70 KiB
多线程探究
平时我们经常使用 GCD、锁、队列、block,那这些概念和本质到底是什么?
线程安全如何实现?
自旋锁、互斥锁区别是什么?
什么是死锁?
如果不清楚这些问题,带着问题,跟随本文来一探究竟
多线程方案
| 技术方案 | 简介 | 语言 | 线程生命周期 | 使用频率 |
|---|---|---|---|---|
| pthread | -一套通用的多线程API 适用于Unix\Linux\Windows等系统 跨平台\可移植 使用难度大 |
C | 开发者手动管理 | 很少,底层监控会用到 |
| NSThread | 使用更加面向对象 简单易用,可直接操作线程对象 |
OC | 开发者手动管理 | 偶尔 |
| GCD | 旨在替代NSThread等线程技术 充分利用设备的多核 |
C | 系统自动管理 | 经常 |
| NSOperation | 基于GCD(底层是GCD) 比GCD多了一些更简单实用的功能 使用更加面向对象 |
OC | 系统自动管理 | 经常 |
| 并发队列 | 自定义串行队列 | 主队列(串行) | |
|---|---|---|---|
| 同步(sync) | 不开新线程、串行执行任务 | 不开新线程、串行执行任务 | 不开新线程、串行执行任务 |
| 异步(async) | 开新线程、并发执行任务 | 开新线程、串行执行任务 | 不开新线程、串行执行任务 |
多线程死锁
什么是死锁?
队列任务引起的循环等待。
看几个 Demo 观察下死锁情况
Demo0
// 死锁
- (void)viewDidLoad {
[super viewDidLoad];
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"task");
});
}
// 死锁
- (void)viewDidLoad {
[super viewDidLoad];
NSLog(@"1");
dispatch_queue_t serialQueue = dispatch_queue_create("com.gcd.test", DISPATCH_QUEUE_SERIAL);
dispatch_sync(serialQueue, ^{
NSLog(@"task");
});
NSLog(@"2");
}
// console
1
task
2
// 死锁
- (void)viewDidLoad {
[super viewDidLoad];
NSLog(@"1");
dispatch_queue_t serialQueue = dispatch_queue_create("com.gcd.test", DISPATCH_QUEUE_SERIAL);
dispatch_sync(serialQueue, ^{
NSLog(@"task");
dispatch_sync(serialQueue, ^{
NSLog(@"3");
});
});
NSLog(@"2");
}
为什么一个死锁了,一个没有死锁?
第一个写法:是因为 viewDidLoad 默认是主队列上跑的,主队列也只有一个主线程。所以 viewDidLoad 和 NSLog(@"task") 这2个任务都被放到主队列上等待被调度,然而主线程在执行的时候, viewDidLoad 的执行依赖 NSLog(@"task") ,NSLog 的执行依赖 viewDidLoad,所以主队列任务循环等待,引起了死锁
第二个写法:创建了一个新的串行队列,队列里只加了1个任务 NSLog(@"task"),主队列中有 viewDidLoad,没有与之相互等待的任务,故而不会产生死锁。
第三个写法:创建了一个新的串行队列。主队列里只有 viewDidLoad 任务。在主线程执行获取任务的时候,先从主队列获取了 viewDidLoad 任务,然后从创建的串行队列中获取任务,先获取了 NSLog(@"task") 任务,由于同步执行,后面的代码执行需要等待当前任务的执行结束,但当前任务的执行结束又依赖后面的任务 NSLog(@"3")
Demo1
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_sync(queue, ^{
NSLog(@"执行任务2");
});
NSLog(@"执行任务3");
// 死锁
分析:主队列是一个串行队列,任务3等待 dispatch_sync 内的任务执行完毕,可 dispatch_sync 内的任务等待任务3执行,互相等待,产生死锁
Demo2
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_async(queue, ^{
NSLog(@"执行任务2");
});
NSLog(@"执行任务3");
// 1 3 2
Demo3
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2")
dispatch_sync(queue, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 Crash
分析:任务4等待 dispatch_sync 内的任务3,dispatch_sync 内的任务3等待任务4执行,互相等待
Demo4
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue2 = dispatch_queue_create("myqueu2", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2");
dispatch_sync(queue2, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 3 4
分析:不会死锁。因为在存在2个任务队列。所以会按照顺序各自从队列上取任务执行。
Demo5
NSLog(@"执行任务1");
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{ // 0
NSLog(@"执行任务2");
dispatch_sync(queue, ^{ // 1
NSLog(@"执行任务3");
});
NSLog(@"执行任务4");
});
NSLog(@"执行任务5");
// 1 5 2 3 4
总结:
-
队列决定了任务执行完是否需要等待。任务决定是否可以产生新线程
-
死锁:使用
sync函数给当前串行队列派发任务,则会卡住当前串行队列,产生死锁
Demo6
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil afterDelay:3];
NSLog(@"3");
});
}
// 1 3
分析:为什么打印1、3,没有打印2。因为 -(void)performSelector:(SEL)aSelector withObject:(nullable id)anArgument afterDelay:(NSTimeInterval)delay; 底层是开启了定时器,定时器运行需要添加到 RunLoop。上述代码是在全局并发队列上开启子线程,子线程中没有 RunLoop,所以定时器没有运行。
Demo7
NSLog(@"1");
dispatch_sync(dispatch_get_global_queue(0, 0), ^{
NSLog(@"2");
dispatch_sync(dispatch_get_global_queue(0, 0), ^{
NSLog(@"3");
dispatch_sync(dispatch_get_global_queue(0, 0), ^{
NSLog(@"4");
});
});
});
NSLog(@"5");
// console
1 2 3 4 5
只要是同步提交任务 dispatch_sync() 不管是提交到串行队列还是并发队列,都是在当前线程执行。所以都是在主线程中执行。
因为是并发队列,所以可以同时执行,不需要互相等待,则先提交 NSLog(@"2") 任务到全局并发队列中,然后执行。由于不需要等待,可以执行后面的代码,继续提交 NSLog(@"3") 到全局并发队列,继续执行,因为不需要等待,继续执行后面的代码。继续提交 NSLog(@"4") 到到全局并发队列,继续执行。之后从主队列取出 NSLog(@"5") 任务
Demo8
dispatch_queue_t queue = dispatch_queue_create("myqueu", DISPATCH_QUEUE_SERIAL);
dispatch_sync(queue, ^{
NSLog(@"1");
});
dispatch_async(queue, ^{
NSLog(@"2");
dispatch_sync(queue, ^{
// 这里有没有具体的逻辑都不影响,本质是一个任务 block,区别是空 block 和非空 block。
});
NSLog(@"4");
});
dispatch_sync(queue, ^{
NSLog(@"5");
});
// console
1
2
死锁
Demo9
dispatch_sync(dispathc_get_main_queue(), ^{
NSLog(@"主队列同步");
});
// 死锁
dispatch_sync(dispathc_get_main_queue(), ^{});
// 死锁
dispatch_sync(dispatch_get_main_queue(), nil);
// 死锁
总结
只要是同步提交任务 dispatch_sync() 不管是提交到串行队列还是并发队列,都是在当前线程执行。
一些经典 Demo
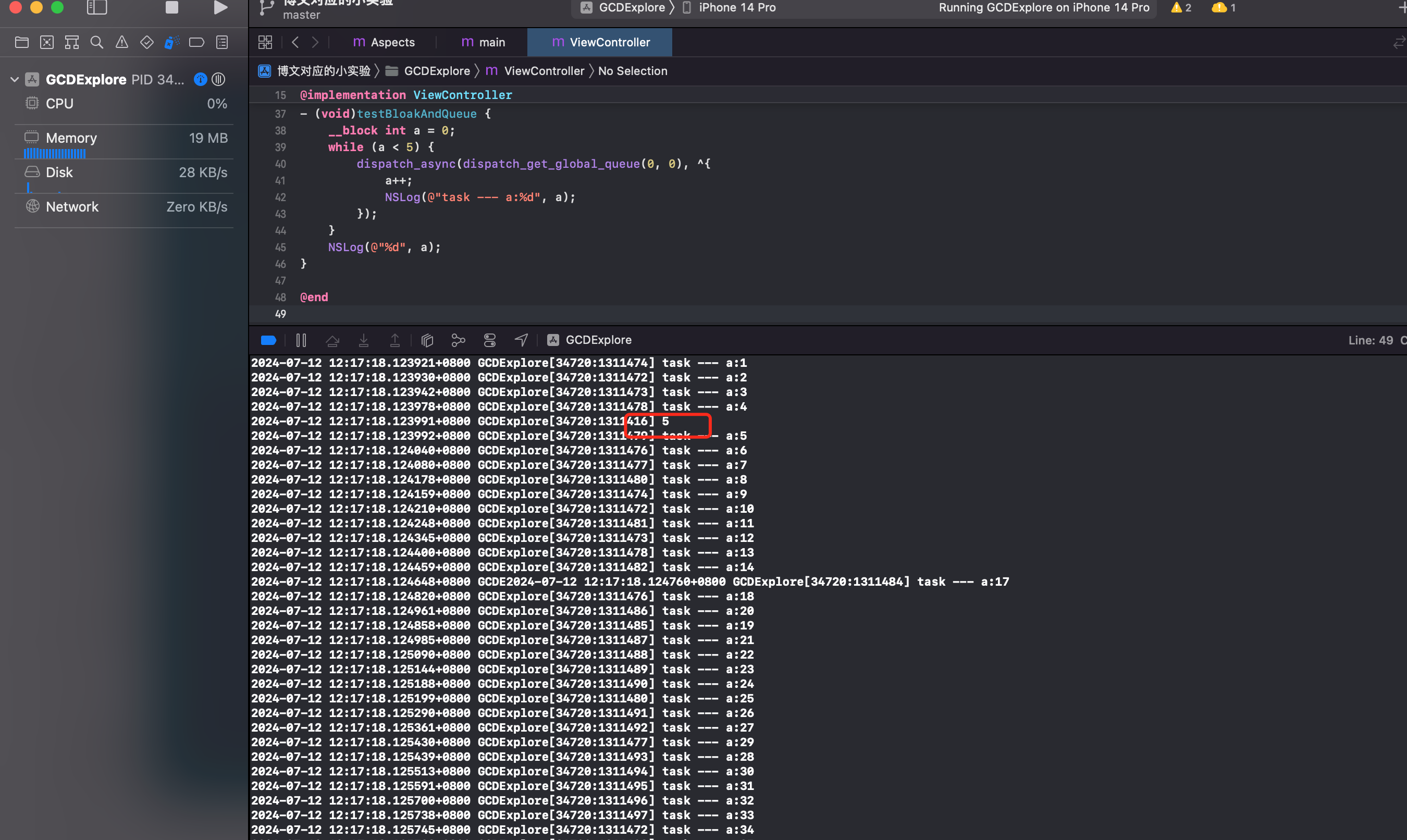
会输出什么?
打印结果,电脑速度快的话,会有很多次打印出5.慢的话,打印出大于5的几次。
分析:因为在循环内部,是全局并发队列。多线程的情况下,执行异步任务,任务的先后顺序没办法保证。可能线程1,拿到a=0,然后内部加了1.线程2一开始拿到a=0,但是代码还没执行到a++,在线程1里面,a就已经变为2,因为是 __block 修饰的。所以线程2里面拿到的a变成了a,然后内部a++后,a就是3.其他线程执行情况类似。
NSLog 属于 IO 流,比普通运算耗时。所以当能执行 NSLog 的时候,a 一定是大于等于5的。某条线程 a 大于等于5之后,就立马结束 while 循环,开始执行最后的 NSLog。
所以电脑越快,打印5的次数更多。电脑慢的情况下,可能会存在几次输出大于5的情况。
performSelector...withObject 研究
performSelector...withObject
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil];
NSLog(@"3");
});
}
// 1 3 2
分析:为什么现在又执行打印2了?因为 -(id)performSelector:(SEL)aSelector withObject:(id)object; 是 Runtime API,本质上就是 objc_msgSend,所以不需要 RunLoop 便可运行
查看 objc4 NSObject.m 即可
+ (id)performSelector:(SEL)sel withObject:(id)obj {
if (!sel) [self doesNotRecognizeSelector:sel];
return ((id(*)(id, SEL, id))objc_msgSend)((id)self, sel, obj);
}
performSelector...withObject...afterDelay
Demo1
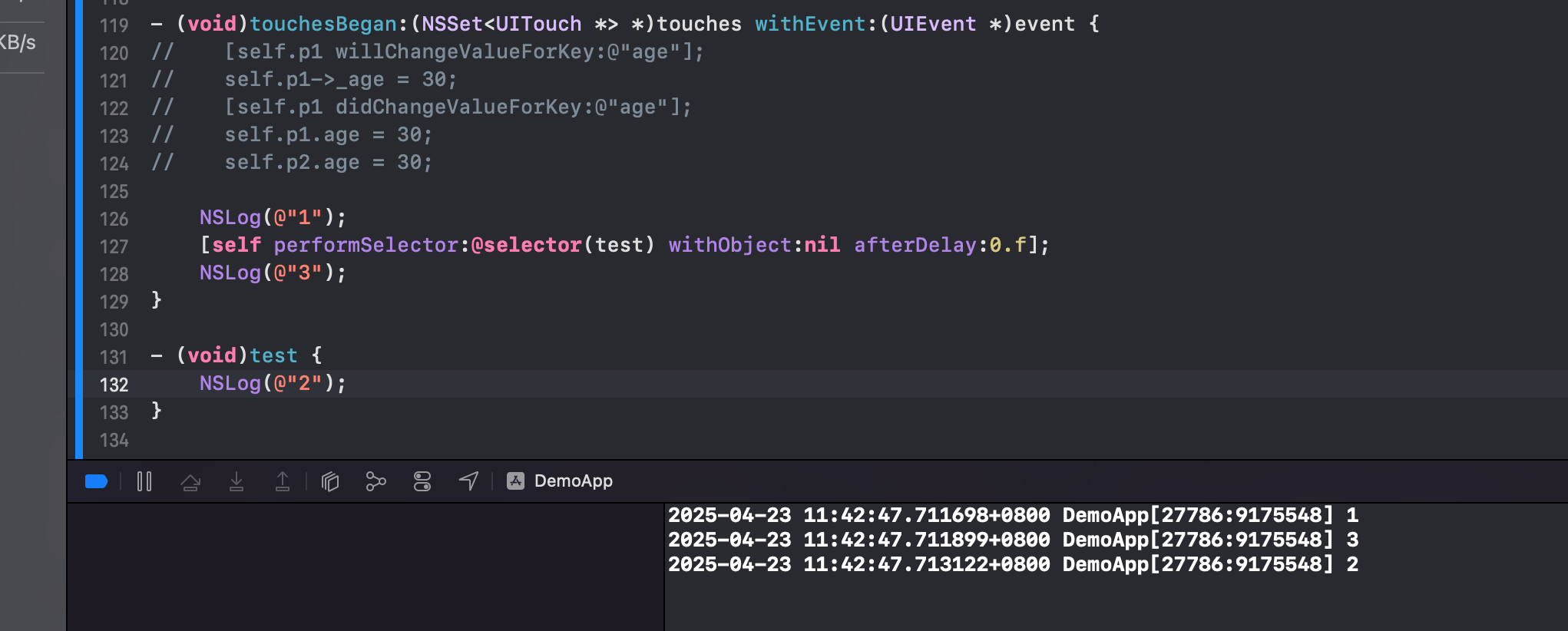
QA:为什么先打印1、3再打印2?因为 performSelector...withObject...afterDelay 相当于给 RunLoop 添加了一个 Timer,Timer 运行需要 RunLoop 配合。RunLoop 在被唤醒的时候会处理定时器。
Demo2:
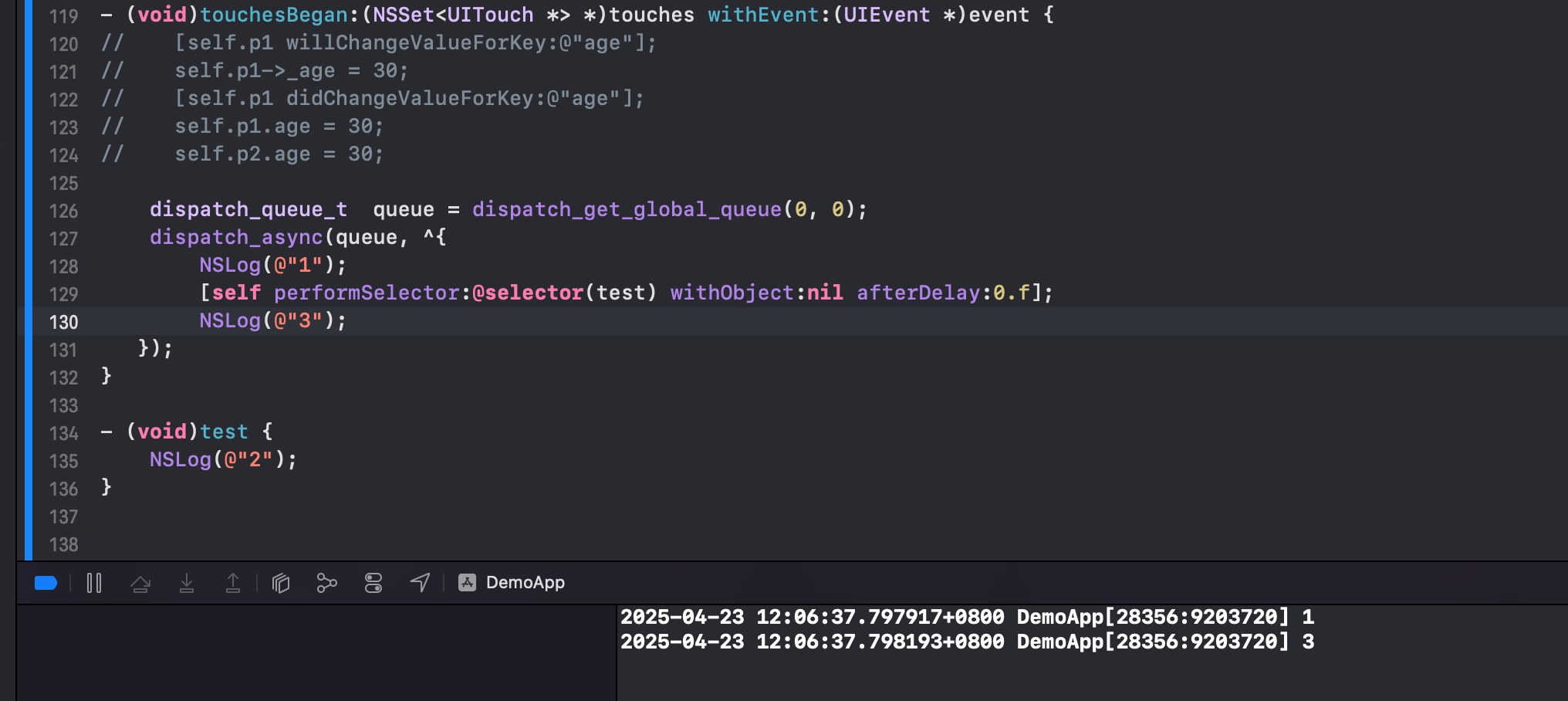
QA:为什么 showLog 里的2没有打印?
查看源码分析,如何查看 -(void)performSelector:(SEL)aSelector withObject:(nullable id)anArgument afterDelay:(NSTimeInterval)delay; 源码。
-
未开源,但是可以设置断点查看汇编分析;
-
Apple 的 XNU 是参考 GNUstep,它将 Cocoa 的 OC 库重新实现并开源。虽然不是官方源代码,但是具有研究参考价值
查看 GUNStep 源码
- (void) performSelector: (SEL)aSelector
withObject: (id)argument
afterDelay: (NSTimeInterval)seconds
{
NSRunLoop *loop = [NSRunLoop currentRunLoop];
GSTimedPerformer *item;
item = [[GSTimedPerformer alloc] initWithSelector: aSelector
target: self
argument: argument
delay: seconds];
[[loop _timedPerformers] addObject: item];
RELEASE(item);
[loop addTimer: item->timer forMode: NSDefaultRunLoopMode];
}
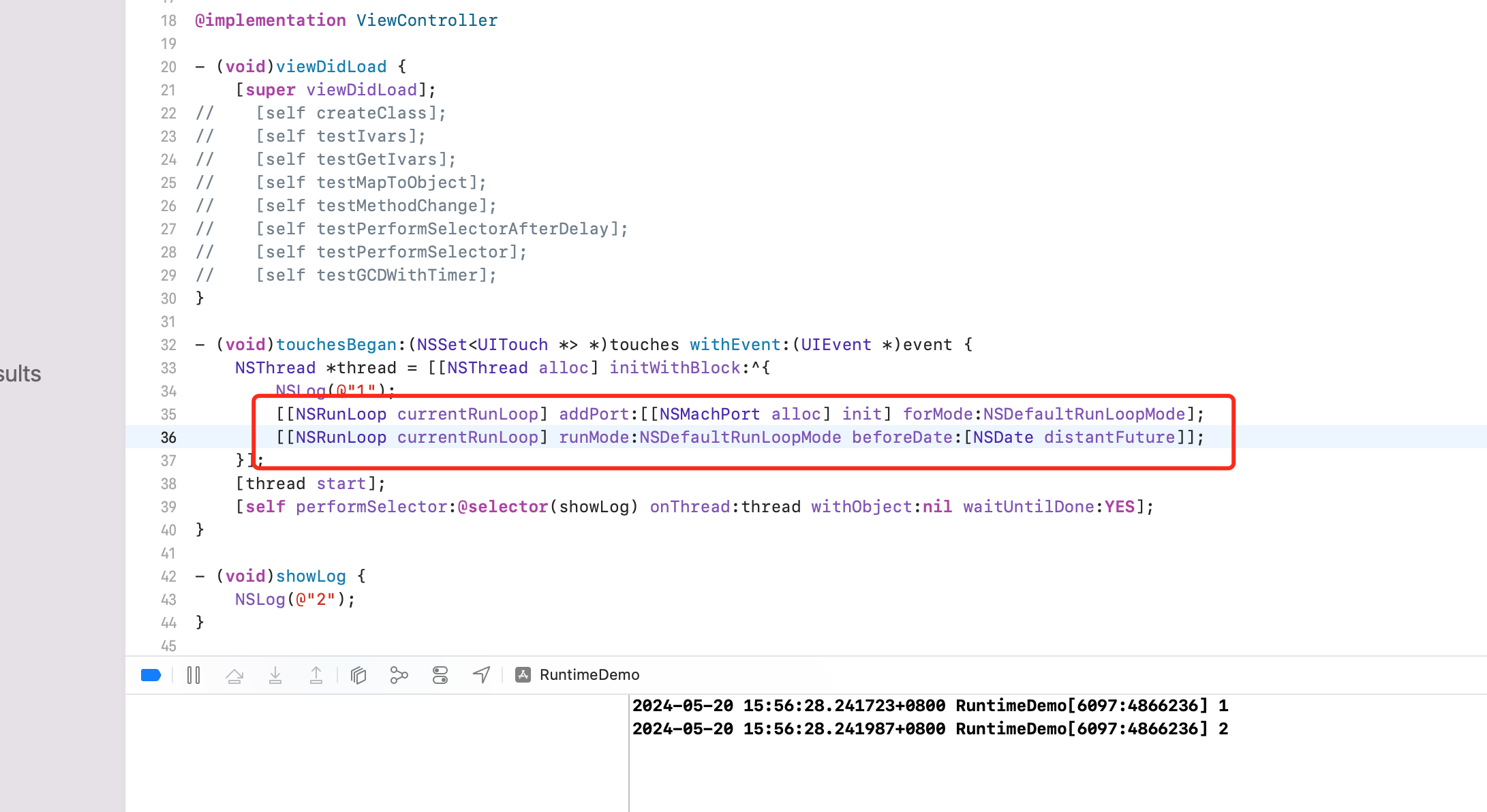
答:通过源码分析可以看到,performSelector...withObject...afterDelay... 本质是开启一个定时器,并添加到 RunLoop。但没有启动 RunLoop。打印1、2是由于他们不需要 RunLoop 的配合,而定时器需要 RunLoop 的配合。
所以代码改下就可运行。
- (void)test{
NSLog(@"2");
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, ^{
NSLog(@"1");
[self performSelector:@selector(test) withObject:nil afterDelay:3];
[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];
NSLog(@"3");
});
}
// 1 2 3
所以要研究 iOS 底层的同学,看看 GUNStep 代码吧,这是宝藏
Demo3:
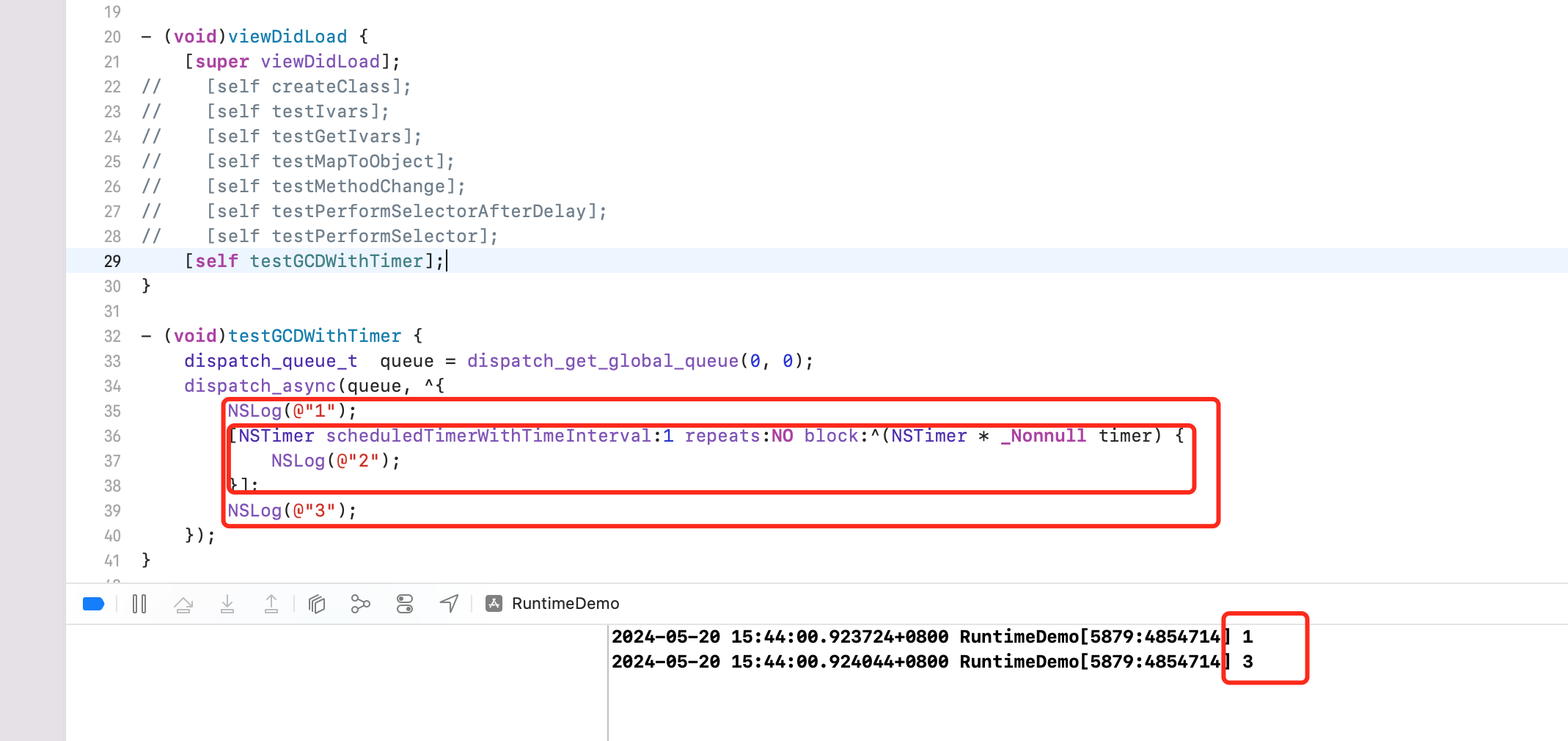
同理,GCD 虽然开启了子线程,但是 Block 结束后,线程也就结束了。所以线程任务中的1秒后的任务肯定也结束了。
Demo4:
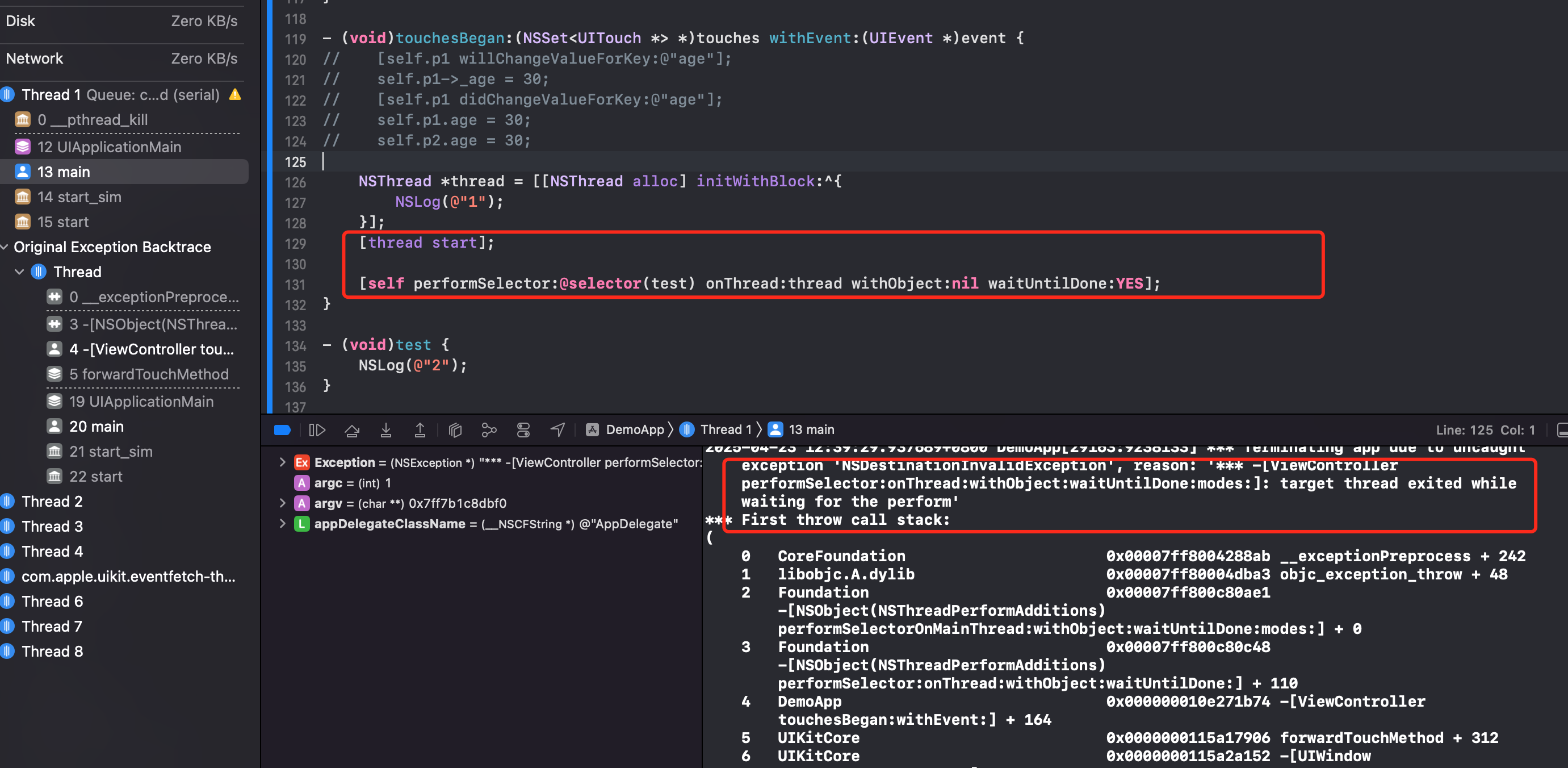
可以看到 NSThread 里的 block 执行结束后,thread 结束了。后面的 performSelector 想在线程里执行任务,就会 crash。
解决办法也是在线程的 block 里面加 RunLoop,让它保活
队列组
-
实现异步并发执行任务1、任务2
-
等任务1、2都执行完毕,再回到主线程执行任务3
dispatch_queue_t queue = dispatch_queue_create("concurrentQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task1: %@ - index:%zd", [NSThread currentThread], index);
}
});
dispatch_group_async(group, queue, ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task2: %@ - index:%zd", [NSThread currentThread], index);
}
});
dispatch_group_notify(group, queue, ^{
dispatch_async(dispatch_get_main_queue(), ^{
for (NSInteger index = 0; index< 5; index++) {
NSLog(@"Task3: %@ - index:%zd", [NSThread currentThread], index);
}
});
});
多线程安全问题-锁
多线程存在资源共享问题。比如1块内存可能会被多个线程共享,同时读或者写,导致不一致,很容易引发数据错乱和数据安全问题。典型的生产者消费者问题。比如多个线程访问同一个对象、同一个变量、同一个文件
解决方案:使用线程同步技术(同步,就是协同步调,按预定的先后次序进行)
常见的线程同步技术是:加锁。
常见的锁有:
- OSSpinLock
- os_unfair_lock
- pthread_mutex
- dispatch_semaphore
- dispatch_queue(DISPATCH_QUEUE_SERIAL)
- NSLock
- NSRecursiveLock
- NSCondition
- NSConditionLock
- @synchronized
OSSpinLock
使用
OSSpinLock 叫做”自旋锁”。缺点是:自旋类似于一个 while 循环,在死等。
使用的时候需要导入 #import <libkern/OSAtomic.h>
OSSpinLock lock = OS_SPINLOCK_INIT 初始化
OSSpinLockLock(&lock); 加锁
OSSpinLockUnlock(&lock); 解锁
bool res = OSSpinLockTry(&lock) 尝试加锁(如果需要等待就不加锁直接返回 false,如果不需等待则加锁,返回 true)
Demo:
@interface ViewController ()
@property (assign, nonatomic) OSSpinLock bankLock;
@property (nonatomic, assign) NSInteger money;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.bankLock = OS_SPINLOCK_INIT;
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self withdrawMoney];
}
});
// 100 + 10*50 - 10*10 = 500
}
- (void)saveMoney {
OSSpinLockLock(&_bankLock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
- (void)withdrawMoney {
OSSpinLockLock(&_bankLock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
@end
存在问题
-
等待锁的线程会处于忙等(busy-wait)状态,一直占用着 CPU 资源
-
不安全,可能会出现优先级反转问题
-
如果等待锁的线程优先级较高,它会一直占用着CPU资源,优先级低的线程就无法释放锁
QA:优先级反转是什么?
