mirror of
https://github.com/NohamR/knowledge-kit.git
synced 2026-07-11 22:42:17 +00:00
docs: 反爬虫之防重放策略
This commit is contained in:
@@ -7,6 +7,8 @@
|
||||
大道理谁都懂,但是按照我知道的情况,还是有非常多的人和公司在 Hybrid 这一块并没有做的很好,所以我将我的经验做一个总结,希望可以帮助广大开发者的技术选型有所帮助
|
||||
|
||||
|
||||
|
||||
|
||||
## Hybrid 的一个现状
|
||||
|
||||
可能早期都是 PC 端的网页开发,随着移动互联网的发展,iOS、Android 智能手机的普及,非常多的业务和场景都从 PC 端转移到移动端。开始有前端开发者为移动端开发网页。这样子早期资源打包到 Native App 中会造成应用包体积的增大。越来越多的业务开始用 H5 尝试,这样子难免会需要一个需要访问 Native 功能的地方,这样子可能早期就是懂点前端技术的 Native 开发者自己封装或者暴露 Native 能力给 JS 端,等业务较多的时候者样子很明显不现实,就需要专门的 Hybrid 团队做这个事情;量大了,就需要规矩,就需要规范。
|
||||
@@ -23,9 +25,13 @@ Hybrid 在大量应用的时候就需要一定的规范,那么本文将讨论
|
||||
- 资源缓存策略,白屏问题...
|
||||
|
||||
|
||||
|
||||
|
||||
## Native 与前端分工
|
||||
在做 Hybird 架构设计之前我们需要分清 Native 与前端的界限。首先 Native 提供的是宿主环境,要合理利用 Native 提供的能力,要实现通用的 Hybrid 架构,站在大前端的视觉,我觉得需要考虑以下核心设计问题。
|
||||
|
||||
|
||||
|
||||
### 交互设计
|
||||
|
||||
Hybrid 架构设计的第一要考虑的问题就是如何设计前端与 Native 的交互,如果这块设计不好会对后续的开发、前端框架的维护造成深远影响。并且这种影响是不可逆、积重难返。所以前期需要前端与 Native 好好配合、提供通用的接口。比如
|
||||
@@ -34,10 +40,16 @@ Hybrid 架构设计的第一要考虑的问题就是如何设计前端与 Native
|
||||
2. 通讯录、系统、设备信息读取接口
|
||||
3. H5 与 Native 的互相跳转。比如 H5 如何跳转到一个 Native 页面,H5 如何新开 Webview 并做动画跳转到另一个 H5 页面
|
||||
|
||||
|
||||
|
||||
|
||||
### 账号信息设计
|
||||
|
||||
账号系统是重要且无法避免的,Native 需要设计良好安全的身份验证机制,保证这块对业务开发者足够透明,打通账户体系
|
||||
|
||||
|
||||
|
||||
|
||||
### Hybrid 开发调试
|
||||
|
||||
功能设计、编码完并不是真正结束,Native 与前端需要商量出一套可开发调试的模型,不然很多业务开发的工作难以继续。
|
||||
@@ -54,6 +66,7 @@ Android 调试技巧:
|
||||
|
||||
|
||||
|
||||
|
||||
## Hybrid 交互设计
|
||||
|
||||
Hybrid 交互无非是 Native 调用 H5 页面JS 方法,或者 H5 页面通过 JS 调 Native 提供的接口。2者通信的桥梁是 Webview。
|
||||
@@ -66,6 +79,9 @@ weixin:// 可以打开微信。
|
||||
|
||||
关于 Url scheme 如果不太清楚可以看看 [这篇文章](https://www.jianshu.com/p/253479ccc83a)
