docs: clang 插件开发
@@ -1,9 +1,13 @@
|
||||
# LLVM
|
||||
LLVM
|
||||
|
||||
[LLVM](https://llvm.org/) 项目是模块化、可重用的编译器以及工具链技术的集合
|
||||
|
||||
> The LLVM Project is a collection of modular and reusable compiler and toolchain technologies.
|
||||
|
||||
LLVM 不是 low level virtual machine 的缩写,就是项目名称。
|
||||
|
||||
|
||||
|
||||
## 结构
|
||||
|
||||

|
||||
@@ -14,7 +18,9 @@ LLVM 由三部分构成:
|
||||
|
||||
- Optimizer(优化器):优化中间代码
|
||||
|
||||
- Backend(后端):生成目标程序(机器码)
|
||||
- Backend(后端):生成目标程序(机器码)。比如编写好的 Swift 代码,在编译后端这一步根据在手机上运行,则生成 arm64 的代码,如果运行在 windows 平台上,则生成 x86_64 的代码。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
@@ -26,12 +32,19 @@ LLVM 由三部分构成:
|
||||
|
||||
- 如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
|
||||
|
||||
- 优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
|
||||
- 优化阶段是一个通用的阶段,它针对的是统一的 LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
|
||||
|
||||
- 相比之下,GCC 的前端和后端没分得太开,前端后端耦合在了一起。所以 GCC 为了支持一门新的语言,或者为了支持一个新的目标平台,就变得特别困难
|
||||
|
||||
LLVM 现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC 家族、Java、.NET、Python、Ruby、Scheme、Haskell、D 等)
|
||||
|
||||
|
||||
|
||||
广义上来讲,LLVM 说的是一种架构。狭义上来讲,LLVM 强调的是偏后端部分,如下图的除了 clang 编译前端外的部分,包括优化器和编译后端,统称为 LLVM 后端。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMFullStructure.png" style="zoom:45%">
|
||||
|
||||
- 相比之下,GCC 的前端和后端没分得太开,前端后端耦合在了一起。所以 GCC 为了支持一门新的语言,或者为了支持一个新的目标平台,就
|
||||
变得特别困难
|
||||
|
||||
LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
|
||||
|
||||
## Clang
|
||||
|
||||
@@ -53,36 +66,734 @@ Clang 相较于 GCC,具备下面优点:
|
||||
|
||||

|
||||
|
||||
### 查看编译过程
|
||||
|
||||
|
||||
## 各个编译阶段
|
||||
|
||||
Demo
|
||||
|
||||
```c++
|
||||
#import <stdio.h>
|
||||
#define AGE 29
|
||||
|
||||
int main(int argc, const char * argv[]) {
|
||||
int a = 10;
|
||||
int b = 20;
|
||||
int sum = a + b + AGE;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
查看 `main.m` 的整个编译过程
|
||||
|
||||
```shell
|
||||
clang -ccc-print-phases main.m
|
||||
```
|
||||
|
||||
对 main.m 文件
|
||||
展示如下:
|
||||
|
||||

|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMDisplayPhases.png" style="zoom:45%">
|
||||
|
||||
可以看到经历了:输入、预处理、编译、LLVM Backend、汇编、链接、绑定架构7个阶段。
|
||||
|
||||
查看 preprocessor (预处理)的结果:`clang -E main.m`。预处理主要做的事情就是头文件导入、宏定义替换等。
|
||||
|
||||
词法分析,生成 Token:`clang -fmodules -E -Xclang -dump-tokens main.m`
|
||||
可以看到经历了:**输入、预处理、编译、LLVM Backend、汇编、链接、绑定架构**7个阶段。
|
||||
|
||||
|
||||
|
||||
### 预处理
|
||||
|
||||
查看 preprocessor (预处理)的结果:`clang -E main.m`。预处理主要做的事情就是头文件导入( include、import)、宏定义替换等。展示如下:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMPreProcessorPhase.png" style="zoom:35%">
|
||||
|
||||
|
||||
|
||||
### 词法分析
|
||||
|
||||
词法分析阶段,主要生成 Token。使用指令 `clang -fmodules -E -Xclang -dump-tokens main.m` 查看具体做了什么
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMAnalysize.png" style="zoom:35%">
|
||||
|
||||
|
||||
|
||||
### 语法分析
|
||||
|
||||
语法分析阶段,生成语法树(AST,Abstract Syntax Tree)。使用指令 `clang -fmodules -fsyntax-only -Xclang -ast-dump main.m` 查看
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMASTAnalysis.png" style="zoom:35%">
|
||||
|
||||
对 main.m 的代码进行改造
|
||||
|
||||
```
|
||||
#import <stdio.h>
|
||||
#define AGE 29
|
||||
|
||||
```c
|
||||
#import <Foundation/Foundation.h>
|
||||
int main(int argc, const char * argv[]) {
|
||||
int a = 1;
|
||||
int b =2;
|
||||
int c = a + b;
|
||||
int a = 10;
|
||||
int b = 20;
|
||||
int sum = a + b + AGE;
|
||||
return 0;
|
||||
}
|
||||
|
||||
void test(int a, int b) {
|
||||
int c = a + b - 4;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
再次查看 AST 可以加深理解
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMASTAnalysis2.png" style="zoom:35%">
|
||||
|
||||
其中:
|
||||
|
||||
- `FunctionDecl` 节点下存在2个 `ParamVarDecl` 和1个 `CompoundStmt` 也就是2个参数和1个函数体
|
||||
- 函数体 `CompoundStmt` 内部存在一个变量声明 `VarDecl`
|
||||
- `-`是一个操作符。
|
||||
- 红色框框内的是第一层树形结构。操作符 `-` 有2个参数。首先是最下面的字面量 `IntegerLiteral` 4。另一个就是蓝色框内的运算结果
|
||||
- 蓝色框内操作符 `+` 也有2个 `DeclRefExpr`
|
||||
|
||||
也就是先运算蓝色框内的值,然后用结果和红色框内的进行相减。所以这是很标准的树形结构。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMASTTreeDemo.png" style="zoom:10%">
|
||||
|
||||
语法分析,生成语法树(AST,Abstract Syntax Tree):`clang -fmodules -fsyntax-only -Xclang -ast-dump main.m`
|
||||
|
||||

|
||||
|
||||
### LLVM IR
|
||||
|
||||
IR 作为中间语言具有语言无关的特性,下面是 IR 中与语言无关的类型信息:
|
||||
|
||||
- 语言共有的基础类型(void、bool、signed 等)
|
||||
- 复杂类型,pointer、array、structure、function
|
||||
- 弱类型的支持,用 cast 来实现一种类型到另一种任意类型的转换
|
||||
- 支持地址运算,getelmentptr 指令用于获取结构体子元素,比如 a.b 或 [a b]
|
||||
|
||||
LLVM IR 有3种表示格式:
|
||||
|
||||
- text:便于阅读的文本格式,类似于汇编语言,推展名为 `.ll`。使用指令 `clang -S -emit-llvm main.m` 进行转换
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMIRType1.png" style="zoom:30%">
|
||||
|
||||
学过 arm64 汇编的话看这段 IR 很眼熟,汇编里 `load` 相关的指令都是从内存中装载数据,比如 `ldr`、`ldur` 、`ldp`。`store` 相关的指令是往内存中写入数据,比如 `str`、 `stur`、 `stp`
|
||||
|
||||
一些读 IR 的 tips:
|
||||
|
||||
- 注释以分号 `;` 开头
|
||||
- 全局变量以 `@` 开头
|
||||
- 局部变量以 `%` 开头
|
||||
- `alloca` 在当前函数栈帧中分配内存,为当前执行的函数分配内存,当该函数执行完毕时自动释放内存
|
||||
- `i32`,表示整数占几位,例如 i32 就代表 32 bit,4个字节的意思
|
||||
- `align` 内存对齐。比如单个 int 占4字节,为了对齐,只占1字节的 char 要对齐,就需要占用 4 字节
|
||||
- `store` ,写入数据
|
||||
- `load` ,读取数据
|
||||
- `icmp`,2个整数值比较,返回布尔值
|
||||
- `br`,选择分支,根据条件跳转到对应的 label
|
||||
- `label`,代码标签
|
||||
|
||||
更多的可以参考[官方文档](https://llvm.org/docs/LangRef.html)
|
||||
|
||||
- memory 格式:内存格式
|
||||
|
||||
- bitcode:二进制格式,拓展名为 `.bc`.使用指令 `clang -c -emit-llvm main.m` 进行转换。
|
||||
|
||||
|
||||
|
||||
## 用途
|
||||
|
||||
LLVM 的一些插件,比如 libclang、libTooling,可以查看官方文档:https://clang.llvm.org/docs/Tooling.html,可以做一些**语法树解**
|
||||
|
||||
**析、语言转换**等工作。
|
||||
|
||||
应用场景分为3大类:
|
||||
|
||||
- Clang 插件开发,可以参考官方文档:
|
||||
|
||||
- https://clang.llvm.org/docs/ClangPlugins.html
|
||||
|
||||
- https://clang.llvm.org/docs/RAVFrontendAction.html
|
||||
|
||||
- https://clang.llvm.org/docs/ExternalClangExamples.html
|
||||
|
||||
应用场景是:代码检查(命名规范、代码规范)等。
|
||||
|
||||
- Pass 开发,可以参考官方文档:
|
||||
|
||||
- https://llvm.org/docs/WritingAnLLVMPass.html
|
||||
|
||||
应用场景是:代码优化、代码混淆、精准测试等
|
||||
|
||||
- [libclang](https://clang.llvm.org/doxygen/group__CINDEX.html)、[Clang plugins](https://clang.llvm.org/docs/ClangPlugins.html)、[libTooling](https://clang.llvm.org/docs/LibTooling.html) 做语法树分析,实现语言转换 OC 转 Swift、JS 等其它语言;字符串加密;开发新的语言,例如 Swift 语言。可以参考博客:
|
||||
|
||||
- https://kaleidoscope-llvm-tutorial-zh-cn.readthedocs.io/zh-cn/latest/
|
||||
- https://llvm-tutorial-cn.readthedocs.io/en/latest/index.html
|
||||
|
||||
|
||||
|
||||
其中:
|
||||
|
||||
libclang 供了一个相对较小的 API,它将用于解析源代码的工具暴露给抽象语法树(AST),加载已经解析的 AST,遍历 AST,将物理源位置与 AST 内的元素相关联。
|
||||
|
||||
libclang 是一个稳定的高级 C 语言接口,隔离了编译器底层的复杂设计,拥有更强的 Clang 版本兼容性,以及更好的多语言支持能力,对于大多数分析 AST 的场景来说,libclang 是一个很好入手的选择。
|
||||
|
||||
##### 优点
|
||||
|
||||
1. 可以使用 C++ 之外的语言与 Clang 交互。
|
||||
2. 稳定的交互接口和向后兼容。
|
||||
3. 强大的高级抽象,比如用光标迭代 AST,并且不用学习 Clang AST 的所有细节。
|
||||
|
||||
##### 缺点:不能完全控制 Clang AST。
|
||||
|
||||
|
||||
|
||||
Clang Plugin 允许你在编译过程中对 AST 执行其他操作。Clang Plugin 是动态库,由编译器在运行时加载,并且它们很容易集成到构建环境中。
|
||||
|
||||
|
||||
|
||||
LibTooling 是一个独立的库,它允许使用者很方便地搭建属于你自己的编译器前端工具,它的优点与缺点一样明显,它基于 C++ 接口,读起来晦涩难懂,但是提供给使用者远比 libclang 强大全面的 AST 解析和控制能力,同时由于它与 Clang 的内核过于接近导致它的版本兼容能力比 libclang 差得多,Clang 的变动很容易影响到 LibTooling。libTooling 还提供了完整的参数解析方案,可以很方便的构建一个独立的命令行工具。这是 libclang 所不具备的能力。一般来说,如果你只需要语法分析或者做代码补全这类功能,libclang 将是你避免掉坑的最佳的选择。
|
||||
|
||||
|
||||
|
||||
### 编写 Xcode 插件
|
||||
|
||||
比如检查类名的合法性,Xcode 默认认为类名带有下划线或者小写开头的类名是合法的。但是这个不符合团队代码规范,使用 LLVM 就可以编写 Xcode 插件,来检查类名的合法性。
|
||||
|
||||
判断类名是否合法,这肯定是编译前端做的事情。搞清楚这点,就好办了
|
||||
|
||||
接下来就一步步实现该功能。
|
||||
|
||||
|
||||
|
||||
#### 下载
|
||||
|
||||
创建文件夹 `llvm_explore` ,shell 进入到文件夹执行指令 `git clone https://github.com/llvm/llvm-project.git`
|
||||
|
||||
|
||||
|
||||
#### 编译
|
||||
|
||||
用 brew 安装 cmake 和 ninja:`brew install cmake` 、`brew install ninja`
|
||||
|
||||
Tips:ninja 如果安装失败,可以直接从 [github]( https://github.com/ninja-build/ninja/releases) 获取 release 版放入`/usr/local/bin`中
|
||||
|
||||
|
||||
|
||||
编译方式有2种:
|
||||
|
||||
- ninja 编译
|
||||
|
||||
在 LLVM 源码同层目录下创建一个 `llvm_build` 目录,最终会在 `llvm_build` 目录下生成 `build.ninja`
|
||||
|
||||
```shell
|
||||
cd llvm_build
|
||||
cmake -G Ninja ../llvm -DCMAKE_INSTALL_PREFIX=LLVM的安装路径
|
||||
```
|
||||
|
||||
然后执行编译指令,使用 `ninja`
|
||||
|
||||
再执行安装指令,使用 `ninja install`
|
||||
|
||||
- Xcode 编译
|
||||
|
||||
在 LLVM 源码同层目录下创建一个 `llvm_xcode_build` 目录
|
||||
|
||||
```shell
|
||||
mkdir llvm_xcode_build
|
||||
cd llvm_xcode_build
|
||||
cmake -S ../../llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"
|
||||
```
|
||||
|
||||
|
||||
因为要编写 Clang 插件,是 c++ 代码,所以需要借助 IDE 的能力,我们选用 Xcode 进行编译。如下图所示,代表编译成功
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMComplieXcode1.png" style="zoom:20%">
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMComplieXcode2.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### LLVM 角色说明
|
||||
|
||||
- LLVM Core:包含一个现在的源代码/目标设备无关的优化器,一集一个针对很多主流(甚至于一些非主流)的 CPU 的汇编代码生成支持。
|
||||
- Clang:一个 C/C++/Objective-C 编译器,致力于提供令人惊讶的快速编译,极其有用的错误和警告信息,提供一个可用于构建很棒的源代码级别的工具
|
||||
- dragonegg: gcc 插件,可将 GCC 的优化和代码生成器替换为 LLVM 的相应工具。
|
||||
- LLDB:基于 LLVM 提供的库和 Clang 构建的优秀的本地调试器。
|
||||
- libc++、libc++ ABI:符合标准的,高性能的 C++ 标准库实现,以及对 C++11 的完整支持
|
||||
- compiler-rt:针对 __fixunsdfdi 和其他目标机器上没有一个核心 IR(intermediate representation) 对应的短原生指令序列时,提供高度调优过的底层代码生成支持
|
||||
- OpenMP:Clang 中对多平台并行编程的 runtime 支持
|
||||
- vmkit:基于 LLVM 的 Java 和 .NET 虚拟机
|
||||
- polly: 支持高级别的循环和数据本地化优化支持的 LLVM 框架。
|
||||
- libclc: OpenCL 标准库的实现
|
||||
- klee:基于L LVM 编译基础设施的符号化虚拟机
|
||||
- SAFECode:内存安全的 C/C++ 编译器
|
||||
- lld: clang/llvm 内置的链接器
|
||||
|
||||
|
||||
|
||||
#### 添加插件目录
|
||||
|
||||
进入目录 `/Users/unix_kernel/Desktop/LLVM_Explore/llvm-project/clang/tools`:
|
||||
|
||||
- 先创建一个插件文件夹 `code-style-validate-plugin`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMAddConfiguration1.png" style="zoom:20%">
|
||||
|
||||
- 编辑 `CMakeLists.txt` 文件,在最后添加 `add_clang_subdirectory(code-style-validate-plugin)`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMAddConfiguration2.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### 配置插件
|
||||
|
||||
在上一步创建的 `code-style-validate-plugin` 文件夹下:
|
||||
|
||||
- 创建插件代码文件 `CodeStyleValidatePlugin.cpp`
|
||||
|
||||
- 创建 `CMakeLists.txt` ,添加配置代码,其中 `FANPlugin` 是插件名,CodeStyleValidatePlugin 是插件源码文件名
|
||||
|
||||
```shell
|
||||
add_llvm_library(CodeStyleValidatePlugin MODULE BUILDTREE_ONLY
|
||||
CodeStyleValidatePlugin.cpp
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
由于新做了配置,并且要开发 `CodeStyleValidatePlugin.cpp` ,所以重新生成 `cmake -S ../../llvm-project/llvm -B ./ -G Xcode -DLLVM_ENABLE_PROJECTS="clang"`
|
||||
|
||||
|
||||
|
||||
#### 编写插件代码
|
||||
|
||||
Xcode 打开项目,选择自动创建 Schemes
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeOpenLLVMProject.png" style="zoom:30%">
|
||||
|
||||
选择 Target 为 `CodeStyleValidatePlugin`,源代码所在文件夹为 `Sources/Loadable modules`,然后选中 CodeStyleValidatePlugin.cpp` 文件进行编写逻辑
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClangPluginSourceCode.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
初步编写后 Command + B 进行编译,在 Products 下可以看到编译产物:`CodeStyleValidatePlugin.dylib` 动态库。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClangCompileProducts.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### 编译 clang/clang++
|
||||
|
||||
此步骤前需要做一步编译 Clang 的动作。Xcode 打开 LLVM 项目,选中 `ALL_BUILD` target,进行编译,此过程耗时较长(1h+)
|
||||
|
||||
此步骤的目的是:在 testLLVM 项目中,加载 `CodeStyleValidatePlugin.dylib` 插件可以成功。因为默认的 Xcode 使用的 clang/clang++ 编译器和编译 `CodeStyleValidatePlugin.dylib` 动态库不是一个版本。不做修改的话,Xcode 加载 `CodeStyleValidatePlugin.dylib` 会报错。所以需要先编译出同一个 LLVM 版本的 clang/clang++。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeCompileClang.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### Xcode 加载插件
|
||||
|
||||
新建一个名字叫做 ` TestLLVM` 的 Xcode 项目。要在 Xcode 中加载指定的动态库,需要修改 Build Settings 配置,操作路径为:`Build Settings -> Other C Flags`。
|
||||
|
||||
添加:
|
||||
|
||||
- `-Xclang`
|
||||
- `-load`
|
||||
- `-Xclang`
|
||||
- 动态库路径
|
||||
- `-Xclang`
|
||||
- `-add-plugin`
|
||||
- `-Xclang`
|
||||
- 插件名称
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeLoadPlugin.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### 设置编译器
|
||||
|
||||
在新创建的 TestLLVM Xcode 项目中加载创建的 `CodeStyleValidatePlugin.dylib` 会报错。原因是:由于 Clang 插件需要使用对应的版本去加载,如果版本不一致则会导致编译错误。如下所示:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeLoadClangPluginError.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
解决方案是在 Build Setiings 中增加2项用户自定义的设置:
|
||||
|
||||
- `CC`:对应的是自己编译的 clang 的绝对路径
|
||||
|
||||
- `CXX`:对应的是自己编译的 clang++ 绝对路径
|
||||
|
||||
如下所示:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeSpecifyClangPath.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
继续编译还是会报错,报错如下:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeLoadClangPluginError2.png" style="zoom:20%">
|
||||
|
||||
解决方案为:在 `Build Settings` 栏目中搜索 `index`,将 `Enable Index-Wihle-Building Functionality` 的 ` Default` 改为 `NO`。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeLoadClangThenBuildErrorFix.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### 编译插件,验证正确性
|
||||
|
||||
编译项目后,会在编译日志看到 `FANPlugin` 插件的打印信息,说明前面的配置没有问题,接下去就是继续编写 `FANPlugin.cpp` 的逻辑代码,继续验证。
|
||||
|
||||
Tips: 由于重新修改了插件的源码,所以每次 Build 构建完 FANPlugin 之后,在 `TestLLVM` Xcode 项目中,最好每次都执行一下 Clean 操作。
|
||||
|
||||
编译成功,可以看到在日志中输出了我们编写的日志信息。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeLoadClangPluginTest.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
#### Clang 插件编写说明
|
||||
|
||||
- `AnalysisConsumer`:`AnalysisConsumer` 是 clang AST 中做实事儿的接口,根据具体情况 `ASTFrontendAction` 可能对应一个或多个 `AnalysisConsumer`
|
||||
- `RecursiveASTVisitor` & `StmtVisitor`:`RecursiveASTVisitor `是顶层的遍历 clang AST 的工具,虽然也能处理 `stmt` 级别的处理,但是终归没有 `StmtVisitor` 用的顺手
|
||||
- `PluginASTAction`:clang 插件的关键组件之一。通过 PluginASTAction,可以在编译过程中运行额外的用户定义操作。这个类允许创建 AST 消费者对象,并处理插件命令行参数,以便根据需要执行特定操作。您可以通过实现 `ParseArgs` 方法来处理插件的命令行选项,以及通过覆盖 `getActionType` 方法来确定插件的执行时机,例如在主要操作之前或之后执行。这样的灵活性使得开发人员能够根据需求定制 clang 插件的行为
|
||||
- `ASTConsumer` :用于处理抽象语法树(AST)的重要组件。ASTConsumer 负责遍历和处理由 clang 前端生成的 AST 节点,执行特定的操作或分析。通过实现 ASTConsumer,开发人员可以访问和处理 AST 中的各种节点,例如函数、变量声明、表达式等,以便进行静态分析、代码转换或其他编译器任务
|
||||
- `MatchFinder`:提供类似 DSL 的方式用于匹配 AST 节点,用于做进一步的检验,获取节点来做判断或者进一步的处理。
|
||||
- `MatchFinder::MatchCallback`:用于在 MatchFinder 中处理匹配结果的回调函数。当 MatchFinder 在抽象语法树(AST)中找到与匹配器描述的模式相匹配的节点时,会调用注册的 MatchCallback 来处理这些匹配结果。MatchCallback 通常包含一些虚拟方法,如 `run()`、`onStartOfTranslationUnit()`、`onEndOfTranslationUnit()` 等,开发人员可以根据需要重写这些方法来实现自定义的处理逻辑。例如,在 `run()` 方法中处理每个匹配结果,在 `onStartOfTranslationUnit()` 方法中处理每个翻译单元的开始,在 `onEndOfTranslationUnit()` 方法中处理每个翻译单元的结束。
|
||||
|
||||
|
||||
|
||||
#### 继续完善代码
|
||||
|
||||
类名不符合规范的情况。
|
||||
|
||||
```objective-c
|
||||
#import <Foundation/Foundation.h>
|
||||
|
||||
NS_ASSUME_NONNULL_BEGIN
|
||||
|
||||
@interface workaholic_person : NSObject
|
||||
|
||||
@end
|
||||
|
||||
NS_ASSUME_NONNULL_END
|
||||
```
|
||||
|
||||
利用 Clang 查看 AST 指令为 `clang -fmodules -fsyntax-only -Xclang -ast-dump workaholic_person.m`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClassNameViaClangAST.png" style="zoom:20%">
|
||||
|
||||
核心思路为:我们要分析类名不符合规范的情况,要精确报错,首先要识别到类名,利用 AST 的能力可以办到(类名在 AST 的 `ObjCInterfaceDecl` 节点上)。然后获取到类名的行号信息,精确报错。
|
||||
|
||||
步骤为:
|
||||
|
||||
- 注册插件,需要指定 Action 是什么。这里我们指定自定义的继承自 `PluginASTAction` 的 `PluginASTAction`
|
||||
- Action 内部会调用 `CreateASTConsumer` 方法,所以需要创建一个继承自 `ASTConsumer` 的 consumer,即 ·`FANCounsumer`
|
||||
- Consumer 在 Xcode 解析完 AST 后会调用 `HandleTranslationUnit` 方法,`HandleTranslationUnit` 方法的参数是一个类行为 `ASTContext` 的对象,携带了 AST 的全部信息
|
||||
- 然后创建一个 `MatchFinder ` 对象。在构造器里指定 Macther 找什么 `matcher.addMatcher(objcInterfaceDecl().bind("ObjCInterfaceDecl"), &handler)`,以及找到后做什么事情,将找到后的逻辑交给了一个 CallBack,即 `handler` 的 `void run(const MatchFinder::MatchResult &Result)` 方法
|
||||
- `size_t pos = decl->getName().find('_')` 用来找类名中有没有下划线 `_`。
|
||||
- `pos != StringRef::npos` 不等于 `StringRef::npos` 则说明找到了下划线,则执行括号里面的逻辑
|
||||
- `DiagnosticsEngine &D = ci.getDiagnostics()` 对象具有报错能力,`D.Report()`
|
||||
- 为了精确报错,需要找到具体的位置信息 `SourceLocation loc = decl->getLocation().getLocWithOffset(pos)`
|
||||
|
||||
|
||||
|
||||
完整代码
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include "clang/AST/AST.h"
|
||||
#include "clang/AST/ASTConsumer.h"
|
||||
#include "clang/ASTMatchers/ASTMatchers.h"
|
||||
#include "clang/ASTMatchers/ASTMatchFinder.h"
|
||||
#include "clang/Frontend/CompilerInstance.h"
|
||||
#include "clang/Frontend/FrontendPluginRegistry.h"
|
||||
|
||||
#include <iostream>
|
||||
#include <string>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace clang;
|
||||
using namespace std;
|
||||
using namespace llvm;
|
||||
using namespace clang::ast_matchers;
|
||||
|
||||
namespace CodeStyleValidatePlugin {
|
||||
// 自定义 handler
|
||||
class CodeStyleValidateHandler : public MatchFinder::MatchCallback {
|
||||
private:
|
||||
CompilerInstance &ci; // 编译器实例
|
||||
|
||||
// 判断是否为开发者写的代码
|
||||
bool isDeveloperSourceCode (string filename) {
|
||||
if (filename.empty())
|
||||
return false;
|
||||
if(filename.find("/Applications/Xcode.app/") == 0)
|
||||
return false;
|
||||
return true;
|
||||
}
|
||||
|
||||
// 检测类名
|
||||
void validateInterfaceDeclaration(const ObjCInterfaceDecl *decl) {
|
||||
StringRef className = decl->getName();
|
||||
|
||||
// 判断首字母不能以小写开头
|
||||
char c = className[0];
|
||||
if (isLowercase(c)) {
|
||||
std::string tempName = decl->getNameAsString();
|
||||
tempName[0] = toUppercase(c);
|
||||
StringRef replacement(tempName);
|
||||
SourceLocation nameStart = decl->getLocation();
|
||||
SourceLocation nameEnd = nameStart.getLocWithOffset(static_cast<int32_t>(className.size() - 1));
|
||||
FixItHint fixItHint = FixItHint::CreateReplacement(SourceRange(nameStart, nameEnd), replacement);
|
||||
|
||||
//报告警告
|
||||
SourceLocation location = decl->getLocation();
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:Class 名不能以小写字母开头 ⚠️", &fixItHint);
|
||||
}
|
||||
|
||||
// 判断下划线不能在类名有没有包含下划线
|
||||
size_t pos = decl->getName().find('_');
|
||||
if (pos != StringRef::npos) {
|
||||
std::string tempName = decl->getNameAsString();
|
||||
std::string::iterator end_pos = std::remove(tempName.begin(), tempName.end(), '_');
|
||||
tempName.erase(end_pos, tempName.end());
|
||||
StringRef replacement(tempName);
|
||||
SourceLocation nameStart = decl->getLocation();
|
||||
SourceLocation nameEnd = nameStart.getLocWithOffset(static_cast<int32_t>(className.size() - 1));
|
||||
FixItHint fixItHint = FixItHint::CreateReplacement(SourceRange(nameStart, nameEnd), replacement);
|
||||
|
||||
//报告警告
|
||||
SourceLocation loc = decl->getLocation().getLocWithOffset(static_cast<int32_t>(pos));
|
||||
showWaringReport(loc, "☠️ 杭城小刘提示你:Class 名中不能带有下划线 ⚠️", &fixItHint);
|
||||
}
|
||||
}
|
||||
|
||||
// 检测属性
|
||||
void validatePropertyDeclaration(const clang::ObjCPropertyDecl *propertyDecl) {
|
||||
|
||||
StringRef name = propertyDecl -> getName();
|
||||
// 名称必须以小写字母开头
|
||||
bool checkUppercaseNameIndex = 0;
|
||||
if (name.find('_') == 0) {
|
||||
// 以下划线开头则首字母位置变为1
|
||||
checkUppercaseNameIndex = 1;
|
||||
}
|
||||
char c = name[checkUppercaseNameIndex];
|
||||
if (isUppercase(c)) {
|
||||
// 修正提示
|
||||
std::string tempName = name.str();
|
||||
tempName[checkUppercaseNameIndex] = toLowercase(c);
|
||||
StringRef replacement(tempName);
|
||||
SourceLocation nameStart = propertyDecl->getLocation();
|
||||
SourceLocation nameEnd = nameStart.getLocWithOffset(static_cast<int32_t>(name.size() - 1));
|
||||
FixItHint fixItHint = FixItHint::CreateReplacement(SourceRange(nameStart, nameEnd), replacement);
|
||||
SourceLocation location = propertyDecl->getLocation();
|
||||
// 报告警告
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:@property 名称必须以小写字母开头 ⚠️", &fixItHint);
|
||||
}
|
||||
|
||||
// 检测属性
|
||||
if (propertyDecl->getTypeSourceInfo()) {
|
||||
ObjCPropertyAttribute::Kind attrKind = propertyDecl->getPropertyAttributes();
|
||||
SourceLocation location = propertyDecl->getLocation();
|
||||
string typeStr = propertyDecl->getType().getAsString();
|
||||
|
||||
// 判断string需要使用copy
|
||||
if ((typeStr.find("NSString")!=string::npos)&& !(attrKind & ObjCPropertyAttribute::Kind::kind_copy)) {
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:NSString 建议使用 copy 代替 strong ⚠️", NULL);
|
||||
}
|
||||
|
||||
// 判断int需要使用NSInteger
|
||||
if(!typeStr.compare("int")){
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:建议使用 NSInteger 替换 int ⚠️", NULL);
|
||||
}
|
||||
// 判断delegat使用weak
|
||||
if ((typeStr.find("<")!=string::npos && typeStr.find(">")!=string::npos) && (typeStr.find("Array")==string::npos) && !(attrKind & ObjCPropertyAttribute::Kind::kind_weak)) {
|
||||
showErrorReport(location, "☠️ 杭城小刘提示你:建议使用 weak 定义 Delegate ⚠️", NULL);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 检测方法
|
||||
void validateMethodDeclaration(const clang::ObjCMethodDecl *methodDecl) {
|
||||
// 检查名称的每部分,都不允许以大写字母开头
|
||||
Selector sel = methodDecl -> getSelector();
|
||||
int selectorPartCount = methodDecl -> getNumSelectorLocs();
|
||||
for (int i = 0; i < selectorPartCount; i++) {
|
||||
StringRef selName = sel.getNameForSlot(i);
|
||||
char c = selName[0];
|
||||
if (isUppercase(c)) {
|
||||
// 修正提示
|
||||
std::string tempName = selName.str();
|
||||
tempName[0] = toLowercase(c);
|
||||
StringRef replacement(tempName);
|
||||
SourceLocation nameStart = methodDecl -> getSelectorLoc(i);
|
||||
SourceLocation nameEnd = nameStart.getLocWithOffset(static_cast<int32_t>(selName.size() - 1));
|
||||
FixItHint fixItHint = FixItHint::CreateReplacement(SourceRange(nameStart, nameEnd), replacement);
|
||||
|
||||
// 报告警告
|
||||
SourceLocation location = methodDecl->getLocation();
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:方法名要以小写开头 ⚠️", &fixItHint);
|
||||
}
|
||||
}
|
||||
|
||||
// 检测方法中定义的参数名称是否存在大写开头
|
||||
for (ObjCMethodDecl::param_const_iterator it = methodDecl->param_begin(); it != methodDecl->param_end(); it++) {
|
||||
const ParmVarDecl *parmVarDecl = *it;
|
||||
StringRef name = parmVarDecl -> getName();
|
||||
char c = name[0];
|
||||
if (isUppercase(c)) {
|
||||
// 修正提示
|
||||
std::string tempName = name.str();
|
||||
tempName[0] = toLowercase(c);
|
||||
StringRef replacement(tempName);
|
||||
SourceLocation nameStart = parmVarDecl -> getLocation();
|
||||
SourceLocation nameEnd = nameStart.getLocWithOffset(static_cast<int32_t>(name.size() - 1));
|
||||
FixItHint fixItHint = FixItHint::CreateReplacement(SourceRange(nameStart, nameEnd), replacement);
|
||||
|
||||
//报告警告
|
||||
SourceLocation location = methodDecl->getLocation();
|
||||
showWaringReport(location, "☠️ 杭城小刘提示你:参数名称要小写开头 ⚠️", &fixItHint);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
template <unsigned N>
|
||||
/// 抛出警告
|
||||
/// @param Loc 位置
|
||||
/// @param Hint 修改提示
|
||||
void showWaringReport(SourceLocation Loc, const char (&FormatString)[N], FixItHint *Hint) {
|
||||
DiagnosticsEngine &diagEngine = ci.getDiagnostics();
|
||||
unsigned DiagID = diagEngine.getCustomDiagID(clang::DiagnosticsEngine::Warning, FormatString);
|
||||
(Hint!=NULL) ? diagEngine.Report(Loc, DiagID) << *Hint : diagEngine.Report(Loc, DiagID);
|
||||
}
|
||||
|
||||
template <unsigned N>
|
||||
/// 抛出错误
|
||||
/// @param Loc 位置
|
||||
/// @param Hint 修改提示
|
||||
void showErrorReport(SourceLocation Loc, const char (&FormatString)[N], FixItHint *Hint) {
|
||||
DiagnosticsEngine &diagEngine = ci.getDiagnostics();
|
||||
unsigned DiagID = diagEngine.getCustomDiagID(clang::DiagnosticsEngine::Error, FormatString);
|
||||
(Hint!=NULL) ? diagEngine.Report(Loc, DiagID) << *Hint : diagEngine.Report(Loc, DiagID);
|
||||
}
|
||||
|
||||
public:
|
||||
CodeStyleValidateHandler(CompilerInstance &ci) :ci(ci) {}
|
||||
|
||||
// 主要方法,分配 类、方法、属性 做不同处理
|
||||
void run(const MatchFinder::MatchResult &Result) override {
|
||||
if (const ObjCInterfaceDecl *interfaceDecl = Result.Nodes.getNodeAs<ObjCInterfaceDecl>("ObjCInterfaceDecl")) {
|
||||
string filename = ci.getSourceManager().getFilename(interfaceDecl->getSourceRange().getBegin()).str();
|
||||
if(isDeveloperSourceCode(filename)){
|
||||
std::string tempName = interfaceDecl->getNameAsString();
|
||||
cout << "ObjCInterfaceDecl" + tempName << endl;
|
||||
// 类的检测
|
||||
validateInterfaceDeclaration(interfaceDecl);
|
||||
}
|
||||
}
|
||||
|
||||
if (const ObjCPropertyDecl *propertyDecl = Result.Nodes.getNodeAs<ObjCPropertyDecl>("ObjcPropertyDecl")) {
|
||||
string filename = ci.getSourceManager().getFilename(propertyDecl->getSourceRange().getBegin()).str();
|
||||
if(isDeveloperSourceCode(filename)) {
|
||||
std::string tempName = propertyDecl->getNameAsString();
|
||||
cout << "ObjcPropertyDecl" + tempName << endl;
|
||||
// 属性的检测
|
||||
validatePropertyDeclaration(propertyDecl);
|
||||
}
|
||||
}
|
||||
|
||||
if (const ObjCMethodDecl *methodDecl = Result.Nodes.getNodeAs<ObjCMethodDecl>("ObjCMethodDecl")) {
|
||||
string filename = ci.getSourceManager().getFilename(methodDecl->getSourceRange().getBegin()).str();
|
||||
if(isDeveloperSourceCode(filename)) {
|
||||
std::string tempName = methodDecl->getNameAsString();
|
||||
cout << "ObjcMethodDecl" + tempName << endl;
|
||||
// 方法的检测
|
||||
validateMethodDeclaration(methodDecl);
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
// 自定义的处理工具
|
||||
class CodeStyleValidateASTConsumer: public ASTConsumer {
|
||||
private:
|
||||
MatchFinder matcher;
|
||||
CodeStyleValidateHandler handler;
|
||||
public:
|
||||
//调用CreateASTConsumer方法后就会加载Consumer里面的方法
|
||||
CodeStyleValidateASTConsumer(CompilerInstance &ci) :handler(ci) {
|
||||
matcher.addMatcher(objcInterfaceDecl().bind("ObjCInterfaceDecl"), &handler);
|
||||
matcher.addMatcher(objcMethodDecl().bind("ObjCMethodDecl"), &handler);
|
||||
matcher.addMatcher(objcPropertyDecl().bind("ObjcPropertyDecl"), &handler);
|
||||
}
|
||||
|
||||
// 遍历完一次语法树就会调用一次下面方法。该方法通常被用来处理整个翻译单元的 AST,进行进一步的分析、处理或者其他操作。在处理完整个 AST 后,开发者可以在这个方法中执行他们需要的操作,比如生成代码、执行静态分析、进行重构等。
|
||||
void HandleTranslationUnit(ASTContext &context) override {
|
||||
matcher.matchAST(context);
|
||||
}
|
||||
};
|
||||
|
||||
// 入口,解析 AST 后的动作
|
||||
class ValidateCodeStyleAction: public PluginASTAction {
|
||||
std::set<std::string> ParsedTemplates;
|
||||
public:
|
||||
// 需要返回一个 Consumer,所以继续创建一个继承自 ASTConsumer 的 Consumer
|
||||
unique_ptr<ASTConsumer> CreateASTConsumer(CompilerInstance &ci, StringRef iFile) override {
|
||||
return unique_ptr<CodeStyleValidateASTConsumer> (new CodeStyleValidateASTConsumer(ci));//使用自定义的处理工具
|
||||
}
|
||||
|
||||
bool ParseArgs(const CompilerInstance &ci, const std::vector<std::string> &args) override {
|
||||
return true;
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
// 注册插件,告诉 LLVM 插件对应的 Action 是 FANAction
|
||||
static FrontendPluginRegistry::Add<CodeStyleValidatePlugin::ValidateCodeStyleAction>
|
||||
X("CodeStyleValidatePlugin", "This plugin is designed for scanning code styles, powered by @FantasticLBP");
|
||||
```
|
||||
|
||||
效果如下:
|
||||
|
||||
- 可以对类名检测,如果带下划线,则报错提示并给出修改意见
|
||||
- 可以对 Category 名做检测,如果带下划线,则报错提示并给出修改意见
|
||||
- 编写的 `CodeStyleValidatePlugin` Demo 中对不符合规范的做了 `DiagnosticsEngine::Warning` 级别的警告。如果遇到1个警告则不影响,继续编译。如果是 `DiagnosticsEngine::Error` 级别的编译报错,遇到1个则终止编译,请注意该区别,按需编写自己的插件逻辑。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLVMClangPluginUseInXcode.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 有没有其他方式?
|
||||
|
||||
利用 LLVM 编译前端 Clang + AST 的能力可以解决大多数编译器相关的问题,但是过程可能较为复杂。还有个思路是利用脚本能力,各种脚本语言,比如 Python、Node 都具备 `glob` 模块。`glob` 可以快速匹配并实现字符串的查找能力。
|
||||
|
||||
利用关键词 `@interface 类名 : 父类名` 的特点,找到到所有的类名,判断类名带有 "_",然后将类名保存起来,最后输出有问题的类信息。
|
||||
|
||||
|
||||
|
||||
### 检查 Category 中重名的方法
|
||||
|
||||
- 使用开源库 [LIEF](https://github.com/lief-project/LIEF) 的能力
|
||||
- 脚本 Python、Node glob 模块的快速匹配能力
|
||||
- 添加 Xcode 环境变量 `OBJC_PRINT_REPLACED_METHODS`,运行时候会打印出来
|
||||
- 使用 LLVM 编写 Clang 插件,解析 AST 拿到所有的 `ObjCInterfaceDecl` 信息,然后结合 `ObjCMethodDecl` 信息便可获取 Category 中的 所有方法,再判断方法是否同名
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClangASTCategoryMethod.png" style="zoom:20%">
|
||||
|
||||
|
||||
|
||||
### Pass 插桩,实现精准测试
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -10,6 +10,8 @@
|
||||
|
||||
偏移地址为16位,16位地址的寻址能力位64kb,所以一个段的长度最大为64kb。
|
||||
|
||||
|
||||
|
||||
## CPU 的典型构成
|
||||
|
||||
- 寄存器:信息存储
|
||||
@@ -22,6 +24,81 @@
|
||||
|
||||
不同的 CPU,寄存器个数、结构是不同的(比如8086是16为结构的 CPU,8086有14个寄存器)
|
||||
|
||||
|
||||
|
||||
## 说明
|
||||
|
||||
- 汇编中,小括号内存放的一定是内存地址。
|
||||
|
||||
- 指令后面的字母代表操作数长度。比如 b = byte(8-bit),s = short(16-bit integer or 32-bit floating point)、w = word(16-bit)、l=long(32-bit integer or 64-bit floating point)、q=quad(64 bit)、t=tem bytes(80-bit floating point)。比如 ` movq $0xa, 0x86c1(%rip)` 是 `let a:Int = 10` 的汇编实现。
|
||||
|
||||
- rip 存储的说指令的地址。CPU 要执行的下一条指令地址就存储在 rip 中
|
||||
|
||||
- rax、rdx 寄存器一般作为函数返回值使用
|
||||
|
||||
```swift
|
||||
func getValue() -> Int {
|
||||
return 10
|
||||
}
|
||||
var v = getValue()
|
||||
```
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssemblyRaxFunctionReturnValueDemo1.png" style="zoom:25%">
|
||||
|
||||
在第5行代码加断点,第4行汇编遇到 call 函数调用,LLDB 输入 `si` 进去,可以看到将十六进制 `0xa` 也就是10,保存到寄存器 `%eax` 也就是`%rax` 中。
|
||||
|
||||
```assembly
|
||||
SwiftDemo`getValue():
|
||||
-> 0x100003b20 <+0>: pushq %rbp
|
||||
0x100003b21 <+1>: movq %rsp, %rbp
|
||||
0x100003b24 <+4>: movl $0xa, %eax
|
||||
0x100003b29 <+9>: popq %rbp
|
||||
0x100003b2a <+10>: retq
|
||||
```
|
||||
|
||||
LLDB 输入 `finsh` 结束函数调用这段汇编,可以看到在汇编的第5行,将 `%rax` 保存的 10 赋值到 `%rip + 0x86d0 ` 地址。可以看 `%rip + 0x86d0` 是个全局变量,大概就是 v 的地址(可以继续用汇编验证,绝对是 v)。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssemblyRaxFunctionReturnValueDemo2.png" style="zoom:25%">
|
||||
|
||||
- rdi、rsi、rdx、rcx、r8、r9 寄存器一般用来存储函数参数。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssemblyFunctionParamsRegisterDemo.png" style="zoom:25%">
|
||||
|
||||
可以看到第四行汇编的 `%edi` ... `%r9d` 和上面描述的寄存器顺序一致。
|
||||
|
||||
- rsp、rbp 寄存器用于栈操作。栈顶指针,指向栈的顶部
|
||||
- leaq 和 movq 是有区别的。`leaq 0xd(%rip), %rax` 是从 `%rip + 0xd` 算出来的地址值赋值给 `%rax` ,`movq 0xd(%rip), %rax` 是从 `%rip + 0xd ` 算出来的地址值,取8个字节给 `%rax`。
|
||||
- `xorl` 抑或运算。
|
||||
|
||||
## 寄存器的高低位兼容设计
|
||||
|
||||
汇编中高位对于低位寄存器的兼容性设计:
|
||||
%r 开头的寄存器都是64位(8 Byte)
|
||||
%e 开头的寄存器都是32位的(4 Byte)
|
||||
那如果所有的寄存器再去分 %r、%e 那就会存在很多寄存器了,使用和记忆很难了。
|
||||
|
||||
同时早期的寄存器之下写的汇编代码,升级的时候要改写,成本太大了。如何设计才可以兼容升级呢?
|
||||
|
||||
设计很巧妙。假设一个 %rax 的64位寄存器(0~63位)
|
||||
|
||||
- 64位:则 all in 全部使用
|
||||
- 32位:为了兼容低的32位寄存器,则拿出低的4字节(0~31位)当作 %eax 32位寄存器来使用
|
||||
- 16位:为了兼容16位的寄存器,则拿出低的2个字节(0~15位)当作 %ax 16位寄存器来使用;
|
||||
- 8位:为了兼容8位的寄存器,则拿出低的2个字节(0~15位)分为2段,高8位、低8位来使用,分别是 %ah、%al 寄存器。
|
||||
|
||||

|
||||

|
||||
|
||||
寄存器:
|
||||
- r 开头:64 bit,8 Byte
|
||||
- e 开头:32 bit,4 Byte
|
||||
- ax、bx、cx、dx:16 bit,2 Byte
|
||||
- ah、al、bh、bl...:8 bit,1 Byte
|
||||
|
||||
|
||||
|
||||
## 通用寄存器
|
||||
|
||||
AX、BX、CX、DX 这4个寄存器通常用来存放一般性的数据,成为通用寄存器(有时候也有特定用途)
|
||||
@@ -36,6 +113,8 @@ AX、BX、CX、DX 这4个寄存器通常用来存放一般性的数据,成为
|
||||
|
||||
- `mov b, ax`。调用 mov 将 ax 中的值赋值给内存空间 b
|
||||
|
||||
|
||||
|
||||
### CS和IP
|
||||
|
||||
CS 为代码段,IP 为指令指针寄存器,它们代表 CPU 当前要读取指令的地址
|
||||
@@ -62,6 +141,8 @@ IP 只为 CS 提供服务。
|
||||
|
||||
- 如果内存中的某段内容曾被 CPU 执行过,那么它所在的内存单元肯定被 `CS:IP` 指向过
|
||||
|
||||
|
||||
|
||||
### jmp 指令
|
||||
|
||||
mov 指令不能用于设置 CS、IP 的值,8086没有提供该功能。可以通过 jmp 指令来实现修改 CS、IP 的值,这些指令被成为转移指令。
|
||||
@@ -80,6 +161,10 @@ jmp ax
|
||||
|
||||
修改了4次。每执行一条指令,IP 都会被修改1次(IP=IP+该条指令的长度),最后一条指令执行后,IP 寄存器的值也会被修改1次,共3+1=4次。
|
||||
|
||||
`jmp *%rax` jmp 后面如果跟寄存器地址,则一定要加 `*`,地址存放在 `%rax` 中
|
||||
|
||||
|
||||
|
||||
### ds 寄存器
|
||||
|
||||
CPU 要读写一个内存单元时,必须要给出这个内存单元的地址,在8086中,内存地址由段地址和偏移地址组成。
|
||||
@@ -142,6 +227,8 @@ mov al, [2]
|
||||
|
||||
此时 al 的值为多少?al 和 ax 的区别在于 ax = ah + al,所以 al 的情况下直接从 10002H 开始取1个16位的数据,所以 al 为 0022。
|
||||
|
||||
|
||||
|
||||
### 大小端序
|
||||
|
||||
小端序,指的是数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中
|
||||
@@ -184,6 +271,8 @@ QA:将 0x1122 存放在 0x40002 中,如何存储?