线程本质上就是 CPU 高速切换,系统分配很少的时间段分别给不同的线程,导致用户看上去是同时在做多个线程内的事情。操作系统会使用基于优先级抢占式调度算法。高优先级的线程始终在低优先级线程前执行。
举个例子:优先级:线程 A < 线程 B < 线程 C,线程A、C 都会使用共享资源 R,该资源由信号量控制进行互斥访问。

线程 A 在 T1 时刻使用资源 R 并拿到锁。开始执行线程内的逻辑。
线程 C 在 T2 时刻被唤醒,但是此时锁被线程 A 使用,线程 C 尝试访问资源 R,但由于自然 R 被 线程 A 所占有,所以线程 C 放弃 CPU 进入阻塞(等待)状态,而线程 A 继续占据 CPU,执行任务
目前来看一切正常。
但是在 T3 时刻,线程 B 被唤醒,由于优先级比较高,所以会立即抢占 CPU,此时线程 A 被迫进入 READY 状态等待(导致线程 A 无法及时释放资源 R)。
T4 时刻,线程 B 放弃 CPU,此时线程 A (优先级10)是唯一处于 READY 状态的线程,所以再次占据 CPU 去执行任务,在 T5 时刻释放锁和资源 R。
在 T5 时刻,线程 A 解锁瞬间,线程 C 立即获取锁,并在优先级20上等待 CPU,因为优先级比较高,所以系统会立刻调度线程 C 的任务执行。此时线程 A 进入 READY 状态。
线程 B 从 T3 到 T4 这个时间段占据 CPU 资源的行为叫做优先级反转。一个优先级 15 的线程B,通过压制优线级10的线程 A,而事实上导致高优先级线程 C 无法正确得到 CPU。这段时间是不可控的,因为线程 B 可以长时间占据 CPU(即使轮转时间片到时,线程 A 和 B 都处于可执行态,但是因为B的优先级高,它依然可以占据 CPU),其结果就是高优先级线程 C 可能长时间无法得到 CPU。
当高优先级任务正等待信号量(此信号量被一个低优先级任务拥有着)的时候,一个介于两个任务优先之间的中等优先级任务开始执行——这就会导致一个高优先级任务在等待一个低优先级任务,而低优先级任务却无法执行类似死锁]的情形发生
为了解决优先级反转问题,可以采取以下策略:
- 优先级天花板策略(Priority Ceiling):当任务使用共享资源时,将其优先级提高到访问该资源的所有任务的最高优先级或某个确定的优先级(即“优先级天花板”)。这样可以确保持有资源的任务不会被其他低优先级的任务抢占,从而避免了优先级反转。
- 优先级继承策略(Priority Inheritance):当一个任务被阻塞并等待一个低优先级任务释放资源时,将低优先级任务的优先级提升到等待它的最高优先级任务的优先级。这样可以确保低优先级任务能够尽快释放资源,从而使高优先级任务能够继续执行。
上面的代码改进下
- (void)saveMoney {
if (OSSpinLockLock(&_bankLock)) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
}
- (void)withdrawMoney {
if (OSSpinLockLock(&_bankLock)) {
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
OSSpinLockUnlock(&_bankLock);
}
}
汇编窥探原理
自旋锁是指在等锁的时候通过类似 while 循环的代码,让线程忙碌等到锁的到来。
自旋锁是一种特殊的锁机制,当线程试图获取锁但失败时,它会在一个循环中持续尝试(即“自旋”),而不是立即阻塞。这可以在某些情况下提高性能,尤其是当锁被持有的时间很短时。
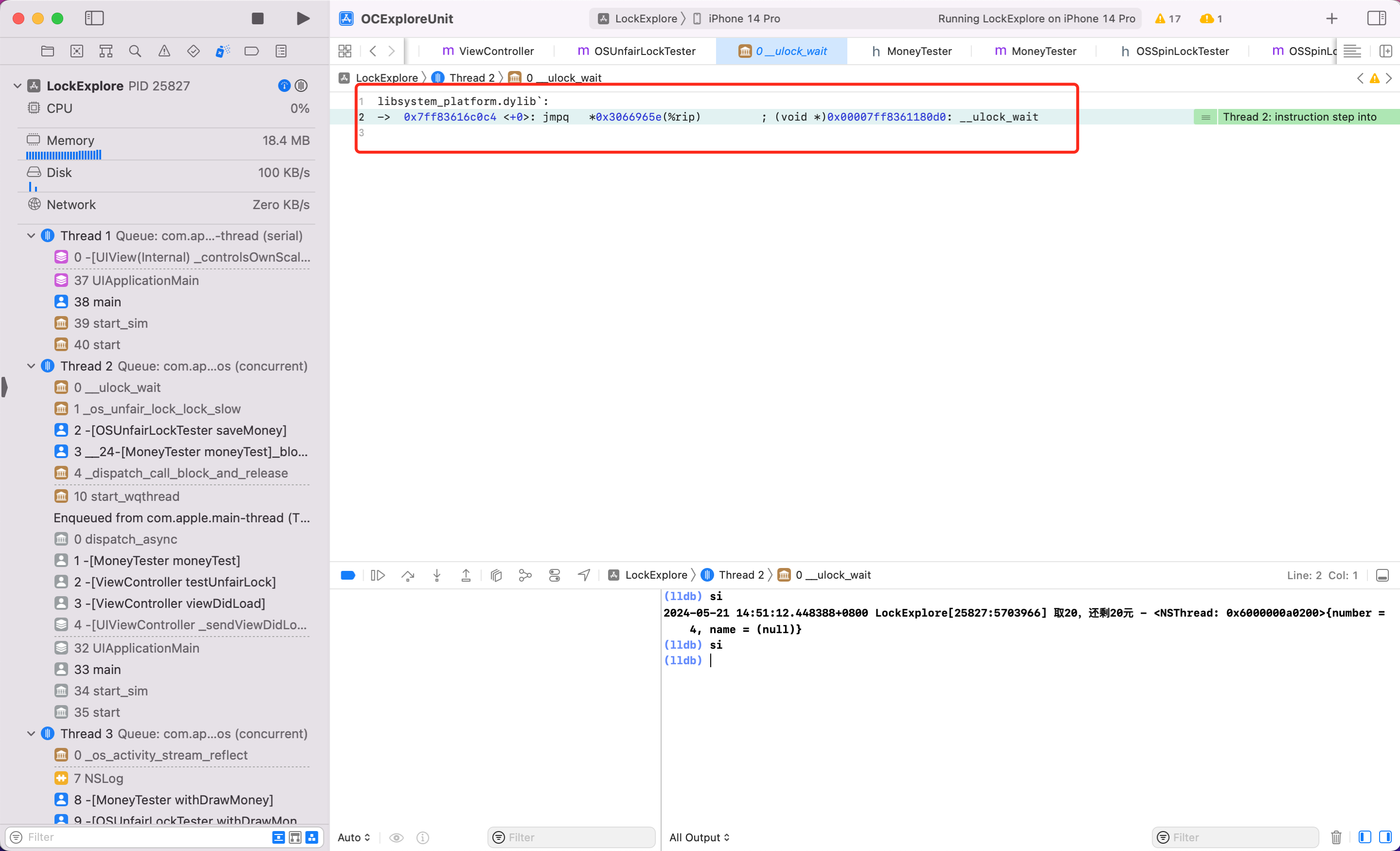
为了调试方便,开启10个线程去执行 saveMoney 方法,为了查看自旋锁的等是什么实现。我们给里面休眠600s。同时 Xcode - Debug - DebugWorkflow - Always Show Disassembly
lldb 模式下调试汇编有几个指令
c: 代表 continue,
si:step instruction,简写为 stepi,si。当你在 Xcode 汇编面板看到某个认识或者可疑符号,断点在这一行的时候,在下方 lldb 面板,属于 si,即可进入内部实现。
第一步:当第二次调用 saveMoney 方法,开启汇编调试
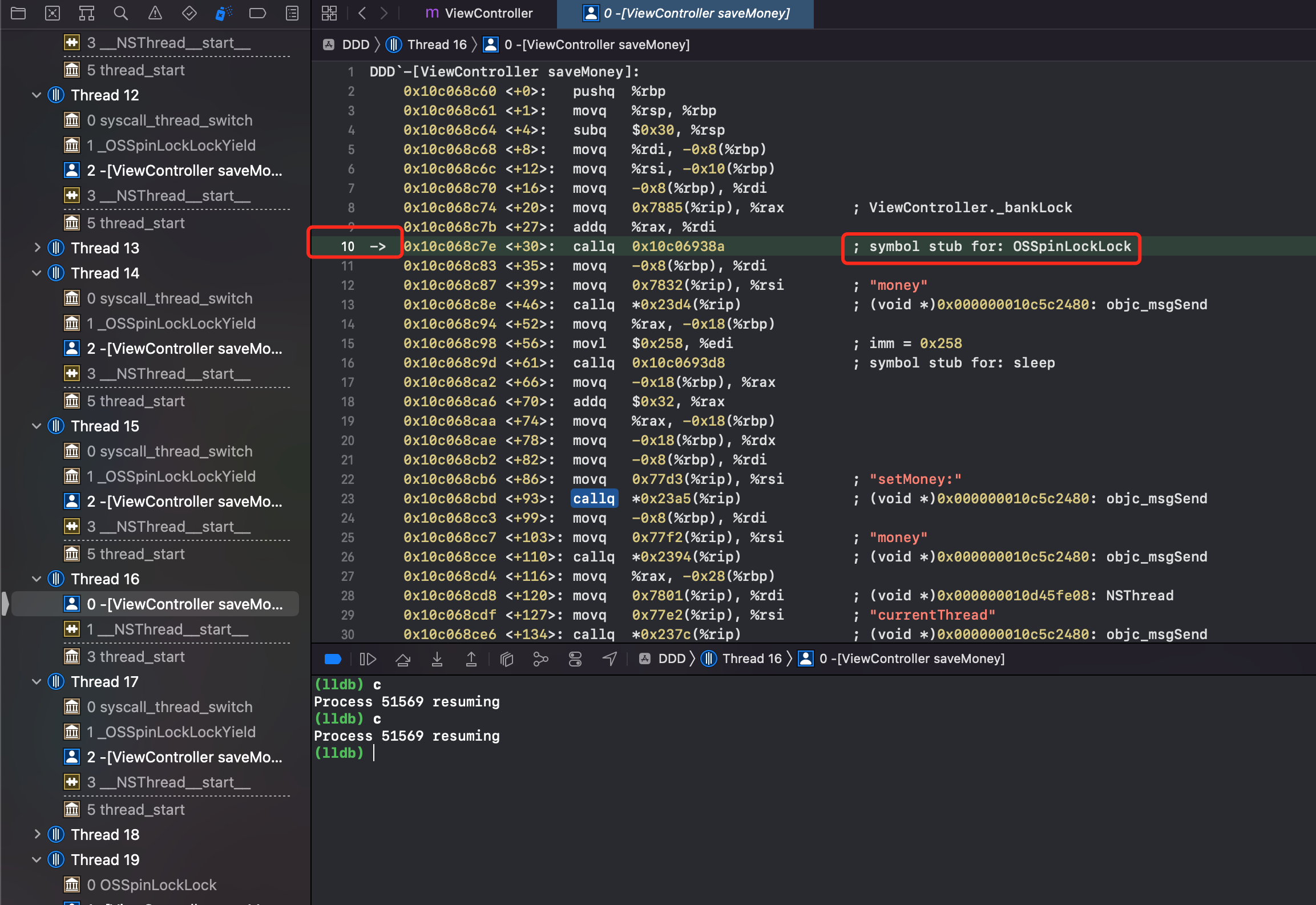
看到可疑方法 OSSpinLockLock,给它加断点,看到第10行高亮了。lldb 模式输入 c,敲回车。次数输入 si 即可进入 OSSpinLockLock 方法内部调试
第二步:继续输入 si,敲回车
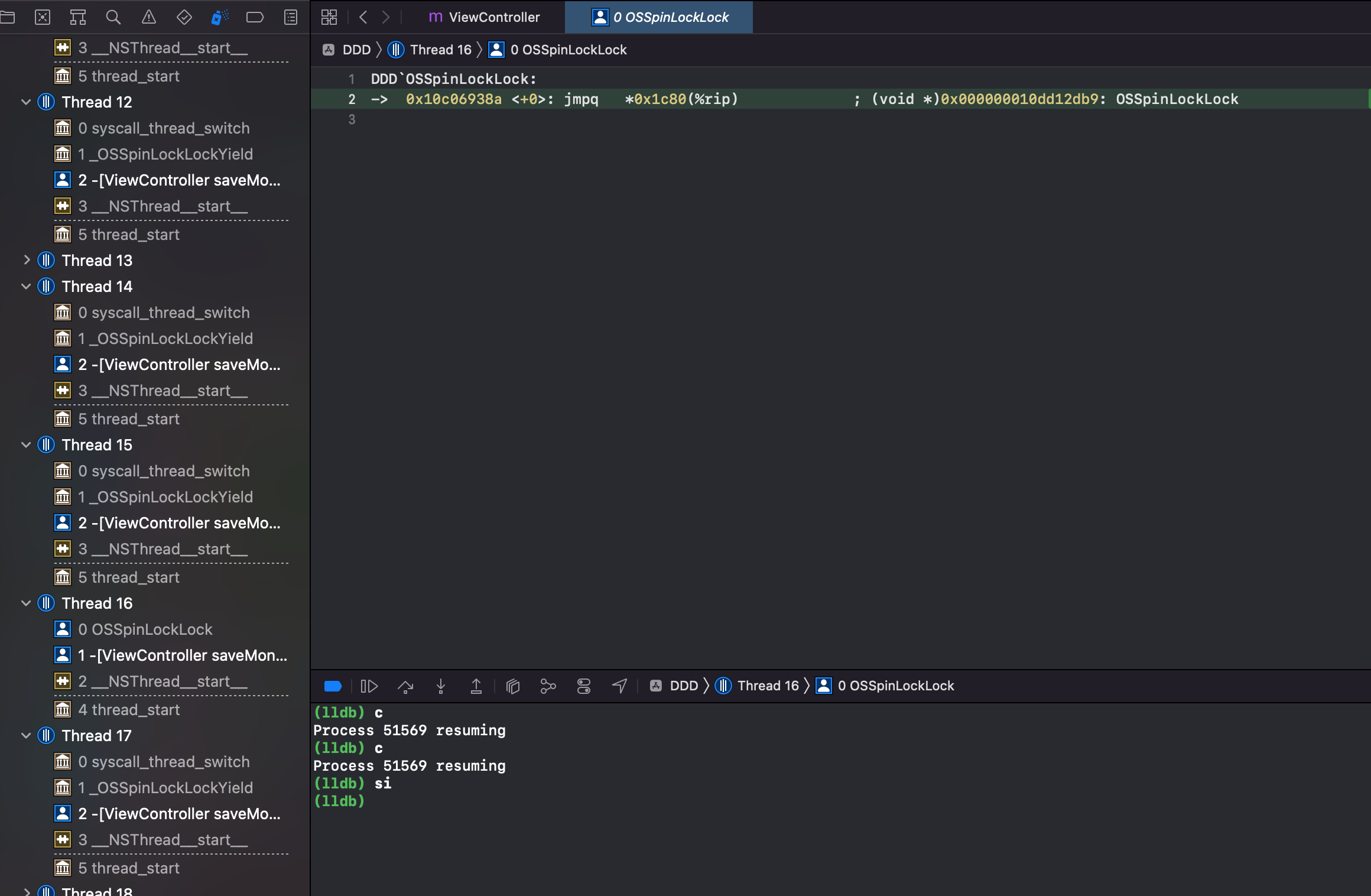
第三步:看到可疑方法 _OSSpinLockLockSlow,给它加断点,lldb 输入 C。此时断点到这一行了,继续输入 si。
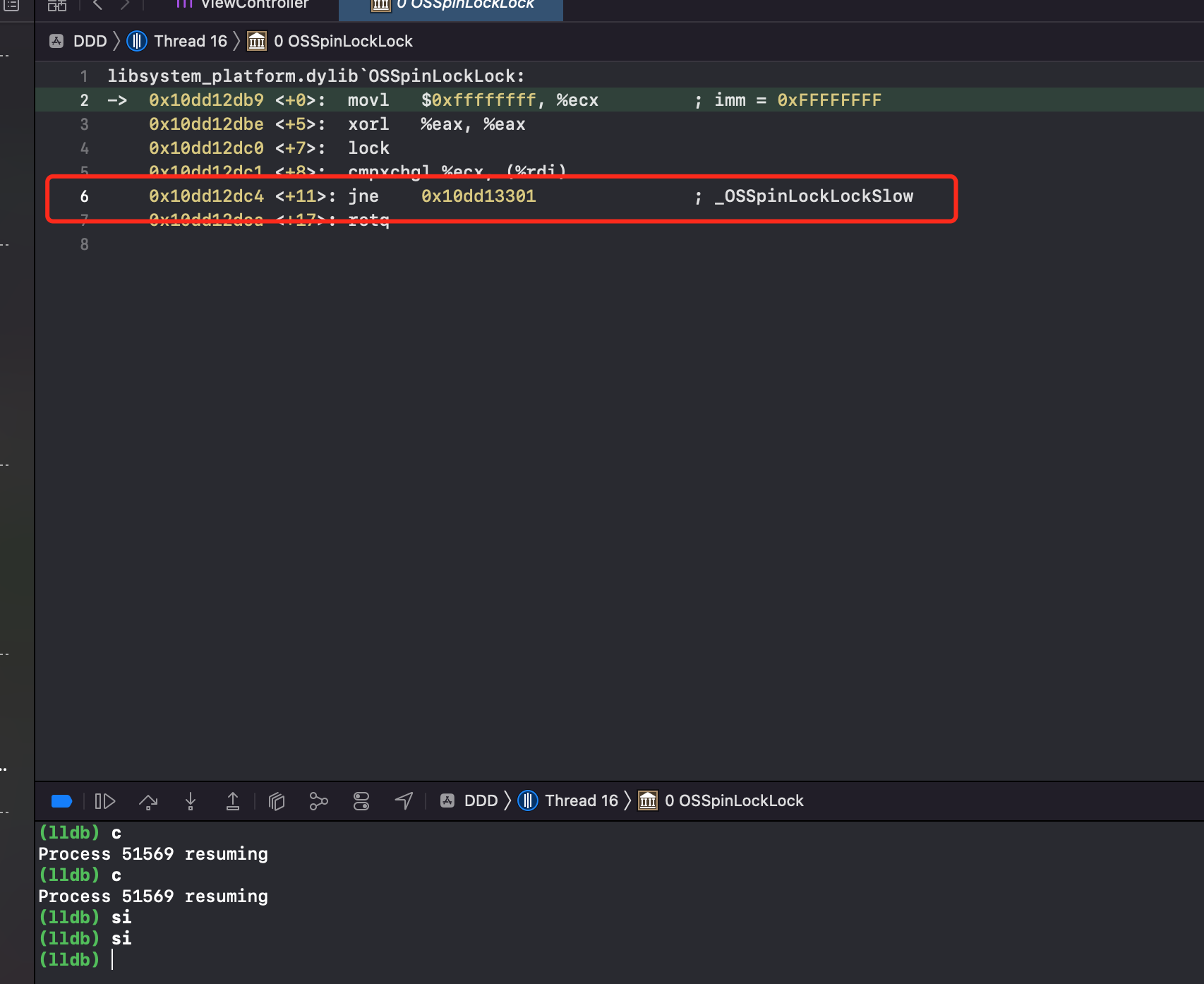
第四步:在 OSSpinLockLockSlow 方法内部调试,不断输入 si。
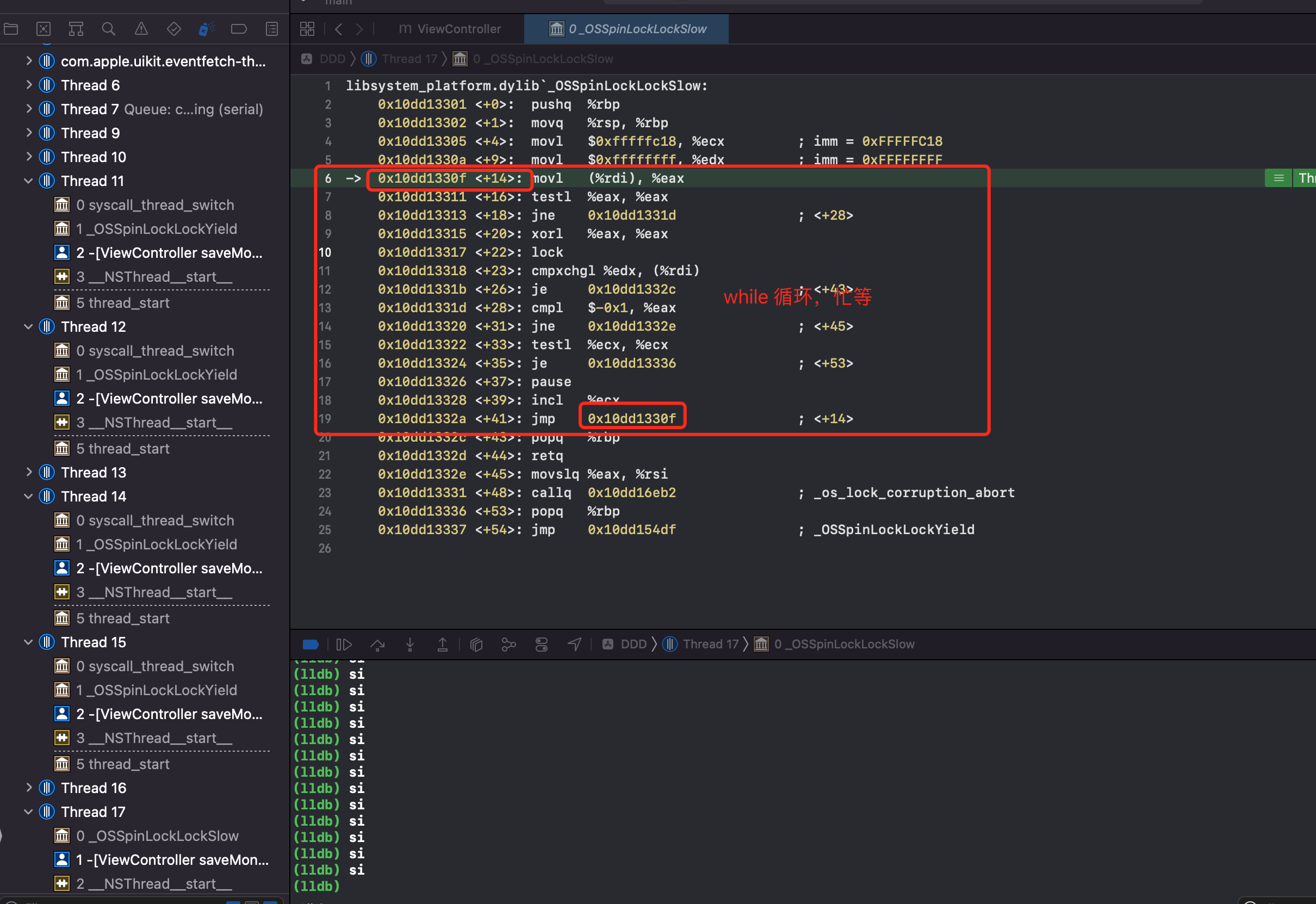