|
||||
|
||||
|
||||
|
||||
|
||||
### JS to Native
|
||||
|
||||
Native 在每个版本都会提供一些 Api,前端会有一个对应的框架团队对其封装,释放业务接口。举例
|
||||
@@ -98,6 +114,8 @@ SDGHybridReady(function(arg){
|
||||
前端框架定义了一个全局变量 SDGHybrid 作为 Native 与前端交互的桥梁,前端可以通过这个对象获得访问 Native 的能力
|
||||
|
||||
|
||||
|
||||
|
||||
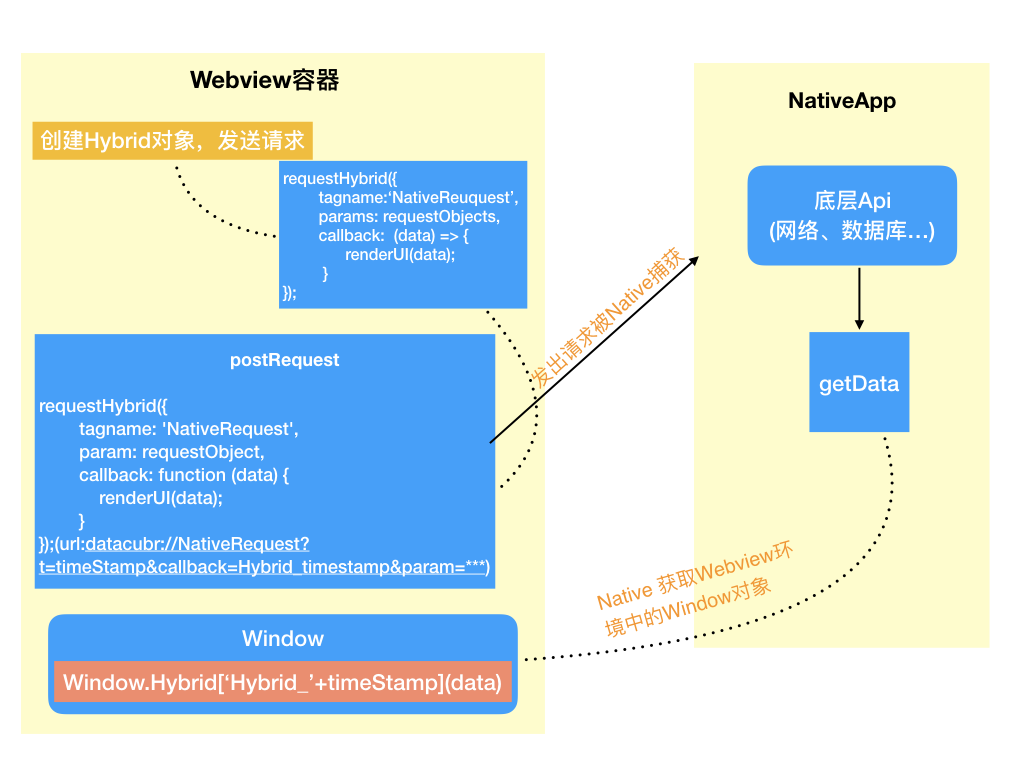
### Api 交互
|
||||
|
||||
调用 Native Api 接口的方式和使用传统的 Ajax 调用服务器,或者 Native 的网络请求提供的接口相似
|
||||
@@ -108,6 +126,8 @@ SDGHybridReady(function(arg){
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 格式约定
|
||||
交互的第一步是设计数据格式。这里分为请求数据格式与响应数据格式,参考 Ajax 模型:
|
||||
|
||||
@@ -160,7 +180,7 @@ Native 的 webview 环境可以监控内部任何的资源请求,判断如果
|
||||
|
||||
简易版本代码实现。
|
||||
|
||||
```
|
||||
```javascript
|
||||
//通用的 Hybrid call Native
|
||||
window.SDGbrHybrid = window.SDGbrHybrid || {};
|
||||
var loadURL = function (url) {
|
||||
@@ -228,7 +248,7 @@ Native 对于 H5 来说有个 Webview 容器,框架&&底层不太关心 H5 的
|
||||
|
||||
上面的网络访问 Native 代码(iOS为例)
|
||||
|
||||
```
|
||||
```objective-c
|
||||
typedef NS_ENUM(NSInteger){
|
||||
Hybrid_Request_Method_Post = 0,
|
||||
Hybrid_Request_Method_Get = 1
|
||||
@@ -272,10 +292,15 @@ typedef NS_ENUM(NSInteger){
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 常用交互 Api
|
||||
|
||||
良好的交互设计是第一步,在真实业务开发中有一些 Api 一定会由应用场景。
|
||||
|
||||
|
||||
|
||||
### 跳转
|
||||
跳转是 Hybrid 必用的 Api 之一,对前端来说有以下情况:
|
||||
- 页面内跳转,与 Hybrid 无关
|
||||
@@ -334,6 +359,9 @@ requestHybrid({
|
||||
|
||||
back 与 forward 一致,可能会有 animatetype 参数决定页面切换的时候的动画效果。真实使用的时候可能会全局封装方法去忽略 tagname 细节。
|
||||
|
||||
|
||||
|
||||
|
||||
## Header 组件的设计
|
||||
|
||||
Native 每次改动都比较“慢”,所以类似 Header 就很需要。
|
||||
@@ -355,7 +383,7 @@ PS: Native 打开 H5,如果 300ms 没有响应则需要 loading 组件,避
|
||||
