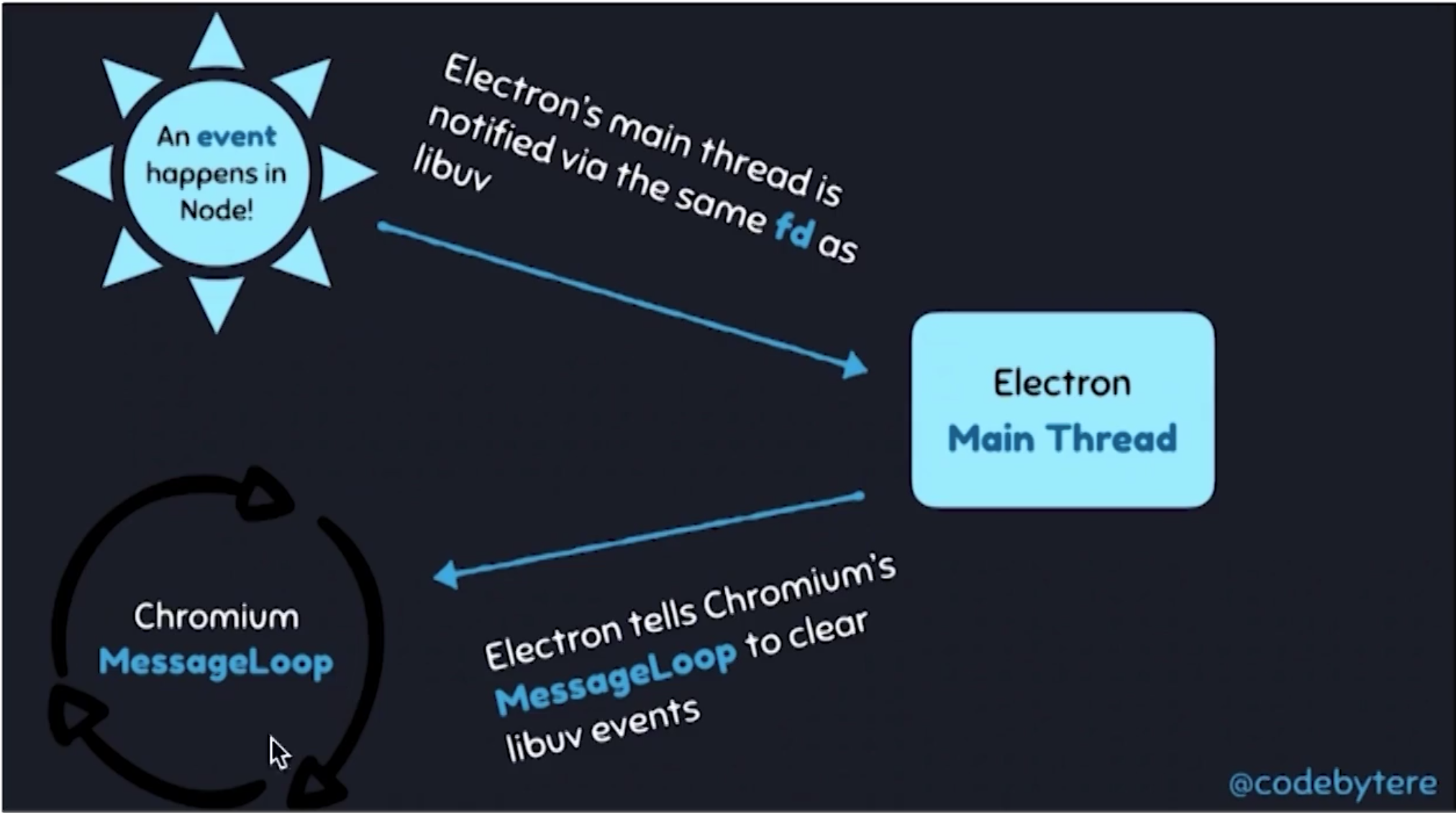
上图描述了 Node.js 如何融入到 Chromium 中。描述下原理
|
||||
|
||||
@@ -380,7 +380,7 @@ Electron 架构和 Chromium 架构类似,也是具有1个主进程和多个渲
|
||||
|
||||
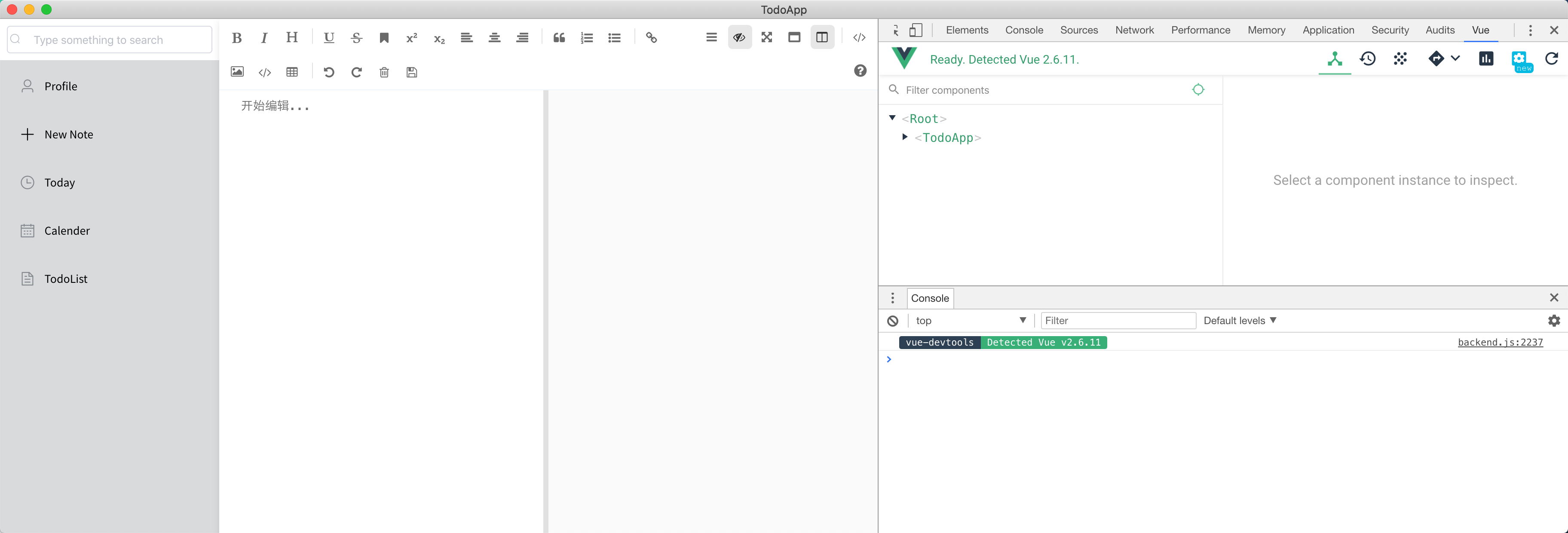
工程采用 Electron + Vue 技术,下面截图 Vue-devtools 很方便查看 Vue 组件层级等 Vue 相关的调试
|
||||
|
||||
|
||||

|
||||
|
||||
### 2. 主进程调试方式
|
||||
|
||||
@@ -395,10 +395,10 @@ Electron 架构和 Chromium 架构类似,也是具有1个主进程和多个渲
|
||||
```
|
||||
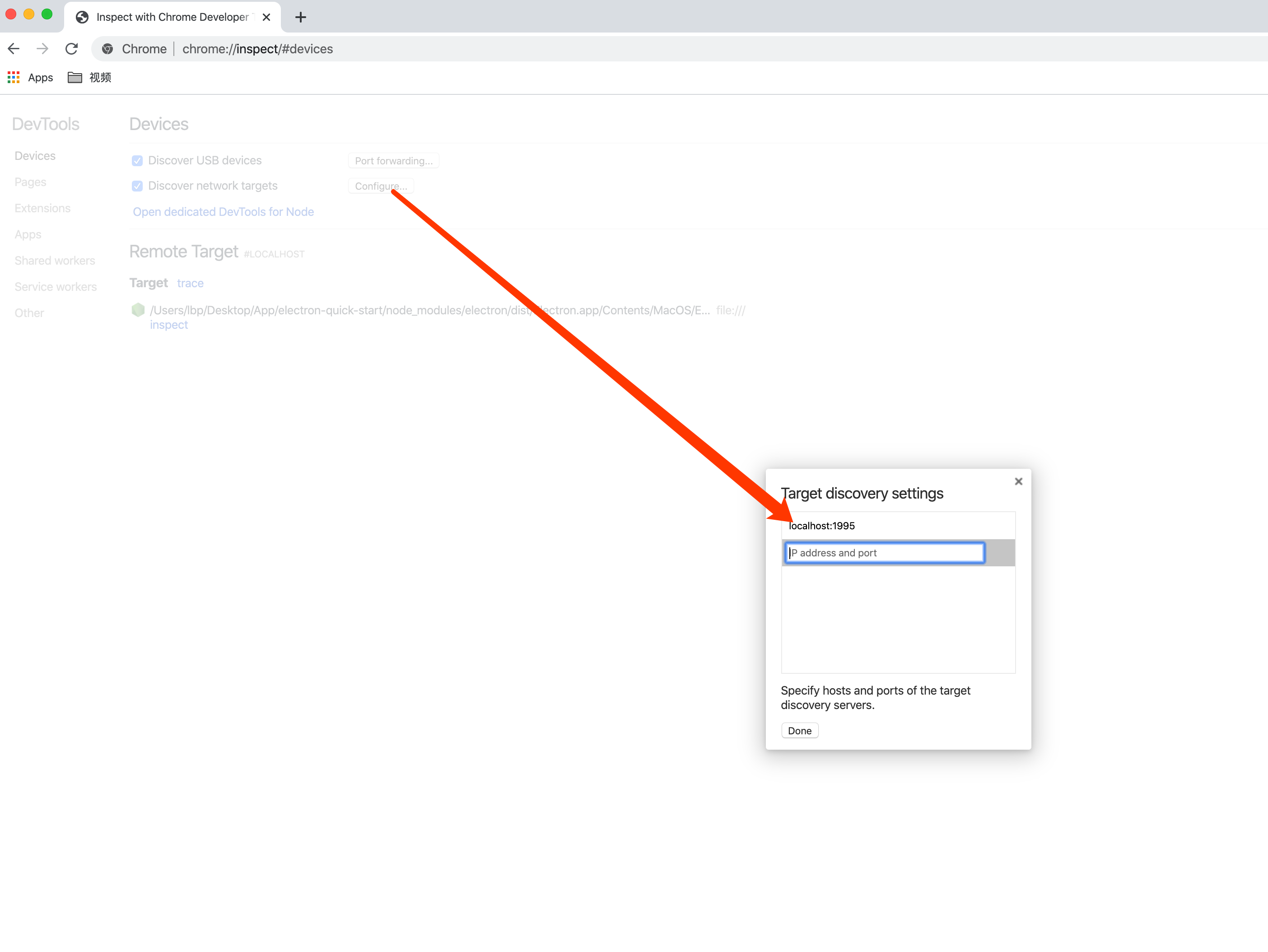
- 然后打开浏览器,在地址栏输入 `chrome://inspect`
|
||||
- 点击 `configure`,在弹出的面板中填写需要调试的端口信息
|
||||
- 
|
||||
- 
|
||||
- 重新开启服务 `npm start`,在 chrome inspect 面板的 `Target` 节点中选择需要调试的页面
|
||||
- 在面板中可以看到主进程执行的 `main.js`。可以加断点进行调试
|
||||

|
||||

|
||||
|
||||
方法二:利用 VS Code 调试 Electron 主进程。
|
||||
|
||||
@@ -428,7 +428,7 @@ Electron 架构和 Chromium 架构类似,也是具有1个主进程和多个渲
|
||||
|
||||
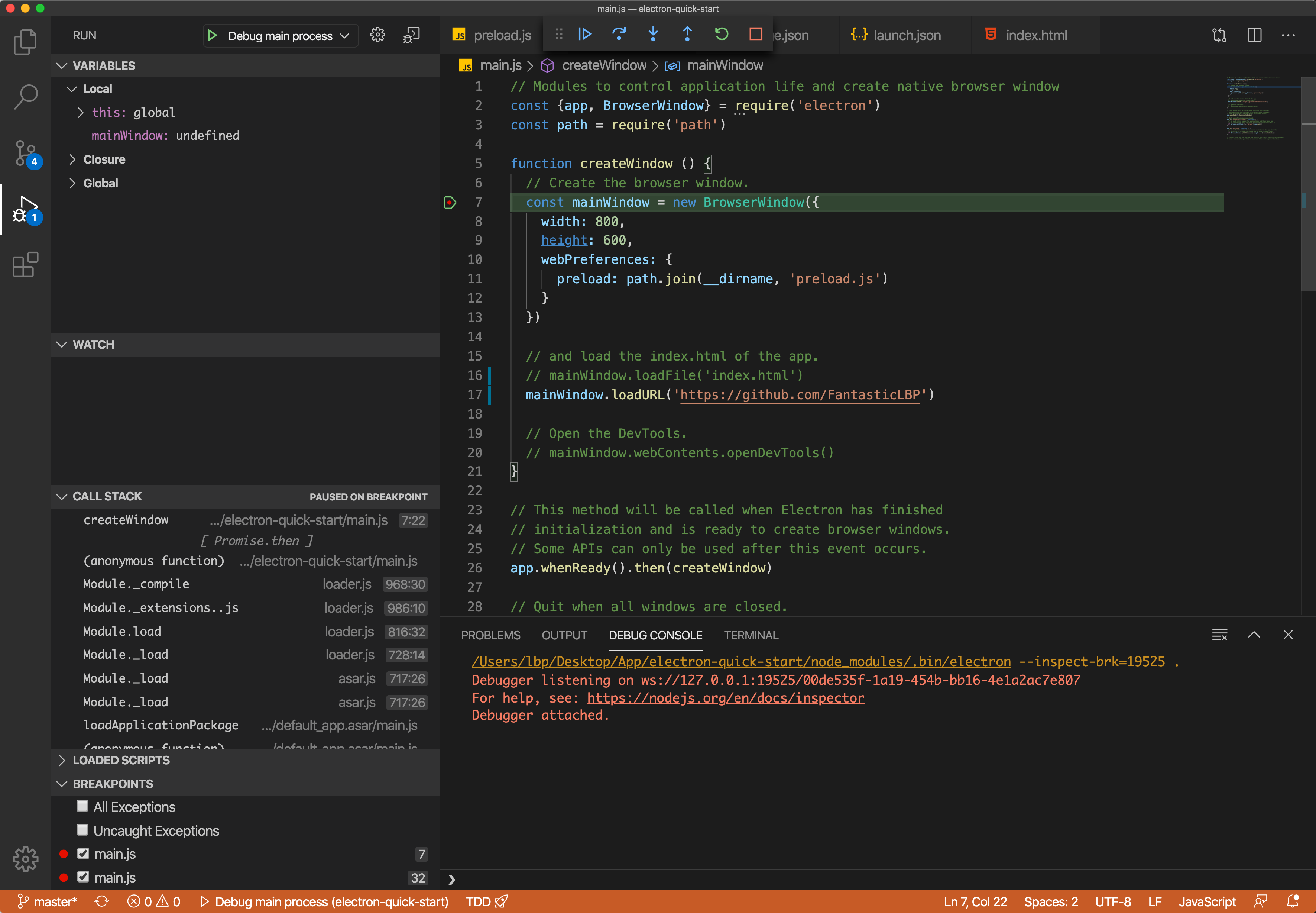
- 在调试模点击绿色小三角,会运行程序,可以添加断点信息。整体界面如下所示。可以单步调试、可以暂停、鼠标移上去可以看到对象的各种信息。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
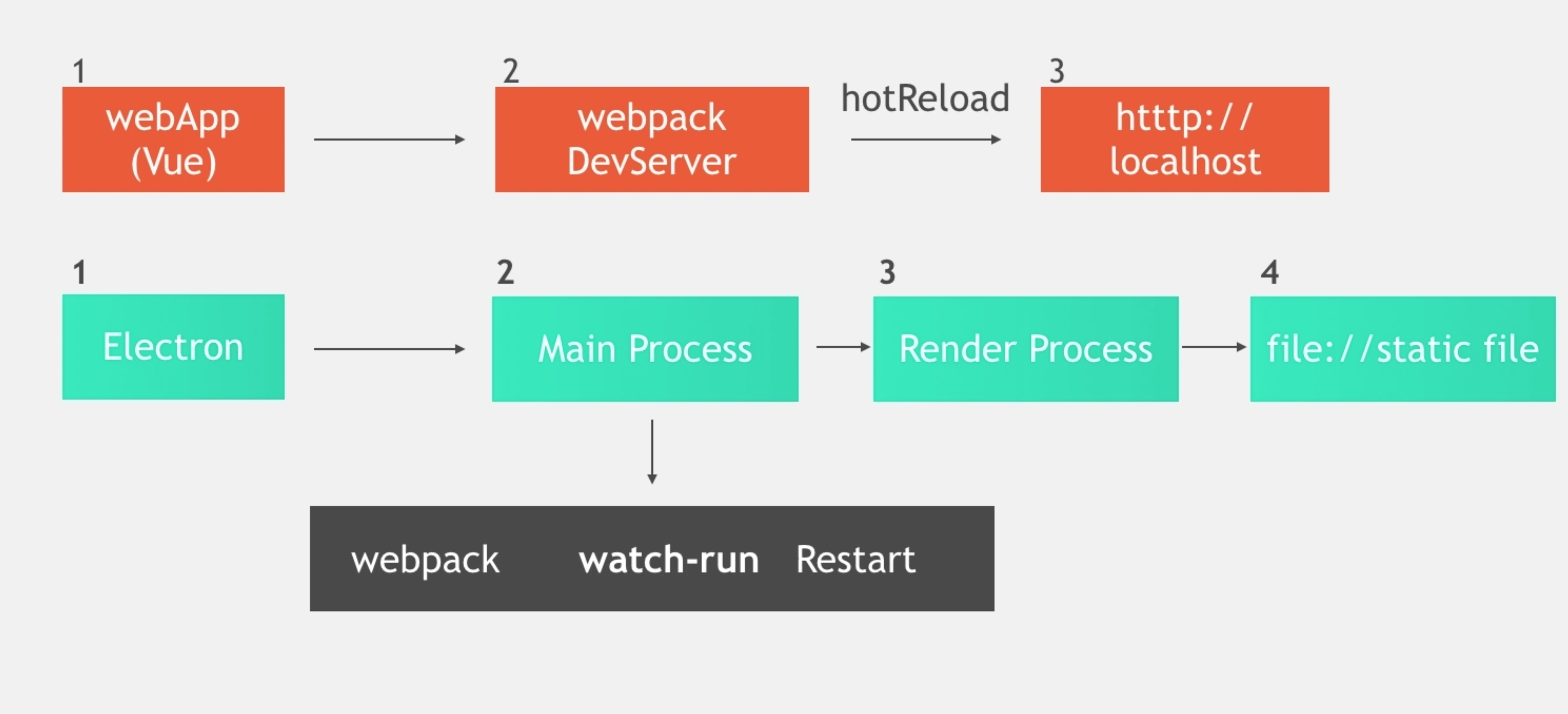
@@ -438,7 +438,7 @@ Electron 的渲染进程中的代码改变了,使用 Command + R 可以刷新
|
||||
|
||||
Webpack 有一个 api: `watch-run`,可以针对代码文件检测,有变化则 Restart
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -527,7 +527,7 @@ Electron 官方给出了解决方案 Squirrel,基于 Squirrel 框架完成的
|
||||
|
||||
9. Electron 多窗口与单窗口应用区别
|
||||
|
||||
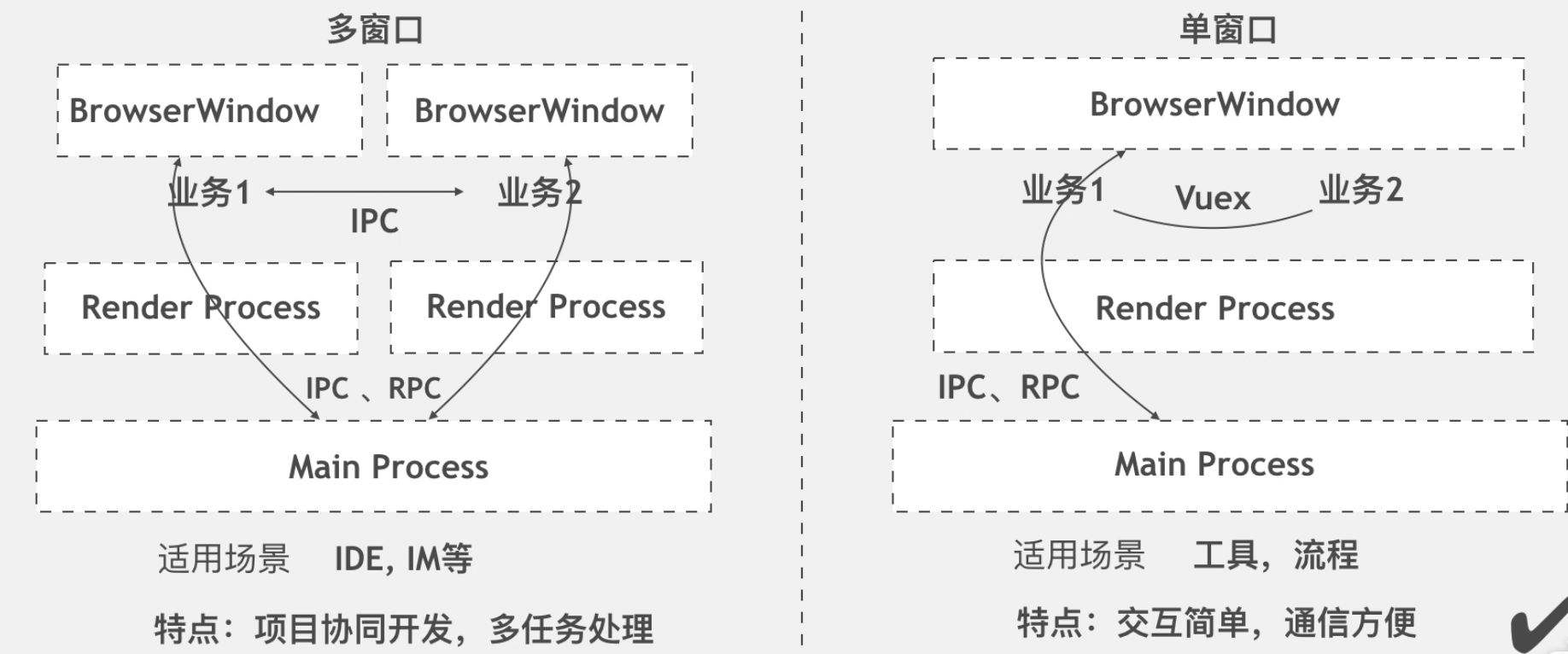
|
||||

|
||||
|
||||
10. 知道 Electron 开发原理,所以大部分时间是在写前端代码。所以根据团队技术沉淀、选择对应的前端框架,比如 Vue、React、Angular。