发现不断 si 最终一直会在第6行到第19行之间执行。懂汇编的会发现这其实是一个 while 循环。便可以证明自旋锁 OSSpinLock 在等锁的时候,底层实现是执行 while 循环,忙等,“太浪费性能了”(如果使用锁资源的线程任务很简单,那自旋也是高效的,可以快速获取锁。)
结论:OSSpinLock 底层就是一个自旋锁,内部不断循环,盲等。
os_unfair_lock
使用
os_unfair_lock 用于取代不安全的 OSSpinLock ,从iOS10开始才支持。使用的时候需要导入头文件 #import <os/lock.h>
从底层调用看,等待 os_unfair_lock 锁的线程会处于休眠状态,并非忙等(自旋锁会忙等)
初始化 os_unfair_lock moneylock = OS_UNFAIR_LOCK_INIT;
加锁 os_unfair_lock_lock(&_moneylock);
解锁 os_unfair_lock_unlock(&_moneylock);
尝试加锁 os_unfair_lock_trylock(&_moneylock)
继续对存取钱 Demo 用 os_unfair_lock 实现
@interface ViewController ()
@property (nonatomic, assign) NSInteger money;
@property (nonatomic, assign) os_unfair_lock moneylock;
@end
@implementation ViewController
- (void)viewDidLoad{
[super viewDidLoad];
self.moneylock = OS_UNFAIR_LOCK_INIT;
self.money = 100;
[self moneyTest];
}
- (void)moneyTest {
dispatch_queue_t queue = dispatch_queue_create("com.lbp.money.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self saveMoney];
}
});
dispatch_async(queue, ^{
for (int i = 0; i < 10; i++) {
[self withdrawMoney];
}
});
// 100 + 10*50 - 10*10 = 500
}
int cursorr = 1;
- (void)saveMoney {
NSLog(@"current cursor %d", cursorr);
cursorr++;
os_unfair_lock_lock(&_moneylock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney += 50;
self.money = previousMoney;
NSLog(@"存50,还剩%zd元 - %@", self.money, [NSThread currentThread]);
os_unfair_lock_unlock(&_moneylock);
}
- (void)withdrawMoney {
os_unfair_lock_lock(&_moneylock);
NSInteger previousMoney = self.money;
sleep(0.2);
previousMoney -= 10;
self.money = previousMoney;
NSLog(@"取20,还剩%zd元 - %@", self.money, [NSThread currentThread]);
os_unfair_lock_unlock(&_moneylock);
}
@end
假如对存钱过程,忘记解锁怎么办?产生死锁,如下
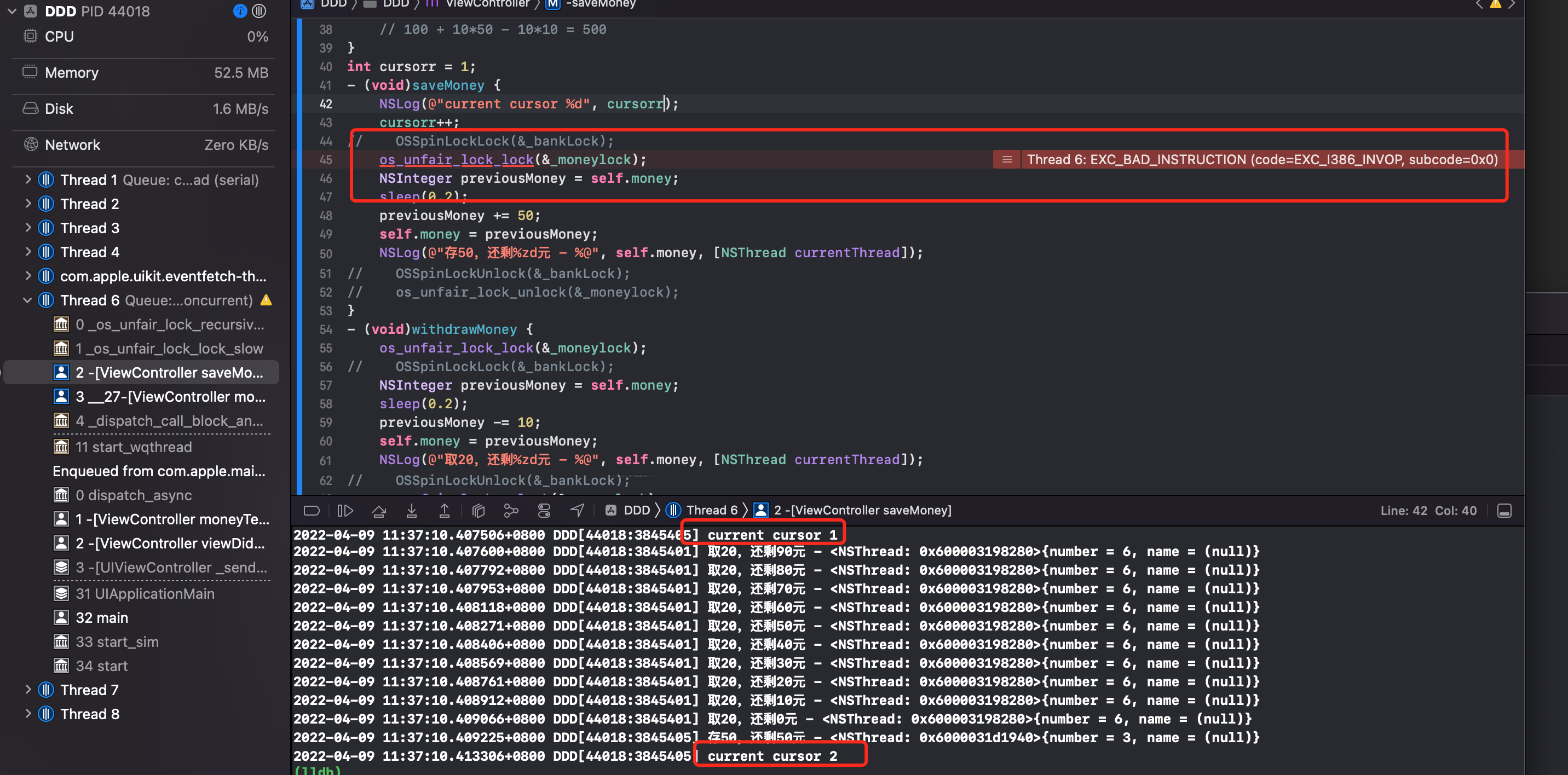
添加 cursor 标记死锁是发生在 saveMoney 方法执行的第几次。发现是第二次。因为第一次锁没有任何使用方,所以加锁成功,当第二次加锁的时候发现锁没有释放,所以产生死锁。
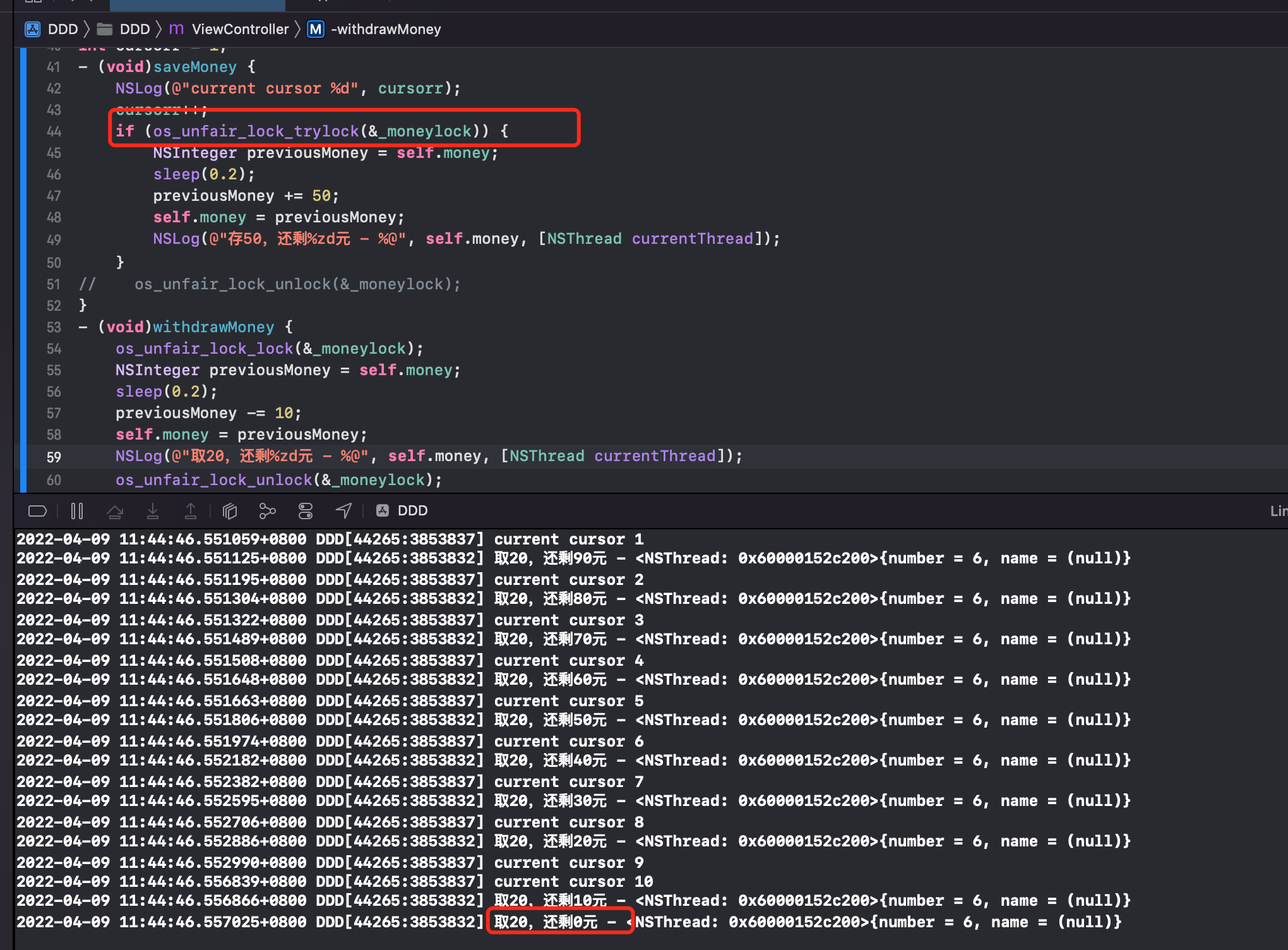
这时候使用尝试加锁 API os_unfair_lock_trylock 即可成功如下
汇编窥探原理
同样方式看看 ,按照上述调试汇编代码的步骤,我将关键步骤截图如下
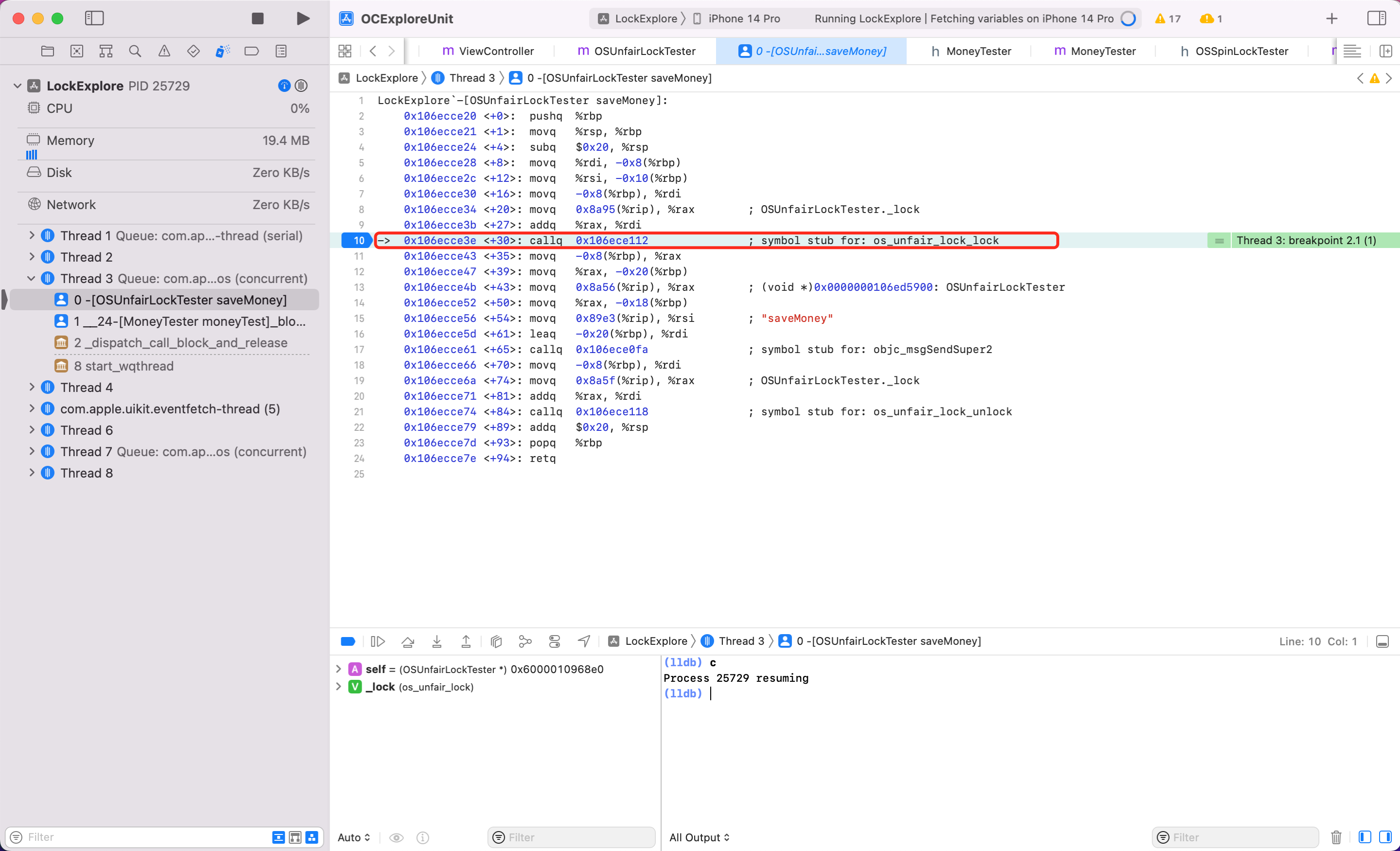
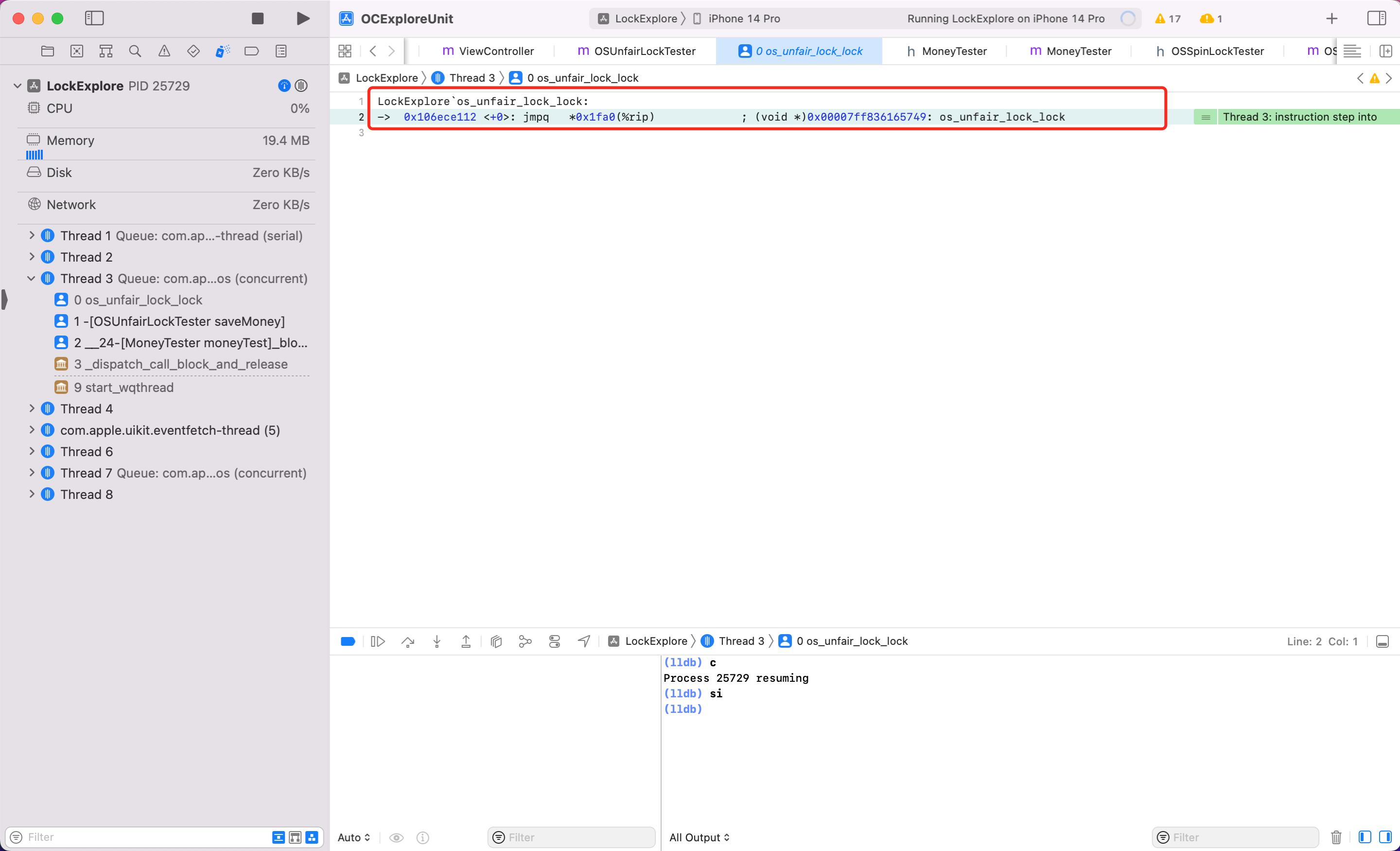
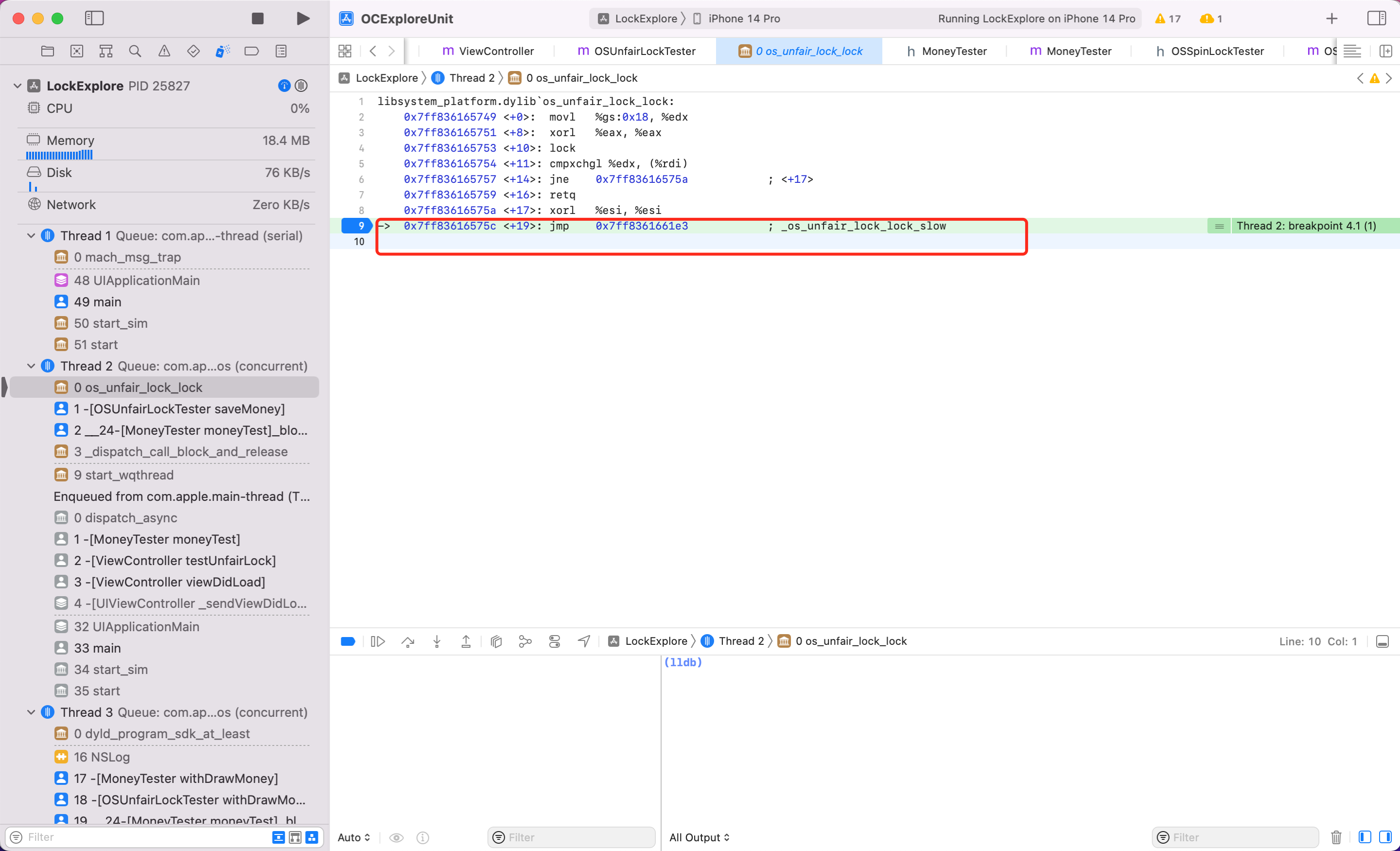
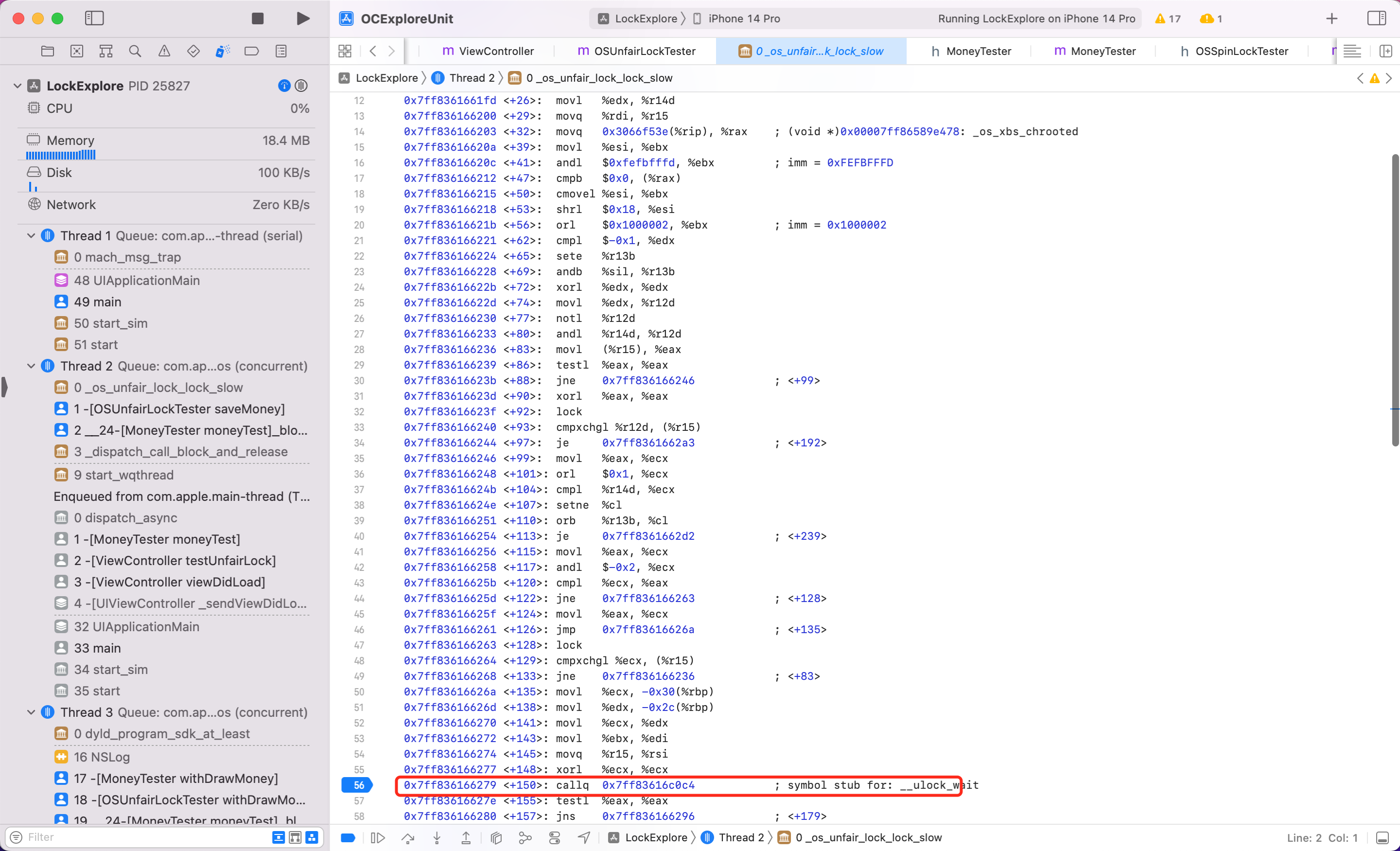
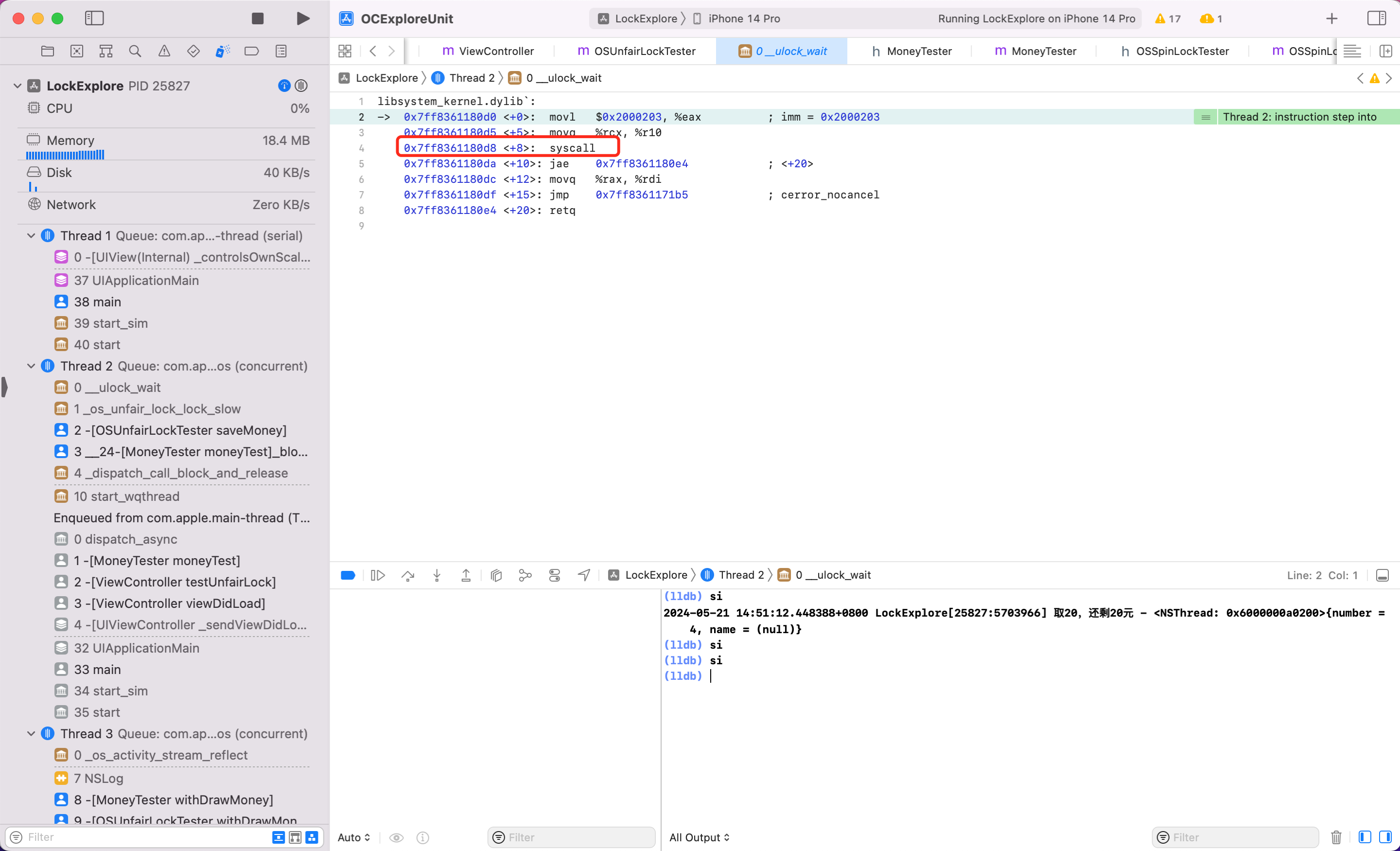
结论:可以看到 os_unfair_lock 在锁等待的时候,底层调用的是 sysCall,当这一步执行后会发现后续代码都不执行了,也就是调用系统底层能力,线程真正休眠了,而不是一个循环忙等,性能也好。