|
||||
所以,站在前端业务方来说,Header 的使用方式为(其中 tagname 是不允许重复的):
|
||||
|
||||
```
|
||||
```javascript
|
||||
//Native以及前端框架会对特殊tagname的标识做默认回调,如果未注册callback,或者点击回调callback无返回则执行默认方法
|
||||
// back前端默认执行History.back,如果不可后退则回到指定URL,Native如果检测到不可后退则返回Naive大首页
|
||||
// home前端默认返回指定URL,Native默认返回大首页
|
||||
@@ -403,7 +431,7 @@ PS: Native 打开 H5,如果 300ms 没有响应则需要 loading 组件,避
|
||||
|
||||
因为 Header 左边一般来说只有一个按钮,所以其对象可以使用这种形式:
|
||||
|
||||
```
|
||||
```javascript
|
||||
this.header.set({
|
||||
back: function () { },
|
||||
title: ''
|
||||
@@ -420,7 +448,7 @@ this.header.set({
|
||||
|
||||
为完成 Native 端的实现,这里会新增两个接口,向 Native 注册事件,以及注销事件:
|
||||
|
||||
```
|
||||
```javascript
|
||||
var registerHybridCallback = function (ns, name, callback) {
|
||||
if(!window.Hybrid[ns]) window.Hybrid[ns] = {};
|
||||
window.Hybrid[ns][name] = callback;
|
||||
@@ -434,7 +462,7 @@ var unRegisterHybridCallback = function (ns) {
|
||||
|
||||
Native Header 组件实现:
|
||||
|
||||
```
|
||||
```javascript
|
||||
define([], function () {
|
||||
'use strict';
|
||||
|
||||
@@ -558,9 +586,11 @@ define([], function () {
|
||||
});
|
||||
|
||||
});
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 请求类
|
||||
|
||||
虽然 get 类请求可以用 jsonp 方式绕过跨域问题,但是 post 请求是一个拦路虎。为了安全性问题服务器会设置 cors 仅仅针对几个域名,Hybrid 内嵌静态资源可能是通过本地 file 的方式读取,所以 cors 就行不通了。另外一个问题是防止爬虫获取数据,由于 Native 针对网络做了安全性设置(鉴权、防抓包等),所以 H5 的网络请求由 Native 完成。可能有些人说 H5 的网络请求让 Native 走就安全了吗?我可以继续爬取你的 Dom 节点啊。这个是针对反爬虫的手段一。想知道更多的反爬虫策略可以看看我这篇文章 [Web反爬虫方案](https://github.com/FantasticLBP/Anti-WebSpider)
|
||||
@@ -569,7 +599,7 @@ define([], function () {
|
||||
|
||||
这个使用场景和 Header 组件一致,前端框架层必须做到对业务透明化,业务事实上不必关心这个网络请求到底是由 Native 还是浏览器发出。
|
||||
|
||||
```
|
||||
```javascript
|
||||