|
||||
|
||||
0x40003 0x11
|
||||
|
||||
|
||||
|
||||
### 指令操作明确 CPU 操作的内存
|
||||
|
||||
```shell
|
||||
@@ -204,6 +293,8 @@ mov word ptr [0], 66h
|
||||
|
||||
指令执行后:1000: 0000 66 22 00 00 00 00 00 00
|
||||
|
||||
|
||||
|
||||
## 栈
|
||||
|
||||
栈是一种后进先出特点的数据存储空间(LIFO)
|
||||
@@ -222,7 +313,9 @@ SS: 栈的段地址
|
||||
|
||||
SP:堆栈寄存器存放栈的偏移地址
|
||||
|
||||
#### push
|
||||
|
||||
|
||||
### push
|
||||
|
||||
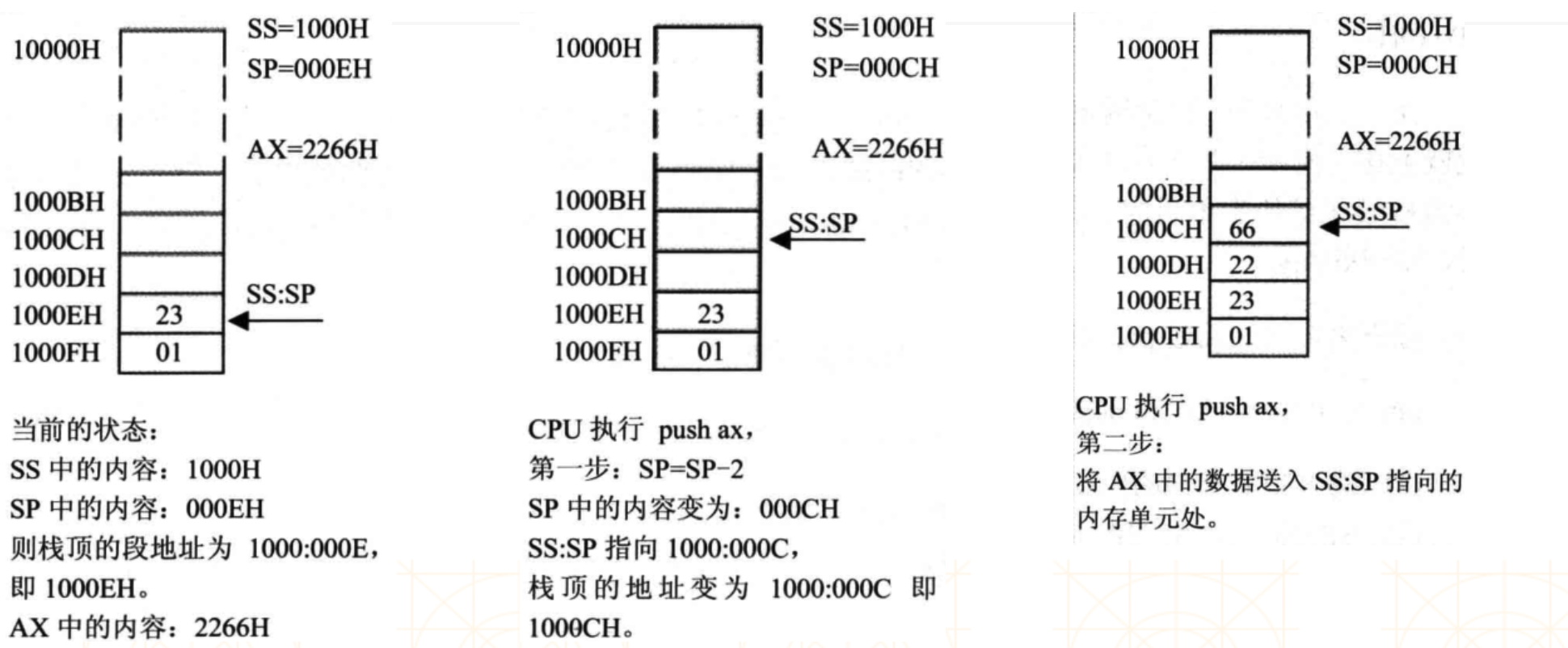
|
||||
|
||||
@@ -234,7 +327,9 @@ SP:堆栈寄存器存放栈的偏移地址
|
||||
|
||||
ax = ah + al,所以 ax 中的数据入栈需要占据2个单位(sp = sp - 2)
|
||||
|
||||
#### pop
|
||||
|
||||
|
||||
### pop
|
||||
|
||||
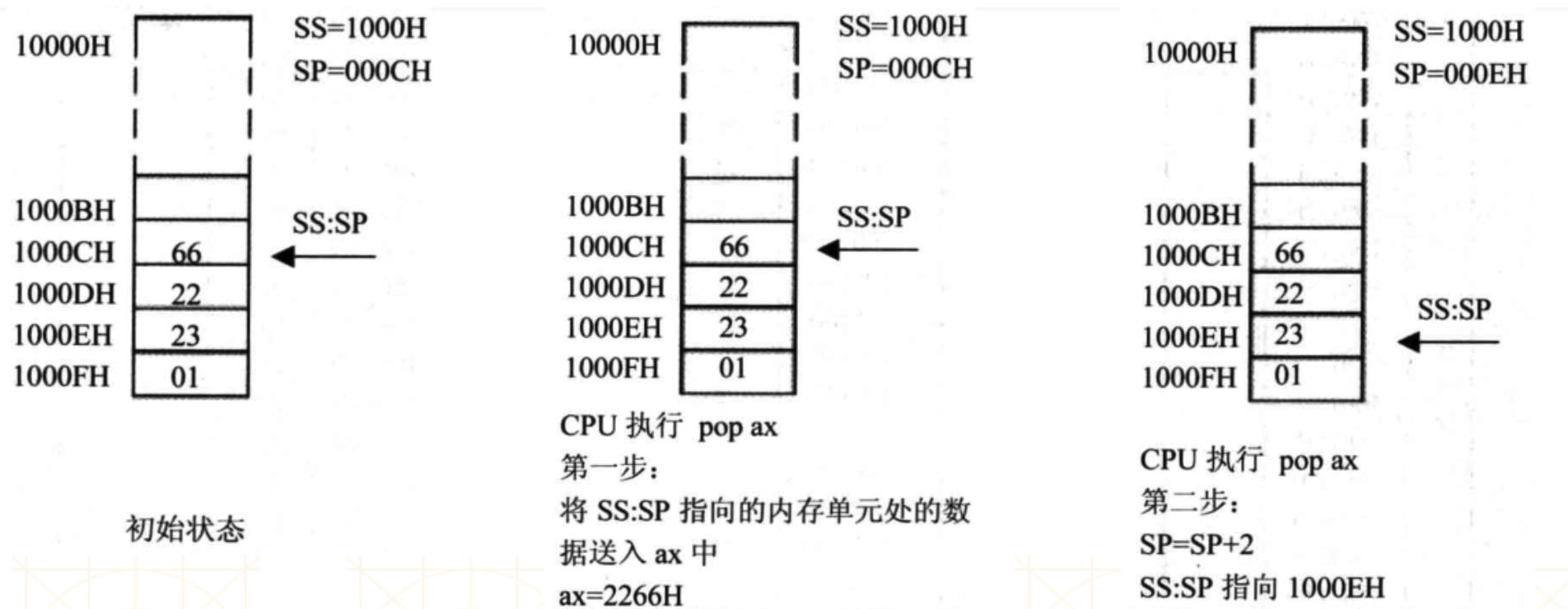
|
||||
|
||||
@@ -275,7 +370,9 @@ pop bx
|
||||
|
||||
对于栈段,将它的段地址存放在 SS 中,将栈顶单元的偏移地址存放在 SP 中,这样 CPU 在进行栈操作(LIFO)的时候比如 push、pop 指令,就可以操作 SP,将我们定义的栈段当作栈空间来使用
|
||||
|
||||
### 中断
|
||||
|
||||
|
||||
## 中断
|
||||
|
||||
中断是由于软件或者硬件的信号,使得 CPU 暂停当前的任务,转而去执行另一段子程序。
|
||||
|
||||
@@ -334,7 +431,9 @@ QA:“全局变量的地址在编译那一刻就确定好了”怎么理解?
|
||||
|
||||
全局变量存放在数据段,我们开发者写的代码存放在代码段,位置不一样,编译期就可以确定全局变量的地址。
|
||||
|
||||
### call 和 ret 指令
|
||||
|
||||
|
||||
## call 和 ret 指令
|
||||
|
||||
实现打印3次 "Hello"
|
||||
|
||||
@@ -441,7 +540,9 @@ ret 会将栈顶的值出栈,赋值给 `CS:IP` ,ret 即 return
|
||||
|
||||
函数的3要素:参数、返回值、局部变量
|
||||
|
||||
#### 返回值
|
||||
|
||||
|
||||
### 返回值
|
||||
|
||||
函数运算的结果,一般是放在 ax 通用寄存器中。可以拿 Xcode 将下面的代码执行下,断点开启在 test 方法内的 return 处(Debug - Debug WorkFlow - Always show Disassembly)
|
||||
|
||||
@@ -461,7 +562,7 @@ int main(int argc, const char * argv[]) {
|
||||
|
||||
可以看到 return 的值是保存在 eax 寄存器中。为什么是 e,e是32位的意思(环境:老款 MBP 电脑运行)。
|
||||
|
||||
#### 参数
|
||||
### 参数
|
||||
|
||||
需要用的时候 push,最后不用则 pop,所以用栈来传参。
|
||||
|
||||
@@ -499,6 +600,8 @@ QA:stack overflow?
|
||||
|
||||
清楚函数调用原理 call、ret、stack 就知道函数调用函数,常见的递归或者循环,其实函数都在 stack 上进行操作,比如函数参数、函数下一条指令也会入栈,在递归或者函数内不断调用函数的过程中,stack 不及时”栈平衡“,很容易出现栈溢出的情况,也就是 stack overflow。
|
||||
|
||||
|
||||
|
||||
### 内平栈/外平栈
|
||||
|
||||
外平栈
|
||||
@@ -534,6 +637,8 @@ sum:
|
||||
|
||||
内平栈的好处是函数调用者不用去处理“栈平衡”
|
||||
|
||||
|
||||
|
||||
### 函数调用的约定
|
||||
|
||||
`__cdecl` 外平栈,参数从右到左入栈
|
||||
@@ -544,6 +649,8 @@ sum:
|
||||
|
||||
寄存器传递参数效率更高,速度更快,iOS 平台函数采用6到8个 寄存器传参,剩余的从右到左入栈。
|
||||
|
||||
|
||||
|
||||
### c 代码可与汇编混合开发
|
||||
|
||||
验证函数的返回值是存放在 eax 寄存器中(eax 和 ax 区别在于位数)
|
||||
@@ -565,6 +672,8 @@ int main(int argc, const char * argv[]) {
|
||||
// 10
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 函数局部变量
|
||||
|
||||
大多数情况下函数内部会存在局部变量,但是不知道局部变量到底有多少,如何保证局部变量不会被污染呢?
|
||||
@@ -631,10 +740,284 @@ sum:
|
||||
pop
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 栈帧
|
||||
|
||||
Stack Frame Layout,代表一个函数的执行环境。包括:参数、返回地址、局部变量和包括在本函数内部执行的所有内存操作等
|
||||
|
||||
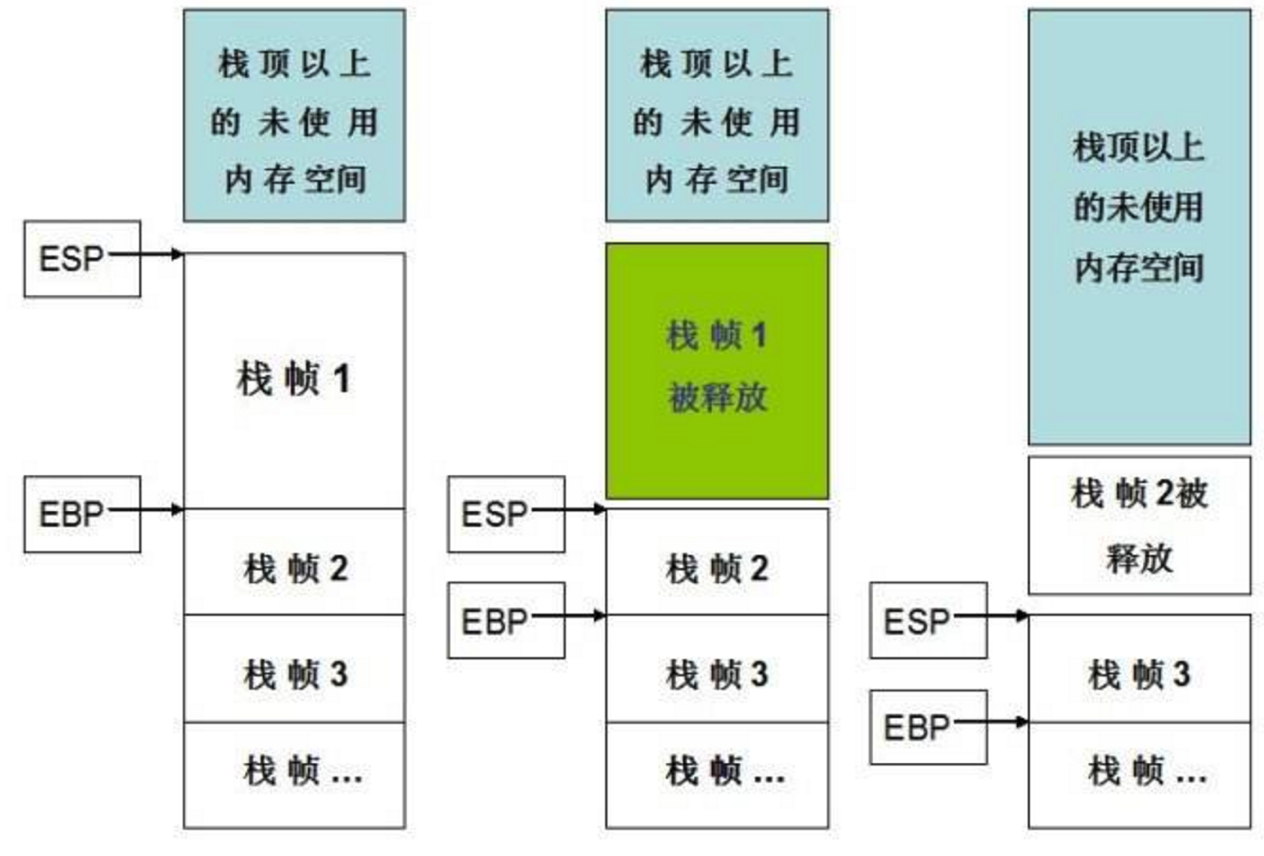
|
||||
|
||||
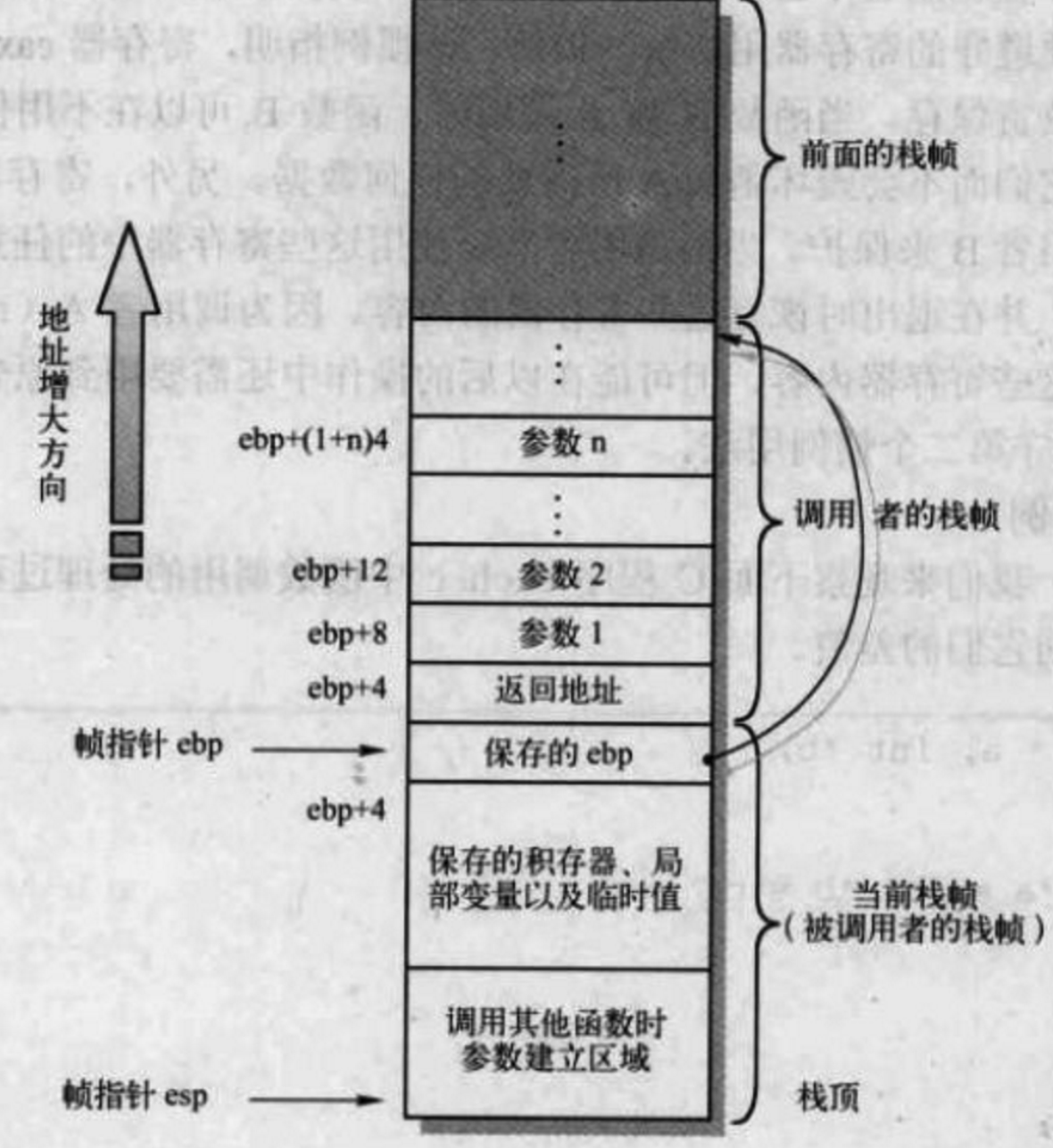
|
||||

|
||||
|
||||
|
||||
|
||||
## iOS 调用汇编
|
||||
|
||||
1. 在 Xcode 工程中创建文件,选择 Other -> empty,保存为 `.s` 拓展名
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeCreateAssembleFile.png" style="zoom:25%">
|
||||
|
||||
2. 编写汇编代码
|
||||
|
||||
```assembly
|
||||
.text
|
||||
.global _test
|
||||
|
||||
_test:
|
||||
movq $0x8, %rax;
|
||||
ret;
|
||||
```
|
||||
|
||||
创建一个名为 `test` 的函数,内部给 rax 寄存器赋值为8,然后 ret 返回。
|
||||
|
||||
`.text` 是保存在 _TEXT 段上。并将函数暴露给全局,函数名为 test,暴露的时候就要写 _test
|
||||
|
||||
3. 汇编函数给外部调用,就需要声明一个头文件 `Asm.h`,写好需要暴露的方法声明
|
||||
|
||||
4. 最后在使用的地方,引入暴露的汇编头文件 `Asm.h`,正常调用函数即可。
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/iOSCallAssemble.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 汇编编写“函数”
|
||||
|
||||
上面的例子也顺带看了汇编是如何编写“函数”的,为什么加引号,因为这个概念是不存在的,汇编只有指令,这个函数概念是方便组织代码,参考定义的。类似给一段代码打了个标签。
|
||||
|
||||
1. 创建汇编文件
|
||||
|
||||
2. 编写代码
|
||||
|
||||
```assembly
|
||||
.text
|
||||
.global _test, _add, _sub
|
||||
|
||||
_test:
|
||||
movq $0x8, %rax;
|
||||
ret;
|
||||
|
||||
_add:
|
||||
movq %rsi, %rax
|
||||
movq %rdi, %rbx
|
||||
addq %rbx, %rax
|
||||
retq
|
||||
_sub:
|
||||
movq %rdi, %rax
|
||||
movq %rsi, %rbx
|
||||
subq %rbx, %rax
|
||||
ret
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/iOSCallAssembleDemo1.png" style="zoom:25%">
|
||||
|
||||
说明:笔者编写平台是老款 MBP,Xcode 连接模拟器跑的代码,也就是 X86_64 架构的汇编。真机运行一般跑 arm64 汇编语法,会 X86_64 的话 arm64 类似,翻译下写法就好。
|
||||
|
||||
看这2个函数,都是从 `rsi` `rdi` 寄存器里面获取函数参数,内部调用系统指令,做了减加运算逻辑后,将函数返回值保存到 `rax` 寄存器中,直接 return。不需要显示声明 `return rax`,汇编会自动将 `rax` 寄存器里的值,交给函数调用者。
|
||||
|
||||
3. 汇编函数给外部调用,就需要声明一个头文件 `Asm.h`,写好需要暴露的方法声明
|
||||
|
||||
4. 最后在使用的地方,引入暴露的汇编头文件 `Asm.h`,正常调用函数即可。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## iOS 源码探索
|
||||
|
||||
经常需要将黑盒的 iOS 代码结合 GNU 之外,还需要将源文件编译成汇编代码去分析。格式为:
|
||||
|
||||
`xcrun --sdk iphoneos clang -S -arch arm64 main.m -o main.s`
|
||||
|
||||
|
||||
|
||||
## arm64 汇编
|
||||
|
||||
### 寄存器
|
||||
|
||||
#### 通用寄存器
|
||||
|
||||
- 64位: x0~x28
|
||||
- 32位:w0~w28(属于 x0~x28 的低32位)
|
||||
- x0~x7 经常用来存放函数的参数,更多的函数参数用堆栈来传递
|
||||
- x0 经常用来存放函数的返回值
|
||||
|
||||
|
||||
|
||||
Demo:汇编定义加减法,OC 去调用
|
||||
|
||||
```assembly
|
||||
// Asm.s
|
||||
.text
|
||||
.global _add, _sub
|
||||
|
||||
_add:
|
||||
add x0, x0, x1
|
||||
ret
|
||||
_sub:
|
||||
sub x0, x0, x1
|
||||
ret
|
||||
|
||||
// ViewContoller.m
|
||||
#import "Asm.h"
|
||||
NSInteger sum = add(2, 4) // 6
|
||||
NSInteger res = sub(4, 2) // 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 程序计数器
|
||||
|
||||
pc(Program Counter)
|
||||
|
||||
|
||||
|
||||
#### 堆栈指针
|
||||
|
||||
- sp(Stack Pointer)
|
||||
- fp(Frame Pointer),也就是 x29
|
||||
|
||||
#### 链接寄存器
|
||||
|
||||
lr(link register),也就是 x30
|
||||
|
||||
|
||||
|
||||
#### 程序状态寄存器
|
||||
|
||||
- cpsr(Current Program Status Register)
|
||||
- spsr(Saved Program Status Register),异常状态下使用
|
||||
|
||||
|
||||
|
||||
### 指令
|
||||
|
||||
- ret:函数返回
|
||||
|
||||
- cmp:将2个寄存器的值相减,结果会影响 cpsr 寄存器的标志位
|
||||
|
||||
- b:跳转指令。格式为:`b{条件} 目标地址` 。b 指令是最简单的跳转指令,一旦遇到一个 B 指令,ARM 处理器将立即跳转到给定的目标地址,从那里继续执行。
|
||||
|
||||
条件跳转一般搭配 cmp 使用。条件跳转对应 `if...else...`
|
||||
|
||||
Demo:定义一段汇编代码一个标签,然后跳转执行。跳转前传递参数,跳转后读取并相加
|
||||
|
||||
```assembly
|
||||
.text
|
||||
.global _jump
|
||||
|
||||
_jump:
|
||||
movq $0x1, %rsi
|
||||
jmp myCode
|
||||
myCode:
|
||||
movq %rsi, %rax
|
||||
movq $0x2, %rbx
|
||||
addq %rbx, %rax
|
||||
ret
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssembleJMPDemo1.png" style="zoom:25%">
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssembleJMPDemo2.png" style="zoom:25%">
|
||||
|
||||
上面是 x86_64 的汇编,`jmp` 跳转指令在 arm64 中对应 `b` 指令。类似下面代码
|
||||
|
||||
```assembly
|
||||
.text
|
||||
.global _jump:
|
||||
|
||||
_jump:
|
||||
// ...
|
||||
b myCode
|
||||
myCode:
|
||||
// ...
|
||||
```
|
||||
|
||||
条件跳转:`bgt conditionJump`
|
||||
|
||||
```assembly
|
||||
.text
|
||||
.global _jump
|
||||
|
||||
_jump:
|
||||
mov x0, #0x5
|
||||
mov x1, #0x5
|
||||
cmp x0, x1
|
||||
bgt conditionJump
|
||||
conditionJump:
|
||||
mov x1, #0x6
|
||||
ret
|
||||
```
|
||||
|
||||
- bl:带返回值的跳转指令。格式为:`bl{条件} 目标地址`。bl 跳转前,会在寄存器 r14 中保存 pc 的当前内容,因此,可以通过将 r14 的内容重新加载到 pc 中,来返回到跳转指令之后的那个指令处执行。该指令是实现子程序调用的一个基本但常用的手段。在 x86_64 中就是 call 指令。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 条件域
|
||||
|
||||
- EQ:equal 相等
|
||||
- NE:not equal 不想等
|
||||
- GT:great than 大于
|
||||
- GE:greater equal 大于等于
|
||||
- LT:less than 小于
|
||||
- LE:less equal 小于等于
|
||||
|
||||
|
||||
|
||||
### 内存操作
|
||||
|
||||
- load 从内存中装载数据
|
||||
|
||||
- ldr
|
||||
|
||||
`ldr x0, [x1]` 代表从地址 x1 处,取8个字节的数据,赋值给 x0(会将 x1 寄存器中存储的内存地址所指向的值加载到 x0 寄存器中)。`ldr w0, [x1]` 代表从地址 x1 处,取4个字节的数据,赋值给 w0。一般会搭配 CPU 寻址能力一起使用。
|
||||
|
||||
- ldur
|
||||
|
||||
和 ldr 一样,作用都是从一个寄存器中存储的内存地址所指向的值加载到某个寄存器上。ldr 搭配正数地址,如 `ldr x1, [sp, #0x28]` ,ldur 搭配负数地址,如 `ldur w8, [x29, #-0x8]`
|
||||
|
||||
- ldp, `ldp w0, w1, [x2, #0x10]` 代表从 x2 + 0x10 计算结果对应的内存出,取出前4个字节的值赋值给寄存器 w0,后4个字节对应的值赋值给寄存器 w1
|
||||
|
||||
- store 往内存中存储数据
|
||||
|
||||
- str。`str w0, [x1, #0x5]` 将 w0 寄存器的值赋值给 `x1 + #0x5` 地址开始,4个字节处。str 搭配正数地址偏移
|
||||
|
||||
- stur。`str w0, [x1, #-0x5]` 将 w0 寄存器的值赋值给 `x1 - #0x5` 地址开始,4个字节处。stur 搭配正数地址偏移
|
||||
|
||||
- stp。`stp w0, w1, [x1, #0x5]` 将 w0 寄存器的值赋值给 `x1 + #0x5` 地址开始,前4个字节处,w1 寄存器的值赋值给后4个字节
|
||||
|
||||
- 零寄存器
|
||||
|
||||
- wzr(32bit)即 word zero register。
|
||||
- xzr(64bit)
|
||||
|
||||
```objective-c
|
||||
int a = 0;
|
||||
long b = 0;
|
||||
```
|
||||
|
||||
转换为 arm64 汇编就是
|
||||
|
||||
```assembly
|
||||
stur wzr, [x29, #-0x14]
|
||||
stur xzr, [x29, #-0x24]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 经验小结
|
||||
|
||||
- 内存地址格式为:`0x7ab60(%rip)` 一般是全局变量
|
||||
- 内存地址格式为:`-0x50(%rbp)` 一般是局部变量
|
||||
- 源代码 -> 汇编 -> 机器码,从机器码到汇编是可逆的。但是无法做到汇编到源代码的反编译,因为不同的源代码可能生成的汇编代码是一样的。
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,4 +1,297 @@
|
||||
# 虚拟内存
|
||||
- 进程隔离的必要性
|
||||
- 虚拟内存是如何实现进程隔离的
|
||||
- 线性地址和物理地址是如何转换的
|
||||
# Swift 枚举值内存布局
|
||||
|
||||
> enum 使用很简单,那大家有没有思考过系统针对枚举的实现是怎么样的?接下去会针对不同情况的枚举,结合汇编来窥探下系统实现原理。
|
||||
|
||||
### 基础枚举
|
||||
|
||||
```swift
|
||||
enum Season {
|
||||
case spring
|
||||
case summer
|
||||
case antumn
|
||||
case winter
|
||||
}
|
||||
|
||||
var season: Season = Season.spring
|
||||
print(Mems.ptr(ofVal: &season))
|
||||
season = Season.summer
|
||||
season = Season.antumn
|
||||
print("over")
|
||||
```
|
||||
|
||||
- `var season: Season = Season.spring` 基础枚举,默认值是0。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/EnumBaseMemoryLayoutDemo1.png" style="zoom:25%">
|
||||
|
||||
- `season = Season.summer`,此时可以看到第一个字节的位置是1.
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/EnumBaseMemoryLayoutDemo2.png" style="zoom:25%">
|
||||
|
||||
- `season = Season.antumn` ,此时可以看到第一个字节的位置是2
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/EnumBaseMemoryLayoutDemo3.png" style="zoom:25%">
|
||||
|
||||
结论:查看内存信息,可以看到基础枚举,只占1个字节大小空间,且值为默认值。
|
||||
|
||||
### 只有原始值
|
||||
|
||||
```swift
|
||||
enum Season:Int {
|
||||
case spring = 1
|
||||
case summer = 2
|
||||
case antumn = 3
|
||||
case winter = 4
|
||||
}
|
||||
|
||||
//print(MemoryLayout<Season>.size)
|
||||
//print(MemoryLayout<Season>.stride)
|
||||
//print(MemoryLayout<Season>.alignment)
|
||||
|
||||
var season: Season = Season.spring
|
||||
print(Mems.ptr(ofVal: &season))
|
||||
season = .summer
|
||||
season = .winter
|
||||
print("over")
|
||||
```
|
||||
|
||||
- `var season: Season = Season.spring` 基础枚举,变量默认值,可以看到第一个字节的位置是0
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/EnumWithRawValueMemoryLayoutDemo1.png" style="zoom:25%">
|
||||
|
||||
- `season = .winter` 基础枚举,当赋值为 winter 的时候,可以看到第一个字节的位置是3
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/EnumWithRawValueMemoryLayoutDemo2.png" style="zoom:25%">
|
||||
|
||||
结论:带有原始值的枚举,同样只占用1个字节,该字节的值为枚举的位置(比如 case1 case2)
|
||||
|
||||
|
||||
|
||||
### 带有关联值的枚举
|
||||
|
||||
```swift
|
||||
enum Season {
|
||||
case spring(Int, Int, Int)
|
||||
case summer(Int, Int)
|
||||
case antumn(Int)
|
||||
case winter(Bool)
|
||||
case unknown
|
||||
}
|
||||
|
||||
print(MemoryLayout<Season>.size)
|
||||
print(MemoryLayout<Season>.stride)
|
||||
print(MemoryLayout<Season>.alignment)
|
||||
|
||||
var season: Season = Season.spring(1, 2, 3)
|
||||
print(Mems.ptr(ofVal: &season))
|
||||
season = Season.summer(4, 5)
|
||||
season = Season.antumn(6)
|
||||
season = Season.winter(true)
|
||||
season = Season.unknown
|
||||
print("over")
|
||||
```
|
||||
|
||||
- `var season: Season = Season.spring(1, 2, 3)` 带有关联值的枚举,`.spring` 有3个 Int,单个 Int 占8个字节空间,所以红色框代表 spring 的1,蓝色框代表 spring 的2,绿色框代表 spring 的3,黄色框代表枚举的第1个 case,剩余7个字节,为空。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutDemo1.png" style="zoom:25%">
|
||||
|
||||
其内存信息如下(8字节为1组,对应上图)
|
||||
|
||||
```shell
|
||||
01 00 00 00 00 00 00 00
|
||||
02 00 00 00 00 00 00 00
|
||||
03 00 00 00 00 00 00 00
|
||||
00
|
||||
00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
这段内存信息怎么看?我划分了下
|
||||
|
||||
```
|
||||
关联值: 01 00 00 00 00 00 00 00
|
||||
关联值: 02 00 00 00 00 00 00 00
|
||||
关联值: 03 00 00 00 00 00 00 00
|
||||
位置值: 00
|
||||
内存对齐占用:00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
下面的几组一样
|
||||
|
||||
- `season = Season.summer(4, 5)` 带有关联值的枚举,`.summer` 有2个 Int,单个 Int 占8个字节空间,所以红色框代表 summer 的4,蓝色框代表 summer 的5,绿色框为空,黄色框代表枚举的第2个 case,剩余7个字节,为空。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutDemo3.png" style="zoom:25%">
|
||||
|
||||
其内存信息如下(8字节为1组,对应上图)
|
||||
|
||||
```shell
|
||||
04 00 00 00 00 00 00 00
|
||||
05 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
01
|
||||
00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
- `season = Season.antumn(6) 带有关联值的枚举,`. `antumn` 有1个 Int,单个 Int 占8个字节空间,所以红色框代表 antumn 的6,蓝色框为空,绿色框为空,黄色框代表枚举的第3个 case,剩余7个字节,为空。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutDemo4.png" style="zoom:25%">
|
||||
|
||||
其内存信息如下(8字节为1组,对应上图)
|
||||
|
||||
```shell
|
||||
06 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
02
|
||||
00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
- `season = Season.winter(true)` 带有关联值的枚举,`. `winter` 有1个 Bool,单个 Int 占1个字节空间,所以红色框代表 winter 的 true,蓝色框为空,绿色框为空,黄色框代表枚举的第4个 case,剩余7个字节,为空。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutDemo5.png" style="zoom:25%">
|
||||
|
||||
其内存信息如下(8字节为1组,对应上图)
|
||||
|
||||
```shell
|
||||
01 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
03
|
||||
00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
- `season = Season.unknown` 带有关联值的枚举,`unknown` 没有关联值,所以红色框为空,蓝色框为空,绿色框为空,黄色框代表枚举的第5个 case,剩余7个字节,为空。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutDemo6.png" style="zoom:25%">
|
||||
|
||||
其内存信息如下(8字节为1组,对应上图)
|
||||
|
||||
```shell
|
||||
00 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
04
|
||||
00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
- `MemoryLayout<Season>.size` :3个 Int 最大为3*8,1个字节用来表达位置信息,`3*8 + 1 = 25`
|
||||
- `MemoryLayout<Season>.stride` :获取系统分配给数据类型的内存大小,也就是实际内存大小(对齐后的)
|
||||
- `MemoryLayout<Season>.alignment` 内存对齐系数,以8 Byte 为单位,对象分配的内存必须是该值的整数倍
|
||||
|
||||
|
||||
|
||||
### 只有一个 case 的枚举
|
||||
|
||||
```swift
|
||||
enum SimpleEnum {
|
||||
case one
|
||||
}
|
||||
var caseOne = SimpleEnum.one
|
||||
print(MemoryLayout<SimpleEnum>.size) // 0
|
||||
print(MemoryLayout<SimpleEnum>.stride) // 1
|
||||
print(MemoryLayout<SimpleEnum>.alignment) // 1
|
||||
```
|
||||
|
||||
为什么 size 为0?看上去是一个变量,但根本不占内存。因为枚举里面就一个 case,所以里面根本不需要存储值来区分是哪个 case。
|
||||
|
||||
```swift
|
||||
enum SimpleEnum {
|
||||
case one
|
||||
case two
|
||||
}
|
||||
var caseOne = SimpleEnum.one
|
||||
print(MemoryLayout<SimpleEnum>.size) // 1
|
||||
print(MemoryLayout<SimpleEnum>.stride) // 1
|
||||
print(MemoryLayout<SimpleEnum>.alignment) // 1
|
||||
```
|
||||
|
||||
现在好理解,2个 case 需要存储1个 Byte 的值来区分是哪个 case,1 Byte 可以代表最多256个 case
|
||||
|
||||
### 只有1个 case 且带关联值的枚举
|
||||
|
||||
```swift
|
||||
enum SimpleEnum {
|
||||
case one(Int)
|
||||
}
|
||||
var caseOne = SimpleEnum.one(4)
|
||||
print(MemoryLayout<SimpleEnum>.size) // 8
|
||||
print(MemoryLayout<SimpleEnum>.stride) // 8
|
||||
print(MemoryLayout<SimpleEnum>.alignment) // 8
|
||||
```
|
||||
|
||||
带有关联值且只有1个 case 的枚举,因为有1个 Int 的关联值,但只有1个 case,所以只需要8 Byte 存储关联值即可。
|
||||
|
||||
请看下面的对照实验
|
||||
|
||||
```swift
|
||||
enum SimpleEnum {
|
||||
case one(Int)
|
||||
case two
|
||||
}
|
||||
var caseOne = SimpleEnum.one(4)
|
||||
print(MemoryLayout<SimpleEnum>.size) // 9
|
||||
print(MemoryLayout<SimpleEnum>.stride) // 16
|
||||
print(MemoryLayout<SimpleEnum>.alignment) // 8
|
||||
```
|
||||
|
||||
2个 case,其中一个 case 有关联值 Int,所以需要8 Byte 存 Int 值,1 Byte 区分是哪个 case,实际需要占用 8 + 1 = 9 Byte,内存对齐单位是8,9向上为16.
|
||||
|
||||
|
||||
|
||||
### 用汇编验证下内存
|
||||
|
||||
```
|
||||
enum Season {
|
||||
case spring(Int, Int, Int)
|
||||
case summer(Int, Int)
|
||||
case antumn(Int)
|
||||
case winter(Bool)
|
||||
case unknown
|
||||
}
|
||||
|
||||
var season: Season = Season.spring(1, 2, 3)
|
||||
print(Mems.ptr(ofVal: &season))
|
||||
season = Season.summer(4, 5)
|
||||
season = Season.antumn(6)
|
||||
season = Season.winter(true)
|
||||
season = Season.unknown
|
||||
print("over")
|
||||
```
|
||||
|
||||
断点停到 `var season: Season = Season.spring(1, 2, 3)` 位置
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/AssociatedEnumMemoryLayoutExplore.png" style="zoom:25%">
|
||||
|
||||
将断点处的汇编单独摘出来研究
|
||||
|
||||
```assembly
|
||||
0x10000334b <+11>: movq $0x1, 0x8eaa(%rip) ; demangling cache variable for type metadata for Swift.Array<Swift.UInt8> + 4
|
||||
0x100003356 <+22>: movq $0x2, 0x8ea7(%rip) ; SwiftDemo.season : SwiftDemo.Season + 4
|
||||
0x100003361 <+33>: movq $0x3, 0x8ea4(%rip) ; SwiftDemo.season : SwiftDemo.Season + 12
|
||||
0x10000336c <+44>: movb $0x0, 0x8ea5(%rip) ; SwiftDemo.season : SwiftDemo.Season + 23
|
||||
0x100003373 <+51>: movl $0x1, %edi
|
||||
```
|
||||
|
||||
`rip` 存储的说指令的地址。CPU 要执行的下一条指令地址就存储在 rip 中。所以在执行第一行的时候,rip 寄存器的值。
|
||||
|
||||
所以第一句汇编代码的意思是:rip 为 `0x100003356`,再加上 `0x8eaa`,得到一个地址值(用 Mac 自带的计算器可以算出)`0X10000C200`,然后 movq 是将十六进制的1赋值给 `0X10000C200` 这个地址。
|
||||
|
||||
第二句汇编代码类似,此时 rip 为 `0x100003361`,再加上 `0x8ea7`,得到一个地址值 `0X10000C208`,然后 movq 将十六进制的2赋值给 `0X10000C208` 这个地址。
|
||||
|
||||
第三句汇编代码类似,此时 rip 为 `0x10000336c`,再加上 `0x8ea4`,得到一个地址值 `0X10000C210`,然后 movq 将十六进制的3赋值给 `0X10000C210` 这个地址。
|
||||
|
||||
第四句汇编代码类似,此时 rip 为 `0x100003373`,再加上 `0x8ea5`,得到一个地址值 `0X10000C218`,然后 movq 将十六进制的0赋值给 `0X10000C218` 这个地址。
|
||||
|
||||
此时断点走到下一行,拿到 season 的内存地址 `0X10000C200` ,查看内存发现和上面理论分析一直
|
||||
|
||||
```shell
|
||||
01 00 00 00 00 00 00 00
|
||||
02 00 00 00 00 00 00 00
|
||||
03 00 00 00 00 00 00 00
|
||||
00 00 00 00 00 00 00 00
|
||||
```
|
||||
|
||||
结论:如果枚举存在关联值,内存大小为:
|
||||
- 1个字节用来存储成员值
|
||||
- n个字节用来存储关联值(n取占用内存最大的关联值),任何一个 case 的关联值都共用这 n 个字节
|
||||
- 且存在内存对齐,所以占用大小为 n 和 1 的最大值,再结合内存对齐。
|
||||
- 如果枚举的定义非常简单,系统会用1个字节来存放值,最大范围是256个 case。
|
||||
- 枚举定义如果有原始值,也不会影响内存布局。
|
||||
225
Chapter1 - iOS/1.113.md
Normal file
@@ -0,0 +1,225 @@
|
||||
# Swift 结构体和类的内存布局
|
||||
|
||||
## 结构体内存布局
|
||||
|
||||
实验1:在 struct 内部自己实现 init
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x: Int
|
||||
var y: Int
|
||||
init () {
|
||||
x = 0
|
||||
y = 0
|
||||
}
|
||||
}
|
||||
var point = Point()
|
||||
```
|
||||
|
||||
在`init` 方法内第一行处加 断点,如下所示
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStructMemoryLayoutDemo1.png" style="zoom:25%">
|
||||
|
||||
实验2:struct 内不自己加 init
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x: Int = 0
|
||||
var y: Int = 0
|
||||
}
|
||||
var point = Point()
|
||||
```
|
||||
|
||||
在`var point = Point()`处加 断点,如下所示
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/StructMemoryLayoutDemo2.png" style="zoom:25%">
|
||||
|
||||
结论:结构体会有一个编译器自动生成的初始化编译器。目的是保证所有成员都有初始值。
|
||||
|
||||
实验3:
|
||||
|
||||
```swift
|
||||
struct CustomDate {
|
||||
var year: Int
|
||||
var month: Int
|
||||
var isLeapYear: Bool
|
||||
}
|
||||
var date = CustomDate(year: 2024, month: 3, isLeapYear: false)
|
||||
print(MemoryLayout<CustomDate>.size) // 17
|
||||
print(MemoryLayout<CustomDate>.stride) // 24
|
||||
print(MemoryLayout<CustomDate>.alignment) // 8
|
||||
print(Mems.memStr(ofVal: &date)) // 0x00000000000007e8 0x0000000000000003 0x0000000000000000
|
||||
```
|
||||
|
||||
Int 占8 Byte,Bool 占1 Byte,共 2*8 + 1 = 17 Byte,由于存在内存对齐,所以17向上到24 Byte。
|
||||
|
||||
|
||||
- 值语义:`struct` 是值类型,这意味着当你将一个 `struct` 赋值给另一个变量或传递给函数时,会创建一个新的副本。每个副本都有其自己的内存空间,对其中一个副本的修改不会影响其他副本。
|
||||
- 内存连续性:`struct` 的成员变量在内存中是连续存储的,没有额外的内存开销(如对象指针或元数据)。这使得访问 `struct` 的成员变量非常高效。
|
||||
- 内存对齐:为了确保访问效率,编译器可能会对 `struct` 的成员变量进行内存对齐。这意味着某些成员变量之间可能会有未使用的内存空间(填充字节)。这种对齐通常是基于目标平台的硬件架构和访问性能考虑。
|
||||
- 嵌套结构体:如果 `struct` 包含其他 `struct` 或枚举作为成员,那么这些嵌套的类型也会按照它们自己的内存布局规则进行排列。
|
||||
- 可变大小结构体:在某些情况下,`struct` 的大小可能不是固定的。例如,如果 `struct` 包含可变长度的数组或字符串,那么它的实际大小将取决于这些成员的大小。然而,即使在这种情况下,`struct` 的内存布局仍然是紧凑的,并且遵循相同的访问规则。
|
||||
- 与类的比较:与 `class`(类)不同,`struct` 不需要额外的内存来存储类型信息、引用计数或其他元数据。这使得 `struct`通常比 `class` 更轻量级,并且在某些情况下具有更好的性能。
|
||||
|
||||
|
||||
## 类的内存布局
|
||||
|
||||
类和结构体类似,但是编译器不会为类自动生成可以传入成员值的初始化器。
|
||||
|
||||
```swift
|
||||
// 写法1
|
||||
class CustomDate {
|
||||
var year: Int = 2024
|
||||
var month: Int = 3
|
||||
}
|
||||
// 写法2
|
||||
class CustomDate {
|
||||
var year: Int
|
||||
var month: Int
|
||||
init () {
|
||||
year = 2024
|
||||
month = 3
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
上面2个写法是等价的。
|
||||
|
||||
结构体和类的区别:
|
||||
|
||||
- 结构体是值类型(枚举也是值类型),类是引用类型(指针类型)
|
||||
|
||||
值类型赋值给 var、let 或者给函数传参,是直接将所有内容拷贝一份。产生了全新副本,属于深拷贝。
|
||||
|
||||
|
||||
|
||||
### 值类型
|
||||
|
||||
```swift
|
||||
func test() {
|
||||
struct Point {
|
||||
var x: Int
|
||||
var y: Int
|
||||
}
|
||||
var point1 = Point(x: 10, y: 20)
|
||||
var point2 = point1
|
||||
|
||||
point2.x = 11
|
||||
point2.y = 22
|
||||
print(point1.x) // 10
|
||||
print(point1.x) // 20
|
||||
print("over")
|
||||
}
|
||||
test()
|
||||
```
|
||||
|
||||
因为是在函数内部变量,所以是在栈上分布
|
||||
|
||||
| 内存地址 | 内存数据 | 说明 |
|
||||
| -------- | ---------------------------------- | -------- |
|
||||
| 0x10000 | 10 ----赋值改变------> 11 | point2.x |
|
||||
| 0x10008 | 20 ----赋值改变------> 22 | point2.y |
|
||||
| 0x10010 | 10 | point1.x |
|
||||
| 0x10018 | 20 | point1.y |
|
||||
|
||||
断点打在 `var point1 = Point(x: 10, y: 20)` 处,查看汇编
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftValuePassDemo1.png" style="zoom:25%">
|
||||
|
||||
乍一看如果不认识的话,先找字面量(立即数),比如红色框内的 `0xa`,就是 10,`0x14` 就是20。[之前](./109.md)学过寄存器的设计,64位寄存器是兼容32位寄存器的。红色框内将 `0xa`,也就是 10 保存到 `%edi ` 寄存器内部,也就是保存到 `%rdi` 中,将 `0x14` 也就是20,保存到 `%esi` 也就是保存到 `%rsi` 寄存器中。
|
||||
|
||||
LLDB 模式下输入 `si` 进入 init 方法内部。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftValuePassDemo2.png" style="zoom:25%">
|
||||
|
||||
可以查看到将 `%rsi` 里的10 保存到 `%rdx` 中了;将 `%rdi` 里的20 保存到 `%rax` 中了。这也就是 struct `init` 方法做的事情。
|
||||
|
||||
LLDB 模式下输入 `finish` 结束 init 方法。
|
||||
|
||||
可以看到下面几句汇编
|
||||
|
||||
```assembly
|
||||
0x1000035ac <+44>: movq %rax, -0x10(%rbp) // rbp - 0x10
|
||||
0x1000035b0 <+48>: movq %rdx, -0x8(%rbp) // rbp - 0x8
|
||||
0x1000035b4 <+52>: movq %rax, -0x20(%rbp) // rbp - 0x20
|
||||
0x1000035b8 <+56>: movq %rdx, -0x18(%rbp) // rbp - 0x18
|
||||
0x1000035bc <+60>: movq $0xb, -0x20(%rbp)
|
||||
0x1000035c4 <+68>: movq $0x16, -0x18(%rbp)
|
||||
```
|
||||
|
||||
可以看到分别将 `%rax` 里的10赋值给内存地址为 `%rbp - 0x10` ,`%rdx` 里的20赋值给内存地址为 `%rbp - 0x8` 了。
|
||||
|
||||
可与看到 `0x10` 和 `0x8` 地址相差8,且地址连续,也就是 point1 的内存地址。同样下面的 `0x20` 和 `0x18` 地址相差8,且地址连续,也就是 point2 的内存地址。
|
||||
|
||||
第五行将 `0xb` 也就是11 赋值给 `%rbp - 0x20`的地址,`0x16` 也就是22赋值给 `%rbp-0x18`的地址,也就是 point2 的 x、y
|
||||
|
||||
|
||||
|
||||
**Swift 标准库中,为了提升性能,String、Array、Dictionary、Set 采取了 Copy On Write 技术**
|
||||
|
||||
比如仅当有“写”操作时,才会真正执行拷贝操作
|
||||
|
||||
对于标准库值类型的赋值操作,Swift 能确保最佳性能,所以没必要为了保证最佳性能来避免赋值。
|
||||
|
||||
|
||||
|
||||
### 引用类型
|
||||
|
||||
引用赋值给 var、let 或者给函数传参,是将内存地址拷贝一份。属于浅拷贝
|
||||
|
||||
```swift
|
||||
func testReferenceType() {
|
||||
class Size {
|
||||
var width: Int
|
||||
var height: Int
|
||||
init(width: Int, height: Int) {
|
||||
self.width = width
|
||||
self.height = height
|
||||
}
|
||||
}
|
||||
|
||||
var size1 = Size(width: 10, height: 20)
|
||||
var size2 = size1
|
||||
size2.width = 11
|
||||
size2.height = 22
|
||||
}
|
||||
testReferenceType()
|
||||
```
|
||||
|
||||
下断点,可以看到下面的汇编:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClassReferenceTypeMemoryLayoutDemo1.png" style="zoom:25%">
|
||||
|
||||
在调用(汇编的 call)完 `allocating_init` 方法后,方法返回值用 `%rax` 保存的。然后打印出 `%rax` 寄存器的值,查看内存信息如下
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClassReferenceTypeMemoryLayoutDemo2.png" style="zoom:25%">
|
||||
|
||||
红色框代表类信息的地址,蓝色框代表引用计数,绿色框代表10,黄色框代表20.