系统对其描述是:Low-level lock that allows waiters to block efficiently on contention.,即低级锁,低级锁的特点是等不到锁就休眠。
pthread_mutex
使用
mutex 叫做”互斥锁”,等待锁的线程会处于休眠状态。使用时需要引入 #import <pthread.h>
使用:
// 初始化属性
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_DEFAULT);
// 初始化锁
pthread_mutex_init(&_moneyLock, &attr);
// 释放属性内存
pthread_mutexattr_destroy(&attr);
// 加锁
pthread_mutex_lock(&_moneyLock);
// 解锁
pthread_mutex_unlock(&_moneyLock);
// 释放锁内存
pthread_mutex_destroy(&_moneyLock);
其中 pthread_mutexattr_settype(pthread_mutexattr_t *, int); 第二个参数有4个枚举值
/*
* Mutex type attributes
*/
#define PTHREAD_MUTEX_NORMAL 0
#define PTHREAD_MUTEX_ERRORCHECK 1
#define PTHREAD_MUTEX_RECURSIVE 2
#define PTHREAD_MUTEX_DEFAULT PTHREAD_MUTEX_NORMAL
如果类型选 PTHREAD_MUTEX_DEFAULT 或者 PTHREAD_MUTEX_NORMAL 则可以省略 pthread_mutexattr_t 的创建,直接传 NULL,即 pthread_mutex_init(&_moneyLock, NULL)
使用如下
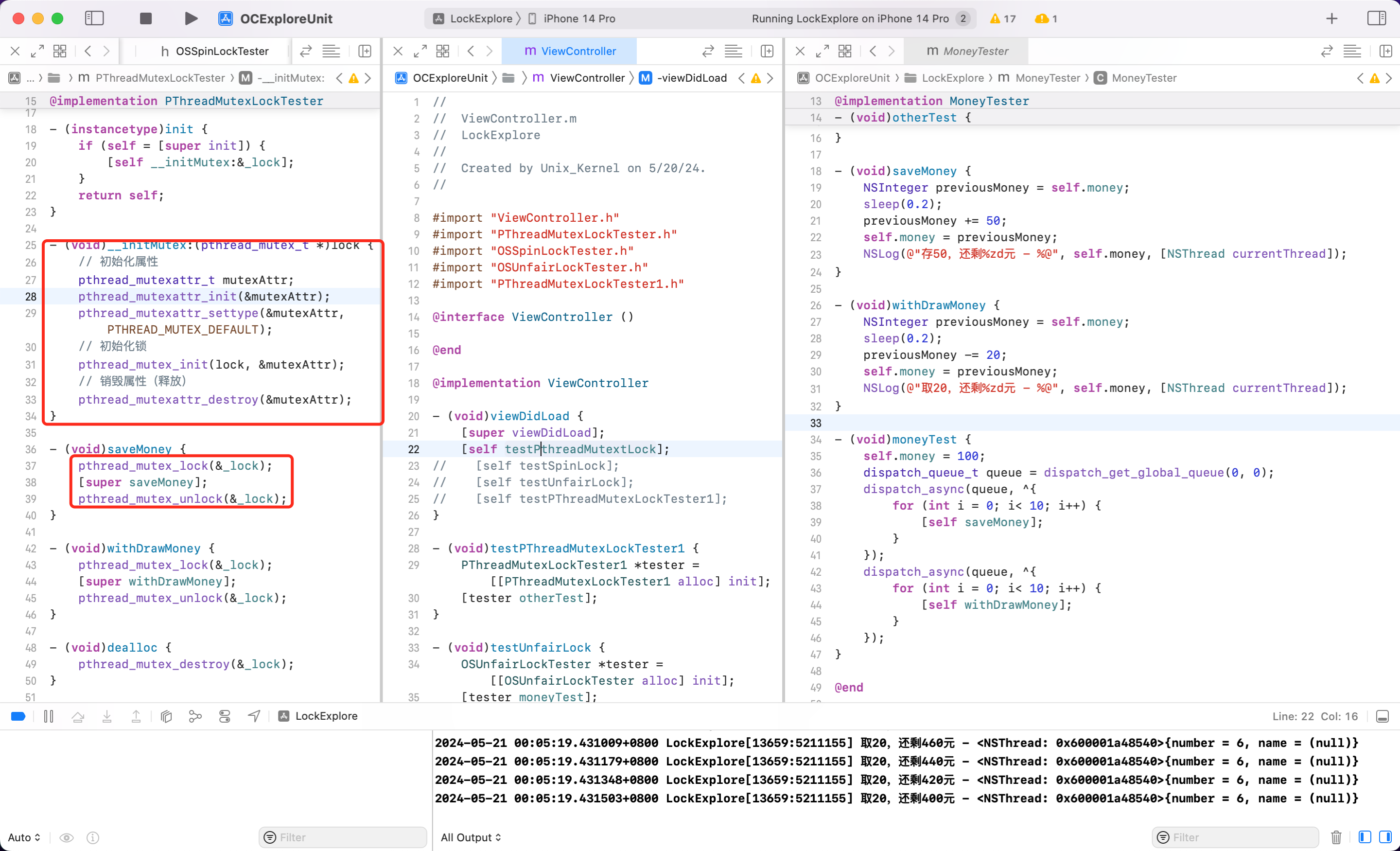
递归锁
如果在某个方法内部递归调用自身怎么实现,好像挺简单的,直接内部调用即可。
- (void)otherTest {
pthread_mutex_lock(&_lock);
static int count = 0;
count++;
NSLog(@"%s", __func__);
if (count<10) {
[self otherTest];
}
pthread_mutex_unlock(&_lock);
}
- (void)sayHi {
NSLog(@"Hello");
}
// console
-[PThreadMutexRecursiveLockTester otherTest]
只打印了 1。为什么?因为第一次调用正常加锁,然后递归调用自身,第二次调用的时候尝试加锁,但是这时候第一次调用时候锁还没释放。
先加锁,然后递归调用,再继续加锁,再调用再加锁,最后一次函数执行完则解锁,出栈后继续解锁,再解锁。效果等价于
+ 代表加锁;- 代表解锁
线程1: otherTest(+ -)
otherTest(+ -)
otherTest(+ -)
互斥锁提供 API 实现该功能。只需要在互斥锁初始化地方将属性修改为 PTHREAD_MUTEX_RECURSIVE。即 pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
在同一个线程中可以多次获取同一把锁。并且不会死锁。
改进后的效果如下
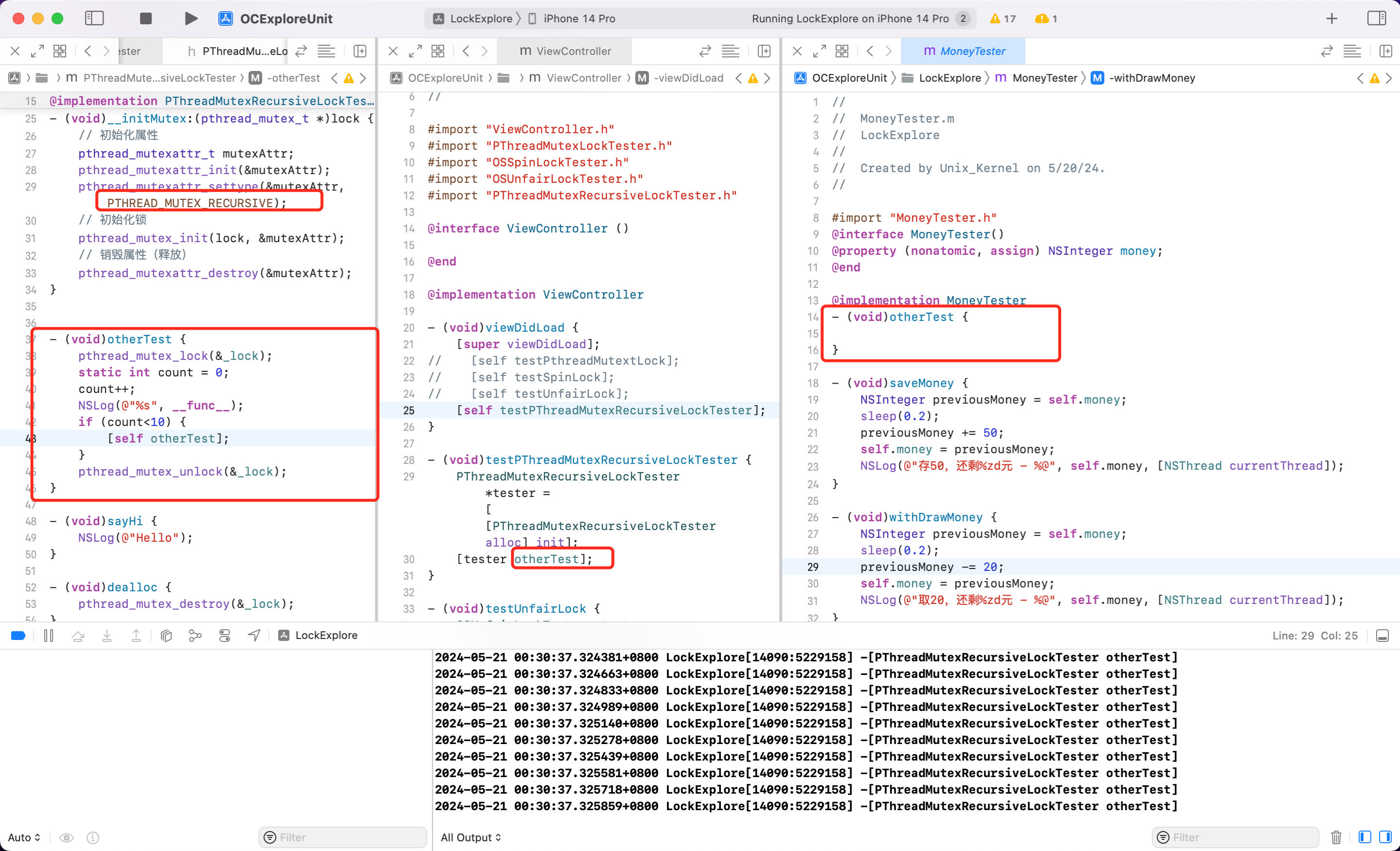
QA:互斥递归锁,可以在不同线程中加锁吗?
不可以,线程1加锁后,线程2尝试加锁的时候,发现锁已经被其他线程所使用,线程2则等待。
汇编窥探原理
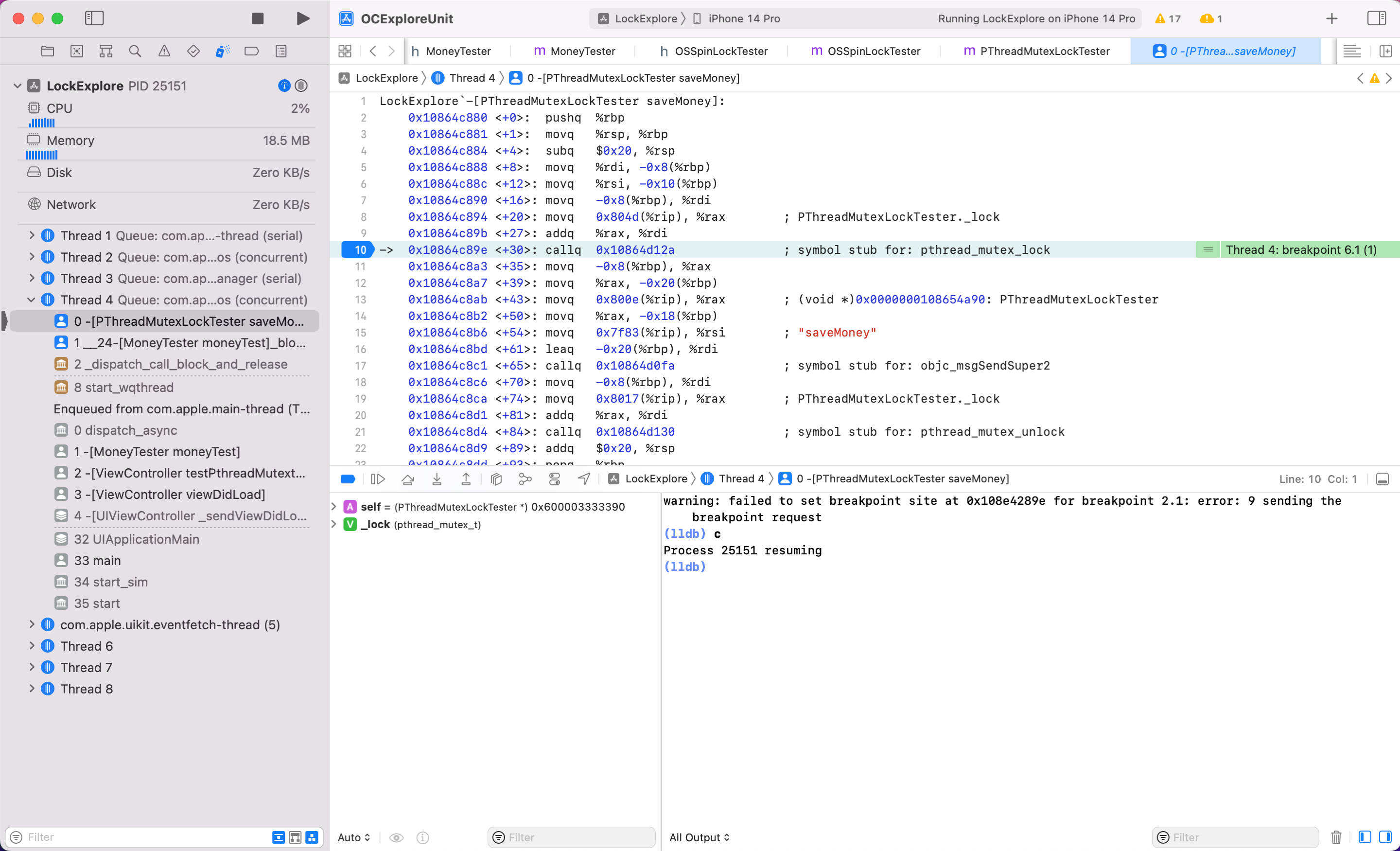
输入 si 继续跟进,可以看到还是在执行我们自己的代码,LockExplore image 的 pthread_mutex_lock 方法
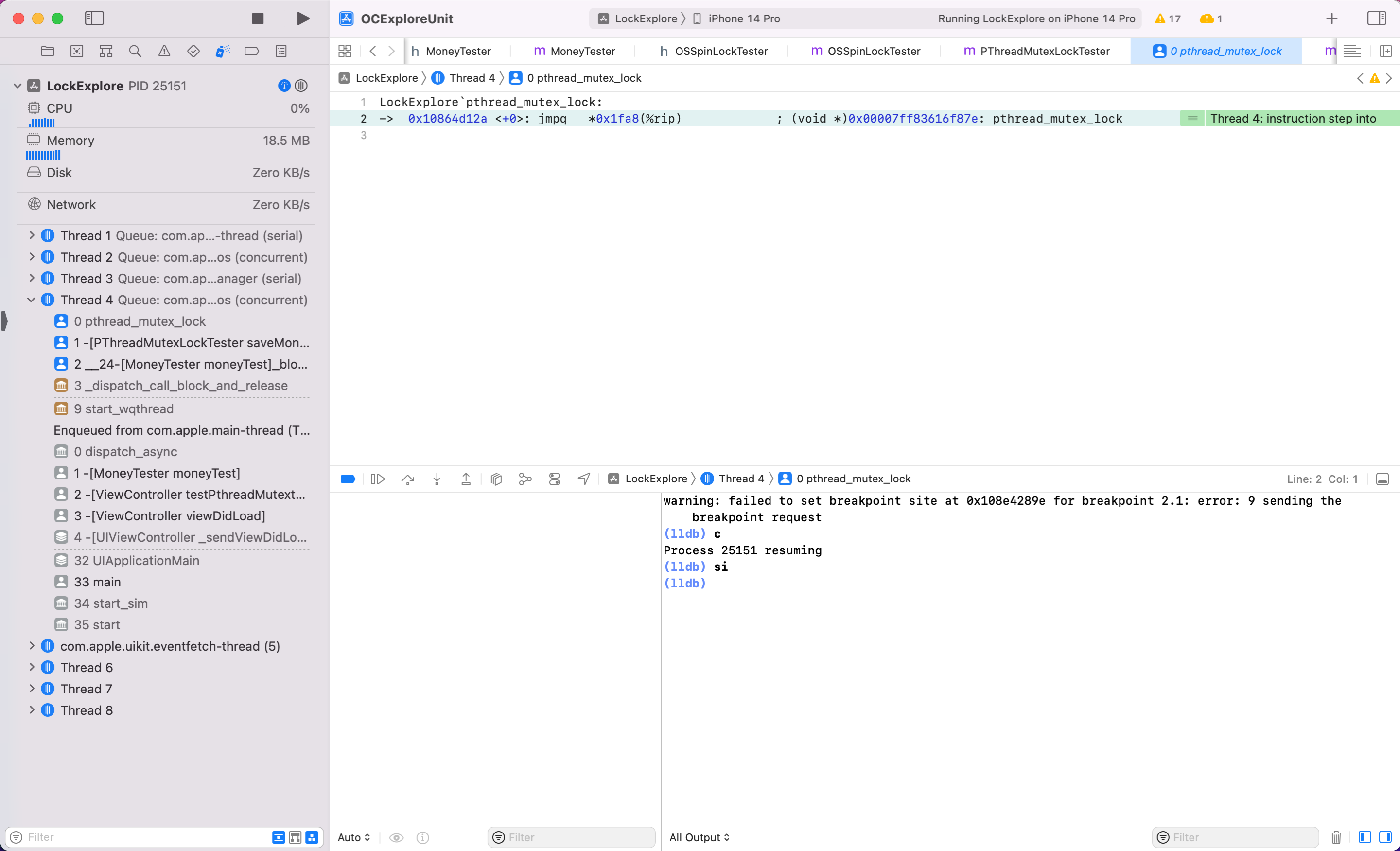
继续输入 si 跟进
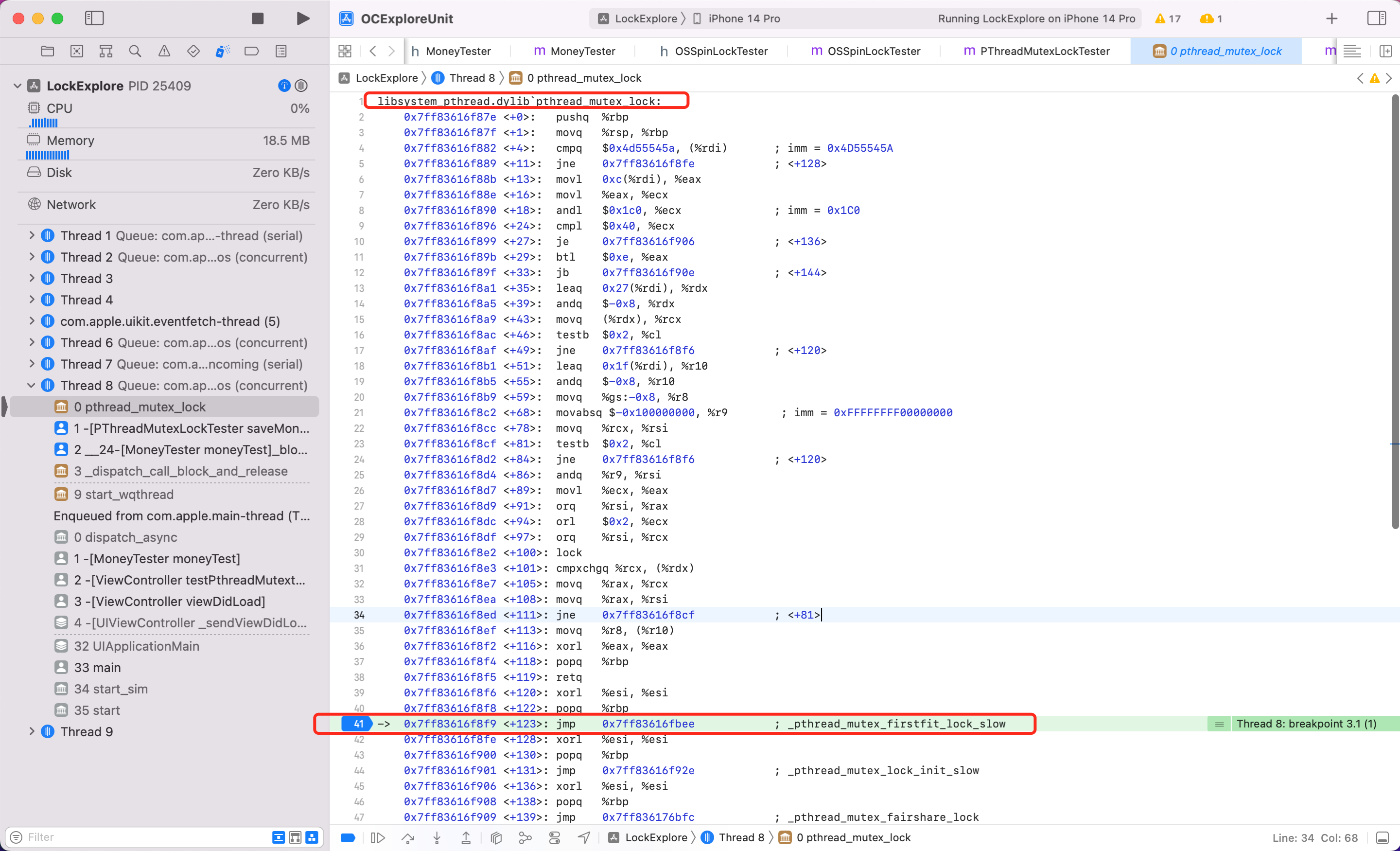
可以看到此时调用到系统 libsystem_pthread.dylib 库的 pthread_mutex_lock 方法了。
第41行看到关键函数,继续输入 si 进去看看
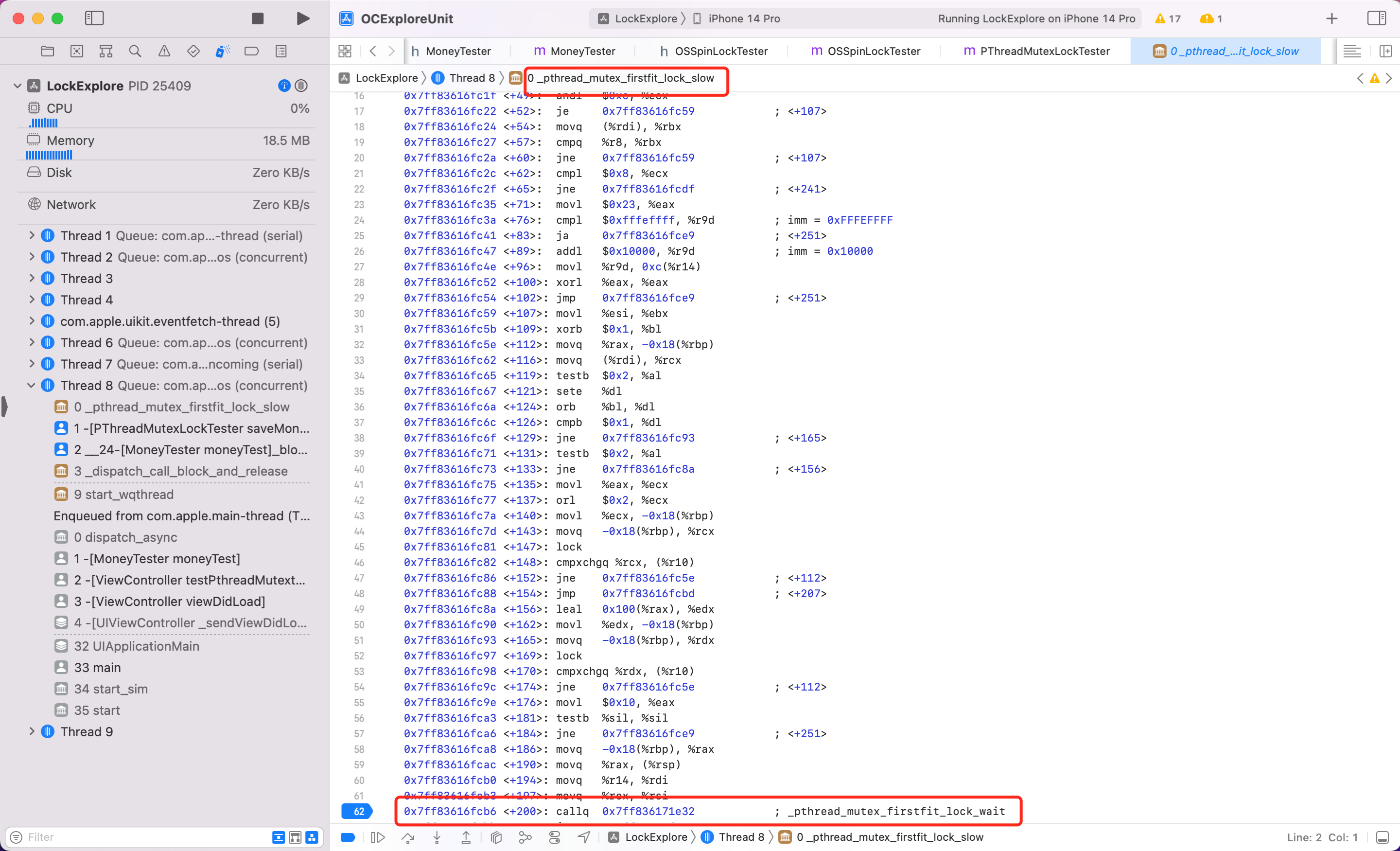
可以看到内部第62行关键函数调用了 _pthread_mutex_firstfit_lock_wait 方法。此时继续输入 si 跟踪看看
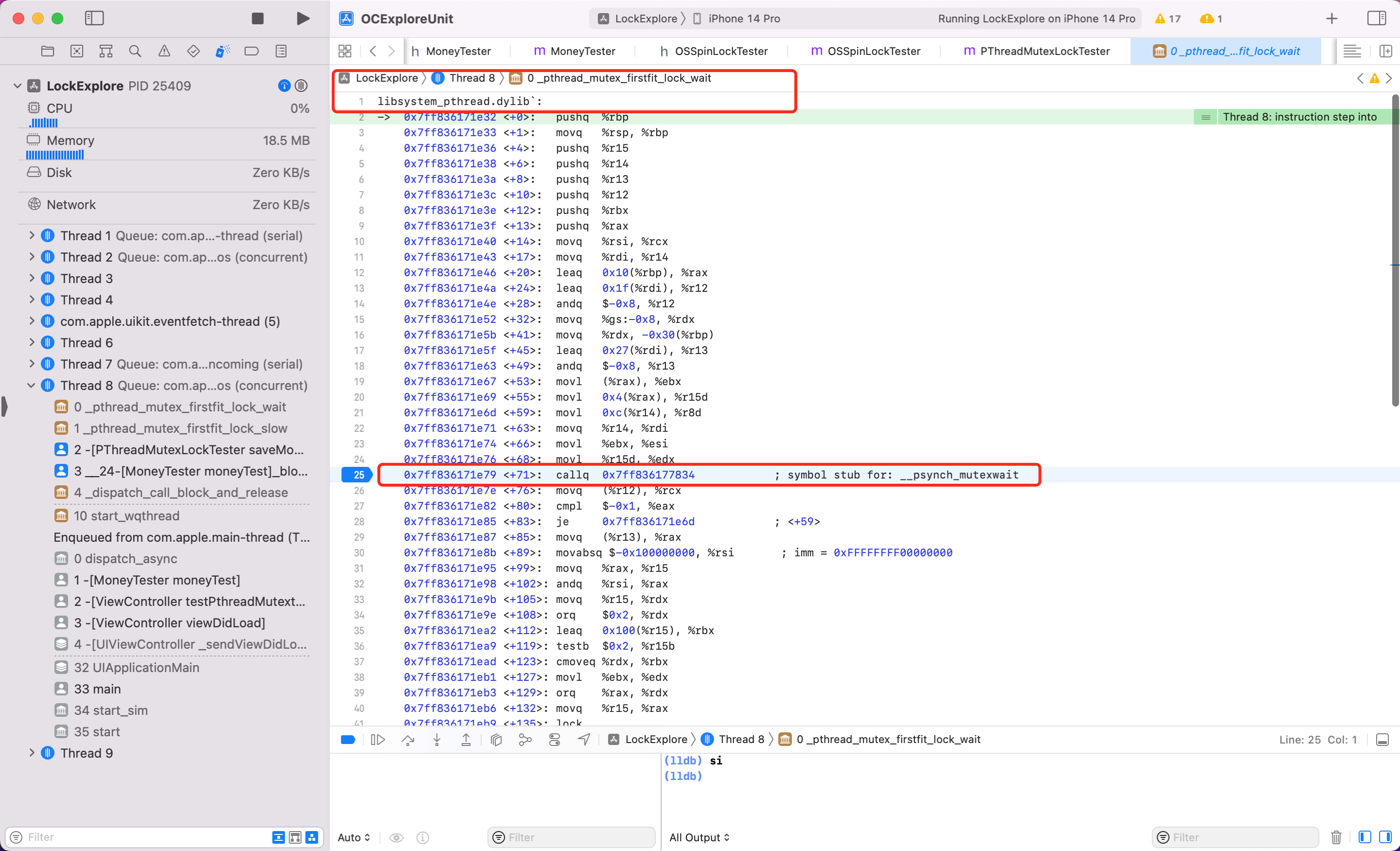
可以看到内部第25行调用了关键函数 __psynch_mutexwait,继续输入 si 看看
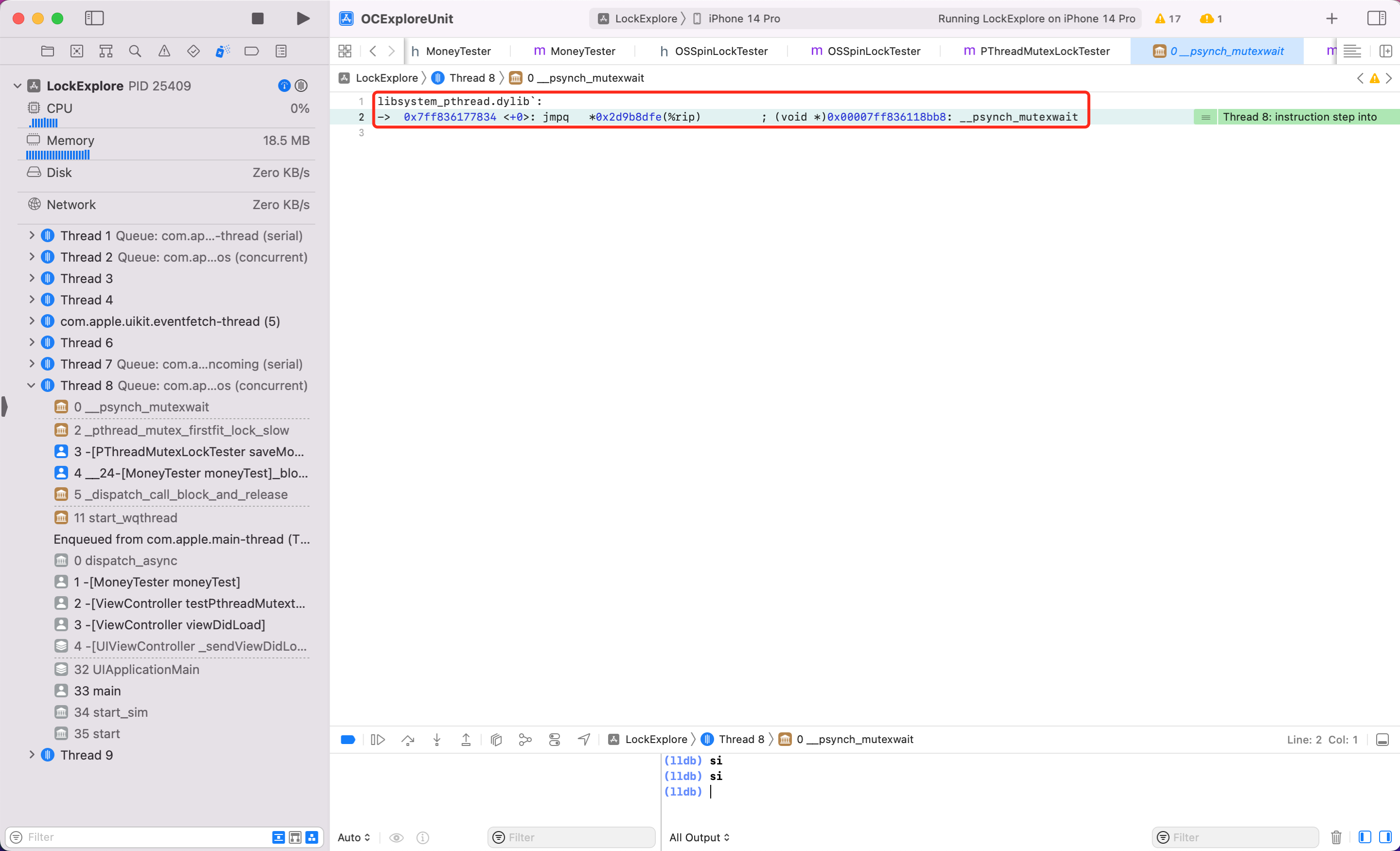
可以看到内部继续调用了系统 libsystem_pthread.dylib 库的 __psynch_mutexwait 方法。继续输入 si