|
||||
|
||||
@@ -535,7 +535,7 @@ Electron 官方给出了解决方案 Squirrel,基于 Squirrel 框架完成的
|
||||
|
||||
12. Electron 和 Web 开发相比,各自有侧重点
|
||||
|
||||

|
||||

|
||||
|
||||
13. 有些人开发 Electron 应用可能不喜欢 [electron-vue](https://github.com/SimulatedGREG/electron-vue) 这样的工具,喜欢自己自定义。假如自己利用 Vue 或者 React 开发的,开发过网页的同学都会习惯使用 Vue-devtools、React-devtools。所以在选用 Vue 或 React 后,习惯使用强大的 Vue-devtools、React-devtools 来查看 State、Action、Redux、Vuex、组件层级树等。
|
||||
|
||||
@@ -591,13 +591,13 @@ node --cpu-prof --heap-prof -e "require('request’)”“
|
||||
|
||||
### 1. 构建
|
||||
|
||||
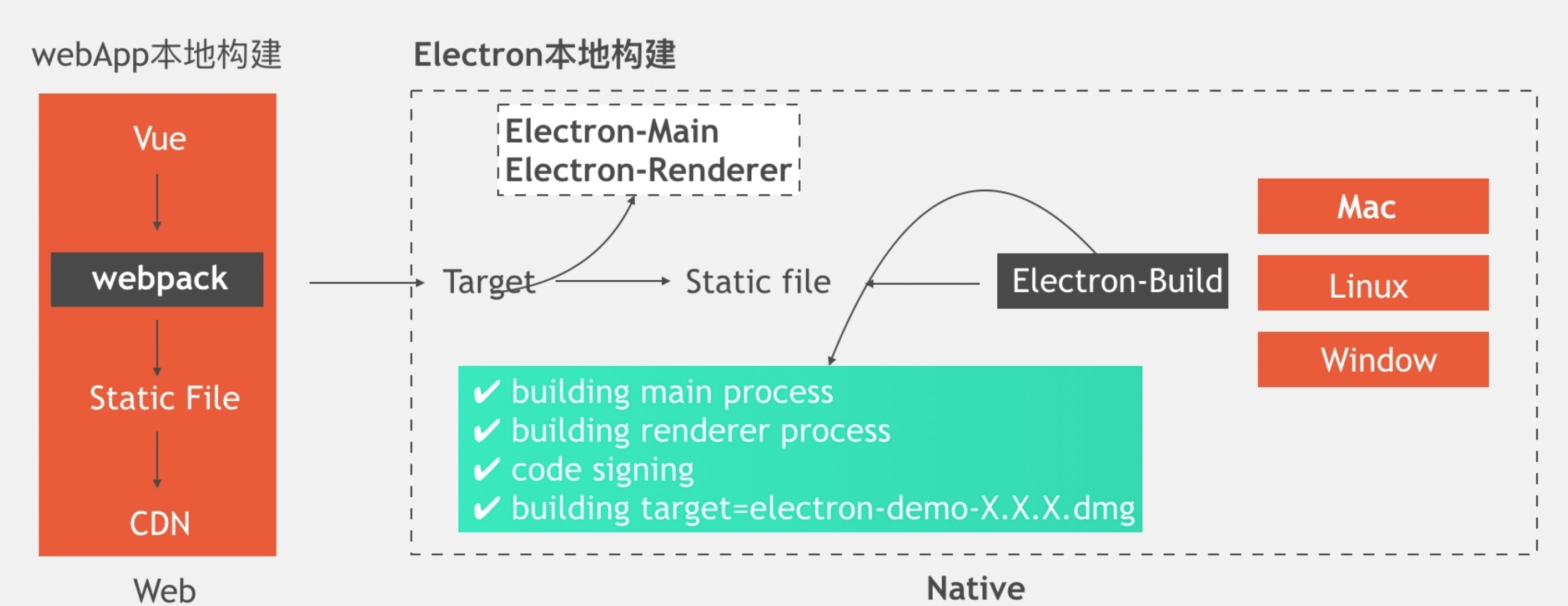
|
||||

|
||||
|
||||
|
||||
|
||||
### 2. 工程解耦
|
||||
|
||||
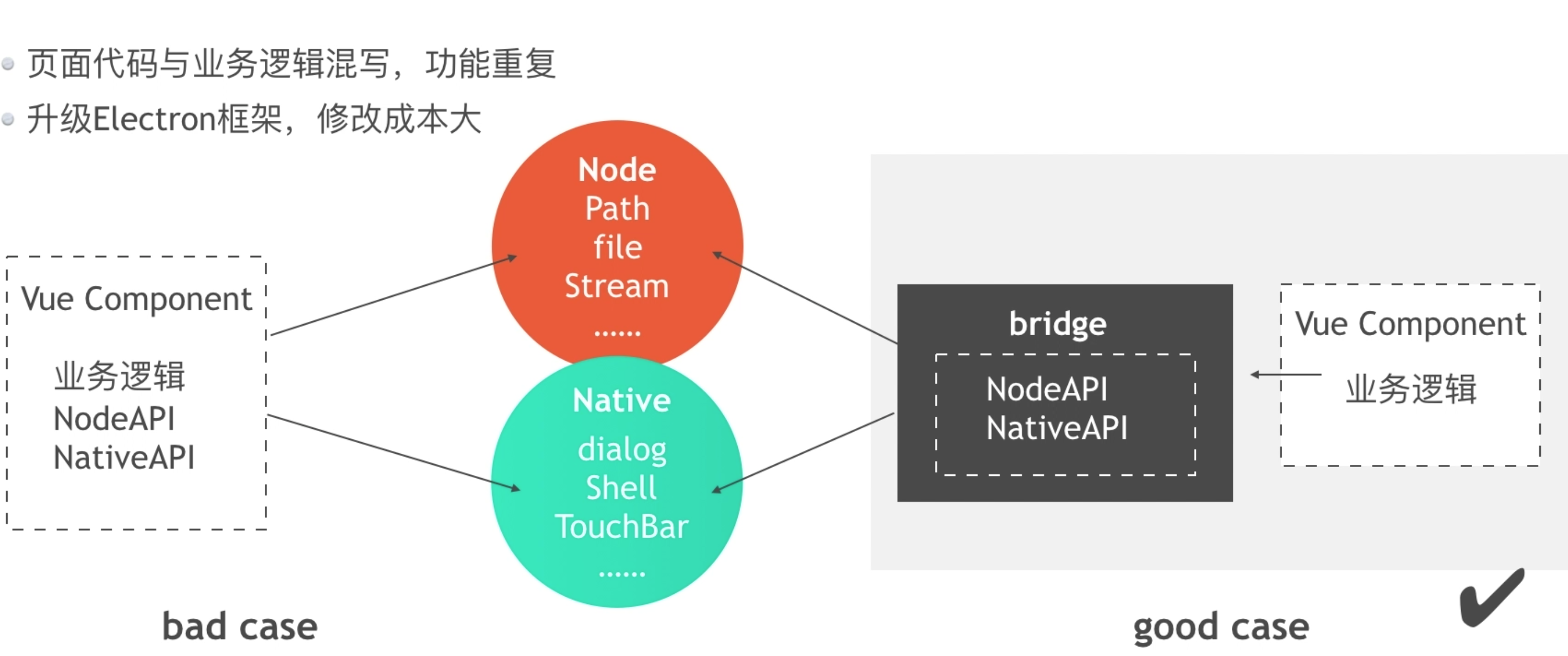
|
||||

|
||||
|
||||
|
||||
|
||||
@@ -605,7 +605,7 @@ node --cpu-prof --heap-prof -e "require('request’)”“
|
||||
|
||||
Electron 提供的 crash 信息进行包装。
|
||||
|
||||
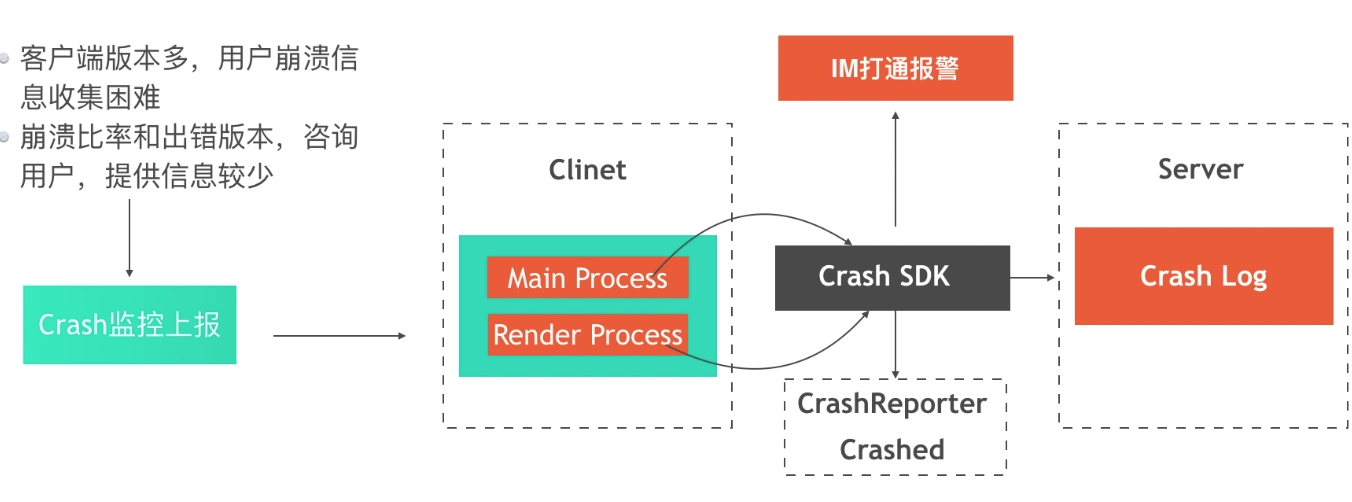
|
||||

|
||||
|
||||
```js
|
||||
import { BrowserWindow, app, dialog} from 'Electron';
|
||||
|
||||
53
Chapter2 - Web FrontEnd/2.44.md
Normal file
@@ -0,0 +1,53 @@
|
||||
# Vue 核心原理探究
|
||||
|
||||
## 一、动手做一个超简易 Vue
|
||||
|
||||
先简单分析下 Vue 做了什么,巴拉巴拉,好多功能。就说一个最基础的,数据改变了页面就改变。如何实现?
|
||||
|
||||
1. `Object.defineProperty` 提供的 getter、setter 便可以拦截到所有 getter 的使用方,做到依赖收集
|
||||
2. 依赖收集:getter 方法内部可以知道谁在调用,此时可以做依赖收集。因为可能某个使用的方法(getFullName)会被调用多次,所以需要用 set 去收集,保持唯一。且给 window 对象上挂载一个内部属性的方式,来记录谁去调用过 getter。收集后立马清空 window 对象的私有属性值
|
||||