|
||||
|
||||
汇编的第17行,`movq %rdi, -0x50(%rbp)` 应该就是将 `%rdi` 里面的 对象内存地址赋值到 `%rbp - 0x50` 中去,也就是 `size1` 指针地址。
|
||||
|
||||
汇编的第20行,`movq %rdi, -0x10(%rbp)` 应该就是将 `%rdi` 里面的 对象内存地址赋值到 `%rbp - 0x10` 中去,也就是 `size12 指针地址。
|
||||
|
||||
再接下去的汇编
|
||||
|
||||
```swift
|
||||
0x100003525 <+133>: movq -0x50(%rbp), %rax
|
||||
0x100003529 <+137>: movq $0xb, 0x10(%rax)
|
||||
0x100003531 <+145>: callq 0x100007434 ; symbol stub for: swift_endAccess
|
||||
0x100003536 <+150>: movq -0x50(%rbp), %rdi
|
||||
0x10000353a <+154>: callq 0x100007476 ; symbol stub for: swift_release
|
||||
0x10000353f <+159>: movq -0x68(%rbp), %rdx
|
||||
0x100003543 <+163>: movq -0x60(%rbp), %rcx
|
||||
0x100003547 <+167>: movq -0x50(%rbp), %rdi
|
||||
0x10000354b <+171>: addq $0x18, %rdi
|
||||
0x10000354f <+175>: leaq -0x48(%rbp), %rsi
|
||||
0x100003553 <+179>: movq %rsi, -0x58(%rbp)
|
||||
0x100003557 <+183>: callq 0x100007410 ; symbol stub for: swift_beginAccess
|
||||
0x10000355c <+188>: movq -0x58(%rbp), %rdi
|
||||
0x100003560 <+192>: movq -0x50(%rbp), %rax
|
||||
0x100003564 <+196>: movq $0x16, 0x18(%rax)
|
||||
```
|
||||
|
||||
可以看到将 `%rbp - 0x50 ` 的值赋值给 `%rax` ,然后将 `oxb` 也就是 11 保存到 `%rax` 也就是 size1 指针的所指向的内存的 `0x10`处,为什么是前面空了16位?因为前8位保存类信息、后8位保存引用计数信息,所以从16位开始。
|
||||
|
||||
`movq $0x16, 0x18(%rax)` 将 `0x16` 也就是 22 保存到 `%rax` 也就是 size1 指针的所指向的内存的 `0x18`处,为什么是前面空了24位?因为前8位保存类信息、中间8位保存引用计数信息,后8位保存 Int 的 width,所以从24位开始。
|
||||
510
Chapter1 - iOS/1.114.md
Normal file
@@ -0,0 +1,510 @@
|
||||
# Swift 闭包研究
|
||||
|
||||
## 方法占用对象内存吗?
|
||||
|
||||
实验一:
|
||||
|
||||
```swift
|
||||
class Point {
|
||||
var test = true
|
||||
var age = 29
|
||||
var height = 175
|
||||
}
|
||||
var p = Point()
|
||||
print(Mems.size(ofRef: p)) // 48
|
||||
```
|
||||
|
||||
为什么是48,而不是40?
|
||||
|
||||
Point 类前16位的前8位表示类信息,后8位表示引用计算信息,2个 Int 占2*8 = 16 Byte,Bool 占用1 Byte。所以实际占用 8 + 8 + 2 * 8 + 1 = 33 Byte。但由于存在内存对齐(内存对齐以8为 base,都是8的整数倍),但 malloc 函数分配的内存都是 16的倍数,所以占用48 Byte。
|
||||
|
||||
|
||||
|
||||
Demo:
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var age = 29
|
||||
func sayHi () {
|
||||
var height = 175
|
||||
print("局部变量", Mems.ptr(ofVal: &height))
|
||||
print("I am \(age) old")
|
||||
}
|
||||
}
|
||||
func sayOuterHi () {
|
||||
print("Hello world")
|
||||
}
|
||||
|
||||
var p = Person()
|
||||
p.sayHi()
|
||||
sayOuterHi()
|
||||
|
||||
print("全局变量", Mems.ptr(ofVal: &p))
|
||||
print("堆空间", Mems.ptr(ofRef: p))
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClassMemoryLayoutExcludeFunction.png" style="zoom:25%">
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClassMemoryLayoutExcludeFunction2.png" style="zoom:25%">
|
||||
|
||||
代码段:Person.sayHi 0x1000034d0
|
||||
|
||||
代码段:sayOuterHi 0x1000038e0
|
||||
|
||||
全局变量: 0x000000010000c388
|
||||
|
||||
堆空间: 0x20c820
|
||||
|
||||
局部变量(栈): 0x00007ff7bfeff2f8
|
||||
|
||||
可以看到写在类里面的方法地址和写在 Class 外部的方法地址差不多,都在代码段。
|
||||
|
||||
结论:方法不占用对象的内存。方法、函数存放于代码段。
|
||||
|
||||
|
||||
|
||||
## 闭包
|
||||
|
||||
### 定义
|
||||
|
||||
什么是闭包?一个函数和它所捕获的变量/常量环境组合起来,称为闭包。
|
||||
|
||||
- 一般指定义在函数内部的函数
|
||||
- 一般捕获的是外层函数的局部变量、常量
|
||||
|
||||
|
||||
|
||||
### 原理窥探
|
||||
|
||||
Demo
|
||||
|
||||
```swift
|
||||
func exec(a: Int, b: Int, fn: (Int, Int) -> Int) {
|
||||
print(fn(a, b))
|
||||
}
|
||||
// 写法1
|
||||
func sum(a: Int, b: Int) -> Int { return a + b }
|
||||
exec(a: 1, b: 2, fn: sum)
|
||||
|
||||
// 写法2:闭包
|
||||
exec(a: 1, b: 2, fn: {
|
||||
(a: Int, b: Int) -> Int in
|
||||
return a + b
|
||||
})
|
||||
// 写法3:闭包简写
|
||||
exec(a: 1, b: 2, fn: {
|
||||
a,b in return a + b
|
||||
})
|
||||
// 写法4:闭包简写
|
||||
exec(a: 1, b: 2, fn: {
|
||||
a,b in a + b
|
||||
})
|
||||
// 写法5:闭包简写。用$0、$1来获取参数。
|
||||
exec(a: 1, b: 2, fn: { $0 + $1 })
|
||||
// 写法5:闭包简写。用 + 来代表操作,让编译器进行推断
|
||||
exec(a: 1, b: 2, fn: + )
|
||||
```
|
||||
|
||||
如果将一个很长的闭包表达式作为函数的最后一个实参,使用尾随闭包可以增强函数的可读性。尾随闭包是一个被书写在函数调用括号外面(后面)的闭包表达式
|
||||
|
||||
上面的写法等价于
|
||||
|
||||
```swift
|
||||
// 写法6:尾随闭包
|
||||
exec(a: 1, b: 2) {
|
||||
$0 + $1
|
||||
}
|
||||
```
|
||||
|
||||
如果闭包表达式是函数的唯一实参,而且使用饿尾随闭包的语法,那就不需要在函数名后面写圆括号
|
||||
|
||||
```swift
|
||||
func exec(fn: (Int, Int) -> Int) {
|
||||
print(fn(1, 2))
|
||||
}
|
||||
|
||||
exec(fn: { $0 + $1 }) // 3
|
||||
exec() { $0 + $1 } // 3
|
||||
exec{ $0 + $1 } // 3
|
||||
```
|
||||
|
||||
来个 Demo 看看系统数组的排序
|
||||
|
||||
```swift
|
||||
var array = [1, 8, 9, 12, 32, 2]
|
||||
//array.sort()
|
||||
func compare(a: Int, b: Int) -> Bool {
|
||||
return a < b
|
||||
}
|
||||
// 写法1
|
||||
//array.sort(by: compare)
|
||||
|
||||
// 写法2
|
||||
// array.sort { $0 < $1 }
|
||||
|
||||
// 写法3
|
||||
//array.sort { a, b in
|
||||
// return a < b
|
||||
//}
|
||||
|
||||
// 写法4
|
||||
//array.sort(by: {
|
||||
// (a: Int, b: Int) -> Bool in
|
||||
// return a < b
|
||||
//})
|
||||
|
||||
// 写法5
|
||||
//array.sort(by: <)
|
||||
|
||||
// 写法6
|
||||
array.sort() { $0 < $1 }
|
||||
|
||||
print(array) // [1, 2, 8, 9, 12, 32]
|
||||
```
|
||||
|
||||
|
||||
|
||||
Demo2
|
||||
|
||||
闭包的变量捕获
|
||||
|
||||
```swift
|
||||
typealias Fn = (Int) -> Int
|
||||
func getFn() -> Fn {
|
||||
var num = 0
|
||||
func plus(_ i: Int) -> Int {
|
||||
return i
|
||||
}
|
||||
return plus
|
||||
}
|
||||
var fn = getFn()
|
||||
print(fn(1)) // 1
|
||||
print(fn(2)) // 2
|
||||
print(fn(3)) // 3
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo1.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
简单修改下代码
|
||||
|
||||
```swift
|
||||
typealias Fn = (Int) -> Int
|
||||
func getFn() -> Fn {
|
||||
var num = 0
|
||||
func plus(_ i: Int) -> Int {
|
||||
num += i
|
||||
return num
|
||||
}
|
||||
return plus
|
||||
}
|
||||
var fn = getFn()
|
||||
print(fn(1)) // 1
|
||||
print(fn(2)) // 3
|
||||
print(fn(3)) // 6
|
||||
```
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到上面有 `allocObject` 方法调用,说明产生了堆空间对象,用于存放 `num` 。是由 `var fn = getFn()` 造成的,调用1次 `getFn` 则产生1次堆空间分配,用于保存 num。
|
||||
|
||||
也就是说如果一个内层函数访问了外层函数的局部变量,也就会发生变量捕获,做法就是延长局部变量的生命周期,在堆空间申请一段内存,用户保存局部变量。
|
||||
|
||||
对代码进行修改
|
||||
|
||||
```swift
|
||||
typealias Fn = (Int) -> Int
|
||||
func getFn() -> Fn {
|
||||
var num = 1
|
||||
func plus(_ i: Int) -> Int {
|
||||
num += i
|
||||
return num
|
||||
}
|
||||
return plus
|
||||
}
|
||||
var fn1 = getFn()
|
||||
var fn2 = getFn()
|
||||
var fn3 = getFn()
|
||||
print(fn1(1)) // 2
|
||||
print(fn2(2)) // 3
|
||||
print(fn3(3)) // 4
|
||||
```
|
||||
|
||||
我们在汇编 `swift_allocObject` 下面下个断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo3.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
第一次:可以看到 `alloc` 在堆空间申请后的内存被存放到寄存器 `rax` 中,此时只是申请内存,没有赋值的。利用 Debug- Debug Workflow - View Memory 查看内存信息`0x0000600000210000`。此时还没值。
|
||||
|
||||
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo4.png" style="zoom:25%">
|
||||
|
||||
可以看到内存数据发生了改变。绿色框内有了值1。
|
||||
|
||||
|
||||
|
||||
第二次:可以看到 `alloc` 在堆空间申请后的内存被存放到寄存器 `rax` 中,此时只是申请内存,没有赋值的。利用 Debug- Debug Workflow - View Memory 查看内存信息`0x00006000002042c0`。此时还没值。
|
||||
|
||||
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo5.png" style="zoom:25%">
|
||||
|
||||
第三次:可以看到 `alloc` 在堆空间申请后的内存被存放到寄存器 `rax` 中,此时只是申请内存,没有赋值的。利用 Debug- Debug Workflow - View Memory 查看内存信息`0x000060000020d460`。此时还没值。
|
||||
|
||||
敏感点,查看到字面量1,给汇编代码15行加断点,执行完15行,继续查看内存信息
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClosureCaptureVariableDemo6.png" style="zoom:25%">
|
||||
|
||||
打印结果也说明了问题,因为调用3次 `getFn()` 所以会在堆上 alloc 3块内存,用于保存捕获的变量。所以调用 fn1 得到 2,调用 fn2 得到 3,调用 fn3 得到 4。
|
||||
|
||||
BTW,堆空间分配的内存,如果没有 `init` 或者赋特定的值,数据会是随机的。因为有可能是之前别的地方使用过的内存。
|
||||
|
||||
|
||||
|
||||
### 闭包内存结构
|
||||
|
||||
先来个简单的函数,看看指针内存结构
|
||||
|
||||
```swift
|
||||
func sum(_ a: Int, _ b: Int) -> Int { return a + b }
|
||||
var fn = sum
|
||||
print(fn(1, 2)) // 3
|
||||
```
|
||||
|
||||
在 `var fn = sum` 处下断点,可以看到下面汇编
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouserMemoryLayoutExploreDemo1.png" style="zoom:25%">
|
||||
|
||||
我们知道 `leaq` 是从 `%rip + 0x10f` 算出来的地址,赋值给 `%rax`。所以大概可以推测 `%rip + 0x10f` 就是 `sum` 函数地址。LLDM p 打印 `sum` 地址为 `0x0000000100003a30`。
|
||||
|
||||
`%rip` 是下一条指令的地址 `0x100003921`,`%rip + 0x10f` 也就是 `0x0000000100003a30`。和猜想一致。
|
||||
|
||||
第六行汇编的意思就是将 `sum` 函数的地址赋值给 `%rax`。
|
||||
|
||||
第七行汇编的意思是将保存在 `%rax` 内的地址,从 `%rip + 0x88d8` 处,取8个字节用来保存 `%rax` 的地址。`0x100003928 + 0x88d8 = 0x10000C200`
|
||||
|
||||
第八行汇编的意思是将保存在 `%rax` 内的地址,从 `%rip + 0x88d85` 处,取8个字节用来保存 `$0x0` 。`0x100003933 + 0x88d5 = 0x10000C208`
|
||||
|
||||
`0x10000C200` 到 `0x10000C208` 差8位,也是连续的。说明分配了一个函数指针,长度为16位。通过`MemoryLayout.stride(ofValue: sum)` 看到也是16位。符合猜想。
|
||||
|
||||
|
||||
|
||||
直奔主题,研究闭包内存
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreNotCaptureVariableDemo1.png" style="zoom:25%">
|
||||
|
||||
可以看到在调用完第六行的函数后将寄存器 `rax`、`rdx` 里的值取出来使用了。进入函数内部看看发生了什么,LLDB 输入 `si`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreNotCaptureVariableDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到 `rax` 里面存放了 `plus` 函数地址。第7行汇编是抑或运算,2个 `ecx` 抑或,结果为0,写入到 `ecx` 里。然后第8行汇编将 `ecx` 里的0写入到 `edx`,`edx` 也就是 `rdx`。走完第6行的汇编,继续看第7、8行
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreNotCaptureVariableDemo1.png" style="zoom:25%">
|
||||
|
||||
将第6行函数的返回结果 `rax` 里的函数地址赋值给 `rip +0x89e7 = 0x100003819 + 0x89e7 = 0x10000C200 `, 第7行的`rdx` 的值赋值个给 `rip +0x89e8 = 0x100003820 + 0x89e8 = 0x10000C208`。
|
||||
|
||||
也就是 fn1 前8个字节存放 plus 的函数地址,后8个字节存放0.
|
||||
|
||||
|
||||
|
||||
继续对比实验,查看闭包放了什么东西(注意和上面的实验不同,下面存在闭包)
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreNotCaptureVariableDemo3.png" style="zoom:25%">
|
||||
|
||||
基本可以断定:函数会返回一个长度为16 Byte 的内存。分别保存在 `rax` 和 `rdx`上。所以针对性的研究 `rdx` 和 `rax`
|
||||
|
||||
汇编第10行,经过在堆上为捕获的变量 alloc 内存后,将内存保存到 `rax` 中,然后赋值给 `rdi`,第11行,将 `rdi` 再赋值给 `rbp - 0x10` 的地址。所以汇编19行的 `rbp - 0x10 ` 保存的也就是堆内存,赋值给 `rdx ` 了。
|
||||
|
||||
20行的 `rax` 保存了一个看似是 `plus` 的函数地址。具体是:`rip + 0x167 = 0x100003969 + 0x167= 0x100003C37 `
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreNotCaptureVariableDemo3.png" style="zoom:25%">
|
||||
|
||||
继续走,走到真正的 `plus` 方法内,可以看到函数地址是 `0x100003970` 。所以返回的 `rax` 里面可能是间接调用真正的 `plus` 函数的。
|
||||
|
||||
|
||||
|
||||
问题变得微妙起来了,`getFn` 方法返回一个地址,占用16个字节,但是前8个字节存储 `plus` 方法地址,后8个字节存储闭包捕获后在堆上申请内存存放的数据地址。那如何根据一个地址的前8位去真正调用方法?
|
||||
|
||||
|
||||
|
||||
Tips:由于地址是动态生成的,所以真正去调用 plus 的时候一定不是写死的地址,一定是动态生成的。这种属于间接调用。
|
||||
|
||||
- call 后面直接加一个函数地址,属于直接调用。类似 `callq 0x100003970`
|
||||
- call 后面的函数地址不是固定的,而是动态生成的叫间接调用。在 `at&t` 汇编里面,间接调用前面要加 `*` 。类似 `callq *%rax`,意思是从 `%rax` 里面取出一个地址值出来,当成函数地址,去调用
|
||||
|
||||
顺着思路,分析下汇编:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo1.png" style="zoom:25%">
|
||||
|
||||
我们看到25行 `callq *%rax` 存在动态调用,所以需要找到 `%rax` 里的值是哪里来的。然后顺着向上找,找到23行 `movq -0x30(%rbp), %rax`。然后继续向上看到16行 `movq %rax, -0x30(%rbp)`。继续向上看到15行 `movq 0x88db(%rip), %rax`。相当于就是在 `rip + 0x88db ` 处取出8个字节出来,当作函数地址调用(汇编代码的右边写了,`fn1` ),地址为:`0x88db(%rip) = rip + 0x88db = 0x10000392d + 0x88db = 0x10000C208` 。
|
||||
|
||||
断点继续放开,在汇编25行处加断点 `callq *%rax`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到在方法内部,第6行汇编处,直接调用一个代码段的函数地址 `jmp 0x1000039f0 `
|
||||
|
||||
指令 `jmp`、`call` 的区别在于:
|
||||
|
||||
- `jmp` 指令控制程序直接跳转到目标地址执行程序,程序总是顺序执行,指令本身无堆栈操作过程。
|
||||
- `call` 指令跳转到指定目标地址执行子程序,执行完子程序后,会返回 `call` 指令的下一条指令处执行程序,执行 `call` 指令有堆栈操作过程
|
||||
|
||||
LLDB 输入 `si`,可以看到是 `plus` 函数真正的地址
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo3.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`fn1` 函数调用的时候,参数如何传递?
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo4.png" style="zoom:25%">
|
||||
|
||||
汇编17行 `movq 0x88d8(%rip), %r13 ; SwiftDemo.fn1 : (Swift.Int) -> Swift.Int + 8`可以看到将返回的 fn1 本身16字节的后8个字节,也就是堆地址空间值,保存到寄存器 `edi` 也就是寄存器 `rdi` 上了。
|
||||
|
||||
汇编24行 `movl $0x1, %edi` 将参数1传给寄存器 `rdi` 了。
|
||||
|
||||
然后 LLDB 输入 `si` 去分析 callq 内部
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo5.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
可以看到 `movq %r13, %rsi` 将寄存器 r13 的值写入到 `rsi` 了。目前为止:`rdi` 保存参数1,`rsi` 保存堆地址值。
|
||||
|
||||
继续输入 `si`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo6.png" style="zoom:25%">
|
||||
|
||||
可以看到汇编的第5行 `movq %rsi, -0x50(%rbp)` 将 `rsi` 里的1,保存到 `rbp - 0x50` 处。第6行汇编 `movq %rdi, -0x58(%rbp)` 将 `rdi` 堆地址值保存到 `rbp - 0x58` 处。
|
||||
|
||||
汇编26行 `movq -0x58(%rbp), %rdi` 将 `rbp - 0x58` 的值写入到 `rdi`,也就是堆地址值。第27行 `movq -0x50(%rbp), %rsi` 将 `rbp - 0x50` 的值写入到 `rsi`,也就是参数值1。
|
||||
|
||||
然后真正做 `plus` 加法运算的就是28行的 `addq 0x10(%rsi), %rdi`, 从 `rsi` 堆地址值的第16个字节的地方取出8个字节的值,也就是捕获的外部变量 `num` 再和参数1相加。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ClouseExploreCaptureVariableDemo7.png" style="zoom:25%">
|
||||
|
||||
可以看到第6行堆地址空间的值写入到 `rbp -0x58` ,第26行又将 `rbp -0x58` 写入到 `rdi`,29行将 `rdi` 的值,写入到 `rbp - 0x48`,34行将 `rbp - 0x48` 写入到 `rcx`,35行将 `rcx` 的地址值,写入到 `rax` 对应的存储空间。也就是堆上的 `num` 值已经修改,被覆盖了。
|
||||
|
||||
|
||||
|
||||
总结:当 `getFn` 内部没有发生闭包的时候,fn1 的地址就是16 Byte,前8 Byte就是 `plus` 的函数地址。当发生函数闭包的时候,`fn1` 的16 Byte,前8 Byte 存储间接调用 `plus` 函数的中转函数,后8 Byte 存储着捕获的且在堆上分配内存的地址值。真正调用 `plus` 的时候会通过寄存器传递2个参数:1个是 fn1 的参数,1个是堆空间的地址值。
|
||||
|
||||
```swift
|
||||
var fn1 = getFn()
|
||||
fn1(1) // 2
|
||||
fn1(3) //4
|
||||
```
|
||||
|
||||
因为只调用1次 `getFn` 所以堆内存分配了1个被捕获的变量地址,调用过1次 fn1 后,堆地址所指向的内存上的数被修改了。当第二次调用的时候操作的还是同一块堆内存地址,也就是同一个被捕获的堆地址所指向的变量。
|
||||
|
||||
```swift
|
||||
var fn1 = getFn()
|
||||
fn1(1) // 2
|
||||
fn1(3) //4
|
||||
var fn2 = getFn()
|
||||
fn2(2) // 3
|
||||
fn2(4) // 5
|
||||
```
|
||||
|
||||
因为调用了2次 `getFn` 所以堆内存分配了2个被捕获的变量地址,调用过1次 fn1 后,堆地址所指向的内存上的数被修改了。当第二次调用的时候操作的还是同一块堆内存地址,也就是同一个被捕获的堆地址所指向的变量。当调用 fn2 的时候操作的是被捕获的新的一个堆地址空间所指向的变量。
|
||||
|
||||
|
||||
|
||||
## 自动闭包
|
||||
|
||||
自动闭包是一种自动创建的,用来把作为实际参数传递给函数的表达式打包的闭包。它不接受任何实际参数,并且当它被调用时,它会返回内部打包的表达式的值
|
||||
|
||||
这个语法的好处在于通过写普通表达式代替显示闭包,而使你省略包围函数的形式参数的括号.
|
||||
|
||||
比如系统的断言 `assert`
|
||||
|
||||
```swift
|
||||
public func assert(_ condition: @autoclosure () -> Bool, _ message: @autoclosure () -> String = String(), file: StaticString = #file, line: UInt = #line)
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
```swift
|
||||
// 语法糖。自动闭包
|
||||
func getPositiveValue(_ v1: Int, _ v2: @autoclosure () -> Int) -> Int {
|
||||
return v1 > 0 ? v1 : v2()
|
||||
}
|
||||
|
||||
//print(getPositiveValue(10, {20}))
|
||||
//print(getPositiveValue(-10) {20})
|
||||
//print(getPositiveValue(-20) {
|
||||
// let a = 10
|
||||
// return a + 1
|
||||
//}
|
||||
//)
|
||||
|
||||
print(getPositiveValue(-10, 22))
|
||||
```
|
||||
|
||||
`@autoclosure` 会自动将 22 封装成闭包 `{ 22 }`。
|
||||
|
||||
`@autoclosure` 只支持 `() -> T` 无参数,并且有一个返回值的闭包。
|
||||
|
||||
`@autoclosure` 并非只支持最后1个参数。
|
||||
|
||||
`??` 函数的本质就是自动闭包
|
||||
|
||||
|
||||
|
||||
自动闭包允许延迟处理,因此任何闭包内部的代码直到你调用的时候才会运行。对于有副作用或者占用资源的代码来说很有用。因为它可以允许你控制代码何时进行求值
|
||||
|
||||
```swift
|
||||
var group = ["zhangsan", "lisi", "wangwu"]
|
||||
//print(group.count)
|
||||
//let groupRemover = { group.remove(at: 0) }
|
||||
//print(group.count)
|
||||
//
|
||||
////print("execute remove function \(groupRemover())")
|
||||
//print(group.count)
|
||||
|
||||
|
||||
func serve(customer customerProvider: @autoclosure () -> String) {
|
||||
print("Now serving \(customerProvider())!")
|
||||
}
|
||||
serve(customer: group.remove(at: 0))
|
||||
// Now serving zhangsan!
|
||||
```
|
||||
|
||||
如果一个闭包作为参数,是可以去掉 `{}` 的,参数加了 `@autoclosure` 后,是会自动转换为闭包的。
|
||||
|
||||
但如果函数参数没有加 `@autoclosure`,在调用函数的时候,传参没有加 `{}` 编译器是会报错的
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftAutoClosureError.png" style="zoom:25%">
|
||||
|
||||
正确的做法是:要么加 `@autoclosure` 要么在函数调用的时候加 `{}`
|
||||
|
||||
```swift
|
||||
// 改法1
|
||||
func collectCustomerProviders(_ customerProvider: @escaping () -> String) {
|
||||
customerProoviders.append(customerProvider)
|
||||
}
|
||||
collectCustomerProviders( { group.remove(at: 0) })
|
||||
// 改法2
|
||||
func collectCustomerProviders(_ customerProvider: @autoclosure @escaping () -> String) {
|
||||
customerProoviders.append(customerProvider)
|
||||
}
|
||||
collectCustomerProviders(group.remove(at: 0))
|
||||
```
|
||||
|
||||
如果你的自动闭包允许逃逸,就可以同时使用 `@autoclosure` 和 `@escaping `
|
||||
|
||||
```swift
|
||||
var customerProoviders: [() -> String] = []
|
||||
func collectCustomerProviders(_ customerProvider: @autoclosure @escaping () -> String) {
|
||||
customerProoviders.append(customerProvider)
|
||||
}
|
||||
collectCustomerProviders(group.remove(at: 0))
|
||||
```
|
||||
|
||||
433
Chapter1 - iOS/1.115.md
Normal file
@@ -0,0 +1,433 @@
|
||||
# 属性
|
||||
|
||||
|
||||
|
||||
计算属性的本质是方法。
|
||||
|
||||
```swift
|
||||
struct Circle {
|
||||
var radius: Int
|
||||
var diameter: Int {
|
||||
set {
|
||||
radius = newValue/2
|
||||
}
|
||||
get {
|
||||
2 * radius
|
||||
}
|
||||
}
|
||||
}
|
||||
var circle = Circle(radius: 10)
|
||||
// print(circle.diameter) // 20
|
||||
circle.diameter = 24
|
||||
// print(circle.radius) // 12
|
||||
let diameter = circle.diameter
|
||||
```
|
||||
|
||||
计算属性 `y` 等价于下面的代码:
|
||||
|
||||
```swift
|
||||
setDiameter (newValue: Int) {
|
||||
radius = newValue/2
|
||||
}
|
||||
getDiameter () {
|
||||
return 2*radius
|
||||
}
|
||||
```
|
||||
|
||||
然后通过汇编来窥探下,在 `circle.diameter = 22` 处加断点,可以看到本质上调用的就是 `setter` 方法,`setter` 内部的实现就不一一窥探了
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStorePropertySetterDemo1.png" style="zoom:25%">
|
||||
|
||||
然后断点继续,在 `let diameter = circle.diameter` 处加断点,可以看到调用了 getter 方法
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStorePropertySetterDemo2.png" style="zoom:25%">
|
||||
|
||||
## 异同点
|
||||
|
||||
存储属性:
|
||||
|
||||
- 类似于成员变量
|
||||
|
||||
- 存储在实例的内存中
|
||||
|
||||
- 结构体、类可以定义存储属性
|
||||
|
||||
- 枚举不可以定义存储属性
|
||||
|
||||
- 在创建类、结构体的实例时,必须为所有的存储属性设置一个合适的初始值
|
||||
|
||||
- 延迟存储属性必须是 `var`,不能是 `let`。 因为 Swift 规定 let 必须在实例的初始化方法完成之前就拥有值
|
||||
|
||||
- `lazy` 在多线程情况下,无法保证属性只被初始化1次。
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x:Int
|
||||
lazy var y = 0
|
||||
init(_ x: Int = 0) {
|
||||
self.x = x
|
||||
}
|
||||
}
|
||||
var p = Point(2)
|
||||
print(p.y)
|
||||
```
|
||||
|
||||
- 当结构体包含一个延迟存储属性时,只有 var 才能访问延迟存储属性(因为延迟属性初始化的时候需要改变结构体内存)。Class 的话,实例可以用 let 修饰,访问延迟存储属性是可以的。
|
||||
|
||||
QA:为什么结构体包含一个延迟存储属性时,只有 var 才能访问延迟存储属性?
|
||||
|
||||
之前在 [Swift 结构体和类的内存布局](./1.113.md) 探究过 `struct` 的内存布局,`struct` 的成员变量在内存中是连续存储的。由于是延迟存储属性,等真正使用的时候才会执行延迟属性的初始化逻辑,才会更改 `struct `的内存,所以 `let` 无法满足更改内存的需求。
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x = 0
|
||||
lazy var y = 0
|
||||
}
|
||||
|
||||
let p = Point()
|
||||
print(p.y) // Cannot use mutating getter on immutable value: 'p' is a 'let' constant
|
||||
|
||||
var p2 = Point()
|
||||
print(p2.y) // 0
|
||||
|
||||
|
||||
class Point {
|
||||
var x:Int
|
||||
lazy var y = 0
|
||||
init(_ x: Int = 0) {
|
||||
self.x = x
|
||||
}
|
||||
}
|
||||
|
||||
let p = Point(2)
|
||||
print(p.y) // 0
|
||||
```
|
||||
|
||||
计算属性:
|
||||
|
||||
- 本质就是方法
|
||||
- 不占用实例内存
|
||||
- 枚举、结构体、类都可以定义计算属性
|
||||
- 计算属性只能用 var,不能用 let
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 枚举 rawValue 的原理
|
||||
|
||||
枚举原始值 rawValue 的本质:只读的计算属性,不占用实例内存。
|
||||
|
||||
```swift
|
||||
enum Season: Int {
|
||||
case spring = 10
|
||||
case summer = 20
|
||||
case autumn = 30
|
||||
case winter = 40
|
||||
}
|
||||
|
||||
let season = Season.summer
|
||||
// season.rawValue = 22 // Cannot assign to property: 'rawValue' is immutable
|
||||
print(season.rawValue)
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftEnumRawValueExplore.png" style="zoom:25%">
|
||||
|
||||
通过汇编可以可以看到,在调用 `enum` 的 `rawvalue` 的时候本质是通过计算属性调用 `getter` 来实现的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 属性观察器
|
||||
|
||||
- 可以为非 `lazy` 的 `var` 存储属性设置属性观察期
|
||||
|
||||
- 在初始化器中设置属性值不会触发 `willSet`、`didSet`
|
||||
|
||||
- 属性观察器、计算属性的功能,同样可以应用在全局变量、局部变量上
|
||||
|
||||
```swift
|
||||
var num: Int {
|
||||
get {
|
||||
return 10
|
||||
}
|
||||
set {
|
||||
print("newValue", newValue)
|
||||
}
|
||||
}
|
||||
num = 11
|
||||
print(num)
|
||||
// console
|
||||
newValue 11
|
||||
10
|
||||
|
||||
func test () {
|
||||
var age: Int {
|
||||
set {
|
||||
print("new age is ", newValue)
|
||||
}
|
||||
get {
|
||||
28
|
||||
}
|
||||
}
|
||||
age = 29
|
||||
print(age)
|
||||
}
|
||||
test()
|
||||
// console
|
||||
new age is 29
|
||||
28
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Inout 核心原理
|
||||
|
||||
### 普通的存储属性
|
||||
|
||||
```swift
|
||||
struct Shape {
|
||||
var width: Int
|
||||
var side: Int {
|
||||
willSet {
|
||||
print("willset side", newValue)
|
||||
}
|
||||
didSet {
|
||||
print("didset side", oldValue, side)
|
||||
}
|
||||
}
|
||||
var girth: Int {
|
||||
set {
|
||||
width = newValue/side
|
||||
print("set girth ", newValue)
|
||||
}
|
||||
get {
|
||||
print("get girth")
|
||||
return width * side
|
||||
}
|
||||
}
|
||||
func show() {
|
||||
print("width is \(width), side is \(side), girth is \(girth)")
|
||||
}
|
||||
}
|
||||
|
||||
func changeValue(_ value: inout Int) {
|
||||
value = 20
|
||||
}
|
||||
|
||||
var shape = Shape(width: 10, side: 4)
|
||||
changeValue(&shape.width)
|
||||
shape.show()
|
||||
|
||||
// console
|
||||
get girth
|
||||
width is 20, side is 4, girth is 80
|
||||
```
|
||||
|
||||
在 `changeValue(&shape.width)` 处加汇编可以看到断点停在第10行 `leaq 0x953c(%rip), %rdi ` 即将 `rip + 0x953c = 0x100002cbc + 0x953c = 0x10000C1F8 ` 赋值给 `rdi`。
|
||||
|
||||
第16行也是一样,`leaq 0x9523(%rip), %rdi ` 即将 `rip + 0x9523 = 0x100002cd5 + 0x953c = 0x10000C1F8 ` 赋值给 `rdi`。
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo1.png" style="zoom:25%">
|
||||
|
||||
然后看到17行的关键代码,LLDB 输入 `si`,可以看到在第6行 `movq $0x14, (%rdi)`,将16进制的 `0x14` 也就是20,移动到指定的内存地址 `rdi` 上
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo2.png" style="zoom:25%">
|
||||
|
||||
因为 `struct` 结构体内存布局中,成员变量在内存中是连续存储的。所以 `struct `的地址也就是 `struct` 中第一个成员变量 `width` 的地址。
|
||||
|
||||
|
||||
|
||||
总结:普通的存储属性,在调用方法的时候,如果参数是 `inout` 传递引用,则直接传递存储属性的地址值即可。在方法内部,对该地址对应的值进行修改即可。
|
||||
|
||||
|
||||
|
||||
### 计算属性
|
||||
|
||||
对调用的代码进行调整
|
||||
|
||||
```swift
|
||||
var shape = Shape(width: 10, side: 4)
|
||||
changeValue(&shape.girth)
|
||||
shape.show()
|
||||
// console
|
||||
get girth
|
||||
set girth 20
|
||||
get girth
|
||||
width is 5, side is 4, girth is 20
|
||||
```
|
||||
|
||||
在 `changeValue(&shape.girth)` 处下断点,查看汇编
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo3.png" style="zoom:25%">
|
||||
|
||||
核心思路:方法参数用 `inout`修饰,则传递的是引用(内存地址)。
|
||||
|
||||
- 汇编19行 `callq 0x1000030e0 ; SwiftDemo.Shape.girth.getter : Swift.Int at main.swift:16` 调用了 `girth` 计算属性的 `getter`,`getter` 的返回值存放在寄存器 `rax` 上
|
||||
|
||||
- 20行将 `movq %rax, -0x28(%rbp)` 函数返回值 `rax` 存放在 `main` 函数的栈空间上(虽然没有写调用函数,但是代码主入口就是 `main` 函数),且 `rbp` 到 `rsp` 之间都是函数的栈空间
|
||||
|
||||
- 21行 `leaq -0x28(%rbp), %rdi` 将栈空间上 `-0x28(%rbp)` 的地址值赋值给 `rdi` 寄存器
|
||||
|
||||
- 22行 `callq 0x1000037b0 ; SwiftDemo.changeValue(inout Swift.Int) -> () at main.swift:26` 调用 `changeValue` 方法,参数通过寄存器 `rdi` 传递,里面是栈空间 getter 值的地址。
|
||||
|
||||
- LLDB 输入 `si` 查看 changeValue 内部。可以看到第6行 `movq $0x14, (%rdi)` 直接将20赋值给 `rdi`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo4.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
- LLDB 输入 `finish` 结束 `changeValue` 细节,查看外部23行汇编 `movq -0x28(%rbp), %rdi` ,将 `main` 函数栈空间上 `getter` 返回值的内存对应的值,保存到寄存器 `rdi` 上。
|
||||
|
||||
- 25行 `callq 0x100003250 ; SwiftDemo.Shape.girth.setter : Swift.Int at main.swift:12` 调用计算属性的 `setter`,函数参数为 `rid` 寄存器里的值(也就是20)
|
||||
|
||||
总结:带有计算属性的存储属性,如果调用的方法参数是 `inout` 类型,系统真正实现,不能直接将对应的地址传进去,因为传进去很多简单,满足了修改值的需求。但是属性观察器的 `set`、`get` 就没办法触发了。所以为了触发属性观察器系统的设计是:
|
||||
|
||||
- 第一步:先将传递进去的属性调用 `getter` ,保存在函数的栈地址空间内的某个内存上
|
||||
- 第二步:然后调用带有 `inout` 属性的方法,将步骤一得到的内存传递当作参数传进去。修改该内存对应的值
|
||||
- 第三步:将步骤二得到的值后,调用 `setter` 方法。
|
||||
|
||||
这个流程下来,满足了修改值,且触发了原始属性观察器的需求。
|
||||
|
||||
|
||||
|
||||
### 带有属性观察器的存储属性
|
||||
|
||||
对调用的代码进行调整
|
||||
|
||||
```swift
|
||||
var shape = Shape(width: 10, side: 4)
|
||||
changeValue(&shape.side)
|
||||
shape.show()
|
||||
// console
|
||||
willset side 20
|
||||
didset side 4 20
|
||||
get girth
|
||||
width is 10, side is 20, girth is 200
|
||||
```
|
||||
|
||||
在 `changeValue(&shape.side)` 处添加断点,查看汇编
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo5.png" style="zoom:25%">
|
||||
|
||||
分析:
|
||||
|
||||
- 17行 `movq 0x9549(%rip), %rax ; SwiftDemo.shape : SwiftDemo.Shape + 8` 将地址格式为 `0x9549(%rip)` 一个全局变量,也就是 `shape` 的地址 + 8 的值,赋值给 `rax` 寄存器
|
||||
|
||||
- 18行 `movq %rax, -0x28(%rbp)` 将寄存器 `rax` 里的值,赋值给 `main` 函数的栈空间上的局部变量 `-0x28(%rbp)`
|
||||
|
||||
- 19行 将 `main` 函数的栈空间上的局部变量 `-0x28(%rbp)` 的地址值,赋值给寄存器 `rdi`
|
||||
|
||||
- 20行 `callq 0x1000037b0 ; SwiftDemo.changeValue(inout Swift.Int) -> () at main.swift:26` 调用 `changeValue `方法。函数参数通过寄存器 `rdi` 传递,函数内部修改了该内存上的值
|
||||
|
||||
- 21行 `movq -0x28(%rbp), %rdi` 将 `main` 函数的栈空间上的局部变量 `-0x28(%rbp)` 的值,赋值给寄存器 `rdi`。也就是修改后的20
|
||||
|
||||
- 23行 `callq 0x100002db0 ; SwiftDemo.Shape.side.setter : Swift.Int at main.swift:3` 调用 setter
|
||||
|
||||
- LLDB 输入 `si`,可以看到 `setter` 方法内部,调用了 `willSet`、`didSet`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInoutExploreDemo6.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
总结:带有属性观察器的存储属性,如果调用的方法参数是 `inout` 类型,系统真正实现,不能直接将对应的地址传进去,因为传进去很多简单,满足了修改值的需求。但是属性观察器的 `willSet`、`didSet` 就没办法触发了。所以为了触发属性观察器系统的设计是:
|
||||
|
||||
- 第一步:先将传递进去的地址,保存在函数的栈地址空间内的某个内存上
|
||||
- 第二步:然后调用带有 `inout` 属性的方法,将步骤一得到的内存传递当作参数传进去。修改该内存对应的值
|
||||
- 第三步:将步骤二得到的值后,调用一个 `setter` 方法,`setter` 方法内,先调用 `willSet`,再修改真正的带有观察属性的存储属性的值,最后调用 `didSet` 方法。
|
||||
|
||||
这个流程下来,满足了修改值,且触发了原始属性观察器的需求。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
1. 如果实参有内存地址,且没有设置属性观察器和计算属性,实现是直接将实参的内存地址传入带 `inout` 函数
|
||||
|
||||
2. 如果实参是计算属性或者设置了属性观察器:系统采用了 Copy In Copy Out 的策略。
|
||||
1. 调用带 `inout` 函数时,先复制实参的值,产生副本 (getter,栈空间上的局部变量)
|
||||
2. 将副本的内存地址传入带 `inout` 函数(副本进行引用传递),在函数内部修改副本的值
|
||||
3. 函数返回后,再将副本的值覆盖实参的值(setter,willSet、set)
|
||||
|
||||
|
||||
|
||||
## 类型属性
|
||||
|
||||
- 不同于存储属性,类型属性必须设置初始值,永伟类型属性不像存储属性那样有 `init` 初始化器来初始化存储属性
|
||||
|
||||
- 类型属性就不存储在每个实例的内存里
|
||||
|
||||
- 存储属性默认就是 `lazy`,会在第一次使用的时候才初始化
|
||||
|
||||
- 存储属性就算被多个线程同时访问,但系统会保证只初始化1次
|
||||
|
||||
- 存储类型属性可以是 `let`
|
||||
|
||||
- 存储属性可以用 `class`、`static` 修饰
|
||||
|
||||
- 枚举 enum 里面不可以实例存储属性,但是可以定义类型存储属性
|
||||
|
||||
```swift
|
||||
enum Season {
|
||||
static let age: Int = 0
|
||||
case spring, summer, antumn, winter
|
||||
}
|
||||
var season = Season.summer
|
||||
```
|
||||
|
||||
- 类型属性的经典场景就是单例模式
|
||||
|
||||
```swift
|
||||
class FileManager {
|
||||
private init() {}
|
||||
public static let sharedInstance: FileManager = FileManager()
|
||||
}
|
||||
|
||||
var manager1 = FileManager.sharedInstance
|
||||
var manager2 = FileManager.sharedInstance
|
||||
var manager3 = FileManager.sharedInstance
|
||||
print(Mems.ptr(ofRef: manager1)) // 0x0000600000008030
|
||||
print(Mems.ptr(ofRef: manager2)) // 0x0000600000008030
|
||||
print(Mems.ptr(ofRef: manager3)) // 0x0000600000008030
|
||||
```
|
||||
|
||||
|
||||
|
||||
Demo1:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftTypePropertyDemo1.png" style="zoom:25%">
|
||||
|
||||
`movq $0xa, 0x86d1(%rip) ` num1 的地址为: `rip + 0x86d1 = 0x100003b0f + 0x86d1 = 0x10000C1E0 `
|
||||
|
||||
`movq $0xb, 0x86ce(%rip)` num2 的地址为: `rip + 0x86ce = 0x100003b1a + 0x86ce = 0x10000C1E8 `
|
||||
|
||||
`movq $0xc, 0x86cb(%rip) ` num3 的地址为: `rip + 0x86cb = 0x100003b25 + 0x86cb = 0x10000C1F0 `
|
||||
|
||||
可以看到 `0x10000C1E0` `0x10000C1E8` `0x10000C1F0` 在内存上是连续的,间隔8Byte。可见分配的3个全局变量内存是连续的
|
||||
|
||||
|
||||
|
||||
Demo2
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftTypePropertyDemo2.png" style="zoom:25%">
|
||||
|
||||
`movq $0xa, 0x8b65(%rip)` num1 的内存为 `rip + 0x8b65 = 0x1000037c3 + 0x8b65 = 0x10000C328 `
|
||||
|
||||
可以看到15行将11赋值给 rax,所以直接读取 rax 的地址:`0x000000010000c330`
|
||||
|
||||
`movq $0xc, 0x8b38(%rip) ` num1 的内存为 `rip + 0x8b38 = 0x100003800 + 0x8b38 = 0x10000C338 `
|
||||
|
||||
可以看到 `0x10000C328` `0x10000c330` `0x10000C338` 也是内存连续的。所以类型属性就是带有访问控制(必须通过类来访问)的全局变量
|
||||
|
||||
|
||||
|
||||
Demo3
|
||||
|
||||
类型属性如何保证线程安全的?如何保证只会初始化一次。
|
||||
|
||||
底层会调用 `swift_once` 进而调用 `dispatch_once_t`,`dispatch_once_t` 会传递一个函数地址进去执行,类型属性的初始化代码将会被包装成一个函数。 由 `dispatch_once_t` 保证线程安全和只初始化1次。
|
||||
646
Chapter1 - iOS/1.116.md
Normal file
@@ -0,0 +1,646 @@
|
||||
# Swift 类底层剖析
|
||||
|
||||
## 类的内存结构
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var age: Int = 0
|
||||
}
|
||||
|
||||
class Student: Person {
|
||||
var score: Int = 0
|
||||
}
|
||||
|
||||
class Worker: Student {
|
||||
var salary: Int = 0
|
||||
}
|
||||
|
||||
let person = Person()
|
||||
person.age = 28
|
||||
print(Mems.size(ofRef: person))
|
||||
print(Mems.memStr(ofRef: person))
|
||||
|
||||
32
|
||||
0x000000010000c400 0x0000000000000003
|
||||
0x000000000000001c 0x0000000000000000
|
||||
|
||||
let student = Student()
|
||||
student.score = 100
|
||||
print(Mems.size(ofRef: student))
|
||||
print(Mems.memStr(ofRef: student))
|
||||
32
|
||||
0x000000010000c4b0 0x0000000000000003
|
||||
0x000000000000001c 0x0000000000000064
|
||||
|
||||
let worker = Worker()
|
||||
worker.salary = 1000
|
||||
print(Mems.size(ofRef: worker))
|
||||
print(Mems.memStr(ofRef: worker))
|
||||
48
|
||||
0x000000010000c580 0x0000000000000003
|
||||
0x000000000000001c 0x0000000000000064 0x00000000000003e8 0x00007ff8501c0938
|
||||
```
|
||||
|
||||
- 内存对齐都是16 Byte 的整数倍
|
||||
- 一个类内存中,至少占16字节的内存。前8位是类信息、其次的8位是引用计数信息,最后跟属性内存
|
||||
- 由于类存在继承,所以子类中,前16字节存储类信息和引用计数信息,其次是属性内存,存在继承的话,前面的属性是父类的属性,后面才是自己的属性。
|
||||
|
||||
所以:
|
||||
|
||||
- Person 类的内存: 8 Byte 的类信息 + 8 Byte 引用计数信息 + 8 Byte Int Age 属性 = 24 Byte,由于需要16的倍数,所以是32 Byte
|
||||
- Student 类的内存: 8 Byte 的类信息 + 8 Byte 引用计数信息 + 8 Byte Int Age 属性 + 8 Byte 的 Int Score 属性 = 32 Byte,由于需要16的倍数,所以是32 Byte
|
||||
- Worker 类的内存: 8 Byte 的类信息 + 8 Byte 引用计数信息 + 8 Byte Int Age 属性 + 8 Byte 的 Int Score 属性 + 8 Byte 的 Int Salary 属性 = 40 Byte,由于需要16的倍数,所以是 48 Byte
|
||||
|
||||
|
||||
|
||||
## 继承
|
||||
|
||||
值类型(枚举、结构体)不支持继承,只有类支持继承
|
||||
|
||||
没有父类的类,称为基类。Swift 并不像 OC、Java 那样规定:任何类最终都要继承自某个基类(OC 的 NSObject)。
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
class Person {}
|
||||
class Student: Person {}
|
||||
print(class_getSuperclass(Student.self)!) // Person
|
||||
print(class_getSuperclass(Person.self)!) // _TtCs12_SwiftObject
|
||||
```
|
||||
|
||||
丛输出可以看出 Swift 还存在一个隐藏基类:`Swift._SwiftObject`,可查看 [Swift 源码](https://github.com/apple/swift/blob/main/stdlib/public/runtime/SwiftObject.h)
|
||||
|
||||
|
||||
|
||||
## 方法
|
||||
|
||||
结构体和枚举是值类型,默认情况下,值类型的属性是不能被自身的实例方法修改。
|
||||
|
||||
如果想在方法内修改,需要在 `func` 前加 `mutating` 才可以
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x: Double = 0.0
|
||||
var y: Double = 0.0
|
||||
func moveBy(_ delatX: Double, _ delatY: Double) {
|
||||
self.x += delatX
|
||||
self.y += delatY
|
||||
}
|
||||
}
|
||||
var point = Point()
|
||||
point.moveBy(0.2, 0.2)
|
||||
// compiler error
|
||||
Left side of mutating operator isn't mutable: 'self' is immutable
|
||||
```
|
||||
|
||||
改进
|
||||
|
||||
```swift
|
||||
struct Point {
|
||||
var x: Double = 0.0
|
||||
var y: Double = 0.0
|
||||
mutating func moveBy(_ delatX: Double, _ delatY: Double) {
|
||||
self.x += delatX
|
||||
self.y += delatY
|
||||
}
|
||||
}
|
||||
var point = Point()
|
||||
point.moveBy(0.2, 0.4)
|
||||
print(point.x, point.y)
|
||||
// 0.2 0.4
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 重写方法
|
||||
|
||||
`override`
|
||||
|
||||
被 class 修饰的类型方法、下标,允许被子类重写
|
||||
|
||||
被 static 修饰的类型方法、下标,不允许被子类重写
|
||||
|
||||
```swift
|
||||
class Animal {
|
||||
static var innerValue:Int = 0
|
||||
class func speak() {
|
||||
print("Animal speak")
|
||||
}
|
||||
|
||||
class subscript(index: Int) -> Int {
|
||||
set {
|
||||
innerValue = newValue
|
||||
}
|
||||
get {
|
||||
innerValue
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
class Dog: Animal {
|
||||
override class func speak() {
|
||||
super.speak()
|
||||
print("dog is bark")
|
||||
}
|
||||
override class subscript(index: Int) -> Int {
|
||||
set {
|
||||
innerValue = newValue
|
||||
}
|
||||
get {
|
||||
innerValue
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Animal.speak() // Animal speak
|
||||
Animal[5] = 3
|
||||
print(Animal[5]) // 3
|
||||
Dog.speak() // Animal speak dog is bark
|
||||
```
|
||||
|
||||
但如果将 `Animal` 方法的 `class` 改为 `static`,就无法 `override` 了
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftCannotOverrideStaticMethod.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
## 重写属性
|
||||
|
||||
- 子类不可以将父类的属性改写为存储属性
|
||||
- 子类可以将父类的属性(存储属性、计算属性)重写为计算属性
|
||||
- 只能重写 var 属性,不能重写 let 属性
|
||||
- 重写时,属性名、类型要一致
|
||||
- 子类重写后的属性权限(读写),不能小于父类属性的权限
|
||||
- 如果父类属性是只读的,子类重写后的属性要么是只读的,要么是可读可写的
|
||||
- 如果父类的属性是可读可写的,子类重写后的属性也必须是可读可写的
|
||||
|
||||
|
||||
|
||||
## 重写类型属性
|
||||
|
||||
- 被 class 修饰的计算类型属性,可以被子类重写
|
||||
- 被 static 修饰的类型属性(存储、计算),不可以被子类重写
|
||||
- 可以在子类中为父类属性(除了只读的计算属性、let 属性)增加属性观察器
|
||||
|
||||
```swift
|
||||
class Shape {
|
||||
var radius: Int = 1 {
|
||||
willSet {
|
||||
print("Shape will set radius", newValue)
|
||||
}
|
||||
didSet {
|
||||
print("Shape did set radius", oldValue, radius)
|
||||
}
|
||||
}
|
||||
}
|
||||
class Circle: Shape {
|
||||
override var radius: Int {
|
||||
willSet {
|
||||
print("Cirle will set radius", newValue)
|
||||
}
|
||||
didSet {
|
||||
print("Circle did set radius", oldValue, radius)
|
||||
}
|
||||
}
|
||||
}
|
||||
var circle = Circle()
|
||||
circle.radius = 2
|
||||
// console
|
||||
Cirle will set radius 2
|
||||
Shape will set radius 2
|
||||
Shape did set radius 1 2
|
||||
Circle did set radius 1 2
|
||||
```
|
||||
|
||||
可以看到输出类似 Node 的洋葱模型,willset 从外到里,didset 从里到外。
|
||||
|
||||
|
||||
|
||||
## final
|
||||
|
||||
- 被 final 修饰的方法、属性、下标是禁止被重写的
|
||||
|
||||
- 被 final 修饰的类,禁止被继承
|
||||
|
||||
|
||||
|
||||
## <span id="target-anchor">多态的实现原理</span>
|
||||
|
||||
OC: Runtime
|
||||
|
||||
C++:虚表
|
||||
|
||||
Swift:没有 Runtime,所以多态的实现类似 C++
|
||||
|
||||
```swift
|
||||
class Animal {
|
||||
func speak () {
|
||||
print("Animal speak")
|
||||
}
|
||||
func eat () {
|
||||
print("Animal eat")
|
||||
}
|
||||
func sleep () {
|
||||
print("Animal sleep")
|
||||
}
|
||||
}
|
||||
|
||||
class Dog: Animal {
|
||||
override func speak() {
|
||||
print("Dog speak")
|
||||
}
|
||||
override func eat() {
|
||||
print("Dog eat")
|
||||
}
|
||||
func run () {
|
||||
print("Dog run")
|
||||
}
|
||||
}
|
||||
|
||||
var animal = Animal()
|
||||
animal.speak()
|
||||
animal.eat()
|
||||
animal.sleep()
|
||||
|
||||
animal = Dog()
|
||||
animal.speak()
|
||||
animal.eat()
|
||||
animal.sleep()
|
||||
// console
|
||||
Animal speak
|
||||
Animal eat
|
||||
Animal sleep
|
||||
Dog speak
|
||||
Dog eat
|
||||
Animal sleep
|
||||
```
|
||||
|
||||
在 `animal.speak()` 处加断点,可以看到
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo1.png" style="zoom:25%">
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo3.png" style="zoom:25%">
|
||||
|
||||
解释:
|
||||
|
||||
- 汇编84行 `movq 0x9356(%rip), %r13 ` 是将全局变量 `animal` 的地址赋值给 `r13`
|
||||
- 汇编90行 `movq (%r13), %rax` 将 `r13` 处取出内存的前8个字节,赋值给 `rax`
|
||||
- 汇编91行 `callq *0x50(%rax)` ,也就是计算出 `rax + 0x50` 的地址,然后取出8 Byte 出来,也就是 `Dog.speak` 然后调用
|
||||
- 汇编107行 `callq *0x58(%rax)` ,也就是计算出 `rax + 0x508` 的地址,然后取出8 Byte 出来,也就是 `Dog.eat` 然后调用
|
||||
- 汇编123行 `callq *0x60(%rax)` ,也就是计算出 `rax + 0x60` 的地址,然后取出8 Byte 出来,也就是 `Animal.sleep` 然后调用
|
||||
|
||||
|
||||
|
||||
画了张图,也就是说 `rax` 中存放了 Dog 对象内存中的前8个字节,也就是下图的最右侧
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo2.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
核心是上面的内存布局图。结合汇编就知道多态是如何实现的。
|
||||
|
||||
总结: **虚函数表**(vtable)是一种用于实现动态多态性的机制,通常用于面向对象的编程语言中(C++ 也是一样)。在 Swift 中,虚函数表用于存储类或协议中方法的地址,以便在运行时进行动态分派。
|
||||
|
||||
在 Swift 中,虚函数表的作用是为每个类或协议创建一个表,其中包含了对应方法的地址。当调用对象的方法时,运行时系统会根据对象的实际类型查找对应的虚函数表,然后调用表中存储的方法地址,从而触发特定的实现。
|
||||
|
||||
虚函数表在 Swift 中的作用是实现动态分派,使得在运行时根据对象的实际类型确定调用的具体实现。这为 Swift 中的多态性提供了基础,允许相同的方法名称根据对象的类型触发不同的实现,从而实现灵活的对象行为。
|
||||
|
||||
|
||||
|
||||
## 类的类型信息存储在哪
|
||||
|
||||
说明:同一个类的不同对象,它的类信息是一样的。也就是说不通的对象指针,所指向的类信息内存是同一块。
|
||||
|
||||
```swift
|
||||
var dog1 = Dog()
|
||||
var dog2 = Dog()
|
||||
```
|
||||
|
||||
存储在全局区。可以利用 MachOView 去查看。
|
||||
|
||||
|
||||
|
||||
## 初始化器
|
||||
|
||||
### require
|
||||
|
||||
- 用 required 修饰的指定初始化器,表明其所有的子类都必须实现该初始化器(通过继承或者重写来实现)
|
||||
- 如果子类重写了 required 初始化器,也必须加上 required,不用加 override
|
||||
|
||||
|
||||
|
||||
## 可失败初始化器
|
||||
|
||||
类、结构体、枚举都可以使用 `init?` 定义可失败初始化器,也可以用 `init!` 来定义可失败初始化器。区别下面会讲
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var name: String
|
||||
init?(_ name: String) {
|
||||
if name.isEmpty {
|
||||
return nil
|
||||
}
|
||||
self.name = name
|
||||
}
|
||||
}
|
||||
|
||||
var person1 = Person("")
|
||||
print(person1) // nil
|
||||
var person2 = Person("FantasticLBP")
|
||||
print(person2) // Optional(SwiftDemo.Person)
|
||||
print(person2!) // SwiftDemo.Person
|
||||
```
|
||||
|
||||
这种设计系统中也存在,比如 Int 的可失败初始化器:`@inlinable public init?(_ description: String)`
|
||||
|
||||
```swift
|
||||
var num = Int("12e2")
|
||||
print(num) // nil
|
||||
num = Int("12")
|
||||
print(num) // Optional(12)
|
||||
```
|
||||
|
||||
注意点:
|
||||
|
||||
1. 不允许同时定义参数标签、参数个数、参数类型相同的可失败初始化器和非可失败初始化器。因为在外部调用的时候,不知道到底是使用哪个初始化方法。编译器会报错 `Invalid redeclaration of 'init(_:)'`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftCanFailedInit.png" style="zoom:25%">
|
||||
|
||||
2. 可以用 `init!` 来定义隐式解包的可失败初始化器
|
||||
|
||||
3. 可失败初始化器可以调用非可失败初始化器,非可失败初始化器调用可失败初始化器需要进行解包。如果直接调用会报错 `A non-failable initializer cannot delegate to failable initializer 'init(_:)' written with 'init?'`
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var name: String
|
||||
init?(_ name: String) {
|
||||
if name.isEmpty {
|
||||
return nil
|
||||
}
|
||||
self.name = name
|
||||
}
|
||||
convenience init() {
|
||||
self.init("")! // 极端 case,设计不合理
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
非可失败初始化器也可以调用可失败初始化器的隐式解包。
|
||||
|
||||
```swift
|
||||
class Person2 {
|
||||
var name: String
|
||||
init!(_ name: String) {
|
||||
if name.isEmpty {
|
||||
return nil
|
||||
}
|
||||
self.name = name
|
||||
}
|
||||
convenience init() {
|
||||
self.init("")
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftCanFailedInit2.png" style="zoom:25%">
|
||||
|
||||
且前面的写法比较危险,假设第一个 `init?` 返回 `nil`,第二个 `convenience init()` 去对 nil 强制解包,则会 crash
|
||||
|
||||
4. 可以用一个非可失败初始化器重写一个可失败初始化器,但反过来不行
|
||||
|
||||
5. 如果初始化器调用一个可失败初始化器导致初始化失败,那么整个初始化过程都失败,并且之后的代码都停止执行
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var name: String
|
||||
init?(_ name: String) {
|
||||
if name.isEmpty {
|
||||
return nil
|
||||
}
|
||||
self.name = name
|
||||
}
|
||||
convenience init?() {
|
||||
self.init("")
|
||||
print("我是后面的代码1")
|
||||
print("我是后面的代码2")
|
||||
}
|
||||
}
|
||||
|
||||
var person1 = Person()
|
||||
print(person1)
|
||||
```
|
||||
|
||||
`init` 初始化失败,后面的 `我是后面的代码1` 均不会执行
|
||||
|
||||
### 可失败初始化器设计哲学
|
||||
|
||||
- 安全性优先:Swift 注重安全性,可失败初始化器的设计使得对象的初始化过程更加可靠和安全。通过返回一个可选值来表示初始化成功或失败,可以避免在初始化失败时产生不确定的对象状态
|
||||
- 错误处理:可失败初始化器与 Swift 的错误处理机制结合使用,使得在初始化失败时能够更好地捕获和处理错误。这种设计哲学强调了对异常情况的处理和错误信息的传递。
|
||||
- **灵活性**:可失败初始化器提供了一种灵活的初始化机制,允许开发者更加精确地控制对象的初始化过程。这种设计哲学使得对象初始化更加灵活和可定制。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 可选链
|
||||
|
||||
```swift
|
||||
var dict:[String: (Int, Int) -> Int] = [
|
||||
"sum": (+),
|
||||
"minus": (-),
|
||||
"multiple": (*),
|
||||
"divide": (/)
|
||||
]
|
||||
print(dict["sum"]) // Optional((Function))
|
||||
var result = dict["divide"]?(40, 20) // 2
|
||||
print(result!)