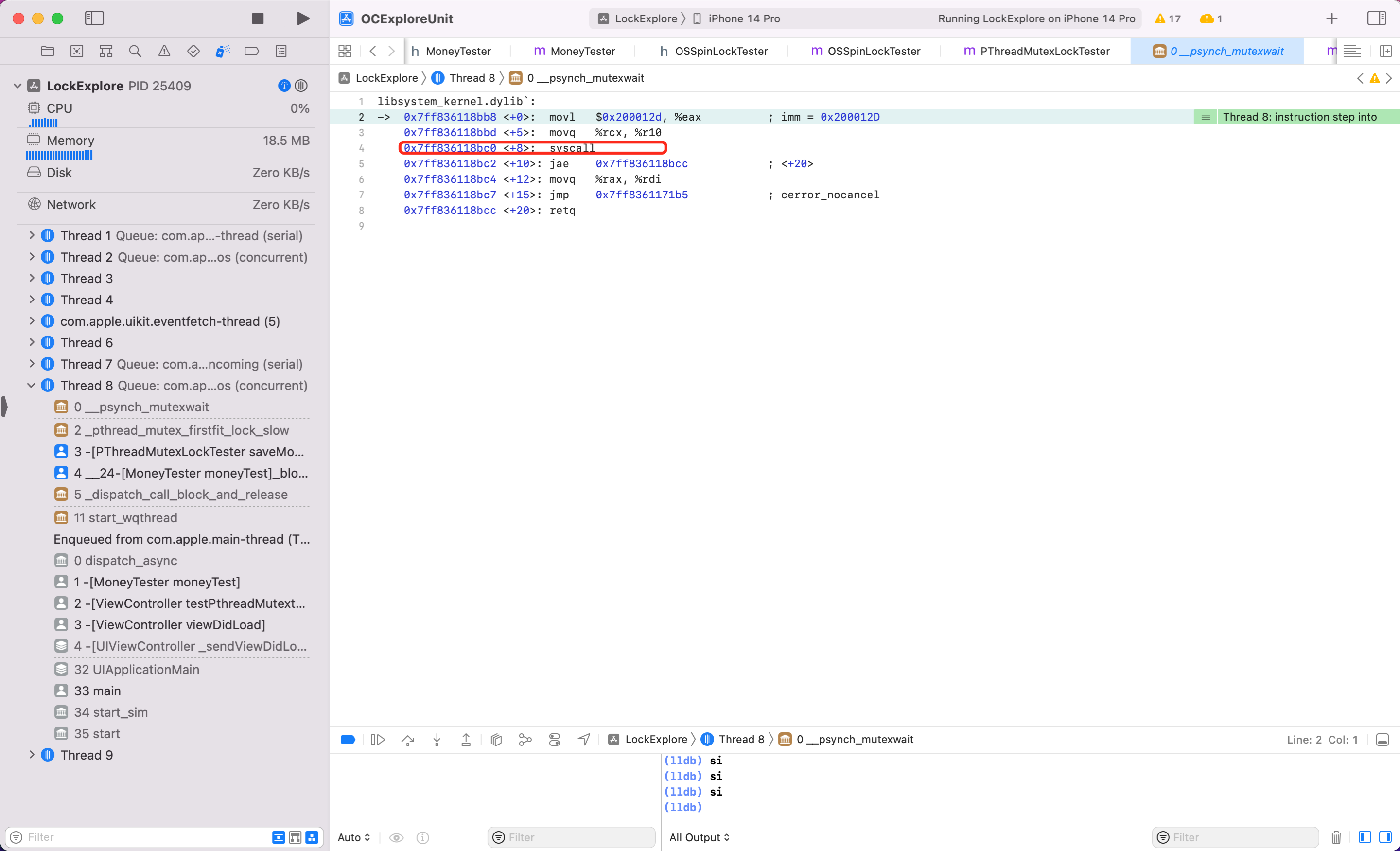
可以看到内部第4行发生了系统调用 sysCall,执行完第四句指令,线程立马就结束了。
结论:汇编逐句研究了 pthread_mutex_t 会发现最后也是调用 syscall 做到线程休眠,不像自旋锁一样,OSSpinLock 在底层实现是 while 循环一样忙等,浪费资源。
互斥条件锁 pthread_cond_t
使用
初始化互斥锁条件 pthread_cond_init(&_condition, NULL);
等待条件进入休眠,放开 mutex 锁,被唤醒后会再次对 mutex 加锁 pthread_cond_wait(&_condition, &_moneyLock);
激活一个等待该条件的线程 pthread_cond_signal(&_condition)
激活所有等待该条件的线程 pthread_cond_broadcast(&_condition)
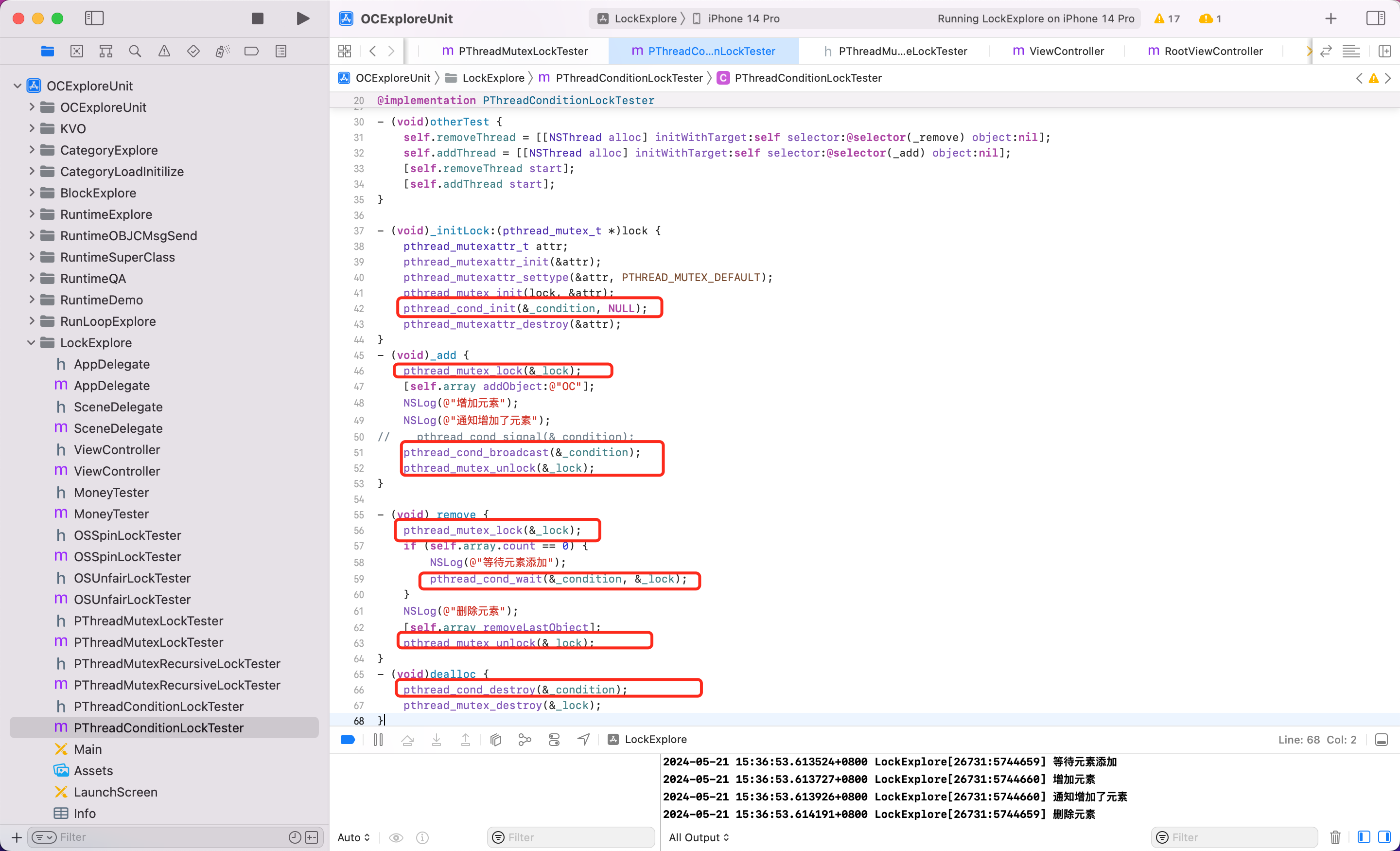
可以看到同时调用 remove、add 方法
- 执行 remove 方法先加锁,但是由于数组为空,这时候就不需要执行删除元素,然后执行 add 方法
- add 方法要加锁,发现锁被 remove 方法占用了
- remove 方法为了等有元素再去执行 remove 引入了互斥锁条件
pthread_cond_t,调用pthread_cond_wait。此时线程进入休眠,同时会释放锁。 - add 方法内加完元素会调用
pthread_cond_signal来激活等待该条件的线程,此时 remove 方法内的线程获得锁,此时再次加锁 - remove 方法执行完线程任务后,再解锁。
NSLock、NSRecursiveLock
使用
NSLock 是对 mutex 普通锁(pthread_mutex_t)的封装
NSRecursiveLock 是对 mutex 递归锁(pthread_mutex_t ,且 attr 为 PTHREAD_MUTEX_RECURSIVE)的封装,API 跟 NSLock 基本一致
区别在于一个是 c 语言版本的 API,一个是 OC 版本的包装。
查看 GUN 源码可以看看到底是如何实现的
+ (void) initialize{
static BOOL beenHere = NO;
if (beenHere == NO){
beenHere = YES;
/* Initialise attributes for the different types of mutex.
* We do it once, since attributes can be shared between multiple
* mutexes.
* If we had a pthread_mutexattr_t instance for each mutex, we would
* either have to store it as an ivar of our NSLock (or similar), or
* we would potentially leak instances as we couldn't destroy them
* when destroying the NSLock. I don't know if any implementation
* of pthreads actually allocates memory when you call the
* pthread_mutexattr_init function, but they are allowed to do so
* (and deallocate the memory in pthread_mutexattr_destroy).
*/
pthread_mutexattr_init(&attr_normal);
pthread_mutexattr_settype(&attr_normal, PTHREAD_MUTEX_NORMAL);
pthread_mutexattr_init(&attr_reporting);
pthread_mutexattr_settype(&attr_reporting, PTHREAD_MUTEX_ERRORCHECK);
pthread_mutexattr_init(&attr_recursive);
pthread_mutexattr_settype(&attr_recursive, PTHREAD_MUTEX_RECURSIVE);
/* To emulate OSX behavior, we need to be able both to detect deadlocks
* (so we can log them), and also hang the thread when one occurs.
* the simple way to do that is to set up a locked mutex we can
* force a deadlock on.