3. 派发执行:当数据改变的时候,也就触发到 setter,此时 setter 内部将该属性收集到的依赖方全部调用一遍方法。
|
||||
|
||||
```js
|
||||
|
||||
/**
|
||||
* 观察数据对象,数据驱动
|
||||
*
|
||||
* @param {any} obj
|
||||
*/
|
||||
function observe(obj) {
|
||||
for (const key in obj) {
|
||||
let getFunctionCallers = new Set();
|
||||
let internalValue = obj[key];
|
||||
Object.defineProperty(obj, key, {
|
||||
set: function (newValue) {
|
||||
internalValue = newValue;
|
||||
// set 完立即调用所有依赖 getter 的方法
|
||||
for (const getCaller of getFunctionCallers) {
|
||||
getCaller();
|
||||
}
|
||||
},
|
||||
get: function () {
|
||||
// 依赖收集
|
||||
if (window.__internalGetFunction) {
|
||||
getFunctionCallers.add(window.__internalGetFunction);
|
||||
}
|
||||
return internalValue;
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* 用于依赖收集,将原始方法绑定到 window 的私有属性上
|
||||
*
|
||||
* @param {any} originalFunction
|
||||
*/
|
||||
function getFunctionProxy (originalFunction) {
|
||||
window.__internalGetFunction = originalFunction;
|
||||
originalFunction();
|
||||
window.__internalGetFunction = null;
|
||||
}
|
||||
```
|
||||
|
||||
498
Chapter2 - Web FrontEnd/2.45.md
Normal file
@@ -0,0 +1,498 @@
|
||||
# 浏览器渲染原理
|
||||
|
||||
## 浏览器是如何渲染页面的
|
||||
|
||||
当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。在事件循环机制下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/BrowserNetworkAndRender.png" style="zoom:20%;">
|
||||
|
||||