|
||||
```
|
||||
|
||||
- 如果可选项为 nil,调用方法、下标、属性失败,结果为 nil
|
||||
- 如果可选项不为 nil,调用方法、下标、属性成功,结果会被包装为可选项
|
||||
- 如果结果本来是可选项,则不会进行再次包装
|
||||
- 如果链中任何一个节点为 nil,那么整个链就会调用失败。`var weight = person?.dog?.weight // Int?`
|
||||
- 多个 `?` 可以链接在一起 `var weight = person?.dog?.weight`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## X.self , X.Type, AnyClass
|
||||
|
||||
- `X.self` 是一个元类型(metadata)的指针,metadata 存放着类型相关信息
|
||||
- `X.self` 属于 `X.type` 类型
|
||||
|
||||
|
||||
|
||||
通过汇编探究下背后细节
|
||||
|
||||
```swift
|
||||
class Person { }
|
||||
var person: Person = Person()
|
||||
var personType: Person.Type = Person.self
|
||||
```
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassMetaDataTypeDemo1.png" style="zoom:25%">
|
||||
|
||||
在第二行代码下断点,可以看到关键的汇编是第8行和第12行:
|
||||
|
||||
- 第14行可以看到 `rip + 0x89ae = 0x10000396a + 0x89ae = 0x10000C318 `,明显是一个堆地址空间,也就是全局变量 `person`
|
||||
- 第15行可以看到 `rip + 0x89af = 0x100003971 + 0x89af = 0x10000C320 `,明显是一个堆地址空间,也就是全局变量 `personType`
|
||||
- 顺着关键代码找上去,看看 `rax`、`rcx` 的值是哪来的
|
||||
|
||||
- 第8行调用函数后可以看到 Xcode 的说明,获取 `metadata`,函数返回值保存到 `rax`,LLDB 打印出为 `0x000000010000c248`
|
||||
|
||||
- 第11行初始化堆内存后,将地址保存到寄存器 `rax`,LLDB 打印出地址为 `0x0000600000004010`,然后查看 `0x0000600000004010` 对应的对象信息,可以看到内存的前8个字节的值,就是上面得到的 `metadata` 对象的地址值
|
||||
|
||||
- `metadata` 结构类似下图右侧
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo2.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`X.self` 和 `type(of:x)` 效果等价
|
||||
|
||||
```swift
|
||||
class Person { }
|
||||
var person: Person = Person()
|
||||
print(Person.self == type(of: person)) // true
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 元类型的应用
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
required init() {}
|
||||
}
|
||||
class Worker: Person {}
|
||||
class Student: Person {}
|
||||
func createInstance(_ items: [Person.Type]) -> [Person] {
|
||||
var people:[Person] = Array<Person>()
|
||||
for item in items {
|
||||
people.append(item.init())
|
||||
}
|
||||
return people
|
||||
}
|
||||
|
||||
let student = Student()
|
||||
let studentType = type(of: student)
|
||||
let workerType = Worker.self
|
||||
var people: Array<Person> = createInstance([studentType, workerType])
|
||||
print(people) // [SwiftDemo.Student, SwiftDemo.Worker]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Self
|
||||
|
||||
Self 一般用作返回值类型,限定返回值跟方法调用者必须是同一类型(也可以当作参数类型)
|
||||
|
||||
```swift
|
||||
protocol Runable {
|
||||
func copy() -> Self
|
||||
}
|
||||
|
||||
class Person: Runable {
|
||||
required init() {}
|
||||
func copy() -> Self {
|
||||
type(of: self).init()
|
||||
}
|
||||
}
|
||||
|
||||
class Student: Person { }
|
||||
|
||||
var person = Person()
|
||||
print(person.copy()) // Person
|
||||
var student = Student()
|
||||
print(student.copy()) // Student
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## OC/Swift 运行时
|
||||
|
||||
### 消息派发方式
|
||||
|
||||
消息派发方式有3种
|
||||
|
||||
#### 直接派发(Direct Dispatch)
|
||||
|
||||
会将整个方法的地址,直接硬编码到函数调用的地方。直接派发是最快的,不止是因为需要调用的指令集会更少,并且编译器还能够有很大的优化空间,例如函数内联等,直接派发也被称为静态调用
|
||||
|
||||
然而,对于编程来水,直接调用也是最大的局限,而且因为缺乏动态性,所以没有办法支持继承和多态等特性。
|
||||
|
||||
|
||||
|
||||
#### 函数表派发(Table Dispatch)
|
||||
|
||||
函数表派发是编译型语言实现动态行为最常见的方式。寒暑表使用了一个数组来存储类生命的每一个函数的指针。大部分语言把整个称为“Virtual table”(虚函数表、虚表,c++),Swift 里称为 “witness table”。每一个类都会维护一个函数表,里面记录着类所有的函数,如果父类函数被 override 的话,表里面只会保存被 overrride 后的函数。一个子类新添加的函数都会被插入到这个数组的最后,运行时会根据这一个表去决定实际需要被调用的函数。
|
||||
|
||||
就像上面[多态实现的原理](#target-anchor)这里讲到的一样
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo2.png" style="zoom:25%">
|
||||
|
||||
查表是一种简单、易实现、性能可预知的方式。然而,这种派发方式比起直接派发来说,还是慢了一点(从字节码的角度来看,多了两次读和一次跳转。由此带来了性能损耗)。另一个慢的原因在于编译器可能会由于函数内执行的任务,导致无法优化(如果函数带有副作用的话)
|
||||
|
||||
这种基于数组的实现,缺陷在于函数表无法拓展。子类会在虚函数表的最后插入新函数,没有位置可以让 extension 安全地插入函数。
|
||||
|
||||
|
||||
|
||||
#### 消息机制派发(Message Dispatch)
|
||||
|
||||
消息机制是调用函数最动态的方式,也是 Cocoa 的基石,催生了 KVO、UIAppearance、CoreData 等,这种运作方式的关键在于开发者可以在运行时改变函数的行为。不止可以通过 swizzling 来改变,甚至可以用 isa-swizzling 修改对象的继承关系,可以在面向对象的基础上实现自定义派发。
|
||||
|
||||
|
||||
|
||||
### OC 运行时
|
||||
|
||||
主要体现在
|
||||
- 动态类型(dynamic typing)
|
||||
- 动态绑定(dynamic binding)
|
||||
- 动态装载(dynamic loading)
|
||||
|
||||
|
||||
|
||||
### Swift 运行时
|
||||
- 纯 Swift 类的函数调用已经不再是 Objective-C 的运行时发消息,而是类似 c++ 的虚表 vtable,在编译时就确定了调用哪个函数,所以没办法通过 runtime 获取方法、属性
|
||||
- 而 Swift 为了兼容 Objective-C,凡是继承自 NSObject 的类都会保留其动态性,所以能够通过 runtime 拿到方法。老版本的 swift(如2.2)是编译期隐式的自动帮你加上了 `@objc`,而4.0以后版本的 swift 编译期去掉了隐式特性,必须显示声明
|
||||
- 不管是 Swift 类,还是继承自 NSObject 的类,只要在属性和方法前面加 `@objc` 关键字,就可以使用 runtime
|
||||
|
||||
|
||||
|
||||
| | 原始定义 | 拓展 |
|
||||
| -------------------- | ---------- | ---------- |
|
||||
| 值类型 | 直接派发 | 直接派发 |
|
||||
| 协议 | 函数表派发 | 直接派发 |
|
||||
| 类 | 函数表派发 | 直接派发 |
|
||||
| 继承自 NSObject 的类 | 函数表派发 | 函数表派发 |
|
||||
|
||||
|
||||
|
||||
- 值类型总是会使用直接派发,简单易懂
|
||||
- 协议和类的 extension 都会使用直接派发
|
||||
- NSObject 的 extention 会使用消息机制进行派发
|
||||
- NSObject 声明作用域的函数都会使函数表进行派发
|
||||
- 协议里声明的,并且带有默认实现的函数会使用函数表进行派发
|
||||
|
||||
|
||||
|
||||
修饰符
|
||||
|
||||
| final | 直接派发 |
|
||||
| ---------------- | ---------------------- |
|
||||
| dynaminc | 消息机制派发 |
|
||||
| @objc & @nonobjc | 改变在 oc 里的可见性 |
|
||||
| @inline | 告诉编译器可以直接派发 |
|
||||
|
||||
|
||||
|
||||
有个特殊的组合 final 和 @objc。在标记为 final 的同时,也可以使用 @objc 来让函数可以使用消息机制派发。这么做的结果就是,调用函数的时候会使用直接派发,但也会在 Objective-C 的运行时里注册对应的 selector,函数可以响应 `perform(selector:)` 以及别的 Objective-C 特性,但在直接调用时,又可以有直接派发的性能。
|
||||
|
||||
266
Chapter1 - iOS/1.117.md
Normal file
@@ -0,0 +1,266 @@
|
||||
# Swift 协议探究
|
||||
|
||||
- 协议可以用来定义属性、方法、下标的声明,协议可以被类、枚举、结构体遵守(多个协议用逗号隔开)
|
||||
|
||||
- 协议中定义的方法不能有默认参数值
|
||||
|
||||
- 协议中定义属性必须是 `var`
|
||||
|
||||
- 实现协议时定义的属性权限,要不小于协议中定义的属性权限
|
||||
|
||||
- 协议定义属性是 `get`、`set` 时,用 `var` 存储属性或者 `get`、`set` 计算属性实现
|
||||
|
||||
- 为了保证通用,协议中必须用 `static` 定义类型方法、类型属性、类型下标
|
||||
|
||||
- 只有将协议中的实例方法标记为 `mutating`
|
||||
|
||||
- 才可以允许结构体、枚举对象在方法里修改自身内存。否则编译器会报错:`Cannot assign to property: 'self' is immutable`
|
||||
- 类遵循协议,实现方法的时候不用加 `mutating`,枚举、结构体的实现需要加 `mutating`
|
||||
|
||||
|
||||
|
||||
```swift
|
||||
protocol Drawable {
|
||||
func draw()
|
||||
}
|
||||
|
||||
class Size: Drawable {
|
||||
var width: Int = 0
|
||||
func draw() {
|
||||
width = 10
|
||||
}
|
||||
}
|
||||
var size = Size()
|
||||
print(size.width) // 0
|
||||
size.draw()
|
||||
print(size.width) // 10
|
||||
|
||||
struct Point: Drawable {
|
||||
var x : Int = 0
|
||||
var y: Int = 0
|
||||
func draw() {
|
||||
x = 10 // Cannot assign to property: 'self' is immutable
|
||||
y = 10 // Cannot assign to property: 'self' is immutable
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要想修改需要加 `mumating`
|
||||
|
||||
```swift
|
||||
struct Point: Drawable {
|
||||
var x : Int = 0
|
||||
var y: Int = 0
|
||||
mutating func draw() {
|
||||
x = 10
|
||||
y = 10
|
||||
}
|
||||
}
|
||||
var point = Point()
|
||||
print(point.x, point.y)
|
||||
point.draw()
|
||||
print(point.x, point.y)
|
||||
```
|
||||
|
||||
- 协议中还可以定义初始化器 `init`,非 `final` 类实现协议时, `init` 方法必须加 `required`
|
||||
|
||||
```swift
|
||||
protocol Drawable {
|
||||
init(x: Int, y: Int)
|
||||
}
|
||||
class Point: Drawable {
|
||||
var x: Int = 0
|
||||
var y: Int = 0
|
||||
required init(x: Int, y: Int) {
|
||||
self.x = x
|
||||
self.y = y
|
||||
}
|
||||
}
|
||||
final class Size: Drawable {
|
||||
var x: Int = 0
|
||||
var y: Int = 0
|
||||
init(x: Int, y: Int) {
|
||||
self.x = x
|
||||
self.y = y
|
||||
}
|
||||
}
|
||||
|
||||
var point = Point(x: 10, y: 20)
|
||||
print(point.x , point.y) // 10 20
|
||||
var size = Size(x: 30, y: 40)
|
||||
print(size.x , size.y) // 30 40
|
||||
```
|
||||
|
||||
- 如果协议声明了初始化器,某个类遵循协议并实现了初始化器。且该初始化器也恰好是父类指定初始化器,那么这个初始化必须同事加 `required` 和 `override`
|
||||
|
||||
```swift
|
||||
protocol Drawable {
|
||||
init(x: Int, y: Int)
|
||||
}
|
||||
|
||||
class Shape {
|
||||
init(x: Int, y: Int) {}
|
||||
}
|
||||
|
||||
class Circle: Shape, Drawable {
|
||||
var x: Int = 0
|
||||
var y: Int = 0
|
||||
required override init(x: Int, y: Int) {
|
||||
super.init(x: x, y: y)
|
||||
self.x = x
|
||||
self.y = y
|
||||
}
|
||||
}
|
||||
var circle = Circle(x: 10, y: 20)
|
||||
print(circle.x , circle.y) // 10 20
|
||||
```
|
||||
|
||||
- 协议也可以继承
|
||||
|
||||
- 协议也可以组合
|
||||
|
||||
```swift
|
||||
protocol Drawable {}
|
||||
protocol Colorable {}
|
||||
func test1(obj: Shape) {} // 参数接收 Shape 类或者 Shape 类的子类
|
||||
func test2(obj: Drawable) {} // 参数接收遵循 Drawable 的实例
|
||||
func test3(obj: Drawable & Colorable) {} // 参数接收同时遵循 Colorable 和 Drawable 2个协议的实例
|
||||
func test4(obj: Shape & Drawable & Colorable) {} // 参数接收同时遵循 Colorable 和 Drawable 2个协议,且是 Shape 的子类的实例
|
||||
```
|
||||
|
||||
- 遵循 `CustomStringConvertible` 可以自定义打印的字符串内容
|
||||
|
||||
```swift
|
||||
class Person: CustomStringConvertible {
|
||||
var name: String
|
||||
var age: Int
|
||||
init(name: String, age: Int) {
|
||||
self.name = name
|
||||
self.age = age
|
||||
}
|
||||
var description: String {
|
||||
"My name is \(name), age is \(age)"
|
||||
}
|
||||
}
|
||||
var p = Person(name: "杭城小刘", age: 28)
|
||||
print(p) // My name is 杭城小刘, age is 28
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Any、AnyObject
|
||||
|
||||
Swift 提供了2种特殊的类型:Any、AnyObject
|
||||
|
||||
- Any 可以代表任意类型(枚举、结构体、类、函数类型)
|
||||
- AnyObject:代表任意类类型。比如可以在协议后面加上 AnyObject 则代表只有类能遵循这个协议。编译器会做检查 `Non-class type 'point' cannot conform to class protocol 'Eatable'`
|
||||
|
||||
```swift
|
||||
protocol Eatable: AnyObject {}
|
||||
class Person: Eatable { }
|
||||
struct point: Eatable {} // Non-class type 'point' cannot conform to class protocol 'Eatable'
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 关联类型
|
||||
|
||||
关联类型的作用:给协议中用到的类型,定义一个占位名称
|
||||
|
||||
协议中可以拥有多个关联类型
|
||||
|
||||
```swift
|
||||
protocol Stackable {
|
||||
associatedtype Element
|
||||
mutating func push(_ element: Element)
|
||||
mutating func pop() -> Element
|
||||
func top() -> Element
|
||||
func size() -> Int
|
||||
}
|
||||
|
||||
class Stack<Element>: Stackable {
|
||||
var elements = Array<Element>()
|
||||
func push(_ element: Element) {
|
||||
elements.append(element)
|
||||
}
|
||||
func pop() -> Element {
|
||||
elements.removeLast()
|
||||
}
|
||||
func top() -> Element {
|
||||
elements.last!
|
||||
}
|
||||
func size() -> Int {
|
||||
elements.count
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Swift 范型本质
|
||||
|
||||
```swift
|
||||
func swapValue<T>(_ value1: inout T, _ value2: inout T) {
|
||||
(value1, value2) = (value2, value1)
|
||||
}
|
||||
var i1 = 11
|
||||
var i2 = 22
|
||||
swapValue(&i1, &i2)
|
||||
|
||||
var s1 = "Hello"
|
||||
var s2 = "world"
|
||||
swapValue(&s1, &s2)
|
||||
```
|
||||
|
||||
在 `swapValue(&i1, &i2)` 处下断点可以看到下面的汇编代码:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftGenericExploreDemo1.png" style="zoom:25%">
|
||||
|
||||
可以看到:
|
||||
|
||||
- 在第一处调用 `swapValue ` 方法的时候,将8字节的 metadata 信息保存到 `rdx` 寄存器了。也就是在调用 `swapValue` 方法的时候,分别将 `i1`(0x000000000000000b,也就是11)的地址值赋值给 rdi 寄存器,将 `i2`(0x0000000000000016,也就是22)的地址值赋值给 rsi 寄存器
|
||||
- 将 `Int` 的 `metadata` 赋值给 `rdx` 寄存器
|
||||
- 然后调用 `swapValue` 方法
|
||||
- 后续的 `String` 的 `SwapValue` 过程类似
|
||||
|
||||
所以编译器最后在执行的时候,会将范型真正的类型对应的 metadata 信息当作函数参数,传递进去,再去执行函数
|
||||
|
||||
|
||||
|
||||
## 范型类型约束
|
||||
|
||||
范型必须遵循协议,可以在方法后加 `<>`,在 `<>` 内写范型 `T: 需要继承的类 & 协议` (也可以是其他名字,大多数语言都写 T),
|
||||
|
||||
```swift
|
||||
protocol Runable {}
|
||||
class Person {}
|
||||
func swapValue<T: Person & Runable>(_ a: inout T, _ b: inout T) {
|
||||
(a, b) = (b, a)
|
||||
}
|
||||
```
|
||||
|
||||
另一种场景是在方法参数是某个范型且遵循协议后,对其范型有更多限制,则用 `where` 去处理。如下例子
|
||||
|
||||
```swift
|
||||
protocol Stackable {
|
||||
associatedtype Element: Equatable
|
||||
}
|
||||
|
||||
class Stack<E: Equatable>: Stackable {
|
||||
typealias Element = E
|
||||
}
|
||||
|
||||
func equal<S1: Stackable, S2: Stackable>(_ s1: S1, _ s2: S2)-> Bool
|
||||
where S1.Element == S2.Element, S1.Element: Hashable {
|
||||
return true
|
||||
}
|
||||
|
||||
let s1 = Stack<Int>()
|
||||
let s2 = Stack<Int>()
|
||||
let s3 = Stack<String>()
|
||||
var result:Bool = equal(s1, s2)
|
||||
print(result) // true
|
||||
result = equal(s1, s3) // Global function 'equal' requires the types 'Stack<Int>.Element' (aka 'Int') and 'Stack<String>.Element' (aka 'String') be equivalent
|
||||
print(result)
|
||||
```
|
||||
|
||||
136
Chapter1 - iOS/1.118.md
Normal file
@@ -0,0 +1,136 @@
|
||||
# Swift 错误处理
|
||||
|
||||
```swift
|
||||
enum SomeError: Error {
|
||||
case illegalArg(String)
|
||||
case outOfBounds(Int, Int)
|
||||
case outOfMemory
|
||||
}
|
||||
|
||||
func divide(_ num1: Int, _ num2: Int) throws -> Int {
|
||||
if num2 == 0 {
|
||||
throw SomeError.illegalArg("分母不能为0")
|
||||
}
|
||||
return num1/num2
|
||||
}
|
||||
|
||||
func testErrorCapture() {
|
||||
print("1")
|
||||
do {
|
||||
print("2")
|
||||
print(try divide(20, 0))
|
||||
print("3")
|
||||
} catch let SomeError.illegalArg(msg) {
|
||||
print("参数异常:", msg)
|
||||
} catch let SomeError.outOfBounds(size, index) {
|
||||
print("下标越界: size = \(size), index = \(index)")
|
||||
} catch SomeError.outOfMemory {
|
||||
print("内存溢出")
|
||||
} catch {
|
||||
print("其他异常")
|
||||
}
|
||||
print("4")
|
||||
}
|
||||
testErrorCapture()
|
||||
// console
|
||||
1
|
||||
2
|
||||
参数异常: 分母不能为0
|
||||
4
|
||||
```
|
||||
|
||||
如果 `try divide(20, 0)` 则输出: 1 、2、参数异常: 分母不能为0、4
|
||||
|
||||
如果 `try divide(20, 2)` 则输出: 1 、2、10、3、4
|
||||
|
||||
说明:如果 do 抛出异常,则作用域内的后续的其他代码都不会被执行
|
||||
|
||||
|
||||
|
||||
## Error 处理方式
|
||||
|
||||
- 通过 do-catch 捕捉 Error
|
||||
|
||||
- 不捕捉 Error,在当前函数增加 throws 声明,Error 继续向上层调用函数抛
|
||||
|
||||
```swift
|
||||
func divide(_ num1: Int, _ num2: Int) throws -> Int {
|
||||
if num2 == 0 {
|
||||
throw SomeError.illegalArg("分母不能为0")
|
||||
}
|
||||
return num1/num2
|
||||
}
|
||||
|
||||
func safeDivide(_ num1: Int, _ num2: Int) -> Int {
|
||||
var result:Int = 0
|
||||
do {
|
||||
result = try divide(num1, num2)
|
||||
} catch let SomeError.illegalArg(msg) {
|
||||
print("参数异常:", msg)
|
||||
} catch let SomeError.outOfBounds(size, index) {
|
||||
print("下标越界: size = \(size), index = \(index)")
|
||||
} catch SomeError.outOfMemory {
|
||||
print("内存溢出")
|
||||
} catch {
|
||||
print("其他异常")
|
||||
}
|
||||
return result
|
||||
}
|
||||
|
||||
print("1")
|
||||
print(safeDivide(8, 2))
|
||||
print("3")
|
||||
// console
|
||||
1
|
||||
4
|
||||
3
|
||||
```
|
||||
|
||||
- 如果有些错误不需要向上抛,可以用 `try?` ` try!` 调用可能会抛出 Error 的函数,这样就不需要去处理 Error
|
||||
|
||||
```swift
|
||||
func testIgnoreError () {
|
||||
print("1")
|
||||
print(try? divide(10, 0))
|
||||
print("2")
|
||||
}
|
||||
testIgnoreError()
|
||||
// console
|
||||
1
|
||||
nil
|
||||
2
|
||||
```
|
||||
|
||||
|
||||
|
||||
## rethrows
|
||||
|
||||
如果一个函数本身不会抛出错误,但某个参数是闭包,且闭包抛出错误,那么函数需要用 `rethrows` 向上抛出错误
|
||||
|
||||
```swift
|
||||
func exec(_ fn: (Int, Int) throws -> Int, _ num1: Int, _ num2: Int) rethrows {
|
||||
print(try fn(num1, num2))
|
||||
}
|
||||
|
||||
func testCaptureClouserError () {
|
||||
do {
|
||||
try exec(divide, 20, 0)
|
||||
} catch let error {
|
||||
switch error {
|
||||
case let SomeError.illegalArgs(msg):
|
||||
print("参数异常:", msg)
|
||||
break
|
||||
case let SomeError.outOfBounds(size, index):
|
||||
print("下标越界: size = \(size), index = \(index)")
|
||||
break
|
||||
case SomeError.outOfMemory :
|
||||
print("内存溢出")
|
||||
break
|
||||
default:
|
||||
print("其他异常")
|
||||
}
|
||||
}
|
||||
}
|
||||
testCaptureClouserError() // 参数异常: 分母不能为0
|
||||
```
|
||||
|
||||
309
Chapter1 - iOS/1.119.md
Normal file
@@ -0,0 +1,309 @@
|
||||
# 剖析 Swift String
|
||||
|
||||
|
||||
|
||||
带着问题研究下 Swift 中的 String
|
||||
|
||||
- 1个 String 变量占用多少内存?
|
||||
- String 存放在什么位置?
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 字符串的创建过程
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789"
|
||||
```
|
||||
|
||||
实验很简单,就一行代码。来窥探下 String 的初始化和内存结构。出发断点看到下面汇编:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo1.png" style="zoom:25%">
|
||||
|
||||
简单分析下:
|
||||
|
||||
- 第4行 `leaq 0x3d45(%rip), %rdi` 将 `rip + 0x3d45` 计算出的地址值赋值给寄存器 `rdi`
|
||||
- 第5行 `movl $0xa, %esi` 将 10 赋值给寄存器 `esi`,也就是 `rsi`
|
||||
- 第6行 `movl $0x1, %edx` 将 1 赋值给寄存器 `edx`,也就是 `rdx `
|
||||
- 第7行 `callq 0x100007578 ; symbol stub for: Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String `
|
||||
- 调用完第7行的方法有2个返回值,保存到寄存器 `rax` 、`rdx` 中
|
||||
- 第8行 `movq %rax, 0x86cf(%rip)` 将 `rax` 的值赋值给 `rip + 0x86cf `
|
||||
- 第8行 `movq %rdx, 0x86d0(%rip) ` 将 `rdx` 的值赋值给 `rip + 0x86d0 `
|
||||
|
||||
可以看到 String 指针占用8 + 8 = 16个字节.
|
||||
|
||||
|
||||
|
||||
QA:这个10是什么东西?1是什么东西?
|
||||
|
||||
结合调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1)` 方法猜测,10 应该是 `utf8CodeUnitCount` 即 utf8格式的字符个数,1 应该是 `isASCII` 即是 ASCII
|
||||
|
||||
做个实验验证下
|
||||
|
||||
```swift
|
||||
var str1: String = "01234"
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到其他和上面的没变化,唯一不同的是 `movl $0x5, %esi` 将5赋值给寄存器 `esi`,即寄存器 `rsi`。实验的字符串 "01234" UTF8 字符个数为5
|
||||
|
||||
继续改变
|
||||
|
||||
```swift
|
||||
var str1: String = "01234😄"
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo3.png" style="zoom:25%">
|
||||
|
||||
可以看到将9赋值给寄存器 `esi` 即 `rsi`,字符串赋值给寄存器 `rdi`,`xorl %edx, %edx` 抑或运算结果 0 赋值给寄存器 `edx` 即 `rdx`,也就是不纯粹为
|
||||
|
||||
所以猜想正确。具体字符串创建过程可以查看 [Swift String 源码](https://github.com/apple/swift/blob/81812eaf2a6589610054a5db655bf7de3f3c8de6/stdlib/public/core/String.swift#L774)
|
||||
|
||||
```swift
|
||||
// stdlib/public/core/String.swift
|
||||
extension String: _ExpressibleByBuiltinStringLiteral {
|
||||
@inlinable @inline(__always)
|
||||
@_effects(readonly) @_semantics("string.makeUTF8")
|
||||
public init(
|
||||
_builtinStringLiteral start: Builtin.RawPointer,
|
||||
utf8CodeUnitCount: Builtin.Word,
|
||||
isASCII: Builtin.Int1
|
||||
) {
|
||||
let bufPtr = UnsafeBufferPointer(
|
||||
start: UnsafeRawPointer(start).assumingMemoryBound(to: UInt8.self),
|
||||
count: Int(utf8CodeUnitCount))
|
||||
if let smol = _SmallString(bufPtr) {
|
||||
self = String(_StringGuts(smol))
|
||||
return
|
||||
}
|
||||
self.init(_StringGuts(bufPtr, isASCII: Bool(isASCII)))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
也就是说 String 本身会占用16个字节长度,会调用 `Swift.String.init(_builtinStringLiteral: Builtin.RawPointer, utf8CodeUnitCount: Builtin.Word, isASCII: Builtin.Int1) -> Swift.String` 方法,该方法传递3个参数:字符串真实地址、字符串 UTF8 格式的个数、是否是 ASCII 。
|
||||
|
||||
|
||||
|
||||
### 字符串长度小于15位的创建
|
||||
|
||||
继续探索:
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo4.png" style="zoom:25%">
|
||||
|
||||
可以看到 `str1` 地址为 `rip + 0x8853 = 0x1000039a5 + 0x8853 = 0x10000C1F8 `,然后读取对应堆上的内容为:
|
||||
|
||||
```shell
|
||||
0x10000c1f8: 30 31 32 33 34 35 36 37 38 39 00 00 00 00 00 ea 0123456789......
|
||||
0x10000c208: 00 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff ................
|
||||
```
|
||||
|
||||
打印出 `0x3736353433323130 0xea00000000003938`。怎么理解呢?
|
||||
|
||||
从 [ASCII 码表](https://www.ascii-code.com) 可以看出 0 对应 `0x30`,1 对应 `0x31`,所以字符串`0123456789` 从 `0x30` 到 `0x39`
|
||||
|
||||
`ea` 代表什么?
|
||||
|
||||
a 即10,代表10个字符。最大为 f,只能存储15个字符。e 代表字符串类型。
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDE"
|
||||
print(Mems.memStr(ofVal: &str1)) // "0x3736353433323130 0xef45444342413938"
|
||||
```
|
||||
|
||||
当把字符改为15个时,输出的内存上的值为 `0x3736353433323130 0xef45444342413938`。
|
||||
|
||||
也就是说:当字符串长度小于16位的时候,通常会使用内联存储来存储字符串的内容。内联存储意味着字符串的实际内容会直接存储在字符串对象本身的内存空间中,而不需要额外的内存分配。类似 OC `NSString` 的 `NSTaggedPointerString`
|
||||
|
||||
|
||||
|
||||
### 字符串长度大于15位
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDEF"
|
||||
print(Mems.memStr(ofVal: &str1))
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo5.png" style="zoom:25%">
|
||||
|
||||
分析下:
|
||||
|
||||
- 第12行 `cmpq $0xf, %rsi` 拿 `0xf` 15 和寄存器 `rsi` 的值进行比较。上面已经分析过了,`rsi` 里面存放的是字符串的长度
|
||||
|
||||
- 第13行 `jle 0x7ff81a7b9017 ` 如果12行比较结果为真,则跳转到 `0x7ff81a7b9017`
|
||||
|
||||
- 实际发现,字符串长度大于15,则继续向下执行
|
||||
|
||||
- 第20行 `movabsq $0x7fffffffffffffe0, %rdx` 则会把立即数 `0x7fffffffffffffe0` 移动到寄存器 `rdx`
|
||||
|
||||
- 第21行 `addq %rdx, %rdi` 将 `rdx` + ` rdi` 的值赋值给 `rdi`,也就是 `rdi` 存放了: 字符串的真实地址 + `0x7fffffffffffffe0。`所以字符串真实地址 = `rdx 的地址` - `0x7fffffffffffffe0`。寄存器 `rdi` 读取出地址为 `0x8000000100007800` 。所以字符串真实地址为:`0x8000000100007800` - `0x7fffffffffffffe0` = `0x100007820`,LLDB 读取下 `x 0x100007820 ` 看到 30、31...46刚好是字符串 `0123456789ABCDEF` 的 ASCII 值。
|
||||
|
||||
所以 `字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
|
||||
|
||||
- 经过23行后 `orq %rdi, %rdx` 可以看到 `rdx` 、`rdi` 里面存储的都是:`字符串真实地址` + `0x7fffffffffffffe0`
|
||||
|
||||
- LLDB 输入 finish 结束函数细节,外部可以看到第10行 `movq %rdx, 0x8864(%rip) ` 将 `rdx` 寄存器里的值(也就是:`字符串真实地址` + `0x7fffffffffffffe0` )赋值给 `str1` 指针的后8个字节
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo6.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
`字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
|
||||
|
||||
|
||||
|
||||
### 字符串存储在内存中什么地方
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDEF"
|
||||
```
|
||||
|
||||
字符串地址为 ` 0x10000397f + 0x3ea1 = 0x100007820`,看着像全局变量、也有可能是常量区?字符串内容写死的情况下,编译器编译后内存地址应该可以确定,那到底在什么地方呢?利用 `MachOView` 窥探下 `MachO` 文件吧
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftStringExploreDemo7.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
利用 MachOView 打开如下
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MacMachOViewExploreStringLocationDemo1.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
X86_64 架构下,我们在 MachOView 看到的地址,真实对应地址为: `0x10000000 + 00007820 = 0x10007820` 好巧啊,发现计算出的值刚好就是字符串 `str1` 的真实地址。MachOView 右侧也显示了字符串的内容,刚好就是 str1
|
||||
|
||||
解释下:
|
||||
|
||||
在 macOS 和 iOS 的二进制文件(如 Mach-O 格式的可执行文件或动态库)中,`Section64` 是一个结构体,用于描述二进制文件中的一个段(section)。每个段包含特定类型的数据或代码,并且具有特定的属性,比如是否可写、是否可执行等。
|
||||
|
||||
`Section64(__TEXT__,__cstring)` 中:
|
||||
|
||||
- `__TEXT__` 是段的段名(segment name),它通常包含代码(`__text`)和常量数据(如 `__cstring`、`__const` 等)。
|
||||
- `__cstring` 是节的节名(section name),它通常包含 C 字符串字面量。这些字符串字面量在编译时被存储在只读数据段中。
|
||||
|
||||
因此,`Section64(__TEXT__,__cstring)` 描述的是二进制文件中存储 C 字符串字面量的一个节。这个节位于 `__TEXT__` 段中,并且包含的是只读数据。
|
||||
|
||||
|
||||
|
||||
再做下调整
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDEF"
|
||||
var str2: String = "012345"
|
||||
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
|
||||
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MacMachOViewExploreStringLocationDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到:
|
||||
|
||||
- str1、str2 指针长度为均为16个字节,且内存连续 `00007820`、`00007830`
|
||||
- 字符串长度小于15的时候,打印出 str2 的内存值的前8个字节存储的就是字符串本身 `0x0000353433323130`,后8个字节 `0xe600000000000000` e 代表字符串类型,6代表字符串长度
|
||||
- 字符串长度大于15的时候,内存值的前8位 `0xd000000000000010` 最后的10也就是16,代表字符串长度。内存的后8位代表字符串计算后的地址(`字符串真实地址` + `0x7fffffffffffffe0` )
|
||||
- 字符串是存储在 `__TEXT__` 段的 `__cstring` 节中,属于常量区。
|
||||
|
||||
做了调整,可以看到 str3 内存值的前8个字节 `0xd000000000000015` 中的15也就是21位字符串,符合预期。
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDEF"
|
||||
var str2: String = "012345"
|
||||
var str3: String = "0123456789ABCDEFGHIJK"
|
||||
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x80000001000077e0
|
||||
print(Mems.memStr(ofVal: &str2)) // 0x0000353433323130 0xe600000000000000
|
||||
print(Mems.memStr(ofVal: &str3)) // 0xd000000000000015 0x8000000100007800
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 字符串拼接
|
||||
|
||||
### 长度小于15的字符串拼接
|
||||
|
||||
```swift
|
||||
var str1: String = "012345"
|
||||
print(Mems.memStr(ofVal: &str1)) // 0x0000353433323130 0xe600000000000000
|
||||
str1.append("ABC")
|
||||
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xe900000000000043
|
||||
str1.append("DEFGHI")
|
||||
print(Mems.memStr(ofVal: &str1)) // 0x4241353433323130 0xef49484746454443
|
||||
```
|
||||
|
||||
可以看到不管字符串怎么拼接,只要拼接后的内容小于小于等于15,则依旧是在字符串的内容存放在自身的16个字节中。
|
||||
|
||||
|
||||
|
||||
### 长度大于15的字符串拼接
|
||||
|
||||
```swift
|
||||
var str1: String = "0123456789ABCDEF"
|
||||
print(Mems.memStr(ofVal: &str1)) // 0xd000000000000010 0x8000000100007800
|
||||
str1.append("G")
|
||||
print(Mems.memStr(ofVal: &str1)) // 0xf000000000000011 0x0000600001700440
|
||||
print("explore")
|
||||
```
|
||||
|
||||
可以看到:长度为16的字符串拼接后
|
||||
|
||||
- 内存的前8个字节,从 `0xd000000000000010` 变到了 `0xf000000000000011`,最后2位代表字符串长度,从16位变成17位。
|
||||
- 内存的后8个字节,字符串的地址改变了
|
||||
|
||||
上面可知, `字符串真实地址 = 指针内存8个字节地址 - 0x7fffffffffffffe0`,又等价于 `字符串真实地址 = 指针内存8个字节地址 + 0x20`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MacMachOViewExploreStringLocationDemo3.png" style="zoom:25%">
|
||||
|
||||
字符串真实地址:`0x0000600001700440 + 0x20 = 0x0000600001700460`,LLDB `x 0x0000600001700460 ` 可以看到字符串拼接后的结果。看上去是存储在堆上。如何验证?