*/
pthread_mutex_init(&deadlock, &attr_normal);
pthread_mutex_lock(&deadlock);
baseConditionClass = [NSCondition class];
baseConditionLockClass = [NSConditionLock class];
baseLockClass = [NSLock class];
baseRecursiveLockClass = [NSRecursiveLock class];
tracedConditionClass = [GSTracedCondition class];
tracedConditionLockClass = [GSTracedConditionLock class];
tracedLockClass = [GSTracedLock class];
tracedRecursiveLockClass = [GSTracedRecursiveLock class];
untracedConditionClass = [GSUntracedCondition class];
untracedConditionLockClass = [GSUntracedConditionLock class];
untracedLockClass = [GSUntracedLock class];
untracedRecursiveLockClass = [GSUntracedRecursiveLock class];
}
}
可以看到 NSLock 底层就是 pthread_mutex_t。
再看看 NSRecursiveLock
@implementation NSRecursiveLock
- (id) init{
if (nil != (self = [super init])) {
if (0 != pthread_mutex_init(&_mutex, &attr_recursive)){
DESTROY(self);
}
}
return self;
}
底层就是 pthread_mutex_init。参数 attr_recursive 其实就是一个递归锁的属性。
pthread_mutexattr_init(&attr_recursive);
pthread_mutexattr_settype(&attr_recursive, PTHREAD_MUTEX_RECURSIVE);
NSRecursiveLock 不能在多线程下递归调用。@synchronized 可以在多线程下递归调用。底层原因是 TLS 有关。
Demo
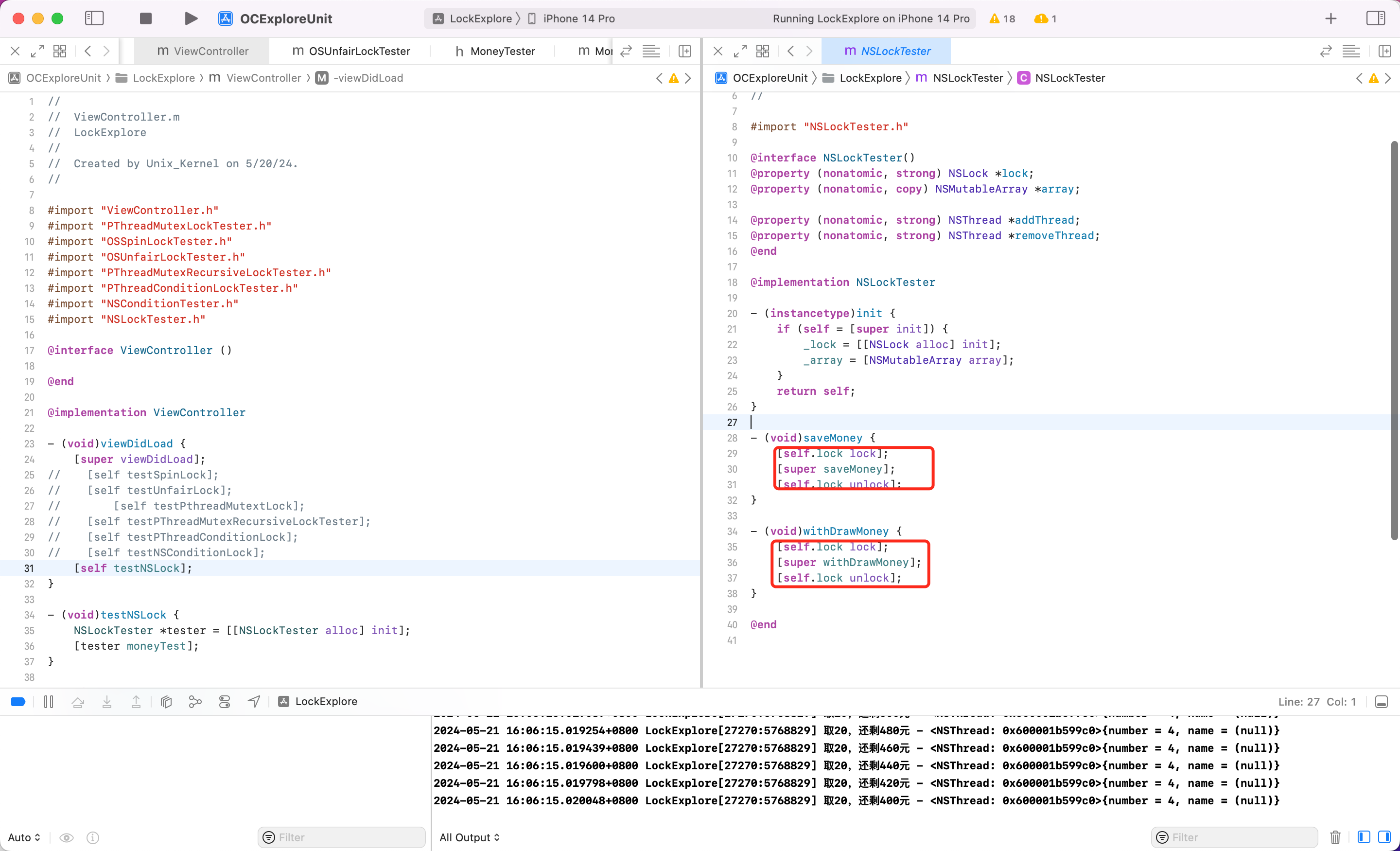
NSLock 死锁
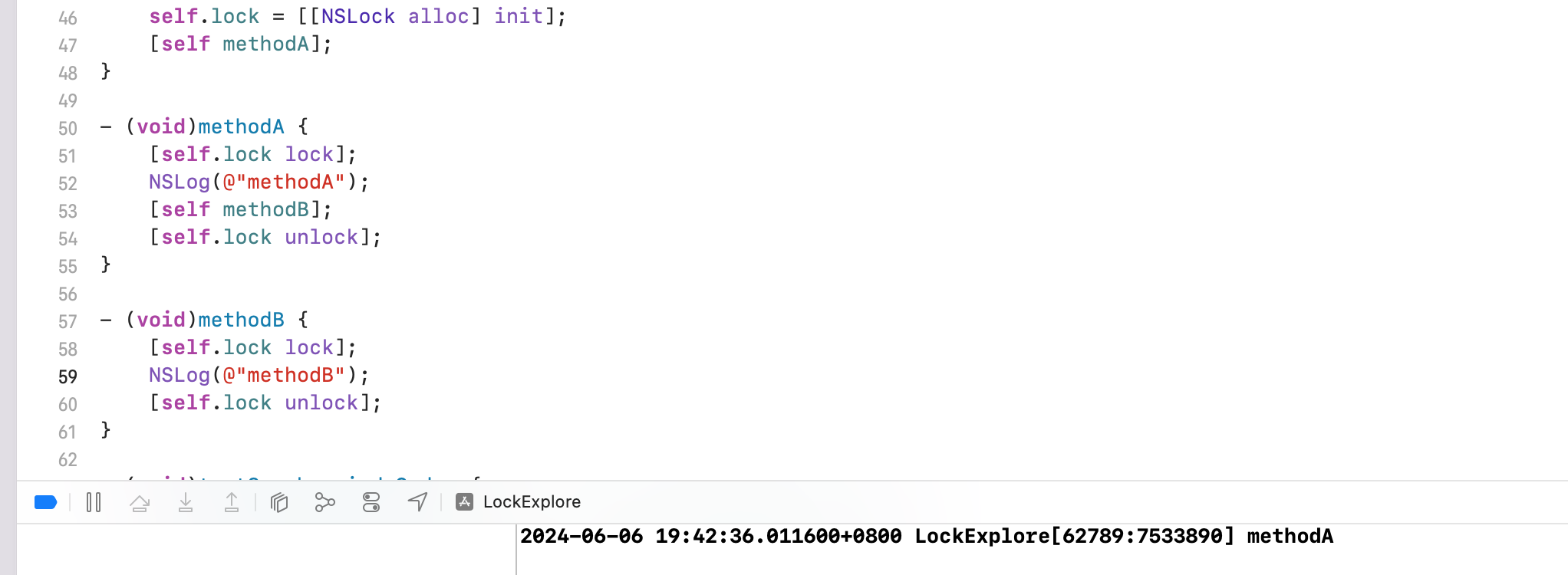
会发生死锁,后续代码无法执行,App 表现就是 ANR。重复对 NSLock 进行加锁可能导致死锁问题,同时也可能引发数据竞争和性能下降等并发相关隐患
针对上述的例子,可以用递归锁解决。可以重复加锁。
NSCondition
NSCondition 是对 mutex 和 cond 的封装。
API
@interface NSCondition : NSObject <NSLocking>
- (void)wait NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (BOOL)waitUntilDate:(NSDate *)limit NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (void)signal NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (void)broadcast;
@property (nullable, copy) NSString *name API_AVAILABLE(macos(10.5), ios(2.0), watchos(2.0), tvos(9.0));
@end
源码
- (id) init {
if (nil != (self = [super init])) {
if (0 != pthread_cond_init(&_condition, NULL)){
DESTROY(self);
} else if (0 != pthread_mutex_init(&_mutex, &attr_reporting)) {
pthread_cond_destroy(&_condition);
DESTROY(self);
}
}
return self;
}
因为 NSCondtion 已经封装好锁和条件,所以直接使即可。pthread_mutex_t 需要搭配 pthread_cond_t 一起使用。
Demo:
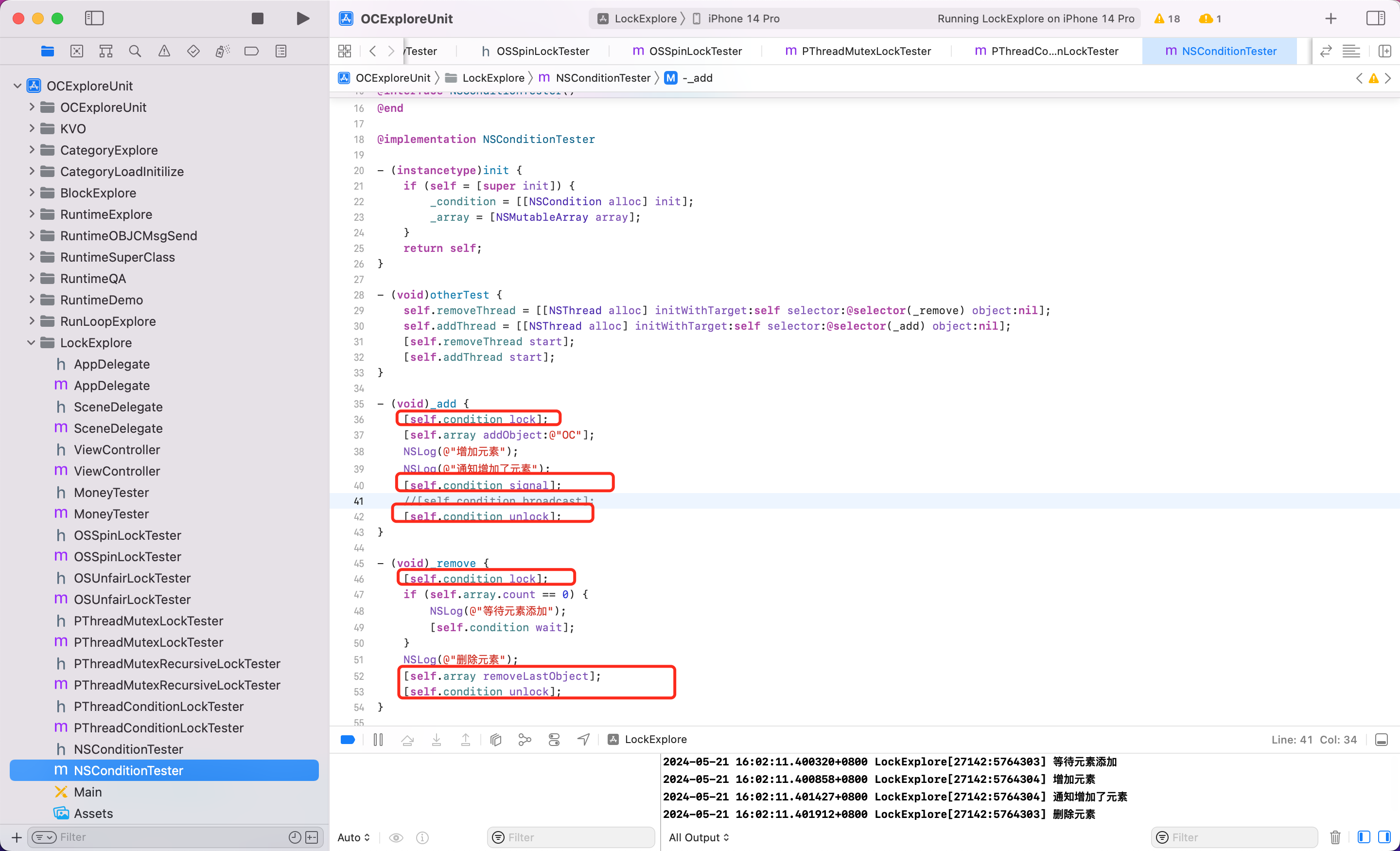
使用 NSCondition 的时候 unlock 和 signal 的顺序可能会对结果造成影响。举个例子
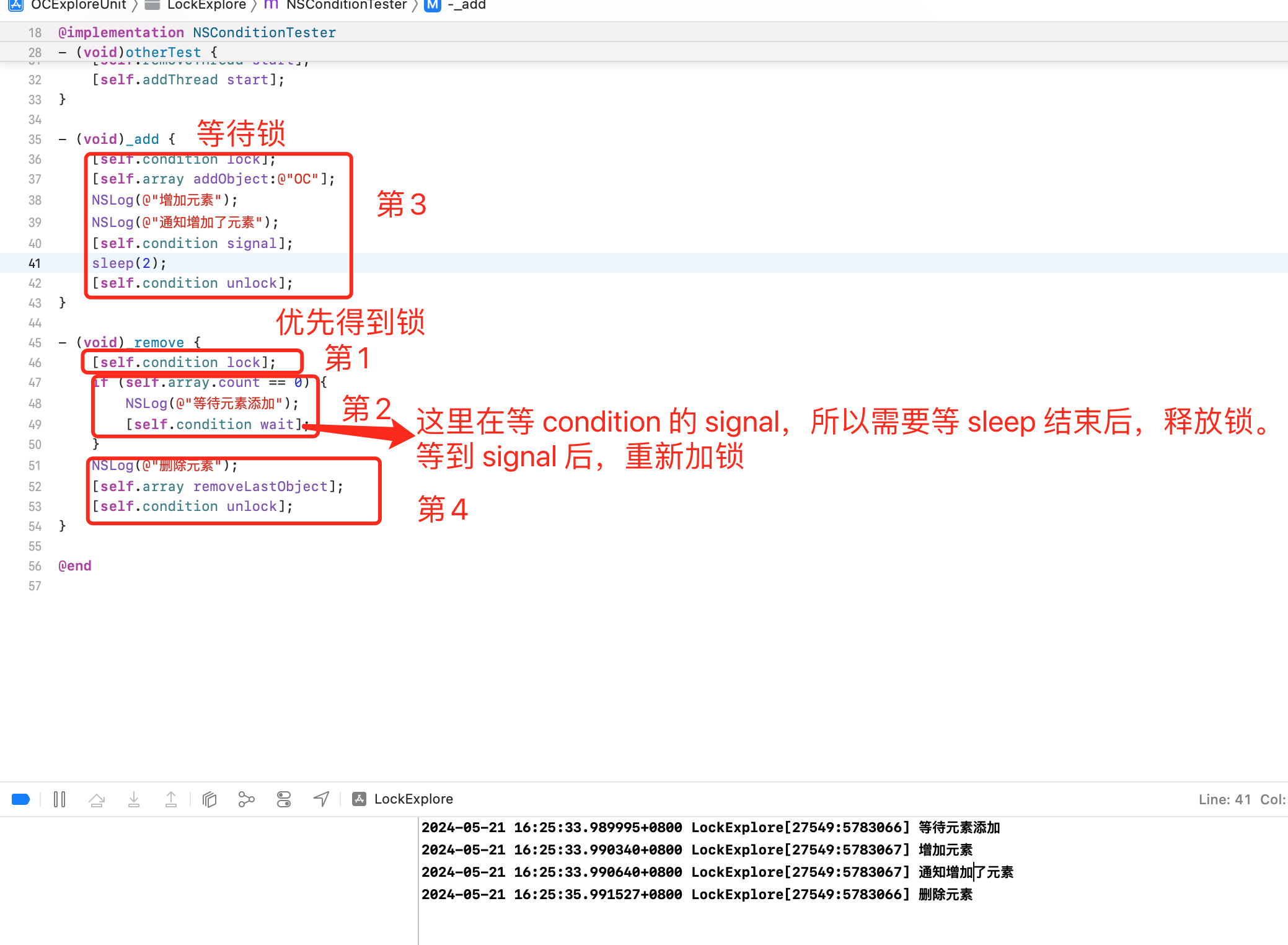
可以看到在这种情况下,由于 NSCondition 另一个地方 wait,wait 也需要释放锁,但是另一个发 signal 的地方,还没释放锁。所以会等待2s。
针对这个情况,可以将 unlock 和 signal 的顺序进行调整。
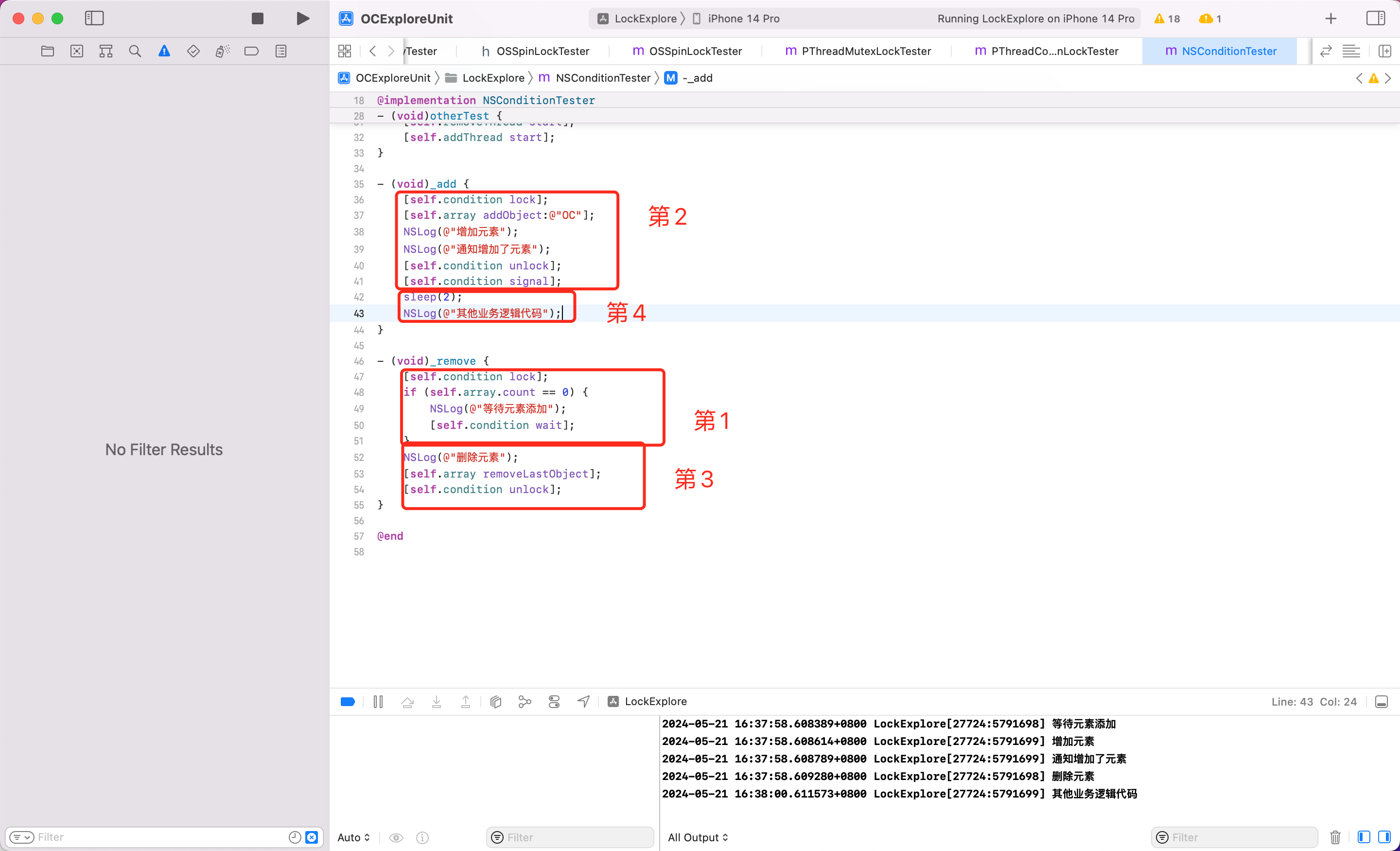
先解锁,然后发送 singal,后续其他的业务逻辑也不影响。当然这个需要针对实际代码进行设计。
存在 虚假唤醒 的问题。则可以将后续的 if 判断换为 while。比如某一时刻发送了一次 signal,然后可能有多个线程收到唤醒的信号,则可能还是会存在问题。所以 if 换为 while。
NSCondtionLock
NSConditionLock 是对 NSCondition 的进一步封装,可以设置具体的条件值(感兴趣的可以查看 GUN 源码)。
API 如下:
@interface NSConditionLock : NSObject <NSLocking>
- (instancetype)initWithCondition:(NSInteger)condition NS_DESIGNATED_INITIALIZER;
@property (readonly) NSInteger condition;
- (void)lockWhenCondition:(NSInteger)condition NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (BOOL)tryLock NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (BOOL)tryLockWhenCondition:(NSInteger)condition NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (void)unlockWithCondition:(NSInteger)condition NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (BOOL)lockBeforeDate:(NSDate *)limit NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
- (BOOL)lockWhenCondition:(NSInteger)condition beforeDate:(NSDate *)limit NS_SWIFT_UNAVAILABLE_FROM_ASYNC("Use async-safe scoped locking instead");
@property (nullable, copy) NSString *name API_AVAILABLE(macos(10.5), ios(2.0), watchos(2.0), tvos(9.0));
@end
Demo
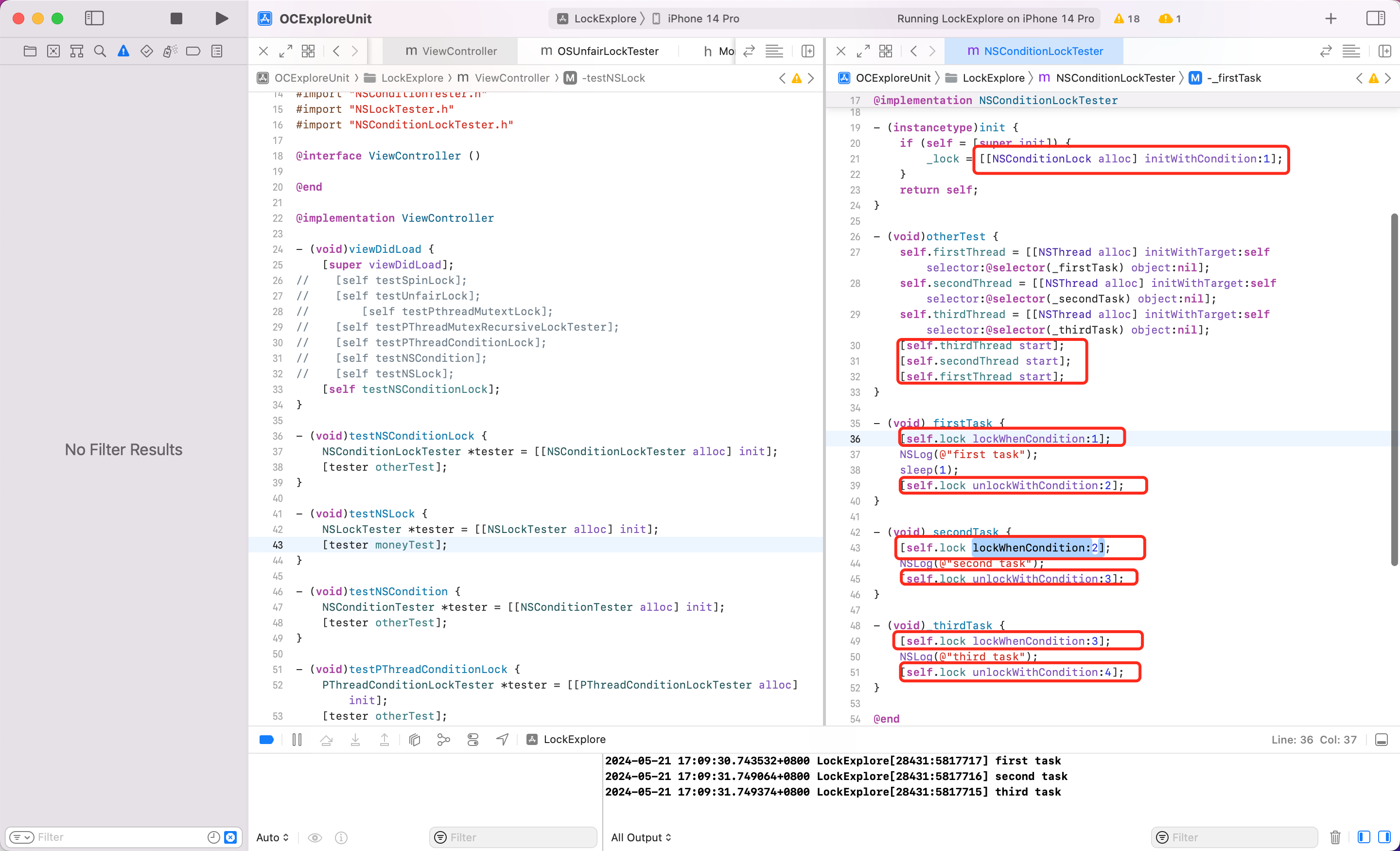
分析:虽然通过3个线程,设置了线程的先后顺序,但是多线程任务执行的时候到底谁先执行,是没办法控制的。但是通过 NSConditionLock lockWhenCondition:* 的能力,可以控制线程的执行顺序。
另外如果初始化设置了 [[NSConditionLock alloc] initWithCondition:1] 但是使用的地方没有用 lockWhenCondition 而是直接用 lock 则会忽略 condition 的值,直接加锁成功。
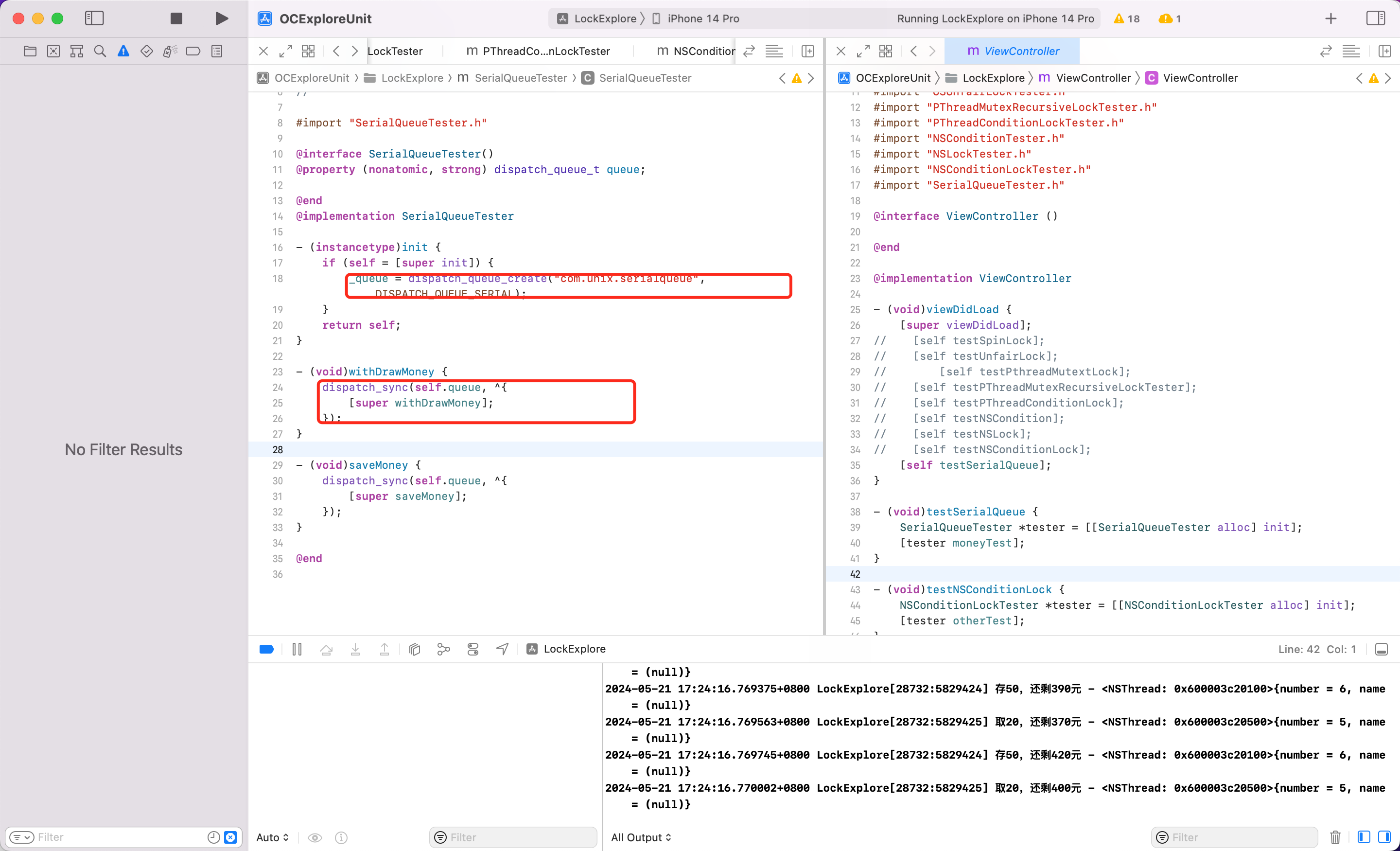
dispatch_queue
使用 GCD 的串行队列,也是可以实现线程同步。
线程同步的本质就是多线程的任务是顺序执行
dispatch_semaphore
使用
semaphore 叫做”信号量”
信号量的初始值,可以用来控制线程并发访问的最大数量
信号量的初始值为1,代表同时只允许1条线程访问资源,保证线程同步
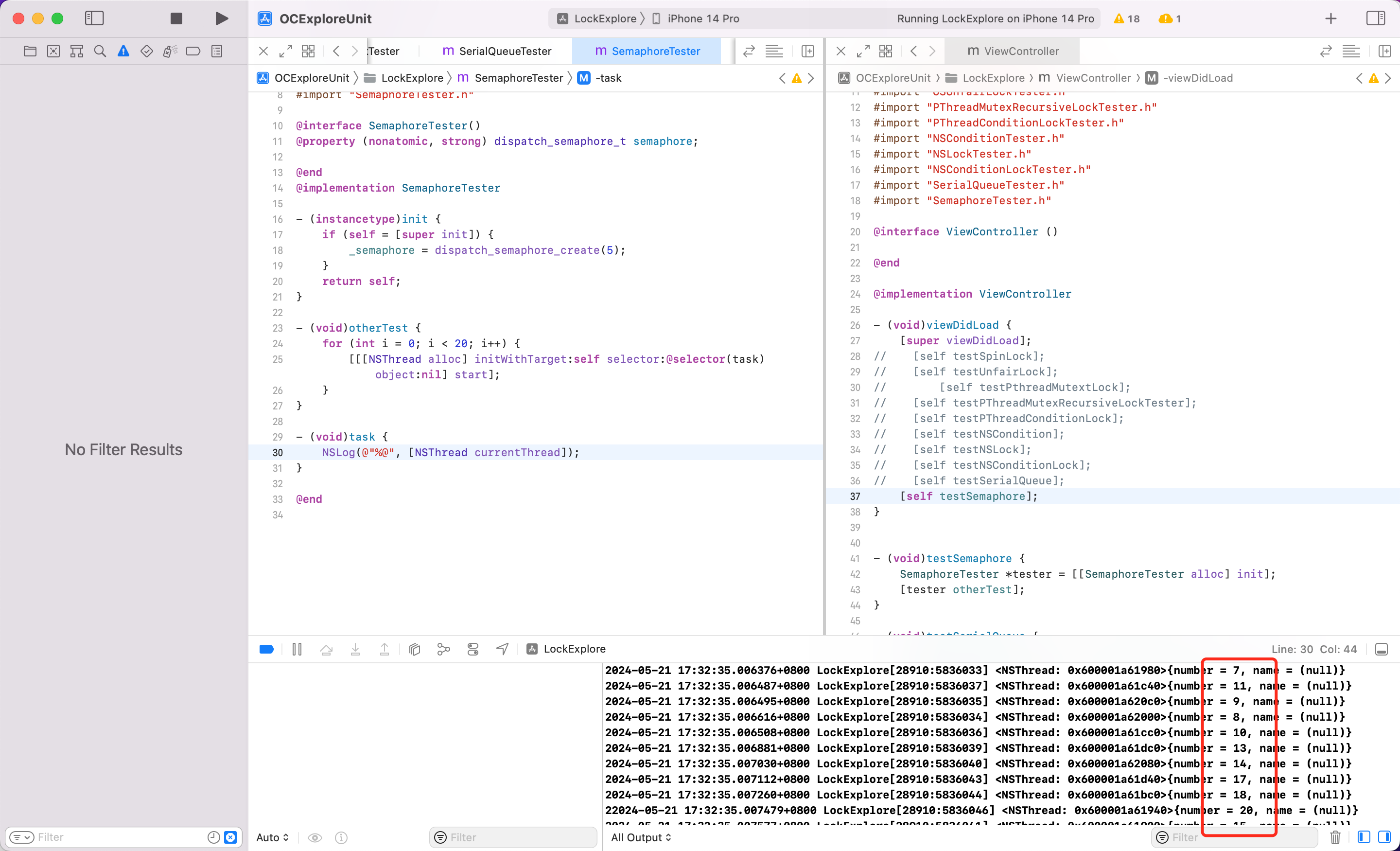
可以看到打印了20个线程,但是我们控制线程最大数量怎么办呢?可以用信号量实现。效果如下:
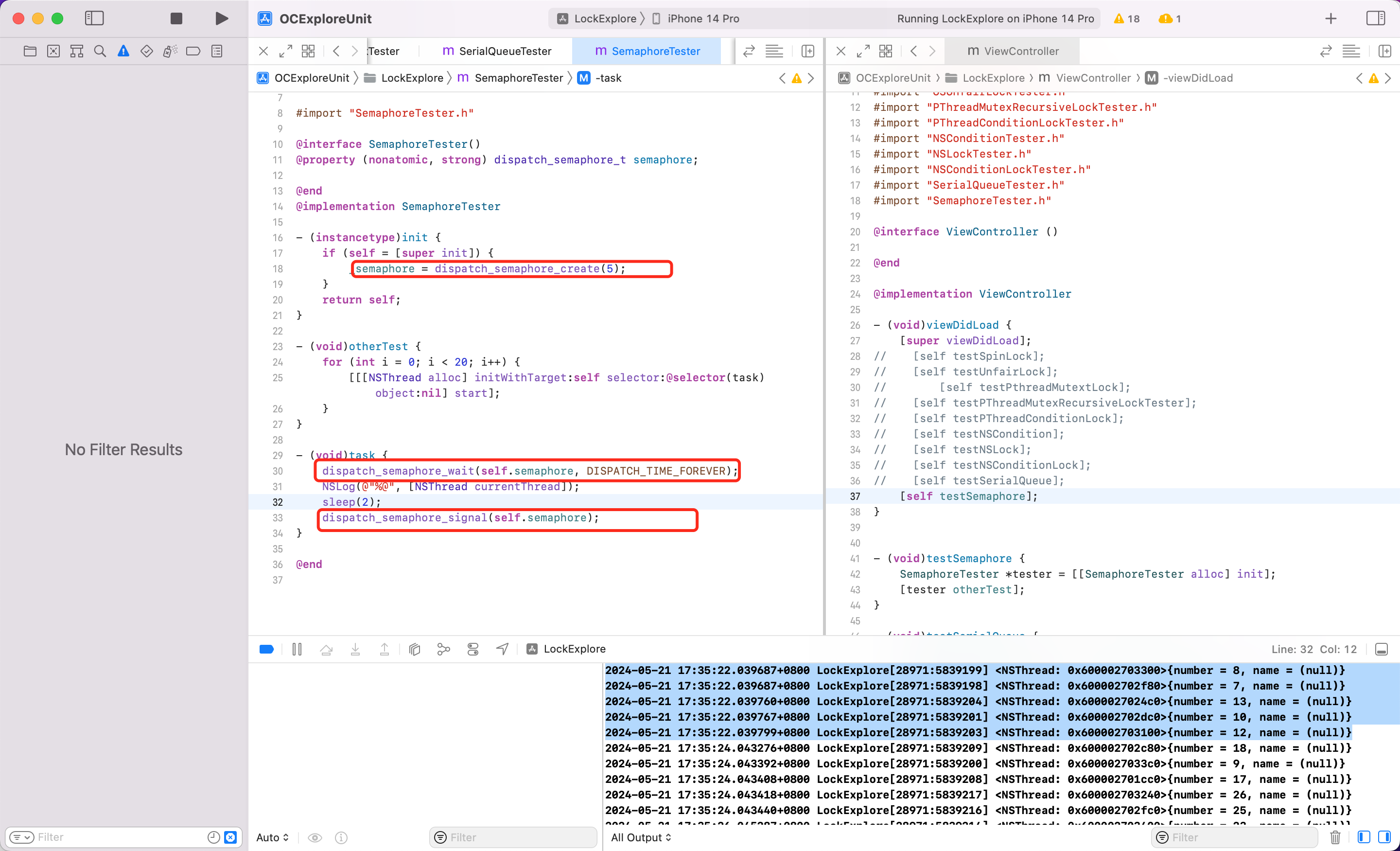
dispatch_semaphore_wait 函数的本质
-
如果信号量的值 > 0,则会让信号量的值 -1,然后继续向下执行代码
-
如果信号量的值 <= 0,则线程休眠等待。等待多久取决于第二个参数。等到信号量的值 > 0(直到其他的线程,任务执行完毕,利用
dispatch_semaphore_signalAPI 让信号量的值+1),此时继续会让信号量的值 -1,然后继续向下执行代码
dispatch_semaphore_signal 函数的本质:让信号量的值 + 1
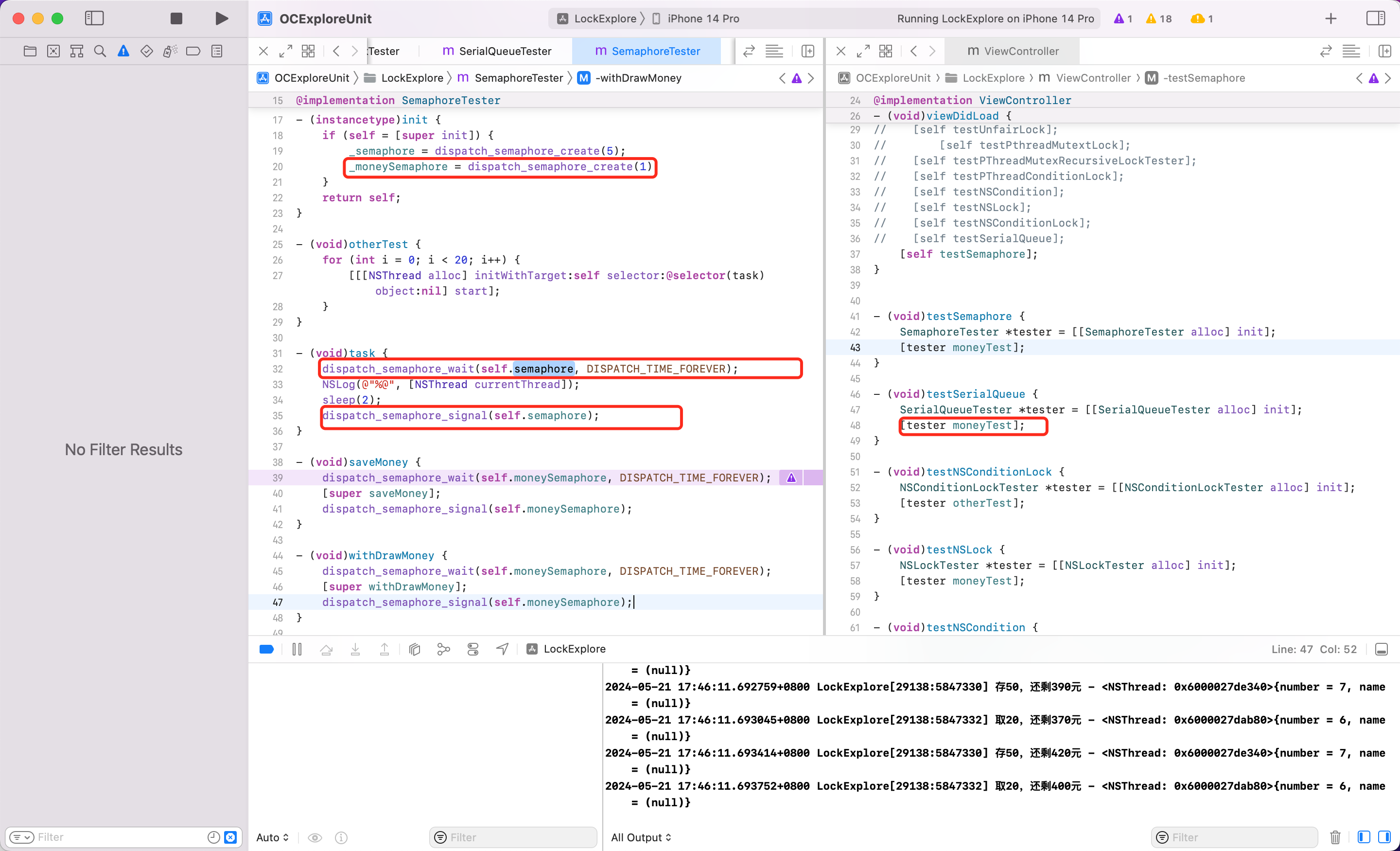
所以如何让线程同步?设置信号量的值=1即可。保证同一时间只有一个线程任务在执行。代码如下
有趣的实验:
self.semaphore = dispatch_semaphore_create(1);
dispatch_semaphore_wait(self.semaphore, DISPATCH_TIME_FOREVER);
上面的代码会 crash。因为创建出来信号量为1,但是经过 dispatch_semaphore_wait 之后信号量变为0,底层会调用到 _dispatch_semaphore_dispose。内部会做判断,就是原始的信号量
void _dispatch_semaphore_dispose(dispatch_object_t dou,
DISPATCH_UNUSED bool *allow_free){
dispatch_semaphore_t dsema = dou._dsema;
if (dsema->dsema_value < dsema->dsema_orig) {
DISPATCH_CLIENT_CRASH(dsema->dsema_orig - dsema->dsema_value,
"Semaphore object deallocated while in use");
}
_dispatch_sema4_dispose(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
}
封装
有的时候我们需要在方法内部创建 semaphore ,则可以创建宏
#define SemaphoreBegin \
static dispatch_semaphore_t semaphore; \
static dispatch_once_t onceToken; \
dispatch_once(&onceToken, ^{ \
semaphore = dispatch_semaphore_create(1); \
}); \
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
#define SemaphoreEnd \
dispatch_semaphore_signal(semaphore);
使用
- (void)withdrawMoney {
SemaphoreBegin
[super withdrawMoney];
SemaphoreEnd
}
@synchronized
@synchronized 可递归重入的原理分析/线程缓存空间
@synchronized 使用很方便,它是对 pthread_mutex_t 递归锁的封装。Demo 如下
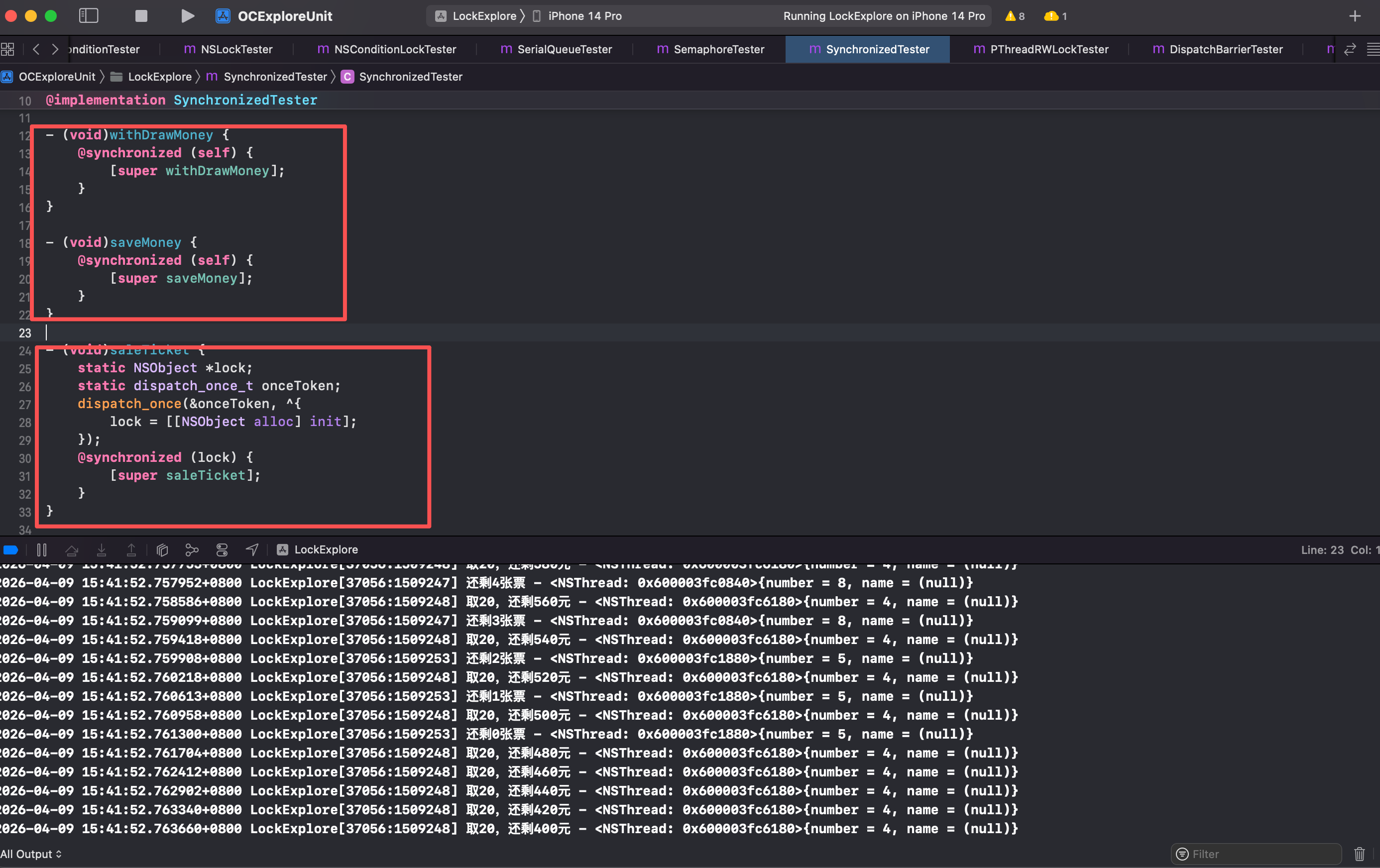
为了探究下实现,开启汇编调试
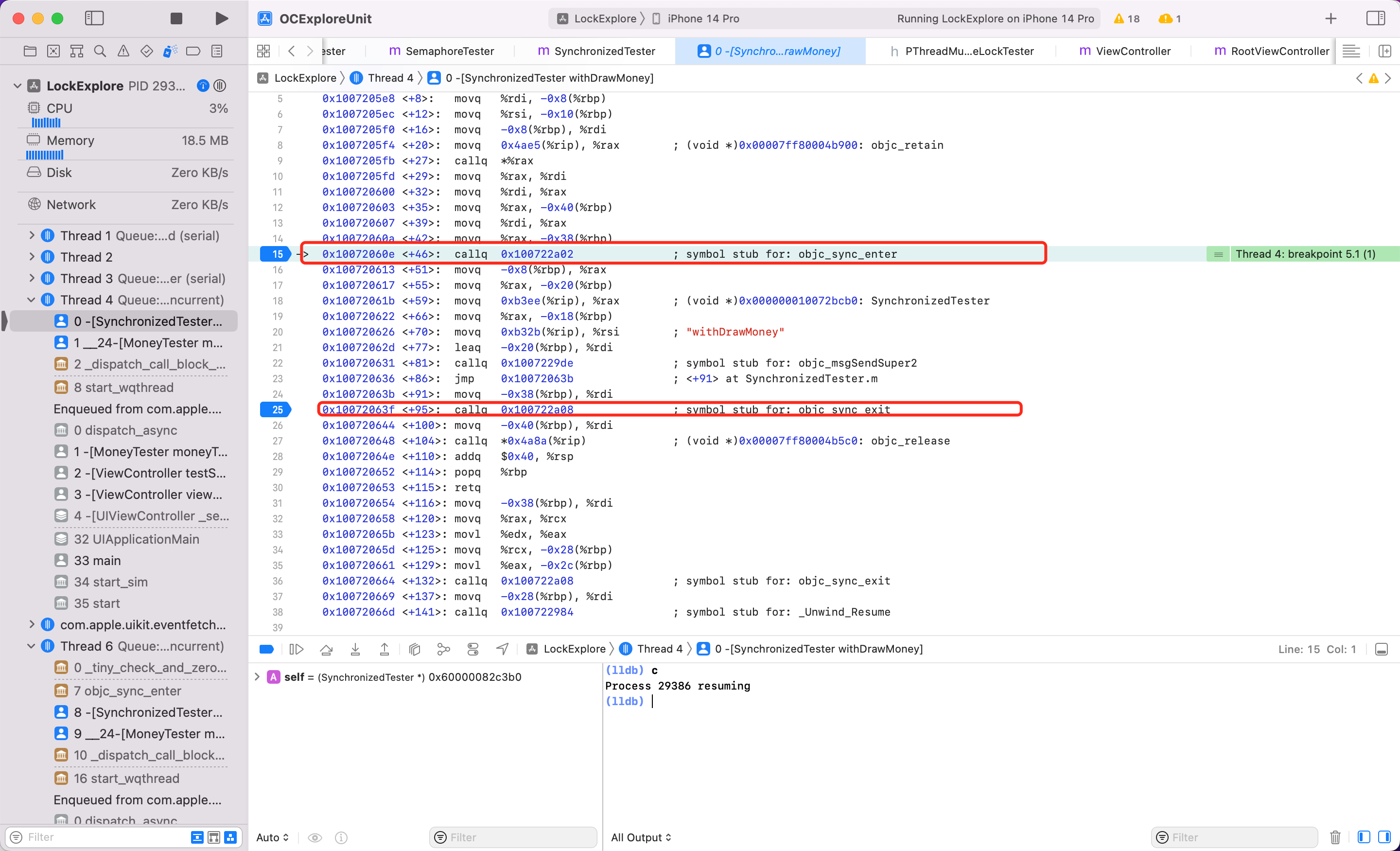
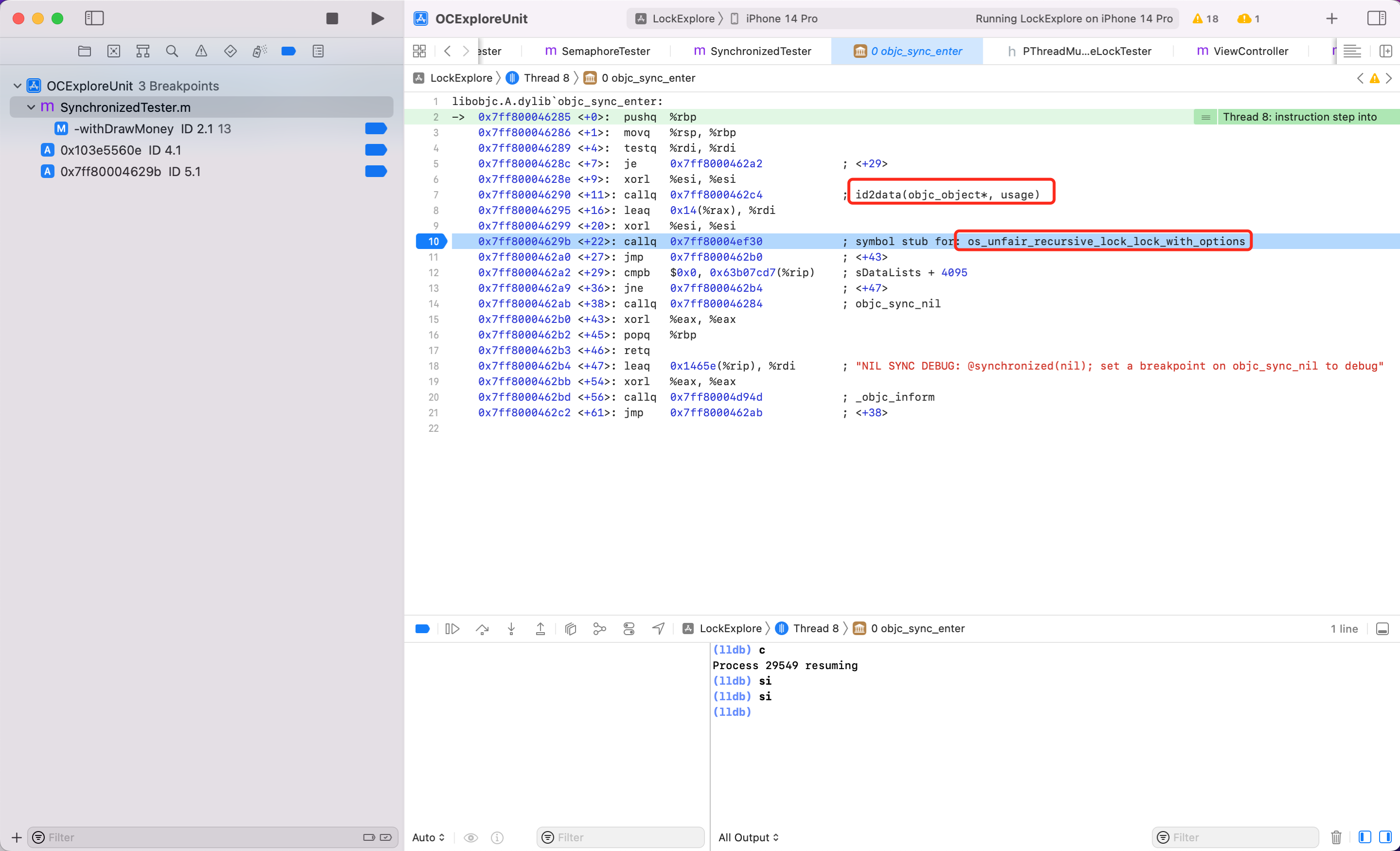