整个渲染流程分为多个阶段:HTML 解析、样式计算、布局、分层、绘制、分块、光栅化、画。每个阶段都有明确的输入输出,上一个阶段的输出就是下一个阶段的输入,整个流程类似流水线一样。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/BrowserRenderFullProgress.png" style="zoom:20%;">
|
||||
|
||||
下面针对每个阶段做详细的研究。
|
||||
|
||||
|
||||
|
||||
## 一、解析 HTML
|
||||
|
||||
解析的过程中遇到 CSS 便解析 CSS,遇到 JS 执行 JS。为了提高解析效率,浏览器会在开始解析器安,启动一个预解析线程,率先下载 HTML 中和外部 CSS、外部 JS 文件。
|
||||
|
||||
如果主线程解析到 link 标签,此时外部的 CSS 文件还没下载解析好,主线程不会等待,会继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的核心原因。
|
||||
|
||||
如果主线程解析到 script 位置,会停止解析 HTML,转而等待 JS 文件下载好,直到脚本加载和解析完成后,才能继续解析 HTML。这是因为 JS 代码执行过程可能会修改当前的 DOM,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。
|
||||
|
||||
第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式、内部样式、外部样式、内联样式均会包含在 CSSOM 树中
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-CSSOMDOM.png" style="zoom:20%;">
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-DOM.png" style="zoom:20%;">
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-CSSOM.png" style="zoom:20%;">
|
||||
|
||||
QA:
|
||||
|
||||
1. 为什么需要解析成 DOM、CSSOM?HTML 本身是字符串,无法操作,抽象成一层 JS 文档对象模型,并暴露一些 API 给 开发者,方便去操作。
|
||||
2. 为什么 HTML、CSS 都有自己对应的 DOM、CSSOM,但 JS 没有自己对应的模型?因为 CSS、HTML 是需要经常变化的,后续的逻辑会经常操作,所以有自己对应的树形模型,JS 执行一次就结束了。
|
||||
|
||||
|
||||
|
||||
### HTML 解析过程中遇到 CSS 怎么处理
|
||||
|
||||
为了提高解析效率,浏览器会启动一个预解析器率先下载和解析 CSS
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-CSSPreload.png" style="zoom:20%;">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 包含哪些样式
|
||||
|
||||
HTML 解析会生成 DOM、CSSOM。StyleSheetList 是所有样式的集合,那包含哪些样式呢?