|
||||
|
||||
|
||||
|
||||
我们知道堆上的内存初始化在 Swift 侧,关键方法为 `swift_allocObject ` -> `swift_slowAlloc` -> `malloc `。给 malloc 下断点,然后在断点出查看调用堆栈,可以看到在 `string.append()` 后有堆分配内存
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MacMachOViewExploreStringLocationDemo4.png" style="zoom:25%">
|
||||
|
||||
结束当前函数调用,在外层可以看到 str2 地址值的后8个字节为 `0x000060000170410`,再 + `0x20` 就是字符串真实地址,打印如下。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MacMachOViewExploreStringLocationDemo5.png" style="zoom:25%">
|
||||
|
||||
0x20 是什么?这32个字节存放了什么信息?存储字符串的描述信息,比如:引用计数、字符串长度等信息。
|
||||
|
||||
|
||||
|
||||
总结:
|
||||
|
||||
- 当字符串长度小于等于 0xF(也就是15),字符串内容直接存放在指针变量对应的内存中
|
||||
- 当字符拼接时候,拼接后字符串长度小于等于15,则字符串内容依旧存储在指针变量的内存中
|
||||
- 当字符串长度大于 0xF(也就是15),字符串的内容存放在 `__TEXT,__cstring` 中(常量区)。字符串的地址值信息存放在指针变量的后8个字节中,且真正的地址值为 (`后8个字节值` + `0x20` ),前32字节存储字符串的基础信息(长度、引用计数等)
|
||||
|
||||
|
||||
|
||||
## dyld_stub_binder
|
||||
|
||||
`__TEXT` 是 Mach-O 文件中通常包含代码和只读数据的段。这个段包含了程序的主要执行代码,以及常量字符串、符号表等。
|
||||
|
||||
`dyld_stub_binder` 是一个由动态链接器(dyld)在运行时生成和使用的函数。它的主要目的是在首次调用某个动态链接的符号(如函数或方法)时,将该符号的实际地址绑定到调用点。
|
||||
|
||||
在编译时,对于动态链接的符号,编译器会生成一个桩(stub),而不是直接调用该符号。桩是一个小段的代码,当被首次执行时,它会触发 `dyld_stub_binder` 的调用。`dyld_stub_binder` 的任务就是找到该符号的实际地址,并将其写入桩中,从而替换桩的原始代,这样,下一次调用该符号时,就可以直接跳转到实际的地址,而无需再次通过桩和 `dyld_stub_binder`。
|
||||
|
||||
|
||||
|
||||
替换桩,位于 `__DATA,__la_symbol_ptr` 数据段可读可写,所以可以修改。
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MachOStubBinderAndLazyBinding.png" style="zoom:25%">
|
||||
|
||||
`__stub_helper` 节是 `__TEXT` 段中的一个特定节,它包含了用于处理符号懒加载的辅助函数和代码。当动态链接的符号首次被调用时,这些辅助函数会被触发,以解析符号并将其地址绑定到调用点。
|
||||
|
||||
这个过程也叫 `Lazy_binding`。懒加载是一种优化技术,允许程序在启动时不必立即解析和绑定所有动态链接的符号。相反,这些符号的解析和绑定被推迟到它们实际被使用时进行。这种延迟可以减少应用程序启动时的内存和性能开销。
|
||||
202
Chapter1 - iOS/1.120.md
Normal file
@@ -0,0 +1,202 @@
|
||||
# Swift 访问控制
|
||||
|
||||
## 访问控制
|
||||
|
||||
在访问权限控制这块,Swift 提供了5个不同的访问级别(以下是从高到低排列, 实体指被访问级别修饰的内容)
|
||||
|
||||
- open:允许在定义实体的模块、其他模块中访问,允许其他模块进行继承、重写(open只能用在类、类成员上)
|
||||
- public:允许在定义实体的模块、其他模块中访问,不允许其他模块进行继承、重写
|
||||
- internal:只允许在定义实体的模块中访问,不允许在其他模块中访问
|
||||
- fileprivate:只允许在定义实体的源文件中访问
|
||||
- private:只允许在定义实体的封闭声明中访问
|
||||
|
||||
绝大部分实现默认都是 internal
|
||||
|
||||
|
||||
|
||||
## 使用准则
|
||||
|
||||
各种 case 如下:
|
||||
|
||||
- 变量类型 >= 变量
|
||||
|
||||
```swift
|
||||
fileprivate class Person {
|
||||
func sayHi() {}
|
||||
}
|
||||
internal var p:Person = Person() // Variable cannot be declared internal because its type uses a fileprivate type
|
||||
class Dog {
|
||||
func sepak() {
|
||||
p.sayHi()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
编译器报错:`Variable cannot be declared internal because its type uses a fileprivate type`。 访问权限前后冲突了。变量 p 被声明为 internal,也就是其他类中也可以使用该对象。但 Person 类被 fileprivate 修饰了,也就是只可以在定义该类的文件中使用。所以会冲突
|
||||
|
||||
- 参数类型、返回值类型 >= 函数
|
||||
|
||||
- 父类 >= 子类
|
||||
|
||||
- 父协议 >= 子协议
|
||||
|
||||
- 原类型 >= typealias
|
||||
|
||||
```swift
|
||||
class Person {}
|
||||
fileprivate typealias People = Person // 编译通过
|
||||
public typealias People = Person // Type alias cannot be declared public because its underlying type uses an internal type
|
||||
```
|
||||
|
||||
`Person` 默认是 internal,所以 typealias 的权限修饰符需要小于等于 internal。
|
||||
|
||||
- 原始值类型、关联值类型 >= 枚举类型
|
||||
|
||||
```swift
|
||||
// 编译通过
|
||||
typealias OwnInt = Int
|
||||
typealias OwnString = String
|
||||
internal enum DataKind {
|
||||
case int(OwnInt)
|
||||
case string(OwnString)
|
||||
}
|
||||
// 编译失败
|
||||
fileprivate typealias OwnInt = Int
|
||||
fileprivate typealias OwnString = String
|
||||
|
||||
public enum DataKind {
|
||||
case int(OwnInt) // Enum case in a public enum uses a fileprivate type
|
||||
case string(OwnString) // Enum case in a public enum uses a fileprivate type
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
- 定义类型 A 时用到的其他类型 >= 类型A
|
||||
|
||||
- 元祖类型:元祖类型的访问级别是所有成员类型最低的那个(木桶原理)
|
||||
|
||||
```swift
|
||||
internal struct Dog {}
|
||||
fileprivate class Person {}
|
||||
|
||||
internal var data1:(Dog, Person) // Error:Variable cannot be declared internal because its type uses a fileprivate type
|
||||
fileprivate var data1:(Dog, Person)
|
||||
private var data2:(Dog, Person)
|
||||
```
|
||||
|
||||
看似规则比较多,实际上就是对「一个实体不可以被更低访问级别的实体定义」的解释。
|
||||
|
||||
|
||||
|
||||
类型的访问级别会影响成员(属性、方法、初始化器、下标)、嵌套类型的默认访问级别
|
||||
|
||||
- 一般情况下,类型为 fileprivate、private,那么成员、嵌套类型默认也是 private、fileprivate
|
||||
- 一般情况下,类型为 internal、public,那么成员、嵌套类型默认也是 internal
|
||||
|
||||
|
||||
|
||||
测试:
|
||||
|
||||
```swift
|
||||
// 编译不通过
|
||||
class TestClass {
|
||||
private class Person {}
|
||||
fileprivate class Student : Person {} // Class cannot be declared fileprivate because its superclass is private
|
||||
}
|
||||
|
||||
// 编译通过
|
||||
private class Person {}
|
||||
fileprivate class Student : Person {}
|
||||
```
|
||||
|
||||
当 fileprivate、private 都写在文件的全局作用域时,访问权限是一样的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## getter、setter
|
||||
|
||||
getter、setter 默认自动接收他们所属换的访问级别
|
||||
|
||||
可以给 setter 单独设置一个比 getter 权限更低的访问级别,用以限制写权限
|
||||
|
||||
```swift
|
||||
private(set) var num = 10
|
||||
class Person {
|
||||
private(set) var age = 0
|
||||
init(age: Int = 0) {
|
||||
self.age = age
|
||||
}
|
||||
public var weight: Int {
|
||||
set {}
|
||||
get { 10 }
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
var p = Person(age: 10)
|
||||
//print(p.age)
|
||||
//p.age = 20
|
||||
print(num)
|
||||
num = 20
|
||||
print(num)
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 初始化器
|
||||
|
||||
- 如果一个 public 类,想在另一个模块调用编译生成的默认无参初始化器,必须显示提供 public 的无参初始化器(因为 public 类的默认初始化器是 internal 级别的)
|
||||
|
||||
```swift
|
||||
// APM.dylib
|
||||
public class APMManager {
|
||||
public init () {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
// 另一个模块(动态库/静态库/主工程)
|
||||
var manager = APMManager()
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 枚举类型
|
||||
|
||||
不能给 enum 的 case 单独设置访问级别,每个 case 自动对齐 enum 的访问级别
|
||||
|
||||
- public 的 enum,各个 case 也是 public
|
||||
|
||||
|
||||
|
||||
## 协议
|
||||
|
||||
协议中定义的要求自动接收协议的访问级别,不能单独设置访问级别
|
||||
|
||||
- public 定义的协议,各个属性、方法也是 public 级别
|
||||
|
||||
协议实现的访问级别 >= 类型的访问级别(协议的访问级别)
|
||||
|
||||
```swift
|
||||
// 编译通过
|
||||
public protocol Runnable {
|
||||
func run()
|
||||
}
|
||||
internal class Person : Runnable {
|
||||
internal func run() { }
|
||||
}
|
||||
// 编译失败
|
||||
public protocol Runnable {
|
||||
func run()
|
||||
}
|
||||
public class Person : Runnable {
|
||||
internal func run() { } // Method 'run()' must be declared public because it matches a requirement in public protocol 'Runnable'
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
462
Chapter1 - iOS/1.121.md
Normal file
@@ -0,0 +1,462 @@
|
||||
# 内存管理
|
||||
|
||||
|
||||
|
||||
## @escaping
|
||||
|
||||
- 非逃逸闭包、逃逸闭包,一般都是当作参数传递给函数
|
||||
- 非逃逸闭包:闭包调用发生在函数结束前,闭包调用在函数作用域内
|
||||
- 逃逸闭包:闭包油可能在函数结束后调用, 闭包调用逃离了函数的作用域,需要通过 `@eascaping` 声明
|
||||
|
||||
```swift
|
||||
typealias Fn = () -> ()
|
||||
var globalFn:Fn?
|
||||
func setFn(_ fn: @escaping Fn) {
|
||||
globalFn = fn
|
||||
}
|
||||
setFn {
|
||||
print("Hello world")
|
||||
}
|
||||
globalFn?() // Hello world
|
||||
```
|
||||
|
||||
|
||||
|
||||
注意点:逃逸闭包不可以捕获 `inout` 参数
|
||||
|
||||
```swift
|
||||
typealias Fn = () -> ()
|
||||
func other1(_ fn: Fn) {
|
||||
fn()
|
||||
}
|
||||
|
||||
func other2(_ fn: @escaping Fn) {
|
||||
fn()
|
||||
}
|
||||
|
||||
func test(value: inout Int) -> Fn {
|
||||
other1 {
|
||||
value += 1
|
||||
}
|
||||
other2 { // compile error:Escaping closure captures 'inout' parameter 'value'
|
||||
value += 1
|
||||
}
|
||||
func add() {
|
||||
value += 1
|
||||
}
|
||||
return add // compile error:Escaping closure captures 'inout' parameter 'value'
|
||||
}
|
||||
```
|
||||
|
||||
原因:因为 `inout` 参数的本质是要求函数在调用期间直接操作变量的内存地址,而逃逸闭包可能会在函数返回后的任何时刻调用(不确定),这时 `inout` 参数所在的内存地址可能已经不再有效或者已经被其他值覆盖。因此,允许逃逸闭包捕获 `inout` 参数会导致潜在的数据不一致和安全问题。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 内存访问冲突
|
||||
|
||||
Confilicting Access to Memory, 内存访问冲突发生在:
|
||||
|
||||
- 至少一个是写入操作
|
||||
- 它们访问的是同一块内存
|
||||
- 它们的访问时间重叠(比如在同一个函数内)
|
||||
|
||||
|
||||
|
||||
Demo1:
|
||||
|
||||
```swift
|
||||
var step = 1
|
||||
func increament(_ num: inout Int) {
|
||||
num += step
|
||||
}
|
||||
increament(&step)
|
||||
```
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftConflictingAccessToMemoryDemo.png" style="zoom:25%">
|
||||
|
||||
解决办法就是打破3个条件之一。显然不可以换函数,只有改变「同时访问一块内存地址」这个条件了
|
||||
|
||||
```swift
|
||||
var step = 1
|
||||
func increament(_ num: inout Int) {
|
||||
num += step
|
||||
}
|
||||
var stepCopy = step
|
||||
increament(&stepCopy)
|
||||
step = stepCopy
|
||||
```
|
||||
|
||||
|
||||
|
||||
Demo2:
|
||||
|
||||
```swift
|
||||
func balance(_ x: inout Int, _ y: inout Int) {
|
||||
let sum = x + y
|
||||
x = sum/2
|
||||
y = sum - x
|
||||
}
|
||||
|
||||
var num1 = 1
|
||||
var num2 = 2
|
||||
balance(&num1, &num2) //
|
||||
balance(&num1, &num1) // compile error: Inout arguments are not allowed to alias each other
|
||||
```
|
||||
|
||||
Demo3: 下面代码虽然看着传入的是不同内存地址,但是 health 和 power 都属于元祖,还是同一个内存地址。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftConflictingAccessToMemoryDemo2.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
如何解决?
|
||||
|
||||
Swift 规定以下 case,就说明重叠访问结构体的属性就是安全的
|
||||
|
||||
- 只访问实例存储属性,不是计算属性或者类属性
|
||||
- 结构体是局部变量而非全局变量
|
||||
- 结构体要么没有被闭包捕获,要么只被非逃逸闭包捕获
|
||||
|
||||
```swift
|
||||
func balance(_ x: inout Int, _ y: inout Int) {
|
||||
let sum = x + y
|
||||
x = sum/2
|
||||
y = sum - x
|
||||
}
|
||||
func testConflictingAccessToMemory() {
|
||||
var tumple = (health: 100, power: 100)
|
||||
balance(&tumple.health, &tumple.power)
|
||||
}
|
||||
testConflictingAccessToMemory()
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 指针
|
||||
|
||||
Swift 也有专门的指针类型,都被定义为 Unsafe(不安全的),有:
|
||||
|
||||
- `UnsafePointer<Person>` 类似于 `const Person *`
|
||||
- `UnsafeMutablePointer<Person>` 类似于 `Person *`
|
||||
- `UnsafeRawPonter` 类似于 `const void *`
|
||||
- `UnsafeMutableRawPonter` 类似于 `void *`
|
||||
|
||||
|
||||
|
||||
Demo1
|
||||
|
||||
因为 changeValue1 的参数是不可变的指针,所以方法内部去修改值,编译器会报错。
|
||||
|
||||
```swift
|
||||
var age = 27
|
||||
func changeValue1(_ num: UnsafePointer<Int>) {
|
||||
num.pointee = 28 // compile error: Cannot assign to property: 'pointee' is a get-only property
|
||||
}
|
||||
func changeValue2(_ num: UnsafeMutablePointer<Int>) {
|
||||
num.pointee = 28
|
||||
}
|
||||
changeValue1(&age)
|
||||
print(age)
|
||||
changeValue2(&age)
|
||||
print(age)
|
||||
```
|
||||
|
||||
- `changeValue1` 的参数是不可变的指针,所以方法内部去修改值,编译器会报错
|
||||
- `changeValue2` 的参数是可变的指针,所以方法内部去修改值,编译没问题
|
||||
- 指针加了范型,访问真实的值可以通过 `指针.pointee` 去访问
|
||||
|
||||
|
||||
|
||||
Demo2
|
||||
|
||||
```swift
|
||||
func changeValue3(_ num: UnsafeRawPointer) {
|
||||
let value = num.load(as: Int.self)
|
||||
print("value is \(value)")
|
||||
}
|
||||
func changeValue4(_ num: UnsafeMutableRawPointer) {
|
||||
num.storeBytes(of: 30, as: Int.self)
|
||||
}
|
||||
changeValue3(&age)
|
||||
print(age)
|
||||
changeValue4(&age)
|
||||
print(age)
|
||||
// console
|
||||
value is 27
|
||||
27
|
||||
30
|
||||
```
|
||||
|
||||
- `changeValue3` 传递了不可变的原始指针,所以访问内存上的值,需要程序员自己指定访问的数据类型。使用 `指针.load(as: 数据类型.self)` 这种格式
|
||||
- `changeValue4` 传递了可变的原始指针,所以修改内存上的值,需要程序员自己指定访问的数据类型。使用 `指针.storeBytes(of: 值, as: 数据类型.self)` 这种格式
|
||||
|
||||
|
||||
|
||||
系统使用场景
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
var objcArray = NSArray(objects: 10, 11, 12, 13)
|
||||
objcArray.enumerateObjects { element, idx, stop in
|
||||
print("element is \(element) at index \(idx)")
|
||||
}
|
||||
print("--------------------")
|
||||
objcArray.enumerateObjects { element, idx, stop in
|
||||
if idx == 1 {
|
||||
stop.pointee = true
|
||||
}
|
||||
print("element is \(element) at index \(idx)")
|
||||
}
|
||||
element is 10 at index 0
|
||||
element is 11 at index 1
|
||||
element is 12 at index 2
|
||||
element is 13 at index 3
|
||||
--------------------
|
||||
element is 10 at index 0
|
||||
element is 11 at index 1
|
||||
```
|
||||
|
||||
tips: 不可以在数组 `enumerateObjects` 方法中使用 break,否则编译器会提示 `Unlabeled 'break' is only allowed inside a loop or switch, a labeled break is required to exit an if or do`
|
||||
|
||||
|
||||
|
||||
## 获取某个变量的指针
|
||||
|
||||
`withUnsafePointer` `withUnsafeMutablePointer` 可以获取到不可变、可变的指针
|
||||
|
||||
```swift
|
||||
var age = 27
|
||||
let pointer = withUnsafePointer(to: &age) { pointer in
|
||||
let address = UnsafeRawPointer(pointer).load(as: Int.self)
|
||||
print("Memory address is \(pointer), the value is \(address)")
|
||||
return pointer
|
||||
}
|
||||
var ptr = withUnsafePointer(to: &age) { $0 }
|
||||
print(ptr)
|
||||
// console
|
||||
Memory address is 0x000000010000c208, the value is 27
|
||||
0x000000010000c208
|
||||
0x000000010000c208
|
||||
```
|
||||
|
||||
继续添加代码,利用指针修改值,编译器报错 `Cannot assign to property: 'pointee' is a get-only property`
|
||||
|
||||
```swift
|
||||
ptr.pointee = 28 // Cannot assign to property: 'pointee' is a get-only property
|
||||
```
|
||||
|
||||
再修改代码
|
||||
|
||||
```swift
|
||||
var mutablePtr = withUnsafeMutablePointer(to: &age) { $0 }
|
||||
mutablePtr.pointee = 28
|
||||
print("mutable address is \(mutablePtr), value is \(age)")
|
||||
// console
|
||||
mutable address is 0x000000010000c218, value is 28
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
```
|
||||
let pointer = withUnsafePointer(to: &age) { pointer in
|
||||
return pointer
|
||||
}
|
||||
```
|
||||
|
||||
等价于下面的写法($0 是第一个参数,return 可以省略)
|
||||
|
||||
```swift
|
||||
let pointer = withUnsafePointer(to: &age) { pointer in
|
||||
return $0
|
||||
}
|
||||
let pointer = withUnsafePointer(to: &age) { $0 }
|
||||
```
|
||||
|
||||
|
||||
|
||||
那如何获取不可变和可变的 rawPointer
|
||||
|
||||
```swift
|
||||
let rawPointer: UnsafeRawPointer = withUnsafePointer(to: &age) {
|
||||
UnsafeRawPointer($0)
|
||||
}
|
||||
print("Raw pointer address is \(rawPointer), the value is \(rawPointer.load(as: Int.self))")
|
||||
|
||||
let mutableRawPointer: UnsafeMutableRawPointer = withUnsafeMutablePointer(to: &age) {
|
||||
UnsafeMutableRawPointer($0)
|
||||
}
|
||||
print("Mutable raw pointer address is \(rawPointer), the value is \(rawPointer.load(as: Int.self))")
|
||||
|
||||
mutableRawPointer.storeBytes(of: 28, as: Int.self)
|
||||
print(age)
|
||||
|
||||
// console
|
||||
Raw pointer address is 0x000000010000c218, the value is 27
|
||||
Mutable raw pointer address is 0x000000010000c218, the value is 27
|
||||
28
|
||||
```
|
||||
|
||||
|
||||
|
||||
pointer、pointee,英语中 er、ee,er 表示主动,ee 表示被动,分别是:指针、被指向的对象。
|
||||
|
||||
上述方式获取的都是指针变量的地址值,而不是堆空间对象的地址值。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 获取堆空间对象的指针
|
||||
|
||||
先获取 `UnsafeRawPointer`,然后利用 `UnsafeRawPointer(bitPattern:**)` 获取堆空间对象的地址值
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var age: Int
|
||||
init(age: Int) {
|
||||
self.age = age
|
||||
}
|
||||
}
|
||||
var p: Person = Person(age: 27)
|
||||
var ptr1 = withUnsafePointer(to: p) { UnsafeRawPointer($0) }
|
||||
var personHeapAddress = ptr1.load(as: UInt.self)
|
||||
var ptr2 = UnsafeRawPointer(bitPattern: personHeapAddress)
|
||||
print(ptr2)
|
||||
print(Mems.ptr(ofRef: p))
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 创建指针
|
||||
|
||||
创建内存方法1: `malloc`
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
var ptr = malloc(16)
|
||||
print("malloc address is \(ptr)")
|
||||
// 存
|
||||
ptr?.storeBytes(of: 10, as: Int.self)
|
||||
ptr?.storeBytes(of: 20, toByteOffset: 8, as: Int.self)
|
||||
|
||||
let firstValue = (ptr?.load(as: Int.self))!
|
||||
let secondValue = (ptr?.load(fromByteOffset: 8, as: Int.self))!
|
||||
print("The first part is \(firstValue), second part is \(secondValue)")
|
||||
|
||||
free(ptr)
|
||||
// console
|
||||
malloc address is Optional(0x0000600000008040)
|
||||
The first part is 10, second part is 20
|
||||
```
|
||||
|
||||
创建内存方法2: `UnsafeMutableRawPointer.allocate(byteCount: 字节数, alignment: 内存对齐)`
|
||||
|
||||
```swift
|
||||
// 创建
|
||||
let ptr: UnsafeMutableRawPointer = UnsafeMutableRawPointer.allocate(byteCount: 16, alignment: 1)
|
||||
print("malloc address is \(ptr)")
|
||||
ptr.storeBytes(of: 10, as: Int.self)
|
||||
// ptr.storeBytes(of: 20, toByteOffset: 8, as: Int.self)
|
||||
ptr.advanced(by: 8).storeBytes(of: 20, as: Int.self)
|
||||
|
||||
let firstValue = ptr.load(as: Int.self)
|
||||
let secondValue = ptr.load(fromByteOffset: 8, as: Int.self)
|
||||
print("The first part is \(firstValue), second part is \(secondValue)")
|
||||
// 释放
|
||||
ptr.deallocate()
|
||||
|
||||
// console
|
||||
malloc address is 0x0000000100604370
|
||||
The first part is 10, second part is 20
|
||||
```
|
||||
|
||||
上面的 `ptr.storeBytes(of: 20, toByteOffset: 8, as: Int.self)` 写法等价于 `ptr.advanced(by: 8).storeBytes(of: 20, as: Int.self)`
|
||||
|
||||
|
||||
|
||||
创建内存方法3: `UnsafeMutablePointer<Int>.allocate(capacity: 2)` 创建2* 8 Byte 大小的内存
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
var ptr = UnsafeMutablePointer<Int>.allocate(capacity: 2)
|
||||
print("malloc address is \(ptr)")
|
||||
// 初始化赋值
|
||||
//ptr.pointee = 27
|
||||
ptr.initialize(to: 27)
|
||||
|
||||
ptr.successor().initialize(to: 10)
|
||||
|
||||
// 访问
|
||||
print(ptr.pointee)
|
||||
print((ptr + 1).pointee)
|
||||
|
||||
print(ptr[0])
|
||||
print(ptr[1])
|
||||
|
||||
print(ptr.pointee)
|
||||
print(ptr.successor().pointee)
|
||||
|
||||
ptr.deinitialize(count: 2)
|
||||
ptr.deallocate()
|
||||
// console
|
||||
malloc address is 0x0000000100604190
|
||||
27
|
||||
10
|
||||
27
|
||||
10
|
||||
27
|
||||
10
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 指针之间的转换
|
||||
|
||||
`unsafeBitCast` 是忽略数据类型的强制转换,不会因为数据类型的变化而改变原来的内存数据。类似 C++ 中的 `reterpret_cast`
|
||||
|
||||
|
||||
## 内存泄漏
|
||||
weak 和 unowned 是两种用于处理引用循环(retain cycles)的关键字,它们主要用在类的属性中,以确保对象之间的引用不会导致内存泄漏。这两种引用类型都用于表示对另一个对象的非拥有(non-owning)引用,但它们在行为上有所不同。
|
||||
|
||||
weak 引用是一个不持有对象引用的引用。这意味着它不会增加对象的引用计数。当对象不再被拥有时(即其引用计数为 0),weak 引用会自动设置为 nil。
|
||||
weak 引用通常用于避免循环引用,特别是在闭包或代理模式中。例如,如果你有一个视图控制器(ViewController)和一个代理(Delegate),并且 ViewController 持有一个对 Delegate 的强引用,那么为了避免循环引用,Delegate 通常会对 ViewController 持有一个 weak 引用。
|
||||
|
||||
|
||||
unowned 引用也是一个不持有对象引用的引用,但它不会在对象被释放时自动设置为 nil。因此,使用 unowned 引用时需要格外小心,因为如果引用的对象被释放了,而你的代码仍然试图访问它,那么你的程序将会崩溃。
|
||||
通常,当你确信引用的对象在其生命周期内始终存在时,才会使用 unowned 引用。例如,在一个父对象和子对象的关系中,如果父对象始终在子对象之前存在,并且子对象需要引用父对象,那么子对象可以使用 unowned 引用指向父对象。
|
||||
|
||||
## inout 参数访问冲突
|
||||
|
||||
```
|
||||
var step = 1
|
||||
func increment(_ number: inout Int) {
|
||||
number += step
|
||||
}
|
||||
let rs = increment(&step)
|
||||
print(rs)
|
||||
```swift
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftInou tReadWriteError.png" style="zoom:25%">
|
||||
|
||||
问题本质是:`inout` 关键词代表要对函数的参数进行写操作,而函数内部的实现利用 step 进行反问操作。读写同时存在就有问题。
|
||||
|
||||
如何解决?产生一个备份,然后调用函数,最后将备份产生的结果覆盖老值
|
||||
```
|
||||
var step = 1
|
||||
func increment(_ number: inout Int) {
|
||||
number += step
|
||||
}
|
||||
// make an explicit copy
|
||||
var copyOfStep = step
|
||||
// invoke
|
||||
increment(©OfStep)
|
||||
// update the original value
|
||||
step = copyOfStep
|
||||
print(step) // 2
|
||||
```swift
|
||||
86
Chapter1 - iOS/1.122.md
Normal file
@@ -0,0 +1,86 @@
|
||||
# Swift 字面量本质
|
||||
|
||||
## 常见的字面量默认类型
|
||||
|
||||
- `public typealias IntegerLiteralType = Int`
|
||||
- `public typealias FloatLiteralType = Float`
|
||||
- `public typealias BooleanLiteralType = Bool`
|
||||
- `public typealias StringLiteralType = String`
|
||||
|
||||
可以通过 typealias 修改字面量的默认类型,Demo 如下:
|
||||
|
||||
```swift
|
||||
typealias IntegerLiteralType = UInt8
|
||||
var val = 8
|
||||
val
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftChangeLiteral.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
## 字面量协议
|
||||
|
||||
Swift 自带的数据类型基本都可通过字面量初始化,本质原因是遵循了对应的协议
|
||||
|
||||
| | | |
|
||||
| ------------- | ------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| Bool | ExpressibleByBooleanLiteral | var b:Bool = false |
|
||||
| Int | ExpressibleByIntegerLiteral | var num:Int = 2 |
|
||||
| Float、Double | ExpressibleByIntegerLiteral、ExpressibleByFloatLiteral | var height:Float = 175 <br>var height1:Float = 175.2 <br>var weight:Double = 130 <br>var weight1:Double = 130.1 |
|
||||
| Dictionary | ExpressibleByDictionaryLiteral | var dic:Dictionary = ["name": "FantasticLBP"] |
|
||||
| String | ExpressibleByStringLiteral | var name:String = "FantasticLBP" |
|
||||
| Array、Set | ExpressibleByArrayLiteral | var arr:Array = [1, 2, 3] |
|
||||
| Optional | ExpressibleByNilLiteral | var o:Optional<Int> = nil |
|
||||
|
||||
|
||||
|
||||
## 字面量协议的使用
|
||||
|
||||
Demo1
|
||||
|
||||
```swift
|
||||
extension Int : ExpressibleByBooleanLiteral {
|
||||
public init(booleanLiteral value: Bool) {
|
||||
self = value ? 1 : 0
|
||||
}
|
||||
}
|
||||
var num: Int = true
|
||||
print(num) // 1
|
||||
num = false
|
||||
print(num) // 0
|
||||
```
|
||||
|
||||
Demo2
|
||||
|
||||
```swift
|
||||
class Student: ExpressibleByIntegerLiteral, ExpressibleByFloatLiteral, ExpressibleByStringLiteral, CustomStringConvertible {
|
||||
var name: String = ""
|
||||
var score: Double = 0
|
||||
|
||||
required init(floatLiteral value: FloatLiteralType) {
|
||||
self.score = value
|
||||
}
|
||||
required init(stringLiteral value: StringLiteralType) {
|
||||
self.name = value
|
||||
}
|
||||
required init(integerLiteral value: IntegerLiteralType) {
|
||||
self.score = Double(value)
|
||||
}
|
||||
required init(extendedGraphemeClusterLiteral value: String) {
|
||||
self.name = value
|
||||
}
|
||||
required init(unicodeScalarLiteral value: String) {
|
||||
self.name = value
|
||||
}
|
||||
var description: String {
|
||||
"name is \(self.name), score is \(self.score)"
|
||||
}
|
||||
}
|
||||
|
||||
var student: Student = "杭城小刘"
|
||||
print(student) // name is 杭城小刘, score is 0.0
|
||||
student = 100
|
||||
print(student) // name is , score is 100.0
|
||||
```
|
||||
|
||||
142
Chapter1 - iOS/1.123.md
Normal file
@@ -0,0 +1,142 @@
|
||||
# Swift 模式匹配
|
||||
|
||||
|
||||
|
||||
## 模式匹配的底层实现
|
||||
|
||||
为了去除其他语句对汇编研究造成的干扰,所以 case 和 default 里面都很简单,聚焦于研究 case 的模式匹配实现。测试代码如下:
|
||||
|
||||
```swift
|
||||
var age = 28
|
||||
switch age {
|
||||
case 0...30:
|
||||
break
|
||||
default:
|
||||
break
|
||||
}
|
||||
```
|
||||
|
||||
在 `case 0...30:` 处加断点可以看到汇编,然后看到可疑方法 `Swift.RangeExpression.~= infix(τ_0_0, τ_0_0.Bound) -> Swift.Bool`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPatternMatchExplore.png" style="zoom:25%">
|
||||
|
||||
LLDB 输入 `si` 进去窥探下
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPatternMatchExplore2.png" style="zoom:25%">
|
||||
|
||||
看样子,函数还没到底,看到地址 `0x00007ff81a86f530` 很大很大,猜测应该是一个系统动态库方法地址,继续跟进去研究 `si`
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
可以看到内部还有函数调用
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPatternMatchExplore3.png" style="zoom:25%">
|
||||
|
||||
继续跟进 `si`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPatternMatchExplore4.png" style="zoom:25%">
|
||||
|
||||
看上去是在做继续 `clasedRange` 区间符合的判断,继续跟进 `si`,里面确实是在判断是否命中区间的判断。不一一研究了,这次目的是判断 switch...case pattern 的实现。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPatternMatchExplore5.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
结论:switch case pattern 模式匹配,系统底层实现是依赖
|
||||
|
||||
|
||||
|
||||
## 模式匹配的应用
|
||||
|
||||
自定义模式匹配。根据上面通过汇编进行分析,我们知道
|
||||
|
||||
- `static func ~=(pattern: case 后面的值, value: switch 后面的值)` pattern 代表的是 case 后面的值,value 代表 switch 后面的值。
|
||||
|
||||
- 当 case 有不同类型的时候,如果编译报错,则需要重写 `static func ~=(pattern: ,value: )` 方法,调整 pattern 的数据类型,数据类型应该和 case 后的数据类型一致(可以是函数等)
|
||||
|
||||
```swift
|
||||
struct Student {
|
||||
var score = 0
|
||||
var name = ""
|
||||
|
||||
|
||||
/// Student 和 Int 模式匹配的方法
|
||||
/// - Parameters:
|
||||
/// - pattern: case 后面的内容
|
||||
/// - value: switch 后面的内容
|
||||
/// - Returns: 是否命中
|
||||
static func ~= (pattern: Int, value: Student) -> Bool {
|
||||
value.score >= pattern
|
||||
}
|
||||
static func ~= (pattern: Range<Int>, value: Student) -> Bool {
|
||||
pattern.contains(value.score)
|
||||
}
|
||||
static func ~= (pattern: ClosedRange<Int>, value: Student) -> Bool {
|
||||
pattern.contains(value.score)
|
||||
}
|
||||
static func ~= (pattern: String, value: Student) -> Bool {
|
||||
Int(pattern) == value.score
|
||||
}
|
||||
}
|
||||
|
||||
var student: Student = Student(score: 55, name: "杭城小刘")
|
||||
switch student {
|
||||
case 100:
|
||||
print(">=100")
|
||||
case 90:
|
||||
print(">=90")
|
||||
case 80..<90:
|
||||
print("[80, 90)")
|
||||
case 60...79:
|
||||
print("[60, 79]")
|
||||
case "55":
|
||||
print("斯国一")
|
||||
default:
|
||||
print("just so so")
|
||||
}
|
||||
// console
|
||||
斯国一
|
||||
```
|
||||
|
||||
修改 `var student: Student = Student(score: 78, name: "杭城小刘")` 则输出 `[60, 79]`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```swift
|
||||
extension String {
|
||||
static func ~=(pattern: (String) -> Bool ,value: String) -> Bool {
|
||||
pattern(value)
|
||||
}
|
||||
}
|
||||
|
||||
func hasPrefix(_ prefix: String) -> (String) -> Bool {
|
||||
{$0.hasPrefix(prefix)}
|
||||
}
|
||||
|
||||
func hasSuffix(_ prefix: String) -> (String) -> Bool {
|
||||
{$0.hasSuffix(prefix)}
|
||||
}
|
||||
|
||||
var name = "城小刘"
|
||||
switch name {
|
||||
case hasPrefix("杭"):
|
||||
print("有杭哦")
|
||||
case hasSuffix("刘"):
|
||||
print("有刘哦")
|
||||
default:
|
||||
print("just a name")
|
||||
}
|
||||
// console
|
||||
有刘哦
|
||||
```
|
||||
|
||||
|
||||
|
||||
##
|
||||
|
||||
|
||||
|
||||
210
Chapter1 - iOS/1.124.md
Normal file
@@ -0,0 +1,210 @@
|
||||
# 从 OC 到 Swift
|
||||
|
||||
## OC 与 Swift 混编模式下,方法调用原理探究
|
||||
|
||||
OC 与 Swift 混编
|
||||
|
||||
`Person.h`
|
||||
|
||||
```objective-c
|
||||
#import <Foundation/Foundation.h>
|
||||
|
||||
NS_ASSUME_NONNULL_BEGIN
|
||||
|
||||
@interface Person : NSObject
|
||||
|
||||
- (instancetype)initWithCat:(id)cat;
|
||||
|
||||
- (void)showPower;
|
||||
|
||||
@end
|
||||
|
||||
NS_ASSUME_NONNULL_END
|
||||
|
||||
#import "Person.h"
|
||||
#import "TestiOSWithSwift-Swift.h"
|
||||
|
||||
@interface Person()
|
||||
|
||||
@property (nonatomic, strong) Cat *cat;
|
||||
@end
|
||||
@implementation Person
|
||||
|
||||
- (instancetype)initWithCat:(id)cat {
|
||||
if (self = [super init]) {
|
||||
_cat = cat;
|
||||
}
|
||||
return self;
|
||||
}
|
||||
|
||||
- (void)showPower {
|
||||
NSLog(@"I have a cat");
|
||||
[self.cat sayHi];
|
||||
[self.cat run];
|
||||
}
|
||||
|
||||
@end
|
||||
```
|
||||
|
||||
`Cat.Swift`
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
|
||||
@objcMembers class Cat: NSObject {
|
||||
var name: String
|
||||
init(_ name: String = "Tom") {
|
||||
self.name = name
|
||||
}
|
||||
|
||||
func sayHi () {
|
||||
print("My name is \(name)")
|
||||
}
|
||||
|
||||
func test1(v1: Int) {
|
||||
print("test1")
|
||||
}
|
||||
|
||||
func test2(v1: Int, v2: Int) {
|
||||
print("test2")
|
||||
}
|
||||
|
||||
func test2(_ v1: Double, _ v2: Double) {
|
||||
print("test2 _")
|
||||
}
|
||||
|
||||
func run () {
|
||||
perform(#selector(test1))
|
||||
perform(#selector(test1(v1:)))
|
||||
perform(#selector(test2(v1:v2:)))
|
||||
perform(#selector(test2(_:_:)))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
点击屏幕触发事件,在 `ViewController.swift`
|
||||
|
||||
```swift
|
||||
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
|
||||
var cat: Cat = Cat("屁屁")
|
||||
var person: Person = Person(cat: cat)
|
||||
person.showPower()
|
||||
}
|
||||
```
|
||||
|
||||
问题:
|
||||
|
||||
1. 为什么 Swift 暴露给 OC 的类最终要继承自 NSObject?
|
||||
|
||||
因为在 OC 中,方法消息走的是消息传递,也就是 Runtime 的机制,Runtime 的实现依赖于 isa 指针,所以类必须继承自 NSObject。
|
||||
|
||||
2. Swift 代码中调用 OC 对象的方法 `person.showPower() ` 底层是怎么调用的?
|
||||
|
||||
底层实现还是需要用汇编来验证。断点加在 `person.showPower() ` 处
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CallOCMethodInSwiftDemo1.png" style="zoom:25%">
|
||||
|
||||
可以看到即使在 Swift 代码中,调用 OC 对象方法,本质上还是走 Objc Runtime 的一套流程。50行代码,将 showPower 的地址赋值给 `rsi` 寄存器,然后调用 `objc_msgSend` 方法。
|
||||
|
||||
LLDB 下 输入 `si` 窥探下实现。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CallOCMethodInSwiftDemo2.png" style="zoom:25%">
|
||||
|
||||
可以看到一个很大的地址 `0x00007ff80002d7c0` 就是动态库的符号方法地址。同时 Xcode 很智能,右侧给出了函数名称。
|
||||
|
||||
3. OC 调用 Swift 底层又是如何调用的?在 OC 类 Person 中,底层调用 Swift Cat 类的 sayHi 方法。
|
||||
|
||||
断点加在 `[self.cat sayHi]` 处,可以看到本质上还是 Runtime objc_msgSend 那一套。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CallOCMethodInSwiftDemo3.png" style="zoom:25%">
|
||||
|
||||
4. `cat.run()` 底层是怎么调用的?
|
||||
|
||||
如果一个 Swift 类,不继承自 NSObject,那么方法调用的本质就是走虚表那套逻辑,找到指针的前8个字节,根据前8个字节找到类信息,然后在类信息中,前面一些内存地址存储类型信息,后续根据偏移在方法列表中,找到需要调用的函数地址。类似下面的图。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassPointerDemo2.png" style="zoom:25%">
|
||||
|
||||
那 Swift 类继承自 NSObject 后,依然在 Swfit 中调用方法,背后的原理是什么?
|
||||
|
||||
在 ViewController.swift 中 `cat.sayHi()` 下断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CallOCMethodInSwiftDemo4.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
## Swift 方法如何走 Runtime 消息机制
|
||||
|
||||
可以看到,即使一个 Swift 类继承自 NSObject,但依旧在 Swift 中调用对象方法,本质上还是走虚表那套方法调用流程,不会走 Runtime 消息机制。
|
||||
|
||||
如果想让 Swift 方法调用走 Runtime 消息机制,可以在方法前加 `@objc dynamic`
|
||||
|
||||
```swift
|
||||
dynamic func sayHi () {
|
||||
print("My name is \(name)")
|
||||
}
|
||||
```
|
||||
|
||||
断点查看,发现在 Swift 代码中调用同样的 Swift 对象方法,此时走了 Runtime 消息机制。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CallOCMethodInSwiftDemo5.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
## Swift OC 混编,内存布局会改变吗
|
||||
|
||||
如果一个 Swift 类继承自 NSObject,内存布局会改变
|
||||
|
||||
```swift
|
||||
class Person {
|
||||
var age: Int = 28
|
||||
var height: Int = 175
|
||||
}
|
||||
let p: Person = Person()
|
||||
print(Mems.memStr(ofRef: p))
|
||||
// console
|
||||
0x0000000100010540 0x0000000000000003 0x000000000000001c 0x00000000000000af
|
||||
```
|
||||
|
||||
可以看到一个 Swift 类,前8个字节用来存放类信息的指针,其次8个字节用来存放引用计数信息,后16个字节用来存放28和175,就是存储属性信息
|
||||
|
||||
调整下:
|
||||
|
||||
```swift
|
||||
import Foundation
|
||||
class Person: NSObject {
|
||||
var age: Int = 28
|
||||
var height: Int = 175
|
||||
}
|
||||
let p: Person = Person()
|
||||
print(Mems.memStr(ofRef: p))
|
||||
// console
|
||||
0x011d8001000104e9 0x000000000000001c 0x00000000000000af 0x0000000000000000
|
||||
```
|
||||
|
||||
可以看到当 Swift 类继承自 NSObject 后,前8个字节存放的是 isa 指针,其次的16个字节存放存储属性信息,最后的8个字节用来内存对齐。
|
||||
|
||||
|
||||
## 混编
|
||||
### Swift 类如何在 OC 中使用
|
||||
OC 项目,使用 Swift 开发默认会创建 `项目名-Swift.swift` 文件。Swift 类都可以在该文件中找到
|
||||
默认情况下生成的 Swift class 是不可以直接在 OC 中使用的,如果需要访问需要在 class 前加 `@objc`,编译器生成的代码如下:
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassCannotUseInOC1.png" style="zoom:25%">
|
||||
|
||||
class 不仅需要创建对象,还需要访问属性和方法,可以在属性或者方法前加 `@objc`,效果如下
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassCannotUseInOC2.png" style="zoom:25%">
|
||||
|
||||
但这样很麻烦,需要给每个属性、方法添加 `@objc`。有简便方法,可以直接在 class 前加 `@objcMembers`,这样该 class 所有的属性、方法都可以在 OC 中访问
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftClassCannotUseInOC3.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
### OC 类、对象方法如何在 Swift 中访问
|
||||
要在 Swift 中访问 OC 类,需要创建桥接文件,OC 工程首次创建 Swift 文件时,Xcode 默认创建桥接文件 `项目名-Bridging-Header.h`。如果是手动创建的,则需要配置(在项目的 Build Settings 中,找到 Objective-C Bridging Header 设置项,并指定桥接头文件的路径。确保桥接头文件的路径正确无误,并且文件名和扩展名都正确)。
|
||||
|
||||
在桥接文件中(`项目名-Bridging-Header.h`) 写好需要在 Swift 中使用的 objective-C 类。
|
||||
|
||||
Swift 中不允许访问 objective-c 的方法或者需要换个方法名去调用,该怎么实现?