通过汇编可以看到 @synchronized 底层调用了 objc_sync_enter 方法,其中又调用了 id2data 和 os_unfair_recursive_lock_lock_with_options 方法。 可以查看 objc4 的源码(笔者的 objc 版本为 objc4-objc4-912.3),查找 objc_sync_enter
// Begin synchronizing on 'obj'.
// Allocates recursive mutex associated with 'obj' if needed.
// Returns OBJC_SYNC_SUCCESS once lock is acquired.
int objc_sync_enter(id obj)
{
int result = _objc_sync_enter_kind(obj, SyncKind::atSynchronize);
if (result != OBJC_SYNC_SUCCESS)
OBJC_DEBUG_OPTION_REPORT_ERROR(DebugSyncErrors,
"objc_sync_enter(%p) returned error %d", obj, result);
return result;
}
int _objc_sync_enter_kind(id obj, SyncKind kind)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, kind, ACQUIRE);
ASSERT(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
if (DebugNilSync == Fatal)
_objc_fatal("@synchronized(nil) is fatal");
}
return result;
}
typedef struct alignas(CacheLineSize) SyncData {
struct SyncData* nextData;
DisguisedPtr<objc_object> object;
SyncKind kind;
int32_t threadCount; // number of THREADS using this block
recursive_mutex_t mutex;
bool matches(id matchObject, SyncKind matchKind) {
ASSERT(matchKind != SyncKind::invalid);
ASSERT(kind != SyncKind::invalid);
return object == matchObject && kind == matchKind;
}
} SyncData;
using recursive_mutex_t = objc_recursive_lock_t;
可以看到 @synchronized 的本质是一个包装了 objc_recursive_lock_t(不同版本的 OBJC ,其内部实现会不同) 的 recursive_mutex_tt C++ 类。
可以发现,如果 @synchronized 参数为nil,@synchronized(nil) 调用 objc_sync_nil(),最终什么也不执行。
static SyncData* id2data(id object, SyncKind kind, enum usage why)
{
ASSERT(kind != SyncKind::invalid);
spinlock_t *lockp = &LOCK_FOR_OBJ(object);
SyncData **listp = &LIST_FOR_OBJ(object);
SyncData* result = NULL;
#if ENABLE_FAST_CACHE
// Check per-thread single-entry fast cache for matching object
bool fastCacheOccupied = NO;
SyncData *data = syncData;
if (data) {
fastCacheOccupied = YES;
if (data->matches(object, kind)) {
// Found a match in fast cache.
result = data;
if (result->threadCount <= 0 || syncLockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
switch(why) {
case ACQUIRE: {
++syncLockCount;
break;
}
case RELEASE:
if (--syncLockCount == 0) {
// remove from fast cache
syncData = nullptr;
// atomic because may collide with concurrent ACQUIRE
AtomicDecrement(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
#endif // ENABLE_FAST_CACHE
// Check per-thread cache of already-owned locks for matching object
SyncCache *cache = fetch_cache(NO);
if (cache) {
unsigned int i;
for (i = 0; i < cache->used; i++) {
SyncCacheItem *item = &cache->list[i];
if (!item->data->matches(object, kind)) continue;
// Found a match.
result = item->data;
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) {
case ACQUIRE:
item->lockCount++;
break;
case RELEASE:
item->lockCount--;
if (item->lockCount == 0) {
// remove from per-thread cache
cache->list[i] = cache->list[--cache->used];
// atomic because may collide with concurrent ACQUIRE
AtomicDecrement(&result->threadCount);
}
break;
case CHECK:
// do nothing
break;
}
return result;
}
}
// Thread cache didn't find anything.
// Walk in-use list looking for matching object
// Spinlock prevents multiple threads from creating multiple
// locks for the same new object.
// We could keep the nodes in some hash table if we find that there are
// more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{
SyncData* p;
SyncData* firstUnused = NULL;
for (p = *listp; p != NULL; p = p->nextData) {
if ( p->matches(object, kind) ) {
result = p;
// atomic because may collide with concurrent RELEASE
AtomicIncrement(&result->threadCount);
goto done;
}
if ( (firstUnused == NULL) && (p->threadCount == 0) )
firstUnused = p;
}
// no SyncData currently associated with object
if ( (why == RELEASE) || (why == CHECK) )
goto done;
// an unused one was found, use it
if ( firstUnused != NULL ) {
result = firstUnused;
result->object = (objc_object *)object;
result->kind = kind;
result->threadCount = 1;
goto done;
}
}
// Allocate a new SyncData and add to list.
// XXX allocating memory with a global lock held is bad practice,
// might be worth releasing the lock, allocating, and searching again.
// But since we never free these guys we won't be stuck in allocation very often.
posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData));
result->object = (objc_object *)object;
result->kind = kind;
result->threadCount = 1;
new (&result->mutex) recursive_mutex_t(fork_unsafe);
result->nextData = *listp;
*listp = result;
done:
lockp->unlock();
if (result) {
// Only new ACQUIRE should get here.
// All RELEASE and CHECK and recursive ACQUIRE are
// handled by the per-thread caches above.
if (why == RELEASE) {
// Probably some thread is incorrectly exiting
// while the object is held by another thread.
return nil;
}
if (why != ACQUIRE) _objc_fatal("id2data is buggy");
if (!result->matches(object, kind)) _objc_fatal("id2data is buggy");
#if ENABLE_FAST_CACHE
if (!fastCacheOccupied) {
// Save in fast thread cache
syncData = result;
syncLockCount = 1;
} else
#endif // ENABLE_FAST_CACHE
{
// Save in thread cache
if (!cache) cache = fetch_cache(YES);
cache->list[cache->used].data = result;
cache->list[cache->used].lockCount = 1;
cache->used++;
}
}
return result;
}
传递一个参数 obj,经过 id2data 方法得到一个结构体对象,访问结构体对象的成员变量 mutex,然后调用 lock 方法。
可以看到是一个哈希表 StripedMap,哈希表工作原理就是传递一个 key,经过哈希算法生成索引,然后获取对应的值。
内部维护了一个哈希表,一个对象对应一个锁(所以为了锁的使用正确,加解锁,需要用同一个对象)
另外 recursive_mutex_tt 在初始化的时候传入 OS_UNFAIR_RECURSIVE_LOCK_INIT,看起来也支持递归。所以 @synchronized 的本质是一个递归互斥锁的封装。
各种锁性能对比
性能从高到低:os_unfair_lock > OSSpinLock > dispatch_semaphore > pthread_mutex > dispatch_queue(DISPATCH_QUEUE_SERIAL) >NSLock > NSCondition > pthread_mutex(recursive) > NSRecursiveLock > @synchronized
自旋锁、互斥锁对比
什么情况适合使用自旋锁?
-
预计线程等待锁的时间很短(假设线程1的任务本来就很短,如果使用其他的锁,比如还需要互斥锁的话,底层实现会调用 sysCall,一个休眠一个唤醒,这个时间可能比如循环忙等更耗时。所以如果一个线程任务执行时间很短,则考虑使用自旋锁会更高效一些。)
-
加锁的代码(临界区)经常被调用,但竞争情况很少发生
-
CPU资源不紧张
-
多核处理器
什么情况使用互斥锁比较划算?