|
||||
|
||||
- 浏览器默认样式(比如 div 独自占一行)
|
||||
- 内联样式
|
||||
- 内部样式
|
||||
- 外部样式
|
||||
|
||||
浏览器默认样式怎么体现。翻阅 Chromium 的源代码可以查看到浏览器为 html 设置的默认样式,针对 div 标签设置了 `display: block` 所以才独占一行,而不是因为是 div 所以就该占一行。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Chromium-BrowserDefaultStyle.png" style="zoom:30%;">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### HTML 解析过程中遇到 JS 代码怎么办
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-JSDownload.png" style="zoom:30%;">
|
||||
|
||||
|
||||
|
||||
浏览器渲染主线程遇到默认的 script 标签(不带 async、defer 修饰)则会暂停解析 HTML,等待 JS 下载并执行完毕后方可继续解析 HTML。
|
||||
|
||||
预解析线程可以分担下载 JS 的任务。
|
||||
|
||||
QA:为什么 JS 不能设计成像 css 那样一边解析,一边执行呢?
|
||||
|
||||
JS 可能会操作当前 DOM,DOM 不是全部的 HTML 解析完才创建的,解析多少 HTML 创建多少 DOM,所以需要暂停 HTML 解析(类似生产者消费者模型,不加锁则可能存在问题。HTML 解析就是在生产 DOM,JS 脚本可能一边在读取 DOM,可能还在增、删 DOM 在消费 DOM)
|
||||
|
||||
|
||||
|
||||
### 为什么浏览器遇到 script 会暂停解析?
|
||||
|
||||
浏览器在解析 HTML 的时候,如果遇到一个没有任何属性的 script 标签,就会暂停 HTML 解析,先发送网络请求获取该 JS 脚本的内容,然后让 JS 引擎执行该代码。 当 JS 执行完毕后恢复 HTML 的解析,整个过程如下
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-JSDefaultBehavior.png" style="zoom:50%;">
|
||||
|
||||
解决方式:`defer ` 和 `async` 都是异步加载的外部 JS 脚本,不会阻塞页面的解析,因此这2个方案都可以规避因为大量 JS 下载影响 HTML 解析的问题
|
||||
|
||||
#### async
|
||||
|
||||
async 表示异步,当浏览器遇到带有 async 的 script 时,浏览器会采用异步的方式去解析,不会阻塞浏览器解析 HTML,一旦网络请求完成后,如果此时 HTML 还没解析完的话,立即暂停 HTML 的解析工作,让 JS 引擎执行 JS 脚本,全部 JS 执行完毕后再去解析后面的 HTML。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-JSAsync1.png" style="zoom:50%;">
|
||||
|
||||
如果遇到 async 修饰的 js 脚本,在异步下载好之后 HTML 已经解析完毕,也一样,直接执行 JS
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-JSAsync2.png" style="zoom:50%;">
|
||||
|
||||
|
||||
|
||||
#### defer
|
||||
|
||||
defer 也表示异步延迟,当浏览器遇到带有 defer 的 script 时,会异步获取该脚本,不会阻塞浏览器解析 HTML,一旦网络请求回来后,如果 HTML 解析还未完成,则会继续解析 HTML,直到 HTML 全部解析完成后才执行 JS 代码。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/HTMLParse-JSDefer.png" style="zoom:50%;">
|
||||
|
||||
如果存在多个 defer 标签修饰的 script 标签,浏览器会按照 script 顺序执行,不会破坏脚本之间的依赖关系
|
||||
|
||||
|
||||
|
||||
## 二、样式计算
|
||||
|
||||
主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出最终的样式,称为 Computed Style。
|
||||
|
||||
在这一过程中,很多预设值会变成绝对值,比如 red 会变为 rgb(255, 0, 0),相对单位也会变成绝对单位,比如 em 变成 px。这一步完成后会得到一颗带有样式的 DOM 树。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/StyleCompute.png" style="zoom:30%;">
|
||||
|
||||
什么叫计算后的样式(Computed Style):指的是元素在渲染时所采用的最终样式。
|
||||
|
||||
样式计算主要包括:CSS 属性值的计算过程(层叠、继承...)、视觉格式化模型(盒模型、包含块、BFC...)
|
||||
|
||||
这个计算涉及到:
|
||||
|
||||
- 确定声明值
|
||||
- 层叠冲突
|
||||
- 使用继承
|
||||
- 使用默认值
|
||||
|
||||
### CSS 属性计算过程
|
||||
|
||||
```css
|
||||
<div>
|
||||
<p>p</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
没有修改p 标签的样式,却可以看到他有一个颜色、字体等样式。
|
||||
|
||||
该元素上会有 css 的所有属性。在 Chrome 审查元素模式下,勾选 Computed 下的 Show all,就可以看到非常多的属性如下图:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CSSStyleComputeDemo.png" style="zoom:20%;">
|
||||
|
||||
也就是说:我们开发的任何一个 HTML 元素,实际上在浏览器显示出来的时候都有一套完整的 css 样式。如果没有显示声明样式,大概率会采用默认值。
|
||||
|
||||
|
||||
|
||||
#### 确定声明值
|
||||
|
||||
```html
|
||||
p {
|
||||
color: red;
|
||||
}
|
||||
<div>
|
||||
<h1>H1标题</h1>
|
||||
<p>段落</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
css 代码明确了 p 标签使用红色,那么浏览器展示就会按照此属性进行展示。
|
||||
|
||||
这种开发者写的代码,叫做作者样式表。一般浏览器还会存在用户代理样式表,可以认为是浏览器内置了一份样式表。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ComputedStyleDemo-p.png" style="zoom:30%;">
|
||||
|
||||
可以看到 p 标签在审查元素模式下,除了作者样式表中设置的 color 属性,其他的都采用了用户代理样式表的属性。比如:display...
|
||||
|
||||
|
||||
|
||||
#### 层叠冲突
|
||||
|
||||
前面看了确定声明值,但可能存在一种情况,声明的样式规则发生冲突。
|
||||
|
||||
此时会进入**解决层叠冲突**的流程,分为3个步骤:
|
||||
|
||||
1. 比较源的重要性
|
||||
2. 比如优先级
|
||||
3. 比较次序
|
||||
|
||||
|
||||
|
||||
#### 比较源的重要性
|
||||
|
||||
当不同的 css 样式来源拥有相同的声明时,此时就会根据样式表来源的重要性来确定该用哪一条样式规则。那,有几种样式表来源:
|
||||
|
||||
- 浏览器会有一个基础的样式表来给任何网页设置默认的样式。该样式被称为:用户代理样式
|
||||
- 网页的作者可以定义文档的样式,这是最常见的样式,被称为:页面作者样式
|
||||
- 浏览器的用户,可以使用自定义样式表定制使用体验。被称为用户样式
|
||||
|
||||
重要性的顺序为:页面作者样式 > 用户样式 > 用户代理样式
|
||||
|
||||
|
||||
|
||||
假设现在有页面作者样式表和用户代理样式表中存在属性冲突,那会以页面作者样式表优先。
|
||||
|
||||
```html
|
||||
p {
|
||||
color: red;
|
||||
display: inline-block;
|
||||
}
|
||||
<div>
|
||||
<h1>H1标题</h1>
|
||||
<p>段落</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStylePriority.png" style="zoom:25%;">
|
||||
|
||||
可以看到 p 标签的 display 属性,在页面作者样式表和用户代理样式表中同时存在时,根据源的重要性判断,最终页面作者样式表优先级更高,display 采用页面作者样式表中的属性值。
|
||||
|
||||
|
||||
|
||||
#### 比较优先级
|
||||
|
||||
如果同一个源中,样式声明一样的情况下,如何决策?此时进入了样式声明的优先级比较。
|
||||
|
||||
```html
|
||||
.container p {
|
||||
color: #00ff00;
|
||||
}
|
||||
p {
|
||||
color: red;
|
||||
display: inline-block;
|
||||
}
|
||||
<div class="container">
|
||||
<h1>H1标题</h1>
|
||||
<p>段落</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
可以看到,在上面的 css 代码中,都在页面作者样式表同一个源中,源一样,解下去根据选择器的权重来比较重要性。
|
||||
|
||||
根据选择器权重规则(ID 选择器 > 类选择器 > 类型选择器)来判断,单独一个标签选择器的 color 属性会被打败。
|
||||
|
||||
关于选择器的比较策略可以查看 [MDN CSS Specificity](https://developer.mozilla.org/zh-CN/docs/Web/CSS/Specificity)
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStyleDeclarationPriority.png" style="zoom:25%;">
|
||||
|
||||
|
||||
|
||||
#### 比较次序
|
||||
|
||||
当样式表同源,权重相同的情况下,进入第三阶段:比较声明的顺序
|
||||
|
||||
```html
|
||||
.container p {
|
||||
color: #00ff00;
|
||||
}
|
||||
.container p {
|
||||
color: #0000ff;
|
||||
}
|
||||
<div class="container">
|
||||
<h1>H1标题</h1>
|
||||
<p>段落</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
都处于页面作者样式表中,选择器的权重也相同,但根据所处位置的不同,下面的样式声明会覆盖上面的值,最终采用 #0000ff。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStylePositionPriority.png" style="zoom:25%;">
|
||||
|
||||
样式声明冲突的情况解决了
|
||||
|
||||
|
||||
|
||||
#### 使用继承
|
||||
|
||||
层叠冲突这一步完成后,解决了相同元素被声明的多条样式规则命中后,到底该采用哪一条样式规则的问题。
|
||||
|
||||
那假设一个元素没有声明的属性,该使用什么属性值?会存在继承这个策略。
|
||||
|
||||
```html
|
||||
.container {
|
||||
color: #00ff00;
|
||||
}
|
||||
<div class="container">
|
||||
<h1>H1标题</h1>
|
||||
</div>
|
||||
```
|
||||
|
||||
只对类名为 container color 进行了设置,针对 p 标签没有任何的设置,但由于 color 可以继承,所以 p 就从最近的 div 继承了颜色。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStyleInherited.png" style="zoom:25%;">
|
||||
|
||||
看另一个现象
|
||||
|
||||
```html
|
||||
.container {
|
||||
color: blue;
|
||||
}
|
||||
.innerContainer {
|
||||
color: red;
|
||||
}
|
||||
<div class="container">
|
||||
<div class="innerContainer">
|
||||
<h1>H1标题</h1>
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStyleDoubleInherited.png" style="zoom:25%;">
|
||||
|
||||
这里继承了 container、innerContainer 2个的属性值,说了继承会选择更近的一个,innerContainer 胜出。
|
||||
|
||||
|
||||
|
||||
#### 使用默认值
|
||||
|
||||
如果前面的步骤都走了,但属性值还没确定下来,就只能选用默认值了。
|
||||
|
||||
```html
|
||||
<div>
|
||||
<h1>H1标题</h1>
|
||||
</div>
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CssStyleDefaultValue.png" style="zoom:25%;">
|
||||
|
||||
任何一个元素要在浏览器上渲染出来,必须具备所有的 css 属性值,但很多属性我们没有去设置,用户代理样式表中也没有设置,也无法从继承中拿到,因此最终都是使用默认值的。
|
||||
|
||||
|
||||
|
||||
## 三、布局 - layout
|
||||
|
||||
布局完成后会得到布局树。
|
||||
|
||||
布局阶段会依次遍历 DOM 树的每一个节点,计算每个节点的几何信息,比如节点的宽高、相对包含块的位置。
|
||||
|
||||
元素的尺寸和位置,会受它的包含块所影响。对于一些属性,例如 width, height, padding, margin,绝对定位元素的偏移值(比如 position 被设置为 absolute 或 fixed),当我们对其赋予百分比值时,这些值的计算值,就是通过元素的包含块计算得来。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Layout.png" style="zoom:25%;">
|
||||
|
||||
大部分时候,DOM 树和 Layout 树并非一一对应的,为什么?