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ObjcMethodCannotUseInSwift.png" style="zoom:25%">
|
||||
|
||||
`- (void)showPower NS_SWIFT_NAME(diaplayPower());` oc 对象方法名,在 Swift 中使用时,想换个名字,可以用 `NS_SWIFT_NAME(新的方法名())`
|
||||
`- (void)displayPower NS_SWIFT_UNAVAILABLE("请使用 showPower");` oc 对象方法名,不想在 Swift 使用时,可以加 `NS_SWIFT_UNAVAILABLE(原因)`
|
||||
190
Chapter1 - iOS/1.125.md
Normal file
@@ -0,0 +1,190 @@
|
||||
# Swift 函数式编程
|
||||
|
||||
## 定义
|
||||
|
||||
函数式编程(Funtional Programming,简称 FP)是一种编程范式,也就是如何编写程序的方法论
|
||||
|
||||
- 主要思想:把计算过程尽量分解成一系列可复用函数的调用
|
||||
- 主要特征:函数是“第一等公民”。函数与其他数据类型一样的地位,可以赋值给其他变量,也可以作为函数参数、函数返回值
|
||||
|
||||
|
||||
|
||||
函数式编程最早出现在 LISP 语言,绝大部分的现代编程语言也对函数式编程做了不同程度的支持,比如:Haskell、JavaScript、Python、Swift、Kotlin、Scala 等
|
||||
|
||||
|
||||
|
||||
函数式编程中几个常用的概念:
|
||||
|
||||
- Higher-Order Function、Function Currying
|
||||
- Functor、Applicative Functor、Monad
|
||||
|
||||
|
||||
|
||||
## 高阶函数
|
||||
|
||||
高阶函数是至少满足下列一个条件的函数:
|
||||
|
||||
- 接受一个或多个函数作为输入(map、filter、reduce等)
|
||||
- 返回一个函数
|
||||
|
||||
FP中到处都是高阶函数
|
||||
|
||||
|
||||
|
||||
## 柯里化(Currying)
|
||||
|
||||
将一个接受多个参数的函数变换成为一系列只接受单个参数的函数
|
||||
|
||||
Demo:
|
||||
|
||||
```swift
|
||||
// 函数式编程,为了过程的复用
|
||||
let num = 10
|
||||
func add(_ v: Int) -> (Int) -> Int {{ $0 + v }}
|
||||
func sub(_ v: Int) -> (Int) -> Int { { $0 - v } }
|
||||
func multiple( _ v: Int) -> (Int) -> Int { { $0 * v }}
|
||||
func divide(_ v: Int) -> (Int) -> Int { { $0 / v } }
|
||||
func mod(_ v: Int) -> (Int) -> Int { { $0 % v }}
|
||||
|
||||
// 函数合成,范型
|
||||
infix operator >>> : AdditionPrecedence
|
||||
func >>><A, B, C>(_ f1: @escaping (A) -> B,
|
||||
_ f2: @escaping (B) -> C)
|
||||
-> (A) -> C {
|
||||
{ f2(f1($0)) }
|
||||
}
|
||||
|
||||
// result = ((((x + 3)*5) - 1 )%10)/2
|
||||
let fn = add(3) >>> multiple(5) >>> sub(1) >>> mod(10) >>> divide(2)
|
||||
|
||||
print(fn(num))
|
||||
|
||||
|
||||
func multipleAdd(_ v1: Int) -> ((Int) -> ((Int) -> Int)) {
|
||||
return { v2 in
|
||||
return { v3 in
|
||||
return
|
||||
v1 + v2 + v3
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/*
|
||||
- multipleAdd(1),调用函数,传递1给参数V3,此时继续返回一个函数。
|
||||
- multipleAdd(1)(2) 拿着上一步返回的函数,再去调用,传入的2给参数V2.此时继续返回一个函数
|
||||
- multipleAdd(1)(2)(3) 拿着上一步返回的函数,再去调用,此时传入的3给参数V1,此时则执行相加操作。V1 + V2 + V3
|
||||
*/
|
||||
let rs = multipleAdd(1)(2)(3)
|
||||
print(rs)
|
||||
```
|
||||
|
||||
参数对应如下图圈选部分
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftFunctionalProgrammingCurrying.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
Demo2:将一个三个参数的函数变成柯里化
|
||||
|
||||
```swift
|
||||
func add(_ v1: Int, _ v2: Int) -> Int { v1 + v2 }
|
||||
func multipleAdd(_ v1: Int, _ v2: Int, _ v3: Int) -> Int { v1 + v2 + v3 }
|
||||
func currying<A, B, C>(_ fn: @escaping (A, B) -> C) -> ((A) -> ((B) -> C)) {
|
||||
return { a in
|
||||
return { b in
|
||||
return fn(a, b)
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
func currying<A, B, C, D>(_ fn: @escaping (A, B, C) -> D) -> ((A) -> ((B) -> ((C) -> D ))) {
|
||||
return { a in
|
||||
return { b in
|
||||
return { c in
|
||||
return fn(a, b, c)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
let rs1 = currying(add)(10)(20)
|
||||
let rs2 = currying(multipleAdd)(10)(20)(30)
|
||||
print(rs1, rs2) // 30 60
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 函子
|
||||
|
||||
像 Array、Optional 这样支持 map 运算的类型,称为函子(Functor)
|
||||
```swift
|
||||
// Array<Element>
|
||||
public func map<T>(_ transform: (Element) -> T) -> Array<T>
|
||||
|
||||
// Optional<Wrapped>
|
||||
public func map<U>(_ transform: (Wrapped) -> U) -> Optional<U>
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 适用函子(Applicative Functor)
|
||||
对任意一个函子 F,如果能支持以下运算,该函子就是一个适用函子
|
||||
```swift
|
||||
func pure<A>(_ value: A) -> F<A>
|
||||
func <*><A, B>(fn: F<(A) -> B>, value: F<A>) -> F<B>
|
||||
```
|
||||
|
||||
Array 可以成为适用函子
|
||||
|
||||
```swift
|
||||
func pure<A>(_ value: A) -> [A] {
|
||||
[value]
|
||||
}
|
||||
|
||||
infix operator <*> : AdditionPrecedence
|
||||
func <*><A, B>(fn:[(A) -> B], value: [A]) -> [B] {
|
||||
var resultArray: [B] = []
|
||||
if fn.count == value.count {
|
||||
for i in fn.startIndex..<fn.endIndex {
|
||||
resultArray.append(fn[i](value[i]))
|
||||
}
|
||||
}
|
||||
return resultArray
|
||||
}
|
||||
print(pure(10))
|
||||
|
||||
var array = [{$0 * 2}, {$0 + 10}, {$0 - 5}] <*> [1, 2, 3]
|
||||
print(array)
|
||||
// console
|
||||
[10]
|
||||
[2, 12, -2]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 单子
|
||||
|
||||
对任意一个类型 F,如果能支持以下运算,那么就可以称为是一个单子(Monad)
|
||||
|
||||
```swift
|
||||
func pure<A>(_ value: A) -> F<A>
|
||||
func flatMap<A, B>(_ value: F<A>, _ fn: (A) -> F<B>) -> F<B>
|
||||
```
|
||||
|
||||
很显然,Array、Optional 都是单子
|
||||
|
||||
|
||||
|
||||
“单子”(Monad)是一个抽象概念,它代表了一种设计模式,用于组合计算并管理可能包含副作用的值。单子是一种在函数式编程中用于封装和组合计算的通用结构,它允许程序员以一致的方式处理各种复杂的计算情况,包括错误处理、异步操作、状态管理等。
|
||||
|
||||
单子通常定义了几个操作,这些操作允许你以统一的方式对封装在单子中的值进行操作。这些操作包括:
|
||||
|
||||
- `return` 或 `pure`:将一个值“提升”到单子中。
|
||||
- `bind` 或 `flatMap`:用于组合单子中的计算,允许你将一个单子的输出作为另一个单子的输入。
|
||||
|
||||
在 Swift 中,单子并没有像在其他一些语言(如 Haskell 或 Scala)中那样作为语言内建的概念,但你可以通过定义自己的类型和方法来实现单子模式。例如,Swift 中的 `Optional` 类型可以看作是一个简单的单子,它表示一个值可能存在或不存在。`Optional` 提供了 `map` 和 `flatMap` 方法,允许你对封装的值进行链式操作。
|
||||
|
||||
其他常见的单子实现包括处理异步操作的单子(如 Promise 或 Future),处理错误和异常的单子,以及管理状态的单子(如 State Monad)。
|
||||
|
||||
单子提供了一种强大的方式来管理复杂性和副作用,使代码更易于理解和测试。然而,它们也增加了抽象层次,可能需要一些时间来适应和理解。在 Swift 中,你可以根据自己的需要选择是否使用单子,以及使用哪种类型的单子。
|
||||
159
Chapter1 - iOS/1.126.md
Normal file
@@ -0,0 +1,159 @@
|
||||
# Swift 面向协议编程
|
||||
|
||||
## 概念
|
||||
|
||||
面向协议编程(Protocol Oriented Programming,简称 POP)
|
||||
|
||||
- 是 Swift 的一种编程范式, Apple 于2015年 WWDC 提出
|
||||
- 在 Swift 的标准库中,能见到大量 POP 的影子
|
||||
|
||||
同时,Swift 也是一门面向对象的编程语言(Object Oriented Programming,简称OOP)
|
||||
在 Swift 开发中,OOP 和 POP 是相辅相成的,任何一方并不能取代另一方,POP 能弥补 OOP 一些设计上的不足
|
||||
|
||||
|
||||
|
||||
## 优势
|
||||
|
||||
OOP 三大特性:继承、封装、多态
|
||||
|
||||
继承的经典使用场合:当多个类(比如 A、B、C 类)具有很多共性时,可以将这些共性抽取到一个父类中(比如 D 类),最后A、B、C类继承 D 类。
|
||||
|
||||
但一些情况下,继承并不能解决问题
|
||||
|
||||
比如 AVC 继承自 UIViewController 有 run 方法,BVC 继承自 UITableViewController,有 run 方法。AVC、BVC 有重复代码,如何消除?继承吗?可能会存在菱形继承问题。
|
||||
|
||||
菱形继承,也称为钻石继承或多头继承,发生在当一个类从两个或多个具有共同父类的类继承时。这种结构形成了一个菱形的继承图,因此得名。菱形继承可能导致一些问题,主要是二义性和数据冗余。
|
||||
|
||||
1. **二义性**:在菱形继承中,子类可能会从多个路径继承同一个基类的方法或属性。这会导致在子类中调用该方法或属性时存在不确定性,编译器或解释器不知道应该使用哪个版本的方法或属性。这种不确定性可能导致难以调试的错误和不可预测的行为。
|
||||
2. **数据冗余**:菱形继承也可能导致数据冗余。如果子类从多个父类继承了相同的数据成员,那么这些数据成员在内存中会有多个拷贝。这不仅浪费了存储空间,而且可能导致数据不一致的问题,因为对其中一个拷贝的修改不会影响到其他拷贝。
|
||||
|
||||
为了解决这些问题,一些编程语言提供了虚继承(virtual inheritance)的机制。虚继承允许子类只继承共享基类的一个拷贝,从而避免了二义性和数据冗余的问题。在虚继承中,共享基类被视为虚基类,子类只通过其中一个父类继承该基类的实现。
|
||||
|
||||
然而,虚继承并不是没有代价的。它可能会引入一些性能开销,因为编译器需要处理额外的间接引用和内存布局问题。此外,虚继承也可能使代码更加复杂和难以理解,特别是对于不熟悉该概念的开发者来说。
|
||||
|
||||
因此,在使用多继承时,需要谨慎考虑其潜在的问题和代价。在可能的情况下,尽量避免菱形继承结构,并通过其他方式(如接口、组合或委托)来实现所需的功能。如果必须使用菱形继承,那么应该仔细规划类的设计和继承关系,并充分利用虚继承等机制来减少潜在的问题。
|
||||
|
||||
采用 POP 实现。
|
||||
|
||||
```swift
|
||||
protocol Runable {
|
||||
func run()
|
||||
}
|
||||
extension Runable {
|
||||
func run() {
|
||||
print("running")
|
||||
}
|
||||
}
|
||||
|
||||
class AVC: UIViewController, Runable {
|
||||
// ...
|
||||
}
|
||||
class BVC: UITableViewController, Runable {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 思想转换
|
||||
|
||||
- 优先考虑创建协议,而不是基类
|
||||
- 优先考虑值类型(struct,enum),而不是引用类型(class)
|
||||
- 巧用协议的拓展功能 (extension Runable { ... })
|
||||
- 不要为了面向协议而使用协议
|
||||
|
||||
|
||||
|
||||
## 应用
|
||||
|
||||
统计字符串中数字个数
|
||||
|
||||
```swift
|
||||
// 方法1
|
||||
var testString: String = "ab1783893cs"
|
||||
extension String {
|
||||
var countOfNumber: Int {
|
||||
var count: Int = 0
|
||||
for c in self where ("0"..."9").contains(c) {
|
||||
count += 1
|
||||
}
|
||||
return count
|
||||
}
|
||||
}
|
||||
print(testString.countOfNumber) // 7
|
||||
|
||||
// 方法2.优雅的 Swift 风格
|
||||
struct Counter {
|
||||
var originalString: String
|
||||
init(originalString: String) {
|
||||
self.originalString = originalString
|
||||
}
|
||||
var countOfNumber: Int {
|
||||
var count: Int = 0
|
||||
for c in originalString where ("0"..."9").contains(c) {
|
||||
count += 1
|
||||
}
|
||||
return count
|
||||
}
|
||||
}
|
||||
extension String {
|
||||
var counter: Counter {
|
||||
Counter(originalString: self)
|
||||
}
|
||||
}
|
||||
print(testString.counter.countOfNumber) // 7
|
||||
```
|
||||
|
||||
上述2个方法虽然实现了统计功能,但是不够优雅,没有那么的 Swift 化。改写如下
|
||||
|
||||
```swift
|
||||
struct MY<Base> {
|
||||
let base: Base
|
||||
init(base: Base) {
|
||||
self.base = base
|
||||
}
|
||||
}
|
||||
|
||||
protocol MyCompitable {}
|
||||
extension MyCompitable {
|
||||
var my: MY<Self> {
|
||||
set{}
|
||||
get{ MY(base: self)}
|
||||
}
|
||||
static var my: MY<Self>.Type {
|
||||
set{}
|
||||
get{ MY<Self>.self }
|
||||
}
|
||||
}
|
||||
|
||||
extension String: MyCompitable { }
|
||||
extension MY where Base == String {
|
||||
func countOfNumber() -> Int {
|
||||
var count: Int = 0
|
||||
for c in base where ("0"..."9").contains(c) {
|
||||
count += 1
|
||||
}
|
||||
return count
|
||||
}
|
||||
|
||||
static func test() {
|
||||
print("I am a static method")
|
||||
}
|
||||
|
||||
mutating func modify() {
|
||||
print("I am a mutating method")
|
||||
}
|
||||
}
|
||||
print(testString.my.countOfNumber())
|
||||
String.my.test()
|
||||
testString.my.modify()
|
||||
// console
|
||||
7
|
||||
I am a static method
|
||||
I am a mutating method
|
||||
```
|
||||
|
||||
要拓展系统提供的类型,可以按照上述模版进行修改。
|
||||
|
||||
- 加前缀 `my` 的目的是防止重复,系统实现是黑盒,如果自己直接提供类似 `testString.countOfNumber` 怕后续系统也提供 `countOfNumber` 方法。所以加前缀 `testString.my.countOfNumber`
|
||||
-
|
||||
14
Chapter1 - iOS/1.127.md
Normal file
@@ -0,0 +1,14 @@
|
||||
# 响应式编程
|
||||
|
||||
|
||||
|
||||
## 概念
|
||||
|
||||
响应式编程(Reactive Programming,简称RP)
|
||||
|
||||
也是一种编程范式,于1997年提出,可以简化异步编程,提供更优雅的数据绑定。一般与函数式融合在一起,所以也会叫做:函数响应式编程(Functional Reactive Programming,简称 FRP)
|
||||
比较著名的、成熟的响应式框架:
|
||||
|
||||
- ReactiveCocoa 简称 RAC,有 Objective-C、Swift版本。[官网](http://reactivecocoa.io/) 、[github](https://github.com/ReactiveCocoa)
|
||||
- ReactiveX 简称 Rx,类似一个规范,有众多编程语言的版本,比如: RxJava、RxKotlin、RxJS、RxCpp、RxPHP、RxGo、RxSwift 等等。[官网](http://reactivex.io/)、[github]( https://github.com/ReactiveX)
|
||||
|
||||
1876
Chapter1 - iOS/1.128.md
Normal file
29
Chapter1 - iOS/1.129.md
Normal file
@@ -0,0 +1,29 @@
|
||||
# Swift Dictionary 扩容机制
|
||||
|
||||
|
||||
|
||||
## Dictionary
|
||||
|
||||
```swift
|
||||
let dic = ["d": 4, "a": 1, "b": 2, "c": 3]
|
||||
print(dic)
|
||||
// ["c": 3, "d": 4, "a": 1, "b": 2]
|
||||
```
|
||||
|
||||
Dictionary 顺序会乱序
|
||||
|
||||
|
||||
|
||||
## KeyValuePairs
|
||||
|
||||
KeyValuePairs 顺序不会乱序
|
||||
|
||||
```swift
|
||||
let kvs: KeyValuePairs = ["d": 4, "a": 1, "b": 2, "c": 3]
|
||||
print(kvs)
|
||||
// ["d": 4, "a": 1, "b": 2, "c": 3]
|
||||
```
|
||||
|
||||
|
||||
|
||||
开放寻址法
|
||||
1
Chapter1 - iOS/1.130.md
Normal file
@@ -0,0 +1 @@
|
||||
# GCD 源码探索
|
||||
124
Chapter1 - iOS/1.131.md
Normal file
@@ -0,0 +1,124 @@
|
||||
# 包管理工具
|
||||
|
||||
## CocoaPods
|
||||
|
||||
CocoaPods 是非常好用的第三方依赖管理工具,它于2011年发布,经过这几年的发展,已经非常完善。CocoaPods 支持项目中采用 Objective-C 或者 Swift 语言。CocoaPods 会将第三方库的源代码编译为静态库 `.a` 文件或者动态库 `.framework` 文件的形式,并将它们添加到项目中,建立依赖关系。
|
||||
|
||||
|
||||
|
||||
## Carthage
|
||||
|
||||
Carthage 是一个轻量级的项目依赖管理工具。Carthage 主张“去中心化”和“非侵入性”。
|
||||
|
||||
CocoaPods 搭建了一个中心库,第三方库被收入到该中心库,所以没有被收录的第三方库是不能使用 CocoaPods 管理的。这就是“中心化”的思想。而 Carthage 没有这样的中心库,第三方库基本都是从 Github 或者私有 git 库中下载的。这就是“去中心化”。
|
||||
|
||||
另外,CocoaPods 下载第三方库后,会将其变异成静态链接库或者动态框架文件,这种做法会修改 Xcode 项目属性依赖关系,这就是所谓的“侵入性”。而 Carthage 下载成功后,会讲第三方库编译为动态框架,由程序员自己配置依赖关系,Carthage 不会修改 Xcode 项目配置,这就是所谓的“非侵入性”
|
||||
|
||||
|
||||
### 安装
|
||||
```
|
||||
brew update
|
||||
brew install carthage
|
||||
```
|
||||
|
||||
觉得 brew update 更新慢,不想更新的也可以执行 `export HOMEBREW_NO_AUTO_UPDATE=true`。由于经常在终端干活,所以设置了别名。
|
||||
|
||||
```shell
|
||||
# 禁止终端利用 homebrew 安装插件时候的自动更新
|
||||
alias disableHomebrewUpdate="export HOMEBREW_NO_AUTO_UPDATE=true"
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CarthageInstall.png" style="zoom:25%">
|
||||
|
||||
### 使用
|
||||
|
||||
- 创建 cartfile 文件 `touch cartfile`
|
||||
- 修改 cartfile 文件
|
||||
```
|
||||
github "Alamofire/Alamofire" "5.0.0-rc.3"
|
||||
github "onevcat/Kingfisher"
|
||||
github "SnapKit/SnapKit" ~> 5.0.0
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CarthageUpdate.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
### cartfile - dependency origin
|
||||
|
||||
Carthage 支持两种类型的源,一个是 github,一个是 git
|
||||
- github 表示依赖源,告诉 Carthage 去哪里下载文件。依赖源之后跟上要下载的库,格式为 `Username/ProjectName`
|
||||
- git 关键字后面跟的是资料库的地址,可以是远程的 URL 地址,使用 `git://` `http://` `ssh://` 或者是本地资料库地址。
|
||||
|
||||
|
||||
|
||||
### cartfile - dependency version
|
||||
|
||||
告诉 Carthage 使用哪个版本,这是可选的。不指定的话,默认使用最新版本
|
||||
|
||||
- `==1.0` 表示使用 `1.0` 版本
|
||||
- `>= 1.0` 表示使用 `1.0` 或更高的版本
|
||||
- `~> 1.0` 表示使用版本 `1.0` 以上,但是低于2.0的最新版本,例如:1.2, 1.6
|
||||
- branch 名称/ tag 名称/ commit 名称,意思是使用特定的分支/标签/提交。比如可以说分支名 master,也可以是 commit id: 5c8w72
|
||||
|
||||
|
||||
|
||||
### 更新
|
||||
|
||||
`carthage update` 但默认会编译4个平台(macOS、iOS、watchOS、tvOS) 会比较耗时,所以可以优化下,指定特定平台
|
||||
`carthage update --platform iOS`
|
||||
|
||||
|
||||
|
||||
|
||||
### 安装后生成的文件
|
||||
|
||||
#### Cartfile.resolved
|
||||
该文件是生成后的依赖关系以及各个库的版本号,不能修改。
|
||||
该文件确保提交的项目可以使用完全相同的配置与方式运行启用。跟踪项目当前所用的依赖版本号,保持多端开发一致,出于这个原因。建议提交这个文件到版 本控制中。
|
||||
```
|
||||
github "Alamofire/Alamofire" "5.0.0-rc.3"
|
||||
github "onevcat/Kingfisher"
|
||||
github "SnapKit/SnapKit" ~> 5.0.0
|
||||
```
|
||||
|
||||
#### Carthage 目录
|
||||
|
||||
该目录包含2个子目录:
|
||||
- Checkouts 保存从 git 拉取的依赖库源文件
|
||||
- Build 包含编译后的文件,包含了4个平台(Mac、iOS、tvOS、watchOS)对应的 `.framework`
|
||||
|
||||
```
|
||||
- Carthage
|
||||
- Build
|
||||
- Checkouts
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 项目配置
|
||||
|
||||
`Target -> Build Setting -> Search Paths -> Framework Search Paths` 添加 `$(PROJECT_DIR)/Carthage/Build/iOS`
|
||||
|
||||
此时可以正常编写代码,和使用库的 api,但项目运行会 crash,报错为:`dyld: Library not loaded: @rpath/SnapKit.framework/SnapKit Referenced from: ...`
|
||||
|
||||
|
||||
|
||||
由于是非侵入式,所以需要程序员自己配置依赖,`Target -> Build Phases -> '+' -> New Run Script Phase`
|
||||
|
||||
- 添加脚本 `/usr/local/bin/Carthage copy-frameworks`。
|
||||
- 添加 "Input Files" `$(SRCROOT)/Carthage/Build/iOS/Alamofire.framework` 等等
|
||||
|
||||
## Swift Package Manager
|
||||
|
||||
Swift Package Manager 是苹果推出的用于管理分发 swift 代码的工具,可以用于创建使用 swift 的库和可执行程序
|
||||
|
||||
能够通过命令快速创建 library 或者可执行的 swift 程序,能够跨平台使用,是开发出来的项目能够运行在不同的平台上。
|
||||
|
||||
|
||||
### Xcode 集成
|
||||
|
||||
Xcode 菜单栏:File -> Swift Packages -> Add Package Dependency...
|
||||
输入项目地址后,在弹出框 Rules 里选择版本策略。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/SwiftPackageRules.png" style="zoom:45%">
|
||||
518
Chapter1 - iOS/1.132.md
Normal file
@@ -0,0 +1,518 @@
|
||||
# 动态调试
|
||||
|
||||
|
||||
|
||||
## Xcode 调试的原理
|
||||
|
||||
Xcode 是电脑端的程序,Xcode 使用 LLDB 进行调试。真机连接 Xcode 运行起来,点击屏幕,对应的事件处理方法里加了断点。手机是如何与 Xcode 断点连接同步的呢?
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeDebugWithiPhone.png" style="zoom:25%">
|
||||
|
||||
Xcode 编译器:GCC -> LLVM
|
||||
|
||||
Xcode 调试器:GDB -> LLDB
|
||||
|
||||
- `debugServer` 存放在:`/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/DeviceSupport/12.2/DeveloperDiskImage.dmg/usr/bin/debugserver`
|
||||
- 当 Xcode 识别到手机设备时,Xcode 会自动将 `debugserver` 安装到 iPhone 上。`/Developer/usr/bin/debugserver`
|
||||
- 一般情况下,Xcode 只可以调试通过 Xcode 安装的 App
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 动态调试任意 App
|
||||
|
||||
### 核心原因
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/XcodeDebugWithAnyAppiPhone.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
上面说了 `debugserver` 只能调试 Xcode 连接安装的程序。这句话不够严谨,Xcode 连接 iPhone 的时候,会自动将 `debugserver` 安装到 iPhone 上,但是权限会做收敛。具体表现就是权限 plist。
|
||||
|
||||
所以我们可以自行修改权限,重新签名即可:
|
||||
|
||||
- 将 `debugserver` 拷贝到电脑上
|
||||
|
||||
- 利用 ` ldid -e debugserver > debugserver.entitlements` 命令导出权限文件
|
||||
|
||||
- 打开 `debugserver.entitlements` 添加 `get-task-allow`、`task_for_pid-allow` 2个权限
|
||||
|
||||
```shell
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
|
||||
<plist version="1.0">
|
||||
<dict>
|
||||
<key>get-task-allow</key>
|
||||
<true/>
|
||||
<key>task_for_pid-allow</key>
|
||||
<true/>
|
||||
<key>com.apple.springboard.debugapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.backboardd.launchapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.backboardd.debugapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.frontboard.launchapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.frontboard.debugapplications</key>
|
||||
<true/>
|
||||
<key>seatbelt-profiles</key>
|
||||
<array>
|
||||
<string>debugserver</string>
|
||||
</array>
|
||||
<key>com.apple.diagnosticd.diagnostic</key>
|
||||
<true/>
|
||||
<key>com.apple.security.network.server</key>
|
||||
<true/>
|
||||
<key>com.apple.security.network.client</key>
|
||||
<true/>
|
||||
<key>com.apple.private.memorystatus</key>
|
||||
<true/>
|
||||
<key>com.apple.private.cs.debugger</key>
|
||||
<true/>
|
||||
</dict>
|
||||
</plist>
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
|
||||
<plist version="1.0">
|
||||
<dict>
|
||||
<key>com.apple.springboard.debugapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.backboardd.launchapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.backboardd.debugapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.frontboard.launchapplications</key>
|
||||
<true/>
|
||||
<key>com.apple.frontboard.debugapplications</key>
|
||||
<true/>
|
||||
<key>seatbelt-profiles</key>
|
||||
<array>
|
||||
<string>debugserver</string>
|
||||
</array>
|
||||
<key>com.apple.diagnosticd.diagnostic</key>
|
||||
<true/>
|
||||
<key>com.apple.security.network.server</key>
|
||||
<true/>
|
||||
<key>com.apple.security.network.client</key>
|
||||
<true/>
|
||||
<key>com.apple.private.memorystatus</key>
|
||||
<true/>
|
||||
<key>com.apple.private.cs.debugger</key>
|
||||
<true/>
|
||||
</dict>
|
||||
</plist>
|
||||
```
|
||||
|
||||
- 利用 ldid `ldid -S debugserver.entitlements debugserver` 进行重签
|
||||
|
||||
|
||||
|
||||
自动安装的 `debugserver` 存放目录为 `Device/Developer/usr/bin` 下的,但是这个目录是只读的。我们没办法将重签后的 `debugserver` 拖放到该位置。
|
||||
|
||||
但以后的使用场景是,在电脑终端 `sh ~/login.sh` 登录到手机后,在命令行模式下使用 `debugserver AppProcessName`,所以 `debugserver` 就需要安装(拖放 )到 `Device/usr/bin`
|
||||
|
||||
此时还是无法使用 `debugserver` ,需要修改权限 `chmod +x /usr/bin/debugserver `
|
||||
|
||||
|
||||
|
||||
### debugserver 附加到某个 App 进程
|
||||
|
||||
`debugserver *:端口号 -a 进程 `
|
||||
|
||||
- `*:端口号` :使用 iPhone 的某个端口启动 `debugserver` 服务(只要不是保留端口号就可以)
|
||||
- `进程`:输入 App 的进程信息(进程 ID 或者进程名称)
|
||||
|
||||
比如:`debugserver *:10011 -a Wechat`
|
||||
|
||||
|
||||
|
||||
### Mac 上启动 LLDB,远程连接 iPhone 上的 debugserver
|
||||
|
||||
- 启动 LLDB,直接在终端输入 `lldb`
|
||||
- 连接 debugserver 服务:`process connect connect://手机 IP 地址:debugserver 服务端口号 `。其中 `connect://` 代表协议
|
||||
- 第二步连接成功后,iPhone 的进程暂时就暂停了,下断点的状态,此时需要使用 LLDB 的 c 命令让程序先继续运行:`c`
|
||||
- 接下来就用 LLDB 常规命令调试 App
|
||||
|
||||
|
||||
|
||||
### 通过 debugserver 启动 App
|
||||
|
||||
`debugserver -x auto *:端口号 App 的可执行文件路径`
|
||||
|
||||
|
||||
|
||||
## LLDB 调试指令
|
||||
|
||||
### 指令格式
|
||||
|
||||
指令格式为:`<command> [<subcommand> [<subcommand>...]] <action> [-options [option-value]] [arguments [argument...]]`
|
||||
|
||||
- `<command>`:命令
|
||||
- `<subcommand>` : 子命令
|
||||
- `<action>` :命令操作
|
||||
- `<options>` :命令选项
|
||||
- `<arguments>`:命令参数
|
||||
|
||||
|
||||
|
||||
比如给函数 sayHi 设置断点:`breakpoint set -n sayHi`,其中
|
||||
|
||||
- breakpoint 是 `<command>`
|
||||
- set 是 `<action>`
|
||||
- -n 是 `<options>`
|
||||
- sayHi 是 `<arguments>`
|
||||
|
||||
|
||||
|
||||
### help 查看帮助
|
||||
|
||||
`help <command> <subcommand>`:用来查看某个指令和子指令 `<command> <subcommand>` 的说明。比如 `help breakpoint set`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBHelpCommand.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
### expression
|
||||
|
||||
`expression <cmd-options> -- <expr>` 用于执行一个表达式
|
||||
|
||||
- `<cmd-options>` :命令选项
|
||||
- `--`:命令选项结束符,表示所有的命令选项已经设置完毕,如果没有命令选项,`--` 可以省了
|
||||
- `<expr>` : 需要执行的表达式
|
||||
|
||||
比如经常在断点的时候,想额外执行某个函数或者处理某个逻辑,举个例子。在 `touchesMoved` 方法的断点模式下,想修改 view 的背景颜色,此时不需要重新运行。利用 expression 执行指令即可
|
||||
|
||||
```swift
|
||||
(lldb) expression self.view.backgroundColor = .red
|
||||
```
|
||||
|
||||
- `expression`、`expression --` 和指令 print、p、call 的效果一样
|
||||
|
||||
- `expression -O --` 和指令 po 效果一样。比如
|
||||
|
||||
|
||||
|
||||
### 堆栈信息
|
||||
|
||||
`thread backtrace` :打印线程的堆栈信息。效果等同于 `bt`
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBThreadBacktrace.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 方法返回
|
||||
|
||||
`thread return [<expr>]` 让函数直接返回某个值,不会执行断点后面的代码
|
||||
|
||||
例如下面的代码,直接将函数的返回值进行修改了
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBThreadReturn.png" style="zoom:25%">
|
||||
|
||||
### frame variable
|
||||
|
||||
`frame variable [<variable-name>]` 打印当前栈帧变量
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBFrameVariable.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
### 调试指令
|
||||
|
||||
`thread continue`、`continue`、`c`:程序继续运行
|
||||
|
||||
`thred step-over`、`next`、`n` :单步运行,把字函数当作整体一步执行
|
||||
|
||||
`thread step-in`、`step`、`s`:单步运行,遇到子函数会进入子函数
|
||||
|
||||
`thread step-out`、`finish`:直接执行完当前函数的所有代码,返回到上一个函数
|
||||
|
||||
`si` 、`ni` 和 `s` `n`:类似
|
||||
|
||||
- `s` `n` 是源码级别
|
||||
|
||||
- `si`、`ni` 是汇编指令级别
|
||||
|
||||
|
||||
|
||||
### breakpoint
|
||||
|
||||
设置断点的指令
|
||||
|
||||
#### 函数名
|
||||
|
||||
`breakpoint set -n "函数名"`,但可能存在多个断点,因为同样方法名称的方法,都会被设置断点
|
||||
|
||||
比如 Person 类和 ViewController 类,都有 `- (NSInteger)add:(NSInteger)a withB:(NSInteger)b` 方法。` breakpoint set -n "add:withB:"` 指令设置了2个断点。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakPointSetSameSymbol.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
当有多个方法同名的时候,只对当前类设置断点,指令格式为 `breakpoint set -n "[类名 方法名]"`。
|
||||
|
||||
比如通过 `breakpoint set -n "[ViewController add:withB:]"` 对 ViewController 类的 `- (NSInteger)add:(NSInteger)a withB:(NSInteger)b` 方法设置断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakPointsSetWithSpecificClass.png" style="zoom:25%">
|
||||
|
||||
如果一个方法没有参数,也可以通过 `breakpoint set -n sayHi` 的方式设置断点
|
||||
|
||||
|
||||
|
||||
#### 函数地址
|
||||
|
||||
在逆向,调试别人的 App 的时候我们无法知道函数名称,所以给函数地址打断点就很重要了。
|
||||
|
||||
`breakpoint set -a 函数地址`。注意:函数地址是需要处理的,因为 iOS 有 `ASLR 技术`。
|
||||
|
||||
|
||||
|
||||
#### 正则表达式
|
||||
|
||||
`breakpoint set -r 正则表达式`,效果就是给所有函数名符合正则表达式的函数,设置断点。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakpointSetRegx.png" style="zoom:25%">
|
||||
|
||||
#### 动态库
|
||||
|
||||
`breakpoint set -s 动态库 -n 函数名`
|
||||
|
||||
|
||||
|
||||
#### 列出所有断点
|
||||
|
||||
`breakpoint list` 用于列出所有的断点,每个断点都有自己的编号
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakPointList.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
#### 断点的删除、禁用、开启
|
||||
|
||||
`breakpoint disable 断点编号` ,比如 `breakpoint disable 2.1 2.2` 禁用了2个断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakpointDisable.png" style="zoom:25%">
|
||||
|
||||
`breakpoint delete 断点编号`,比如 `breakpoint delete 2`。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakpointDelete.png" style="zoom:25%">
|
||||
|
||||
比较奇怪,断点开启、禁用是可以跟子序号的,比如2.1 2.2,而断点删除必须是一级序号
|
||||
|
||||
|
||||
|
||||
#### 断点指令信息
|
||||
|
||||
`breakpoint command add 断点编号`,该指令会给断点预先设置需要执行的命令,到触发断点时,就会按照指令添加的顺序执行。
|
||||
|
||||
指令可以添加多个,最后以 "DONE" 结束。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakpointAddCommand.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`breakpoint command list 断点编号` 用于查看该断点下的所有指令
|
||||
|
||||
`breakpoint command delete 断点编号` 用于删除该断点下的所有指令
|
||||
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBBreakpointCommandList.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 内存断点
|
||||
|
||||
在内存数据发生改变时触发
|
||||
|
||||
`watchpoint set variable 变量`
|
||||
|
||||
在 `viewDidLoad` 中 通过 `watchpoint set variable self->_age` 给 age property 设置了断点。当改变的时候就触发断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBWatchpoint.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`watchpoint set expression 变量地址`
|
||||
|
||||
在 `viewDidLoad` 中 通过 `watchpoint set expression 0x00007fcd20306a60` 给 age property 设置了断点。当改变的时候就触发断点
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBWatchpointExpression.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`watchpoint list`
|
||||
|
||||
`watchpoint disable 断点编号`
|
||||
|
||||
`watchpoint enable 断点编号`
|
||||
|
||||
`watchpoint disable 断点编号`
|
||||
|
||||
`watchpoint delete 断点编号`
|
||||
|
||||
`watchpoint command add 断点编号`
|
||||
|
||||
`watchpoint command list 断点编号`
|
||||
|
||||
`watchpoint command delete 断点编号`
|
||||
|
||||
|
||||
|
||||
### image
|
||||
|
||||
#### image list
|
||||
|
||||
`image list` 列举所加载的模块信息
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBImageList.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`image list -o -f` 打印出模块的偏移地址、全路径
|
||||
|
||||
|
||||
|
||||
#### image lookup
|
||||
|
||||
`image lookup -t 类型`:查找某个类型的信息
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBImageLookupT.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
`image lookup -a 地址`:根据内存地址查找在模块中的位置
|
||||
|
||||
举例:声明一个数组,只有5个元素,但通过下标6来访问数组的时候 crash 了,假设我们代码很长,crash 后想知道具体是哪一行代码造成了 crash,怎么办呢?
|
||||
|
||||
我们项目叫做 Demo111,那么 crash 堆栈中第4行有个地址 `0x000000010d534dfc`,可以通过该地址来分析具体的 crash 位置。通过
|
||||
|
||||
`image lookup -a 0x000000010d534dfc` 可以知道 `Summary: Demo111 -[ViewController touchesBegan:withEvent:] + 108 at ViewController.m:29:18` 是在 ViewController 的29行处发生了 crash。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBImageLookupAddress.png" style="zoom:25%">
|
||||
|
||||
`image lookup -n 符号或者函数名`:查找某个符号或者函数的位置
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/LLDBImageLookupSymbol.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -110,4 +110,7 @@
|
||||
部代码,并可以找到出处!同时,结合下符号断点的方式,能够更清晰的跟踪源码实
|
||||
现。
|
||||
|
||||
13.
|
||||
13. Xcode 运行项目,模拟器启动失败。报错 `Failed to start launchd_sim: could not bind to session, launchd_sim may have crashed or quit respond`
|
||||
- 关闭Xcode,在终端中键入以下命令:sudo chmod 1777 /tmp
|
||||
- 清理此路径中的dyld文件夹:/Library/Developer/CoreSimulator/Caches
|
||||
- 重新启动Xcode,完成!
|
||||
@@ -2,6 +2,8 @@
|
||||
|
||||
> 很多人都知道类别、分类的用法,但是对于一些细节就不是很清楚了,本文主要梳理下这3个概念的细节
|
||||
|
||||
|
||||
|
||||
## 类别(Category)
|
||||
|
||||
### 文件特征
|
||||
@@ -59,48 +61,60 @@
|
||||
|
||||
5. Category 的作用是向下有效的。即只会影响到该类的所有子类。比如 A 类和 B 类是继承自 Super 类的2个子类,当给 A 类添加一个 Category sayHello 方法,仅有A 类的子类才可以使用 sayHello 方法
|
||||
|
||||
|
||||
|
||||
## Category 底层原理
|
||||
|
||||
### Category 是 category_t 结构体
|
||||
|
||||
Demo
|
||||
来一个简单的 Person 类,为其添加一个 Category,增加一些属性和类方法、对象方法、遵循协议
|
||||
|
||||
```objectivec
|
||||
// Person
|
||||
#import <Foundation/Foundation.h>
|
||||
NS_ASSUME_NONNULL_BEGIN
|
||||
@interface Person : NSObject
|
||||
@property (nonatomic, strong) NSString *name;
|
||||
- (void)sayHi;
|
||||
- (void)sleep;
|
||||
@end
|
||||
NS_ASSUME_NONNULL_END
|
||||
|
||||
// Person.m
|
||||
#import "Person.h"
|
||||
@implementation Person
|
||||
- (void)sayHi{
|
||||
NSLog(@"Person sayHi");
|
||||
- (void)sayHi {
|
||||
NSLog(@"Hello world");
|
||||
}
|
||||
- (void)sleep{
|
||||
NSLog(@"人生无常,抓紧睡觉");
|
||||
NSLog(@"Time to slepp");
|
||||
}
|
||||
@end
|
||||
|
||||
@end
|
||||
|
||||
// Person+Study.h
|
||||
#import "Person.h"
|
||||
NS_ASSUME_NONNULL_BEGIN
|
||||
@interface Person (Study)<NSCopying>
|
||||
@property (nonatomic, strong) NSString *no;
|
||||
@property (nonatomic, assign) NSInteger score;
|
||||
- (void)study;
|
||||
+ (void)sleep;
|
||||
@end
|
||||
NS_ASSUME_NONNULL_END
|
||||
|
||||
// Person+Study.m
|
||||
#import "Person+Study.h"
|
||||
@implementation Person (Study)
|
||||
- (void)study{
|
||||
- (void)study {
|
||||
|
||||
}
|
||||
+ (void)sleep{
|
||||
|
||||
+ (void)sleep {
|
||||
NSLog(@"Time to sleep");
|
||||
}
|
||||
- (void)setNo:(NSString *)no{
|
||||
|
||||
- (void)setScore:(NSInteger)score {
|
||||
|
||||
}
|
||||
- (NSString *)no{
|
||||
return nil;
|
||||
- (NSInteger)score {
|
||||
return 100;
|
||||
}
|
||||
- (id)copyWithZone:(NSZone *)zone{
|
||||
return self;
|
||||
@@ -108,153 +122,237 @@ Demo
|
||||
@end
|
||||
```
|
||||
|
||||
clang 转为 c++ 代码
|
||||
clang 转为 c++ 代码,具体指令为 `xcrun --sdk iphoneos clang -arch arm64 -rewrite-objc Person+Study.m`
|
||||
|
||||
查看到 Category 本质是一个结构体
|
||||
|
||||
```c
|
||||
struct _category_t {
|
||||
const char *name;
|
||||
struct _class_t *cls;
|
||||
const struct _method_list_t *instance_methods;
|
||||
const struct _method_list_t *class_methods;
|
||||
const struct _protocol_list_t *protocols;
|
||||
const struct _prop_list_t *properties;
|
||||
};
|
||||
查看 `Person+Study.cpp` 文件,可以看到 Category 本质是一个结构体
|
||||
|
||||
```c++
|
||||
struct _class_t {
|
||||
struct _class_t *isa;
|
||||
struct _class_t *superclass;
|
||||
void *cache;
|
||||
void *vtable;
|
||||
struct _class_ro_t *ro;
|
||||
struct _class_t *isa;
|
||||
struct _class_t *superclass;
|
||||
void *cache;
|
||||
void *vtable;
|
||||
struct _class_ro_t *ro;
|
||||
};
|
||||
|
||||
struct _category_t {
|
||||
const char *name;
|
||||
struct _class_t *cls;
|
||||
const struct _method_list_t *instance_methods;
|
||||
const struct _method_list_t *class_methods;
|
||||
const struct _protocol_list_t *protocols;
|
||||
const struct _prop_list_t *properties;
|
||||
};
|
||||
extern "C" __declspec(dllimport) struct objc_cache _objc_empty_cache;
|
||||
#pragma warning(disable:4273)
|
||||
|
||||
static struct /*_method_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[4];
|
||||
} _OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_objc_method),
|
||||
4,
|
||||
{{(struct objc_selector *)"study", "v16@0:8", (void *)_I_Person_Study_study},
|
||||
{(struct objc_selector *)"setScore:", "v24@0:8q16", (void *)_I_Person_Study_setScore_},
|
||||
{(struct objc_selector *)"score", "q16@0:8", (void *)_I_Person_Study_score},
|
||||
{(struct objc_selector *)"copyWithZone:", "@24@0:8^{_NSZone=}16", (void *)_I_Person_Study_copyWithZone_}}
|
||||
};
|
||||
|
||||
static struct /*_method_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
} _OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"sleep", "v16@0:8", (void *)_C_Person_Study_sleep}}
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"sleep", "v16@0:8", (void *)_C_Person_Study_sleep}}
|
||||
};
|
||||
|
||||
static const char *_OBJC_PROTOCOL_METHOD_TYPES_NSCopying [] __attribute__ ((used, section ("__DATA,__objc_const"))) =
|
||||
{
|
||||
"@24@0:8^{_NSZone=}16"
|
||||
"@24@0:8^{_NSZone=}16"
|
||||
};
|
||||
|
||||
static struct /*_method_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
} _OBJC_PROTOCOL_INSTANCE_METHODS_NSCopying __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"copyWithZone:", "@24@0:8^{_NSZone=}16", 0}}
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"copyWithZone:", "@24@0:8^{_NSZone=}16", 0}}
|
||||
};
|
||||
```
|
||||
|
||||
可以看到 Person+Study 的Category 底层赋值代码如下,就是结构体对象的初始化。
|
||||
struct _protocol_t _OBJC_PROTOCOL_NSCopying __attribute__ ((used)) = {
|
||||
0,
|
||||
"NSCopying",
|
||||
0,
|
||||
(const struct method_list_t *)&_OBJC_PROTOCOL_INSTANCE_METHODS_NSCopying,
|
||||
0,
|
||||
0,
|
||||
0,
|
||||
0,
|
||||
sizeof(_protocol_t),
|
||||
0,
|
||||
(const char **)&_OBJC_PROTOCOL_METHOD_TYPES_NSCopying
|
||||
};
|
||||
struct _protocol_t *_OBJC_LABEL_PROTOCOL_$_NSCopying = &_OBJC_PROTOCOL_NSCopying;
|
||||
|
||||
static struct /*_protocol_list_t*/ {
|
||||
long protocol_count; // Note, this is 32/64 bit
|
||||
struct _protocol_t *super_protocols[1];
|
||||
} _OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
1,
|
||||
&_OBJC_PROTOCOL_NSCopying
|
||||
};
|
||||
|
||||
static struct /*_prop_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _prop_t)
|
||||
unsigned int count_of_properties;
|
||||
struct _prop_t prop_list[1];
|
||||
} _OBJC_$_PROP_LIST_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_prop_t),
|
||||
1,
|
||||
{{"score","Tq,N"}}
|
||||
};
|
||||
|
||||
extern "C" __declspec(dllimport) struct _class_t OBJC_CLASS_$_Person;
|
||||
|
||||
```c
|
||||
static struct _category_t _OBJC_$_CATEGORY_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) =
|
||||
{
|
||||
"Person",
|
||||
0, // &OBJC_CLASS_$_Person,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study,
|
||||
(const struct _protocol_list_t *)&_OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study,
|
||||
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_Person_$_Study,
|
||||
"Person",
|
||||
0, // &OBJC_CLASS_$_Person,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study,
|
||||
(const struct _protocol_list_t *)&_OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study,
|
||||
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_Person_$_Study,
|
||||
};
|
||||
static void OBJC_CATEGORY_SETUP_$_Person_$_Study(void ) {
|
||||
_OBJC_$_CATEGORY_Person_$_Study.cls = &OBJC_CLASS_$_Person;
|
||||
}
|
||||
```
|
||||
|
||||
可以看到 `Person+Study` 的 Category 底层赋值代码如下,就是结构体对象的初始化(参考上面的结构体各个成员变量)
|
||||
|
||||
```c++
|
||||
static struct _category_t _OBJC_$_CATEGORY_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) =
|
||||
{
|
||||
"Person",
|
||||
0, // &OBJC_CLASS_$_Person,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study,
|
||||
(const struct _method_list_t *)&_OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study,
|
||||
(const struct _protocol_list_t *)&_OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study,
|
||||
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_Person_$_Study,
|
||||
};
|
||||
```
|
||||
|
||||
`_OBJC_CATEGORY_INSTANCE_METHODS_Person__Study` 结构体存放的是对象方法信息,如下
|
||||
`_OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study` 结构体存放的是对象方法信息,如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
static struct /*_method_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[4];
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[4];
|
||||
} _OBJC_$_CATEGORY_INSTANCE_METHODS_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_objc_method),
|
||||
4,
|
||||
{{(struct objc_selector *)"study", "v16@0:8", (void *)_I_Person_Study_study},
|
||||
{(struct objc_selector *)"setNo:", "v24@0:8@16", (void *)_I_Person_Study_setNo_},
|
||||
{(struct objc_selector *)"no", "@16@0:8", (void *)_I_Person_Study_no},
|
||||
{(struct objc_selector *)"copyWithZone:", "@24@0:8^{_NSZone=}16", (void *)_I_Person_Study_copyWithZone_}}
|
||||
sizeof(_objc_method),
|
||||
4,
|
||||
{{(struct objc_selector *)"study", "v16@0:8", (void *)_I_Person_Study_study},
|
||||
{(struct objc_selector *)"setScore:", "v24@0:8q16", (void *)_I_Person_Study_setScore_},
|
||||
{(struct objc_selector *)"score", "q16@0:8", (void *)_I_Person_Study_score},
|
||||
{(struct objc_selector *)"copyWithZone:", "@24@0:8^{_NSZone=}16", (void *)_I_Person_Study_copyWithZone_}}
|
||||
};
|
||||
```
|
||||
|
||||
`_OBJC_CATEGORY_CLASS_METHODS_Person__Study` 结构体存放的是类方法信息,如下
|
||||
`_OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study` 结构体存放的是类方法信息,如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
static struct /*_method_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
unsigned int entsize; // sizeof(struct _objc_method)
|
||||
unsigned int method_count;
|
||||
struct _objc_method method_list[1];
|
||||
} _OBJC_$_CATEGORY_CLASS_METHODS_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"sleep", "v16@0:8", (void *)_C_Person_Study_sleep}}
|
||||
sizeof(_objc_method),
|
||||
1,
|
||||
{{(struct objc_selector *)"sleep", "v16@0:8", (void *)_C_Person_Study_sleep}}
|
||||
};
|
||||
```
|
||||
|
||||
`_OBJC_CATEGORY_PROTOCOLS*_Person__Study` 结构体存放的是遵循的协议信息,如下
|
||||
`_OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study` 结构体存放的是遵循的协议信息,如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
static struct /*_protocol_list_t*/ {
|
||||
long protocol_count; // Note, this is 32/64 bit
|
||||
struct _protocol_t *super_protocols[1];
|
||||
long protocol_count; // Note, this is 32/64 bit
|
||||
struct _protocol_t *super_protocols[1];
|
||||
} _OBJC_CATEGORY_PROTOCOLS_$_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
1,
|
||||
&_OBJC_PROTOCOL_NSCopying
|
||||
1,
|
||||
&_OBJC_PROTOCOL_NSCopying
|
||||
};
|
||||
```
|
||||
|
||||
`_OBJC_PROP_LIST_Person__Study` 存放的是 Category 中的属性信息,如下
|
||||
`_OBJC_$_PROP_LIST_Person_$_Study` 存放的是 Category 中的属性信息,如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
static struct /*_prop_list_t*/ {
|
||||
unsigned int entsize; // sizeof(struct _prop_t)
|
||||
unsigned int count_of_properties;
|
||||
struct _prop_t prop_list[1];
|
||||
unsigned int entsize; // sizeof(struct _prop_t)
|
||||
unsigned int count_of_properties;
|
||||
struct _prop_t prop_list[1];
|
||||
} _OBJC_$_PROP_LIST_Person_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
|
||||
sizeof(_prop_t),
|
||||
sizeof(_prop_t),
|
||||
1,
|
||||
{{"no","T@\"NSString\",&,N"}}
|
||||
1,
|
||||
{{"score","Tq,N"}}
|
||||
};
|
||||
```
|
||||
|
||||
查看 Objc 4 源代码,Category 定义如下
|
||||
查看 [Objc 4 源代码](http://opensource.apple.com/tarballs/objc4/),Category 定义如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
struct category_t {
|
||||
const char *name;
|
||||
classref_t cls;
|
||||
struct method_list_t *instanceMethods;
|
||||
struct method_list_t *classMethods;
|
||||
WrappedPtr<method_list_t, method_list_t::Ptrauth> instanceMethods;
|
||||
WrappedPtr<method_list_t, method_list_t::Ptrauth> classMethods;
|
||||
struct protocol_list_t *protocols;
|
||||
struct property_list_t *instanceProperties;
|
||||
// Fields below this point are not always present on disk.