HybridGet = function (url, param, callback) {
|
||||
|
||||
};
|
||||
@@ -580,7 +610,7 @@ HybridPost = function (url, param, callback) {
|
||||
|
||||
真实的业务场景,会将之封装到数据请求模块,在底层做适配,在H5站点下使用ajax请求,在Native内嵌时使用代理发出,与Native的约定为
|
||||
|
||||
```
|
||||
```javascript
|
||||
requestHybrid({
|
||||
tagname: 'NativeRequest',
|
||||
param: {
|
||||
@@ -595,11 +625,14 @@ requestHybrid({
|
||||
});
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 常用 NativeUI 组件
|
||||
|
||||
一般情况 Native 通常会提供常用的 UI,比如 加载层loading、消息框toast
|
||||
|
||||
```
|
||||
```javascript
|
||||
var HybridUI = {};
|
||||
HybridUI.showLoading();
|
||||
//=>
|
||||
@@ -629,6 +662,7 @@ Native UI与前端UI不容易打通,所以在真实业务开发过程中,一
|
||||
|
||||
|
||||
|
||||
|
||||
## 账号系统的设计
|
||||
|
||||
Webview 中跑的网页,账号登录与否由是否携带密钥 cookie 决定(不能保证密钥的有效性)。因为 Native 不关注业务实现,所以每次载入都有可能是登录成功跳转回来的结果,所以每次载入都需要关注密钥 cookie 变化,以做到登录态数据的一致性。
|
||||
@@ -665,15 +699,13 @@ HybridUI.logout = function () {
|
||||
```
|
||||
|
||||
|
||||
|
||||
在设计 Hybrid 层的时候,接口要做到对于处于 Hybrid 环境中的代码乐意通过接口获取 Native 端存储的用户账号信息;对于处于传统的网页环境,可以通过接口获取线上的账号信息,然后将非敏感的信息存储到 LocalStorage 中,然后每次页面加载从 LocalStorage 读取数据到内存中(比如 Vue.js 框架中的 Vuex,React.js 中的 Redux)
|
||||
|
||||
|
||||
|
||||
|
||||
## Hybrid 资源管理
|
||||
|
||||
|
||||
|
||||
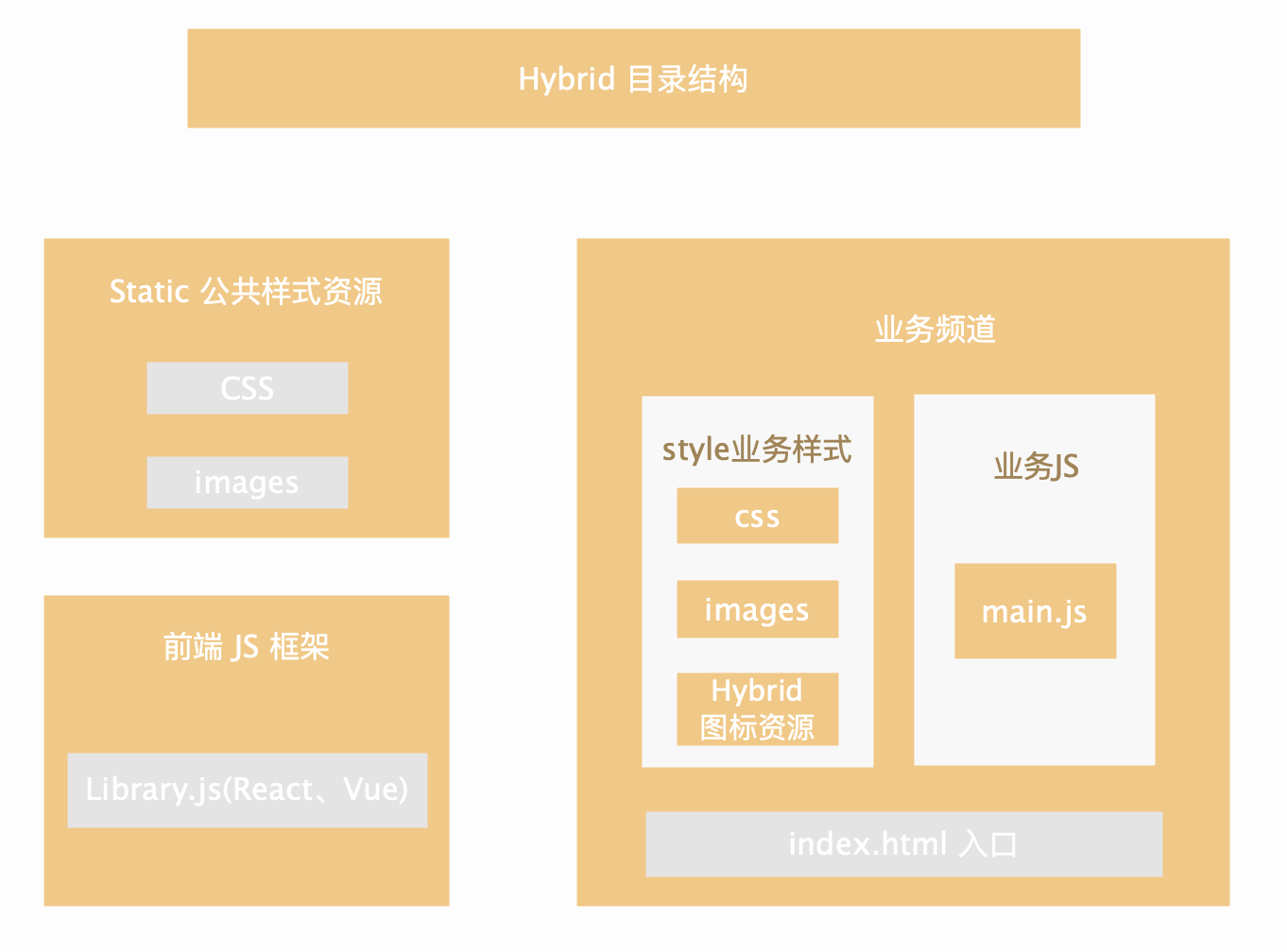
Hybrid 的资源需要 `增量更新` 需要拆分方便,所以一个 Hybrid 资源结构类似于下面的样子
|
||||
|
||||
|
||||
@@ -705,29 +737,24 @@ WebApp
|
||||
|
||||
|
||||
|
||||
|
||||
## 增量更新
|
||||
|
||||
|
||||
|
||||
每次业务开发完毕后都需要在打包分发平台进行部署上线,之后会生成一个版本号。
|
||||
|
||||
|
||||
|
||||
| Channel | Version | md5 |
|
||||
| ------- | ------- | ----------- |
|
||||
| Mall | 1.0.1 | 12233000ww |
|
||||
| Cart | 1.1.2 | 28211122wt2 |
|
||||
|
||||
|
||||
|
||||