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CSSLayoutTreeDisplay.png" style="zoom:25%;">
|
||||
|
||||
比如某个节点的 display 设置为 none,这样的节点就没有几何信息,因此不会生成到 layout 树。有些使用了伪元素选择器,虽然 DOM 树中并不存在这些伪元素节点,但它们需要显示在浏览器上,所以会生成到 layout 树上。还有匿名行盒、匿名块盒等等都会导致 DOM 树和 layout 树无法一一对应。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CSSLayoutTreePseudoClass.png" style="zoom:25%;">
|
||||
|
||||
```html
|
||||
div::before {
|
||||
content: '';
|
||||
}
|
||||
<div></div>
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CSSPseudoClassLayout.png" style="zoom:25%;">
|
||||
|
||||
## 四、分层 Layer
|
||||
|
||||
浏览器拿到布局后的 layout tree 会思考一些事情。大多数页面不是绘制后静止的,经常会有一些动画、用户点击后一些交互处理等,需要经常刷新页面。但如果整个页面直接重新刷新,这个性能开销是很大的。能不能提高效率?能,于是现在浏览器支持了分层。
|
||||
|
||||
主线程会使用一套复杂的策略对整个布局树进行分层。
|
||||
|
||||
分层的好处在于,将来在某一个层改变后,仅会对该层进行后续处理,从而提高效率。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Layer.png" style="zoom:25%;">
|
||||
|
||||
滚动条、堆叠上下文有关的(z-index、transform、opacity )样式都会或多或少影响分层结果,也可以通过 will-change 属性更大程度的影响分层的结果。
|
||||
|
||||
```html
|
||||
<div>
|
||||
100个<p>Lorem</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Layer-Demo.png" style="zoom:25%;">
|
||||
|
||||
可以看到默认情况下浏览器对该代码分了2层。为什么滚动条需要单独设置一个 layer?因为100个 p 标签一定会超出一屏,所以会存在滚动条,且用户可能会高频滚动去查看内容,为了高效渲染,所以将滚动条单独设置了一个层。
|
||||
|
||||
假设我们已经通过技术手段得知某些内容经常会改变,但直接页面整体重刷会很耗费资源,那如何只对某一块区域设置一个 layer 呢?通过 `will-change: transform` 告诉浏览器,这块区域的 transform 属性经常会变。
|
||||
|
||||
`will-change`是一个用于通知浏览器某个元素即将发生变化的CSS属性。它可以被应用到任何元素上,用于提前告知浏览器该元素将要有哪些属性进行改变,从而优化渲染性能。
|
||||
|
||||
通过在元素上设置`will-change`属性,开发者可以明确指示浏览器对该元素进行优化处理。这样一来,浏览器可以提前分配资源和准备工作,以便在实际改变发生之前进行相应的合成操作。这样做有助于避免不必要的重绘和重排,提高页面的响应速度和动画的流畅度。
|
||||
|
||||
`will-change`属性可以接受多个属性值,表示将要改变的属性。例如,`will-change: transform`表示元素即将进行变形操作,`will-change: opacity`表示元素的透明度即将发生变化。
|
||||
|
||||
需要注意的是,`will-change`属性应在实际变化发生前的一段时间内被设置,以便浏览器有足够的时间进行准备和优化。另外,`will-change`属性并不会自动触发硬件加速,但它可以为浏览器提供一种优化渲染的提示。
|
||||
|
||||
此外,`will-change`属性的使用应谨慎,避免滥用。**只有在明确知道元素即将发生某种变化,并且这种变化对性能有影响时,才应使用`will-change`属性。过度使用`will-change`属性可能会导致浏览器进行不必要的优化,反而降低性能**。
|
||||
|
||||
总的来说,`will-change`属性是一个用于优化渲染性能的CSS属性,通过提前告知浏览器元素即将发生的变化,使浏览器能够提前进行准备和优化,从而提高页面的响应速度和动画的流畅度
|
||||
|
||||
Demo:
|
||||
|
||||
```
|
||||
div {
|
||||
will-change: transform;
|
||||
width: 200px;
|
||||
background-color: red;
|
||||
margin: 0 auto;
|
||||
}
|
||||
```
|
||||
|
||||
通过上面的 css 设置,告诉浏览器:这个 div 的 transform 经常会变,浏览器会为该元素创建一个独立的图层,将这个图层标记为“即将变换”。这样,在进行布局和绘制时,浏览器就可以更高效地处理这个元素,而无需重新计算整个渲染树。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Layer-Demo2.png" style="zoom:25%;">
|
||||
|
||||
|
||||
|
||||
## 五、绘制 - Paint
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Paint.png" style="zoom:25%;">
|
||||
|
||||
第四步的产出就是分层。第五步绘制阶段,会分别对每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来(类似 canvas 代码,告诉计算机从哪个点经过中间几个点,最后到哪个点绘制一条线,中间内容用什么颜色填充)
|
||||
|
||||
渲染主线程的工作到此为止,剩余步骤交给其他线程完成。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-MainThread-duty.png" style="zoom:25%;">
|
||||
|
||||
## 六、分块 - Tiling
|
||||
|
||||
完成绘制之后,主线程将每个图层的绘制信息提交给合成线程,剩余的工作将由合成线程完成。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Tilling.png" style="zoom:25%;">
|
||||
|
||||
合成线程首先对每个图层分块(Tiling),将其划分为更多的小区域。合成线程类似一个任务调度者,它会从线程池中拿出多个线程来完成分块的工作。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Tilling-Worker.png" style="zoom:25%;">
|
||||
|
||||
QA:浏览器渲染过程中分块的作用是什么?
|
||||
|
||||
1. 提高渲染性能:当浏览器需要渲染一个复杂的网页时,如果一次性将所有内容加载并渲染出来,可能会消耗大量的计算资源和时间,通过网页分成多个较小的块(tiling)浏览器可以并行地加载和渲染这些块,从而充分利用计算资源,提高渲染性能。
|
||||
2. 优化内存占用:如果浏览器一次性加载和渲染整个网页,可能会消耗大量的内存。通过将网页分成多个图块,浏览器可以更好的管理内存,避免不必要的内存消耗
|
||||
3. 实现懒加载:通过分块,浏览器可以实现懒加载,即只有当某个图块进入视口可见区域时,才开始加载和渲染该图块。这样可以减少不必要的加载和渲染,提高页面的加载速度和性能
|
||||
4. 方便进行并行处理和异步操作:通过将网页分成多个图块,浏览器可以更容易地进行并行处理和异步操作。例如,在移动端设备上,可以利用 GPU 进行图块的并行渲染,提高渲染效率。
|
||||
|
||||
分块 tiling 技术是浏览器渲染过程中提高性能、优化内存使用和实现懒加载的重要手段之一。
|
||||
|
||||
|
||||
|
||||
## 七、光栅化
|
||||
|
||||
分块完成后会进入光栅化阶段。光栅化是将每个块变成位图。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Raster.png" style="zoom:25%;">
|
||||
|
||||
|
||||
|
||||
合成线程将分块后的块信息交给 GPU 进程,以极高的速度完成光栅化,并优先处理靠近视口的块。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Raster-GPU.png" style="zoom:25%;">
|
||||
|
||||
|
||||
|
||||
## 八、画 - Draw
|
||||
|
||||
合成线程计算出每个位图在屏幕上的位置,交给 GPU 进行最终的呈现。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Draw.png" style="zoom:25%;">
|
||||
|
||||
合成线程拿到每个层(Layer)、每个块(Tile)的位图(bitmap)后,生成一个个指引(quad)信息。指引信息标识出每个位图应该画到屏幕上的哪个位置,此过程会考虑到旋转、缩放、变形等。
|
||||
|
||||
因为变形发生在合成线程,与渲染主线程无关,这也是 transform 效率高的本质原因。
|
||||
|
||||
合成线程会把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕显示
|
||||
|
||||
|
||||
|
||||
完成过程如下
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Full-Progress.png" style="zoom:50%;">
|
||||
|
||||
|
||||
|
||||
## reflow
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Reflow.png" style="zoom:40%;">
|
||||
|
||||
比如某个业务逻辑,导致我们用 js 脚本修改了某个节点的宽度、颜色,这其实修改的是 cssom,假设业务逻辑导致操作了 DOM,DOM 节点增删了,cssom、DOM 改变了,则会触发一系列的的流程,比如重新计算样式 style、布局(layout)、分层 layer、绘制 paint、分块 tiling、光栅化 raster、画 draw、系统调用 GPU 去真正显示。
|
||||
|
||||
当渲染树 render tree 中的一部分(或者全部)因为元素的尺寸、布局、颜色、隐藏等改变而需要重新构建,这就情况被称为回流。图上的 style 这部分。
|
||||
|
||||
回流发生时,浏览器会让渲染树中受到影响的部分失效,并重新构建这部分渲染树。完成回流 reflow 后,浏览器会重新绘制受影响的部分到屏幕中,该过程称为重绘。
|
||||
|
||||
**简单来说,reflow 就是计算元素在屏幕上确切的位置和大小并重新绘制。回流的代价远大于重绘。回流必定重绘,重绘不一定回流。**
|
||||
|
||||
|
||||
|
||||
## repaint
|
||||
|
||||
当渲染树 render tree 中的一些元素需要更新样式,但这些样式只是改变元素外观、风格,而不影响布局(位置、大小),则叫重绘。
|
||||
|
||||
**简单来说,重绘就是将渲染树节点转换为屏幕上的实际像素,不涉及重新布局阶段的位置与大小计算**
|
||||
|
||||
|
||||
|
||||
QA:为什么 transform 效率高?