-
预计线程等待锁的时间较长
-
单核处理器
-
临界区有IO操作(IO 操作一般占用 CPU 资源较多,互斥锁本身就占用 CPU,所以不适合)
-
临界区代码复杂或者循环量大
-
临界区竞争非常激烈
atomic
源码探究
atomic 用于保证属性 setter、getter 的原子性操作,相当于在 getter 和 setter 内部加了线程同步的锁。
与之相对的是 nonatomic,也就是非原子性的。假设多线程下,针对一个属性的 setter、getter,需要自己加锁来保证读写问题。
使用 atomic 则属性类似下面的伪代码
@property (atomic, strong) NSString *name;
- (NSString *)name {
// 加锁
// logic
// 解锁
return _name;
}
- (void)setName:(NSString *)name {
// 加锁
// logic
_name = name;
// 解锁
}
用 atomic 修饰就是线程安全的吗?不是的
比如 atomic 修饰了数组,那么对数组指针的读取和赋值(数组的地址修改)是线程安全的,但是数组的操作不是线程安全的,比如增加元素、删除元素、读取元素。
具体实现,可以参考源码 objc4 的 objc-accessors.mm
属性取值逻辑:
id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) {
if (offset == 0) {
return object_getClass(self);
}
// Retain release world
id *slot = (id*) ((char*)self + offset);
if (!atomic) return *slot;
// Atomic retain release world
spinlock_t& slotlock = PropertyLocks.get()[slot];
slotlock.lock();
id value = objc_retain(*slot);
slotlock.unlock();
// for performance, we (safely) issue the autorelease OUTSIDE of the spinlock.
return objc_autoreleaseReturnValue(value);
}
可以看到在获取属性值的时候,判断是不是 atomic
-
不是 atomic 则直接 return
-
如果是 atomic,则调用自旋锁
slotlock加锁,取值,解锁,return
属性赋值逻辑:
static inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy)
{
if (offset == 0) {
object_setClass(self, newValue);
return;
}
id oldValue;
id *slot = (id*) ((char*)self + offset);
if (copy) {
newValue = [newValue copyWithZone:nil];
} else if (mutableCopy) {
newValue = [newValue mutableCopyWithZone:nil];
} else {
if (*slot == newValue) return;
newValue = objc_retain(newValue);
}
if (!atomic) {
// nonatomic,直接赋值
oldValue = *slot;
*slot = newValue;
} else {
// atomic,加锁
spinlock_t& slotlock = PropertyLocks.get()[slot];
slotlock.lock();
oldValue = *slot;
*slot = newValue;
slotlock.unlock();
}
objc_release(oldValue);
}
void objc_setProperty(id self, SEL _cmd, ptrdiff_t offset, id newValue, BOOL atomic, signed char shouldCopy)
{
bool copy = (shouldCopy && shouldCopy != MUTABLE_COPY);
bool mutableCopy = (shouldCopy == MUTABLE_COPY);
reallySetProperty(self, _cmd, newValue, offset, atomic, copy, mutableCopy);
}
void lock() {
lockdebug_mutex_lock(this);
// <rdar://problem/50384154>
uint32_t opts = OS_UNFAIR_LOCK_DATA_SYNCHRONIZATION | OS_UNFAIR_LOCK_ADAPTIVE_SPIN;
os_unfair_lock_lock_with_options_inline(&mLock, (os_unfair_lock_options_t)opts);
}
可以看到设置属性的时候会判断是不是 atomic
- atomic 类型,则直接赋值
- 非 atomic 类型,则先自旋锁加锁、赋值、解锁
它并不能保证使用属性的过程是线程安全的。
QA:为什么在 iOS 上几乎没有使用?
因为属性 getter、setter 使用太高频了,另外 atomic 内部实现是自旋锁,自旋锁是忙等,针对移动设备上那寸土寸金的 CPU,太奢侈了,太耗费性能了。
atomic 并不能保证使用属性的过程是线程安全的
@property (atomic,copy) NSString *name;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
@synchronized(self){
for (int i = 0; i<100; i++) {
self.name = @"杭城小刘";
NSLog(@"线程1 : %@",self.name);
}
}
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
@synchronized(self){
for (int i = 0; i<100; i++) {
self.name = @"魅影";
NSLog(@"线程2 : %@",self.name);
}
}
});
预期:线程 A 打印出来一定是杭城小刘,线程 B 打印出来是魅影。但事实上可能存在乱序。
atomic 是原子属性,它内部实现是针对属性的 setter、getter 进行加锁(早期实现是自旋旋,因为存在问题,后续替换为了 os_unfair_lock)。但是事实上在进行多线程编程的时候,我们针对数据的操作并不是修改指针本身(思考 NSString 的 getter、setter),而是操作类似 NSArray、NSDictionary 这样的 case。比如 @property(atomic, strong)NSMutableArray *hobbies; 如果在多线程情况下进行处理,一边生产者添加数据,一边消费者消费数据,则会产生内存问题。
所以多线程并发编程来说,推荐使用锁是一个合理的方案。此外自旋锁不推荐使用,互斥锁中 pthread_mutex 等性能高一些的锁推荐使用。
多线程读写安全
读写的特点:
- 同一时间,只能有1个线程进行写的操作(只能有1个写)
- 同一时间,允许有多个线程进行读的操作(可以同时读)
- 同一时间,不允许既有写的操作,又有读的操作(读写不能同时进行)
“多读单写”问题,经常用于文件、数据的读写操作。iOS 主流方案有:
-
pthread_rwlock:读写锁
-
dispatch_barrier_async:异步栅栏调用
pthread_rwlock
初始化 :
pthread_rwlock_t lock
pthread_rwlock_init(&_lock, NULL)
读操作-加锁: pthread_rwlock_rdlock(&_lock)
读操作-尝试加锁: pthread_rwlock_tryrdlock(&_lock);
写操作-加锁: pthread_rwlock_wrlock(&_lock);
写操作-尝试加锁: pthread_rwlock_trywrlock(&_lock);
解锁: pthread_rwlock_unlock(&_lock);
销毁: pthread_rwlock_destroy(&_lock);
Demo
dispatch_barrier_async
多读单写,
// 初始化队列
self.queue = dispatch_queue_create("rwqueue", DISPATCH_QUEUE_CONCURRENT);
// 读
dispatch_async(self.queue, ^{
});
// 写
dispatch_barrier_async(self.queue, ^{
});
注意:
- 这个函数传入的并发队列必须是自己通过dispatch_queue_cretate创建的
- 如果传入的是一个串行或是一个全局的并发队列,那这个函数便等同于dispatch_async函数的效果
上 Demo
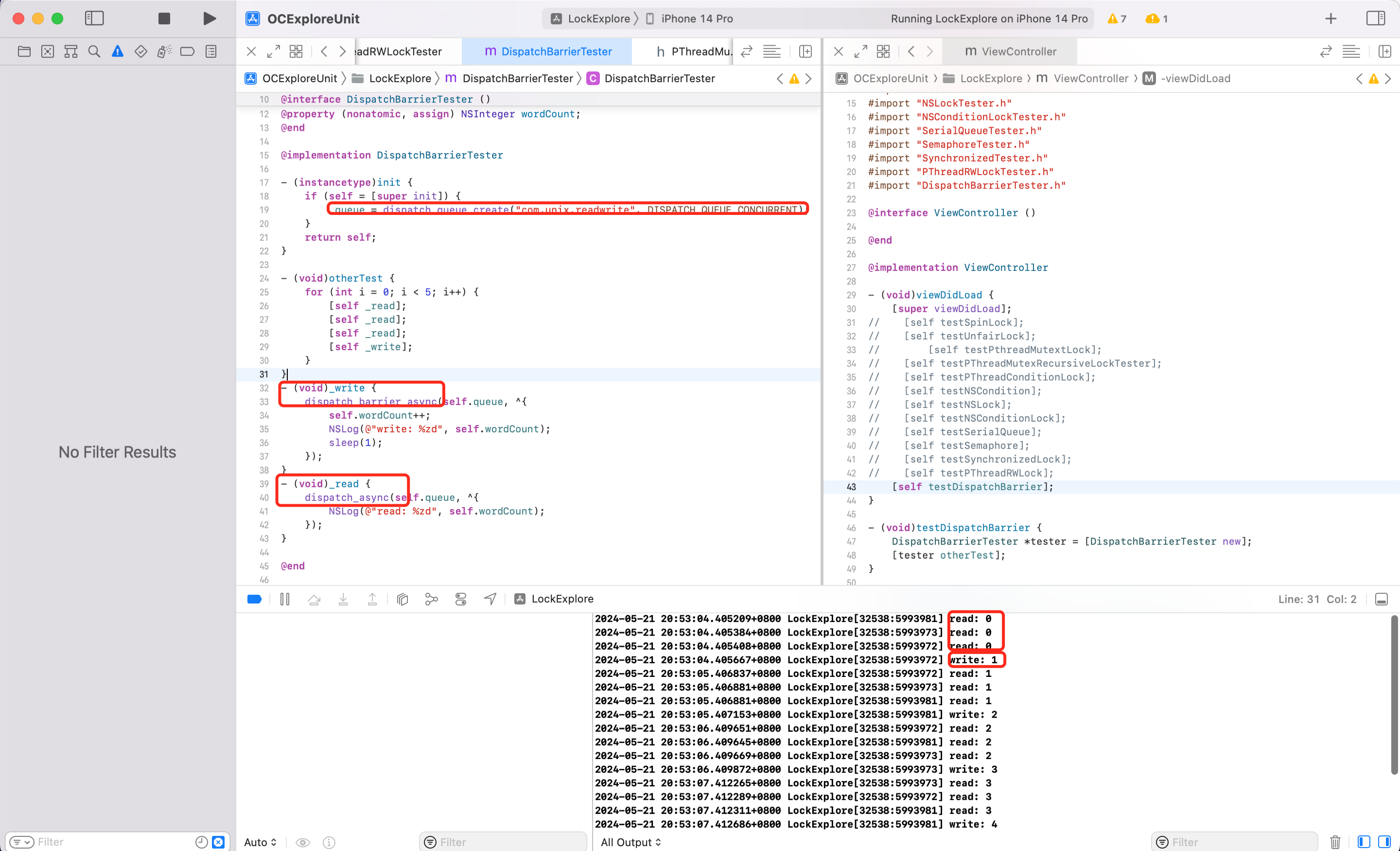
栅栏函数拦不住全局队列
Demo
- (void)testBarrierWithGlobalQueue {
NSLog(@"%s", __func__);
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
for (int i = 0; i < 100; i++) {
dispatch_async(queue, ^() {
NSLog(@"%d", i);
});
}
dispatch_barrier_async(queue, ^() {
NSLog(@"100");
});
dispatch_async(queue, ^() {
NSLog(@"101");
});
NSLog(@"%s", __func__);
}
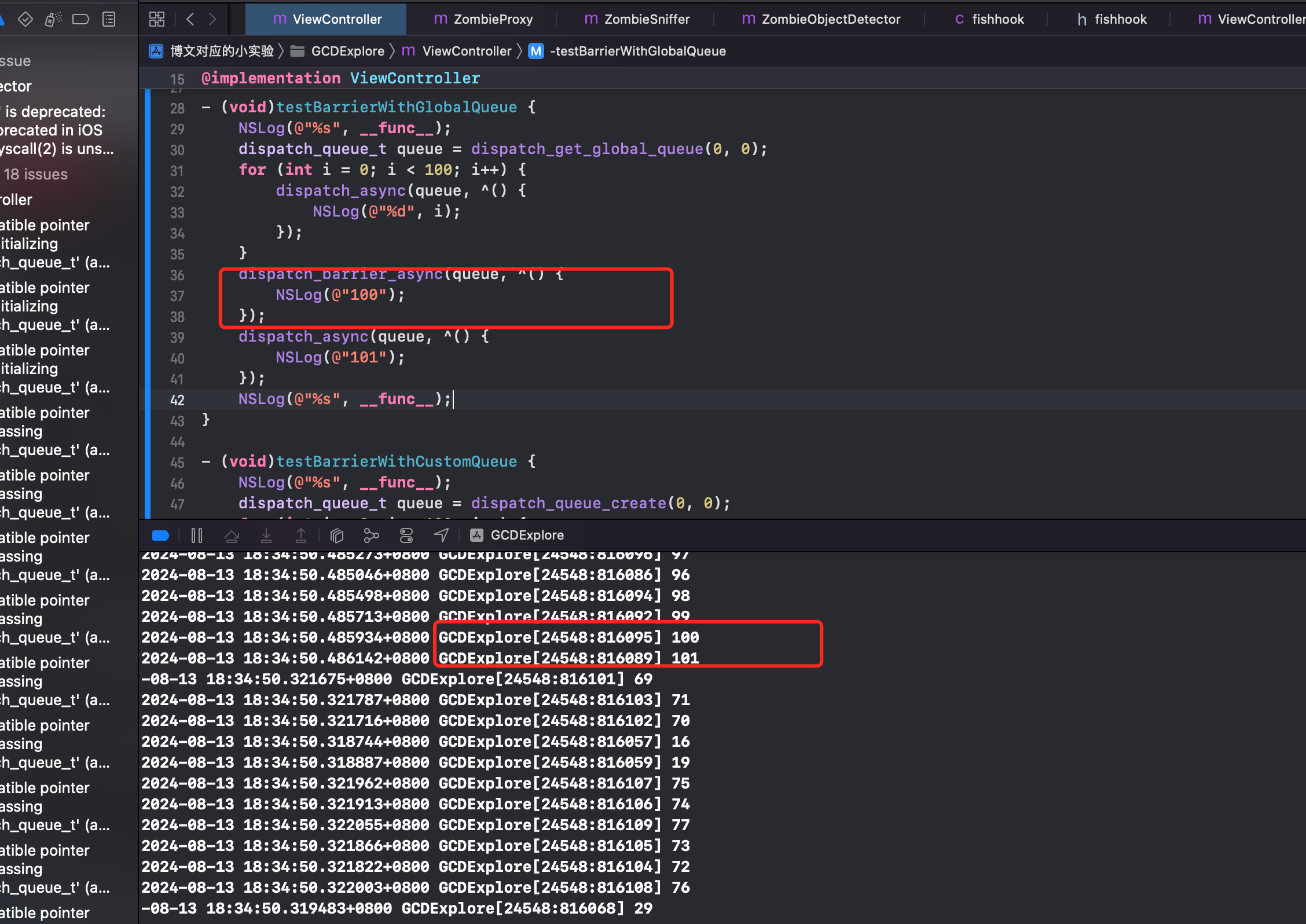
- (void)testBarrierWithCustomQueue {
NSLog(@"%s", __func__);
dispatch_queue_t queue = dispatch_queue_create(0, 0);
for (int i = 0; i < 100; i++) {
dispatch_async(queue, ^() {
NSLog(@"%d", i);
});
}
dispatch_barrier_async(queue, ^() {
NSLog(@"100");
});
dispatch_async(queue, ^() {
NSLog(@"101");
});
NSLog(@"%s", __func__);
}
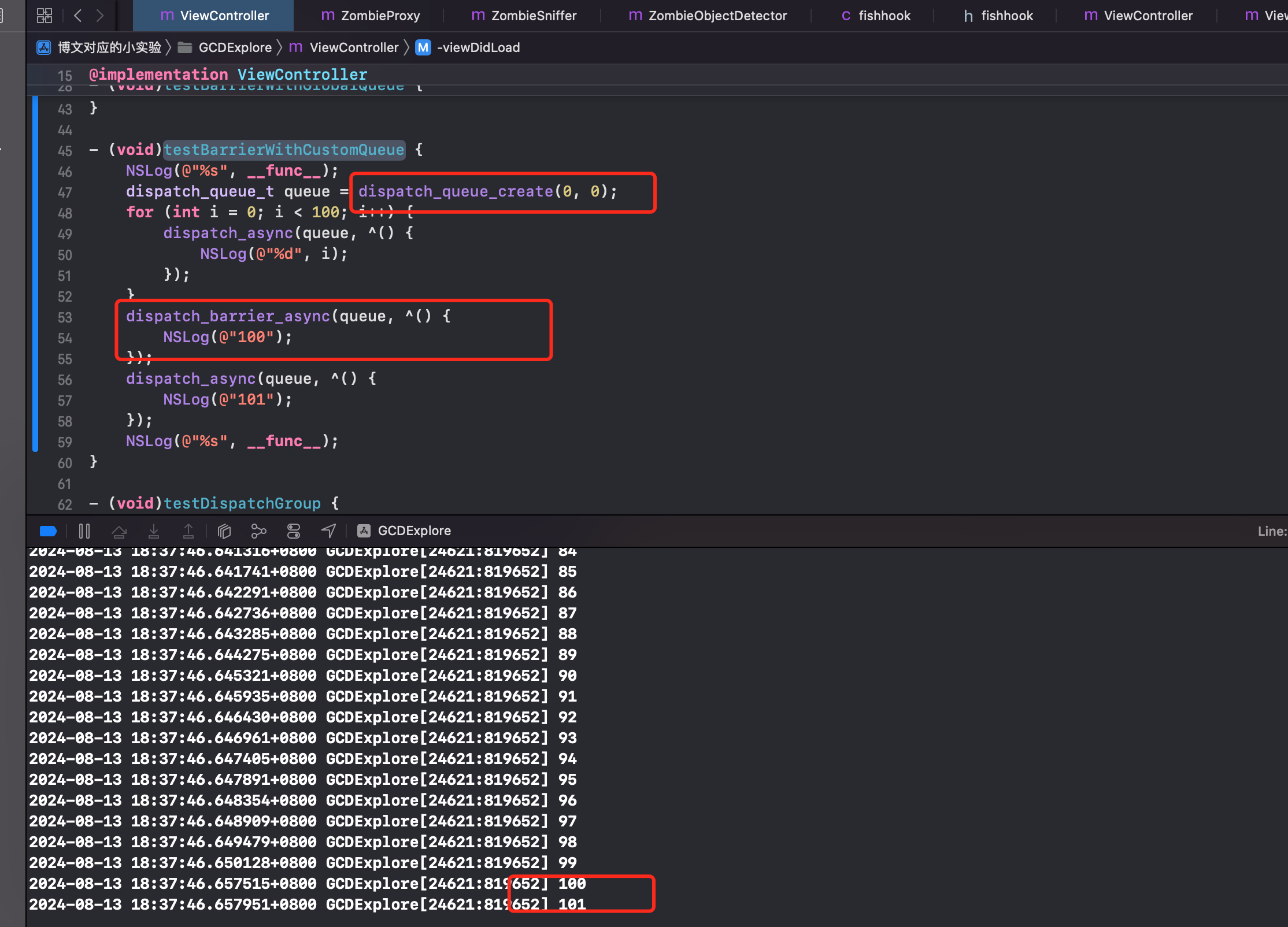
结论:可以发现 GCD 的栅栏函数,拦不住全局队列,却可以拦住普通的队列。这是为什么?
全局队列的业务方不只是当前 App 进程,还有一些系统任务(全局并发队列中不仅有开发者的任务,还有系统的任务),如果我们用我们的任务去栏住系统的任务,可能会导致一些未知的错误。栅栏函数对全局并发队列无效,所以我们在开发的时候一定要注意
dispatch_group_async
如何实现 A、B、C 三个任务并发执行完,再去执行任务 D ?假设需求是根据省市区下载 json,然后根据 json 数据,选中地址 picker view。
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t queue = dispatch_queue_create("com.unix.concurrentQueue", DISPATCH_QUEUE_CONCURRENT);
for (NSURL *url in addressArray) {
dispatch_group_async(group, queue, ^{
// 根据 url 请求 json 数据
});
}
// 会等到上面加入到 group 的3个并发任务全部执行完,再执行下面的 block 任务
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
// 根据下载好的省市区 json 去更新 picker view 。
});
NSOperation
需要和 NSOperationQueue 配合使用。优点:
-
可以添加任务依赖
-
任务执行状态控制
- isReady
- isExecuting
- isFinished
- isCancelled
如果只重写了 main 方法,底层控制变更任务执行完成状态,以及任务退出。
如果重写了 start 方法,自行控制任务状态
-
最大并发量
系统是怎么样移除一个 isFinished = YES 的 NSOperation 的?
看看 GNU 源码。
- (void) start
{
ENTER_POOL
// 获取线程优先级
double prio = [NSThread threadPriority];
AUTORELEASE(RETAIN(self)); // Make sure we exist while running.
[internal->lock lock];
NS_DURING
{
// 做一些状态判断
if (YES == [self isExecuting])
{
[NSException raise: NSInvalidArgumentException
format: @"[%@-%@] called on executing operation",
NSStringFromClass([self class]), NSStringFromSelector(_cmd)];
}
if (YES == [self isFinished])
{
[NSException raise: NSInvalidArgumentException
format: @"[%@-%@] called on finished operation",
NSStringFromClass([self class]), NSStringFromSelector(_cmd)];
}
if (NO == [self isReady])
{
[NSException raise: NSInvalidArgumentException
format: @"[%@-%@] called on operation which is not ready",
NSStringFromClass([self class]), NSStringFromSelector(_cmd)];
}
if (NO == internal->executing)
{
// 如果调用 start 方法,通过 KVO 将 isExecuting 更改为 YES
[self willChangeValueForKey: @"isExecuting"];
internal->executing = YES;
[self didChangeValueForKey: @"isExecuting"];
}
}
NS_HANDLER
{
[internal->lock unlock];
[localException raise];
}
NS_ENDHANDLER
[internal->lock unlock];
NS_DURING
{
if (NO == [self isCancelled])
{
[NSThread setThreadPriority: internal->threadPriority];
// 内部调用 main 方法
[self main];
}
}
NS_HANDLER
{
[NSThread setThreadPriority: prio];
[localException raise];
}
NS_ENDHANDLER;
// 调用完 start,内部调用 finish 方法
[self _finish];
LEAVE_POOL
}
可以看到,内部会调用 _finish 方法
- (void) _finish
{
[internal->lock lock];
if (NO == internal->finished)
{
if (YES == internal->executing)
{
[self willChangeValueForKey: @"isExecuting"];
[self willChangeValueForKey: @"isFinished"];
internal->executing = NO;
internal->finished = YES;
[self didChangeValueForKey: @"isFinished"];
[self didChangeValueForKey: @"isExecuting"];
}
else
{
[self willChangeValueForKey: @"isFinished"];
internal->finished = YES;
[self didChangeValueForKey: @"isFinished"];
}
if (NULL != internal->completionBlock)
{
CALL_BLOCK_NO_ARGS(
((GSOperationCompletionBlock)internal->completionBlock));
}
}
[internal->lock unlock];
}
可以看到在 _finish 方法中,系统通过 KVO 移除 NSOperationQueue 中 NSOperation 的。
NSThread
NSThread 的一个工作流程如下:
start() -> 创建 pthread -> main() -> [target performSelector:selector] -> exit
NSThread 需要保活。为什么会死掉?看看 gnu 源码
- (void) start
{
pthread_attr_t attr;
if (_active == YES)
{
[NSException raise: NSInternalInconsistencyException
format: @"[%@-%@] called on active thread",
NSStringFromClass([self class]),
NSStringFromSelector(_cmd)];
}
if (_cancelled == YES)
{
[NSException raise: NSInternalInconsistencyException
format: @"[%@-%@] called on cancelled thread",
NSStringFromClass([self class]),
NSStringFromSelector(_cmd)];
}
if (_finished == YES)
{
[NSException raise: NSInternalInconsistencyException
format: @"[%@-%@] called on finished thread",
NSStringFromClass([self class]),
NSStringFromSelector(_cmd)];
}
/* Make sure the notification is posted BEFORE the new thread starts.
*/
gnustep_base_thread_callback();
/* The thread must persist until it finishes executing.
*/
RETAIN(self);
/* Mark the thread as active while it's running.
*/
_active = YES;
errno = 0;
pthread_attr_init(&attr);
/* Create this thread detached, because we never use the return state from
* threads.
*/
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
/* Set the stack size when the thread is created. Unlike the old setrlimit
* code, this actually works.
*/
if (_stackSize > 0)
{
pthread_attr_setstacksize(&attr, _stackSize);
}
// 设置回调函数
if (pthread_create(&pthreadID, &attr, nsthreadLauncher, self))
{
DESTROY(self);
[NSException raise: NSInternalInconsistencyException
format: @"Unable to detach thread (last error %@)",
[NSError _last]];
}
}
看看 pthread 创建后的回调函数
static void *
nsthreadLauncher(void *thread)
{
NSThread *t = (NSThread*)thread;
setThreadForCurrentThread(t);
/*
* Let observers know a new thread is starting.
*/
if (nc == nil)
{
nc = RETAIN([NSNotificationCenter defaultCenter]);
}
// 发送通知
[nc postNotificationName: NSThreadDidStartNotification
object: t
userInfo: nil];
// 设置线程名
[t _setName: [t name]];
// 调用 main 方法
[t main];
// 线程退出
[NSThread exit];
// Not reached
return NULL;
}
看了源码,会发现 NSThread 调用 start 内部就会调用 [NSThread exit] 所以会退出。要想常驻,就需要在 main 方法做 runloop 保活。
- (void) main
{
if (_active == NO)
{
[NSException raise: NSInternalInconsistencyException
format: @"[%@-%@] called on inactive thread",
NSStringFromClass([self class]),
NSStringFromSelector(_cmd)];
}
[_target performSelector: _selector withObject: _arg];
}
main 方法内其实就是在执行 _selector。也就是在 NSThread 的初始化方法中,传入的 selector 中进行 runloop 保活逻辑。
其他常见的多线程编程模式
Promise
Promise 在多线程解决方案中比较常见,比如在前端中 Promise 就是一个标准解决方案。同样的,iOS 界也有三方开发者写的 PromiseKit。也有对应的 AFNetworking Promise 版本。
Promise 解决了什么问题?
-
在需要多个操作的时候,我们可能会设置多个回调参数嵌套,导致代码很长,也就是传说中的“回调地狱”(Callback Hell)
-
丧失了 return 特性
Promise 就是一个对象,用来传递异步操作的消息。代表了某个未来才会知道结果的事件(也就是异步操作),并且这个事件提供统一的 API,可以供进一步处理
对象的状态不受外界影响。Promise 对象代表一个异步操作,有三种状态:Pending(进行中,又称 Incomplete)、Resolved(已完成,又称 Fulfilled)和 Rejected (已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是 Promise 这个名字的由来,它的英语意思就是「承诺」,表示其他手段无法改变。
一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从 Pending 变为 Resolved 和从 Pending 变为 Rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果。就算改变已经发生了,你再对 Promise 对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
APIClient.fetchData(...).then().onFailure();
Pipeline
将一个任务分解为若干个阶段(Stage),前阶段的输出为下阶段的输入,各个阶段由不同的工
作者线程负责执行。
各个任务的各个阶段是并行(Parallel)处理的。
具体任务的处理是串行的,即完成一个任务要依次执行各个阶段,但从整体任务上看,不同任务的各个阶段的执行是并行的。
Master-Slave
将一个任务分解为若干个语义等同的子任务,并由专门的工作者线程来并行执行这些子任务,既 提高计算效率,又实现了信息隐藏。
比如 Jekins
Serial Thread Confinement
如果并发任务的执行涉及某个非线程安全对象,而很多时候我们又不希望因此而引入锁。
通过将多个并发的任务存入队列实现任务的串行化,并为这些串行化任务创建唯一的工作者线程进行处理。
比如 FMDB 的设计,内部就是一个串行队列。
总结
- 怎么样实现多读单写?GCD dispatch_barrier_async
- iOS 提供了几种多线程技术
- GCD:简单的任务处理,以及多读单写、读写锁、dispatch_group_async
- NSOperationQueue、NSOperation:AFNetworking、SDWebImage ,可以方便对 Operation 的状态管理和依赖管理
- NSThread,主要用于实现常驻线程
- NSOperation Finished 之后如何移除?KVO