当 Native App 启动的时候会从服务端请求一个接口,接口的返回一个 json 串,内容是 App 所包含的各个 H5 业务线的版本号和 md5 信息。
|
||||
|
||||
拿到 json 后和 App 本地保存的版本信息作比较,发现变动了则去请求相应的接口,接口返回 md5 对应的文件。Native 拿到后完成解压替换。
|
||||
|
||||
全部替换完毕后将这次接口请求到的资源版本号信息保存替换到 Native 本地。
|
||||
|
||||
|
||||
|
||||
因为是每个资源有版本号,所以如果线上的某个版本存在问题,那么可以根据相应的稳定的版本号回滚到稳定的版本。
|
||||
|
||||
|
||||
|
||||
@@ -606,7 +606,9 @@ $ node app.js
|
||||
目前 App 的网络通信基本都是用 HTTPS 的服务,但是随便一个抓包工具都是可以看到 HTTPS 接口的详细数据,为了做到防止抓包和无法模拟接口的情况,我们采取以下措施:
|
||||
|
||||
1. 中间人盗用数据,我们可以采取 HTTPS 证书的双向认证,这样子实现的效果就是中间人在开启抓包软件分析 App 的网络请求的时候,网络会自动断掉,无法查看分析请求的情况
|
||||
|
||||
2. 对于防止用户模仿我们的请求再次发起请求,我们可以采用 「防重放策略」,用户再也无法模仿我们的请求,再次去获取数据了。
|
||||
|
||||
3. 对于 App 内的 H5 资源,反爬虫方案可以采用上面的解决方案,H5 内部的网络请求可以通过 Hybrid 层让 Native 的能力去完成网络请求,完成之后将数据回调给 JS。这么做的目的是往往我们的 Native 层有完善的账号体系和网络层以及良好的安全策略、鉴权体系等等。
|
||||
<details>
|
||||
<summary>JS端发起网络请求代码:点击展开</summary>
|
||||
@@ -656,7 +658,17 @@ $ node app.js
|
||||
```
|
||||
</details>
|
||||
|
||||
4. 有些人觉得利用 RSA 加密虽然可以保证数据的安全,但是因为每次都是大量字符串的运算,觉得数据量大的情况下用 RSA 加解密会非常耗时。对,肯定耗时,所以较好的做法就是将通信的 Alice 和 Bob 两方利用 **RSA** 的方式交换密钥。然后两方在通信的时候数据内容采用**对称加密**的方式进行。但是私钥在本地如何存放呢?想到的办法就是将关键密钥的字符串提高到较高的安全级别,比如这个文件用加密保存。接下来推荐一个[工具](https://github.com/RNCryptor/RNCryptor),可以将代码文件进行加密保存和解密访问。
|
||||
4. 针对抓包工具可以截获 HTTPS 数据的情况,我们可以对请求参数和返回内容再做一次 **RSA** 加密处理。
|
||||
|
||||
- 客户端和服务器各自生成公钥、私钥
|
||||
- 互相交换公钥
|
||||
- 通信流程:客户端利用服务端的公钥加密请求参数 -> 服务端收到请求后利用服务端的私钥解密,验证合法性 -> 做可能的逻辑处理(DB、缓存、ES),组装数据 -> 处理数据到合适的格式 -> 利用客户端公钥加密数据 -> 客户端收到数据后利用客户端私钥解密。(服务器主动发起的请求也是一样的逻辑)
|
||||
|
||||
有些人觉得利用 RSA 加密虽然可以保证数据的安全,但是因为每次都是大量字符串的运算,觉得数据量大的情况下用 RSA 加解密会非常耗时。
|
||||
|
||||
对,肯定耗时,所以较好的做法就是将通信双方使用的密钥(对称加密)利用 **RSA** 的方式交换,然后两方在通信的时候,数据内容采用**对称加密**的方式进行。
|
||||
|
||||