|
||||
|
||||
假设在 css 中针对某个元素写了 `transform: rotate(100deg)`,transform 既不会影响布局也不会影响绘制指令,它影响的是渲染流程的最后一个阶段,图上的 draw 阶段。由于 draw 阶段发生在合成线程中,不在渲染主线程,所以 transform 的任何变化几乎不会影响主线程。同样,不管主线程如何繁忙,都不影响合成线程中 transform 的变化。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/Browser-Reflow.png" style="zoom:40%;">
|
||||
@@ -32,7 +32,7 @@
|
||||
* [28、神器Puppeteer](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.28.md)
|
||||
* [29、从Vue.js谈谈前端开发的技术栈演变](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.29.md)
|
||||
* [30、Javascript 常用工具封装](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.30.md)
|
||||
* [31、浏览器布局与DOM绘制](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.31.md)
|
||||
* [31、事件循环](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.31.md)
|
||||
* [32、React核心技术剖析](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.32.md)
|
||||
* [33、ES6学习总结](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.33.md)
|
||||
* [34、富文本编辑器的原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.34.md)
|
||||
@@ -43,4 +43,6 @@
|
||||
* [39、前端模块化演进之路](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.39.md)
|
||||
* [40、“Electron” 一个可圈可点的 PC 多端融合方案](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.40.md)
|
||||
* [41、sourceMap 闪亮登场](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.41.md)
|
||||
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
|
||||
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
|
||||
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
|
||||
* [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
|
||||
38
Chapter7 - Geek Talk/7.24.md
Normal file
@@ -0,0 +1,38 @@
|
||||
## 晋升答辩的逻辑是什么?
|
||||
<img src="./../assets/upgrageReviewMeeting.png" style="zoom:30%; align:left;">
|
||||
|
||||
> 来源是脉脉 App 的一张图,这里做简单的扯淡。这个老前端的具体背景是什么不清楚,评委还问了什么也不清楚。
|
||||
|
||||
|
||||
## 面试官的提法有些尖锐
|
||||
面试官的提法有些尖锐、不合理。但可能(😂为什么是可能?可能有些面试官就是在扯犊子)是在考核:极限施压,看你抗压和思维能力,另外想问你真的是否理解自己的价值,对自身有没有认证思考过
|
||||
主要晋升名额少,上去的除了关系户,一定需要脑子清晰、业务和技术都很能打的人。同样的问题,回答好的人,在同一批里面,通过的概率更大。
|
||||
|
||||
假设您提法是对的,我觉得其项目会办法落地了的。什么意思呢?因为以您的逻辑来推导:
|
||||
- idea 的提出者提出创意就好了,其他项目部门和同事没有任何价值
|
||||
- 如果上面的没有价值成立,那正常项目所需的头脑风暴、prd、mrd 需求评审会议、kick-off meeting,开发、测试、发布、运维质量保证、线上数据运营分析,再次迭代发布新版本等一系列流程。都没意义了
|
||||
- 显然这些动作是有价值,那么之前的假设就应该被推倒,同样问题的前提就不合理,也就是您所说的「需求都是产品给的方案,价值跟你有什么关系?」这个提法就不存在了
|
||||
|
||||
然后我们从正面聊聊这个问题。
|
||||
|
||||
## 工程师的差异在什么地方?
|
||||
首先,优秀工程师和普通的工程师,差异主要存在2个方面:基础的技术知识、业务领域知识。那么优秀工程师的价值就体现在可以凭借扎实的业务领域知识,更好的理解业务问题、业务现状、准确的理解好业务问题,然后利用我自身的技术知识,设计面向未来、架构合理、具备可拓展性、维护清晰简单的技术架构,更好的赋能业务。
|
||||
|
||||
业务领域知识和技术如何结合?
|
||||
举个例子,比如电商公司一个 App 有商品业务域、订单业务域名、营销业务域,商品业务域的核心功能是什么,展示不同的商品列表、商详信息。商品有多规格、无规格、多单位 等不同 SKU 信息,商品业务域和上下游链路的交互动作是什么,也就是商品业务域对外提供什么能力、接口。
|
||||
低阶工程师只是会写代码,翻译需求成“只是能跑的业务代码”。那这个代码的拓展性、可测性、维护性、性能怎么样?线上问题多不多、用了一个可能会死锁的锁、会内存泄漏的代码,虽然简单的操作下 QA 没有发现问题,但是线上用户的使用环境千变万化,可能卡顿、crash、业务异常造成资损故障… 。
|
||||
这里的陈述有些不那么聚焦,这么说吧,业务方面,业务领域知识扎实和不扎实的体现在,QA 在有限时间内的测试 case 并不能穷举所有代码分支路径,也就是每个 case 并不能走完,只能证明他给的测试用例走完了,那 QA 给的测试用例走完就可以保证所有的用户不会产生异常吗?显然不会。
|
||||
所以如果开发自身业务知识稳定,写的代码一来可以 cover 一些 QA 没有列举到的业务 case,二来写的代码面向未来(比如目前有 n 种订单类型1、2、3、4、5,某次需求修改了类型2的字段 sku UI 样式,其中 sku 是基础属性,会影响到其他订单类型,如果没有测试好就会产生问题,low 的写法就是多个 if… else… 加测试了,好的实现就是工厂设计模式 + 单测了,测试覆盖率所保证,或者精准测试覆盖率)