|
||||
struct property_list_t *_classProperties;
|
||||
|
||||
method_list_t *methodsForMeta(bool isMeta) {
|
||||
method_list_t *methodsForMeta(bool isMeta) const {
|
||||
if (isMeta) return classMethods;
|
||||
else return instanceMethods;
|
||||
}
|
||||
|
||||
property_list_t *propertiesForMeta(bool isMeta, struct header_info *hi);
|
||||
property_list_t *propertiesForMeta(bool isMeta, struct header_info *hi) const;
|
||||
|
||||
protocol_list_t *protocolsForMeta(bool isMeta) const {
|
||||
if (isMeta) return nullptr;
|
||||
else return protocols;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
结论:
|
||||
|
||||
- 为某个类添加的分类,分类中可能有属性、对象方法、类方法、遵循的协议、协议方法,本质都是存储到 `category_t` 结构体里面。
|
||||
- 当有多个分类的时候,是通过分类数组来承载的
|
||||
|
||||
|
||||
|
||||
### category 中定义的方法,存储在哪?
|
||||
|
||||
查看 objc4 的源代码 `objc-os.mm` 文件中的 `_objc_init` 方法
|
||||
抛个问题:当对象调用方法的时候,不管这个方法是类自身的方法,还是通过分类添加的方法,本质都是通过 isa 指针去寻找方法实现,(如果是对象方法,则通过 instance 的 isa 去找到类对象,最后找到对象方法的实现去调用;如果是类对象方法,则通过 class 的 isa 找到元类对象,最后找到类方法的实现进行调用),那给 Category 添加的方法,是「**如何“塞到”类对象或者元类对象的方法列表中去的**」?
|
||||
|
||||
```c
|
||||
带着问题查看 [objc4 的源代码](http://opensource.apple.com/tarballs/objc4/) `objc-os.mm` 文件中的 `_objc_init` 方法
|
||||
|
||||
```c++
|
||||
/***********************************************************************
|
||||
* _objc_init
|
||||
* Bootstrap initialization. Registers our image notifier with dyld.
|
||||
* Called by libSystem BEFORE library initialization time
|
||||
**********************************************************************/
|
||||
void _objc_init(void) {
|
||||
static bool initialized = false;
|
||||
if (initialized) return;
|
||||
@@ -271,13 +369,24 @@ void _objc_init(void) {
|
||||
|
||||
`_objc_init` 内部会调用 `map_images` 方法,其内部如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
/***********************************************************************
|
||||
* map_images
|
||||
* Process the given images which are being mapped in by dyld.
|
||||
* Calls ABI-agnostic code after taking ABI-specific locks.
|
||||
*
|
||||
* Locking: write-locks runtimeLock
|
||||
**********************************************************************/
|
||||
void map_images(unsigned count, const char * const paths[],
|
||||
const struct mach_header * const mhdrs[]) {
|
||||
rwlock_writer_t lock(runtimeLock);
|
||||
return map_images_nolock(count, paths, mhdrs);
|
||||
}
|
||||
```
|
||||
|
||||
`map_images` 内部会调用 `map_images_nolock`
|
||||
|
||||
```c++
|
||||
void map_images_nolock(unsigned mhCount, const char * const mhPaths[],
|
||||
const struct mach_header * const mhdrs[]) {
|
||||
static bool firstTime = YES;
|
||||
@@ -418,9 +527,9 @@ void map_images_nolock(unsigned mhCount, const char * const mhPaths[],
|
||||
}
|
||||
```
|
||||
|
||||
`map_images` 内部会调用 `map_images_nolock`, `map_images_nolock` 会调用 `_read_images`
|
||||
`map_images_nolock` 会调用 `_read_images` 方法,如下:
|
||||
|
||||
```c
|
||||
```c++
|
||||
void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses)
|
||||
{
|
||||
header_info *hi;
|
||||
@@ -823,7 +932,7 @@ static void remethodizeClass(Class cls){
|
||||
|
||||
可以看到内部调用 `attachCategories` 方法。 `attachCategories` 方法传入 3个参数,第一个是类对象(Person),第二个参数是 Category 数组。内部实现如下
|
||||
|
||||
```c
|
||||
```c++
|
||||
static void attachCategories(Class cls, category_list *cats, bool flush_caches){
|
||||
if (!cats) return;
|
||||
if (PrintReplacedMethods) printReplacements(cls, cats);
|
||||
@@ -878,7 +987,9 @@ static void attachCategories(Class cls, category_list *cats, bool flush_caches){
|
||||
}
|
||||
```
|
||||
|
||||
可以看到通过传入的类对象 `cls` 调用其 `cls->data()` 方法,找到对应的类 `class_rw_t` 信息,里面存放方法、属性、协议信息。
|
||||
观察到采用 `i--` 的方式,当 while 循环结束的时候,方法数组 `mlists` 保存了全部分类中的方法,属性数组 `proplists` 保存了全部分类中的属性,协议数组 `protolists` 保存了所有分类所遵循的协议。
|
||||
|
||||
可以看到通过传入的类对象 `cls` 调用其 `cls->data()` 方法,找到对应的类 `class_rw_t` 信息,里面存放:方法列表、属性列表、协议列表信息。
|
||||
|
||||
```c
|
||||
// 类对象结构体
|
||||
@@ -944,34 +1055,56 @@ void attachLists(List* const * addedLists, uint32_t addedCount) {
|
||||
|
||||
其中关键函数 `memmove` 代表将 __src 中的前 __len 个字节长度移动到 __dst 中去。
|
||||
|
||||
```c
|
||||
```c++
|
||||
memmove(array()->lists + addedCount, array()->lists,
|
||||
oldCount * sizeof(array()->lists[0]));
|
||||
memcpy(array()->lists, addedLists,
|
||||
addedCount * sizeof(array()->lists[0]));
|
||||
```
|
||||
|
||||
等价于
|
||||
|
||||
```c++
|
||||
memmove(类对象原来的方法列表 + addedCount,
|
||||
类对象原来的方法列表,
|
||||
oldCount * sizeof(array()->lists[0]))
|
||||
|
||||
memcopy(类对象原来的方法列表,
|
||||
所有分类的方法列表,
|
||||
addedCount * sizeof(array()->lists[0]))
|
||||
```
|
||||
|
||||
其中,`array()->lists` 代表类对象原来的方法列表、`oldCount * sizeof(array()->lists[0])` 代表类对象原来方法列表长度,`addedCount` 代表 category 方法列表长度。
|
||||
|
||||
c 数组指针 `array()->lists + addedCount` 可以代表其中的位置。
|
||||
|
||||
`memmove` 效果为将类原方法列表移动到第 n个(n为 category 方法列表长度位置,前面空出n个坑位。
|
||||
`memmove` 的效果是,将类原来的方法列表移动到第 n个(n为 category 方法列表长度位置,前面空出n个坑位,预留坑位给所有分类的方法)
|
||||
|
||||
`memcopy` 效果将 category 方法列表拷贝到类原方法列表的前面去。位置刚好是 `memmove` 留出的坑位。
|
||||
`memcopy` 效果将 Category 方法列表拷贝到类原方法列表的前面去。位置刚好是 `memmove` 留出的坑位。
|
||||
|
||||
过程如下
|
||||
|
||||

|
||||
|
||||
QA:
|
||||
结果就是类方法列表中,最前面的就是所有分类的方法列表,最后是类自身的方法列表。
|
||||
|
||||
分类中可以写属性吗?
|
||||
总结:
|
||||
|
||||
不可以,查看分类的 category_t 结构体可以看到没有 `**const** ivar_list_t * ivars;` ,所以 category 声明属性底层只会生成 setter、getter 方法声明,没有实现。需要程序员利用 runtime 关联属性自己实现
|
||||
Category 编译之后 底层结构为 struct category_t,里面存储着分类的对象方法、类方法、属性、协议信息
|
||||
|
||||
程序运行的时候,runtime 会将 Category 中的数据,合并到类自身信息中(类对象、元类对象)
|
||||
|
||||
|
||||
|
||||
### QA
|
||||
|
||||
#### 分类中可以写属性吗?
|
||||
|
||||
不可以。从源码角度来讲,查看分类的 category_t 结构体可以看到没有 `const ivar_list_t * ivars;` ,所以 category 声明属性底层只会生成 setter、getter 方法声明,没有实现。需要程序员利用 runtime 关联属性自己实现
|
||||
|
||||
同理,分类中也不可以添加成员变量,下面代码会报错。
|
||||
|
||||
```
|
||||
```objective-c
|
||||
@interface Person (Study)<NSCopying>
|
||||
{
|
||||
int _age;
|
||||
@@ -979,11 +1112,85 @@ QA:
|
||||
@end
|
||||
```
|
||||
|
||||
总结:
|
||||
|
||||
Category 编译之后 底层结构为 struct category_t,里面存储着分类的对象方法、类方法、属性、协议信息
|
||||
|
||||
程序运行的时候,runtime 会将 Category 中的数据,合并到类自身信息中(类对象、元类对象)
|
||||
从代码设计角度来讲,假设一个 Person 类只有1个 `_age` 成员变量,其内存布局在编译阶段就可以确定。内存布局大概为:
|
||||
|
||||
```objective-c
|
||||
struct Person_IMPL {
|
||||
Class isa;
|
||||
int _age;
|
||||
}
|
||||
```
|
||||
|
||||
但 Category 是苹果利用 Runtime 实现的,是运行期动态修改 `class_rw_t` 决定的。
|
||||
|
||||
|
||||
|
||||
#### 为什么分类中的方法需要放在类自身方法列表的开头?
|
||||
|
||||
查看源码为什么分类中的方法需要放在类自身方法列表的开头?因为需要优先保证 Category 中的方法优先被调用。
|
||||
|
||||
|
||||
|
||||
#### 分类中存在同名方法存在什么问题
|
||||
|
||||
对象调用方法的时候会根据对象的 isa 指针,找到类对象方法列表,然后查找方法,由于分类方法在方法列表的前面,类自身方法在方法列表的后面,所以当优先找到分类方法实现的时候就停止查找了,给人的感受就是,方法”被覆盖了 “
|
||||
|
||||
Demo: 为 Person 类创建2个 Category,分别存在同名方法 study,具有不同实现。在控制器的手势事件中打印方法列表
|
||||
|
||||
```objective-c
|
||||
- (void)displayMethodName:(Class)cls {
|
||||
unsigned int count;
|
||||
Method *methodList = class_copyMethodList(cls, &count);
|
||||
NSMutableString *methodNames = [NSMutableString string];
|
||||
for (int i = 0; i < count; i++) {
|
||||
Method method = methodList[i];
|
||||
NSString *methodName = NSStringFromSelector(method_getName(method));
|
||||
[methodNames appendString:methodName];
|
||||
[methodNames appendString:@", "];
|
||||
}
|
||||
free(methodList);
|
||||
NSLog(@"className: %@, methodNames: %@", NSStringFromClass(cls) , methodNames);
|
||||
}
|
||||
|
||||
- (void)viewDidLoad {
|
||||
[super viewDidLoad];
|
||||
self.p = [[Person alloc] init];
|
||||
}
|
||||
|
||||
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event {
|
||||
[self.p study];
|
||||
[self displayMethodName:[Person class]];
|
||||
}
|
||||
```
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryMethodOrderExplore.png" style="zoom:25%">
|
||||
|
||||
可以看到 sayHi 方法存在多个,但是由于 Category 同名的方法在方法列表的前面,所以类自身的方法实现”被覆盖了“(根据 isa 查找方法实现的时候,优先查找到 Category 的方法实现,则停止查找了)
|
||||
|
||||
|
||||
|
||||
#### 2个分类存在同名方法,谁先调用
|
||||
|
||||
- 分类方法优先级高于类自身方法
|
||||
- 同样是分类方法,由编译顺序决定哪个方法会被调用(Xcode:Build Phases -> Compile Sources),编译顺序越后面的方法优先被调用
|
||||
|
||||
Demo: 为 Person 类创建2个 Category,分别存在同名方法 study,具有不同实现。探索编译顺序决定方法实现
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo1.png" style="zoom:25%">
|
||||
|
||||
2个对比实验:
|
||||
|
||||
让 `Person+Study` 参与后编译
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo2.png" style="zoom:25%">
|
||||
|
||||
让 `Person+Learn` 参与后编译
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/OCCategoryBuildOrderDemo3.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
## 拓展(Extension)
|
||||
|
||||
@@ -1224,7 +1431,9 @@ void attachLists(List* const * addedLists, uint32_t addedCount) {
|
||||
|
||||
- 合并后的 Category 数据(属性、方法、协议)插入到类原来数据的前面(比如class_rw_t->methods)
|
||||
|
||||
## 小插曲:为 Category 实现属性的 Setter 和 Getter
|
||||
|
||||
|
||||
## 为 Category 实现属性的 Setter 和 Getter
|
||||
|
||||
```objectivec
|
||||
#import "Person.h"
|
||||
@@ -1317,7 +1526,9 @@ NS_ASSUME_NONNULL_END
|
||||
@end
|
||||
```
|
||||
|
||||
## 底层窥探 load 方法
|
||||
|
||||
|
||||
## 底层剖析 load 方法
|
||||
|
||||
Demo 验证。
|
||||
|
||||
@@ -1357,14 +1568,28 @@ Student *st = [[Student alloc] init];
|
||||
|
||||
QA:
|
||||
|
||||
- 为什么 load 方法打印顺序是这样的?
|
||||
- 为什么 `initialize`方法存在“覆盖”的情况?
|
||||
|
||||
因为调用 student alloc,相当于发送了消息。则肯定先执行 load 方法。类在 Runtime 启动阶段会调用 `schedule_class_load` 方法。方法内部递归调用,如果当前类存在父类则递归调用,否则将当前类加载到 loadable_classes 最后面。load 方法在本质上是执行 `call_load_methods`,方法地址是确定的。不走 objc_msgSend 这套流程。所以先打印父类 load、再打印子类 load、最后打印分类 load。如果存在多个分类,则按照编译顺序打印 load。
|
||||
就是打印了 Student Category 的 `initialize`,却没有打印 Student 自身的 `initialize`。
|
||||
|
||||
查看 objc 源码发现调用 `initialize` 方法本质上就是通过 runtime 的 `objc_msgSend ` 发消息来实现的。也就是通过 isa 指针查看类对象或元类对象的方法列表中(方法列表中包含当前类各个 Category 的各个方法)查找方法实现。所以当找到方法列表中排列较前的 `initialize` 时,就不再继续查找方法实现了。也就出现了 `initialize` 被覆盖的情况了。
|
||||
|
||||
```c++
|
||||
void callInitialize(Class cls)
|
||||
{
|
||||
((void(*)(Class, SEL))objc_msgSend)(cls, @selector(initialize));
|
||||
asm("");
|
||||
}
|
||||
```
|
||||
|
||||
- 为什么 load 方法打印顺序是这样的?
|
||||
|
||||
因为调用 student alloc,相当于发送了消息。则肯定先执行 load 方法。类在 Runtime 启动阶段会调用 `schedule_class_load` 方法。方法内部递归调用,如果当前类存在父类则递归调用,否则将当前类加载到 loadable_classes 最后面。load 方法在本质上是执行 `call_load_methods`,方法地址是确定的(查看下面的源代码可以发现 `load` 方法是在编译期就可以确定的)。不走 `objc_msgSend` 这套流程。所以先打印父类 load、再打印子类 load、最后打印分类 load。如果存在多个分类,则按照编译顺序打印 load。
|
||||
|
||||
- 为什么 load 方法不是按照 Category 编译顺序倒序调用 load 方法?
|
||||
|
||||
|
||||
看源代码 Objc4
|
||||
|
||||
|
||||
```c
|
||||
void _objc_init(void){
|
||||
static bool initialized = false;
|
||||
@@ -1525,15 +1750,15 @@ QA:
|
||||
return new_categories_added;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
会发现源码中先调用类的 load 方法,再调用 category 的 load 方法。
|
||||
|
||||
|
||||
再看看 `call_class_loads`、`call_category_loads` 方法内部实现,是直接找到 `load_method_t load_method = (load_method_t)classes[i].method;` 类对象的 load 方法地址。最后直接调用 `(*load_method)(cls, SEL_load);` 方法本身。
|
||||
|
||||
|
||||
test 方法是走消息发送流程 `objc_msgSend()` 所以会走 isa、superclass 这一套流程,test 是对象方法,所以需要根据 isa 找到类对象,从类对象的对象方法列表找到 test 方法,找不到则根据 superclass 找到当前类对象的父类对象,继续查找方法列表。直到 NSObject、nil 对象为止,然后走消息起死回生的阶段。
|
||||
|
||||
|
||||
看2个结构体
|
||||
|
||||
|
||||
```c
|
||||
struct loadable_class {
|
||||
Class cls; // may be nil
|
||||
@@ -1694,7 +1919,9 @@ Extension 在编译阶段,数据已经包含在类信息中。
|
||||
|
||||
Category 是在运行阶段,才会将数据合并到类信息中。
|
||||
|
||||
## 底层窥探 Initialize 方法
|
||||
|
||||
|
||||
## 底层剖析 Initialize 方法
|
||||
|
||||
上 Demo
|
||||
|
||||
@@ -1724,19 +1951,18 @@ Category 是在运行阶段,才会将数据合并到类信息中。
|
||||
|
||||
|
||||
|
||||
+initialize 和 +load 最大区别是 +initialize 是通过 objc_msgSend 进行调用的
|
||||
`+initialize` 和 `+load` 最大区别是 `+initialize` 是通过 `objc_msgSend` 进行调用的
|
||||
|
||||
- 调用方式:load 根据函数地址直接调用,initialize 是根据 objc_msgSend 调用的
|
||||
- 调用方式:`load` 根据函数地址直接调用,`initialize` 是根据 `objc_msgSend` 调用的
|
||||
|
||||
- 调用时刻:load 是 runtime 加载类、分类的时候调用的。initialize 是在类第一次接收消息的时候调用的。每个类只会 initialize 一次,但是父类的 initialize 可能会调用多次
|
||||
|
||||
- 调用顺序:
|
||||
|
||||
- load:先调用类的 load(先编译的类优先调用 load、调用子类的 load,会先调用父类的 load)、再调用分类的 load(先编译的分类,优先调用 load )
|
||||
|
||||
- 如果子类没有实现 +initialize 则会调用父类的 +initialize(所以父类的 +initialize 可能会被调用多次)
|
||||
|
||||
- 如果分类实现了 +initialize,就会覆盖类本身的 +initialize 调用
|
||||
- 如果子类没有实现 `+initialize` 则会调用父类的 `+initialize`(所以父类的 `+initialize` 可能会被调用多次)
|
||||
- 如果分类实现了 `+initialize`,就会覆盖类本身的 `+initialize` 调用
|
||||
|
||||
|
||||
查看源码,伪代码如下:
|
||||
|
||||
|
||||
@@ -17,24 +17,3 @@
|
||||
| NSNotification.Name.UITextFieldTextDidChange | UITextField.textDidChangeNotification |
|
||||
|
||||
2. 当你修改完语法问题的时候,编译工程,发现还是存在一些问题。大体意思是说 Swift 的编译版本不再支持。所以我们需要选中 targets ,切换到 「Build Settings」 下面,搜索 「Swift Language Version」,在后面勾选合适的 Swift 版本。在这里我选择了 Swift 5
|
||||
|
||||
|
||||
|
||||
## 手淘 App 落地 Swift,推进生态
|
||||
|
||||
经过技术调研、基础设施建设、工具链升级、里程碑业务上线和社区培训,得出“拥有一把锤子可以敲一个钉子,拥有一个工具箱可以造一艘航母”。
|
||||
|
||||
首先是业务视角:
|
||||
- 在业务需要快速迭代的时候,现有的 iOS 工程师主要以 Objective-C 为主,转战 Swift 需要一定的学习曲线,而且采用 Swift 效率是否一定有提高也有待考证;
|
||||
- Swift 只能解决 iOS 侧 Native 研发问题,对于高迭代效率的跨平台技术,收益不足。
|
||||
|
||||
其次是技术视角:
|
||||
- Swift 早期由于 ABI 不稳定,只能将 Runtime 内置在 IPA 包里面,占用约 3M 的下载空间,苹果还有 150M 的蜂窝网络下载大小的限制,且对启动性能有 150ms 的影响,在各家公司拼体验的时代,这些都会对公司的业务造成负担和损耗;
|
||||
- 由于语法不固定,每次升级都会造成源码级别的 Break Change,对开发者也会造成负担。淘宝、美团等巨型 App 都采用了二进制组建化研发模块,Swift 只能固定开发工具版本,对大型团队是一种负担和制约,反而极大的降低了研发效率。
|
||||
|
||||
未来一两年内国内 Swift 生态还是会有巨大改善的,主要有以下几个方面:
|
||||
- iOS 12.2 以上内置 Swift Runtime, 包大小随着存量旧版本操作系统升级后得到缓解;
|
||||
- iOS 12.2 以上也没有启动性能的影响;
|
||||
- Swift 语法不再大变,不会对开发者造成负担;
|
||||
- 苹果继续强势推进,Swift 社区热度持续提升。
|
||||
相信生产力大幅提高后,没有人会放任好用的工具不用而去用一把快要锈掉的锤子(Objective-C )。
|
||||
@@ -599,14 +599,115 @@ NSData *businessData = [NSData dataWithContentsOfFile:businessBundle options:NSD
|
||||
|
||||
|
||||
|
||||
## 学习方面
|
||||
## Fabric 新渲染器
|
||||
|
||||
学过 React.js 之后你再去学习 React Native 会很简单,一些核心的东西理解之后会很简单。比如 React 中的单向数据流、虚拟 Dom、diff 算法、数据变动的批量更新机制、diff 之后的 UI 渲染。
|
||||
React Native 开源之初的宏大愿景是:将现代 Web 技术引入移动端(Brighing modern web techniques to mobile)
|
||||
想来也是,Web 开发历史悠久,沉淀了很多优秀的 UI 开发实践和基础设置。随着 React Web 的出现,将现代的 Web 中积累的开发理念、语言、框架、规范也带入到移动端,
|
||||
但也有难点。如何打通 Web 和移动端
|
||||
|
||||
换言之,问题就是语言之间相互调用,也就是通信。本质上,JavaScript 如何与 OC/Java 通信。彼此可以互相调用方法、访问属性。
|
||||
|
||||
### 老架构渲染器
|
||||
|
||||
- 老渲染器的主要职责之一,就是将 JavaScript 侧声明的组件转换为 iOS/Android 侧的 Api 命令。
|
||||
```
|
||||
const App = () => <Text>Hello world</Text>
|
||||
AppRegistry.registerComponent(appName, () => App)
|
||||
```
|
||||
当声明一个包含 `<Text>Hello world</Text>` App 组件,并将该 App 组件传递给 `registerComponent` 方法后,通过渲染器,会将声明式的代码转换为原生指令。
|
||||
以上 Hello World 应用中会包括一个用于布局的 View 视图和显示文本的视图。在 iOS 端,会生成一个 UIView 用于布局,并会创建 NSAttributedString 用于显示文本。在 Objective-C 中调用相关以上创建视图的 API 后,操作系统就会将 Hello World 文字显示在屏幕上了。
|
||||
|
||||
- 老渲染器的另一个重要职责是实现 Flex 布局。
|
||||
开源的第一版 Flex 布局是直接用原生代码实现的,后来该功能独立了出来,作为一个 C++ 第三方库 Yoga 被 React Native 引入。
|
||||
假设想实现文字居中
|
||||
```
|
||||
<view style={{flex:1, justifyContent: 'center', alignItems: 'center'}}>
|
||||
<Text>Hello world</Text>
|
||||
</view>
|
||||
```
|
||||
渲染器会将 style 属性设置,转换为包裹 Hello World 视图容器的 x/y 轴坐标使其实现屏幕居中。
|
||||
|
||||
- 老版渲染器还有一个职责就是尽可能的提升渲染性能。
|
||||
RN 在第一版的时候就设置为双线程异步消息通信架构,后来 RN 团队又为 Yoga 布局引擎,新增了一个线程,专门用于处理布局。
|
||||
相较于单线程同步调用的架构,多线程异步消息架构更能大幅减少卡顿。一方面,渲染任务被分解到3个线程中(JS 线程、布局线程、UI 线程),所以 UI 线程的任务量会变少,UI 线程卡顿的几率也会减少。另一方面,采用异步通信,JS 线程任务的执行不会阻塞 UI 线程。
|
||||
|
||||
|
||||
样式布局方面增加了 flexbox,这样子布局在移动端会非常方便,非常简单,
|
||||
### Fabric 新渲染器
|
||||
Fabric 新渲染器是基于老渲染器的重构升级,而重构升级过程中不变的是核心责任,是组件化 / 声明式、Flex 布局和多线程模型。升级的是开发者体验,以及性能提升带来的用户体验。
|
||||
Fabric 渲染器完成的主要任务还是将声明的组件转换为最终原生 Api 调用。转换过程涉及到3颗树:
|
||||
- Element Tree
|
||||
- Fiber Tree
|
||||
- Shadow Tree
|
||||
|
||||
#### Element Tree
|
||||
Element Tree 是 Javascript 侧,由 React 通过开发者书写的 JSX 创建而成,由若干个 Element 组成。
|
||||
一般而言,根结点 `<App />` 就是一个 Element,同时它也是 Element Tree。一个 Element 其实就是一个普通的 Object,该对象描述组件的实例或宿主视图实例。
|
||||
```
|
||||
const App = () => {
|
||||
return (
|
||||
<View style={{opacity: 0.99, flex:1, justifyContent: 'center', alignItems: 'center'}}>
|
||||
<Text style={{opacity: 0.88}}>Hello World</Text>
|
||||
</View>
|
||||
);
|
||||
};
|
||||
// Element Tree
|
||||
<App/>
|
||||
```
|
||||
整个应用的根节点是 `<App />`,`<App />` 的子节点是 `<View />`,`<View />` 子节点是 `<Text />`,共同构成了一棵 Element Tree。
|
||||
Element Tree 的每个节点都是一个 Element,React Element 有2种类型:一种是通过函数或者自定义合成组件生成的、一种是宿主组件生成的。其中,宿主组件指的是框架通过 JS 引擎暴露给 JS 的原生组件(Native 组件)
|
||||
|
||||
`<App />` 根节点是自定义函数创建的,属于合成组件生成的节点,由 type、props、concurrentRoot 等属性组成的对象,type 属性是一个 function 函数,函数名 name 是 App。打印信息如下
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNative-ElementTreeDemo1.jpeg" style="zoom:40%">
|
||||
|
||||
`<Text />` 节点是由框架暴露组件生成的节点,信息如下
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNative-ElementTreeDemo2.webp" style="zoom:40%">
|
||||
|
||||
可知,一个 Element 也是一个普通的对象,该对象的 type 属性为 RCTText,style 属性值由设置透明属性 `opacity:0.9` 和设置居中布局的属性组成,子节点 children 属性值为 `Hello world`
|
||||
|
||||
从 Hello World 应用中的 <App> <Text> 节点的构成,我们可以看出,一个 Element 常见的属性包括 type 、props、concurrentRoot、style、children 等属性。
|
||||
- type:type 代表该 Element 的类型。如果 type 的值是 RCTText、RCTView 之类的字符串,那么该 Element 对应着一个宿主视图。如果 type 的值是函数或类,那么该 Element 是由合成组件生成的,并且没有对应的宿主视图。
|
||||
- props:Element 初始化传入的属性,其中又包括当前根节点 concurrentRoot、样式 style、子节点 children,或者例如 Text 组件的 ellipsizeMode 文本省略属性等等。
|
||||
|
||||
在 React 层, Element Tree 会被映射为 Fiber Tree。
|
||||
|
||||
#### Fiber Tree
|
||||
Fiber Tree 由若干个 FIber 节点组成。如果某个 Fiber 节点是通过用于描述宿主视图的 Element 生成的,那么该 Fiber 节点会对应一个同样的宿主视图。
|
||||
|
||||
Fiber 是 React16 之后引入的新能力,使得 React 每次可渲染的颗粒度变小了。由 React 16 之前的一次 render 所有节点,变成了一次 render 时可分批次对节点进行操作。因此,从渲染角度,我们还可以将 Fiber 节点当作每次 render 的最小渲染单位,让 Fabric 渲染器更快更智能。
|
||||
|
||||
在 React 内部,Fiber 节点是由 `function createFiberFromElement(element, mode, lanes)` 函数创建的。顾名思义,Fiber 节点是由 Element 节点生成的,换言之 Fiber Tree 可以看成是 Element Tree 的映射。
|
||||
|
||||
同样 Fiber Tree 分为2种,一种是由合成组件生成的 Element 所映射得到的 Fiber 节点,它没有对应的宿主组件实例;一种是由宿主组件生成的 Element 所映射得到的 Fiber 节点,它拥有对应的宿主组件实例。
|
||||
|
||||
以 Hello world 威力,打印 App 组件所创建的 Fiber 节点
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNativeFiberNodeDemo.webp" style="zoom:40%">
|
||||
|
||||
可以看到 App Fiber 也是一个 JS 对象,也拥有 type、child、props 等属性,这些属性在 Element 上也有。例如 App 组件创建的 Element、Fiber 的 Type 都是一个名为 App 的函数。Fiber 节点上的属性比 Element 多,比如 Fiber 节点拥有兄弟节点 sibling、父节点 return、状态节点 stateNode 等属性。
|
||||
|
||||
状态节点是一个特殊的属性,关联了渲染器在 C++ 层生成的 Shadow 节点。App Fiber 节点的 stateNode 为 null,代表的就是合成组件所对应的 Fiber 节点是没有关联的 Shadow 节点的,也就没有对应的宿主视图。
|
||||
|
||||
打印 Text 组件所创建的 Fiber 节点,如下:
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNativeFiberNodeDemo2.webp" style="zoom:40%">
|
||||
Text Fiber 节点和 App Fiber 节点属性都一样,比如:类型 type、子节点 child、兄弟节点 sibling、父节点 return、状态节点 stateNode 等。不同的是 Text Fiber 节点的 type 是 RCTText,App Fiber 的 type 是个函数。Text Fiber 的 stateNode 是有值的,node 属性值是一个 CallbackObject,而 App Fiber 的 node 是 null。该 CallbackObject 类型的值代表的是一个在 C++ 层的 shadow 节点。
|
||||
|
||||
|
||||
#### Shadow Tree
|
||||
Shadow Tree 是 C++ 层创建的树,由若干个 Shadow 节点组成,这些 Shadow 节点是在创建对应的拥有 stateNode 值的 Fiber 节点时,同步创建的。
|
||||
```
|
||||
<Text style={{opacity: 0.88}}>Hello world</Text>
|
||||
```
|
||||
Xcode 打印如下:
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNativeShadowNode.webp" style="zoom:40%">
|
||||
<Text>元素对应的 Shadow 节点是个 Native 对象,拥有属性 props、子节点 children、布局 layoutMetrics 等属性。
|
||||
|
||||
其中,Shadow 的 props 的透明度 opacity: 0.88 来自于 JSX 中的 style={{opacity: 0.88}} 的设置;子节点 children 的 text="Hello World" 来自于 JSX 标签括起来的内容 Hello World。而 x/y 轴坐标以及 width/height 视图大小是根据其自身 style 布局属性,以及父节点和其他节点 style 布局属性计算出来的。
|
||||
|
||||
Shadow Tree 不仅继承了由 JSX 所创建的 Element Tree 相关属性、父子节点关系,还新增了该视图如何在屏幕上进行布局的具体值。
|
||||
|
||||
最后 Fabric 渲染器的 C++ 层,通过 diff 算法对比更新前后的2颗 Shadow Tree,计算出更新视图的操作指令,完成最终的渲染。整个流程就是 Fabric 渲染器将 JSX 渲染成原生视图的完整流程。
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ReactNative-RenderPhase.png" style="zoom:40%">
|
||||
可以访问完整的[渲染、提交与挂载流程](https://reactnative.cn/architecture/render-pipeline)
|
||||
|
||||
## 经验小结
|
||||
|
||||
|
||||
@@ -470,6 +470,15 @@ class_rw_t *personMetaClassData = personClass->metaClass()->data();
|
||||
```
|
||||
|
||||
## 五、 内存对齐
|
||||
内存对齐是指数据在内存中存储时按照一定规则对齐到特定的地址上。在 iOS 开发中,内存对齐是为了提高内存访问的效率和性能。内存对齐的原因主要包括以下几点:
|
||||
1. 提高访问速度:内存对齐可以使数据在内存中的存储更加高效,因为大部分计算机体系结构都要求数据按照特定的边界对齐,这样可以减少内存访问的次数,提高访问速度。CPU访问非对齐的内存时需要进行多次拼接。
|
||||
如下图,比如需要读取从[2, 5]的内存,需要分别读取两次,然后还需要做位移的运算,最后才能得到需要的数据。这中间的损耗就会影响访问速度。
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MemoryAlignReason.png" style="zoom:30%">
|
||||
|
||||
2. 为了方便移植。CPU是一块块的进行进行内存访问。有一些硬件平台不允许随机访问,只能访问对齐后的内存地址,否则会报异常。
|
||||
很多 CPU(如基于 Alpha,IA-64,MIPS,和 SuperH 体系的)拒绝读取未对齐数据。当一个程序要求这些 CPU 读取未对齐数据时,这时 CPU 会进入异常处理状态并且通知程序不能继续执行。举个例子,在 ARM,MIPS,和 SH 硬件平台上,当操作系统被要求存取一个未对齐数据时会默认给应用程序抛出硬件异常。
|
||||
3. 硬件要求:某些硬件平台对于数据的访问有特定的要求,例如ARM架构的处理器对于某些数据类型的访问需要按照特定的对齐方式进行
|
||||
4. 数据结构优化:内存对齐也有助于优化数据结构的布局,使得数据在内存中的存储更加紧凑和高效。
|
||||
|
||||
Demo1
|
||||
|
||||
@@ -492,7 +501,7 @@ NSLog(@"%zd", malloc_size((__bridge const void *)person)); // 16
|
||||
NSLog(@"%zd", sizeof(struct Person_IMPL)); // 16
|
||||
```
|
||||
|
||||
isa 指针8字节 + int _age 4字节 + _hright 字节 = 16 字节
|
||||
`isa 指针 8字节` + `int _age 4字节` + `_hright 字节` = 16 字节
|
||||
|
||||
Demo2
|
||||
|
||||
@@ -513,15 +522,17 @@ struct Person_IMPL {
|
||||
};
|
||||
|
||||
Person *person = [[Person alloc] init];
|
||||
NSLog(@"%zd", malloc_size((__bridge const void *)person)); // 32
|
||||
NSLog(@"%zd", sizeof(struct Person_IMPL)); // 24
|
||||
NSLog(@"%zd", malloc_size((__bridge const void *)person)); // 32
|
||||
```
|
||||
|
||||
isa 指针8字节 + int _age 4字节 + _hright 字节 + _no 4 字节 = 20 字节,因为存在内存对齐,因为结构体本身对齐内存对齐,必须为8的倍数,所以占据24个字节的内存。
|
||||
`isa 指针8字节` + `int _age 4字节` + `_height 4字节` + `_no 4 字节` = 20 字节,因为存在内存对齐,因为结构体本身对齐内存对齐,必须为8的倍数,所以占据24个字节的内存。结构体成员变量,内存对齐时,对齐基数必须是各个成员变量中最大字节数的一个。
|
||||
|
||||
结构体占据24字节,为什么运行起来后通过 `malloc_size` 得到32个字节?这个涉及到运行时内存对齐。规定 **iOS 中内存对齐以 16 的倍数为准**。
|
||||
|
||||
Demo
|
||||
|
||||
|
||||
Demo
|
||||
|
||||
```objectivec
|
||||
void *temp = malloc(4);
|
||||
@@ -531,7 +542,7 @@ NSLog(@"%zd", malloc_size(temp));
|
||||
|
||||
可以看到 malloc 申请了4个字节,但是打印却看到16个字节。
|
||||
|
||||
查看源码也可以出来分配内存最小是以16的倍数为基准进行分配的。
|
||||
查看 libmalloc源码也可以出来分配内存最小是以16的倍数为基准进行分配的。
|
||||
|
||||
```c
|
||||
#define NANO_MAX_SIZE 256 /* Buckets sized {16, 32, 48, 64, 80, 96, 112, ...} */
|
||||
@@ -539,4 +550,8 @@ NSLog(@"%zd", malloc_size(temp));
|
||||
|
||||
为什么系统是由16字节对齐的?
|
||||
|
||||
成员变量占用8字节对齐,每个对象的第一个都是 isa 指针,必须要占用8字节。举例一个极端 case,假设 n 个对象,其中 m 个对象没有成员变量,只有 isa 指针占用8字节,其中的 n-m个对象既有 isa 指针,又有成员变量。每个类交错排列,那么 CPU 在访问对象的时候会耗费大量时间去识别具体的对象。很多时候会取舍,这个 case 就是时间换空间。以16字节对齐,会加快访问速度(参考链表和数组的设计)
|
||||
成员变量占用8字节对齐,每个对象的第一个都是 isa 指针,必须要占用8字节。举例一个极端 case,假设 n 个对象,其中 m 个对象没有成员变量,只有 isa 指针占用8字节,其中的 n-m个对象既有 isa 指针,又有成员变量。每个类交错排列,那么 CPU 在访问对象的时候会耗费大量时间去识别具体的对象。很多时候会取舍,这个 case 就是时间换空间。以16字节对齐,会加快访问速度(参考链表和数组的设计)
|
||||
|
||||
|
||||
|
||||
Todo: 研究探索 glibc 源代码,分析内存对齐、内存分配的原理
|
||||
@@ -4525,6 +4525,8 @@ XMLHttpRequest.prototype.open(function(...args) {
|
||||
})
|
||||
|
||||
```
|
||||
这是切面处理,所以为了保证监控代码不影响原有逻辑,用一个变量记录原本的函数地址,内部处理完之后再调用原始方法
|
||||
|
||||
|
||||
|
||||
## 七、 电量消耗
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
# Runtime
|
||||
|
||||
> 做很多需求或者是技术细节验证的时候会用到 Runtime 技术,用了挺久的了,本文就写一些场景和源码分析相关的文章。
|
||||
> 做很多技术项目或者业务项目、再或者是技术细节验证的时候会用到 Runtime 技术,用了挺久的了,本文就写、结合一些场景和源码分析来系统化学习。
|
||||
|
||||
|
||||
|
||||
## 动态语言
|
||||
|
||||
@@ -8,11 +10,11 @@ Runtime 是实现 OC 语言动态的 API。
|
||||
|
||||
静态语言:在编译阶段确定了变量数据类型、函数地址等,无法动态修改。
|
||||
|
||||
动态语言:只有在运行的时候才可以决定变量属于什么类型、方法真正的地址,
|
||||
动态语言:只有在运行的时候才可以决定变量属于什么类型、方法真正的地址。
|
||||
|
||||
对象 `objc_object` 存了:isa、成员变量的值
|
||||
|
||||
类 objc_class: superclass、成员变量、实例变量
|
||||
类 `objc_class` 存了isa、 superclass、成员变量、实例变量、对象方法、协议
|
||||
|
||||
```objectivec
|
||||
@interface Person : NSObject
|
||||
@@ -26,17 +28,19 @@ malloc_size((__bridge const void *)(p)) // 24 isa占8字节 + _name 指针占
|
||||
class_getInstanceSize(p.class) // 32 ,系统内存对齐
|
||||
```
|
||||
|
||||
|
||||
|
||||
为什么系统是由16字节对齐的?
|
||||
|
||||
成员变量占用8字节对齐,每个对象的第一个都是 isa 指针,必须要占用8字节。举例一个极端 case,假设 n 个对象,其中 m 个对象没有成员变量,只有 isa 指针占用8字节,其中的 n-m个对象既有 isa 指针,又有成员变量。每个类交错排列,那么 CPU 在访问对象的时候会耗费大量时间去识别具体的对象。很多时候会取舍,这个 case 就是时间换空间。以16字节对齐,会加快访问速度(参考链表和数组的设计)
|
||||
成员变量占用 8 字节对齐,每个对象的第一个都是 isa 指针,必须要占用8字节。举例一个极端 case,假设 n 个对象,其中 m 个对象没有成员变量,只有 isa 指针占用8字节,其中的 n-m个对象既有 isa 指针,又有成员变量。每个类交错排列,那么 CPU 在访问对象的时候会耗费大量时间去识别具体的对象。很多时候会取舍,这个 case 就是时间换空间。以16字节对齐,会加快访问速度(参考链表和数组的设计)