但是私钥在本地如何存放呢?想到的办法就是将关键密钥的字符串提高到较高的安全级别,比如这个文件用加密保存。接下来推荐一个[工具](https://github.com/RNCryptor/RNCryptor),可以将代码文件进行加密保存和解密访问。
|
||||
|
||||
|
||||
|
||||
@@ -674,7 +686,7 @@ $ node app.js
|
||||
|
||||
|
||||
|
||||
以上是第一阶段的安全性总结,后期应该会更新(App逆向、防重放、Canvas 反爬虫技术方案做深入探讨等)。
|
||||
以上是第一阶段的安全性总结,后期会从更多、更深入的角度剖析大前端安全性的策略和方案
|
||||
|
||||
|
||||
补充:
|
||||
|
||||
@@ -15,7 +15,8 @@ API 接口存在很多常见的安全性问题,常见的有下面几种情况
|
||||
所以针对上述的问题也有一些解决方案:
|
||||
1. HTTPS 证书的双向认证解决抓包工具问题
|
||||
2. 假如通过网络层高手截获了 HTTPS 加证书认证后的数据,所以需要对请求参数做签名
|
||||
2. 「防重放策略」解决请求的多次发起问题
|
||||
3. 「防重放策略」解决请求的多次发起问题
|
||||
4. 请求参数和返回内容做额外 RSA 加密处理,即使截获,也无法查看到明文。
|
||||
|
||||
关于 HTTPS 证书双向认证和 Web 端反爬虫技术方案均在[大前端时代的安全性](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.56.md)一文中有具体讲解。接下来引出本文主角:防重放
|
||||
|
||||
@@ -96,7 +97,11 @@ API 接口存在很多常见的安全性问题,常见的有下面几种情况
|
||||
|
||||
## 四、 计算机网络时间同步技术原理
|
||||
|
||||
客户端和服务端的时间同步在很多场景下非常重要,比如秒杀系统(页面打开,各个类目的商品展示倒计时秒杀功能。如果直接请求接口页面数据,然后拿到服务器时间进行倒计时,则会因为网络传输的耗时,导致时间不精确)、接口 timestamp 等。
|
||||
客户端和服务端的时间同步在很多场景下非常重要,举几个例子,这些场景都是经常发生的。
|
||||
- 一个商品秒杀系统。用户打开页面,浏览各个类目的商品,商品列表界面右侧和详情页都有倒计时秒杀功能。用户在详情页加购、下单、结算。发现弹出提示“商品库存不足,请购买同类其他品牌商品”
|
||||
- 一个答题系统,题目是该公司核心竞争力。所以有心的程序员为接口设计了「防重放」功能。但是前端小哥不给力,接口带过去的 timestamp 与服务器不在一个时区,差好几秒。别有用心的竞品公司的爬虫工程师发现了该漏洞,爬取了题目数据。
|
||||
|
||||
所以该现象在计算机领域有非常普遍,有解决方案。
|
||||
|
||||
1. 如果精度要求不高的情况下:先请求服务器上的时间 ServerTime,然后记录下来,同时记录当前的时间 LocalTime1;需要获取当前的时间时,用最新的当前时间 (LocalTime2 - LocalTime1 + ServerTime)
|
||||
|
||||
@@ -109,4 +114,4 @@ API 接口存在很多常见的安全性问题,常见的有下面几种情况
|
||||
|
||||
2. 如果需要精度更高,比如 100纳秒的情况,则需要使用 NTP(Network Time Protocol)网络时间协议、PTP (Precision Time Protocol)精确时间同步协议了。
|
||||
|
||||
NTP、PTP 不在本文的范畴,不懂得可以查看这篇[文章](https://segmentfault.com/a/1190000005337116)
|
||||
NTP、PTP 不在本文的范畴,感兴趣的可以查看这篇[文章](https://segmentfault.com/a/1190000005337116)