|
||||
|
||||
## 换个前端来做有何不同?
|
||||
第二个问题,换个前端来做有何不同?同样从2个方面出发(技术知识 + 业务知识)业务领域知识、业务 sense、更好的理解业务问题和梳理咱们公司业务未来可能的走向,看看业界其他公司的产品形态都是什么样的(比如淘宝就在做竞品分析的时候,实验室机房高速摄像机去录像,逐帧分析 App启动时长。可能有些人会问为什么不从技术手段分析启动时长?这是个技术问题,自身 App 可以去分析,但是对于竞品分析来说,不精确,所以为了统一分析标准,采用该方案),未来可能存在的业务 case 是什么,我会分析现状、疏离问题、主动去挖掘问题,拼接技术功底,挖掘技术问题、性能体验问题,不断去优化和体验,持续打造领先竞品的产品。抛开数据空谈理想类似耍流氓,我也会埋点统计线上性能数据,不断去量化定量分析问题,可能存在 n个 问题,我会根据业务现状和体验问题的严重性,衡量 ROI、PK 问题优先级,着重解决用户和业务中最痛、最有价值的事情,这也是优秀工程师和普通工程师的区别,不只是任务的执行者、需求的翻译者,而是业务的 owner、做有价值事情的挖掘者。
|
||||
|
||||
## 优秀工程师其他的软技能
|
||||
1. 同时也会挑战一些不合理的业务需求。对于产品设计师的不合理需求勇于说不
|
||||
2. 展示自己的可以体现软实力的东西。比如在某个项目中承担了一些 PM 的角色,然后某个项目有危险,通过自己什么样的有效动作(协调上下游资源、攻坚不属于自己的技术问题、私下个人时间推广跟进落地取得额外的价值等),做了几次技术分享等
|
||||
|
||||
核心逻辑:
|
||||
1. 需要不丢面试官面子,合乎礼仪(以他的问题思路作为前提,来推导一些结论,再和大家认可的事实作为矛盾冲突,巧妙反驳他)
|
||||
2. 凸显自己的价值,从技术 + 业务知识2个方面展开回答
|
||||
|
||||
千言万语:晋升的本质就是做了一些超越你当前职级能力边界的事情,并在业务上有价值
|
||||
32
Chapter7 - Geek Talk/7.25.md
Normal file
@@ -0,0 +1,32 @@
|
||||
## 短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力
|
||||
|
||||
早上刷朋友圈看到一则动态,大概讲的是他平时会尽量不让小朋友去刷短视频。虽然未婚未育,但还是想扯几句。
|
||||
|
||||
自媒体时代、信息大爆炸。当文字表达所期望的受众面越广,易读、上口、受众面广、易流传,其用语和举例都会追求更简单、更直白,比如“绝绝子”、“666”、“这也太那个了吧”等网络用语。回想下,小学时代,我们正在学习语文,学习语法、成语,那什么是“绝绝子”? vocal 还可以这么表达吗?那学习的最初都是重复和模仿,小朋友会按照“形容词+形容词+子”的形式发挥了,会不会说遇到美丽的会不会说美美子、遇到害怕的说怕怕子,那要成语干啥,表述最佳的信达雅效果,如何实现。
|
||||
|
||||
所以刷短视频这个事情,对于学习期的小朋友来说弊大于利。不是说没有好的方面(什么开拓视野、什么劳逸结合),有,但还是弊大于利。这样的语言环境对于求学阶段的孩子来说非常不友好。
|
||||
|
||||
信息大爆炸时代,一个是信息流变多了,对于接收者的甄别能力提出更高要求;另外就是大数据推荐更精确,基于你的用户行为数据(视频停留时长、点赞、收藏、评论、转发等活跃行为)会推导出你偏好,接下去推荐的都是绝绝子、这也太那个了吧 😂
|
||||
|
||||
所以处于学习阶段的孩子,在打好自身基础、培养好甄别能力前,还是不能随意刷短视频。信息有别于知识,因为有局限性和对错,小朋友明显不具备很强的甄别能力
|
||||
|
||||
|
||||
引出另一个问题:短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力
|
||||
问题就不做回答了,小朋友刷短视频、有甄别能力的大人、带有娱乐消遣目的的大人等不同人刷短视频,这个问题的答案都会不一样。因此没必要大而全的回答这个问题。ROI 太低
|
||||
|
||||
|
||||
1. 代词太多,影响表述的精准性。在上下文信息拉齐前,尽量避免使用代词。当然口语环境下,上下文信息拉齐的时候,用代词没有任何问题。
|
||||
在做技术方案、技术分享的时候,你在跟别人阐述你的思路的时候,当语境、上下文信息没有拉齐前,你可能会不消息使用一些代词,比如:这种堆栈抓取方案使得 crash 发生时堆栈 dump 耗时减少50%,可能场景严肃,没有人立马制止,问你“这种抓取方案是什么方案呀,这个方式是什么,能不能先聊清楚、交代清楚。再做代词”
|
||||
|
||||
把你想表达的表达的清清楚楚,用最精准的词告诉别人、告诉倾听者。如果你找不到这个词的话,那么就是**你的语言没有跟上你的思维**,这是非常危险的,说明你没有语言作为载体去深入地形成自己的理解和自己的思想。
|
||||
|
||||
为什么短视频会让我们变笨,不会表达呢?因为整个平台、整个话语空间的词库都太同质化、太扁平、太局限了,看似每天接触很多内容,但实际都是一些很重复的流行语料库,它大大压缩了我们日常的词汇量,而这些语料库越模糊,大家的理解成本越低,得到的关注就会越多。 比如遇到美食,大多数短视频的描述就是,这个食物实在是“太那个了吧” or “这谁顶得住啊”。或者一些旅行的视频,文案千篇一律就是“一辈子总得去哪里哪里吧”(可能这个词第一次出来的时候作者就是这么想的,因为工作、生活节奏告诉运转,努力打破循环,去哪里玩了一趟,但后来就背离初衷了吧,大家跟风文案都是如此)。很少是在精准描绘一种食物的味道或者对一隅风景的感受。那在这样的语言浸泡下,我们看似摄入了很多信息,但我们会渐渐失语,当我们吃了好吃的食物,平时刷到的网络用语潜意识里就迸出来了。网络用语变成唯一的表意媒介,可能会说“天啦,这是我吃过最好吃的食物了”、“天啦,难顶”、“天啦,这也太那个了吧” 。但那个到底是哪个呀?无数个这种有太多想象空间的场景出来,我们就会渐渐的失去信达雅的表述能力,同时也可能偏离表述者真正要表达的意图
|
||||
|
||||
语言的匮乏会让我们变笨是因为,语言是构成思维的“官能”,语言的边界就是世界的边界。语言塑造思维,这个观点其实是哲学里的常常被讨论的一组二元命题。从维特根斯坦他开始认为我们认识世界和思维的能力,在很大程度上受限于我们的语言能力。有本反乌托邦小说,乔治奥威尔的《1984》里 “newspeak” 这个概念是去探讨语言对思想的控制,就是小说里的权力机构通过限制和简化语言,限制了人们的思考和表达的自由。以及波兹曼《娱乐至死》提到过的“当媒体重视娱乐性而非深度思想的时候,公众的认知能力和批判思维就会收到影响“。
|
||||
|
||||
网络空间(爬虫、数据发布;自媒体炒作热点、借鉴文体和表述)实在是太多同质化和重复的信息了,这些日渐模糊的表述和代词,企图减少理解成本的用于,实际上是在重塑和简化我们的思维
|
||||
|
||||
2. 多读一些严肃的书籍、作品。或者多听一些非批量生产的“洞见”。多摄入有深度的信息。因为知识的载体不一定是书籍,可能是大佬的博客、动态、有深度的微博等。
|
||||
3. 尽量去精准化自己的用词。少用代词、尽量信达雅。
|
||||
最简单的练习抓手:比如去四季酒店餐厅点菜,不要说“我要这个、我要那个”,我要“西湖醋鱼,地道的西湖醋鱼,可以体现水平的烧法是选用草鱼,而非简单的笋壳鱼,咱们店里是什么鱼呀?哦,草鱼啊,太好了,那就上一道西湖醋鱼吧”。少用代词,尝试更多更准确的词去描述需求、去描述感受。核心就是为自己模糊的想法找到一个精准的词去描述出来。
|
||||
|
||||
@@ -144,7 +144,7 @@
|
||||
* [28、神器Puppeteer](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.28.md)
|
||||
* [29、从Vue.js谈谈前端开发的技术栈演变](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.29.md)
|
||||
* [30、Javascript 常用工具封装](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.30.md)
|
||||
* [31、浏览器布局与DOM绘制](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.31.md)
|
||||
* [31、事件循环](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.31.md)
|
||||
* [32、React核心技术剖析](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.32.md)
|
||||
* [33、ES6学习总结](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.33.md)
|
||||
* [34、富文本编辑器的原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.34.md)
|
||||
@@ -156,7 +156,8 @@
|
||||
* [40、“Electron” 一个可圈可点的 PC 多端融合方案](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.40.md)
|
||||
* [41、sourceMap 闪亮登场](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.41.md)
|
||||
* [42、JS原型链与Objective-C内存布局不能说的秘密](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.43.md)
|
||||
|
||||
* [43、Vue 核心原理探究](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.44.md)
|
||||
* [44、浏览器渲染原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.45.md)
|
||||
* [Chapter3 - Server](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/chapter3.md)
|
||||
* [1、利用分页和模糊查询技术实现一个App接口](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.1.md)
|
||||
* [2、网页端扫码登录实现原理](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter3%20-%20Server/3.2.md)
|
||||
|
||||
BIN
assets/Browser-Draw.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 171 KiB |
BIN
assets/Browser-Full-Progress.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 66 KiB |
BIN
assets/Browser-Layer-Demo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 311 KiB |
BIN
assets/Browser-Layer-Demo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 311 KiB |
BIN
assets/Browser-Layer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 249 KiB |
BIN
assets/Browser-Layout.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 105 KiB |
BIN
assets/Browser-MainThread-duty.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
BIN
assets/Browser-Paint.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 231 KiB |
BIN
assets/Browser-Raster-GPU.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
BIN
assets/Browser-Raster.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 112 KiB |
BIN
assets/Browser-Reflow.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 105 KiB |
BIN
assets/Browser-Tilling-Worker.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 153 KiB |
BIN
assets/Browser-Tilling.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
assets/BrowserNetworkAndRender.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 172 KiB |
BIN
assets/BrowserRenderFullProgress.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 181 KiB |
BIN
assets/CSSLayoutTreeDisplay.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 104 KiB |
BIN
assets/CSSLayoutTreePseudoClass.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
assets/CSSPseudoClassLayout.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 241 KiB |
BIN
assets/CSSStyleComputeDemo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 304 KiB |
BIN
assets/CSSStyleDefaultValue.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 332 KiB |
BIN
assets/CSSStyleDoubleInherited.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 265 KiB |
BIN
assets/CSSStyleInherited.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 244 KiB |
BIN
assets/CSSStylePositionPriority.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 237 KiB |
BIN
assets/Chromium-BrowserDefaultStyle.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 616 KiB |
BIN
assets/ComputedStyleDemo-p.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 228 KiB |
BIN
assets/CssStyleDeclarationPriority.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 233 KiB |
BIN
assets/DevEco-Studio-DownloadNetworkErrror.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 155 KiB |
BIN
assets/HTMLParse-CSSOM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 221 KiB |
BIN
assets/HTMLParse-CSSOMDOM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 425 KiB |
BIN
assets/HTMLParse-CSSPreLoad.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 168 KiB |
BIN
assets/HTMLParse-DOM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 285 KiB |
BIN
assets/HTMLParse-JSAsync1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 48 KiB |
BIN
assets/HTMLParse-JSAsync2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
assets/HTMLParse-JSDefaultBehavior.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
assets/HTMLParse-JSDefer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
BIN
assets/HTMLParse-JSDownload.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 212 KiB |
BIN
assets/JS-UIClickLag1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
BIN
assets/JS-UIClickLag2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
assets/JS-UIClickLag3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
BIN
assets/JSEventLoop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
assets/JSMainThreadEventLoop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
BIN
assets/StyleCompute.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 169 KiB |
BIN
assets/upgrageReviewMeeting.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 236 KiB |