|
||||
|
||||
|
||||
|
||||
## class_rw_t、class_ro_t、class_rw_ext_t 区别?
|
||||
|
||||
class_ro_t 在编译时期生成的,class_rw_t 是在运行时期生成的。
|
||||
`class_ro_t` 在编译时期生成的,`class_rw_t` 是在运行时期生成的。
|
||||
|
||||
那么什么是 `class_rw_ext_t`?首先明确2个概念
|
||||
那么什么是 `class_rw_ext_t`首先明确2个概念
|
||||
|
||||
- clean memory:加载后不会被修改。当系统内存紧张时,可以从内存中移除,需要时可以再次加载
|
||||
|
||||
@@ -58,14 +62,18 @@ const method_array_t methods() const {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 有类对象、为什么设计元类对象
|
||||
|
||||
复用消息机制。比如 `[Person new]`。
|
||||
|
||||
元类对象: isa、元类方法、
|
||||
元类对象:isa、元类方法、
|
||||
|
||||
`objc_msgSend` 设计初衷就是为了消息发送很快。假如没有元类,则类方法也存储在类对象的方法信息中,则可能需要加额外的字段来标记某个方法是类方法还是对象方法。遍历或者寻找会比较慢。所以引入元类(单一职责),设计元类的目的就是为了提高 `objc_msgSend` 的效率。
|
||||
|
||||
|
||||
|
||||
## isa 本质
|
||||
|
||||
在 arm64 架构之前,isa 就是一个普通的指针,存储着 Class或Meta-Class 对象的内存地址。
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
# DYLD 及 Mach-O
|
||||
DYLD 及 Mach-O
|
||||
|
||||
dynamic loader,动态加载器。在 MacOS/iOS 中,是使用 `/usr/lib/dyld` 程序来加载动态库的。
|
||||
|
||||
|
||||
dynamic loader,动态加载器。在 MacOS/iOS 中,使用 `/usr/lib/dyld` 程序来加载动态库的。
|
||||
|
||||
## DYLD(dyld shared cache) 动态库共享缓存
|
||||
|
||||
@@ -18,6 +20,8 @@ ImageLoader* load(const char* path, const LoadContext& context, unsigned& cacheI
|
||||
|
||||
某个 App 被第一次打开时候, dyld 根据动态库的依赖,循环加载动态库到动态库共享缓存中(内存),后续其他 App 第一次打开发现使用了动态库A已经在动态库共享缓存中存在,则不需要加载。这一步调用方法为 `findInSharedCacheImage`
|
||||
|
||||
|
||||
|
||||
## dyld 应用
|
||||
|
||||
窥探系统库底层实现的时候可能需要从动态库共享缓存中提取出某个 Framework,比如 UIKit。这时候要么用第三方工具,要么用 dyld 的能力。
|
||||
@@ -63,6 +67,16 @@ int main(int argc, const char* argv[])
|
||||
|
||||
将编译后的产物复制到动态库共享缓存目录下去。然后执行命令`./dsc_extractor dyld_shared_cache_armv7s armv7s`,代表将动态库提取到 armv7s 目录下。
|
||||
|
||||
|
||||
|
||||
dyld 本身就是一种 MachO 文件,MachO 文件类型为7,是一种包含多种架构的结构,如下图:
|
||||
|
||||
<img src="./../assets/DyldStructure.png" style="zoom:25%">
|
||||
|
||||
可以加载以下类型的 Mach-O 文件:MH_EXECUTE、MH_DYLIB、MH_BUNDLE
|
||||
|
||||
|
||||
|
||||
## Mach-O
|
||||
|
||||
Mach Object 的缩写,是 iOS/MacOS 上用于存储程序、库的标准格式
|
||||
@@ -87,57 +101,66 @@ Mach Object 的缩写,是 iOS/MacOS 上用于存储程序、库的标准格式
|
||||
#define MH_KEXT_BUNDLE 0xb /* x86_64 kexts */
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 常见的 Mach-O 文件类型
|
||||
|
||||
MH_OBJECT
|
||||
- MH_OBJECT
|
||||
- 目标文件(.o)
|
||||
- 静态库文件(.a),静态库其实就是 N 个 `.o` 合并在一起
|
||||
|
||||
- 目标文件(.o)
|
||||
- MH_EXECUTE:可执行文件
|
||||
|
||||
- 静态库文件(.a),静态库其实就是 N 个 `.o` 合并在一起
|
||||
|
||||
MH_EXECUTE:可执行文件
|
||||
|
||||
MH_DYLIB:动态库文件
|
||||
|
||||
- dylib
|
||||
|
||||
- .framework
|
||||
|
||||
MY_DYLINKER:动态链接编辑器 (/usr/lib/dyld)
|
||||
|
||||
MH_DSYM:存储着二进制文件符号。`.dSYM/Contents/Resource/DWARF/xx` 常用于还原堆栈
|
||||
- MH_DYLIB:动态库文件
|
||||
- dylib
|
||||
- .framework
|
||||
- MH_DYLINKER:动态链接器 (/usr/lib/dyld)
|
||||
- MH_DSYM:存储着二进制文件符号。`.dSYM/Contents/Resource/DWARF/xx` 常用于还原堆栈
|
||||
|
||||
Xcode 中也可以查看 Mach-O 文件类型
|
||||
|
||||

|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/MachOFileType.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
源代码(比如c文件),编译变为目标文件(比如.o文件),再经过链接变为可执行文件。
|
||||
|
||||
Tips:`file` 命令可以查看文件类型。
|
||||
|
||||
<img src="./../assets/FileCommandToWatchFileType.png" style="zoom:45%">
|
||||
|
||||
`find . -name "*.c"` 比如在当前路径查找 .c 文件
|
||||
|
||||
|
||||
|
||||
### Universal Binary
|
||||
|
||||
通用二进制文件,可以同时适用于多种架构的二进制文件,包含多种不同架构的独立的二进制文件。
|
||||
|
||||
因为要存储多种架构的代码,所以通用二进制文件通常比单一平台的二进制程序更大
|
||||
- 因为要存储多种架构的代码,所以通用二进制文件通常比单一平台的二进制程序更大
|
||||
|
||||
由于两种架构有共同的一些资源,所以并不会达到单一版本的2倍多。
|
||||
- 由于两种架构有共同的一些资源,所以并不会达到单一版本的2倍多。
|
||||
|
||||
执行的过程中,只调用一部分代码,运行起来不需要额外的内存。
|
||||
- 执行的过程中,只调用一部分代码,运行起来不需要额外的内存。
|
||||
|
||||
因为通用二进制文件比原来的大,所以被成为“胖二进制文件”(Fat Binary)
|
||||
因为通用二进制文件比原来的大,所以被成为“胖二进制文件”(Fat Binary),使用 Hopper 打开会显示 “FAT archive”
|
||||
|
||||
查看某可执行文件(Test)支持的架构指令集
|
||||
信息查看:
|
||||
|
||||
`lipo -info Test`
|
||||
- 查看某可执行文件(Test)支持的架构指令集 :`lipo -info Test`
|
||||
|
||||
将某个指令集拆出来比如 arm64
|
||||
- 将某个指令集拆出来比如 arm64:`lipo Test -thin arm64 -o Test_arm64`
|
||||
|
||||
`lipo Test -thin arm64 -o Test_arm64`
|
||||
- 也可以将多个指令集合并:`lipo -create Test_arm64 Test_armv7 -output Test_universal`
|
||||
|
||||
也可以将多个指令集合并
|
||||
Xcode 中可以修改指令集。由 Build Settings 的2个配置决定: `Architectures->Architectures` `User-Defined->VALID_ARCHS`,取2者的交集。
|
||||
其中 `Architectures->Architectures` 的值 `$(ARCHS_STANDARD)` 是 Xcode 内置的环境变量,不同版本的 Xcode 值不一样,是通用的一些架构值。比如 Xcode9下,`$(ARCHS_STANDARD)` 可能为 arm64、armv7。Xcode 4下,`$(ARCHS_STANDARD)` 可能为 armv7
|
||||
|
||||
`lipo -create Test_arm64 Test_armv7 -output Test_universal`
|
||||
|
||||
## Mach-O 结构
|
||||
|
||||

|
||||
### Mach-O 结构
|
||||
|
||||
<img src="./../assets/Mach-OStructure.png" style="zoom:45%">
|
||||
|
||||
一个 Mach-O 文件包含3块
|
||||
|
||||
@@ -147,20 +170,26 @@ Xcode 中也可以查看 Mach-O 文件类型
|
||||
|
||||
- Raw segment data:在 Load Commands 中定义的 segment 的原始数据
|
||||
|
||||
可以用 [GitHub - fangshufeng/MachOView: 分析Macho必备工具](https://github.com/fangshufeng/MachOView) 和系统自带的 atool 查看 Mach-O 信息
|
||||
可以用 [MachOView:](https://github.com/fangshufeng/MachOView) 和系统自带的 atool 查看 Mach-O 信息
|
||||
|
||||

|
||||
<img src="./../assets/otoolhelp.png" style="zoom:25%">
|
||||
|
||||
比如我用 otool 查看我编写的一个 SwiftUIDemo 所依赖的共享缓存库
|
||||
|
||||
<img src="./../assets/SwiftUIDemoDependencyLibrary.png" style="zoom:25%">
|
||||
|
||||
用 MachOView 查看 DDD Mach-O 文件
|
||||
|
||||

|
||||
<img src="./../assets/MachOPageZero.png" style="zoom:35%">
|
||||
|
||||

|
||||
<img src="./../assets/MachOText.png" style="zoom:35%">
|
||||
|
||||
可以看到在 Mach-O 文件上,`__PAGEZERO` 的 `VM Size` 有值,但是 File Size 为0,也就是说 `__PAGEZERO` 在 Mach-O 中不占据内存,但是程序运行起来之后,会占据虚拟内存。所以代码段在 Mach-O 中 File Offset 为0(如果前面的 `__PAGEZERO` 的 File size 有值,这里的 File Offset 就不为0)。
|
||||
|
||||
**在没有 ASLR 的时候:__TEXT 代码段地址 = __PAGEZEROR 地址**
|
||||
|
||||
|
||||
|
||||
## ASLR
|
||||
|
||||
### 未使用 ASLR 的问题
|
||||
@@ -173,29 +202,75 @@ Xcode 中也可以查看 Mach-O 文件类型
|
||||
|
||||
- 可执行文件 Header 的内存地址,就是 `LC_SEGMENT(__TEXT)` 中的 VM Address
|
||||
|
||||
- arm64 :0x100000000
|
||||
- arm64 :`0x100000000`
|
||||
|
||||
- 非 arm64:0x4000
|
||||
- 非 arm64:`0x4000`
|
||||
|
||||
也可以使用 `size -l -m -x DDD` 指令来查看 Mach-O 的内存分布
|
||||
|
||||

|
||||
<img src="./../assets/MachOInsepect.png" style="zoom:35%">
|
||||
|
||||
利用 MachOView 查看如下:
|
||||
|
||||
<img src="./../assets/MachOViewDemo1.png" style="zoom:25%">
|
||||
|
||||
<img src="./../assets/MachOViewDemo2.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
- _PAGEZERO
|
||||
- VM Address:0x0
|
||||
- VM Size:0x100000000
|
||||
- _TEXT
|
||||
- VM Address:0x100000000
|
||||
- VM Size:0x4000
|
||||
- _DATA_CONST:
|
||||
- VM Address:0x10004000
|
||||
- VM Size:0x4000
|
||||
- _DATA
|
||||
- VM Address:0x10008000
|
||||
- VM Size:0x4000
|
||||
- _LINKEDIT
|
||||
- VM Address:0x1000C000
|
||||
- VM Size:0x8000
|
||||
|
||||
|
||||
|
||||
<img src="./../assets/ASLRDemo.png" style="zoom:45%">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
File Offset:在 Mach-O 文件中的位置
|
||||
|
||||
File Size:在 Mach-O 文件中的占据的大小
|
||||
|
||||
从下面的图可以看出,`_PAGEZERO` 在真实的 Mach-O 文件中不存在,不占据大小。只在虚拟内存中存在。
|
||||
|
||||
<img src="./../assets/MachOViewDemo1.png" style="zoom:25%">
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
我们会发现根据 Mach-O 文件中的信息,File Size、File Offset、VM Address、VM Size 可以判断出 `__TEXT` 段内函数信息,这样子不够安全
|
||||
|
||||
|
||||
|
||||
### ASLR 诞生
|
||||
|
||||
Address Space Layout Randomization,地址空间布局随机化。是一种针对缓冲区溢出的安全保护技术,通过堆、栈、共享库映射等线性区布局的随机化,通过增加攻击者预测目的地址的难度,防止攻击者直接定位攻击代码的位置,达到阻止溢出攻击目的的一种技术。在 iOS 4.3 引入。
|
||||
|
||||

|
||||
<img src="./../assets/ASLROffset.png" style="zoom:45%">
|
||||
|
||||
- LC_SEGMENT (__TEXT) 的 VM Address 0x10005000
|
||||
|
||||
|
||||
- LC_SEGMENT (__TEXT) 的 VM Address `0x10005000`
|
||||
|
||||
- ASLR 随机偏移 0x5000,也就是可执行文件的内存地址
|
||||
|
||||
在有 ASLR 的时候:__TEXT 代码段地址 = __PAGEZEROR 地址
|
||||
在有 ASLR 的时候:__TEXT 代码段地址 = __`PAGEZEROR 地址`
|
||||
|
||||
在 Mach-O 文件中的地址是原始地址
|
||||
|
||||
|
||||
@@ -113,4 +113,7 @@
|
||||
* [107、IM技术](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.107.md)
|
||||
* [108、精准测试](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.108.md)
|
||||
* [109、汇编学习](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.109.md)
|
||||
* [110、妙用设计模式来设计一个客户端校验器](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.110.md)
|
||||
* [110、妙用设计模式来设计一个客户端校验器](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.110.md)
|
||||
* [111、写给 iOSer 的鸿蒙开发 tips](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.111.md)
|
||||
* [112、Swift 枚举值内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.112.md)
|
||||
* [113、Swift 结构体和类的内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.113.md)
|
||||
370
Chapter7 - Geek Talk/7.27.md
Normal file
@@ -0,0 +1,370 @@
|
||||
# 敏捷软件开发和 Scurm Master
|
||||
|
||||
> Scrum 是迭代式增量软件开发过程,是敏捷方法论中的重要框架之一,通常用于敏捷软件开发。Scrum 包括了一系列实践和预定义角色的过程骨架。Scrum 中的主要角色包括同项目经理类似的 Scrum 主管角色负责维护过程和任务,产品负责人代表利益所有者,开发团队包括了所有开发人员。
|
||||
|
||||
|
||||
|
||||
## 常见的问题是什么
|
||||
|
||||
需求经常在变。当下成立的需求,可能过几天就是伪需求了。
|
||||
|
||||
于是经常会出现:一个团队花了大量的时间和资源却做出一个根本没有市场的产品。在瞬息万变的今天,试图预测用户需求已经变得几乎不可能了。
|
||||
|
||||
Scrum 敏捷开发是解决该问题的一个有效抓手。
|
||||
|
||||
|
||||
|
||||
## Scrum指南的目的
|
||||
|
||||
在 1990 年代初,我们开发了 Scrum。在 2010 年,我们撰写首版 Scrum 指南,以帮助全世界的人们理解 Scrum。自那时起,我们通过小的功能更新对 Scrum 指南进行了演进。我们是 Scrum 指南的共同后盾。
|
||||
|
||||
Scrum 指南包含了 Scrum 的定义。框架的每个元素都有其特定的目的,这对于使用 Scrum 实现全部价值和成果是至关重要的。如果更改 Scrum 的核心设计或理念、遗漏元素或不遵循 Scrum 的规则,将掩盖问题并限制 Scrum 的好处,甚至可能变得毫无用途。
|
||||
|
||||
我们关注到 Scrum 在日益复杂的世界中应用越来越广泛。我们很荣幸地看到Scrum 在许多本质上具有复杂性的工作领域中被采用,超越了 Scrum 的起源领域——软件产品开发。随着 Scrum 的应用范围不断扩大,开发者(developers)、研究人员、分析师、科学家和其他专家都能在工作中应用。因此,我们在 Scrum 中使用 “developers” 一词并不是为了排除其他使用者,而是为了简化统称。如果您从 Scrum 中获得价值,那么您可以将自己视为其中一员。
|
||||
|
||||
在使用 Scrum 时,可以找到、应用和设计适合本文中所描述的 Scrum 框架的模式、过程和见解。对它们的描述超出了 Scrum 指南的目的,因为它们因 Scrum 的使用具体情境不同而不同。这些使用 Scrum 框架的特定技巧有很大的差异,因此不在本文中描述。
|
||||
|
||||
|
||||
|
||||
## Scrum 的定义
|
||||
|
||||
Scrum 是一个轻量的框架,它通过提供针对复杂问题的自适应解决方案来帮助人们、团队和组织创造价值。
|
||||
简而言之,Scrum 需要 Scrum Master 营造一个环境,从而:
|
||||
|
||||
- 一名产品负责人将解决复杂问题所需的工作整理成一份产品待办列表
|
||||
- Scrum 团队在 一个 Sprint 期间将选择的工作转化为价值的增量
|
||||
- Scrum 团队和利益攸关者检视结果并为下一个 Sprint 进行调整
|
||||
- 重复
|
||||
|
||||
Scrum 是易于理解的。原封不动地去尝试,并确定其哲学、理论和结构是否有助于实现目标和创造价值。Scrum 框架故意不完整,仅定义了实施 Scrum 理论所需的部分。Scrum 建立在其使用者的集体智慧之上。Scrum 的规则没有为人们提供详细的使用说明,而是指导他们之间的关系和互动。
|
||||
|
||||
在 Scrum 框架中,可以使用各种不同的过程、技术和方法。Scrum可以将一些已有的实践包装进来,也可以甄别出非必须的实践。Scrum 可以凸显当前管理、环境和工作技术的相对成效,以便可以进行改进。
|
||||
|
||||
|
||||
|
||||
## Scrum 理论
|
||||
|
||||
Scrum 基于经验主义和精益思维。经验主义主张知识源自实际经验以及根据当前观察到的事物作出的判断所获得。精益思维减少浪费,专注于根本。
|
||||
|
||||
Scrum 采纳一种迭代和增量的方法来优化对未来的预测性并控制风险。Scrum 让一群共同拥有所有技能和专长的人员参与进来完成工作,并根据需要分享或获得所需技能。
|
||||
|
||||
Scrum 将四个正式事件组合在一起以在一个容器型事件 Sprint 中进行检视和适应。这5个事件之所以起作用,是因为它们实现了基于经验主义的 Scrum 的三个支柱:透明、检视和适应。
|
||||
|
||||
### 透明(Transparency)
|
||||
涌现的过程和工作成果必须对执行工作的人员和接受工作的人员都是可见的和一致理解的。在 Scrum 中,重要的决策是基于其 3 个正式工件的感知状态。透明度较低的工件可能导致做出降低价值并增加风险的决策。
|
||||
|
||||
透明使检视成为可能。没有透明和共识的检视会产生误导和浪费。
|
||||
|
||||
### 检视(Inspection)
|
||||
Scrum 工件和实现商定目标的进展必须经常地和勤勉地检视,以便发现潜在的不良的差异或问题。为了帮助检视,Scrum 以 5 个事件的形式提供了稳定的节奏。
|
||||
检视使适应成为可能。没有适应的检视是毫无意义的。Scrum 事件旨在激发改变。
|
||||
|
||||
### 调整(Adaptation)
|
||||
如果过程的任何方面超出可接受的范围或所得的产品不可接受,就必须对当下的过程或过程处理的内容加以调整。调整工作必须尽快执行以最小化进一步的偏差。
|
||||
当所涉人员没有得到授权或不能自管理时,则适应将变得更加困难。在通过检视学到任何新东西时,Scrum 团队会做出相应调整。
|
||||
|
||||
|
||||
|
||||
## Scrum 价值观
|
||||
|
||||
Scrum 的成功应用取决于人们变得更加精通践行并内化 5 项价值观:承诺, 专注, 开放, 尊重,勇气
|
||||
|
||||
Scrum 团队致力于达成其目标并且相互支持。他们主要专注于 Sprint 的工作,以便尽可能地向着这些目标获取最好的进展。Scrum 团队及其利益攸关者对工作和挑战持开放态度。Scrum 团队成员相互尊重,彼此是有能力和独立的人,并因此受到与他们一起工作的人的尊重。Scrum 团队成员有勇气做正确的事并处理那些棘手的问题。
|
||||
|
||||
这些价值观为 Scrum 团队的工作、行动和行为指引方向。做出的决定、采取的步骤以及使用Scrum 的方式应强化这些价值观,而不是削弱或破坏它们。Scrum 团队成员通过 Scrum 事件和工件来学习和探索这些价值观。当 Scrum 团队和与他们一起工作的人们体现这些价值观时,基于经验主义的 Scrum 的三个支柱:透明、检视和适应,就成为现实,并在每个人之间构建信任。
|
||||
|
||||
|
||||
|
||||
## Scrum 团队(Scrum Team)
|
||||
|
||||
Scrum 的基本单位是小团队,称为 Scrum Team。Scrum 团队由一名 Scrum Master,一名产品负责人和开发人员组成。在 Scrum 团队中,没有子团队或层次结构。Scrum 团队是具有凝聚力的专业团体,一次专注于一个目标,即产品目标。
|
||||
|
||||
Scrum 团队是跨职能的,这意味着团队成员具有在每个 Sprint 中创造价值而所需的全部技能。他们也是自管理的,这意味着他们在团队内部决定谁做什么、何时做以及如何做。
|
||||
Scrum 团队规模足够小以保持灵活,同时足够大以便可以在一个 Sprint 中完成有意义的工作,通常只有 10 人或更少。总的来说,我们发现较小的团队沟通更好,效率更高。如果 Scrum 团队变得太大,则应考虑将他们重组为多个具有凝聚力的 Scrum 团队,每个团队都专注于同一产品。因此,他们应该共享相同的产品目标、产品待办列表和产品负责人。
|
||||
Scrum 团队负责所有与产品相关的活动,包括与利益攸关者的协作、验证、维护、运营、实验、研究和开发,以及可能需要进行的其他任何活动。组织组建并授权 Scrum 团队自行管理他们自己的工作。以可持续的速度在 Sprint 中工作可以提高 Scrum 团队的专注度和一致性。
|
||||
|
||||
整个 Scrum 团队都有责任在每个 Sprint 中创建有价值的、有用的增量。Scrum 在 Scrum 团队中定义了三种特定的职责担当(Accountability):开发人员、产品负责人和 Scrum Master。
|
||||
|
||||
|
||||
|
||||
## 开发人员(Developers)
|
||||
|
||||
开发人员是 Scrum 团队中致力于创建每个 Sprint 可用增量的任何方面的人员。
|
||||
开发人员所需的特定技能通常很广泛,并且会随着工作领域的不同而变化。但是, 开发人员始终要负责:
|
||||
- 为Sprint创建计划,即 Sprint 待办列表;
|
||||
- 通过遵循完成的定义来注入质量;
|
||||
- 每天根据 Sprint 目标调整计划;
|
||||
- 和作为专业人士对彼此负责。
|
||||
|
||||
|
||||
|
||||
## 产品负责人(Product Owner)
|
||||
|
||||
产品负责人负责将 Scrum 团队的工作所产生的产品价值最大化。如何做到这一点可能在组织、Scrum 团队和个体之间存在很大差异。
|
||||
|
||||
产品负责人还负责对产品待办列表进行有效管理,包括:
|
||||
- 开发并明确地沟通产品目标;
|
||||
- 创建并清晰地沟通产品待办列表项;
|
||||
- 对产品待办列表项进行排序;
|
||||
- 确保产品待办列表是透明的、可见的和可理解的。
|
||||
|
||||
产品负责人可以自己做上述工作,或者也可以将职责委托他人。然而无论如何, 产品负责人是担当最终责任的人。
|
||||
|
||||
为保证产品负责人取得成功,整个组织必须尊重他们的决定。这些决定在产品待办列表的内容和顺序中可见,并在 Sprint 评审会议时透过可检视的增量予以体现。
|
||||
|
||||
产品负责人是一个人,而不是一个委员会。在产品待办列表中,产品负责人可以代表许多利益攸关者的期望要求。那些想要改变产品待办列表的人可以尝试去说服产品负责人来做到这一点。
|
||||
|
||||
|
||||
|
||||
## Scrum Master (敏捷教练和领导者)
|
||||
|
||||
Scrum Master 负责按照 Scrum 指南的游戏规则来建立 Scrum。他们通过帮助 Scrum 团队和组织内的每个人理解 Scrum 理论和实践来做到这一点。
|
||||
|
||||
Scrum Master 对 Scrum 团队的效能负责。他们通过让 Scrum 团队在 Scrum 框架内改进其实践来做到这一点。
|
||||
|
||||
Scrum Masters 是真正的领导者,服务于 Scrum 团队和作为更大范围的组织。
|
||||
|
||||
Scrum Master 以多种方式服务于 Scrum 团队,包括:
|
||||
- 作为教练在自管理和跨职能方面辅导 Scrum 团队成员;
|
||||
- 帮助 Scrum 团队专注于创建符合完成的定义的高价值增量;
|
||||
- 促使移除 Scrum 团队工作进展中的障碍;
|
||||
- 和确保所有 Scrum 事件都发生并且是积极的、富有成效的,并且在时间盒内完成。
|
||||
|
||||
Scrum Master 以多种方式服务于产品负责人,包括:
|
||||
- 帮助找到有效定义产品目标和管理产品待办列表的技巧;
|
||||
- 帮助 Scrum 团队理解为何需要清晰且简明的产品待办列表项;
|
||||
- 帮助建立针对复杂环境的基于经验主义的产品规划;
|
||||
|
||||
当需要或被要求时,引导利益攸关者协作。Scrum Master 以多种方式服务于组织,包括:
|
||||
- 带领、培训和作为教练辅导组织采纳 Scrum;
|
||||
- 在组织范围内规划并建议 Scrum 的实施;
|
||||
- 帮助员工和利益攸关者理解并实施针对复杂工作的经验主义方法;
|
||||
- 消除利益攸关者和 Scrum 团队之间的隔阂。
|
||||
|
||||
|
||||
|
||||
## Scrum 事件
|
||||
|
||||
Sprint 是所有其他事件的容器。Scrum 中的每个事件都是检视和适应 Scrum 工件的正式机会。这些事件都是为实现所需的透明度而特别设计的。未能按规定运作任何事件将导致失去检视和适应的机会。Scrum 使用事件来创造规律性,并以此最小化对 Scrum 中未定义的会议的需要。最理想的是,所有事件都在同一时间同一地点举行,以便减少复杂性。
|
||||
|
||||
|
||||
|
||||
### Sprint (短迭代时间盒)
|
||||
|
||||
Sprint 是 Scrum 的核心,在这里创意转化为价值。
|
||||
|
||||
它们是固定时长的事件,为期一个月或更短,以保持一致性。前一个 Sprint 结束后,下一个新的 Sprint 紧接着立即开始。
|
||||
|
||||
实现产品目标所需的所有工作,包括 Sprint 计划会议、每日 Scrum 会议、Sprint 评审会议和 Sprint 回顾会议,都发生在 Sprint 内。
|
||||
|
||||
在 Sprint 期间:
|
||||
- 不能做出危及 Sprint 目标的改变;
|
||||
- 不能降低质量;
|
||||
- 产品待办列表按需进行精化;
|
||||
- 随着学到更多,可以与产品负责人就范围加以澄清和重新协商。
|
||||
|
||||
Sprint 通过确保至少每个自然月一次对达成产品目标的进展进行检视和适应,来实现可预测性。当 Sprint 的时间长度拉得太长时,Sprint 目标可能会失效,复杂性可能会上升,同时风险可能会增加。可以使用较短的 Sprint 来产生更多的学习周期,并将成本与工作投入的风险限制在更短的一段时间内。每个 Sprint 都可以视为一个短期的项目。
|
||||
|
||||
存在各种各样的实践来预测进展,例如,燃尽图、燃起图或累积流图。尽管被证明是有用的,然而这些实践并不能用来取代经验主义的重要性。在复杂的环境中,未来将要发生什么是未知的。只有已经发生的事情才能用来做前瞻性的决策。
|
||||
|
||||
如果 Sprint 目标已过时,那么就可以取消 Sprint。只有产品负责人拥有取消 Sprint 的权力。
|
||||
|
||||
|
||||
|
||||
### Sprint 计划会议(Sprint Planning)
|
||||
|
||||
Sprint 计划会议通过安排在 Sprint 中要做的工作来启动 Sprint。最终的计划是由整个 Scrum 团队协作创建的。
|
||||
|
||||
产品负责人要确保与会者准备好讨论最重要的产品待办列表项 ,以及它们如何映射到产品目标。Scrum 团队还可以邀请其他人参加 Sprint 计划会议以提供建议。
|
||||
|
||||
Sprint 计划会议处理以下话题:
|
||||
#### 话题一:为什么这次 Sprint 有价值?
|
||||
产品负责人提议产品如何在当前的 Sprint 中增加其价值和效用。然后,整个 Scrum 团队将共同制定一个 Sprint 目标,用以沟通当前 Sprint 对利益攸关者有价值的原因。必须在 Sprint 计划会议结束之前最终确定 Sprint 目标。
|
||||
|
||||
#### 话题二:这次 Sprint 能完成(Done)什么?
|
||||
通过与产品负责人讨论, 开发人员从产品待办列表中选择一些产品待办列表项,放入当前 Sprint 中。Scrum 团队可以在此过程中精化这些产品待办列表项,从而增加理解和信心。
|
||||
选择在 Sprint 中可以完成多少任务可能会有挑战。但是,开发人员对他们以往的表现,他们在即将到来的 Sprint 内的产能以及对他们的完成的定义了解得越多,他们对 Sprint 预测就越有信心。
|
||||
|
||||
#### 话题三:如何完成所选的工作?
|
||||
对于每个选定的产品待办列表项,开发人员都会规划必要的工作,以便创建符合完成的定义的增量。这通常是通过将产品待办列表项分解为一天或更短的较小项来完成的。开发人员自行决定如何完成这一工作。没有人告诉他们如何将产品待办列表项转化为价值的增量。
|
||||
|
||||
Sprint 目标、这次 Sprint 所选出的产品待办列表项加上如何交付它们的计划称之为 Sprint 待办列表。
|
||||
|
||||
Sprint 计划会议是有时间盒限定的,以一个月的 Sprint 来说最多为 8 个小时。对于更短的 Sprint,Sprint 计划会议所需时间通常会更短。
|
||||
|
||||
|
||||
|
||||
### 每日 Scrum 会议(Daily Scrum)
|
||||
|
||||
每日 Scrum 会议的目的是检视达成 Sprint 目标的进展,并根据需要调整适应 Sprint 待办列表,以调整即将进行的计划工作。
|
||||
|
||||
每日 Scrum 会议是一个属于 Scrum 团队的开发人员的 15 分钟的事件。为了降低复杂性,它在 Sprint 的每个工作日都在同一时间同一地点举行。如果产品负责人或 Scrum Master 正在积极处理 Sprint 待办列表上的项,那么他们将作为开发人员参与其中。
|
||||
|
||||
开发人员可以选择他们想要的任何举行每日 Scrum 会议的结构和技术,只要他们专注于实现 Sprint 目标的进展,并为下一工作日的工作制定可行的计划即可。这可以创建专注点并改进自管理。
|
||||
|
||||
每日 Scrum 会议改善沟通,发现障碍,促进快速决策,从而消除其他会议的需要。
|
||||
|
||||
每日 Scrum 会议并不是唯一一次允许开发人员调整计划的时间。他们可以在一天中任何时间碰面,详细讨论如何调整适应或重新规划 Sprint 的剩余工作。
|
||||
|
||||
|
||||
|
||||
### Sprint 评审会议(Sprint Review)
|
||||
|
||||
Sprint 评审会议的目的是检视 Sprint 的成果并确定未来的适应性。Scrum 团队向关键利益攸关者展示他们的工作结果,并讨论产品目标的进展情况。
|
||||
|
||||
在 Sprint 评审会议期间,Scrum 团队和利益攸关者将评审在这次 Sprint 中完成了什么,以及环境发生了什么变化。基于这些信息,与会者可以就下一步的工作进行协作。产品待办列表也可能会进行调整以适应新的机会。Sprint 评审会议是一个工作会议,Scrum 团队应避免将其仅限于展示。
|
||||
|
||||
Sprint 评审会议是 Sprint 的倒数第二个事件,Sprint 评审会议是有时间盒限定的,以一个月的 Sprint 来说,最多为 4 个小时。对于更短的 Sprint,Sprint 评审会议通常所需的时间更短。
|
||||
|
||||
|
||||
|
||||
### Sprint 回顾会议(Sprint Retrospective)
|
||||
|
||||
Sprint 回顾会议的目的是规划提高质量和效能的方法。
|
||||
|
||||
Scrum 团队检视最近 Sprint 中有关个体、交互、过程、工具和他们的完成的定义的情况如何。被检查的元素通常随工作领域而变化。识别使他们误入歧途的假设,并探究其起源。Scrum 团队讨论在 Sprint 期间哪些进展顺利,遭遇到哪些问题以及这些问题是如何解决(或未解决)的。
|
||||
|
||||
Scrum 团队识别出最有用的改变以提高其效能。最有影响力的改进将尽快得到执行。甚至可以将它们添加到下一个 Sprint 的 Sprint 待办列表中。
|
||||
|
||||
Sprint 回顾会议结束 Sprint。它是有时间盒限定的,以一个月的 Sprint 来说,最多为 3 个小时。对于更短的 Sprint, Sprint 回顾会议通常所需的时间更短。
|
||||
|
||||
|
||||
|
||||
## Scrum 工件
|
||||
|
||||
Scrum 的工件代表工作或价值。它们旨在最大限度地提高关键信息的透明度。因此,为适应而检视它们的每个人对工件都有相同的基础。
|
||||
|
||||
每个工件都包含一个承诺,以确保它提供可增强透明度并聚焦于可度量进展的信息:
|
||||
- 对于产品待办列表而言,它是产品目标。
|
||||
- 对于 Sprint 待办列表而言,它是 Sprint 目标。
|
||||
- 对于增量而言,它是完成的定义。
|
||||
这些承诺的存在是为了强化经验主义和 Scrum 团队及其利益攸关者的 Scrum 价值观。
|
||||
|
||||
|
||||
|
||||
### 产品待办列表(Product Backlog)
|
||||
|
||||
产品待办列表是一份涌现的和有序的清单,它列出了改进产品所需的内容。它是 Scrum 团队所承担工作的唯一来源。
|
||||
|
||||
能够被Scrum 团队在一个 Sprint 中完成(Done)的产品待办列表项被认为准备就绪,在 Sprint 计划会议事件中可供选择。它们通常在精化活动后获得这种透明度。产品待办列表精化是将产品待办列表项分解并进一步定义为更小更精确的行为。这是一项持续进行的活动,为产品待办列表项增添细节,例如描述、优先顺序和规模。这些属性通常随工作领域而变化。
|
||||
|
||||
将要做这项工作的开发人员负责使其适当的大小。产品负责人可以通过帮助开发人员理解和权衡取舍来影响他们。
|
||||
|
||||
|
||||
|
||||
### 承诺:产品目标(Product Goal)
|
||||
|
||||
产品目标描述了产品的未来状态,可以作为 Scrum 团队制定计划的目标。产品目标在产品待办列表中。产品待办列表的其余部分涌现,用来定义“做什么”将实现产品目标。
|
||||
产品是传递价值的载体。它具有明确的边界、已知的利益攸关者和定义明确的用户或客户。产品可以是一种服务、实体产品或其他更抽象的东西。
|
||||
|
||||
产品目标是 Scrum 团队的长期目标。他们必须先实现(或放弃)一个目标,然后再开始下一个目标。
|
||||
|
||||
|
||||
|
||||
### Sprint 待办列表(Sprint Backlog )
|
||||
|
||||
Sprint 待办列表由 Sprint 目标(为什么做)、为 Sprint 选择的产品待办列表项(做什么)以及交付增量的可执行计划(如何做)组成。
|
||||
|
||||
Sprint 待办列表是开发人员为其制定的计划。它是开发人员在 Sprint 期间为实现 Sprint 目标而计划完成的工作,是一个高度可视且实时的工作画面。因此,随着学到更多,Sprint 待办列表在整个 Sprint 期间会进行更新。它应该有足够的细节,以便他们可以在每日 Scrum 会议中检视其进展。
|
||||
|
||||
|
||||
|
||||
### 承诺:Sprint 目标(Sprint Goal)
|
||||
|
||||
Sprint 目标是 Sprint 的单个目标。尽管 Sprint 目标是开发人员的承诺,但它为实现该目标所需的确切工作方面提供了灵活性。Sprint 目标还创造了连贯性和专注点,鼓励 Scrum 团队一起工作而不是分开独自行动。
|
||||
|
||||
Sprint 目标在 Sprint 计划会议事件中确定,然后添加到 Sprint 待办列表中。当开发人员在 Sprint 期间工作时,他们将 Sprint 目标铭记在心。如果需要做的工作与预期的不同,他们将与产品负责人协作,在不影响 Sprint 目标的情况下,协商本次 Sprint 待办列表的范围。
|
||||
|
||||
|
||||
|
||||
### 增量(Increment)
|
||||
|
||||
一个增量是迈向产品目标的一块坚实垫脚石。每个增量都是之前所有的增量累加起来的,并经过彻底地验证,以确保整合在一起的所有增量都能工作。为了提供价值,增量必须是可用的。
|
||||
|
||||
在一个 Sprint 中可以创建多个增量。增量的总和在 Sprint 评审会议中展示,从而支持经验主义。但是,增量可以在 Sprint 结束之前交付给利益攸关者。Sprint 评审会议决不应该被视为发布价值的关口。
|
||||
|
||||
一项工作除非符合完成的定义,否则不能将其视为增量的一部分。
|
||||
|
||||
|
||||
|
||||
### 承诺:完成的定义(Definition of Done)
|
||||
|
||||
完成的定义是当增量符合产品所需的质量度量标准时对其状态的正式描述。
|
||||
当一个产品待办列表项符合完成的定义时,就会产生一个增量。
|
||||
|
||||
完成的定义通过使每一个人对作为增量的一部分、什么样的工作算是已完成的工作有一个共同的理解来创建透明。如果一个产品待办列表项不符合完成的定义,那么它就不能发布,甚至不能在 Sprint 评审会议中展示它。相反,它返回到产品待办列表中以供将来考虑。
|
||||
|
||||
如果增量的完成的定义是组织标准的一部分,那么所有 Scrum 团队都必须以此为最低标准来遵守。如果它不是组织标准的一部分,那么 Scrum 团队必须制定适合于该产品的完成的定义 。
|
||||
|
||||
开发人员需要遵守完成的定义。如果有多个 Scrum 团队在同一产品上一起工作,那么他们必须一起制定并遵守同样的完成的定义。
|
||||
|
||||
|
||||
|
||||
## 思考
|
||||
|
||||
自己所在公司推崇 Scrum 开发。也践行了很久的 Scrum 开发模式。然后公司也花钱在工作日请 Scrum 教练给大家上课,提供 Scrum 培训,自己最后也考了 Scrum Master 证书。
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/ScrumMasterCertificate.png" style="zoom:30%">
|
||||
|
||||
思考几个问题,来更好的理解 Scrum 敏捷开发模式。
|
||||
|
||||
|
||||
|
||||
### Scrum 敏捷开发模式的优势
|
||||
|
||||
1. 快速迭代与反馈:通过较短周期的迭代方式,快速交付可用的软件功能,从而能更及、更早期获取用户或者市场的反馈。这些即时反馈可以使团队及时调整方向,动态满足客户需求和市场环境。
|
||||
2. 高度适应性:敏捷开发非常适合不断变化的项目需求。传统的瀑布开发模式,一旦需求变更后,往往需要重新规划、设计、开发,导致项目延期和一些潜在风险,而 Scrum 则通过灵活的迭代计划和调整,使得团队可以轻松硬对变化,甚至将变化转换为机会,从而保证项目的竞争力和市场的适应性
|
||||
3. 持续交付价值:Scrum强调在每个迭代周期结束时交付可用的软件增量,这意味着客户可以更早地看到产品的实际价值。这种持续交付的方式有助于增强客户的信心,同时也有助于团队及时发现问题并进行修复,确保最终交付的产品能够满足客户的期望。类似数学中积分的思想。不积小流无以成江海。
|
||||
4. 强化团队协作:Scrum敏捷开发强调跨职能团队之间的紧密协作和沟通。团队成员共同制定目标、计划和任务,通过每日站会、迭代评审和回顾会议等方式保持信息的实时共享和问题的及时解决。这种团队协作方式有助于打破部门壁垒,提高团队的凝聚力和工作效率。
|
||||
5. 不断改进:通过对每个 Sprint 结束后的回顾,团队有机会一起聊聊这个 Sprint 中的问题并提出建议,以改进问题,更好的开展下一个 Sprint 的工作。
|
||||
|
||||
|
||||
|
||||
这些优势,核心原因就是组建了一个相同价值观,认可敏捷开发文化的一群人,当然这群人不是随意组建的,而是同一个 Squad 内,最小可执行作战单元组成的,比如常见的配置是:一个 Scrum Master、一个产品 PM、一个产品设计师、2个 UI 设计师、2名 iOS、2名 Android、2个 Web 前端开发、3名后端开发,被组织任命,自管理。里面的开发基本都是资深工程师起步,有的会是技术专家。
|
||||
|
||||
然后按照 Sprint 一个周期去开发迭代,交付最小 MVP 的原则开展。一个 Sprint 可能就是2周。基于这些现状和共同任何的 Scrum 价值观,产品的开发迭代势必比较敏捷。
|
||||
|
||||
忽然觉得一个 Scrum 团队,和业务域有点相似,也有很大区别。假如你在做客户端,是一个电商业务,那么为了方便的开展工作和更聚焦,端上也划分了很多业务域,比如商品域、购物车域、营销域、订单域等等。区别在于开发所说的业务域一个是在面上的纵向划分。都是客户端 iOS 开发,商品域有10名 iOS 开发,其中1位是架构师,9位是开发主力。需求来了按照资源和人员闲置情况,安排任务。
|
||||
|
||||
但 Scrum 团队是为了区域自治,找了每个端所需要的人。
|
||||
|
||||
|
||||
|
||||
一个典型的工作流程是:
|
||||
|
||||
- 项目负责人(一般是 PM)牵头,和积分产品设计师,主持会议。会议主要目的是:根据前期和用户的沟通发现的产品问题、需求;结合公司战略考虑,当下需要做的一些 feature;对于线上的产品,主动发现或者用户咨询,对于一些不合理的流程进行优化,归纳整理出一些需要做的功能列表
|
||||
|
||||
- 继续召开会议,PM、产品负责人和 Squad 内各个端负责人(前端、客户端、后端、设计)召开会议,大致根据目前人力资源评估工期,基于优先级和工期综合排序,产出一个该 Sprint 的待办列表
|
||||
|
||||
- 一般一个 Sprint 周期为2周,即14天
|
||||
|
||||
- 然后开会同步需求和做一些会上的讨论。聊透需求
|
||||
|
||||
- 各团队调研编写技术方案,尽可能准确的评估开发周期(包括开发开始时间、单测时间、联调时间、提测时间等具体的时间节点。开发上下游互相有依赖的需要搞清楚依赖情况,确保时间是正确的)
|
||||
|
||||
- 各端项目时间交给 PM 看完,觉得没问题,大家就会在效率平台上创建任务。及时更新任务状态
|
||||
|
||||
- 每天会有 Sprint 的日会,大家同步下目前手头任务进度,有风险的提早暴露风险,看看是加配资源,还是个人加班消化,还是某些需求可以砍掉,起个分支保存代码,下个 Sprint 再上。
|
||||
|
||||
- 开发结束后,开始 ShowCase,各端演示各个 case 功能点
|
||||
|
||||
- 整个释放到市场后,找时间召开该 Sprint 的回顾会议,看看哪些点做得好,哪些点做的不好。及时更改,打造更好的团队。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
107
Chapter7 - Geek Talk/7.28.md
Normal file
@@ -0,0 +1,107 @@
|
||||
# 工作感悟和职场思考
|
||||
|
||||
|
||||
|
||||
## 关于 OKR
|
||||
|
||||
很多人都会写 OKR,OKR 做的好不好可以从以下点做 check:
|
||||
|
||||
- 许多 TODO 没有继续展开
|
||||
|
||||
改进:分清楚优先级,如果不打算做,就干脆不要列为 TODO,如果列为 TODO,就投入精力将其做好做完。而不是留在文档和 OKR 上,分散精力,干扰视线,造成事情堆叠在一起。
|
||||
|
||||
- 做了很多无谓的尝试
|
||||
改进:职场中已经不是单打独斗了,一个人可以高效灵活地无头苍蝇似的去做探索。当想法在脑子里时,可以天马行空,一旦落在纸上,就得落有所依,落有所据,把 why 先想清楚。
|
||||
|
||||
- 虎头蛇尾。一些工作,别说“做好了”,就“连做到了”,都没有完成
|
||||
|
||||
改进:强化DDL意识,能力不足,就潜心去补足能力,人手不够,就去找资源。定期邀请 high level 的人,一起复盘。
|
||||
|
||||
|
||||
- 做事犹疑,不果断
|
||||
改进:做事情犹疑的原因,是没有把利害想清楚,没有成功的说服自己。把事情的 ROI 和价值想清楚,ROI 不仅要来说服自己,还要说服合作方,说服队友,说服 leader,说服资源提供和配合者。
|
||||
|
||||
- 依赖合作方进度,规划不合理
|
||||
改进:提前列出自己的工作规划和 roadmap ,与合作方定期沟通,进行迭代后对齐。
|
||||
|
||||
- 没有 DDL 意识,导致 “重要的事情” 变为 “紧急的事情”。
|
||||
改进:自己有些完美主义倾向,本质上是由于不自信导致的,导致事情必须做好才能开展下一步的工作。本性上东西很难改,有利有弊。
|
||||
- 强化惩罚
|
||||
- 排好优先级
|
||||
- 以身作则
|
||||
|
||||
|
||||
|
||||
## 关于项目
|
||||
|
||||
- 做事情缺乏规划,“多了撸起袖子开干,少了系统性的思考”;
|
||||
- 想要推动一件事情,自身必须有所牺牲,无利不起早;
|
||||
- 不同团队,核心利益必然不同,否则早就合并为一个团队了,要尊重合作团队的核心利益诉求;
|
||||
- 合作的前提是开放和互信;
|
||||
- 开放,让信息进行充分的自由流动
|
||||
- 互信,提升合作效率
|
||||
- 在复杂的现实场景中,往往简单的模型更可靠,更有持久性
|
||||
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/WhyWhatWhoHow.png" style="zoom:45%">
|
||||
|
||||
- 先把为什么要做想清楚,WHY
|
||||
- 共同描绘出那个WHAT
|
||||
- 谁会从中受益,WHO
|
||||
- 怎么展开,HOW
|
||||
- 最后进入最后的 plan do check action 的循环
|
||||
|
||||
|
||||
当然这里有很多问题需要回答:
|
||||
- 事情的收益能不能讲的清楚?
|
||||
- 业务是做什么的?
|
||||
- 业务负责人是谁?
|
||||
- 业务遇到了哪些问题?
|
||||
- 业务未来发展的重点是什么?
|
||||
- 自己的 repution 如何?
|
||||
- 自己有多少人力?
|
||||
- 需要哪些资源?
|
||||
- 这些资源分别在谁手里?
|
||||
- 需要协调哪些人?
|
||||
- 合作团队的排期和节奏?
|
||||
- ROI 如何如何说服合作团队?
|
||||
|
||||
|
||||
|
||||
## 心态
|
||||
|
||||
- 处于上升阶段的人,更应该以包容的心态接受不同的观点、接触不同的人,先接纳再甄别,博观而约取。重博观而轻约取,易人云亦云,轻博观而重约取,易夜郎自大
|
||||
- 多培养自己的钝感
|
||||
- take initiative,主动
|
||||
- 注重沟通
|
||||
- 注重建立自己的 repution,积攒 credit,把每条 commit message,每篇文档,每次 oncall,做好,做扎实
|
||||
- 先 do it well,再 make things happen
|
||||
- 在团队内,一定找准自己的定位,或者寻求 mentor 的帮助来强化自己的定位,从而能够找到归属感。
|
||||
|
||||
|
||||
|
||||
## 不要陷于“忙”的假象
|
||||
|
||||
<img src="https://github.com/FantasticLBP/knowledge-kit/raw/master/assets/CannotStudyTechButNoCommunication.png" style="zoom:45%">
|
||||
|
||||
做技术很容易陷入孤芳自赏,我就认识很多这样的人,认为自己才是最牛逼的,反而丧失了最基本的沟通能力。懂的这个道理的人肯定是很多的,可惜当落在自己身上时,还是会只缘身在此山中的。
|
||||
|
||||
疲于奔命也是一种舒适区,忙不一定等于有效, 在字节这种互联网公司中,自己每天都是很忙的,“忙”会给人一种安全感,但它也是一种舒适区。有理智的主动的做事情,而不是被动的疲于奔命无方向感的忙。例如经典三问:
|
||||
|
||||
- 你正在做什么?
|
||||
- 为什么要做这个?
|
||||
- 这是你当前最重要的吗?
|
||||
|
||||
|
||||
|
||||
## 晋升的源动力
|
||||
|
||||
晋升最直接的一个原因是你所做的事情超越了你所在职级的边界,你的影响力辐射自己团队或者辐射合作团队的好几个人。但是当晋升名额有限的时候,僧多粥少的时候,你如何脱颖而出?
|
||||
|
||||
一方面,你要选择正确的 direction 就需要收集很多信息,例如公司未来计划是什么,重点会在哪方面投入,近期最大的障碍会是什么。这些信息都在不同的人手上,你需要很多的沟通才能收集回来。另一方面,一个人的 technical 再怎么厉害也是有上限的,你要你的输出程指数级增长,唯一的办法就是借助别人的 technical 能力帮你解决部分你的问题,否则你达到自己的上限了就上不去了。
|
||||
|
||||
对于科技公司来说,级别增长对于输出的要求都是指数级增长的,线性增长是没办法帮你晋升的,只能拿更多的奖金。作为 senior,输出至少要相当于几个 junior,而且最好能做一些几个 junior 各自为政做不到的事情,其它 junior 修改几天才能完美的代码他一天就写出来完美的版本。后者他可能就做不到了,因为 junior 需要别人给他们定义问题,需要别人告诉他怎样成长。
|
||||
|
||||
从 senior 到 principal 或 staff 的过程也是类似的,你的输出至少是一个顶几个,而且最好能做到几个低一级的人各自为政做不了的事情。这时候 direction 和 people 就会显得越来越重要,因为你要说服别人各自带领自己的团队单干效果不如多个团队分工合作完成你的目标好,那首先你要有个好目标,其次你要能说服人。
|
||||
|
||||
回到最初的问题上来,其实很多人晋升的瓶颈真的不在 technical 上面,但 technical 在优化下去对全局的贡献不大。你需要意识到自己当前的瓶颈在哪里,是什么阻碍了你的输出指数级上升,然后专注于解决这些障碍。还是回到上面所说的,不要等着别人告诉你你的问题在哪里,你要在千千万万的问题里面找出来你身上的什么问题如果解决了你能更快地成长
|
||||
@@ -26,4 +26,6 @@
|
||||
* [22、2022年度总结](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.23.md)
|
||||
* [23、晋升答辩的逻辑是什么?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.24.md)
|
||||
* [24、短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.25.md)
|
||||
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
|
||||
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
|
||||
* [26、敏捷软件开发和 Scurm Master](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.27.md)
|
||||
* [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
|
||||
@@ -113,6 +113,9 @@
|
||||
* [108、精准测试](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.108.md)
|
||||
* [109、汇编学习](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.109.md)
|
||||
* [110、妙用设计模式来设计一个客户端校验器](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.110.md)
|
||||
* [111、写给 iOSer 的鸿蒙开发 tips](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.111.md)
|
||||
* [112、Swift 枚举值内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.112.md)
|
||||
* [113、Swift 结构体和类的内存布局](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter1%20-%20iOS/1.113.md)
|
||||
* [Chapter2 - Web FrontEnd](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/chapter2.md)
|
||||
* [1、-last-child与-last-of-type你只是会用,有研究过区别吗?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.1.md)
|
||||
* [2、正则表达式](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter2%20-%20Web%20FrontEnd/2.2.md)
|
||||
@@ -240,4 +243,6 @@
|
||||
* [22、2022年度总结](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.23.md)
|
||||
* [23、晋升答辩的逻辑是什么?](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.24.md)
|
||||
* [24、短视频刷多了会变笨吗?怎么样提升我们的表达和思辨能力](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.25.md)
|
||||
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
|
||||
* [25、对于”文件“的新认识](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.26.md)
|
||||
* [26、敏捷软件开发和 Scurm Master](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.27.md)
|
||||
* [27、工作感悟和职场思考](https://github.com/FantasticLBP/knowledge-kit/blob/master/Chapter7%20-%20Geek%20Talk/7.28.md)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 74 KiB After Width: | Height: | Size: 90 KiB |
BIN
assets/AssembleJMPDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 342 KiB |
BIN
assets/AssembleJMPDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 383 KiB |
BIN
assets/AssemblyFunctionParamsRegisterDemo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 210 KiB |
BIN
assets/AssemblyRaxFunctionReturnValueDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 244 KiB |
BIN
assets/AssemblyRaxFunctionReturnValueDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 230 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 498 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 440 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 472 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 450 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 436 KiB |
BIN
assets/AssociatedEnumMemoryLayoutDemo6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 485 KiB |
BIN
assets/AssociatedEnumMemoryLayoutExplore.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 626 KiB |
BIN
assets/CallOCMethodInSwiftDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 752 KiB |
BIN
assets/CallOCMethodInSwiftDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 275 KiB |
BIN
assets/CallOCMethodInSwiftDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 724 KiB |
BIN
assets/CallOCMethodInSwiftDemo4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 712 KiB |
BIN
assets/CallOCMethodInSwiftDemo5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 596 KiB |
BIN
assets/CannotStudyTechButNoCommunication.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 206 KiB |
BIN
assets/CarthageInstall.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 311 KiB |
BIN
assets/CarthageUpdate.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
BIN
assets/ClangASTCategoryMethod.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.5 MiB |
BIN
assets/ClangASTMethod.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.5 MiB |
BIN
assets/ClangCompileProducts.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 483 KiB |
BIN
assets/ClangPluginSourceCode.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 511 KiB |
BIN
assets/ClassMemoryLayoutExcludeFunction.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 527 KiB |
BIN
assets/ClassMemoryLayoutExcludeFunction2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 500 KiB |
BIN
assets/ClassNameViaClangAST.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 626 KiB |
BIN
assets/ClassReferenceTypeMemoryLayoutDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 557 KiB |
BIN
assets/ClassReferenceTypeMemoryLayoutDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 353 KiB |
BIN
assets/ClosureCaptureVariableDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 669 KiB |
BIN
assets/ClosureCaptureVariableDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 513 KiB |
BIN
assets/ClosureCaptureVariableDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 740 KiB |
BIN
assets/ClosureCaptureVariableDemo4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 725 KiB |
BIN
assets/ClosureCaptureVariableDemo5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 748 KiB |
BIN
assets/ClosureCaptureVariableDemo6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 724 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 561 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 194 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 599 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 478 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 595 KiB |
BIN
assets/ClouseExploreCaptureVariableDemo7.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 539 KiB |
BIN
assets/ClouseExploreNotCaptureVariableDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 511 KiB |
BIN
assets/ClouseExploreNotCaptureVariableDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 310 KiB |
BIN
assets/ClouseExploreNotCaptureVariableDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 477 KiB |
BIN
assets/ClouseExploreNotCaptureVariableDemo4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 614 KiB |
BIN
assets/ClouserMemoryLayoutExploreDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 568 KiB |
BIN
assets/DyldStructure.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 272 KiB |
BIN
assets/EnumBaseMemoryLayoutDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 417 KiB |
BIN
assets/EnumBaseMemoryLayoutDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 399 KiB |
BIN
assets/EnumBaseMemoryLayoutDemo3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 374 KiB |
BIN
assets/EnumWithRawValueMemoryLayoutDemo1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 430 KiB |
BIN
assets/EnumWithRawValueMemoryLayoutDemo2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 421 KiB |
BIN
assets/FileCommandToWatchFileType.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
BIN
assets/LLDBBreakPointList.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 254 KiB |
BIN
assets/LLDBBreakPointSetSameSymbol.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 452 KiB |
BIN
assets/LLDBBreakPointsSetWithSpecificClass.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 468 KiB |
BIN
assets/LLDBBreakpointAddCommand.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 517 KiB |
BIN
assets/LLDBBreakpointCommandList.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 254 KiB |
BIN
assets/LLDBBreakpointDelete.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 619 KiB |
BIN
assets/LLDBBreakpointDisable.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 461 KiB |
BIN
assets/LLDBBreakpointSetRegx.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 601 KiB |