|
||||
|
||||
@@ -7,12 +7,14 @@
|
||||
|
||||
## 实现
|
||||
|
||||
可以马上想到的是利用 shell 结合 git hook 实现在 git commit 阶段检查输入是否符合规范。符合就通过,不符合就不通过,抛出警告信息,并给出提示信息。
|
||||
可以马上想到的是利用 shell 结合 git hook 实现在 git commit 阶段检查输入是否符合规范。符合就通过,不符合就终止,并给出提示信息。
|
||||
|
||||
|
||||
|
||||
|
||||
### 规范是什么
|
||||
|
||||
常见的分类有下面几种情况:
|
||||
常见的分类有下面几种:
|
||||
|
||||
- build:修改项目的的构建系统(xcodebuild、webpack、glup等)的提交
|
||||
- ci:修改项目的持续集成流程(Kenkins、Travis等)的提交
|
||||
@@ -28,6 +30,7 @@
|
||||
|
||||
|
||||
|
||||
|
||||
### 轮子
|
||||
|
||||
在 github 上有 [commitlint](https://github.com/conventional-changelog/commitlint) 这个项目,它可以很方便的在工程中做配置,并允许你自定义上面说的「规范」、「分类」。
|
||||
@@ -92,23 +95,18 @@
|
||||
```
|
||||
|
||||
|
||||
上面的流程配置完成,当你在提交 commit 信息的时候如果输入不符合 `<type>: <subject>` 规则,会给出提示信息。
|
||||
上面的流程配置完成,当你在提交 commit 信息的输入的内容,如果不符合 `<type>: <subject>` 规则,会终止并给出提示信息。
|
||||
|
||||
type 就是上面的种类;subject 就是需要提交的文字概括。比如:feature:增加摇一摇推荐酒店功能。
|
||||
|
||||
|
||||
小说明:
|
||||
- 如果某次提交想禁用 husky,可以添加参数 `--no-verify`
|
||||
```shell
|
||||
git commit --no-verify -m "xxx"
|
||||
```
|
||||
小说明:如果某次提交想禁用 husky,可以添加参数 **--no-verify**。`git commit --no-verify -m "xxx"`
|
||||
|
||||
|
||||
|
||||
|
||||
### 大体流程
|
||||
### 流程说明
|
||||
|
||||
安装包 husky 的时候,会在目录 `.git/hooks/` 下生成一堆 shell 脚本,负责 hook git 相关时机。
|
||||
安装包 husky 的时候,会在目录 `.git/hooks/` 下生成一堆 shell 脚本,负责 git 的 hook。
|
||||
|
||||
`"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"` 这个配置告诉 git hooks,当执行 `git commit -m` 的时候触发 commit-msg 钩子,并通知 husky,从而执行 `commitlint -E HUSKY_GIT_PARAMS`,实际上执行的是 `./node_modules/husky/bin/run.js`,读取 commitlint.config.js 里的配置,然后对我们 commit -m 里的字符串校验,如不通过则输出错误信息并终止。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user